
Abstract
A cognitive-analysis of facial features can make facial expression recognition system more robust and efficient for Human-Machine Interaction (HMI) applications. Through this work, we propose a new methodology to improve accuracy of facial expression recognition system even with the constraints like partial hidden faces or occlusions for real time applications. As a first step, seven independent facial segments: Full-Face, half-face (left/right), upper half face, lower half face, eyes, mouth and nose are considered to recognize facial expression. Unlike the work reported in literature, where arbitrarily generated patch type occlusions on facial regions are used, in this work a detailed analysis of each facial feature is explored. Using the results thus obtained, these seven sub models are combined using a Stacked Generalized ensemble method with deep neural network as meta-learner to improve accuracy of facial expression recognition system even in occluded state. The accuracy of the proposed model improved up to 30% compared to individual model accuracies for cross-corpus seven model datasets. The proposed system uses CNN with RPA compliance and is also configured on Raspberry Pi, which can be used for HRI and Industry 4.0 applications which involve face occlusion and partially hidden face challenges.
Keywords
Introduction
Facial expression recognition has a significant role in the growth of cognitive system for Human Machine Interaction (HMI). There is a surge in development of collaborative and social robots due to rapid progress in robotic technology, hardware efficiency and artificial intelligence. Progress in HMI has inspired a few implementations where robot is programmed to follow human emotions. In many applications, such as E-Learning feedback mechanism, entertainment industry, driver mindfulness ready framework, legitimate sciences, helpful guide, cerebrum science, situation analysis of social interaction, robot interaction therapy for autistic children, affective computing, depression Level Analysis etc. [1, 2, 3, 4, 5, 6, 7, 8, 9], the task efficiency gets enhanced with facial expression recognition.
Since Darwin’s work in 1872, facial expression analysis has been an active and interesting research areas for cognitive psychologists and behavioral scientists [8]. Facial expressions are the changes in facial features in response to internal mental states, social experiences or intention of individuals. Literature on psychology suggests that isolating facial features like eyes, mouth, nose etc., is necessary for human cognitive system to identify face identity [11, 12, 13, 14]. The shape of facial features, color, facial hair and texture differ with ethnic background, sex and age. These facial features may affect robustness of facial expression recognition. Also, facial features can be occluded by beard, spectacles or by other faces in crowd, which provide more challenges to recognize facial expression accurately [8]. Hence, individual facial features or segment analysis can play an important and central role to recognize facial expression correctly.
In this work, Convolution Neural Networks is used to train different models for chosen facial features: full Face, half face (left/right), upper half face, lower half, eyes, mouth and nose. These facial feature models are compared and analyzed in the context of facial expression recognition. All the models are then integrated using stacked generalized ensemble method to develop an efficient and improved facial expression recognition system. The proposed Stacked Generalized Convolution Neural Networks Facial Expression Recognition (SGCFER) integrated system achieves better accuracy compared to individual models for FER and is shown to be efficient and robust in emotion recognition under various constraints such as partial occlusion, pose, age and illumination variations. The database used for training is CMU Multi-PIE database [15]. The proposed system uses CNN with RPA compliance and is also configured on Raspberry Pi [16], which can be used for HRI and Industry 4.0 applications.
The main contributions of the proposed work are as follows: A new methodology is proposed to recognize facial expressions through facial images using CNN and stacked generalization. Seven different FER models are implemented and analyzed using seven facial features. Based on the analysis, an integrated system, Stacked Generalized Convolution neural networks Facial Expression Recognition (SGCFER) is proposed to improve accuracy for FER task. A detailed cognitive-analysis of facial features in the context of facial expression recognition has been carried out using the seven models. In previously reported literature only upper/lower parts of face are analyzed for FER [17, 19].
The overview of rest of the paper is as follows: reviews of the related work and contributions are discussed in Section 2. Section 3 describes proposed seven CNN models for seven facial features and architecture of integrated SGCFER. Section 4 presents results, analysis and discussion. Conclusion and future directions are in Section 5.
Related work
The related work is presented here under two aspects related to the proposed work: Facial features segmentation for facial expression recognition and CNN based facial expression recognition.
Facial features segmentation for facial expression recognition
Facial feature or facial components such as eyes, nose, mouth, chin and forehead are important aspects that define facial expressions. In 1995, Ekman and Friesen proposed Facial Action Coding System (FACS) also known as Action Units (AUs) [17]. They proposed that the combination of different AUs is used to represent specific facial expression. In 2006, Pantic used 27 AUs and presented how to achieve automatic detection of AUs and their temporal segments in a face-profile image sequence [18]. In 2008, Kotsia et al. used upper face, lower face and left/right half face segment to analysis the effect of occlusion for facial expression recognition task using Gabor filter classification [19]. In 2011, Cotter used eye and mouth segmentation for Fusion of Local Sparse Representation Classifiers (FLSRC) and combined both with square block occlusion (size:50 x50) [20]. In 2014, Cheng et al. used Gabor filters and deep neural networks for facial expression recognition with JAFFE database [21]. They used eyes, mouth, lower face and upper face for occlusion challenge. Liu et al., proposed Weber Local Descriptor histogram feature and decision fusion for facial expression recognition by dividing facial image into many non-overlapping rectangular regions of equal size [22]. Liu et al., used deep action units graph network (DAUGN) with segmentation method for small key areas of face for facial expression recognition [23]. In 2020, Deb et al., used eye and mouth patches for parallel CNN model to recognize facial expression [24].
In the literature so far, authors have used some segmented regions of face for facial expression recognition, however, there is no analysis to determine the extent to which each facial feature and different areas of interest between features contribute to facial expression recognition task. Also, to find how these segmented areas can be ensembled to get more accurate classification under different occlusion conditions. This paper addresses these issues and proposes a system to improve the accuracy.
CNN based facial expression recognition
In the recent years, CNN has been used widely in many images classification tasks which includes facial expression recognition. Jung et al., used CNN and Deep Neural Networks (DNN) techniques to recognize emotions in real time [25]. Deng et al. have proposed deep network using three convolution layers with more number of filters and two FC layers with Real-world Affective Face Database (RAF-DB) [26]. Mayya et al. have used transfer learning technique [27]. Yang et al., also used transfer learning pre-trained VGG16 network to recognize emotions. They have used JAFFE, CK+ and Oulu-CASIA databases to train top layer of network [28]. In 2018, Siqueira et al., proposed ensemble-based CNN semi-supervised learning technique for facial expression recognition [29]. CNN based multiple face emotion recognition is proposed by Saxena et al. in 2019 [30]. This work involved full facial image to extract feature vectors for training and testing. In 2020, Sun et al., proposed CNN with attention mechanism for region of interests (ROIs) feature extraction [31]. In 2020, Shao et al. used Edge-aware Feedback CNN (E-FCNN) for facial expression recognition [32]. Li et al. used reinforcement-learning techniques with DCNN for facial expression classification, using image selector and rough emotion classifier [33]. In 2021, Saurav et.al., proposed a deep integrated CNN model, which consisted of two structurally similar CNN models and their integrated variant, jointly-optimized using a joint-optimization technique to predict facial expression [34].
Algorithm for proposed stacked CNN facial expression recognition system SGCFER
Algorithm for proposed stacked CNN facial expression recognition system SGCFER
Block diagram of SGCFER architecture.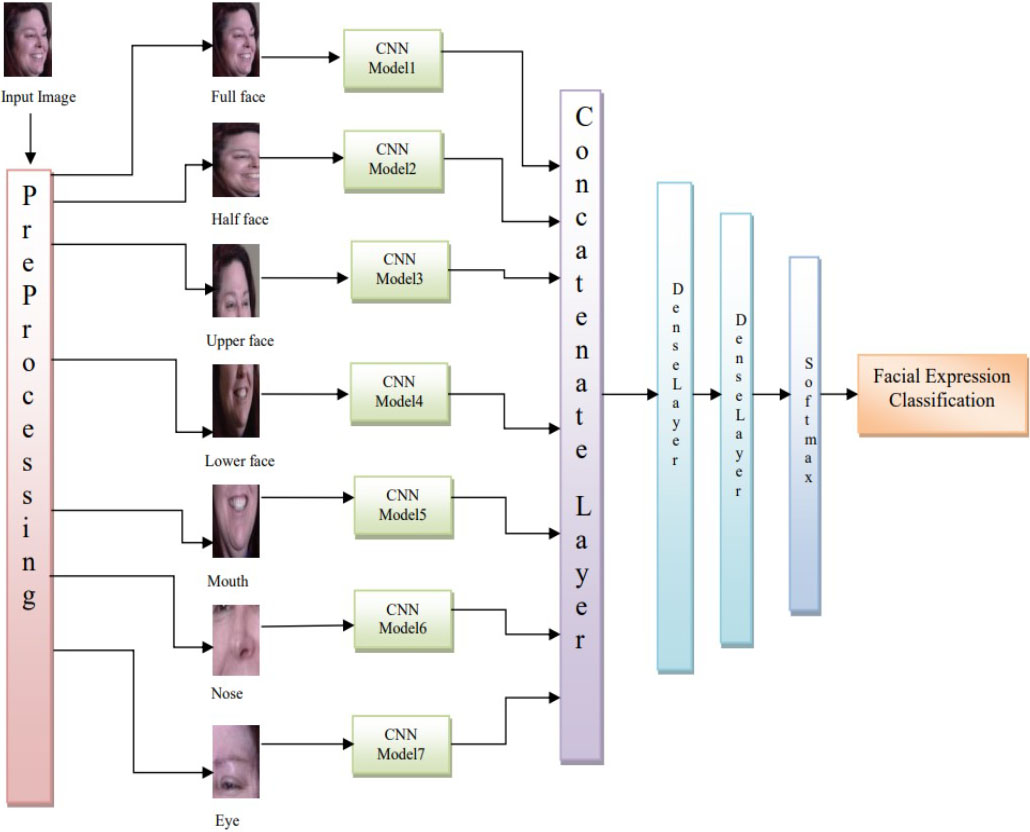
In summary, most of the work reported, uses holistic approach where full face is considered and individual facial features are not used explicitly to recognize facial expression. In the literature, there exists a gap to recognize how CNN works for individual facial features and facial regions explicitly. In this proposed work, analysis of individual facial features and implementation of a CNN based model for each facial feature and different region of interest which contribute to facial expression recognition has been carried out. Later on, we combine individual models using stacked generalized ensemble method to improve accuracy for FER task for different parts of facial occlusions.
Researchers have made notable contributions in facial expression recognition using facial features and CNN and demonstrated that facial features (eyes or mouth etc.) contribute significantly to shape facial expressions [17, 26, 27, 28, 29, 30, 31, 32, 33, 34, 36].
(a) Few sample of CMU Multi-PIE database (b) Preprocessing of raw image to crop and resize in 93x63 (These images are used for Full-face model) (c) Few Samples of created database for other six facial segment models after cropped from CMU Multi-PIE database (after preprocessing of raw images as in 2(b)).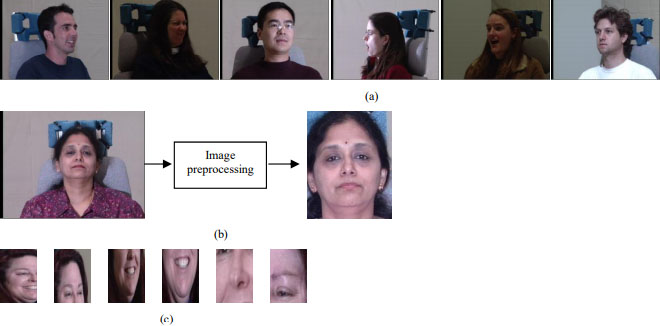
Enlightened by these facts, we propose a new method using convolution neural networks and stacked generalization to improve accuracy of recognition in images with occlusion constraint. This section describes the sub models used for seven facial segments and integrated CNN stacked generalization architecture. The block diagram of proposed architecture and algorithm are shown in Fig. 1 and Table 1 respectively.
Details of Layered CNN network for individual seven segments
CNN Layered Model for seven individual facial segments.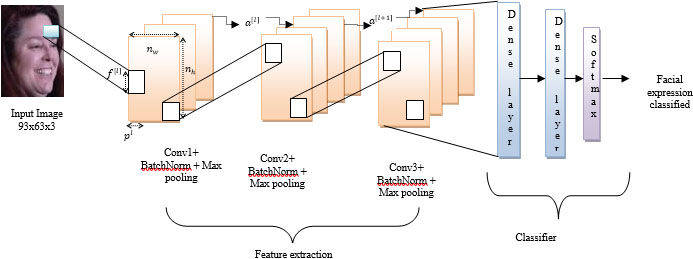
The CMU Multi-PIE database is used for training and testing. The dimension size of full raw image is 3072x2048. Total 337 subjects posed different facial expression in four sessions under different pose and illumination conditions as shown in Fig. 2(a). Using pre-processing, Full face segment is cropped from raw image to remove background information as shown in Fig. 2b which results in image dimension of 260x 205. Further, as illustrated in Fig. 3. image pre-processing is also used to crop the six facial segments from full face segment. All the seven facial segments are resized to 93x69 for reducing computational requirement, which is the smallest dimension for which facial expression recognition task would be possible [37].
CNN based sub model for seven facial segments
To analyze seven facial segments on common ground, we use same framework and use same layered CNN model for the seven segments illustrated in Fig. 3. Details of layers are given in Table 2. The proposed CNN layered network consists of three convolution layers for feature extraction. Each convolution layer is succeeded by batch normalization layer and max pooling layer. During learning process, non-linearity element is added as Rectified Linear Units (ReLu) activation function in each convolution layer, to get more flexibility and to create complex function. Two dense layers of vector dimensions 64, 5 respectively are used for classification. Softmax function is used to classify 5 emotions (Anger, Disgust, Happy, Neutral and Surprise). The detailed architecture of CNN and its formulation are as follows:
Convolution neural networks: Convolution neural networks are series of layers (convolution layer with activation function, pooling layer, dense layer) connected to each other in different ways. These layers take input as feature map from other layers and transform it into another using differential function.
Convolution layers with activation function: Convolution layers are the first layer of CNN, which takes image as input. In this layer input image is convolved with filters or kernels. The kernel matrix is passed over the image which transforms it and gives output feature map based on its kernel weights. The output feature map can be determined as follows:
If,
The convolution of image and filters can be expressed mathematically as:
where
The dimension of output matrix is calculated using following equations:
where,
The convolution operation is followed by an activation function
And we have:
Thus output of convolution with activation function is:
with:
The learned parameters at the
Pooling layer: Pooling layer is used for down sampling the number of features of the input without changing number of channels after convolution layer.
If pooling layer is after
with
The learned parameters are zero for pooling layer.
Batch Normalization: In the intermediate layers, the internal covariate shift problem arises because of the constant change in distribution of the activations during training. This continuous change slows down the training process since each layer adapts to a new distribution in every training step. To address this iernal covariate problem batch normalization is used and inputs are normalized at each layer [38].
In training phase, if each batch has
where,
Dense layer: A dense layer consists of finite neurons that takes a one-dimensional vector as input and returns another one dimensional vector.
Mathematically, considering the
The input
The learned parameters at the
Softmax classifier: The softmax function is used to classify and find estimated probability of each class. Mathematically, softmax function is given as:
Learning algorithm: For learning algorithm in CNN, weights of learning parameters (see Eqs (3.2), (3.2) and (3.2)) is calculated to minimize loss function,
The learning algorithm is formulated as:
First, model parameters are initialized randomly. Then, for
where
Stochastic Gradient Descent is applied for backpropagation to update the learning parameters:
(*) The cost function evaluates the function between the actual and predicted value on a single point.
After implementation of seven individual models for each facial segment, these models are tested for unseen cross-corpus seven model datasets. These datasets include images, which are not seen by trained models and have cropped facial segments (see Fig. 2b). Testing of these models on cross-corpus datasets will prove the ability to apply these trained models for occlusion and hidden faces constraints and propose one generalized system which can be used for various FER applications under different constraints. Further, a stack generalized method is used to combine individual outputs and used as input to train deep neural network (meta learner) to improve accuracy of these models for facial expression recognition under different occlusions. Stacking ensemble is a learning technique in which multiple classification sub models (base models) are combined with stacking ensemble model (meta-classifier). The base level models are trained using training set and later higher-level meta-model is trained on the outputs of the base level models as features vector and tested [38]. At level-0 sub models are embedded in neural network, which learns and combines the prediction from each sub model (Fig. 4). At level-1, two dense layers with 35, 5-dimensional vectors are used for meta classifier. Softmax function is used for classification in last dense layer with cross entropy loss function.
Stacked generalized CNN model.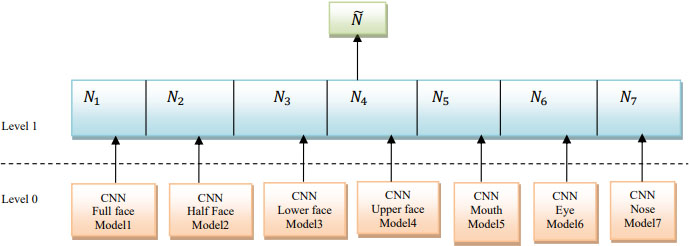
Stacking algorithm
To test robustness and efficiency of this method different samples are used.
The estimated probabilities of output of submodels
where,
After combining, these models the predicted probability of all the sub models
The output of the dense
Hyper parameter for Proposed CSGFERS
Recognition accuracy of seven segment models for facial expressions
Recognition Accuracy of seven segment models for facial expressions with cross dataset (a) Full Face (b) Half Face (c) Upper face (d) Lower Face (e) Mouth (f) Nose (g) Eye
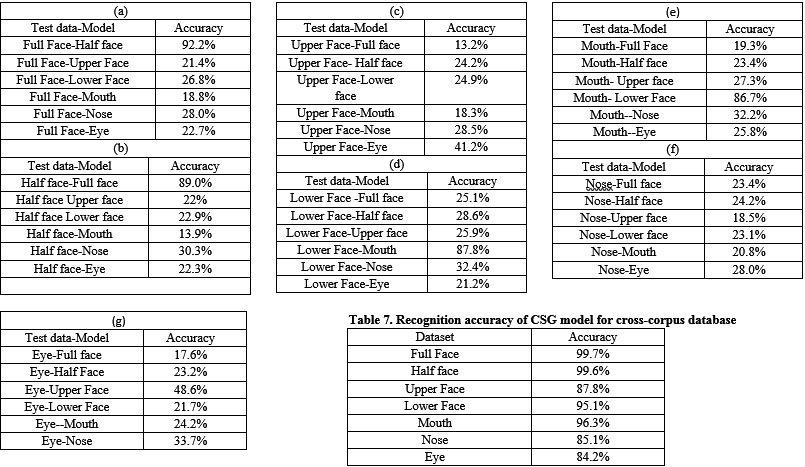
Training and validation accuracy plot for individual seven segments models (a) Full face (b) Half Face (c) Upper face (d) Lower face (e) Mouth (f) Nose (g) Eye .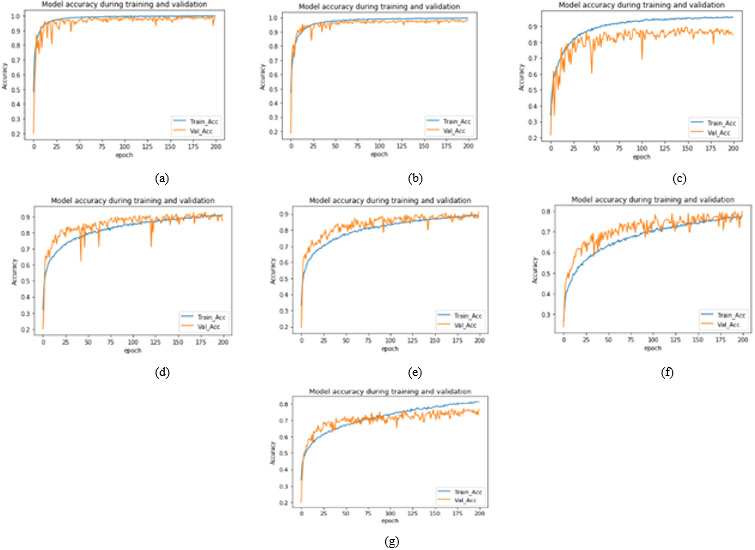
The input
The output of this dense layer is given as input to last dense layer with 1D vector (
The results, analysis and experimentation details are discussed in following section.
Consolidated plot for Recognition Accuracy of seven segment models for facial expressions with cross dataset (a) Full Face (b) Half Face (c) Upper face (d) Lower Face (e) Mouth (f) Nose (g) Eye.
Training and validation accuracy plot for seven segments models with cross datasets for full face (a) Full face-Half face (b) Full Face-Upper face (c) Full Face-Lower face (d) Full face-Mouth (e) Full face- Nose (f) Full face-Eye.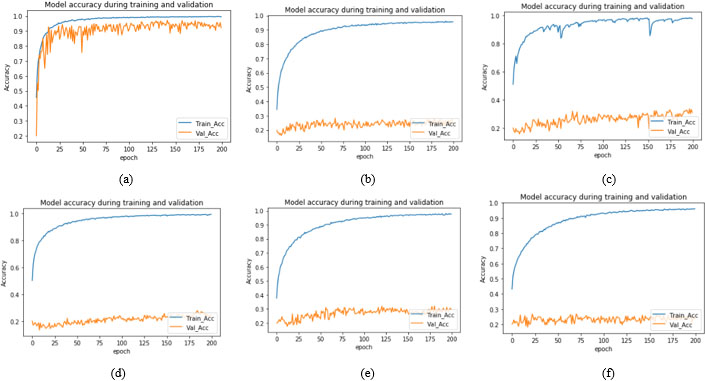
Training and validation accuracy plot for seven segments models with cross datasets for half face (a) Half face-Full face (b) Half face-Upper face (c) Half face-Lower face (d) Half face-Mouth (e) Half face-Nose (f) Half face-Eye.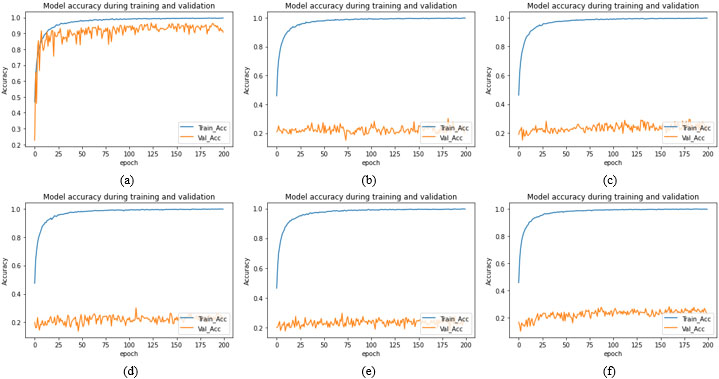
Training and validation accuracy plot for seven segments models with cross datasets for upper face (a) Upper Face-Full face (b) Upper face-Half face (c) Upper Face-Lower face (d) Upper Face-Mouth (e) Upper Face-Nose (f) Upper Face-Eye.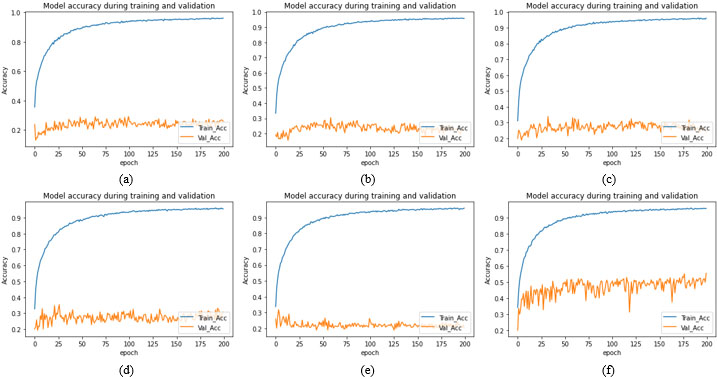
Training and validation accuracy plot for seven segments models with cross datasets for lower face (a) Lower face- Full face (b) Lower face-Half face (c) Lower Face-Upper face (d) Lower face- Mouth (e) Lower face- Nose (f) Lower Face-Eye.
Training and validation accuracy plot for seven segments models with cross datasets for mouth (a) Mouth-Full face (b) Mouth-Half Face (c) Mouth-Upper face (d) Mouth-Lower face (e) Mouth-Nose (f)Mouth-Eye.
Comparison with state of the art
Training and validation accuracy plot for seven segments models with cross datasets for nose (a) Nose-Full face(b) Nose-Half face (c) Nose-Upper face (d) Nose-Lower face (e) Nose-Mouth (f) Nose-Eye.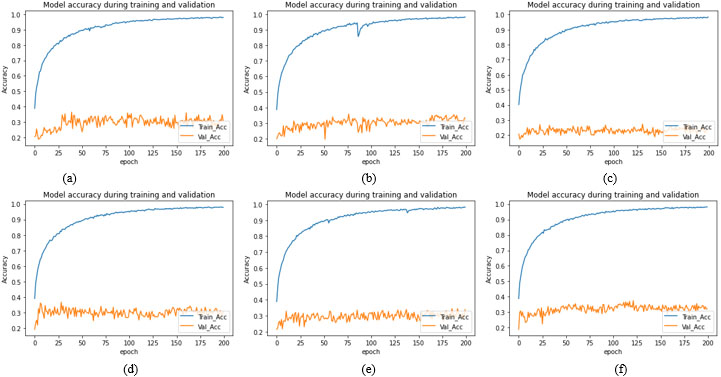
Training and validation accuracy plot for seven segments models with cross datasets for nose (a) Nose-Full face (b) Nose-Half face (c) Nose-Upper face (d) Nose-Lower face (e) Nose-Mouth (f) Nose–Eye.
Accuracy-loss plot for CSGFERS (a) Full face (b) Half Face (c) Upper face (d) Lower face (e) Mouth (f) Nose (g) Eye.
Comparison of CGSFERS with seven individual model accuracies shown in Table 5 and Table 7 (in seven datasets (a) Full face (b) Half Face (c) Upper face (d) Lower face (e) Mouth (f) Nose (g) Eye).
Facial emotion recognition results (a) offline images (b) Real time.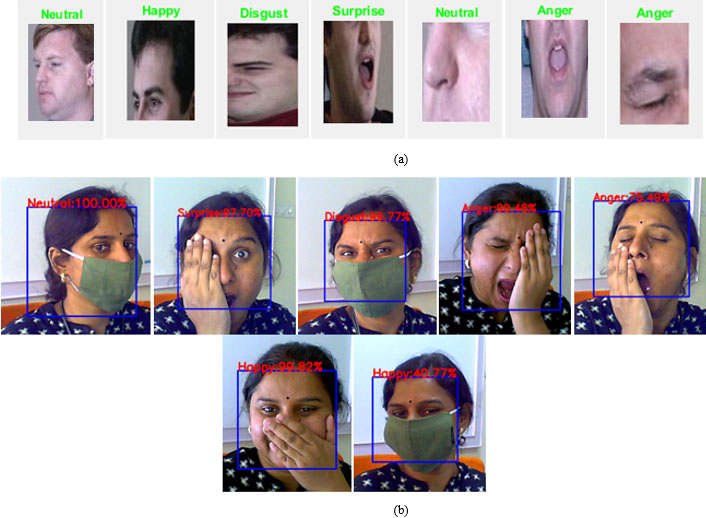
Failure cases of Facial emotion recognition offline images and in real time.
CMU- MultiPIE database is used for training, validation and testing the proposed method. Total 10,590 images are used from the database. 74,130 images are used for training and validation of 10,000 per seven facial segment CNN models. 4130 images are used for stacked generalized CNN model to test the accuracy of the proposed SGCFER for unseen data with 590 images used for each of seven segments. For individual facial segment model, out of 10,000 images, total 9000 images where 1800 images per emotion class are used namely Neutral, Anger, Happy, Surprise and Disgust, for training and a total of 1000 images where 200 images per emotion are used for validation for each of seven facial segment models. The optimum values for hyper parameters used to train seven facial segments models and SGC model are shown in Table 4. The accuracy achieved by the proposed seven models: Full face, Half face, Upper face, Lower face, Mouth, Nose and Eyes are 98.96%, 98.47 %, 84.21%,90.84%, 89.03%,74.52% and 70.1% respectively for individual seven segment dataset and shows promising results (see Table 5 and Fig. 5). However, when all seven models are tested on cross-corpus datasets, very low accuracy is achieved. The achieved accuracies for seven models are reported in Tables 6a–g and consolidated in Fig. 6. The training and validation plots for the seven models with cross-corpus dataset are shown in Fig. 7a–g–Fig. 13a–g. After analysis of facial feature segment results, it is observed that full face gives best accuracy for FER. Since no occlusion is present and all features are available to learn, hence there is less confusion in recognizing facial expression. In half-face occlusion there is a difference of only 0.63%. Since half face is symmetrical to other half and all the features of full face are present, the accuracy is almost same. The accuracies achieved for lower and upper occlusion are 8% and 14% less compared to full face respectively. FER accuracy is more if lower half face is present and upper half is occluded compared to lower face occlusion for upper face segment.
However, accuracies for FER are reduced by 11%–19% compared to full face, if only mouth, nose and eyes segments are visible. It is observed from the results that mouth plays an important role compared to nose and eyes in facial expression recognition. Influence of mouth is more on neutral, happy and disgust expressions compared to other two facial features eye and nose. In CMU Multi-PIE database anger and surprise are expressed with mouth open which increases confusion and decreases recognition rate. Eyes play a major role in case of these two expressions as eyes are open in surprise and closed in anger and model can learn difference between them and hence improve recognition rate. With these observations, the proposed SGCNN model shows an improved accuracy of upto 30% for cross-corpus datasets compared to individual seven facial segment models. The accuracies are reported in Table 7 for cross-corpus datasets and accuracy plot is shown in Fig. 14a–g. Comparison with seven individual models with corresponding datasets is shown using the plot in Fig. 15. The snapshots of results for facial emotion recognition of offline images and in real time are shown in Fig. 16a–b. The system fails to recognize emotion correctly in some cases as shown in Fig. 17. The implementation of the proposed method is done in the environment of python 3.7 using keras TensorFlow as backend. Intel i7-7700 CPU @ 3.60 GHz and 16 GB RAM operating system windows 7 and GeForce GTX1660 with CUDA 9.0 GPU with 4 GB RAM, Linux operating system are used to perform benchmarks. OpenCV are used to resize and crop images to create datasets for seven facial segments. Result of proposed CGS model is compared with existing literature as shown in Table 8. The overall facial recognition accuracy for full face is used for comparison. Compared to the state-of-art techniques, IFERIS achieved precision with various variations in illumination and head pose for facial emotion recognition shows considerable improvement.
Conclusion and future work
In this work, analysis on contribution of key seven facial segments for facial expression recognition task has been carried out using CNN. These segments can be used to recognize facial expressions under occlusion constraints. Seven individual datasets are created from CMU Multi-PIE database raw facial images. Facial expression recognition accuracies are reported for each of the seven facial segment models individually. These models were also tested for unseen cross-corpus datasets and accuracies are reported. It is observed that FER does not perform well under cross-corpus dataset testing. Hence, stacked generalized CNN model, SGCFER is proposed in which first, all seven facial segment trained models are concatenated together as base learners for stacked generalized ensemble method and used as input to train meta-learners. Deep neural network with two dense layers is used for meta learner in SGC model. Results shows up to 30% improvement for cross-corpus datasets. The proposed method can be used for Human Machine Interaction (HMI) applications which involve face occlusion and hidden face constraints.
Future work would involve testing the system in real time environment for human robot interaction. Also, physiological signals would be explored and combined with proposed method to improve accuracy for facial expression recognition with the help of these signals.
Footnotes
Acknowledgments
The authors would like to thank all the volunteers for participating in the experimentation and also would like to thank the host organization for providing CMU Multi PIE database. We thank all other researchers for making other relevant databases available for such research experiments.