
Abstract
In many important application domains, such as text categorization, biomolecular analysis, scene or video classification and medical diagnosis, instances are naturally associated with more than one class label, giving rise to multi-label classification problems. This has led, in recent years, to a substantial amount of research in multi-label classification. More specifically, feature selection methods have been developed to allow the identification of relevant and informative features for multi-label classification.
This work presents a new feature selection method based on the lazy feature selection paradigm and specific for the multi-label context. Experimental results show that the proposed technique is competitive when compared to multi-label feature selection techniques currently used in the literature, and is clearly more scalable, in a scenario where there is an increasing amount of data.
Introduction
A large body of research in supervised learning deals with the analysis of single-label data, where each instance is associated with only one class label from a fixed set of possible class labels. However, in many data mining applications, an instance may be associated with more than one class label. This characterizes the multi-label (ML) classification task, which has become a common real-world task [32] and a relevant topic of research.
Classification strategies that handle multi-label data can be divided into two groups: transformation and adaptation strategies. Transformation strategies, such as Label Powerset and Binary Relevance transformations, convert the multi-label data into single-label data and then use traditional single-label classifiers. Adaptation strategies adapt or extend single-label classifiers to cope with multi-label data directly, such as the Multi-Label
The performance of a classification method is closely related to the quality of the training data. Redundant and irrelevant features may not only decrease the model’s accuracy but also make the process of building the model or running the classification algorithm slower. Feature selection is traditionally a data preprocessing step which aims at identifying relevant features for a target data mining task – particularly in this paper, the multi-label classification task.
There is an extensive literature regarding feature selection for single-label classification, which has been summarized in surveys such as in [5, 7]. Given the increasing popularity of multi-label classification and the challenge of selecting features in this context, there has been significant research specifically on feature selection for multi-label classification [15]. Most methods proposed for this task rely on the transformation of the multi-label data set into a single-label one. This can cause the loss of some information present in the original multi-label data set related to the dependence between labels, an issue previously studied in multi-label learning [23].
In this work, we propose and evaluate a new method for multi-label feature selection. This method has two main characteristics: (a) it is a lazy multi-label feature selection method and was designed based on the single-label lazy feature strategy proposed in [17]; and (b) it uses the information gain (IG) measure that was previously adapted for the multi-label setting in [14].
The remainder of this paper is organized as follows. In Section 2, we revisit the multi-label classification problem. In Section 3, we describe the multi-label feature selection process and past work in the area. In Section 4, we describe our adaptation proposal of a novel multi-label feature selection technique. In Section 5, we present the experiments that compare our proposal with methods currently used in the literature. Finally, in Section 6, we make our concluding remarks and point to directions for future research.
Multi-label classification
In the multi-label classification task, each data instance may be associated with multiple labels. Multi-label classification is suitable for many domains, such as text categorization, scene or video classification, medical diagnosis, bioinformatics and microbiology. In all these applications, the task is to assign for each unseen instance a label set whose size is unknown a priori [32].
Strategies proposed to deal with multi-label classification rely mainly on problem transformation, where the multi-label problem is transformed into one or more single-label problems; or on algorithm adaptation, where single-label learning algorithms are adapted to handle multi-label data directly.
The simplest way to apply a classification algorithm to multi-label data is to transform them into single-label data. Then, a traditional classification technique – such as
A simple transformation technique used to convert a multi-label data set into a single-label one consists of copying each multi-label instance
A popular transformation is the Label Powerset (LP) technique, which creates one label for each different subset of labels that exists in the multi-label training data set. Thus, the new set of labels corresponds to the powerset of the original set of labels. After this transformation, a single-label classification learning algorithm can handle the transformed data set and produce a classifier. This classifier can then be used to assign to new instances one of these new labels, which can be mapped back to the corresponding subset of the original labels [28].
Binary Relevance (BR) is a well-known transformation technique that produces a binary classifier for each different label of the original data set [4, 26]. In its simplest implementation, each resulting classifier is capable of predicting if a label is relevant or not for a new instance. So, each classifier handles the data as single-label, since it gives a relevance feedback for just one specific label.
Regarding algorithm adaptation, most traditional classifiers employed in single-label problems have been adapted to the multi-label paradigm [27]. C4.5 decision-tree induction algorithm was adapted in [3], by allowing multiple labels in the leaves of the tree. An adaptation of the SVM algorithm has been proposed in [6]. A
Related work
Feature selection techniques are primarily employed to identify relevant and informative features [7]. Besides this, there are other important motivations: improvement of the classifier predictive accuracy, reduction and simplification of the data set, acceleration of the classification task and even the construction of classification models that can be understood, analyzed, and qualitatively evaluated by domain experts [12].
Feature selection techniques intended specifically for multi-label classification have been developed recently [9, 8, 15]. Analogous to multi-label classification, the simplest way to employ feature selection to a multi-label data set is to change it into single-label data and apply a traditional feature selection technique.
In [1], the following common simple transformation techniques have been employed to allow the application of traditional feature selection for the multi-label text categorization problem: select-max, select-min, select-random, select-ignore and copy. These strategies are used to convert a multi-label data set into a single-label one.
In [25], several multi-label classification strategies were evaluated and compared for the task of automated decision of emotion in a music data set. The Label Powerset transformation was used to produce a single-label data set, and then a common feature selection measure was employed (
The Label Powerset transformation is also used before the feature selection process in [22], in conjunction with the relief and information gain measures. With this feature selection, it was possible to reduce the size of the data sets without compromising the classification performance.
Some text classification work [29, 13, 33] has employed the Binary Relevance technique before applying single-label feature selection measures, like information gain and
There are also recently proposed multi-label feature selection techniques that do not require transformation of the data set – the feature selection is built as an adaptation of techniques suited for the single-label paradigm, or as a wrapper-based technique.
In [10], the well-known technique FCBF (Fast Correlation-Based Filter), introduced in a previous work [30], is extended to handle multi-label data. In that work, the technique consists of transforming the data set into a directed graph and applying the symmetrical uncertainty measure to evaluate the features of the data set. This feature selection is applied to the IBLR-ML [2] and ECC [20] classifiers, and data sets from multiple domains are evaluated. In [31], a wrapper technique is used to identify the best feature set. This wrapper feature selection implements a genetic algorithm as the search component. To evaluate this method, the Multi-label Naive Bayes classifier is proposed and used as the wrapper classifier. The classification coupled with the feature selection achieved a better result, even when compared with other classifiers.
Single-label feature selection techniques were recently adapted to the multi-label paradigm. The ReliefF measure was adapted in [23] and in [18]. The Mutual Information measure was adapted in [11]. Correlation-based feature selection, capable of handling subset of features, was adapted to the multi-label setting in [9].
In [14], a comprehensive evaluation of various multi-label feature selection techniques was performed, along with an adaptation of the Information Gain metric to handle multi-label data directly. Using data sets from various domains, including large data sets, the proposed algorithm was experimentally compared to well-known transformation-based feature selection techniques coupled with multi-label classifiers. The results showed that the proposed algorithm is competitive and more scalable than the other compared techniques.
The lazy multi-label feature selection proposal
In conventional feature selection strategies, features are usually selected in a preprocessing phase. The features that are not selected are discarded from the data set and no longer participate in the classification process.
In [17], a lazy feature selection strategy was proposed based on the hypothesis that postponing the selection of features to the moment at which an instance is submitted for classification can contribute to identifying the best features for the correct classification of that particular instance. For each different instance to be classified, it is possible to select a distinct and more appropriate subset of features to classify it. The technique was implemented for single-label data.
Table 1 presents a multi-label example that could benefit from a lazy strategy of feature selection. The data set, composed of two features –
Multi-label data set example
Multi-label data set example
It can be observed in the left occurrence that the values of
On the other hand, as shown in the right occurrence, the values
So, we present in this small multi-label example a motivation for postponing the selection of features to the moment at which an instance is submitted for classification. This way, the selection can take a more informed decision on which features to keep in the data set.
Lazy feature selection is a general strategy, since it can employ different evaluation measures to assess the quality of the features. In this work, we propose to instantiate the strategy analogously to the original work [17] – which deals with the single-label scenario – using an entropy-based criterion to rank features [29]. This entropy measure was extended to the multi-label setting in [3], where the C4.5 algorithm was adapted for handling multi-label data. This decision tree algorithm allowed multiple labels at the leaves of the tree, by using an adaptation of entropy measure, described by Eq. (1), for computing the entropy of the label distribution in a multi-label data set
where
The formula for computing the entropy of the label distribution in
where
These equations were used in the MLInfoGain technique [14], as an adaptation of the Information Gain Ranking [19] for the multi-label context. The adaptation was able to handle multi-label data directly, and it was implemented as a filter. MLInfoGain technique is considered as “eager”, which is the opposite of “lazy”, selecting the features as a data preprocessing step.
In this work, our proposal is to extend this information gain adaptation to the lazy paradigm. Each individual feature value needs to be measured separately from the others, and for each label. The entropy of the label distribution in
where
Equation (4) aggregates the result for all
For computing the lazy multi-label information gain (MLIG), for each feature
The choice of considering the minimum value from both the entropy of the specific value and the overall entropy of the feature was motivated in [17] by the fact that some instances to be classified may not have any relevant features considering their particular values. In this case, features with the best overall discrimination ability will be selected. In other words, if the values of the instance to be classified do not help the lazy feature selection, then select the best features in the data set regardless, considering the eager multi-label information gain measure.
The proposed lazy adaptation of the multi-label information gain works as follows: for an entry instance
Any lazy feature selection technique should be coupled with a lazy multi-label classifier, because the ‘lazy module’ is called at classification time for every new instance. This restriction is justified by the target classifier not requiring to construct a model in a previous step. For instance, a decision tree classifier would not benefit from the lazy feature selection in terms of scalability, because the tree model would need to be reconstructed for every new instance. On the other hand, the
In Algorithm 1 we show the pseudo-code of the proposed multi-label lazy strategy called LazyMLInfoGain. This algorithm is activated by the multi-label classifier during the classification phase. The equations presented before are indicated in the pseudo-code accordingly.
Pseudo-code for the proposed multi-label lazy feature selection – LazyMLInfoGainTraining multi-label dataset
In order to build the rank of features, we have introduced the variable quality-
The features not selected in a lazy fashion for a given instance are not needed to be removed from the dataset, but only disregarded by the classifier when performing its algorithm. This proves to be more efficient in terms of memory and performance than removing the features each time, as each new instance will almost certainly make use of a different subset of features.
The goal of this novel technique is to benefit the multi-label classification in terms of predictive accuracy, as achieved by the lazy single-label adaptation in [17], and in terms of scalability, as achieved by the direct information-gain adaptation in [14]. This lazy multi-label adaptation is compared experimentally with other feature selection techniques used in the literature and the results are reported in the next section.
The goal of these experiments is to evaluate if the proposed multi-label lazy feature selection achieves a competitive result when compared with other feature selection techniques in the multi-label paradigm coupled with traditional multi-label classifiers.
The multi-label lazy feature selection (Lazy MLInfoGain) was implemented in Mulan [27]. Mulan is an open-source Java library for learning from multi-label data sets. The library includes a variety of state-of-the-art algorithms for performing multi-label classification, ranking and feature selection.
The Lazy MLInfoGain was coupÄ°ed with two multi-label classifiers: BRKNN and ML-KNN. The experiments with these classifiers are detailed in the next subsections.
Experiments with the BRKNN classifier
The BR transformation coupled with the
The lazy feature selection was first evaluated when coupled with the BRKNN classifier. The feature selection was executed within the algorithm just before the actual classification happens. The classifier considered only the
Throughout this work, we elected the following measures to evaluate our algorithms: Hamming Loss, Subset 1/0 Loss, Example-Based Accuracy and Ranking Loss. These measures are commonly used in multi-label classification work, and the decision on this subset is supported by [16]. Example-Based Accuracy was inverted (1
Table 2 shows the overall result of each feature selection technique coupled with the BRKNN classifier. Each table section presents the result for a specific performance measure. The first column indicates the data set used, and the other columns indicate which feature selection technique was applied. “BR
“No Sel.” is the result without feature selection, and also the baseline. Each cell shows the achieved result in terms of the multi-label performance measure, varying between 0 and 1, and the lower the value, the better. In parentheses, we show the percentage of selected features that achieved the best value for each technique, and in case of ties we report the smaller percentage. Bold values show the results that achieved a score equal or better than the baseline, and underlined values show the best result achieved in each row. At the end of the table we summarize the results.
Best results achieved using each feature selection technique with BRKNN
Best results achieved using each feature selection technique with BRKNN
With the BRKNN classifier, the proposed lazy multi-label information gain technique (Lazy MLInfoGain) achieved a competitive result, holding the best performance in 21 cases, out of the 44 experiments. The non-lazy MLInfoGain technique achieved the best result in 18 cases, and the BR
These preliminary results indicate an improvement over the non-lazy MLInfoGain technique proposed in [14]. To confirm this, in the next subsection a statistical analysis is used to evaluate these results.
Statistical analysis was used to evaluate if the differences in performance of the multi-label feature selection techniques are statistically significant.
The five feature selection techniques were ranked according to their performance for each data set and for each percentage of selected features. The best performing technique was ranked first, the second best was ranked second, and so on. In case of ties, the ranks were averaged. From the average ranks of the techniques, the Friedman statistic was calculated, and then, at a significance level of 5%, the hypothesis that the techniques performed equally well in average ranking was rejected.
Then a post-hoc Nemenyi test was used to compare the feature selection techniques to each other. The performance of two techniques is considered significantly different if their average ranks differ by more than a critical distance value. Figure 1 shows the results from the Nemenyi post-hoc test for the four different measures used in the experiments for the BRKNN classifier. Each diagram presents an enumerated axis with the average ranks of each technique. The best rankings are at the right-most side of the diagram. The lines for the average ranks of the algorithms that do not differ significantly (at the significance level of 0.05) are connected by a horizontal line.
Critical diagram for the Nemenyi post-hoc test at 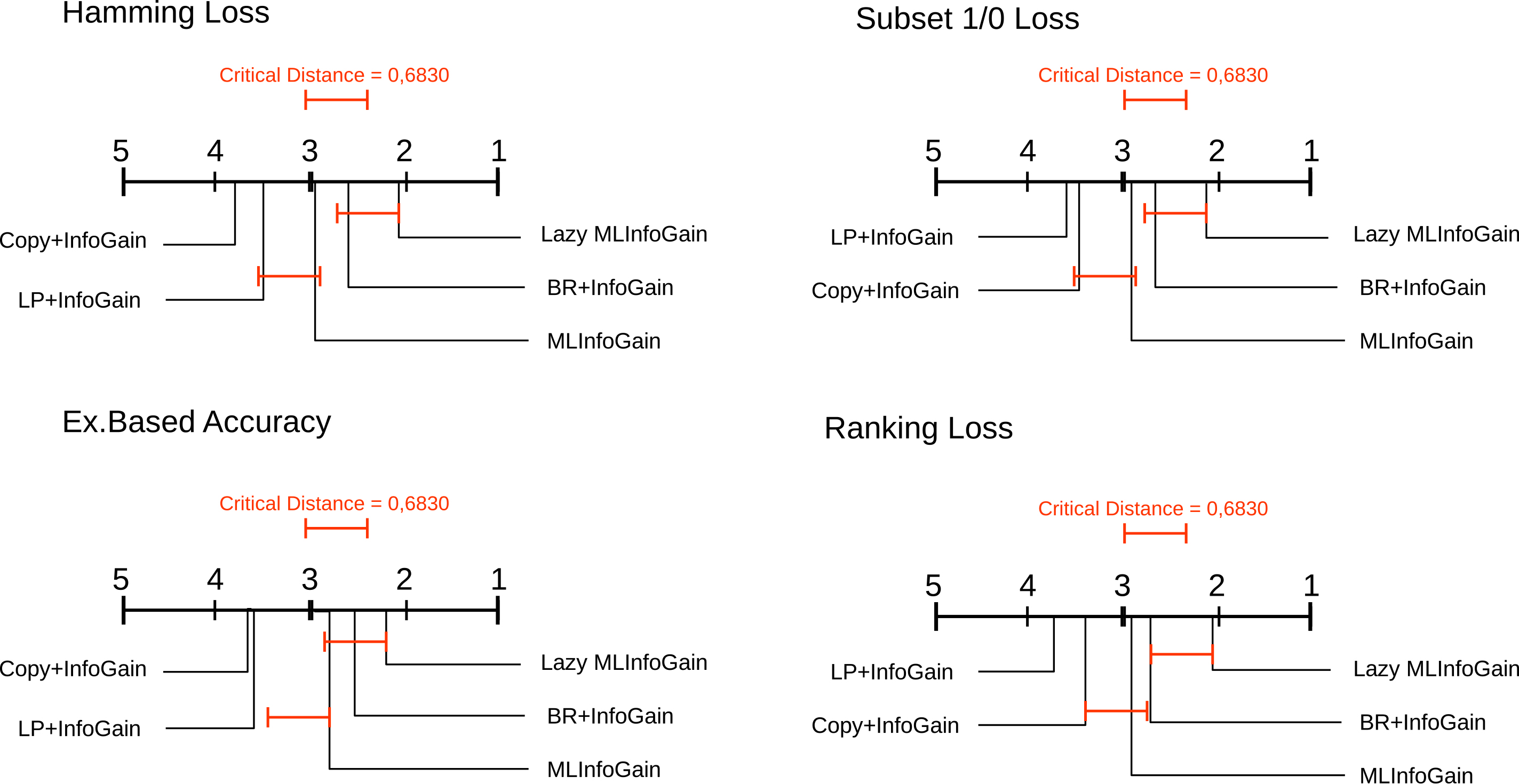
The diagrams show that the proposed Lazy MLInfoGain generally outperforms the original MLInfoGain (eager) with a significant difference, except for the Example-based Accuracy measure. It also outperforms the Copy
We have also incorporated the lazy feature selection into the ML-KNN, which is another classifier capable of handling multi-label data directly. The lazy attribute selection was executed within the algorithm just before the actual classification takes place. Analogously to the BRKNN implementation, the classifier considered only the
Table 3 shows the overall result of each feature selection technique coupled with the ML-KNN classifier. The results are reported similarly to the experiments with the BRKNN classifier in Table 2.
Best results achieved using each feature selection technique with ML-KNN
Best results achieved using each feature selection technique with ML-KNN
With the ML-KNN classifier, the proposed lazy multi-label information gain technique (Lazy MLInfoGain) also achieved a competitive result, holding the best performance in 19 cases, out of the 44 experiments. The non-lazy MLInfoGain technique achieved the best result in 13 cases, and the BR
The corresponding statistical evaluation yields a similar result when compared with the experiments using the BRKNN classifier. These results indicate that the lazy MLInfoGain technique is also a competitive feature selection technique when coupled with other multi-label classifiers.
This section reports the experiments on larger multi-label data sets. Eleven independently compiled data sets from the Yahoo! directory [24] were chosen, each one with more than 5,000 instances and 30,000 features.
Table 4 shows the result of the experiment with larger data sets executed in a similar fashion than the previous one. The feature selection techniques compared are BR
Result of experiments on large data sets with BRKNN classifier, comparing BR
InfoGain, MLInfoGain and Lazy MLInfoGain feature selection strategies
Result of experiments on large data sets with BRKNN classifier, comparing BR
Even though the results from most measures favor slightly the BR
For these Yahoo! directory data sets, Lazy MLInfoGain generally outperformed the original non-lazy MLInfoGain technique, specially for the Example-Based Accuracy and Ranking Loss measures. The Lazy technique was slower than the non-lazy MLInfoGain technique due to the overhead associated with the postponement of feature selection to the classification time. This difference is not significant when compared with transformation-based techniques, represented here by the BR
The experiments with large data sets and the ML-KNN classifier led to similar results as the ones with BRKNN and reinforced the conclusion that the proposed technique is more scalable than the well-known techniques used in the literature and which rely on transformation.
In this work, a new method for multi-label feature selection was proposed, based on the lazy paradigm. We motivated this proposal presenting a multi-label data set example which indicated how a lazy strategy could benefit the multi-label feature selection by postponing the selection to the classification moment.
The proposed lazy strategy for the multi-label context was implemented as a new feature selection method adaptation based on the information gain measure. An experimental evaluation was conducted with various multi-label feature selection methods and data sets from different domains. Two multi-label classifiers were used to assess the lazy adaptation: BRKNN and ML-KNN.
Experimental results and a statistical analysis confirmed that the Lazy MLInfoGain outperformed the non-lazy (eager) MLInfoGain proposed in [14]. Since the MLInfoGain method was already competitive compared with other techniques, the lazy adaptation can be also considered as a competitive feature selection technique for multi-label classification. In terms of scalability, the experiments evidenced that the proposed technique is able to run at faster times than the transformation-based techniques. This reinforces the importance of employing feature selection methods adaptations that handle larger data sets directly, without transformation.