
Abstract
Due to the rapid growth of web platforms such as blogs, discussion forums, peer-to-peer networks, and various other types of social media, Sentiment Polarity Detection (SPD) (classifying texts by “positive” or “negative” orientation) has become more important and challenging task in recent years. There is a growing need for management and study of SPD not only in English, but also in other languages. The key reason for using Machine Learning (ML) for SPD lies in engineering a representative set of features. This paper explores different (byte, character and word)
Introduction
Sentiment Analysis (SA) is a challenging task that combines natural language processing (NLP) and text mining techniques in order to automatically identify and analyze emotions and opinions in text. In the process of analyzing emotions we generally speak of three text classification (TC) types: (1) identification of subjectivity (opinion classification or subjectivity identification) used to divide texts into those that carry emotional content and those that only have factual content; (2) sentiment classification (sentiment polarity detection – SPD) of texts that carry emotional content into those with positive and those with negative emotional content; (3) determination of the strength or intensity of emotional polarity (strength of orientation). In this paper, we focus on SPD problem that has attracted a great deal of attention, partly due to its potential applications.
Different approaches have been used for SPD, but the mainstream approach basically consists of two major methodologies: a supervised statistical methodology based on the application of Machine Learning (ML) algorithms (when a collection of labeled training data is available), and an unsupervised semantic methodology usually applied when linguistic resources are available, but training data have not been provided. In order to take advantage of both methodologies, some studies apply a hybrid statistical-semantic approach. Regardless of the chosen approach, there are a number of challenges to be dealt with. Pang and his colleagues [36] concluded that the sentiment classification problem is more challenging than traditional topic-based classification problem. Moreover, Turney [49] found movie reviews to be the most difficult of several domains for sentiment classification. Also, one of the difficulties with handling texts written by web users is the presence of different kinds of textual errors, such as typing, spelling and grammatical errors.
Although most of the research activity on sentiment analysis has been concentrated on texts in English [36, 32, 44, 39], people increasingly express their points of views, experiences and opinions in many other languages. Therefore, there is a growing need for management and study of SPD in languages other than English. The aim of this paper is to determine if there is a unique type of features representing text documents, and if it can be valuable regardless of the language, so as to be successfully used by statistical ML classification techniques for solving SPD efficiently and avoiding previously mentioned challenges. We explore byte, character and word n-gram based document representation models in conjunction with k Nearest Neighborhood (kNN), Support Vector Machine (SVM) and Maximum Entropy (MaxEnt) ML algorithms solving SPD task in different natural languages. The effectiveness of techniques and language independence have been demonstrated in experiments performed on publicly available benchmark datasets of movie reviews in seven languages: English, Spanish, Arabic, French, Czech, Turkish and Serbian. Note that English, Spanish, Arabic and French are among top ten languages most used on the Internet according to the Internet World State rank.1
The rest of the paper is organized as follows: the next section presents previous work related to using n-gram based models in order to solve SPD task. Section 3 presents the proposed n-gram based document representation models and ML classification techniques used in this work, and Section 4 describes the experimental framework. The results obtained by experiments are expounded in Section 5, while Section 6 presents the results of comparison with the previously published SPD techniques. Section 7 concludes the paper.
SA in multiple natural languages is explored in [25] as SPD classification task, where the authors applied SVM classifier on character n-grams document representation model. The training data sources were Amazon local websites in English, German and French. The experiments showed that classification model based on multilingual labelled data outperforms the models that utilize the training set only from a single language. The experiments on different n-grams features were not performed. In [12] the authors compared character with word n-grams in solving SPD on a standard corpus composed of 1600 hotel reviews. They concluded that character
To our knowledge, although byte n-grams have been used in many other text classification tasks, there has been only one example of using byte n-grams in solving SPD task. In [17] the authors used byte n-gram frequency statistics method for document representation, and variant of kNN (for
Document representation models
The role of the document representation component is to represent a text document so as to facilitate machine manipulation but also to retain as much information as needed. Text documents should be transformed into a compact and applicable representation which will be used uniformly in training, validation and classification. A text document
A common and often overwhelming characteristic of text data is its extremely high dimensionality. Feature selection techniques are widely employed to reduce the dimensionality of data and enhance the discriminatory information. The word “feature” usually has two different but closely related meanings in the context of text classification. One meaning refers to the unit (corresponding to a term) used to represent or to index a document, while the other focuses on how to assign an appropriate weight to a given term.
A typical choice of “feature” in its first meaning is to identify terms with words. This is often called either set-of-words or bag-of-words (BoW) approach to document representation, depending on whether weights are binary or not. This approach treats text as a set of words ignoring the fact that text is a sequence of data [36].
Moreover, in morphologically rich languages, [47] a word can get a large number of derived word forms (for example, in Serbian, lemma ljubav ‘love’ has 15 inflected words [33]). Since word forms of one word have the same or similar meaning, sometimes it is useful to replace them by the single one, which is usually stem or lemma. The process of replacement is used as a part of a space dimensionality reduction in many NLP tasks. Stemming (a process of reducing inflected or derived word forms to their stem, base or root form) and lemmatization (a process of reducing inflected word forms to the basic word form – lemma) are language-dependent dimensionality reduction techniques, and a raw text has to be previously tokenized (divided into single words). But, many Asian languages (Chinese and Japanese, for example) actually do not have explicit word boundaries in text. Beside BoW model, there are many studies that use n-gram models.
Term
When used in processing natural language documents, character and byte n-grams exhibit many good features:
Language and topic independence: There is no need for any text preprocessing or higher level processing, such as tagging, parsing, or other language dependent and nontrivial NLP tasks;
Robustness: There is relative insensitivity to spelling variations and errors. Since each string is decomposed into small parts, any errors that are present tend to affect only a limited number of these parts, leaving the rest intact;
Word stemming is got essentially for free: The n-grams for related forms of a word (e.g., “advance”, “advanced”, “advancing”, “advancement”, etc.) intrinsically have a lot in common when viewed as sets of n-grams;
No linguistic knowledge is required: It is not necessary to have any linguistic information, even about space character used for word separation, the new line character, uppercase and lowercase letters, and the like;
Completeness: Token alphabet is known in advance;
Efficiency: Only one pass processing is required.
Using of char and byte
The main disadvantage of using n-gram techniques is that they yield a large number of n-grams. But in the case of relatively small-scale text collections, possibility to easily render several thousands of distinctive features can actually be an advantage.
N-gram techniques have been successfully used for a long time in a wide variety of problems and domains. In NLP they turn out to be effective in many applications, for example, text compression [51], information retrieval [8], authorship attribution [24], flat and hierarchical topic text classification [14, 15, 16] etc.
In our experiments we used byte, character and word n-grams with their normalized frequencies as document representation models. For producing n-grams and their normalized frequencies, the variant of publicly available software package Text:Ngrams3
The first technique that we present in this paper for SPD is a variant of the kNN (for
Note that dissimilarity measure plays an important role. We used dissimilarity measure in a form of relative distance presented in [24]:
where
The SVM classifiers have been shown to be efficient and effective for TC. It is a supervised ML method that generates input-output mapping functions from a set of labeled training data. Although the original model of SVMs was designed to do binary classification, for the purpose of this research we used
Available at
where
Maximum entropy modeling is a supervised ML method for prediction probability distribution of data labels y by maximizing following entropy function Eq. (3) that fits training data x, i.e. satisfies given constraints.
It can be shown that there is always a unique model
In this paper we used SharpEntropy library – a part of SharpNLP,5
In this section, we describe the framework used to evaluate the experiments carried out in this work.
Performance evaluation
The performance evaluation of classification methods can be measured in different ways. Frequently used measures for classification are: ROC curve (for imbalanced datasets), Gmean (the geometric mean of accuracies measured on each class separately), Dominance Index (difference between true positive and true negative rates which can be interpreted as a measure of balancing these rates), etc. In this research, we used the typical evaluation metrics that come from information retrieval – Precision (P), Recall (R), F1 measure and Accuracy [2]:
where TP (True Positives) is defined as the number of documents that were correctly assigned to the considered category, TN (True Negatives) is the number of the assessments where the system and a human expert agree on a negative label, FP (False Positives) is the number of documents that were incorrectly assigned to the considered category, and FN (False Negatives) is the number of negative labels that the system assigned to documents otherwise assessed as positive by the human expert [22]. All presented measures can be aggregated over all categories in two ways: micro-averaging – the global calculation of measure considering all the documents as a single dataset regardless of categories, and macro-averaging – the average on measure scores of all the categories. In this research we used macro-averaged P, R, F1 and Acc.
Benchmarks of movie reviews used for SPD
For empirical evaluation of the SPD techniques presented, eight balanced and publicly available benchmark movie reviews datasets were used (see Table 1):
CornellPD:
MuchoCine is available at:
OCA is available at:
TMR is available at:
CSFD is available at:
http://www.csfd.cz/.
Results for movie reviews in English, Spanish and Arabic
Notes: Bold numbers denote the best results for each SPD technique and each dataset among byte, character and word
We have made byte, character and word n-gram representation of all mentioned benchmarks used in our work publicly available13
Comparison of different 
In order to compare different
Feature selection performed automatically and no additional knowledge about the domain was used. In the case of byte and character n-grams we performed experiments for n-gram lengths between 2 and 9, while for word n-grams we used n-grams with lengths between 1 and 3, for all methods. We used available optional parameters related to noise and missing values – cutoff frequency and smoothing. In the case of kNN, classification parameter L (number of the most frequent
We can conclude that the best results have been obtained for MaxEnt ML technique, with the exception of OCA in Arabic (where the best results have been obtained for kNN). Comparison of different n-gram models for each benchmark and each ML technique is graphically represented in Fig. 1. From this figure we conclude that accuracy of SPD technique strongly depends on the dataset used, so for a fair benchmarking process the same datasets need to be used for SPD techniques comparison. Also, from the obtained results, it is obvious that byte and character n-gram models outperform word n-gram model for all benchmarks and all ML techniques, while, as we expected, the results for byte and character n-grams are quite similar. In the case of word n-grams, the best results have been obtained for
Results for movie reviews in French and Turkish
Notes: Bold numbers denote the best results for each SPD technique and each dataset among byte, character and word
Results for movie reviews in Czech and Serbian
Notes: Bold numbers denote the best results for each SPD technique and each dataset among byte, character and word
In order to evaluate performance of the
Comparison results with other supervised statistical SOA results
Comparison results with other supervised statistical SOA results
Notes: Bold numbers denote the best results for each dataset. In brackets we indicated how much our results differ from the best published results. In our approach we performed two-class (positive and negative) classification, while other authors performed three-class (positive, neutral, negative) classification.
Comparison with unsupervised semantic SOA results
Notes: Bold numbers denote the best results for each dataset. In brackets we indicated how much our results differ from the best published results. DAL
Comparison of different 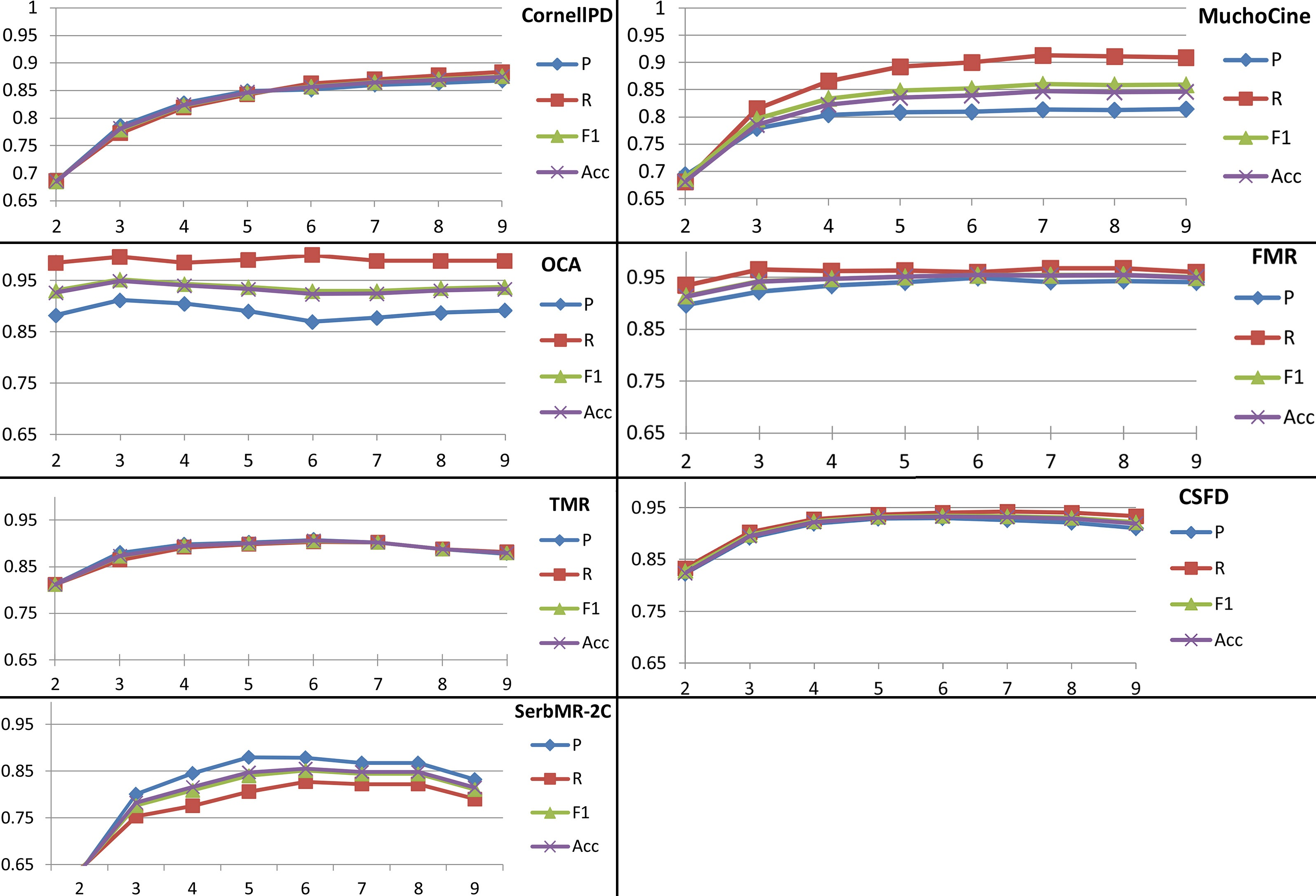
tion marks and digits and did uppercase conversion, while in the case of byte-level n-grams model there was no need for any preprocessing steps. Except for the supervised statistical ML technique, our technique outperforms other unsupervised semantic techniques (see Table 6) and in some cases (Arabic, French and Czech) other hybrid statistic-semantic techniques that have been at least partially knowledge-based (see Table 7). Some of them used valence shifters (negations, intensifiers, diminishes) [23], some
Comparison with hybrid statistical-semantic SOA results
Notes: Bold numbers denote the best results for each dataset. In brackets we indicated how much our results differ from the best published results. GIL
used text mining techniques to extract frequent word sub-sequences and dependency sub-trees from sentences in a document dataset [31], some of them embedded background knowledge derived from Wikipedia into a semantic kernel used to enrich the document representation model [52], while some of them used Dictionary of affect in language (DAL) [9] to determine an “evaluation” value to each word depending on its affective contents. Comparing results in Table 7 with those in Table 5 we conclude that hybrid SOA approaches outperform statistical supervised ML techniques. This further leads to the conclusion that our supervised ML techniques have a great potential to be combined with some knowledge-based techniques using some additional linguistic resources, such as SentiWordNet [11], WordNet-Affect or General Inquirer [45] in order to improve accuracy. Regardless, our supervised ML (byte and character) n-gram based techniques in many cases (Arabic, Czech, French, Serbian and Turkish) have achieved SOA results.
In this paper we explored byte, character and word n-gram document representation models in order to see if there is a unique valuable type of features that can be used for representing text documents in different languages, so as to be successfully used by machine learning (ML) classification techniques to efficiently solve SPD. In our experiments we used kNN, SVM and MaxEnt ML supervised techniques. We demonstrated presented n-gram models on seven different publicly available benchmark corpora of movie reviews in paradigmatically quite different languages (Cornell Polarity Dataset in English, MuchoCine in Spanish, OCA in Arabic, FMR in French, TMR in Turkish, CSFD in Czech and SerbPD and SerbMR-2C in Serbian). We have found that byte and character n-gram models outperform word n-gram model. There is no need for any text preprocessing or higher level processing, so the necessity for the usage of taggers, parsers or other language-dependent and non-trivial natural language processing tools is avoided. They are fully language and topic independent and they do not require any prior information about document content or language. Despite their simplicity and broad applicability, we have obtained the best results among all other ML supervised statistical techniques, and in some cases (Serbian, Arabic, French, Turkish, Czech) we have obtained state-of-the art results.
The overall success of the presented techniques testifies that character and especially byte n-gram based document representation models are sound and promising in solving SPD task. They provide an inexpensive and effective way for sentiment analysis of large collections of documents written in any language, so we are encouraged to continue this line of research. Since semantic content in texts and knowledge of the domain are very important, and
Footnotes
Acknowledgments
The work presented has been financially supported by the Ministry of Science and Technological Development, Republic of Serbia, through Projects No. 174021 and No. III47003.