
Abstract
Time series similarity search is an essential operation in time series data mining and has received much higher interest along with the growing popularity of time series data. Although many algorithms to solve this problem have been investigated, there is a challenging demand for supporting similarity search in a fast and accurate way. In this paper, we present a novel approach, TS2BC, to perform time series similarity search efficiently and effectively. TS2BC uses binary code to represent time series and measures the similarity under the Hamming Distance. Our method is able to represent original data compactly and can handle shifted time series and work with time series of different lengths. Moreover, it can be performed with reasonably low complexity due to the efficiency of calculating the Hamming Distance. We extensively compare TS2BC with state-of-the-art algorithms in classification framework using 61 online datasets. Experimental results show that TS2BC achieves better or comparative performance than other the state-of-the-art in accuracy and is much faster than most existing algorithms. Furthermore, we propose an approximate version of TS2BC to speed up the query procedure and test its efficiency by experiment.
Introduction
A time series is a sequence of real numbers, each of which represents a value measured at a point in time. In recent years, time series have extended to many scientific and social domains, including medicine [1], economics [2], engineering fields [3], and so on. With the growing popularity of time series data, there are various kinds of time series related research, an important one which has received an increasing amount of attention lately is the similarity search in time series databases.
Similarity search is of great significance for time series prediction [4], clustering [5], classification [6] and knowledge discovery [7]. Therefore, the problem of time series similarity search has been the focus of many research activities in the data mining community for the past few years. A multitude of methods have been proposed [8, 9, 10, 11]. Most of them can be classified as one of two types [11]:
Time series representation. Time series are always high-dimensional data. Therefore, working directly on the raw data requires a lot of computing resources and storage space. Thus, representing a time series in a concise form is an essential step of time series similarity search. Additional benefits gained are efficient storage, speedup of processing, as well as implicit noise removal [12]. The ideal representation method should be computationally efficient and significantly reduce data dimensionality. Besides, it should be able to maintain the essential characteristics of the raw data.
Similarity measure. The similarity measure is of fundamental importance for a variety of time series analysis and data mining tasks. Most time series analysis techniques, including clustering, classification and querying, critically depend on the choice of similarity measure. However, devising a similarity function in the time series domain is by no means trivial. It should be consistent with human intuition and can consider the most salient features on both local and global scales. Moreover, similarity measure should be performed with reasonably low complexity.
Although many representation techniques and similarity measures have been investigated, most of them can not solve the problem of time series similarity search perfectly, due to some basic requirements which should be satisfied by all methods.
Low computational cost. Time series are mostly high-dimensional data. Therefore, a method should be performed with low computational complexity for computing the representation or similarity measure.
Capability to handle shifted time series. Commonly, time series in a database are shifted in the time axis [13]. From the perspective of human cognition, two shifted time series are very similar to each other. However, not all similarity measures can handle this type of similarity.
Capability to deal with time series of unequal lengths. Some algorithms can only address time series of the same length. However, in practical scenarios, most of the time series are not equal in length, which leads to severe limitations for these algorithms in practical applications.
Each proposed method offers different trade-offs between the requirements listed above. For example, the Euclidean Distance and, in general,
Based on the above requirements, in this paper, we propose a novel method named TS2BC (
TS2BC is devised based on the intuition that similar time series always pass through similar cells in a plane. It is consistent with human cognition and can be applied to different kinds of datasets. TS2BC can handle shifted time series and remove the effects of noise and missing values by using appropriate parameters and can deal with time series of unequal lengths. Besides, it has low computational complexity to calculate the representation and similarity measure.
The main contributions of our work are as follows:
We propose a novel approach, TS2BC, which can handle time series similarity search efficiently by transforming time series into binary codes in linear time and using Hamming Distance to measure the similarity between pairwise time series. We present an approximate version of TS2BC (ATS2BC) to speed our approach up because there are many situations in which a user would be willing to sacrifice some accuracy for a significant speedup. To demonstrate the efficiency and effectiveness of the proposed approach, we conduct extensive experiments on public datasets by using classification frameworks. Experimental results show that our proposed method can achieve better or comparative performance in accuracy than other state-of-the-art algorithms, and can achieve much higher efficiency than most existing algorithms.
The rest of the paper is organized as follows. Section 2 introduces the related works on time series representation methods and similarity measures. Section 3 presents the TS2BC algorithm in detail and Section 4 discusses some important aspects of TS2BC. Approximate version of the TS2BC can be found in Section 5. Section 6 shows the experimental results. Finally, the paper is concluded in Section 7.
Time series similarity search is mainly studied in two aspects, time series representation and similarity measure. In this section, we briefly introduce the representation methods and similarity measures.
Time series representations
Representing a time series in a concise form that can be effectively processed is an essential step of time series similarity search.
Piecewise Aggregate Approximate (PAA) [21] reduces the time series from
Most of the techniques described so far are representing time series data in the time domain directly. Representing time series in the transformation domain is another large family of methods. These commonly used representations include Discrete Fourier Transform (DFT) [29], Single Value Decomposition (SVD) [30], Discrete Wavelet Transform (DWT) [31], and Chebyshev Polynomials (CP) [32].
Recently, in [9], the authors present an algorithm named STS3, which can transform time series into sets. It is the first work using set techniques to accelerate time series search. Inspired by the idea of STS3, in this work, we present a binary code-based representation method for time series. The STS3 algorithm has played a significant role in the design of our method and will be discussed at greater depth in Sections 4.1 and 6.2.
Time series similarity measures
The similarity measure is a significant aspect of similarity search in time series data mining. Given two time series
The simplest way to estimate the similarity between two time series is the lock-step measure [14], which compares the
Unlike the lock-step measure, elastic measure allows comparison of one-to-many/one-to-none points. For example, Dynamic Time Warping (DTW) [16] is a classic elastic measure for executing similarity search in time series. DTW is more robust than ED and can handle shifted time series and time series with different lengths. DTW has been successfully used for time series similarity search and shown to be very hard to beat [33, 34, 14]. It can be computed using dynamic programming with time complexity
Based on the proposed binary code-based representation method, in this paper, a matching algorithm, Hamming Distance, is adapted to measure the similarity between pairwise time series.
Approach: TS2BC
In this section, we present our novel approach, Time Series to Binary Code (TS2BC). We will briefly introduce the background and overview of the TS2BC, followed by a detailed introduction of our algorithm.
Background and overview
A time series is defined as a sequence of pairs
In order to make meaningful comparisons between two time series, both must be normalized [42]. Therefore, before we process the time series, we assume that
in which
After the normalization step, the scaling factor in the comparison is reduced, thus making any subsequent distance computation invariant to amplitude changes. With such definitions and assumptions, we introduce our idea briefly.
A time series can be treated as a set of points in a
From the algorithm descriptions, we need to solve three critical problems. How to divide the plane into several cells? How to determine the
In this subsection, we discuss in detail how to represent a time series as a binary code.
For the convenience of our discussions, in this subsection, we assume all time series in a plane are limited by a fixed boundary. Note that some time series may have points (only in the query time series) outside the boundary. We will discuss this situation and provide a solution for it later. In the following, we present a detailed calculation algorithm for transforming a time series into the binary code.
An example of converting time series data into binary code.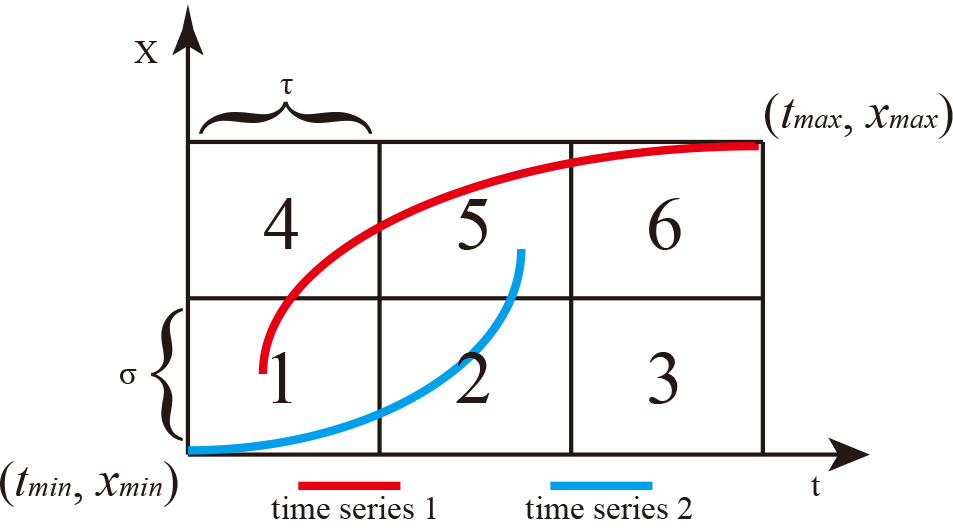
where COLUMN_NUM is the number of columns in the grid. We also define the ROW_NUM, which is the number of rows in the grid. For example, we can see from Fig. 1 that the number of columns is 3, and the number of rows is 2. Therefore, the ID of the cell in the second column and second row of the grid is
After calculating the row and column, we use Eq. (2) to compute the ID of the cell. We finally set the value of the corresponding index in
We get the corresponding
Algorithm 1 shows the pseudo-code of transforming a time series
TimeSeriesTranstoBinaryCode[1]
The TS2BC algorithm for time series similarity search[1]
When time series are converted into binary codes, their similarity can be computed with the Hamming Distance. For two binary codes
where
For two binary codes, the smaller the Hamming Distance between them, the more similar they are. We emphasize that the Hamming Distance computation is extremely fast on modern CPUs. Specifically, the Hamming Distance between two binary codes can be calculated very fast, just using simple machine instructions such as xor and popcnt [43].
In this part, we propose the TS2BC algorithm for time series similarity search. We here consider the one nearest neighbor search. As shown in Algorithm 1, it first converts query time series
The transformation cost from
The differences between STS3 and TS2BC
Set-based Time Series Similarity Search (STS3) [9] is a novel method to measure the similarity between two time series. STS3 also divides the plane into several cells but represents a time series as a set of cells. When time series are converted into sets, their similarity can be computed with Jaccard metric. It is computed as follows:
where
Two examples: the differences between STS3 and TS2BC (a) and the points outside the boundary (b).
Different representation methods and different similarity measures lead to different results between TS2BC and STS3. For example, in Fig. 2a, the binary code representations of query, time series 1 and time series 2 are [1, 1, 1, 0], [1, 0, 1, 1] and [1, 0, 0, 0], respectively. Obviously, the Hamming Distance between query and time series 1 is equal to the Hamming Distance between query and time series 2, both of which are 2. However for STS3, the set representations are {1, 2, 3}, {1, 3, 4} and {1}, respectively.
For STS3, the time complexity of converting a time series with
In the previous discussion, we assumed that all time series are limited in a
Processing time series with missing values and noise
Time series with missing values and noise occur in many applications. Missing data and noise in practice can significantly deviate the outcomes of time series data mining, and, thus, it is crucial to treat them properly. In this part, we show that, with suitable parameters, our algorithm is not sensitive to missing data and noise, and we can eliminate the impact of them on time series.
An example of processing time series with missing values and noise.
Figure 3 shows an example of the TS2BC algorithm for processing time series with missing values and noise. Figure 3a–c present the original time series, time series with Gaussian noise and time series with missing data, respectively. Given suitable parameters, their corresponding binary code representations can be found in Fig. 3d–f. Obviously, it can be seen from Fig. 3 that the three time series have the same binary code representation: [000111, 101101, 111000]. Thus, TS2BC has the ability to eliminate the effect of noise and missing data on time series. In fact, it is parameters,
From the TS2BC algorithm descriptions, we observe that the major factor that affects the search results is the size of cell (
The impact of parameters: small cell (a), appropriate cell (b) and large cell (c).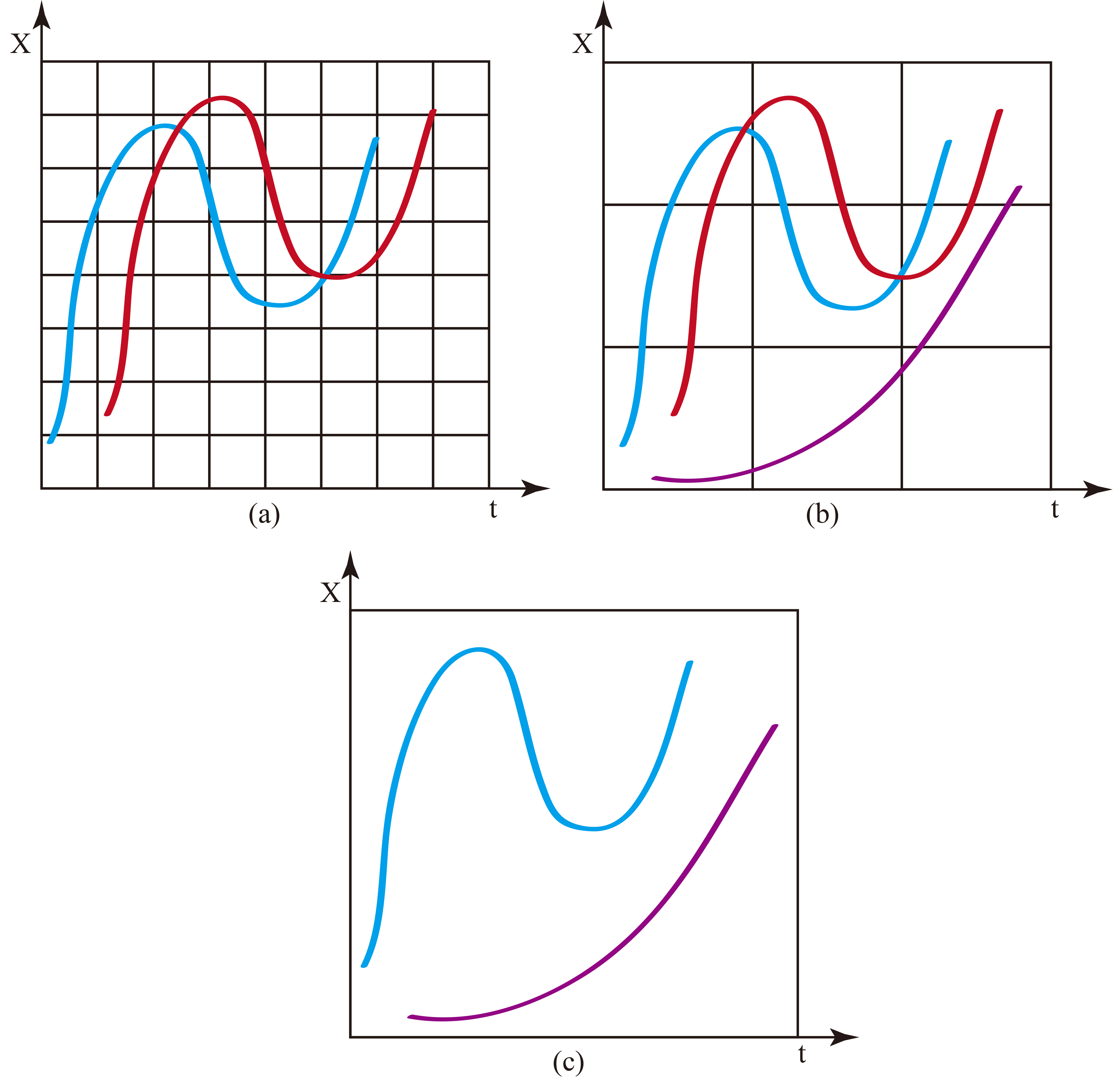
Figure 4a demonstrates that a small cell will lose the ability to handle the time shift and value shift: two shifted time series in Fig. 4a almost pass through completely different cells. Visually, anyone would confirm that the two time series in the Fig. 4a are very similar to each other, however, in our TS2BC method, these two time series are totally different. On the other hand, a large cell may cause different points to fall into the same cell and to be regarded as one point. An extreme example can be found in Fig. 4c, in which the cell has the same size as the boundary. Two completely different time series have the same binary code in Fig. 4c, which would overestimate the similarity. Thus, proper parameters can make our algorithm perform better, as shown in Fig. 4b. TS2BC can handle shifted time series and has the ability to distinguish between different classes of time series data when cells have the appropriate parameters.
Parameters are important for our method, and they need to balance the ability to hold shift and distinguish between different classes time series. We will discuss the choice of parameters in Section 6.
The value of the
To facilitate concise discussions, we divide the plane into
Two time series in different scales.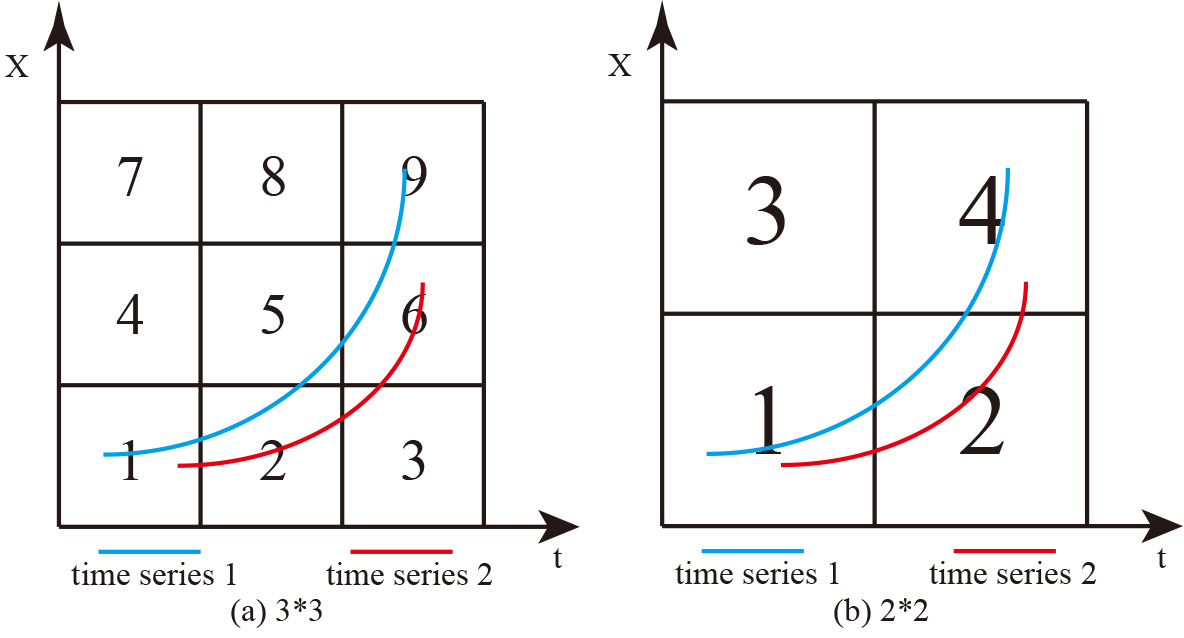
The approximate algorithm is based on the observation that if two time series are similar in a refined scale, then they are probably similar in a coarse scale [9]. We present a concrete example to illustrate this observation graphically. In Fig. 5a, when
Based on this observation, we propose the ATS2BC algorithm. Given a query time series
ATS2BC can be divided into offline pre-processing process and online query process. Algorithm 5 is the pre-processing process of the ATS2BC. It first divides the plane into several cells in scale from minScale to maxScale and then computes the binary code representation of each time series in each level.
Pre-processing of the ATS2BC[1] minScale, maxScale: parameters;
Scale_BC;
The procedure of ATS2BC[1]
The detailed online query process of ATS2BC can be found in Algorithm 5. We initialize the candidates with all time series in the database (Line 1). The binary code representation of the query time series in each scale is computed in Line 3. We calculate the minimal Hamming Distance to query in scale (Lines 4–10) and preserve all time series with the minimal Hamming Distance while removing others from candidateSet (Lines 11–17). If the size of the candidateSet is less than the specified threshold, we exit the loop (Lines 18–20). It is worth noting that the threshold should be much smaller than the size of the database. We finally call TS2BC to calculate the nearest neighbor in candidateSet (Line 22).
Although the ATS2BC can improve efficiency, only approximate nearest neighbor results can be obtained. It may miss the time series that are most similar to the query, for example, in Fig. 6a, time series 1 is most similar to the query. The Hamming Distance between query and time series 1 is 0, while it is 6 between query and time series 2. However, as Fig. 6b illustrates, when the plane is divided into a coarse scale, obviously, time series 2 is most similar to the query, both have the same binary code of [1, 1, 0, 1]. Therefore, the time series, which is most similar to the query, is missed in a coarse scale according to Algorithm 5. Fortunately, this situation is rare on the real datasets [9].
Note that the ATS2BC method described here follows the approximate STS3 (ASTS3) algorithm presented in [9]. However, ASTS3 is based on the Jaccard Metric, while ATS2BC is based on Hamming Distance. Thus, ATS2BC can take advantage of binary code. Moreover, in ASTS3, minScale and threshold are fixed to 2 and 1 respectively, however, in our method ATS2BC, minScale and threshold are two parameters, and their values will be adjusted according to different datasets. Therefore, compared with ASTS3, our algorithm has better flexibility.
Example of missing the time series that are most similar to the query when using ATS2BC.
To empirically evaluate the effectiveness and efficiency of the proposed methods, we conduct extensive experiments. In this section, we report and analyze the experimental results. We implemented all algorithms in MATLAB, and ran all the experiments using Windows 7 enterprise with 3.30 GHz CPU and 8GB memory.
Experimental setting
Datasets
We conduct our experiments on the well-known UCR archive [44], which is the primary benchmark for most time series classification studies. Detailed information on the sizes of datasets and lengths of time series can be found on the UCR website. Each dataset has two parts, TRAIN and TEST, and each time series in the dataset is labeled. As we will see, we use this split of the datasets for the similarity measure evaluation; we also use the TRAIN for tuning the parameters. Before performing the experiments, all datasets were normalized for all algorithms.
Experiment scheme
The proposed methods are validated by the one-nearest neighbor (1NN) classification method. Specifically, For each time series in TEST, the 1NN classifier calculates the similarity between it and all the time series in TRAIN, and its class is computed according to its nearest neighbor in TRAIN. We select the 1NN classifier as the validation method because it has several advantages [14]. First, the accuracy of the 1NN classifier directly reflects the effectiveness of the similarity measure. Second, the 1NN classifier is straightforward to implement and is parameter-free, which makes it easy for anyone to reproduce our results. Third, it has been suggested that the 1NN classifier can obtain the best results in time series classification.
Three representative approaches are selected to compare with the proposed method, including Euclidean Distance (1NN-ED), Dynamic Time Warping (1NN-DTW) and STS3. Besides, we also compare ATS2BC and TS2BC in terms of efficiency and effectiveness in this section.
Parameter settings
Proper parameters can make our algorithm perform better, and practically, the parameters of the TS2BC should be determined before testing.
The value of
Parameter settings for TS2BC in the second step
Parameter settings for TS2BC in the second step
We first compare our method with STS3 for two reasons.
Our method is inspired by the STS3 but uses different representation method and similarity measurement. We are very interested in which of these two algorithms performs better. From [9], we know that STS3 is faster than most existing methods. For example, STS3 is 2905 times faster than FastDTW on CinC_ECG_torso dataset. FastDTW [45] is an optimization technique based on DTW. If experiments show TS2BC is more efficient than STS3, we can indirectly explain that our method is also faster than most existing algorithms.
Datasets descriptions
In this subsection, we mainly compare TS2BC with STS3 in terms of efficiency. Effectiveness comparisons with STS3 and other algorithms can be found in the next subsection. We use six datasets to evaluate the efficiency of TS2BC. These six datasets are selected because we want to test the impact of time series length on efficiency. The information on the datasets and the parameters for STS3 and TS2BC are described in Table 2, where #TRAIN means the total number of time series in TRAIN. Without loss of generality, in this subsection, we set the same parameters for both algorithms.
Before the query process is executed, the time series in TRAIN need to be transformed into sets or binary codes. This experiment aims to test the pre-processing time on real datasets.
We report the speedup rate, which reflects how fast an algorithm is with respect to another algorithm. Let
Figure 7a illustrates that the pre-processing time of the TS2BC is very small compared to the STS3. TS2BC can achieve 80 to 550 times faster than STS3. Moreover, we find that the length of the time series has a significant impact on efficiency: speedup rate increases as the length of the time series increases. It is easy to understand because for STS3, the time complexity for a time series with
Pre-processing time speedup rate (a) and query time speedup rate (b) of TS2BC compared to STS3 on various datasets.
The relationship between 
A practical and important issue is the efficiency of the query processing time. As analyzed theoretically, in general, STS3 has a higher time complexity than TS2BC. We compare the empirical running time of two algorithms on the above 6 UCR datasets. We also report the speedup rate of TS2BC compared to STS3.
Figure 7b demonstrates the query processing time for each of the methods on various datasets. It can be seen that TS2BC performs fast than STS3 on all datasets. Specifically, TS2BC can achieve 2 to 26 times faster than STS3. In most of the situations, as the length of the time series increases, the efficiency of the TS2BC decreases. However, for the three datasets OliveOil, Haptics and HandOutlines, the situation is quite different.
We briefly explain the reasons for these situations. The Jaccard similarity computation cost of the sets is
The relationship between speedup rate and
Effectiveness
We compare TS2BC with STS3 and two state-of-the-art techniques, including 1NN-ED and 1NN-DTW, to evaluate the effectiveness of TS2BC. We use 61 representative datasets in the UCR Archive and one nearest neighbor classifier to evaluate the effectiveness of the four algorithms. The error rate is reported, which is calculated as follows:
The results for STS3, 1NN-ED and 1NN-DTW are taken directly from publications or websites of the authors. We document error rates of four algorithms in Appendix A. The lowest error rate on each dataset is highlighted in bold font.
Figure 9 represents visually the error rates of TS2BC paired with 1NN-ED, 1NN-DTW and STS3. Each axis represents a method, and each point represents the error rate for a particular dataset. The line
The classification error rates of four methods. Each point represents a dataset. Points below the line mean that TS2BC is more accurate than the other method in the pair.
Number of datasets in each compression ratio interval.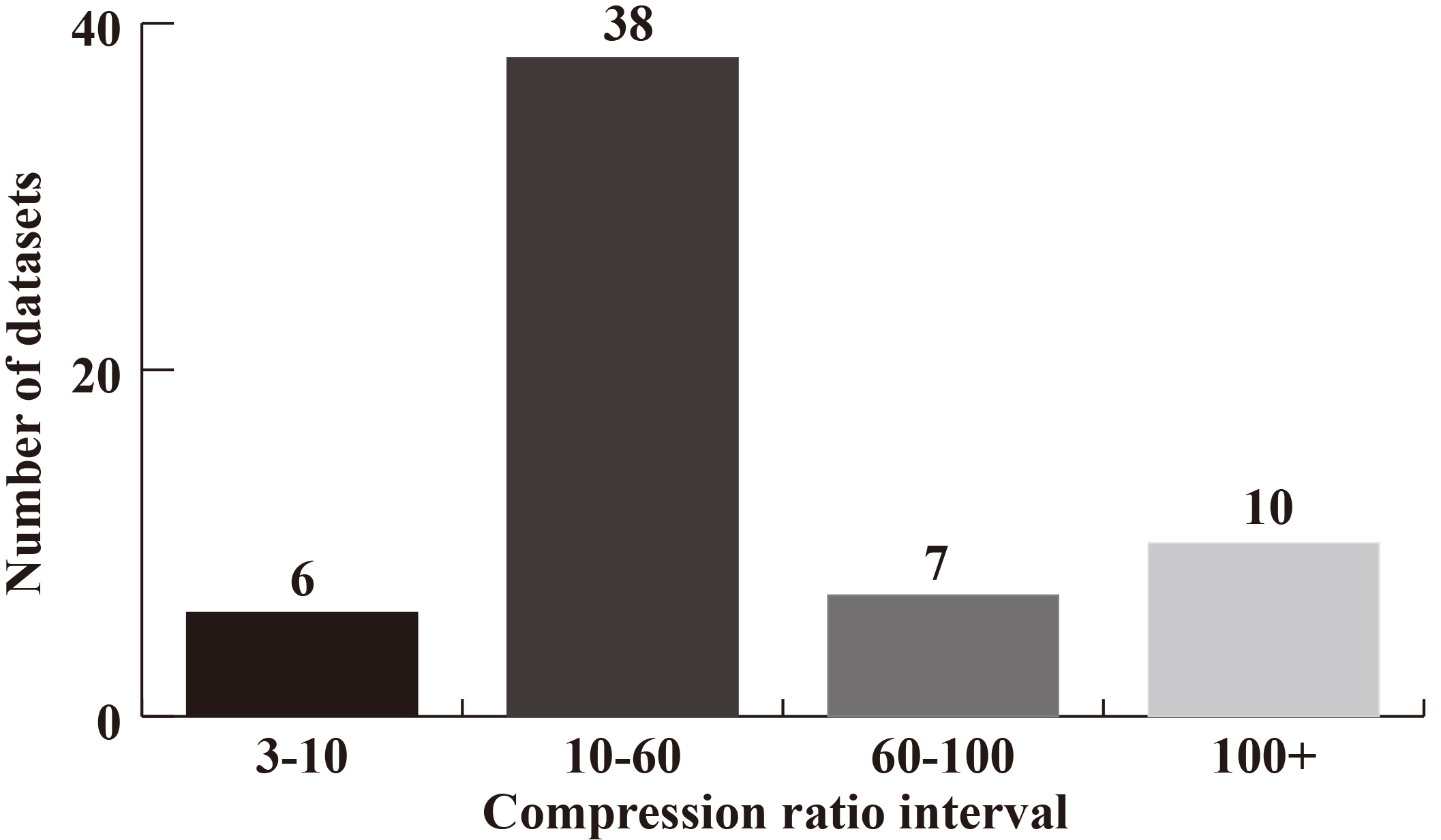
Furthermore, the average error rate of each method for all datasets is calculated. 1NN-DTW has a minimum average error rate of 0.2513. It is understandable because 1NN-DTW has been successfully used for time series similarity search and shown to be very hard to beat [33, 34, 14]. Just inferior to the 1NN-DTW, our method achieves 0.2794 for average error rate, followed by the STS3, which achieves an average error rate of 0.2883. The 1NN-ED is not stable, and its performance mainly depends on the dataset. Although it can achieve the best results in some datasets, in other datasets, its performance is not good enough, with an average error rate of 0.3001.
Overall, our proposed method TS2BC performs best on some datasets in accuracy and achieves comparative performance on remaining datasets. Moreover, TS2BC can achieve much higher efficiency than most existing algorithms in all cases. For example, it is 3596 times faster than DTW on the Coffee dataset and 939 times faster than DTW on the ECG200 dataset. Thus, TS2BC can be applied in different fields, especially in real-time applications where the responsiveness is important.
As mentioned earlier, TS2BC is storage efficient. As traditional time series compression algorithms did, we define the compression ratio as the ratio between the size of the original datasets and that of the compressed one. Formally, we reasonably assume each time series value is a 32-bit float number, then the storage cost of the raw time series dataset
From the TS2BC descriptions, we know that the storage cost of the proposed representation method mainly depends on one factor,
Figure 10 shows the results of compression ratio on 61 UCR datasets. TS2BC can achieve 59.56 compression ratio on average, with a maximum compression ratio of 661 on InlineSkate datasets. This suggests that TS2BC can compactly represent the original time series.
We conduct this experiment to compare the efficiency and accuracy between TS2BC and ATS2BC. We use three datasets in the UCR Archive: ECG5000, Haptics, uWaveGestureLibrary_Y (UWGLY). The information on these datasets and the setting of parameters are listed in Table 3. The parameter minScale is set to 5, maxScale is set to 7 and threshold is set to
Datasets descriptions on three datasets
Datasets descriptions on three datasets
Evaluation of ATS2BC in terms of efficiency (a) and accuracy (b).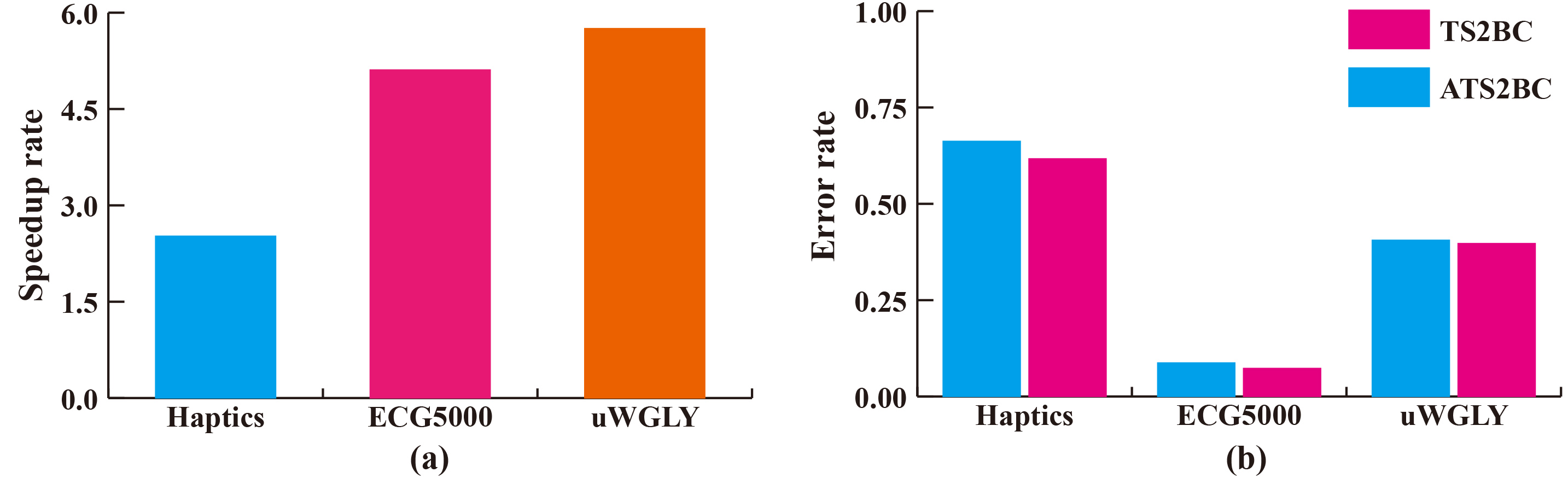
The speedup rate of ATS2BC is shown in Fig. 11a. From the results, we observe that ATS2BC is faster than TS2BC as we expected. However, as shown in Fig. 11b, the classification accuracy of the ATS2BC is only a little smaller than TS2BC. Therefore, ATS2BC is an effective method that can improve the efficiency of the TS2BC.
We provide a case study in which we applied our method to a dataset. This subsection demonstrates that TS2BC is useful and helps the reader gain an appreciation for the TS2BC.
DistalPhalanxTW dataset
There are 6 classes in this dataset which contains 539 time series of length 80, with 139 time series as TRAIN and other 400 as TEST. For this dataset, both ROW_NUM and COLUMN_NUM have a value of 5, and thus the
In our experiment, we select two different classes of time series in TEST as our queries and then use TS2BC algorithm to find their nearest neighbor in TRAIN. Figure 12 shows the results. For the convenience of our explanation, we use (a) to represent the time series in Fig. 12(a), the same for (b), (c) and (d). In this experiment, (a) and (c) are queries, and (b) and (d) are their nearest neighbor, respectively.
Binary code representations for four time series in Fig. 12
Binary code representations for four time series in Fig. 12
A case study on DistalPhalanxTW dataset. (a) and (c) are queries, and (b) and (d) are their nearest neighbor obtained by TS2BC, respectively.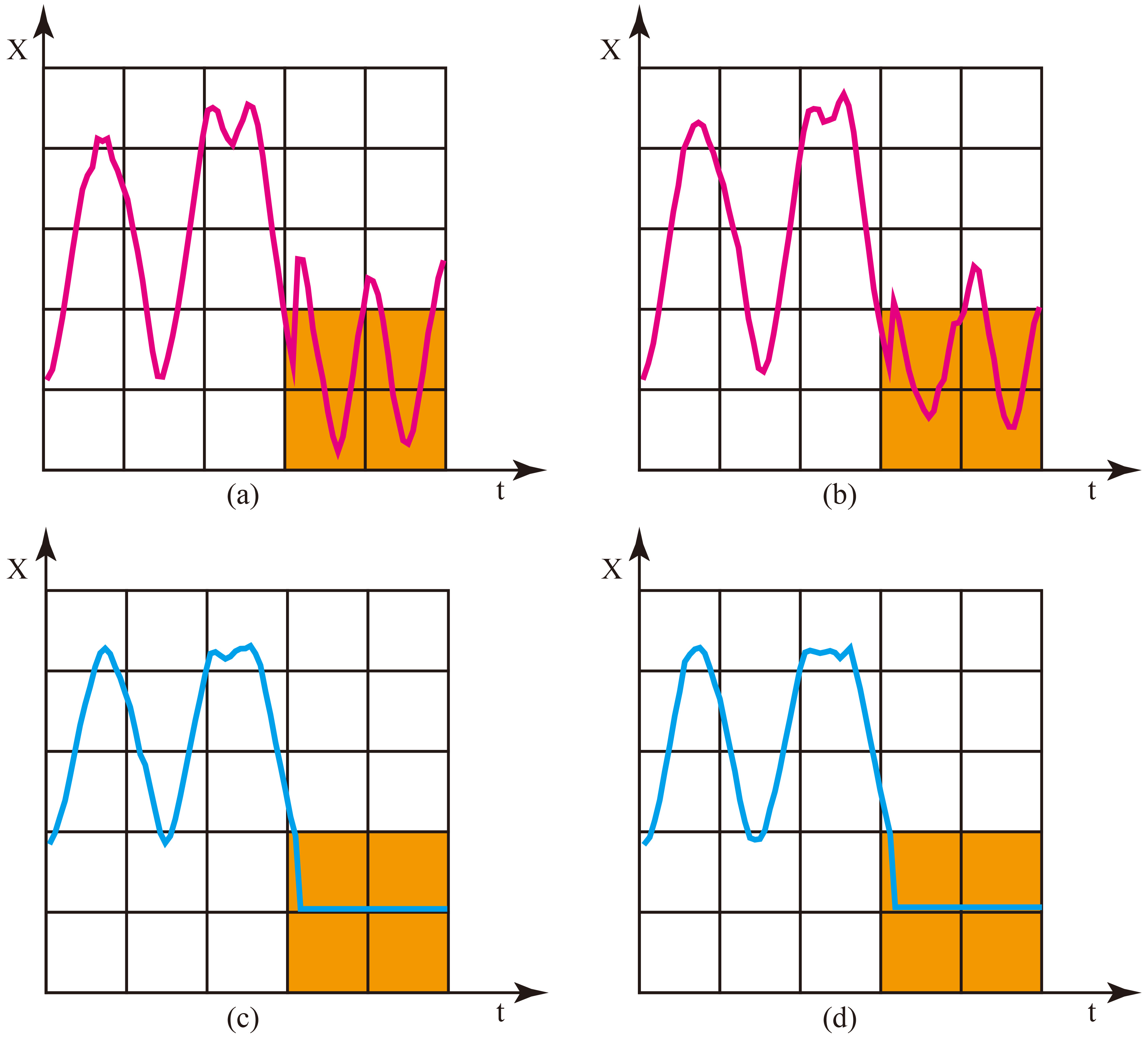
Our algorithm is based on the idea that similar time series always pass through similar cells in a plane. We use a query time series (a) as an example to illustrate the effectiveness of our algorithm. We could discover that (a) and (b) are similar, and from Table 4, we know the Hamming Distance between their corresponding binary code is 0. In fact, (a) and (b) belong to the same class and they pass through the same cells. On the other hand, for time series (a) and (d) belonging to different categories, although their first half is similar, they are quite different in the colored region, and the Hamming Distance between their binary code is 4. Therefore, under TS2BC, (d) cannot be the nearest neighbor of (a).
In this paper, we propose a method, TS2BC, for processing time series similarity search problem. TS2BC uses binary code to represent time series and adopts Hamming Distance to measure the similarity between two time series. TS2BC is based on the notion that similar time series always pass through similar cells in a plane. The idea of TS2BC is consistent with human intuition. We extensively compare TS2BC with the state-of-the-art time series similarity search algorithms on 61 public datasets. Experimental results show that the accuracy of TS2BC is comparable to Dynamic Time Warping (DTW), and TS2BC can achieve much higher efficiency than most existing algorithms. Furthermore, we propose ATS2BC algorithm to speed up the query procedure and test its efficiency by experiment.
The experiment in this paper has focused on classification of the time series. It is pretty straightforward to also apply our method for clustering time series. It will be interesting to evaluate the clustering results under the Hamming Distance. Another interesting direction is applying our method for multivariate time series.
Footnotes
Acknowledgments
This work was supported by National Key Research&Development Program of China (No. 2019YFC1520905), Key Scientific Research Base for Digital Conservation of Cave Temples (Zhejiang University), State Administration for Cultural Heritage.
Appendix A: More experimental results
Error rates of different algorithms on 61 time series datasets
Datasets
1NN-ED
1NN-DTW
STS3
TS2BC
50words
0.369
0.299
0.2857
Adiac
0.391
0.435
0.4578
ChlorineConcentration
0.395
0.4271
CinC_ECG_torso
0.103
0.07
0.07
Coffee
0.036
0.035
Computers
0.424
0.38
0.324
Cricket_X
0.423
0.308
0.3051
Cricket_Y
0.433
0.326
0.3128
Cricket_Z
0.413
0.3
0.2744
DistalPhalanxTW
0.273
0.272
0.308
Earthquakes
0.326
0.317
0.304
ECG200
0.16
0.13
ECG5000
0.075
0.075
0.075
ECGFiveDays
0.225
0.228
FaceAll
0.286
0.267
0.268
FacesUCR
0.231
0.195
0.2024
FISH
0.217
0.246
0.217
FordB
0.442
0.488
0.4543
Gun_Point
0.227
0.12
HandOutlines
0.199
0.213
0.225
Haptics
0.63
0.653
0.6169
Herring
0.484
0.469
0.469
InlineSkate
0.658
0.696
0.7145
InsectWingbeatSound
0.438
0.454
0.4333
ItalyPowerDemand
0.126
0.0544
Lighting7
0.425
0.288
0.301
MALLAT
0.135
0.1458
Meat
0.1
0.1167
MedicalImages
0.316
0.357
0.3737
MiddlePhalanxOutlineAgeGroup
0.26
0.253
0.245
MiddlePhalanxOutlineCorrect
0.318
0.327
0.2917
MiddlePhalanxTW
0.439
0.456
0.4286
Error rates of different algorithms on 61 time series datasets: continued
Datasets
1NN-ED
1NN-DTW
STS3
TS2BC
MoteStrain
0.134
0.167
0.1789
OliveOil
0.2
0.2
PhalangesOutlinesCorrect
0.268
0.3205
Phoneme
0.891
0.873
0.8581
ProximalPhalanxOutlineAgeGroup
0.215
0.215
0.19
ProximalPhalanxOutlineCorrect
0.21
0.203
0.244
ProximalPhalanxTW
0.292
0.263
0.2775
RefrigerationDevices
0.605
0.56
0.5493
ScreenType
0.64
0.589
0.616
ShapesAll
0.248
0.225
0.2433
SmallKitChenAppliances
0.659
0.363
0.365
SonyAIBORobotSurface
0.388
0.3095
SonyAIBORobotSurfaceII
0.297
0.2403
SwedishLeaf
0.211
0.16
0.17
synthetic_control
0.12
0.05
0.0333
ToeSegmentation1
0.32
0.25
0.18
ToeSegmentation2
0.192
0.092
0.146
Trace
0.24
0.12
0.04
Two_Patterns
0.09
0.032
0.028
uWaveGestureLibrary_X
0.261
0.253
0.261
uWaveGestureLibrary_Y
0.338
0.323
0.397
uWaveGestureLibrary_Z
0.35
0.332
0.349
UWaveGestureLibraryAll
0.052
0.041
0.047
wafer
0.009
0.0115
Wine
0.481
0.444
WordsSynonyms
0.382
0.346
0.3621
Worms
0.635
0.586
0.558
WormsTwoClass
0.414
0.414
0.392
yoga
0.17
0.196
0.1743