
Abstract
Network Embedding (NE) has emerged as a powerful tool in many applications. Many real-world networks have multiple types of relations between the same entities, which are appropriate to be modeled as multiplex networks. However, at random walk-based embedding study for multiplex networks, very little attention has been paid to the problems of sampling bias and imbalanced relation types. In this paper, we propose an Adaptive Node Embedding Framework (ANEF) based on cross-layer sampling strategies of nodes for multiplex networks. ANEF is the first framework to focus on the bias issue of sampling strategies. Through metropolis hastings random walk (MHRW) and forest fire sampling (FFS), ANEF is less likely to be trapped in local structure with high degree nodes. We utilize a fixed-length queue to record previously visited layers, which can balance the edge distribution over different layers in sampled node sequence processes. In addition, to adaptively sample the cross-layer context of nodes, we also propose a node metric called Neighbors Partition Coefficient (NPC). Experiments on real-world networks in diverse fields show that our framework outperforms the state-of-the-art methods in application tasks such as cross-domain link prediction and mutual community detection.
Introduction
Networks are ubiquitous data structures and are used to model relations among entities such as social networks, co-authorship networks, biological networks. Network analysis and mining have become one of the most active research fields. In the real world, the information of a certain entity can actually be collected from various sources and in different scenarios [57]. Take social networks for example. The type of social relationship is diverse, e.g. Facebook, Twitter, LinkedIn [19], Lunch, Leisure, Co-authorship and Work [2]. These multi-relational social networks with rich information are able to reflect comprehensive and accurate user profiles. Therefore, taking together these type and source data that describe the same entities, we can give a more accurate and nuanced picture of network structure than any single one can alone [39]. In the relation extraction task of multi-source and multi-modal data [38, 14, 49], in particular, networks can be extracted from video, text, and audio, respectively. Each network only reflects the connectivities among nodes in a single view. Therefore, data analysis results can be easily misinterpreted if we only rely on data from a single source or modal. In the process of fusion and expansion of domain-specific knowledge graph [4], we use domain-specific knowledge graphs from many other domains to achieve the relationship expansion of an existing knowledge graph. In social network analysis [56, 55], lots of new online social networks have emerged and start to provide services, the information available for the users in these emerging networks is usually very limited. The abundant information available in mature networks can actually be useful for link prediction and community detection in the emerging networks. In biological multi-omics research [33, 25], by using the individual’s expression in each omic, researchers can construct a network structure of different omics. One can integrate different data types by constructing a network of samples (rather than genomic features) for each data type, and then fuse these networks into one comprehensive network. Using this network can achieve more accurate prediction and analysis. To model such heterogeneous information networks, a multiplex network is an effective and reliable model.
Multiplex network is made up of multiple layers, each of which can represent a given social scenario, relationship type, view, dimension, or temporal instance. Therefore, we utilize a multiplex network to model multi-source, multi-relational and multi-view networks in which different types of entity interactions are regarded as different layers. Multi-source networks are multiple networks, which constructed from different sources. Multi-view networks also are multiple networks, which are different views captured from a comprehensive network or data. Multiplex networks model these networks data with each type of relation or view as one layer. Each layer has the same set of nodes. In a multiplex network, the information fusion of multiple layers of nodes is a significant fundamental issue for the joint analysis of networks. In addition, network embedding is an effective method to analyze and mine the network. It can project node (or network) into a continuous low-dimensional space. Intuitively, modeling the information fusion problem of nodes as a feature fusion problem is a straightforward way. Based on the fused embedding, we can further mine the network data for node classification, link prediction, node clustering, and visualization [45, 46]. Thus, in this paper, we are motivated to focus on multiplex network embedding. What’s more, cross-domain link prediction and mutual community detection tasks in multiplex networks are also conducted by the latent representation.
In the past few years, some methods have been proposed for multiplex network embedding. Intuitively, according to the resulted embedding of nodes, we divide these methods into two categories: Fused embedding and Separate embedding. As for fused embedding method, to precisely capture the structure of a node in multiple layers as a comprehensive representation, Liu et al. [26] extended Node2vec [11] to project the multilayer network representation learning. Then, Zitnik and Jure [60] proposed OhmNet framework to learn protein features in different tissues. OhmNet applied the Node2vec to construct network neighbors for each node in each layer. As for separate embedding method, Bagavathi and Krishnan [1]presented a fast and scalable embedding technique for multilayer networks. To model both within-layer connections and cross-layer network dependencies simultaneously, Li et al. [23] designed a unified optimization framework for multilayer network embedding. Lu et al. [27] proposed four multilayer network embedding algorithms based on non-negative matrix factorization. However, there are some gaps in the above algorithms. On the one hand, the scalability of factorization-based methods is a major bottleneck. Such methods are memory intensive, computationally expensive, even infeasible [53]. On the other hand, network sampling-based methods such as random walk (RW), breadth-first sampling (BFS) and depth-first sampling (DFS), are not only biased towards high degree nodes (hubs) but also are limited capacity to capture complex interaction of nodes. Furthermore, once a hub is picked, every node connected to the hub is selected in the next step. It is more likely to get stuck in the local structure and less likely to jump around the network [16, 21, 42]. Besides, in the multiplex network sampling process, existing methods are hard to balance different relationship types for cross-layer sampling by setting a fixed parameter, which can result in the loss of a certain relationship type. To solve the above problems, major challenges are as follows:
In response to these challenges, we propose an adaptive node embedding framework for multiplex networks (ANEF). The ANEF samples the cross-layer context of a node by metropolis hastings random walk (MHRW) and forest fire sampling (FFS). Both of the sampling methods can not only avoid the bias towards node with a high degree but also sample several nodes simultaneously to improve efficiency. It is less likely to be trapped locally and thus can generate more accurate node sequences. Specifically, MHRW fits symmetric and asymmetric distributions to sample complex network structural by acceptance/rejection function. FFS can adjust the balance between staying local and jumping around the network by changing the burning probability parameter. In addition, inspired by JUST algorithm [17], we construct a fixed-length queue to balance the edge distribution over different layers. To achieve an adaptive cross-layer sampling method, we propose a neighbors-partition coefficient (NPC) as an indicator of cross-layer jumping. The main contributions of this paper are listed as follows:
We propose an adaptive node embedding framework for multiplex networks, named ANEF. We implement two representation learning instance methods for multiplex networks through more effective MHRW and FFME sampling methods to avoid bias towards high degree nodes. We modify two sampling algorithms (MHRW and FFS) to balance the edge distribution over different layers in sampled node sequences. We utilize a fixed-length queue to record previously visited layers. The cross-layer jumping operation of MHRW and FFS are constrained by this queue. We propose a neighbors partition coefficient, named NPC, which is intended to reveal the link modes of a node in different layers. Considering the distribution of node neighbors in different layers, NPC can supervise the cross-layer jump process in an adaptive manner. We compare the results of cross-domain link prediction and mutual community detection tasks to that of state-of-the-art methods using six real networks as the datasets. Experiments verify that our methods outperform existing state-of-the-art approaches.
Furthermore, ANEF can not only be applied to the embedding of multi-relational networks but also be easily extended to the analysis of dynamic networks. For dynamic network embedding, the additional condition is to restrict the order of cross-layer jumping. The remainder of the paper is organized as follows. In Section 2, we summarize related works on network embedding and network sampling. In Section 3, the definitions can help to understand the problem, framework, and algorithm. In Section 4, we introduce the proposed framework and algorithms. In Section 5, we then describe our experimental setup and evaluate the proposed approach. Finally, in Section 6, we draw our conclusions and discuss future research directions.
In this section, we first briefly describe the ideas of network embedding and network sampling, as well as their correlation. Then, we respectively introduce related works about traversal-based network embedding and network sampling methods. Finally, we review related work on network sampling and analyze the bias of familiar sampling algorithms.
The relation between network embedding and network sampling. Traversal-based network embedding methods have the same goal as network sampling, which is to preserve the original network structural information by sampling path or nodes sequences.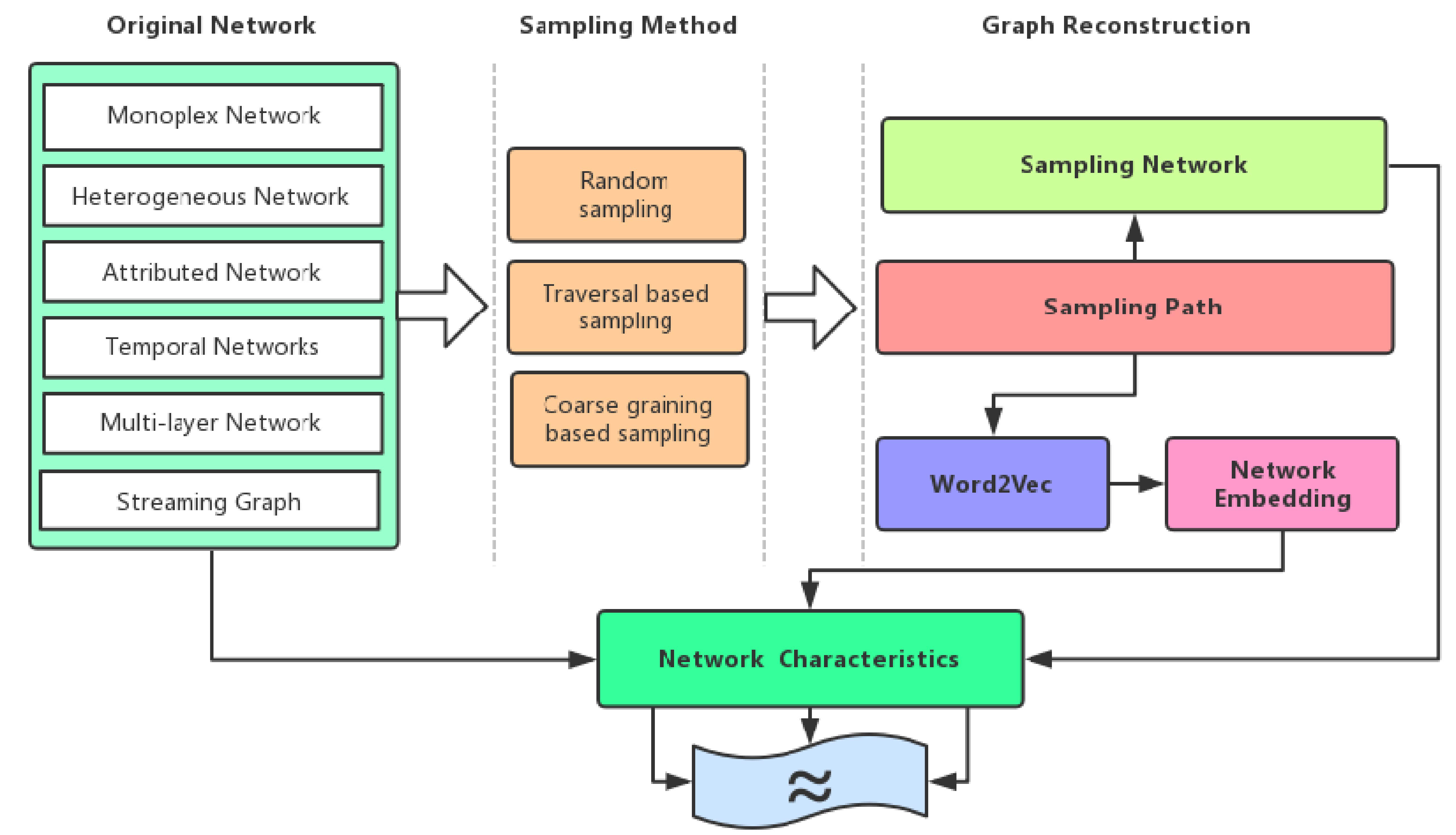
The structure-property of networks can be divided into three categories such as microscale structure, mesoscale structure, and macroscopic structure. It mainly includes the in/out degree distribution, path length distribution, clustering coefficient, eigenvalues, community structure, motif, shrinking diameter, higher-order types connection, note type distribution, average clustering coefficient over time, intra-link and inter-link type and so on. It can be seen from Fig. 1 that we can know that network sampling methods and network embedding methods have some similar parts. In both processes, it is necessary to generate the sampling paths or node sequences. Moreover, these paths or sequences need to preserve the property of the original network. Many network sampling methods have been proposed to capture the microscale, mesoscale and macroscopic structure of the original network. The network sampling method is not all a chaining process like random walk, but a diffusion structure process like forest fire sampling.
Embedding techniques using random walk to obtain node representations have been proposed: DeepWalk [40] is the first algorithm based on random walk to learn node representation. Node2vec [11] is based on Breadth-First-Search (BFS) and Depth-First Search (DFS). Both algorithms are traditional network embedding examples. Perozzi et al. introduced DeepWalk, inspired by language modeling, more precisely by word2vec [35] algorithm with the goal of learning representation of nodes. Grover et al. presented Node2vec, an extension of DeepWalk algorithm. Their model is based on the design of a biased random walk mechanism controlled by two parameters
In order to learn the representation of multi-relations heterogeneous information networks based on traversal-based methods, the following algorithm is proposed recently. Dong et al. [8] proposed a strategy for random walk sampling from heterogeneous networks, where the random walk is restricted to transition between particular types of nodes. This strategy allows many methods to be applied to heterogeneous graphs and is complementary to the idea of taking type-specific encoders and decoders into account. Leonardo et al. [43] presented Struc2vec, a novel and flexible framework with the target to learn latent representations for the structural identity of nodes. The framework uses a hierarchy to measure node similarity at different scales, and constructs a multilayer graph to encode structural similarities and generate a structural context for node. It constructs a weighted multilayer graph based on measuring structural similarity where all nodes in the network are present in every layer. In some cases, graphs have multiple “layers” that contain copies of the same nodes. In these cases, it can be beneficial to share information across layers so that a node’s embedding in one layer can be informed by its embedding in other layers. Qu et al. [41] proposed an attention based method (MVE) to learn the weights of views for different nodes with a few labeled data. MVE can get the robust node representations across different views by vote strategy. Zitnik et al. [60] proposed OhmNet framework to learn features of proteins in different tissues. They represented each tissue as a network, where nodes represent proteins. Individual tissue networks act as layers in a multilayer network, where they use a hierarchy to model dependencies between the layers (i.e., tissues). Recently, Liu et al. [26] extended a standard graph mining into the area of multilayer network. The proposed methods (“network aggregation”, “results aggregation” and “layer co-analysis”) can project a multilayer network of a continuous vector space. On one hand, without leveraging interactions among layers, “network aggregation” and “results aggregation” apply the standard network embedding method on the merged graph or each layer to find a vector space for multilayer networks. On the other hand, in order to consider the influence of interactions among layers, “layer co-analysis” expands arbitrary single-layer network embedding method to a multilayer network. Aakas et al. [58] proposed highly scalable node embedding for link prediction in large-scale networks. The method learns the co-occurrence features of node pairs to embed a node into a vector by a damping-based random walk algorithm. In the nodes sampling process, there is a bias problem with these existing methods that samples are trapped in a local structure. In addition, cross-layer sampling heavily depends on fixed parameters, which is an inflexible manner. Ma et al. [29] implemented node embedding for multi-dimensional networks with hierarchical structure. They simply added up node embedding in multiple dimensions as the fusion feature of nodes in multiple networks. Matsuno et al. [34] presented a multilayer network embedding method (MELL) that captures and characterizes each layer’s connectivity. The method utilizes the overall structure to consider similar or complementary structure of the layer. Finally, the fusion feature learning of nodes in multiplex networks is obtained by combining node embedding in each layer with layer vectors. Zhang et al. [54] proposed a scalable multiplex network embedding method (MNE), which assumes that the same nodes in multiple networks preserve certain common features and unique features of each layer. Thus, the common and unique embedding of nodes in each layer is learned by the Deepwalk algorithm separately. Sun et al. [44] presented a framework MEGAN for multi-view network embedding by generative adversarial network, aimed at preserving the information from the individual network views, while accounting for connectivity across different views. Wei et al. [47] proposed an attributed node random walk framework, which can not only be able to incorporate both the topology and attribute information flexibly but also easily deals with missing data and is applied to large networks. For multiple network alignment problem, Chu et al. [5] proposed a cross-network embedding method (CrossMNA). CrossMNA defines two categories of embedding vectors for each node, inter-vector and intra-vector. The idea of CrossMNA is the same as that of MNE. They think intra-vector contains both the commonness among counterparts and the specific local connections in its selected network due to the semantics. Cen et al. [3] focused on embedding learning for attributed multiplex heterogeneous networks, where different types of nodes might be linked with multiple different types of edges, and each node is associated with a set of different attributes. GATNE splits the overall node embedding of GATNE-I into three parts: base embedding, edge embedding, and attribute embedding. GATNE-T contains only the first two parts.
Network sampling
In the above methods based on random walks, these researchers utilize random walk to generate the context of nodes that preserve the local topology properties of nodes. The random walk method is one of network sampling approaches. The sampling of large networks is a fundamental data mining problem. When the network is huge and it is costly or infeasible to process the network in its entirety, the network sampling is often the most realistic option to infer network properties and to obtain estimates about basic topological properties [10, 51]. The sampling methods have been successfully used for many network-related measurements, ranging from estimating the size of the network or even to higher-order properties such as the motif, clustering coefficient, community structure [31, 18], and more. Actually, the goal of network sampling method is similar to that of network representation. Both the local and global topological structural properties of the network are preserved by the generated node sequence or edges chain. The network sampling depends on appropriate criteria for choosing sampling methods to measure the properties more accurately.
Crucial sampling strategies include BFS, DFS, FFS, snowball sampling, random walk, metropolis hastings random walk, reweighted random walk and respondent-driven sampling. The BFS method begins with a random node and visits its neighbors iteratively. Similar to BFS, DFS is derived from the depth-first search algorithm. Snowball sampling is another traversal-based sampling. First, it randomly selects a starting node and puts it into the current nodes set, and then all nodes connected to any node in the current nodes set are chosen and put into the current nodes set recursively until required number of nodes have been selected. Simple random walk, BFS, DFS, snowball sampling are biased towards high degree nodes. Another example is the forest fire sampling (FFS) method [21] which takes advantage of partial BFS where only a fraction of neighbors is followed for each node. The algorithm starts by picking a node uniformly at random and adding it to the sample sequences. Then it “burns” a random proportion of its outgoing links and adds those edges, along with the incident nodes, to the sample. Metropolis-hasting random walk(MHRW) is an example of node sampling-based algorithms. In the node sampling process, nodes are sampled independently and uniformly at random.
However, the existing network embedding and network sampling algorithms are difficult to adaptively be extended to multiplex networks adaptively, and there is a problem that the relationship type of sampling is imbalanced. Hence, we propose two adaptive multiplex network sampling algorithms based on MHRW and FFS to solve the above problems. Each algorithm has different biases [32]. MHRW can avoid the biased to high degree nodes of random walk. FFS can capture module structure information of network. Also, in order to achieve a more efficient representation of multiplex networks, we propose a traversal-based network embedding learning method based on NPC. The detailed definitions and implementation steps are presented in the next section. Noboa et al. [9] studied the influence of network structure and sampling on relational classification. Network structure factors contains heterophilic/homophilic networks, link density and degree assortativity and the selection of seed nodes.
Problem definition
In this section, we describe related concepts and definitions in detail. Firstly, the basic concepts of network sampling and multiplex networks are as shown below. Secondly, we formulate generalized random walk in multiplex networks. Lastly, we define a node embedding problem for multiplex network embedding.
.
Network sampling. Let
.
Multiplex networks. Considering
.
Generalized Random Walk in multiplex networks. Suppose the walker starts at node
where
.
Node embedding on multiplex network. Suppose the methods can make use of a real-valued adjacency tensor A,
ENC is a mapping function with the target to learn for d-dimensional representation of node
Inspired by a family of network embedding methods based on random walk [26, 11, 40, 43, 22, 52, 24, 59], we intuitively summarize the processes of representation learning methods based on random walk for multiplex networks are as follows:
The first step is to calculate the probability of intra-layer and inter-layers jump between nodes according to a certain topology property
The second step aims at generating node context by a sampling method with an instance of
The third step is to feed the node sequences to a Skip-Gram [20] model for learning embedding, including the optimization of learning model and the update of parameters. Empirically, the quality of the generated node context directly affects the quality of the final learned embedding vectors.
Taking literature [26] as an example.
[htbp]The generalized multiplex network embedding based on truncate network samplingGraph
Our sampling-based node embedding framework for multiplex networks. This framework contains two components: A. Node sample process and B. Representation Learning process.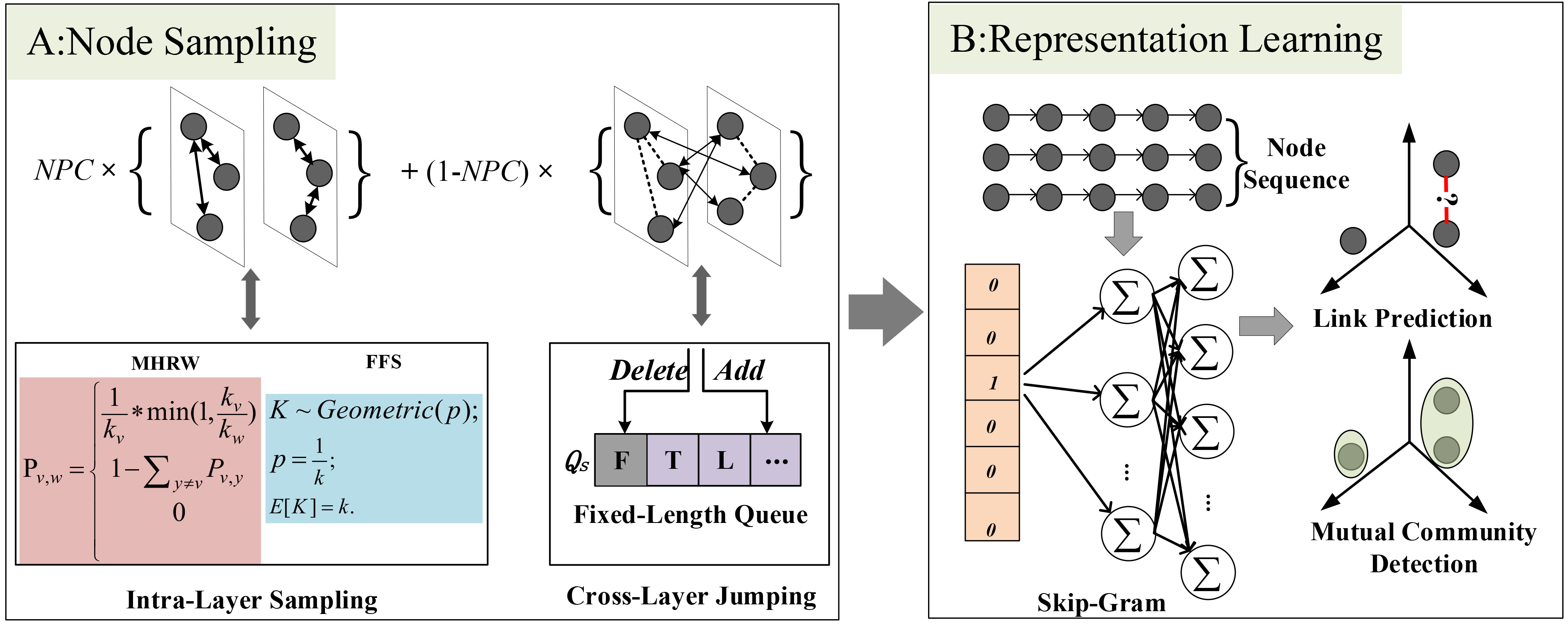
In this section, we first present the definition of neighbors partition coefficient to achieve adaptively cross-layer jumping. Then we propose a method to solve the type imbalance of sampling nodes problem using a fixed-length queue. We implement two adaptively node embedding methods for multiplex networks based on MHRW and FFS, named MHME and FFME respectively. Both of them can alleviate the biased problem of random walk, DFS, BFS, etc. Finally, the optimization of network representation learning is given for iteratively updating vectors. In two parts of Fig. 2, the intra-layer sampling, NPC, cross-layer jumping are shown in ANEF.
In order to achieve adaptive cross-layer sampling of nodes, we propose a neighbors partition coefficient (NPC). It is used to measure the multiplexity property of nodes in a multiplex network to decide whether to stay in the original layer or cross-layer jump to other layers. The original multiplexity of node in a multiplex network only considered the number of neighbors of the node and did not distinguish the overlapping neighbors of the node.
.
Neighbors Partition Coefficient(NPC) of Node in Multiplex Networks. Supposing
where
In terms of node properties, the node’s neighbor distribution in each layer reveals the node’s link mode. In addition, when a specific node in a certain layer is deleted, the impact on the whole network is also different. In the node sampling process, nodes with larger NPC should have a smaller cross-layer jumping probability. The goal of setting is to make the sampling path contain as many different neighbors as possible by frequent jump between inter-layers. Therefore, the NPC of a node is regarded as an indicator of staying the original layer for the next sampling operation.
For this problem, we use a fixed-length queue to memorize the layers that were previously visited. We will select a layer that is not in the queue to treat as a target layer will jump.
.
Cross-layer jumping strategy. We define a fixed-length queue
To gracefully balance types of edges sampled among different layers without missing information of some layers, the strategy considers the NPC of node and memorizes the visited queue. If the candidate set isn’t empty, we choose to jump to other layers except for the candidate set. Then, we update
In terms of
MHME
For taking the superiority of MHRW into account, we propose a truncate metropolis-hastings random walk based on NPC and
.
Metropolis-hastings random walk. The algorithm is an application of the metropolis-hastings (MH) strategy for random walk, for unbiased graph sampling. The probability of node
where min(1,
[htbp]The Sampling_Function based on MHRWGraph
In capturing the ability of modules, FFS outperforms other sampling strategies in the aspect of network visualization. Moreover, Wu et al. [48] validated that FFS is modularity sensitive. We also propose another node embedding instance method (FFME) of ANEF based on adaptive FFS. FFS first choose node
[htbp]The Sampling_Function based on FFSGraph
Optimization
We conduct MHME and FFME methods to generate sequences of nodes. Then, we perform Skip-Gram over the sequences to learn the node embedding with a given dimension d. For a node v, assuming it appears in position j, we define
Hence, we need to minimize Eq. (6)
For each
where
where
Then, we update node embedding vectors, as follows:
where
In this section, we validate the performance of ANEF model1
The source code is available at:
Properties of the datasets
GATNE-T [3]: is a representation learning method based on self-attention mechanism for multiplex heterogeneous networks with both transductive and inductive settings. The base embedding is shared among edges of different types, while the edge embedding is computed by aggregation of neighborhood information with the self-attention mechanism.
In this paper, we apply
Cross-domain link prediction
In this section, we perform a cross-domain link prediction task on the multiplex networks. Supposing there is a target layer in multiplex networks, cross-domain link prediction task is to deduce whether the node pair in this specific layer is connected on the basis of the node embedding of other layers. The cross-domain link prediction task can also be applied to evaluating the interdependent and interactional relationship in different layers between the same nodes pairs. Through the task, we can mitigate the cold start problems of the recommendation system and the problem that information available for the users tend to be limited in emerging networks.
We refer to the experimental setup of link prediction in the multilayer network of literature [13]. We remove a certain layer of original multiplex networks and use Area Under Curve (AUC) and Accuracy scores to evaluate the performance of algorithms to predict missing edges in the target layer. These removed node pairs are regarded as positive examples. We randomly sample an equal number of node pairs from this layer which has no edge connecting them as negative examples. First, our ANEF model can learn the latent vector representation of nodes for the residual network. Then, we use logistic regression as a prediction model. Finally, we also use a 5-fold stratified cross-validation testing strategy: for each test, we use 80% of the data for training and the remaining 20% for testing. With each target class as the complete set, each fold set contains approximately the same percentage of samples since prediction items are sorted in the data. For every test set, the node pairs are sorted according to the scores returned by the classified for the positive class label, i.e., an existing link. Subsequently, we use AUC score from these curves to indicate the relative performance of each task by averaging the results across all folds. We are interested in the fraction of positive examples correctly classified instead of the fraction of negative examples incorrectly classified.
The averaged Accuracy score of cross-domain link prediction
The averaged Accuracy score of cross-domain link prediction
The AUC scores of different walk length in cross-domain link prediction task.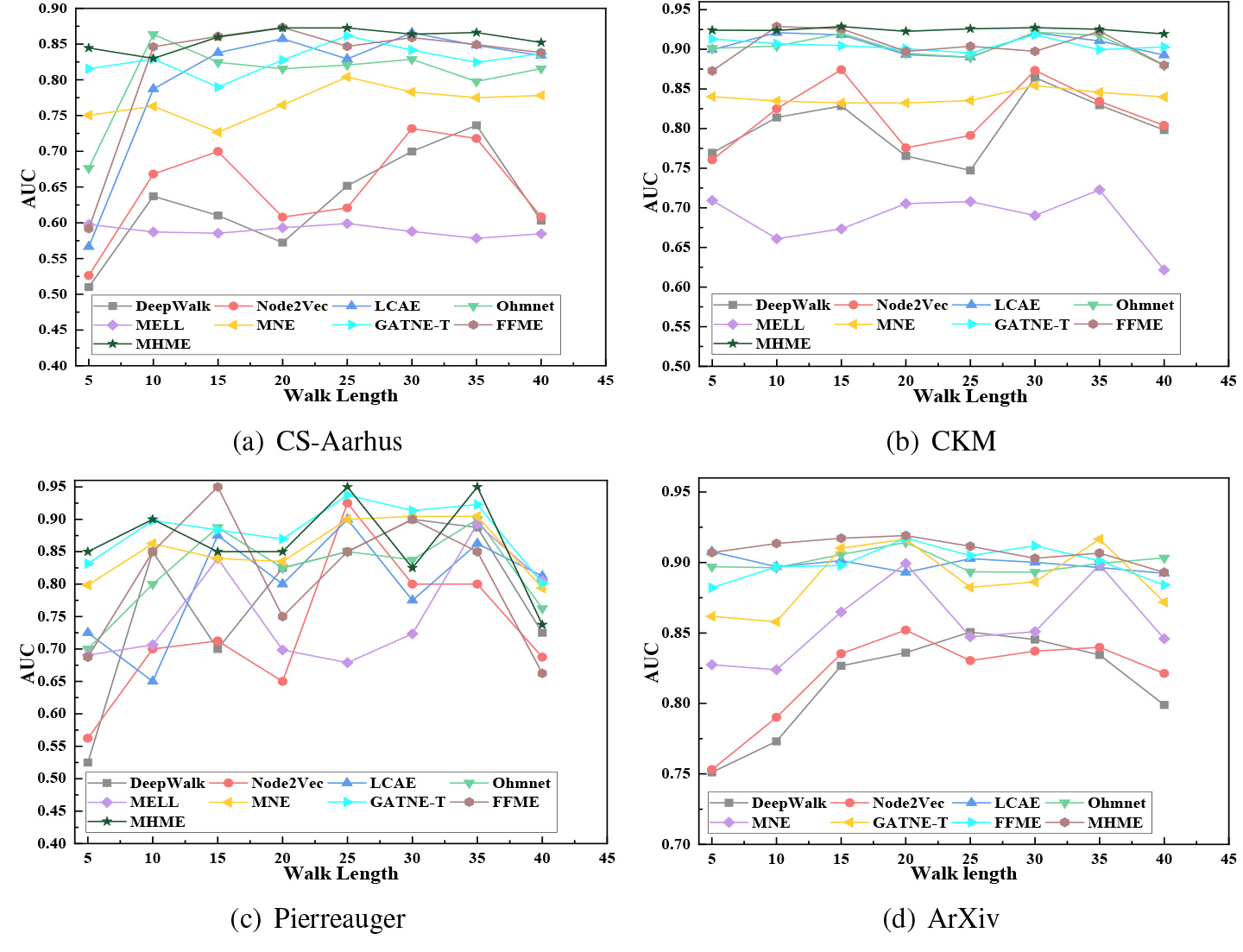
As we can see from Table 2 and Fig. 3, we compare the performance of MHME and FFME with Deepwalk, Node2vec, LCAE, Ohmnet, MELL, MNE and
Overall, these results indicate that the two adaptive cross-layer sampling of MHRW and FFS based on neighbors partition coefficient (NPC) can outperform state-of-the-art methods, like MELL, MNE, GATNE-T. Through the comparison of proposed ANEF model (MHME and FFME), we believe that the proposed methods can get more accurate multiplexity and adjacency properties of nodes in multiplex networks. It should be noted that the reason why the results are missing in ArXiv is that we get an Out-of-Memory exception.
Node clustering aims to group similar nodes together so that nodes in the same group are more similar to each other than those in different groups. Mutual Community Detection (MCD) task is to distill relevant information from other aligned social networks for complement information. It can improve the clustering or community detection while preserving the distinct characteristics of each individual network. After representing nodes as vectors, the traditional clustering algorithms can be applied to the node embedding matrix. To evaluate the result of mutual community detection, we use k-means algorithm to cluster node and cosign function to compute similarities between vectors. In terms of the evaluation metric, the literature[37] developed a generalized modularity framework for studying the community structure of multiplex networks. We adopt a generalized modularity value as an evaluation criterion that measures the tightness of connections within the community after obtaining node clustering.
where
The modularity scores of compared algorithms
The Table 3 illustrates that the FFME method generally outperforms other methods, which contains Ohmnet, MNE and GATNE-T. As for CS-Aarhus data set, Ohmnet algorithm obtains better experimental results on account of it is relatively sparse and the size of the community is small. Moreover, in the experiment setting, the value of walks length is set to 25 will cause distortion of community information. The result of FFME also indicates that the FFS can capture the modules property. There is a significant positive correlation between the modularity score of FFME and the size of the network. This is an interesting outcome that FFME is suitable to detect mutual communities of large-scale networks. However, MHME avoids the sampling bias problem using the same probability of each node being sampled, which leads to the loss of network community structure information. Therefore, the performance of MHME is worst in the mutual community detection task. It also verifies that the performance of ANEF depends on the characteristic of specific sampling algorithm implemented in community detection tasks.
To summarize, the proposed MHME can preserve local adjacency information of nodes and FFME can precisely detect community structure of multiplex networks. Our model based on different sampling algorithm outperforms state-of-the-art baselines in real network data sets. It is obvious that different sampling strategies have different degrees of competitiveness for different goals.
In this section, we investigate the impact of node embedding dimension and the sampling length walk_length on the quality of node embeddings in CS-Aarhus social multiplex networks. Similar results are also observed on the node clustering task.
Impact of three parameters on Area Under Curve (AUC) scores in link prediction task: (a) node embedding dimension in the left column; (b) walk length of node sampling in the right column; (c) burning probability parameter 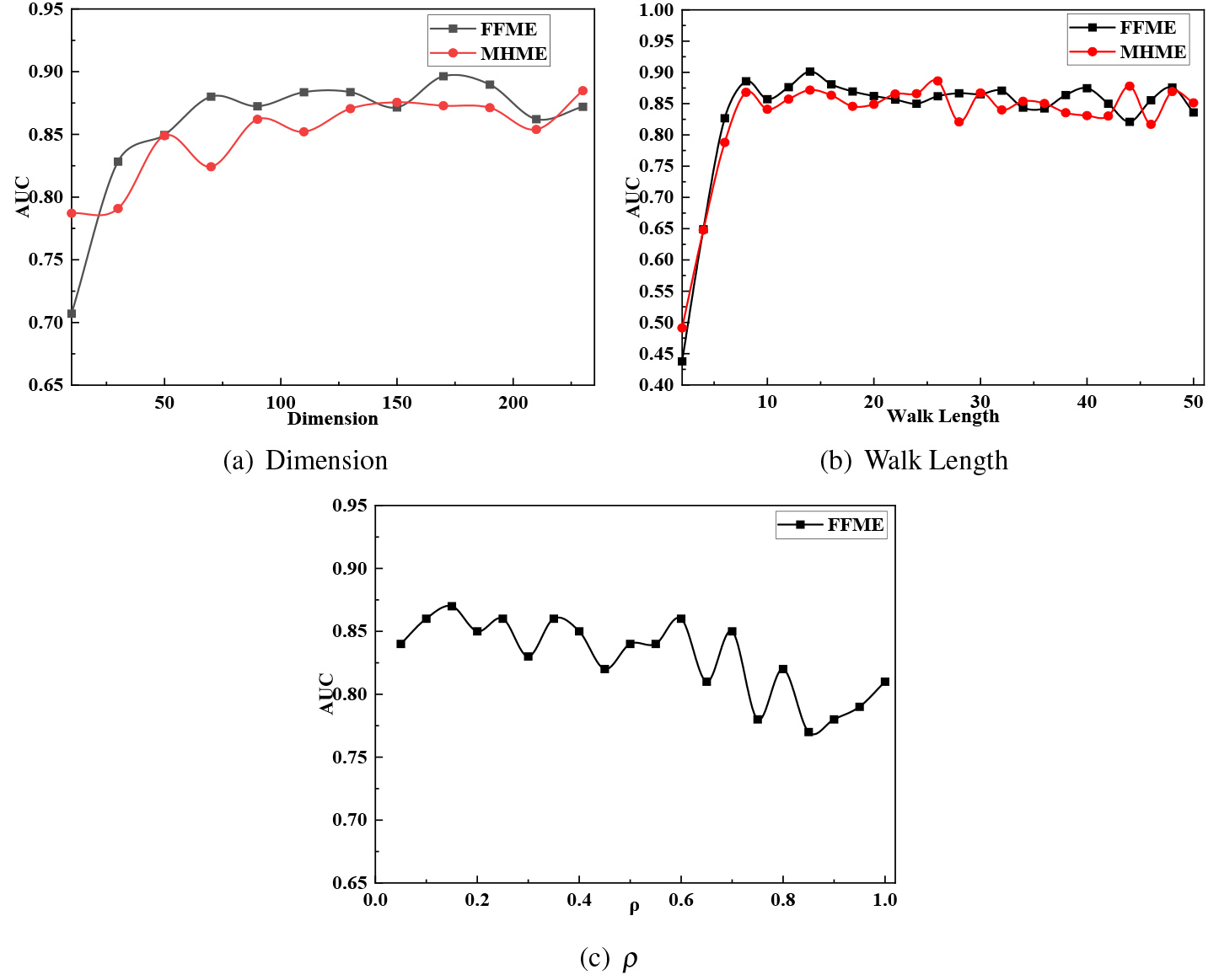
Multiple-sources, multiple-relational and multiple-dimensional networks are ubiquitous in the real world. We model these kinds of networks as a multiplex network or multilayer network. In this paper, we mainly focus on multiplex network representation learning and propose a novel adaptive model of node embedding(ANEF). We implement the node sampling process of ANEF based on metropolis hastings random walk method (MHRW) and forest fire sampling method (FFS), respectively. These two sampling methods can not only capture complex interaction mode and module information of network respectively but also be less likely to be trapped in local with a high degree node. Initially, to construct node sequences by adaptive network sampling algorithms proposed, we propose an efficient neighbors partition coefficient (NPC) as a jumping indicator. Then, ANEF also takes the imbalanced relation type problem into consideration in the process of cross-layer sampling. We utilize a fixed-length queue to memorize previously visited layers. Finally, the embedding vectors of nodes are obtained through feeding the node visited sequence to Skip-Gram model. We evaluate our methods and baseline methods in cross-domain link prediction and Mutual community detection tasks. The experimental results show that our methods have superior performance in different tasks for four real-world datasets. For future work, we will make use of other effective sampling algorithms and strategies to preserve structure information of different scales in multiplex networks. In addition, according to the current research on network representation learning, few research works involve the sensitivity of the algorithm to noise or the network vulnerability. Therefore, it is also an interesting research direction.
Footnotes
Acknowledgments
This work is supported by the National Key Research and Development Program of China (2018YFC0831500), the National Natural Science Foundation of China under Grant No.61972047 and the NSFC-General Technology Basic Research Joint Funds under Grant U1936220.