
Abstract
With the application of big data, various queries arise for information retrieval. Spatial group keyword queries aim to find a set of spatial objects that cover the query keywords and minimize a goal function such as the total distance between the objects and the query point. This problem is widely found in database applications and is known to be
Introduction
With the rapid development of the mobile Internet, artificial intelligence, and other such technologies, the number of spatial objects with textual descriptions will increase enormously. Such objects are named spatial keyword objects, e.g., a restaurant with keywords “Wi-Fi”, “chinese food” and “afternoon tea” or a shopping mall with keywords “free parking lot” and “big sale”. Spatial keyword objects are frequently used in spatial data analysis [1, 2] to retrieve useful information. Furthermore, these objects can be processed and queried for particular occasions.
In combination with business scenario requirements, applications in social sensing, intelligent logistics, and other fields have offered various queries. The nearest neighbor query [3] is a classical query for a spatial database that returns a single object nearest to the query point. Textual descriptions are considered to generate the top-
It was reported in [7] that along with storm and flooding, Hurricane Maria, which was the strongest hurricane to ever hit Puerto Rico, left the island severely damaged and caused thousands of fatalities. Relief operations following this hurricane required the use of medical supplies and lifesaving equipment obtained from aid agencies around the world. A top-
The
A novel approach reported in [13] studied the trade-offs between the approximation ratio and time consumption, which is suitable for problems that are solvable in polynomial time but have poor approximation ratios. This approach leds us to find that a parametric approximation algorithm for the WSC problem in exponential time was given in [14]. This algorithm has redundant loops related to the size of data, resulting in a high runtime. Several other parametric approximation algorithms for the WSC problem were designed in [15]. However, all of these algorithms focus on the unweighted set cover problem and cannot be extended directly to the query problem.
Based on these previous works, we optimize the methods from [14, 13]to present a parametric approximation algorithm that we call Para-Appro for the SGK query. This algorithm manages to balance three crucial factors for the query: a) finding the set of objects with the minimal goal value to satisfy the query keywords, b) determining the parameter for scalability to large number of instances, and c) processing the data efficiently.
The proposed Para-Appro algorithm attempts to meet the approximation ratio of
Algorithm comparsion
Algorithm comparsion
Finally, the contributions of this paper are summarized as follows.
A parametric approximation algorithm for the SGK query is proposed that is scalable to large instances by setting the parameter. The notion of RIR-tree with necessary operations is introduced for efficient storage and retrieval of spatial keyword objects. Experiments on real datasets indicate that compared to the existing approximation algorithms, our algorithm improves the accuracy of the SGK query.
Section 2 proposes the SGK query problem. Section 3 introduces the RIR-tree with necessary operations. Section 4 describes the parametric approximation algorithm, whose experiments are delivered in Section 5. Section 6 reviews the related work, and Section 7 is the conclusion.
Preliminaries
This section is devoted to formalizing the spatial group keyword query. It uses a group of objects instead of a single one to cover the query keywords and minimize the goal function. Let
Now we are ready to give a formal definition of spatial group keyword query.
.
Given a database
We use an example to illustrate the SGK query.
.
This example illustrates a simple situation in which the objects are points rather than regions. In Fig. 1, we use 8 objects listed in Table 2and a query point
Objects and their bounding rectangles.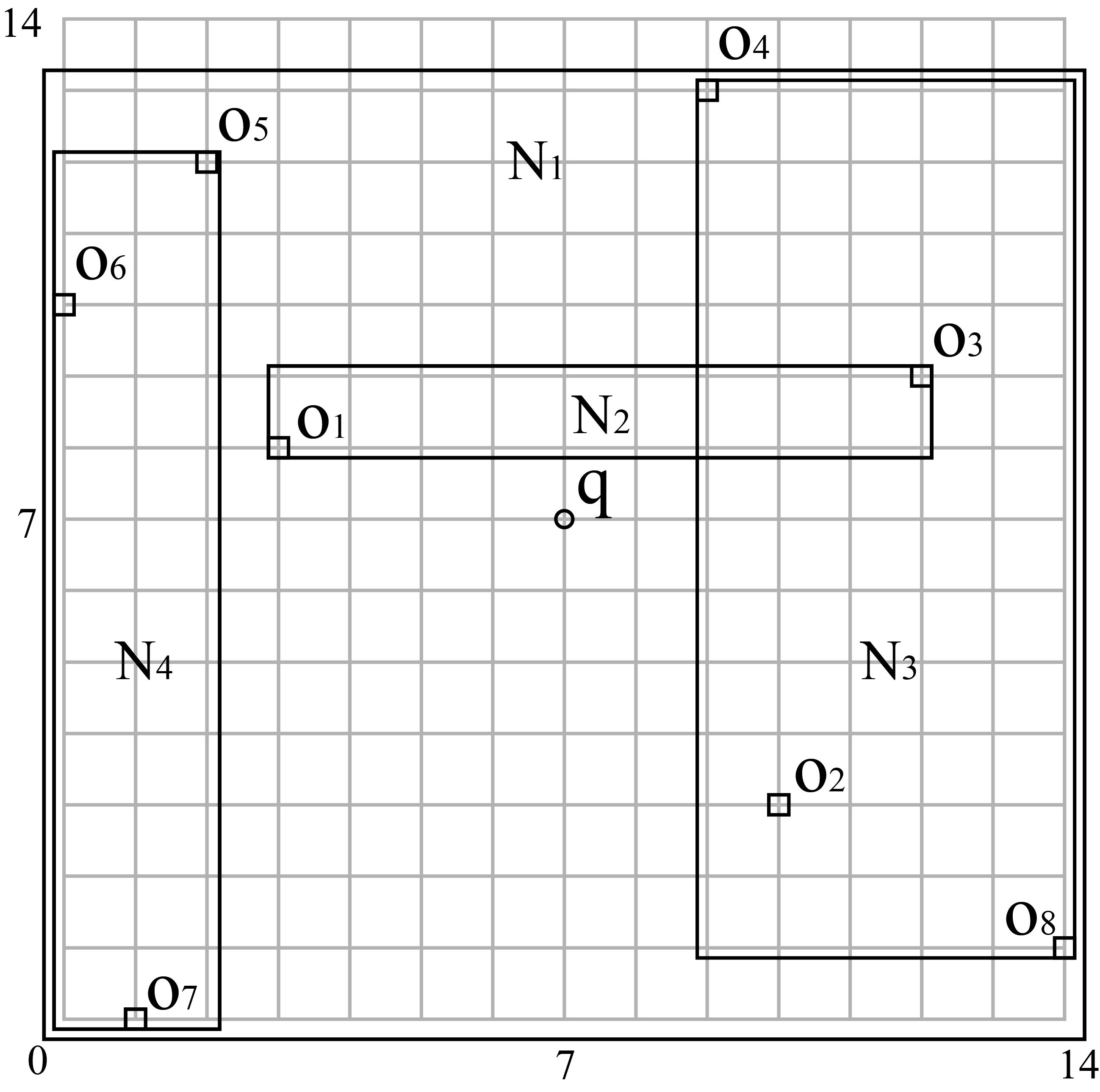
Object information
Let
.
The SGK query problem cannot be approximated within a factor of
This theorem gives a strictly lower bound of the SGK query problem, so that in theoretical, no polynomial-time algorithm can solve it.
Properties of the RIR-tree
The authors in [16] integrate R-tree and textual descriptions into the IR-tree where each keyword in the textual descriptions has a different frequency of occurrence. We modify their index structure using a map, named reduced inverted-file (RI), to store distinct keywords for each node and save memory. The RI of a node contains two elements, key and value. The key is a distinct keyword
In an RIR-tree, a leaf node consists of a few entries
A non-leaf node consists of a few entries
As in an R-tree, two important properties are always perserved in an RIR-tree. First, let
We now describe Algorithm 3.2 used for inserting data into an RIR-tree, where constant MAXE stands for the initial maximum rectangle enlargement adding any entry to a node. For an entry
[ht] Insertion (
We review the process of splitting a node
.
Let
The MBR for each node is illustrated in Fig. 1. Table 3 lists the updated RIs of the different nodes in Fig. 2e. The optimal result of Example 1 returned by the SGK query should be
Reduced inverted-files
Reduced inverted-files
RIR-tree index structure.
Algorithm framework
A parametric approximation algorithm for the SGK query is presented in this section. We handle the query with the greedy method at the beginning, iteratively putting the object that contains most query keywords and are closest to the query point into the result. When the unsatisfied number of query keywords is decreased to the threshold value, we invoke the Sum-Exact (see Algorithm 4.1) as the subprocess, where the input should be adjusted from RIR-tree to a min-priority queue. We omit the contents of the algorithm for conciseness and interesting readers can refer to [12]. Finally, we return the desired result set for a given query accuracy.
[ht] Sum-Exact (
For a query with query point
when
where
Previous work has calculated the distance between a query point and the nearest vertex or edge of the rectangle to compute the distance
The algorithm adopts the best-first strategy to traverse the RIR-tree and a min-priority queue to store the intermediate results, where the best-first strategy finds an object with the minimal relative cost. The keyvalue of each element in the queue is the relative cost that should be adjusted each time we pick an object greedily. However, when invoking Algorithm 4.1, the keyvalue of an object in the queue is
We set
[ht] Para-Appro (
child node
Let
.
For each
Proof..
In each iteration, the leftover objects of the optimal result, denoted as
Among
where the last sub-equation follows from the fact that the keywords of all objects in
In the iteration, when
.
For any
Proof..
We obtain the optimal result
Therefore,
If the algorithm pops a node from queue
The space consumption will not exceed
The algorithm can be adapted to various objectives by setting
The first condition stands since the approximation ratio of Para-Appro should be less than
.
In Example 2, Sum-Appro will return
Dequeue Dequeue Dequeue Dequeue
Therefore, Para-Appro is effective in solving the SGK query problem and yields a higher accuracy of the result requires a lower
The experiments studied the performance of our algorithm compared with Sum-Exact and Sum-Appro. All of the algorithms were implemented in Java and executed in a Windows 10 System on an Intel Core i5-4570 CPU @3.2GHz with 8GB RAM. Our datasets and index are all memory resident.
Experimental setup
We use three real datasets adopted in [8, 12], named Hotel, Web and Nation. The properties of the datasets are listed in Table 4. Missing values in the data are set to be null. Dataset Hotel1
Properties of datasets
Dataset Web is created from two real datasets, WEBSPAM-UK2007 and TigerCensusBlock.2
Dataset Web is offered by [8].
Dataset Nation3
geonames.usgs.gov.
We generate 50 queries for each trial to avoid noisy data. For a query with
Experimental results
Results on Hotel
Figure 3 shows that the runtime of Para-Appro is close to that of Sum-Appro, while its approximation ratio is lower. In both subfigures, the
Results on Hotel.
Although the number of objects is of the same magnitude as Hotel, the runtime of Web is clearly longer as shown in Fig. 4. This is because Web contains a very high number of keywords. On the one hand, the RIs occupy great memory space. On the other hand, it takes more time to search and prune the RIR-tree to find query keywords. However, we can still observe that compared to Sum-Appro, Para-Appro obtains more accurate results in a reasonable time.
Results on Web.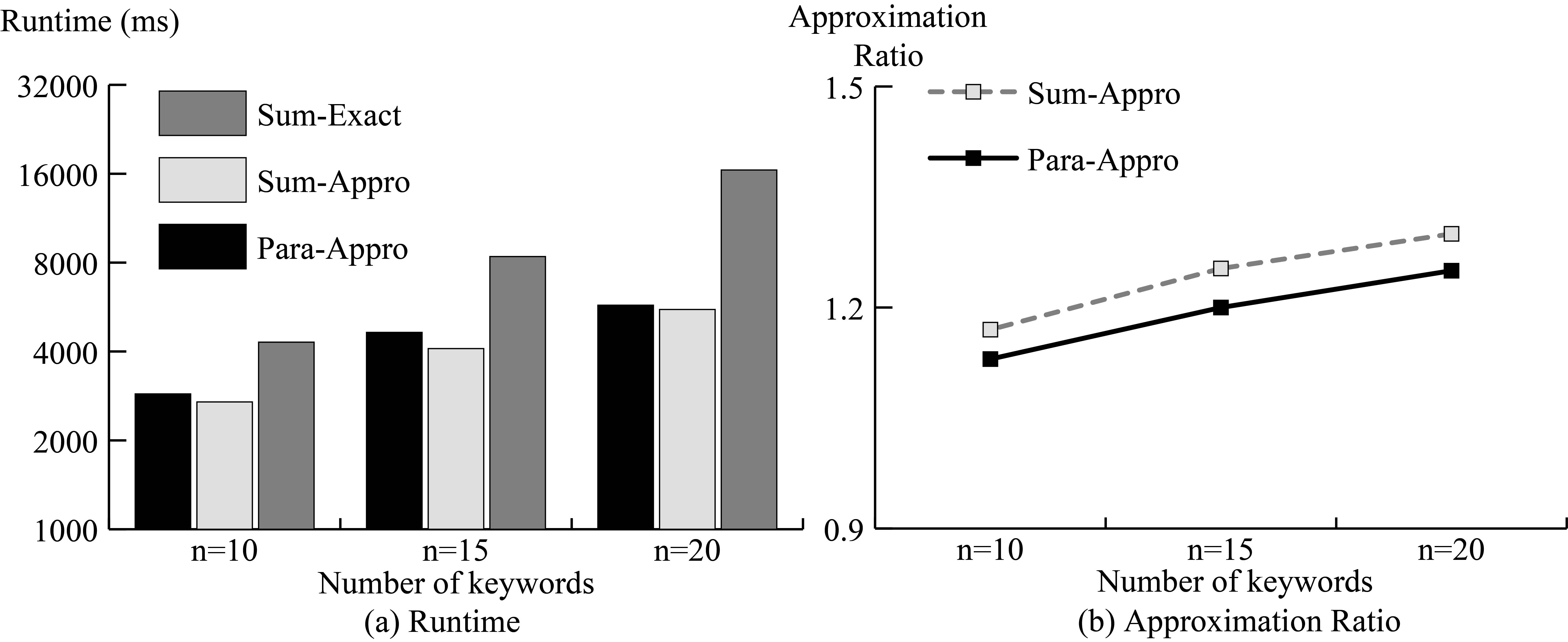
As the number of objects reaches millions, the runtime of Sum-Exact grows exponentially as shown in Fig. 5 and the preponderance of approximation algorithms is more clear. Since the number of the keywords associated with a single object in Nation is approximately 10 while this number can be in the hundreds for Web, approximation algorithms for Web cost more time when querying the same number of keywords. Similar results for the approximation ratio appear in Fig. 5b.
Results on Nation.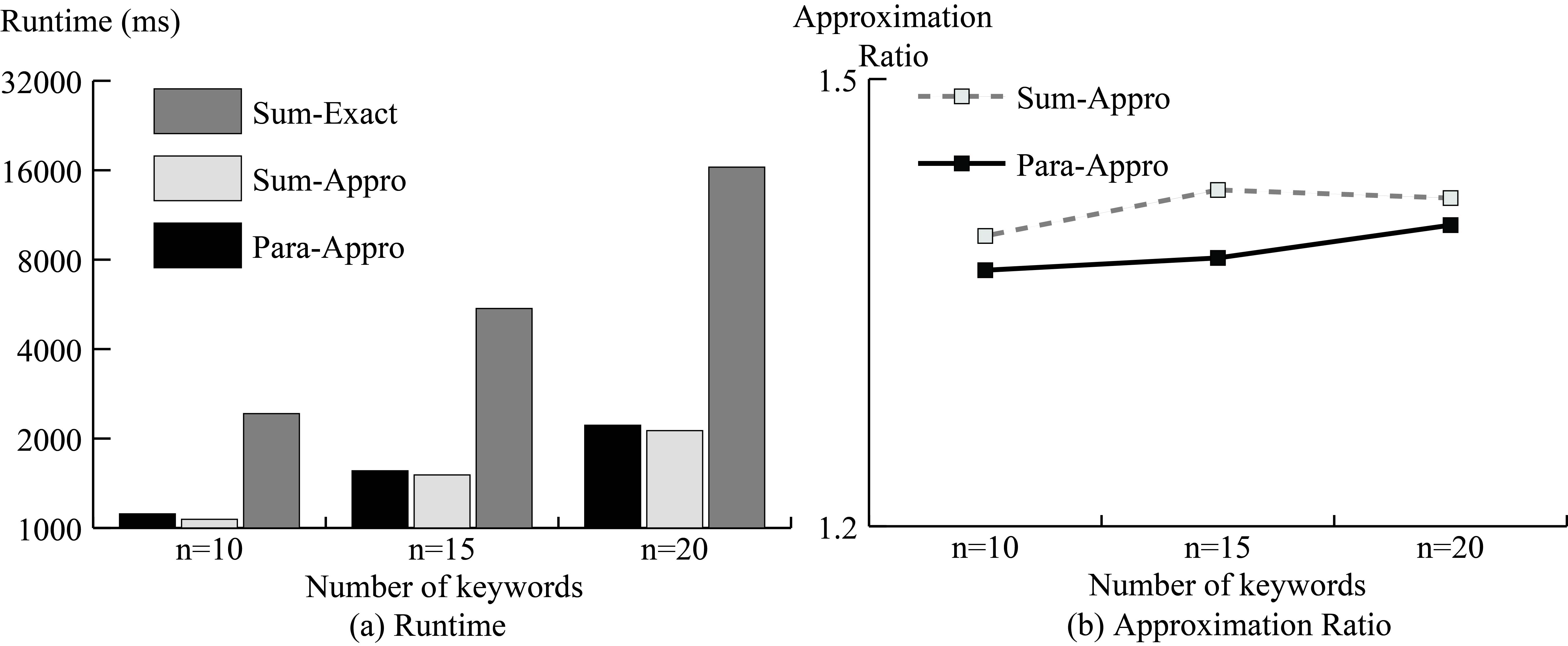
Figure 6 intuitively presents the relation between the tolerable time consumption
Relation between time consumption and query accuracy.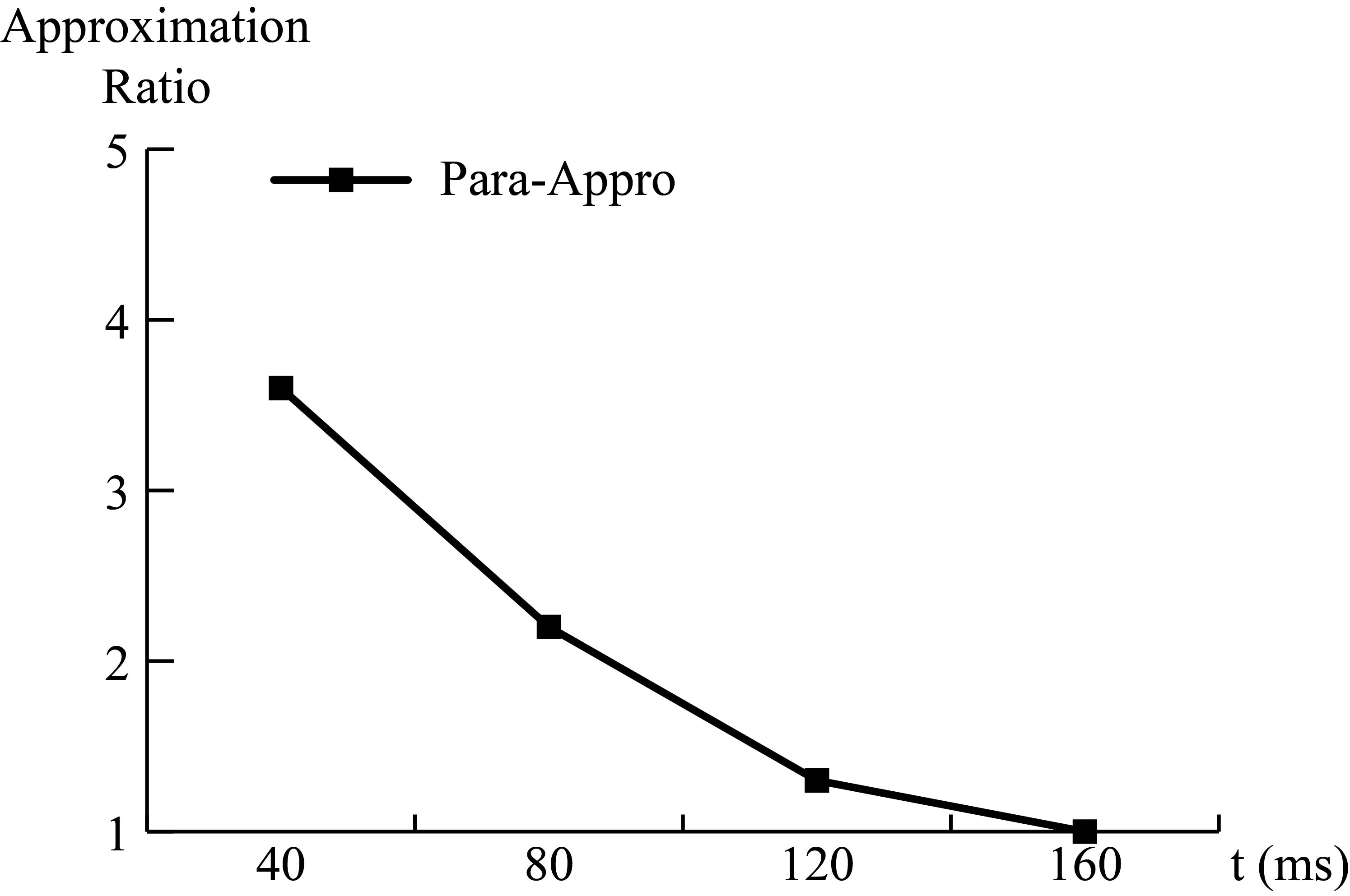
To verify the scalability to large number of instances, the first experiment is set to search 600 keywords on Nation and the number of objects
Result on scalability with different number of objects.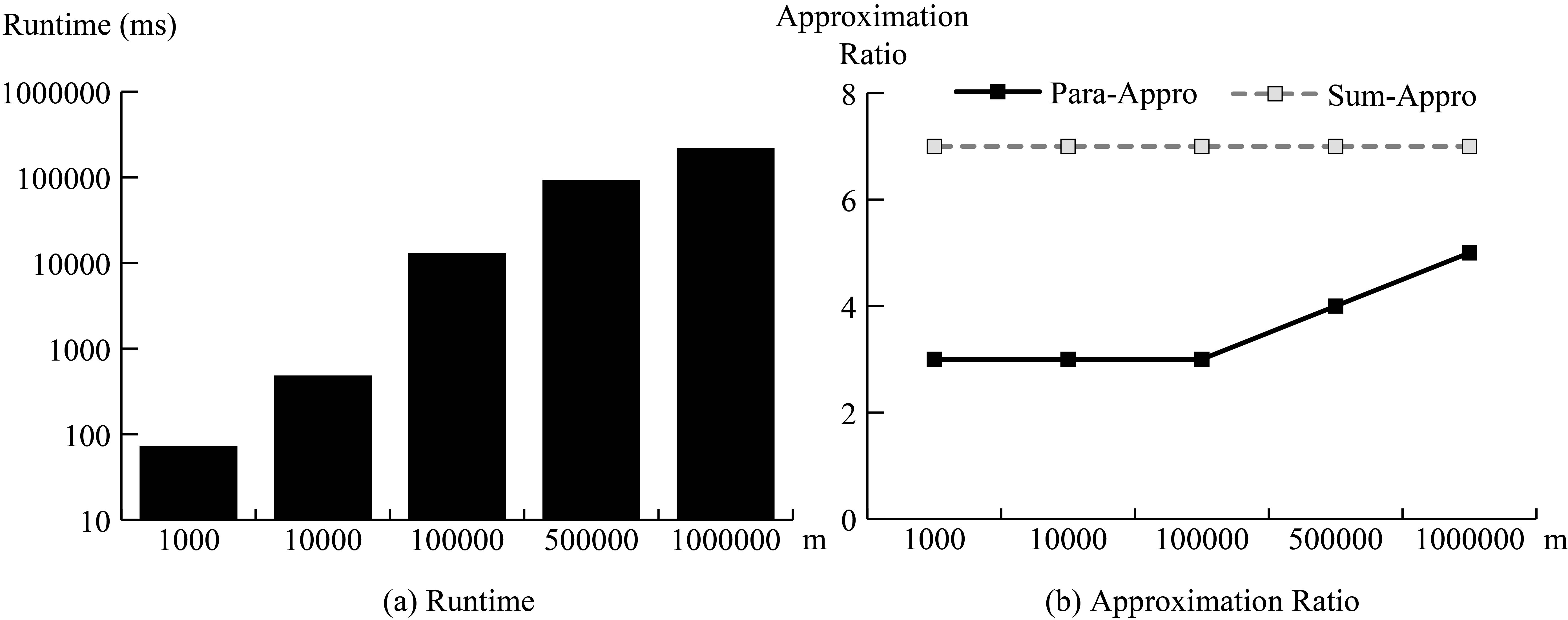
Result on scalability with different number of query keywords.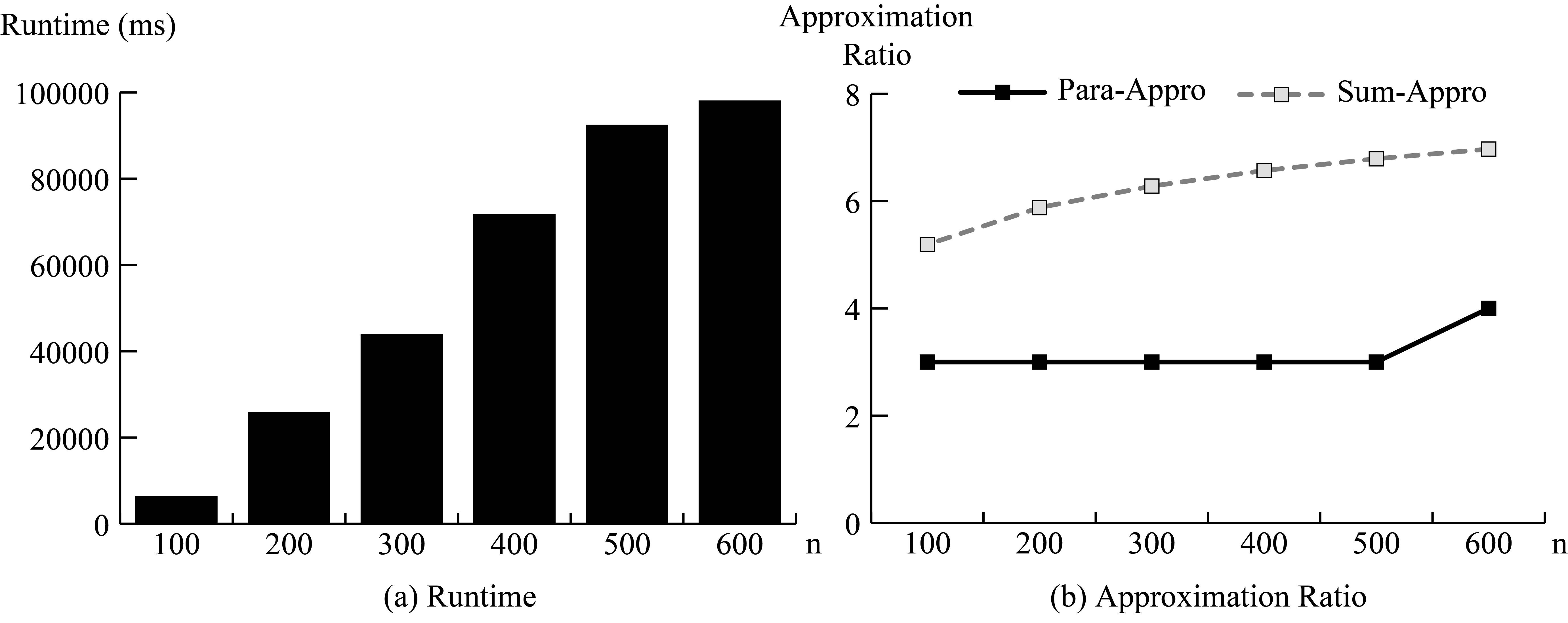
The second experiment is set to search different number of keywords among 500000 objects on Nation, where the number of keywords
In processing the SGK query, data structures are necessary for retrieving massive spatial keyword objects. Most location-aware queries adopt R-tree [17] as the data structure; R-tree is developed from B-tree [19] to multidimensional space and uses rectangles to store the location information of each node. To efficiently handle textual descriptions, information retrieval R-Tree (IR
Previous work in [6, 12] indicates that the SGK query can be reduced from the set cover problem [23], which is a notable combinatorial optimization problem with applications in a variety of areas. For solving the set cover problem, either approximation algorithms with greedy methods or exact algorithms with exhaustive methods are considered. By contrast, the use of parametric methods is relatively rare. Despite the lack of practical and effective applications, parametric methods for the set cover problem were introduced in [15, 14] to provide a new perspective for solving this problem. The inapproximability result for the set cover problem has been proved in [24], so that parametric methods for this problem is incapable of obtaining a solution in polynomial time. Thus, in this work, we accomplished a practical application that generalizes parametric methods from the set cover problem to the SGK query.
Conclusion
In this paper, we proposed an approximation algorithm, Para-Appro, for the SGK query with a parametric approximation ratio. Even though the algorithm does not represent a large advance relative to the existing approximation algorithms because it improves query accuracy at the cost of time consumption, it offers an approach for proposing new approximation algorithms. Para-Appro was verified to run in an on-the-fly manner on some benchmark datasets, and is potentially scalable to large number of instances.
In the future, we will consider more efficiently-operated data structures for retrieving spatial keyword object and will apply Para-Appro to variants of the SGK query, in which the goal functions are replaced with other measures, such as the maximum distance between the resulting objects.
Footnotes
Acknowledgments
The authors thank Cheng Long of Nanyang Technological University for offering the real datasets. The work is supported by the National Natural Science Foundation of China (No. 11871221) and the Fundamental Research Funds for the Central Universities.