
Abstract
Neural Machine Translation (NMT) for low resource languages is a challenging task due to unavailability of large parallel corpus. The efficacy of Transformer based NMT models largely depends on scale of the parallel corpus and the configuration of hyperparameters implemented during model training. This study aims to delve into and elucidate the impact of hyperparameters on the performance of NMT models for low resource languages. To accomplish this, a series of experiments are conducted using an open-source Hindi-Kangri corpus to train both supervised and semi-supervised NMT models. Throughout the experimentation process, a significant number of discrepancies were identified within the data-set, necessitating manual correction. The best translation performance evaluated with respect to the metrics such as BLEU (0–1), SacreBLEU (0–100), Chrf (0–100), Chrf+ (0–100), Chrf++ (0–100) and TER (%) is (0.15, 14.98, 41.43, 41.49, 38.77, 68.20) for Hindi to Kangri direction, and (0.283, 28.17, 49.71, 50.64, 48.63, 51.25) for Kangri to Hindi direction.
Keywords
Introduction
The task of machine translation is to develop a model for translating a piece of text from one language into another. Within the realm of natural language processing, machine translation stands out as one of the most intricate tasks. The history of machine translation can be traced back to Cold War in 1954, where an experiment was initiated at the IBM headquarters involving the use of the IBM 701 computer to translate sentences from Russian to English [1]. In recent years, NMT has emerged as a groundbreaking approach in the field of natural language processing, revolutionizing the way languages are translated in various domains. NMT models are build over the neural networks which allows them to grasp complex relationships between words and phrases in diverse languages, resulting in more fluent and contextually accurate translations compared to traditional statistical methods [2–4].
The pivotal moment arrived in 2017 when the transformer architecture was introduced, revolutionizing NMT [4]. The Transformers architecture laid the foundation for the latest advancements in AI models, including BERT (Bidirectional Encoder Representations from Transformers), and GPT (Generative Pre-trained Transformer) [5]. The effectiveness of transformers based NMT models is heavily contingent upon both the size of the parallel corpus and the configuration of hyperparameters employed during the model training process [6, 7]. India is a linguistically diverse nation boasting over 22 officially recognized languages and hundreds of dialects [8]. Many of these languages lack the vast amounts of parallel data required to effectively train a robust NMT system. This leads to a necessity for exploring an efficient technique or a methodology to effectively use small parallel corpus for building an NMT system for low resource language such as Kangri, Dogri, Kashmiri etc.
The efficacy of transformers based NMT models are greatly effected by the configuration of hyperparameters such as embedding dimension, feed-forward dimension and number of encoder-decoder layers [6, 7, 9]. All these hyperparameters effects the complexity of the model and directly depends on the size of the parallel corpus and vocabulary size of the language. Large sized parallel corpus tends to have a larger vocabulary size. The objective of this study is to delve into and elucidate the impact of hyperparameters on the performance of NMT models. All the experimentation has been done over an open source Hindi-Kangri corpus. Kangri is an extremely low resource language which is mostly spoken in few regions of Himanchal Pradesh, India [10, 11]. Throughout the experimentation, a substantial number of inconsistencies were detected within the dataset. Comprehensive insights into these discrepancies, along with the procedures employed for rectification, are elaborated upon in section 4 of this paper.
The research contribution shared through this paper are: A cleaner version of the existing open source Hindi-Kangri corpus. \\ Demonstrated the impact of hyperparameter over the performance of NMT models. A new baseline score for the translation performance over the Hindi-Kangri corpus.
Next, in the paper the related works (section 2), dataset (section 3), proposed work (section 4), results (section 5) and implementation is discussed in complete detail.
In this section, a thorough and detailed survey of the literature has been discussed. This survey centers on various neural machine translation models that have been previously proposed by researchers. More emphasis has been given over the methodologies and techniques which has been adopted for dealing with low resource language scenarios, particularly in the context of Indian languages.
General survey for NMT architectures
Constructing a neural model stands as the contemporary and efficient method for developing a Machine Translation system, as it harnesses the embeddings of individual tokens within the vocabulary. This capability facilitates the capture of enhanced semantic and syntactic structures within sentences [12, 13]. First end-to-end deep learning NMT framework, featured a Recurrent Neural Network (RNN) encoder-decoder structure [3]. This network comprised a bidirectional RNN encoder and a unidirectional RNN decoder, with an essential attention layer bridging the two. The attention layer is an important component in the architecture of any NMT system. RNN cells, however, are highly prone to the vanishing gradient problem and struggle to effectively handle long-term dependencies [14]. Consequently, RNN cells were subsequently replaced by Long Short-Term Memory (LSTM) cells [15]. The introduction of the Transformer architecture marked a significant breakthrough in the realm of deep learning research [4]. The Transformer model laid the groundwork for the latest advancements in AI models such as BERT and GPT [5]. Following the advent of the Transformer architecture, researchers worldwide have shifted their focus toward employing this architecture and its variations for diverse language pairs [16–18].
NMT for low-resource languages
Availability of large parallel corpus is a prerequisite for building a robust NMT system, and the languages for which large parallel corpus is not available are usually referred as Low-Resource language. The two possible scenarios with respect to low resource languages are: No parallel corpus, Large Monolingual Corpus Small parallel corpus, Large Monolingual Corpus
In case of zero availability of parallel corpus, researchers have adopted to unsupervised techniques to build an NMT system. The idea behind the design of an UNMT system is to combine the technique of denoising auto-encoder (base on reconstruction error) and On-the-Fly back translation. The fundamental concept is to establish a shared latent space for both languages, allowing the model to acquire translation capabilities by reconstructing content in both language domains. The model gets trained in a similar way as a language model is getting trained with noisy input data and reconstructing the original data [19]. Using this methodology a BLEU score of 15.56 is achieved on WMT 2014 dataset for French to English translation direction [20] and on adding a small parallel corpus the performance increases to 21.81 BLEU. This implies that the availability of small parallel corpus helps to improve the UNMT system performance.
Transfer learning is another approach for building low resource language NMT system. One common approach is to utilize a high-resource language pair data to pretrain a generic translation model. At a later stage the pre-traine model can be used to finetune over another dataset (low resource language data). This implies that the weights trained over a high resource language pair are used an initialization for fine tuning over low resource language [21, 22]. Using this approach a change of +5 BLEU is observed for Uzbek-English translation with a parent model of French-English translation [21].
Machine translation for Indian languages poses a significant challenge due to the existence of large morphological differences [23, 24]. Much of the research conducted in the field of machine translation for Indian languages has primarily focused on NMT system for translating English to Telugu [25], Kannada [26, 27], Hindi [28], Malayalam [29] etc. These languages hold official status and are equipped with more readily available linguistic resources [8, 30].
Recently, there has been a shift in focus towards addressing the challenges of extremely low-resource languages like Kashmiri [31], Kangri [10], and Kumaoni [32]. To facilitate research on Kangri languages for various natural language processing (NLP) applications, an open-source Hindi-Kangri small parallel corpus and a Kangri monolingual corpus were released [11]. These resources not only promote Kangri language research but also establish baselines for unsupervised neural machine translation (UNMT) and unsupervised statistical machine translation (USMT). Using USMT and UNMT models, they achieved BLEU scores of 4.98 and 3.25, respectively, for translating from Kangri to Hindi.
Furthermore, a comparative study on semi-supervised and unsupervised neural machine translation for the Hindi-Kangri language pair was conducted using the same dataset [10]. This study included two main models: A shared encoder model implementing back-translation, incorporating both fully unsupervised and semi-supervised techniques. A language model featuring a denoising auto-encoder, leveraging fully unsupervised learning.
The highest BLEU score reported in this study was 21, achieved in the semi-supervised translation scenario with semi-supervised cross-lingual word embeddings.
As per the literature discussed in this section it is very much evident that very limited research work is available for low resource Indian languages and recently attention is drawn towards the extremely low resource languages like Kashmiri and Kangri. In this study the objective is to explore the methodology and techniques which can be opted to build an NMT system with a very limited parallel corpus for Kangri. A special focus has been drawn towards the quality of the dataset and to improve the quality a manual audit has been done. The impact of hyperparameter over the performance of transformer based NMT system has been discussed in detail.
This study exclusively focused on conducting experiments with a low-resource Indian language (Kangri) to explore methods for building an effective NMT system using a limited parallel corpus. All the experimentation has been done over an open source Hindi-Kangri parallel and monolingual corpus dataset. 1 . Kangri is an extremely low resource language which is mostly spoken in few regions of Himanchal Pradesh, India. Kangri and Hindi are Indo-Aryan languages that use the Devanagari script for writing [10, 11].
Tables 1 and 2 shows that data statistics of the raw corpus as mentioned in [11] and data available on Github, respectively. After collecting the dataset from Github (open-source) the dataset is processed. The complete procedure for data pre-processing is discussed in Section 4.
Data statistics mentioned in [11]
Data statistics mentioned in [11]
Data statistics from data avaliable on GitHub
In this section the complete detail of the methodology used in this research study has been discussed. This section discuss about the data preprocessing, model architecture, hyperparameters, training mechanism, implementation details and the performance evaluation metric used in this study.
Data preprocessing
In data preprocessing the raw data is converted into a usable form. The basic data preprocessing step involves removal of punctuation, converting text to lower case etc. The sequence of steps which are used to preprocess the parallel and monolingual data are: Removal of punctuation characters. Removal of web-links or html links. Removal of numeric characters. Removal of English alphabet characters. Removal of extra white-spaces
During the data analysis procedure a significant number of discrepancies were identified in the raw corpus which was obtained from the original source. All the different types of discrepancies in the dataset is summarized as:
A large number of parallel sentence pairs ( Duplicates of
The steps taken to remove all the different types of discrepancies in the dataset are: Removed the false parallel sentences from the training set. Manually corrected the alignment of the parallel sentences in the training set. Removed the duplicates from the training and leaked data from the test set.
Table 3 shows that data statistics of the final data retrieved from the original corpus 2 . The monolingual corpus for Hindi is acquired from IITB English-Hindi parallel corpus [33]. From the Kangri and Hindi monolingual corpus only those sentences are considered which had more than or equal to three words.
Data statistics after removing discrepancies
In the practical scenario of machine learning, a random data split is often employed to generate training and test sets. However, there is a possibility that a random split may yield a fortuitous outcome. To mitigate such occurrences, multiple splits of equal size are generated in a manner ensuring that each test set is unique; in other words, no two test sets contain the same parallel sentence pairs. Five different splits are created, and percentage of Out-of-Vocabulary (OOV) words (tokens) are calculated for the both Hindi and Kangri language. The performance of a Machine Translation system greatly depends on the spectrum of the vocabulary it holds. Out of all the 5 splits, one with the least OOV% is selected as the best split for building an NMT system. The training and test set for each split comprises of
Out-of-vocabulary ratio after parallel dataset split
Out-of-vocabulary ratio after parallel dataset split
Data statistics after train-test split
The performance of NMT systems is directly influenced by the chosen tokenization scheme, which has a direct impact on the OOV%. The most efficient technique for effectively managing OOV% is Byte Pair Encoding (BPE) [34]. The choice of tokenizer is primarily dependent on the specific language, especially the writing script used in that language. In this case, both Hindi and Kangri share the Devanagri writing script. Therefore, joint BPE codes are learned through 10,000 merge operations. These learned joint BPE codes are then used to tokenize the dataset, and their vocabularies are extracted individually (with no shared vocabulary). Table 4 represents the statistics of the OOV% for each split. For the
The Transformer architecture represents a significant advancement in the fields of NMT and LLM [4]. In this study, the same Transformer architecture (refer Fig. 1) has been used for constructing an NMT system for the Hindi-Kangri language pair. The transformer architecture is an encoder-decoder network which utilizes the concept of Multi-Head Attention (extended version of self attention) in the encoder part of the network. The Masked-Multi Head Attention block in the decoder gives an auto-regressive ability to the model during the training and inference stage. Positional Encoding carries the information regarding the sequence in which text appears in the corpus. Input embedding and target embedding refers to the word embedding (vector representation) for the words or tokens in source and target language corpus, respectively. While training an NMT model over a large parallel corpus, pre-trained word embeddings are used like FastText [35], Glove [36], Word2Vec [37] etc. Utilizing the pre-trained embeddings become effective when they are trained over a sufficiently large corpus so the semantics of the sentence can be effectively captured [38]. Since, in this study large corpus is not available so the embeddings are trained during the training of NMT model. Transformer architecture consists of number of hyperparameters which are discussed in the next section
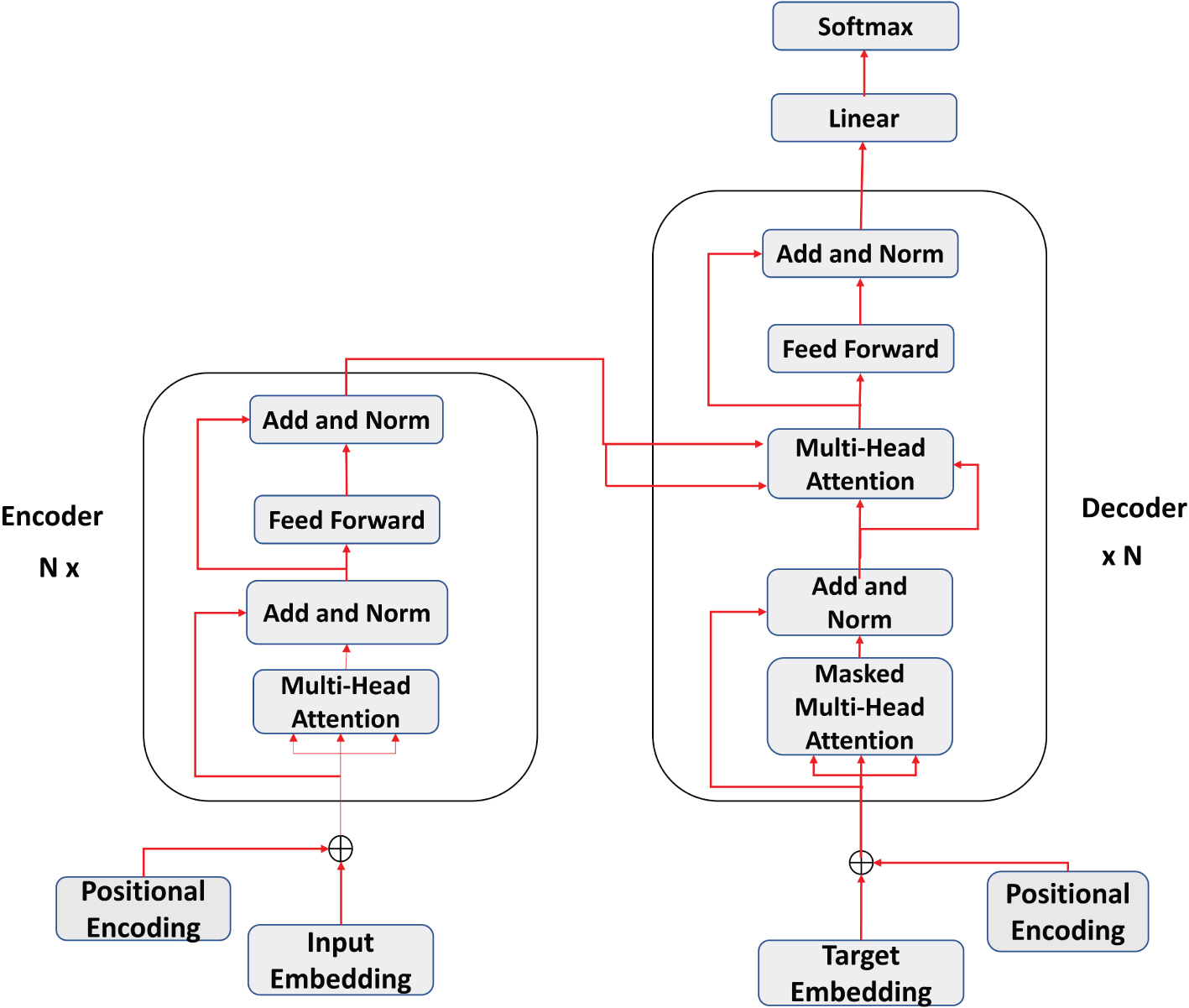
Transformer architecture.
In machine learning models, the total parameters can be categorized into two distinct groups: learnable parameters and hyperparameters. Learnable parameters are those that undergo training, meaning they are updated using techniques like backpropagation. These parameters adapt to the underlying distribution of the training data. In contrast, hyperparameters are independent of the data distribution and are specified by the user. They remain fixed throughout both the training and testing phases of the model.
The Transformer architecture is known for having a substantial number of hyperparameters, and its performance is highly influenced by the selection of the optimal set of hyperparameters. Discovering the most effective hyperparameter combinations often involves conducting numerous experiments. Some crucial hyperparameters within the Transformer architecture include: Embedding Dimension Feed Forward Dimension (Latent Dimension) Number of Encoder-Decoder Layers Tokenizer Dropout Attention Dropout Learning Rate Label Smoothing Number of Attention Heads Loss Function and Optimizer Batch Size Maximum Tokens Training Epochs
Among the listed hyperparameters, Embedding Dimension, Feed Forward Dimension (Latent Dimension), and Number of Encoder-Decoder Layers, these are the ones that directly impact the model’s complexity, specifically in terms of the number of learnable parameters. To determine the best set of hyperparameter values, hyperparameter optimization techniques like Random Search, Grid Search, Bayesian Optimization, etc., are typically employed. These techniques are predominantly used for optimizing parameters like learning rate and label smoothing, which don’t significantly affect the model’s complexity.
However, when it comes to optimizing parameters like embedding dimension and feed-forward dimension, a more intricate approach is needed, often requiring multiple GPUs to handle the abrupt changes in memory requirements as different combinations of hyperparameters are explored.
The size of the dataset or vocabulary plays a vital role in determining these three hyperparameter values. In scenarios with limited linguistic resources, such as low-resource languages, the availability of a parallel corpus is consistently constrained, resulting in a notably smaller vocabulary. Transformer based NMT models or language model are usually trained over large dataset which has a large vocabulary size and in such cases the hyperparameter values for embedding dimension, latent dimension and no. of encoder-decoder layers are usually set to (1024 or 2048), (2048 or 4096) and (6, 8 or 12), respectively. Using similar range values for low resource language doesn’t yields an optimal result [7, 8].
To harness the potential of both parallel and monolingual data, both supervised and semi-supervised training mechanisms are used. Supervised training mechanism is the most common training mechanism in NMT. In this study two supervised NMT models (
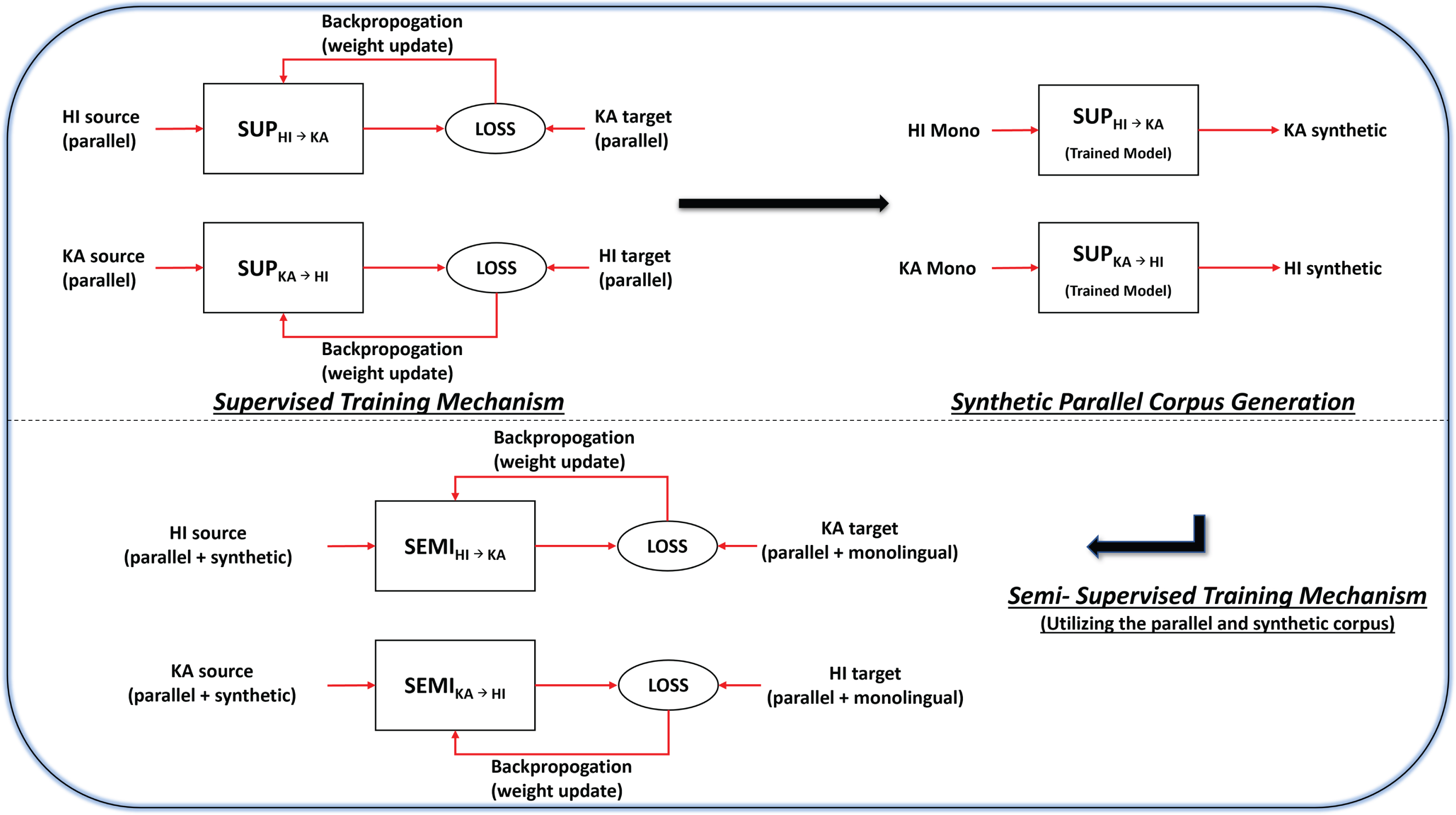
Training mechanism for NMT model.
In a semi-supervised training approach, both parallel and monolingual datasets are employed. This methodology utilizes a technique known as
To circumvent this situation an alternative technique is used to utilize the monolingual data and it is referred as
All experiments in this research were fully implemented using the Google Colab-Pro platform, with access to the paid NVIDIA A100-SXM4-40 GPU machine. The Python modules, libraries and toolkits employed in this work include Fairseq [40], Numpy [41], NLTK [42] and Sacrebleu [43].
Performance evaluation metric
The evaluation metric which has been used to evaluate the performance of trained NMT models are SacreBLEU [43], Bilingual Evaluation Understudy (BLEU) [44], Translation Error Rate (TER) [45] and the variants of CHaRacter-level F-score like Chrf, Chrf+ and Chrf++ [46]. The evaluation conditions or the arguments which are need to be defined for calculating the metric score is mentioned in Table 6. For Chrf, Chrf+ and Chrf++ the tokenizer is not required to be defined and for TER the tokenizer and smoothing operation is not required to be defined.
Evaluation conditions
Evaluation conditions
In this section a detailed discussion over the results obtained for all the experiments conducted in this research study is presented. Analysis of the results obtained for the trained NMT models has been discussed.
Hyperparameter selection
To find the best set of hyperparameter values for Hindi-Kangri corpus (low resource scenario) multiple experiments are performed to observe the effect of the each hyperparameter on the model’s performance. All the hyperparamters opted for training of the model are listed in Table 7. Parameters marked bold are need to be optimized for which multiple experiments are performed. For the selection of best hyperparameter combination, an NMT model is trained for Hindi to Kangri translation direction under different combination of hyperparameter. The performance of the Hindi to Kangri direction translation NMT model under different hyperparameter configuration is presented in Table 8. The performance is evaluated over 521 test sentences using SacreBLEU as evaluation metric. The decoding is performed using Beam search algorithm [47] using beam length as 5 (B5).
Training parameters for transformer based NMT model
Training parameters for transformer based NMT model
Hyperparameter selection for Hindi to Kangri translation direction NMT model
When embedding dimension and the no. of encoder-decoder layers are held constant, and only the latent dimension is varied from 68 to 1024, there is no notable impact on the SacreBLEU score (refer Fig. 3(b)). SacreBLEU score variation under different hyperparameter configuration.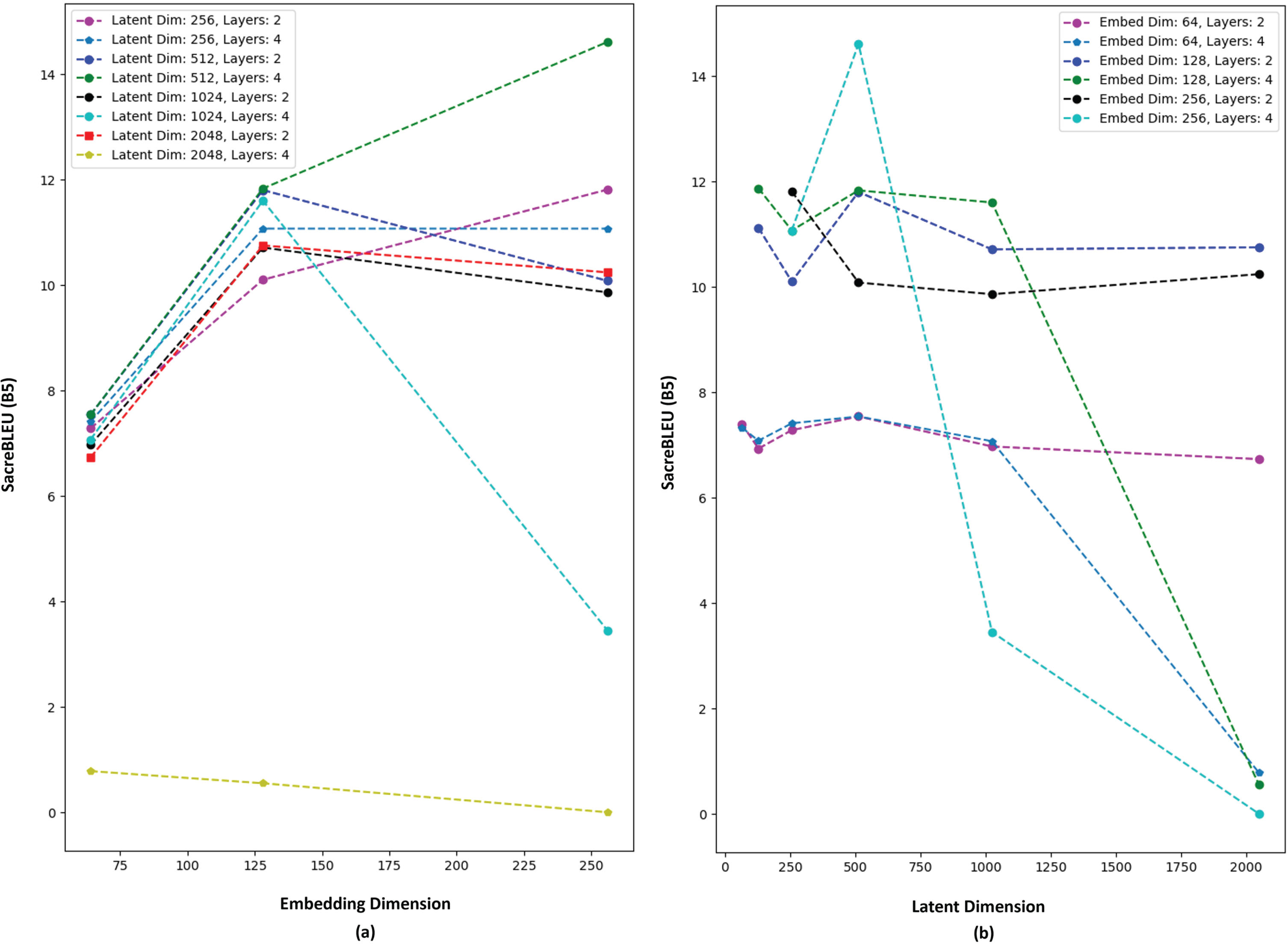
When altering the latent dimension from 1024 to 2048 while keeping the embedding dimension constant, there is no substantial effect on the SacreBLEU score when using 2 layers of encoder-decoder. However, with 4 layers, a notable decrease in the SacreBLEU score becomes apparent.
This suggests that the selection of the latent dimension has minimal impact on the performance of the NMT model. However, when the latent dimension is significantly increased, the performance experiences a sharp decline.
When altering the no. of encoder-decoder layers while keeping the other parameter constant, no significant change is observed in SacreBLEU score.
When altering the embedding dimension while keeping the other parameter constant, an increase of 3 to 5 points is observed on SacreBLEU score (refer Fig. 3(a)).
The highest SacreBLEU score is achieved with 4 encoder-decoder layers, 256 and 512 as the embedding dimension and latent dimension, respectively.
Based on the analysis of Table 8, it can be concluded that in a low-resource language scenario (with a parallel corpus of 20K to 30K), the selection of the embedding dimension significantly impacts the NMT model’s performance. Furthermore, other parameters like the number of encoder-decoder layers and latent dimension can markedly influence the model’s performance, especially when the latent dimension exceeds 512, and the model’s depth exceeds 4. The results mentioned in the further section of this paper is obtained with respect to the best hyperparameter values i.e.,
In this section the results obtained for the final experiment for training NMT model with supervised and semi-supervised training mechanism is discussed. The results are obtained by using the best hyperparameter combination obtained. The evaluation metric used to evaluate the performance of NMT models are mentioned in Table 6. These performance metrics were computed at the corpus level, which is the standard approach for evaluating machine translation systems. NMT models undergo supervised and semi-supervised training, as elaborated in sub-section 4.5, for translation between Hindi and Kangri in both directions. Their performance scores are displayed in Tables 9 and 10 for the respective translation directions. The decoding process employs the Beam search algorithm with varying beam lengths of 1, 5, and 8 denoted as B1, B5 and B8, respectively. It’s worth noting that using a beam length of 1 in Beam search is analogous to employing a greedy algorithm.
Performance for Hindi to Kangri translation
Performance for Hindi to Kangri translation
Performance for Kangri to Hindi translation
In the Hindi to Kangri translation direction, the top-performing model is the supervised model (
One potential explanation for this behavior may be attributed to the significant linguistic similarity between the two languages. To understand this behavior, a manual analysis of the system’s translation has been conducted. Table 11 presents a concise set of Hindi words and their corresponding counterparts in Kangri. In most cases, a single Hindi word can be associated with multiple Kangri words, and at times, Hindi words are directly used within the Kangri language.
Hindi-Kangri corresponding word list
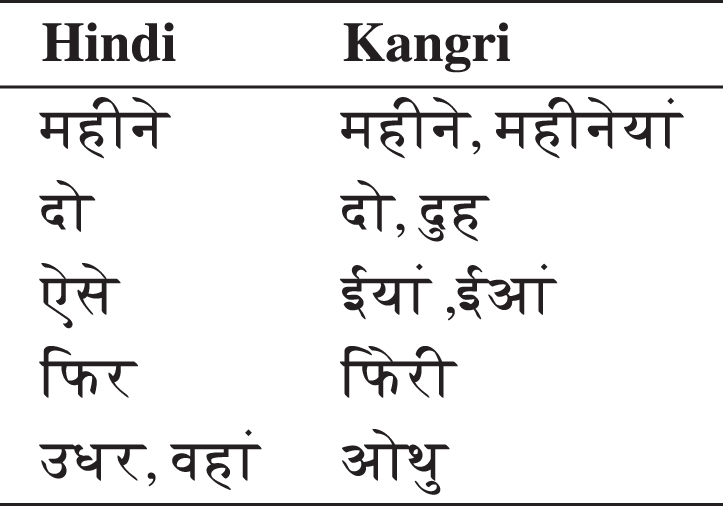
Figure 4 provides two examples of genuine parallel sentence pairs. It is evident that in the first example, the Hindi sentence contains the word  with its corresponding Kangri counterpart being
with its corresponding Kangri counterpart being  . In contrast, in the second example, the Hindi sentence includes the word
. In contrast, in the second example, the Hindi sentence includes the word  and its corresponding word in Kangri is also
and its corresponding word in Kangri is also  . Such scenarios arise because it is a natural tendency for bilingual individuals, who are proficient in two highly similar languages, to mix words and accents.
. Such scenarios arise because it is a natural tendency for bilingual individuals, who are proficient in two highly similar languages, to mix words and accents.
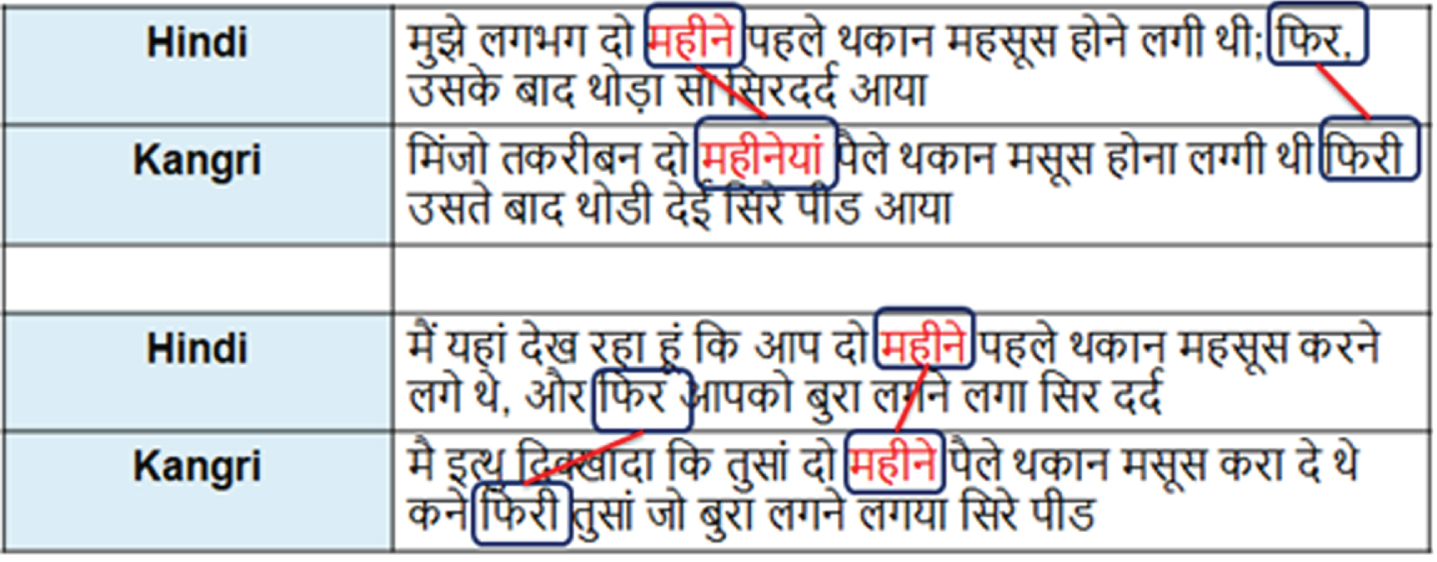
Sample of true parallel sentence pairs.
Due to this observed pattern when sentences are translated from Hindi to Kangri and in the input sentence the word  comes then on the basis of the context information, while generating the sentence in Kangri language the probability gets distributed between the words
comes then on the basis of the context information, while generating the sentence in Kangri language the probability gets distributed between the words  and
and  due to which the word prediction can go wrong and evaluation metric score decreases. Whereas, when translation is done from Kangri to Hindi and in the input sentence the word
due to which the word prediction can go wrong and evaluation metric score decreases. Whereas, when translation is done from Kangri to Hindi and in the input sentence the word  or
or  comes, then majority of the probability weights goes to the word
comes, then majority of the probability weights goes to the word  which leads to correct word prediction and does not leads to decrement in the metric score (refer Fig. 5). This is one of the possible reason for a gap of 12-13 SacreBLEU points between the two supervised trained models.
which leads to correct word prediction and does not leads to decrement in the metric score (refer Fig. 5). This is one of the possible reason for a gap of 12-13 SacreBLEU points between the two supervised trained models.
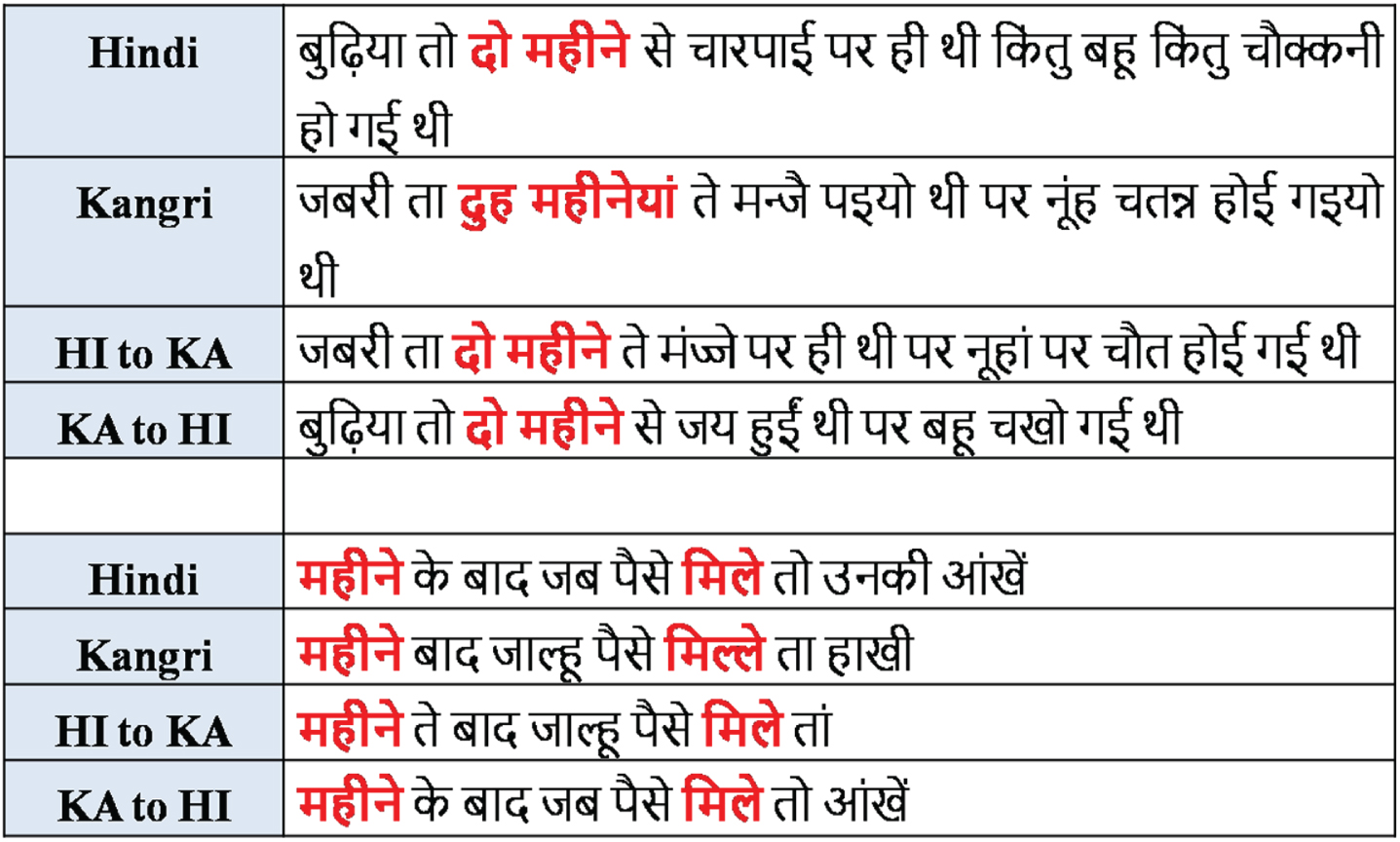
Translation output from the best NMT systems.
The supervised trained models (
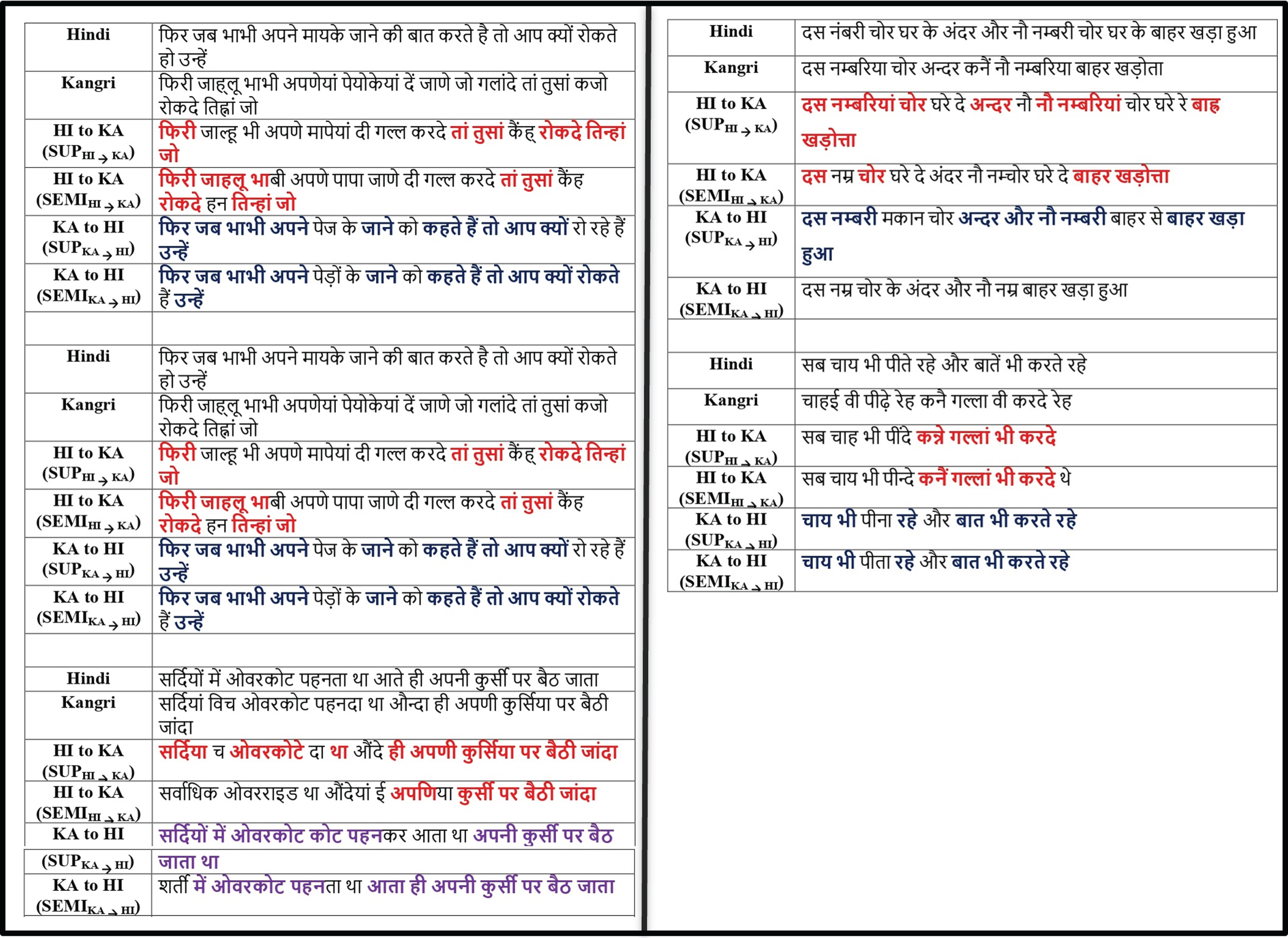
Sample translations for all 4 NMT systems.
Kangri is considered an extremely low-resource language, with its inaugural dataset being published as recently as 2021 [11]. Consequently, there is a scarcity of relevant research and resources available for this language. The source dataset1 was employed in a prior study [10] as part of a research work in NMT.
However, because of the identified discrepancies within the raw corpus, as discussed in Section (4.1), it became necessary to rectify them. This rectification process led to the creation of a new data split for training and testing purpose. As a result, the test set utilized in this study differs from the one used in the earlier work [10]. This disparity in test sets makes it challenging to directly compare the performance of the NMT systems between the two studies.
The best translation model proposed in [10] achieve BLEU score and TER as (21, 7) and (20, 7) for Hindi to Kangri and Kangri to Hindi translation direction, respectively. BLEU assesses the likeness between the machine-generated translation and the reference translation by examining n-gram overlap. In contrast, TER gauges the edit distance or the number of edits needed to transform the machine-generated translation into the reference translation.
If a BLEU score of 21 is obtained, signifying a low degree of similarity between the system translation and the reference, it suggests that a considerable number of tokens in the translation output do not correspond to those in the reference, and the sequence of tokens may also exhibit significant differences. In such a context, a TER score of 7 appears inconsistent. Typically, a TER score of 7 would indicate a relatively low number of edits necessary, implying that the machine translation closely resembles the reference. Due to the mentioned contradiction over BLEU and TER score value it brings a question mark over considering as a baseline.
This study explores the NMT systems for low resource language. Experiments are done over Hindi-Kangri language pair where Kangri is an extremely low resource language. The research contribution shared through this paper are: A cleaner version of the existing Hindi-Kangri corpus. Explored the impact of hyperparameter over the performance of NMT models. A new baseline score for NMT over the Hindi-Kangri corpus.
After cleaning the dataset, a large number of experiments were conducted to obtain the best combination of hyperparameter used in transformer architecture. Using the best hyperparameter combination obtained, NMT models were trained in supervised and semi-supervised manner. For (HI to KA) NMT model, the SacreBLEU score achieved was (supervised:
The future work involves investigating the methods to filter poor translations within the synthetic corpus. The quality of this synthetic corpus significantly impacts the performance of NMT systems. Therefore, to enhance the effectiveness of semi-supervised models, it is imperative to implement filtering techniques. Notably, not all languages have readily available parallel corpora, so addressing such situations also involves exploring unsupervised techniques, which is part of the ongoing research agenda.