
Abstract
In this paper, a novel Feature-Reduction Fuzzy C-means (FRFCM) with Feature Linkage Weight (FRFCM-FLW) algorithm is introduced. By the combination of FRFCM and feature linkage weight, a new feature selection model is developed, called a Feature Linkage Weight Based FRFCM using fuzzy clustering. The larger amounts of features are superior to the complication of the problem, and the larger the time that is exhausted in creating the outcome of the classifier or the model. Feature selection has been established as a high-quality method for preferring features that best describes the data under certain criteria or measure. The proposed method presents three stages namely, 1) Data Formation: The process of data collection and data cleaning; 2) FRFCM-FLW. The proposed method can decrease feature elements routinely, and also construct excellent clustering results. The proposed method calculates a novel weight for every feature by combining modified Mahalanobis distance with feature δm variance in FRFCM algorithm; 3) Fuzzy C-means (FCM) cluster. The proposed FRFCM-FLW method proves high Accuracy Rate (AR), Rand Index (RI) and Jaccard Index (JI) ratio when compared to other feature reduction algorithms like WFCM, EWKM, WKM, FCM and FRFCM algorithms.
Introduction
Data mining is the procedure of discovering formerly unidentified patterns and trends in databases and using feature information to create projecting models. Data mining combines arithmetical analysis, machine learning and database knowledge to mine hidden patterns and interaction from huge databases.
Clustering is a method that automatically examines the relations between data and categorizes them to form thematically coherent structures—clusters of texts that distribute related topics. Automatic clustering does not need any human interference, nor does it need any preceding knowledge about the inputs, which makes it an extensively applied technique for information analysis [1].
Data clustering is predictable as a significant area of data mining [1]. This is the method of separating data elements into special clusters (recognized as clusters) in such a system that the essentials within a collection acquire high distance while they are different from the essentials in a different group.
In data mining, clustering can be categorized as two portions namely, (i) Soft Clustering (Overlapping Clustering) and (ii) Hard Clustering (or restricted Clustering). In soft clustering methods, fuzzy positions are used to group data, so that every position might fit into two or additional groups with dissimilar degrees of membership. At this point, data will be connected to a right membership value. In several conditions, fuzzy clustering is added more normally than hard clustering. Objects on the limitations among several classes are not compulsory to completely fit into one of the classes, but rather are assigned membership degrees among zero and one demonstrating their incomplete membership. Subsequently in hard clustering methods, data are clustered in a limited approach, so that if a convinced datum fits into an explicit cluster then it could not be incorporated in a new cluster. Fuzzy C Means (FCM) is an especially accepted soft clustering method, and similarly K-means is an essential hard clustering method. The proposed technique is based on a soft clustering category with the base of Feature-Reduction FCM (FRFCM) algorithm.
The objective of cluster examination is to allocate data samples with related belongings to similar clusters with different data samples to dissimilar groups [2]. Because the majority data formation issues attributes are not measured to be similarly significant.
The proposed work presents an enhanced Feature-Reduction FCM (FRFCM) clustering with new Feature Linkage Weight (FRFCM-FLW) procedure. The proposed method is an extension of FRFCM [13] method of combining Feature Linkage Weight method to determine the significance of each feature. A feature selection process is able to compute the Feature Linkage Weight (FLW) of every feature. The advantages of the proposed FLW method are that the modified Mahalanobis distance is used. It means that the inconsistency and correspondence of data is taken into account in manipulative the clusters. The main contribution of this paper is that the feature linkage weight index has a great role in shaping the clusters.
The feature estimation index is the smaller the distance value of attribute is the relevant significant feature. The modified Mahalanobis distance, which acquires into account the FLW of features in adding to inconsistency of data features.
The objective of this work is to develop a novel fuzzy based automatic feature selection algorithm which is efficient to remove the irrelevant features.
Related work
Coletta et al., 2012 [7] has reviewed various deviations of the extensively used Fuzzy C-Means (FCM) algorithm to maintain clustering data disseminated diagonally dissimilar locations. Those techniques have been deliberated below special types, approximating parallel fuzzy and collaborative clustering. The authors offered various augmentations of the two FCM-based clustering algorithms used to group circulated data by incoming at various positive behavior of determining an important parameters of the algorithms (counting the amount of clusters) and structuring a set of analytically prepared strategy such as an assortment of detailed algorithm depends on the environment of the data surroundings.
M. Gong, L. Su, M. Jia, and W. Chen, 2014 [8] has proposed an approach centers on adjusting the membership as a substitute for adjusting the objective function. The membership approach is computationally easy in all steps concerned. Its objective function can immediately arrival to the unique form of FCM, which directs to its fewer time utilization compared to that of several observably freshly enhanced FCM algorithms. Next, their advance adjusts the membership of every pixel according to a narrative form of MRF energy utility throughout which the adjacency of every pixel, as well as their association, are concerned. Theoretical examination and new outcomes on real-world datasets showed that the proposed approach can discover the actual changes as well as reasonable the effect of speckle noises.
S. T. Chang, K. P. Lu, and M. S. Yang, 2015 [9] has designed a technique, called “Fuzzy Change Point (FCP) algorithm is to discover the Change Points (CP’s) and concurrently approximate the constraints of failure form. The fuzzy c-partitions concept is initially surrounded into the CP failure models. Some promising group of all CPs was measured as a screening of data with a fuzzy membership. They transferred these memberships into the simulated memberships of data points to every individual cluster, and so they obtained an approximate for model constraints by the fuzzy c-regressions technique. Consequently, authors utilized the fuzzy c-means clustering to attain novel iterates of the CPs collection memberships by reducing an objective function relating to the deviations among the predicted reply values and data values”.
Miin-Shen Yang and Yi-Cheng Tian, 2015 [10] proposed a bias-alteration expression with a revising equation to fine-tuned the property of initializations on fuzzy clustering algorithms. They initially proposed the so-called bias-alteration fuzzy clustering of the comprehensive FCM algorithm. The authors created the bias-alteration FCM, bias- alteration Gustafson and Kessel clustering and bias-alteration inter-cluster partition algorithms. They evaluated their proposed bias- alteration fuzzy clustering algorithms with additional fuzzy clustering algorithms with statistical illustrations. They also functional the bias-alteration fuzzy clustering algorithms to real-world data sets.
G. Teng, et al., 2016[11] has introduced Group Method of Data Handling (GMDH) to cluster simultaneously, and a group set outline pointed as cluster ensemble framework based on the cluster technique of data handling (CE-GMDH). CE-GMDH depends on three mechanisms: a primary resolution, a transfer function and an outside measure. Numerous CE-GMDH models can be built according to dissimilar categories of transfer functions and outside criterion. In their study, three narrative techniques were illustrated based on special transfer functions: cluster-based similarity partitioning algorithm, least squares approach and semi-definite programming.
C. C. Yeh and M. S. Yang, 2017[12] has discussed assessment procedures for cluster ensembles based on the fuzzy generalized Rand index (FGRI). The authors first exploited a graph based and relation matrices to renovate a membership matrix into a signal relation matrix, and have the outline of matrix multiplication to compute correspondence procedures. The authors utilized a broad range of other scenarios so that it can treat the following situations to analyze similarity measures: (1) connecting a fuzzy cluster ensemble and a crisp separation, (2) connecting a fuzzy cluster ensemble and a cluster ensemble, (3) connecting a fuzzy cluster ensemble and a fuzzy separation, (4) between two fuzzy cluster ensembles, and (5) connecting two different object data sets with the same cardinal amount and the similar separation technique.
Miin-Shen Yang and Yessica Nataliani, 2018 [13] have designed a narrative technique for progressing fuzzy clustering methods that can consistently estimate entity attribute weight, and concurrently decrease these unimportant variables. The authors measured the Fuzzy C-Means aim task with feature-weighted entropy, and build knowledge scheme constraints, and then reduced this inappropriate attribute mechanism. They called it a feature-reduction FCM (FRFCM). Through FRFCM procedure, a novel process for removing incomplete attribute(s) through low weight(s) is shaped for attribute elimination.
Lin et al., 2018 [20] has proposed a novel fuzzy rough set representation for attribute or feature reduction in multi-label classification. Dissimilar from single-label feature elimination, a bottleneck of fuzzy rough set for multi-label feature elimination is to discover the accurate dissimilar classes’ instances for the output instance, which extremely changes the heftiness of fuzzy lower and upper approximations. They defined the gain vector of every instance to estimate the likelihood of individual different class’s sample with deference to the output sample. Then, restricted sampling is leveraged to build a strong distance among instances. It can realize the heftiness beside noisy information when manipulative the fuzzy upper and lower approximations below the entire labels.
Zixiao Shen, Xin Chen, Jonathan M. Garibaldi, 2019 [19] has proposed a narrative weighted mixture feature selection technique using bootstrap and fuzzy sets. The technique generally assigned of three measures, with fuzzy sets creation using bootstrap, weighted permutation of fuzzy sets and feature ranking based on defuzzification. The authors implemented the technique by merging four state-of-the-art feature selection techniques and assessed the performance based on three widely available biomedical datasets using fivefold cross validation. Based on the feature selection consequences, their technique formed similar classification accuracies to the finest of the entity feature selection techniques for the entire assessed datasets.
S. Kashef and H. Nezamabadi-pour, 2019 [21] has reviewed a fast accurate filter-based feature selection technique is entirely considered for multi-label datasets to discover label-particular attributes. It plots the attributes to a multi-dimensional space supported on a filter technique, and chooses the majority significant features with the assist of Pareto-dominance models from multi-objective normalization area. Their technique can be used as online feature selection that covenants with troubles in which features appear consecutively while the amount of data samples is predetermined.
Sun, et al., 2019 [22] has proposed a novel neighborhood rough sets and entropy measure-based gene selection with Fisher score for tumor classification, which has the capability of dealing with real-value data even as preserving the unique gene classification information. Foremost, the Fisher score technique is engaged to remove irrelevant genes to considerably decrease computation difficulty. After that, several neighborhood entropy-based uncertainty actions are examined for handling the uncertainty and noisy of gene expression data.
Sun, et al., 2020 [23] has proposed a novel NMRS-based attribute reduction technique using Lebesgue and entropy procedures in incomplete neighborhood decision systems. Initially, a few concepts of positive and negative NMRS forms in incomplete neighborhood decision systems are known, correspondingly. Then, a Lebesgue determine was shared with NMRS to learn neighborhood tolerance class-based ambiguity measures. To examine the ambiguity, redundancy and noise of incomplete neighborhood decision methods in feature, several neighborhood multi-granulation entropy-based improbability procedures are illustrated by integrating Lebesgue and entropy procedures.
Proposed methodology
The proposed FRFCM-FLW method performs to test all the experimentations that were conducted on a high dimensional dataset [12]. The FRFCM-FLW algorithm successfully removes unimportant features with dissimilar weights, which resources that data with attributes of different selected weights of features are clustered. The overall FRFCM-FLW flow diagram is described in Fig. 1.
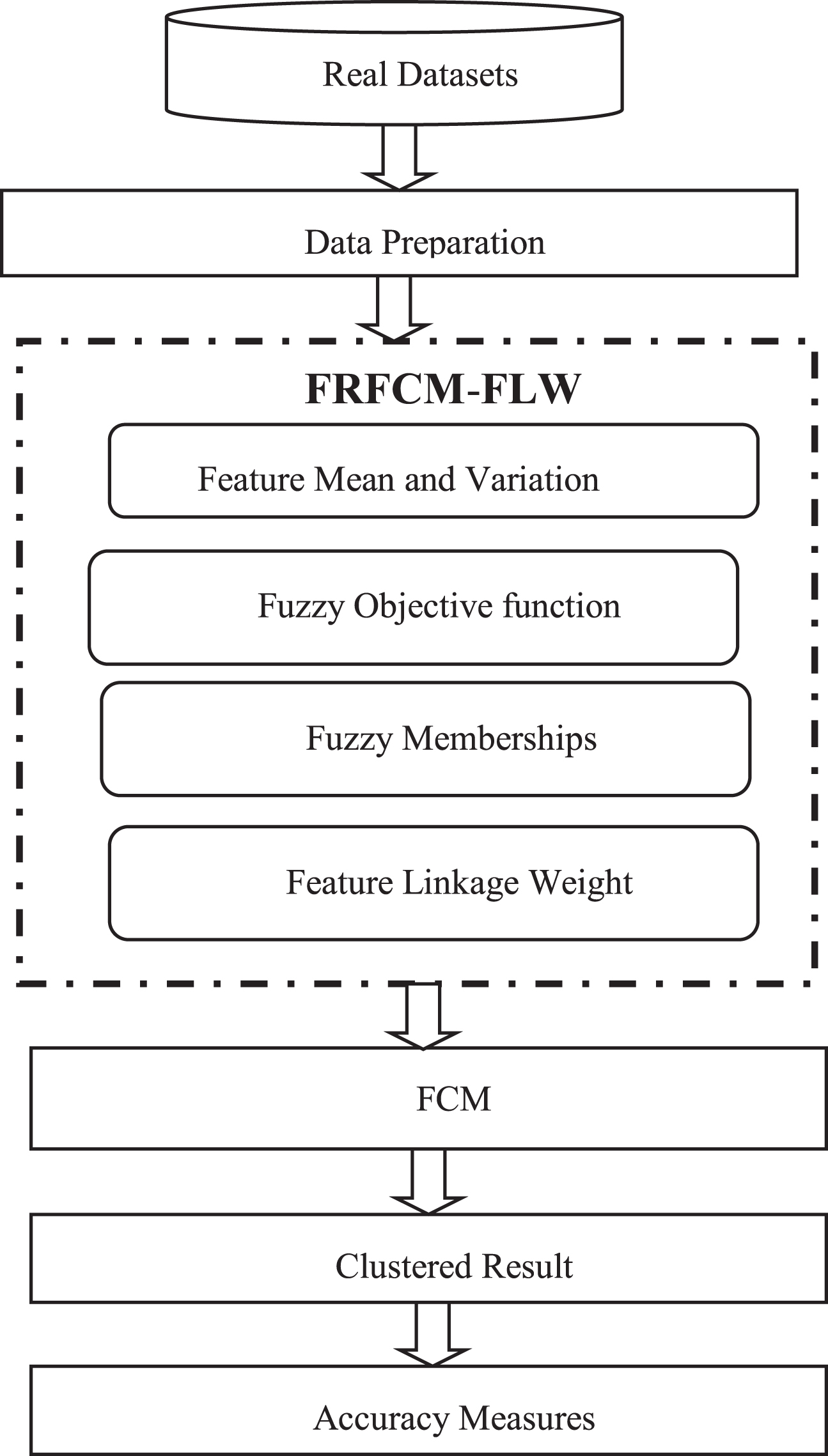
Proposed FRFCM-FLW algorithm Flow Diagram.
In Fig. 1, a real time and synthetic datasets are taken as inputs in MATLAB simulation. The first procedure of data preparation predicts the quantity of instances, quantity of features and classes. Next FRFCM-FLW algorithm works with four steps namely (i) Feature Mean and Variation; (ii) Fuzzy objective; (iii) Fuzzy Memberships and (iv) Feature Linkage weight. In this last step the proposed algorithm performs feature reduction process with appropriate feature linkage weight measure. The final process is clustering the obtained features and computing the cluster accuracy.
Data preparation is the process of data cleaning. Data cleaning guarantees that data gathered is accurate such that the related decisions are valid. Data is collected from different varieties of data sources from the different web pages. The additional real datasets which include plant data (soybean, seeds), cancer data (colon cancer, breast cancer, ovariance cancer), disease data (thyroid, pima Indians, bupa), handwritten data (USPS), and text data (basehock), taken from UCI data repository [17] and Kent Ridge Biomedical Data Set [18]. The real-world datasets are described in Table 1.
Real Datasets
Real Datasets
The data thus attained, might not be prepared and might include incomplete information. Consequently, the together data is necessary to be subjected to data cleaning. The data that is composed must be developmental or prearranged for examination. This comprises construction of the data as an essential for the relevant examination tools. For instance, the data might have to be placed into rows and columns in a table within a worksheet or arithmetical application.
The processed data may be imperfect, contain replicas, or surround errors. Data cleaning is the procedure of identifying and accurate (or eliminating) corrupt or incorrect records from a dataset, and refers to identifying shortened, inaccurate, imprecise or inappropriate parts of the data and then restoring, adjusting, or removing the unclean or coarse data. There are numerous categories of data cleaning that depend on the category of data. For illustration, while cleaning the unqualified data might be evaluated against reliable published numbers or defined thresholds.
The Enhanced Feature-Reduction FCM with Feature Linkage Weight (FRFCM-FLW) is an extended version of FRFCM algorithm. In general existing Feature Reduction FCM (FRFCM) algorithm that can automatically compute different feature weights by considering the FCM objective function with feature-weighted entropy. Moreover, we create a feature-reduction schema to eliminate these irrelevant features with small weights such that the computational time can be decreased with better clustering performance. The proposed FRFCM-FLW algorithm randomly updates feature-weight vectors in its training phase rather than exploiting a permanent feature-linkage weight vector. Since the feature linkage weight vector of the conventional FRFCM algorithm remains not fixed throughout the clustering process, the implication of weighted features to the altering cluster information cannot be properly manifested.
Let the dataset set D = {x1, x2, x3 ... x n } indicate a set of data points to be grouped into c clusters, where x i (i = 1, 2, ... n) is the data points. The fuzzy objective function is to find out nonlinear associations between the data points using embedding linking’s that connect features of data with new feature linkage weight spaces. The proposed FRFCM based feature linkage weight algorithm is an iterative feature reduction method that reduces the objective function (discover the non-linear relationship among the dataset).
Given an dataset, D = {x1 ... x
n
}⊂Rp (Represent pattern), the proposed algorithm divides X into c fuzzy separations by reducing the following objective function as,
Where U is objective function, V is centre point, w is weight, m is exponent value 2, d stands for the a priori likelihood distance measure for the class C
k
and the distance of the model i,j. The cluster center V
kj
as follows,
To discover the expression (μ(z)/ σ(z))
q
for the feature q in the FRFCM algorithm preserve really switch a scattering among clusters in the dataset. Consequently, utilize(mean(z)/var(z))
q
to estimate δq. That is, to judge the estimate for δ
q
as follows:
Where μ is mean and σ is variance.
To build a feature-reduction process using FRFCM-FLW algorithm, with assists of threshold value removes the unimportant features. In a feature, a threshold value is used to decide which the important features will be chosen. To identify the dataset with n data samples in which every dataset has f feature classes with the restraint
Proposed a new feature linkage weight clustering method, which is based on FRFCM expanded technique that is illustrated by [13] for formative FLW features or attributes and, furthermore, utilizes customized Mahalanobis distance with feature δ m determine of weight, which takes into explanation the FLW of features in accumulation to irrelevant of data. FRFCM features are initialized based on the input dataset. FRFCM-FLW method executed on the data set, but here the method utilizes altered Mahalanobis distance with feature δ m distance determined in FRFCM algorithm. The primary difference is of Mahalanobis distance along with feature δ m measure is performed. In this approach, feature variation and association of data is in use into account in computing feature clusters.
The proposed FRFCM-FLW algorithm determines the new set of features with modified feature linkage weight used for further clustering. In general FCM clustering method widely used Euclidian and Mahalanobis distance measure. The Euclidian distance between a and b is:
Let the a and b model vector (every model is particular data point in the data set and a model vector in which a and b fundamentals are the assessments that the model attributes presume in the data samples) be characterized as a p = [a1 p .,a2 p , ... ,a n p ], b p = [b1 p .,b2 p , ... ,b n p ].
The Mahalanobis distance among a and center v (the inconsistency and association of the data) is:
In Mahalanobis distance calculate CV is the co-variance matrix. Using CV matrix in Mahalanobis distance performs the irrelevant and association of the data. To take into consideration the weight or distance of the features in computation of weight among two data points, FLW technique suggest the utilization of (a-b)δ
m
(personalized feature variance (a-b)) instead of (a-b) in distance calculate, whether it is Mahalanobis (a-b)δ
m
is a vector that its i
th
component is attained by development of i
th
element of vector (a –b) and i
th
element of vector “FLW”. Now, using feature index to calculate the FLW of every feature. So to calculate the FLW of a feature this way: suppose f1, f2, ... , f
n
are n features of a data set and feature index (f
i
) and FLW (f
i
) are feature index and Feature Linkage weight of feature f
i
, respectively so,
Feature Linkage weight assignment is a unique case of feature selection where different features are ranked according to their significance. The feature is assigned a value in the interval [0, 1] indicating the significance of that feature value is called “FLW”. To define a vector whose FLW which its i
th
element is FLW (f
i
). Till now to calculate FLW of every feature of the data set. Currently must take into explanation these standards in computing the distance among data points, which is of great significance in feature selection. So, with this alteration, Equations 4 and 5 will be derived to this form:
and
respectively, where
The modified distance method is proposed in FRFCM-FLW algorithm of clustering data set with special feature linkage weights (i.e., feature similarity). Therefore, the proposed FLW value with consider a
The feature elimination action from FRFCM-FLW in Iris database is revealed in Table 2. Following the initial round, the third and fourth attributes provide better attribute weights than the primary with subsequent attributes. Because a primary with subsequent attributes has extremely little attribute weights, according to as two features are unnecessary throughout clustering procedures. FRFCM-FLW lastly keeps the two relevant attributes, i.e., the attribute (PL) and the attribute (PW), after the three rounds through an extremely fine clustering consequence of AR = 0.985.
Feature Elimination Performance for Iris Dataset with FRFCM-FLW Algorithm
The experimental result has been evaluated with the proposed FRFCM-FLW feature selection algorithm. The results executed on Intel I5-7200U series 2.71 GHz, x64-based processor, 8GB main memory, and runs on the Windows 10 operating system using MATALB R2017a simulation.
To evaluate the feature reduction based fuzzy clustering performance of the proposed FRFCM-FLW achieves better clustering accuracy with existing FRFCM [13], FCM [3], Entropy-Weighted k-means (EWKM) [5], Weighted K-means (WKM) [4], Weighted FCM (WFCM) [6]. In this experimental using synthetic and real-world datasets are obtainable. The proposed FRFCM-FLW feature reduction with Fuzzy C-means clustering algorithm executed to predict accuracy of datasets to meet the needs of various test requirements.
In this experimentation, proposed FRFCM-FLW algorithm works with real-world dataset of Iris data, that include four features, (i.e., “sepal length (SL, in cm), sepal width (SW, in cm), petal length (PL, in cm), and petal width (PW, in cm)”) with 150 data samples. Three different cluster classes of Iris dataset are i.e., setosa, versicolor, and virginica. Table 3 demonstrates an Accuracy Rates (ARs) of FRFCM with special attributes. By using every features, FRFCM provides the AR of 0.973 (4 incomplete points of 150 samples), although utilizing the features PW and PL. The feature decrease actions from FRFCM-FLW for the Iris dataset are exposed in Table 2. Furthermore, using Feature Linkage Weight method of modified Mahalanobis distance measure with feature mean and variance (δm) performs very best quality clustering outcome of AR = 0.985 (2 incomplete data of 150 data). It means, using FRFCM-FLW, feature PL is the majority relevant feature and PW is the subsequent the majority relevant feature for Iris dataset. Meanwhile, the proposed method performs good clustering result with high dimensional dataset of Basehock and Colon cancer with AR 0.831 and 0.682.
The Best AR’s Using Dissimilar Primary Cluster Centers with Predetermined Primary Feature Weights
The Best AR’s Using Dissimilar Primary Cluster Centers with Predetermined Primary Feature Weights
In [2] authors discussed an Iris database considers four features or attributes, i.e., Sepal Length (SL), Sepal Width (SW), Petal Length (PL) and Petal Width (PW). Figure 2 demonstrates a clustering for Iris dataset dependent on features SL and SW (i.e, purple and gray colors), while Fig. 3 demonstrates a clustering depends on PL and PW (i.e, sky blue and brown colors). In Fig. 2, individuals can observe that are greatly additional crossover among the classes. It is complicated for us to separate the class from the feature points. Figure 3 demonstrates that for the categorization of Iris dataset, features PL and PW are more significant than SL and SW. The cluster similarity (SL = 0, SW = 0, PL = 1, PW = 1) is better than (SL = 1, SW = 1, PL = 0, PW = 0) for Iris database categorization.
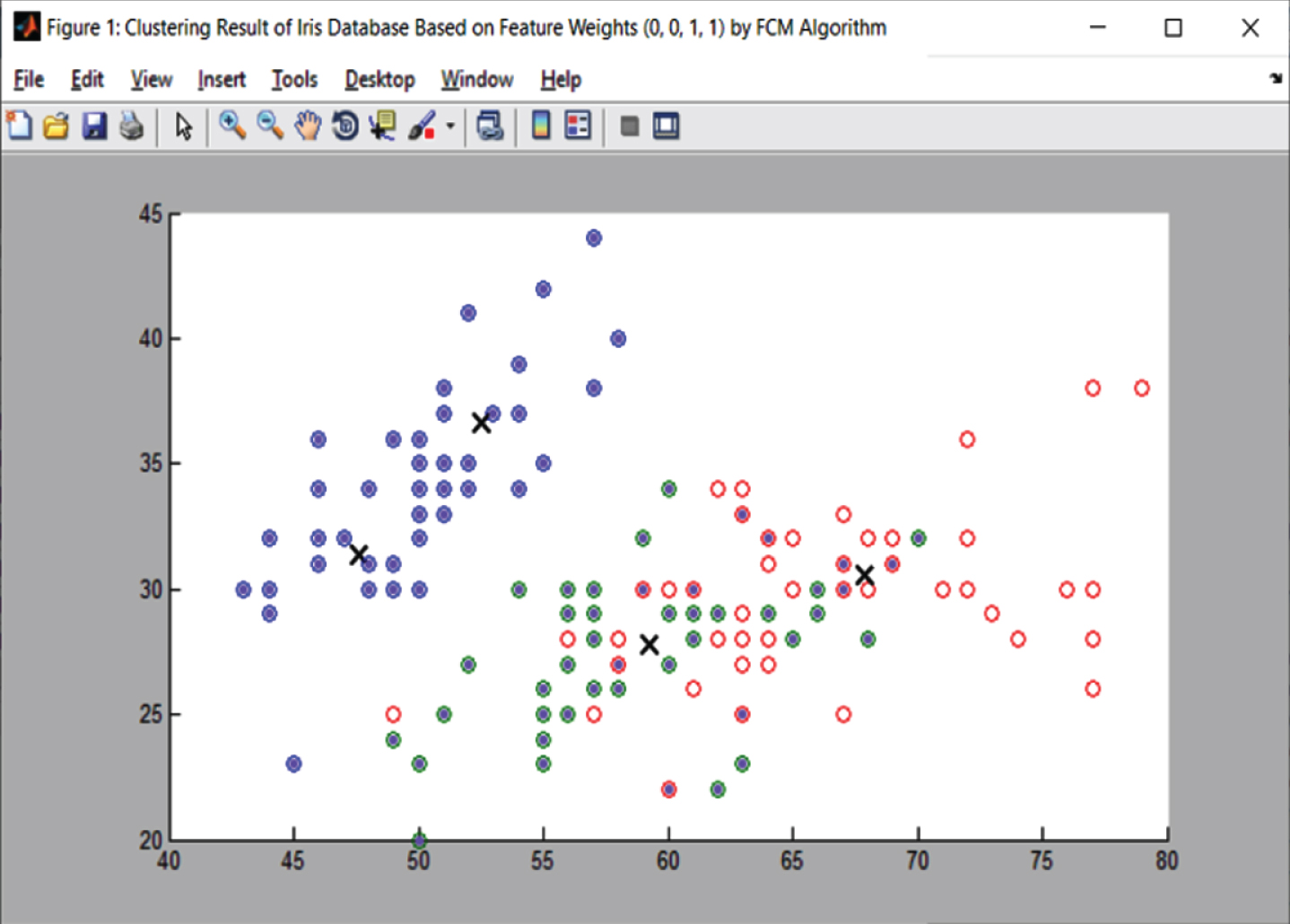
Result of Iris Feature Weights (1, 1, 0, 0) with Fuzzy c-means Algorithm.
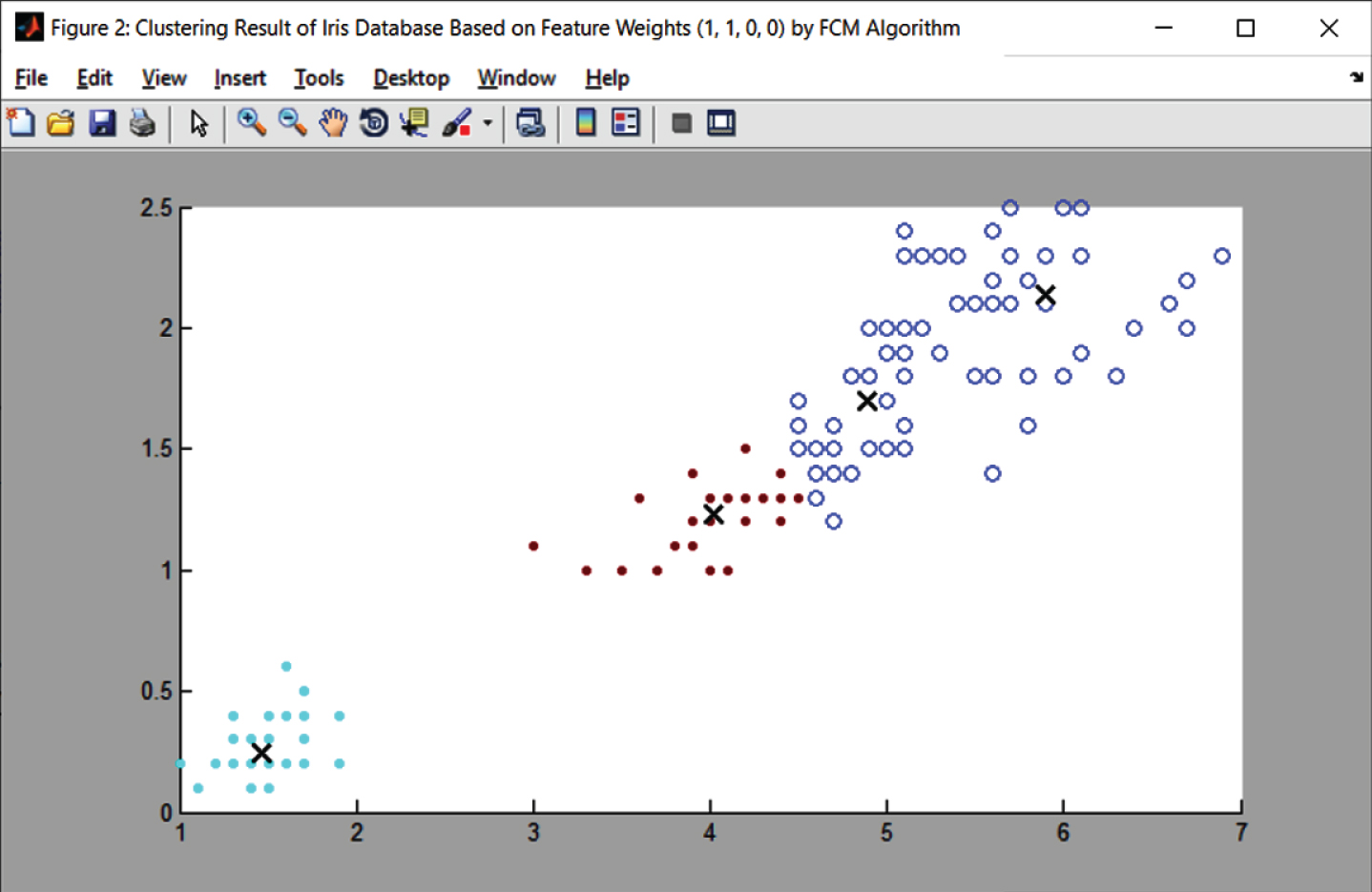
Result of Iris Feature Weights (0, 0, 1, 1) with Fuzzy c-means Algorithm.
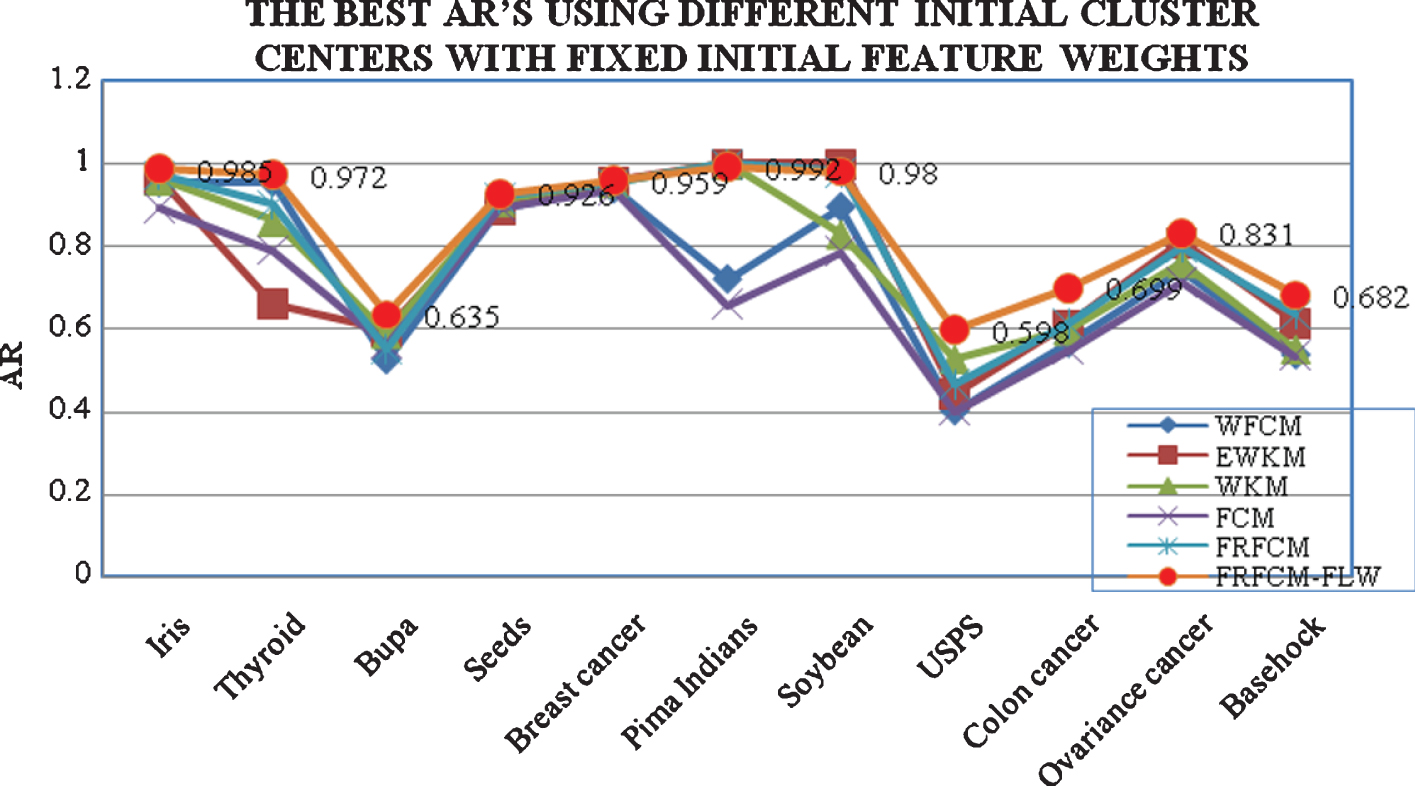
Comparison of Accuracy Rate (AR) values with Real world datasets.
Comparison of Jaccard Index (JI) values with Real world datasets.
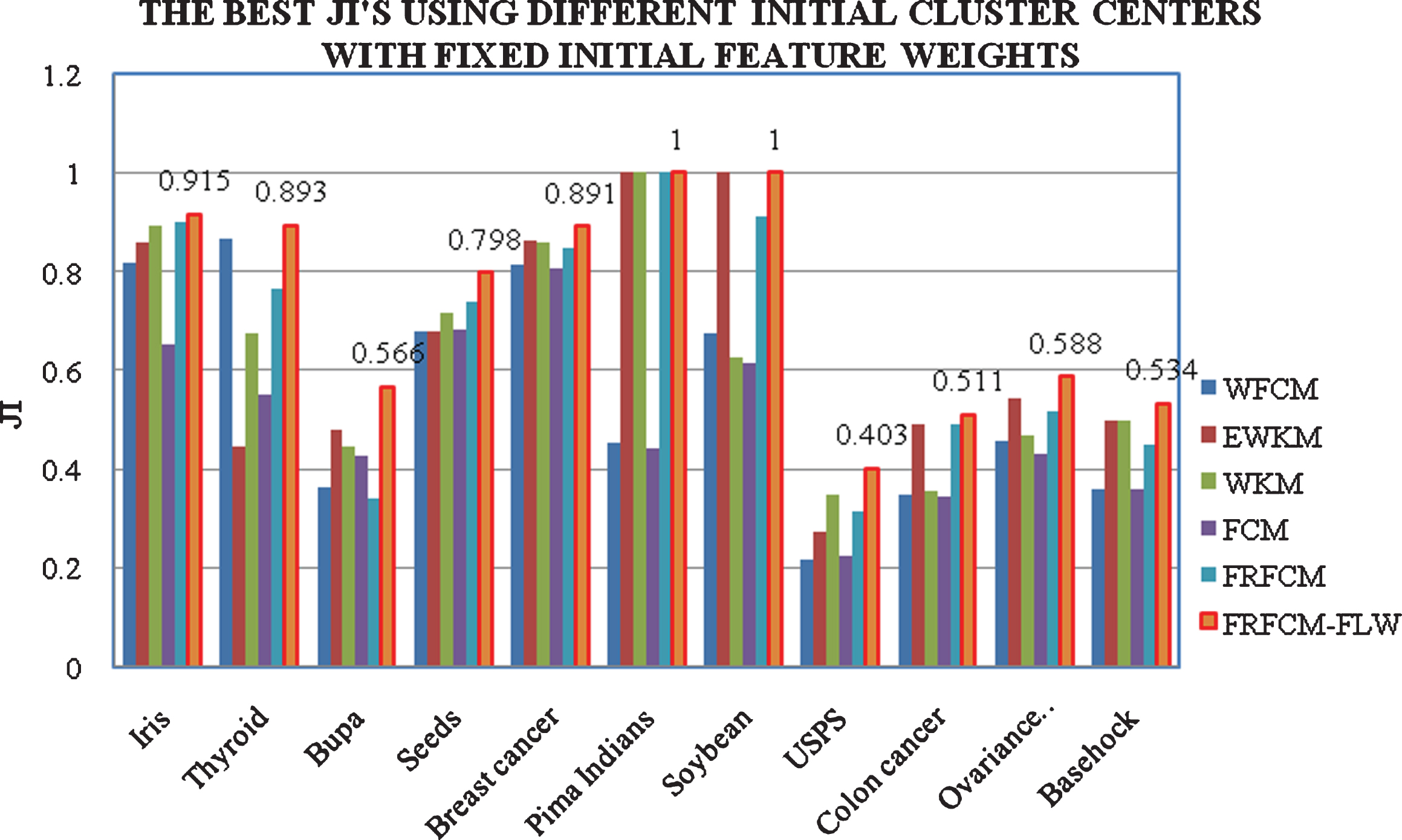
Comparison of Jaccard Index (JI) values with Real world datasets.
Quantifying proposed FRFCM-FLW clustering accuracy measures with Accuracy Rate (AR), Rand Index (RI), and Jaccard Index (JI). To computing clustering presentation, Accuracy Rate (AR),
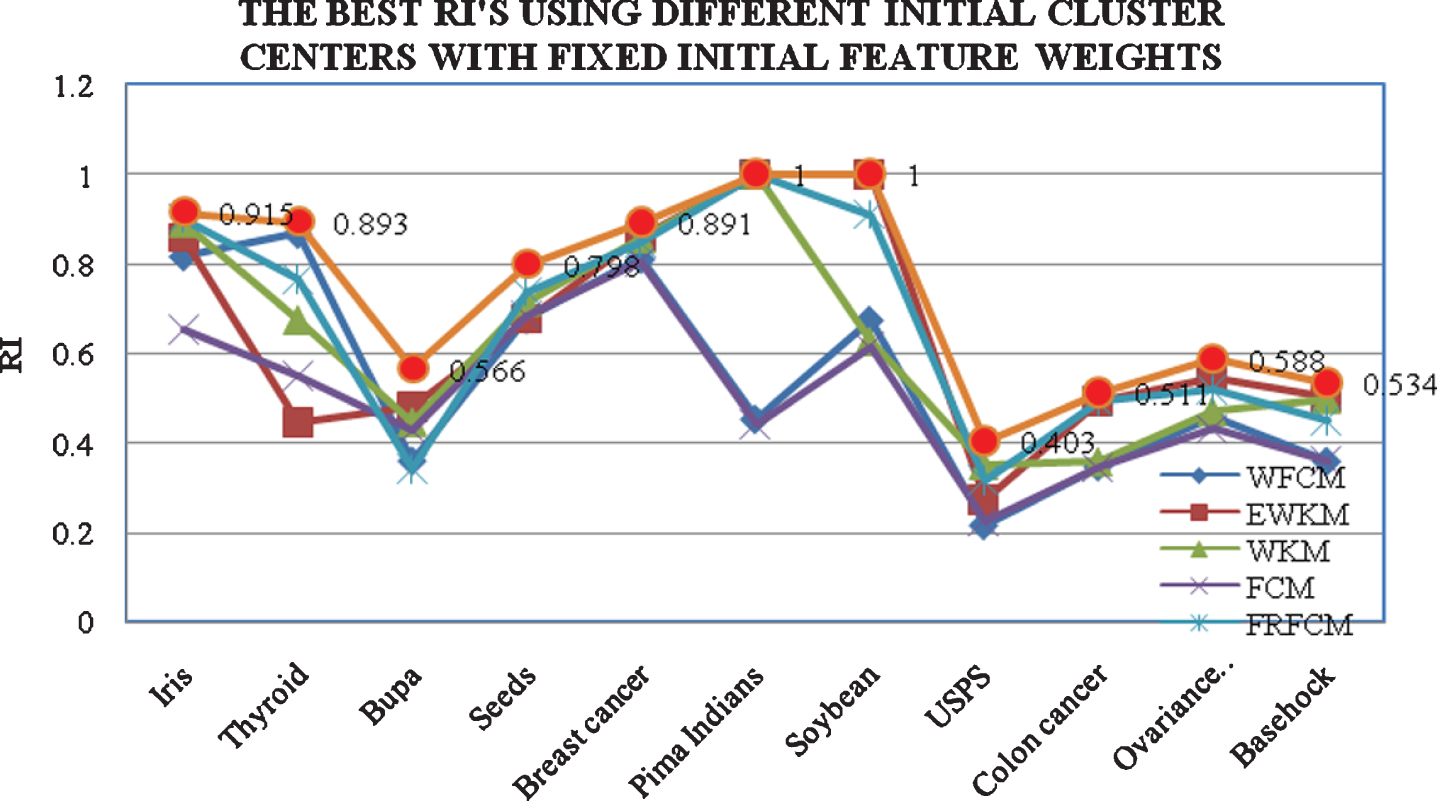
The Best RI’s Using Dissimilar Primary Cluster Centers With Predetermined Primary Feature Weights
The Best JI’s Using Dissimilar Primary Cluster Centers with Predetermined Primary Feature Weights
Rand [15] proposed an objective criterion for assessment of clustering techniques, recognized as RI (Rand index). At the present, RI comprises commonly used for computing similarity among two clustering separations. The RI is defined by
An additional quantity of clustering is JI (Jaccard Index) proposed by Jaccard [16]. The JI is described as JI = x/(x + y + z), where z refers number of times a pair of elements that negative for the different clusters and positive for the same clusters. Superior JI performs an enhanced clustering performance.
In this paper analyzed the advancement of the data feature reduction concepts in the field of feature reduction with Fuzzy C-means clustering technique. The proposed algorithm works with three stages namely Data formation, Enhanced Feature-Reduction FCM with Feature Linkage Weight (FRFCM-FLW) and FCM Clustering. The original synthetic and raw datasets are preprocessed using data cleaning process. The proposed feature selection is carried out using FRFCM-FLW method to remove the features with low feature weight. Different feature selection algorithms are discussed in related work. The proposed FRFCM-FLW clustering algorithm reduces the feature size automatically, and produced superior quality clustering outcomes. The FRFCM-FLW algorithm calculates a novel weight value of every feature by combining Mahalanobis distance with feature δ m distance measure in FRFCM algorithm. The clustering results of feature weight play a significant role in forming the feature dimension of clusters. These novel weights are utilized to modernize the fuzzy memberships and cluster centers for the dataset throughout the iterations. It also proves that FRFCM-FLW method obtains high AR, RI and JI ratio when compared to other feature reduction algorithms like WFCM, EWKM, WKM, FCM and FRFCM algorithms.