
Abstract
Collaborative filtering is a popular tool for recommendation systems. However, collaborative filtering technologies often suffer from high time complexity, the cold-start problem, and low coverage. Recent research shows that social networks and trust-aware methods can effectively solve these problems. Therefore, we propose a Trust Domain Expert Collaborative Filtering recommendation system. First, we divide the user item rating matrix into multiple sub-matrices based on the domain attributes of each item. For each sub-matrix, we then use domain experts to construct a user–expert trust matrix. Finally, combined with the target user’s domain of interest, we predict their missing ratings. Experimental results show that this method not only improves the accuracy and recommended coverage of collaborative filtering-based methods, but also reduces the computation time.
Introduction
Rapid developments in science and technology have resulted in increasingly serious data overloading problems [35], whereby users struggle to find the information they need in an ocean of data. Recommendation systems are an important tool for solving this problem, as they provide users with helpful suggestions that aid the decision-making process [24]. Recommendation system algorithms can be roughly divided into demographic-based [26], content-based [9], and collaborative filtering (CF) [39, 40, 41] algorithms. The most widely used scheme is CF, which determines whether to recommend an item to the user by predicting the ratings of unknown items from the user’s previous article scores [29]. CF recommendation systems are generally based on nearest-neighbor CF [16]. There are two main types of nearest-neighbor filtering in CF: filtering based on the user CF recommendation [30] and filtering based on project (item) CF recommendations [31]. The basic idea of user-based CF recommendation systems is that users may like items that are liked by other users who have similar interests. Here, similar users are identified from the target user’s historical ratings. However, traditional CF has the following major problems.
Sparsity problem [13, 15, 10, 3]: Users typically rate only a small fraction of available items. Most users rate fewer than 1% of items, and the density of available ratings in recommendation systems is often less than 1%. This limits the prediction quality of CF.
Cold-start problem [1, 2, 6]: The cold-start problem occurs when users have rated few or no items, or an item has been rated by few or no users. The CF approach requires many user/item ratings for effective recommendations, and does not work for new users who have not rated any items or new items that have not received any ratings [36]. Similarity-based methods thus fail to identify suitable neighbors and return low-quality recommendations.
Scalability: Traditional CF generally calculates the similarity among all users. Thus, when the number of users is large, the time complexity of the algorithm becomes excessively high.
Because of the above limitations, traditional CF only considers the user-item rating matrix for recommendations, and does not provide a quality recommendation. Besides the rating data, many researchers have used additional information to solve the problems of traditional CF methods. For instance, the social recommendation method was developed to solve the cold-start problem. This method builds a social network from the social relationships within user information. As long as a new user has a direct or indirect social relation network with others, user interest models can generate recommendations for the new user. Massa and Bhattacharjee [21] first introduced the idea of trust into recommendation systems, and proposed the trust perception recommendation system framework. The foundation of trust-based recommendations is the hypothesis that people usually like to refer to the preferences of trusted friends rather than those of the mass population when making decisions. Massa and Bhattacharjee [21] used a trust value between users to replace traditional similarity; such trust values are given explicitly. Experimental results showed that this method could solve the cold-start problem and predict the coverage rate. However, this value of trust between users is Boolean (i.e., 0 or 1), which is a weakness of the trust expression. The trust perception recommendation system has been extended to a trust transmission method, and the user trust matrix has been combined with the user similarity matrix to jointly predict ratings [19, 18]. The results from these approaches indicate that the trust perception recommendation system effectively improves the recommendation coverage without affecting the recommendation accuracy. For the scalability problem, we present an expert strategy that reduces the time complexity of the proposed system. Employing this method requires a small number of high-quality users to predict missing ratings in place of the neighbors in traditional systems. This article refers to these high-quality users as experts.
The remainder of this paper is organized as follows. Section 2 discusses some related studies, before Section 3 introduces the proposed algorithm for the trust-aware method and the selection of expert users. Section 4 presents performance and quality results from applying the trust-aware domain expert collaborative filtering (TDE-CF) recommendation system to the MovieLens dataset. Our conclusions are presented in Section 5.
Related work
In recent years, the scale of web-based social network services has developed rapidly. A social network service requires users to register a real identity and maintain real interpersonal relationships. The authenticity of the interpersonal relationships is thus important. The trust between users has positive significance.
The authenticity of the interpersonal relationship is thus useful. In particular, the trust relationship among users has positive meaning. However, research on trust relationships among users is still in its infancy [22]. Most trust-aware research is based on explicit trust, which means there is a user–user trust matrix that provides information. Trust represents the relationship between the source user and target user, and expresses the quality of service providers; e.g., the Epinions open dataset is based on a network of trust whereby users indicate which users they trust or distrust. Therefore, the dataset already has an extra attribute for users. FilmTrust is an online social network combined with a movie rating system where users are encouraged to evaluate their friends’ favorite movies on a scale from 1 to 10. An explicit trust network calculates the value of trust between non-adjacent user nodes in the trust network, and uses trust propagation and aggregation rules. Well-known trust calculation models include the TidalTrust model proposed by Golbeck [8] and the Moletrust model proposed by Massa and Avesani [19]. However, the trust between users is difficult to obtain directly, because many film or music criticism websites dilute the creation of social networks. In a previous study on trust, Liu et al. [14] proposed a novel recommendation method that first generates a domain-specific trust network pertaining to each domain, and then builds a unified objective function to improve the recommendation accuracy by incorporating hybrid direct/indirect trust information into a matrix factorization recommendation model. Qiao et al. [27] proposed a method of calculating the trust value based on user context, with the trust principle from social psychology applied to calculate trustworthiness from user context in a social network. This method divides trust in the social network into the trust produced by familiarity and the trust produced by similarity. Moreover, similarity is divided into internal similarity and external similarity according to its level of importance. The notation used to describe conventional approaches and the proposed method is presented in Table 1.
Notation and symbols used in this paper
Notation and symbols used in this paper
Traditional CF predicts missing ratings using a version of the following expression:
where
However, this method does not consider the rating metrics of different users, i.e., some users treat ratings fairly casually while others treat the item ratings more seriously. To overcome this problem, [30] proposed the classic CF formula given in Eq. (2), which includes the mean ratings of each user.
where
There are a variety of similarity metrics, with the most commonly used being the cosine similarity, Pearson similarity, and modified cosine similarity.
Cosine similarity[31, 37, 38]:
Modified cosine similarity:
Recommendation based on trust aware and domain expert description
Traditional CF algorithms often have high time complexity. Some user-provided information cannot be used by most other users, e.g., many users have few item ratings in common with other users. Even though the similarity between the source user and target user may be high, the source user cannot be effectively used to predict the missing ratings of the target user if there are few common ratings. Thus, the present study employs an expert user strategy to select a small number of high-quality users. The selection of expert users reduces the number of neighbors required, which may lessen the sparseness and cold-start problems. Here, we propose the TDE-CF method shown in Fig. 1, which combines trust awareness with expert users. The TDE-CF method predicts missing ratings according to
where trust
TDE-CF algorithm flow chart.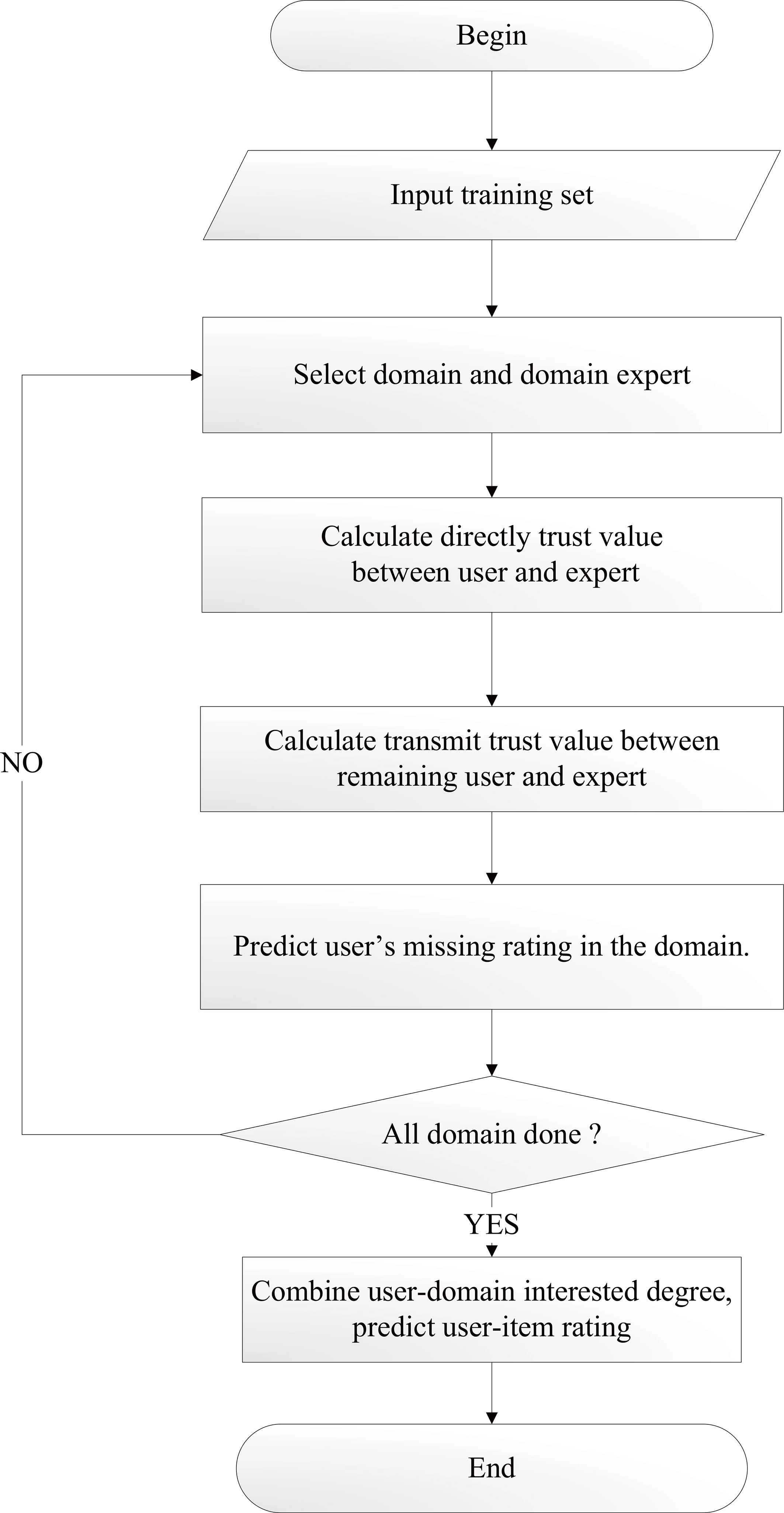
Because an item has different degrees of belonging to different domains, we introduce a measure
The algorithm presented in this paper proceeds as follows.
Select the domain expert user Calculate the direct trust relationship between all users and expert users. Calculate the transmitted trust relationship between the remaining users and expert users. Predict the user’s rating for an the item in the domain. If all domains have been selected and processed in the previous steps, go to Step 6; else, return to Step 1. For all users, combine the degree of user–domain interest and predict the user–item rating.
In the social recommendation system, the most popular social relations networks are based on a trust score. The trust relationship is the most widely used social networking relationship in socialized recommendation systems [22]. Trust has subjectivity, domain relevance, asymmetry, and is not fully transitive [44]. In similarity calculations, for example, the similarity between users in the direction A
Assuming that users have interacted in the past, if user A has provided a greater number of reliable recommendations to user B, then user B has greater trust in user A. Consider an example in which users a, b, and c have a past recommendation history. Users a and b have each made 10 recommendations to user c, although, according to feedback, user c was only satisfied with one of user a’s recommendations but was satisfied with nine of user b’s recommendations. Obviously, user c will have much higher confidence in user b than in user a. In future interactive behavior, user c will be more inclined to adopt the recommendations of user b. The construction of a trust computing model is proposed on this basis. The leave-one-out method is used to determine the user recommendation in the recommendation system. First, Eq. (8) is used to predict the rating of item
where
where
where
where
Trust network.
where com
Trust propagation.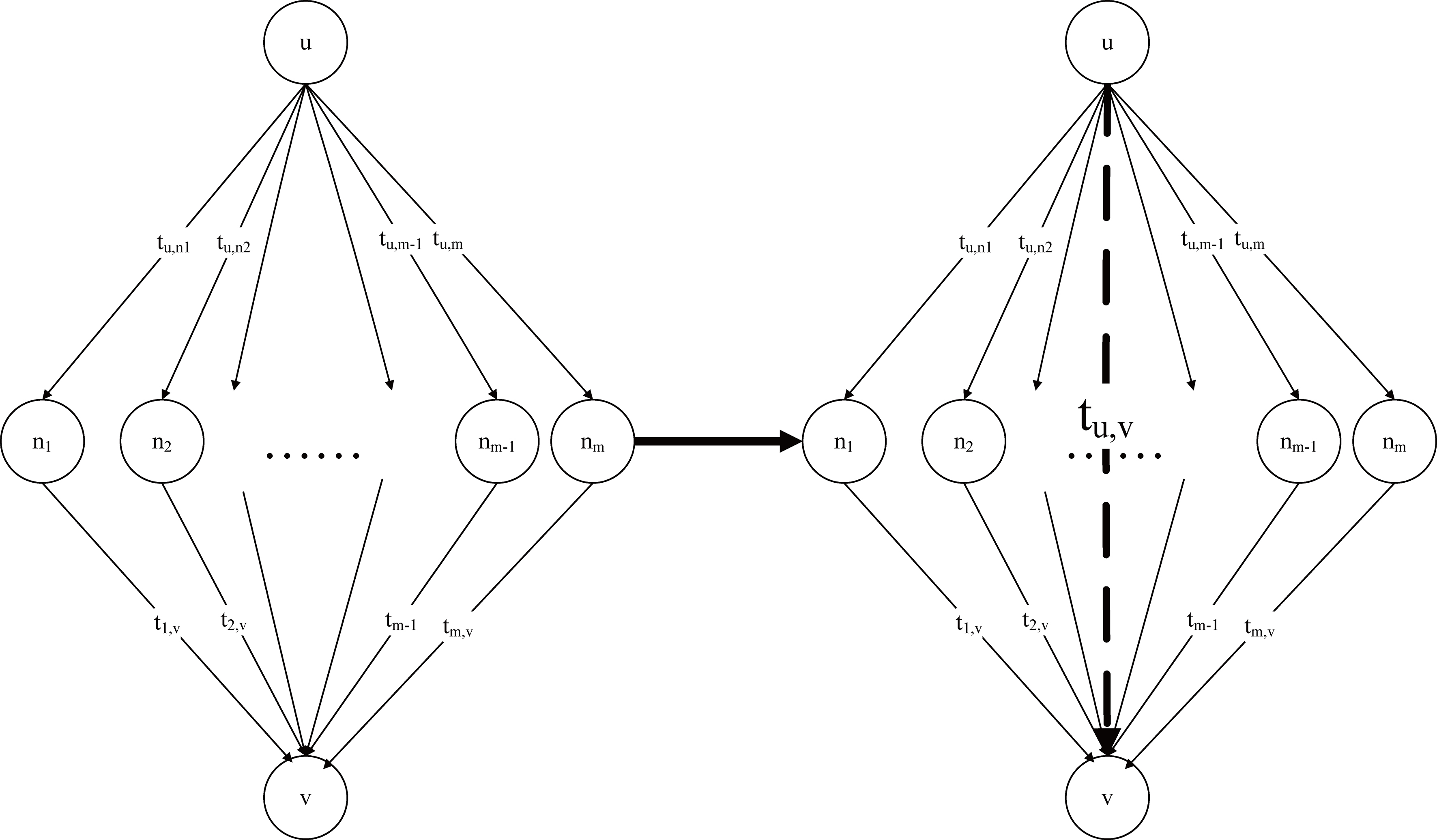
From the above analysis, we know that the scale of the trust network grows exponentially with the number of users. As the number of items in the recommendation system is very large, there will be some users who have rated very few items. These users will have few ratings in common with other users, which may lead to them being highly trusted by other users (if these items are popular). However, such users with a high degree of trust but very few ratings may not give good recommendations. Therefore, although their trust value may be lower, users with additional scoring knowledge may give better recommendations. Hence, we consider this situation and propose a novel algorithm based on filtering expert users to improve the performance of recommendation systems. An expert is someone who has professional expertise in an academic, technical, or other domain. Ordinary users are more inclined to trust such experts. For example, in the spheres of microblogging and Twitter, star users have much greater influence than ordinary users. However, most of these users are only effective in certain areas, e.g., the influence of movie stars is limited to the film domain. Based on this, we shrink the selection of expert users to a certain domain. As mentioned above, our expert users produce information for a number of other users. Expert users are those who have given the most rating information on particular items [34]. On this basis, we derive the following expert selection procedure.
First, we obtain the user-item rating matrix
The first column of matrix
Because an item may belong to multiple domains and user interests vary across each domain, we separately calculate the user interest in each domain as follows. The items rated by user
where
where
where
In [4], various memory-based and model-based algorithms are analyzed. Under the same conditions, memory-based algorithms generally perform better than model-based algorithms in terms of accuracy, but high numbers of users or items induce high computation times for CF. Thus, we do not consider model-based algorithms further, and instead compare five CF-based methods: traditional user-based CF recommendations (UBR), CF-DNC [7], a domain-expert-only method (EXP), a combined expert users and trust-aware method (EXP-TST), and the proposed TDE-CF, which adds user-domain degree information. These four methods are summarized in Table 2.
Owing to the similarity calculation, the time complexity of traditional user-based CF recommendation algorithms is
UBR: Traditional user-based collaborative filtering recommendation. It use similarity to find neighbour users, then use these users to predict the rating.
EXP method: Add expert user in trust aware recommendation algorithm to predict rating. Namely, use expert users to replace traditional selected neighbour users in predicting rating.
EXP-TST method: Add trust propagation method in EXP method. The method is ready for expand predicting coverage. CF-DNC method: Firstly, on the basis of the computational result of user similarity, the preferred similar users of target users are chosen dynamically. The trust computing model is then designed to measure the trust relation between users according to the ratings of similar users. The trustworthy-neighbor set of the target user is selected in accordance with the degree of trust between users. Finally, a novel CF recommendation algorithm based on the double-neighbor selection strategy is designed to generate a recommendation for the target user.
TDE-CF: Consider that many items belong to more than one domain, and that there are multiple predicted ratings for the item. Thus, it is necessary to fuse these ratings. User–domain degree is also considered in this method. First, experts are identified using the expert user calculation method. The network of trust values between users and experts is then constructed and the interest score of all users in each domain is calculated. Finally, in each domain, the user’s predicted rating is calculated and combined with the user domain interest to give the target user’s final predicted rating for an item.
Comparison of methods
Comparison of methods
Data set introduction
Considering the auxiliary information used in our algorithm, we conducted experiments on the well-known MovieLens rating datasets provided by the GroupLens research project team at the University of Minnesota: the MovieLens 100K data set (ML-100K) [33] and MovieLens 1M data set (ML-1M)[45, 12]. The ML-100K data set contains 100,000 ratings given by 943 users for 1682 movies, whereas the ML-1M data set contains 1 million ratings from 6040 users for 3952 movies. Each user has rated at least 20 movies. Users and items are numbered consecutively from 1. The data are randomly ordered.
Evaluation metrics
The present paper uses the mean absolute error (MAE); root-mean-squared error (RMSE), which is widely used in recommendation research[17, 32]; running time and coverage as evaluation indicators. The MAE and RMSE are calculated as
where
Some recommendation systems may not be able to predict ratings for all test data. The introduction of trust can enhance the coverage. Thus, we use the coverage metric to measure whether a value can be predicted. For test ratings, if the recommender cannot find a prediction on the rating, it means that the recommender cannot cover this rating. The coverage metric is computed as
where
Where the maximum possible error is set to 4 because the ratings are in the range [1, 5]. The F-measure is
Because the two data sets are very different in size, we add the running time as an evaluation metric. The experiments were executed in MATLAB running on a 3.30-GHz Intel Core-i5 processor with 64-bit Windows 10 and 8-GB RAM.
We conducted multiple experiments with different values of
Experimental results and analysis
To avoid effects of the division of the data set, we consider five-fold cross-validation for the ML-100K data set. Results are presented in Table 4. It is seen that in each data set, the MAE and RMSE differences are less than 2%, and the variances in MAE and RMSE have a magnitude of 0.0001. All results subsequently discussed are the averages of five-fold cross-validation. To evaluate the recommendation quality of the proposed algorithm, we compare the performances of EXP, EXP-TST, CF-DNC, TDE-CF, and a traditional user-based CF recommendation algorithm (UBR).
Figure 4a and c show MAE results for different data sets and different numbers of neighbors. Figure 4b and d show RMSE results for different data sets and different numbers of neighbors. In the case of the ML-100K data set, the EXP and EXP-TST methods were more accurate than UBR and CF-DNC methods because the EXP method selects expert users as high-quality neighbors. The trust-aware value is considered to reinforce the expert user’s weight. The TDE-CF method has the highest accuracy. It not only employs the above idea but also introduces the degree of interest that the user has in the domain, which increases the accuracy. The same applies to the ML-1M data set. The five methods have lowest values of MAE and RMSE when there are 70 experts (neighbors); MAEs (ML-100K, ML-1M) are (0.8888, 0.9512), (0.7725, 0.7375), (0.7837, 0.7418), and (0.7548, 0.7322) while RMSEs (ML-100K, ML-1M) are (1.134, 1.216), (0.9919, 0.9454), (1.011, 0.9555), and (0.9637, 0.9382) for UBR, EXP, EXP-TST, and TDE-CF methods respectively.
Figure 5 shows coverage rates of the EXP, EXP-TST, TDE-CF, CF-DNC, and UBR methods versus the number of experts for different data sets. The coverage represents the percentage of unseen movies for which the rating can be predicted with each method, with higher percentages being better [23]. EXP-TST and TDE-CF have higher coverage (99.66%, 99.90%) than EXP (99.32%, 99.74%) on ML-100K
| 10 | 20 | 30 | 40 | 50 | 60 | 70 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| 1.0 | 0.76976 | 0.98446 | 0.76128 | 0.97221 | 0.75908 | 0.96867 | 0.75773 | 0.96590 | 0.75698 | 0.96439 | 0.75578 | 0.96260 | 0.75560 | 0.96237 |
| 1.1 | 0.77098 | 0.98743 | 0.76129 | 0.97298 | 0.75875 | 0.96907 | 0.75694 | 0.96581 | 0.75596 | 0.96396 | 0.75445 | 0.96191 | 0.75410 | 0.96145 |
| 1.2 | 0.77323 | 0.99145 | 0.76163 | 0.97439 | 0.75870 | 0.96980 | 0.75648 | 0.96594 | 0.75518 | 0.96372 | 0.75346 | 0.96133 | 0.75295 | 0.96068 |
| 1.3 | 0.77572 | 0.99542 | 0.76224 | 0.97586 | 0.75891 | 0.97066 | 0.75628 | 0.96633 | 0.75480 | 0.96385 | 0.75280 | 0.96114 | 0.75215 | 0.96037 |
| 1.4 | 0.77814 | 0.99898 | 0.76279 | 0.97745 | 0.75885 | 0.97156 | 0.75606 | 0.96686 | 0.75447 | 0.96423 | 0.75231 | 0.96127 | 0.75166 | 0.96043 |
| 1.5 | 0.77879 | 1.00065 | 0.76287 | 0.97830 | 0.75842 | 0.97178 | 0.75553 | 0.96707 | 0.75372 | 0.96407 | 0.75125 | 0.96074 | 0.75047 | 0.95978 |
| 1.6 | 0.78356 | 1.00709 | 0.76550 | 0.98197 | 0.76019 | 0.97451 | 0.75687 | 0.96913 | 0.75489 | 0.96599 | 0.75217 | 0.96223 | 0.75144 | 0.96129 |
| 1.7 | 0.78678 | 1.01155 | 0.76689 | 0.98428 | 0.76090 | 0.97606 | 0.75733 | 0.97028 | 0.75521 | 0.96693 | 0.75237 | 0.96315 | 0.75161 | 0.96215 |
| 1.8 | 0.78953 | 1.01580 | 0.76811 | 0.98641 | 0.76170 | 0.97768 | 0.75792 | 0.97158 | 0.75557 | 0.96794 | 0.75252 | 0.96391 | 0.75161 | 0.96281 |
| 1.9 | 0.79216 | 1.01993 | 0.76937 | 0.98861 | 0.76275 | 0.97960 | 0.75868 | 0.97310 | 0.75616 | 0.96923 | 0.75295 | 0.96497 | 0.75196 | 0.96377 |
| 2.0 | 0.79415 | 1.02285 | 0.77030 | 0.99022 | 0.76350 | 0.98101 | 0.75924 | 0.97422 | 0.75658 | 0.97018 | 0.75332 | 0.96579 | 0.75221 | 0.96443 |
Five-fold cross-validation results
and ML-1M. UBR has the lowest coverage. This is because highly similar neighboring users may not have much item rating information, leading to many items not being predicted by these so-called neighbors. The same applies to CF-DNC. With an increase in the number of neighbors, the user can acquire more information on items, and the coverage gradually increases. However, this situation rarely occurs for our method that selects the user with the most ratings as the expert user. It therefore remains possible to maintain high coverage even if we have only 10 expert users. It is possible for a small number of domain experts to rate most items in the domain. In the case of UBR, the coverage of the algorithm is low (18.615%) when there are 10 neighbors.
Coverage of different methods in different dataset.
RMSE, coverage, and F-measure with different methods
Coverage of different methods in different dataset.
MAE with ML-100K dataset
MAE with ML-1M dataset
ML-100K and ML-1M running time.
To give a fair comparison, Table 5 presents the RMSE, coverage, and F-measure achieved by each method with their optimal number of experts for both the 100 k and 1 M datasets. The results show that our TDE-CF method achieves better performance in terms of both precision and coverage.
Figure 6a and b show the running-time results of UBR, CF-DNC, EXP, EXP-TST, and TDE-CF methods for the data sets. Figure 6a presents results for the smaller data set. CF-DNC has the highest time cost because it needs to calculate twice the relationship value between users. EXP and EXP-TST methods have the lowest running times because the EXP method does not need to calculate the transmitted trust or user–domain degree of interest and the EXP-TST method does not need to calculate the user–domain degree of interest. These two methods thus have a running time less than that of TDE-CF. The time complexity increases with the number of users for our EXP, EXP-TST, and TDE-CF methods, but this increase slows with an increasing number of neighbors until the time complexity is almost unchanged. The reason is that the time consumption of the UBR algorithm is mostly in computing the users’ similarity, and selecting the number of neighbors has little effect on the overall time complexity of the algorithm. However, with an increase in the number of expert users, our TDE-CF method requires an additional calculation of trust between users and experts, resulting in a longer running time. Figure 6 presents results for the larger data set. EXP, EXP-TST, and TDE-CF methods perform well in terms of their running time. The two figures reveal that our TDE-CF method performs well on both data sets, but especially on the large data set.
Comparison of prediction shift with 1% filler size.
Comparison of prediction shift with 3% filler size.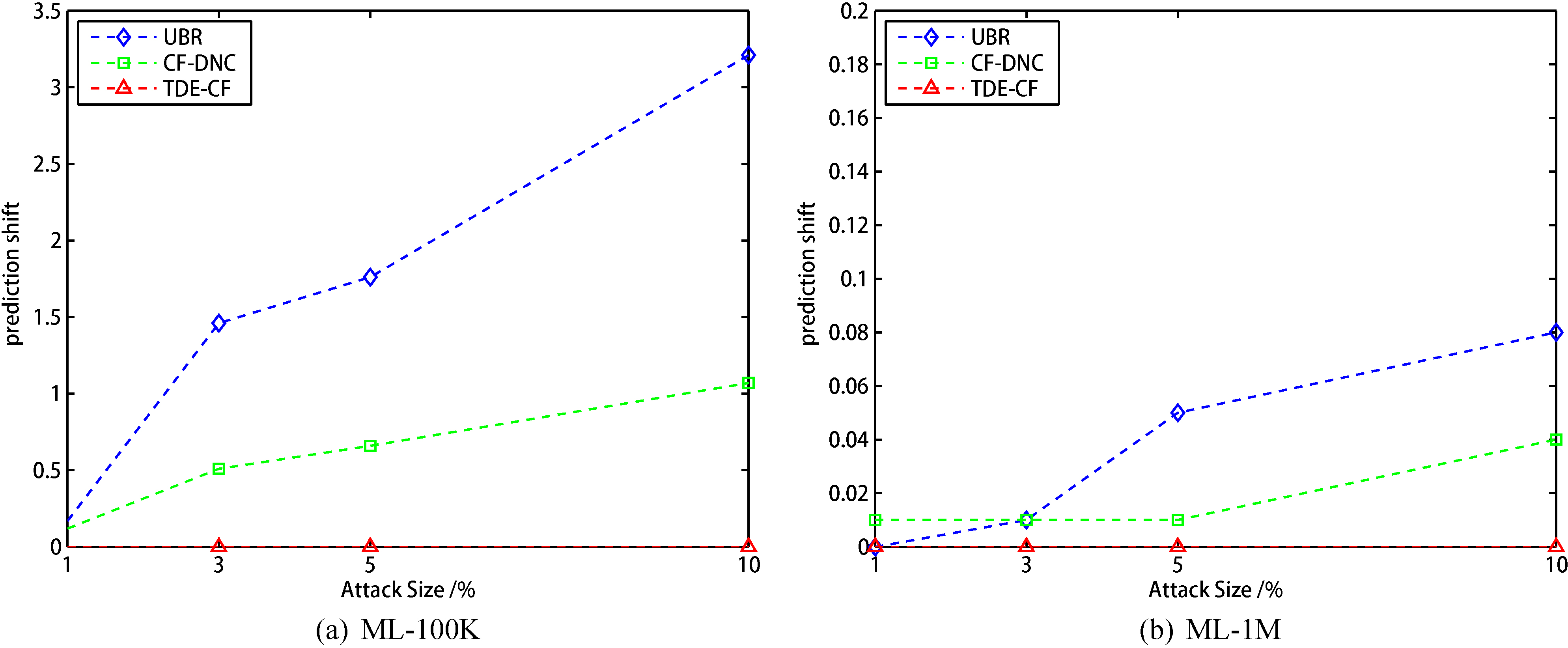
Comparison of prediction shift with 5% filler size.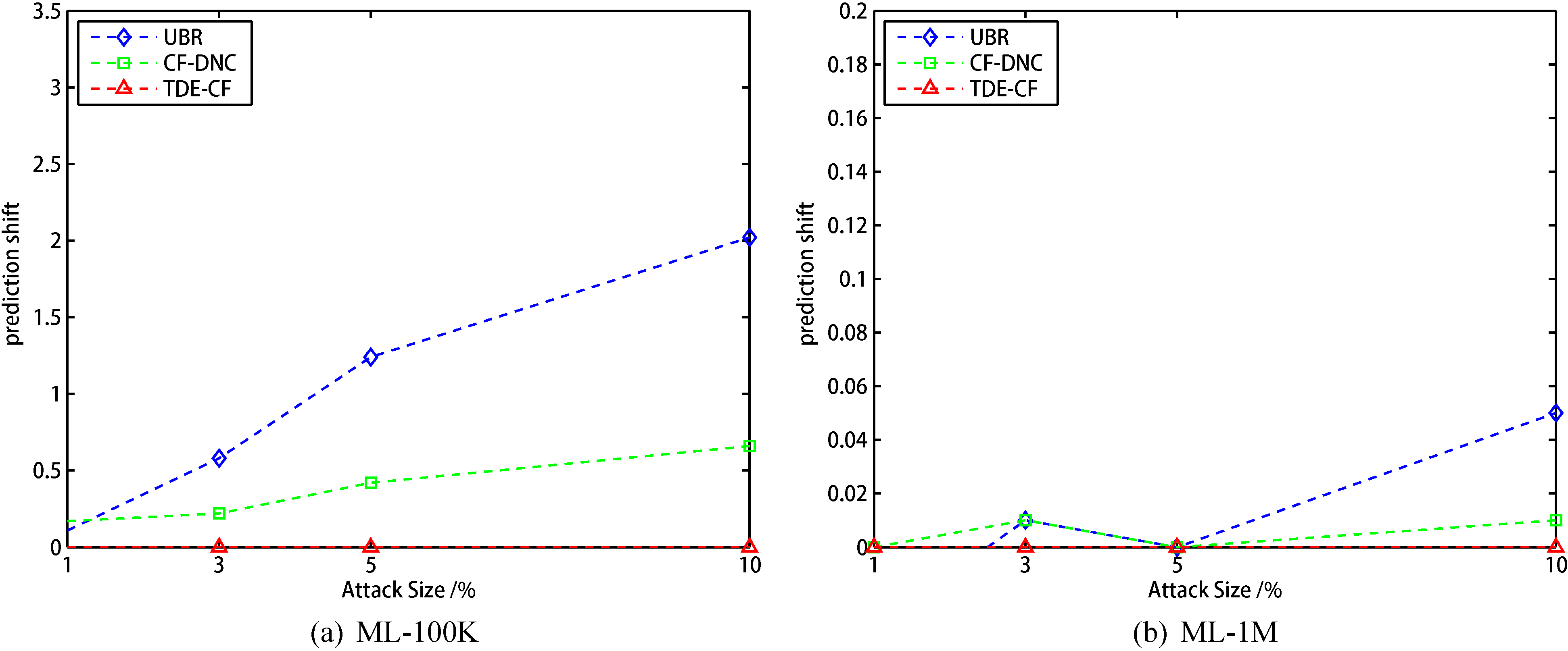
In this section, we have compared our method with traditional CF methods in terms of accuracy, coverage, F-measure, and runtime performance. The TDE-CF method, which combines expert users, trust-awareness, and trust transmission, exhibits a tradeoff between accuracy and execution time, and outperforms traditional methods in terms of coverage.
In order to evaluate the anti-attack capability of these three recommended algorithms, we injected attack data into the data set (average attack). In order to ensure fairness, we select 70 as neighbour number which have the best performance. Attack size are selected as 1%, 3%, 5%, 10%. Filling size are selected as 1% , 3%, 5%, 10%, 20%. We record MAE value in Tables 6 and 7.
From the Fig. 7a, 8a, 9a, in Movielens 100K dataset, when the filling of scale is constant, the MAE of the CF algorithm and the CF-DNC algorithm show an increasing trend with the increase of the attack scale. It can be seen that in the CF algorithm and CF-DNC algorithm, the performance of the recommendation system will be affected by the attacked users. The more attack users, the worse result. And under the same filling scale and attacking scale, our TDE algorithm is better than CF and DNC algorithm, our TDE-CF algorithm is almost unaffected by this attack. Only when there are a large number filling scale in dataset, the MAE value will become worse. This may be caused by these attack users who replace the expert users. As for Movielens 1M dataset, like Fig. 7b, 8b, 9b show, the situation are similar to 100 K dataset.
Conclusion
With the widespread application of CF recommendation algorithms, improving the accuracy, real-time performance, and coverage has become a very important research issue. Due to traditional algorithm in trust calculation will bring the rough particle of trust and the higher computation in global trust-relationship, we proposed an algorithm which combining trust-aware and domain expert recommendation to reduce the impact of these problems. According to our theoretical and experiment analysis. Its show that the algorithm not only improves the accuracy of recommendation, but also reduce time consuming. However, because of narrowed down the trust into range of domain, the algorithm will not be able to provide a novel recommendations, and when the dataset are not explicitly give the relationship between the item and domain, the algorithm will be powerless. Next, we will focus on better expert user selection algorithm and solving the impact of dataset relationship issues.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 61572204, the Project of Science and Technology Plan of Fujian Province of China (No. 2017H01010065) and Science and Technology Planning Project of Quanzhou (Grant No. 2017G019).