
Abstract
Intrusion detection plays a very important role in the field of network security. In order to improve the intrusion detection rate, intrusion detection algorithms based traditional machine learning are widely used in this field. These methods generally satisfy the following two assumptions: the training and the testing data must be under the condition of the independent and identical distribution; the training samples are sufficient. However, in practice, the above assumptions are difficult to satisfy, which will result in poor intrusion detection. This paper proposes an intrusion detection algorithm based on active transfer learning ACTrAdaBoost. ACTrAdaBoost takes advantage of transfer learning and need not to satisfy the two assumptions of the traditional machine learning. In addition, ACTrAdaBoost utilizes active learning and maximum mean discrepancy knowledge to obtain maximum knowledge with minimum training sample cost and solve the problem of negative transfer. The ACTrAdaBoost compared with the traditional machine learning method on the KDDCUP99, DARPA1998 and ISCX2012 datasets. The experimental results show that the intrusion detection rate of the ACTrAdaBoost algorithm is greater than benchmark algorithms, and the training time efficiency improves at the same time. The performance of ACTrAdaBoost is better than the traditional machine learning classification algorithm. The ACTrAdaBoost algorithm improves the accuracy of intrusion detection and provides a new research method for intrusion detection.
Introduction
With the rapid development of network, it plays an increasingly important role in national life and people’s daily activities. Therefore, the importance of network security technology has become prominent. Nowadays, network security is facing more and more challenges such as viruses, system vulnerabilities and hacker attacks. Therefore, how to identify various network attacks is an important technology to protect network security. Intrusion detection is one of the core technologies in network security. It can detect malicious attacks that are happening or have happened in time [1, 2, 3]. Intrusion detection system with intrusion detection technology as the core is an active system of network security defense. It not only remedies the deficiencies of firewall, but also can effectively detect attacks and propose corresponding defense measures. However, the traditional intrusion detection system has many problems, such as false positive rate and false negative rate. It can only detect the existing attacks, but it is more and more difficult to detect new attacks and massive attacks.
In recent years, the intrusion detection method based on machine learning algorithm makes it possible to detect network attacks intelligently with the rising of machine learning. Compared with traditional intrusion detection methods, on the one hand, it improves the efficiency of intrusion detection, on the other hand, it reduces the false positive rate and false negative rate [2]. Therefore, the emergence of machine learning has pointed out a new direction for the development of intrusion detection technology [5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]. At present, the commonly used machine learning algorithms have applied in intrusion detection, such as common decision tree algorithm, neural network algorithm, support vector machine, Bayesian classification and K-means clustering algorithm. Yin et al. [1] proposed a deep learning model RNN-IDS of intrusion detection based on recurrent neural network. The experimental results show that RNN-IDS model improves the accuracy of intrusion detection and provides a new research method for intrusion detection. Quamar et al. [5] designed an effective and flexible intrusion detection system with STL, a self-learning technology based on deep learning, the experimental results show that the performance of the system is better than that of the previous system on NSL-KDD dataset. Yan et al. [6] constructed an optimization model with degenerate solutions by introducing smoothing functions to construct smooth unconditional optimization problems on the base of transductive support vector machine, and applied this model to generate a new method of network intrusion detection. Tiwari et al. [7] proposed a new method of the network intrusion detection with neural networks, rough set and the scheme of firefly intrusion detection. Pichara et al. [8] proposed a new semi-supervised algorithm, which detects relevant anomalies through active learning and expert interaction to obtain semantic information about user preferences. Makanju et al. [9] utilized genetic programming technology to apply classifiers and artificial neural networks to denial-of-service attacks. In addition, [10, 11, 12, 13, 14, 15] put forward many intrusion detection models based on machine learning algorithms. These algorithms greatly promote the wide application of machine learning in intrusion detection.
At present, although traditional machine learning is widely used in intrusion detection, most of them regard several different kinds of attacks as one attack without specific distinction, and adopt a single detection algorithm to detect them. This may lead to the detection success rate of each attack out of balance. For example, the classifier trained by one machine learning algorithm has a high detection rate for one type of attack, while the other one type of attack is difficult to detect, especially for the type of attack with few samples. In general, the classifier will omit these samples. In addition, traditional machine learning algorithms usually need to satisfy the following two assumptions: (1) training and testing samples satisfy the conditions of independent and identical distribution; (2) a large number of training samples are necessary to learn a good learning model. However, in practical applications, the distribution of testing and training data is difficult to achieve consistency, and some sample resources are very scarce. For example, data classification in biology often requires a large number of long-term and expensive experiments to label training samples. In the field of text classification, people find that the existing training samples are far from enough to establish a reliable classification model, and the experts need label abundant documents, which need high salaries resulting in a high cost of obtaining labeled training samples. In short, on the one hand, people need a large number of training samples to build a classification model with high accuracy; on the other hand, it is almost impossible to obtain a number of the training samples in many practical applications. In order to solve the problem of sample scarcity, researchers have proposed the transfer learning method, which is a new machine learning method for solving related domain problems by applying existing knowledge. Transfer learning relaxes two basic assumptions in traditional machine learning. Its purpose is to utilize existing knowledge to solve problems in which there are only a few samples in the target domain or even there is no learning [20, 21, 22, 23]. Transfer learning represents the future development direction of machine learning for intrusion detection. Compared with other machine algorithms, it can save the cost of data collection by using the existing knowledge in the source domain. The distribution of training and testing data can be different. Besides, it can effectively solve the problem of sparse samples of attack and unbalanced detection. Therefore, transfer learning has great advantages over traditional machine learning algorithms.
Differences between transfer learning and traditional machine learning process (a) the traditional machine learning process (b) the learning process of transfer learning.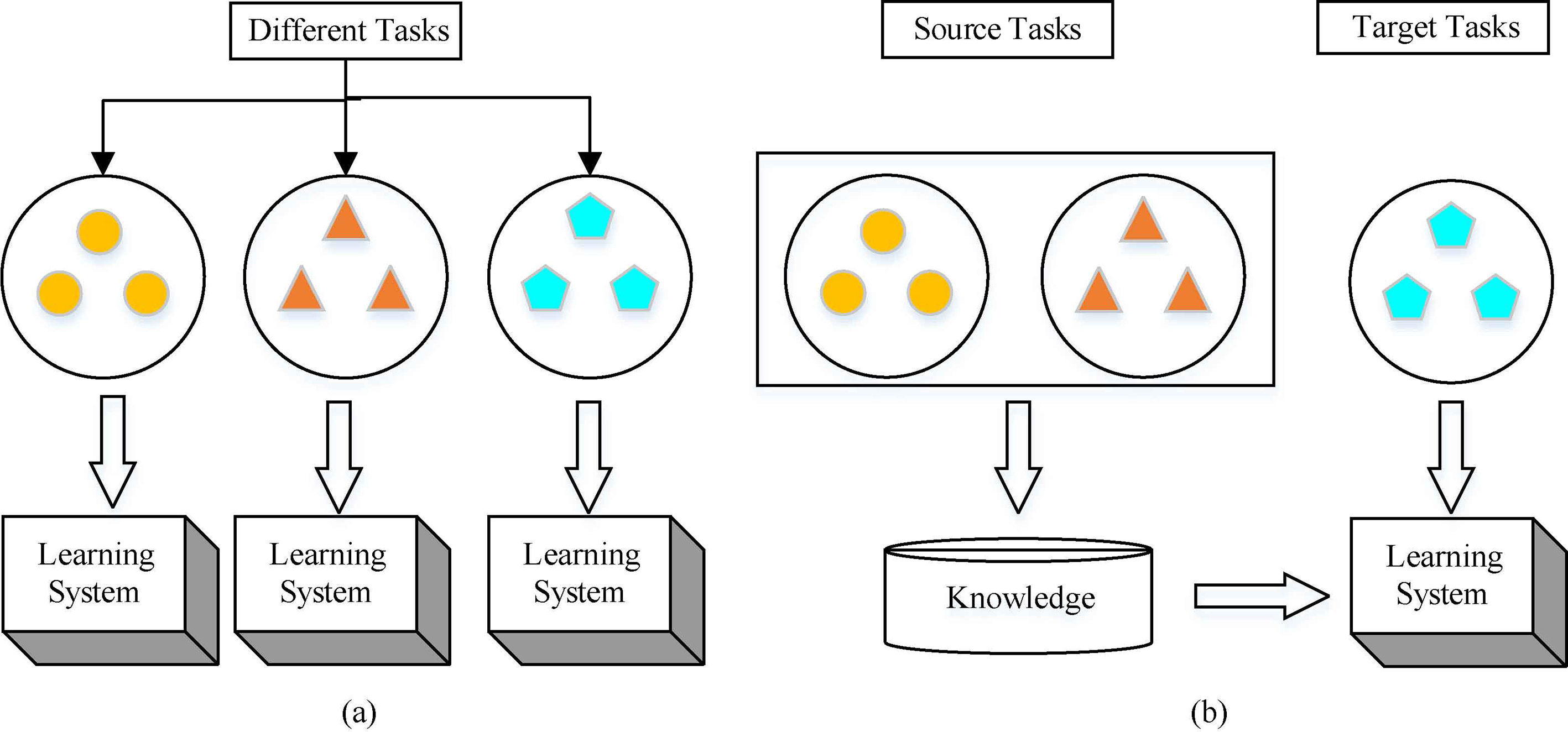
Figure 1 shows the differences of the learning processes between traditional learning and transfer learning techniques. It shows that traditional machine learning technology tries to learn every task from the starting, while the technology of transfer learning tries to transfer knowledge from some previous tasks to target tasks, and the latter has fewer high-quality training data. Therefore, in transfer learning task, not only the knowledge in the current domain (Target domain) are necessary, but also the knowledge in the source domain (Source domain) are required to assist the learning task in the current domain. As a strategy to solve the lack of training samples, transfer learning has the following problems, which make it difficult to popularize and apply. Firstly, the training dataset in the source domain is large, and the cost of labeling samples task is still great; secondly, when the data in the target and source domain are very different, transferring knowledge may greatly reduce the learning effect and easily lead to the phenomenon of ‘negative transfer’.
In this paper, based on the advantages of transfer learning and active learning, combined with the knowledge of maximum mean discrepancy, an active transfer learning algorithm – ACTrAdaBoost is proposed for intrusion detection. ACTrAdaBoost utilizes the maximum mean discrepancy to measure the difference of samples between the source and the target domain, and selects the samples in source domain with the more similarity with the samples in target domain to form the new source domain. On this basis, further active learning labeling the training samples, the purpose is to try to select the data in the source domain with large amount of information as the training data, and a high accuracy classification model is established with the least training samples. Compared with the semi-supervised learning method [35], they all can solve the problem of sample sparsity. However, the semi-supervised learning method is to add a large number of unlabeled training samples to a small number of labeled training samples for training to improve learning performance. It requires that both labeled and unlabeled samples must come from the same domain; in addition, the training and test samples must satisfy the same assumptions as traditional machine learning methods. Unlike the semi-supervised learning method, in order to improve the learning effect of the target domain, ACTrAdaBoost uses a large number of source domain samples to assist the learning task of target domain, that is, to solve the target domain based on the existing knowledge of the source domain. The learning problem of the sample [22] does not require learning from scratch every time, nor does it require that the training samples and the test samples must satisfy the same assumptions.
The rest of the paper is organized as follows. Section 2 introduces related works, including maximum mean discrepancy, active learning and TrAdaBoost algorithm. In Section 3, we present our algorithm and detail the construction process of framework based on active learning and transfer learning. In the Section 4, we analyze experimental results. The Section 5 summarizes the main works in this paper.
Maxinum discrepancy
Most of transfer learning algorithms assume that the samples in the source domain are available when constructing the learning model, that is to say, all the samples in the source domain have correlation with the target domain, but in fact, this is not the case. If all the knowledge of samples in the source domain are transferred into the target domain, negative transfer often occurs, resulting in poor learning effect in target domain. In order to avoid the negative transfer and better assist the learning task in the target domain, it is particularly important to select the samples with high similarity with the samples of the target domain from source domain. Maximum mean discrepancy (MMD) is an effective method to measure the distance between different distributions [24]. Its idea is to project and sum each sample, and use the sum to express the distribution difference between the data under two distributions.
Given a source domain
The definition of the measurement method of selective maximum mean discrepancy is as follows:
In Eq. (2), the correlation between the
In Eq. (3), the first term of the right is the constants, which is omitted, and only the last two terms need to be minimized. Therefore, the following Eq. (4) is as follows:
By simplifying Eq. (4), the objective function is as follows:
In Eq. (2.1),
It can be concluded that the objective Eq. (2.1) is a standard quadratic programming problem, so quadratic programming solver can be used to solve it. Maximum discrepancy measurement method can easily solve sample dataset with high similarity in source domain with the target domain. Transferring knowledge of these samples in the source domain can effectively avoid the occurrence of negative transfer in transfer learning.
When supervised learning method constructs a classifier, it usually needs a large number of labeled training samples. In theory, the more labeled training samples, the higher the quality of labeled the training samples, the better the learning effect is. However, in the practical applications of machine learning, the most time-consuming and expensive task is to obtain labeled training samples, and because of human subjective factors, it is easy to make mistakes [16]. Faced with this situation, traditional supervised learning methods are difficult to construct classifiers with high accuracy. Active learning method can effectively solve the problem. In active learning method, we can independently select unlabeled samples with large amount of information to label by experts, and then add the labeled samples to the training dataset. Thus, we can get a higher classification accuracy and effectively reduce the cost of building a classifier when the training set is relatively small [17].
The model of active learning is as follows:
In the model
Execution process of the active learning.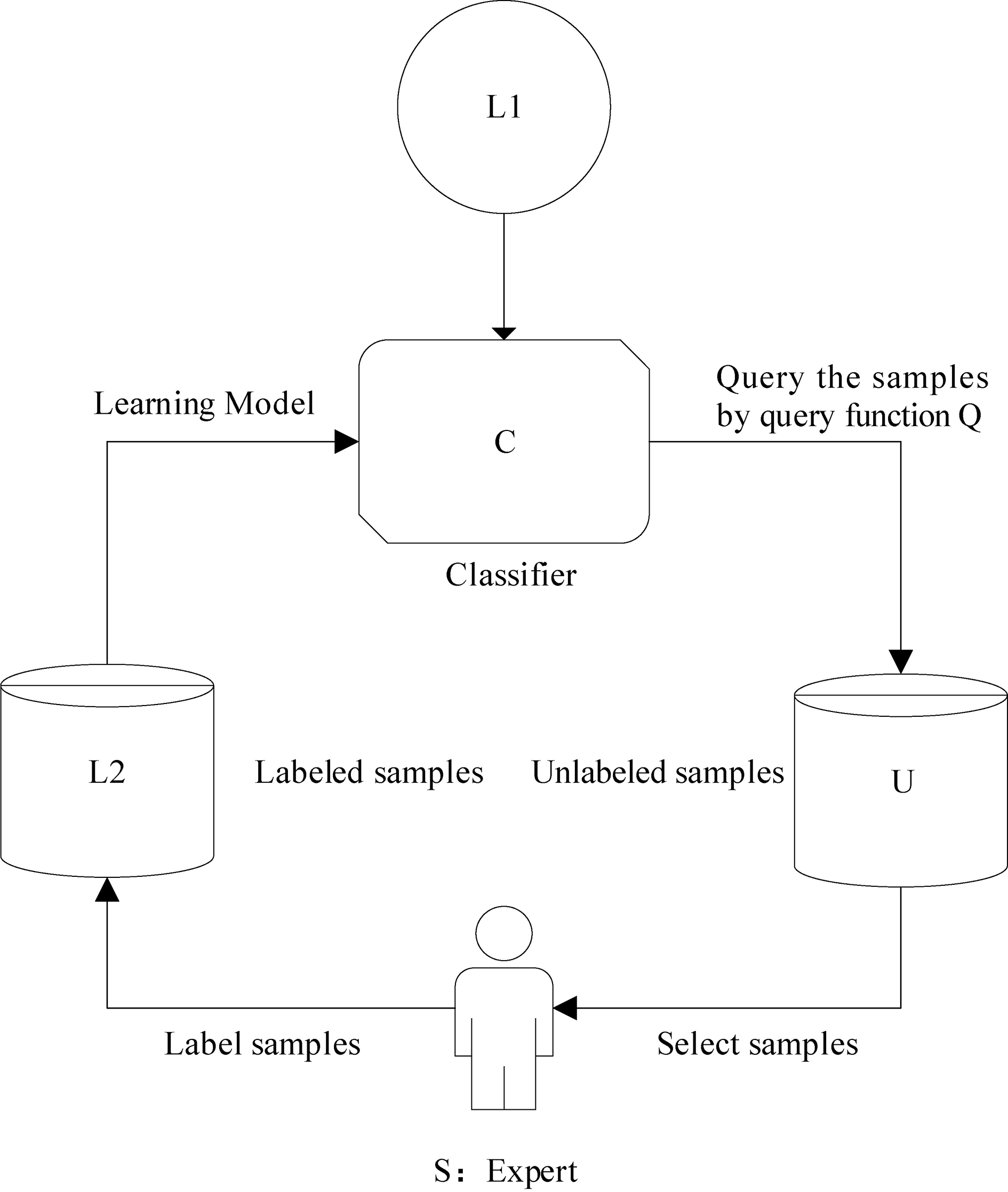
Figure 2 is a schematic diagram of the active learning execution process. The diagram shows that the process is cyclic iteration. Firstly, the algorithm randomly selects a small number of samples from unlabeled samples
The purpose of active learning is obtaining and labeling the samples from a large number of unlabeled samples, and then add labeled samples to the training set, so as to effectively reduce the size of the training set and greatly reduce the complexity of learning model construction. Compared with the traditional supervised learning method, it can deal with large-scale training set well, selects high-quality samples, decreases the scale of training set, and reduces the cost of labeling samples manually. Active learning has proved to be very effective in machine learning [18] combined low-level transformation (LRT) with active learning based on SVM. The appropriateness of active learning labeling data improves the performance of LRT and further improves the accuracy of SVM classifier [19] proposed an active learning technology using clustering hypothesis batch processing model. Similarly, active learning can be applied to transfer learning to improve the classification effect. In transfer learning, a large number of unlabeled samples are required as auxiliary data. Active learning is applied to the screening out auxiliary data, the large amounts of information samples can be obtained as training set, which will greatly reduce the number of training samples in transfer learning, thus reducing the scale of training set and assisting in improving the training efficiency of transfer learning.
Training process of TrAdaBoost algorithm
Training process of TrAdaBoost algorithm
TrAdaBoost algorithm is a weight-based transfer learning method proposed by Dai in 2007. The core of this algorithm is to use Boosting technology to select samples with the smallest difference between the samples in source domain and in target domain [26]. In TrAdaBoost, Boosting establishes an automatic weight adjustment mechanism. The more similar the samples in the source domain with the target domain, the larger the weight of samples; otherwise, the weight will decrease. In the algorithm, in order to ensure the accuracy of classification model in source domain, AdaBoost is used for training in target domain; at the same time,
In TrAdaBoost, in each iteration, if the sample in the source domain is misclassified, it contradicts the samples in target domain. In the next iteration, we reduce the weight of this sample, so the misclassified training sample will have a smaller impact on the classification model than the previous round iteration. After many iterations, the samples in the source domain that are similar to the samples of target domain will have a higher weight, but weight of those samples that do not meet will decrease. Eligible the samples in source domain will help learning task training in the target domain to get a better classification model. In extreme cases, the samples in source domain are completely ignored, and TrAdaBoost degenerates into the traditional AdaBoost algorithm. Therefore, the TrAdaBoost algorithm can be seen as an extension of the AdaBoost. [27] proposed a multi-source domain version of the TrAdaBoost algorithm, which greatly reduced the impact of negative transfer and effectively improved the classification effect.
Basic ideology of ACTrAdaBoost
This paper proposes an active transfer learning algorithm ACTrAdaBoost based on transfer learning TrAdaBoost. ACTrAdaBoost is formally described as
On the one hand, active learning in ACTrAdaBoost algorithm reduces the scale of available source domains, while MMD method can filter out samples with less similarity to target domains. On the other hand, it is helpful to solve the problem of negative transfer. In addition, the transfer function of TrAdaBoost algorithm itself can give different weights to the samples labeled in the training samples again, and further screen out the samples in the source domain that conform to the target domain for knowledge transfer. ACTrAdaBoost uses active learning and MMD to reduce the scale of samples in the source domain. The selected samples have a high similarity with the samples in the target domain, which is conducive to solving the negative transfer in transfer learning. Therefore, ACTrAdaBoost not only improves the training efficiency, but also more effectively inhibits the occurrence of negative transfer.
Set Set Training dataset Function
At this point, the problem of transfer learning can be defined as follows: given a small intrusion detection dataset
The input and output of the problem are as follows:
Framework of the ACTrAdaBoost.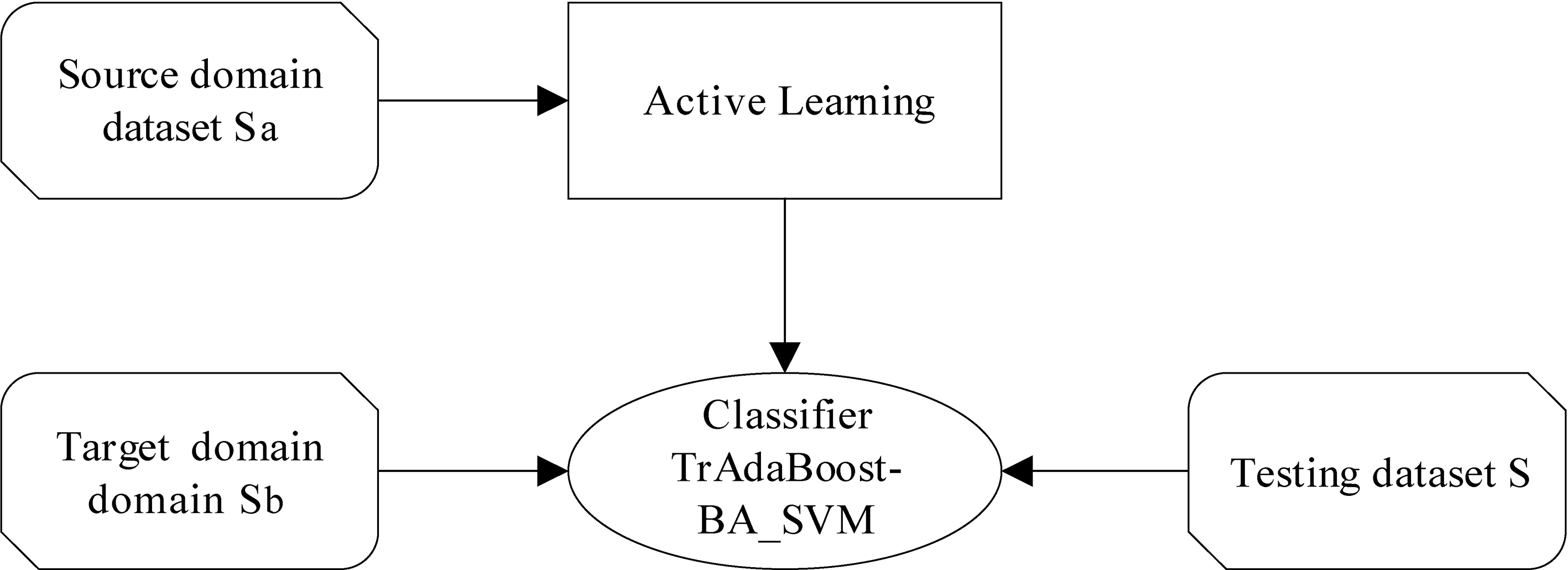
The framework of ACTrAdaBoost algorithm is shown in Fig. 3, and the detailed training process is shown in Table 2.
Training process of ACTrAdaBoost algorithm
Training process of ACTrAdaBoost algorithm
In this section, we analyze and verify the effectiveness of ACTrAdaBoost algorithm. EvaluatingACTrAdaBoost on intrusion datasets, the results show that ACTrAdaBoost can assist current intrusion detection learning tasks by transfer knowledge from existing intrusion detection datasets, and improves detection rate and time efficiency. The following contents will describe the experimental settings and the analysis of the experimental results in detail.
Experimental environment and evaluation criteria
In order to verify the effectiveness of ACTrAdaBoost algorithm in intrusion detection, it is validated on KDD CUP99, DARPA 1998 and ISCX2012 dataset. The experimental environment is configured as follows: Intel Core (TM), 3.6 GHz, 8 GB, Windows 10 operating system. The benchmark algorithms used in the experiment are: SVM, SVMt [29] and TrAdaBoost [26], in which SVM is implemented with LIBSVM [30] toolkit and the average of the all experimental results repeated 10 times are used as the final comparison results.
The detection rate, false positive rate and false negative rate of each algorithm in all attack types are as evaluation criteria [1, 5]. The detection rate reflects the proportion of the number of attacks detected by the intrusion detection system to the total number of attacks, indicating the accuracy of intrusion detection. The false positive rate reflects the proportion of the number of intrusion detection systems that incorrectly detect normal behavior as attack behavior to the total number of normal behavior. The false negative rate reflects the number of intrusion detection systems that incorrectly detect attack behavior as normal behavior to the total number of attacks. The definitions of detection rate, false positive rate and false negative rate are as follows:
Intrusion detection dataset
KDD CUP99
KDD CUP99 is a widely used dataset for intrusion detection provided by Lincoln Laboratory of Massachusetts Institute of Technology [31]. The number of dataset is 5*106, each of which has 41 feature attributes and a class identifier. There are about 38 types of attack, 21 of which appear in the training dataset, and 17 unknown attack types only appear in the testing dataset. The purpose of this design is to test the generalization ability of the classifier model. The ability to detect unknown attack types is also one of the important indicators to evaluate the application effect of classifiers in intrusion detection.
So far, researchers have used 10% KDDCUP99 dataset (including training and testing dataset), which is a sample set of 10% of all KDDCUP99 datasets. The 10% KDDCUP99 dataset is used in paper, which contains one normal type, four major network attack types, DOS, Probing, U2R and R2L. In testing and training of 10% KDDCUP dataset, the number of attack in the four types of network attacks is different. Table 3 lists 22 kinds of attack type in the training dataset, 39 kinds of attack type in the testing dataset, and the normal type is as an attack type in the table.
10% KDDCUP99 intrusion detection dataset
10% KDDCUP99 intrusion detection dataset
Distribution of attack types in 10% KDDCUP99 dataset
In order to enable intrusion detection algorithm to recognize new attacks by learning the training dataset, the testing dataset in Table 3 contains more new attacks than the training dataset. In Table 4, the content in parentheses is the proportion of the attack type to the dataset. The proportion of Normal in two datasets is basically the same, but the proportion of the other four types of attacks is obviously different. Because the proportion of U2R and R2L is very small, most of the existing detection algorithms are difficult to detect these two types of attacks.
Both 10% KDD CUP99 datasets with the same record format are stored in text format. In addition, the only difference between the testing dataset and the training dataset is that there is no last attack type. The following two join record formats are listed, in which each feature is separated by commas. The first 41 features of each record represent the attributes of the data, the last one represents the data identification. The first one represents the normal record Normal, and the second one represents satan, which is one of the denial of service DOS. The first data represents the type of TCP protocol, and the second data represents the type of UDP protocol.
0, tcp, http, SF, 290, 3084, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 0.00, 0.00, 0.00, 0.00, 1.00, 0.00, 0.00, 145, 255, 1.00, 0.00, 0.01, 0.02, 0.00, 0.00, 0.00, 0.00, normal.
0, udp, private, SF, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 4, 0.00, 0.00, 0.00, 0.00, 0.17, 0.12, 0.00, 255, 4, 0.02, 0.22, 1.00, 0.00, 0.00, 0.00, 0.00, 0.00, satan.
Character exists in data records, and there are two types of numerical values in fixed feature attributes: discrete and continuous. On the one hand, machine learning algorithm is good at numerical data. On the other hand, the difference of measurement methods between continuous and discrete affects the calculation results, so it is necessary to pre-process the dataset. Preprocessing operations mainly include converting character type data into numerical type and standardizing continuous feature attributes.
DARPA 1998 is a dataset used by DARPA at the Massachusetts Institute of Technology’s Lincoln Laboratory for intrusion detection [33]. The DARPA1998 dataset contains 7 weeks of training data, 2 weeks of test data, including normal behavior Normal and Probe, DoS, R2L, U2R four types of attacks. See Table 5 below for details.
Distribution of attack types in DARPA dataset
Distribution of attack types in DARPA dataset
In the experiment, 2% data is selected in the training dataset, and all the label information is deleted as the unlabeled training dataset; the same operation is performed on testing dataset, and the obtained dataset is used as the testing dataset.
In 2012, the Information Security Center of Excellence (ISCX) at the University of New Brunswick (UNB) in Canada released an intrusion detection dataset called ISCX2012 [34]. This dataset contains seven days of raw network traffic data, including normal traffic and four types. Some researchers have noticed that the types of attacks considered in KDD99 are now obsolete. In contrast, the ISCX2012 attack types are more modern and closer to reality. See Table 6 for details.
Distribution of attack types in ISCX2012 dataset
Distribution of attack types in ISCX2012 dataset
In the experiment, 2% data is selected in the training dataset, and all the label information is deleted as the unlabeled training dataset; the same operation is performed on testing dataset, and the obtained dataset is used as the testing dataset.
In order to make intrusion detect dataset suitable for machine learning algorithm, it is necessary to convert its character type into numerical type and standardize the continuous feature attributes.
Converting character type to numerical type
For example, in KDD CUP99 three network connection types, 70 network service types, 23 attack types (including normal type) and 11 network connection states of character types in datasets are converted into the numerical types, the results are saved into CSV type files. The transformed forms of 11 the type of network connection shows in Table 7.
Forms of network connection states converted
Forms of network connection states converted
In most the same way, the corresponding values of three network connection types are 0–2, 70 network service types are 0–69, and 23 attack types are 0–22.
ACTrAdaBoost algorithm uses maximum mean discrepancy to select data, and calculates distance during the process. For continuous feature attributes in datasets, the measurement methods of attributes are different. Therefore, the distance between data has a great influence on the accuracy of calculation results. In order to avoid the above situation and eliminate the influence of attribute measurement differences, it is necessary to standardize continuous feature attributes, but not discrete feature attributes. Assuming that there are N connected records, every record contains the vector of 20 continuous attributes is
Equation (8) denotes the average value, and Eq. (9) represents the average absolute deviation. The following judgments need to be made in the above calculation:
After standardization, it is necessary to normalize the values to [0, 1] for the convenience of calculation. Set it to the normalized value.
Detection rate, false alarm rate and false alarm rate of ACTrAdaBoost
The number of five types of attacks on 10% KDDCUP99 and DARPA 1998 dataset is different. The intrusion detection algorithm has high prediction accuracy, low false alarm rate and low false alarm rate for more number of attacks, and vice versa. Classifiers trained by traditional machine learning algorithms are based on sufficient training samples. Therefore, the detection accuracy of attack types such as Normal, Probe and DOS is high, while the detection accuracy of U2R and R2L attack types is low. Traditional machine learning intrusion detection algorithm divides all attack types into an attack type, but does not distinguish each attack. Therefore, it may have higher detection accuracy for one attack type, but lower detection accuracy for other types, so it is difficult to balance the prediction accuracy of all attack types. ACTrAdaBoost can train for each specific attack, and will not regard all attacks as an attack. ACTrAdaBoost transfers the knowledge of a large number of existing intrusion detection samples into the train process of intrusion detection with the sparse samples, which effectively alleviate the low detection rate of U2R and R2L due to fewer samples. Therefore, ACTrAdaBoost can effectively solve the problem of low detection rate of sparse sample attacks, which can make all attack detection rates show considerable effect, and give good consideration to the balance of intrusion detection behavior. Table 8 shows the detection rate, false positive rate and false negative rate of ACTrAdaBoost on intrusion detection datasets.
Detection rate, false positive rate and false negative rate of ACTrAdaBoost on KDD CUP99 and DARPA 1998
Detection rate, false positive rate and false negative rate of ACTrAdaBoost on KDD CUP99 and DARPA 1998
Detection rate, false positive rate and false negative rate of ACTrAdaBoost on ISCX2012
As can be seen from Tables 8 and 9, similar to traditional machine learning algorithms, the detection rate of ACTrAdaBoost algorithm is higher for Normal, DOS and Probe attack types with sufficient training samples, while the detection rate of U2R, R2L and HttpDoS attack types with few samples is relatively low. In terms of false positive rate and false negative rate, for attack types with more training samples, the false positive rate are higher and false negative rate are lower, and vice versa.
In order to better illustrate the application effect of ACTrAdaBoost in intrusion detection, this part compares ACTrAdaBoost with three benchmark algorithms in terms of time cost, detection accuracy, false positive rate and false negative rate.
Time consumption of ACTrAdaBoost on DARP1998 and ISCX2012
Time consumption of ACTrAdaBoost on DARP1998 and ISCX2012
Comparison of detect rate (%), false positive rate (%) and false negative rate (%) of ACTrAdaBoost, TrAdaBoost, SVMt and SVM on DARPA1998 dataset
Comparison of ACTrAdaBoost, TrAdaBoost, SVMt and SVM in time consumption.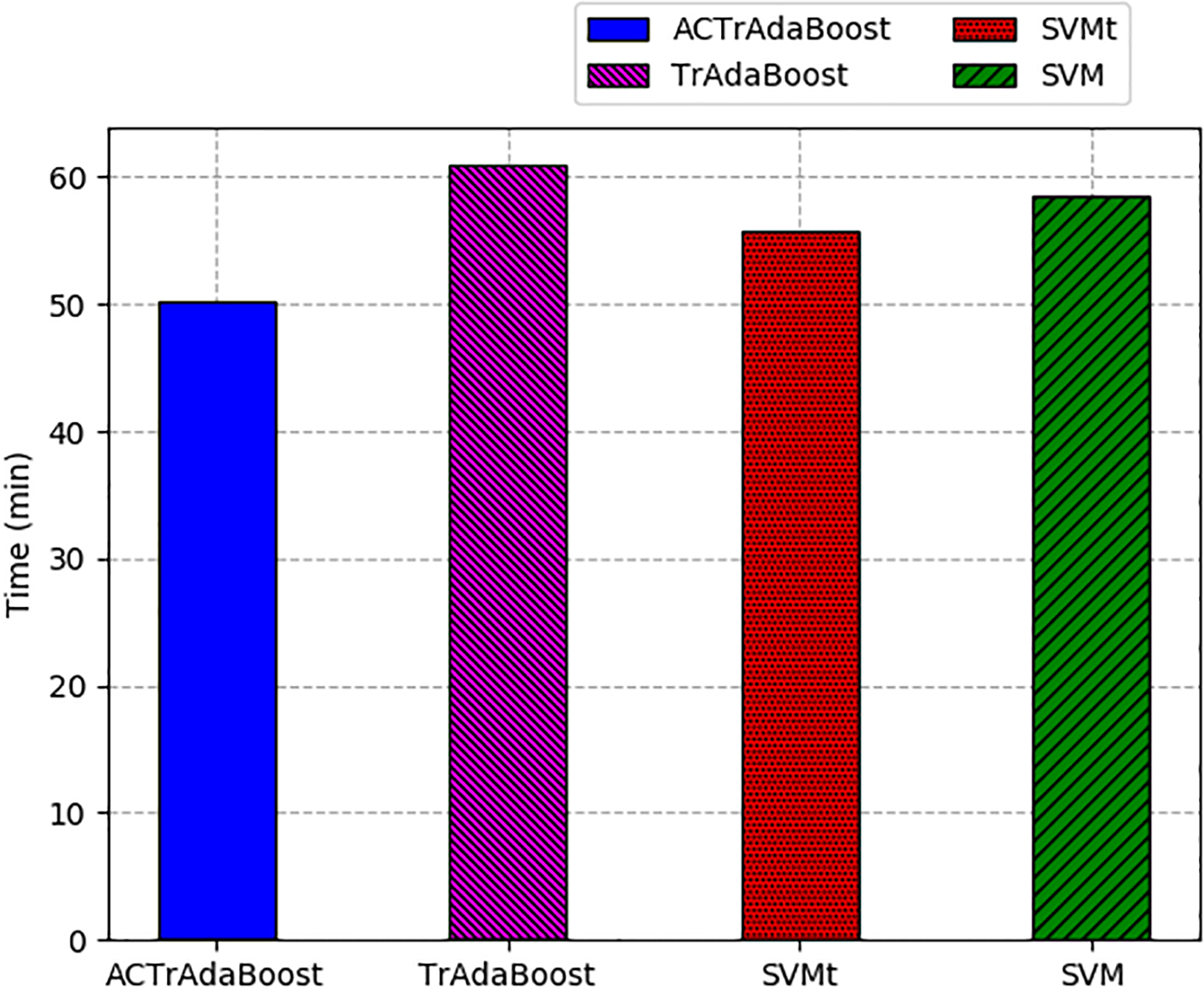
Figure 4 and Table 10 show the training time of ACTrAdaBoost algorithm and three contrast algorithms. We can see that the training time of ACTrAdaBoost algorithm is better than three contrast algorithms. The reason is that ACTrAdaBoost algorithm actively labels large information samples and reduces the size of training samples, so it can reduce the cost of training classifier and the time consumption decreases.
Comparison of detect rate (%), false positive rate (%) and false negative rate (%) of ACTrAdaBoost, TrAdaBoost, SVMt and SVM on ISCX2012 dataset
Comparison of detection rates of ACTrAdaBoost, TrAdaBoost, SVMt and SVM on KDD CUP99 dataset.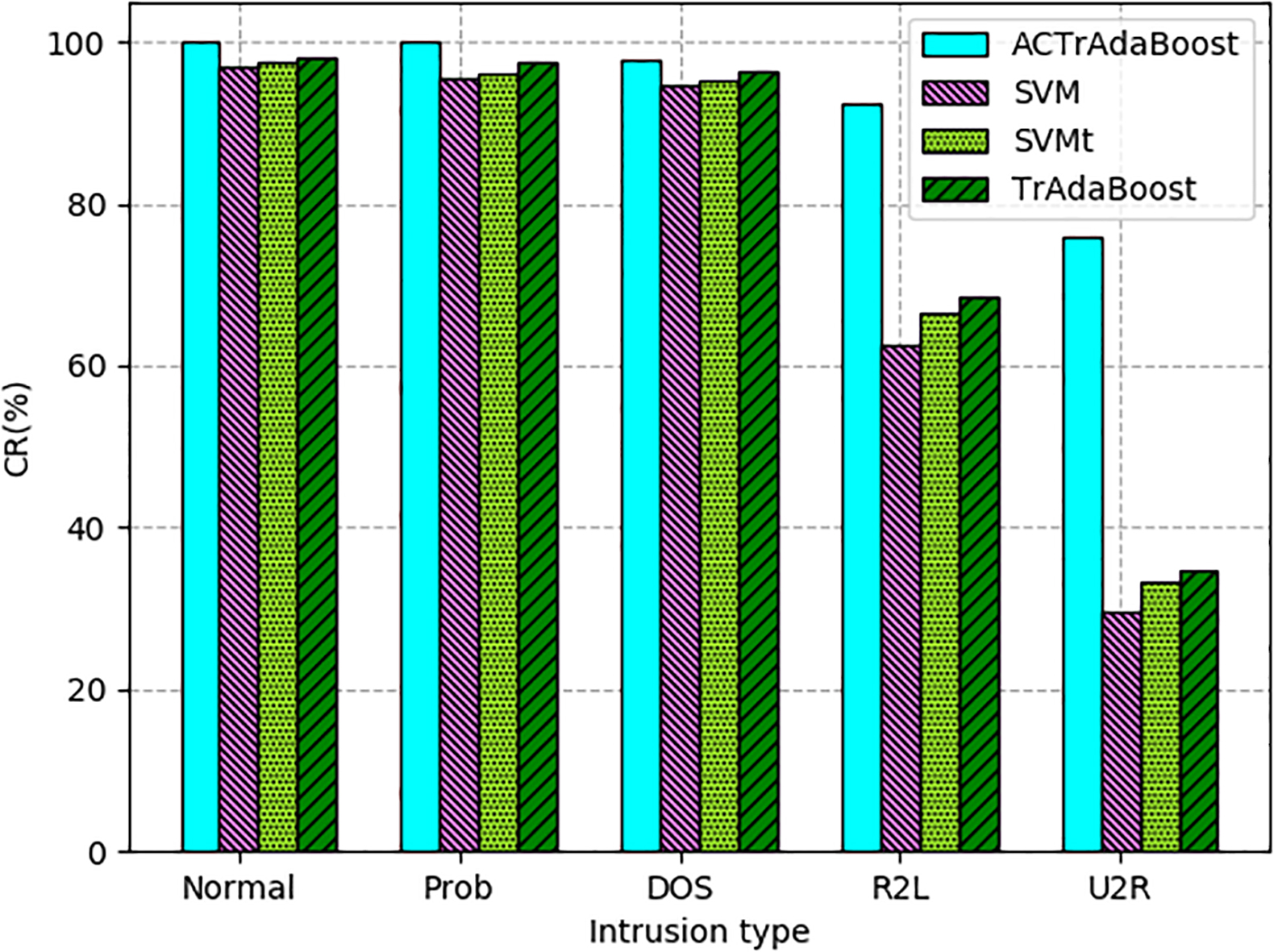
Comparison of false positive rate of ACTrAdaBoost, TrAdaBoost, SVMt and SVM on KDD CUP 99 dataset.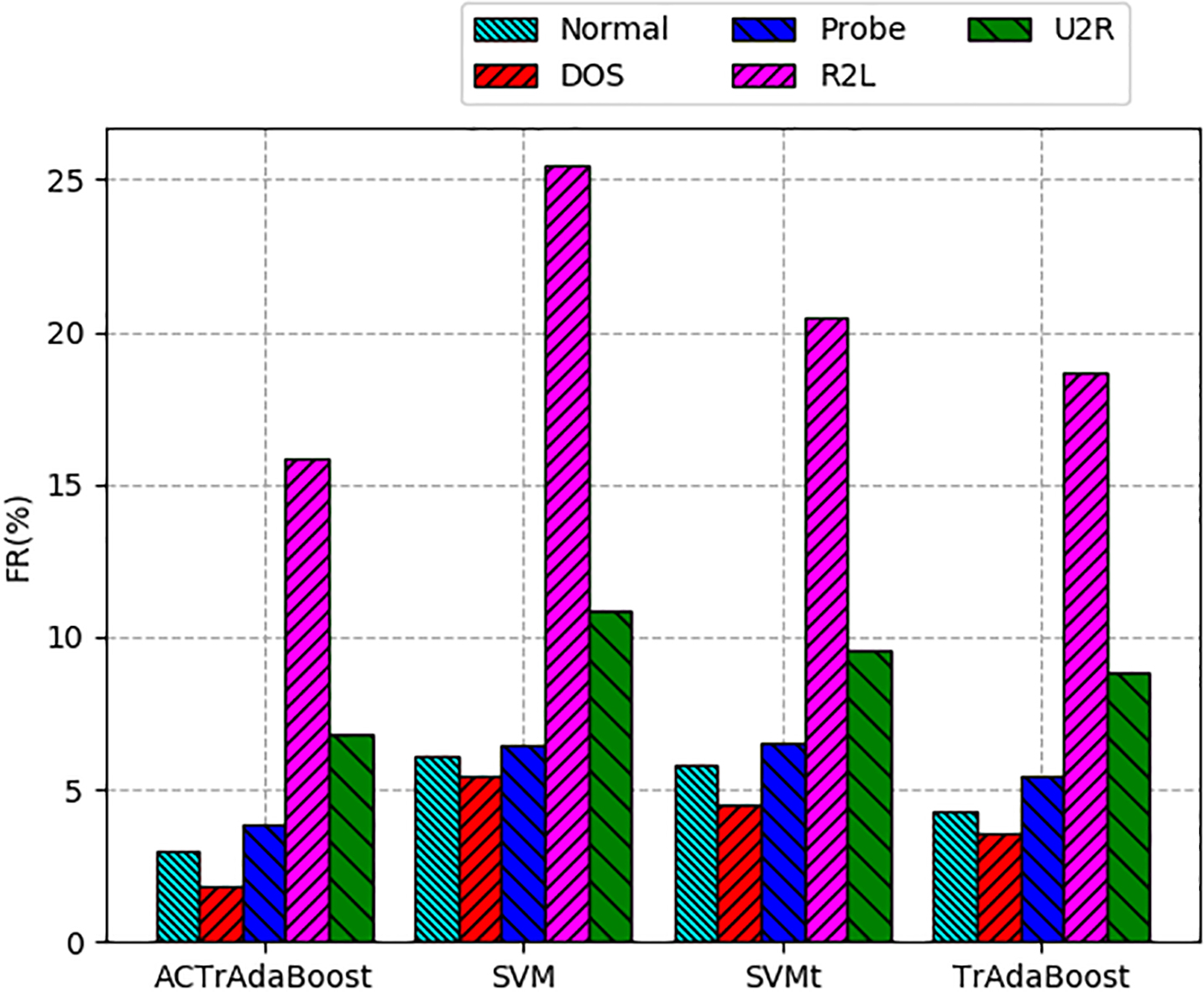
Comparison of false negative rate of ACTrAdaBoost, TrAdaBoost, SVMt and SVM on KDD CUP 99 dataset.
Iteration curve of ACTrAdaBoost, TrAdaBoost.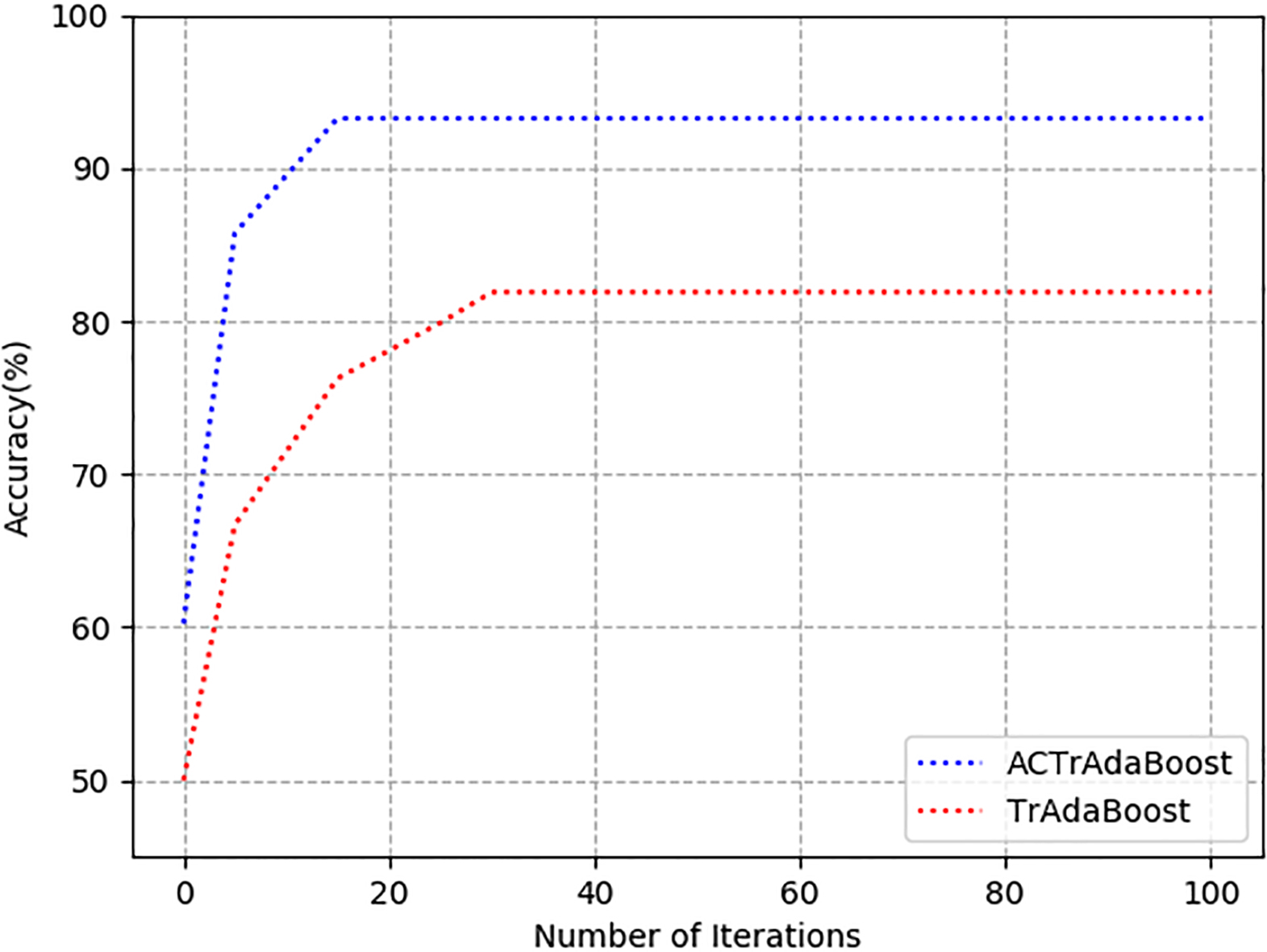
The following conclusions can be drawn from Tables 11 and 12, Figs 5–8:
Adequate training samples are the basis of training machine learning algorithm to get a classifier with high accuracy. Normal, Prob and DOS attack types have a large number, so the detection rate of ACTrAdaBoost and benchmark algorithm for these three types of attacks is very high, reaching more than 97% on DRAPA 1998 and KDD CUP 99 datasets. Similarly, on the ISCX2012 dataset, the detection rate of the larger number of BFSSH, Infiltration, and DDoS attack types reached more than 95%. Compared with benchmark algorithms, ACTrAdaBoost detection rate is higher on DRAPA 1998, KDD CUP 99 and ISCX2012 datasets. Because of the fewer samples of attack types U2R and R2L, the detection rate of traditional intrusion detection algorithms is low. ACTrAdaBoost transfers knowledge from a large number of existing intrusion detection samples, then the knowledge is applied to detect attack types with insufficient samples, so the detection rate of ACTrAdaBoost for U2R and R2L is improved in a certain extent. From Fig. 5, it can be seen that the detection rate of ACTrAdaBoost on U2R and R2L has reached more than 75%, especially the detection rate of R2L has been greatly improved; and the detection rate of U2R has been greatly improved. The detection rate is less than 70%, and the detection rate of R2L is less than 35% on three benchmark algorithms. As can be seen from Table 11, the detection rate of ACrAdaBoost for U2R and R2L is best among algorithms, too. Therefore, ACTrAdaBoost can improve the detection rate of U2R and R2L attack types with a small number of samples. Figure 6 and Table 11 show that the false positive rate of Normal, Probe, and DOS on the KDD CUP99 and DARPA1998 datasets do not exceed 6.5%, and ACTrAdaBoost performs best, which reduces the false positive rate to less than 4%. In the intrusion detection behaviors U2R and R2L, the three benchmark algorithms performed poorly. The false positive rate of U2R and R2L on the KDD CUP 99 and dataset reached 8.5% and 18.5%. It has reached more than 10% on DARPA1998 dataset. However, ACTrAdaBoost performed relatively well below 10% on both datasets. In terms of positive negative rate, as can be seen from Fig. 7, Tables 11 and 12, ACTrAdaBoost has some advantages over the benchmark algorithms in five attack types. ACTrAdaBoost is an iterative algorithm like TrAdaBoost. Convergence is an important indicator. In Fig. 8, the convergence curves of the two algorithms on the intrusion detection dataset are given. We can see that ACTrAdaBoost converges faster than TrAdaBoost, so the ACTrAdaBoost algorithm performs better.
The detection rate of ACTrAdaBoost for five attack types is higher than that of three benchmark algorithms, and the detection rate for attack types with fewer samples is significantly improved. The experimental results show that the detection rate of ACTrAdaBoost algorithm for all five kinds of attacks has been improved, especially for R2L attacks with sparse samples. There is no problem that the detection rate of an attack is too low and the detection rate is very different. ACTrAdaBoost effectively alleviates the imbalance problem of attack type detection in machine learning algorithm. In addition, ACTrAdaBoost has significant advantages over the benchmark algorithm in terms of false positive rate and positive negative rate. In addition, the results on the three datasets show a better generalization performance of ACTrAdaBoost.
In this paper, the ACTrAdaBoost algorithm for intrusion detection based on TrAdaBoost, which utilizes transfer learning, active learning and Maximum mean discrepancy knowledge is proposed. ACTrAdaBoost uses active learning to label a large number of intrusion detection samples in the source domain to form a new source domain, whose samples need contain abundant information. MMD can effectively avoid negative transfer because it selects the more similarity samples between source domain and target domain. On one hand, ACTrAdaBoost can not only utilize the information from the historical intrusion detection samples to transfer the knowledge from the historical information to the current target domain learning task, which reduces the cost of collecting samples. On the other hand, active learning labels the samples with large amount of information in the source domain, and MMD screens samples in the source domain that have greater similarity with the target domain to reduce the scale of training samples. ACTrAdaBoost not only reduces the cost of the generation of classifier, but also effectively solves the problem of negative transfer in transfer learning, and improves the classification effect. In order to prove that the ACTrAdaBoost algorithm has good generalization performance, experiments were carried out on three intrusion detection public data sets KDD CUP99, DARPA1998 and ISCX2012 data sets. Experimental results on 10% KDDCUP99 and DARPA1998 dataset show that the detection rate of ACTrAdaBoost, especially for U2R and R2L attack types with fewer samples, is much higher than that of the benchmark algorithm. The detection balance of each attack type is better than the benchmark algorithm. The time efficiency of the algorithm also has great advantages. In the future work, we plan to study the multi-classification problem of ACTrAdaBoost. In addition, in view of the limitation that ACTrAdaBoost can only transfer knowledge from one source domain, how to transfer knowledge from multiple source domains needs further study.