
Abstract
Spatial co-location mining is a useful tool for discovering spatial association patterns of feature sets which are frequently observed together in nearby geographic space. Most of co-location mining techniques aim to find all prevalent co-located feature sets which satisfy a given prevalence threshold. However the result is often large, especially when the prevalence threshold is set low, or long co-location patterns present. Moreover the output has many redundant information which makes it difficult for users to filter useful patterns. This work introduces the problem of mining reduced sets of co-location patterns in order to concisely represent interesting spatial relationship patterns. With aiming two such outputs in the form of maximal and closed co-locations, this paper proposes an algorithmic framework to discover maximal co-location patterns and closed co-location patterns as well as all prevalent co-location patterns, and presents the algorithm details for each pattern discovery. The developed algorithms are correct and complete in finding maximal co-locations and closed co-locations. The experiment result shows that the framework reduces candidate feature sets effectively and finds co-location patterns efficiently.
Introduction
The evolution of location sensing, wireless networks and ubiquitous computing is generating large quantities of rich spatial data with geographic references. Spatial data mining has been used for extracting interesting, previously unknown, and potentially useful patterns or knowledge from large spatial databases [26, 28, 11, 7]. In spatial data analysis, spatial proximity is an important concept to determine spatial dependencies or spatial auto correlations among objects since nearby objects are more related than distant objects [32, 28]. As family of spatial data mining, co-location mining has been used to uncover implicit spatial dependency patterns from large spatial datasets.
Given a data set of spatial objects, where each object is presented with a tuple
Spatial data and neighbor relationships.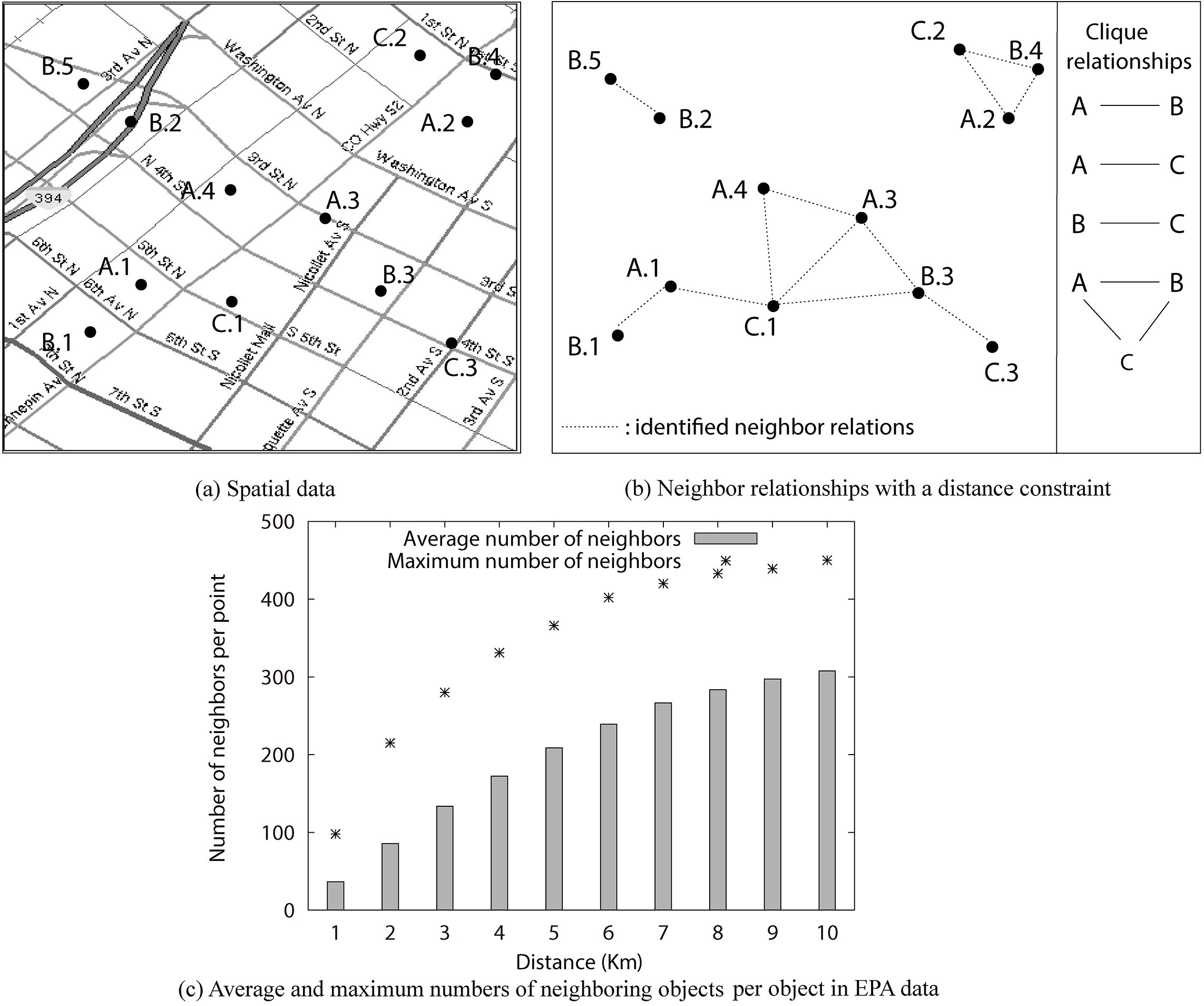
Spatial co-location mining is useful in many application domains including geographic information systems [17], public safety [19], public health [6], ecology [30], agriculture [36], social science [35], environmental science [3, 20], Earth science [9], criminology [24, 18], urban planning [16, 21], and business [23, 42]. For example, co-located plant species discovered from plant distribution data sets can contribute to plant geography and phytosociology study. As another application, consider location-based services. Finding what services are frequently requested by users in geographic proximity is an interesting problem. For example, consider an E-commerce service company which provides different types of services, such as weather, movie timetabling, ticketing and parking queries [23]. The requests for those services may be sent from different locations by mobile users. The service provider may be interested in discovering types of services that are requested by geographically neighboring users, in order to provide location-sensitive advertisement and recommendation. For instance, having known that ticketing requests are frequently asked close to timetabling requests, the provider may choose to advertise the ticketing service to all customers that ask for a timetabling service.
Spatial co-location mining is a computationally expensive and resource intensive task. Figure 1c shows the average and maximum numbers of neighbor objects per object by different neighbor distances, with the facility data of two counties from the Environmental Protection Agency (EPA) databases [1]. It is computationally expensive to search all possible co-location instances directly from such dense spatial data sets. Moreover, the number of co-located feature sets discovered is often large, especially when the prevalence threshold is set low, or when there exist long patterns present in the spatial neighborhoods. A length
This work studies the problem of finding compact sets of co-location patterns in order to concisely represent interesting relationship patterns in spatial data. We adopt relevant models from frequent itemset mining literature [12], and present the compact representation of co-location patterns with the terms of maximal and closed co-locations. A maximal co-location is a prevalent co-located feature set for which none of its immediate supersets are prevalent. The result of maximal co-location discovery makes the smallest output of co-location mining from which all co-location patterns can be derived. They are useful for spatial datasets which have long length co-location patterns; however maximal co-locations lead to a loss of information since the prevalence values of all co-locations cannot be specified with the maximal result set. In contrast, the output of closed co-locations provides the minimal representation of co-located feature sets that preserves the prevalence information of all co-location patterns.
The contributions of this paper are summarized like following: First, we introduce the problem to find the compact representation set of co-location patterns with maximal co-locations or closed co-locations. Second, we aim to develop an algorithmic framework which can discover maximal co-locations and closed co-locations as well as all prevalent co-located feature sets. The common mining procedures of three different outputs are identified for the framework. Third, two algorithms, MaxColoc and ClosedColoc, for mining maximal co-locations and closed co-locations, respectively, are developed on the framework. The proposed algorithms adopt several schemes for reducing the number of candidate sets examined, efficiently searching their co-location instances, and effectively determining the maximality or closeness of a prevalent co-located feature set. Forth, we prove that the proposed algorithms are correct and complete in finding maximal co-locations and closed co-locations. Moreover they are experimentally evaluated with real data and synthetic data. The experiment result shows that the framework reduces candidate feature sets effectively and finds maximal co-location and closed co-location patterns efficiently.
The remainder of the paper is organized as follows. Section 2 begins with an introduction to the traditional co-location model, and defines maximal co-location and closed co-location patterns for the compact representations of co-locations. Section 3 describes an algorithmic framework for mining maximal and closed co-locations as well as all prevalent co-located feature sets. Section 4 presents the MaxColoc algorithm and ClosedColoc algorithm. The analysis of the proposed algorithms is given in Section 5. The experimental results are presented in Section 6. In Section 7, we conclude this paper by discussing related work and future work.
This section describes key terms used in co-location mining, and then gives the formal definitions of maximal co-locations and closed co-locations.
General co-location semantics
Let a set of
.
For example, in Fig. 2a, {A.2, B.4, C.2} is a co-location instance of {A, B, C} because the instance includes objects of the three features, A, B and C, and they are neighbors each other. A co-location instance with
Co-locations, closed co-locations, and maximal co-locations.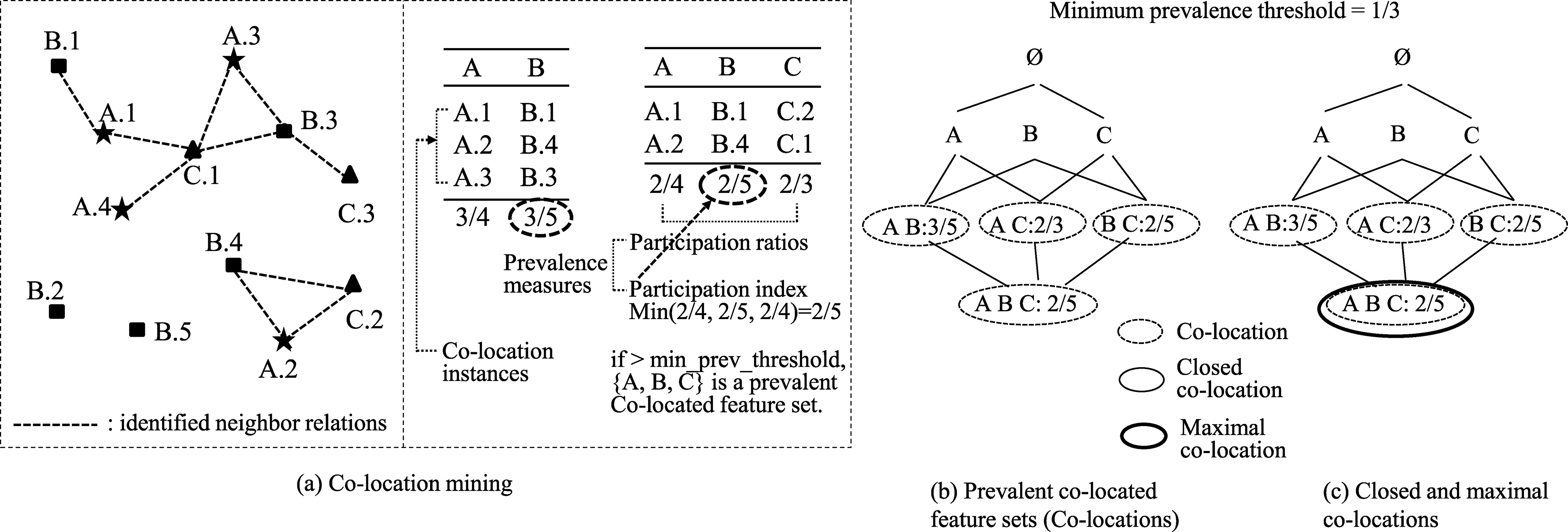
The prevalence strength of a co-location pattern is often measured with participation ratio and participation index [29].
.
Participation index measure indicates wherever a feature
.
The closed co-location and maximal co-location patterns we propose are defined as following:
.
A closed co-location is a prevalent co-located feature set if none of its immediate supersets has exactly the same prevalence value as it. For example, in Fig. 2, when the minimum prevalence threshold
.
A maximal co-location is a prevalent co-located feature set that does not appear as a subset of other co-location patterns. For example, in Fig. 2c, only {A, B, C} is a maximal co-location.
Algorithmic framework
Co-location pattern discovery is challenging because spatial objects are distributed on continuous space, and share complex spatial relationships with each others [28]. A large fraction of the computation time in mining co-location patterns is devoted to finding co-location instances. This section presents an algorithmic framework to efficiently discover maximal and closed co-location patterns as well as all prevalent co-located feature sets. The framework focuses on reducing the number of candidate sets examined, efficiently searching their co-location instances, and effectively checking the maximality or closedness of prevalent co-locations. Figure 3 shows the framework proposed with main components.
An algorithmic framework of mining co-location patterns.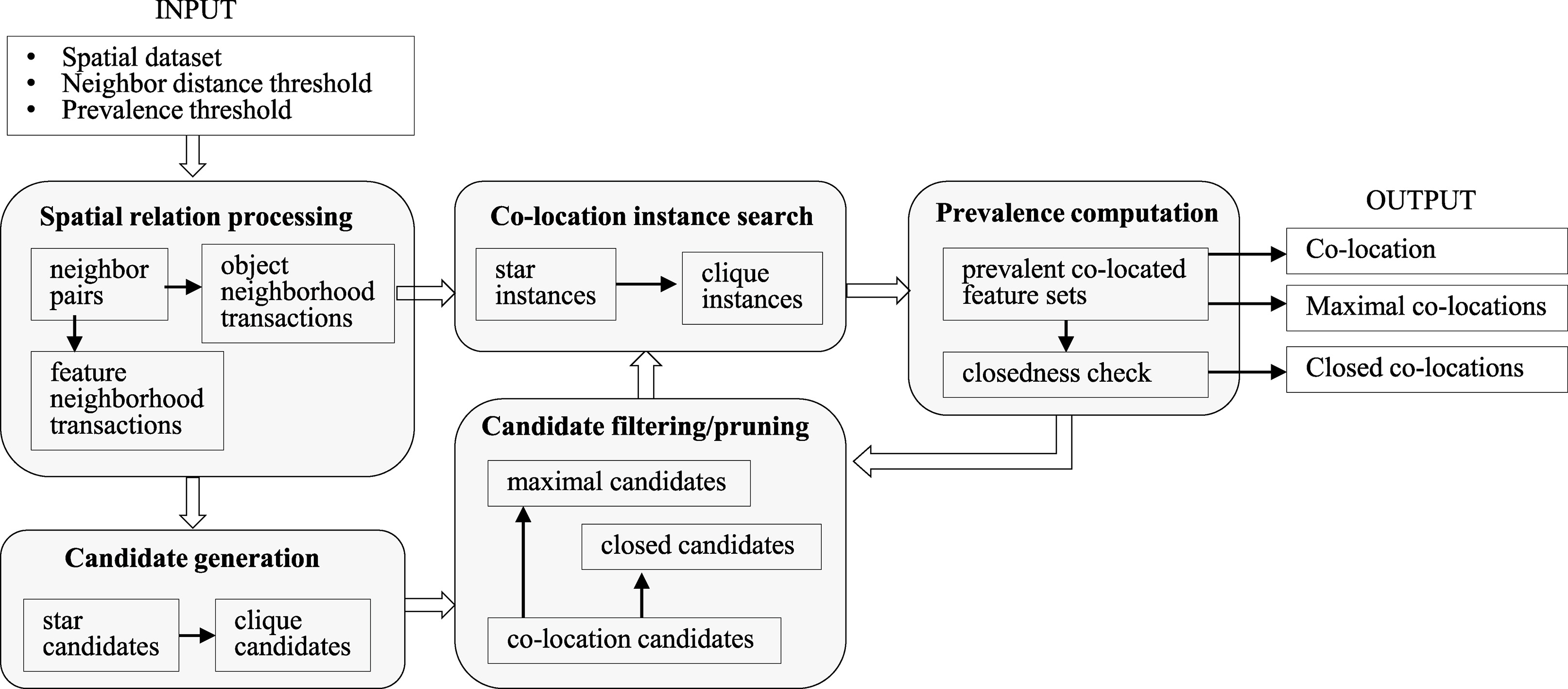
As pointed out by Shekhar and Chawla [28], the cost of fully exploring a spatial dataset for finding all co-location instances having clique neighbor relationships can, in some cases, be more expensive than co-location pattern search. Our framework adopts the idea of neighborhood materialization [41] in order to effectively handle spatial relations for co-location mining, but organize spatial relations in two different data structures: feature neighborhood transaction record, and neighborhood transaction record. Feature neighborhood records are used for generating candidate co-located feature sets. Neighborhood records are used for finding potential co-location instances.
Given a set of spatial features
.
The
The feature neighborhood transaction of each object gives the information of other features presented in its neighborhood area. In the example with Fig. 4a,
Different data structures to store spatial neighbor relations.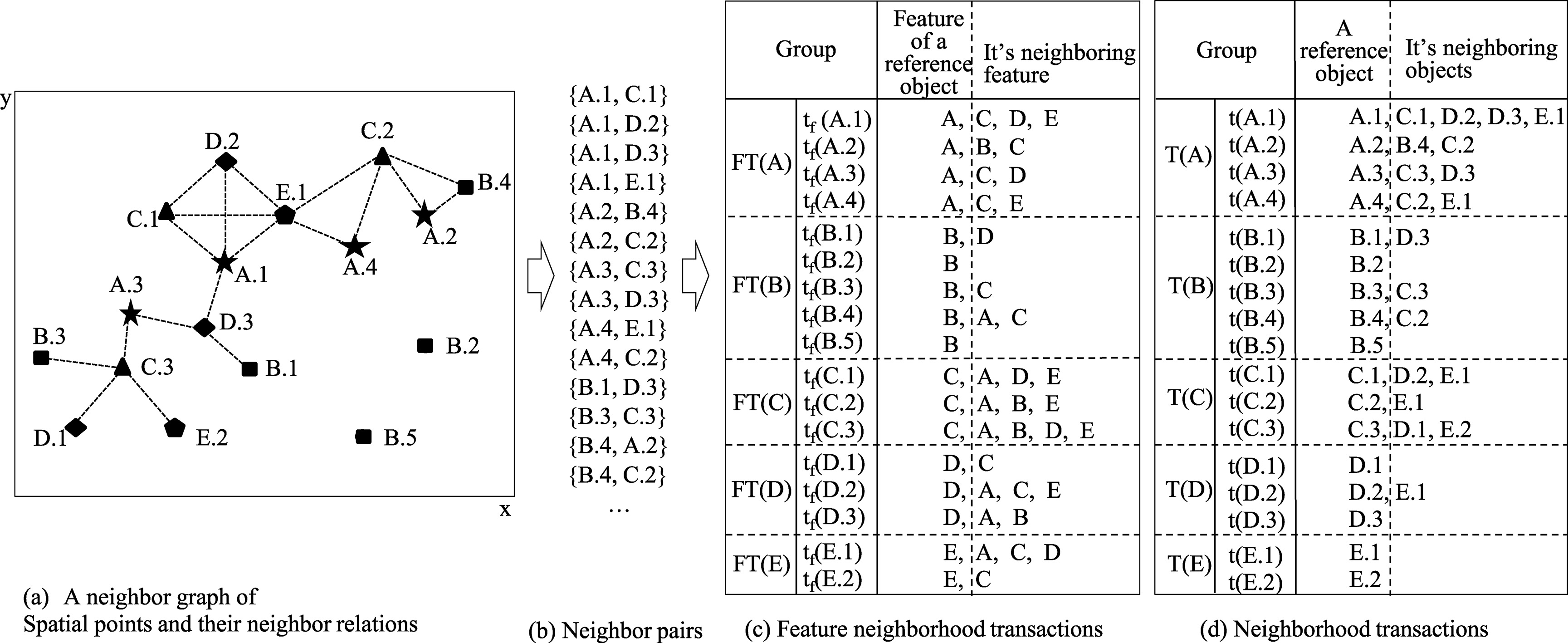
.
The
We assume there is a total ordering of feature types, such as lexicographic. The neighborhood transaction informs conditional neighboring objects presented in the neighborhood of each object. For example, in Fig. 4c, the neighborhood transaction record of C.1,
Algorithm 1 shows the pseudo code of the spatial relation processing. All neighboring object pairs can be found using a geometric method such as plane sweep [5], a spatial range query method using quaternary trees or R-trees [28]or a grid-based neighbor search [43]. We use a plane sweep algorithm [5] for neighbor pair search (Line 1 in Algorithm 1) because as argued in [15], it might be more beneficial to operate on raw spatial data than spatial query methods which requires building indexes especially for the operation. The neighborhood transactions are simply generated by grouping the neighboring objects per each object and checking the condition of the neighborhood transaction by Definition 7 (Line 2 in Algorithm 1). The feature neighborhood transactions are also generated by grouping the neighboring objects per each object, extracting distinct feature types from them according to Definition 6 (Line 3 in Algorithm 1).
The search space of co-location patterns has 2
Generation of star candidates
Potential candidate feature sets are generated with feature neighborhood records using a tree structure called Candidate Pattern tree. A Candidate Pattern tree (CP-tree) is a prefix tree structure defined like followings: (1) It consists of one root labeled as a reference feature and a set of prefix subtrees of neighbor features of the reference feature as the children of the root. (2) Each node keeps following information: feature, count, and node links to its parent node, children nodes and other nodes containing the same feature. The count of a node registers the number of objects of the node feature neighboring with other features on the path reaching the node from the root. The CP-tree rooted with a feature
CP-tree is a tree data structure similar with FP-tree [13], which is used for finding frequent itemsets in general association rule mining. We use this tree structure for co-location candidate generation. We construct one CP-tree per each feature
Generation of co-location candidates.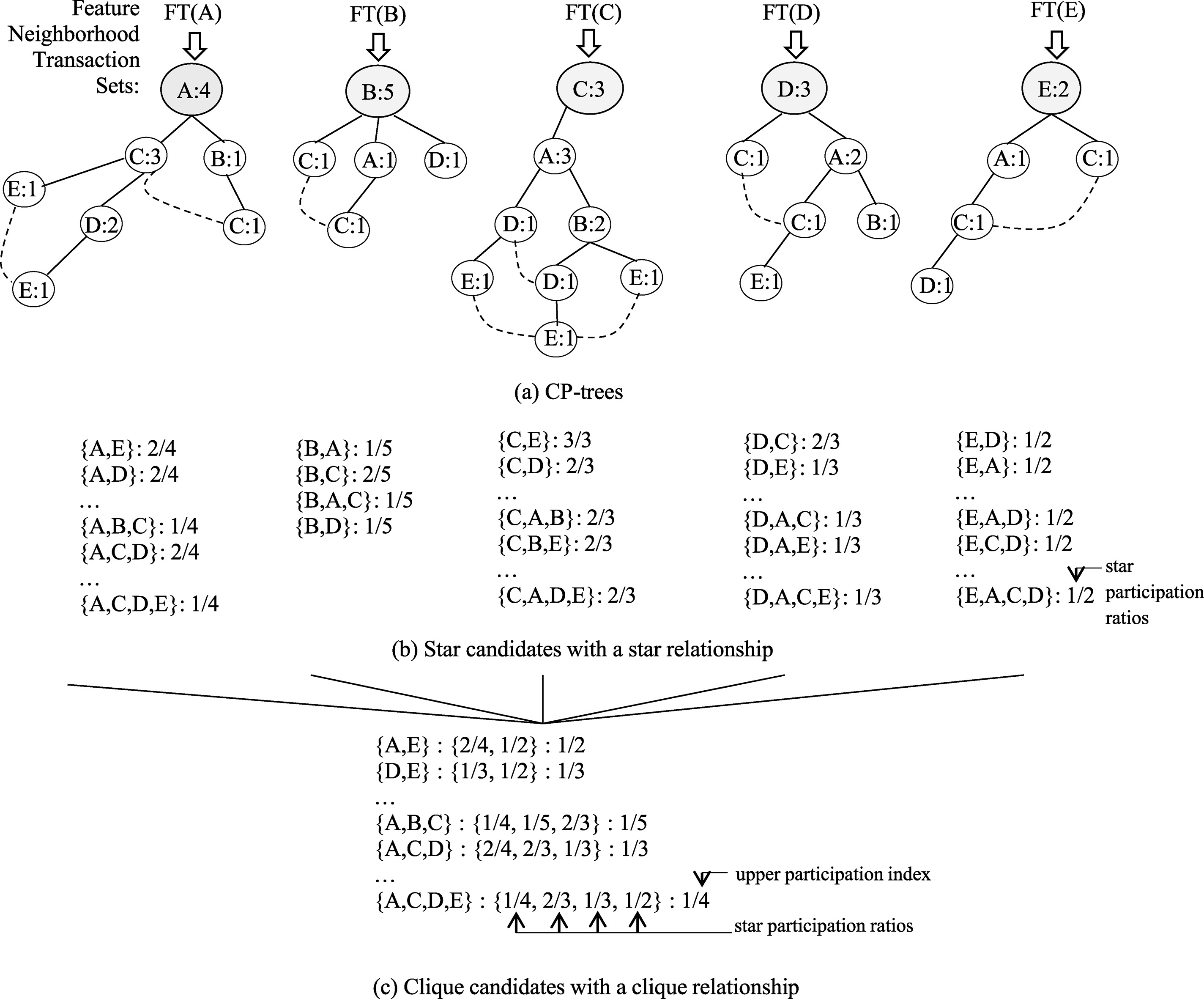
Next, we accumulate all possible subsets of features with following each branch path of the CP-tree (Line 6 in Algorithm 2). The feature type of the root node is added to each sub set as the first element of the set. The feature subsets generated are called to star candidates because the first item in a candidate set has neighbor relationships with all other items in the set. For example, in Fig. 5a, all star candidates generated from
.
Co-location candidates (also called clique candidates) are generated with combining the star candidates survived from the star participation ratio-based pruning (Line 11 in Algorithm 2). For examples, a candidate {A, B, C} is generated with combining star candidates with three features A, B, and C, i.e., {A, B, C}, {B, A, C} and {C, A, B}.
.
We already know that each star participation ratio of a co-location candidate satisfies the prevalence threshold (line 11 in Algorithm 2). Thus the upper participation ratio index of the candidate is always greater than or equal to a given minimum prevalence threshold.
Candidate pruning
The co-location candidates generated can be presented using an enumeration tree. The co-location pattern search strategy is relevant to how the search space is traversed for the pattern discovery. This framework can adopt different search strategies. First, the general-to-specific search traverses the candidate space in a breadth-first manner and finds length
Co-location instance search
To discover co-location patterns, we need to find the co-location instances of each candidate. This framework uses a filter-and-refine approach for efficiently finding the instance of co-locations.
.
A set of spatial objects,
In the filter step, potential co-location instances of candidates (which are called star instances) are collected with scanning the neighborhood transaction records. To reduce the search space of star instances of candidates, we consider only “
Co-location instance search with relevant neighborhood transactions and subinstance lookups.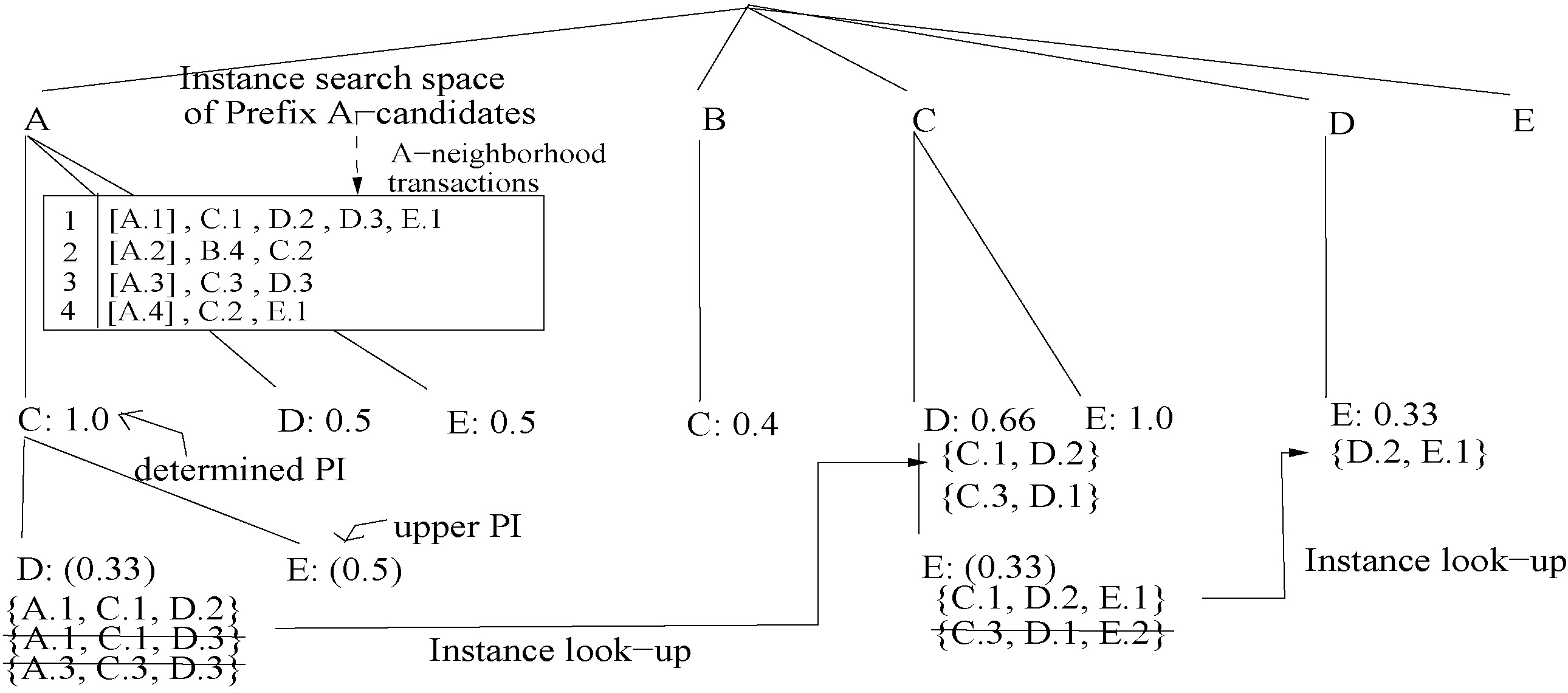
In the refine step, true co-location instances of a candidate can be filtered from its star instances. A star instance
The participation index value of a candidate is computed with its true co-location instances. If the prevalence value is greater than a given minimum threshold, the candidate becomes a prevalent co-located feature set.
Maximal and closed co-location mining
So far, we showed the main procedure of the algorithmic framework and how to find all prevalent co-location feature sets. Next, we present how maximal co-locations and closed co-locations are discovered in this framework. This section describes additional algorithmic strategies for mining maximal co-locations and closed co-locations in three parts: 1) candidate space browsing and pruning, 2) instance search, and 3) maximality or closeness check.
Maximal co-location mining algorithm
Algorithm 3 shows the pseudo codes of Maximal Co-location mining algorithm (MaxColoc).
Candidate space browsing and pruning
MaxColoc traverses the enumeration tree of candidates in a hybrid manner, using both depth-first and breadth-first traversals as shown in Fig. 7. The depth-first traversal is used for quickly determining maximal co-located feature sets. We consider only maximal candidates.
Candidate set pruning by a maximal set.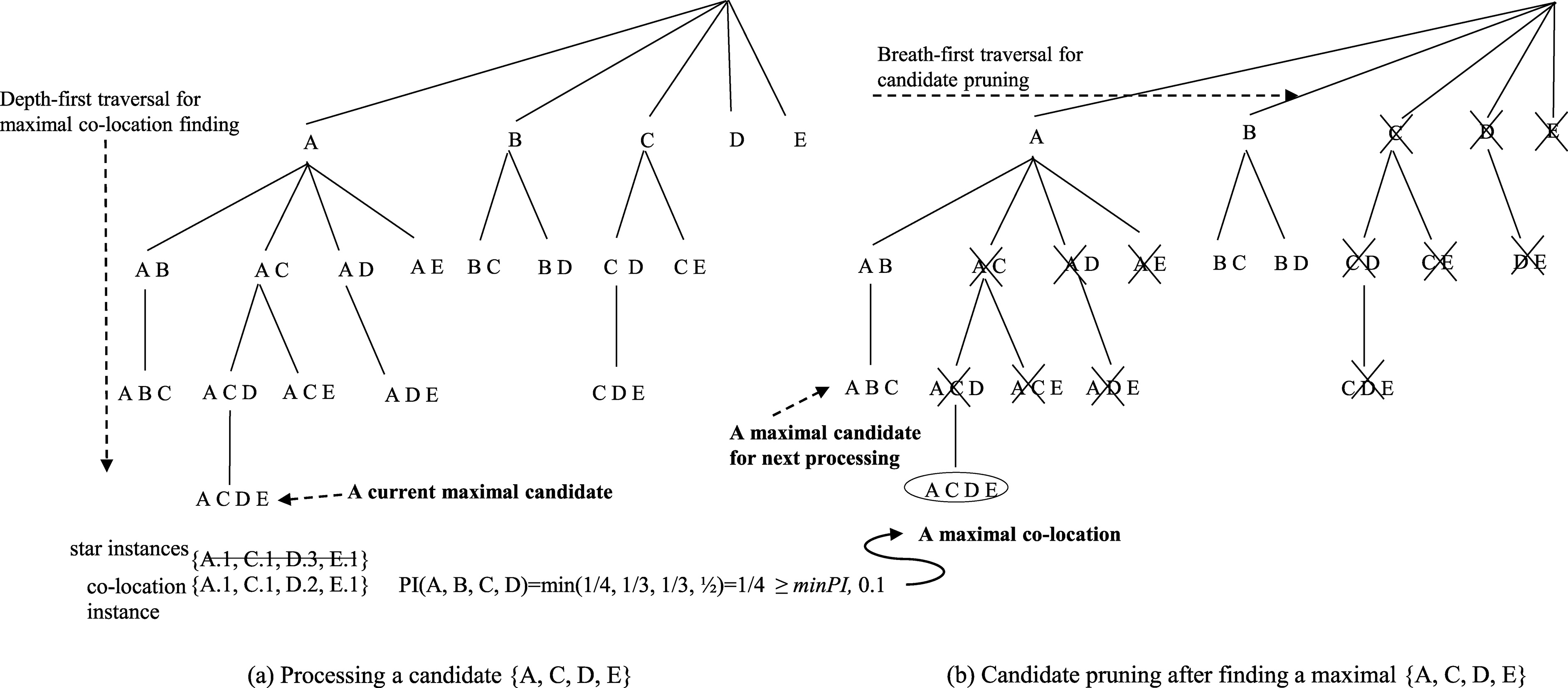
.
After uncovering maximal co-locations in the level, MaxColoc prunes out all sub candidate sets of the maximal co-location for further reducing candidate feature sets using the subset-pruning-by-supersets scheme (Line 23 in Algorithm 3). For the subset pruning, the candidate tree is navigated in the top-down and breadth-first manner. Let the feature set of a node in the candidate tree be termed the node’s head, and the possible extensions of the node be the tail. Let the head union tail of a node be HUT. The subsets of a maximal co-location are pruned out by determining whether or not the HUT of each node in the tree is a subset of the maximal co-location. If the HUT of a node is a subset of a maximal co-location, the subtree rooted at the node is pruned out. In the example of Fig. 7a, suppose that {A, C, D, E} is a maximal co-location. In the first level of the co-location candidate tree, the HUT of node A is {A, B, C, D, E} because its head is {A} and its tail is the set {B, C, D, E}. We cannot prune out the subtree of node A because its HUT is not a subset of {A, C, D, E}. However, the HUT of the node of C, {C, D, E}, is a subset of the maximal {A, C, D, E}. Thus, the subtree rooted at C is pruned out. Figure 7b shows the status of the subset tree after finding a maximal co-location {A, C, D, E}. This pruning scheme ensures we consider only maximal candidates for co-location instance search in the next step.
For finding the instances of maximal co-location candidates, we follow the filter-and-refine idea. The star instances of candidates are first collected from their relevant neighborhood transactions (Line 16 in Algorithm 3). The refinement step filters out co-location instances from the star instances with the information of neighbor pair relations prepared in the preprocess stage (Line 18 in Algorithm 3).
Maximality check
MaxColoc finds prevalent co-located feature sets from only maximal candidates because non-maximal candidates are pruned out in the step of the subset-pruning-by-supersets. If a maximal candidate set is prevalent, it becomes a maximal co-location without any other check (Line 20 in Algorithm 3).
Closed co-location mining algorithm
Algorithm 4 shows the pseudo codes of Closed Co-location mining algorithm (ClosedColoc).
Candidate space browsing and pruning
ClosedCloc processes the candidate at each level of the candidate tree in a top-down and breadth-first manner. For further reducing candidates, ClosedColoc filters length
.
Instance search
ClosedColoc finds co-location instances using the filter-and-refine method explained in the framework. In the filter step, the star instances of candidates are collected form their relevant neighborhood records (Line 16 in Algorithm 4). In the refinment step, ClosedColoc reuses co-location instance information from the previous level output. A star instance
Length 2 and Length-3 closed co-location mining.
If a candidate’s participation index satisfies a given prevalence threshold, the candidate is a prevalent co-located feature set (Line 21 in Algorithm 4). However we need to check whether the prevalent set is a closed set or not. We use two strategies for that. First, we use a hash-based subsumption check strategy (Line 22 in Algorithms 4 and 6). Let
Correctness and completeness
In this section, we prove the proposed algorithms are correct and complete in finding maximal and closed co-location patterns, respectively. We first give related lemmas.
.
Let
.
Let
.
Let
.
The MaxColoc algorithm is complete and correct.
.
The ClosedColoc algorithm is complete and correct.
Experiment result
This section presents the result of experimental evaluation of proposed MaxColoc and ClosedColoc algorithms.
Experimental setting
We used real data as well as synthetic data for this experiment. We generated synthetic data on a study area of 1,000
Experimental procedure.
We compared MaxColoc and ClosedColoc with GeneralColoc+Maximal and GeneralColoc+Closed, which are based on a state-of-art co-location mining algorithm [29] but have a post-processing module for the final result pattern, maximal co-locations or closed co-locations. Figure 9 diagrams the experiment procedure. All the experiments were performed on a PC Linux system with 2.0 GB main memory.
Comparisons of candidates.
To examine the effect of our candidate pruning schemes, we counted candidate feature sets considered for finding maximal co-locations and closed co-locations. In this experiment, the prevalence thresholds were 0.1 for DATA#1 and 0.1 for DATA#2. The prevalence threshold for DATA#3 was 0.4 because this dataset is a dense dataset. As shown in Fig. 10, the proposed approach generated significantly smaller number of candidates than the alternative methods in all the experimental settings. The comparison algorithm (GeneralColc) is one of co-location mining algorithms based on Apriori [12] which is a generation-and-test approach. It first finds prevalent length 2 (
In the result with DATA#2 (Fig. 10b), MaxColoc considered no length-2 candidates, because it processes long candidates in advance and prunes out all the subsets of discovered maximal co-locations. In contrast, MaxColoc+Maximal examined all possible pair feature sets. ClosedColoc also considered much fewer candidates compared to GeneralColoc+Closed. ClosedColoc started with small number of length-2 candidate sets which are generated in the preprocess stage. In contrast, the alternative method considers all possible length-2 feature sets. In Fig. 10f, the number of length 3 candidates of GeneralColoc+Closed was 40% less than ClosedColoc. This case happened when the number of length
Comparisons of performance.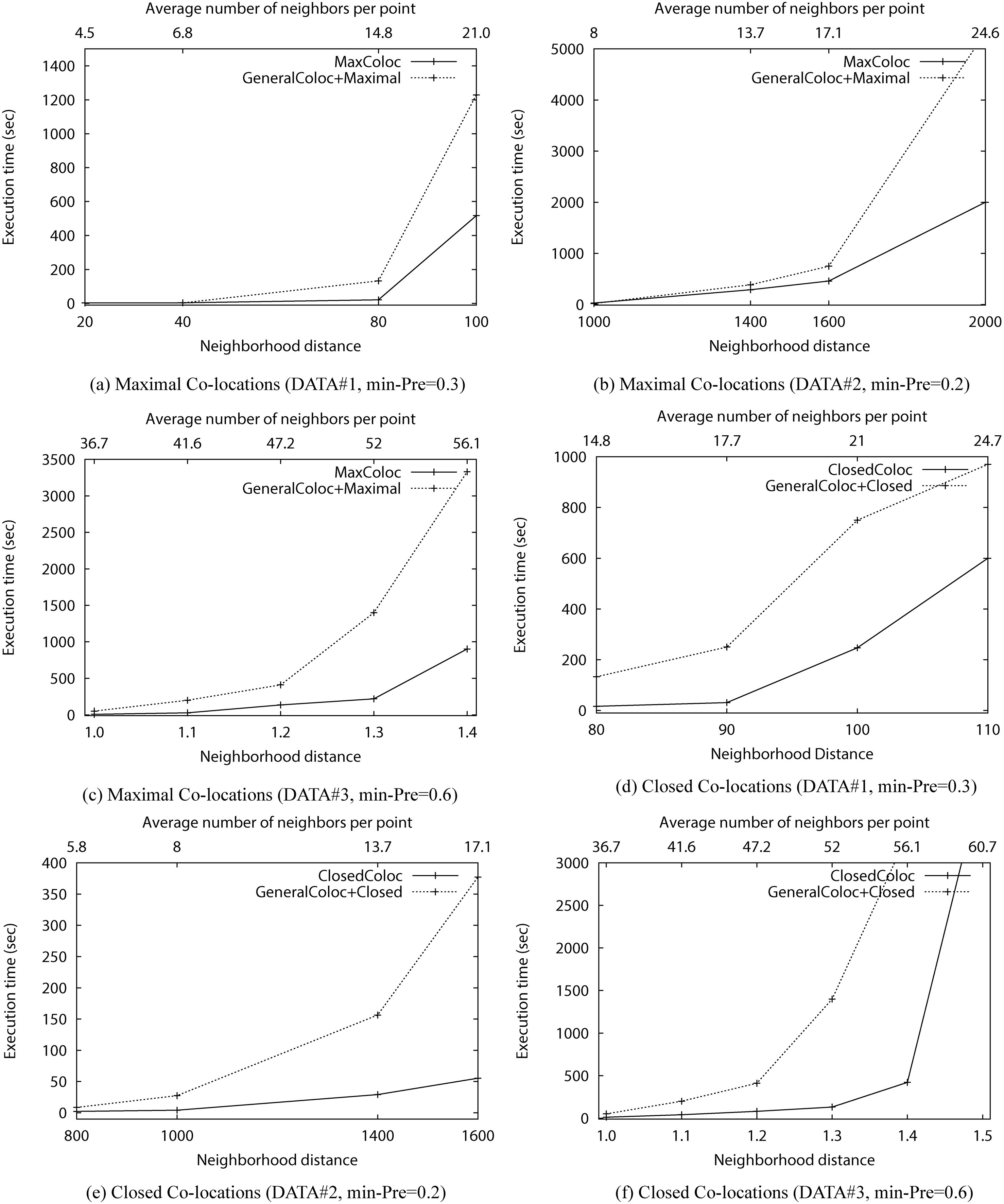
Next, we examined the effect of performance by neighborhood size. When the neighborhood size is larger, an object has a chance to have more neighbors. Figure 11 shows the results in finding maximal co-location and closed co-location patterns. X axis shows two values, neighbor distance threshold in the bottom X axis, and in the upper X axis, average number of neighbors per data object at each distance threshold. Different distance units were used on experiment datasets depending on the coordinate system of the real data or the data generator setting of the synthetic data. In the experiment with DATA#1, we used various distance thresholds from 20 to 110 units. When the distance was 20, the max number of neighboring objects of a data object was 17, and the average number of neighboring objects was 4.5. When the distance was 100, the max number of neighboring objects was 63, and the average number of neighbors per data object was 21. The prevalence threshold value was fixed to 0.3. In the experiment of DATA#2, we used 1,000, 1,400, 1,600 and 2,000 unites for the neighbor distance. When the distance was 2,000, the max number and average number of neighboring objects per data object were 184 and 24.6, respectively. In experiments with DATA#2, the prevalence threshold was 0.2, The difference between the running times of the two algorithms dramatically increased in larger distances, i.e., after distance 1600. In the last experiment with DATA#3, we increased the distance to a very small proportion, i.e., from 1.0 to. 1.5, because the EPA data is very dense. We also set a high prevalence threshold of 0.6. As shown in Fig. 11, MaxColoc always shows better performance than GeneralColoc+Maximal. In Fig. 11a, both MaxColoc and GeneralColoc+Maximal showed similar running times until distance value of 40. However, the difference of the running times dramatically increases after distance 80. Figure 11 also shows the results with ClosedColoc. The proposed algorithm also showed better performance than GeneralCloloc+Closed in the execution time.
Discussion
This section first describes the related works and then concludes this paper.
Related work
The problem of mining association rules, based on spatial relationships such as proximity and adjacency, is first discussed in Koperski and Han [17]. The work discovers subsets of spatial features frequently associated with a specific reference feature, e.g., the incidence of cancer. First, transaction records are created around instances of the reference feature. Then spatial association rules are derived using the apriori algorithm [2]. Morimoto [23] proposes a problem which finds frequent neighboring class sets using space partitioning and non-overlap grouping schemes for identifying neighboring objects. Since Shekhar and Huang [29] formalized spatial co-location mining problem, the problem has been popularly studied in spatial data mining literature [14, 39, 38, 41, 8, 23, 34, 37, 22, 33]. Huang et al. [14] define participation index which is statistically meaningful for co-location patterns and propose a spatial join-based co-location algorithm. Some studies indicates that the join-based method becomes inefficient with increasing data size because it requires massive amount of the pattern instance generation operations. Approaches to reduce expensive spatial join operations in co-location mining are proposed in the partial join method [39] and the join-less method [41]. The partial join approach [39] partitions the space with a set of neighborhood size grids disjointly, and keeps track of only neighbor relationships split across partitions using the spatial join operation. Xiao et al. [37] propose a density based approach which uses a clustering technique to find co-location patterns with a definition of density ratio to describe the neighbor relationship. Xiong et al. [38] study the co-location pattern mining problem for extended objects, such as lines and polygons. Zhang et al. [43] generalized the co-location mining problem to discover three types of patterns: star, clique, and generic patterns. Eick et al. [8] work on the problem of finding regional co-location patterns for sets of continuous variables in spatial datasets. Mohan et al. [22] propose a graph based approach to regional co-location pattern discovery. Qian et al. [25] find regional co-location patterns with
Conclusion
Spatial co-location mining is a useful tool for uncovering implicit spatial relationship patterns in spatial data. However, identifying all prevalent co-located feature sets is computationally expensive, and many of result patterns have redundant information. This paper proposes the problem to discover compact sets of co-location patterns with maximal co-locations and closed co-locations. Our work focuses on developing an algorithmic framework to discover these reduced sets of co-location patterns as well as all prevalent co-locations. Two co-location algorithms, MaxColoc and ClosedColoc, are presented on the common framework. They use several schemes for reducing the number of candidate sets examined, efficiently searching co-location instances, and effectively determining the maximality or closedness of prevalent co-located feature sets. We proved that MaxColoc and ClosedColoc algorithms are correct and complete in finding maximal co-locations and closed co-locations, respectively. The empirical evaluation with real and synthetic datasets showed that the proposed framework is effective in generating the reduced sets of co-location patterns.
In the future, we plan to develop a unified framework for mining various co-location patterns in cloud computing environment. We expect that our algorithmic schemes such as the divide-and-conquer method for candidate generation and the filter-and-refine method for co-location instance search can be easily parallelized in a modern distributed computing platform such as Hadoop and Spark.
Footnotes
Acknowledgments
We thank Yeisol Woo for her support to help improve the presentation of this paper.