
Abstract
The prediction of coal and gas outburst is very necessary for the prevention of gas disaster, so an outburst prediction model coupled with feature extraction and feature weighting using optimized classifier is proposed. First, Pearson correlation coefficient(PCC) and symmetric uncertainty(SU) are employed to measure the effective information in outburst sample data. Second, Kernel principal component analysis(KPCA) and linear discriminant analysis(LDA) methods are used to extract the exiting discriminate information, and the extracted linear and nonlinear feature information can effectively reflect significant information of outburst influencing factors. Third, the combination of gradient boost decision tree(GBDT) and grey relation analysis(GRA) is used to weight and fuse the extracted linear and nonlinear feature components, then form a new feature set as important discriminant information. Forth, the weighted and fused features of the coal and gas outburst influencing factors are used as the input of support vector machine(SVM) classifier with optimized parameters, it can classify outburst states, and the achieved classification accuracy can obtain 95%. Finally, the proposed model and the existing outburst classification models in literatures are used to predict outburst, then the experiment results verify the effectiveness of the proposed model and conclude that the performance of the proposed predication model are significant than present outburst prediction models.
Introduction
With the deepening of mining depth and the increasing of gas content, the role of in-situ stress and gas release gravity in the mining coal seam makes the soft coal seam break through its resistance boundary, and suddenly eject many coal and gas in the space working face with high-pressure shock wave at a very short time. Outburst disaster is very great, and now the process and mechanism can’t be controlled by human beings, which have seriously polluted the environment. Therefore, the outburst prediction is very important for coal mine safety production [1]. For the outburst classification problem solved, the comprehensive classification models that consist of feature selection or feature extraction methods are as following: MIC-MRMR-RF-GBDT-KNN [2], KPCA-LDA-BO-MKRM [3], DWT-ICA-LDA-QPSO-DELM [4], EMD-Boruta+LDA-BO-SVM [5] and Boruta-Apriori-BO-SVM [6]. These classification models are not suitable for solving all problems, and their classification performance can be improved further.
Based on the above analysis and discussion, a new model based on PCC-SU feature measurement, KPCA-LDA feature extraction, GBDT-GRA feature weighting and SVM classifier are proposed. The research contents are as follows: First, the outburst feature extraction model based on KPCA-LDA is proposed through the feature measurement method of PCC and SU. Second, in view of the defects of single assignment method and the importance of coal and gas outburst characteristics, the GBDT-GRA feature weighting model based on comprehensive weight coefficient is proposed, which can solve the feature fusion of linear and nonlinear components in outburst feature components; Thirdly, A feature extraction and weighting model is proposed to extract and weight the linear and nonlinear components of outburst sample data and features, then obtain the optimal combination of extracted components. Finally, after feature weighting model is made, then the optimized SVM classifier is used to classify the coal and gas outburst, the rationality and effectiveness of the algorithm are verified.
Related work
Because there are many uncertain and random factors affecting coal and gas outburst, and complex linear and nonlinear relationships for coal and gas outburst influencing factors are contained in outburst sample data, the effective features that accurately reflect the feature indexes of outburst [7] can contribute to outburst classification. Now the related feature extraction methods of outburst are shown in Table 1, and we can find out their scope. It is necessary for us to use effective methods to extract the important features that comprehensively and accurately reflect the correlation of coal and gas outburst influencing factors. The sample data of coal and gas outburst contains linear and nonlinear components, and which also has the subjective evaluation of decision makers and objective reflection of the physical attributes of indicators. Among these factors, the geological factors play a decisive role. From the objective point of view, according to the previous research, outburst is greatly influenced by the following factors such as excessive gas, formation pressure and weak structural performance of coal body. Geological structure and other objective all take a decisive role in gas outburst. The high-pressure state of gas provides power for outburst, and weak structural strength or damage of coal seam is also a favorable factor for outburst, and the production movement is the main inducing factor.
Performance comparison of different feature extraction
Performance comparison of different feature extraction
At the same time, considering the different contributions of the extracted feature component information for the outburst classification, now many methods are used to weight the different influencing factors to improve outburst classification performance [17], and the traditional methods can be divided into objective weight coefficient(factor analysis, principal component analysis, correlation coefficient, mean square error, entropy weight and rough set), subjective weight coefficient(analytic hierarchy process, network analysis, fault tree analysis) according to the different influences of human factors in the determination process. The calculation process of objective weight coefficient is not affected by human factors, it mainly depends on the original sample data, but sometimes there is difference with expert understanding; The subjective weight coefficient fully considers the knowledge and experience of experts, but it is also affected by experts emotion and other factors, so it is difficult to avoid the subjective effect, and these methods have some limitations. The traditional weighted model assumes that the relationship between linear and nonlinear components keeps fixed. However, due to the complexity of outburst process and the existence of subjective and objective factors, they are constantly dynamic factors in coal and gas outburst. Such characteristics make the single weighted model difficult to obtain good results. The reason for the poor prediction performance of the model is that the linear and nonlinear components of influencing factors are not effectively weighted and fused. The importance of extracted linear and nonlinear components in outburst is not the same, so the appropriate methods are used to determine the influencing weights. Feature weighting can effectively measure the importance of extracted linear and nonlinear components, which gives higher weights to more important components and lower weights to unimportant components. The reliability and accuracy of the exiting evaluation methods cannot assign the suitable weights which reflect the difference of these components. Because the index system established by objective weighting and subjective weighting methods is relatively one-sided, in order to fully tap the various effective feature information beneficial to outburst classification existing in the influencing factors of coal and gas outburst, and provide high-quality features for outburst classification. Therefore, this paper utilizes the GBDT-GRA to weight the extracted components, then obtain the optimal combination of linear and nonlinear information, it can avoid or minimize the error of weight coefficient, then improves the prediction accuracy.
In terms of the outburst classifiers, KNN [2], SVM [6] and RVM [4] classifiers are used. The process of KNN is as following: If most of the k nearest samples in the feature space belongs to a certain category, the sample also belongs to this category and has the characteristics of the sample data in this category. In the classification decision, the method only determines the category of the sample data to be classified according to the category of the nearest one or several sample data. The KNN is only related to a very small number of adjacent sample data in category decision-making. It mainly depends on the surrounding limited adjacent sample data, rather than the method of discriminating class fields to determine the category, the KNN is more suitable than other methods for the sample set to be divided with more overlapping or overlapping class fields. SVM can analyze linear separable cases, for linear non separable cases, the linear non-separable sample data in the low-dimensional input space are transformed into the high-dimensional feature space by using the nonlinear mapping algorithm to make them linearly separable. Coal and gas outburst belongs to great disaster in coal mines, due to the limitations of space and other conditions after the occurrence of coal and gas outburst, we have very limited information related to outburst, but SVM classification model is less sensitive to outburst sample data. For the coal and gas outburst, we can obtain better outburst classification effect than other traditional methods. Therefore, in view of the advantages of SVM in small sample data processing and the characters of probabilistic prediction output, this paper adopts SVM classifier as the classification model of coal and gas outburst.
There exist all kinds of relationships in coal and gas outburst influencing factors, a hybrid feature extraction KPCA-LDA is proposed to increase the effective information of obtained feature vectors; In view of the different importance of linear and nonlinear components in coal and gas outburst prediction, the GBDT-GRA is used to evaluate and fuse the extracted linear and nonlinear components; Aiming at the problems existing in effective classifier selection, we propose SVM classification model to improve the nonlinear and adaptive ability of processing data. The structure of proposed prediction model is shown in Fig. 1.
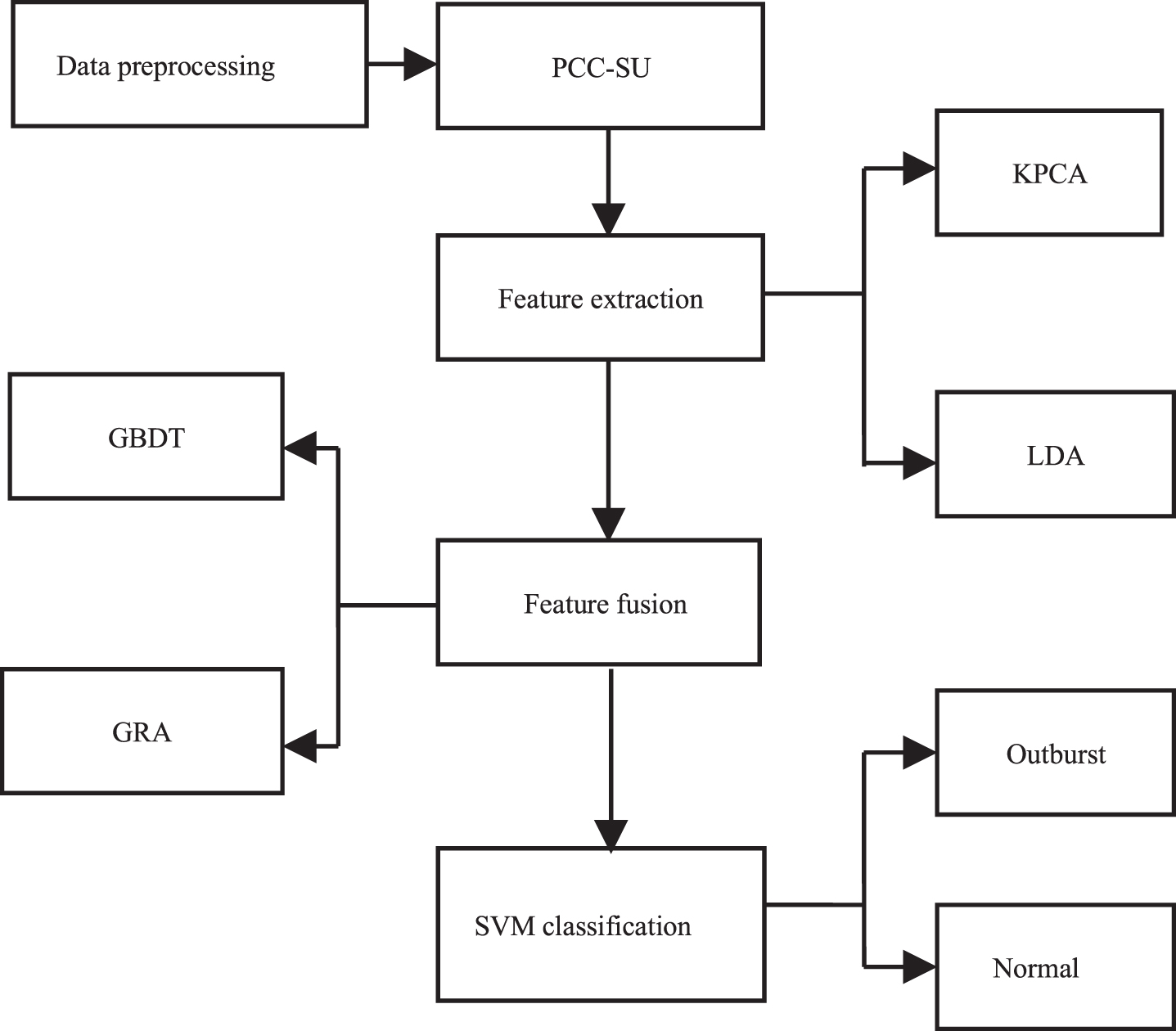
Structure of proposed model.
There exit linear and non-linear correlation between random variables [18, 19]. At the same time, there are two types of measurement: linear and non-linear methods. PCC can measure linear between random variables, while SU can show non-linear between two random variables, we can measure the correlation degree in coal and gas outburst by PCC and SU, which is conducive to the following effective feature extraction.
PCC
PCC is linear measurement method, for example, the variables (x, y) are given, the PCC of two variables is defined as:
Where,
Information entropy is a measure of event uncertainty, and SU is a nonlinear correlation measure described by information entropy, which is used to evaluate the correlation between two random variables [13, 14]. Random variable x is {x1, x2, …, xn}. The information entropy is as follows:
Where, p (x
i
) is the prior probability of random variable, p (x|y) denotes the uncertainty of random variable x under the condition of known random variable y. H (x|y) denotes the posterior probability when y is y and x is x.
IG (x|y) is called information gain, which denotes the reduction of entropy of variable x in the case of given variable y. Therefore, the more uncertainty of x decreases, the higher the dependence of x and y are, that is, the stronger the correlation between them is, it is as follows:
However, IG (x|y) is affected by the units and values of random variables, which needs further homogenization. the influence of variable units and values is necessary to be deleted, and we can use the normalized information gain, that is the SU (x, y). With the help of entropy in information theory, SU measures the non-linear correlation of two variables by measuring the difference between the distributions of x and y, and SU can be calculated by normalizing mutual information between them by entropy of x and y. The feature is regarded as a variable, and the feature value in different instances is the variable value. Therefore, the correlation between two features can be measured by SU, and the formula is as follows
In this way, the deviation of information gain to the feature with more values is compensated and its value is limited to [0,1]. A value of 1 indicates that x can predict y, a value of 0 means that x and y are independent. In addition, it still processes a pair of features symmetrically.
There are linear components between outburst influencing factors and outburst classification. Because LDA has good linear fitting ability, and it is very suitable to capture this kind of signal with linear characteristics. There are nonlinear components among the prominent influencing factors. KPCA method can extract the feature component information which is beneficial to the prominent classification. After these different feature component information are fused, the prominent classification effect can be improved. A variety of feature information extracted can be complementary to improve the classification effect. Therefore, this paper uses the combination of KPCA and LDA to achieve the effective features from the outburst influencing factors.
LDA
LDA [20, 21] is based on Fisher criterion and it can find out the sample data of different classes in the far away vector, the ideas are as follows:
Where, g
i
is the eigenvector corresponding to the eigenvalue λ of matrix
The correlation between the characteristics is very complex. Besides linear relationship, there are also nonlinear relationships. But the linear discriminant method is a transformation method based on linear correlation, we cannot extract the nonlinear features in the model. We can only extract the local information between the sample data. The extraction of the nonlinear features and global information in the data is ignored, which leads to the incomplete extraction of prominent features. Therefore, the nonlinear components and global information in the features must be considered to improve the classification performance.
KPCA [16, 22] can adopt a nonlinear kernel method, the ideas are as follows: The dimension of the coal and gas outburst x is n, the nonlinear kernel function is used to map it to a high-dimensional feature space, and the mapping function is defined ∅ (x), then the covariance matrix is denoted by the following:
So λ represents the eigenvalue, and v represents the eigenvector, then γv = cv, and an inner product of the expression can denote the sample.
Where, k = 1, 2, …, n, a set of coefficients are as following: a1, a2, …… a n , so that the eigenvector of c is denoted by ∅ (x):
Combing Equations (13–15), the result is as following:
Then a symmetric matrix k of n * n is denoted.
If formula (17) is put into the formula (15), then the formula (15) is denoted.
Therefore, eigenvalues are y1, y2, y3, y4, …, y
n
, and the corresponding eigenvectors are a1, a2, a3, a4, … a
n
. The first k eigenvectors are selected from the formula (15).
After the normalization of v is made, we united a1, a2, a3, a4, a
n
then the formula (20) is the following:
The [v
k
] projection of the mapping data ∅ (x) is calculated on the eigenvector v
K
in the Eigenspace H, then we can obtain the nonlinear data.
Where, k = 1, 2, 3 … , n, for example, the contribution rate of the cumulative variance of the eigenvalue can determine the selection of the number of principal components k, and the formula is as follows:
KPCA can extract effectively feature information that describe the feature space, but it cannot obtain effective features in the features. It is necessary to mine the discrimination information from coal and gas outburst.
GRA
The coal and gas outburst are typical grey system with small sample data and poor information, the grey system theory is fit for the coal and gas outburst. GRA [23] is used to analyze the behavior, situation and boundary relationships between the objects. Through the calculation and ranking of the correlation degree of the influencing factors, the main control influencing factors affecting the risk of coal and gas outburst are determined. The ideas are as follows.
Where, ρ is the resolution coefficient, the value is between 0-1, usually its value is 0.5, Δ min and Δ Max are the minimum absolute difference and the maximum absolute difference, respectively.
Where, r i is the sequence correlation degree, namely is the average correlation degree, the closer the value of r i is to 1, the better the correlation is.
There exist random and fuzzy and uncertain in outburst, we can use objective weighting method to improve the prediction performance. In this paper, different features are assigned different weights obtained from the GBDT [24]. The global importance of each feature J of index is determined by the average importance degree of feature J in a single tree. The feature weights can be obtained in feature selection of GBDT, and different features are given corresponding weight coefficient. Different weights strength are set, and the weight coefficient can be used to calculate the weight of each feature. The feature of high relevant to the target is transformed, and the feature of little correlation with the target is weakened. In this paper, different optimal features are weighted.
Where, m is the tree size, and the importance J in single tree is denoted:
Where, L denotes the number of leaf nodes in the tree, L-1 denotes the number of non-leaf nodes in the tree, V
t
denotes the feature associated with the node, and
Outburst influencing factors not only contain subjective and objective information, but also have linear and nonlinear components. It need an appropriate weighted fusion method to effectively mine the complete information contained in the highlight. However, single method may have defects. GRA weighting can reduce the loss caused by information asymmetry to a great extent, and require less data and workload, but its disadvantage is that it need determine the average optimal values of various indicators, which has subjective characters, and the optimal values of some indicators are difficult to obtain. The objective weighting of GBDT can establish a certain number of mathematical models. Sometimes, there is a big gap between the weighted results of indicators and the objective reality, and sometimes the calculation results cannot be explained. GBDT-GRA weighting is that the weight coefficients obtained by different weighting methods are combined according to certain methods, so that the weighted results can reflect subjective and objective information. Proposed combination weighting refers to the combination of two weighting methods to regain the final weights of indicators. On the one hand, we can use the knowledge and experience of experts to fully reflect the importance of subjectivity weight. We can employ the relationships between different indexes. The obtained weights have the objectivity and subjective information. We can optimize the allocation of feature weights, reduce the artificial influence of subjective weight, and avoid the difference of objective weight. So this paper combines the GBDT and GRA methods to perform feature fusion on extracted linear and non-linear features based on comprehensive weight coefficient, the formula of comprehensive weight coefficient is as follows:
For the above formula, where w
i
and w
j
represent the weighted values, respectively. So we can determine the optimal proportion of linear and non-linear components in the extracted feature information through the following optimization algorithm.
Where, σ and θ represent the optimal proportion of the extracted linear and nonlinear components, respectively. The flowchart of proposed GBDT-GRA is seen in Fig. 2.
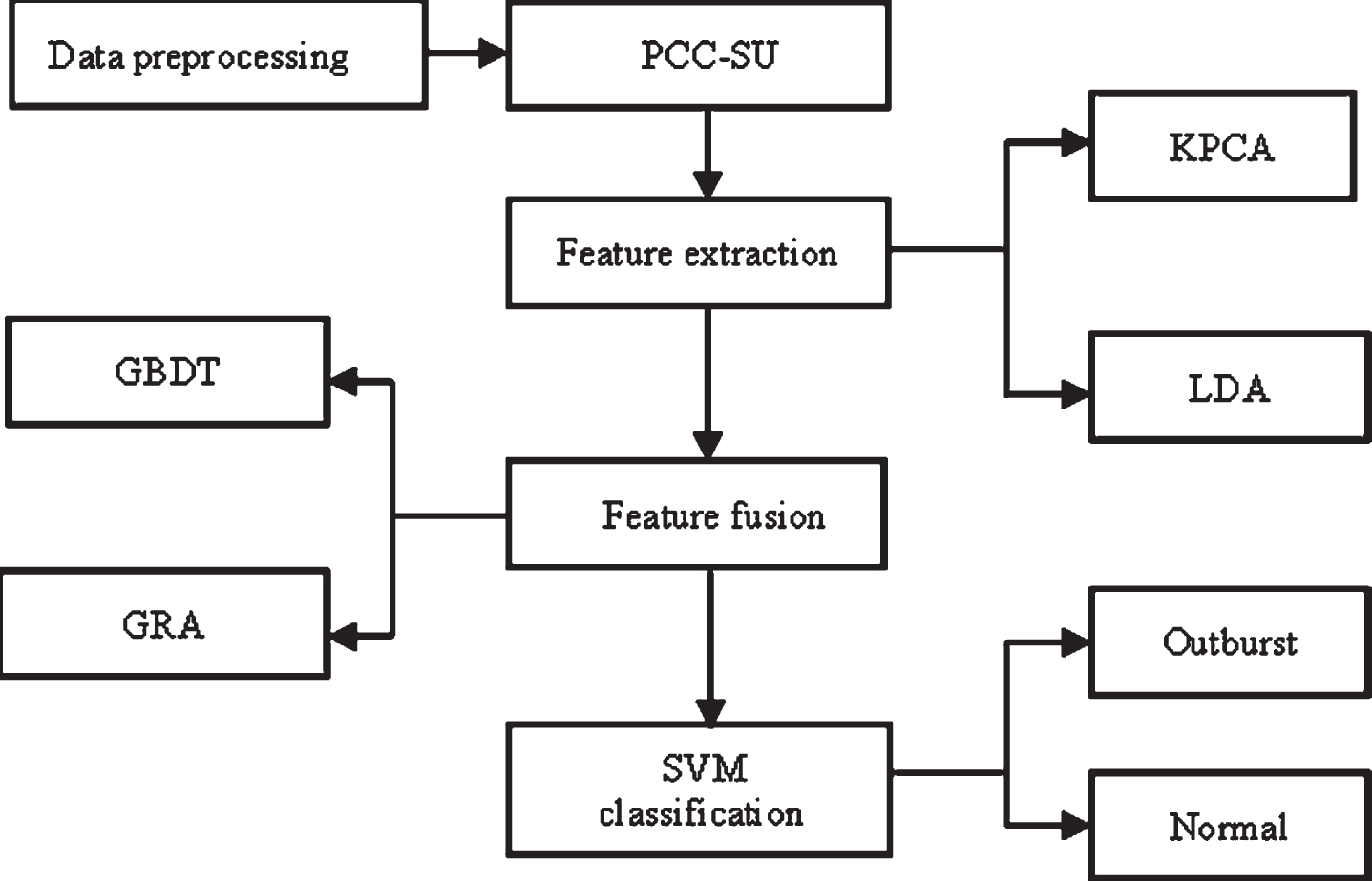
Flowchart of GBDT-GRA feature weighting model.
For SVM [28, 29], nonlinear kernel function can make sample space from high-dimensional to infinite dimensional feature space, The principle is as follows:
The training sample set are
Where, the ∅ (x) is a nonlinear mapping function, it can transform the input space x to high-dimensional feature space, w is the weight vector, b is the bias value, and the classification hyperplane should satisfy following constraints:
Then we can measure the degree of w and b which violate the constraint conditions, then a non-negative relaxation variable ɛ
Then the following dual optimization problem can express the linear decision function:
The nonlinear decision function is as follows:
In the formula,
Where C, Gamma are the parameters of SVM. In this paper, the optimal parameter combination is obtained by maximizing the posterior distribution of parameters. Bayesian optimization [26, 27] determines the next most “potential” evaluation point through active selection strategy. It can effectively balance the relationship between width search (Exploring uncertain areas to obtain more unknown information) and depth search (using existing information to find the current optimal), so as to reduce unnecessary objective function evaluation. It is guaranteed that the optimal solution can be obtained only after a few times of objective function evaluation. Bayesian optimization assumes the prior distribution on the parameter set, and the optimal parameter combination is obtained by maximizing the posterior distribution of the parameters. The flowchart of proposed BO-SVM optimized classification model is shown in the following Fig. 3.
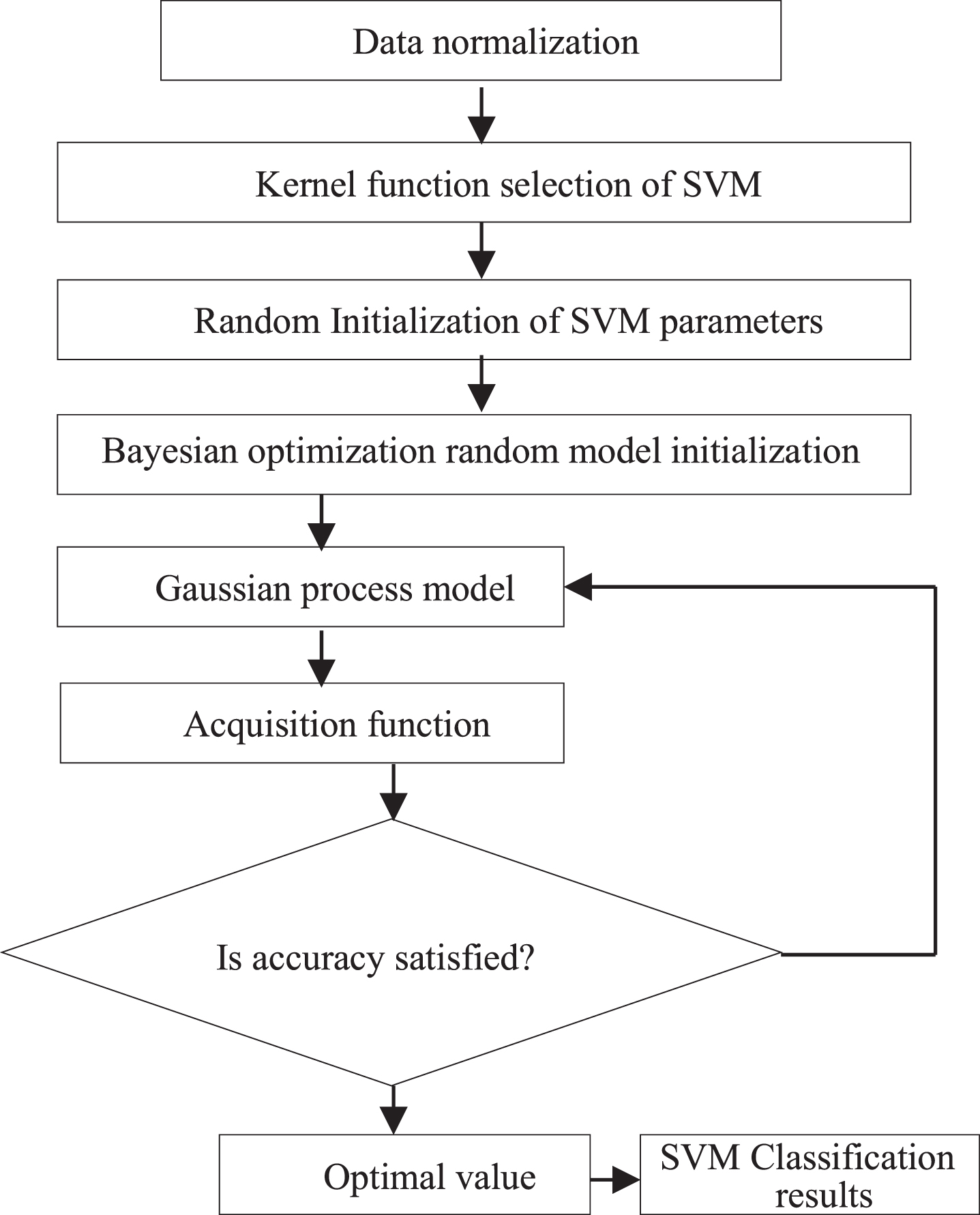
Flowchart of optimized SVM classifier.
Dataset and data enhancement
From the distribution of coal and gas outburst points, the outburst points are mainly distributed in faults, coal seam softening, coal thickness change, coal seam dip change, coal body damage and roof breakage. Taking into account the influence factors of coal and gas outburst and the feasibility of data acquisition, too many or too few indicators will lead to unsatisfactory outburst classification results. In combination with the related reference, we selected the coal and gas outburst sample data which collected from an air tunnel working face in the mining area and part of the data collected as the experimental data set, and the selected six coal and gas outburst influencing factors are from three aspects which are gas, geology and coal body structure. The influencing factors of coal and gas outburst are as follows: gas pressure, initial velocity of gas emission, initial velocity of gas emission, thickness of structural coal, solidity coefficient and complexity of fault structure. For the specific meaning of these six indicators, we can refer to relevant references. The coal and gas outburst influencing factors refers to related literature [30]. Six index parameters of geological in-situ stress, gas and coal seam physical properties are selected to analyze and evaluate the risk of coal and gas outburst, and the early warning index of coal and gas outburst is constructed. Gas characteristic variables mainly include: gas pressure (0) and initial velocity of gas emission (1); In situ stress characteristic variables mainly include: initial gas emission velocity (2), structural coal thickness (3) and firmness coefficient (4); The characteristic variables of coal structure mainly include: complexity of fault structure (5). These six indicators are used as the specific influencing factor indicators of coal and gas outburst classification. Coal and gas outburst are binary problem, that is, the outburst type is 1 and the non-outburst type is 0. The unit letter m represents meter and t represents second. In order to achieve the unification of data in different units, we conducted normalization processing, and all the data were between (0,1). Because the number of original coal and gas outburst data sets is too small, it is easy to cause the over-fitting problem of the classification model. Therefore, this paper uses synthetic data to generate a considerable number of data to train the classification model. According to the characteristics of the data and references [31], the original data is scaled by 85%, and then the number of generated data is 500 with 3% random perturbation. It will not interfere with the feature extraction, and the 3% random disturbance can be regarded as white noise of the original data. The white noise can increase the accuracy of data set in recognition. The use of 3% white noise will not have a significant impact on the trend of the original data, but it will make the generated data closer to the real data. The data generation method is shown in formula (37):
Comparison of combined feature using SVM
Comparison of combined feature using SVM
The classifiers parameters are as follows: Some experiments use RBF as kernel of SVM, and the parameters optimization of SVM is accomplished by BO algorithm, and the search space is limited in interval [0.1,100]. The optimization results are: C is 45 and gamma is 1, and the parameters of RF, DT, ELM, PNN and BP are obtained by default setting and experiment results.
Experimental result and analysis
Feature measurement and extraction
From Tables 2–4 we can see that all kinds of indicators of feature extraction methods and proposed method. The performance are as follows, the KPCA+ LDA on different classifiers obtain the higher performance, the accuracy of SVM are 0.94 and 0.99, that of KNN are 0.93 and 0.87, that of NB are 0.93 and 0.96 respectively. we conclude that the classification performance of proposed method on SVM are 0.94,0.99,0.99 and 0.90, respectively, which shows excellence ability in obtaining effective information, Although the PCA can effectively compress the spectral data, it cannot reflect the nonlinear relationship between influencing factors. LDA can be used to reduce the original feature space to one dimension, then the feature space is used as the input of SVM for training. The linear component of LDA feature extraction is 1, then the nonlinear principal component of KPCA and linear principal component of LDA are fused by parallel feature fusion. Although the dimension of the extracted features is not reduced, the effective feature information are extracted from coal and gas outburst. The linear and nonlinear feature information obtained by different feature extraction methods are used as the input of all kinds of classifiers, and the classification indicators are obtained by ten-fold cross-validation, so the KPCA-LDA feature extraction can obtain highest performance and it is very suitable for the following classifier.
Comparison of combined features using KNN
Comparison of combined features using KNN
Comparison of combined features using NB
It can be seen from the Tables 5–7 that the accuracy of the evaluation results obtained by the combined weighting method are higher than that of single methods, the highest classification accuracy is 0.95 of GBDT-GRA and GBDT-XGBOOST on SVM, and the highest accuracy of other classifier are 0.91 and 0.80,respectively, the accuracy of GBDT-XGBOOST is similar with GBDT-GRA on different classifiers, among them, we also find out that the accuracy of GBDT and XGBOOST on KNN are similar with the above combination weighting methods, this is because KNN classifier is affected by the subjective weighted input sample, the effect of other classifiers are not dominant when the input features are weighted.
The GBDT-GRA feature weighting and fusion method is feasible and effective. The reason is that the importance of different influencing factors are not the same, the EW method is used to determine the objective weight of each evaluation index, which overcomes the shortcomings of index equal weight and expert assignment in the original grey correlation, but the entropy weight method is more sensitive to the index difference degree; GRA weighting method can use all the information of each index, GBDT weighting method can contribute to the importance of different features. Based on GBDT-GRA method combining with subjective and objective significance are obtained, which avoids the problem of human factors caused. In this paper, it can continuously adjust the parameters of the membership function combined with the actual data, which makes the algorithm results more discriminative and accurate in efficiency evaluation, and has certain practicability, further verify the weighting importance of obtained linear features and nonlinear features. Therefore, we choose ours to weight obtained linear and nonlinear feature components, and give optimal proportions to for new input features, improving the classification accuracy.
Feature weighting using SVM
Feature weighting using SVM
Feature weighting using KNN
Feature weighting using NB
Next, SVM, RF, DT and NB classifiers for experimental comparison. Table 8 shows that the prediction accuracy of this model with different classifiers, and the accuracy are 0.95, 0.93, 0.90,0.89, 0.93 respectively; From the above comparison, we can see that the classification effect of ours are higher than those of other classifiers, the effect of SVM are the second, and the effect of RF and DT are very close. Through the optimization of BO algorithm, the optimal parameter combination of SVM can be found in a short time, and the classification performance are further improved. Compared with the classical SVM, RF is an integration model, but the time complexity is very high, which cannot effectively eliminate noise; Experiment results conclude that the performance of ours are better than other traditional algorithms in accuracy and running time, so it is the most suitable algorithm among all classifier algorithms
Performance of different classification algorithms
Performance of different classification algorithms
Next we verified the importance of every stages through the related experiments. Through the simulation results in Table 9, we can see that the SVM is 0.89 without feature preprocessing, which is the lowest, it fully shows that there exit redundant and irrelevant information in the original feature components, which leads to the low classification accuracy; After feature extraction is made, the classification accuracy can obtain 0.92, which shows that there exit many components information in the original features. The acquisition of these information greatly improves the accuracy of the classifier and fully proves the correctness of feature extraction. At the same time, after GBDT-GRA feature weighting and fusion are performed, the classification accuracy can achieve 0.93. The importance of each feature is different for classification, and the optimal proportion of linear and nonlinear components in feature extraction is determined by combining subjective and objective weighting method. Finally, the classification accuracy of 0.95 is obtained on BO-SVM, BO algorithm can find a set of parameters after less iteration in a short time. Therefore, it is reasonable to choose BO to optimize the relevant parameters of SVM, so our proposed model has higher performance and is very suitable for the prediction of coal and gas outburst. In the test, where KPCA-LDA+GBDT-GRA is applied, the highest obtained accuracy is 0.95 with BO-SVM classifier. So it can conclude that KPCA-LDA+GBDT-GRA can correctly extract and weight significant attributes since the extracted and weighted attributes can perform well in terms of classification performances, and BO-SVM classifier can outperform other classifier models in the outburst accuracy.
Performance comparison of different stages
Performance comparison of different stages
It can be seen from the analysis of the data in Table 13 that there is no data enhancement, the classification accuracy and precision of the model are 92% and 90%. Before data enhancement, it indicates that the model has over-fitting. Although in design of the neural network uses a method to prevent over-fitting. However, it cannot make up for the lack of data used in this article According to the enhancement method without changing the data characteristics, training sample data are added to reduce the error rate of classification performance. The fitting phenomenon is significantly improved, and the accuracy and precision can obtain 95% and 93%, respectively.
We also compared ours with prediction models mentioned in the related outburst literatures on this dataset. From Table 11, we can conclude that the accuracy, specificity and sensitivity of the model are higher than that of other models in the literatures, and the best prediction results are obtained. Through comparative experiments, it is further proved that the extracted features using proposed method contribute to the good classification performance. We also know that the proposed feature extraction and weighting methods spend much time, because the complexity of the feature extraction and weighting methods are high. But the proposed feature measurement, feature extraction, feature fusion and BO-SVM classifier are effectively combined, so it is more suitable for predicting coal and gas outburst. However, with good hardware configuration, it can speed up and meet the requirements of real-time classification of coal and gas outburst. At the same time, we are also trying to improve the classification efficiency, and we will propose better solving method to improve the efficiency of coal and gas outbursts prediction.
Performance comparison of data enhanced
Performance comparison of data enhanced
Performance comparison with literatures
If the feature dimension of the coal and gas outburst data set is m, the number of samples is n, the depth of the GBDT decision tree is k, and the calculation complexity depends on the sum of the feature measures used to calculate the feature correlation, feature extraction and feature weighting. The computational complexity of feature measurement is O (PCC) + O (SU) = O (m * n) + O (n2m2), the computational complexity of feature extraction algorithm is O (KPCA) + O (LDA) = O (m2) + O (m3 + n * m2), the computational complexity of feature weighting is O (GRA) + O (GBDT) = O (m * n) + O (nlogn * m * k), and the final time complexity is O(proposed model) = O(feature measurement)+O(feature extraction)+O (feature weighting).
At the same time, we calculated the calculation time of each stage of the proposed model. Figure 4 and Figure 5 shows the time consumed in seconds in different stages of the proposed model on the dataset. The calculation time of feature correlation measurement, feature extraction and feature weighting in the model is 0.146 s, 1.93 s and 2 s respectively, and the total calculation time is about 4 s. Due to the high computational complexity of most feature extraction and weighting methods, feature fusion methods take a long time. Compared with most feature fusion methods in the literature, the feature fusion method proposed in this chapter has a slightly longer running time, because in the process of feature extraction, linear and nonlinear features need to be extracted. In the process of feature weighting, the combination weighting method combining GRA and GBDT is used. The classification time of the algorithm is closely related to the number of extracted features and the weighting time, and the more features and the more time it takes to weigh, the more pairs it takes. Although their real-time performance is slightly deficient, the hardware implementation can basically meet the real-time requirements, and can still be applied to the classification of coal and gas outburst.
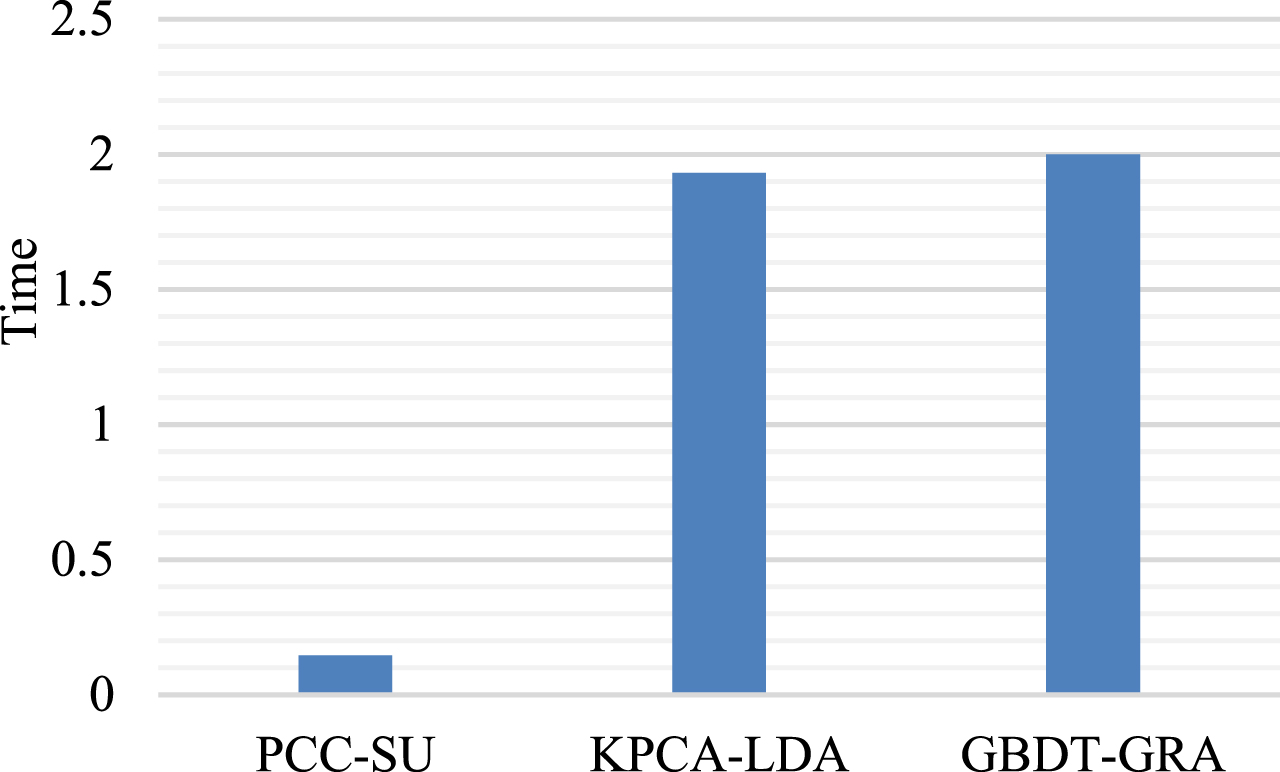
Computation time of the proposed model.
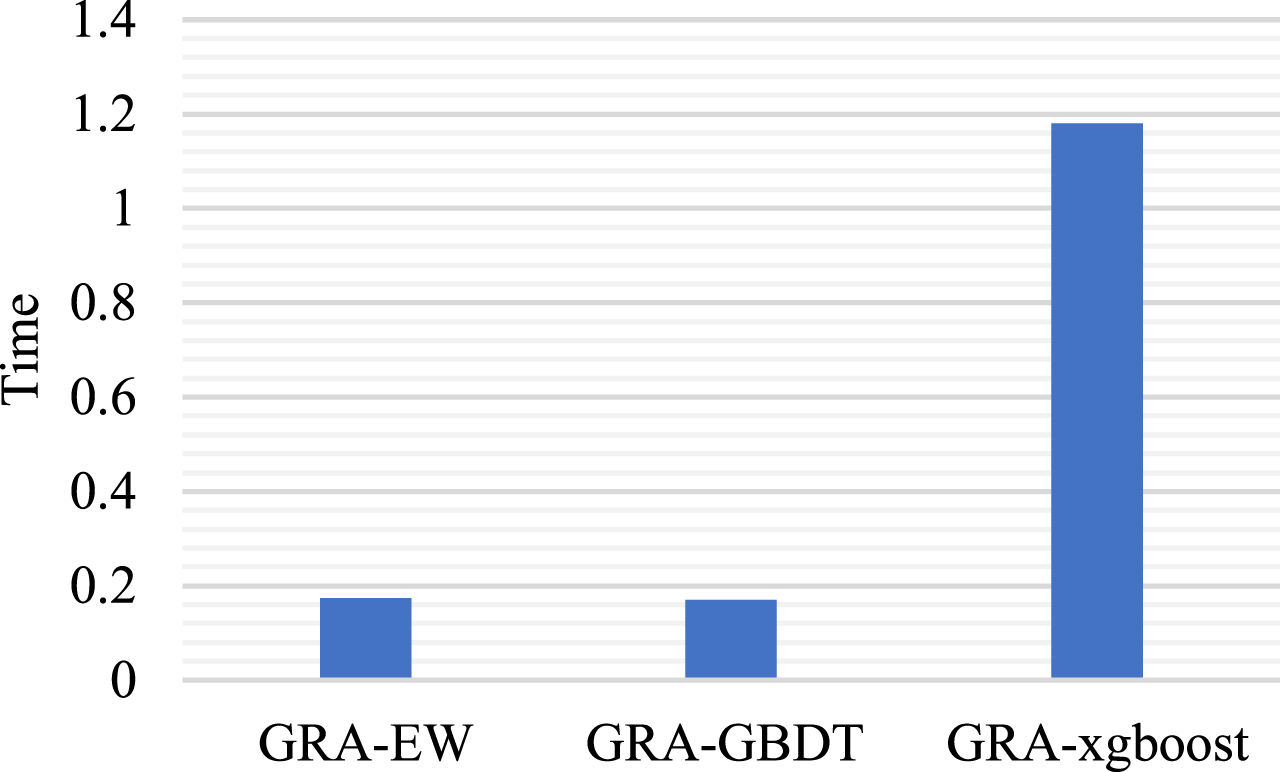
Efficiency performance of different weighting models.
A model using multi-feature extraction, feature weighting and fusion, optimized classification algorithm is proposed in this paper. First, PCC-SU is employed to perform the feature measurement for outburst, and we can find out that there exit linear and non-linear feature information. Second, the effective features of outburst influencing factors are extracted by KPCA-LDA, so the global nonlinear information and local linear discriminant information in the features are obtained, and the extracted information are complete and have strong expression ability for outburst, so as to obtain the classification effect with high accuracy and strong robustness. Third, a feature weighting method of GBDT-GRA is proposed, the weighting results can reflect both subjective information and objective information, improve the importance of different components information in features and contribute to the higher accuracy. Finally, through the combination of BO optimization algorithm, the SVM classifier obtains the optimal kernel function parameters, which can obtain higher and more robust classification performance. Through the comparative analysis with other feature extraction methods on the dataset demonstrates that the model proposed has higher prediction effect and execution efficiency compared with the other models.
However, this method also has some shortcomings. For example, it takes a lot of time to calculate GBDT-GRA, so it need improvement greatly in efficiency. In the future, we will screen out the most discriminating features and improve the prediction effect, it is necessary to develop a new combination feature and classification algorithm. During the process of constructing combination features, the algorithm should fully consider the complexity of combination features and the classification performance of the classifier, so as to obtain effective and robust classification performance.
Footnotes
Ethical approval
Not applicable
Competing interests
The authors declare no competing financial interest.
Authors’ contributions
Hongqiang Hu, Ce Zhai, Xuning Liu, Jiu Feng, Genshan Zhang wrote the main manuscript text and Jiu feng prepared figures. Genshan Zhang prepared data; Yunxia Chu also did some experiments in revision stage. Hongqiang Hu and Xuning Liu did all experiments. All authors reviewed the manuscript.
Funding
This research was supported by the Hebei Key Laboratory of IOT blockchain integration.
Availability of data and materials
Some or all data, models, or code generated or used during the study are available from the corresponding author by request.