Least absolute shrinkage and selection operator (LASSO) is one of the most commonly used methods for shrinkage estimation and variable selection. Robust variable selection methods via penalized regression, such as least absolute deviation LASSO (LAD-LASSO), etc., have gained growing attention in works of literature. However those penalized regression procedures are still sensitive to noisy data. Furthermore, “concept drift” makes learning from streaming data fundamentally different from the traditional batch learning. Focusing on the shrinkage estimation and variable selection tasks on noisy streaming data, this paper presents a noise-resilient online learning regression model, i.e. canal-LASSO. Comparing with the LASSO and LAD-LASSO, canal-LASSO is resistant to noisy data in both explanatory variables and response variables. Extensive simulation studies demonstrate satisfactory sparseness and noise-resilient performances of canal-LASSO.
Selecting significant explanatory variables is one of the most vital issues in statistical analysis and data mining [1]. Penalized regression methods consisting of loss function and penalized term (also known as regularization term) are widely used to select variables, such as LASSO [2], SCAD [3], and adaptive LASSO [4], etc. However, most of those methods are closely related to the least squares method. As far as we know that the ordinary least squares (OLS) method is sensitive to outliers in the scenario of finite samples, and consequently, the outliers may cause serious problems for the least squares based methods for variable selection. It is desirable to replace the least squares criterion with a noise-resilient one. To construct a robust objective function for regression, Fan and Li proposed a general framework of penalized objective function, i.e. to minimize following objective function with respect to [3].
where is the Huber’s function. Since then, various noise-resistant loss functions and regularization terms have been proposed and studied widely. Among them, based on the least absolute deviation (LAD) criterion [5], Wang et al. proposed the LAD-LASSO where and [6]. This procedure was proved to be able to reduce the impact of outliers to a certain extent. However, the impact of outliers is not eliminated completely. A loss function with a superior robustness performance is very fascinating and in urgent need. As discussed above, the motivation aims to study a noise-resilient procedure for variable selection, which inspires us to introduce a more robust loss function.
Besides, due to the rapid development of the Internet and the Internet of things, an ever increasing amount of data is available in streaming fashion [7]. It has been a critical problem to learn the prediction model from streaming data [8, 9]. Moreover, the statistical properties of the target variable, i.e. , which the model is trying to predict, may vary over time. It would reduce the accuracy of the prediction model as time goes by [10]. Thus, learning from streaming data has become increasingly critical [11, 12, 13] in the community of machine learning and data mining.
To tackle the above issues, in this paper, we have proposed a new noise-resilient online linear regression method that is robust to outliers for streaming data. Specifically, we introduce a noise-resilient loss function named as canal loss to resist the negative impact of the noisy data and further put forward the canal-LASSO method for noise-resilient variable selection. Employing the online gradient descent (OGD) algorithm, we optimize the objective function (canal-LASSO) in the online setting. Furthermore, to reduce the impact of noisy data effectively, an adjusting strategy is given to dynamically tune the threshold parameters and of canal loss in the proposed algorithm. Assuming large-scale examples arrive consecutively one by one, in the online learning process, the regression coefficients and regularization parameters are updated iteratively with sequential incorporated examples. The noise-resilient online canal-LASSO we proposed in this paper has three major merits:
Model sparsity: as can be seen from Fig. 2, only a fraction of examples (with the residual error in () and ()) will be used to adjust regression coefficients. It is designed to reduce the computational cost and enjoy the perfect scalability property.
Noise-resilient: by tuning threshold parameter dynamically, the noisy data which would lead to large absolute error (larger than the threshold parameter ) will be identified and not be used to adjust regression coefficients.
Real-time: the proposed canal-LASSO tunes the regularization parameters and updates the regression coefficients for regularized linear model dynamically in real time.
The remainder of this paper is organized as follows. In Section 2, we review the related work along LASSO-type procedures and then introduce the noise-resilient online learning algorithm for linear regression. In Section 3, we conduct numerical simulations and experiment on benchmark datasets to compare the performance of the proposed canal-LASSO with LASSO and LAD-LASSO. Finally, Section 4 concludes the paper with a short discussion.
Related works
In this section, we review the related work from two aspects: robust regression estimators and online learning.
variable selection has a rich history in statistics. Various insights of variable selection were proposed (Non-negative Garrote, Bridge regression) before Tibshirani introduced the celebrated LASSO estimator [14, 15, 2]. Due to the lack of desired statistical properties, different penalties that satisfy some criteria such as sparsity, persistency, etc. were introduced in the past decades, like SCAD [3], MCP [16] and Adaptive LASSO [4]. On the other hand, the variable selection methods with structured penalties (e.g. features are dependent and/or there exists group structures between features) have become more popular because of the ever-increasing need to deal with complicated data, such as Elastic Net [17], Group LASSO [18], and so forth. The robust variable selection is a new topic by incorporating the robust losses in robust statistics area into the model, which performs well under noisy scenarios empirically [19, 20, 21]. For instance, LAD-LASSO is a typical example of consistent variable selection method that is noise-resilient [6].
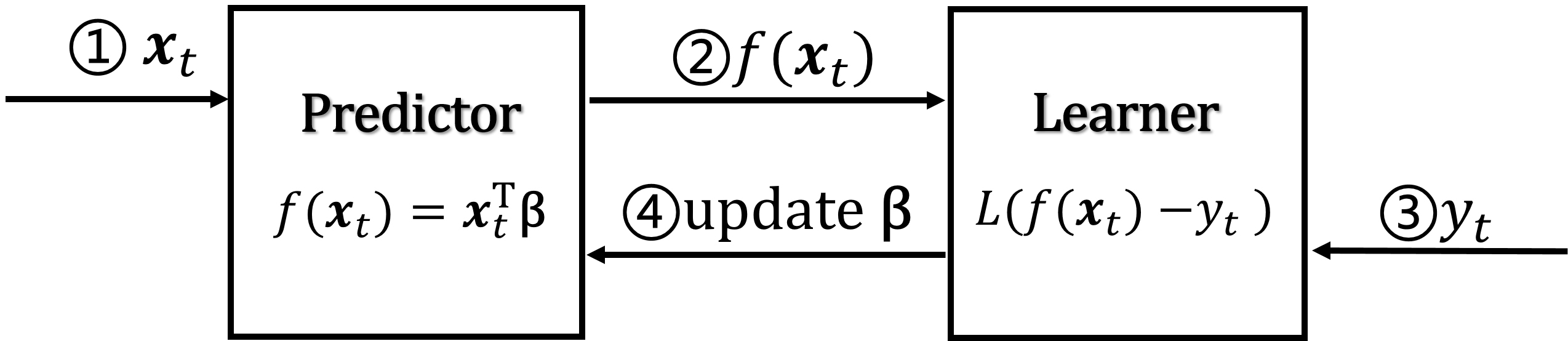
In the past decades, a great deal of research has been performed on inductive learning methods such as LASSO [2], artificial neural networks [22, 23], and support vector regression [24], etc. All of these techniques have been successfully applied to a lot of real-world problems. However, their standard application requires the availability of all of the training data at the same time [25], which makes them problematic in large-scale data mining applications and streaming data mining tasks [26, 27]. Comparing with the traditional batch learning framework, online learning algorithm (shown in Fig. 1) is another learning framework for samples learning in the streaming fashion so that it enjoys good properties of scalability and real-time. In recent years, great attentions have been paid to develop online learning methods in the machine learning community, such as online ridge regression [28, 29], adaptive regularization for LASSO [30], Projectron [31] and bounded online gradient descent algorithm [32], etc.
An illustration schematic of the online regression learning procedure.
Method
Most of the existing online regression algorithms are primarily designed to learn information from clean data [30, 33]. However, due to the imperfect human labeling process and the sensor fault, noisy data is inevitable and ruinous. In this section, we have proposed a noise-resilient online learning algorithm for linear regression on streaming data. Motivated by the ramp loss designed for classification problem [34], we have proposed a noise-resilient loss function, named canal loss, for regression based on the well-known -insensitive loss [24]. Furthermore, we have exploited a novel strategy to adjust the canal loss parameters and dynamically.
Canal-LASSO
Consider the linear regression model
where is d-dimensional explanatory variable, are the associated regression coefficients, are iid random errors with mean of 0. Usually, regression coefficients of Eq. (2) can be estimated by minimizing the ordinary least squares (OLS) criterion. Meanwhile, to shrink insignificant coefficients to 0, Tibshirani proposed the primary LASSO criterion [2]:
where is a fixed tuning parameter. Since all regression coefficients are penalized by the same regularization parameter , the resulting estimators of may suffer an apparent bias. To deal with this issue, Zou developed the following adaptive LASSO criterion [4]:
which allows for different tuning parameters corresponding to different coefficients . As a result, the modified is able to produce sparse solutions more effectively than ordinary . Since the OLS criterion used in and is more sensitive to outliers than the LAD criterion [5], Wang et al. further modified the as following [6]:
As can be seen, the LAD-LASSO combines the LAD criterion and the regularization, hence the resulting estimator is expected to be more robust than LASSO and also enjoys the property of sparse representation. After replacing the OLS criterion with the LAD criterion, the LAD-LASSO become more robust than . Unfortunately, LAD-LASSO can not eliminate the negative influence of noise data completely.
To obtain a noise-resilient LASSO-type estimator, we propose the following canal loss by modifying the classical -insensitive loss function with a noise-resilient parameter :
where , and are the threshold tuning parameters.
I. Absolute loss; II. -insensitive loss; III. Canal loss.
The illustration of three loss functions is shown in Fig. 2. Both the absolute loss function and the -insensitive loss function are sensitive to outliers. The upper bound of the proposed canal loss function is fixed as a constant, i.e. , which would significantly reduce the negative impact of outliers and make it a noise-resilient loss function. Taking advantage of canal loss, we have modified the LAD-LASSO and proposed the following canal-LASSO:
It is obvious that canal loss approximates to the absolute loss under the process of and , which is shown more clearly in the following equation:
It is expected that the proposed canal-LASSO is robust against outliers and also enjoys the property of sparse representation.
Online learning algorithm for canal-LASSO
In order to solve the canal-LASSO model effectively, we have employed the online gradient descent (OGD) algorithm proposed our optimization strategy by minimizing
where .
Firstly, many methods have been put forward to determine the regularization parameter in literatures, such as cross-validation, AIC, BIC, etc. In order to facilitate the computation and ensure the consistent variable selection, we have optimized the regularization parameter by minimizing a BIC-type objective function [6], i.e.,
This leads to , i.e., . Note that the update of is dependent on the estimation of .
Secondly, Eq. (9) is not a convex optimization problem but it can be reformulated as a difference of convex (DC) programming. The Concave-Convex Procedure (CCCP) may be applied to solve this problem. However, CCCP belongs to the category of batch learning algorithms and does not satisfy the real-time requirement when dealing with streaming data. To find a near-optimal solution, in this work, we have employed the well-known OGD framework. It is a trade-off between the accuracy and scalability. In order to minimize Eq. (9) by OGD, we reformulate it to be
and then we solve the optimization problem under the basic framework of OGD algorithm,
Here, is the t-th stepsize satisfying the following constraints and when [35]. Instead of computing the full gradient of exactly, the notation stands for the derivative of with regard to . We can deduce as following
where . Substituting the gradient Eq. (13) into Eq. (12),
Note that the update of is dependent on .
Finally, as shown in Eq. (14), there are a sparse parameter and a noise-resilient parameter in the proposed canal-LASSO. If the parameter approximates 0 and gets closer to , the proposed method is equivalent to the classical LAD-LASSO [6]. The parameter controls the sparsity and indicates the noise-resilient level of the proposed model. It is an urgent issue to give a parameter setting strategy to adjust the canal loss parameters and automatically. In this study, we set the parameters as:
Adjusting the parameters and is equal to adjusting and . Meanwhile, when the parameter is set as 0, the proposed algorithm will not learn from any examples and will only update according to the regularization term. Contrarily, if is large enough, our canal-LASSO will no longer resist noisy data.
Above all, in each iteration under the OGD framework, we calculate the parameters and of canal-LASSO, and then update so that we can update with the new . We summarize the proposed noise-resilient online canal-LASSO algorithm as follow.
In this section, we have conducted experiments to evaluate the performance of the proposed canal-LASSO algorithm. Firstly, we have performed the parameter sensitivity study to show the impact of canal loss parameters and on one benchmark prediction task. Secondly, simulation experiments are carried out to show the efficacy and efficiency of our method for noisy data on the synthetic data. Additionally, we have been conducted extensive experiments to evaluate the performance of the proposed algorithm on four benchmark prediction tasks.
Benchmark datasets used in the experiments can be obtained from UCI1
website [37]. All experiments are performed in MATLAB R2016a environment on a PC with 2.5 GHz Intel Core i5 processors and 8 G RODRAM running under the Windows 10 operating system. The source code of the proposed algorithm will be released upon the acceptance of the manuscript.
Parameter sensitivity study
There are two important hyper parameters in the proposed online canal-LASSO algorithm: and . The parameter controls the sparsity and is noise-resilient level. To ascertain how these parameters affect the prediction result, we have tested our algorithm on the “Letters” dataset from UCI with artificial perturbation, which consists of 5000 15-dimension samples (with 30% examples held out for testing).3
Henceforth we use the same proportion for all of the datasets.
In the current experiments, we run the algorithm on data set “Letters” for three rounds. As shown in Fig. 3, two extreme situations, i.e., and corresponding to the loss functions of and are considered respectively.
Canal loss of two extreme cases, i.e., II () and III ().
To show that the parameter of canal-LASSO indeed induces sparsity and its superiority, we have analyzed the parameter sensitivity of in shown in Fig. 3a-II. Specifically, we have adjusted by ranging ranges in and for each we perform Algorithm 1 on “Letter” dataset. As we can see from Table 1, when a small number of sample points are discarded (), the prediction accuracy is relatively stable. However, when , the prediction performance becomes worse. It is a trade-off between prediction accuracy and model sparsity. Due to the powerful online learning algorithm, online canal-LASSO costs very little running time as shown by the row of Time.
To show the noise-resistance effect of parameter in canal-LASSO, we range in shown in Fig. 3b-III. Specifically, we adjust for each experiment by ranging in and for each we perform Algorithm 1 on “Letter” dataset. Considering that noises come from two main sources, and , we first select a certain proportion ( 0.1 or 0.2) of the samples from the training set. For each selected sample, we randomly set an element of to be 0 so that the training set contains noisy data. All compared models are trained on the noisy training data set and then we test the estimated model in the clean testing data set. The purpose of this experiment is to estimate the influence relation between the prediction accuracy (RMSE) and the discarded rate so that we can determine the optimal parameter . As shown in Tables 2 and 3, most of the samples are discarded when the is small enough. Empirically, when the discarded rate is approximately equal to the noise ratio , the prediction accuracy of canal-LASSO is the highest one. In order to compare the trend charts of RMSE and discarded rate, we have ploted the 2D performance variations under different parameter settings of in Fig. 4. Due
Sensitivity analysis result of
0.005
0.010
0.015
0.020
0.025
0.030
RMSE
0.3381 0.0016
0.3376 0.0010
0.3365 0.0000
0.3360 0.0009
0.3344 0.0021
0.3356 0.0013
MAE
6.5824 0.0831
6.5827 0.0290
6.4911 0.0670
6.5383 0.0870
6.4043 0.1055
6.4948 0.0272
Discarded samples
105 11
221 12
346 6
449 16
570 25
661 23
Discarded rate
0.7%
1.5%
2.3%
3.0%
3.8%
4.4%
Time
0.8412 0.0344
0.8336 0.0193
0.7999 0.0430
0.7970 0.0169
0.8187 0.0432
0.7822 0.0388
0.035
0.040
0.045
0.050
0.055
0.060
RMSE
0.3361 0.0009
0.3349 0.0027
0.3350 0.0010
0.3334 0.0032
0.3340 0.0015
0.3343 0.0004
MAE
6.5241 0.0033
6.5148 0.0548
6.5009 0.0169
6.4130 0.1266
6.4837 0.0480
6.4389 0.0352
Discarded samples
782 11
893 30
1044 1
1102 8
1222 9
1386 21
Discarded rate
5.2%
6.0%
7.0%
7.3%
8.1%
9.2%
Time
0.8076 0.0299
0.8177 0.0425
0.8108 0.0655
0.7908 0.0346
0.8147 0.0457
0.8028 0.0376
0.065
0.070
0.075
0.080
0.085
0.090
RMSE
0.3329 0.0022
0.3346 0.0006
0.3328 0.0029
0.3346 0.0019
0.3351 0.0004
0.3325 0.0003
MAE
6.4465 0.0483
6.4964 0.0032
6.4225 0.1574
6.4943 0.0543
6.5216 0.0753
6.4260 0.0143
Discarded samples
1483 55
1561 42
1724 37
1827 45
1931 13
2068 7
Discarded rate
9.9%
10.4%
11.5%
12.2%
12.9%
13.8%
Time
0.8035 0.0545
0.8288 0.0571
0.7847 0.0381
0.8300 0.0351
0.8189 0.0542
0.8169 0.0401
0.095
0.100
0.105
0.110
0.115
0.120
RMSE
0.3395 0.0017
0.3402 0.0006
0.3410 0.0018
0.3421 0.0038
0.3428 0.0007
0.3461 0.0018
MAE
6.5179 0.0867
6.5267 0.0200
6.5541 0.0854
6.5870 0.1784
6.6069 0.0338
6.7460 0.0985
Discarded samples
2705 18
2853 62
2989 16
3137 1
3299 38
3403 15
Discarded rate
18.0%
19.0%
19.9%
20.9%
22.0%
22.7%
Time
0.8370 0.0292
0.8410 0.0091
0.8212 0.0399
0.8751 0.0287
0.8044 0.0556
0.8446 0.0727
Sensitivity analysis result of for 0.10
0.1
0.2
0.3
0.4
0.5
0.6
RMSE
0.3392 0.0009
0.3370 0.0001
0.3505 0.0143
0.3563 0.0089
0.3630 0.0024
0.3604 0.0011
MAE
6.4228 0.0748
6.4694 0.0155
6.8468 0.4892
7.0441 0.3288
7.2801 0.0507
7.2033 0.0377
Discarded samples
13882 30
12313 128
10496 339
8928 71
7441 16
6522 47
Discarded rate
92.5%
82.1%
70.0%
59.5%
49.6%
43.5%
Time
0.7407 0.0376
0.7934 0.0028
0.7898 0.0242
0.7906 0.0424
0.8048 0.0329
0.8097 0.0206
0.7
0.8
0.9
1
1.1
1.2
RMSE
0.3573 0.0016
0.3519 0.0018
0.3465 0.0001
0.3415 0.0023
0.3405 0.0021
0.3377 0.0022
MAE
7.1069 0.0446
6.9679 0.0260
6.7781 0.0434
6.6168 0.1112
6.6210 0.1093
6.5590 0.0268
Discarded samples
5696 54
4970 85
4489 8
3980 35
3516 13
3171 43
Discarded rate
38.0%
33.1%
29.9%
26.5%
23.4%
21.1%
Time
0.8035 0.0185
0.7789 0.0281
0.7980 0.0518
0.7978 0.0025
0.7975 0.0315
0.7968 0.0204
1.3
1.4
1.5
1.6
1.7
1.8
RMSE
0.3351 0.0016
0.3345 0.0009
0.3357 0.0001
0.3347 0.0032
0.3341 0.0013
0.3339 0.0020
MAE
6.4611 0.0809
6.4748 0.0814
6.5118 0.0482
6.4848 0.0508
6.4724 0.1043
6.4516 0.1677
Discarded samples
2844 3
2568 1
2253 7
2035 6
1872 23
1501 1
Discarded rate
19.0%
17.1%
15.0%
13.6%
12.5%
10.0%
Time
0.8235 0.0400
0.8299 0.0450
0.8272 0.0342
0.8213 0.0375
0.8128 0.0340
0.8005 0.0506
1.9
2.0
2.1
2.2
2.3
2.4
RMSE
0.3338 0.0013
0.3358 0.0008
0.3375 0.0001
0.3370 0.0014
0.3387 0.0003
0.3390 0.0025
MAE
6.4467 0.0665
6.5627 0.0238
6.5251 0.0411
6.5486 0.0403
6.6019 0.0298
6.5651 0.1817
Discarded samples
1500 0
1500 0
0 0
0 0
0 0
0 0
Discarded rate
10.0%
10.0%
0.0%
0.0%
0.0%
0.0%
Time
0.8038 0.0164
0.8092 0.0302
0.8073 0.0156
0.8132 0.0160
0.8241 0.0299
0.8076 0.0233
Sensitivity analysis result of for 0.20
0.1
0.2
0.3
0.4
0.5
0.6
RMSE
0.3515 0.0054
0.3386 0.0023
0.3528 0.0086
0.3459 0.0006
0.3620 0.0002
0.3611 0.0004
MAE
6.8539 0.1198
6.5090 0.1583
6.8951 0.2006
6.7279 0.0208
7.2863 0.0594
7.2686 0.0051
Discarded samples
14165 53
12803 194
11912 898
10083 53
8400 88
7495 59
Discarded rate
94.4%
85.4%
79.4%
67.2%
56.0%
50.0%
Time
0.7840 0.0095
0.8227 0.0029
0.8118 0.0288
0.7913 0.0230
0.7945 0.0302
0.8410 0.0282
0.7
0.8
0.9
1
1.1
1.2
RMSE
0.3575 0.0014
0.3545 0.0004
0.3493 0.0001
0.3451 0.0032
0.3432 0.0000
0.3398 0.0019
MAE
7.1052 0.0953
7.0560 0.0022
6.9031 0.0780
6.7887 0.1358
6.7499 0.0497
6.6483 0.0978
Discarded samples
6703 50
6067 35
5589 2
5136 34
4808 23
4435 1
Discarded rate
44.7%
40.4%
37.3%
34.2%
32.1%
29.6%
Time
0.8405 0.0550
0.8575 0.0511
0.8694 0.0273
0.8611 0.0953
0.8658 0.0234
0.8606 0.0671
1.3
1.4
1.5
1.6
1.7
1.8
RMSE
0.3403 0.0005
0.3380 0.0007
0.3384 0.007
0.3380 0.0001
0.3375 0.0017
0.3369 0.0018
MAE
6.6777 0.0371
6.6273 0.0165
6.6325 0.0301
6.6409 0.0891
6.5741 0.0351
6.5418 0.0884
Discarded samples
4167 7
3950 16
3675 20
3468 4
3293 18
3002 1
Discarded rate
27.7%
26.2%
24.6%
23.1%
22.0%
20.0%
Time
0.8403 0.0538
0.7940 0.0203
0.8469 0.0401
0.8349 0.0652
0.8414 0.0362
0.8578 0.0047
1.9
2.0
2.1
2.2
2.3
2.4
RMSE
0.3371 0.0011
0.3380 0.0009
0.3521 0.0002
0.3511 0.0017
0.3544 0.0002
0.3528 0.0014
MAE
6.6098 0.0548
6.6642 0.0706
6.9432 0.0099
6.8854 0.0582
7.0526 0.0043
6.9483 0.0795
Discarded samples
3000 0
3000 0
0 0
0 0
0 0
0 0
Discarded rate
20.0%
20.0%
0.0%
0.0%
0.0%
0.0%
Time
0.8174 0.0448
0.8338 0.0389
0.8721 0.0573
0.8669 0.0350
0.8564 0.0246
0.8625 0.0183
to the initialization of the model coefficients , a small may discard most of the noisy samples and lead to only a small part of confidence samples to be used for training model. So the RMSE curve begins with a small value. However, the estimation of small samples can lead to the instability of the model. When increases from 0.1 to 0.5, more and more noisy samples are incorporated into the training process, so the RMSE increases.
Sensitivity analysis result of for 0.1 and 0.2.
Simulation settings
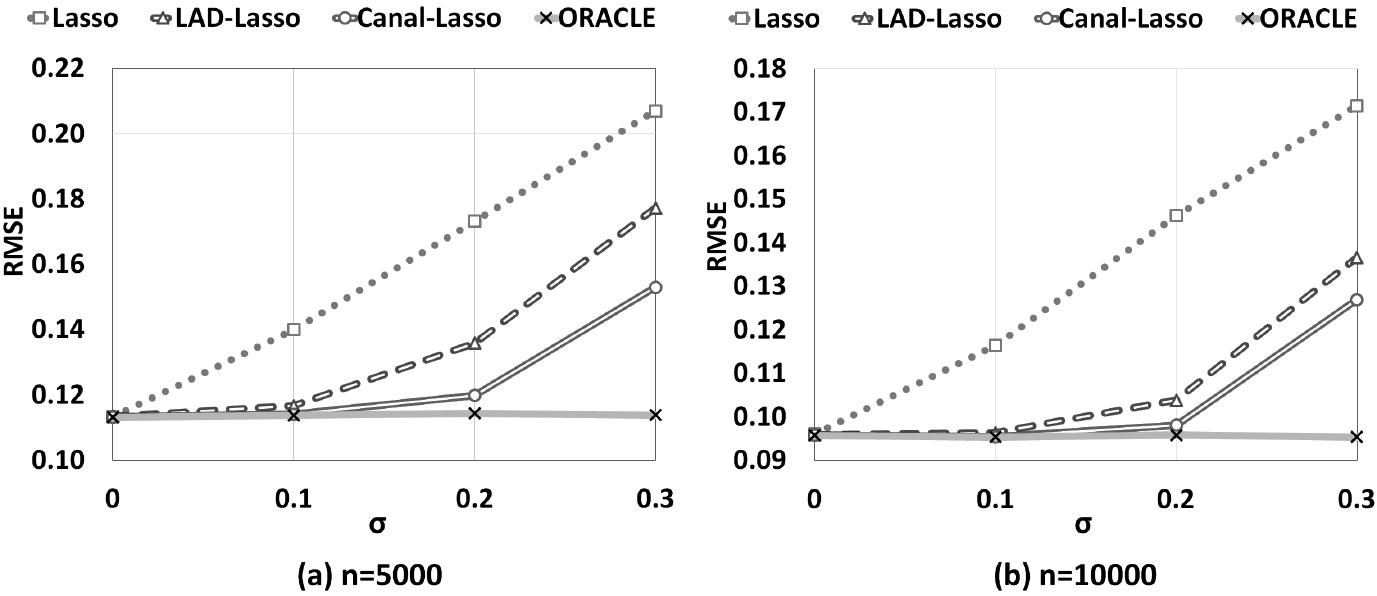
We investigate the proposed noise-resilient online regression algorithm on synthetic data sets in the case of noisy data. Specifically, we attempt to answer the question about how effective the proposed canal-LASSO method is in handling data with noise input and output. In this subsection, we have reported a number of simulation studies on finite-sample performance evaluation ( 5000, 10000) of canal-LASSO on streaming noisy data. For comparison, LASSO, LAD-LASSO, canal-LASSO, together with the oracle estimator, are evaluated. Specifically, we set the feature dimension as 50 and let be . Here, the first 6 regression coefficients are significant, while the remaining 44 regression coefficients are not. For a given , the covariate is generated from a standard -dimensional multivariate normal distribution so that the components of are independent and standard normal. Furthermore, the response variables are generated according to
where 0.5 and is generated from normal distribution . Here we change the noisy ratio from . Specifically, we randomly select some samples at a rate of and change the explanatory variable of into 0 in the training set and then test the learning model in the true testing data set. We have reported the corresponding results in Table 4. At the same time, to explore the influence of noisy response variable, we randomly tamper the response variable to 0 at a rate of in the training set and then test the learning model by the true testing samples. Corresponding results are reported in Table 5. For each parameter setting, a total of 50 random experiments are carried out to evaluate the average performance (for sample sizes equals 5000 and 10000, respectively). The absolute error of coefficient , which stands for the normalized distance between estimated and true is introduced to compare the capability of avoiding the interference from noisy response variable of different algorithms. The closer the is to 0, the higher accuracy of model coefficient estimation is. We list as an assessment criterion in Tables 4 and 5 to evaluate the learning models. For a fair comparison, the compared models, i.e., LASSO, LAD-LASSO and canal-LASSO are solved by the online gradient descent method (OGD). In our experiment, the parameter is set to be 0.8.
We begin by demonstrating that the canal-LASSO is capable of avoiding the interference from explanatory variable . As can be seen from the column of in Table 4, LASSO and LAD-LASSO deviate severely from true value and the proposed canal-LASSO method outperforms the two competing methods (LASSO, LAD-LASSO) in noisy data cases. Especially in the case of high noisy level ( 0.3), canal-LASSO significantly outperforms LASSO and LAD-LASSO. Due to the intrinsic flaw of loss, original LASSO method is very sensitive to noise. Least absolute deviation can reduce the impact of noise data in some sense, but the impact of noise remains seriously. The prediction performances of different algorithms are list in Fig. 5 for comprehensive comparison. As can be observed, the average performance of canal-LASSO outperforms LASSO and LAD-LASSO in noisy input cases. It indicates that canal-LASSO is indeed a noise-resilient method to deal with noisy data when the explanatory variables are contaminated.
Simulation results for noisy covariate
n
Method
No. of zeros
RMSE
5000
0
LASSO
0.048
0.002
0.014
0.004
0.002
0.004
0.073
44 (100.0%)
0.9669
0.1135 0.0008
LAD-LASSO
0.042
0.011
0.022
0.005
0.010
0.004
0.093
43.95 (99.9%)
0.9664
0.1136 0.0012
canal-LASSO
0.040
0.013
0.023
0.009
0.008
0.002
0.095
44 (100.0%)
0.9669
0.1135 0.0006
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9670
0.1134 0.0006
0.1
LASSO
0.118
0.010
0.005
0.008
0.004
0.227
0.372
44 (100.0%)
0.9445
0.1244 0.0007
LAD-LASSO
0.075
0.008
0.005
0.008
0.004
0.089
0.188
44 (100.0%)
0.9573
0.1163 0.0008
canal-LASSO
0.072
0.008
0.006
0.004
0.009
0.069
0.169
44 (100.0%)
0.9590
0.1152 0.0010
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9608
0.1139 0.0010
0.2
LASSO
0.107
0.063
0.019
0.008
0.002
0.429
0.628
44 (100.0%)
0.8976
0.1473 0.0016
LAD-LASSO
0.040
0.035
0.034
0.009
0.034
0.185
0.336
44 (100.0%)
0.9479
0.1239 0.0016
canal-LASSO
0.039
0.028
0.023
0.009
0.020
0.135
0.254
44 (100.0%)
0.9542
0.1201 0.0011
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9620
0.1147 0.0008
0.3
LASSO
0.117
0.027
0.035
0.034
0.007
0.613
0.833
44 (100.0%)
0.8233
0.1724 0.0021
LAD-LASSO
0.057
0.056
0.031
0.021
0.042
0.319
0.525
43.6 (99.1%)
0.9211
0.1404 0.0054
canal-LASSO
0.103
0.037
0.027
0.028
0.027
0.218
0.441
42.85 (97.4%)
0.9425
0.1301 0.0059
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9676
0.1130 0.0008
10000
0
LASSO
0.048
0.002
0.014
0.004
0.002
0.004
0.073
44 (100.0%)
0.9669
0.1135 0.0008
LAD-LASSO
0.014
0.006
0.002
0.007
0.010
0.002
0.041
44 (100.0%)
0.9593
0.0956 0.0006
canal-LASSO
0.025
0.018
0.005
0.007
0.003
0.004
0.062
44 (100.0%)
0.9590
0.0958 0.0005
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9591
0.0957 0.0005
0.1
LASSO
0.102
0.015
0.018
0.010
0.011
0.209
0.364
44 (100.0%)
0.9436
0.1041 0.0007
LAD-LASSO
0.056
0.006
0.002
0.003
0.008
0.043
0.117
44 (100.0%)
0.9596
0.0958 0.0006
canal-LASSO
0.065
0.010
0.003
0.002
0.005
0.018
0.102
44 (100.0%)
0.9607
0.0952 0.0006
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9610
0.0950 0.0005
0.2
LASSO
0.012
0.037
0.007
0.004
0.009
0.405
0.473
44 (100.0%)
0.8935
0.1245 0.0009
LAD-LASSO
0.020
0.022
0.018
0.006
0.021
0.094
0.181
44 (100.0%)
0.9580
0.0984 0.0007
canal-LASSO
0.032
0.050
0.020
0.018
0.009
0.040
0.168
44 (100.0%)
0.9615
0.0966 0.0007
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9626
0.0959 0.0006
0.3
LASSO
0.026
0.018
0.040
0.010
0.004
0.610
0.707
44 (100.0%)
0.8071
0.1467 0.0008
LAD-LASSO
0.065
0.065
0.031
0.052
0.024
0.227
0.464
43.7 (99.3%)
0.9408
0.1090 0.0022
canal-LASSO
0.023
0.059
0.037
0.033
0.005
0.095
0.251
43.8 (99.5%)
0.9600
0.0990 0.0013
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9660
0.0951 0.0006
Simulation results for noisy response variable
n
Method
No. of zeros
RMSE
5000
0
LASSO
0.092
0.011
0.003
0.007
0.013
0.011
0.137
44 (100.0%)
0.9626
0.1133 0.0013
LAD-LASSO
0.084
0.007
0.006
0.004
0.014
0.009
0.124
44 (100.0%)
0.9622
0.1135 0.0009
canal-LASSO
0.079
0.015
0.005
0.006
0.014
0.006
0.124
44 (100.0%)
0.9625
0.1132 0.0007
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9626
0.1131 0.0007
0.1
LASSO
0.242
0.153
0.180
0.254
0.207
0.194
1.230
43.95 (99.9%)
0.9202
0.1399 0.0020
LAD-LASSO
0.063
0.023
0.045
0.049
0.048
0.035
0.263
43.95 (99.9%)
0.9623
0.1166 0.0037
canal-LASSO
0.048
0.008
0.017
0.016
0.017
0.004
0.109
44 (100.0%)
0.9658
0.1141 0.0009
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9662
0.1137 0.0009
0.2
LASSO
0.752
0.361
0.331
0.441
0.401
0.416
2.703
43.25 (98.3%)
0.7981
0.1732 0.0027
LAD-LASSO
0.334
0.164
0.136
0.222
0.169
0.178
1.202
43.15 (98.1%)
0.9235
0.1358 0.0055
canal-LASSO
0.174
0.067
0.059
0.112
0.065
0.066
0.543
43.55 (99.0%)
0.9537
0.1198 0.0026
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9618
0.1143 0.0007
0.3
LASSO
1.000
0.669
0.627
0.602
0.603
0.610
4.112
43.15 (98.1%)
0.5871
0.2069 0.0036
LAD-LASSO
0.686
0.461
0.343
0.464
0.415
0.413
2.782
41.6 (94.5%)
0.7774
0.1772 0.0058
canal-LASSO
0.668
0.346
0.167
0.325
0.228
0.261
1.996
40.3 (91.6%)
0.8664
0.1529 0.0184
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9625
0.1137 0.0008
10000
0
LASSO
0.041
0.004
0.004
0.007
0.004
0.010
0.070
44 (100.0%)
0.9592
0.0960 0.0006
LAD-LASSO
0.039
0.003
0.008
0.008
0.003
0.011
0.072
44 (100.0%)
0.9590
0.0959 0.0004
canal-LASSO
0.055
0.008
0.007
0.002
0.006
0.012
0.090
44 (100.0%)
0.9596
0.0958 0.0005
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9597
0.0958 0.0005
0.1
LASSO
0.259
0.202
0.204
0.199
0.189
0.211
1.264
44 (100.0%)
0.9172
0.1164 0.0014
LAD-LASSO
0.013
0.044
0.029
0.032
0.023
0.029
0.169
44 (100.0%)
0.9610
0.0963 0.0007
canal-LASSO
0.033
0.007
0.010
0.005
0.003
0.001
0.059
44 (100.0%)
0.9622
0.0954 0.0004
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9623
0.0953 0.0004
0.2
LASSO
0.881
0.383
0.420
0.408
0.411
0.421
2.923
43.7 (99.3%)
0.7651
0.1462 0.0016
LAD-LASSO
0.134
0.075
0.151
0.129
0.120
0.110
0.718
43.6 (99.1%)
0.9399
0.1039 0.0014
canal-LASSO
0.055
0.021
0.104
0.054
0.062
0.032
0.328
43.3 (98.4%)
0.9526
0.0981 0.0016
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9569
0.0958 0.0006
0.3
LASSO
0.855
0.624
0.609
0.587
0.595
0.606
3.876
42.9 (97.5%)
0.5231
0.1714 0.0020
LAD-LASSO
0.596
0.286
0.329
0.303
0.325
0.390
2.229
40.2 (91.4%)
0.8066
0.1366 0.0044
canal-LASSO
0.464
0.205
0.216
0.236
0.292
0.334
1.747
41.4 (94.1%)
0.8536
0.1269 0.0086
ORACLE
0.000
0.000
0.000
0.000
0.000
0.000
0.000
44 (100.0%)
0.9544
0.0954 0.0005
Simulation results for noisy covariate .
When response variable are contaminated, each coefficient may be affected. Considering the overall impact of noise , we focus on that emphasizes the overall variation of . As can be seen from the column of in Table 5, the proposed canal-LASSO outperforms the two competing methods (LASSO, LAD-LASSO) significantly in noisy data cases. Due to the least square deviation, original LASSO method is very sensitive to noise data. For the estimation of , LASSO deviate severely from true value coefficient than LAD-LASSO and canal-LASSO. Compared to least square deviation, least absolute deviation (LAD) can effectively reduce the impact of noise data, but the negative impact of noise is still serious. To compare the models more comprehensively, the prediction performances of different models are listed in Fig. 6. As can be observed, the average performance of canal-LASSO outperforms LASSO and LAD-LASSO in noisy output cases. It indicates that canal-LASSO is a noise-resilient method to deal with noisy data when the response variable is contaminated.
Details of benchmark datasets
Dataset
#Samples
#Features
#Train number
#Test number
Kin
3000 3
8
2100 3
900 3
Abalone
4177 3
7
2924 3
1253 3
Letters
5000 3
15
3500 3
1500 3
Pendigits
7129 3
14
4990 3
2139 3
Parameter setting of canal loss for four benchmark datasets
Dataset
Kin
Abalone
Letters
Pendigits
0.1
0.1
0.1
0.1
1.2
1.4
1.6
1.6
Simulation results for noisy response variable .
Benchmark data sets
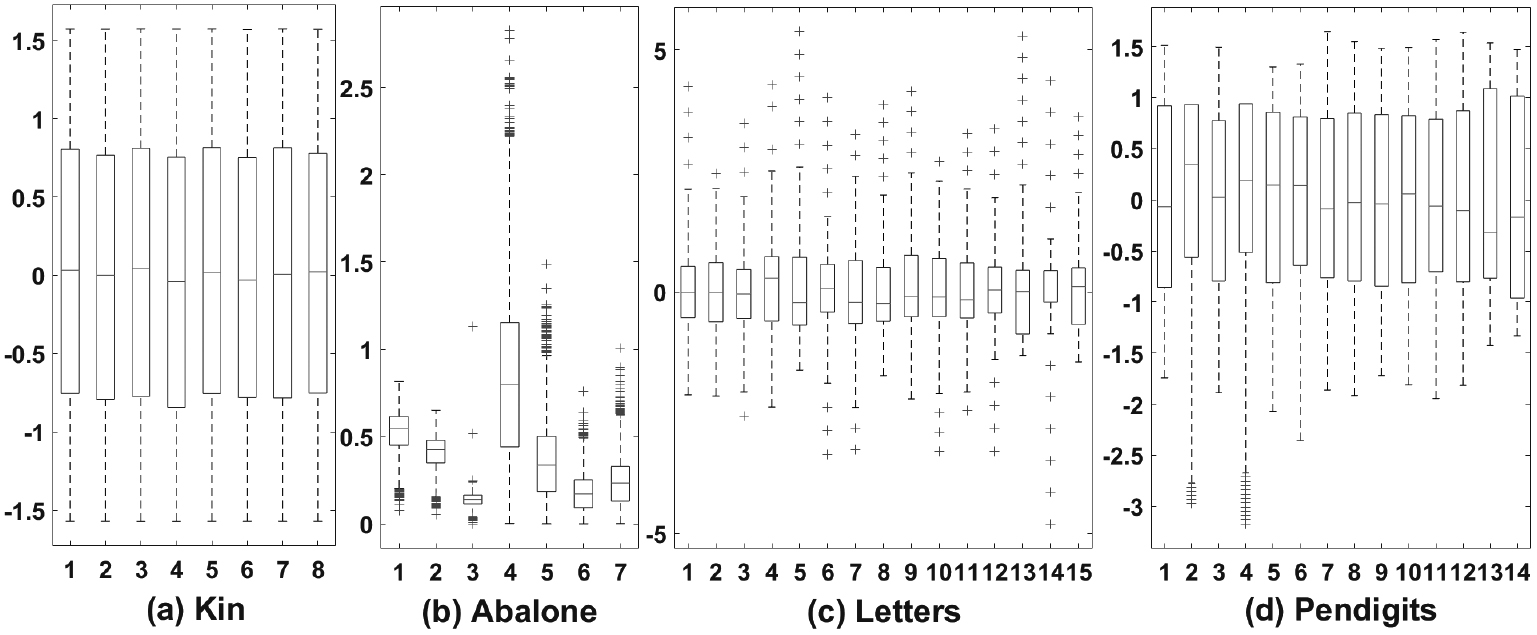
In this subsection, we conduct extensive experiments to evaluate the performance of the proposed online canal-LASSO algorithm on linear regression tasks. Four benchmark datasets including “Kin”, “Abalone”, “Letters” and “Pendigits” are used for the experimental evaluation. Details of the datasets used in this experiment are listed in Table 6. In order to show the statistical properties of different data sets, we drew a box plot as shown in Fig. 7. Before the experiment, the parameter sensitivity of our model should be analyzed and designated by domain expert according to the parameter sensitivity study in Section 4.1. For four benchmark datasets, our parameter settings are shown in Table 7. To simulate the setting of streaming data, we duplicate the samples by three times. Additionally, all the experiments are randomly performed 20 times repeatedly and the average performance is reported.
Experimental results on benchmark datasets
Dataset
Method
RMSE
MAE
Discarded samples
Discarded rate
Time (s)
Kin
0
LASSO
0.0715 0.0006
0.2166 0.0049
0
0
0.0%
0.3676 0.0677
LAD-LASSO
0.0720 0.0004
0.2208 0.0033
0
0
0.0%
0.3854 0.0416
canal-LASSO
0.0719 0.0003
0.2199 0.0026
657
22
7.3%
0.3829 0.0259
0.1
LASSO
0.0730 0.0006
0.2238 0.0034
0
0
0.0%
0.3797 0.0692
LAD-LASSO
0.0720 0.0006
0.2188 0.0036
0
0
0.0%
0.4057 0.0762
canal-LASSO
0.0718 0.0005
0.2199 0.0039
1499
32
16.7%
0.4028 0.0636
0.2
LASSO
0.0764 0.0009
0.2453 0.0065
0
0
0.0%
0.3532 0.0213
LAD-LASSO
0.0736 0.0006
0.2270 0.0037
0
0
0.0%
0.3716 0.0184
canal-LASSO
0.0718 0.0005
0.2200 0.0037
2337
24
26.0%
0.3717 0.0246
0.3
LASSO
0.0806 0.0004
0.2732 0.0022
0
0
0.0%
0.3607 0.0186
LAD-LASSO
0.0771 0.0010
0.2490 0.0064
0
0
0.0%
0.3714 0.0225
canal-LASSO
0.0720 0.0003
0.2202 0.0024
3171
21
35.2%
0.3752 0.0238
Abalone
0
LASSO
0.2261 0.0016
2.3521 0.0295
0
0
0.0%
0.5315 0.0336
LAD-LASSO
0.2290 0.0020
2.3600 0.0420
0
0
0.0%
0.5562 0.0217
canal-LASSO
0.2281 0.0021
2.3735 0.0390
1349
31
10.8%
0.5628 0.0241
0.1
LASSO
0.2333 0.0029
2.3884 0.0572
0
0
0.0%
0.5433 0.0263
LAD-LASSO
0.2321 0.0022
2.3813 0.0353
0
0
0.0%
0.5697 0.0242
canal-LASSO
0.2280 0.0022
2.3945 0.0433
2516
39
20.1%
0.5655 0.0284
0.2
LASSO
0.2516 0.0026
2.7840 0.0578
0
0
0.0%
0.5315 0.0236
LAD-LASSO
0.2358 0.0020
2.4291 0.0490
0
0
0.0%
0.5782 0.0265
canal-LASSO
0.2300 0.0015
2.4129 0.0288
3681
22
29.4%
0.5664 0.0163
0.3
LASSO
0.2652 0.0039
3.1682 0.1161
0
0
0.0%
0.5546 0.0356
LAD-LASSO
0.2411 0.0029
2.4951 0.0702
0
0
0.0%
0.5766 0.0164
canal-LASSO
0.2292 0.0033
0.2202 0.0024
4863
23
38.8%
0.5720 0.0422
Letters
0
LASSO
0.3345 0.0011
6.5444 0.0443
0
0
0.0%
0.7345 0.0299
LAD-LASSO
0.3310 0.0009
6.3388 0.0633
0
0
0.0%
0.7462 0.0442
canal-LASSO
0.3321 0.0009
6.3192 0.0474
1307
22
8.7%
0.7475 0.0281
0.1
LASSO
0.3370 0.0011
6.6093 0.0458
0
0
0.0%
0.7240 0.0296
LAD-LASSO
0.3360 0.0017
6.4904 0.0745
0
0
0.0%
0.7664 0.0619
canal-LASSO
0.3349 0.0017
6.4423 0.0878
2684
25
17.9%
0.7280 0.0282
0.2
LASSO
0.3441 0.0024
6.7572 0.1015
0
0
0.0%
0.7146 0.0257
LAD-LASSO
0.3519 0.0014
6.9318 0.0622
0
0
0.0%
0.7539 0.0587
canal-LASSO
0.3404 0.0017
6.6541 0.0806
4496
35
30.0%
0.7429 0.0455
0.3
LASSO
0.3561 0.0026
7.1115 0.1078
0
0
0.0%
0.7183 0.0343
LAD-LASSO
0.3764 0.0021
7.6620 0.1152
0
0
0.0%
0.7700 0.0372
canal-LASSO
0.3419 0.0019
6.7535 0.0791
5386
22
35.9%
0.7556 0.0368
Pendigits
0
LASSO
0.1898 0.0005
2.5112 0.0199
0
0
0.0%
1.2365 0.0474
LAD-LASSO
0.1875 0.0007
2.4515 0.0324
0
0
0.0%
1.2491 0.0335
canal-LASSO
0.1884 0.0008
2.4805 0.0285
2497
25
10.2%
1.2647 0.0544
0.1
LASSO
0.1914 0.0009
2.5208 0.0273
0
0
0.0%
1.2485 0.0296
LAD-LASSO
0.1895 0.0010
2.4600 0.0285
0
0
0.0%
1.2697 0.0733
canal-LASSO
0.1880 0.0011
2.4776 0.0373
4365
15
17.8%
1.2541 0.0370
0.2
LASSO
0.1936 0.0005
2.5733 0.0123
0
0
0.0%
1.2719 0.0629
LAD-LASSO
0.1973 0.0010
2.5898 0.0293
0
0
0.0%
1.3072 0.0983
canal-LASSO
0.1871 0.0008
2.4594 0.0247
6271
16
25.5%
1.2847 0.0636
0.3
LASSO
0.1992 0.0011
2.6751 0.0226
0
0
0.0%
1.2328 0.0375
LAD-LASSO
0.2124 0.0023
2.9270 0.0649
0
0
0.0%
1.2500 0.0431
canal-LASSO
0.1874 0.0009
2.4696 0.0315
8130
14
33.1%
1.2756 0.0587
Box plots of four benchmark datasets.
Experimental results on benchmark datasets.
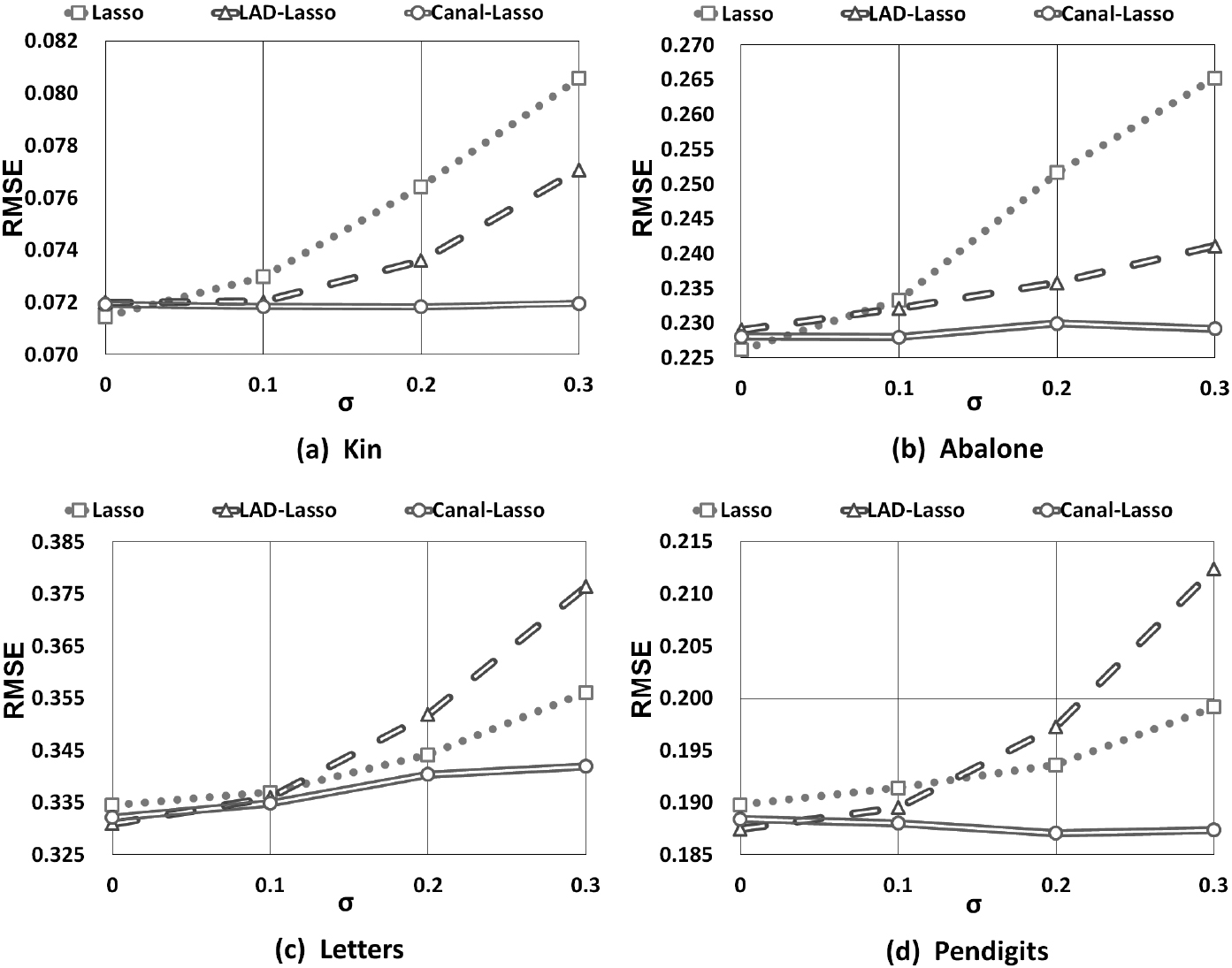
Table 8 shows the running time, discarded rate and the regression accuracy (RMSE and MAE) of three compared methods, i.e., LASSO, LAD-LASSO, and canal-LASSO on the benchmark datasets. The column of RMSE and MAE show that the performance of three compared methods is similar when data is clean ( 0). But in the scenario of noisy data ( 0.1, 0.2 and 0.3), the proposed canal-LASSO outperforms LASSO and LAD-LASSO. Moreover, the performance of canal-LASSO is steady in both cases of clean data and noisy data. The column of discarded rate shows that the only partial of learning samples are learned by the canal-LASSO model. The discarded rate increases according to the noise level parameter . As the running time is concerned, thanks to the efficient OGD framework, it can be observed that LASSO, LAD-LASSO and canal-LASSO only takes little running time. To have a more comprehensive comparison, we show the average RMSE in Fig. 8. On datasets “Kin” and “Abalone”, LASSO is more sensitive to noise. However, on datasets “Letters” and “Pendigits”, LAD-LASSO is more sensitive to noisy data. The proposed canal-LASSO is the most stable one on all of the four datasets, so it is a good candidate to deal with noisy data streams.
Conclusion
In this work, we have studyed a novel problem of online learning from noisy data streams and proposed a linear regression model canal-LASSO. Furthermore, an efficient algorithm based on the online gradient descend framework is presented to solve canal-LASSO. Simulated experiments have shown that the proposed canal-LASSO is noise-resilient in the scenarios of both noisy covariate and response variable . At last, we have conducted extensive experiments on benchmark datasets to validate that canal-LASSO is robust and a good candidate to deal with noisy data streams. Future work will involve extending the linear regression model to non-linear regression model by the introducing of kernel trick [38].
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant No. 61873279, National Key Research and Development Program of Shandong Province under Grant No. 2018GSF120020, National Natural Science Foundation of Shandong Province under Grant No. ZR2019MA016, and Fundamental Research Funds for the Central Universities under Grant No. 20CX05003B.
References
1.
MeinshausenN. and BühlmannP., Stability selection, Journal of the Royal Statistical Society: Series B (Statistical Methodology)72(4) (2010), 417–473.
2.
TibshiraniR., Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society58(1) (1996), 267–288.
3.
FanJ. and LiR., Variable selection via nonconcave penalized likelihood and its oracle properties, Journal of the American Statistical Association96(456) (2001), 1348–1360.
4.
ZouH., The adaptive lasso and its oracle properties, Journal of the American Statistical Association101(476) (2006), 1418–1429.
5.
BloomfieldP. and SteigerW.L., Least absolute deviations: Theory, applications and algorithms, Springer, 1984.
6.
WangH.LiG. and JiangG., Robust regression shrinkage and consistent variable selection through the lad-lasso, Journal of Business & Amp; Economic Statistics25(3) (2007), 347–355.
7.
BottouL., Large-scale machine learning with stochastic gradient descent, in: Proceedings of COMPSTAT’2010, Springer, 2010, pp. 177–186.
8.
DitzlerG.RoveriM.AlippiC. and PolikarR., Learning in nonstationary environments: A survey, IEEE Computational Intelligence Magazine10(4) (2015), 12–25.
9.
SunD. and HuangR., A stable online scheduling strategy for real-time stream computing over fluctuating big data streams, IEEE Access4 (2016), 8593–8607.
10.
AggarwalC.C., Data streams: models and algorithms, Vol. 31, Springer Science & Amp; Business Media, 2007.
11.
GamaJ., Knowledge discovery from data streams, Intelligent Data Analysis13(3) (2009), 403–404.
12.
JianL.LiJ. and LiuH., Toward online node classification on streaming networks, Data Mining and Knowledge Discovery32(1) (2018), 231–257.
13.
JianL.GaoF.RenP.SongY. and LuoS., A noise-resilient online learning algorithm for scene classification, Remote Sensing10(11) (2018), 1836.
14.
LeoBreiman, Better subset regression using the nonnegative garrote, Technometrics37(4) (1995), 373–384.
15.
HastieT. and MallowsC., A statistical view of some chemometrics regression tools: Discussion, Technometrics35(2) (1993), 140–143.
16.
ZhangC.H., Nearly unbiased variable selection under minimax concave penalty, Annals of Statistics38(2) (2010), 894–942.
17.
ZouH. and HastieT., Regularization and variable selection via the elastic net, Journal of the Royal Statistical Society: Series B (Statistical Methodology)67(2) (2005), 301–320.
18.
YuanM. and LinY., Model selection and estimation in regression with grouped variables, Journal of the Royal Statistical Society: Series B (Statistical Methodology)68(1) (2006), 49–67.
19.
WangX.JiangY.HuangM. and ZhangH., Robust variable selection with exponential squared loss, Journal of the American Statistical Association108(502) (2013), 632–643.
20.
ChangL.RobertsS. and WelshA., Robust lasso regression using tukey’s biweight criterion, Technometrics60(1) (2018), 36–47.
21.
XuS. and ZhangC.-X., Robust sparse regression by modeling noise as a mixture of gaussians, Journal of Applied Statistics46(10) (2019), 1738–1755.
22.
ZuradaJ.M., Introduction to artificial neural systems, Vol. 8, West publishing company St. Paul, 1992.
23.
BhadeshiaH., Neural networks and information in materials science, Statistical Analysis and Data Mining: The ASA Data Science Journal1(5) (2009), 296–305.
24.
GunnS.R. et al., Support vector machines for classification and regression, ISIS Technical Report14(1) (1998), 5–16.
25.
WangZ. and VuceticS., Online training on a budget of support vector machines using twin prototypes, Statistical Analysis and Data Mining: The ASA Data Science Journal3(3) (2010), 149–169.
26.
AggarwalC.C., Data mining: the textbook, Springer, 2015.
27.
BottouL., Online learning and stochastic approximations, On-line Learning in Neural Networks17(9) (1998), 142.
28.
ArceP. and SalinasL., Online ridge regression method using sliding windows, in: Chilean Computer Science Society (SCCC), 2012 31st International Conference of the, IEEE, 2012, pp. 87–90.
29.
GaoF.SongX.JianL. and LiangX., Toward budgeted online kernel ridge regression on streaming data, IEEE Access7 (2019), 26136–26145.
30.
MontiR.P.AnagnostopoulosC. and MontanaG., Adaptive regularization for lasso models in the context of nonstationary data streams, Statistical Analysis and Data Mining: The ASA Data Science Journal11(5) (2018), 237–247.
31.
OrabonaF.KeshetJ. and CaputoB., The projectron: a bounded kernel-based perceptron, in: Proceedings of the 25th International Conference on Machine Learning, ACM, 2008, pp. 720–727.
32.
ZhaoP.WangJ.WuP.JinR. and HoiS.C., Fast bounded online gradient descent algorithms for scalable kernel-based online learning, arXiv preprint arXiv:1206.4633.
33.
GarriguesP. and GhaouiL.E., An homotopy algorithm for the lasso with online observations, in: Advances in Neural Information Processing Systems, 2009, pp. 489–496.
34.
HuangX.ShiL. and SuykensJ.A., Ramp loss linear programming support vector machine, The Journal of Machine Learning Research15(1) (2014), 2185–2211.
35.
RobbinsH. and MonroS., A stochastic approximation method, The Annals of Mathematical Statistics (1951), 400–407.
36.
BlakeC. and MerzC., Uci repository of machine learning databases, department of information and computer science, University of California, Irvine, CA 55.
37.
ChangC.-C. and LinC.-J., Libsvm: A library for support vector machines, ACM Transactions on Intelligent Systems and Technology (TIST)2(3) (2011), 27.
38.
LiuW.PokharelP.P. and PrincipeJ.C., The kernel least-mean-square algorithm, IEEE Transactions on Signal Processing56(2) (2008), 543–554.