
Abstract
Cross language plagiarism is the unacknowledged reuse of text across language pairs. It occurs if a passage of text is translated from source language to target language and no proper citation is provided. Although various methods have been developed for detection of cross language plagiarism, less attention has been paid to measure and compare their performance, especially when tackling with different types of paraphrasing through translation. In this paper, we investigate various approaches to cross language plagiarism detection. Moreover, we present a novel approach to cross language plagiarism detection using word embedding methods and explore its performance against other state-of-the-art plagiarism detection algorithms. In order to evaluate the methods, we have constructed an English-Persian bilingual plagiarism detection corpus (referred to as HAMTA-CL) comprised of seven types of obfuscation. The results show that the word embedding approach outperforms the other approaches with respect to recall when encountering heavily paraphrased passages. On the other hand, translation based approach performs well when the precision is the main consideration of the cross language plagiarism detection system.
Introduction
Plagiarism is the unacknowledged reuse of others’ ideas or text without giving a proper credit [37]. In recent years, researchers enjoy easy access to a wide range of information via the Internet, especially across languages. Unfortunately, this also causes plagiarism occurs more simply. There are many attempts to detect plagiarism, especial across languages. In a research accomplished by Stein et al. [38], a generic three-step retrieval process for a plagiarism detection (PD) system was proposed. They have presented the retrieval process for external plagiarism detection as depicted in Fig. 1. In the candidate retrieval step, a heuristic task to retrieve potential source documents is done. In the text alignment step, an exhaustive comparison of suspicious document against selected source documents is applied. In the final stage named as knowledge-based post-processing step, those detected fragments with proper citation are discarded as they are not plagiarized. The result is offered to a human expert to take the final decision. It should be noted that textual similarity detection methods are not exactly the methods to detect plagiarism. Plagiarism occurs when someone deliberately copy a passage of text without proper attribution, while these methods only detect textual similarities. Therefore, it is not enough to just recognize text similarities and to consider these similarities as plagiarized passages [11].
Generic retrieval process for external plagiarism detection.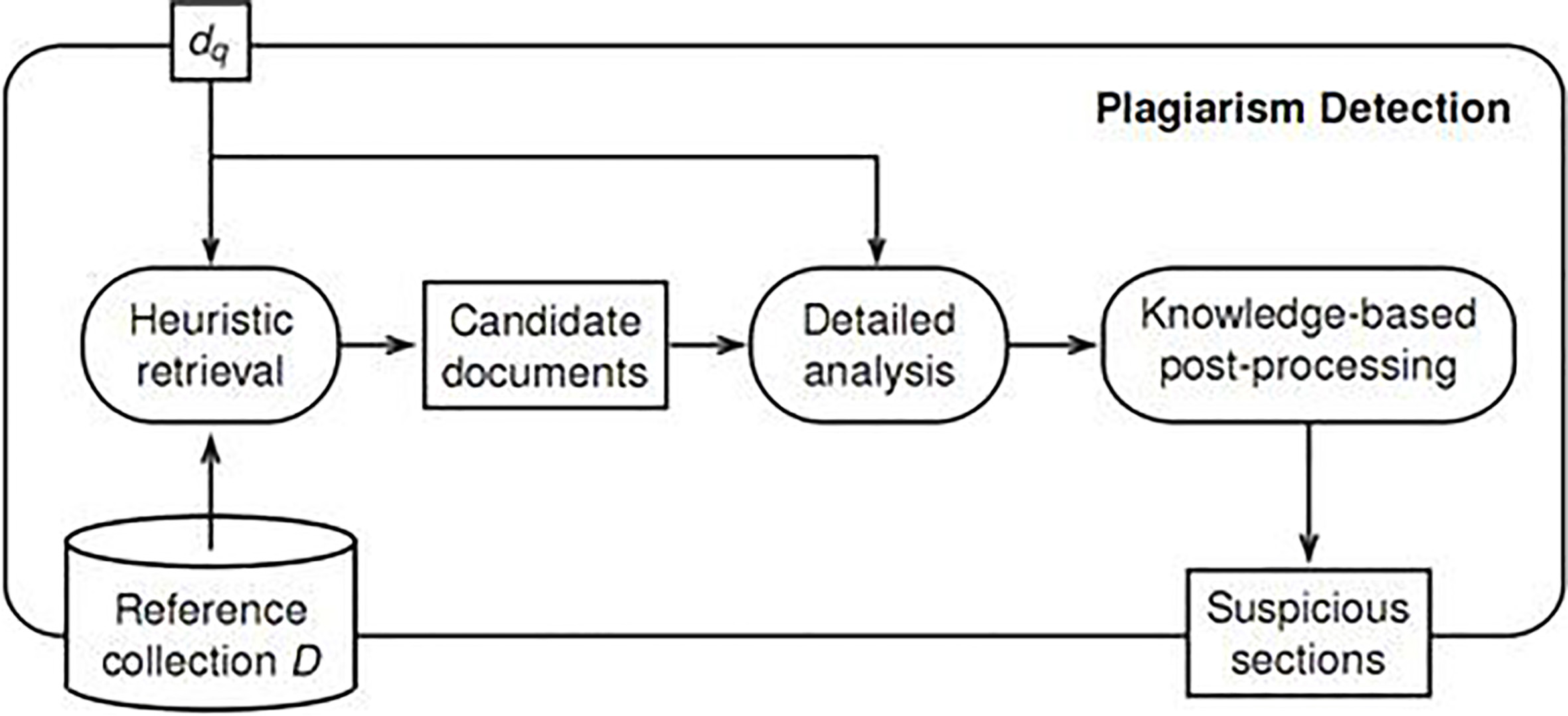
The problem of detecting plagiarism does not end at language boundaries. When plagiarism is done by a translation process, it is known as cross-language plagiarism. Nowadays, a vast amount of knowledge is created in rich resource languages like English, and students and re- searchers, especially in low resource languages, have a motivation to bring the knowledge to their language through translation. Cross Language Plagiarism Detection (CLPD) systems try to find plagiarism cases between language pairs. Cross-language plagiarism detection is to identify the text reuse given suspicious documents in one language L
In this paper we have focused on English-Persian language pairs as two distant languages, in which English is a rich resource language, while Persian is a low resource one. Therefore, the task of a CLPD system is to find the source document(s) in English for the given suspicious document in Persian in order to detect possible re-use of text.
There are some drawbacks of applying current algorithms to CLPD in Persian. In this research we challenge with the following problems:
Persian is a less-resourced language which has a low degree of representation on the Web and few numbers of NLP algorithms and techniques as well. They are often referred to as low profile languages. Because of the shortage of resources and tools in Persian, machine translation tools do not work well, especially when we deal with passages that are heavily paraphrased. Persian and English are distant languages, so some approaches such as ordinary cross-lingual character n-gram (CL-CNG) algorithm cannot be applied in an English-Persian text reuse detection system. Persian is an Arabic-Script based language. There are many problems to basic preprocessing tasks in this language such as normalization, stemming and recognizing word and multi-token word boundaries [10]. Various types of paraphrasing can be done through translating a text passage from a language into other languages. In other words, translation and paraphrasing can be considered as two connected natural language processing tasks. In order to investigate the effect of paraphrasing via translation, we compiled a plagiarism detection corpus with different types of paraphrasing such as summarizing, splitting the sentence to two or more sentences, merging two or more sentence to one sentence and heavy paraphrasing of the sentence in the target language. Since CLPD systems would have different performances facing different types of paraphrasing, different approaches can be evaluated properly using the proposed corpus. To the best of our knowledge, no work has been done before considering these differing types of paraphrasing.
Word embedding methods showed their effectiveness in text similarity in recent years [17]. In this paper, we present a word embedding based approach to cross language plagiarism detection and compare its performance against five different categories of algorithms for the task of CLPD.
The rest of the paper is organized as follows. Section 2 describes some of the recent works in the field of cross-language plagiarism analysis. Section 3 presents our methodology for investigating various CLPD algorithms with a broad type of parameters. The data preparation and corpus construction for evaluating the algorithms are also described in this section. Section 4 gives a detailed description of the experiments carried out in our work. Finally, Section 5 includes the discussion and the future work.
In this section, we present some of the previous methods on cross-language plagiarism detection. Figure 2 depicts the taxonomy of various approaches on CLPD. As shown in the figure, there are five main categories for the task of CLPD. Moreover, some of the recent works have tried to combine different approaches to benefit from advantages of two or more methods. In the following subsections, we describe the recent approaches based on the above mentioned taxonomy.
Taxonomy of approaches to CLPD.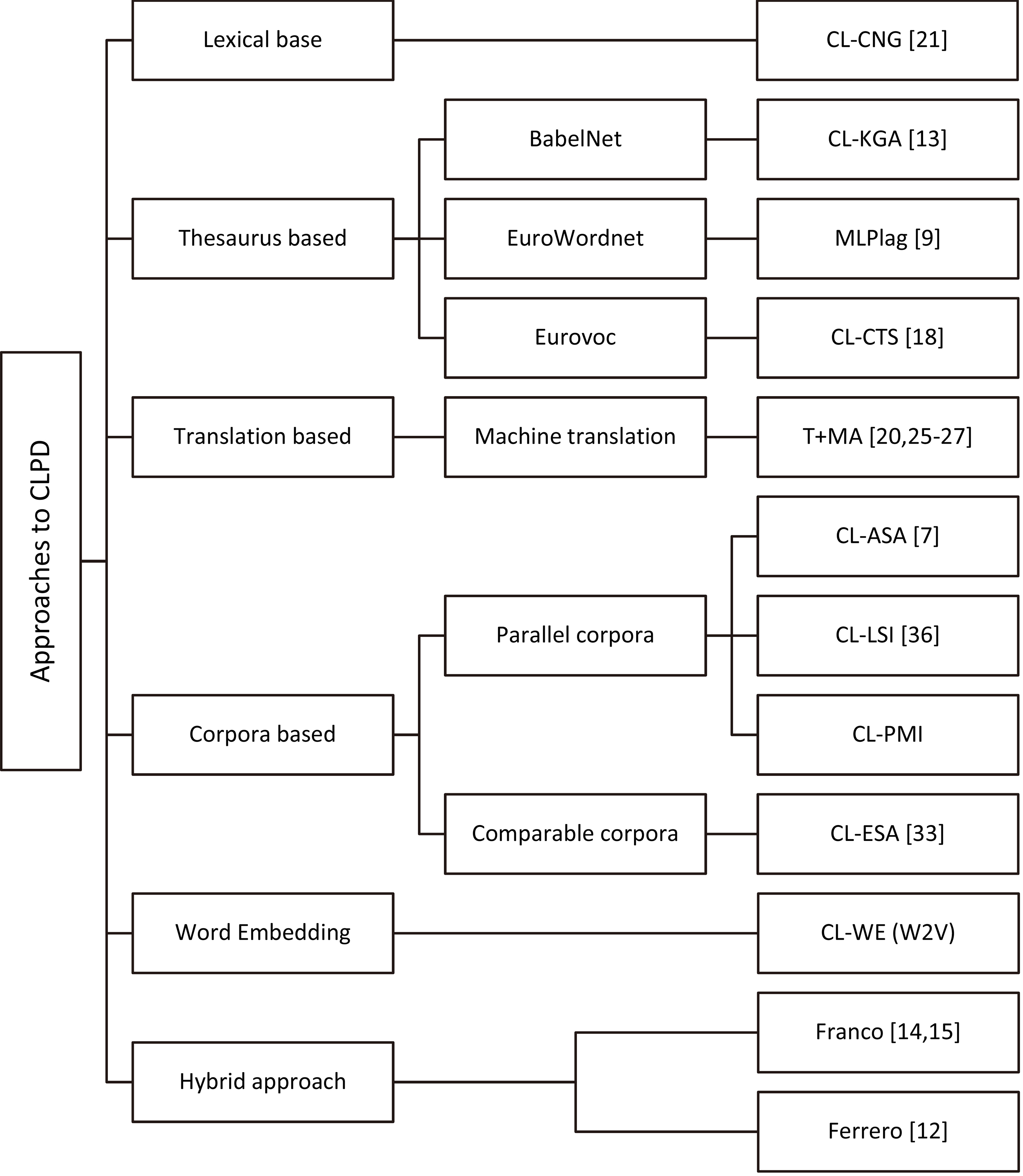
Lexical based approaches try to compare multilingual documents without using translation systems or any multi-lingual resources of data. They analyze cross-lingual similarity considering the structural and lexical similarity between languages. Cross-Language Character N-Gram model (CL-CNG), which uses overlapping character N-gram tokens, has been proposed in [21]. The method is based on the fact of lexical similarity between languages sharing similar syntactic structure (e.g., related European language pairs). The obtained results for European languages show a competitive accuracy with respect to language-specific approaches. This approach can compare multilingual documents without using translation systems. However, due to lexical differences and different writing alphabets between distant languages with different lexicon, this method cannot be applied for detecting cases of similarity while encountering different lexicon [41].
Thesaurus based approaches
Thesaurus based approaches use multi-lingual resources to transform passages in different languages into a unique language independent form. The BabelNet and EuroWordNet are the most popular resources for different cross language tasks including CLPD. BabelNet is a very large, wide-coverage multilingual semantic network which is automatically constructed by integrating lexicographic and encyclopedic knowledge from WordNet and Wikipedia[24]. The BabelNet version 3.7 covers more than 270 languages and made up of about 14 million entries, called Babel synsets.1
MLPlag system is proposed by Ceska et al. [9] is based on the analysis of word positions for plagiarism detection across languages. The proposed approach utilizes the EuroWordNet thesaurus which transforms words into language independent form. In the case of ambiguous words, two words from different languages have been considered as plagiarized if one of the senses matches with the one in the other language. They compared the influence of multilingual pre-processing and also two different similarity measures, named as symmetric and asymmetric measures on the performance of their plagiarism detection system [9].
An approach to identify very similar documents among a collection of candidate documents has been proposed in [35]. The proposed method is based on representing the document contents by a vector of thesaurus terms from a multilingual thesaurus, and measuring the similarity between vectors. In their proposed method, they used a “Length Factor” based on the observation of differences between the lengths of original and translated texts in Spanish, French and English. They found that the variation of the length difference approximately follows a normal distribution and considered it as a factor for computing the similarity between documents. The proposed length factor has also been used as a separated score for measuring cross-lingual text similarity for CLPD in [18].
CL-CTS method is proposed by [18] to measures the cross-lingual similarity based on a conceptual thesaurus by representing documents in the conceptual space using a domain specific Eurovoc conceptual thesaurus. The proposed model represents documents as vectors after filtering stop words, stemming and using term frequency weighting schema to build the vectors. At the final step, they compare the similarity between vectors using the cosine similarity measure in addition to named entities matching and “Length Model” similarity.
A knowledge graph-based approach is proposed in [13] by using BabelNet to obtain and compare context models of document fragments in different languages. To build their knowledge graph, at the first step, a set of concepts in each fragment of text is extracted in different languages. In the next step, they obtain a set of paths (P) by searching the BabelNet for paths between each pairs of concepts. The knowledge graph is constructed by joining the paths from P. Then the concepts and relations have been weighted based on the degree of relatedness. Finally, to compare pairs of fragments in different languages, the resulted graphs are compared based on conceptual graph similarity algorithm. Their results show better performance of the proposed model with respect to other lexical and distributional based models [13].
Translation based models use dictionaries and machine translation systems to translate suspicious document into the source language and then do a mono-lingual analysis. Automatic machine translation tools have been used by many researches for detecting cases of cross-lingual plagiarism [27, 25, 26, 20]. In translation plus monolingual analysis (T+MA) approach, the suspicious documents are translated to the same language as the source documents, and mono-lingual PD methods applied to find plagiarized cases. Different monolingual PD methods (e.g. word N-Gram similarity and vector space model similarity detection) can be applied to compare the resulted mono-lingual documents. However, the accuracy of CLPD systems based on these approaches is constrained by the availability and quality of translators; in other words, it is limited to and upper bounded by quality of Machine Translation tools [19].
Corpora based approaches
Corpora based approaches use different multi-lingual resources to train similarity detection models. Although most methods use sentence aligned parallel corpora, some approaches have been proposed based on comparable resources.
Cross-language explicit semantic analysis (CL-ESA) retrieval model is proposed in [33] for cross-language similarity analysis. The proposed model is an extension to previously proposed explicit semantic analysis (ESA) model. ESA uses a document collection (D) with n documents, and measure the cosine similarity of target document (d) with the collection (D). In the proposed model, each document can be represented with a vector (V) of n dimensions, where the ith index in V shows the cosine similarity between d and the ith document of D. The similarity between two documents under the ESA model is defined as the similarity between resulted vectors (e.g. cosine similarity). CL-ESA uses same principle as ESA to compare documents in different languages. For this purpose, a collection of comparable Wikipedia documents in different languages (D) is used to measure the cosine similarity between document d in the language L
Cross-lingual latent semantic analysis (CL-LSA) has been proposed by Rehder et al. [36] to construct a multilingual semantic space. LSA creates a reduced-dimension feature space by applying singular value decomposition (SVD) on word-document matrix, in which words that occur in similar contexts are near to each other. The proposed CL-LSA method uses manually or automatically translated documents to create a set of bilingual training documents. Based on the structure of training documents that contain terms from both languages, the resulting LSA model is a bilingual vector space.
An approach for cross lingual plagiarism detection by using statistical bilingual dictionaries based on the IBM-1 alignment model has been proposed in [7, 28]. Given the suspicious and source texts
This model has been tested on a mini-corpus of original plagiarized pair of texts. Moreover, in [28] the proposed statistical approach based on IBM1 has been evaluated on different cross-lingual tasks of NLP such as bilingual text classification, cross-language information retrieval and cross-language plagiarism detection. In contrast to current approaches that ignore or do not take full advantage of multi-linguality, the aim of the presented approach was to capture word correlation across languages. The obtained results in different tasks show the benefits of the IBM1 model and the advantageous of learning cross-lingual information directly from cross-lingual resources.
Word Embedding approaches
Word Embedding (WE) methods, which map words or phrases to vectors of real numbers, have shown tremendous success in numerous NLP tasks in recent years. According to good performance of word embedding methods, some of the more traditional distributional representation models have been fully replaced with these novel approaches. Cross-lingual word embedding models try to learn features (em-bedding) for each word in such a way that similar words in each language are assigned similar embedding (that meets monolingual objective function), and also similar words across languages to have similar representations (that meets cross-lingual objective function) [17]. To achieve this goal, different bilingual resources (i.e. parallel corpora, word aligned corpora or comparable corpora) have been used by different approaches.
The use of word embedding methods in mono-lingual plagiarism detection has been used by Gharavi et al. [16]. In this paper we investigate the performance of cross-lingual word embedding in the task of CLPD.
Hybrid approaches
In addition to the mentioned approaches for measuring cross-lingual similarity and cross-language plagiarism detection which use different resource to train their models, some of the recent hybrid methods try to combine the benefits of different approaches to improve accuracy.
A new model based on knowledge graph and continuous space representation of words has been proposed in [15, 14]. The presented method basically follows the previously proposed CL-KGA model [13]. For weighting the obtained BabelNet semantic relations, instead of using the BabelNet’s relation weights, the continuous Skip-gram and SenVec models have been used in this approach [15]. Moreover, in this research the impact of relevant aspects of the model has been studied for the task of CLPD which includes word sense disambiguation (WSD), vocabulary expansion, language independence and representation by similarities with a collection of concepts. The obtained results show the importance of WSD for improving the model’s performance in the task of cross-language plagiarism detection [15].
Ferrero et al. presented different syntax-based, dictionary-based, context-based and MT-based methods and a hybrid method by combining some of these approaches for the task of cross-lingual textual similarity in SemEval-2017, named as CompiLIG system [12]. Among all of their runs, the Cross-Language Conceptual Thesaurus-based Similarity (CL-CTS) achieved the best result, which consists of representing texts as bag of words (or concepts) to compare them [12]. As a hybrid method, the most similar words from the embedding space have been added to the main concepts of the sentences from a multi-lingual semantic network. In other words, they use word embedding methods to enrich the basically extracted concept from the thesaurus [12].
In this paper, we have investigated various approaches that are proved to be efficient in CLPD and compared them with each other. It should be noted that a comprehensive investigation and comparison of monolingual plagiarism detection algorithms in Persian has been done in a PAN-FIRE shared task on plagiarism detection [2]. In this paper, we focused on English-Persian CLPD. Shortly our contributions are as follows:
Benchmarking the state-of-the-art CLPD and cross-lingual text similarity detection approaches Investigating the performance of CLPD approaches applied to low resource languages (e.g. Persian) Applying the above mentioned approaches on the HAMTA-CL corpus with various types of obfuscation (paraphrasing)
Moreover, in this research we have investigated cross lingual word embedding method on the task of plagiarism detection and compared it to the other previously proposed approaches. In order to compare the performance of the proposed approach, we have applied the above mentioned approaches on the HAMTA-CL corpus with various types of obfuscation.
In this section, the selected methods and the evaluation framework for measuring the performance of algorithms are described in detail. Moreover, the proposed approach on CLPD based on cross-lingual word embedding is also described.
Choosing the algorithms
In order to compare the performance of the word embedding method against the other algorithms, a collection of state-of-the-art approaches including CL-ESA, CL-KGA, CL-LSA and T+MA were selected and applied on the proposed HAMTA-CL corpus. Due to lexical and syntactical differences between Persian and English as two distant languages, the CL-CNG method cannot be applied for detecting cases of similarity, so we ignored this method.
As mentioned in [33], the collection D should contain documents from a broad range of domains, and each index document should be of “reasonable” length. While a subset of the documents in Wikipedia can fulfills both properties, for the training phase, we used a collection of 20000 comparable articles from Wikipedia. The selected articles cover broad ranges of topics, contains both Persian and English Wikipedia pages and also contains more than 500-words length in both languages.
In our experiments, the suspicious and corresponding source documents have been split into sentences. We embed each sentence in the source and suspicious documents into vectors using CL-ESA. For this purpose, each sentence has been compared with a collection of 20000 documents under cosine similarity measure. The Persian sentences have been compared with Persian Wikipedia pages and English ones have been compared against equivalent English pages. To detect cases of plagiarism between documents, the cosine similarity between derived vectors in two documents has been computed.
Given a source document and a suspicious document we compare document fragments in following steps as described in [13]: We segment the original document in a set of fragments, using a 5-sentence sliding window with a 2-sentence step on the input document. The paragraphs are lemmatized and tagged according to their grammatical category. The knowledge graphs from the tagged fragments are built using the BabelNet. Finally we compare these graphs to measure similarity between different fragments.
In our experiments, the source and suspicious documents are split into sentences. The BILBOWA has been used to convert constitutive words into 200 dimensional vectors. We used a simple averaging approach to combine word-vectors to create vectors of sentences. It has been shown that the averaging approach has the best performance for the task of sentence embedding for semantic similarity detection [39]. The resulted vectors of sentences have been compared using cosine similarity measure to detect cases of similarity between source and suspicious documents.
Evaluation framework
For investigating the performance of the CLPD algorithms, an evaluation framework is required. The framework is comprised of an evaluation corpus along with evaluation measures. In the following subsections we will thoroughly describe the construction of the HAMTA-CL English-Persian corpus and the measures that have been employed for evaluation of the methods.
Corpus construction
In order to compare the performance of different algorithms on English-Persian plagiarism detection, a CLPD evaluation corpus should be constructed. In this section, we first review some of the recently developed corpora and then describe our methodology for building an English-Persian plagiarism detection corpus.
A cross-language plagiarism detection corpus has been constructed by Ceska et al. [9] for evaluating CLPD methods using JRC-EU and Fairy-tale multilingual corpora. The proposed corpus consists of 200 English reports from JRC-EU and 27 English document of Fairy-tale as source documents and the same number of documents in Czech as the suspicious ones.
A cross-language PD corpus has been compiled in [30] using 23,000 JRC-Acquis parallel corpus documents and 45,000 Wikipedia documents, in which 10,000 aligned documents have been used to test the algorithms.
The first English-Persian corpus has been proposed by Asghari et al. [1] in PAN 2015 text alignment corpus construction shared task. An English-Persian sentence aligned parallel corpus was used to compile cases of plagiarism across the two languages. Plagiarized fragments in suspicious document have been constructed from Persian sentences and corresponding source fragments have been constructed from English sentences. To consider the degree of obfuscation in plagiarized fragments, a combination of sentences with different similarity scores were chosen. The number of sentences and their similarity score in a fragment specifies the four degree of obfuscation in the fragments.
A Hindi-English corpus which includes 5032 English documents from Wikipedia and 388 Hindi documents has been used for the CL!TR task on cross-language text re-use detection [6]. To generate cases of plagiarism, the participants are asked to write a short answer to a set of questions either by re-using the source documents or by using learning materials. To simulate real cases of plagiarism, they asked participants to answer questions with 4 different levels of obfuscation including: near copy, light revision, heavy revision and no-plagiarism [6].
A multi-style multi-granularity corpus for cross-language textual similarity detection has been proposed by Ferrero et al. [11]. The proposed corpus is in French, English and Spanish and is based on a parallel corpus along with a comparable corpus. Both human translated texts from multiple types of authors and also machine translated texts have been used for constructing the corpus. They have prepared different granularities in document-level, sentence level and chunk-level (noun chunks).
Figure 3 demonstrates the flow diagram for construction of the cross-language PD corpus with the above mentioned paraphrasing techniques. Wikipedia articles are used as primary resource to create the HAMTA-CL corpus. Because of its scale, context and open accessibility, Wikipedia is the best available resource to compile such a corpus. Due to the importance of documents’ length in compiling a realistic PD corpus, among the whole Wikipedia documents, 1904 documents with a variety of lengths have been used to compile the proposed corpus. Parsivar pre-processing toolkit was used to normalize the Wikipedia documents [23]. The statistics of documents is represented in Table 1.
Corpus statistics
Since in real situations, the plagiarism can be done in different lengths, a broad range of lengths is considered to create potential plagiarized fragments. The lengths of fragments are distributed between 20 and 300 words to simulate all types of plagiarism and the distribution of fragments’ length are depicted in Table 2 and Fig. 4, respectively. Moreover, the statistics of the different types of obfuscations in proposed corpus is represented in Table 3.
Plagiarism case statistics
Flow diagram of bilingual PD corpus construction.
As shown in the Fig. 4, the Merge obfuscated fragments have the shortest length on average among all the passages. Also, the average length of Summarization obfuscated fragments (SUM) are the longest among different types of passages. This is because we have selected long passages for the source documents in such a way that the summarization process could be easier for crowd-workers. Moreover, the mean length of all plagiarized passages except summarization is almost the same.
Statistics of different types of obfuscation
Ratio of plagiarism fragments in documents
Length distribution of the fragments.
We should also cover different situations concerning ratio of plagiarized fragments per suspicious document. To this aim, a wide range of plagiarism ratio is considered from hardly (i.e., low ratio of plagiarized fragments per suspicious document) to much (i.e., most parts of the document is plagiarism) as shown in Table 4.
The corpus was automatically validated considering the ratio of the length of plagiarized passages to the length of the documents, and the distribution of plagiarized passages across the documents. Moreover, a manual checking was done for evaluating the quality of plagiarized fragments. It should be noted that the constructed corpus is freely available to use for the research community.2
The ordinary measures for evaluating the performance of NLP algorithms are precision, recall and F-measure. In plagiarism detection tasks, we use character-level precision and recall. Besides this performance measures, another measure that characterizes the goodness of a detection algorithm have been defined in [34, 4]; whether a plagiarism case is detected as a whole or it has been detected in several pieces. Granularity quantifies whether the contiguity between plagiarized text passages is properly recognized. A low granularity simplifies both the human inspection of algorithmically detected passages as well as an algorithmic analysis within a potential post-process [34]. To capture this characteristic, they have introduced the granularity of R under S as follows:
The range of gran(S, R) is between [1, R], with 1 indicating the desired one-to-one correspondence and R indicating the worst case. Precision, recall (both at character-level) and granularity have been combined to an overall score based on following equations:
The three measures can be applied in isolation, but they can also be combined into a single, overall performance score as follow:
Where
We investigate the performance of CL-LSA, CL-ESA, BILBOWA, CL-KGA and T+MA on the task of English-Persian plagiarism detection in the following experiments.
Experiment 1
In this experiment, we have measured the performance of CL-ESA, CL-LSA, BILBOWA, CL-KGA and T+MA algorithms in detecting cases of plagiarism on the whole HAMTA-CL corpus. Our goal is to measure the performance of CLPD methods on the proposed corpus that contains various types of obfuscation against the BILBOWA.
The graphs of precision, recall and F1 measure versus different similarity thresholds are depicted in Fig. 5.
Performance of algorithms on the HAMTA-CL corpus in terms of Cosine similarity between sentence pairs.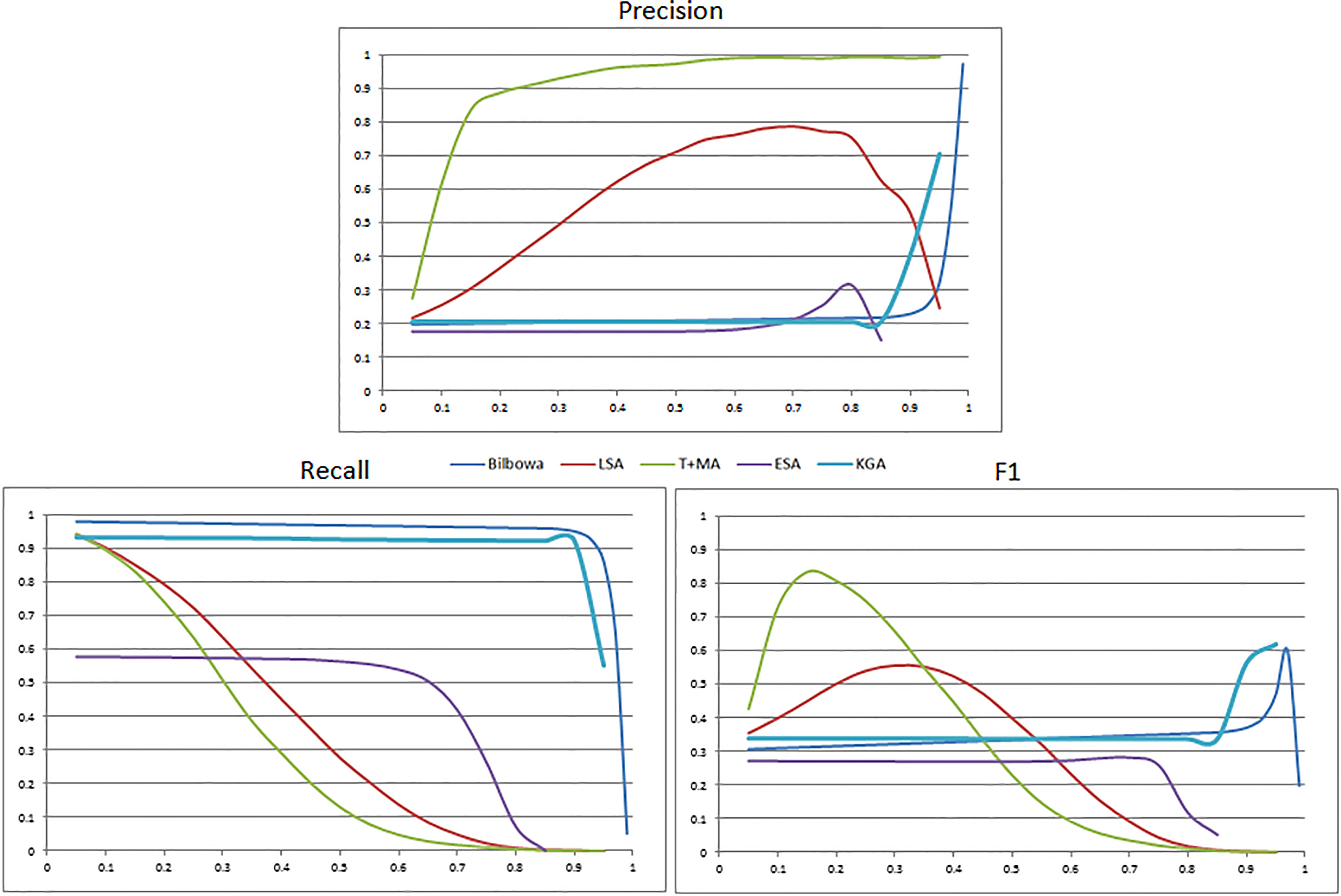
As shown in the figure, the T+MA algorithm obtains the best F1 and precision in the whole corpus. Moreover, BILBOWA outperforms other approaches with respect to recall for different ranges of cosine similarity threshold. In comparison to other approaches, CL-ESA obtains the worst results among all the algorithms, especially in the case of precision. In the graph that represents F1, T+MA performs well when the threshold is less than 0.15. After this threshold, the performance of T+MA decreases monotonically. There is a similar trend in CL-LSA except that the best performance achieved under the threshold of about 0.35. On the contrary, the behavior of BILBOWA and CL-ESA remains constant in most of the ranges of similarity thresholds. The best performance for BILBOWA is achieved with threshold of about 0.98 which obtaining on F1 measure of 0.61.
In the second experiment, the performance of the CLPD methods is computed against separate sub-corpora containing different types of paraphrasing. Our purpose is to evaluate the capability of the methods on detecting different types of obfuscation.
Performance measure for different types of obfuscation.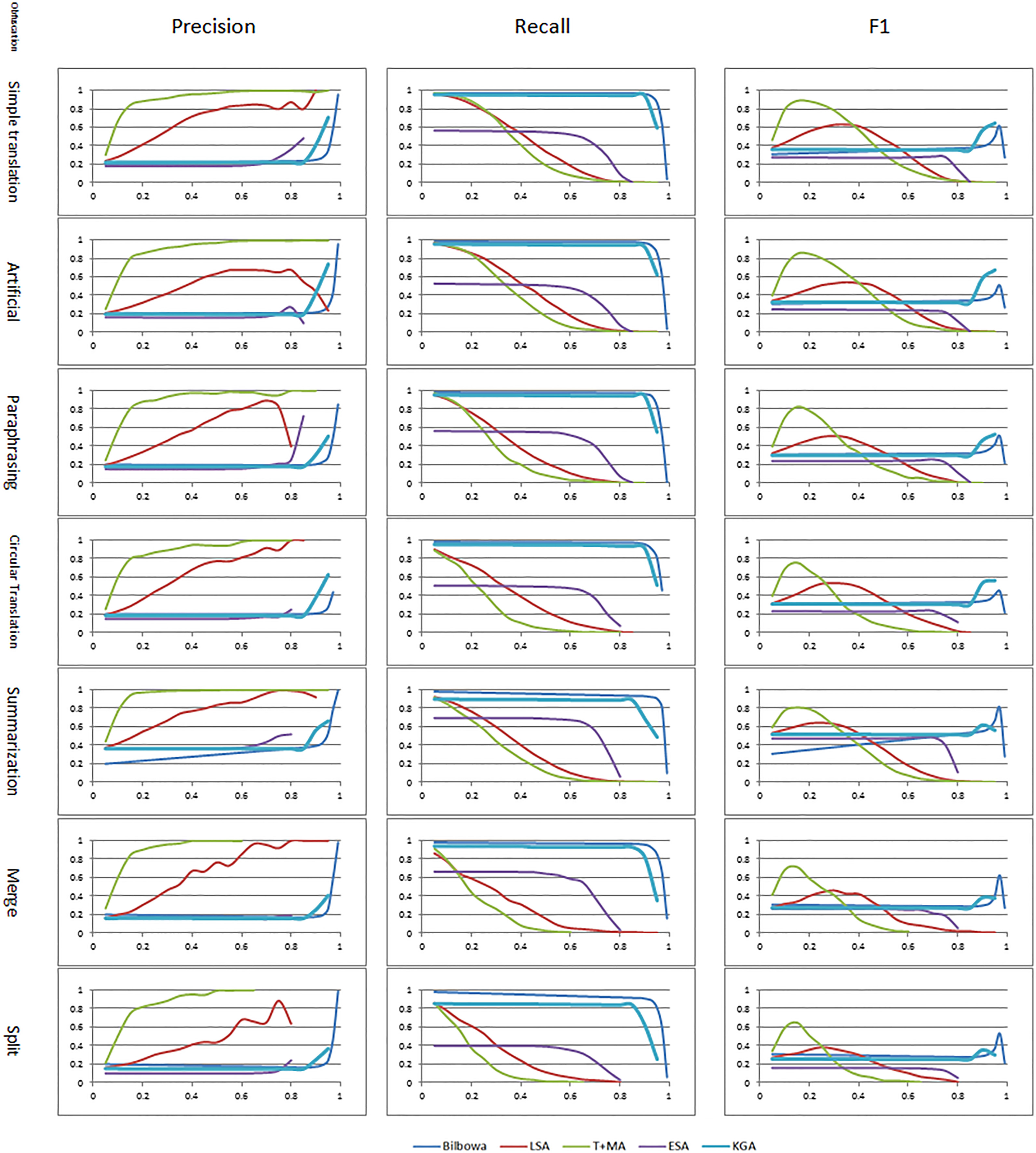
The performance of the methods to recognize cases of plagiarism with different types of paraphrasing is presented in Fig. 6. As shown in the figure, the T+MA method outperforms the other approaches in F1 and precision. Also, BILBOWA achieved the best results in the case of recall measure for different types of obfuscation. Although T+MA performs better than the other methods, however BILBOWA shows a close performance to T+MA for more complicated types of paraphrasing (e.g. Merge and Split) and outperforms T+MA in detecting summarization cases of obfuscation. Table 5 shows Plagdet and granularity obtained by each method. We discuss the performance of methods on the sub-corpora from three perspectives as follows.
In the first perspective, we focus on the performance of algorithms over sub-corpora. Since T+MA is a precision-oriented method, its best performance is when the obfuscation complexity is low. For inst-
Comparison of performance measures in each method vs. different types of obfuscation
ance, the performance of T+MA on STR sub-corpus is highest with respect to the other sub-corpora. BILBOWA is a semantic based and recall oriented method. So, it can be seen when the obfuscation complexity is high (such as summarization), it outperforms the other algorithms. In LSA algorithm, the precision value increases monotonically, but when the threshold value reaches around 0.7, the precision of LSA decreases. Since the recall is very low at the values above this threshold, the change in F1 is not perceptible. ESA is a recall oriented semantic approach and it can be seen that its precision is very low. The precision doesn’t leverage with the increase in threshold value. This method has also the lowest recall among the other algorithms and decreases rapidly in threshold value around 0.7. Since ESA is inherently a semantic approach, it works better in fragments with complex obfuscation.
In the second perspective, we focus on the effect of obfuscation complexity on the performance of the above mentioned methods. From a general point of view, it is expected that the performance of the methods decreases when the obfuscation complexity increases. In simple translation (STR), since there is no obfuscation in the fragments, all of the methods have their best results. In the artificial obfuscation (ART), the fragments are constructed automatically, while the fragments in paraphrase obfuscation (PAR) have been manually changed by human. As a result, the PAR fragments have more complexity with respect to the ART fragments. As shown in Fig. 6, the algorithms have better performances in artificial obfuscation with respect to the paraphrase obfuscation. Merge (MRG) and Split (SPL) obfuscations cause the structure of sentences to be messed up, whereas all of the methods work on a sequence of individual sentences to detect cases of plagiarism. Therefore, the worst performance of the methods occurs with MRG and SPL types of obfuscations. Moreover, the performance of all of the methods in SPL obfuscation is lower than MRG. As a last point, it seems that the most complex obfuscation is summarization (SUM), but since the summarized passages are relatively long (with respect to merge and split passages), the performance of the methods on SUM is better than MRG and SPL.
In the third perspective, we consider the sensitivity of methods on each sub-corpus with respect to the whole HAMTA-CL corpus as shown in Table 6. It can be seen in the table that the performance of BILBOWA on Merge (MRG) and Split (SPL) obfuscation has the lowest change with respect to the whole corpus among the other methods. In other words, MRG and SPL obfuscation decreases the performance of all algorithms except BILBOWA. On the other hand, BILBOWA has the most change in the performance among all of the approaches in the case of Artificial (ART) and Paraphrase (PAR) obfuscation. Another issue is that all of the methods have the lowest change in performance in simple translation (STR) and have the highest growth of performance when facing summarization (SUM) obfuscation as well.
Changes in the performance of algorithms with respect to the whole corpus
In this paper we presented a novel approach to cross language plagiarism detection using word embedding methods and explore its performance against other state-of-the-art plagiarism detection algorithms. Moreover, we investigated various algorithms on the task of cross language plagiarism detection. We categorized the methods, described their pros and cons and compared them in the task of CLPD, focusing on English and Persian as two distant languages. We also investigated the performance of CLPD approaches applied to Persian as a low resource language.
For investigating the performance of the algorithms, a corpus comprised of seven different types of obfuscation was constructed. The simulated cases of plagiarism were compiled by graduated crowd workers, while the artificial ones were compiled automatically. For validation of the corpus, it was automatically checked considering the ratio of length of plagiarized passages to length of the documents and the distribution of plagiarized passages across the documents as well. Moreover, for evaluation of the corpus, a manual checking was done for investigating the quality of plagiarized fragments. We compared the performance of the algorithms on the whole corpus and also on separate sub-corpora containing different types of paraphrasing as well.
For comparing the methods on CLPD, we implemented five algorithms and evaluated them using the constructed corpus. The performance of the algorithms on detecting cases of plagiarism in different types of paraphrasing showed that T+MA method outperforms other approaches in F1 and precision. Also, BILBOWA achieved the best results in the case of recall for different types of obfuscation. The results can also show that BILBOWA can detect more complicated types of plagiarism (e.g. Merge, Split and Summarization).
As a future work, we plan to focus our research on improving the performance of the above mentioned algorithms concerning Persian specific features. Another research that can be investigated in the future is to work on bilingual plagiarism detection when the source and target languages are both less resourced.