
Abstract
Harmful information identification is a critical research topic in natural language processing. Existing approaches have been focused either on rule-based methods or harmful text identification of normal documents. In this paper, we propose a BERT-based model to identify harmful information from social media, called Topic-BERT. Firstly, Topic-BERT utilizes BERT to take additional information as input to alleviate the sparseness of short texts. The GPU-DMM topic model is used to capture hidden topics of short texts for attention weight calculation. Secondly, the proposed model divides harmful short text identification into two stages, and different granularity labels are identified by two similar sub-models. Finally, we conduct extensive experiments on a real-world social media dataset to evaluate our model. Experimental results demonstrate that our model can significantly improve the classification performance compared with baseline methods.
Introduction
With the rapid development of the mobile Internet, many mobile applications encourage users to comment freely, making these applications more attractive to users. Netizens can interact through social media such as forums, Twitter or Facebook, and they can also post comments on news sites. On the Internet, any user can hide personal information, such as name, occupation and home address. Therefore, some netizens employ the anonymity and high efficiency of the Internet to spread a lot of harmful information, such as pornography, advertisements and violence [1]. These harmful information spreads quickly to every corner of the Internet, which not only affected the community environment, but also increased the difficulty for netizens to obtain useful information. It can be seen that how to detect harmful information is of great significance to improve user experience and information retrieval efficiency.
The rule-based harmful text identification method can identify whether the text contains sensitive information. However, this kind of method is difficult to understand the semantics of the text, which in turn cannot distinguish harmful words after deformation. Harmful text identification technology based on content understanding can identify standard length documents such as news, blogs and so forth. Nevertheless, for short texts on social media such as news headlines and tweets, their length is short and their language is not standardized. These features make this kind of method less effective for short texts.
Recently, the Bidirectional Encoder Representations from Transformers (BERT) model has achieved great success in the field of natural language processing [2, 3]. BERT is a bidirectional variant of the Transformer model [4] that is trained to classify whether two sentences are consecutive and predict a masked word from its context. The trained BERT model can be fine-tuned for downstream natural language processing tasks such as recommend system [5], lexical substitution [6] and sentiment analysis [7]. The performance of BERT in the eleven tasks has been significantly improved over previous state-of-the-art models [2]. This extraordinary result shows that BERT can learn the structural and semantic information about language.
Inspired by this, we propose a novel model for harmful short text identification to address the above challenges, named Topic-based Bidirectional Encoder Representations from Transformers (Topic-BERT). The main idea of Topic-BERT comes from the answers to the following two questions: (1) How to learn more robust short text representations to extract text features suitable for harmful short text identification? (2) How to extend short texts with additional information to alleviate the data sparsity problem in short text classification [8]?
Specifically, after encoding the short text as part of the feature, our model transforms BERT by making full use of all hidden states as our main encoder. In addition to the short text content itself, there are several types of additional information, such as number of likes, retweets and so forth, which can be modeled as features. Topic-BERT exploits parts of additional information as input, and calculates the attention weight using topic information. Different from other researches, we regard harmful short text identification as a fine-grained multiple-classification task. In aspect-based fine-grained sentiment analysis, researchers generally classify aspects first, and then perform sentiment analysis according to the classified aspects. Inspired by this, we adopts a two-stage model to distinguish labels of different granularities for multiple-classification. The major contributions of this paper are summarized as follows:
We propose a novel model to identify harmful information from short texts. The model employs BERT to take part of additional information as input to solve the sparseness of short texts, and uses GPU-DMM (Generalized Pólya Urn – Dirichlet Multinomial Mixture) [9] to learn the topic information of short texts for attention weight calculation. To the best of our knowledge, this is the first work to integrate topic knowledge based on GPU-DMM into BERT. Our model divides the recognition of harmful short texts into two stages, distinguishing different granular labels at different stages. Furthermore, unlike the BERT model that uses only the first hidden state as a sequence representation, Topic-BERT uses all hidden states and applies a topic feature attention mechanism to calculate weights. The performance of Topic-BERT is evaluated on a real-world short text corpus against four baseline models. Experimental results on binary-classification and multiple-classification tasks show that the proposed model is better than other baselines in precision, recall, and F1 measure.
The rest of the paper is organized as follows. In Section 2, we gives a brief overview on related work. The details of the proposed model are presented in Section 3. We describe datasets and experimental results in Section 4 and finally, Section 5 concludes.
Harmful short text identification can be regarded as a binary-classification task, that is, short texts are classified as harmful short texts and normal short texts. Unlike lengthy documents such as news and academic papers, short text are more ambiguous because they do not have enough contextual information, which brings great challenges for classification [10, 11, 12].
One type of research extends text features by increasing the topic information of short texts to enhance classification accuracy. Chen et al. proposed a method for short text classification using K-nearest neighbor clustering algorithm and the Latent Dirichlet Allocation (LDA) [13] topic model [14]. This approach leverages topic features to tackle the data sparseness problem and increases the semantic information of short text. Boom et al. proposed a hybrid method that combines word vectors, tf-idf similarity and dense distributions to reduce the impact of sparse terms on short text classification [15]. Rao et al. proposed a method for social emotion classification of short texts based on a Topic-level Maximum Entropy (TME) model. TME utilizes reader ratings, emotion labels and topic modeling to generate topic-level short text features. However, the texts on social media usually cover a wide range of topics, with non-standard terminology and little co-occurrence information. Therefore, it is difficult for traditional topic models to extract high-quality topics from short texts, resulting in low accuracy of harmful short text identification. By contrast, our method exploits GPU-DMM to extract high-quality topic features of short texts.
Recently, with the success of deep learning algorithms in natural language processing, many studies have focused on using word embeddings to expand the features of short texts, thereby solving the problems of sparse data and insufficient information in short texts [16]. Based on convolutional neural network [17] and word embedding clustering, Wang et al. proposed a unified framework to expand the features of short texts [18]. This method first generates semantic cliques by a clustering algorithm, and then calculates the semantic unit in the short text through the combination of word embeddings and context. Lee et al. proposed a new short text classification model by combining convolutional neural network and recurrent neural network [19]. Zhang et al. proposed a new Cluster-Gated Convolutional Neural Network model (CGCNN) that simultaneously classifies words and short texts in an end-to-end manner [20]. CGCNN first learns word representations using a bi-directional long short-term memory. Then, it uses a soft clustering method to extract the semantic relationship between short texts and cluster centers.
BERT first obtains a pre-trained model by training on a large-scale unlabeled corpus, and then fine-tunes the pre-trained model and applies it to other tasks such as text classification, reading comprehension and relation extraction [2]. Zhang et al. introduced BERT to encode the input sequence into context representations and applied it to text generation tasks [21]. Through exhaustive experiments, Sun et al. investigated different fine-tuning methods of the BERT model in text classification tasks, and provided a general solution for the fine-tuning process of BERT [22]. Their model obtained new state-of-the-art results on eight text classification datasets. Zhang et al. proposed a BERT-based model for a factuality analysis and classification task [23]. The model feeds the representations of an event and its sentence into an output layer for text classification. However, the above strategies neglect the fact that related additional information may help to classify short texts.
Methodology
The architecture of Topic-BERT, a two-stage model based on BERT, is shown in Fig. 1. In this section, we first introduce the representation of short texts, and then illustrate the role of additional information and how to use it. Finally, the two phases of our model and their connections are explained separately.
The architecture of Topic-BERT.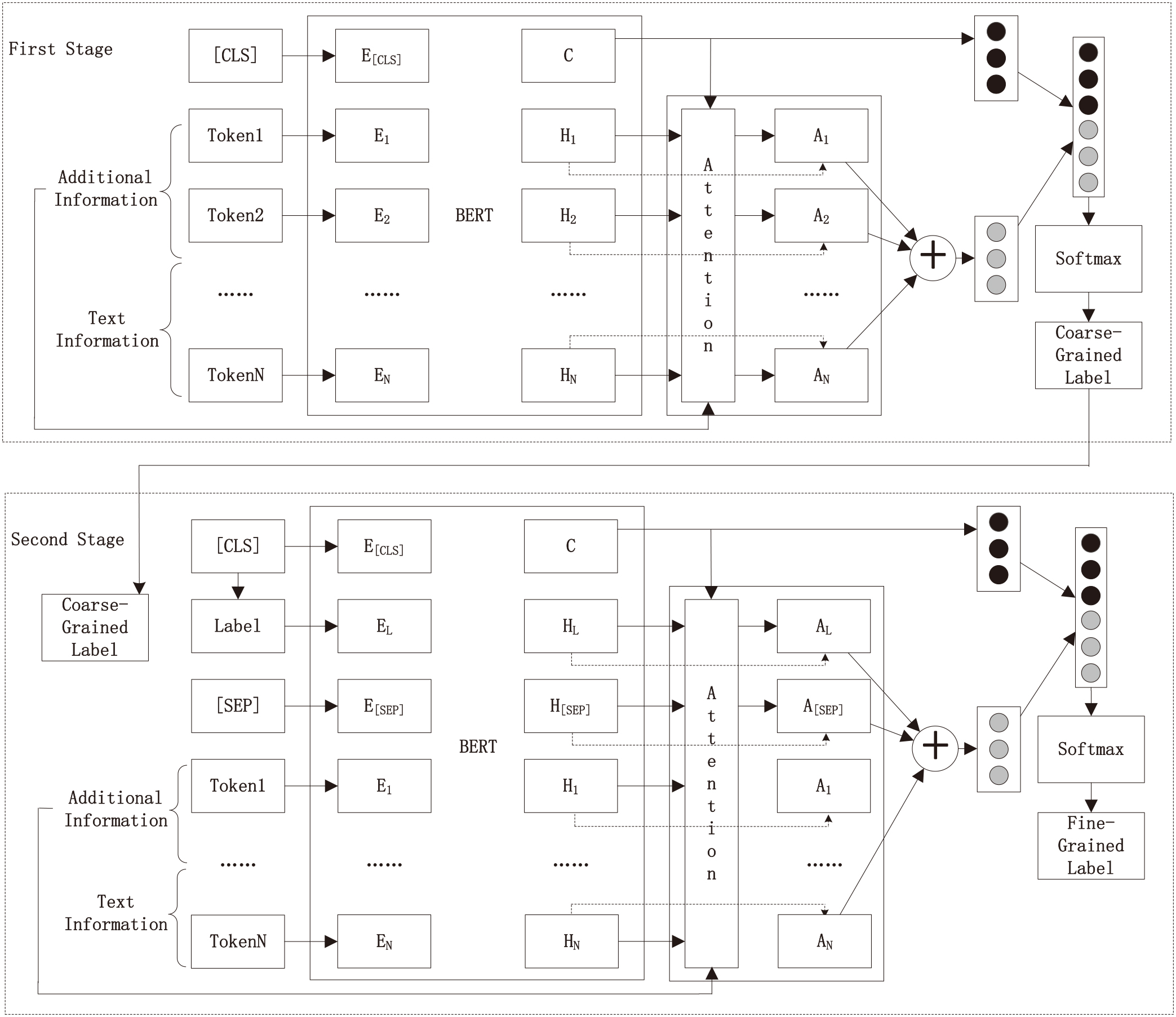
In the Topic-BERT model, BERT is used as the encoder to represent short texts. Without convolutional neural networks and recurrent neural networks, BERT is based on a multi-layer Transformer, which has proven to be a more powerful feature extractor [24]. With the help of large-scale corpora pre-training, BERT captures rich external knowledge, and learns the semantic information of words to help us train Topic-BERT. Based on the BERT model, Topic-BERT is fine-tuned by using harmful short text datasets, which alleviates the sparsity problem of short texts.
Let
where
Multi-head attention allows the model to capture different relationships in a sentence at different positions, which can increase the diversity of attention. All heads are connected and the final hidden state is determined by:
where Concat denotes the concatenation function,
In the original BERT model, [CLS] is added to the word sequence as the first token, and its hidden state is employed as the input vector representation of the classification task. In contrast, our model makes full use of each hidden state to obtain semantic vectors, and merges the original state into the final classification input vector representation. To achieve this, Topic-BERT introduces additional information to extend the entire calculation process.
Harmful short texts are prone to misleading and confusing, so the identification of harmful short texts is more difficult than other classification tasks [25]. In the meanwhile, the authenticity of harmful short texts tend to be more susceptible to other factors. In our habitual thinking, what reliable people say is often real, and people who behave badly are more likely to spread harmful short texts. Therefore, in addition to using the short text itself, other relevant additional information can also be a strong support for classifying harmful short texts. For short texts, author information and all relevant content can be part of the additional information. As an effective method of mining document structure and topic information from short text, topic models have been widely used in the field of short text classification. The topics of short texts can also be used as additional information. In this paper, we utilize GPU-DMM to obtain topic information of short texts, which improves short text topic modeling through the semantic information provided by word embeddings.
Based on the Dirichlet Multinomial Mixture (DMM) model, GPU-DMM leverages the Generalized Pólya Urn (GPU) model to merge word correlations learned from external text corpora. Specifically, after sampling the topic of short texts, GPU-DMM increases the probability of semantically related words under the same topic. Although the number of co-occurrences in short text collections currently being modeled is very low, GPU-DMM links semantically related words together to improve topic coherence. In the GPU-DMM model, the cosine similarity between word embeddings of two words is used to measure the semantic relevance between them. Furthermore, GPU-DMM also introduces a filtering strategy to assist the process of topic inference, so that external knowledge is only used for specific topics. Since GPU-DMM utilizes word embeddings learned from external text collections, the model can flexibly receive word embeddings learned from any other text corpus, thereby applying the model to different fields.
In the Topic-BERT model, the additional information is divided into two parts. To alleviate the sparseness of short texts, additional information can be used to help short texts enrich their semantics. Therefore, the first part of additional information is added to the head of the sentence, resulting in a longer and more complete short text representation. The Transformer structure will extract the connection between text information and additional information, making the model more robust. The second part is the hidden topic of short texts, which is used to calculate attention weights. The weight determines the usage of all hidden states in the output representation. The stronger the token is associated with the topic of a short text, the higher the attention weight. As a result, the attention can be measured by the relationship between additional information representation
where score denotes the score function, which can be defined as:
where tanh represents the non-linear activation function,
Finally, Topic-BERT combines the original short text representation
In common text classification tasks, each category is independent and easy to distinguish. However, for harmful short text identification, sometimes it is difficult to define their categories. Because many harmful short texts are intentionally created to confuse and mislead readers, a harmful short text may contain both real and harmful text information. Therefore, in most cases, harmful short text identification cannot be simply regarded as a binary classification task, which also includes a variety of categories such as advertising, violence, pornography and sensitivity.
It can be seen that “true” or “false” cannot cover all cases of harmful short texts, and more tags should be used for classification, which is more suitable for actual situations. Therefore, we need to make corresponding changes to the binary classification model. Inspired by aspect-based sentiment analysis [26], this type of method divides the classification task into two stages: sentiment and aspect. There is a specific connection between sentiment and aspect, and the classification result of aspect has an impact on sentiment classification. Similarly, Topic-BERT subdivides fine-grained labels into original and auxiliary categories, and exploits a two-stage model to distinguish coarse-grained and fine-grained labels.
The two stages of Topic-BERT have a similar structure, as shown in Fig. 1. The proposed model first divides all short texts into two categories, namely coarse-grained labels. Secondly, the different situations of the dataset determine the number of fine-grained labels. The first stage model uses the above methods to learn coarse-grained labels of short text. After this, Topic-BERT adds coarse-grained labels to the second stage model as part of the input. Following a similar process, the second stage model will encode inputs and coarse-grained labels, and then learn to classify fine-grained labels. Fine-grained and coarse-grained labels together determine the final labels of short texts.
The cross entropy loss function is used to train the model. The loss function is defined as shown in Eq. (7):
where
This section first introduces the collection process of short text corpora. Secondly, we briefly analyzes the characteristics of the corpus and settings. Finally, we verifies the effectiveness of the proposed model by comparing with baseline methods on multiple evaluation indicators.
Datasets
We use the open platform of microblog1
The text length distribution of the microblog dataset.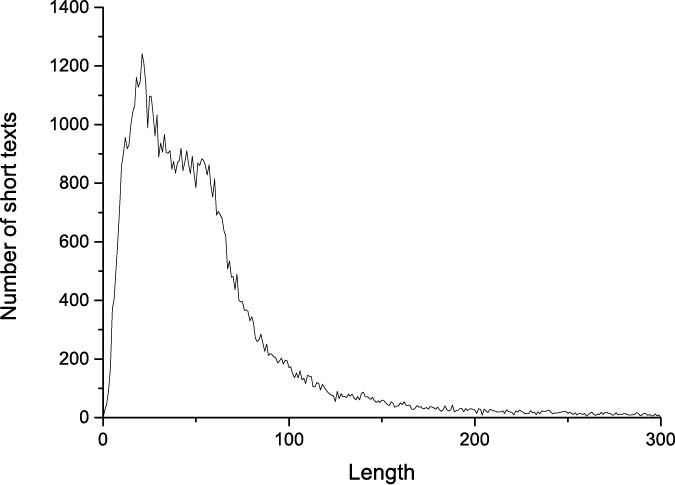
Figure 2 shows the text length distribution of the microblog dataset. As shown in the figure, the majority of short texts are less than 100 words in length, and over 94% of them are less than 150 words. As a result, the microblog dataset is typical short text. To better train Topic-BERT, we performed the following pre-processing steps on the dataset: (1) segment the sentence and remove stop words;2
GPU-DMM
Unlike lengthy documents such as blogs and news, short texts are noisy and sparse [27, 28]. To improve the topic quality of short texts, we utilize the GPU-DMM topic model which is more suitable for short texts to extract topic features. For the word embeddings used in the model, we employ 100-dimensional Chinese word embeddings trained by Li et al. [9] using Skip-Gram [29] on 7 million Chinese documents collected from Baike website.3
To verify the difference between harmful short text and normal short text in document-topic distribution, we compares the GPU-DMM topic model with Biterm Topic Model (BTM) and DMM.
For all topic models in comparison, we set the Dirichlet hyperparameters
Topic distribution of BTM.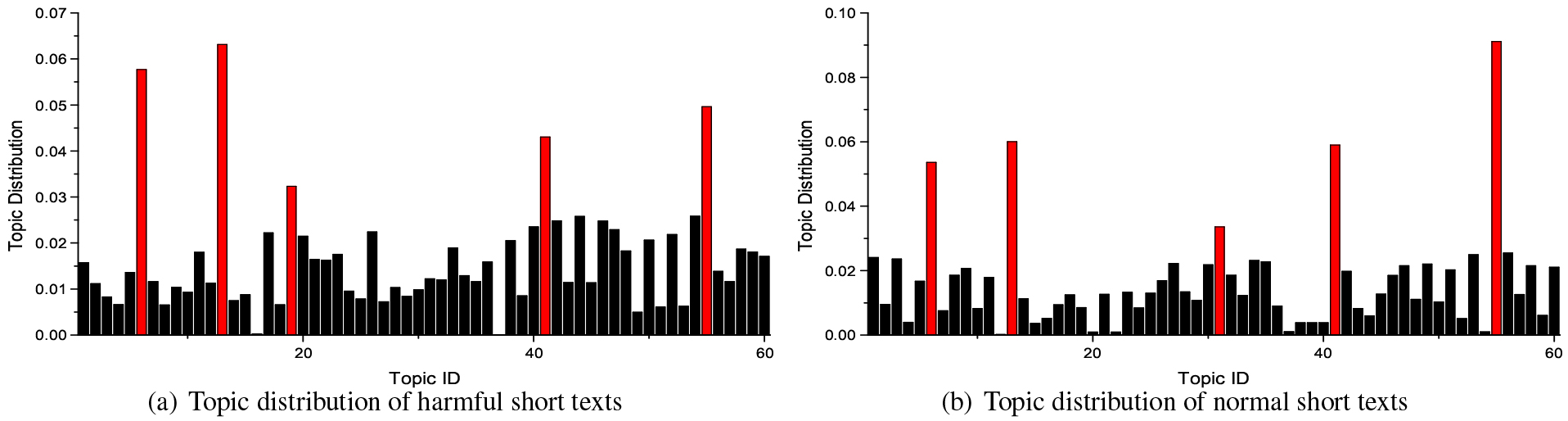
Topic distribution of DMM.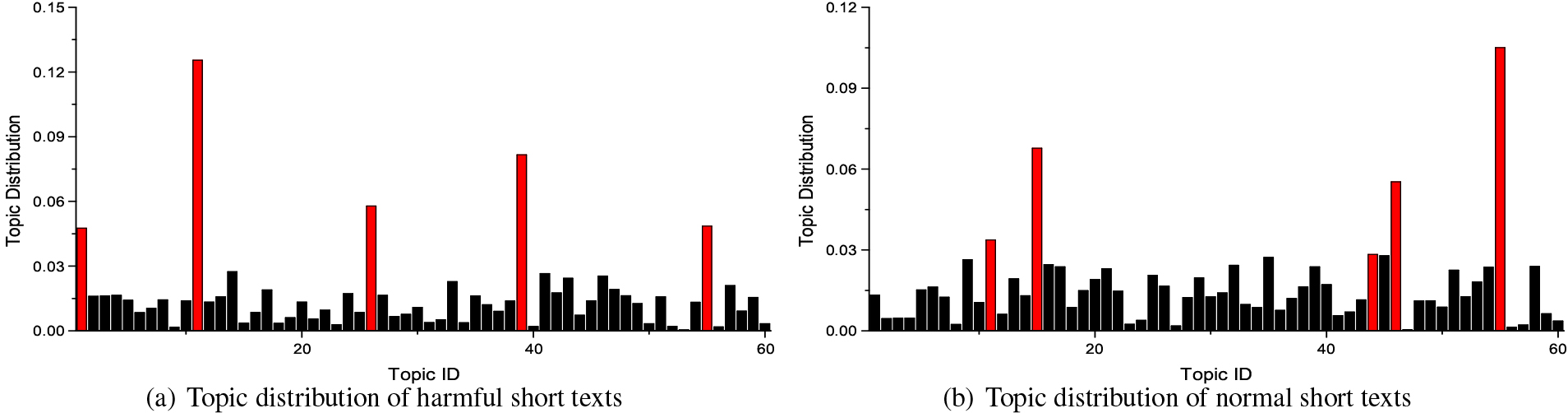
Topic-BERT is based on pre-trained
For additional information, the number of likes, comments, retweets, author’s followers and posts are divided into 20 categories by a discretization method directly as tokens in the input sequence. The document-topic distribution of the short text is used to calculate the attention weight of the proposed model. To verify the validity of our method, the Topic-BERT model is compared with the following methods:
Topic distribution of GPU-DMM.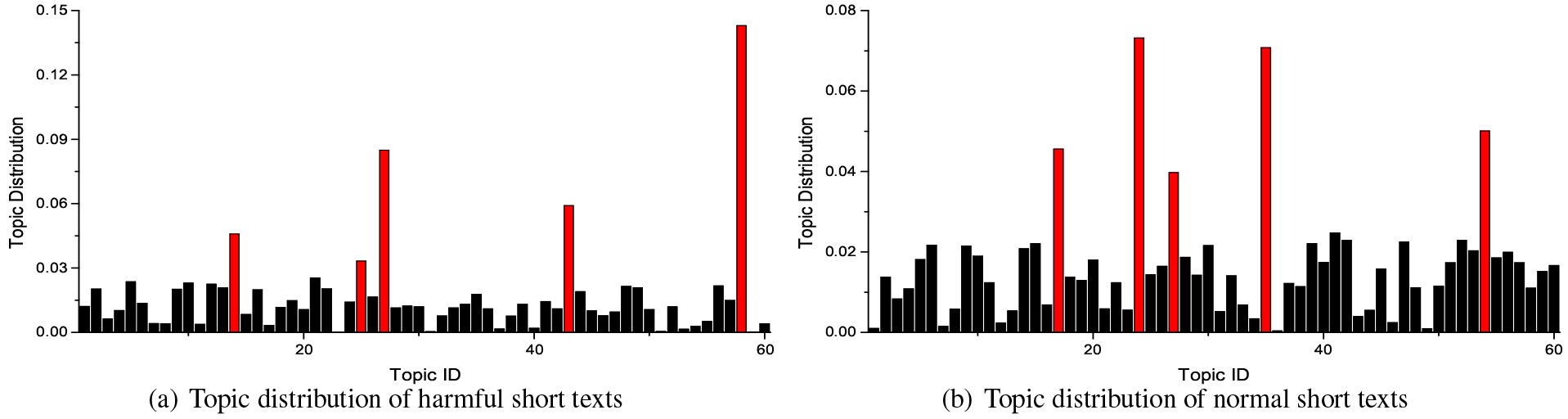
Classification of harmful short texts.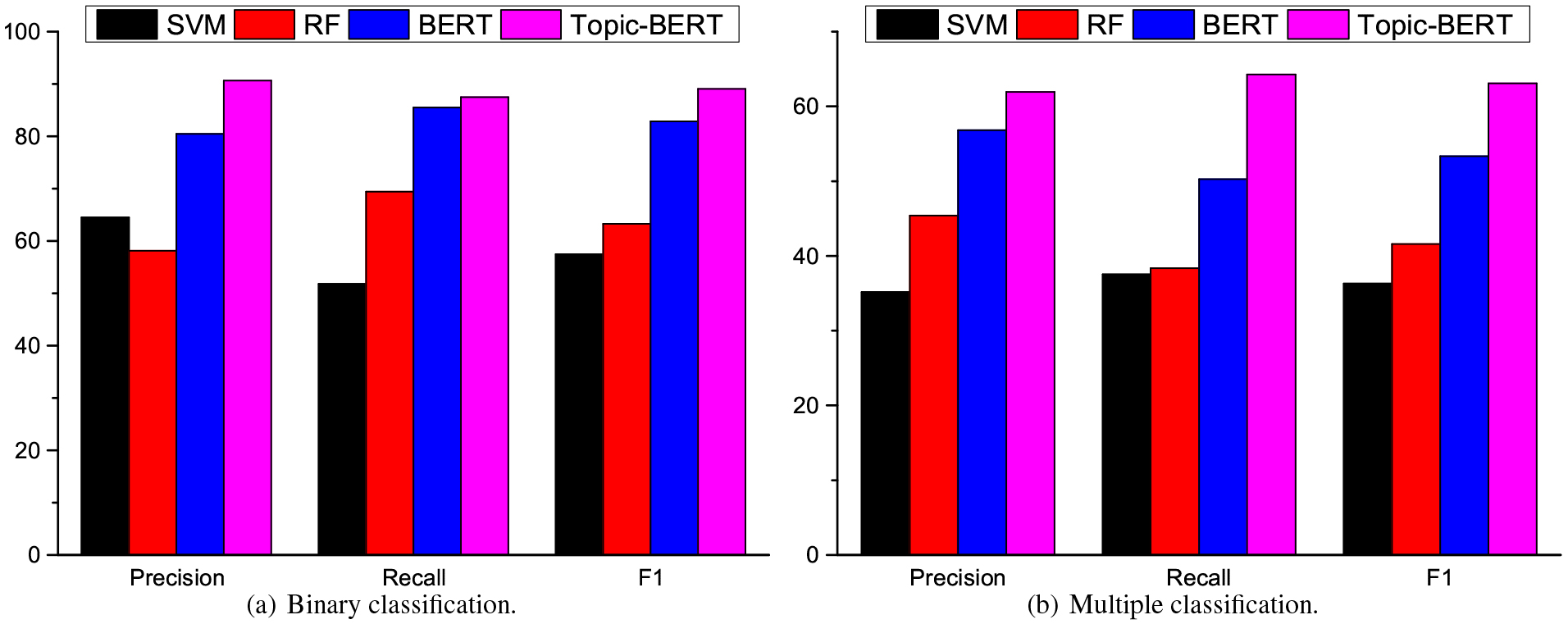
Topic distribution
To verify the difference between the topic distribution of harmful short texts and normal short texts, we first employ DMM, BTM and GPU-DMM to extract 60 topics in the training set, respectively. Then, we record the proportion of short texts belonging to each topic. Since DMM and GPU-DMM follow the assumption that each short text has only one topic, for comparison, BTM only utilizes the topics with the highest probability in the topic distribution of each short text.
Figures 3–5 illustrate the topic distribution of BTM, DMM and GPU-DMM, respectively. Red columns indicate the five topics with the highest number of short texts. From the figures, we can notice that GPU-DMM achieves the highest discrimination in the topic distribution of two types of short texts, which verifies the effectiveness of GPU-DMM in harmful short text identification. The topics extracted by GPU-DMM are more discriminative and representative. The topic distribution of BTM is not highly discriminative, which is not helpful for harmful short text filtering systems. This may be because BTM only adds less word co-occurrence information and does not fundamentally solve the sparsity problem, as discussed in [33], which leads to the lack of better distinguishability of extracted topics. Furthermore, DMM is better than BTM in topic differentiation, which indicates that the assumption that each text has only one topic is applicable to short texts.
Harmful short text identification
We employ SVM, RF, BERT and Topic-BERT for harm short text identification, and Precision (P), Recall (R) and F1-measure (F1) are used to measure performance.
where
In this section, we first compare the performance of four models for binary classification of harmful short texts. The proposed model directly uses coarse-grained labels to identify harmful short texts.
Figure 6a shows the precision, recall and F1-measure of four models on the binary classification task. From the figure, we observe that the performance of BERT is better than SVM and RF. This may be because BERT pre-trains a large network through massive external text corpus, and then uses the network to extract short text features and classify harmful short texts. This mechanism can effectively improve the performance of text classification tasks, which is consistent with the findings of [2]. The other observation is that Topic-BERT achieves the best performance compared with three baseline methods. The reason is that our model utilizes additional information such as likes, comments, retweets and topics to identify harmful short texts, which can alleviate the sparsity problem.
Next, we compare the performance of four methods for multiple classification of harmful short texts. In the Topic-BERT model, fine-grained labels are used to identify harmful short texts.
Figure 6b shows the precision, recall and F1-measure of four models on the multiple classification task. It can be intuitively found from the experimental results that all four models perform worse than the binary classification. This is because the multiple classification of harmful short texts is more difficult. The proposed model achieves the best results on three evaluation indicators. The experimental results verify that the two stages of Topic-BERT can promote each other and improve the performance effectively.
The experimental results of ablation study are shown in Fig. 7, which reveals the reasons that may affect the results. “One-stage” represents using only the first stage of Topic-BERT to classify harmful short texts, which still uses additional information and attention mechanism. It can be considered as the upper part of Fig. 1, and short texts are directly classified into fine-grained labels. As shown in Fig. 7, the precision, recall and F1 measure of the one-stage model all achieve the worst results, and precision is 9.56% lower than the complete two-stage model. This means that two-stage model can extract more semantic features, which is helpful for fine-grained multiple-classification.
Ablation study.
For the two-stage model, we ablates some components of Topic-BERT to evaluate their effects. “Only text” denotes that only short texts are used and directly input into the two-stage model without using attention mechanism and additional information. Unsurprisingly, its performance is worse than the other two-stage models, but still better than the one-stage model. “
In this paper, we propose a two-stage model based on BERT for harmful short text identification, namely Topic-BERT. Topic-BERT first leverages part of additional information as inputs to solve the sparsity problem of short texts. Topics learned by GPU-DMM are used as another part of additional information to calculate the weight of the attention mechanism. Furthermore, the proposed model constructs two similar sub-models to distinguish labels of different granularities. Coarse-grained labels and fine-grained labels can promote each other and improve the performance effectively. As there are more multiple-classification tasks in real life, this modeling approach will have greater application prospects. The experimental results indicate the effectiveness of the proposed model compared with existing state-of-the-art methods. In the future, we will study how to extract image information to improve our model.
Footnotes
Acknowledgments
We would like to thank the anonymous reviews for their valuable comments. This work was funded by Jianghan University Doctoral Research Startup Fund Project (No. 1028/06060001).