
Abstract
Because of high dimensionality, correlation among covariates, and noise contained in data, dimension reduction (DR) techniques are often employed to the application of machine learning algorithms. Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and their kernel variants (KPCA, KLDA) are among the most popular DR methods. Recently, Supervised Kernel Principal Component Analysis (SKPCA) has been shown as another successful alternative. In this paper, brief reviews of these popular techniques are presented first. We then conduct a comparative performance study based on three simulated datasets, after which the performance of the techniques are evaluated through application to a pattern recognition problem in face image analysis. The gender classification problem is considered on MORPH-II and FG-NET, two popular longitudinal face aging databases. Several feature extraction methods are used, including biologically-inspired features (BIF), local binary patterns (LBP), histogram of oriented gradients (HOG), and the Active Appearance Model (AAM). After applications of DR methods, a linear support vector machine (SVM) is deployed with gender classification accuracy rates exceeding 95% on MORPH-II, competitive with benchmark results. A parallel computational approach is also proposed, attaining faster processing speeds and similar recognition rates on MORPH-II. Our computational approach can be applied to practical gender classification systems and generalized to other face analysis tasks, such as race classification and age prediction.
Keywords
Introduction
Due to advances in data collection and storage capabilities, the demand has been growing substantially for gaining insights into high-dimensional, complex-structured, and noisy data. Researchers from diverse areas have applied DR techniques to visualize and analyze such data [17, 60]. DR techniques are also helpful to address the issues of collinearity and “
Given the problems in image analysis of high dimensionality and complex correlation structures, DR techniques are often a necessary step [27]. Thus, variants of PCA, LDA, and their kernel extensions have been popular in computer vision with applications of image classification and discrimination [82, 41, 74]. Studies include Eigenfaces [63], Fisherfaces [8], face recognition with KPCA [33], face recognition with Kernel Direct LDA [38], 2D-PCA [75], 2D-LDA [36], among many others. When there are sufficient labeled face images, LDA is experimentally reported to outperform PCA for face recognition [8]. In the case of a small training set, the conclusion could be reversed [41]. Studies comparing classification performance of PCA, LDA, and their kernel variations include [32, 77]. The connections among KLDA, KPCA, and LDA are further discussed in [72]. By incorporating labeling information into the construction of the objective function, Supervised Kernel PCA (SKPCA) [5] has been proposed for visualization, regression, and classification. A modified version of SKPCA for classification problems can be found in [65]. These studies suggest that SKPCA works well in practice among different DR algorithms [15, 53, 68]. Moreover, it has been found in [4] that with bounded kernels, projections from SKPCA are uniformly converging, regardless of the input features’ dimension.
Associated work
In recent years, facial demographic analysis has become popular in computer vision, because of its broad applications in human-computer interaction (HCI), security, surveillance, and marketing, which can benefit from the automatic estimation of characteristics like age, gender, and race. Recent surveys on demographic estimation from biometrics are presented in [18, 62]. Specifically, a major task is gender classification, aiming to automatically determine if a person is male or female. Beyond computer vision, the topic has been studied extensively by anthropologists, sociologists, and psychologists. Gender can easily be identified by humans, achieving 96% accuracy in an experiment classifying photographs of adult faces [9]. Automating gender classification has been a priority in real-world applications.
A number of biometrics have been used to identify gender, including face, voice, gait, handwriting, and even the iris [62]. However, gender classification from faces is the most common, probably because photography of faces is non-intrusive and ubiquitous. Ng et al. provide a survey of gender classification via face and gait [44].
Gender classification with faces launched in 1990, when neural networks were applied directly to pixels from face photographs [19, 12]. Many other early studies utilized the geometric-based approach to represent human faces, relying on measurements of facial landmarks [49, 67]. Though intuitive, such approaches are sensitive to the placement of landmarks, which can only accommodate frontal representations of the face, and may omit some important information from the face (such as texture of the skin). In recent years, the appearance-based methods have been more commonly adopted, which rely on a transformation of an image’s pixels [22, 24, 58]. Such methods capture both the geometric relationships of the face and texture information. However, a drawback is their sensitivity to illumination and viewpoint variations. Other issues are associated with the high dimensionality of the transformed pixels, which will be discussed further in the next paragraph. Some most recent gender classification studies involve convolutional neural networks (CNN) [71, 78, 3, 2]. Though CNNs have reached state-of-the-art accuracy rates, they are known to be less interpretable than some other methods.
Pixels often contain high redundancy and noise, which cannot be removed completely by pre-processing steps. Hence, the vectors resulting from appearance-based feature extraction methods genetically inherit redundancy and noise. Popular image feature extraction methods include local texture techniques such as local binary patterns (LBP) [76, 37, 40, 1], Gabor filters [69], biologically-inspired features (BIF) [21, 26], and histogram of oriented gradients (HOG) [21]. Such methods could lead to a high dimension of extracted features, thwarting practical applications by increasing runtime and memory consumption. When “
Even though PCA and LDA have been widely considered as popular and effective approaches for DR in machine learning, their kernel versions are much less investigated. To our best knowledge, KPCA, KLDA, and SKPCA have never before been directly compared on visualization and classification performance through simulations and practical applications to face image analysis problems.
Our main contributions in this study can be summarized as follows. (1) The nonlinear manifold learning projections for KPCA, KLDA, and SKPCA are directly compared with visualization through simulated datasets. (2) Motivated by the nonlinear nature of soft-biometric analysis problems, we utilize KPCA, KLDA, and SKPCA for dimension reduction on four types of appearance-based extracted features (BIF, HOG, LBP, and AAM) for the gender classification task. Moreover, the classification performance is compared systematically on parameter optimization. (3) For applications to practical large-scale systems, we propose an additional parallel computational framework that can decrease runtime while maintaining similar classification rates.
The remainder of the paper is structured as follows. In Section 3, we review the theory of KPCA, SKPCA, and KLDA. In Section 4, we conduct simulation studies to visualize projections. We propose our machine learning methods for gender classification on Morph-II in Section 5. The comparative performance of KPCA, SKPCA, and KLDA on Morph-II is presented and discussed in Section 6. The performance of these DR methods is further compared in Section 7 through application to the FG-NET dataset. The computational framework for large-scale practical systems is proposed in Section 8 and investigated on Morph-II. Finally, we conclude and offer future directions of research in Section 9.
Kernel-based dimension reduction methods
The nonlinearity in a classification problem can often be addressed by kernel-based DR methods, with the appropriate choice of kernels. The driving reasons are the nonlinearity of chosen kernels, flexibility of tuning parameter selection, and most importantly, the kernel tricks. Mercer’s theorem guarantees that a symmetric positive-definite function can be written as the sum of a convergent sequence of product functions, which potentially project the data into infinite-dimensional space [54]. Thus, it is feasible to separate the data in the new space. On the other hand, Representer Theorem shows that the solution for certain kernel methods lies in the finite-dimensional span of the training data [64, 54]. This is very helpful, since we do not need to compute the coordinates of the projected data in the infinite-dimensional space, but only the inner products between all pairs of data in the feature space.
Notations
With the goal of emphasizing the connections between KPCA, SKPCA, and KLDA, we define the following notations for classification problems.
Let
Without loss of generality, we may assume that each column of the
Let
We then have
Let
For the kernel
such that for all
where
where
In standard PCA, we seek an orthogonal transformation matrix
where
where
Following the work of [57], PCA can be extended to KPCA by first choosing a Mercer kernel
where
where
We note that
PCA and KPCA are unsupervised methods, since they do not consider the response variable, only considering directions of maximum variability in the covariates. If the goal is classification, this may not be ideal, since the principal components may be unrelated to the class difference. SKPCA is a supervised generalization of KPCA, which aims to find the principal components with maximal dependence on the response variable. Drawing from [5, 65], we formulate SKPCA as follows.
In SKPCA, class information is incorporated by maximizing the Hilbert Schmidt independence criterion (HSIC) [20]. With the aforementioned reproducing kernel Hilbert spaces
where
With the results from [20], an empirical estimator of (9) is
where
Similarly as for KPCA,
where
On another note, in the binary gender classification problem,
It can be shown that maximization of Eq. (10) is equivalent to solving the generalized eigenvalue problem
where
Given a dataset with finite classes, LDA aims to find the best set of features to discriminate among the classes. We first review standard LDA, then generalize to KLDA. We note that sometimes parametric assumptions for LDA are made, such as that observations from each class are normally distributed with common covariance. Here, we make no such assumptions.
Suppose that each observation
In standard LDA, we seek to maximize the objective function
where
Hence, maximizing
Maximization of
where each
LDA is generalized to KLDA using the kernel representation from Eq. (3). Analogously to LDA above, we seek a solution
where now
The above expressions involve knowledge of
where
Maximization of
where each
Comparing the generalized eigenvalue problems in Eqs (16) and (21), the structures of matrices
Let
Thus, the matrix
To visualize and improve understanding of the manifold learning methods KPCA, SKPCA, and KLDA, we apply them in three simulation studies. For comparison, the linear techniques PCA and LDA are also considered. Each dataset contains nonlinear patterns, and the goal is to transform the data to be linearly separable. For this reason, the radial basis function (RBF)
is chosen as a kernel for each pair of observed vectors
Wine chocolate simulation study.
In the first simulation study, the original data are plotted in 3D in Fig. 1a; the green sphere is embedded within the magenta group, necessitating nonlinear manifold learning. The KLDA projections in Fig. 1b are linearly separable with very good variation between the classes and a fair amount of variation within the classes. KPCA and SKPCA projections in Fig. 1c and d are at least approximately linearly separable, as it is not clear whether there is a linear boundary that perfectly separates the two classes. In Fig. 1e, PCA fails to linearly separate the groups, rotating the wine chocolate in 2D. The maximum dimension LDA can retain is
Apple tart simulation study.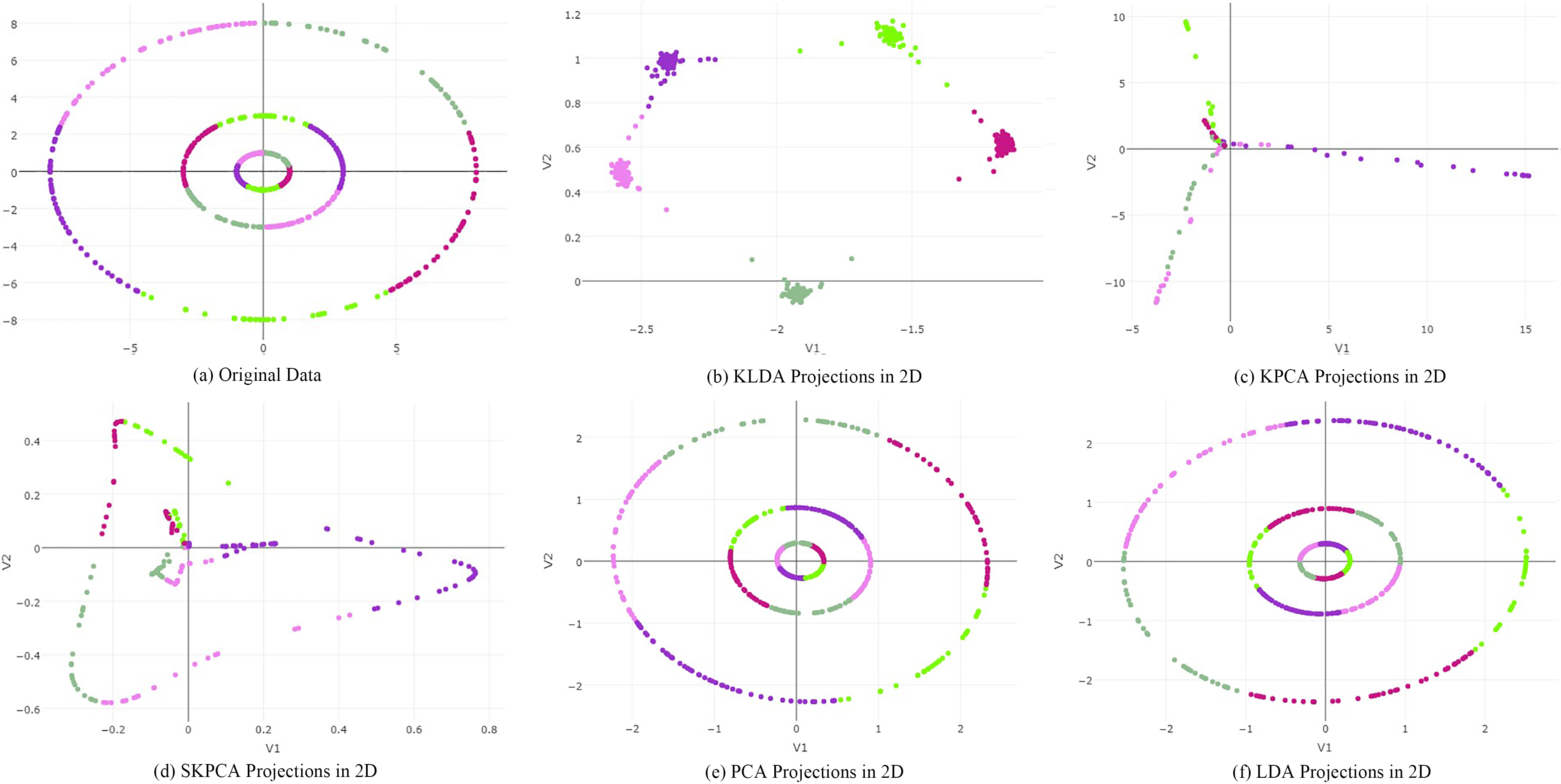
In the second simulation study, the original data in Fig. 2a follow a nonlinear pattern. In Fig. 2b, KLDA produces groups which are linearly separable. The KPCA projections are approximately linearly separable in Fig. 2c; however, there is some overlap between groups, especially the green and pink groups in the third quadrant. In Fig. 2d, SKPCA produces almost linearly separable groups. In Fig. 2e and f, PCA and LDA simply rotate the original data in 2D space, as expected.
Swiss roll simulation study.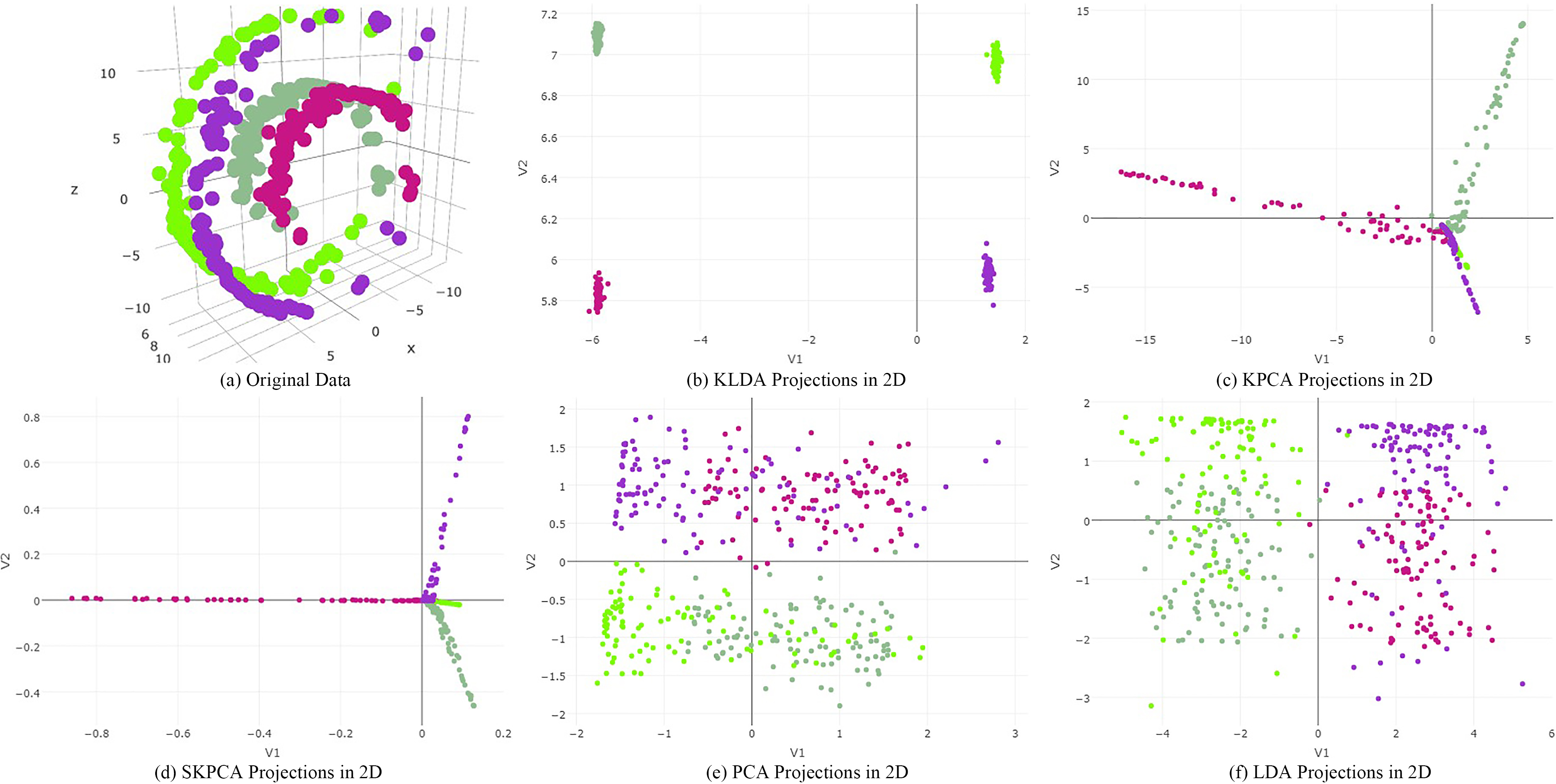
For the third simulation study, the original data in Fig. 3a are in 3D and follow a swirling, nonlinear pattern. In Fig. 3b, KLDA yields favorable results; the groups are well-separated linearly. KPCA and SKPCA in Fig. 3c and d also produce good results, although in Fig. 3c more separation between the purple and bright green groups would be ideal. In Fig. 3e and Fig. 3f, respectively, PCA and LDA merely rotate the original data projected in 2D space; there is no linear separation between the magenta and purple groups, nor between the two green groups.
For all three simulation studies, KLDA, KPCA, and SKPCA are effective to transform the data into linearly separable groups. In all cases, the projected data become approximately linearly separable after applying KLDA, KPCA, or SKPCA. In general, KLDA and SKPCA perform the best here. Their success over KPCA is expected, since KLDA and SKPCA are supervised techniques. On the other hand, results indicate that KPCA and SKPCA are more sensitive than KLDA to different choices of tuning parameters. Hence, SKPCA and KPCA may perform better for alternative choices of parameters. In all our studies, the nonlinear techniques outperform linear PCA and LDA. These preliminary studies suggest the radial kernel is appropriate for our face analysis experiments.
Motivated by the nonlinear nature of facial demographic analysis, we propose and implement a novel machine learning process for the Morph-II dataset. We consider the kernel-based DR methods KPCA, SKPCA, and KLDA on three types of appearance-based extracted features (LBP, BIF, and HOG) for the gender classification task. We illustrate parameter optimization and compare the performance of these methods on Morph-II.
Longitudinal face database
MORPH [52] is one of the most popular face databases available to the public, especially for age estimation, race classification, and gender classification. Multiple versions of MORPH have been released, and the version adopted in this work is the 2008 MORPH-II non-commercial release (referred to as Morph-II in this paper). Morph-II includes over 55,000 mugshots with longitudinal spans and metadata such as date of birth, race, gender, and age.
In addition to its size, Morph-II presents challenges because of disproportionate race and gender ratios. About 84.6% of images are of males, while only about 15.4% of images are of females. Imbalanced classes are known to negatively affect certain classification algorithms [30]. Moreover, Morph-II is skewed in terms of race, with approximately 77.2% of images picturing black subjects. Guo et al. found that age, gender, and race interact for demographic analysis tasks including gender classification, race classification, and age prediction [21, 23, 22], so both race and gender imbalance in Morph-II can hamper gender classification.
Subsetting scheme
To overcome the uneven race and gender distributions in Morph-II, Guo et al. proposed a subsetting scheme [22]. Since then, many studies on Morph-II have adopted such an evaluation protocol. Based on discussions in Guo et al. [22], a new automatic subsetting scheme is proposed in [80], aiming to automatically ensure independent training and testing sets. Additionally, inconsistencies in age, gender, and race in Morph-II have been identified and corrected in [80]. After following the steps to clean MORPH-II outlined in [80], we apply the automatic subsetting scheme, summarized in Fig. 4 and described below.

Let
Number of images in subsets by race and gender
Race-gender combinations are abbreviated, e.g., BF represents the black female group. Abbreviations dF and dM represent those who are neither black nor white in race.
In computer vision, image preprocessing is often an essential first step to reduce unnecessary variation, decrease pixel dimension, and simplify pixel encoding. Despite the standard format of police photography in mugshots, Morph-II photographs vary in head-tilt, camera distance, occlusion, and illumination. We address this variation as follows. Images are first converted to grayscale. Next, faces are automatically detected, eliminating the background and hair, so that no external cues can be used to classify gender. The resulting images are centered and scaled with respect to the center of the irises. Finally, the images are cropped to be 70 pixels tall by 60 pixels wide. Full methodological details are given in [81] and align with standard preprocessing protocols from face analysis.
After preprocessing, pixel-related features are extracted from the face images in Morph-II. As discussed previously, there are numerous approaches for feature extraction. In this study on Morph-II, we incorporate domain expertise by choosing three well-established appearance-based models from image analysis: local texture techniques such as local binary patterns (LBP) [76, 37, 40, 1], biologically-inspired features (BIF) [21, 26], and histogram of oriented gradients (HOG) [21]. Additionally, these model-based approaches provide “robust interpretation
Parameter summary
Parameter summary
Tuning parameter selection is essential for kernel-based methods in order to achieve good results. Within the framework of feature extraction, dimension reduction, and the classification model, there are many combinations of parameters to be considered. The main parameters and tested values are summarized in Table 2 and discussed as follows. LBP features have two main parameters: block size
For each dimension reduction method, the radial kernel
is used for each pair of observation vectors
for all observed responses
Finally, we choose a linear SVM to classify gender based on the dimension-reduced, transformed features. The motivation for this classifier is discussed in the next section. The main parameter for linear SVM is the cost
Tuning results on a subset of MORPH-II
We tune on small subsets of Morph-II to reduce runtime, memory consumption, and risk of over-fitting. 1000 images from
Gender classification results on MORPH-II
(1) Acc represents mean accuracy. (2) TPR represents mean true positive rate (recall/sensitivity): the proportion of male faces correctly classified. (3) TNR represents mean true negative rate (specificity): the proportion of female faces correctly classified. (4) Mem represents mean memory in gigabytes. (5) Time represents mean runtime in hours for training and testing.
For the classification part of the modeling, linear SVM is adopted. Many face analysis studies have involved SVM, as summarized in [10]. Briefly, SVM identifies a separating hyperplane with maximal margin between the classes. Several popular kernels for SVM include linear, polynomial, and RBF [61]. We select the linear kernel, because directions of variability in the data are expected to be linear after the nonlinear transformations of KPCA, SKPCA, or KLDA. Indeed, Schölkopf et al. observed this to be true for KPCA in their landmark study [57]. The linear kernel for SVM also reduces computational cost, compared to nonlinear kernels.
With the parameters in Table 3 that are selected from tuning on subsets, we implement dimension reduction and classification on the full Morph-II dataset, following the subsetting scheme discussed in Section 5.2. The challenges of the large size of Morph-II, the high dimensionality of the features, and the computational complexity of these dimension reduction methods necessitate the use of high-performance computing (HPC). For example, the kernel matrix for each dimension reduction method is 55134
Experiment results
The kernel-based DR methods KPCA, SKPCA, and KLDA are applied to three facial feature extraction methods: BIF, HOG, and LBP. The DR methods transform the feature data, then reduce the dimension. In all cases, a dimension of 100 is retained, substantially lower than the dimension of the original feature space. The dimensionality of 100 is selected as a trade-off between computation time and classification accuracy based on our preliminary studies. The transformed and dimension-reduced data serve as input for the linear SVM, which classifies each image subject as male or female. Additionally, these predicted gender classes are mapped to probabilities through a sigmoid function, following [48]. This process is applied to each alternation of the evaluation protocol: 1) train on
These mean classification results from Morph-II are shown in Table 4. In addition to the accuracy, the true positive rate (also known as sensitivity or recall) and true negative rate (also called specificity) are given. For this study, we define the true positive rate (TPR) as the proportion of male faces correctly classified, while the true negative rate (TNR) as the proportion of female faces correctly classified. The memory and runtime are also listed in Table 4. The runtime is the total time for training and testing on HPC, i.e., the average of time1 (train on
Receiver operating characteristic (ROC) curve and area under the curve (AUC) are compared by method for gender classification on Morph-II. Each color corresponds to a DR method paired with feature type. For each probability threshold, the true and false positive rates are reported as the averages from the testing sets of the alternating evaluation protocol.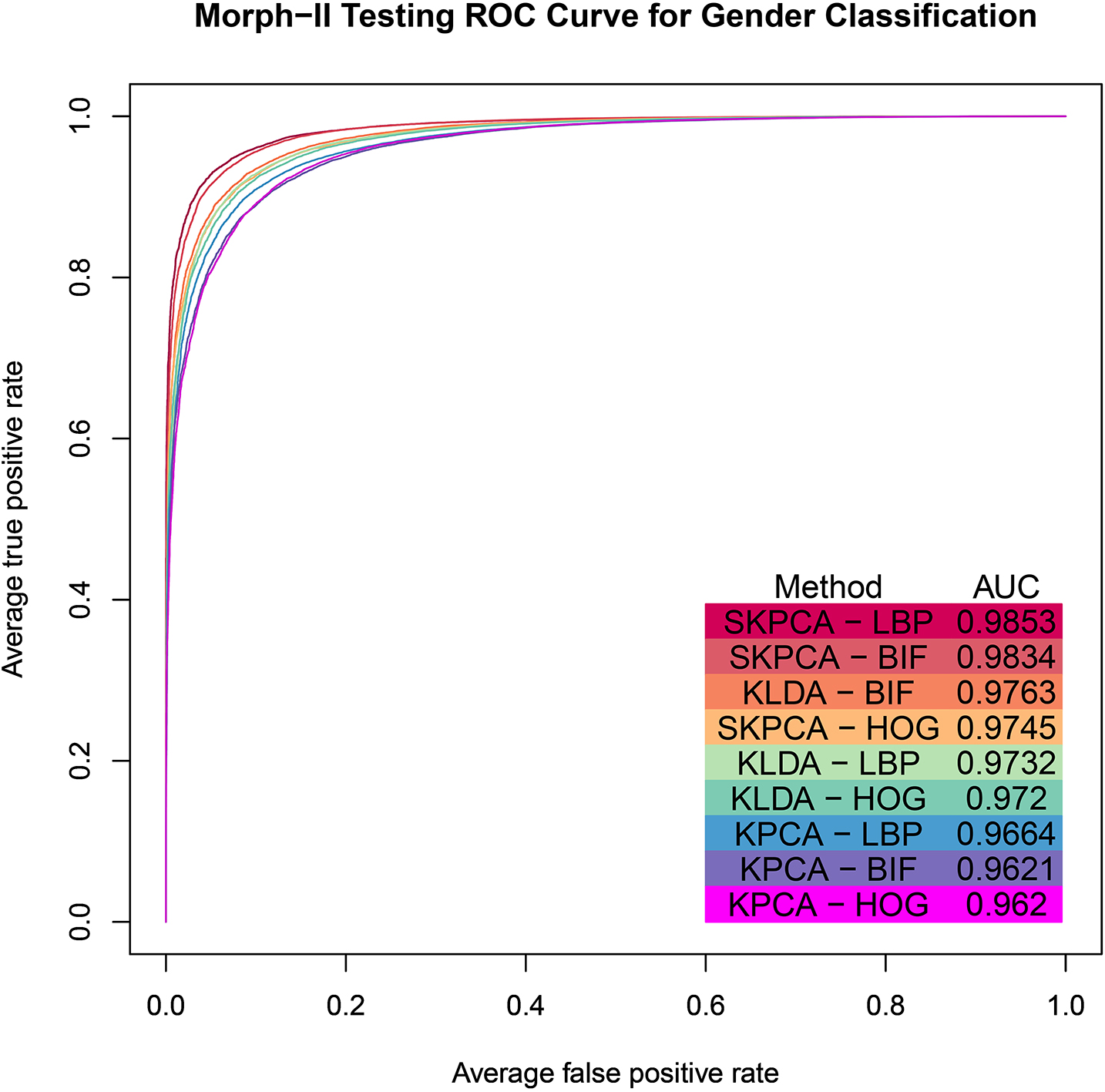
The classification performance is further visualized in Fig. 5 through receiver operating characteristic (ROC) curves for the nine combinations of DR method and feature extraction type. For each combination, its displayed curve corresponds to the “best” results from Table 4 (the combination of parameters reaching maximum mean classification accuracy or maximum mean true positive rate in the event of ties). For each alternation of the evaluation protocol, the true and false positive rates in testing are calculated for each probability threshold. To construct the ROC curves, each of the resulting rates for each threshold is averaged over the testing sets.
Table 4 shows that for the feature BIF, SKPCA and KLDA outperform KPCA. For the feature HOG, SKPCA achieves higher accuracy than both KPCA and KLDA, while the latter two techniques perform very similarly. Last, for the feature LBP, SKPCA produces better classification accuracy than KPCA and KLDA. In summary, our experiment’s results indicate that SKPCA outperforms KLDA consistently, while KLDA outperforms KPCA for all three features BIF, LBP, and HOG. On the other hand, for KPCA, the features HOG and LBP produce approximately the same accuracies, outperforming BIF. For SKPCA, LBP achieves slightly better results than BIF, while LBP and BIF both outperform HOG. Finally, for KLDA, BIF reaches slightly higher accuracy than LBP, while BIF and LBP both exceed HOG.
In most cases, the accuracy (in Table 4) and AUC (in Fig. 5) metrics agree on the best methods. An exception is that SKPCA with the HOG features achieves slightly higher accuracy (94.89%) than KLDA with the BIF features (94.18%), but SKPCA with HOG has lower AUC than KLDA with BIF. The other exception is that KPCA with the HOG features has the lowest AUC of the nine methods, but its accuracy is higher than KPCA with the BIF features. In summary, the accuracy and AUC results imply that SKPCA generally performs best for gender classification on Morph-II, while KLDA tends to outperform KPCA. Meanwhile, the LBP and BIF features often yield better classification performance, with less memory usage, than the HOG features.
It is interesting that, overall, LBP achieves even slightly better performance than BIF for the dimension reduction method SKPCA on the task of gender classification, since BIF is popular in demographic analysis such as age estimation, gender classification, and race classification [21, 23, 22, 24, 25]. Another interesting fact is displayed by the results of the true positive and negative rates in Table 4: males have a higher probability of correct identification than females, with the biggest margin exceeding 20%. Our finding is consistent with [26]: females are more challenging to correctly classify than males, both for automatic approaches and human perception. Similarly, for race classification on Morph-II, Guo and Mu found in [23] that training a model on female faces (and testing on male faces) contributed to significantly more errors on average than training on male faces (and testing on female faces), even when controlling for differences in the training sample sizes. Our results also indicate that, overall, HOG and LBP outperform BIF for males, while BIF works consistently better than LBP and HOG for females.
Next, in Table 5 we compare our results to studies using similar methods on Morph-II, as well as recent state-of-the-art works with deep learning on MORPH-II. With the exception of [26], all studies’ results in the table are mean testing classification accuracy from an alternating evaluation protocol based on Guo et al [22]. Hence, our results can be directly compared to these studies. With LBP features, SKPCA, and a linear support vector machine (SVM), our gender classification accuracies approximate 96%, competitive with benchmark results. Interestingly, several reported accuracy rates from human observers of gender range from 96% [9] to 96.9% [26]. The similarity in recognition rates between our methods and human observers can further validate the success of our approach.
Comparison results for gender classification on MORPH-II
For further comparison between KPCA, SKPCA, and KLDA, we apply a modification of our approach from Section 5 to a smaller face dataset, the face and gesture recognition network (FG-NET). FG-NET is a popular, publicly available database used for age estimation, gender classification, face recognition, and other demographic analysis tasks [46]. It contains 1002 images from 82 subjects: 47 males and 35 females with ages varying from 0 to 69 years [46].
For each image, 109 features are extracted using the Active Appearance Model (AAM), a commonly adopted appearance-based approach that models the shape and texture of the face [14, 11]. As in Section 5.4, the radial kernel defined in Eq. (24) is chosen for each of the DR methods KPCA, SKPCA, and KLDA. Additionally, the modified link function from Eq. (25) is applied in the SKPCA algorithm. Thus, the tuning parameter
Parameter summary for FG-NET
Parameter summary for FG-NET
For cross-validation, we use leave-one-person-out (LOPO), the most well-accepted scheme for FG-NET [46]. LOPO is a variation of
Gender classification results on FG-NET
(1) Acc represents mean accuracy. (2) TPR represents mean true positive rate (recall/sensitivity): the proportion of male faces correctly classified. (3) TNR represents mean true negative rate (specificity): the proportion of female faces correctly classified.
Receiver operating characteristic (ROC) curve and area under the curve (AUC) are compared by method for gender classification on FG-NET. Each color corresponds to a DR method.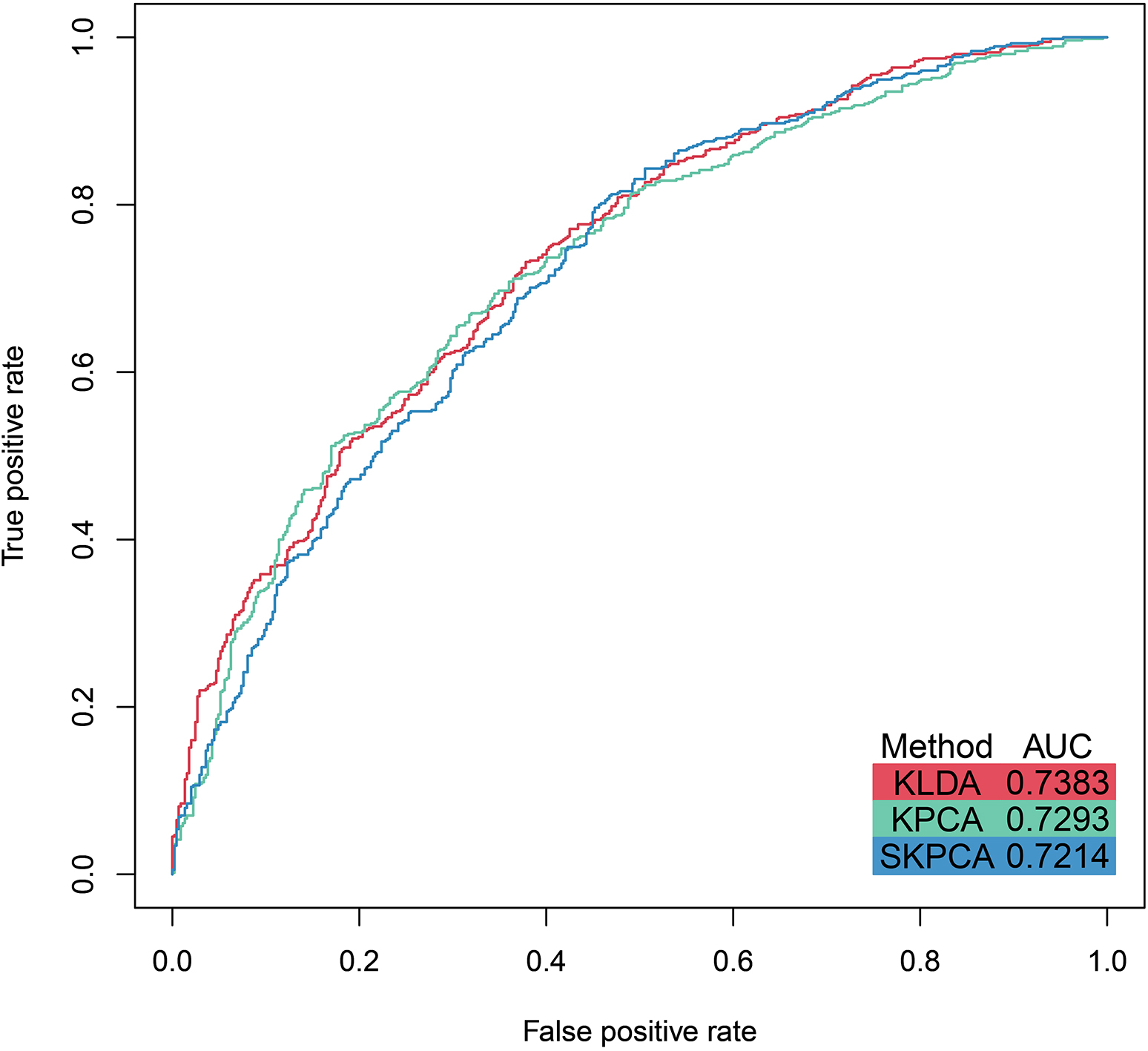
For each fold, we transform and reduce the dimension of the features through each DR method. In all cases, a dimension of 100 is retained to facilitate comparison with the results on Morph-II. The transformed, dimension-reduced features then predict the gender of the testing fold’s images through a linear SVM. The predicted classes from SVM are also mapped to probabilities through [48], similarly as in Section 6. The gender classification accuracy is calculated for the testing fold. Finally, all such testing classification accuracies are averaged to compute the mean classification accuracy from testing; the testing probabilities are used to form ROC curves.
The optimum gender classification results on FG-NET are presented in Table 7. The maximum classification accuracy of about 72.25% is achieved by KLDA. For other choices of parameters, KLDA reaches above 71% accuracy, which is close to the maximum accuracy attained by SKPCA. Meanwhile, the peak accuracy reached by KPCA is 70.25%. In general here, KLDA is observed to outperform SKPCA and KPCA, while SKPCA tends to surpass KPCA. In most cases, the probability of correctly classifying males (sensitivity/true positive rate) is higher than the probability of correctly classifying females (specificity/true negative rate). For each DR method, an ROC curve (corresponding to the results from Table 7 with maximal mean classification accuracy) is displayed in Fig. 6. The area under the curve (AUC) is highest for KLDA, followed by KPCA then SKPCA.
Overall, the gender classification results on Morph-II are stronger than on FG-NET. Lower accuracy on FG-NET could be caused by the greater number of minors (aged 0-18), who have been more difficult to classify than adults in some studies [65, 66]. Additionally, there are substantially fewer faces for training in FG-NET versus Morph-II (under 1000 versus 10280 images). Another contributor could be the choice of features and its dimension; the AAM features have dimension 109 on FG-NET, while the HOG, LBP, and BIF features have dimensions ranging from 500 to thousands on Morph-II. SKPCA reaches peak performance on Morph-II, while KLDA attains optimal results on FG-NET. However, the results on Morph-II and FG-NET are similar in that the supervised methods KLDA and SKPCA outperform the unsupervised method KPCA for gender classification. Further, both datasets evidence that female faces are more challenging to classify than male faces.
To tackle the challenges of high dimensionality and intensive computation for large-scale databases (like Morph-II, as shown in the Time column of Table 4) in real-world applications, we propose a computational framework to substantially decrease runtime.
Our approach involves parallel computing, the bootstrap resampling method, and ensemble learning. Let
To explore the effectiveness, this framework is applied to Morph-II with a selection of BIF, LBP, and HOG features as preliminary studies. This experiment is implemented through the HiPerGator 2.0 supercomputer at University of Florida with five cores per combination of feature and dimension reduction method. Following the subsetting scheme discussed in Section 5.2, for simplicity, we consider only the case of bootstrapping image samples from
Classification results based on bootstrapping
Classification results based on bootstrapping
Flowchart representing the parallel computational framework for practical systems proposed for Morph-II and other large datasets.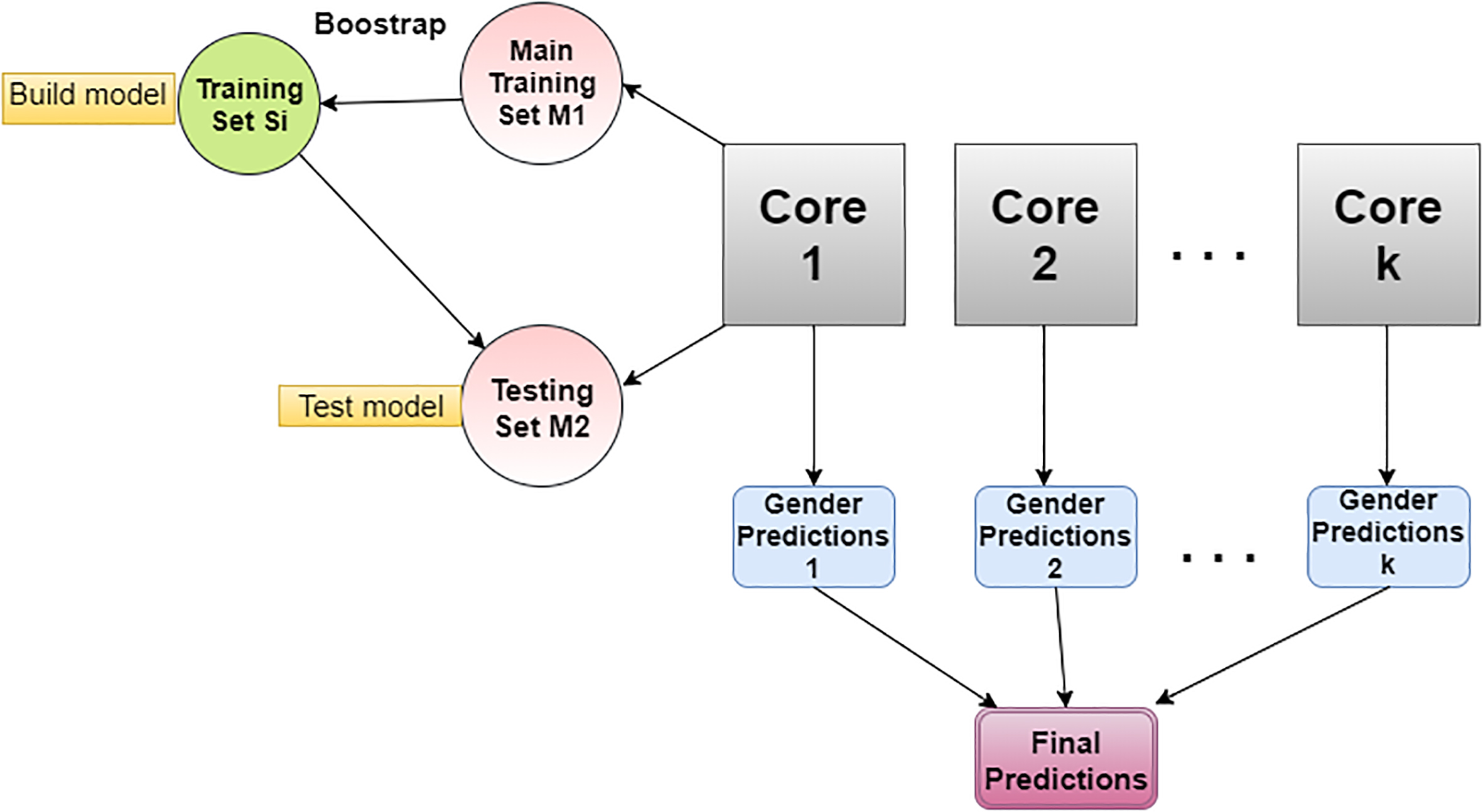
We evaluate this framework by comparing the approximated results in Table 8 to the results from Table 4. For each combination of feature and dimension reduction method, each of the five cores independently trains a bootstrapped sample of 1000 images from
It is shown in Table 8 that, in many cases, the accuracy rates from the approximations are similar to those from the main approach in Table 4. This is a very good result, especially considering that the bootstrapping approach uses no more than 5000 images total for training, while the main approach used all 10280 images for training. This finding suggests that our methods may perform reasonably well on Morph-II with smaller training sets. The most substantial difference between the bootstrapped approach and the main approach is in the runtime. For all combinations of features and dimension reduction methods, the bootstrapping approach has decreased the runtime to under two hours. Meanwhile, the main approach in Table 4 yields runtimes exceeding 20 hours. Hence, our preliminary results indicate the parallel approximation approach can attain similar accuracy rates to the main approach, while substantially saving time. Such a result is promising for practical gender classification systems, where gender predictions must be made in real-time.
We have performed a comparative study of the nonlinear dimension reduction methods KPCA, SKPCA, and KLDA. These kernel-based methods are first applied to three simulated datasets for visualization and comparison. SKPCA and KLDA outperform KPCA, reinforcing the need for supervised approaches in classification tasks. The radial kernel performed well, encouraging its use for face analysis.
Next, we have proposed and evaluated a new machine learning process for Morph-II. First, we use a novel subsetting scheme that reduces class imbalances while establishing independence between training and testing sets. Then we preprocess Morph-II photographs and extract three appearance-based features: HOG, LBP, and BIF. We transform and reduce the dimension of these features through KPCA, SKPCA, and KLDA. Linear SVM classifies the gender of Morph-II subjects, reaching accuracy rates of 95%. With promising preliminary results on Morph-II, a practical computational framework is offered that reduces runtime through parallelization and approximation.
The performance of the dimension reduction methods are further compared through an application to the FG-NET dataset. Images are represented through the appearance-based AAM features; transformed and reduced in dimension through KPCA, SKPCA, and KLDA; and classified as containing a male or female subject through linear SVM. While SKPCA performed optimally on Morph-II, KLDA reached top performance on FG-NET with 72% leave-one-person-out (LOPO) accuracy.
Further directions of research involve automatic tuning parameter selection, reduction of computational cost, and application to other face analysis tasks. Our approach could yield improved results with better choices of parameters, but it is impossible to anticipate and try all combinations. Automatic parameter selection for kernels could help identify a good set of parameters more easily. Perhaps the most important future direction of research on Morph-II is to reduce computational cost. For many practical demographic analysis systems, predictions must be made in real-time. For our gender classification methods, our parallel approximation approach substantially reduced runtime while attaining similar accuracy rates to the main approach. Such computational strategies should be further investigated to help bring gender classification and other face analysis tasks to practical implementation. Finally, our machine learning pipeline for Morph-II could be generalized to race classification or even age estimation.
Footnotes
Acknowledgments
This material is based in part upon work supported by the National Science Foundation under Grant Numbers DMS-1659288. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. The authors would like to thank the reviewers for the helpful comments that significantly improve the presentation of the paper.