
Abstract
Clustering algorithm is the foundation and important technology in data mining. In fact, in the real world, the data itself often has a hierarchical structure. Hierarchical clustering aims at constructing a cluster tree, which reveals the underlying modal structure of a complex density. Due to its inherent complexity, most existing hierarchical clustering algorithms are usually designed heuristically without an explicit objective function, which limits its utilization and analysis.
Introduction
Clustering is a basic and important technique for exploratory data analysis [26, 25, 31, 32]. However, flat clustering(partition-based) methods, e.g.,
Although hierarchical structure is ubiquitous in real world [15, 4, 10, 21, 28], it is usually difficult to explore the underlying hierarchical structure in practice due to its intrinsic complexity. Therefore, most existing methods usually employ heuristic or/and greedy strategies to constructing hierarchical structure. Generally, these methods can be roughly categorized into two lines, i.e., agglomerative [8, 11, 7] and divisive [12, 9, 13] based. Both of these two types usually construct a hierarchical structure in the single-pass manner, i.e., constructing a tree in one pass, and thus there is no guarantee for the hierarchical structure to be globally reasonable and it is generally difficult to be further improved. For example, agglomerative hierarchical clustering performs tree construction with a bottom-up merging manner, which starts with assigning each data point with a separate cluster and then recursively merges clusters that are similar according to predefined metric. The merging rules are usually heuristics (e.g. Euclidean distance between cluster means or distance between nearest points). These existing methods may be effective in practice, but they are not yet well-understood. The main reason lies in that these methods are specified procedurally rather than in terms of the objective functions they are trying to optimize [14]. With an explicit objective function, the problem definition is more clear and convenient to analyze.
Bayesian hierarchical 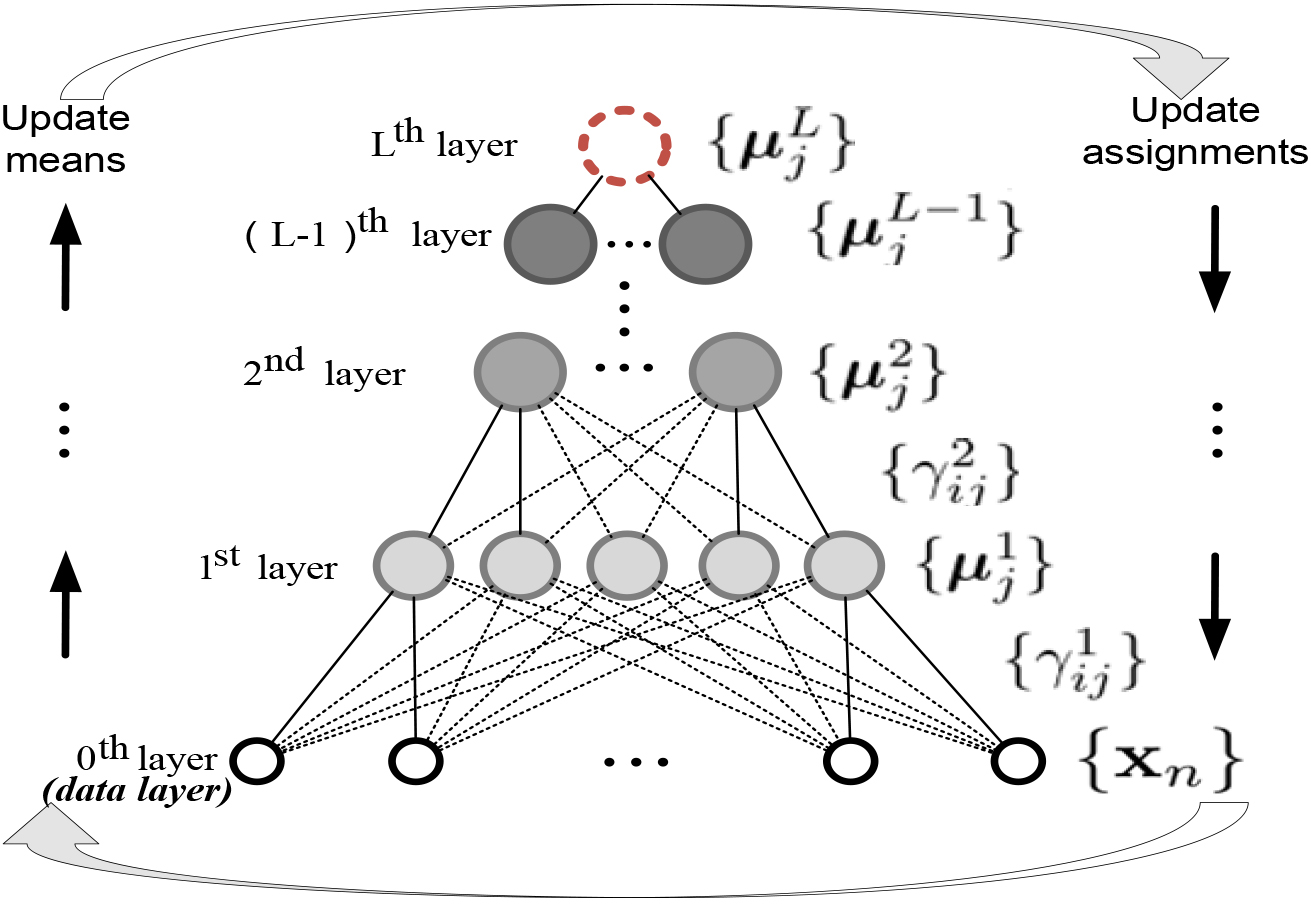
The recent work in [14] proposes a cost function which assigns a score to any possible tree with given pairwise similarities between data points. The tree corresponds to the hierarchical decomposition of the data and its score reflects the quality of the solution. Unfortunately, the objective function of this method is NP-hard to optimize. Although the performance is improved by introducing the ultrametrics [23], the computation complexity is still an issue. Instead of complex objective functions, under the hierarchical Bayesian model [20], we introduce a novel explicit objective function for hierarchical clustering from the view of probability distribution, which could be easily optimized. Bayesian hierarchical models have been widely used in many applications, including computer vision [1, 4, 33], decision making [3, 5], signal processing [6]. Specifically, based on the well-known
The existing Bayesian methods (e.g., [2]) usually predefine a prior placed over all possible trees and then perform sampling from the posterior distribution given the observations. Thus, these methods tend to be rather complex and difficult to optimize, which has also been recognized by the reference [14]. In our paper, we provide a simple, interpretable and effective global objective function for hierarchical clustering. Based on the Bayesian hierarchical model, our model is derived and in the form of hierarchical
To summarize, the main contribution of this work includes:
We propose an explicit objective function for hierarchical clustering, termed as Bayesian hierarchical In our method, we construct a cascade clustering tree in which all layers interact in the network-like manner. According to the global hierarchical clustering objective function, the clustering results of each layer are improved dynamically, and be solved with Expectation-maximization algorithm.
Hierarchical clustering result on toy data (selected from Caltech-256 Object Category Dataset [30]). The non-leaf nodes are visualized by averaging the images contained in the corresponding clusters. The dashed green rectangles indicate clusters discovered, while the highlighted images with red borders are wrongly clustered.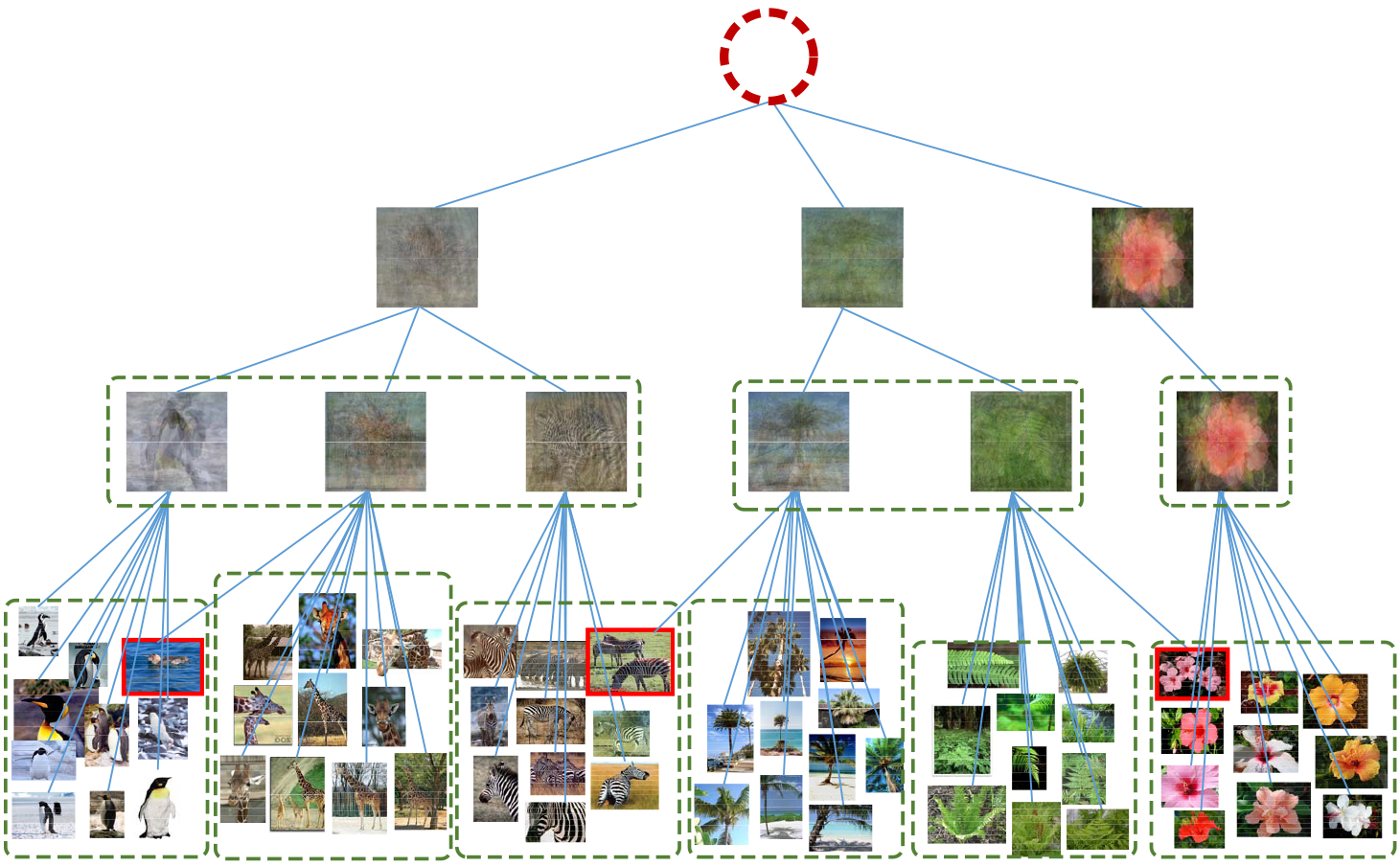
The most well-known hierarchical clustering models construct the tree structure based on a bottom-up agglomerative way, i.e., single linkage (SL), average linkage (AL), and complete linkage (CL) [8], and the variants [42]. These methods are usually equipped with heuristic strategies instead of designing explicit objective functions to optimize. Thus the performances are much lower than those of other clustering methods with global objective functions. On the other hand, the method [14] proposes an explicit cost function for hierarchical clustering by considering the entire structure of the tree, and is further improved by HCSM [23] in computational complexity under the reasonable approximation. However, its computational cost is still high, which makes it is difficult to handle a large dataset. In the context of systematic genetics and taxonomy [37, 38, 39], some hierarchical clustering methods have been proposed. The LP (linear programming) relaxation of hierarchical clustering was studied in [40], where the goal is fitting a tree metric to given pairwise dissimilarities of data. Different from above methods, our method utilizes an interpretable, effective and efficient global objective function for hierarchical clustering under the hierarchical probability framework. Our method achieves a balance between the performance and computation. The computation complexity of our method is comparable with the complexity of
Background
-means clustering with Mixture of Gaussians
where
Based on the above, the assignment probability can be induced as
where the covariance matrices of these mixture components are given by
where
Based on the above analysis, it is observed that there is a close connection between
The connection between MoG and
where
Accordingly, by using Bayes’ theorem, we can maximize the following posterior to obtain model parameters, it is
The likelihood
In this section, we will introduce our Bayesian hierarchical
Bayesian hierarchical Mixture of Gaussian
Our goal is multi-layer hierarchical clustering, so we extend the above two-stage model to multi-stage Bayesian hierarchical one. Specifically, we extend MoG to hierarchical MoG under Bayesian hierarchical model. By denoting the parameter of the
where parameter (e.g.,
Specifically, for multi-layer model we have
Note that, similarly to the above mentioned two-layer hierarchical model, the likelihood depends on
The generation of the parameter corresponding to the
where
According to Eqs (3)–(5), we maximize the likelihood of the observed data and obtain the following
where
Similarly, by maximizing the posterior probability
Intuitively, by directly summing together SSE (Sum Square Error) of different layers as in Eq. (15), the adjacent layers are dependent and could interact with each other. This makes the hierarchical clustering result towards a global reasonable structure which is different from the greedy manner.
For conciseness, we define
where weight factor
We optimize our objective function in Eq. (4.2) layer by layer, and alternatively optimize the objective function with respect to
Accordingly, we can update
Note that, the updating of cluster centers of the current layer
In practice, we initialize our hierarchical model with
Remarks
Firstly, our method is exactly induced from the Bayesian hierarchical model. Both
Experiment setting
Dataset
There are 4 datasets from the UCI Machine Learning Repository,1
Compared methods
We compare our proposed approach with several hierarchical clustering methods, including conventional agglomerative single linkage (SL)/complete linkage (CL)/average linkage(AL), binary
Evaluation metrics
Due to Euclidean distance involved in all compared methods except the method in [23], SSE (Sum Square Error) is reasonable to evaluate the cluster compactness. Different metrics prefer different properties, thus we employ three diverse types of metrics, i.e., SSE as the internal criterion, Normalized mutual information (NMI) and Accuracy (ACC) as external criterion and dendrogram purity as external criterion for hierarchical structure. For all these metrics, the higher value indicates the better clustering performance. Note that, like the work [7], we employ dendrogram purity (DPurity) as the main metric since it is used to evaluate the hierarchical structure. We specify the definition of accuracy used in our experiments as follows. Given a sample
where
where the probabilities
Visualization of clustering results on synthetic data with t-SNE [22]. The first row and bottom row with dash borders correspond to the results of SPHK and our BHK-means, respectively. The parts marked with solid rectangles demonstrate the results with clear differences between SPHK and our BHK-means.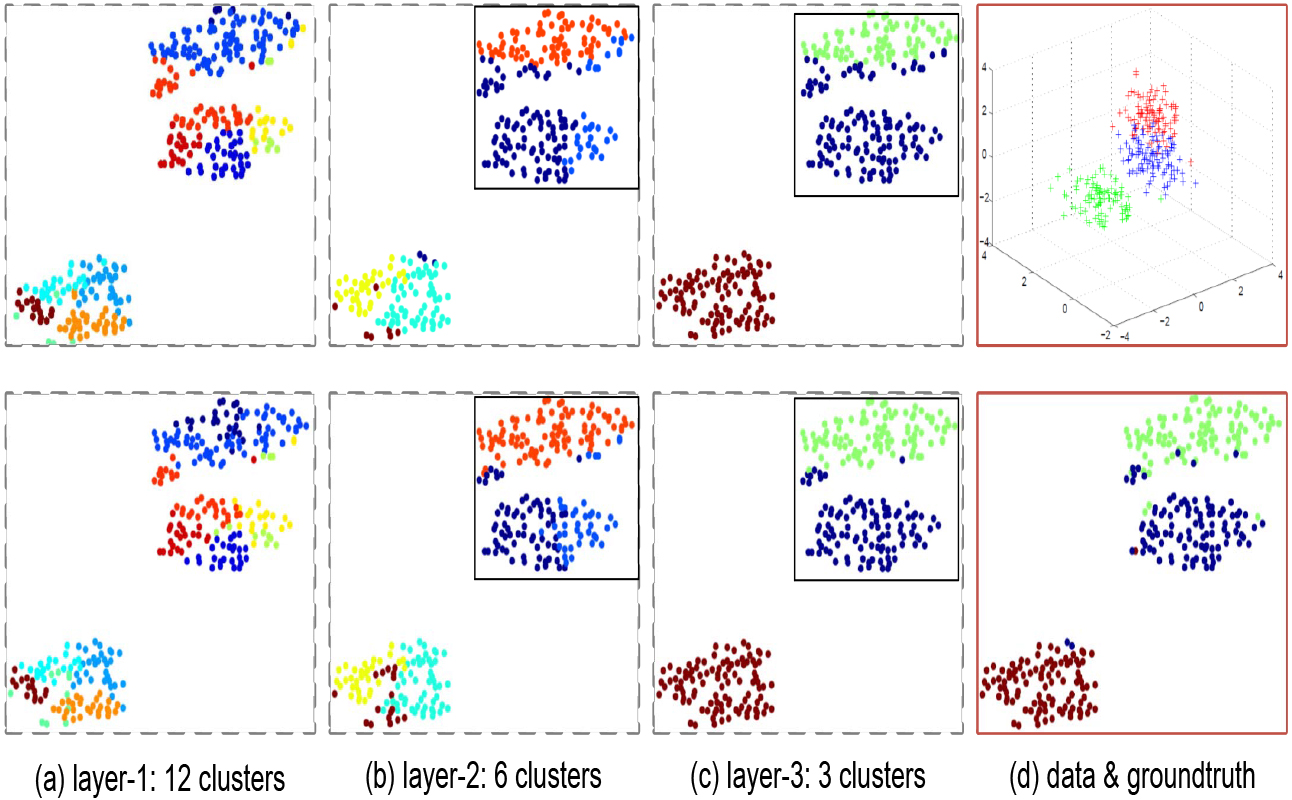
Firstly, we generate synthetic data from three different Gaussian distributions, with 100 data points sampled from each Gaussian, as shown in Fig. 3d. The means of these three Gaussians are [0.5, 0.5, 0.5], [1.5, 1.5, 1.5] and [
Results on real-world datasets
To specify the number of clusters at each layer, firstly we suppose the ground truth number of classes is
Evaluation with internal criterion
Firstly, we provide experimental results to evaluate our method on 4 UCI datasets in terms of the internal criterion, i.e., two SSE metrics: cluster-oriented SSE and data-oriented SSE. The first one measures the compactness of a cluster on the
Hierarchical clustering comparison in terms of SSE (normalized to [0, 1]) with respect to original data points and cluster centers, receptively. For the bottom row, dash lines are performance curves of 5 random runs and solid lines indicate the averaged ones. Unlike SPHK in the greedy manner, our model seeks the optimal hierarchical tree structure from a holistic view.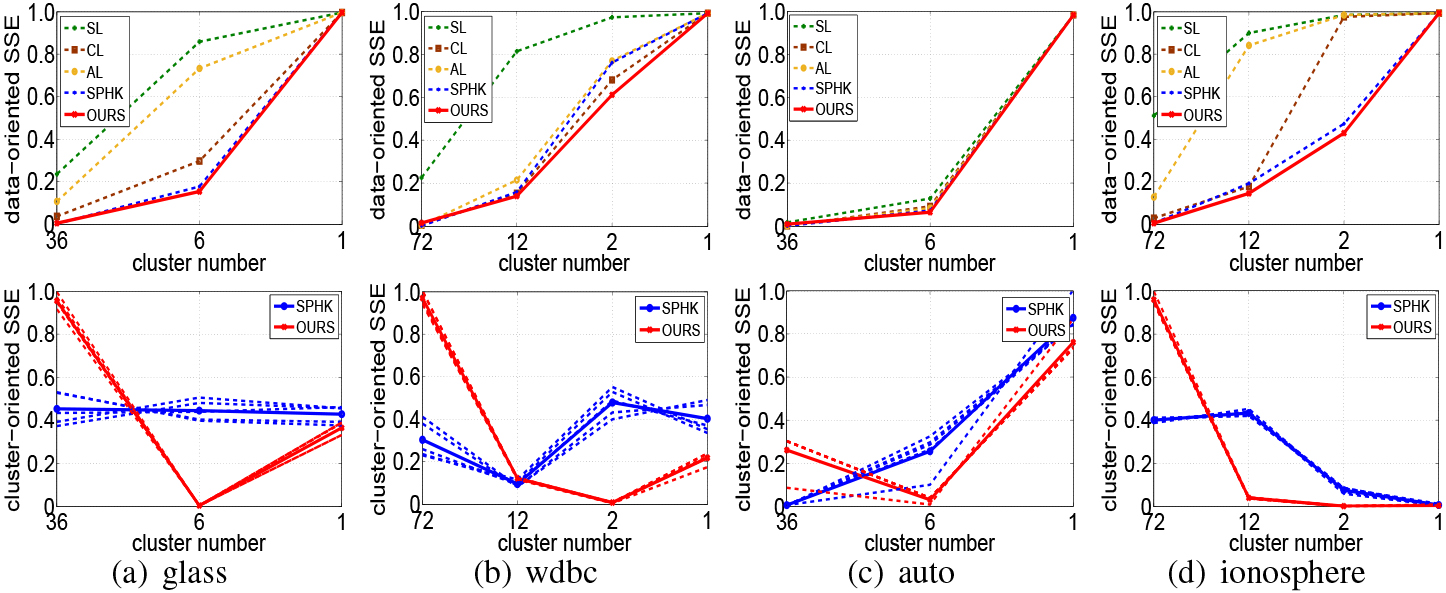
Performance (mean
Evaluation with external criterion
With the ground truth label, we evaluate clustering results at the layer with
Different from above methods, our method utilizes an interpretable, effective and efficient global objective function for hierarchical clustering under the hierarchical probability framework. Our method achieves a balance between the performance and computation. The computation complexity of our method is comparable with the complexity of
Time (mean
Performance (mean
Convergence curves on benchmark datasets.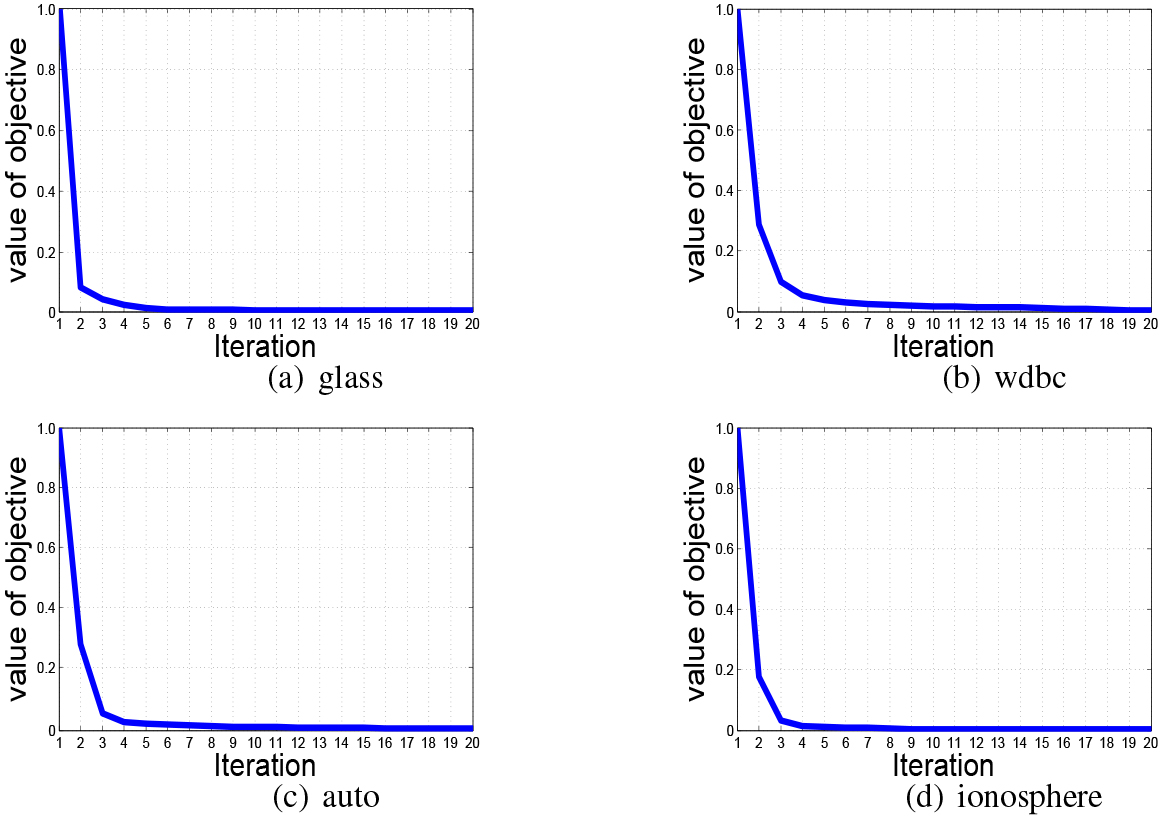
Different from existing hierarchical methods [23, 1] which conducted experiments on small dataset limited by their high computational cost, we also use 2 relatively large image datasets in our experiments, i.e., Natural Scene Category Dataset [1]2
We also conduct experiment on the dataset SUN [29]4
Performance comparison on SUN.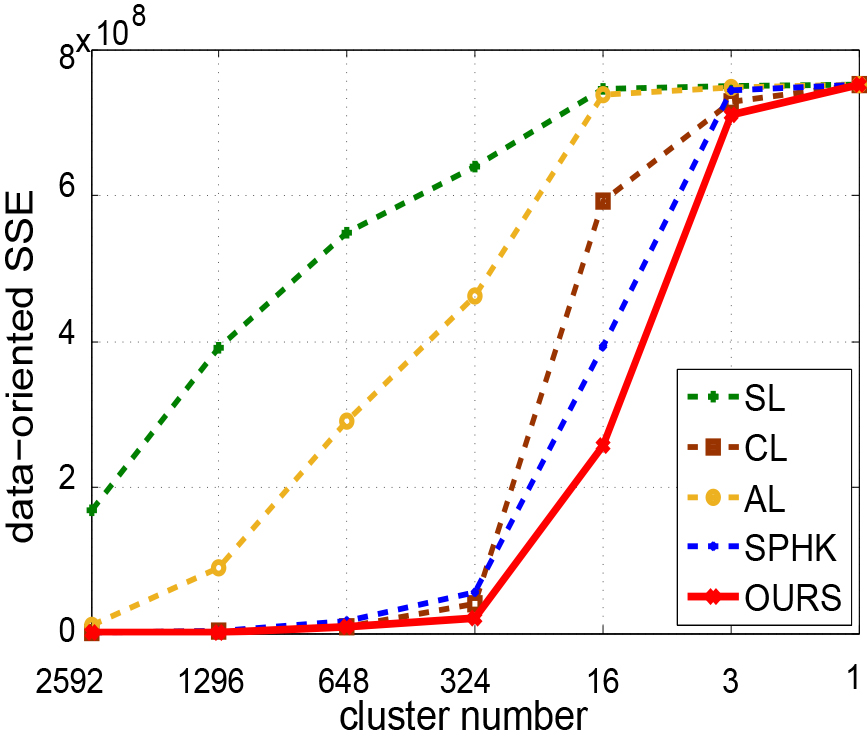
In this paper, we have presented a simple yet effective model for hierarchical clustering. Our method has an explicit objective function which makes the model more interpretable over traditional approaches. Moreover, our model holds a clear interpretation from the view of hierarchical probability model. Compared with the most recent method [23] which also provides an explicit objective function, empirical results validated that our method is more effective and efficient. The limitations of our approach include the bias towards spherical clusters and the computational complexity inherited from