
Abstract
Topic Modeling encompasses a set of techniques for text clustering and tag recommendation with significant advantages such as unsupervised learning. Based on Latent Dirichlet Allocation (LDA) topic modeling, every single word is related to a set of topics with different weight. The weights are further estimated in order to determine the semantic relation between the words and the rest of the documents. Apparently the chief drawback of topic modeling techniques, specifically LDA, lies on their incapability in clustering short texts in which semantic relation between words is neglected. This issue is deemed more severe when analyzing social networks such as Twitter wherein short texts are the case. It is assumed that semantic relation between a document and the target short text helps obtain efficient clustering of short texts via topic modeling. Hence, the current paper proposes a method of topic modeling named Semantic Knowledge LDA based on semantic relations between the words in tweets from Twitter social network based on the co-occurrence of words. Additionally, we propose a method of hashtag recommender system based on topic vector (TV) text similarity, named TV based Hashtag Recommender System (TVHRS). Accordingly, we applied our word co-occurrence LDA (SKLDAC) method together with WordNet lexical database to cluster the short texts from Twitter. The clustered topics are later used as the repository for the proposed hashtag recommender system. The proposed system of both SKLDA and TVHRS were applied to a set of 12,309,911 real tweets for testing purposes. When comparing the components of the proposed system to the existing methods, we recorded higher performance in terms of precision, recall and F-Score of 0.551, 0.682 and 0.526, respectively.
Introduction
Social Networking (SN) services have created a suitable environment for users to maintain rather high interaction with each other, which in turn leads to creation of rich contents in the forms of textual and graphical posts [6]. However, such data are unstructured and need to be analyzed for precise information extraction.
Labeling the contents generated by users is a good idea for clustering the texts and extracting precise information. This kind of information is useful for analyzers of different fields such as socialists, politicians, industries of all kinds, etc. The main problem is that labels are generated by users which are not structured as well as non-heterogeneous. May be different labels are used for a unique topic but because the labels are not the same, the analysis faces difficulties in the information extraction process. It is believed that recommending these kinds of labels for people who are not familiar with the topic or use different language/words for explaining the topic, is a practical way for solving the problem of different labels for the same topic.
In the users’ point of view, recommending labels will speed up finding information about the topic without being confused among different labels. Hence, contents generated by users can be joined with the topic if the generated contents use same labels.
While classification and clustering techniques are known tools for extracting information from textual data [3], obtaining information from the text contents generated by users [19, 1] is better performed using clustering. Among text clustering methods, topic modeling (TM) as a text clustering method, is known as top semantic similarity determination tool.
Apart from its advantages, TM usually lags when dealing with short texts. The significance of this issue is due to the popularity of short texts in both social networks and mobile communications, e.g. Twitter messages are short texts limited to 140 characters. The reason for such an issue with TM is that latent relations are eventually not fully discoverable in short texts using TM.
A possible solution for efficiently clustering short texts is to use marked words throughout the text, known as hashtags. Hashtags are sets of unspaced characters, regardless of the meaning, and begin with a #symbol, such as #FollowFriday. Hashtags are widely, even optionally used by members of almost all social networks. While hashtags are provisioned as prominent remedy to classification problems, they introduce some areas of concern. Firstly, users may not use hashtags despite the relevancy of the context, and that different users may use different sets of characters as hashtag addressing an identical subject. It is believed that a recommender system once designed to recommend hashtags to users during their tweets, can overcome both the challenges above mentioned. To achieve such a goal, hashtags should be initially collected from the tweets history. In addition, a part of the issue with using different hashtags can be resolved via finding semantic similarity between words with the use of systems such as WordNet [17] or DISCO [9, 8], i.e., using semantic similarity, it is possible to detect the synonyms of a meaningful hashtag word. Another possible solution to the problem of short text clustering, is to use semantic similarity of the words within the context.
The current paper introduces a short text clustering and recommendation system which proposes a two-fold mechanism to address clustering problems of short texts. To achieve an efficient clustering, we first classify the tweets based on two strategies named Semantic Knowledge LDA (SKLDA); determining the semantic similarity of the tweet words using WordNet [17], and utilizing the co-occurrence of the words within all tweets. This leads us to construct a set of relevant hashtags for each cluster. Furthermore, we find the target cluster of new tweets and recommend hashtags from the relevant hashtag set, again with two strategies; using top hashtags and topic vector strategy.
We used the recommender system tests in order to evaluate the proposed SKLDA. The proposed system underwent several performance evaluations under various conditions. The evaluation outcomes indicate that the proposed SKLDA with co-occurrency considerations performs well with rather high efficiency in terms of recall, while the proposed topic vector based semantic similarity shows higher accuracy for hashtag recommendation process.
In particular, this study aims at designing and implementing a recommender system of hashtags for short text in two operational steps; a topic modeler named SKLDA, and a hashtag recommender system named TVHRS. Accordingly, the performance of the proposed system in terms of precision and recall is the main goal of improvement in comparison to the existing methods. Hence hashtags can be suggested simultaneously while a user types the tweet.
The rest of the paper is organized as follows. Section 2 presents a report on the recent related efforts on investigating several aspects of the concerned topic, then prepares a brief description on LDA as the foundation of the proposed clustering method. The proposed system comprising SKLDA as well as TVHRS are described in details in Section 3. Then in Section 4 we provide a detailed report on the experiments and analysis results of the proposed system. Finally, in Section 5 we conclude the paper.
Fundamentals and related works
Apparently, LDA is the most popular method known for clustering and classification of texts. The practicality of LDA has gone beyond text clustering over many other applications during the recent years. After a brief description on how the method works, we will discuss a number of related works on LDA-based hashtag recommendation systems (HRS).
With the consideration of documents in the form of bag of words, Latent Dirichlet Allocation is used to assign words for topics via estimation of random variable values. The accuracy of this estimation directly affects the clustering precision. The process starts by assigning a topic to each word in document randomly. In order to calibrate the topic assignment process, the next step is to find the topic of next iteration via determining the assignment probability. This procedure is continued until a robust situation is achieved.
Once documents are clustered using LDA, several applications specifically hashtag recommendation based on topic modeling can be performed. For recommending hashtags based on LDA, three steps of procedure are necessary. The whole process is described as follows:
Clustering Short Text: In this step, input documents ( Detecting Topic of Unseen Data: In this step the new document ( Recommending Hashtags: Depending on the documents in a cluster where topic of
Applicability of LDA in clustering short texts has been the concern of several approaches. A group of studies propose the aggregation of tweets based on items such as author, hashtag, time, etc., then using the new text as LDA input. For instance, Mehrotra et al. used author, time interval, burst-wise, and hashtag to aggregate tweets in the form of three main datasets including: 1) Generic dataset consists of 359478 tweets, 2) specific dataset which consists of 214580 tweets referred to named entities, 3) event dataset, reflecting the real world events and comprising 207128 tweets. As reported, the best result was achieved in clustering via hashtag aggregation [16]. Tweet aggregation based on hashtag was the interest of another study whereas for clustering, Author-Topic model (AT) was used in line with LDA [25]. They used a number of techniques to determine the optimal number of clusters in their dataset. Hashtag based aggregation, as reported, showed significant precision on clustering results.
Twitter-LDA (TLDA) is one of the most popular approaches as Twitter clustering. In TLDA, the Bayesian graph was constructed using two main parameters including Author and Background Words. Background Words are the noisy words which assign more than one topic to the tweet while the main assumption in TLDA is about considering one topic for each tweet due to character limits in Twitter. The graph was further used for clustering short texts [31] after removing tweets which have more than one topic and exceed a threshold in the training phase.
There are also several approaches that have attempted to employ certain topic modeling techniques with learning phase for large texts, and adopt them in short text. An instance of such studies is the approach conducted by Phan et al. [21]. They used semi-supervised learning on their large texts then applied the results on a classifier for classifying short texts. In a similar study, the authors determined a large text corresponding to the target tweet and then attempted to cluster those long texts using topic modeler [7]. They further used the resulted classifier on the rest of the tweets. Another method of relating a short text to a larger one was introduced by Qiang et al. in [22]. Accordingly, the authors used the previous knowledge of the words in order to extend the tweets by applying Word Embedding in the form of large texts, for what they used Markov Random Field for clustering purpose. Due to the use of previous knowledge, our approach follows a similar line with this study. However, unlike [22], the previous knowledge in our approach is used in Bayesian graph and further, the tweet is untouched.
Zirn and Stuckenschmidt proposed classification of textual system for specific domain of politics by taking advantage of LDA method [32]. They have used two extensions of LDA for classification, one included text labels in the training process, and another one, through adding rules of the domain knowledge.
Vathi et al. worked on finding interested topics in Twitter user communities based on LDA [27]. User communities are found by a method introduced by the authors and then LDA is used to find the interesting topics of each Twitter user.
Vavliakis et al. used LDA as a part of their event detection system among the blogposts [28]. They have proposed a framework including a Name Entity Recognizer, Topic Detector and Event Detection, applying on a dataset consisting of 7 million blogposts. The topic detection was performed by both LDA and domain experts indicating better results when topics are detected by domain expert.
In another study, Otsuka et al. proposed a method for recommending hashtags based on TF-IDF weighting scheme named HF-IHU to calculate the weight of hashtags by means of Hashtag Frequency – Inverse Hashtag Ubiquity [18]. They calculated the number of terms occurred with a hashtag as HF and the number of all terms divided by the number of terms occurred with the hashtag as IHU. Later, HF-IHU was used for weighting hashtags and for scoring the weight of hashtag to be recommended. The HF-IHU scheme was evaluated using precision and recall measures and the results were claimed to convey better results in comparison to the best results experimented by Naive Bayes classification method.
Using additional features extracted from graphical data and hashtags beside textual features, Gong et al. proposed an LDA based hashtag recommender system [5]. They have clustered the extracted features of text, graphical data and hashtags and recommended hashtags for newly composed tweets meanwhile users receive better recommendations in the presence of graphical data. For evaluation purposes, precision and recall were used to compare the performance with Naive Bayes, Support Vector Machines, Neighbor Voting, and Topical Word Trigger Model.
Hashtags are recommended by finding similar users based on Explicit User Collaborative Filtering and Hashtag LDA methods introduced by Zhao et al. [29]. They modeled each user as two vectors; one vector based on hashtags used by other users, and another based on hashtags used by himself/herself. The hashtag recommendation was performed after the extraction of similar users via cosine similarity of the two vectors, each pertaining to one user.
There are other studies on topic modeling with the objective of speeding up the modeling via reducing hardly occurred terms without changing the result of topic modeling. Lu et al. [15] conducted a study on such a system. Beside the decrease in the processing time of modeling, the achieved results evidence negligible performance degradation in topic modeling.
Lee and Brusilovsky worked on a recommender system with the information of users inside communities [10]. They categorized user similarities into two groups consisting of similarities based on bookmarks marked on articles, named Bookmark-based Similarity, and Metadata-based Similarity calculated from similarities of authors, titles and tags of articles. The recommendations were based on group membership information. The reported performance evaluation of the proposed recommender system shows signs of efficiency.
Sentiment analysis is another field of natural language processing (NLP) in the focus of researchers and has its difficulties in short texts. Saif et al. worked on a new method named SetiCircle which models the similarity of words in a circle consisting of four quadrants, each pertaining to one of the classes namely; Positive, Very Positive, Negative, and Very Negative [23]. They have used two methods for finding similarity of terms inside tweets; an alternative version of TF-IDF weighting scheme, and using predefined lexicons. Using the two similarity measures, they built SentiCircle and sentimentally analyzed Twitter data in both entity and tweets level.
Li et al. used biterms, words that are similar semantically, for classification of a topic modeler in order to classify textual data in the process of sentiment analysis. They have showed that using biterms and a topic modeler based classifier, the classification process was improved [13].
Li and Xu suggested a hashtag recommendation framework for Twitter stream data [11]. They have used two topic modeler for finding user interests and topics of tweets. The hashtag recommendation was then performed based on the tweet topic as well as the hashtag used by the user in the same topic.
Hashtag recommendation system
Hashtag Recommender Systems were also the concern of some recent studies. One study used LDA-based approach to find the users with the highest similarity to a specific user and then to recommend the hashtags to the user based on the hashtags of the similar users [30].
Li et al. used machine learning techniques to classify the words of documents and to identify the important words to incorporate in the topic modeling process [14]. For clustering purposes they used several machine learning techniques including LDA, SVM, TTM, LSTM and variations of LSTM, and concluded that the best performance was achieved using LSTM-TAB.
She and Chen proposed an LDA based method named ToMoHa for recommending hashtags in Twitter [24]. The main consideration of the work relies on assuming one topic for each tweet. As the hashtag assignment step, the authors select top hashtags from the topic corresponding the tweet.
In another work, the authors used a Naive Bayesian classifier for the classification of tweets’ language, and then used LDA for clustering tweets. As for HRS they used TH method based on the clusters [4].
One initial remark on TH lies on the fact that number of hashtags are barely changed by increasing the number of tweets in normal mode. Hence, the recommended hashtags seem to be unchanged for various instances. On the other hand, the lack of semantic relation in designing HRS can lead to recommending inaccurately due to the user behavior of symbolizing the same manner of speech in different form of hashtags.
Semantic knowledge LDA for hashtag recommendation
We introduce SKLDA, semantic knowledge topic modeling based on LDA, to achieve efficient clustering of tweets and thereby, design a hashtag recommender system based on topic vector. Accordingly, we first classify the tweets based on two strategies including SKLDA and topic vector. This way, we determine the semantic similarity of the tweet words using WordNet [17], and utilize the co-occurrence of the words within all tweets to construct a set of relevant hashtags to each cluster. Then, we find the target cluster of new tweets and recommend hashtags from the relevant hashtag set, again with two strategies; using top hashtags and topic vector strategy. The whole method is described in details in the following.
Semantic knowledge LDA
As the foundation of SKLDA, we use Bayesian graph to model documents and estimate word relation to each topic. The initial step for SKLDA is the generation of the documents, called Generative SKLDA, which is a modification of Generative LDA [2]. The modification improves the conventional generation method by consideration of the semantic similarity when selecting the word.
The main issue in LDA is the lack of precise estimation of word-to-topic relation factor especially when the document length is short. In addition, the words might be used in irregular format, e.g. #FFriday, which leads to major flaws in recommendation process.
The semantic knowledge of words leads to generation of documents with higher relevancy of words. We first build a matrix named
where,
The generative model of SKLDA is therefore proposed as the following operational steps in Algorithm 3.1:
Generative model for SKLDA
where,
In order to estimate the LDA parameters, generative LDA model uses joint probability distribution in the form of Eq. (2) as follows.
where,
Bayesian graph of models.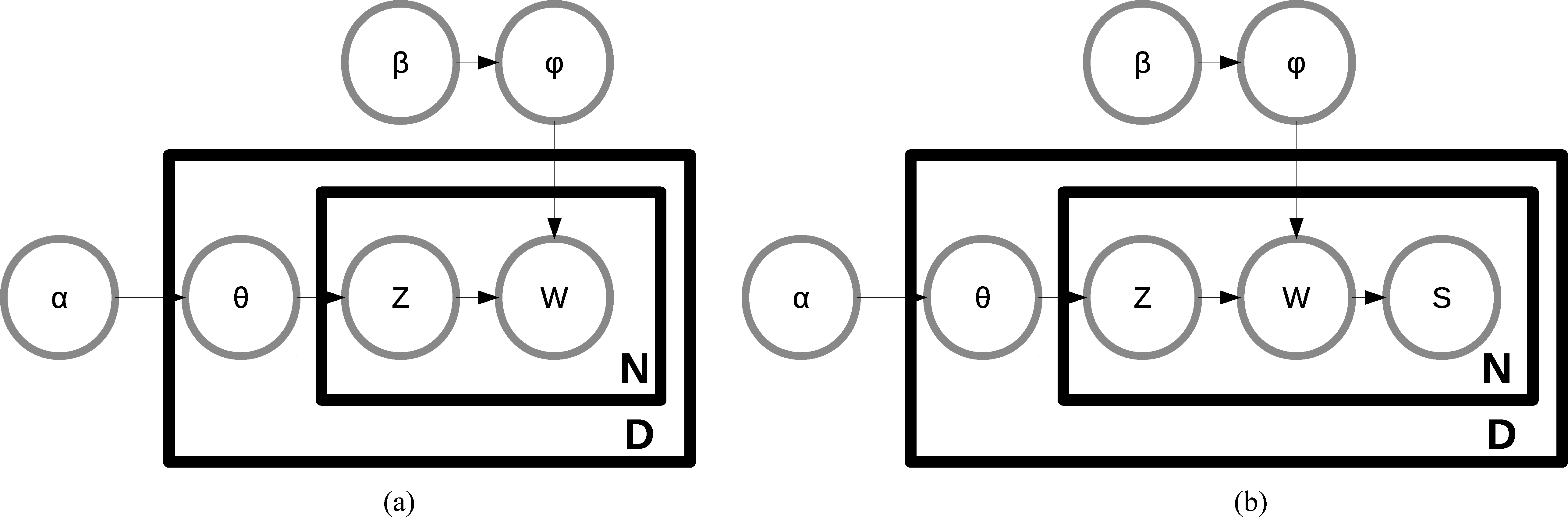
On the contrary to the generative model in conventional LDA,
The Bayesian graph of SKLDA is depicted in Fig. 1b. As shown in the figure, the random variable
So far, we were able to calculate
The recommender system we propose in this paper is eventually a Hashtag Recommender System (HRS) for clustered documents acquired from short texts. We use the proposed HRS to recommend from any clustered documents, i.e. the topics modeled by any topic modeler. However, in order to evaluate the performance of the proposed SKLDA, we specifically focus on the precision of SKLDA against other techniques. The HRS itself is also proposed as two separate strategies, both applied to any topic clusters.
The initial step of both strategies is to assign the target document, henceforth denoted as
where,
Once the target document is assigned to a topic, one of the two HRS strategies described as follows, will be active.
The first strategy for HRS is based on Top Hashtags (TH). In TH strategy, after
Topic vector
As a natural behavior of hashtagging in social networks, one might see many different hashtags used to address the same word. When using top hashtags as the basis of HRS, there will be a number of popular words referred by users with different hashtags and hence the word corresponding to hashtag might not fall within the TopN list. A more practical solution is to determine TopN documents based on semantic similarity and prepare the list of hashtags from the TopN documents.
Accordingly, we first create a vector corresponding to each document, whether it be a new document or from the list of documents. With the vectors in hand, it is feasible to determine the semantic similarity of the vectors using Cosine Coefficient.
The foundation of Topic Vector (TV) comes from the idea of Semantic Vector (SV) introduced in [26]. The SV method builds a semantic relation between the words of a document and their synonyms from other documents. This relation is important due to the deficiency of TF-IDF method in matching the words between documents to find conventional similarity.
In TV, each document is transformed into a unique vector denoted by
where,
After building
where,
Due to the semantic nature of determining vectors,
In order to evaluate the performance of the proposed method, we intended to implement the SKLDA algorithms both using WordNet [17] and co-occurrence, together with ToMoHa LDA [24] (TOMOHA), as well as TwiterLDA [31] (TLDA). As for the second fold, we built a simulation environment for Top hashtags and TV algorithms to evaluate the system based on recommendations. For the purpose of all operations, we utilized a dataset containing 61,732,969 tweets belonging to 147,909 users of Twitter Social Network, pertaining the activities in May, 2011. For the analysis purpose, we calculated Precision, Recall and F-Score as evaluation metrics [20].
Dataset
The dataset that was downloaded from [12], contains a total of 61,732,969 tweets with nearly 80% lacking hashtags, i.e. the remaining 20% consists of at least one hashtag. The distribution of hashtags throughout the remaining 20% is depicted in Fig. 2. As the figure shows, the number of used hashtags has a reverse proportion to the number of tweets, i.e. there are less tweets using more hashtags.
Hashtag distribution in [12].
The implementation is performed in two steps, comprising four scenarios in Step 1 and two scenarios in Step 2, which comprises a total of 8 distinct tests.
We applied topic modeling algorithms on the dataset including TLDA, TOMOHA, SKLDAW, and SKLDAC in order to cluster the tweets. After the clustering step, hashtag recommendation was applied on each cluster. In each of the four topic modeling algorithms, the number of topics was incrementally altered from 2,000 to 16,000 by increments of 2,000, equally for all four algorithms. For each scenario the information of the clusters are stored in separate databases. After the cluster information is built in Step 1, we complete the scenarios by applying both HRS algorithms to all four groups of Step 1 outputs.
We applied the two-step implementation process to our training set which is comprised of 80% of the total dataset. Once the training is done, for testing we establish 8 distinct outputs containing the lists of TopN hashtags as well as TopN similar tweets per each input document of the remaining 20% of the dataset. The whole process is repeated using a 5-fold cross validation method. The evaluation metrics including Precision and Recall are calculated at the end of each fold.
Table 1 lists the results of the four scenarios pertaining HRS with
Precision and recall for TOMOHA, TLDA, SKLDAW, and SKLDAC using TH strategy
Precision and recall for TOMOHA, TLDA, SKLDAW, and SKLDAC using TH strategy
As it is shown from the results, the four algorithms can be clearly distinguished based on their operability across all tests. Accordingly SKLDAW lacks in the performance due to its nature of string match word search, while both hashtags and tweets rarely follow regular vocabulary rules. On the other hand, TOMOHA was performed as expected, placing the second worst. This is due to the fact that LDA was not optimized for short texts. For its specialty in using user and tweet information, TLDA performs rather high with short texts. As for the purposed SKLDAC method, it ranks on top due to its semantic nature of short text clustering. While the ranking list of algorithms stays unchanged, we can see that precision is decreased by increasing the number of recommended items. This trend is also maintained test-wide. However, there is an improvement in the overall performance when the number of topics in increased until it reaches 8000, and there is again a decreasing trend when number of topics exceed 8000. Since this trend is identical for all four algorithms, a number of 8000 topics is deemed a near-optimum value for our tests.
Table 2 lists the results of TV-based HRS for all four algorithms. Similarly, the results comprise a total of four clustering algorithms over a topic distribution of 2000–16000 for determining both Precision and Recall. Different from the scenarios implemented for THHRS, the N in this series of tests implies the number of similar tweets, instead of hashtags.
Precision and recall for TOMOHA, TLDA, SKLDAW, and SKLDAC using topic vector strategy
The results of these tests are also similar to those with THHRS in the number of topics acheiving the best results for 8000. However, variable N in these scenarios corresponds to the number of tweets. It is also obvious that the increase of number of tweets, which implies increase in number of hashtags, which leads to performance improvement in terms of both Precision and Recall. One distinct result which is present throughout all tests is that we can see improvement in both precision and recall in TVHRS against THHRS for any identical number of recommended hashtags. As we previously discussed, from Fig. 2 we can determine the median and the average number of hashtags as 1 and 2.21, respectively. This implies that among tweeter users that use hashtags, the number of 2.21 is a nominal hashtag use frequency. Hence, we could deduct that increase in the number of recommended hashtags facilitates the users for choosing rather more hashtags, which in turn increases the respected precision.
However, despite the expected trend of precision and recall with the increase in the number of recommended hashtags, the achieved highest value of recall, equal to 0.68, is still a sign of lag in comparison to the average number of hashtags, which is equal to 2.21. For instance, the number of two recommended hashtags from a list of 11 is expected a better hit than what has been achieved. In order to justify this implication, we base our analysis on the distribution of hashtags as shown in Fig. 2. As shown, the percentage of the users with the hashtag usage of below 3 is around 81%, while the percentage for 5 hashtag usage reaches as high as 88%. Hence, achieving an average recall of around 0.68 for recommending 2 hashtags to a user with 5 hashtags usage implies rather high deviation for even a minimum range of calculated similarity. Based on the value of precision, we argue that the achieved recall under the mentioned conditions is satisfactory, especially that such a value corresponds to the worst case scenario.
In order to provide further discussions, we evaluated all scenarios via calculating F-Score for near-optimum number of topics. F-Score is a metric that reflects a harmonious trend on the changes in the precision and recall. Accordingly F-Score is calculated via following equation.
where,
Figure 3 depicts the results of F-Score for SKLDA applied in both scenarios, using WordNet as the reference of similarity and calculating co-occurrence of words in the target documents. As expected, the proposed topic modeler, SKLDA, performs higher in terms of F-Score with the calculated co-occurrence, rather than using WordNet as the basis of similarity. This is due to the fact that co-occurrence of words, which is extracted from the working documents that in turn maintains a close relationship to the social behavior of the users, reflects rather high similarity in comparison to the output of WordNet. Hence, while the value of F-Score for case of SKLDAW hardly reaches 0.16, SKLDAC for TH scenario can perform an F-Score of as high as 0.37. However, the results for TV method is even better, with SKLDAW barely reaching the value of 0.23 and for SKLDAC reaching the high value of 0.52.
F-Score for TH and TV with both SKLDAs.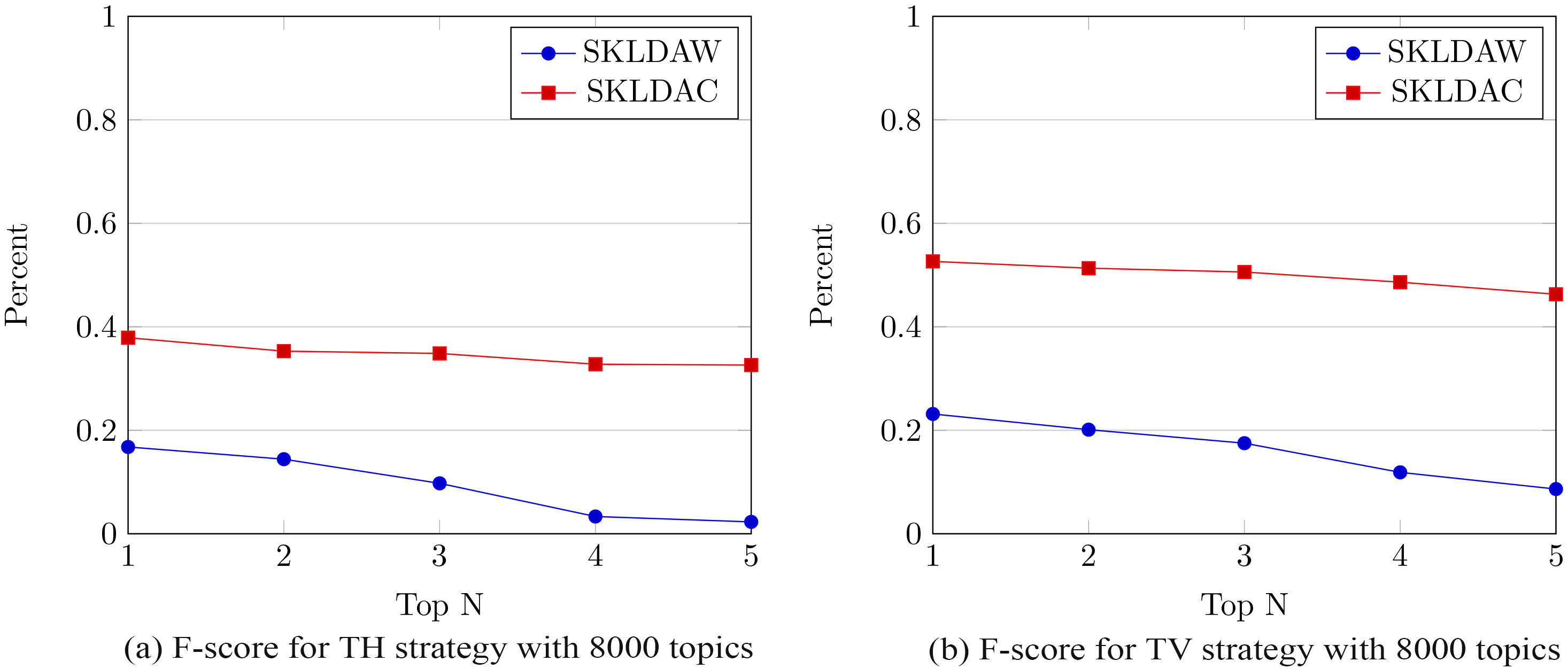
For further evaluations, we intend to compare the proposed topic model method, SKLDAC with the existing methods in terms of F-Score. Accordingly, we calculated F-Score for all three methods for both HRS scenarios, i.e. HRS using TH and HRS using TV. The results are shown in Fig. 4. As seen, SKLDAC performs better than TLDA and TOMOHA in terms of F-Score in either of the scenarios. While the highest achieved value for TLDA and TOMOHA are 0.30 and 0.20, respectively, SKLDA could yield a higher value of 0.37 for THHRS scenario. As for the TVHRS scenario, SKLDAC still maintains a higher performance of 0.52, while TLDA hardly reaches 0.40 and TOMOHA stays as low as 0.37.
Figure 4a and b show the results of F-Score for near optimum number of topics for both THHRS and TVHRS systems.
For further analysis of the results, we provide the top words for the topic of #followfriday, the assumed hashtag. The #followfriday is used among Twitter users for recommending someone to others in order to be followed. Table 3 shows the top words of the cluster which #followfriday is in it.
Top 5 words of the cluster for #followfriday
Tweets which #followfriday was the most probable recommended hashtag
F-Score for THHRS and TVHRS.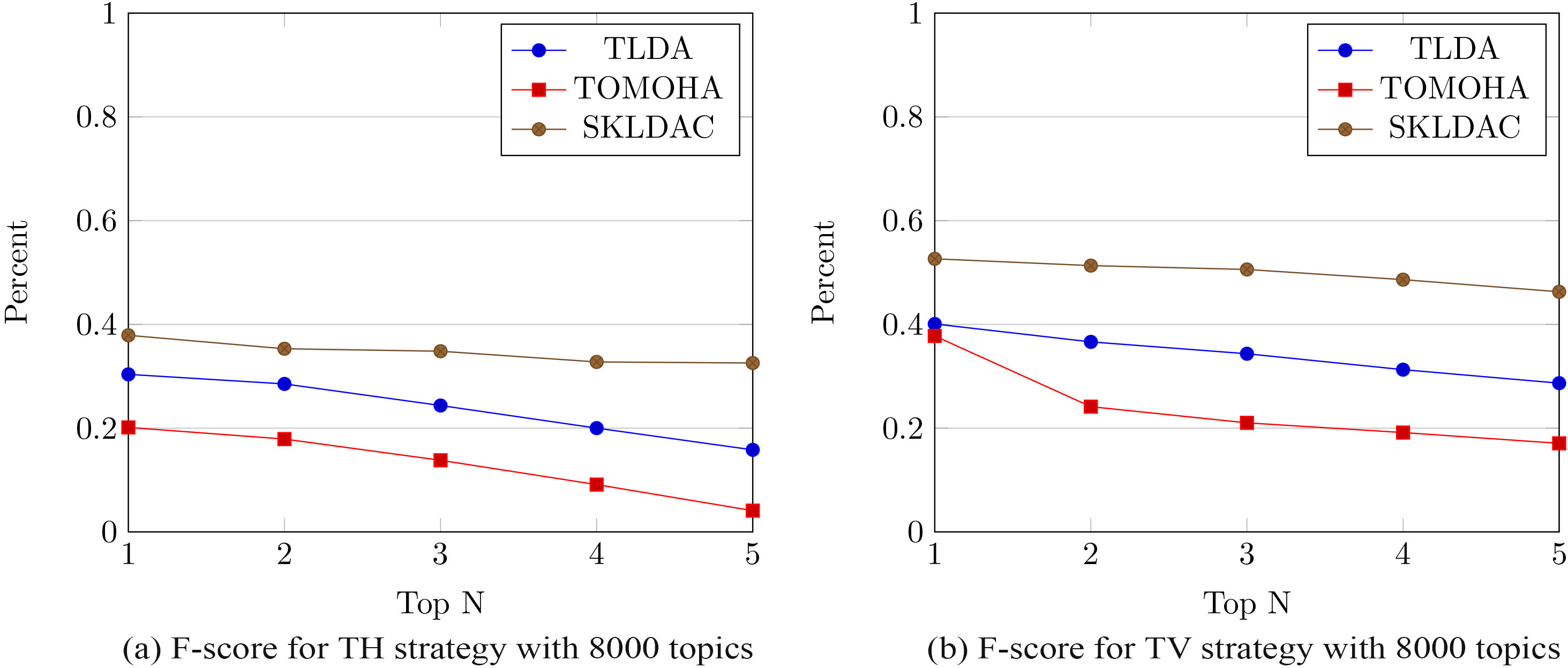
In the recommendation phase, here are tweets which the hashtag #followfriday has the most probability for being recommended. The results are depicted in Table 4.
As it is shown, the words in LDA and SKLDAW are not about recommending people to others. TLDA contains community and mike which are about recommending people among the top 5 words of the topic, but the other words are not related to recommending people. The words in SKLDAC are about or related to recommending people; colleagues, community and michael are about recommendation, 2017 and retweet are related to the subject.
According to the achieved results we can conclude that the proposed topic modeling method maintained higher performance in comparison to the existing methods. This is because of the close relevance with the existing short text modeling in the working domain, i.e. the batch of documents. The performance, as seen throughout the results, is maintained for all scenarios. Moreover, our proposal on recommending hashtags, which led to introducing a topic vector-based system, named TVHRS, has shown better performance in terms of Precision, Recall, and F-Score when tested with the existing and the proposed topic modelings and in comparison to THHRS.
It is to be noted that due to several constrains in the current study, we list the major implications and conditions under which, we have conducted the experiments. Primarily, the dataset includes real Twitter data with some specifications including but not limited to the following. The majority of the data does not include any hashtags, the dataset comprises some spam data, and finally it includes re-tweets which potentially contain no information. The tweets are processed using three computers connected over a GigaBit Ethernet network, comprising of total of 28 Gb of RAM, 10 cores of 2.5 GHz of CPU. As for the experiments, we ran SKLDA in 10000 steps of learning process, same as what recommended for LDA.
In order to overcome the drawbacks of current topic modeling methods in clustering short texts, this paper introduced SKLDA, a semantic topic modeler based on semantic co-occurrence of words in short documents. The paper also introduced TVHRS, a semantic similarity based hashtag recommender system to recommend hashtags for Twitter users. Using a dataset of 12,309,911 tweets collected from Twitter, we compared SKLDA with the existing short text modelers including TLDA, TOMOHA in the first fold. We further compared TVHRS with THHRS in terms of precision, recall and F-Score as the second fold. The results indicate higher performance of the proposed system in both folds. However, the achieved results are based solely on finding semantic relations from current documents. Our future direction is to focus on analyzing user behavior in order to achieve higher accuracies in both methods.