
Abstract
In the context of expensive and time-consuming acquisition of reliably labeled data, how to utilize the unlabeled instances that can potentially improve the classification accuracy becomes an attractive problem with significant importance in practice. Semi-supervised classification that fills the gap between supervised learning and unsupervised learning is designed to take advantage of the unlabeled data in regular supervised learning procedure for classification tasks. In this paper we proposed a self-learning framework, that firstly pre-learns a classification model using the labeled data, then makes the prediction of unlabeled instances in the form of soft class labels, and re-learned a model based on the enlarged training data. Two multi-label Learning Vector Quantization Neural Networks (LVQ-NNs) are proposed, namely multi-label online LVQ-NN (mLVQo) and multi-label batch LVQ-NN (mLVQb), to work with the soft labels of training instances. The experiments demonstrate that the semi-supervised models using multi-label LVQ-NN as the base classifier can produce better generalization accuracy than the supervised counterpart.
Keywords
Introduction
Machine learning is a computer science field to learn some knowledge from data with respect to a task and performance measure. From the perspective of data, machine learning tasks can be divided into three categories: supervised learning, unsupervised learning, and semi-supervised learning. Supervised learning is intended to exploit the labeled data with desired input and output, and infer a mapping function that describes definitely the relation between the input features and the target. The map function can be represented as a mathematical formalization, decision tree, decision rule, neural network or other structures, and used on new data to produce a prediction in response to a query. The typical examples of supervised learning include face recognition, medical diagnosis, image classification, risk assessment, natural language processing, fault detection and so forth. The widely studied supervised learning problems are binary classification, multi-class classification, multi-label classification, ranking problem, and real-valued prediction. Classification is a typical and integral supervised machine learning task to separate the data into distinct classes using adequate labeled instances. A diversity of classification methods have been proposed in the literature including decision tree, multilayer perceptron neural network, support vector machine, nearest neighbor and so forth.
Unsupervised Learning concerns on the raw data without the desired output, and intends to discover the hidden patterns under specific assumptions about the structural properties of the investigated data. A diverse array of clustering methods such as hierarchical clustering, partitional clustering, density-based clustering, self-organizing feature map, have been developed to detect the clusters embedded in data.
Due to the difficulty (e.g., high cost in time and effort, technical problems) of acquiring the labeled data, the decision makers usually face with a small amount of labeled instances and a large quantity of unlabeled instances in real world classification tasks. How to utilize the unlabeled instances that can potentially improve the classification accuracy during the learning procedure becomes an attractive problem with significant importance in reality. Semi-supervised learning (SSL) is devoted to making use of the abundant unlabeled data along with the limited labeled data in the context of supervised learning. It falls between supervised learning and unsupervised learning and usually performs through a direct combination of these strategies.
In this paper we propose a semi-supervised classification framework that makes use of the unlabeled instances to enhance the generalization capability of the supervised counterpart. The Learning Lector Quantization Neural Networks (LVQ-NNs) (for pre-learning) and its extension working with multi-labeled data (for re-learning) are used as the base classifier. Firstly, a regular LVQ-NN classifier is constructed based on the available labeled data, then the classification of unlabeled instances is performed using the initial classifier. Afterwards, the assessment procedure selects the highly confident unlabeled instances which achieve an entropy value over a preset threshold. The selected instances are used as the supplement of labeled data in the subsequent re-learning phase. However, the prediction of unlabeled instances is sometimes unreliable and therefore downgrades the accuracy of subsequent classification due to the mislabeling problem. The motivation of this paper is to perform a soft (fuzzy) labeling of the unlabeled instances that specifies an unlabeled instance with different membership values to each class, resulting in a weight (membership) matrix. In other words, each instance has multiple class labels with different weights. A new classifier capable to tackle the soft-labeled data together along with the weight matrix is then re-learned based on the enlarged training data set using the proposed multi-label LVQ-NN algorithms. Two algorithms, called multi-label online LVQ-NN (mLVQo), and multi-label batch LVQ-NN (mLVQb) are presented to handle the multi-label instances during the learning phase. Experiments on some benchmark datasets from UCI database and a real-world financial database reveal that the semi-supervised learning approaches can achieve significantly better generalization accuracy when compared to the supervised counterpart.
The rest of this paper is organized as follows. The related research background of semi-supervised learning is introduced in Section 2. Section 3 describes the methodology of a self-training classification framework that utilizes the unlabeled instances for boosting the accuracy of supervised learning. Two multi-label learning vector quantization neural networks are proposed to work with the soft-labeled training data. Section 4 describes the databases, experimental design, and comparative study of competing algorithms. Finally, we conclude the paper and give some future research lines in Section 5.
Research background
In many real applications such as remote sensing, medical diagnosis, text and image classification, and speech recognition, the acquisition of reliably labeled data is difficult due to the high cost in labor and time. In such scenarios that the labeled data are rare, learning with partially or weakly labeled data, called Partially Supervised Learning (PSL) or Semi-Supervised Learning (SSL), has become a challenging branch of machine learning and pattern recognition. From the general view, PSL is a machine learning task under weak supervision lying between supervised learning and unsupervised learning. In the past two decades, a variety of approaches have been proposed from different directions, including active learning, semi-supervised classification, learning with fuzzy labels, and semi-supervised clustering [19].
Active learning is essentially a supervised learning procedure by selecting the most informative unlabeled instances through an uncertainty sampling (a single query) or a committee query, and asking an expert add the label information [25]. The active learning procedure can be performed in sequential or pool-based manner [20]. When used for classification tasks, active learning mainly concerns on the highest generalization ability with the lowest labeling labor due to the need of an expert as the supervisor to offer the label for the informative samples.
Semi-supervised classification (SSC) aims to take advantage of the unlabeled data that can potentially improve the classification during the supervised learning phase. Different from active learning, the labels are generated automatically by the learning machine itself without the human intervention. The unlabeled instances are ranked by some confidence measure and the highly confident ones are selected to the pool of training set. Then the classifier is re-trained using the augmented training data set. The state-of-the-art SSC algorithms are categorized into self-training SSC [18], SSC with generative models [23], semi-supervised support vector machines [1, 4], graph-based SSC [14], SSC with disagreement [37], and transductive learning [2]. The disagreement-based SSC can be further divided into single-view (one attribute set) and multi-view (several disjoint attribute sets) semi-supervised learning [36]. Nevertheless, they are relied on the interaction among learners to exploit the disagreement on unlabeled data. Particular self-training SSC is a promising learning paradigm applicable to any supervised learning algorithm. A recent review on self-trained techniques for semi-supervised learning is presented in [28].
Learning with fuzzy labels is a particular supervised learning that incorporates the fuzzy (soft) labels of input data into the learning phase. Some variants of Multivariate Polynomials (MP), Multi-layer Perceptrons (MLP), Support Vector Machine (SVM), Radial Basis Function Neural Networks (RBF-NN), have been proposed to handle the training set with soft labels [11, 26]. In [27], the standard Learning Vector Quantization Neural Network (LVQ-NN) was enhanced to work with soft labels in the context of noise data. Initially both training data and prototypes are assigned soft labels. During the learning, the prototype
As opposed to semi-supervised classification, semi-supervised clustering is intended to integrate the labeled instances into the clustering process. The prior knowledge is represented as constraints in form of must-link (instances belonging to the same group) or cannot-link (instances belonging to different groups), and integrated into the error function of clustering [6]. Various semi-supervised clustering algorithms were proposed based on K-means, hierarchical clustering, hidden Markov random fields (HMRFs), and kernel function [3, 14, 29]. In [9] a semi-supervised fuzzy c-means algorithm is used to boost the classification incrementally by producing the membership degree of unlabeled data to different classes, creating labels for the unlabeled data, re-training the classifier with labeled and newly labeled data, and re-clustering the remaining unlabeled data until all unlabeled data are labeled. In general semi-supervised clustering concerns on the inherent clustering task that is out of the scope of this paper.
Table 1 lists the well-known approaches used for semi-supervised classification including the category, method, role of human, methodology, and examples.
Some research directions for semi-supervised classification
Some research directions for semi-supervised classification
Given a set of labeled instances:
In this paper, we proposed a LVQ-NN SSC approach that integrates fuzzy labeling strategy during the self-learning phase to avoid the accumulation of mislabeling noise.
LVQ-NN is widely applied in a diversity of domains such as image analysis, document categorization, natural language processing, financial risk assessment. The superiority of LVQ on classification was demonstrated compared with support vector machines, multivariate statistical methods, and other state-of-the-art learning methods [35]. Moreover, the neurons of LVQ convey the important information regarding the confidence of unlabeled instance prediction and thus could be used for the self-learning.
Scheme of the semi-supervised classification using multi-label LVQ-NN as the base classifier.
In Fig. 1, the scheme of the proposed semi-supervised classification is outlined, along with the experimental design described in detail in Section 4. In the first phase, a standard LVQ-NN classifier is constructed based on the labeled data set (
Learning vector quantization (LVQ) neural network (NN) is a supervised learning variant of self-organized feature map (SOM) with an array of neurons arranged regularly on the map. Each neuron is associated with a prototype that defines the class region. LVQ-NN is trained in a competitive manner that the best matching neuron (BMU) is activated and strengthened (or weakened) with respect to the input depending on the match (or mismatch) of class label between the input and BMU, so that the class boundary is adjusted accordingly. When the input has the same class label with the BMU, it poses a positive influence on the prototype (i.e., shifts the prototype close to the input), otherwise a negative influence (i.e., shifts the prototype far from the input).
The standard LVQ-NN can be trained in two ways. In the sequential manner, the neuron is updated immediately according to each input, whereas in the batch manner, the neuron updating is performed at the end of one epoch when all training examples have been processed. The online LVQ-NN and batch LVQ-NN are described in the Algorithms 1 and 2 respectively [13].
Confidence assessment of unlabeled instances
One fundamental aspect of self-learning algorithms is to define the assessment measure to estimate the annotation confidence of unlabeled data. The effectiveness of subsequent classification mostly relies on the quantity and quality of the selected confident examples, that is to say, which examples should be considered as confident.
Information entropy introduced by Claude Shannon [21] is one of the most popular measures to characterize the uncertainty and irregularity of a system. The larger the entropy is, the more disorder and irregular the system is. On the contrary, the smaller the entropy is, the more ordered and deterministic the system is. It performed well for evaluating the quality of features in feature selection [5], evaluating the cutting sets in data discretization [33] etc. Entropy is simple but effective measurement, and moreover it is stable and robust for noise. In this method, information entropy is used as a diversity measurement of the Voronoi set corresponding to each neuron. The unlabeled samples that has smaller entropy value indicate the higher certainty of belonging to one class.
Given an information system X with a number of possible values:
where
When using LVQ-NN as the base classifier, the confidence values for its predictions can be estimated by the Voronoi set of neurons. Regarding a map neuron
The entropy of a Voronoi set
In the proposed semi-supervised classification framework, the confidence of unlabeled instances is estimated by the entropy of the corresponding Voronoi set on the pre-learned map following the nearest principle. The unlabeled instances
Weight matrix of instances
Weight matrix of instances
The standard form of LVQ-NN is designed for the training data with definite class, i.e., each instance has a unique label. In this paper we extend the LVQ-NN algorithms for multi-label instances using a weight matrix denoting the membership of the instance w.r.t. the class labels. In other words, the definite class is replaced with a fuzzy class specification along with the membership values. Accordingly, two multi-label learning vector quantization algorithms, namely mLVQo (online multi-label LVQ-NN) and mLVQb (batch multi-label LVQ-NN) are presented for the same purpose. Both are designed to adjust the class boundary by updating the prototypes with respect to the response to the training data. The mLVQo algorithm is described in Algorithm 3. For each input, the distance between the input and each neuron is calculated and the BMU is obtained. The difference from standard batch LVQ-NN is that the weight matrix of instances is incorporated into the updating of prototypes so that a given input has accumulative influence on the BMU with respect to the membership of class labels. For boosting the efficiency of online learning, we propose a batch version of multi-label LVQ-NN shown in Algorithm 4.
Experiments and results
In the experiments, we carry out an empirical study of the proposed SSC approaches built on two multi-label LVQ-NN algorithms respectively. The performance is compared with the regular supervised learning counterpart in term of prediction accuracy.
Experimental design
The experiments are conducted in the MATLAB environment as follows:
Given an experimental data set For each generated training data set, the semi-supervised classifiers are constructed using the proposed multi-label LVQ-NN algorithms. The threshold The test data is input to the re-learned classifier, and the performance is evaluated in terms of prediction accuracy. The process is repeated 10 times with random data division, and the average results are calculated.
In the experiments, 9 datasets obtained from UCI database [7] in different domains varying in number of classes, features, and instances are used for performance comparison. Another benchmark dataset studied in the experiments is French, a financial data set of small or middle scaled business companies described in Table 3. It was used to predict the status (healthy or distress) of a company over a period of years. A balanced subset for experiments is composed of 600 distressed companies and 600 healthy ones. The properties of the experimental data sets are characterized in Table 4. The categorical features are converted to several binary ones by means of one categorical value corresponding to one binary feature in the new data set.
Financial ratios of French database
Financial ratios of French database
Data set description (N: numerical feature, C: categorical feature)
It is known that the quantity and quality of confident instances selected from the unlabeled data set is a vital factor for the final classification. In the proposed framework it is depended on the entropy value and a preset threshold. Figure 2 investigates the projection of labeled data set (
Visualizations of learned map in the first phase (French data set, 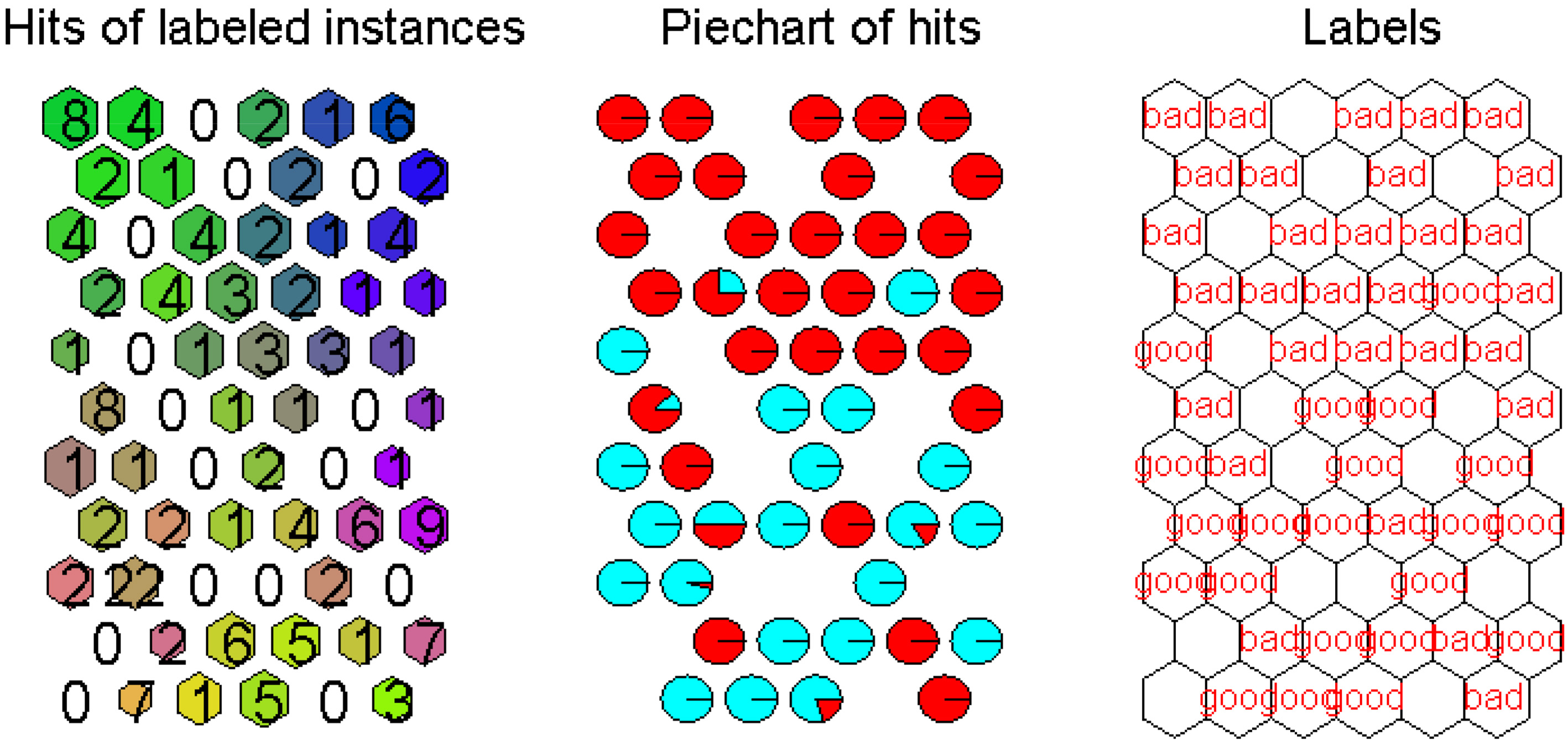
As mentioned the entropy value indicates the confidence in labeling an instance in
Visualization of entropy value on the map (French data set, 
Performance comparison in terms of accuracy.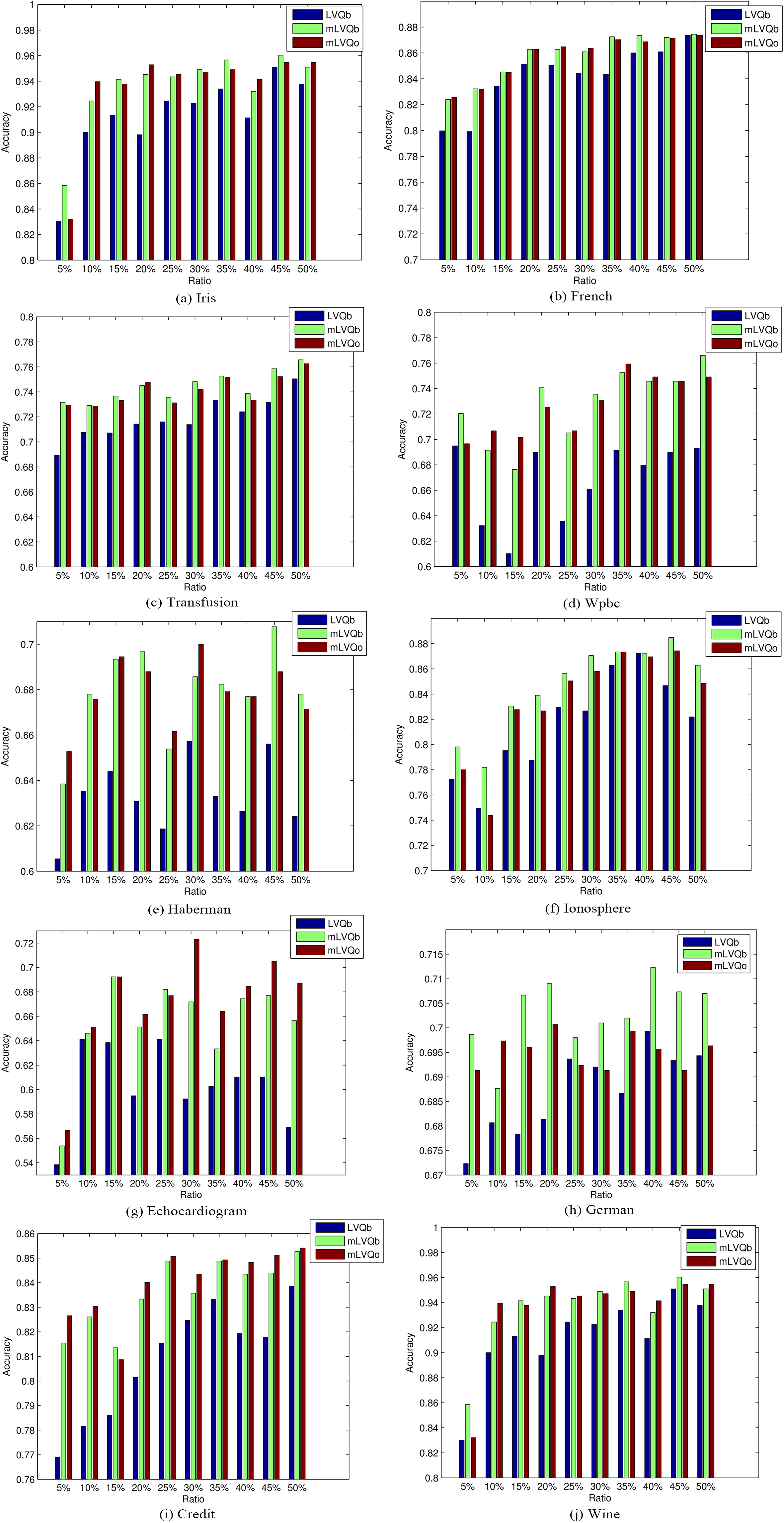
Performance comparison of two multi-label LVQ-NN algorithms in terms of average accuracy and standard deviation in brackets. The best results for each dataset and ratio are underlined and * denote the statistical significance at 5% level w.r.t. the regular LVQ-NN
In Table 5, the performance results of two multi-label LVQ-NN algorithms are shown in the context of semi-supervised classification. For easy comparison the results of these datasets are shown in Fig. 4. The prediction accuracy averaged on ten runs for different ratio values varying from 5% to 50% is compared with the regular batch LVQ-NN (without the use of unlabeled instances) as the baseline. In general, almost all classifiers receive better accuracy by increasing the size of labeled data. It is shown that the two multi-label LVQ-NN algorithms always have better prediction accuracy than the baseline, with statistical significance at 5% level in most cases. In the case of good data such as Iris and Wine, by exploiting the unlabeled data the self-training paradigm is able to achieve satisfactory prediction accuracy using a smaller amount of labeled examples than the regular supervised classifier. When the original dataset contains much noise such as Wpbc, increasing the size of labeled data does not result in better generalization capability. For example, when increasing the ratio
In many scenarios, label annotation is a difficult, expensive, time consuming, labor insensitive, and error-prone task where a lot of human efforts and experience is involved, whereas, the unlabeled data is abundant and easily obtained. Due to the fact that the small amount of labeled data and a large amount of unlabeled data exist simultaneously in practice, semi-supervised classification aiming to leverage the presence of unlabeled examples receives more and more attention in recent decades. Among a variety of approaches, self-learning algorithms are attractive that attempt to pre-learn the class of unlabeled data automatically and select the instances of high confidence for the re-learning phase. In this paper, we proposed two multi-label LVQ-NN algorithms to work with soft-labeled data. Both algorithms are based on the same idea, that an input with multiple labels has accumulative influence on the best-matching neuron with respect to the membership to class labels. The multi-label LVQ-NN algorithms are integrated in a semi-supervised classification framework and tested on some real databases from diverse domains. The results show the benefit of incorporating unlabeled instances of high confidence in the form of soft class labels during the supervised learning procedure on improving the generalization performance.
In the future work, some limitations of this empirical study will be addressed as the research directions. Firstly, the most confident instances are selected with respect to a preset threshold in the current framework. As a deeper study the best threshold value will be optimized automatically through some strategies such as cross-validation and global optimization. Secondly, the proposed framework is inherently a wrapper applicable for any classification methods. In the further study, we will investigate the performance of the framework constituted on state-of-the-art supervised learning algorithms as the base classifier. Further comparative experiments with competing SSC solutions will also be done in future research.
Footnotes
Acknowledgments
This work was supported by national funds through the Beijing National Science Foundation (9182017), National Natural Science Foundation of China (11601129), and Introduction of Talent Research Fund of Henan Polytechnic University (Y2017-1).