
Abstract
Data collection plays an important role in business agility; data can prove valuable and provide insights for important features. However, conventional data collection methods can be costly and time-consuming. This paper proposes a hybrid system R-EDML that combines a sequential feature selection performed by Reinforcement Learning (RL) with the evolutionary feature prioritization of Evolutionary Distance Metric Learning (EDML) in a clustering process. The goal is to reduce the features while maintaining or increasing the accuracy leading to less time complexity and future data collection time and cost reduction. In this method, features represented by the diagonal elements of EDML matrices are prioritized using a differential evolution algorithm. Further, a selection control strategy using RL is learned by sequentially inserting and evaluating the prioritized elements. The outcome offers the best accuracy R-EDML matrix with the least number of elements. Diagonal R-EDML focusing on the diagonal elements is compared with EDML and conventional feature selection. Full Matrix R-EDML focusing on the diagonal and non-diagonal elements is tested and compared with Information-Theoretic Metric Learning. Moreover, R-EDML policy is tested for each EDML generation and across all generations. Results show a significant decrease in the number of features while maintaining or increasing accuracy.
Introduction
In the last few years, a massive amount of data is created daily; however, the continuous growth of these data presents a challenge in the IT world regarding the ways to determine the important portions and select from such large volume of data in an efficient and timely manner.
From the economic point of view, many organizations are unable to cope with the amount of data present in their warehouses and external data not in their possession. Because of the overload problem associated with these data, a way to provide insights on the important features of the data are vital for business agility.
To overcome the problems associated with data processing, machine learning and data mining algorithms aim to process data and extract valuable information. However, these tools may be inefficient for the ever-growing amount of data over the last few decades. Furthermore, data collection can also be time consuming and expensive. For example, medical data collected using Magnetic Resonance Imaging or sensory input data collected through the Global Positioning System can be expensive and time consuming to process. That is why data processing algorithms can offer insights on which portions of data is important which helps reduce the amount of data needed and the data collection cost.
Data processing algorithms in machine learning like clustering algorithms [6] make sense of data by grouping similar objects using their features. Another example of data processing algorithms, such as Distance Metric Learning (DML) algorithms [10], can improve the clustering quality. DML increases the clustering accuracy by learning a distance function over objects and uses a distance transformation matrix M (in case of Mahalanobis distance-based metric learning) for input space transformation where the diagonal elements represent scaling factors applied on corresponding features.
Evolutionary Distance Metric Learning (EDML) [17] is a DML algorithm that optimizes the Mahalanobis-based transformation matrix M using Evolutionary Algorithms (EA). However, EDML particularly struggles to solve high dimensional problems. Furthermore, EDML needs to optimize the elements in the matrix simultaneously, for which it requires access to all the features, including the unimportant ones in the transformation process. Additionally, EDML fails to filter or select features; instead, it uses a technique of including weights as a scaling factor to prioritize features. Thus, metric filtering and selecting the right features in EDML is crucial because wrong features may be cost-ineffective and can produce worse results.
Feature selection [20, 12], which removes useless features from the original feature set, can alleviate the EDML high dimensionality problems as it can reduce the EDML search space and complexity. However, conventional feature selection processes are unsuitable because they assume free access to the data set as a whole and select a specific subset of features for any input regardless of the behavior of DML on them.
For that purpose, sequential feature selection with Reinforcement Learning (RL) [22] is introduced. RL is a machine learning technique that maps situations to actions and adapts according to its environment behavior. RL-based feature selection can learn different subsets of features according to the input and can explicitly select and learn the important elements in a sequential manner based on performances.
In this work, we propose an alternate hybrid optimization framework in the DML field called R-EDML that combines EDML and RL-based feature selection, in which RL learns how to add features sequentially based on the accuracy resulted from DML. This hybrid system can take advantage of the evolutionary feature weighting process and the optimization of distance transformation matrix M in EDML along with the RL sequential decision making that directs attention to important portions of the input space. Moreover, the hybrid system enables R-EDML to reach better solutions and achieves promising results by dramatically reducing the feature space while increasing or maintaining accuracy. This helps to reduce the time complexity and cost of future data collection.
The rest of the paper is structured as follows: Section 2 reviews briefly the literature of conventional feature selection and RL-based feature selection. Section 3 discusses the EDML. Section 4 describes the RL. Section 5 describes the methodology along with the modeling of the RL selection control strategy. In Section 6, different testing approaches and scenarios are explained in addition to the experimental results where the hybrid system performance is tested on the UC Irvine (UCI) Machine Learning database [5]. Finally, Section 7 concludes the paper.
Related work
Conventional feature selection
Feature selection methods are categorized into three main classes: Filter, Wrapper, and Embedded [12]: Filter methods use variable ranking approach for variable selection, which depends on general features like variable correlation for prediction or classification. Filter methods are time-efficient; however, they sometimes select the same variables by ignoring variable relationships. The Wrapper methods keep the relations between variables, by choosing a subset of variables instead of an individual variable; this facilitates the detection of possible relations between these variables. However, they are time inefficient and suffer from the risk of overfitting if the number of observations is low. When a greedy search is used, they fail to obtain optimal solutions. Embedded methods are a combination of the previous methods; thus, they take advantage of the Filter method variable selection, feature selection, and classification tasks simultaneously.
Regularization [1] is another effective approach in feature selection; for example,
RL-based feature selection
Conversely, RL has been successful when applied to feature selection. RL is chosen because of its ability to learn the important parts of data, useful for high dimensional data sets. RL simplifies the problem by proposing a reward maximization. The RL main applications in feature selection are discussed below:
Norouzi et al. [7] suggested an RL-based attention control strategy for image recognition, in which a sequential block-based approach was used to increase the correct classification rate of partially occluded faces. In this approach, the faces were partitioned into blocks and their importance in the classification task was learned by an RL agent who learned the exact number and order of blocks needed for correct classification. This approach could reduce the number of features needed for image recognition especially if the image was incomplete or impartial.
Dulac-Arnold et al. [11] proposed an approach that used policy iteration approximation in classification, where the policy was redefined at each step until it converged. These authors converted the classification into a sequential process where RL selected the features and classified the input into one of the available classes. In that way, classification and feature selection was done by a single component.
Rückstieß [25] suggested RL-based sequential online feature selection in supervised learning domains to convert classification into a sequential decision process. The approach helped to select the next feature depending on the previously-selected features and on the performance of the classifier. The approach fed features in a sequential manner to the classifier until a correct classification was achieved.
Nguyen et al. [24] introduced an online learning algorithm using sparse coding for feature selection in high-dimensional spaces and applied it to simulated and real robotics domains. They created a different MDP formulation that incorporates a principled way to factorize the state space in a compact way, while capturing the comprehensive transition and reward dynamics information. In their work, they separated the state-attributes that define the state from the informative state-features and applied feature selection on a large number of state features to capture the transition dynamics, while maintaining a compact state space.
Hachiya et al. [13] proposed a new framework that used filter-type feature selection for RL. They used the conditional mutual information as feature selection to evaluate the independence between return and state-feature sequences. The conditional mutual information was approximated by a least-squares method.
Nezhad et al. [21] proposed a feature selection method based on deep architecture and applied it to a specific medical problem to decrease the risk of heart disease. They used individual clinical data with many features and stacked auto-encoders for feature representation in higher-level abstraction. This approach applied deep learning to identify personalized features in order to control and predict the amount of left ventricular mass indexed (LVMI). This could help identify significant risk factors affecting LVMI to body surface area.
Janisch et al. [16] tackled the problem where feature collection is costly with the goal to optimize a trade-off between the expected classification error and the feature cost. They defined the problem as a sequential decision-making problem and used Deep Q-learning where individual actions are either requesting the feature values or terminating the episode by providing a classification decision. They used neural networks for value function approximations and showed that their approach outperformed the most recent methods specifically designed for the costly features classification.
These examples use an RL-based feature selection to take advantage of RL sequential decisions in the classification process. In this study, however, we use an RL feature selection to solve the metric filtering problem by combining RL with an EDML technique in a clustering algorithm. The approach not only reduces the features but also selects the correct number of features along with specific scaling factors determined by the EDML EA for each of the selected features in the transformation metric.
EDML
Various DML methods, such as the nearest neighbor classification method [19] and clustering techniques [8, 23], aim to improve the clustering and classification accuracy by learning a distance metric from a data set. DML is divided into two learning techniques [10]:
Unsupervised DML: This can achieve dimensionality reduction as it identifies geometric relationships in the Euclidean data space. Additionally, it can convert the input space into a low dimensional space. Simultaneously, it can avoid losing data point relationships. Semi-supervised DML: This uses auxiliary information like class labels and pairwise constraints of must-links and cannot-links in its learning. It aims to optimize a common metric transformation function by preserving similar classes and separating different classes.
EDML [17] is a semi-supervised DML technique that uses an EA to optimize its distance matrices. EDML relies on a clustering index with neighbor relation to evaluate inter- and intra-clusters and to optimize a distance transform matrix based on the Mahalanobis distance defined as:
where
jDE creates the first generation of candidates which are the distance transformation matrices. The input space is transformed using Mahalanobis distance in Eq. (1). The cluster structure is created by any clustering technique. The clusters are evaluated with class labels and pairwise constraints using the clustering index like pairwise F-measure [18] described in Section 5. The evaluation result is sent back to jDE as the fitness for these candidates. According to the fitness, jDE selects the individuals for the next generation using a probability-based mutation and cross over and creates the next generation. This cycle is repeated until the termination condition is satisfied, and the result shows the matrix with the best performance among all its peers in all generations. Figure 1 describes this cycle.
EDML life cycle.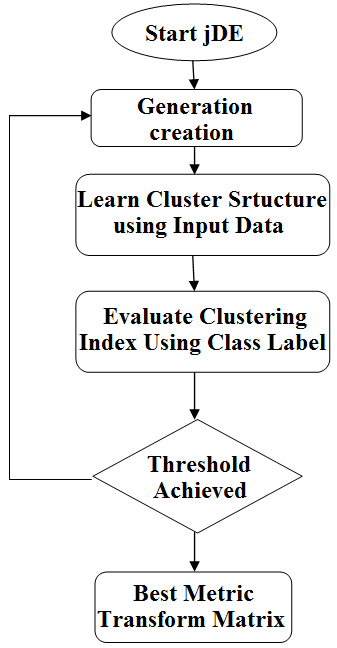
RL [22] is a learning technique that focuses on the interaction between an agent and the surrounding world. RL enhances the agent’s behavior over time by learning from trials and errors. The agent produces an output that represents an action of the state of the world the agent is in. The state here represents the virtual representation of the world at a specific time. Moreover, the world interacts with the agent’s actions by giving a scalar value called a reward, informing the agent in this state how well its action is. The goal of the agent is to maximize the expected discounted cumulative reward.
RL overview
One of the strongest points of RL is that a model of the environment is unnecessary. Through the agent’s life span, the agent can learn a policy to follow through an interaction and a reward system. The policy defines the agent’s behavior at any given state. This is a function that maps any state of the environment with an action to be performed by the RL agent. RL algorithms are divided into two types using the agent’s information:
Model-based: where the agent creates a model of the environment and finds the optimal policy by performing a planning algorithm on the model. Model-free: where the agent does not know the model of the environment. Regardless, the agent learns a policy by trial and error through a series of interactions with the environment.
An episode is a sequence of interactions between the agent and the environment from the start state to the terminal state. The agent chooses an action using the policy derived from the value function, performs this action, and observes the reward of the environment. Afterward, the agent updates its estimate of the value function associated with the policy. Then, the optimal policy is inferred by choosing the highest state-action value.
Q-learning is a model-free RL technique that aims to maximize a value function Q. In Q-learning, the optimal policy is derived from the highest Q-value in the current state. This is carried out by iteratively updating the Q-value function.
This process is done to optimize the Q-value function and to reach the optimal policy, described by the following equation:
where
The goal of this study is to minimize the used elements (features) in M in Eq. (1) while maintaining or enhancing the clustering accuracy as much as possible. K-means is the clustering algorithm used in this study using a K-nearest neighbor graph of cluster centroids. Since the EA in EDML constantly mutates and changes the elements in the distance matrices for every generation, the approach is to merge the RL sequential decision process in the EDML evolutionary generation process, taking place by inserting the elements in a sequential manner in the matrices and by learning the correct number of elements for any given EDML generation. This helps to learn the best features that suit the matrices for every generation. RL-based feature selection is suitable for EDML because RL can learn a selection control strategy, unrequired for a model of the environment, tailored to each EDML generation.
In this study, we focus on two types of EDML matrices: One is diagonal EDML where R-EDML will select from only the diagonal elements as they represent the features. The second is the Full Matrix EDML where R-EDML selects from both diagonal and non-diagonal elements to use the full power of EDML matrices transformations. Since RL is based on Markov Decision Processes (MDP), R-EDML as an MDP model is introduced; then, the life cycle of this model is described.
R-EDML model as an MDP
RL is based on MDP processes characterized by the Markov property. In MDP, every Markov state captures all the relevant information from history and independently describes the sequence of states leading to this state in the environment. The following concepts are discussed to enhance a greater understanding of the R-EDML Model as an RL model based on MDP:
States Actions State transition function Reward function Terminal function
As for R-EDML, the following concepts are described:
Satisfactory condition Policy
where
The F-measure ( The number of elements of
After both conditions are met, the values of the current best EDML accuracy and the fewest elements recorded are updated according to
The agent learns a new policy for each generation ( A unified policy across all generations is used that is continuously updated for all generations (
The policy used in this research is an Epsilon greedy policy, which allows the agent to be greedy with respect to rewards with a probability of
The overall R-EDML life cycle is divided into two phases: The EDML phase and the RL phase that run after each other in a loop for a specific number of generations. The EDML phase prepares the generation for the RL phase, whereas the RL phase gives feedback to the EDML phase to create the new generation. The detailed steps are as follows:
EDML evaluates the candidates using the K-means clustering algorithm and selects the elite results for the new generation using an EA. This generation’s population is a set of distance matrices
Elements of each M are stored for future reference. In the case of Diagonal R-EDML, the diagonal elements for each M are stored. In the case of Full Matrix R-EDML, both the diagonal and non-diagonal elements are stored. All the elements in the matrices for this generation are reset to zero. Several episodes will start, in each episode, the RL agent will insert the stored original elements in a sequential manner into the matrices Based on this evaluation, the agent either stops or continues to insert new elements (back to (c)). The termination of each episode depends on either achieving the satisfactory condition after evaluation or inserting all the elements. After all the episodes finish, RL will use the learned policy to identify the elements that offer the best performance in this generation. The selected features will either be saved for later comparisons or will be fed back to EDML and used in creating the next generation. The feedback (important features learned) from the RL phase to the EDML phase is constructed in two ways: Change EDML and No Change EDML.
Resetting the non selected elements to zero or decreasing their value by a certain fixed ratio. Setting the selected elements to their original values.
EDML phase will create a new generation and RL will start learning for the new generation. The entire process continues until a fixed number of generations are created. The output is the selection of the best M that has the closest accuracy to EDML and the least number of elements possible.
As for the evaluation process, the evaluation measure used is the F-measure (
Given
Class and cluster confusion matrix of data pairs
The precision
which ensures an incremental behavior in the performance with every generation having better accuracy or at least equal to the generation before. This gives RL an incentive to keep updating its goal and to keep up with the incremental accuracy. Figure 3 shows an example of Diagonal R-EDML system architecture with each generation having a population of 3 matrices and 3 diagonal elements (features), whereas Fig. 2 shows the R-EDML RL phase pseudo-code.
R-EDML RL phase pseudo-code.
R-EDML life cycle (diagonal R-EDML).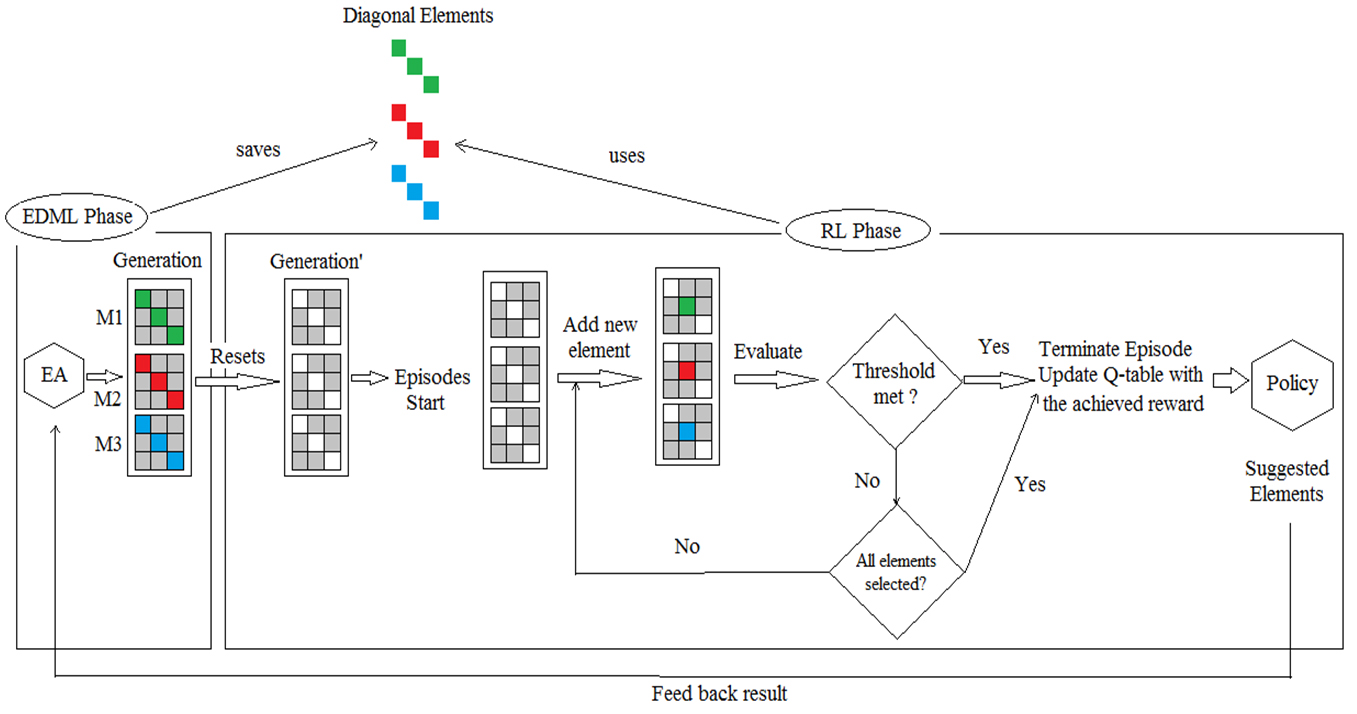
Overview
The goal of this section is to test the effect of the learned selection control strategy on the EDML transformation matrices. F-measure (
Tested scenarios
A multitude of approaches are tested and compared, the approaches are as follows: For each generation/N generations, Change/No Change EDML, Resettable/Appendable learning, learn from Policy (P)/Highest Accuracy (HA). The idea behind these scenarios is testing different ways of interaction between EDML and RL, some scenarios wait for EDML to converge first then change it or change EDML before it converges, others explore not changing EDML and run RL independently in parallel with it.
For each generation: Run RL for each EDML generation. For every N generations: Run RL each time EDML finishes N generations.
Change EDML: After RL finishes with a generation, only the learned elements are passed on to the next generation and the rest is either set to zero (Change EDML 1) or reduced by a certain fixed ratio (0.2 No Change EDML: After RL finishes with a generation, all the elements pass on to the next generation. In that case, RL does not affect EDML; however, it acts as an observer that records the results and picks the best after learning.
Resettable learning: Before each RL episode starts, the generation matrices are reset from all the elements (Section 5.2, RL phase step b). Appendable learning: Before each RL episode starts, the generation matrices are reset from all the elements except for the elements learned from the previous RL phases. After the current RL phase ends, the elements learned from the current RL phase are appended to the elements learned from the previous RL phases; and the next RL phase resets its elements except for these appended elements. This appending cycle will continue until the appended elements are equal to the total number of elements. In that case, the appended elements list will be emptied and the appending cycle starts again.
Learn from Policy (P): For the current generation, after RL finishes its episodes, the learned elements are chosen by the RL policy described in Section 5.1. Learn from Highest Accuracy (HA): For the current generation, after RL finishes its episodes, the learned elements are chosen from the HA episode in this phase.
Figure 4 shows the process of No Change EDML, whereas Fig. 5 shows the process of both Change EDML and Change EDML 2. Moreover, Fig. 6 shows the Resettable learning approach, whereas Fig. 7 shows the Appendable learning approach. A multitude of combinations between the described scenarios in this section is tested. Figure 8 shows the Merge technique combinations, whereas Fig. 9 shows the normal (non Merge) scenarios combinations.
Diagonal No Change EDML scenario: given a generation with 3 matrices (m1, m2, and m3), and each matrix has 5 diagonal elements, denoted by x. After the RL phase finishes, the generation is unchanged and is passed to the next EDML phase.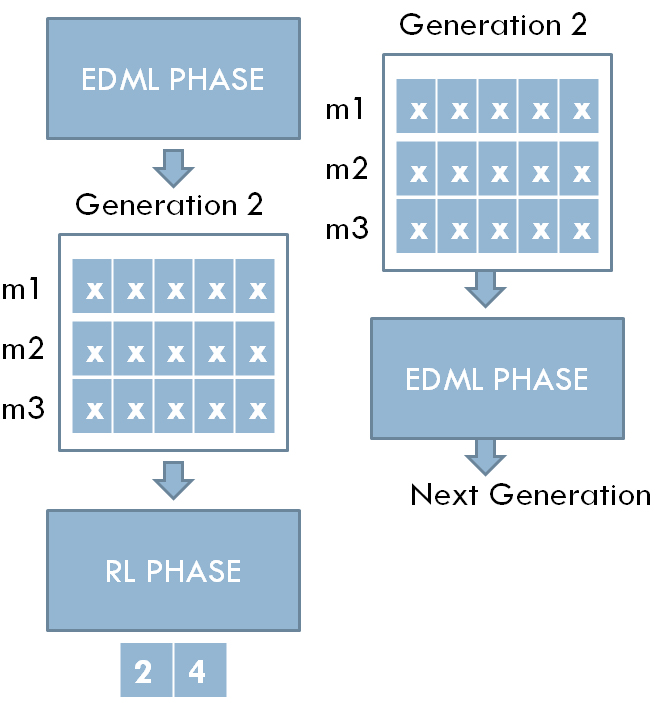
Diagonal Change EDML scenarios: given a generation with 3 matrices (m1, m2, and m3), and each matrix has 5 diagonal elements, denoted by x. After the RL phase finishes and indices 2 and 4 are the elements learned. Before the EDML phase starts, the current generation matrices change where the learned elements keep their values, whereas the rest are either set to zero denoted by an empty cell (Change EDML 1) or reduced by a certain ratio denoted by a red x (Change EDML 2).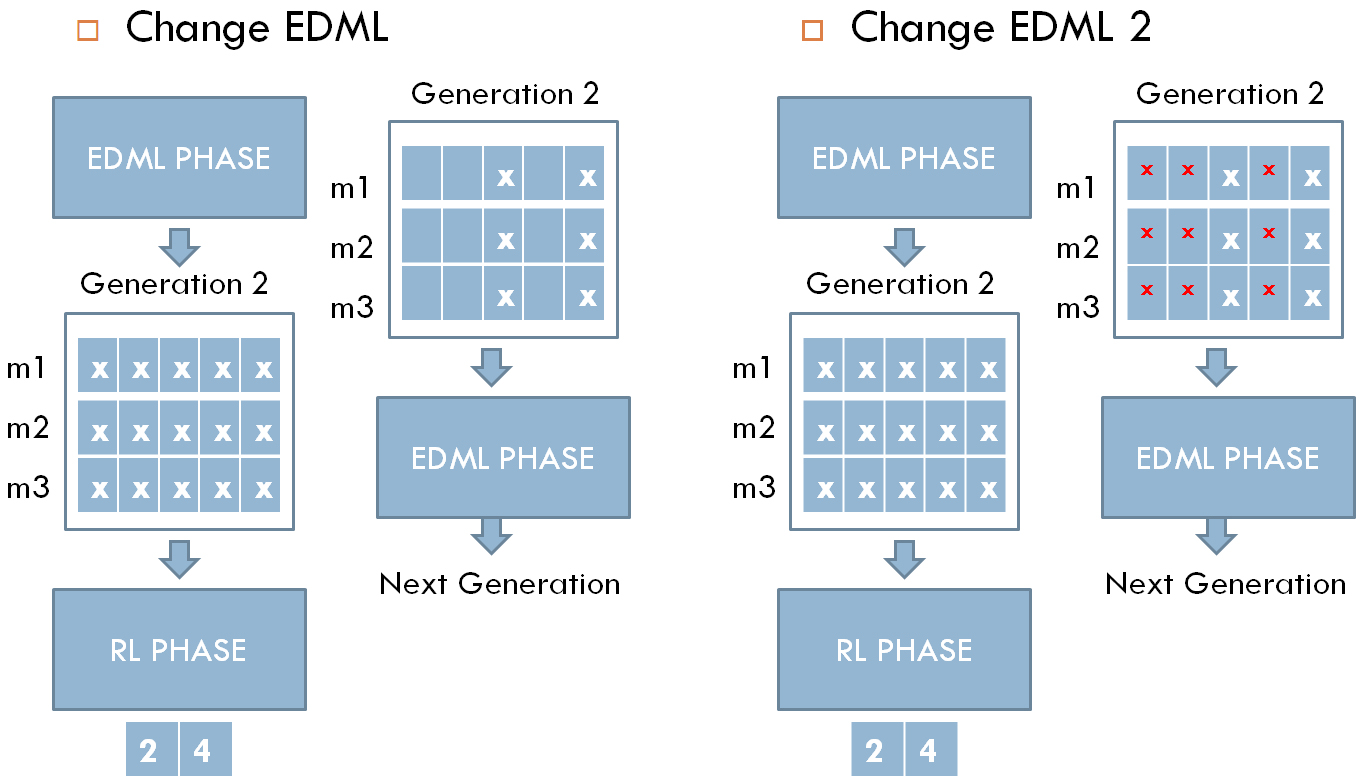
Diagonal resettable learning scenario: in a generation with 3 matrices each (m1, m2, and m3), and each matrix has 5 diagonal elements. In the current RL phase and before every episode, the learned elements from the previous RL phase are not appended to the matrices.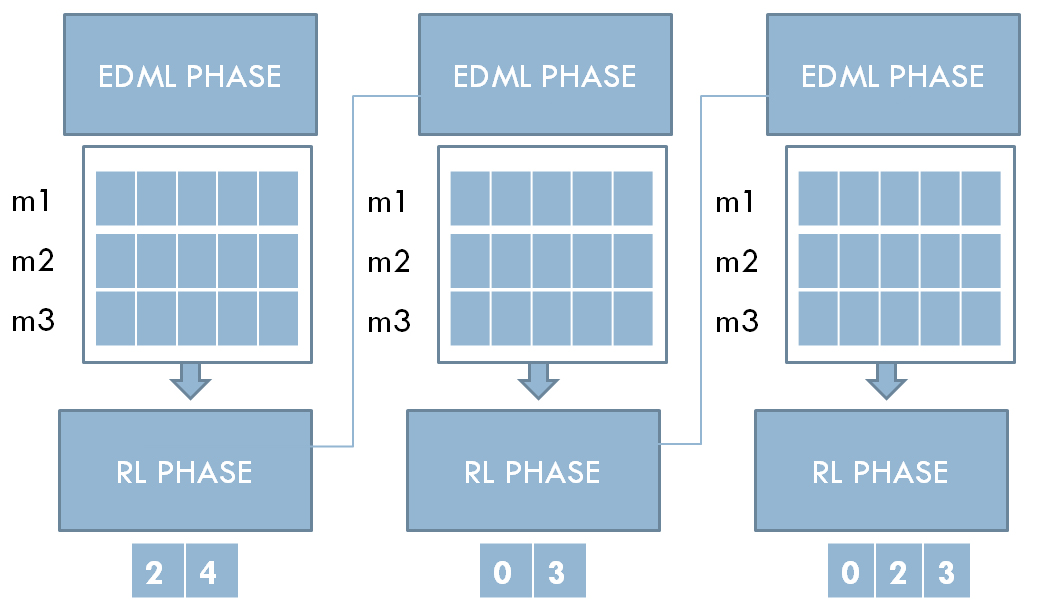
Diagonal appendable learning scenario: in a generation with 3 matrices each (m1, m2, and m3), and each matrix has 5 diagonal elements. In the current RL phase and before every episode, the learned elements from the previous RL phase are appended to the matrices.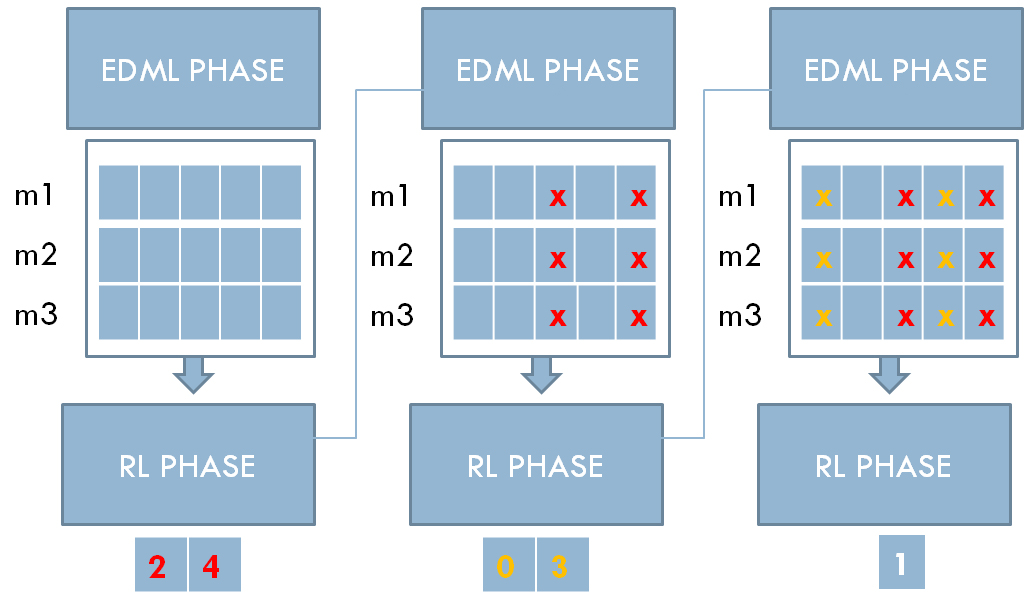
Merge technique scenarios combinations.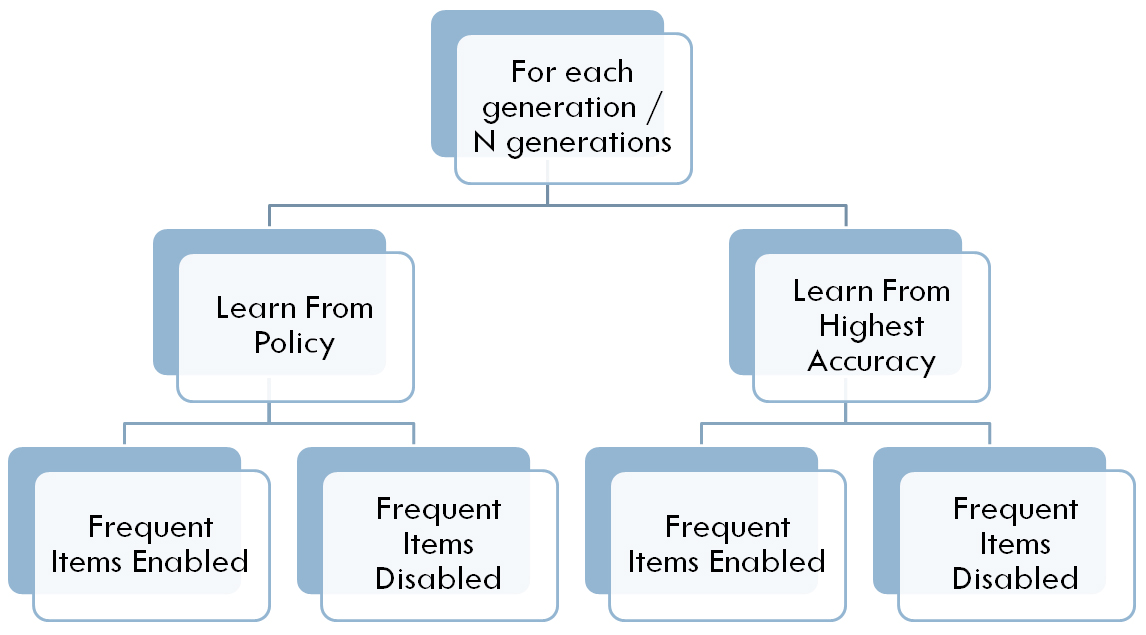
Non Merge technique scenarios combinations.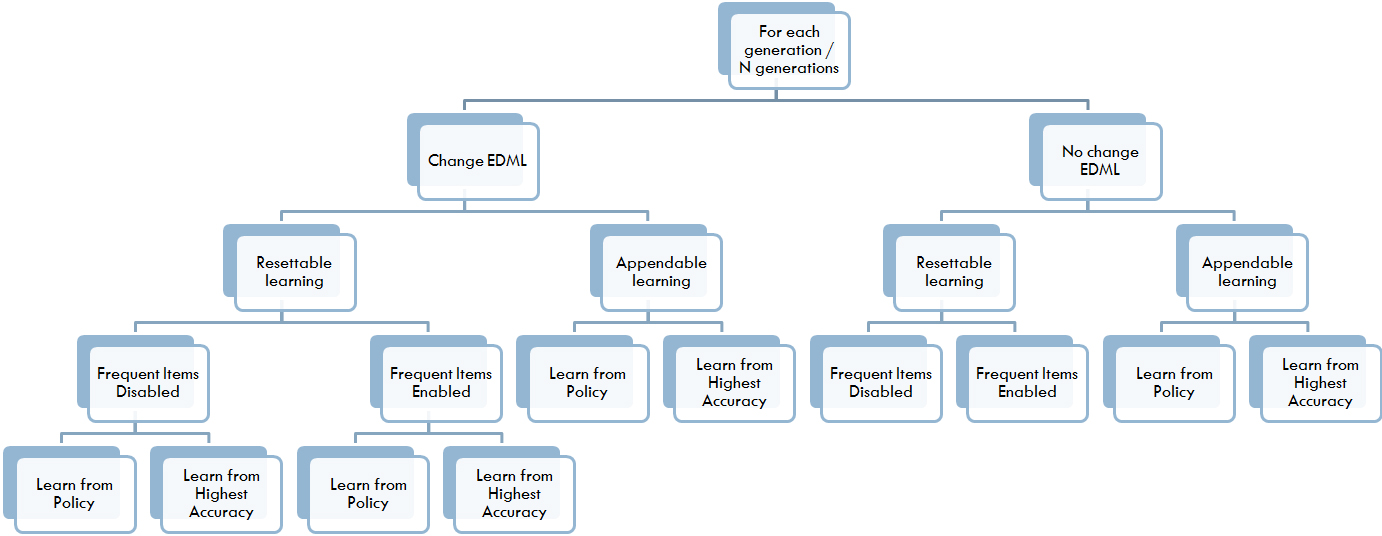
The tests are carried out on the UCI machine learning database [5]. The data sets are Iris, Glass, Wine, Vehicle, and Segment; Iris data set contains 150 data points, 4 features, and 3 classes, Glass data set contains 214 data points, 9 features, and 6 classes, whereas Wine data set contains 178 data points, 13 features, and 3 classes. The Vehicle data set contains 846 data points, 18 features, and 4 classes. Finally, the Segment data set contains 2310 data points, 19 features, and 7 classes. The UCI data sets used in this research are used as is, i.e., we did not add any noise nor remove any values in the data sets. We choose those UCI data sets as they are reliable and they do not have missing values and are correctly labeled as well as containing little noise to consider in this research.
Experiment settings
Initial tests are carried out to filter out the best scenario combinations (described in Section 6.2) according to the best pair of accuracy and number of selected features. The tests are also conducted to choose the best margin
Scenarios filtering in Glass data set
Scenarios filtering in Glass data set
Scenarios filtering in Wine data set
Scenarios filtering in Vehicle data set
The following experiments use diagonal EDML, in which removing these elements is the same as removing features from the input space. The only exception is the Full Matrix R-EDML experiment that uses the entire EDML matrix. All experiments are performed 25 times and the average result is recorded for each data set.
R-EDML vs. EDML
The idea behind this experiment is to compare R-EDML to normal EDML to check if this hybrid system will improve EDML in terms of features and accuracy. EDML is used as a basis for comparison. Although EDML does not explicitly select features, it has its feature prioritizing process. We observed the EDML optimal matrices results and the ratios between all the elements’ weights and we picked a threshold of 0.05. The prioritizing method of EDML important features number is as follows: after all generations are created, the diagonal elements weights of the optimal matrix are analyzed. Weights that are less than the threshold (0.05) are immediately discarded, and the rest is filtered according to the following formula:
Given M* as the optimal EDML matrix with elements
Conventional feature selection is applied to EDML to test if it is superior to R-EDML in terms of feature reduction. Two types of feature selection are tested, both concentrate on different aspects of the features:
Full Matrix R-EDML uses a combination of diagonal and non-diagonal elements. The purpose of this test is to take advantage of the Full Matrix capability in transforming the input space and see if the result can be improved while trying to use diagonal and non-diagonal elements. Full Matrix R-EDML is compared to another semi-supervised DML technique called Information-Theoretic Metric Learning (ITML) [15], which is the most famous DML method. A weight prioritizing process similar to that of EDML is carried out on ITML, later compared with R-EDML. A GitHub implementation1
In all the previous tests, in each R-EDML generation, a new policy tailored for the generation is learned because the assumption is that the R-EDML evolution algorithm changes and mutates the elements of each generation. In this experiment, the policy is unified across all generations to determine if a unified updated policy has potential validity.
Results and observations
Table 5 shows the feature weighting results of EDML and ITML, whereas Table 6 shows the comparison result between Full Matrix R-EDML and ITML. Tables 7–9 show the comparison between all the previous experiments among all data sets.
Feature weighting results in EDML and ITML
Feature weighting results in EDML and ITML
ITML comparison results
F-measure comparison results
# Features comparison results
# Generations comparison results
In Table 9, # Generations refers to the number of generations needed to reach the best result (highest F-measure and lowest number of features), which is a measurement to verify the approach that converges faster.
In Table 8, # Features in Diagonal EDML refers to the number of the selected diagonal elements. In Full Matrix EDML, # Features refers to diagonal elements (whether these diagonal elements are explicitly selected by R-EDML or they are not explicitly selected but non-diagonal elements associated with these diagonal elements are selected; in this case, they are considered selected).
In Table 5, EDML EA important feature weighting has decreased the required features for every data set. Even though feature weighting is not a considered feature selection, EDML still uses all the features. Typically, R-EDML explicitly selected fewer features than EDML important features in Table 8.
Diagonal R-EDML vs Full Matrix R-EDML
Surprisingly, Full Matrix R-EDML selected fewer features than Diagonal R-EDML, even though the former used a Full Matrix instead of the diagonal one. In Table 8, Full Matrix R-EDML offered the best feature reduction in 3 out of 5 data sets as compared with the diagonal approach, where each policy method offered the least features in 2 out of 5 data sets. In Table 9, Full Matrix R-EDML converged faster in Vehicle data set, whereas in Iris, Glass, and Wine data sets Diagonal R-EDML converged faster. As for the F-measure, Table 7 shows that Full Matrix R-EDML offered better accuracy compared with Diagonal one, with higher accuracy in 3 out of 5 data sets.
Policy unification vs policy separation
In comparison to the policy separation approach, Table 8 shows that the unified policy selected fewer features in 2 out of 5 data sets, the same number of features in 2 out of 5 data sets and more features in only 1 data set. In terms of features, this shows better results. Regarding the F-measure, Table 7 shows that this approach offered the same accuracy in 4 out of 5 data sets. As for the number of generations to converge, Table 9 shows that the unified approach converged faster in 4 out of 5 data sets. This shows potential in the policy unification method.
R-EDML vs (EDML, feature subset and scoring)
R-EDML (Diagonal policy separation, Diagonal policy unification, and Full Matrix) showed better results in terms of F-measure, number of features, and convergence compared with conventional feature selection. In Table 7, R-EDML achieved better accuracy in all data sets. In Table 8, R-EDML selected fewer features in all data sets, and in Table 9, R-EDML needed a fewer number of generations to converge as it reached the best result in fewer generations in 4 out of 5 data sets. Thus, R-EDML feature selection strategy has led to a high average feature reduction % while keeping a high F-measure: 65% in Iris, 88% in Glass, 74% in Wine, 88% in Vehicle, and 94% in Segment. This shows that this method offers a great advantage.
Full Matrix R-EDML vs ITML
Since ITML uses a Full Matrix, only Full Matrix R-EDML is comparable to it. In Table 6, the comparative result is displayed for each data set showing the F-measure and the number of features. Even though ITML does not explicitly select features, but prioritize them instead, R-EDML selected fewer features than ITML. Since no advantage in F-measure between the two techniques is noted, we conclude that R-EDML is better than ITML.
Effect of the acceptance margin of F-measure
This section investigates the effect of the acceptance margin of F-measure (
R-EDML margin evaluation graph.
In this paper, a hybrid system R-EDML is introduced that takes advantage of the sequential decision making in RL and the evolutionary process in EDML to produce an optimal distance metric with the same performance while extremely reducing the feature space. This approach reduces time complexity, saves future data collection time, and reduces the future cost of data collection since the unneeded features are costly or time-consuming. The experiments performed on UCI data sets show consistent superiority of R-EDML as they reduce the required features while maintaining or increasing the clustering performance when compared to the normal EDML and EDML with conventional feature selection. Full Matrix R-EDML is compared with ITML and produces good results. Similarly, R-EDML with policy unification is explored and achieves good results. These new changes in this hybrid system show promising potential and a chance for future improvements. For future work, it would be worth investigating the R-EDML performance on noisy data by adding synthetic noise to the UCI data as well as adding more performance measurements like Purity and Entropy.
Footnotes
Acknowledgments
This work was supported in part by the Network Joint Research Center for Materials and Devices.