
Abstract
Intrusion detection can effectively detect malicious attacks in computer networks, which has always been a research hotspot in field of network security. At present, most of the existing intrusion detection methods are based on traditional machine learning algorithms. These methods need enough available intrusion detection training samples, training and test data meet the assumption of independent and identically distributed, at the same time have the disadvantages of low detection accuracy for small samples and new emerging attacks, slow speed of establishment model and high cost. To solve the above problems, this paper proposes an intrusion detection algorithm-TrELM based on transfer learning and extreme machine. TrELM is no longer limited by the assumptions of traditional machine learning. TrELM utilizes the idea of transfer learning to transfer a large number of historical intrusion detection samples related to target domain to target domain with a small number of intrusion detection samples. With the existing historical knowledge, quickly build a high-quality target learning model to effectively improve the detection effect and efficiency of small samples and new emerging intrusion detection behaviors. Experiments are carried out on NSL-KDD, KDD99 and ISCX2012 data sets. The experimental results show that the algorithm can improve the detection accuracy, especially for unknown and small samples.
Introduction
With the rapid development of networks, they play a crucial role in national life and people’s daily activities [1]. However, network attacks highly emerge, which seriously threatens the security of cyberspace. Therefore, protecting the network from attacks has become an important research field. In order to deal with different network attacks, network security technologies such as firewall, cryptography, network isolation and identity authentication have gradually developed. However, these network security technologies are passive defense technologies, that cannot efficiently deal with the current complex and changeable network threats. The intrusion detection system (IDS) is a security management system, which is used to detect the intrusion on the network. It is an indispensable part of the modern network security system [2]. It not only makes up for the shortcomings of the traditional network security technologies, but also independently and efficiently detects attacks and takes corresponding protective measures. However, most of the intrusion detection systems are built based on the traditional matching method. In addition, several problems exist. More precisely, the system establishment speed is slow, the false positive rate and false negative rate are high, only existing attack behaviors can be detected, the detection rate of new attack behaviors and massive attack behaviors is low, and the detection rate of each attack behavior is unbalanced.
In recent years, with the development of machine learning, several machine learning algorithms have been applied to intrusion detection. For instance, LV et al. [3] propose a new accurate and efficient misuse intrusion detection system based on hybrid kernel extreme learning machine, which depends on specific attack characteristics in order to distinguish normal and malicious activities. Wang et al. [4] propose an efficient intrusion detection framework based on support vector machine, which performs LOG edge density ratio transformation to form original features, in order to obtain new and better transformed features. This framework greatly improves the detection ability of the model based on support vector machine. Gu et al. [5] propose a support vector machine intrusion detection framework based on Naive Bayesian feature embedding. This framework applies the naive Bayesian feature transformation on the original features in order to generate high-quality new data. It then uses the transformed data to train the support vector machine classifier, in order to develop the intrusion detection model. Al turaiki et al. [6] propose two models based on deep learning to solve the two classification and multi classification problems of network attacks. A hybrid hierarchical intrusion detection system, which combines different machine learning and feature selection technologies to provide high-performance intrusion detection in different attack types, is proposed in [7]. Aburomman et al. [8] propose a new integration construction method, which uses the weights generated by PSO to create an intrusion detection classifier integration with higher accuracy. This method also uses the local unimodal sampling (LUS) as the meta optimizer in order to find better behavior parameters for PSO. Practice has proved that the intrusion detection method based on machine learning improves the accuracy and efficiency of intrusion detection, and reduces the false alarm rate [9, 10].
Although the traditional machine learning methods achieved satisfactory results in the intrusion detection, their shortcomings restrict further development:
a large number of well-labeled training datasets are required for model training, and the training data and test data satisfy the independent and identical distribution conditions to make the detection model having a high detection accuracy [11, 12]. However, in practical applications, the distribution of the test and training data is difficult to be consistent. When the data distribution changes, it is necessary to recollect and label the training data, and train the model from scratch. The uneven number of attack behavior samples in the intrusion detection samples leads to an imbalance in the detection success rate of each attack behavior. Consequently, the data resources are wasted, and therefore more costs are spent to mark samples and reconstruct models. In addition, the detection rate of attacks with sufficient samples is relatively high, and it cannot efficiently detect new network attacks with scarce samples.
In recent years, transfer learning, which is a new machine learning method, has been widely used [13]. Compared with the traditional machine learning algorithms, it can use the knowledge in existing historical (source domain) data, save cost of data collection and model construction, and improve the speed of model training. Moreover, the data distribution of training and test data does not have to meet the independent and identical distribution. At present, it has been widely used in image recognition [14], machine fault diagnosis [15], system filtering [16] and computer vision [17], where it achieved satisfactory results. In order to solve the problems of current intrusion detection algorithms, this paper proposes an intrusion detection algorithm (TrELM) based on transfer learning and extreme learning machine.
TrELM is applied to the scene where the source domain contains a small number of labeled intrusion detection samples, and the training samples in the target domain are scarce enough to train a reliable classifier. Combined with the advantages of extreme learning machine, the source domain samples and weight vectors are first calculated using the maximum mean discrepancy (MMD). Afterwards, using the weight information, the learning model is trained for the samples with large amount of information and that are similar to the target domain in the source domain. Finally, the objective function of TrELM is constructed using the source domain model knowledge and data of target domain. Simultaneously the domain similar distance terms and constraints are constructed to further increase the knowledge similar to the target domain in the source domain, in order to obtain the target strong learning model, avoid negative transfer and improve the detection effect.
The main contributions of this paper are summarized as follows:
An intrusion detection algorithm based on transfer learning and extreme learning machine TrELM is proposed. This algorithm integrates the idea of transfer learning into extreme learning machine, transfers the knowledge of source domain through MMD, similar distance term and objective function constraints, and helps create a high-quality target learning model in the target domain. A large number of experiments on the intrusion detection datasets NSL-KDD, KDD99 and ISCX2012 demonstrate the efficiency and accuracy of the proposed algorithm. The results of the experiments also show that the detection accuracy of the proposed algorithm is better or at least comparable to the benchmark algorithms.
The remainder of this paper is organized as follows. Section 2 reviews the related works of transfer learning, extreme learning machine and maximum mean discrepancy. The proposed intrusion detection algorithm based on transfer learning and extreme learning machine is detailed in Section 3. In Section 4, the efficiency of the proposed algorithm is verified using the NSL-KDD, KDD99 and ISCX2012 datasets. Finally, the conclusions are drawn in Section 5.
Transfer learning
Transfer learning is a machine learning method which can use the knowledge in existing historical data to solve the learning problems in different but related fields. It relaxes the two basic assumptions in traditional machine learning, and transfers the existing knowledge in order to solve the learning problem that the target domain contains only a small amount of label data or even no label data [18, 19, 20]. Transfer learning has been widely used and studied with different concepts such as learn learning, lifelong learning, knowledge transfer, inductive transfer, multitasking learning, knowledge consolidation, context sensitive learning, knowledge-based inductive bias, meta learning and incremental/cumulative learning [12], for example. In transfer learning, the main research contents include what to transfer, how to transfer, when to transfer and negative transfer.
The transfer learning is defined in [21] as follows.
Given a source domain
According to whether the samples in the source domain are labeled, and whether the learning tasks are the same, the transfer learning tasks can be divided into inductive transfer learning, direct push transfer learning and unsupervised transfer learning. According to the technology used in transfer learning, the transfer learning methods can be divided into feature selection, feature mapping and instance based on transfer learning algorithm. These two definitions classify the transfer learning from different points of view. In general, the two classification methods are not different. In special cases, the transfer learning problem with multiple source domains can be extended according to this definition of single source transfer learning [22]. In the practical application of transfer learning, if the data that are not related to the target domain are forcibly transferred to the source domain, this will not help the learning of the target domain. On the contrary, it will be worse than the learning effect without transfer, that is, the negative transfer effect. Negative transfer has been widely studied since the transfer learning has been developed. In order to avoid negative transfer and better assist the learning tasks in the target domain, it is crucial to select the sample data with high similarity with the sample data of the target domain in the source domain [23].
Extreme learning machine
The extreme learning machine (ELM) is a new learning algorithm [24], used to train the single hidden layer feedforward neural network (SLFN). By randomly selecting the input layer weight and hidden layer bias, the output layer weight is computed and analytically calculated according to the Moore Penrose (MP) generalized inverse matrix theory, by minimizing the loss function composed of the training error term and regular term of the output layer weight norm. As a nonlinear model, ELM has a good generalization and nonlinear mapping. In addition, it can be used to solve dimensional disaster problems. Compared with other machine learning algorithms, such as BP neural network and SVM, it has the advantages of fast learning speed, less intervention and high computational scalability [25].
Given a training data set
Framework of the extreme learning machine.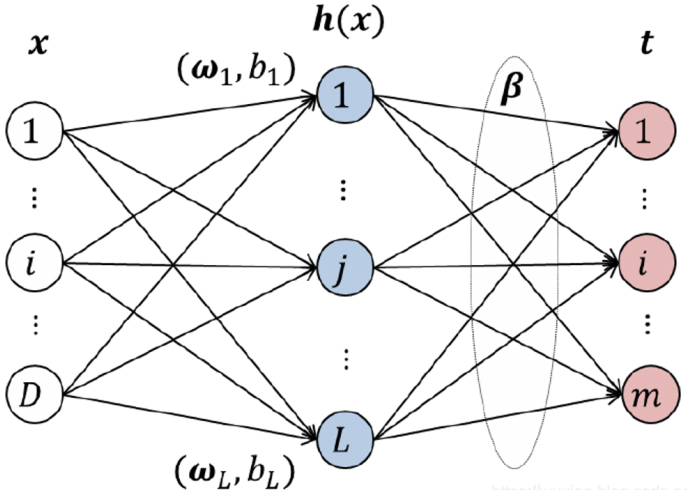
It can be seen from Fig. 1 that the output matrix
where
where
where
The unknown quantities in Eqs (2) and (3) are
ELM aims at minimizing the training error and obtaining the parameters with better learning effect on the training dataset
According to [27], the Moore Penrose generalized inverse matrix
Although ELM has made some achievements, there is still room for improvement. Several researchers also propose some algorithms to optimize ELM [28, 29]. At present, the traditional extreme learning machine is limited by the fact that the training and test data meet the constraints of independent, identically distributed and sufficient available training data. In fact, it is often hoped to use only a small amount of new data and a large amount of historical data in order to learn an accurate model. This is possible for the further development of ELM due to the emergence of transfer learning.
Transfer learning requires to transfer knowledge similar to the target domain in the source domain. Otherwise, negative transfer will occur, which results in a worse learning effect. Therefore, it is necessary to choose a method to calculate the distribution difference between the domains, in order to transfer knowledge with high similarity between them. In this paper, the Maximum mean difference (MMD) [30, 31] is used to reduce the distribution difference between domains. The square form of the MMD is given by:
Given a labeled data set
In Eq. (7), the smaller the MMD value, the closer the two domains. If the value is 0, the distribution is completely consistent. At present, the MMD measurement method has been widely used in the algorithm research of transfer learning [32, 33]. In fact, it can make the features learned from different domains more similar by constructing regularization terms.
In this paper, a large number of labeled intrusion detection data samples in the source domain are used to solve the application scenario, with a small number of labeled intrusion detection data samples in the target domain. The intrusion detection based on transfer extreme learning machine is constructed using the transfer learning, maximum mean discrepancy and extreme learning machine. The framework of the algorithm is presented in Fig. 2.
Framework of TrELM.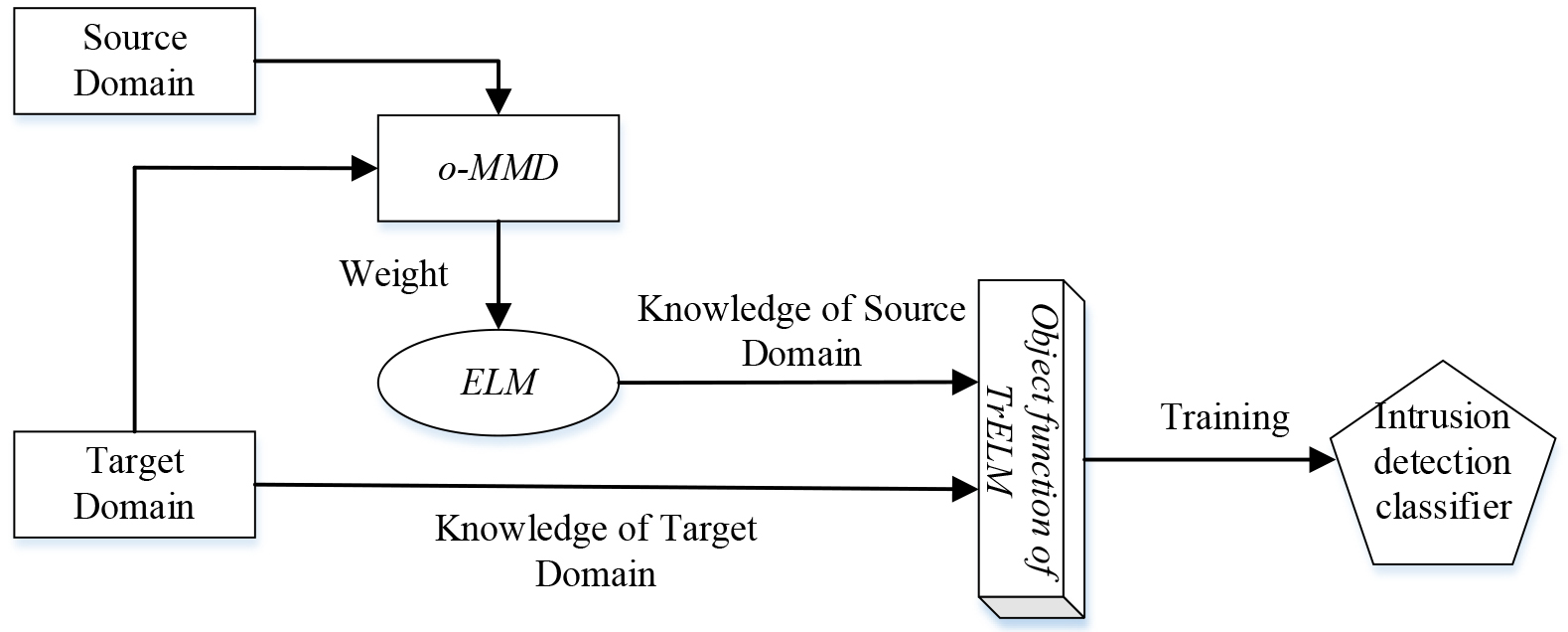
It can be seen from Fig. 2 that TrELM first uses o-MMD to calculate the similarity weight between the source and target domain, and trains ELM in order to obtain the source domain model knowledge. The objective function of TrELM is then constructed using the samples of target domain and the model knowledge of the source domain. Finally, TrELM is trained to obtain the intrusion detection classifier. In the algorithm, o-MMD is used to select the knowledge with great similarity between the source and target domain, which reduces the size of the samples, and uses the weight information to reduce the negative transfer. The constraints of objective function and similarity distance term limit the negative transfer again. Therefore, TrELM improves both the training efficiency and learning effect.
Given a source domain
where
Therefore, the training dataset is expressed as:
Given a target domain dataset
Implementation of TrELM
It can be observed from Fig. 2 that the extreme learning machine, MMD and transfer learning are fused. In addition, the construction process is divided into: calculation process of source domain weight and model training, TrELM objective function construction and related theorem proof, and intrusion detection classifier training.
(1) Calculation similarity weight of samples in the source domain
MMD is transformed to obtain its derivation form o-MMD, and the similarity weight vector of the samples in the source domain can be calculated.
According to Eq. (7), o-MMD is obtained on the target and source domains:
In Eq. (8), the first term is a constant which can be ignored, and only the last two terms should be minimized. Therefore:
By simplifying Eq. (9), the objective function can be obtained:
where
Equation (3.2) is a standard quadratic programming problem. Therefore, it can be solved using a quadratic programming solver in order to obtain the weight
(2) Construction, solution and steps proving the TrELM objective function
The optimal solution of the ELM model
where constants
By calculating Eq. (3.2), a classifier is obtained in the target domain, which can correctly classify the samples in the target domain.
where
By simplifying Eqs (13) and (14), the following is obtained:
Equation (3.2) is solved as in [34], and the result is substituted into Eq. (15) in order to obtain the parameter value of the target domain and the decision function of TrELM.
(3) The intrusion detection classifier is obtained by training the TrELM decision function in 2).
The TrELM training is presented in algorithm 1.
In summary, it can be seen that the TrELM algorithm first uses o-MMD to select the intrusion detection data samples from the source domain that are similar to the target domain, and initially reduces the impact of negative transfer. ELM is then trained on the dataset selected from the source domain, in order to obtain the model knowledge. The target transfer model TrELM is constructed with the target domain dataset and model knowledge of the source domain. On the one hand, it uses the existing source domain knowledge to speed up the training process. On the other hand, the objective function constraints and similar distance terms are used to further restrict the negative transfer. Finally, TrELM is trained on the target dataset in order to obtain the intrusion detection classifier.
Compared with the traditional ELM algorithm, TrELM can use a small amount of target intrusion detection data samples and a large number of source domain intrusion detection data samples, in order to construct a high-quality classification model. It fully uses the advantages of ELM and makes up for the shortcoming of inability to use the existing knowledge.
The pseudocode of the testing and evaluation stage is given by:
class ELM_Core (object): def __init__(self, X, y, num_hidden): Initialization parameters … end def sigmoid (self, x): return 1.0/(1
Experimental results
Experimental setting evaluation criteria
In order to verify the efficiency of the TrELM, the common datasets NSL-KDD, KDD99 and ISCX2012 are used. The benchmark algorithms used in the experiment are: SVM [38], ELM [24], the algorithm proposed in [6] and TrAdaBoost [39], in which SVM is implemented using the LIBSVM toolkit. The average of all the experiments repeated ten times is considered as the final comparison result.
The commonly used evaluation indicators for detection include the precision, detection rate and accuracy, false positive rate and miss rate. The precision reflects the proportion of correctly classified samples to the total number of samples (the larger the better). The accuracy denotes the proportion of true positive samples to the total number of samples classified as positive (the larger the better). The detection rate reflects the proportion of positive samples classified as positive in all the positive samples. The accuracy and detection rates are a pair of contradictory indicators. The higher the accuracy, the fewer the false positives, while the higher the detection rate, the fewer the false negatives. When the precision increases, the detection rate increases, while the accuracy decreases, and vice versa. In intrusion detection, the false positive rate refers to the proportion of the number of misclassified positive samples to the number of all the negative samples. A smaller value denotes a better performance, which is prone to “the wolf is coming”.
The formal description of the precision rate, detection rate, accuracy rate, false positive rate and miss rate is given by:
Precision:
where
In the experiments, the accuracy rate, false negative rate and miss rate are selected as indicators used to evaluate the algorithms. Note that an Intel Core i3-4160 processor with 8GB memory, win10 operating system and Python 3.6.3, is used.
Dataset
This section describes the NSL-KDD, KDD99 and ISCX2012 datasets and preprocesses them.
a. Dataset
ISCX2012 dataset
Several researchers demonstrated that the attack types considered in the KDD99 intrusion detection dataset are out of date. In 2012, the center of information security Excellence (iscx) of the University of New Brunswick (UNB) released an intrusion detection dataset, referred to as ISCX2012 [35]. This dataset comprises seven days of original network traffic data, including normal traffic and four intrusion types Dos and Prob, R2L and U2R (cf. Table 1). In the experiment, 2% of the data are selected from the training dataset, most of the labeled information are considered as source domain dataset and therefore deleted, the remaining labeled data are composed of target domain dataset, and the two datasets together constitute the training dataset. Similarly, 1% of the data are extracted from the test dataset and considered as the test data.
Distribution of attack types in the ISCX2012 dataset
Distribution of attack types in the ISCX2012 dataset
KDD 99
KDD99 is a widely used competition data for intrusion detection provided by Lincoln Laboratory of Massachusetts Institute of Technology. It is an intrusion detection dataset having the best influence and credibility in academia [36]. The dataset has 5*106 pieces of data, while each piece of data has 41 characteristic attributes and 1 class identifier. It contains almost 38 attack types, of which 21 attack types appear in the training dataset, and other 17 unknown attack types only exist in the test dataset. This design aims at testing the generalization ability of the classifier model. The ability to detect unknown attack types is also one of the crucial indicators to evaluate the effect of the classifiers in intrusion detection applications.
The researchers mostly use the 10% KDD99 dataset (including training dataset and test dataset), which is a sample of 10% of all the datasets of KDD99. This dataset is also used in this paper. The 10% dataset contains 1 type normal with normal signs, and 4 major network attack types: DOS, Probing, U2R and R2L. In the two 10% datasets, the four types of cyber attacks contain different amounts of attack behavior. Table 2 presents 22 attack behaviors in the training dataset, 39 attack behaviors in the test dataset, while the normal data are also counted as one type of attack.
KDD 99 dataset
Distribution of attack types in the KDD 99 dataset
In order for the intrusion detection algorithm to be able to recognize new attack behaviors by learning from the training dataset, the test dataset in Table 3 contains more new attack behaviors than the training dataset. In Table 3, the proportion of normal in the two 10% datasets is mainly the same. However, the proportions of the other four attack types are significantly different. Due to the fact that U2R and R2L have very small proportions, most of the current detection algorithms have difficulties in detecting these two types of attacks.
NSL-KDD
NSL-KDD [37] is an optimized version of the KDD99 dataset, where some duplicate records are deleted. It includes different classification difficulty levels, and the number is more balanced, so that it can be used as an efficient benchmark dataset to correct and efficiently detect the ability of the model. The NSL-KDD dataset includes 4 sub-datasets: KDDTrain
Distribution of attack types in the KDD 99 dataset
b. Data preprocessing
In the intrusion detection dataset, non-numerical data and dimension difference between the values exist. In addition, these data should be converted into numerical data and unified dimension processing. Therefore, the data preprocessing operation includes two steps: character type digitization and data normalization.
1) Character type digitization
The ISCX2012, NSL-KDD and KDD99 dataset processing methods are also the same. In each record, their symbol characteristics are converted into numerical data using 1 to N encoding. Considering KDD99 as example, 3 network connection types, 70 network service types, 23 attack types (including normal type) and 11 network connection states of the character type of the dataset are converted into numerical types. The converted forms of the 11 network connection types are shown in Table 5, while the other character types are similar.
Network connection type conversion
2) Data normalization
After digitization, the TrELM algorithm uses MMD to select the data. In the MMD, the distance is calculated. For the continuous feature attributes in the dataset, the measurement methods of each attribute are different. Therefore, the calculation of the distance between the data has a higher impact, which affects the accuracy of the calculation results. In order to avoid this situation, the difference between the different features can be eliminated. The method of MMD normalization is used for the discrete features. For the continuous features, the method of Z-Score is used to fix the value between 0 and 1, as shown in Eqs (18) and (19).
where
3) Data cleaning
Data cleaning is an indispensable link in machine learning. The quality of its results is directly related to the effect of the learning model and the final conclusion. In the actual data preprocessing, data cleaning usually occupies 50%–80% of the time in the data analysis process. In the experiment, for the missing values of the data, the fillna() method provided by pandas is used to fill in the missing values with the mean. For the noise of the data, the binning method is used to smooth the data by examining the “nearest neighbors” (i.e. the surrounding values) of the data. The ordered data values are distributed into some bins. For example, a set of data {2, 3, 4, 15, 21, 24, 28, 34, 13} sorted and divided into 3 bins, is given by:
{2, 3, 4} {13, 15, 21} {24, 28, 34}
After applying mean smoothing, it becomes:
{3, 3, 3} {16, 16, 16} {28, 28, 28}
A high-quality dataset is obtained by a process of data cleaning to replace, modify or delete the portions of the data that are incorrect, incomplete, irrelevant, inaccurate or questionable (“dirty”).
This section analyzes the experimental results of the SVM, ELM, algorithm proposed in [6], TrAdaBoost and the proposed TrELM algorithm using the NSL-KDD, KDD99 and ISCX2012 datasets, in order to verify and compare the efficiencies. In addition, the influence of the adjustable parameter
Average accuracy rate, false positive rate (%) and miss rate, for the NSL-KDD dataset
Average accuracy rate, false positive rate (%) and miss rate, for the NSL-KDD dataset
Average accuracy rate, false positive rate (%) and miss rate, for the KDD 99 dataset
Average accuracy rate, false positive rate (%) and miss rate, for the ISCX2012 dataset
Tables 6–8 present the average accuracy, false positive rate and miss rate of the algorithms on the NSL-KDD, KDD99 and ISCX2012 datasets. The obtained conclusions can be summarized as follows:
The sufficient available intrusion detection training samples are the base of the high-accuracy trained classifier. Using the intrusion detection datasets NSL-KDD and KDD99, there is a large number of the three types of attacks: Normal, Prob and DOS. All the algorithms have a high accuracy for these three types of attacks, reaching over 96%. Similarly, using the ISCX2012 dataset, the accuracy of all the algorithms against a large number of Normal, Infiltration and DDoS attacks, reaches 90%. Using the intrusion detection datasets NSL-KDD and KDD99, for the attack types U2R and R2L with a small number of samples, the traditional intrusion detection algorithms are not sufficient for training and obtaining a high-accuracy detection model. Therefore, they have a low accuracy against the two types. TrELM and TrAdaBoost are transfer learning algorithms that use knowledge from a large number of well-labeled intrusion detection samples, in order to train the detection types for U2R and R2L. Therefore, their detection rates for U2R and R2L are improved. It can be seen from Tables 6 and 7 that TrELM and TrAdaBoost have an improved accuracy on U2R and R2L, especially the accuracy rate of R2L which is greater than 88%, and that of U2R which is greater than 65%. It can be observed from Table 8 that, using the ISCX2012 dataset, the TrELM and TrAdaBoost transfer learning algorithms are more accurate than ELM, [6] and SVM for the smaller number of attack types HttpDos and BFSSH. Therefore, TrELM highly improves the detection rate of the U2R and R2L attack types that contain a small number of samples. Tables 6 and 7 show that the false alarm rate of all the algorithms for the three intrusion attack behaviors (Normal, Probe and DOS) using the intrusion detection datasets NSL-KDD and KDD99, does not exceed 5%. TrELM has the lowest false alarm rate, which is less than 4%. In the intrusion detection behavior U2R and R2L, the three non-transfer benchmark algorithms poorly perform. The false alarm rates of R2L and U2R using the NSL-KDD dataset are respectively greater than 10% and 9%, while using the KDD99 dataset, they are greater than 9%. However, TrELM has a relatively high performance on these two datasets, reaching false alarm rates below 5%. It can be seen from Table 8 that using the ISXC2012 dataset, TrELM has the lowest false positive rate for all the attack types. It can be seen from Tables 6–8 that TrELM has the lowest miss rate in the nine attack behaviors.
The experimental results show that using the KDD 99 and NSL-KDD datasets, TrELM has higher accuracy than that of the benchmark algorithms, for the five attack types. In addition, the accuracy of the attack type with a small number of samples has also been significantly improved. Using the ISCX2012 dataset, TrELM has also higher accuracy than that of the benchmark algorithms, for the five attack types.
In order to facilitate the discussion and prove that TrELM has a better effect, only the Wilcoxon test results of the algorithm accuracy on NSL-KDD, KDD99 and ISCX2012, are discussed.
Average training accuracy (%) on NSL-KDD, KDD99 and ISCX2012
It can be seen from Table 9 that using.
NSL-KDD, the classification accuracy of TrELM is 7.82% higher than that of TrAdaBoost, and the values of W
Using KDD99, the classification accuracy of TrELM is 7.79% higher than that of TrAdaBoost, and the values of W
Using ISCX2012, the classification accuracy of TrELM is 2.98% higher than that of TrAdaBoost, and the values of W
Average training time (s) on NSL-KDD, KDD99 and ISCX2012
Table 10 shows the average training time of the algorithms on three intrusion detection datasets. Compared with the TrAdaBoost and TrELM migration learning algorithms, the ELM and SVM non-migration learning algorithms do not require auxiliary source domain datasets. Therefore, they require less training time. TrELM selectively uses a large amount of data in the source field that is similar to the target field, and the training time is increased within an acceptable range.
TrELM improves the detection rate of all the 9 types of attack behaviors, especially for R2L attacks with sparse samples, which has a significant effect. In fact, there is no problem that the accuracy of a certain attack behavior is too low, and the accuracy is very different, which is efficiently alleviated problems of imbalance in the detection of attack types in the machine learning algorithms. TrELM has significant advantages in both the false positive rate and false negative rate. The experimental results on the three datasets also show that the TrELM algorithm has a better generalization performance. In addition, it has certain advantages in terms of the training time.
It can be seen from Eq. (3.2) that the objective function of TrELM includes parameter
Sensitivity analysis of parameter 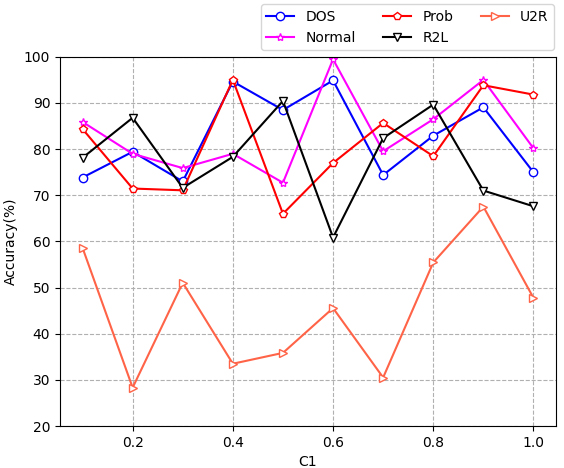
Sensitivity analysis of parameter 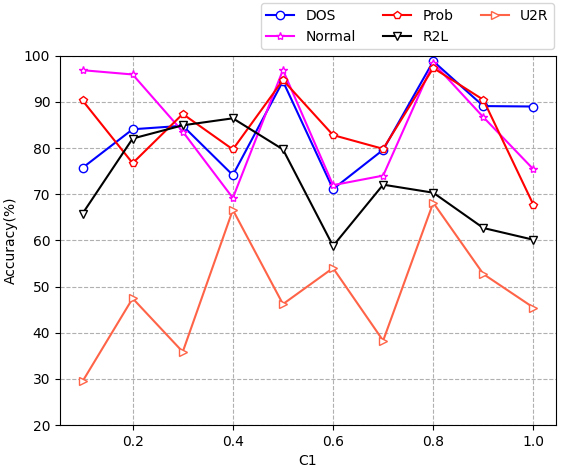
Sensitivity analysis of parameter 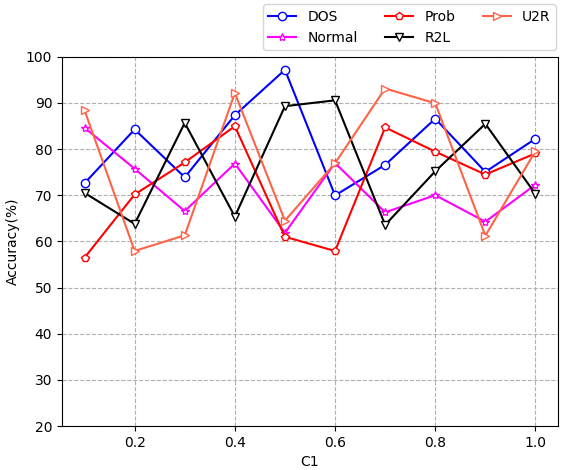
By analyzing the results in Figs 3–5, the following conclusions can be drawn:
Using the parameter grid search method presented in [19], the value of
This paper proposes an intrusion detection algorithm (TrELM) based on transfer extreme learning machine. TrELM first uses o-MMD to select intrusion detection data samples having high similarity with the target domain from the source domain. This initially reduces the impact of negative transfer. The model knowledge trained on the selected source domain and target domain dataset, is then used to construct the target model TrELM. The existing source domain knowledge is used to speed up the training process. In addition, the objective function constraints and similar distance terms are used to further limit the negative transfer. Finally, TrELM is trained on the target dataset in order to obtain the intrusion detection classifier. The experimental results show that TrELM efficiently solves the problems of low detection accuracy, slow model establishment speed and high cost of the traditional intrusion detection algorithms for small samples and emerging attacks. It also improves the classification accuracy and efficiency. Although the proposed TrELM algorithm achieves satisfactory results, it still has some limitations that should be tackled in future work. In fact, it considers the difference of conditional probability between the test and training data. Furthermore, the protection of the data privacy of network users should be tackled.
Footnotes
Acknowledgments
The authors would like to express their gratitude to EditSprings (https://www.editsprings.cn) for the expert linguistic services provided.
This work was partially supported by major special fund projects in Heilongjiang Province, China [Grant No. 2020-230100-54-01-000358].