
Abstract
The use of multivariate time series generation in industrial settings such as the automotive industry continues to increase. The complexity of data analysis requirements in such industries has led to an urgent need to develop effective methods for extracting structural information from data based on the clustering of system behavior time series. Because there are complex interactions between vehicle data variables, the time series clustering of single variables can lead to insufficient results. To the best of our knowledge, only univariate dynamic time warping (DTW) approaches have thus far been applied in an automotive context. To close this research gap, this paper presents a review of generic approaches in multivariate dynamic time warping (MDTW) to determine the most promising approaches for use in the automotive domain. Four approaches are found to be particularly useful for tasks such as the objective assessment of subjective driving perceptions.
Keywords
Introduction
The increasing power of data storage and processing, in many real-world applications in the fields of, for instance, finance and automotive engineering, results in data being stored not only as sets of data points but also as time series. Therefore, the field of multivariate time series analysis is promising in these applications [1, 2]. This is especially true for automotive applications because vehicular behavior is influenced by various variables. For specific driving maneuvers, the values of these variables vary over time and evoke complex processes. Therefore, the analysis of multivariate time series is highly promising and essential for understanding and controlling such vehicular behavior. There are two major applications for knowledge discovery in multivariate time series: clustering of these time series is used to discover insights regarding the structure of the data and time-related patterns [1, 2]; classification based on multivariate time series is a second application [3].
However, analyzing multivariate time series is nontrivial. This is due to the potentially complex interrelations between the variables, which can even vary over time [4]. In [5] three major challenges for time series analysis are given. First, many methods only accept input data as a vector of features. Unfortunately, there are no explicit features in sequence data. Second, the feature selection is far from trivial because even with feature selection methods, the dimensionality of the feature space can be very high and the computation can be costly. Third, an interpretable classifier or clustering method is often desired. With no explicit features, it is difficult to build an interpretable sequence classifier or clustering method.
Raw-data-based clustering and classification approaches based on multivariate dynamic time warping (MDTW) are promising because they do not require feature selection and discretization using the raw data of the entire time series [5]. To the authors’ best knowledge, there has to date been no specific MDTW approach developed for automotive applications. To help bridge this gap, this paper reviews generic MDTW approaches to find the most promising ones for use in the automotive domain. The main contribution of this paper is to review current MDTW approaches with regard to automotive applications in order to present the recent progress in this field and to derive possibilities for future research.
The structure of this paper is shown in Fig. 1. The main focus of the paper is a review of generic MDTW approaches based on automotive requirements. Section 2 compares clustering of static data with the clustering of time series data. Section 3 describes the use-case of objective assessment and discusses the current use of univariate dynamic time warping (DTW) in automotive applications. Section 4 describes and classifies the current research approaches to MDTW, which are further discussed in terms of their respective research applicability. These approaches are rated with respect to automotive requirements in Section 5, leading to the selection of the four generic MDTW approaches most suitable for automotive applications. Finally, the conclusion is presented and future work described in Section 6.
Deriving the most suitable generic MDTW approaches for automotive applications.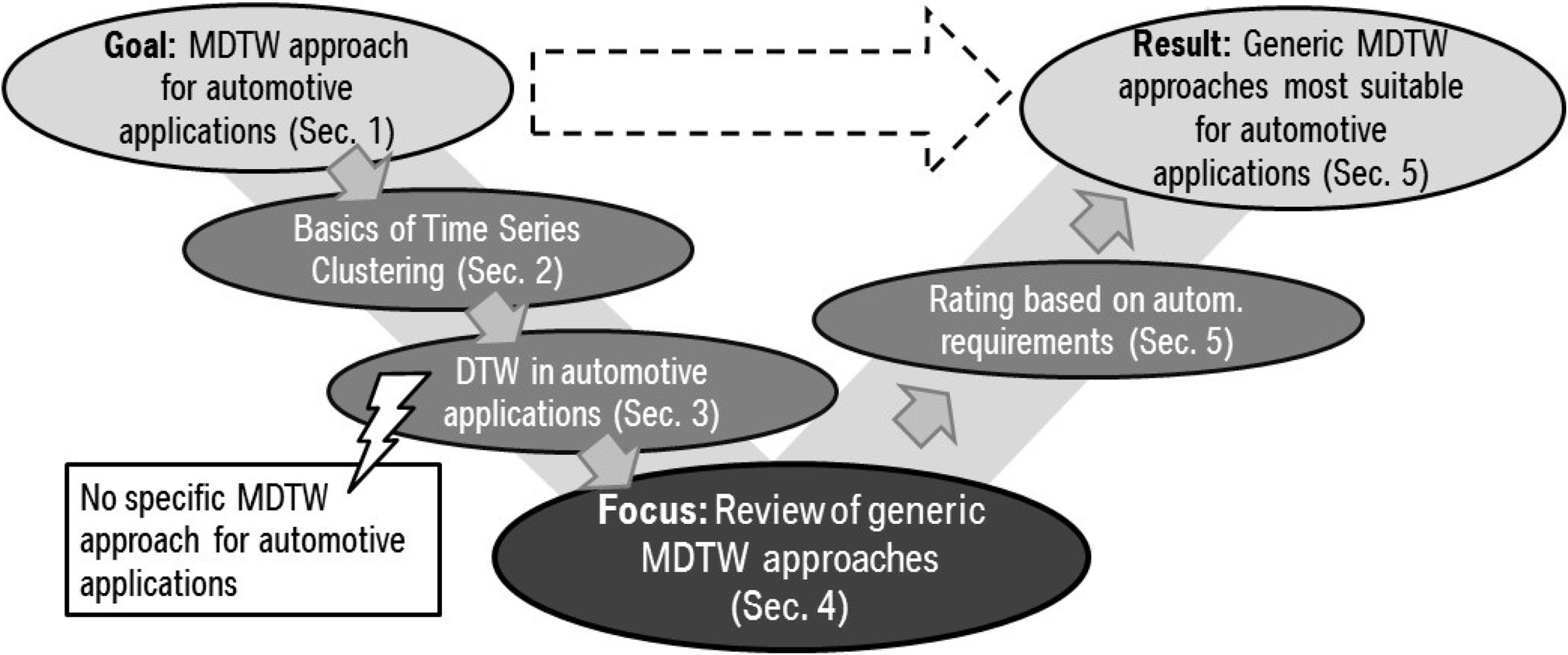
This section explains the clustering of static data, describes how it differs from the clustering of time series data and presents the terminology that is used in this paper.
Clustering
The goal of clustering is to partition a set of data points into a set of groups that are as similar as possible [6]. In [7], clustering approaches are divided according to their input, into similarity-based clustering and feature-based clustering. In similarity-based clustering, the input to the clustering algorithm is an
Time series clustering
In contrast to static data, discussed in Section 2.1, the time series of a variable comprises values that change over time. Although time series have high significance in many industrial applications, the majority of work on clustering has focused on static data[2]. In general, most algorithms for time series have been derived by modifying existing algorithms for clustering static data to adapt them for processing time series data [2].
The focus of this paper is on applications for which an automated process is required to minimize user impact on the clustering process and on defining suitable multivariate automated clustering processes for use in driving applications. An example that explains the benefits of an automated clustering process can be found in Section 3.1. For such applications, expert guessing of parameters is undesirable, as it could significantly change the output; thus, a suitable clustering method must be selected. Three types of time series clustering approaches have been identified: feature-based, model-based, and raw-data-based[2].
In feature-based approaches, an expert must engineer features such as the maximum and minimum of the time series, and a clustering method such as
In model-based approaches, the time series is approximated using a model upon which clustering is conducted. An advantage of this approach is that models such as continuous time Bayesian networks can be used to represent temporal dynamics by allowing the states to continuously evolve over time. Such discrete states can provide an understanding of the system and reduce noise [9]. Unfortunately, the states must be defined by an expert, a limitation that occurs in other model-based approaches. In any case, as a model is essentially an approximation of reality, some expert assumptions must be made [10]; as is true under the feature-based approach, such expert influence impedes the automated process because the clustering becomes highly dependent on the user’ model assumptions.
In raw-data-based approaches, clustering is performed using a distance measure on the raw data. By definition, such approaches use the highest potential amount of information and, by working directly with raw data, provide an approach in which clustering is achieved without the need for expert input. However, raw data are potentially prone to noise, and the choice of a suitable distance metric is highly dependent on the characteristics of the time series data.
Nevertheless, raw-data-based methods are probably the optimal approach to implementing automated processes, as the raw data can be processed without expert knowledge and the highest information gain is obtained.
Raw-data-based time series clustering approaches are distinguishable by the underlying similarity measure used. Similarity measures can be divided into lock-step measures, elastic measures, threshold-based measures, and pattern-based measures[11]. Threshold-based measures are not considered in this work because the threshold must be defined by the user, leading to a high degree of user-dependence of the clustering result. Pattern-based measures search for recurring patterns and therefore are more suitable for long time series. However, because the time series focused upon in this work, such as the variables measured during a lane change, are too short for significant recurring patterns to appear, pattern-based measures are not considered here.
Lock-step measures such as the Euclidean distance compare the
Elastic measures such as dynamic time warping (DTW) compare the
For applications in which time shifts and observations of different lengths occur, elastic measures are optimal because they have the capacity to deal directly with time series of different lengths and compensate for small offsets in comparable patterns. Elastic measures can be further divided into dynamic time warping and edit distance-based measures [11]. In the former, time steps are only stretched, whereas in the latter, time steps are also skipped; however, skipping time steps can result in the loss of potentially valuable information, and therefore edit distance-based measures are excluded from further consideration in this work.
Thus, DTW is the most promising approach for applications in which an automated time series clustering process without an educated guess is required for analyzing data with time shifts and varying temporal lengths without skipping time steps.
Integrating DTW into the research context of time series clustering.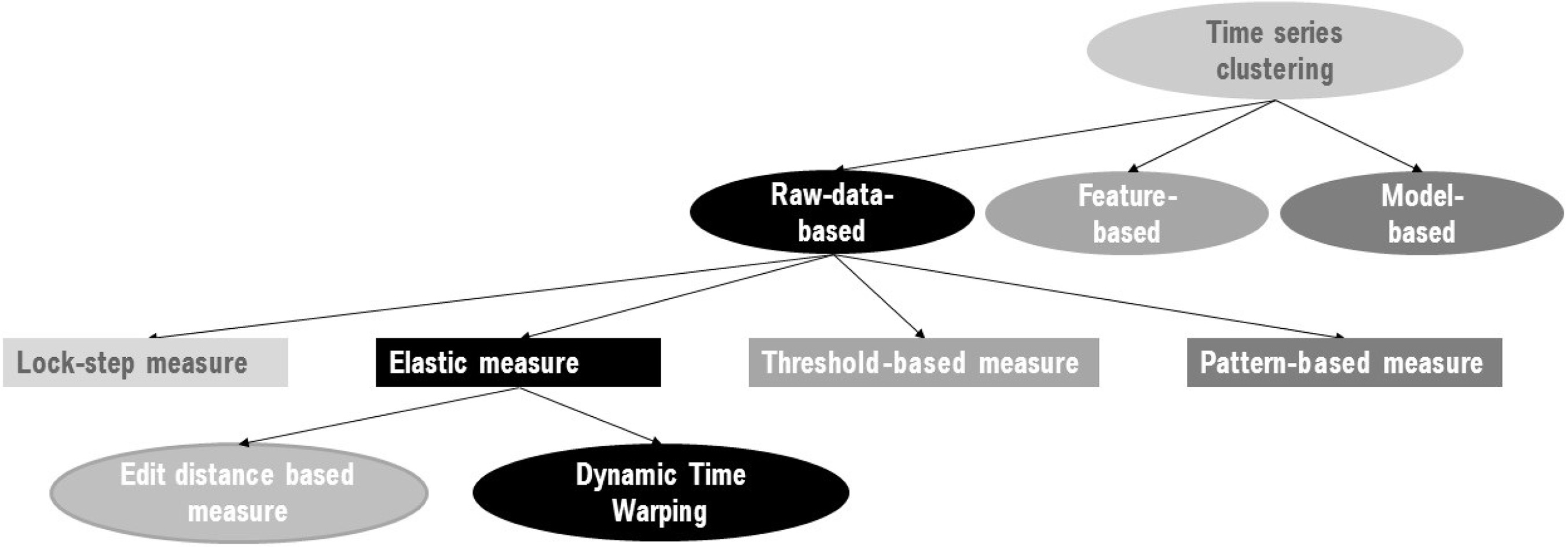
Figure 2 illustrates the integration of DTW into the context of time series clustering. When dealing with vehicle data, single time series are logged in parallel with other variables, leading to multivariate time series. The clustering of lane change maneuvers is an example of this, in which, in addition to other variables such as longitudinal and lateral acceleration, velocity and steering angle are logged. In applications such as these, clustering of one variable does not lead to sufficient results; in the lane-changing case, for example, the process of changing a lane is not sufficiently represented by a single variable. In [15], this problem is confirmed; it states that valid information can be lost when only one variable of a multivariate time series is considered. To group multivariate time series data, a multivariate time series clustering approach, namely multivariate dynamic time warping (MDTW), is required. To provide an understanding of MDTW, Section 2.3 presents the terminology and the problem definition for this paper, and Section 2.4 explains the univariate case of DTW.
This paper uses the following terminology: scalar
the distance measure
With univariate time series,
This subsection presents the formal definition of DTW. For further information on the univariate case of DTW, see [13, 18]. The aim of DTW is to align two time series
Hence, a
The warping path must follow three constraints:
Boundary conditions:
Continuity: The allowable steps in the warping path are limited to the adjacent cells. If
Monotonicity: The points in
Many warping paths
This warping path can be found using a dynamic programming approach in which the cumulative distance
As the DTW distance does not satisfy the triangle inequality, it is a pseudo-metric. In the following section, the univariate DTW approaches used in automotive applications are reviewed.
This section begins with an automotive example, the objective assessment of subjective driving perception (Section 3.1), where an MDTW approach is required. As there is no current MDTW approach specifically tailored to automotive challenges, the example helps to describe the characteristics of the data and the automotive requirements. These requirements will be applied in Section 5 to select the most suitable generic MDTW approaches. Section 3.2 reviews univariate DTW approaches for automotive applications to provide evidence for the method’s usefulness in the automotive context. The major research directions in MDTW are used in these subsections to classify the approaches explored and are discussed in detail in Section 4.
An automotive example: objective assessment of subjective driving perceptions
The objective assessment of subjective driving perceptions in Advanced Driver Assistance Systems (ADAS) is an automotive example in which MDTW-based time series clustering appears to be promising but has not yet been applied. The gain in comfort and safety provided by ADAS can only be appreciated when the driver perceives the driving behavior of the ADAS to be positive; therefore, subjective perception must be assessed in the development of a customer-centered ADAS. Furthermore, the objective assessment of ADAS requires the correlation of subjective perceptions with objectively measurable variables that occur in time series. This in turn necessitates the clustering of time series of measured observations to extract recurring patterns in terms of, e.g., acceleration. An automated clustering process such as the one described in Section 1 is therefore compulsory for this use-case. The aim of clustering time series in objective assessment is to determine the most influential objectively measurable variables; using an expert-dependent approach such as feature-based clustering could lead to expert-dependent variation in the clustering. Such human-induced variation is by definition subjective and can therefore distort any objective process. This example is used as representative of various scientific problems in the automotive industry. Based on data obtained from objective assessment, Table 1 summarizes the most important automotive data characteristics focused upon in this research.
Description of automotive data used for objective assessment
Description of automotive data used for objective assessment
Working with vehicle data poses special requirements in terms of the methods used for time series analysis; the requirements for generic MDTW approaches used in this study are based on informal expert interviews at BMW AG and can be divided into four main aspects:
Time dependency of the variables: In automotive applications, many variables – for instance, steering angle and lateral acceleration – have a high degree of interdependence. To obtain a realistic description of system behavior, all variables must be considered at specific time steps to capture their interaction.
Interpretability of the system: In automotive use-cases such as objective assessment, an attempt is made to understand the different types of system behavior through representation using clusters with several time series. Correspondingly, the process of clustering needs to be highly traceable.
Variables with different magnitudes and units: The units and magnitudes of data such as velocity and acceleration can differ significantly (e.g., velocity, 0–200 km/h, and acceleration, 0–3 m/s
Variables with different influence: As stated in requirement 1 (a), variables can influence each other significantly. However, the intensity of interdependence is generally not the same for all variables, and it is often useful to know how interdependencies vary. Variable influence can also be driving maneuver-specific.
In Section 5, requirements 1 (a) and 1 (b) will be used to assess the general research direction, with the respective approaches analyzed in more detail based on requirements 2 (a) and 2 (b). In the following subsection, the terminology used in this paper is explained and the problem of calculating the distance between two multivariate time series is defined mathematically.
Because there is currently no MDTW approach focusing on automotive applications, the authors conducted a review of univariate DTW applications in this domain. The review was subsequently extended to MDTW approaches (Section 4) from other domains to evaluate their defined requirements (Section 5). DTW originally emerged from speech recognition [18] but has been widely applied to other fields; in this subsection, an overview of the use of univariate DTW in the automotive context is provided.
In [19], fast DTW was used in combination with spectral clustering to cluster multiple velocity profiles to enable the prediction of behavior or the future state of a vehicle. Because velocity profiles can be considered time series, the use of DTW was suggested as a highly accurate method for finding a distance measurement between time series.
In [20], the focus was on the detection of “aggressive” and “non-aggressive” driving styles using a smartphone-based sensor fusion of an accelerometer, gyroscope, magnetometer, GPS, and video. Such recognition of driving styles and maneuvers via DTW is useful in vehicle safety systems.
In [21], the problem of tracking fine-grained speed variations of vehicles was tackled. This research proposed a technique based on derivative DTW that aligns a received signal strength trace from a moving cell phone handset with a reference trace for a given road segment.
In [22], DTW was used to measure the similarity between two time series of speeds taken from two vehicles driven on the same road segment. This method allows for early detection of vehicles driving at abnormal speeds.
In [23], a
In [19, 20, 21, 22], it was demonstrated that DTW performs very well in terms of analyzing velocity and acceleration time series. According to [23], using time series of these variables in combination with the steering angle leads to results sufficient for detecting lane changes.
In [24], the DTW approach was adopted to measure the similarity of two magnetic signatures of a wireless magnetic sensor network for vehicle speed estimation.
In [25], a metric based on DTW was proposed to compare the time histories of the outputs of simulation models with time histories obtained from experimental tests with an emphasis on vehicle safety applications.
In [26], the use of DTW was presented to process electric motor current signals to detect and quantify common faults in a downstream two-stage reciprocating compressor.
In [27], a method using the scale of matched SURF image features and DTW was proposed to perform stable ego-localization for driver assistance and autonomous driving systems.
In [28], driver heterogeneity in car-following behavior and heterogeneous situation-dependent behavior while driving were examined. The DTW algorithm was used to calibrate a microscopic simulation model by synthesizing driver trajectory data.
In [24, 25, 26, 27, 28], the use of DTW was studied for variables beyond those in the previous works cited.
From this brief review, it is seen that DTW is a promising approach to tackling a range of problems in the automotive domain. One challenge is that under the original definition of DTW, 1-D time series are compared, meaning that each element of a sequence is described in a 1-D space (see Section 2.4). The inherent inability of DTW to handle observations of differing or higher dimensionality limits the application of DTW under its original definition. As stated in Section 1, in real-world applications (e.g., capturing data from multiple sensors) high-dimensional data are common [29]. This is especially true for the introductory example of objective assessment (Section 3.1) because, in most driving scenarios, the perception of the driver is influenced by more than one objectively measurable variable. Therefore, a univariate DTW approach leads to insufficient results. In such applications, each element of a sequence is described in an
Review of the generic MDTW approaches
In Section 3.2, it was noted that the univariate version of DTW does not provide sufficient results for applications in which multiple variables with high degrees of interrelation occur. The importance of this is striking when considering that most dynamical systems are characterized by multivariate time series [32]. Thus, obtaining sufficient clustering results requires the use of MDTW approaches, which in turn leads to the challenge of determining the appropriate approach for a given application. The three major directions in MDTW research that have emerged in the last few years are also discussed in this section.
Respective warping paths of 
In [33], one of the first studies referring to a multidimensional DTW concept is documented. The primary goal of this work was to directly control the warping function curvature by augmenting the dimensionality of DTW. Because the dimensionality increase was used to increase the robustness of speech recognition against colored noise, it represented only a generalization of DTW for similar variables.
In [34], a multipattern DTW was presented in which an optimum path in multidimensional space was determined to increase noise robustness in speech recognition. Similar to that in [33], this approach compared only multiple versions of univariate time series.
The approaches in [33, 34] were in fact the first MDTW approaches to appear in the literature. However, they did not provide a generalization of MDTW compatible with the focus of this work, as they involved the use of only one type of multivariable (speech signals); as discussed in the preceding section, approaches involving multiple variables of differing types (e.g., steering angle and velocity) are more appropriate to automotive applications and are therefore focused on in this review.
The first multidimensional MDTW approach was reported in [30], where two primary MDTW methods are given. Under the first, called
The following subsections describe current MDTW approaches, which, as identified above, are divided into
This subsection describes
In [35], a DTW kNN classifier for time series with missing data was presented in which a DTW is calculated for each dimension and later aggregated into one distance measurement using the Euclidean distance. In this case, normalization is necessary, particularly for variables with different scales, and therefore a standard deviation vector
In [31, 36], a threshold-based learning approach was used for which either
In [37],
In [8], MDTW was applied in human activity recognition based on the use of the DTW to compute a distance for each dimension, with the resulting vector of distances treated as a feature vector. A dimensionality reduction algorithm such as principal component analysis (PCA) is then applied to this feature vector and a classifier such as signal vector magnitude (SVM) is used to predict the correct class. Relative to previous approaches, this method uses a genuinely different approach.
This subsection describes the
The
In [38], DTW was used as a tool to match movement patterns. In this study, such patterns were represented as sequences of feature vectors, and the distance between the
In [39], multivariate time series were treated as sequence of feature vectors, in a manner similar to that in [38]. Stating that in principle any
In [40], an algorithm was proposed for similarity search in trajectories and archival data. This paper was the first to extend DTW to cases of greater than three dimensions and applied the
In [41], the dimensionality of DTW was expanded by indexing multidimensional time series for the task of efficient retrieval and analysis of trajectory similarities. These authors described an extension from the classical one dimensional DTW to a two dimensional search space to obtain optimal alignment using the
In [42], the approach of [39] was applied by using the
In [43], an approach similar to that in [38, 39] was presented in which time series were treated as sequences of feature vectors. As had been demonstrated in [39], the Euclidean distance with weights
In [30], the two possible types of MDTW discussed in Section 4 were recognized, but
In [44], the DTW algorithm uWave for gesture recognition using a three-axis accelerometer was developed. In this method, a feature vector with three elements per time sample corresponding to the components of acceleration along the three spatial axes is used. The algorithm employs the Euclidean distance Eq. (13) for matching quantized time series of acceleration; as all three dimensions represent acceleration signals, no weight vector is needed.
In [16], a measure was proposed for the discrepancy
In [45], a DTW-based algorithm was presented to classify any
In [46], regular and derivative DTW (DDTW) were combined into one parametric distance measure, allowing the contributions of the two respective methods to be defined individually for any data set. In this method, it is assumed that multivariate time series are one-dimensional trajectories in an
In [47], DTW was applied in a clinical test to measure balance and mobility. In this case, the data were generated by a wearable inertial sensor unit, and the Euclidean distance Eq. (13) was used to generalize to the multivariate case.
As previously stated in Section 4.1, two studies [31, 36] applied both
In [48], a new lip-reading system was presented based on the classification of lip geometry features using a template probabilistic multi dimensional DTW approach. In the opinion of the authors, it would have been possible in principle to apply DTW to each feature separately and subsequently select the class with the shortest distance, but in their use-case they did not obtain sufficient results; therefore, a new MDTW distance designed specifically for lip-reading was developed Eq. (15)
The distance function used in this study differed significantly from those used in other approaches in that it was highly tuned to the use-case of classifying lip geometry features; correspondingly, it is not further considered in this paper.
As mentioned in Section 4.1, both
In [49], a new ensemble classifier was proposed based on the DTW, and a method for combining information from time series extracted from multiple sensors was demonstrated. In this method, the signal vector magnitude (SVM) for the three dimensional case is calculated and used to generalize to Eq. (17) for the
In [50], an MDTW measure was proposed based on the Mahalanobis distance Eq. (18) for use in data-driven fault diagnosis. A metric learning algorithm was used to learn the static feature vectors in measurement signals to obtain the Mahalanobis distance over the feature space. In this paper, the authors discussed the Euclidean distance approach mentioned in Section 4.2 and noted that this method fails in assigning different weights to each variable. According to them, the assumption that every variable is equally important does not hold for process monitoring and fault diagnosis. Their approach was further developed in [51].
In [52], DTW approaches were divided into methods employing early and late fusion of signals, a classification corresponding to
In [31], there was a discussion of how the two primary modalities of MDTW identified in [30] can produce different classifications in which neither dominates the other. In this study,
In [4], a fundamentally different approach was presented, one that cannot be classified into either
where
In [29], a method called deep canonical time warping (DCTW) was proposed in which multiple sequences are aligned to discover complex hierarchical representations. DTW-based temporal alignment methods are extended to encompass heterogeneous collections of features that can be connected via non-linear hierarchical mappings. This method was the first deep learning approach to temporal alignment and thus represented a fundamental break with earlier approaches.
Section 4 presented what the authors believe to be the most relevant publications regarding MDTW. The methodologies examined in this section can be classified as either
Comparison of MDTW research directions in terms of requirements 1(a) and 1(b)
Comparison of MDTW research directions in terms of requirements 1(a) and 1(b)
Table 2 shows a comparison of the research directions for
Comparison of
From this perspective,
Comparison of
This increased interpretability occurs under
This first comparison has shown that all three research directions are in principle suitable for working with vehicle data, with efficacy varying depending on the emphasis placed on requirement 1(a) or 1(b). Now follows a detailed qualitative comparative analysis of the respective approaches.
Table 3 shows a comparison of the
Table 4 shows a comparison of the
This characteristic also causes these two approaches to fail requirement 2(b); because they sum all variables, the influence of a single variable cannot be determined. However, the
Table 5 shows a comparison of the integrated approaches in terms of requirements 2(a) and 2(b). The approaches of [4, 29] are the only integrated approaches that fulfill requirement 2(a). Because PCA is magnitude- and unit-invariant, the former approach has no problem handling variables of different magnitudes and units. In the latter approach, the variables are transformed into a feature space that is unit- and magnitude-invariant. The approach of [52] and the
Comparison of integrated approaches in terms of requirements 2(a) and 2(b)
By definition, these approaches are more complex, making it more difficult to trace the influence of different variables. The weighting factor in [52] can solve this problem partially but, as there is only one weighting factor, this solution is limited. In the approach of [31], only
To summarize the discussion in this section, as an automotive application the most promising
Overview of distance functions used in the most promising approaches
The goal of this paper was to review the current approaches in MDTW and to identify the most appropriate of these with respect to automotive applications. The paper began with a discussion of the need for an MDTW approach in the automotive domain. Subsequently, the current research directions in terms of generic MDTW approaches were discussed, followed by a classification of approaches and an assessment of the respective approaches with regard to automotive applications. Although no approach specifically designed to handle vehicle data could be found, four existing approaches that fulfill the defined automotive requirements were identified.
A core insight of this literature review is that no approach currently exists that fulfills all of the requirements of automotive applications. There is a high demand from industry, where a massive amount of time series data is created. Although the research on MDTW is relatively new, three main research directions have evolved. The first on,
Possibilities for future work lie in an experimental comparison of the MDTW approaches on an open source database with automotive time series data to achieve deeper insights for the user. Furthermore, it is necessary to analyze how well the MDTW approaches react to high dimensionality data and highly noisy data without filtering. This can give an estimation of the use-cases for which the MDTW approaches are also promising. In the next step, the applicability for these use-cases must be evaluated with experimental data. In addition, the data preparation that is necessary for MDTW must be analyzed in depth, and the possibility of combining the MDTW approaches with other machine learning methods in order to create a hybrid approach should be explored.