
Abstract
Oversampling ratio
Introduction
Imbalanced data classification serves as the focus of machine learning and data mining. The traditional machine learning algorithm is based on the maximum overall classification accuracy, which is likely to make the model incline to the majority class and ignore the minorities. As a result, despite the high classification accuracy of the majority class, the generalization ability of the model is very poor. If the test set contains more instances of the minority class, the classification accuracy will be quite low. The actual classification application often pays more attention to the prediction results of the minority class. Due to the lack of training for them, the model fails to grasp useful information, so the classification results with high accuracy become meaningless for imbalanced datasets. In reality, the data is often high latitude and imbalanced. In many fields, such as medical diagnosis [1], image recognition [2], network intrusion detection [3], data imbalance problems happen from time to time. Generally, the misclassification cost of the minority class is higher. Therefore, in the face of imbalanced data, we are supposed to strive to improve the classification performance of the minority class.
Currently, the Internet mainly adopts large-scale machine learning to process data, despite of this, in real practice, most of the categories have no data accumulation, therefore, large-scale learning is not fully applicable. Under this situation, learning the model from small sample data within a short period of time turns out to be necessary. In the few-shot learning, the imbalance of data has a significant impact on the classification performance, so the quality of training set is quite significant. In this paper, it will study the unbalanced data classification in few-shot learning based on data enhancement.
SMOTE is widely used as an oversampling technique to improve the class distribution of datasets. However, it is difficult to select the optimal variables
The remainder of the paper is organized as follows. Section 2 summarizes the current related methods on imbalanced classification. Section 3 presents the SMOTE algorithm and points out its blindness. Section 4 constructs the AdaRBFNN classifier. Section 5 describes the details of the proposed hyperparameter optimization algorithm, and briefly introduces the metaheuristic techniques used. Experimental results on 7 groups of imbalanced datasets are discussed in Section 6. Finally, the conclusion is presented in Section 7.
Related work
At present, the research of imbalanced data classification can be divided into two categories: data level and algorithm level. As for the data level, the main methods are oversampling and under-sampling. That is to say, the dataset is balanced by copying the minority class instances or deleting the majority class instances. The synthetic minority oversampling technique (SMOTE) proposed by Chawla et al. in 2002 is deemed as a representative one [4], which manages to balance the dataset by synthesizing the new instances by random linear interpolation between the minority class and their
When it comes to the algorithm level, the main methods include cost sensitive learning [7] and ensemble learning [8]. Cost sensitive learning focuses on the cost of misclassification, which deals with data imbalance by assigning different penalty parameters to the majority class and the minority class. In ensemble learning, several weak classifiers are combined into one strong classifier to improve the overall generalization performance, including boosting algorithm and bagging algorithm. Among them, AdaBoost algorithm is one of the typical algorithms of boosting algorithm. In the iterative process, the method reduces the weight of the correctly classified instances and improves the weight of false classification instances in the previous round. Later, it obtains different base classifiers through various training data, and finally constructs a strong classifier by weighted voting.
At present, many researches have integrated the sampling method on the basis of ensemble learning. In 2010, Seiffert et al. proposed an algorithm named RUSBoost [9], which combines random under-sampling (RUS) with AdaBoost algorithm. Because of the uncertainty of random sampling method, sometimes the instances are not representative, so the improvement of model is not obvious. In 2003, Chawla et al. proposed SMOTEBoost algorithm [10]. Through the combination of SMOTE with AdaBoost algorithm, SMOTEBoost is able to create more extensive decision-making areas for the minority class compared to the standard boosting, but does not consider the impact of the number of synthetic minority class instances on the performance of model. In 2017, Rayhan et al. proposed a new clustering-based undersampling approach with AdaBoost, called CUSBoost algorithm [11]. It uses k-means algorithm to cluster the majority class instances into several clusters and selects some instances from each cluster to form a balanced dataset. However, when the feature space is not suitable for clustering, the performance of CUSBoost will be greatly reduced.
SMOTE algorithm
SMOTE is an improved algorithm based on random oversampling technology, which improves the generalization ability of classifier in test set and reduces the risk of over fitting. It concentrates on creating synthetic minority class instances by random linear interpolation between the minority class and its nearest neighbors and adding them to the original dataset, thus improving the imbalance of the dataset. The algorithm flow is as follows:
Suppose the original training set is Determine a sampling rate The new minority class instances are synthesized by random linear interpolation between
A new training set is formed by combining the newly synthesized instances with the original training set
It can be told from the algorithm flow that the parameter
Radial Basis Function Neural Network (RBFNN) [12] is a kind of Feedforward Neural Network with simple topological structure. It can approximate any nonlinear function with any precision and embraces strong nonlinear mapping ability. Compared with the traditional BP neural network, RBF neural network has only one hidden layer. The transformation from the input layer to the hidden layer is nonlinear, while the transformation from the hidden layer to the output layer is linear. The distance between the input mode and the center vector is taken as the function independent variable, and the radial basis function is used as the activation function. As a result, RBF neural network is not only equipped with excellent generalization performance, but also enjoys the best approximation performance. It is able to overcome the defect that BP neural network falls into local minima easily. Moreover, it has fast training speed, and has does well in classification problems.
With the intention of further improving the classification performance and generalization ability of the model, we work to train multiple RBF neural networks to integrate a new classifier AdaRBFNN based on AdaBoost algorithm. The classifier is applied to the proposed hyperparameter optimization algorithm, so as to evaluate the impact of training data under different hyperparameter combinations on the classification performance of the model. In this paper, the radial basis function is Gaussin function:
At this time, the output of RBF neural network is:
The training process of AdaRBFNN is as follows:
Input: Training data
Initialize the weight distribution of training data:
For
The base classifier is trained by the weight distribution
Calculate classification error rate:
Calculate the weight of the base classifier:
Update the weight of training data:
End for Construct a linear combination of base classifiers and output a strong classifier AdaRBFNN:
As for grid search, parameters are required to be adjusted according to step size within the specified parameter range. This method needs to go through all possible hyperparameter combinations, which is quite expensive in computing resources. Sometimes to save time and cost, the relatively sparse grid structure will be selected, but the optimal value might be missed. Therefore, we propose to optimize the selection of these two hyperparameters based on SA and PSO, so as to improve the classification performance of AdaRBFNN and effectively cope with the problem of imbalanced data classification.
Simulated annealing algorithm
Simulated annealing algorithm (SA) is a stochastic optimization algorithm based on Monte Carlo iterative solution strategy [13], which adopts the Metropolis algorithm and properly controls the temperature drop process to realize simulated annealing. The algorithm steps are as follows:
When the initial temperature
According to the temperature at present, apply a random disturbance to Suppose
In the iterative process of the algorithm, the optimal solution is searched according to the probability by decreasing the control parameter value, so the algorithm jumps out of the local optimal solution. When the initial temperature is high enough and annealing is slow enough, it can converge to the global optimal solution with probability 1. The acceptance probability of annealing process decreases as the temperature drops, and various states are generated randomly. The new one is not necessarily better than the previous one. The search strategy of SA is conducive to avoiding falling into the local optimal solution and has strong robustness. However, high initial temperature and proper annealing speed are usually required. If the parameters are not set properly, the search efficiency and performance definitely will be affected.
Particle swarm optimization (PSO) is an intelligent algorithm designed by simulating the predatory behavior of birds [14]. PSO is initialized as a group of random particles, and then the optimal solution is found through iteration. In the
Each particle in the solution space moves at a certain speed and gathers to its historical best position
In order to avoid the local convergence of PSO, we introduce simulated annealing mechanism into its optimization process. Moreover, this the proposed hybrid metaheuristic will be used as framework of hyperparameter optimization algorithm to search the ideal
Flow chart of hyperparameter optimization algorithm.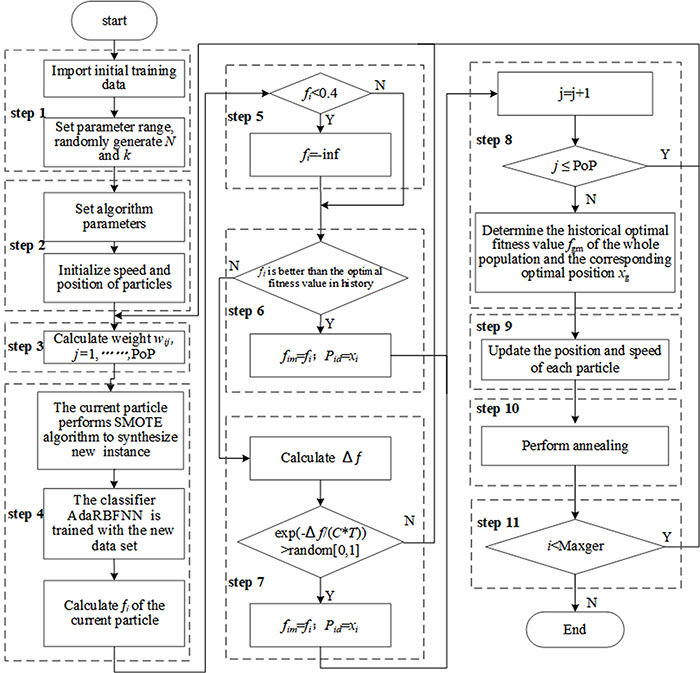
Kappa coefficient is calculated based on confusion matrix, which is used for consistency test and measure classification accuracy. This indicator is able to tell whether the classification accuracy is in the confidence interval. The calculation formula is:
The algorithm first initializes the population and parameters, and calculates the weight of each generation. Then SMOTE algorithm is implemented for each particle, and AdaRBFNN is trained by the new class distribution. According to the classification results, the Kappa coefficient of each generation of particles is calculated. The new solution is accepted by the Metropolis criterion
The time complexity of the algorithm is able to be analyzed by the big
Experiment
Data set description
To test the high applicability of the algorithm in this paper, 7 groups of imbalanced datasets in different fields of KEEL database are applied in the experiment. The source of selected datasets is reliable and no missing value exists there. Through drawing the boxplot, we manage to describe the discrete distribution of the data, during which no obvious abnormal value is found, thus cleaning is unnecessary. Finally, we carry out the assimilated processing towards the data. Referring to Table 1 for more details. In these datasets, the number of classes is two, which means we are dealing with imbalanced binary classifications. IR is the ratio between the number of instances from the majority and minority classes.
Datasets
Datasets
In the task of classification II, the majority class is regarded as negative and the minority class as positive. The confusion matrix of classification results is shown in Table 2.
Confusion matrix of classification results
Confusion matrix of classification results
The following measures can be defined by confusion matrix:
The relative importance of recall to precision is measured by
This index requires to take the classification performance of the model for two types of instances into consideration at the same time. When both are large, it can get better G-mean. The larger the G-mean is, the better the overall classification performance of the model is. When the data is imbalanced, the index is of great reference value. In this paper, F-measure and G-mean are used to evaluate the classification effect of different algorithms on imbalanced data.
Firstly, according to the classification accuracy and Kappa of the model, the optimization effect of this algorithm on SMOTE is verified. The experimental results are shown in Table 3.
Optimal hyperparameter combination, Kappa and classification accuracy based on hyperparameter optimization algorithm
Optimal hyperparameter combination, Kappa and classification accuracy based on hyperparameter optimization algorithm
Figure 2 demonstrate the convergence of the proposed hyperparameter optimization algorithm on seven datasets. The horizontal axis is the number of iterations, and the vertical axis represents the optimal value of the objective function in the population.
The convergence curve of the optimal fitness value in the population changing along with the number of iterations. a. Wisconsin convergence curve. b. Glass6 convergence curve. c. Yeast-2vs4 convergence curve. d. Ecoli4 convergence curve. e. Led7digit convergence curve. f. Page blocks-1-3vs4 convergence curve. g. Abalone-21vs8 convergence curve.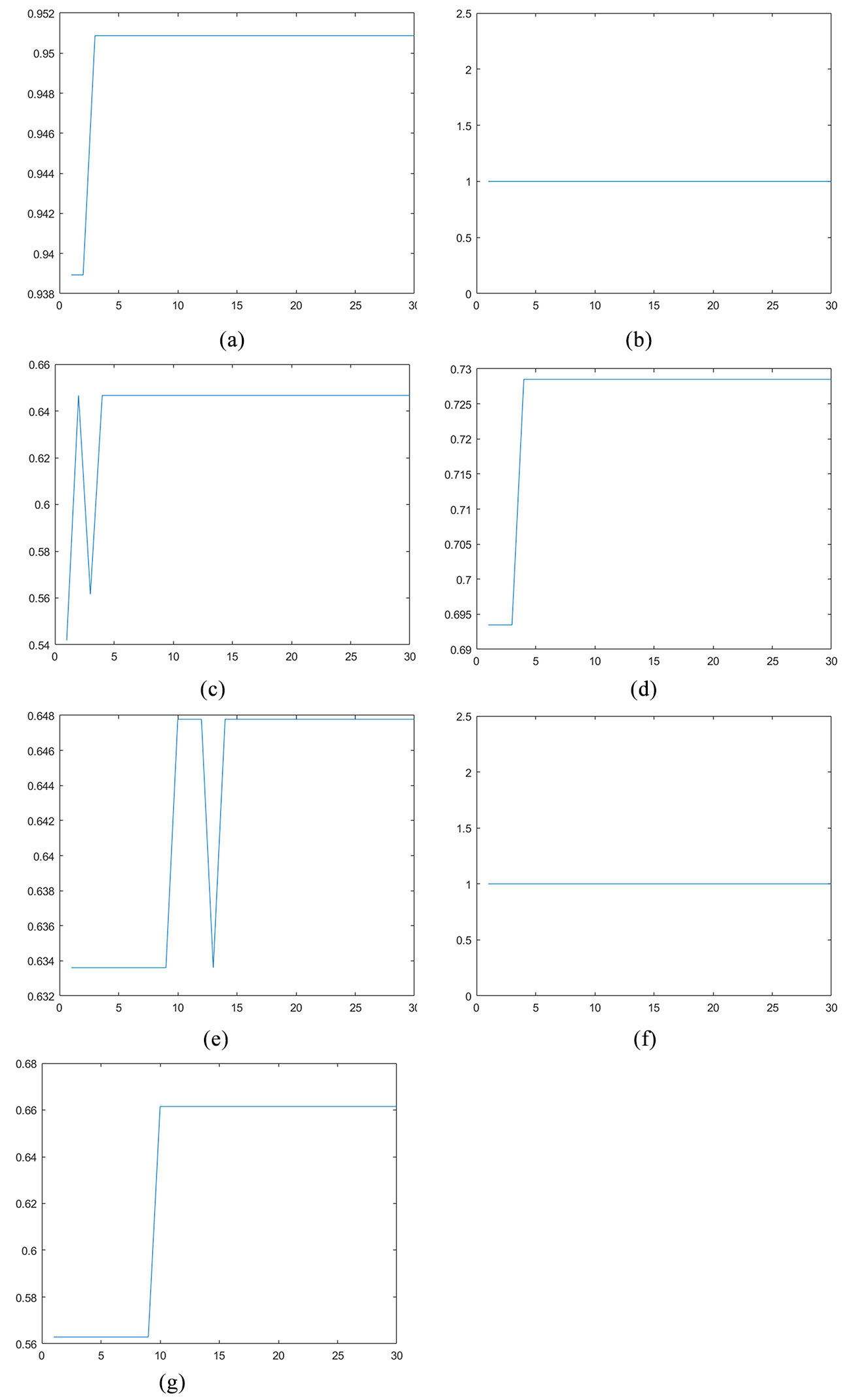
According to the experimental results, the Kappa values are greater than 0.4, and the classification accuracy is higher than 90%, which proves that the optimization of SMOTE algorithm is successful. Among them, the Kappa values of four datasets rank between 0.61 and 0.80, indicating that the model classification results are highly consistent with the actual results; the Kappa values of the dataset Wisconsin are greater than 0.8, proving that the model classification results are almost identical with the actual results; the datasets Glass6 and Page blocks-1-3vs4 are completely classified correctly. Due to the randomness of metaheuristic algorithm, the algorithm in this paper can find a set of hyperparameter subsets which are close to the absolute optimum in 30 iterations, so that it is able to converge to a better Kappa, and make the model obtain reliable classification results. The grid search requires to try every parameter combination, and the time will increase with the increase of
Next, we compare the proposed hyperparameter optimization algorithm with CUSBoost and RUSBoost, and use G-mean and F-measure for each data set to verify the classification performance of the model. The experimental results are shown in Table 4.
G-mean and F-measure drawn from three algorithms
From Table 4, it can be told that that the hyperparameter optimization algorithm does better than RUSBoost and CUSBoost in the F-measure of the selected datasets, and its G-mean is better in most datasets. Among them, the datasets Glass6 and Page blocks-1-3vs4 are completely classified correctly, as both of them reach 1. The experimental results prove that the algorithm in this paper is better for the classification of the minority class, and helps effectively cope with the problem of imbalanced data classification.
This paper works to study the unbalanced classification in few-shot Learning, and in pursuit of this goal, it adopts the research method of making full use of the existing data for data enhancement. The hyperparameter optimization algorithm put forward in this paper is based on PSO framework. By introducing simulated annealing mechanism, particles manage to jump out of local optimization at a high speed and convergence speed get improved. When it comes to the optimization process, the fitness function is constructed based on Kappa coefficient. And the proposed AdaRBFNN is regarded as a classifier, which works to evaluate the effect of different combination of hyperparameters on the model classification according to the Kappa value. Through iteration, we are allowed to find a set of ideal hyperparameters to implement SMOTE algorithm. It can not only deals with dataset imbalance, but also gets high-quality data sets by synthesizing a minority of instances. By doing this, it manages to train a classifier with excellent performance, thus obtaining the reliable classification results.
Metaheuristic algorithm helps avoid blind selection of parameters. It follows the optimization goal step by step, adopting heuristic search in the pre-set search space to efficiently search the improved solution for iteration, which is more time efficient than grid search. Through extensive experiments and comparison with other classification techniques, the results demonstrate that the proposed method embraces high applicability and competitiveness. The trained AdaRBFNN model is equipped with strong generalization ability and excellent classification performance, which can significantly improve the classification accuracy of the minority class. The proposed method helps effectively deal with imbalanced classification, which can provide a new idea for this kind of problem in data mining. Taking the computing power of traditional computers into account, AdaRBFNN is more suitable for few-shot Learning. However, the hyperparameter optimization algorithm in this paper is universal, and users are able to choose any classifier according to different datasets.
The specificity of the proposed method is that the fitness function is designed for SMOTE. Since Kappa coefficient serves as an effective method to measure the classification performance in response to the consistency of test dataset, we choose Kappa to define the fitness function, thus telling if the classification accuracy is within the confidence level. With the aid of this method, it helps explain the reliability of AdaRBFNN model. Moreover, it also directly reflects the enhancement effect of SMOTE after parameter optimization. The universality of this method lies in that users are allowed to define classifiers freely based on different data sets, or apply the proposed framework based on PSO and SA to parameter optimization of other algorithms. During this process, we are required to do nothing but define a reasonable fitness function. For example, it can be applied to seek the optimal solution of penalty factor
Footnotes
Acknowledgments
This research was supported by the Natural Science Foundation of Liaoning Province under Grant No. 201602259. The authors sincerely thank the laboratory of science college of Northeastern University for its equipment support and the Liaoning natural science foundation for its financial support.