
Abstract
The goal of research in Facial Expression Recognition (FER) is to build a robust and strong recognizability model. In this paper, we propose a new scheme for FER systems based on convolutional neural network. Part of the regular convolution operation is replaced by depthwise separable convolution to reduce the number of parameters and the computational workload; the self-adaption joint loss function is adopted to improve the classification performance. In addition, we balance our train set through data augmentation, and we preprocess the input images through illumination processing, face detection, and other methods, effectively maximizing the expression recognition rate. Experiments to validate our methods are conducted based on the TensorFlow platform and Fer2013 dataset. We analyze the experimental results before and after train set balancing and network model modification, and we compare our results with those of other researchers. The results show that our method is effective at increasing the expression recognition rate under the same experiment conditions. We further conduct an experiment on our own expression dataset relevant to driving safety, and it yields similar results.
Keywords
Introduction
Facial expression is human’s most effective way of emotional communication other than language. Mehrabian [1], a well-known American psychologist, proposed a formula stating that words, tone of voice, and facial expression account for 7%, 38%, and 55% of emotional exchange, respectively. Facial expression recognition extracts the facial expression features from the original input images and classifies them according to human emotional expressions, such as anger, disgust, fear, happiness, sadness and surprise, and is thus deemed to be the critical technology of an emotion monitoring system. Facial expression recognition is widely applied to scenarios such as driver-emotion monitoring in smart transportation, clinical testing in medical systems, and lie-detection analysis in criminal cases and has attracted much research in recent years.
With the development of computer GPUs and the establishment of massive facial expression databases, many researchers now work on expression recognition using deep learning technology. Deep learning combines feature extraction and facial expression classification, using multi-layer nonlinear transformation to implicitly extract the features to obtain more abstract high-level feature expression. With improved representation ability and robustness, this model can significantly boost the performance of FER. Convolutional Neural Network (CNN) [2] is a popular subfield of deep learning for computer vision, which is widely used in the facial expression recognition problem [3]. A CNN is a type of deep neural network with convolutional layers. It can directly use pixel values as input. By using local receptive fields, parameter sharing, sparse connections and down-sampling of the face image space in the neural network, a CNN extracts the locality and other features from the input data to complete its autonomous learning, implicitly attaining more abstract global feature expression of the image. A CNN is also robust to shifting, scaling, rotation, and other transformations on the image. Deep convolutional neural networks have impressive performances on face-related recognition tasks [4, 5]. However, the increase in the network layers not only brings about stronger feature extraction capability but also significantly increases the computational cost and storage requirements [6]. In addition, traditional CNNs use softmax loss to penalize the misclassified samples, which thus forces the features of different classes apart. However, facial expression recognition also suffers from high intra-class variations. The differences in the facial features can hinder expression classification. Some expression classes are less distinct from each other: happy expressions are usually exaggerated, with distinct features; on the other hand, sad expressions are more subtle, and they have features similar to those of fear expressions.
Having sufficient and balanced training data is important for the design of a deep expression recognition system. However, in many facial expression databases, the number of expressions in each class is not balanced, which would cause insufficient training of expression classes with fewer samples.
In this paper, we propose a new scheme for an FER system based on convolutional neural network:
Adopting depth separable convolution to replace part of the convolution operation to optimize the training model; applying the self-adaption joint loss function to decrease the feature diversity within classes and increase the feature distance between different expression classes to help differentiate the facial expressions; and conducting training and test analysis on the Fer2013 datasets using data augmentation in the preprocessing phase to increase the sample size of the insufficient classes. In addition, we compile a facial expression dataset containing five hazardous emotions related to driving safety, and then, we test our methods on this dataset. The results of our experiment show that the proposed method has decent generalizability.
The work presented in the literature to solve the facial expression recognition problem with deep learning includes two main groups: dynamic sequence-based and still image approaches. The former classification exploits emotional recognition for dynamic image sequences [7, 8], and the latter recognizes expressions from still images. Since facial expression recognition for dynamic image sequences can benefit from the results from still images, our study focuses on static images.
To increase the network depth without efficiency reduction, based on the foundation architecture of a CNN, Kaiming He et al. introduced residual networks that are easier to optimize and can improve the accuracy through the considerably increased depth [9].
For face recognition, Schroff et al. [10] proposed FaceNet, which directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. To distinguish the features, triplet loss was proposed. The idea is that the feature distance between the same identities should be as small as possible, and the feature distance between different identities should be as large as possible. For FER, exponential triplet-based loss [11] was utilized to give difficult samples more weight when updating the network. Li et al. [12] proposed a loss function that can effectively enhance the discriminant force of the depth features between different categories, namely, the loss function combining the angular margin loss and center loss, and they used the VGGFace2 dataset to conduct face classification training on the network.
Deep neural networks require sufficient training data to ensure generalizability to a given recognition task [13]. However, most publicly available databases for FER do not have a sufficient quantity. Currently, most deep learning models of FER are trained on standard datasets. They usually yield fair results on these datasets, but their accuracy tends to severely drop once applied to real-life scenarios. This phenomenon is due to the following: 1) The training datasets mostly come from posed photos taken in laboratories. These photos are largely different from data collected from daily life, which lowers the models’ generalizability. 2) Many datasets have a small data volume. Datasets such as JAFFE and CK+ have less than 100 training samples for each facial expression class.
A large, complete dataset is a fundamental requirement for a method to be reliable. The Fer2013 facial expression (Goodfellow, 2013) dataset is an official dataset for the Facial Expression Recognition Challenge on Kaggle. It contains facial expression data of people from different races, age groups, and genders. All its images are downloaded by a web crawler, and some contain noise such as illumination, variations in pose (side face), and occlusions (glasses, hands, hair, beard, accessories), which resemble real-life scenarios. Models trained on this dataset have stronger generalizability and are thus more practical. On the Fer2013 dataset, Tang et al. [14] researchers combined the CNN and SVM loss function, building a model that won the Fer2013 Kaggle Expression Recognition Challenge in 2013, with a recognition rate of 71.2%. Devries et al. [15] added predictions of the locations of facial landmarks in facial expression prediction, which is a multitask model with a final recognition rate of 67.21%. Zhang et al. [16] implemented a bridging layer on Tang et al.’s work, fusing data from multiple sources, including the Fer2013 dataset, and adding additional input into the fully connected layer for face representation learning, with a better performance of 75.1%. Guo et al. [17] adopted an additional classifier and an exponential triplet loss function, increasing the weight of the hard samples, and raised the recognition rate to 71.33%. Kim et al. [18] integrated 9 CNNs, pushing the rate to 73.73%. Pramerdorfer et al. [19], by integrating 8 DCNNs of changed structure including VGG, Inception, and ResNet, finally achieved a recognition rate of 75.2%.
Some emotions could jeopardize driving safety. According to research performed at Virginia Tech, sadness or anger can be more hazardous than cell phone use while driving – the odds of traffic accidents under such emotions is 5 times that with cell phone use. Excitement makes people drive faster; disgust causes a more offensive driving style; and dullness distracts a driver’s attention. These five emotions are considered to be harmful to driving. To further study their corresponding expressions, we constructed a dataset consisting of 1,580 raw images of eleven subjects. Each image is 1280
Proposed scheme
In this study, we propose an efficient scheme to improve the recognition accuracy based on a convolutional neural network, which includes 3 parts: optimizing the network architecture with depthwise separable convolution, adopting a self-adaption joint loss function, and using data augmentation in the preprocessing phase to increase the sample size for the insufficient classes.
Optimizing the network architecture
In this paper, we design an improved convolutional neural network architecture for facial expression recognition. This network is modified on the basis of a baseline convolutional neural network, as shown by Fig. 1. In addition to the input layer, this network has a depth of 15 layers, including 6 convolutional layers (C1, C2, C3, C4, C5*, and C6*), 3 pooling layers (P1, P2, and P3), 2 shortcut layers (S1 and S2), one separable convolutional layer (SC), 2 fully connected layers, and one classifier. A batch normalization layer is added after the convolutional layers, shortcut layers, and separable convolutional layer for normalization.
The input layer is a 48
Schematic diagram of the improved network architecture.
Lin et al. [20] proposed a network structure, namely, “Network-In-Network” (NIN), which enhances the model discriminability. Learning from them, we use a 1
A stack of small kernels replacing large kernels
In convolutional neural networks, larger kernels have larger receptive fields, thus capturing more context at once. A large kernel is good at extracting features, but at the cost of a greater computation workload [21], which is a burden for model optimization. To solve this problem, Karen et al. [22] replaced the large convolutional kernel in the VGG network with a stack of small kernels. They discovered not only that the number of parameters had decreased, preventing overfitting, but also that the feature recognition capability after training had been improved. In this paper, we thus use a stack of two 3
Applying depthwise separable convolution
François Chollet [23] proposed depthwise separable convolution as almost an extreme version of Inception modules [24, 25, 26]. Regular convolution considers mapping cross-channel correlations and spatial correlations simultaneously. Depthwise separable convolution first maps the spatial correlations only and then maps cross-channel correlations separately. This change in the convolution operation also changes the computational complexity. For example, Fer2013’s input feature map has 2 spatial dimensions (width and height) of 48 respectively, and one channel dimension of 1. Suppose that the 2 output spatial dimensions remain as 48, with a channel dimension of 64 and a kernel size of 3
Explicitly utilization of the feature information extracted by convolution
Different convolutional layers extract different features. These features are complementary. For deeper neural networks, if expression recognition and classification rely exclusively on features extracted from the last layer, then a proportion of the information in the mid-layers will be neglected. Lu et al. [27] used residual learning blocks to improve the training and optimization process of the deep convolutional neural network model, which improved the generalization ability of the network model for facial expression recognition while reducing the time cost of the model convergence. In this paper, we adopt a residual learning method. The connection based on multi-layer residuals is used at the underlying layer to perform feature fusion on the mapping results, fully utilizing the underlying features and thus enriching the convolutional features. Before introducing residual learning, the underlying mapping
Self-adaption joint loss function
Softmax loss is frequently used in multi-classification tasks in FER. It can be used to classify the extracted features and normalize the classification result. The formula [28] is given as follows:
In the formula,
To increase the intra-class compactness and the network’s feature recognition capability, Wen et al. [29] proposed the center loss function as given in the following formula:
In our study, to enhance this inter-class distinction as well as minimize the intra-class distance, we adopt the self-adaption joint function of softmax loss and center loss, and the joint formula is given as follows:
In the formula,
To guarantee the model’s generalizability, a deep neural network requires enough training data [13]. Given that transformations such as shifting, scaling, and rotation of images do not affect the CNN’s classification result, data augmentation increases the quantity of images by randomly varying the sample data, combines multiple operations, and generates more unseen training samples to make the network more robust to deviated and rotated faces. Data augmentation is divided into real-time augmentation and offline augmentation. Real-time augmentation involves conduct online cropping, scaling and other transformations of input model data in mini-batch, and it is already imbedded in the deep learning kit. Offline augmentation preprocesses data through spatial geometric, visual, and other transformations, further expanding the data volume and diversity. In our case, even though the Fer2013 dataset already has a large data volume, data augmentation can still improve the overall performance of our constructed model.
In general, the quantity distribution of various categories in the dataset is inconsistent, which would cause insufficient training of those classes with fewer samples and reduce the classification accuracy of the samples. Balancing out the class that has fewer expression samples than the other classes has become especially important. Commonly used data augmentation methods to solve the imbalance of a dataset usually involve resampling the data, including the following [31]:
Random undersampling: The distribution of classes is balanced by randomly removing samples of most classes. Random oversampling: The distribution of classes is balanced by increasing the number of samples in the minority classes by randomly enhancing the minority classes.
In addition, Cluster-based Sampling, Synthetic Minority Over-sampling Technique, Modified Synthetic Minority Oversampling Technique etc. can also be used. In this study, we use the random oversampling offline-augmentation method “four-corner cropping
Algorithm 1 summarizes the face expression recognition algorithm based on a convolutional neural network proposed in this paper.
The experiment in this paper uses the Fer2013 expression dataset as the object to evaluate the performance of the proposed methods. The experiment is set up based on the TensorFlow deep learning framework with the Python programming language, and it operates on the Ubuntu16.04 system The Fer2013 dataset images vary in illumination and contrast. In an unconstrained environment, this difference would cause significant variance within classes, hindering expression recognition. Illumination processing is thus necessary. In addition, face detection is necessary for many facial applications, such as facial recognition and facial expression analysis [32]. Although the Fer2013 dataset has already eliminated most irrelevant image areas, certain images still contain too many non-face areas.
Jin et al. [33] adopted the Gamma transformation to improve the facial recognition ability under uneven illumination. The Gamma transformation is a non-linear gray transformation in image processing, which can expand the dynamic range of images with dark or shaded areas and improve the recognizability of the details. When the Gamma value is less than one, the transformation stretches low grayscale areas of the image while squeezing the high grayscale areas; when the Gamma value is greater than one, the transformation does the opposite. In this paper, we also adopt the Gamma transformation for illumination processing.
Distribution diagram of various expression data in the Fer2013 dataset.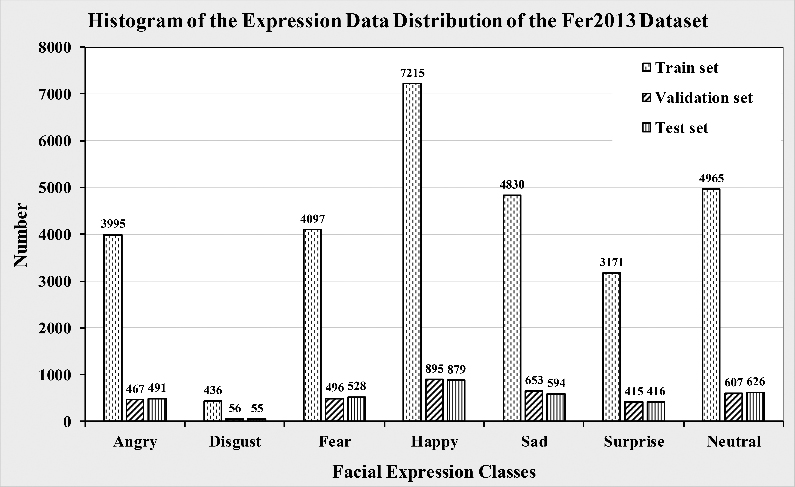
Viola and Jones [34] proposed a detection framework with a cascade architecture (V-J algorithm), which extracts Haar-Like features from images and trains the cascade classifiers using AdaBoost. This detection method has a fast calculation speed, decent detection performance, and real-time capability. In this paper, the V-J algorithm is also used in the image’s preprocessing phase.
The preprocessing of input images is a prerequisite for feature extraction and expression classification. The number distribution of various expression samples in the Fer2013 dataset is shown in Fig. 2. The train set, validation set and test set have 28709, 3589 and 3589 samples respectively. Data preprocessing mainly includes the following:
Balancing out the “disgust” class which has fewer expression samples than the other classes and using the offline-augmentation method “four-corner cropping Setting the Gamma value to 0.8, adopting the Gamma transformation for all of the image data, weakening the illumination’s impact on the face images, and making the textures in the shaded areas clearer Detecting faces in the images by the V-J algorithm face detector encapsulated in OpenCV, and scaling the images to a 48 Applying real-time augmentation to the train set before feeding it into the training model. Data are processed through random cropping, random scaling, and horizontal flipping with mini-batches of batch size 32. Such augmentation methods are embedded in the TensorFlow toolkit and supported by GPU acceleration.
It should be noted that all the data need Gamma illumination processing and V-J face detection, but only the training set needs augmentation and balancing.
Figure 3 shows the flow of the facial expression recognition. We use Stochastic Gradient Descent as the optimization method, 1e-2 as the learning rate, Xavier for uniform initialization, and ReLU as the non-linear activation function. However, we choose to use a linear activation function for dimension reduction at the C6* convolutional layer to prevent further loss of features since the compressed feature will lose part of its negative input through the ReLU activation function. This approach helps preserve more feature information, improving the model’s performance.
Facial expression recognition flow chart.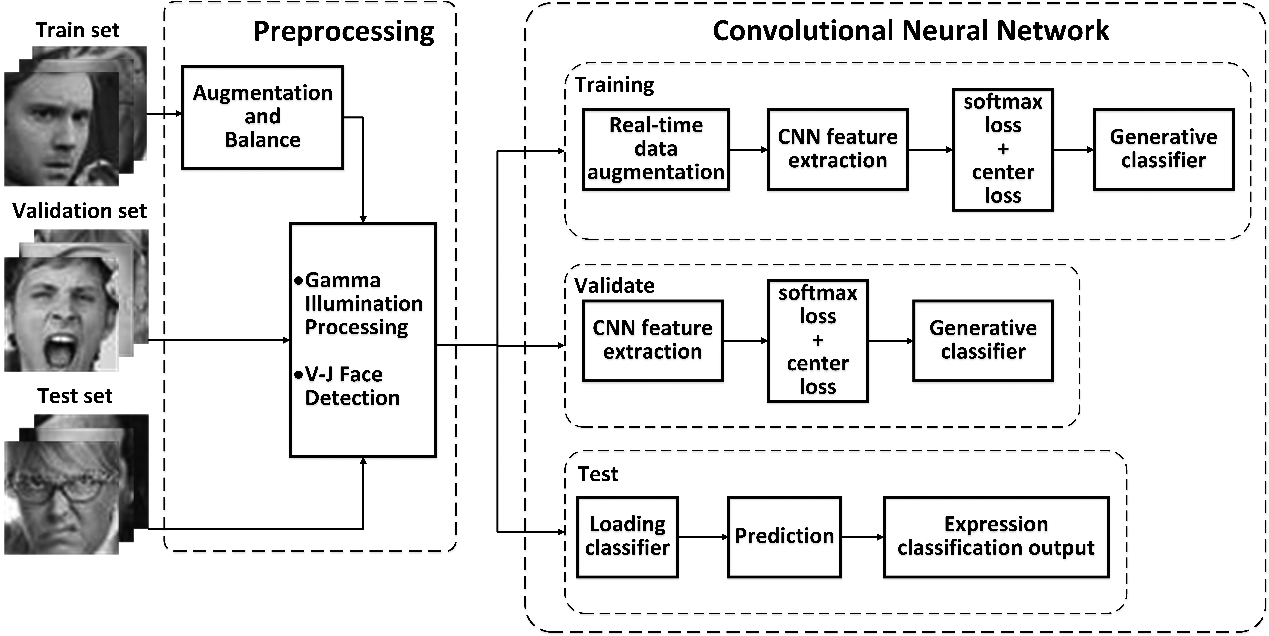
The experiment is divided into three parts:
Comparing the recognition rate of our model with and without balancing classes Conducting a comparison experiment on the modification of the network model, analyzing each adjustment’s impact on the expression recognition rate Comparing the results of our experiment to other results using different network structures on the same dataset, and testing the effectiveness of the model proposed in this paper.
For convenience of expression, we use abbreviations for the following operations: “minus” represents the class balance method involving cutting other classes’ data volume to the same level as the smallest class; “plus” represents conducting offline data augmentation on the smallest class to increase its data volume tenfold through “four-corner cropping
Table 1 lists the average expression recognition rates of each trial and their neural network structures and settings. Figure 4 illustrates the baseline model’s network architecture, which is represented by Model 1 in the table. All the modifications are made step by step. We compare the results before and after each adjustment and analyze the impact on the recognition rate. Figure 1 illustrates the final version of our improved network architecture.
In the experiment, we set the network structure according to the gradually improved model, and the average recognition rate based on the model training is obtained
In the experiment, we set the network structure according to the gradually improved model, and the average recognition rate based on the model training is obtained
Schematic diagram of the network architecture of the baseline model.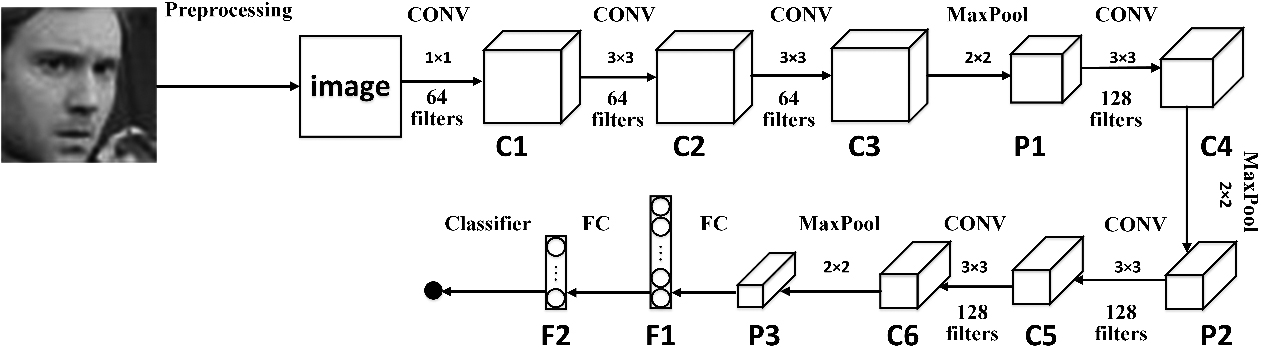
We compare the results of three models in this experiment: Model 1 adopts the baseline network architecture. It uses the original samples without class balancing and uses only the softmax loss function Model 2 balances classes by reducing the sample volume of large classes on the basis of Model 1. The “disgust” class has the smallest sample volume among all seven classes. Model 2 reduces the sample volume of the other classes to the same level as the “disgust” class. In contrast to Model 2, Model 3 balances the classes by data augmentation.
Influence of category balance on the expression recognition rate.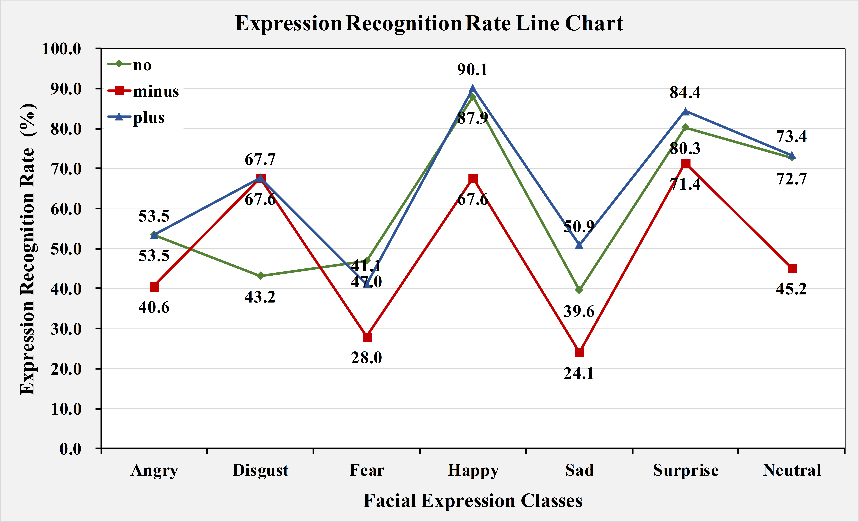
We compare the experiment results of these three models and illustrate the results using a line chart as shown in Fig. 5:
In Model 1 which does not involve class balancing, the recognition rates of the “happy” and “surprise” classes are notably higher than those of the other expression classes as well as the average recognition rate. Two possible reasons for this result are as follows: i) These two expression classes are more distinctive. In real life, happy expressions and surprised expressions are often exaggerated and easy to read. ii) Unbalanced classes in the train set could affect the recognition rate. In this train set, the “happy” class has a much larger data volume than the other classes, and it also has the highest recognition rate. The “disgust” class has the smallest data volume and the lowest recognition rate of 43.2%, which is much lower than the average recognition rate. To prove our hypotheses, we conduct experiments on Model 2 and Model 3. In Model 2, all the other sample classes are reduced to the size of the “disgust” class, which leads to a great increase in the recognition rate of the “disgust” class. However, the recognition rates of the other six classes drop. This finding shows that i) balancing the training sample of different classes helps increase the recognition rate of the smallest class and ii) decreasing the data volume hurts the model’s recognition rate on the corresponding classes. Additionally, despite a drop, the recognition rates for the “happy” and “surprise” class are still higher than or at least equal to those of the other expression classes and are much higher than the average rate. This finding further proves that these two expression classes are rather distinctive. In Model 3, which uses data augmentation for class balancing, the “disgust” class sample size is enlarged tenfold using offline augmentation of four-corner cropping
Comparison of the feature graphs before and after adding a residual connection.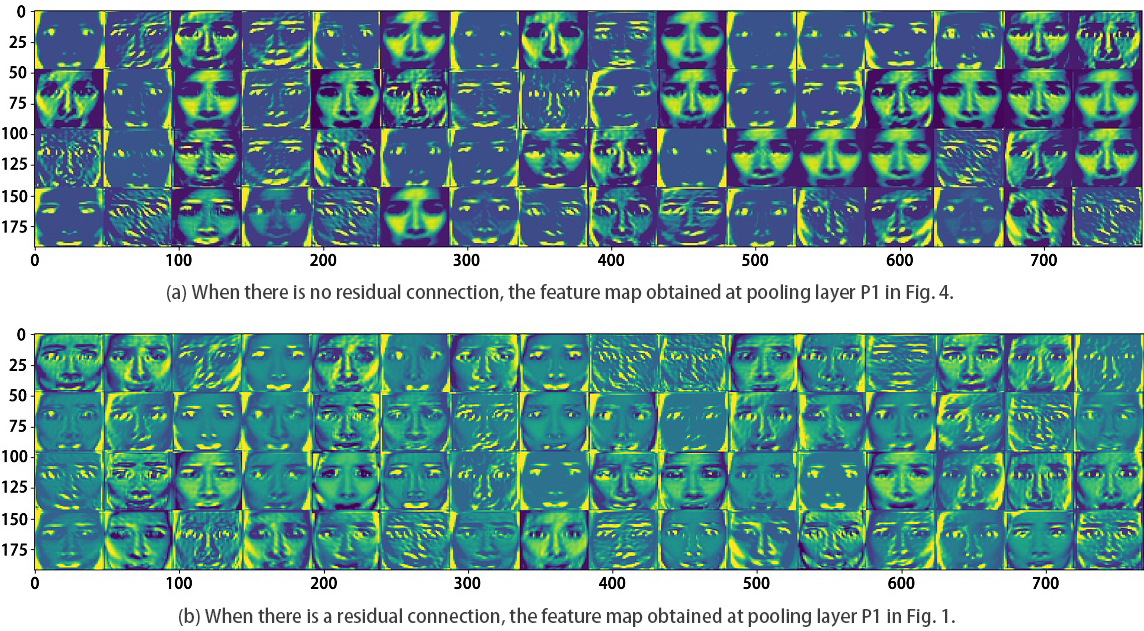
Comparison of various expression recognition rates before and after adding a residual connection.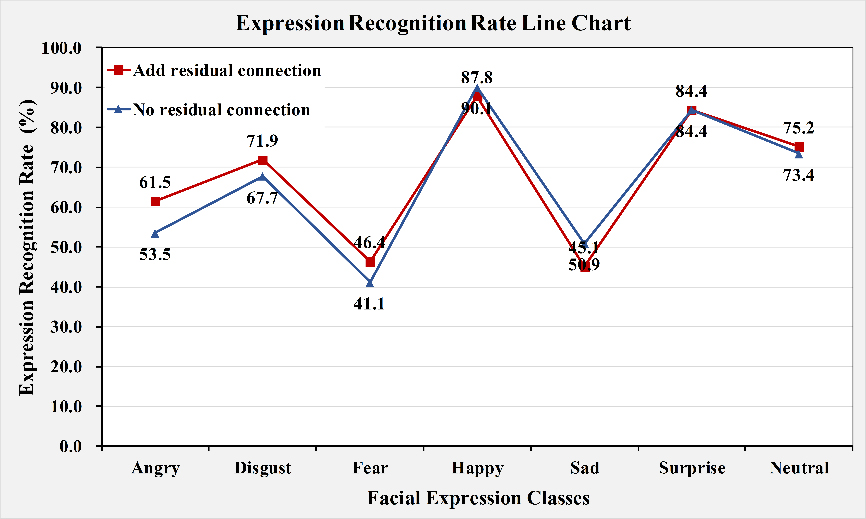
In this part, we build three models for the comparison.
Experiment on the residual connection
We build Model 4 by adopting the residual module on the basis of Model 3, and we conduct this comparison experiment to test its effect. We capture a feature map at pooling layer P1 in Fig. 1 and another at pooling layer P1 in Fig. 4. The resulting images are shown in Fig. 6a and b. By comparison, we discover that by adding a residual connection, we can extract richer convolutional features. Figure 7 shows a comparison of the two models. Compared to Model 3, which does not use a residual connection, Model 4 has much higher recognition rates for the classes “angry”, “disgust”, “fear”, and “neutral”. It is also shown in Table 1 that by using a residual connection, the average recognition rate rises to 70.356%, which is 1.173% higher than that of Model 3. This finding supports that residual learning improves the model’s recognition rate.
Experiment on the self-adaption joint loss function
In Model 5, we replace the softmax loss function in Model 4 with the self-adaption joint function of softmax loss and center loss. Figure 8 shows a comparison of the results. By adopting the joint loss function, the recognition rates largely increase in the classes “fear”, “happy”, “sad”, and “surprise”, and especially for the classes “fear” and “sad”, the increases in the recognition rates are relatively large. In addition, the recognition rates slightly decrease for the classes “neutral”, “angry”, and “disgust”. The overall average recognition rate rises 0.391% with the self-adaption joint loss function. This finding shows that the self-adaption loss function can increase the intra-class compactness, which is helpful in distinguishing the expression classes that are less distinct from each other.
Influence of the loss function on the expression recognition rate.
Experiment on the separable convolutional layer
Influence of the separable convolutional layer on the expression recognition rate.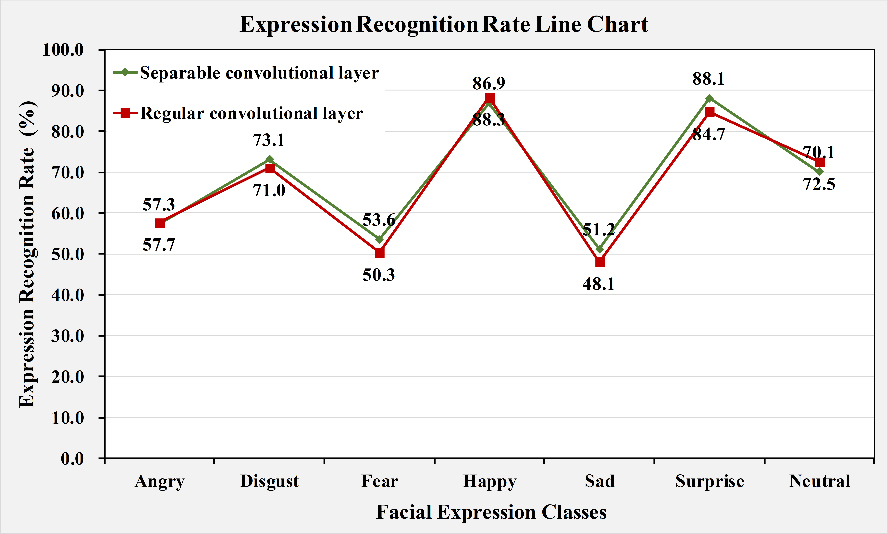
To analyze the effect of separable convolutional layers, we build Model 6 and Model 7 on the basis of the baseline model and keep their number of network layers constant. In Model 6, which uses data augmentation for class balancing, we replace the two 3
In Model 8, we augment its sample volume for class balancing and modify its network architecture by using the joint self-adaption function of softmax loss and center loss, adding the residual learning module and adopting the separable convolutional layer. The final architecture is shown in Fig. 1. The training results on this model achieve an expression recognition rate of 71.842%. Compared to the initial Model 1, this expression recognition rate is 4.763% higher, and it is also higher than the human eye’s average recognition rate of the same expression dataset, which is 65
Performance comparison with other methods for FER based on the Fer2013 dataset
Performance comparison with other methods for FER based on the Fer2013 dataset
We compile five facial expression datasets that correspond to the emotions hazardous to driving safety, and then, we test the improved model on this dataset. Our results for this experiment show that the proposed methods had decent generalizability.
Anger, disgust, excitement, sadness, and dullness are five emotions that have negative effects on driving safety. We build a dataset consisting of 1,580 720p expression images corresponding to these five emotions. Each class of emotion has 371, 413, 271, 304, and 221 images respectively. In this experiment, we divide the dataset into the train set, validation set, and test set. We use the methods mentioned in our previous text for image preprocessing, and then, we apply data augmentation to the smallest “dullness” class of the train set, increasing its images to the same level as the other expression classes. On this dataset we train and test Model 8. Of course, the classification layer has 5 neurons, and it classifies the output of the fully connected layer into the 5 emotional classes: anger, disgust, excitement, sadness and dullness. We obtain a recognition rate of 98.361%. This finding supports the effectiveness and generalizability of the model we proposed.
Conclusion
Facial expression recognition has wide applicability in real life scenarios. In this paper, we propose a new scheme for FER based on a convolutional neural network. Our contributions include the following: replacing part of the regular convolution operation with depthwise separable convolution to reduce the number of parameters and the computation workload; adopting the self-adaption joint function of softmax loss and center loss to mitigate the influence of subject identity bias, minimize the intra-class distance in acquiring shared features, and increase the inter-class distance in differentiating different expression classes; and balancing the train set through data augmentation to increase the expression recognition rate of our model. We conduct our experiment on TensorFlow as the platform, adopting the Fer2013 dataset for multiple controlled experiments. We compare our results with the results of other researchers. The comparison proves our methods and model to be effective, and we can increase the recognition rate of human facial expressions. Last, by applying our methods to our dataset of emotions hazardous to driving and analyzing the results, we further prove the effectiveness and generalizability of our methods. We thus look forward to further applications of our scheme in monitoring drivers’ emotional states and improving driving safety. In the next phase of our research, external datasets can be introduced. Multiple deep convolutional neural networks can also be integrated into our method to further increase the recognition rate.
Footnotes
Acknowledgments
The research is supported by the State Key Laboratory of Geo-Information Engineering of China (Grant No. SKLGIE2017-M-4-6) and the National Natural Science Foundation of China (Grant No. 41701537). We would like to thank Kaggle Inc for providing dataset for the studied FER. We also acknowledge Sicheng Zhao for his English editing support.