
Abstract
Existing location-privacy-preserving methods primarily focus on solving the problem of location-privacy preservation in the global space. This not only increases the response time of the location service, it also degrades the data quality. In this paper, a k-anonymity algorithm based on locality-sensitive hashing is proposed to solve the problem of location-privacy preservation in the subspace. In the proposed algorithm, higher efficiency and higher quality of service are achieved by applying a bottom-up grid-search method. Further, reasonable division is obtained based on locality-sensitive hashing by retaining position characteristics. The results of experiments conducted to evaluate the proposed algorithm indicate that the proposed algorithm provides a smaller anonymous spatial region, higher data quality, and lower time cost than methods with no subspace.
Keywords
Introduction
Location-based services (LBSs) [1, 2, 34], such as finding the nearest convenience services, coupon-release services, and real-time location-information services for locating friends and family, have rapidly grown in mobile social network applications in recent years [5]. To enable and obtain their desired location-based services, mobile users must send their exact location information to an LBS provider [6].
However, location-privacy leaks can occur when the servers of these LBS providers are compromised. The location information embedded in the LBS query can be collected by an adversary connected to the LBS server. Sensitive information of service recipients, such as home locations, lifestyles, health conditions, and political and religious associations, can be inferred from the information on the server [7]. Thus, as serious privacy threats can result from use of LBSs, users need to consider the risk of privacy disclosure. Further, as use of LBS applications has become more widespread, location privacy protection is becoming increasingly more critical and a primary concern for information security.
An effective LBS privacy protection method is k-anonymity [8, 9, 10, 11], which has gained considerable attention in recent years. It requires at least
Existing location-privacy-protection methods primarily solve the privacy problem only in the global view, which results in difficulties solving complex problems. To rectify this issue, a k-anonymity algorithm based on the subspace, which is built by a bottom-up grid-cloaking method that helps to reduce the problem complexity, is proposed in this paper.
The main contributions of this work are summarized as follows:
Instead of solving the problem in the global space, we propose a subspace concept in which anonymous areas are created from the adjacent areas of the query point. The proposed method more closely approximates a human’s approach to solving the problem in the real world. Furthermore, we provide a common solution for k-anonymous privacy protection research. The subspace is created using a bottom-up grid-cloaking method to narrow the search range and reduce the time complexity. Moreover, it can improve the service quality and reduce the response time. As the locality-sensitive hash function has a position-sensitive characteristic, based on locality sensitive hashing (LSH), the space position can maintain similarity with high probability. Therefore, the proposed algorithm makes the partition reasonable and improves the data quality.
The remainder of this paper is organized as follows. Section 2 discusses related work. Section 3 presents the background to this study and introduces related studies, along with related concepts and problems. Section 4 describes and analyzes the proposed LSH-based subspace k-anonymity privacy protection algorithm. Section 5 discusses the experiments conducted to evaluate the proposed method and the results obtained. Section 6 concludes this paper and outlines future research.
K-anonymity algorithms are widely used in privacy preservation of location data mining [16] and ubiquitous vehicular ad hoc networks (VANETs) [17], as well as preventing neighborhood attacks in social networks [18], anonymizing data and protecting sensitive labels [19], anonymizing collections of tree-structured data [20], and anonymizing transactions with sensitive items [21]. In addition, they are used for privacy preservation in high-dimensional data sharing [22], supervisory control, data acquisition publishing [23], transaction data anonymization [24], and publication of sensitive transactional data [25].
Furthermore, LSH has been proposed as an efficient technique for similarity joining for high-dimensional and large-scale data [26]. It is widely used in various applications [27]. Personalized locality sensitive hashing (PLSH), for example, has been implemented in a parallel framework to address similarity joins on large-scale data in the approximate nearest-neighbor problem [26]. Tag assignment stream clustering (TASC), an incremental scalable community detection method, has been proposed based on locality-sensitive hashing for social tagging systems [28]. In addition, randomness-based locality-sensitive hashing (RLSH), based on p-stable LSH, has been introduced for the approximate nearest-neighbor problem [27]. Moreover, use of the LSH-based adaptive mean-shift algorithm with bandwidth estimation (LSH-AMS-BE) in an approximate-neighborhood query method has been proposed for computation of high-dimensional data. In this approach, LSH is used to reduce the computational complexity of the adaptive mean-shift algorithm [29].
Interpreting LSH as a means for data clustering can solve the difficult problem of clustering transactional data with very high dimensions [30]. The index-aware nearest-neighbor search method based on LSH can be used to handle large compound databases with several million entries for accelerated similarity searching and clustering of very large compound sets [31]. Meanwhile, the single-linkage method reduces the time complexity by rapidly finding nearby clusters to be connected using LSH to search for the nearest approximate neighbor [32]. MinHash and SimHash use two respective LSH strategies to group high-dimensional data for the design of intelligent systems. This approach has been incorporated in numerous real-world applications [33].
The LSH function can maintain a proximate position in the mapping process [34, 35, 36, 37]. It has therefore been used in the spatial k-anonymity algorithm. Datar et al. [38] proved that the LSH function has a position-sensitive characteristic. Based on hashing, the space position can maintain similarity with high probability, which can enable reasonable space partitioning. Vu et al. [39] designed a spatial k-anonymity privacy protection scheme with an LSH mechanism that exhibited good performance and moderate computational complexity.
Numerous algorithms based on LSH have an obvious influence on computational complexity. However, these LSH-based algorithms are directly performed in the global data space. In this scenario, they have to search for the optimal value of all location points, which requires considerable service time for responding with results. In general, finding k–1 points in k-anonymity does not involve a large distance in the real world. The search must only be confined to the adjacent regions of the query point.
Related concepts and problems
LBS privacy protection model
In this section, we review LBS selection techniques and consider several recently proposed LBS privacy protection methods. A typical LBS system architecture is shown in Fig. 1. The LBS system is mainly composed of four parts: LBS servers, mobile terminal users, positioning system, and communication network. Most basic daily-use information, such as traffic maps, vehicle tracking, and entertainment information, is related to the user’s location. Services can locate the user through the positioning system, and appropriate information and services can be provided through the communication network.
LBS system architecture.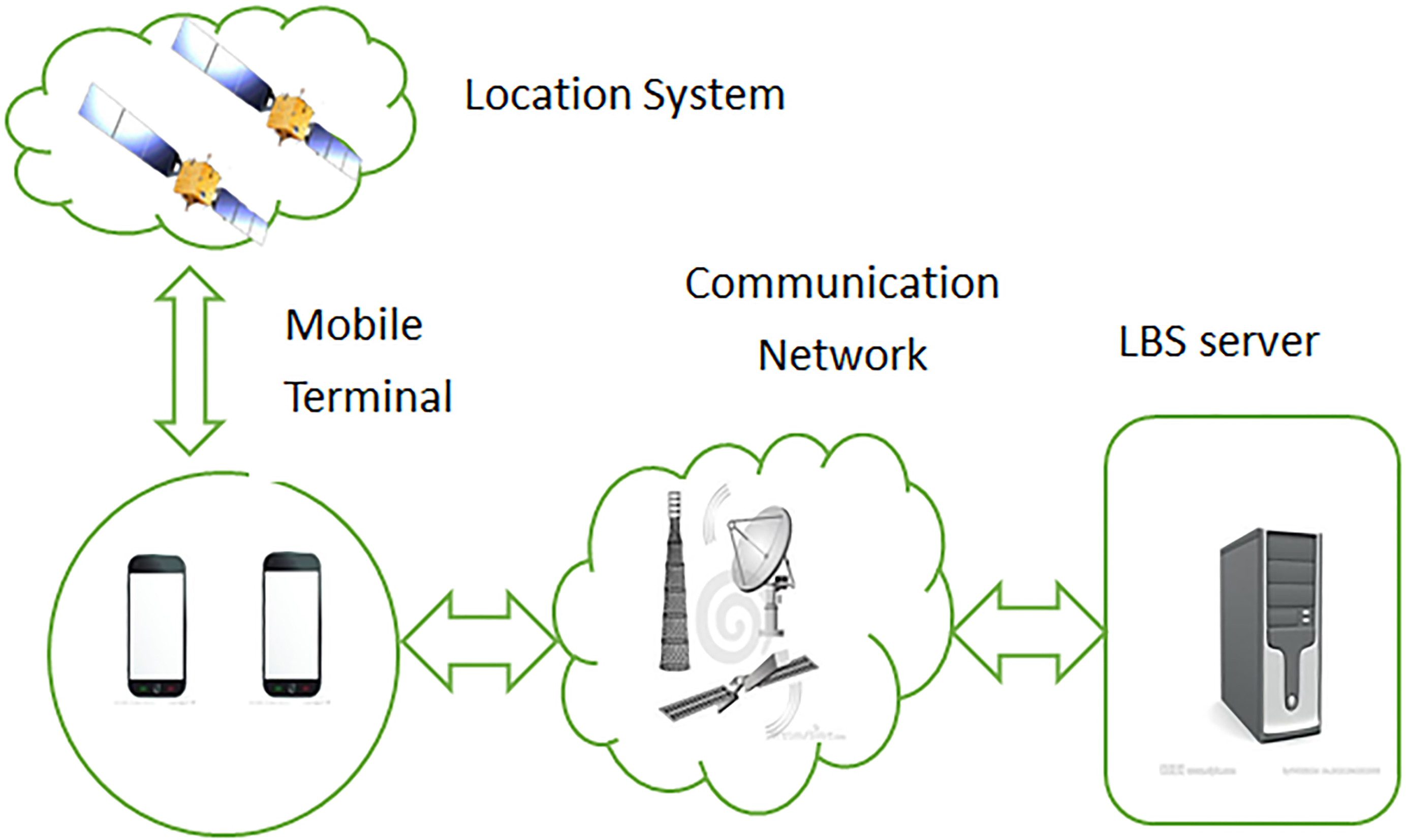
In this paper, a centralized architecture is adopted that comprises three parts: user, anonymizer, and LBS server. The LBS privacy-preserving query system is shown in Fig. 2. In the model, a trusted third-party anonymous server is established between the user and the location service provider. Firstly, the query information is sent to the anonymous server from the user through the network. The anonymous server then sends the user’s location together with other k–1 locations to the LBS server. Next, the LBS server returns all results to the anonymous server. Finally, the anonymous server returns the relevant information to the user. In this way, the service provider cannot know the user’s information and confidentiality is maintained.
LBS privacy-preserving query system.
In this model, the identification (ID) of the user who submitted the query is hidden by the anonymous server. The anonymizing spatial region (ASR) is constructed using at least k different users. ASR can be surrounded by a circle, rectangle, etc. The minimum bounding rectangle (MBR) encapsulation method is adopted in this paper.
LSH is one of the most effective search techniques for high-dimensional data with probabilistic guarantees. Its key concept is to hash data points into one or more hash tables after random projection, and then search within the hash table buckets [30]. LSH is used in the projection of a point in the space to a vector L. It maintains the distance in both the space and projection to vector L. After being hashed, the given points can be guaranteed as being near each other. However, ensuring that distant points remain far apart is difficult. The following example illustrates the problem.
Example of LSH partition.
As shown in Fig. 3, suppose that the distance between C and D is very far, while the projected distance of point C1, D1 in the projection on L1 is near. Then, it is necessary to project multiple vectors to form a hash cluster. Accordingly, the original nearby points in all vectors are still very close to each other in the projection. The point that is far from the others may be close in the vector projection; however, most of the points projected on the vector remain far.
In this paper, the bottom-up grid cloaking method is used to create the subspace. The whole data space is divided into many grids, with the number in each grid representing the number of location points included in the region. The subspace contains only the area around the query point, with its size determined by the threshold. To reduce the number of iterations, the extension principle of the subspace is used to find the grid of the maximum number of locations. The principle is illustrated by an example as follows.
Assume that SN is a two-dimensional array for storing the number of data points in each small grid. The number of points in the grid of the query point is denoted as SN[u][v]. We select the maximum value of the set (SN [v], [u
Problem description
When the data scale is large, the efficiency of the spatial k-anonymity algorithm based on the LSH partition (SKA_LSHP) remains very large because it solves the problem only in the global space. Therefore, to improve the availability and quality of the data, and to reduce the problem complexity, the proposed subspace k-anonymity algorithm through a bottom-up grid searching method based on the LSH partition (SKA_BGSM_LSHP) is presented.
Algorithm description
The basic idea underlying the SKA_BGSM_LSHP algorithm is described as follows.
Initialize the structure array. Read n two-dimensional location points from the dataset and store these points in the structure array. Divide the location region into M Locate the grid of the query point, which is extended along the grid. The extension principle is presented as follows. Firstly, the algorithm searches from four different directions to identify the grid with the largest number of points. Then, it connects these grids to a rectangular area. If this extension is in the horizontal direction, then the next expansion is in the vertical direction, and vice versa, until the given threshold conditions are met. In this way, the subspace is constructed. Read all the points in the subspace that were obtained in Step 3 and store them in a new structure array. Project these points onto one random vector, sort the projection points on each vector as a sorted table, and divide the table into many k-size buckets. Remove the first point in the first bucket, list the other points in the same bucket from each sorted list, and screen out k–1 nearest points. Next, delete these selected points in the sorted tables. Repeat the operation until the number of points in the sorted table is less than 2
The SKA_BGSM_LSHP algorithm is composed of two parts, as shown below in respective Algorithms 1 and 2 pseudo-code. Algorithm 1 is a subspace-search algorithm based on the bottom-up grid method. It is abbreviated as CSABGM (n, SK) and is initially executed to form a subspace. Next, the sub-spatial k-anonymity algorithm based on LSH partition SKA_LSHP (Q, u, k) is executed.
First, a subspace of the problem is created by the CSABGM algorithm presented as Algorithm 1.
The CSABGM algorithm first reads all points from the dataset (Line 1). Then, it divides the region of the points into
Calculation steps of the bottom-up grid search algorithm.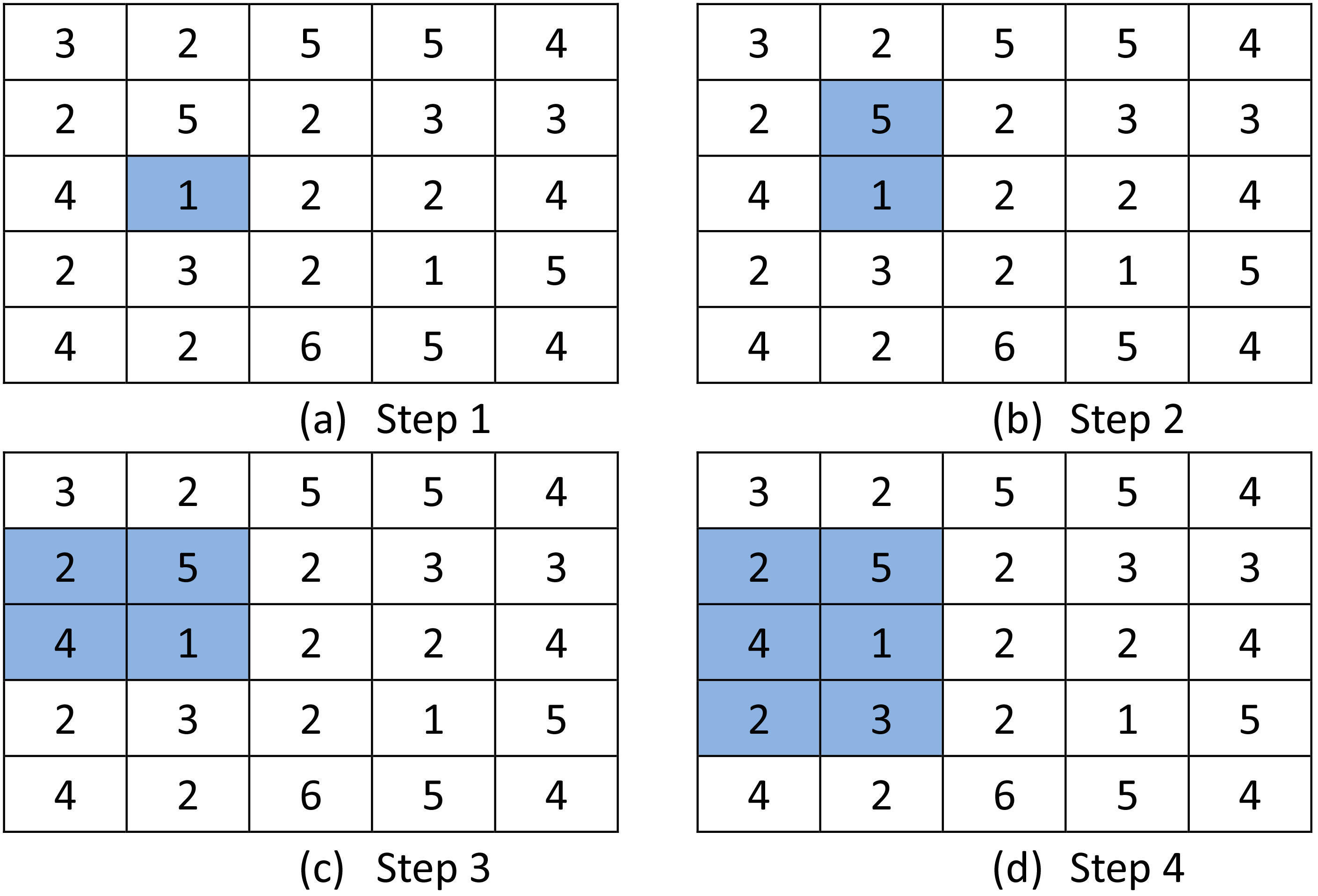
An example of Algorithm 1 is illustrated as follows. Assume that threshold SK
Thus, the second determination is made in the horizontal direction, as shown in Fig. 4c; SN
The subspace k-anonymity algorithm based on LSH is outlined in Algorithm 2.
First, all points in the subspace are projected onto a set of vectors. A sort table is obtained in the SKA_LSHP algorithm (Line 1). Then, each table is divided into several buckets according to the value of k (Line 2). All points from the buckets are identified in each sort table (containing query point u), and they are stored in Set B (Lines 3 to 12). The nearest k–1 points are selected from Set B through Set R (Line 13). Finally, the ASR is returned (Lines 14 to 20). The partition with the LSH function can appropriately divide the space. Compared with other algorithms, this algorithm has a smaller anonymous spatial region. An example of Algorithm 2 is detailed as follows:
Suppose the query point is the fourth point, k is 4, l is 2, and ten points of the subspace are obtained after the grid search. The ten points are: a1(3,6), a2(4,8), a3(5,4), a4(4,6), a5(2,7), a6(2,4), a7(5,5), a8(6,7), a9(7,5), and a10(6,5). Vector l1 is 4x
Example of the k-anonymity algorithm based on LSH.
By creating a subspace to generate anonymous regions, the search area, scope, and complexity of the problem are significantly reduced and the efficiency improves. Furthermore, high-dimensional data space is mapped into low-dimensional linear space by hash projection, which also significantly reduces the complexity of the problem.
Because a single hash function has the probability of dividing two distant points into the same bucket, multiple hash functions are used to reduce the probability of misallocation, improve the accuracy and improve the quality of data. Each sequence table is divided into buckets comprising k elements, and all elements in the same bucket as query points are selected as candidate sets to select the k–1 nearest neighbors. Because LSH has the characteristic of local location preservation, it can guarantee the correctness of candidate sets. Further, because the size of the candidate sets is generally small, this method can further reduce the search scope and improve the efficiency of the algorithm.
Inference
The probability that all the nearest neighbors of query point Q fall into the hash bucket is positively correlated with the number of functions
Proof
Assuming that the hash function is “
Suppose there are
Thus, the probability of occurrence of
Suppose there are
Suppose
Assume that
Assume that
Thus, the probability of occurrence of
Therefore, the probability of finding the nearest neighbor of
The time complexity analysis is presented as follows. In Algorithm 1, Line 1, the time complexity for reading
In Algorithm 2, Lines 3 to 11, for each array Li in sort table
Experimental classification results and analysis
We evaluated the quality of service and its response time with different values of
Influence of 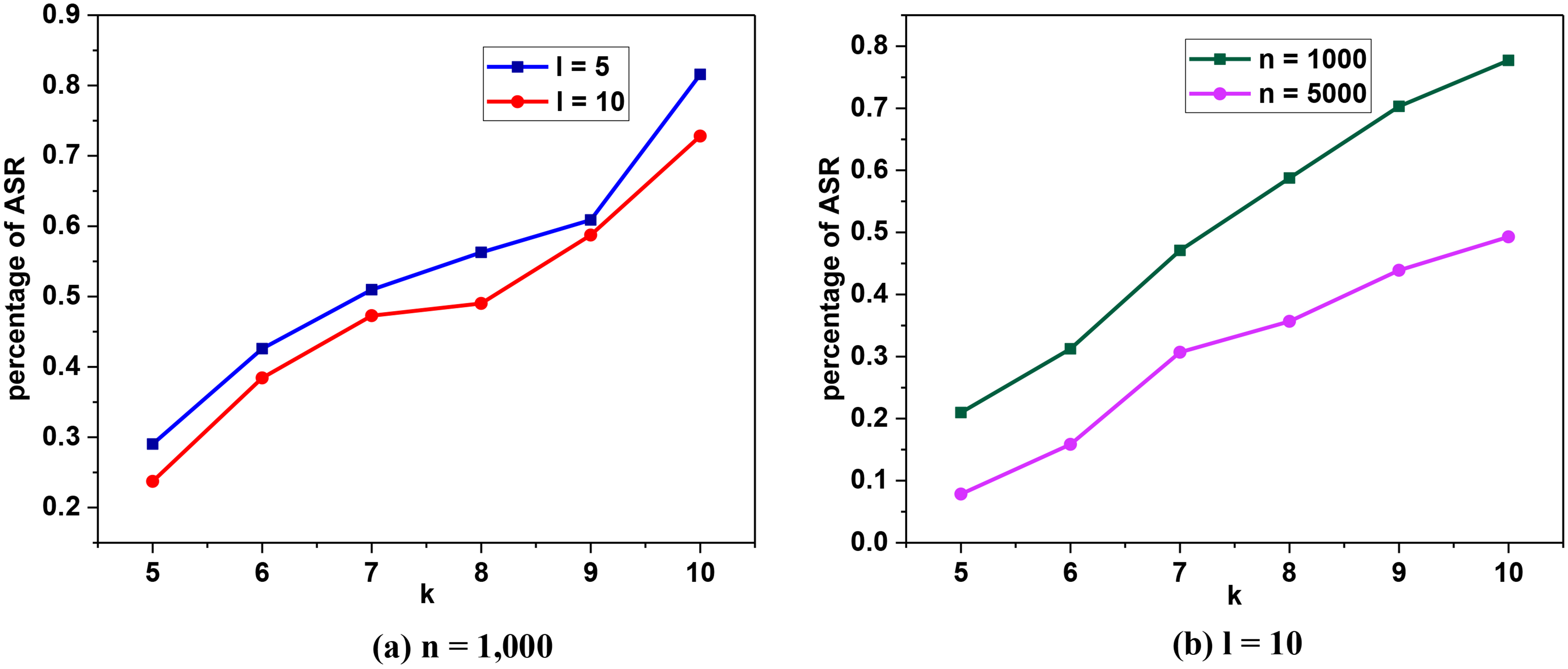
The evaluation primarily focused on the ASR percentages and execution times. Calculation of the ASR percentage is shown in Eq. (9).
where
The simulation experiments on dataset1 of the algorithm were coded in VC++ 6.0. The main parameters of dataset1 were as follows. The size of the region was 1,000
All the curves in Fig. 6 demonstrate an upward trend, which indicates that the
Figure 7 shows that the ASR percentage decreases with the increase of the
Influence of n on the ASR percentage.
Influence of l on the ASR percentage (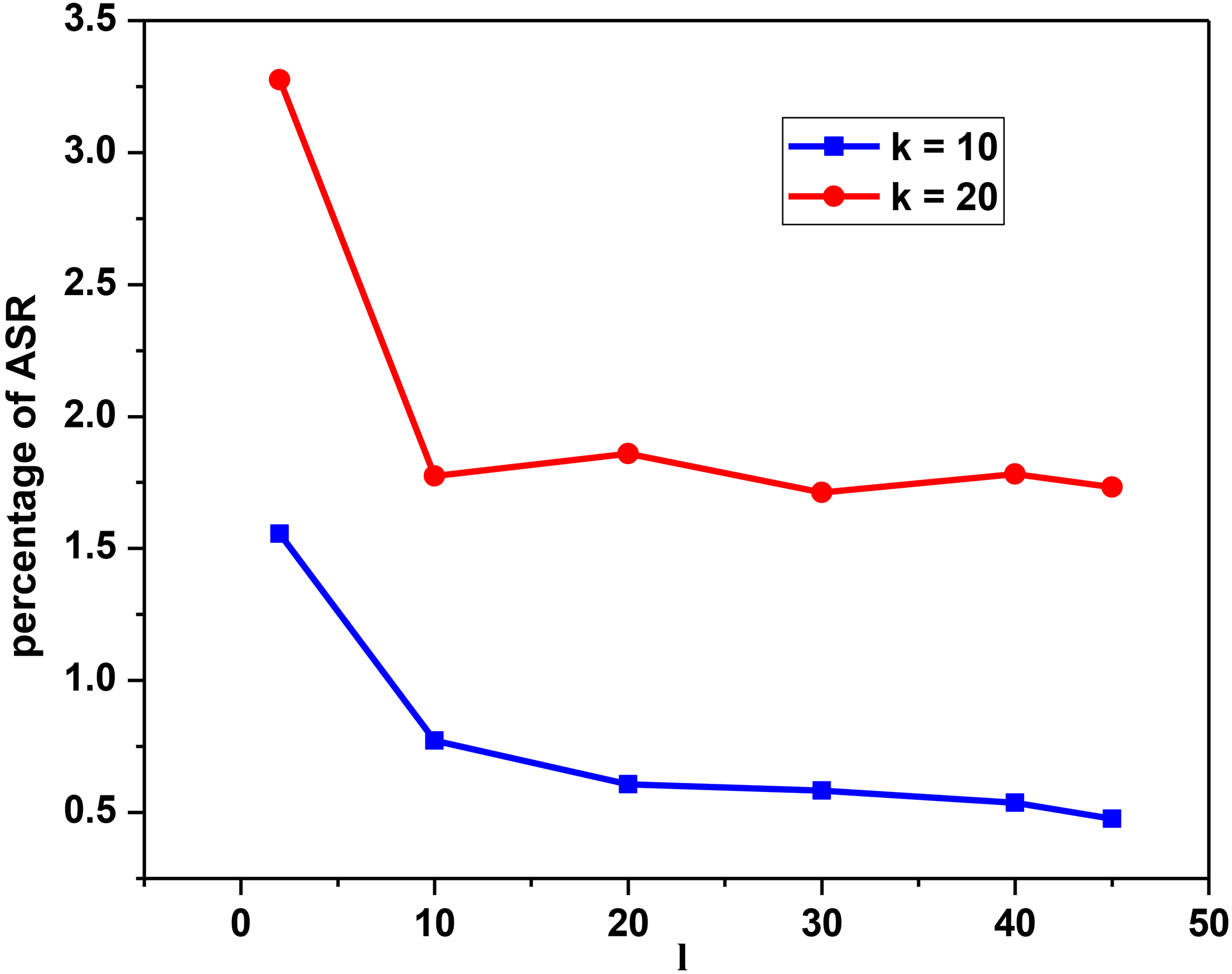
Influence of 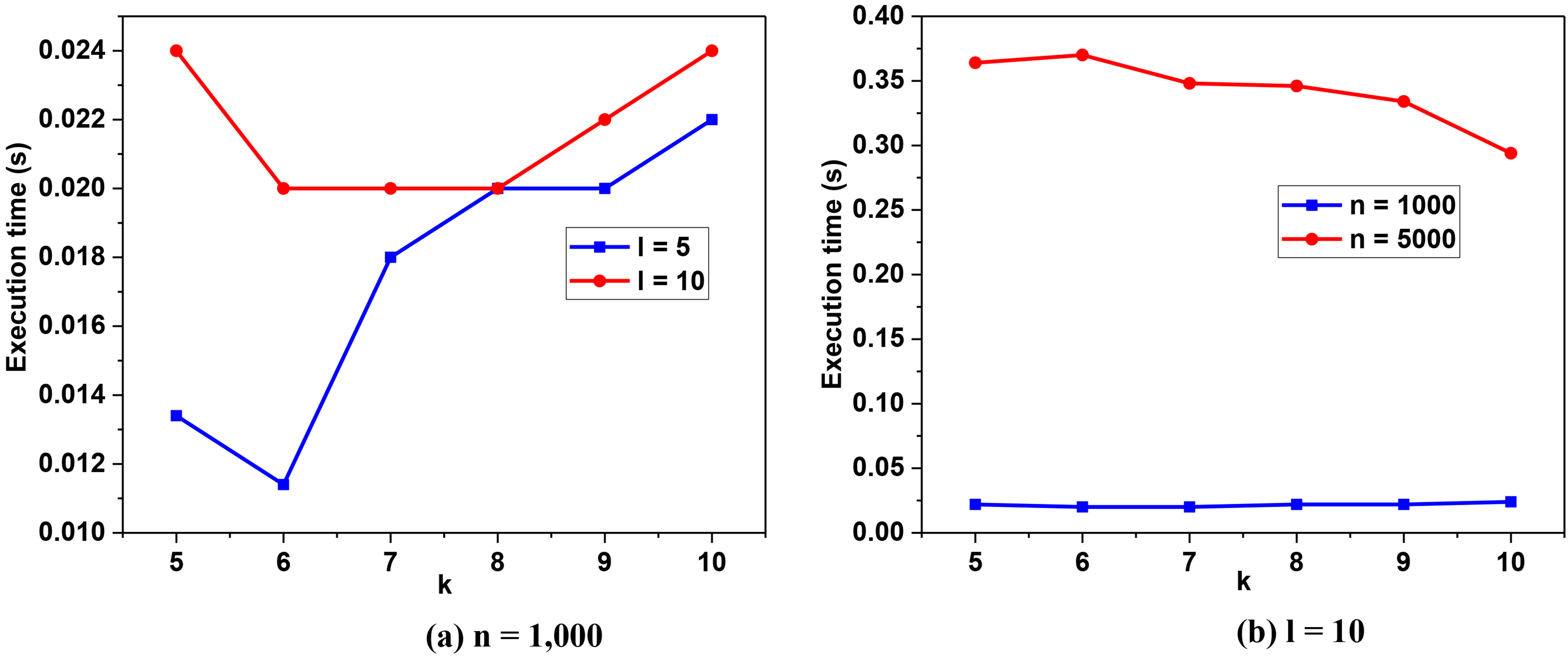
Comparison of execution time of the two algorithms.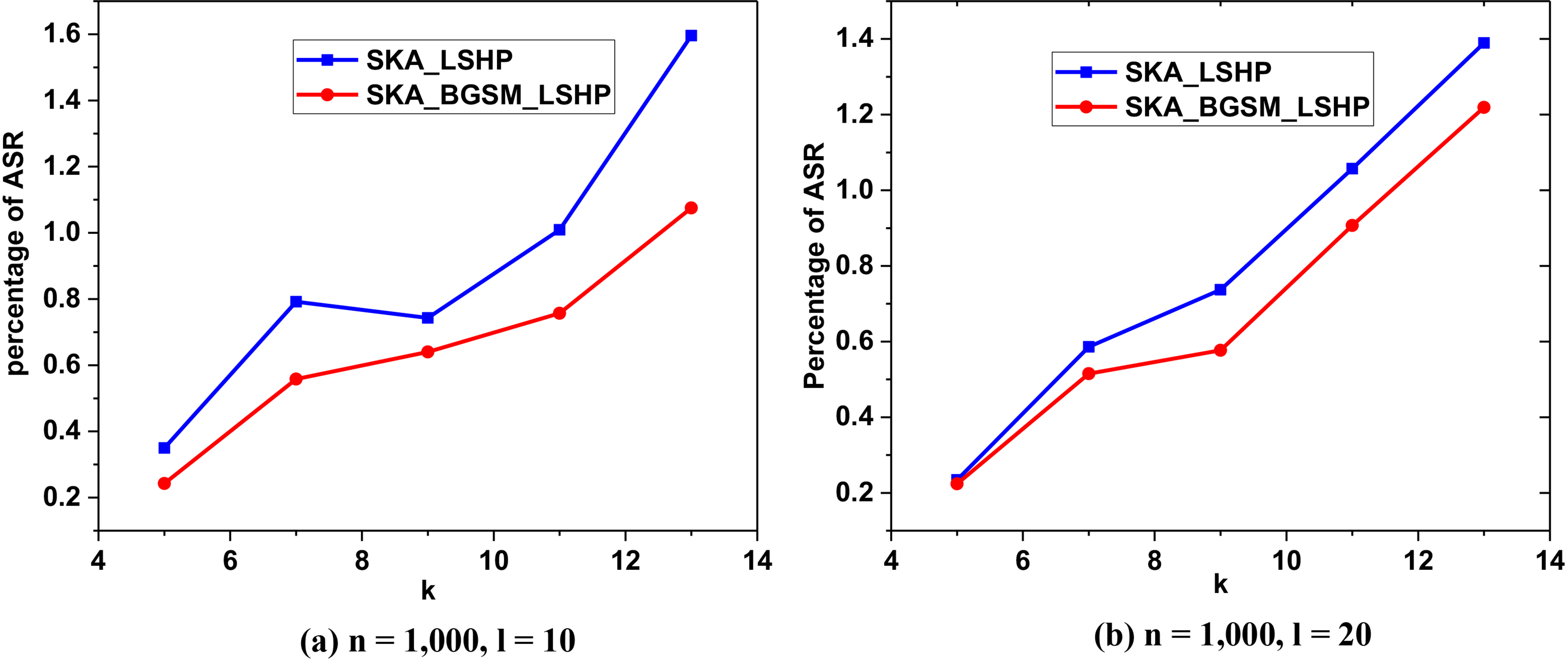
Comparison of ASR percentages of the two algorithms.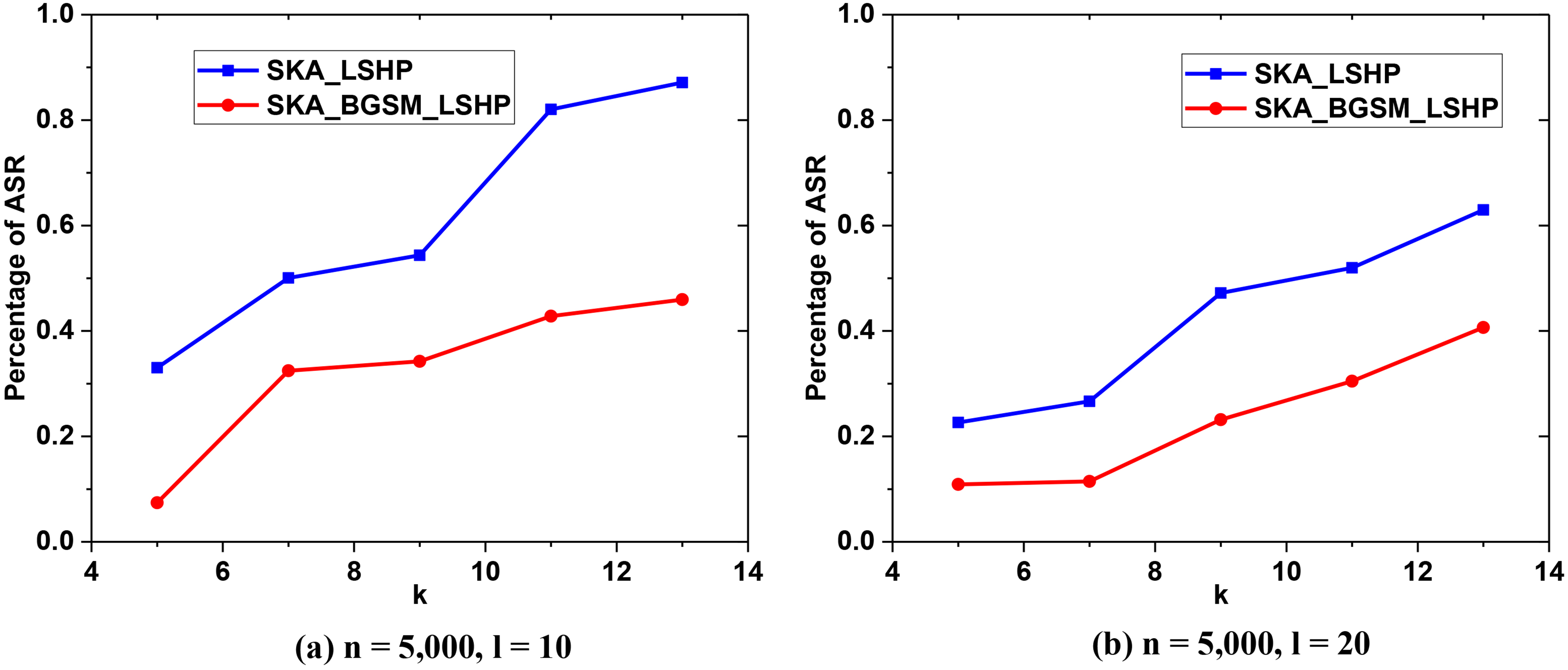
ASR percentage of SKA_BGSM_LSHP with different parameters.
Execution time of SKA_BGSM_LSHP with different parameters.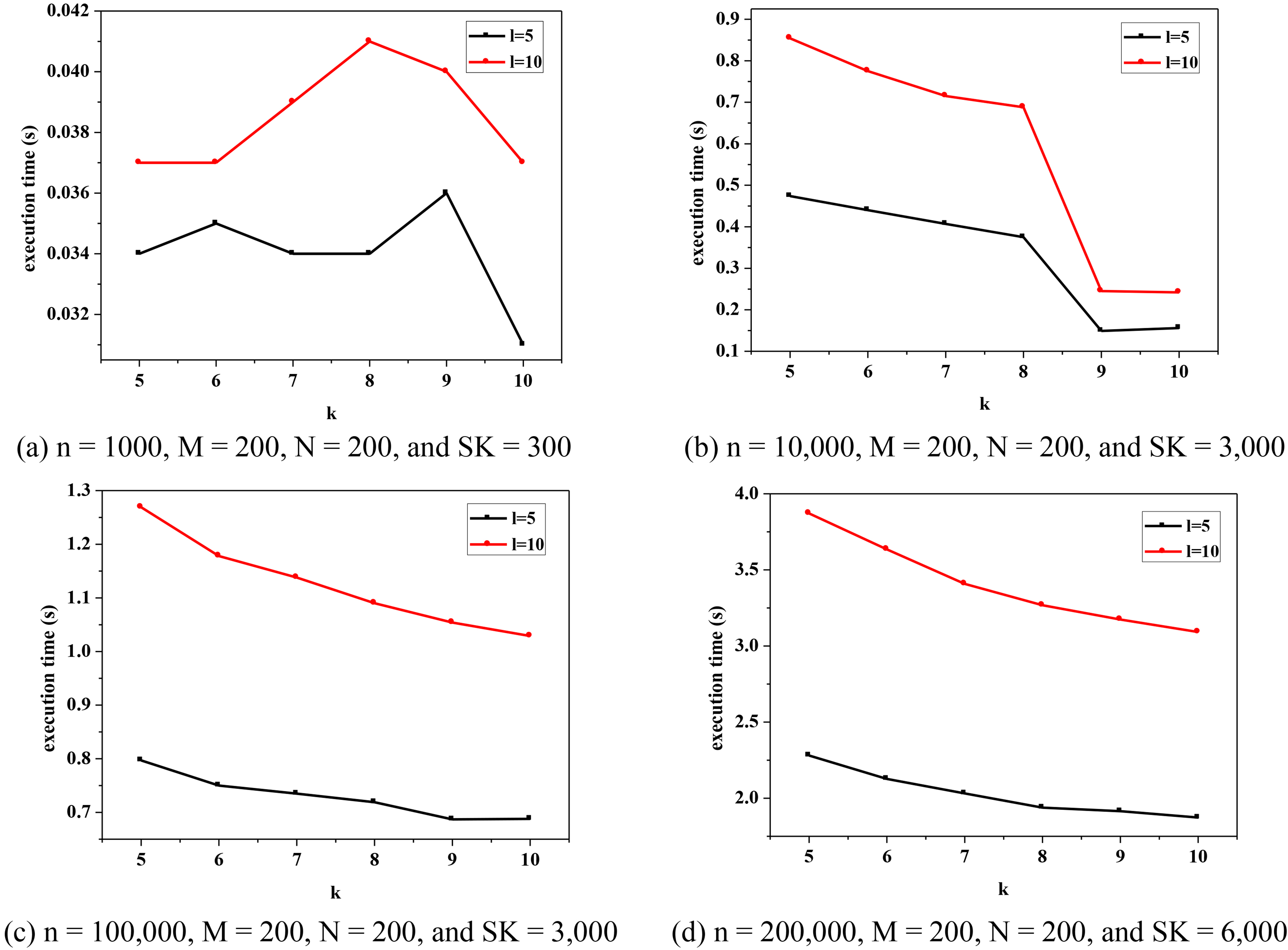
In Fig. 9a, when the data set size is 1,000, the curves show no regular trend. In other words, there is no dependency between the execution time and
To verify the effectiveness of the proposed algorithm, it was compared with the algorithm based on LSH partitioning only. The experimental results are shown in Figs 10 and 11.
In Fig. 10, the ASR percentage curves of the two algorithms are the same. They both increase with the increase of
In Fig. 11, the respective curves of the two algorithms do not change when the data size increases. The ASR percentage increases with the increase of
As shown by the above results, compared with the SKA_LSHP algorithm, the proposed algorithm has a smaller ASR and lower time cost. The results demonstrate that the proposed SKA_BGSM_LSHP algorithm is effective and promising. Furthermore, it promotes reasonable partitioning and significantly improves the data availability.
We employed dataset2 to test the performance of the proposed algorithm on large datasets. Our simulation was implemented with Java and executed on the Microsoft Windows 8 operating system running on a 2.40-GHz Intel (R) Core (TM) i5 4528U PC with a 500 GB hard drive. Dataset2 comprised approximately 2.7 million data items from the locations of a social networking service user who accessed the data for geographic locations (
Influence of n on IO execution time of SKA_BGSM_LSHP.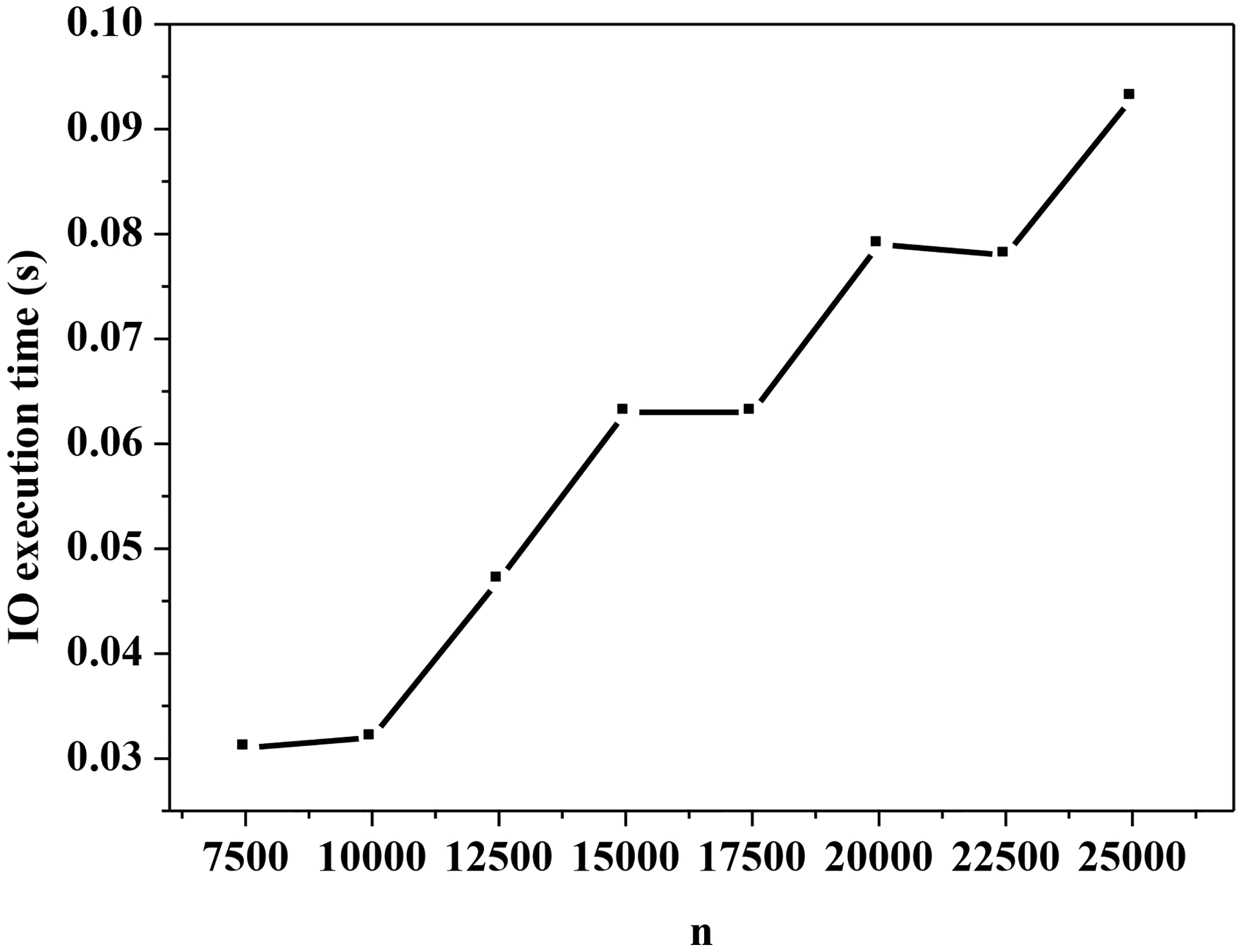
Comparison of ASR percentage of the two algorithms with different parameters.
First, the performance of SKA_BGSM_LSHP was evaluated; the experimental results are shown in Figs 12–14.
Figure 12 depicts the influence diagram of
Figure 13 shows the change of the program execution time in accordance with the data value. Figure 13a to d present time diagrams in which the data points are taken as 1,000, 10,000, 100,000, and 200,000, respectively. Figure 13 presents the execution time comparison of different data. As shown in Fig. 13, when the data points increase, the execution times of the program increase with the increase of the program number. The algorithm shows good stability when the points increase to 200,000, which indicates that the algorithm has strong adaptability to a large number of data items.
In Fig. 14, by increasing the dataset size from 7,500 to 25,000, the IO execution time under SKA_BGSM_LSHP is approximately linear, showing a good performance.
In addition, we compared the proposed SKA_BGSM_LSHP algorithm and SKA_ LSHP algorithm on dataset2. The comparative results are shown in Figs 15–17.
From Fig. 15, it is clear that the SKA_BGSM_LSHP algorithm is superior according to the ASR percentage, which indicates that the SKA_BGSM_LSHP algorithm promotes high data quality.
Comparison of execution time of the two algorithms with different parameters.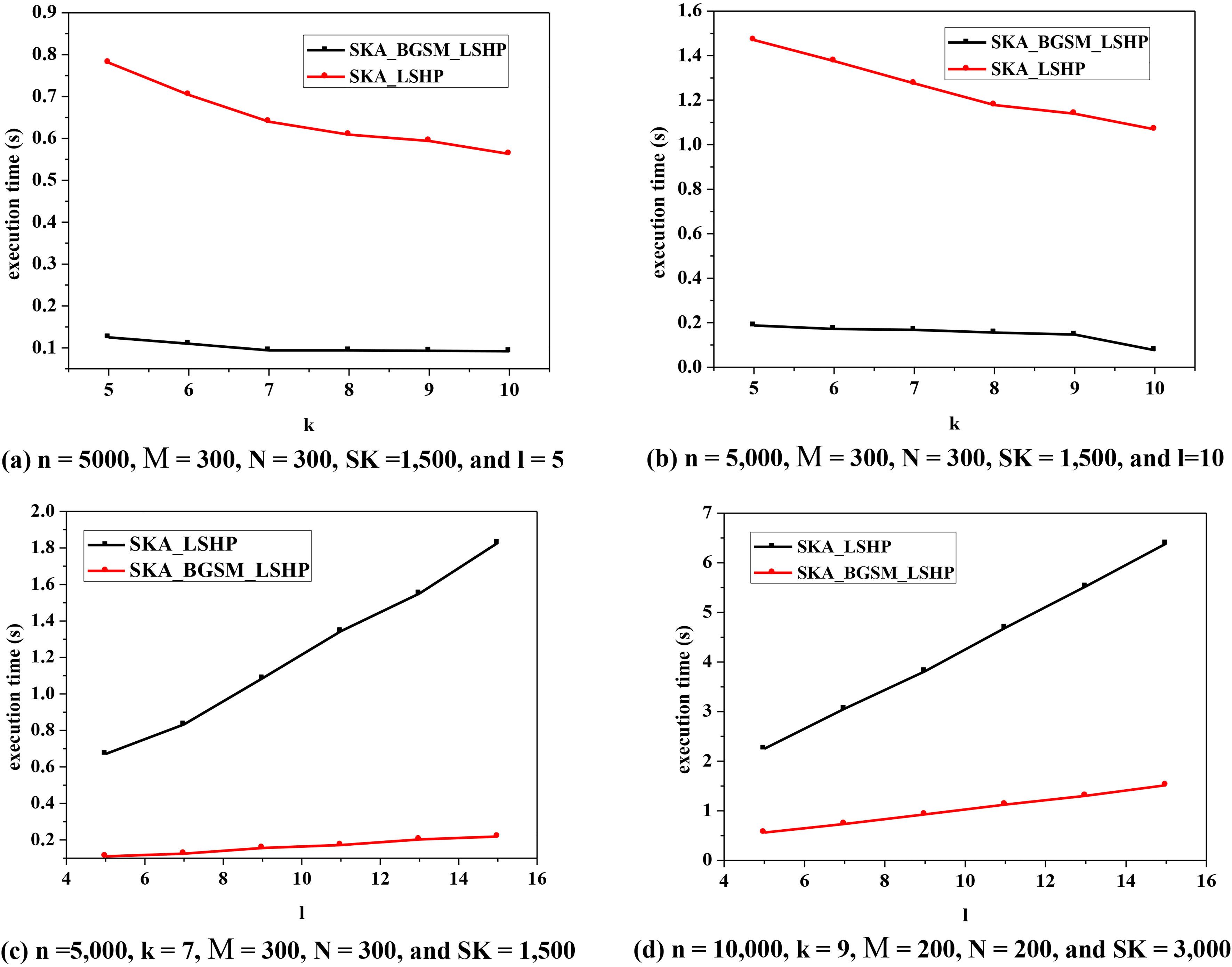
In Fig. 16, by increasing the dataset size from 5,000 to 1,0000, the curve of the SKA_ LSHP algorithm shows a significant rising trend, while the curve of the SKA_BGSM_LSHP algorithm shows a slightly rising trend. This indicates that it has better efficiency and stability compared to the SKA_ LSHP algorithm, which resulted in a lower time cost and high LBS quality.
Comparison of memory usage of the two algorithms with different parameters.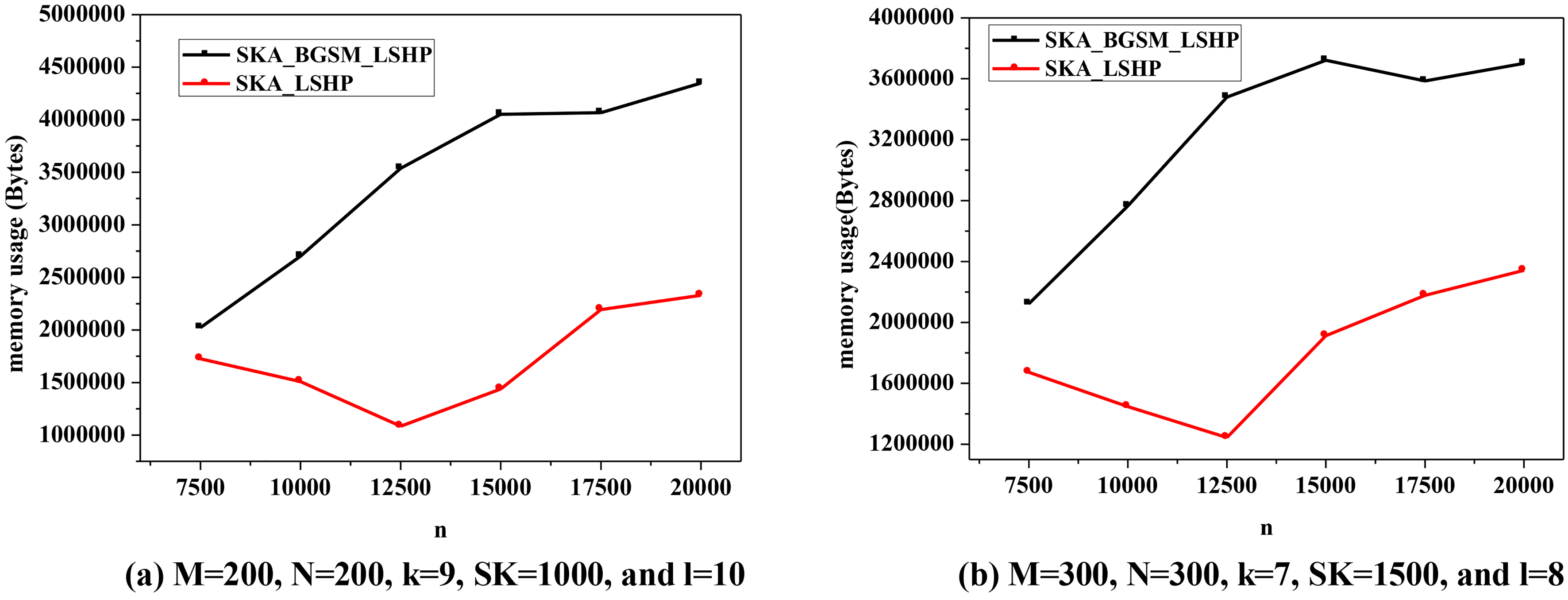
In Fig. 17, by increasing the dataset size from 6,500 to 20,000, the memory usage under SKA_ BGSM_LSHP is also lower than SKA_ LSHP .
In summary, the experimental results show that the proposed SKA_BGSM_LSHP algorithm is superior to the SKA_ LSHP algorithm in terms of data quality and efficiency.
In this paper, we described k-anonymity privacy protection requirements and proposed a subspace algorithm for solving the complex problem of privacy protection for LBSs from a novel perspective. In the proposed algorithm, the subspace is created via a bottom-up method to narrow the search range and reduce the time complexity. This approach more closely approximates a human’s approach to solving the problem by using the subspace as opposed to the global view. Furthermore, the LSH makes the partition reasonable for producing high-quality data.
Compared with the SKA_LSHP algorithm, both the theoretical analysis and experimental results showed that the proposed SKA_BGSM_LSHP algorithm reduces the anonymous region, reduces the communication and computation times, and improves the service quality. In the future, we intend to use different granularities in the subspace, and also explore further optimization in the partition.
Footnotes
Acknowledgments
The authors would like to thank the reviewers for their useful comments and suggestions for improving this paper. This work was supported by the National Natural Science Foundation of China (Grant Nos. 61672039, 61772034 and 61602009), the Key Project of Academic Support for the Top Talents in Anhui Universities (Grant No. gxbjZD2016011), and the Novation Foundation of Anhui Normal University (Grant No. 2017XJJ93).