
Abstract
In order to improve the robustness of speech recognition systems, this study attempts to classify stressed speech caused by the psychological stress under multitasking workloads. Due to the transient nature and ambiguity of stressed speech, the stress characteristics is not represented in all the segments in stressed speech as labeled. In this paper, we propose a multi-feature fusion model based on the attention mechanism to measure the importance of segments for stress classification. Through the attention mechanism, each speech frame is weighted to reflect the different correlations to the actual stressed state, and the multi-channel fusion of features characterizing the stressed speech to classify the speech under stress. The proposed model further adopts SpecAugment in view of the feature spectrum for data augment to resolve small sample sizes problem among stressed speech. During the experiment, we compared the proposed model with traditional methods on CASIA Chinese emotion corpus and Fujitsu stressed speech corpus, and results show that the proposed model has better performance in speaker-independent stress classification. Transfer learning is also performed for speaker-dependent classification for stressed speech, and the performance is improved. The attention mechanism shows the advantage for continuous speech under stress in authentic context comparing with traditional methods.
Introduction
Speech is the most significant mode of communication among human beings and a potential method for human-computer interaction (HCI) by using a microphone sensor [1]. Speech recognition technology has achieved significant progress with strides in large data and deep learning technologies. However, the accuracy of speech recognition is influenced by various factors regarding its actual application. The variation in stressed speech caused by internal and external environmental factors mainly contribute to the decline in speech recognition performance [2]. Therefore, stress classification is mainly applied to enhance the robustness of speech recognition system and anomaly detection.
The use-case of stressed speech classification model in the whole speech analysis system is shown in Fig. 1. The stressed speech classification model provides the system with the ability of anomaly detection caused by workloads and improves the robustness of automatic speech recognition.
Stressed speech is produced from physiological and psychological factors. The physiological variation mainly caused by pathological factors, including (1) diseases of vocal cords; (2) lesions in the vocal tract caused by occlusal muscle, labial muscles, lingual muscles and facial symmetry. In the psychological, speech under stress usually refers to variations in phonation caused by workloads, specific emotion, sleep deprivation and perceived threat. For example, a speaker focuses on a certain task, with speaking only serves as a secondary task. Here, due to the load on the brain as well as mental stress, the speaker experiences an abnormal mental state characterized by nervousness and absent-mindedness, greatly affecting his/her phonation. This paper is devoted to classification for stressed speech under multitasking workloads.
The recognition/classification system for speech under stress has two stages, feature extraction stage and classification stage [3]. Researchers have done lots of research works on feature extraction. First, various spectral features include linear prediction coefficients (LPC) and mel frequency cepstral coefficients (MFCC) [4] have acted a pivotal part in stressed speech analysis these year. A method to automatically obtain an optimized filter bank for stress recognition in speech was proposed in [5]. A new method of feature extraction using Fourier model for out-of-breath speech was presented in [3]. Various classifiers were also used for recognition of stressed state or different emotions in speech, such as hidden Markov models (HMM), Gaussian mixture model (GMM), Support vector machine (SVM) and so on [6, 7, 8, 9]. Recently, Besbes proposed a method to extract advanced acoustic features from pressure speech signals and employed a multi-class Support Vector Machines (SVM) with different kernels to recognize speech under stress, achieving favorable results [10]. Bandela put forward Gaussian mixture model (GMM) for emotional recognition of stressed speech with a combined feature, containing Teger energy operator (TEO) and linear prediction coefficients (LPC) [11]. Dumpala employed a deep neural network (DNN) to analyze the breathing sounds of speakers and showed that the increasing number of hidden layers improves performance [12]. MUSTAQEEM presented CNN model to extract normalized features from the speech spectrogram and then feed them into deep bi-directional long short-term memory (BiLSTM) for recognizing the final state of emotion [13]. Badshah [14] transformed emotional speech classification into image classification, combined with convolution neural network (CNN) and spectrogram. Roza [15] designed a curriculum during the training process of deep neural network (DNN) for speech emotion, that used the disagreement between evaluators as a measure of difficulty for the classification task. Zhang [16] proposed a multiscale deep convolutional long short-term memory (LSTM) framework for spontaneous speech emotion recognition, that a deep LSTM was adopted on the basis of the learned segment-level CNN features for utterance-level emotion recognition. However, the above research did not take into account the instantaneous characteristic of stressed speech, and ignored the significance of the key frame for stressed speech under workloads.
The use-case of stressed speech classification in the whole speech analysis system.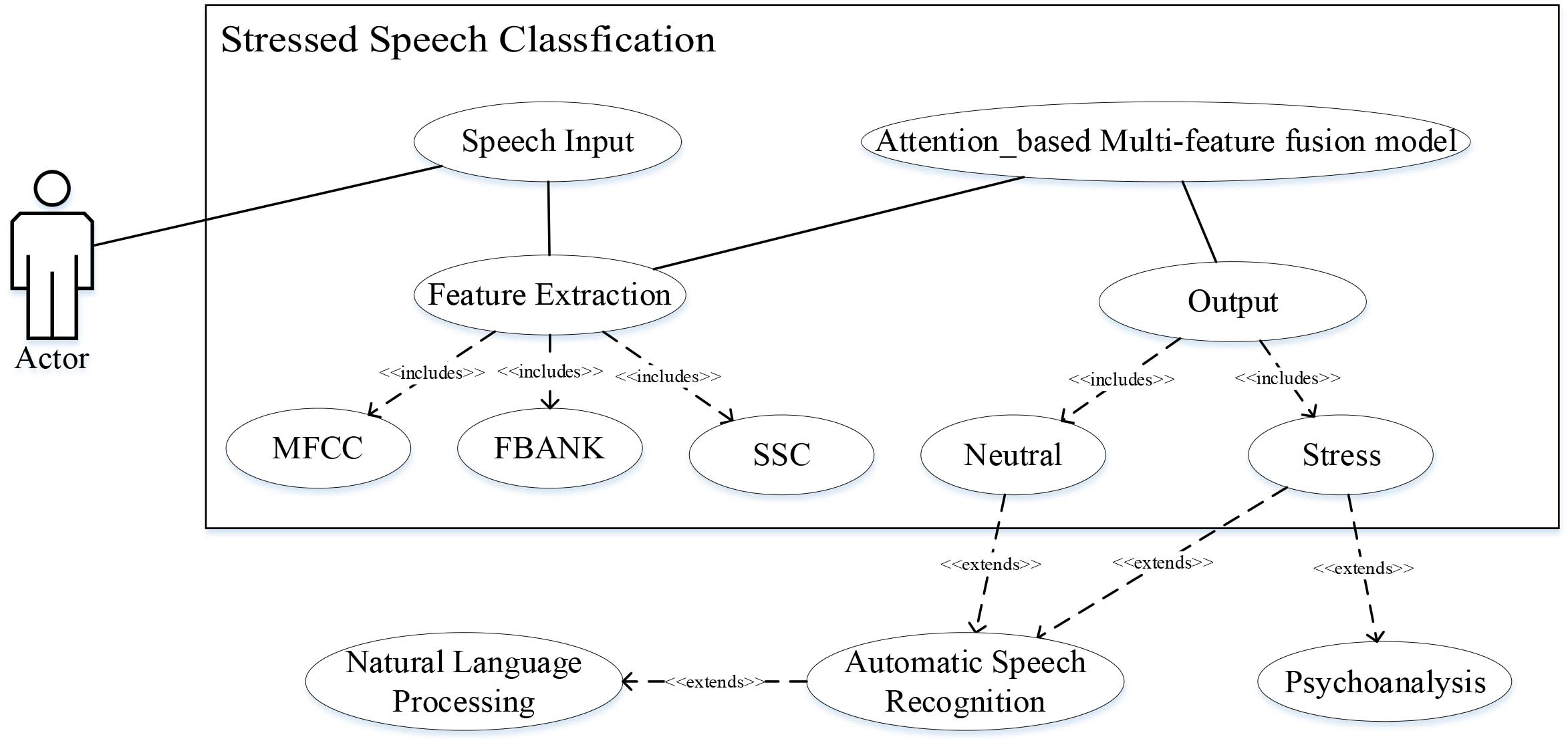
Although the above algorithms and models have been successfully applied in emotion recognition, traditional methods also face numerous challenges in speech under stress. Due to the transient nature and ambiguity of stressed speech under multitasking workloads, it is not certain whether stressed speech is produced by simply exerting pressure on the speakers. Therefore, the speech labeled as stress not only contains truly stressed segments, but also includes many neutral speech segments. Each part of the stressed speech is of varying importance in the classification. However, in traditional machine learning algorithms and deep learning networks, the importance difference for segments in stressed speech is not represented and quantified. Stress-irrelevant neutral speech segments as well as vital stress-relevant speech segments contribute equally toward the result in the traditional model. In addition, due to the existence of a large number of neutral segments in stressed speech, the number of truly stressed segments is relatively small, causing stressed speech classification to suffer a small samples problem. Hence, overfitting is caused in traditional models.
This paper discusses stressed speech caused by psychological stress under multitasking workloads and a stressed classification framework for multi-feature fusion LSTM based on the attention mechanism is proposed. In the study, speech frames are weighted using the attention mechanism to reflect the different correlations to the actual stressed state, and the solution for the problems of ambiguous sample label is achieved. Furthermore, the multi-channel fusion of features representing the stressed speech for classification, and modified SpecAugment and transfer learning are proposed to solve the small sample problem.
Our major contributions in this paper are documented below:
We propose a classification learning framework for stressed speech under multitasking workloads, which improves the robustness of the automatic speech recognition. The framework models continuous temporal signal for stressed speech based on time series learning mechanism. In addition, small sample problem in stressed speech is solved by modified SpecAugment and transfer learning. We proposed a learning strategy for stress classification based on attention mechanism. In view of the transient nature and ambiguity of stressed speech under multitasking workloads, the model can learn effectively the weights of different frames to solve the quantization problem of stressed states in continuous speech. Our study is a success of quasi end to end neural network learning for stress classification under multitasking workloads. We tested the proposed framework on different dataset and evaluated from different perspectives, and the proposed framework achieved accuracy of 80.0% and 86.7% in Fujitsu stressed speech and CASIA dataset respectively, which performed superiorly over traditional method and shown generalization for different datasets.
The rest of the paper is organized as follows: In Section 2, related works for attention mechanisms and long short-term memory model are introduced, Section 3 elaborates proposed framework of stressed speech recognition, the experimental result of the mentioned technique and comparison evaluations with traditional are discussed in Section 4, finally Section 5 presents the conclusions and the feature work of the proposed framework.
Long-Short Term Memory Model
Owing to lack of public dataset for stressed speech under multitasking workloads, there are few works of Long-Short Term Memory Model (LSTM) on stress classification. However, LSTM has made progress in speech emotion recognition (SER). Since Wöllmer [17] first applied LSTM to SER, the application of LSTM in SER has achieved continuous development in recent years, which mainly follows two streams: distinguishing features [18, 19, 20] and emotion recognition [21, 22, 23].
The LSTM network includes an input layer, an output layer, and several recursive hidden layers. The recursive hidden layer consists of several memory modules, containing one or more self-connected memory units as well as three gates that control information flow: the input gate, output gate, and forget gate. The structure of LSTM is shown in Fig. 2.
The internal structure of LSTM. 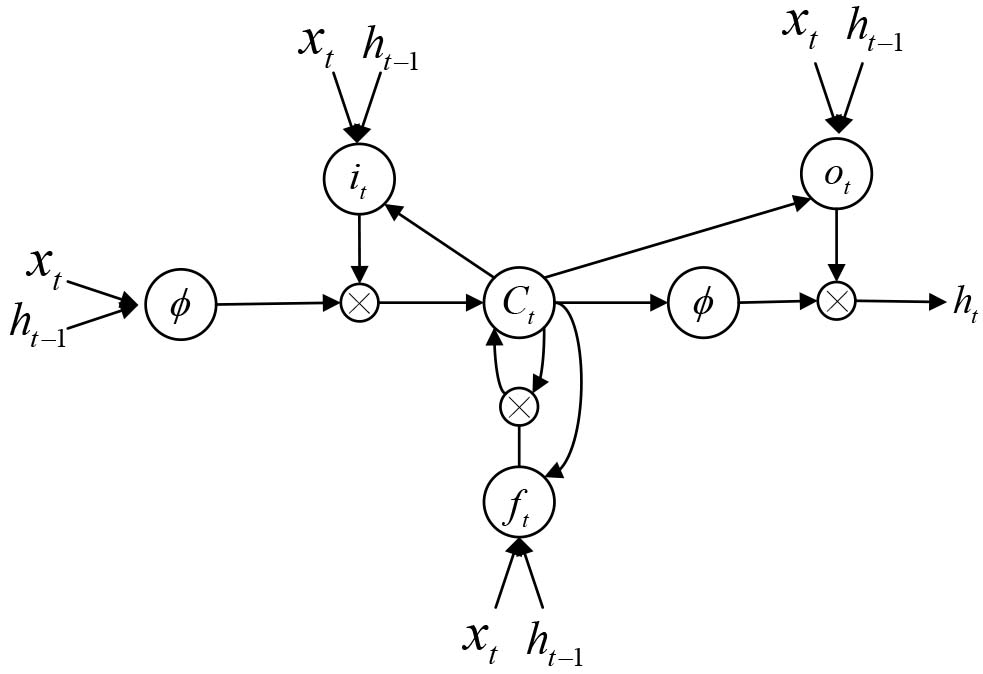
The input sequence is shown as
Input gate:
Forget gate:
Memory unit:
Output gate:
Hidden layer output:
Here,
Due to the transient nature and ambiguity of stressed speech, the speech sentence labeled as stressed wholly may not only contains truly stressed segments, but also includes some neutral phonation segments. Hence, the silence and neutral segments in the continuous stressed speech have adverse effect on the final recognitive decision.
Attention mechanism is widely used in natural language processing (NLP) and automatic speech recognition (ASR) [24, 25, 26, 27, 28]. Researchers have also applied attention mechanism to speech emotion recognition (SER). Mirsamadi [29] proposed a novel strategy for emotion recognition which used local attention in order to focus on specific regions of a speech signal that are more emotionally salient. Huang [30] explored a convolutional attention mechanism to learn the utterance structure relevant to the task.
The attention mechanism is a model simulating the attention system of the human brain, which was proposed by Treisman and Gelade [31]. Moreover, it is viewed as a combination function, highlighting the impact of key inputs on output by calculating the probability distribution of attention. Most attention mechanisms are generally based on the Encoder-Decoder abstraction framework, especially in the field of natural language processing, as shown in Fig. 3
Abstract Encoder-Decoder framework. The model maps a variable-length input 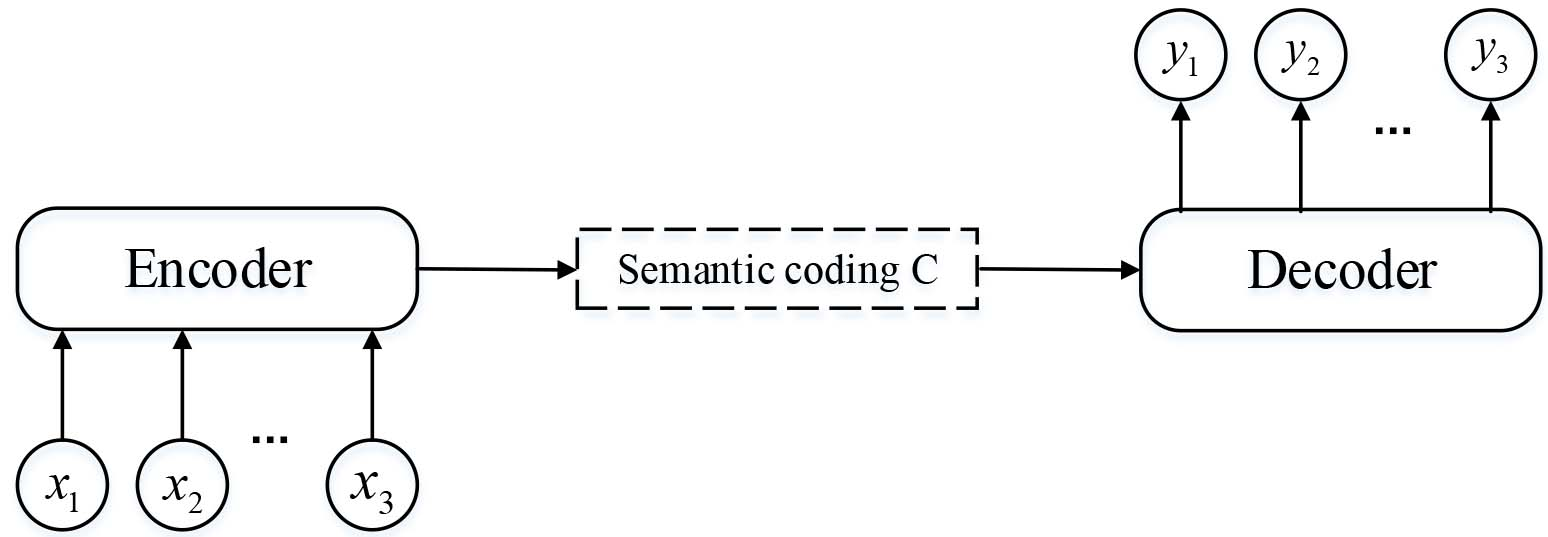
The model maps a variable-length input
Schematic diagram of the attention mechanism mechanism.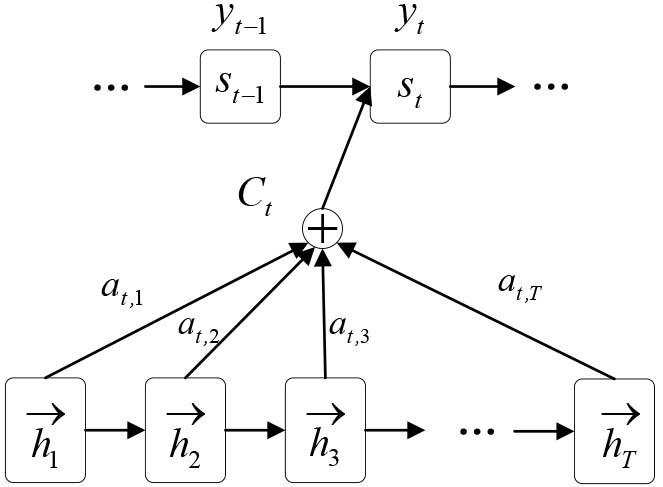
Here,
depends on the hidden layer representation of the input sequence at the encoding end and can be expressed after weighting, as:
where
Here,
The proposed stress classification framework is shown in Fig. 5, which is divided into four parts: speech preprocessing, feature selection, data augment and classification.
The proposed framework for stress classification.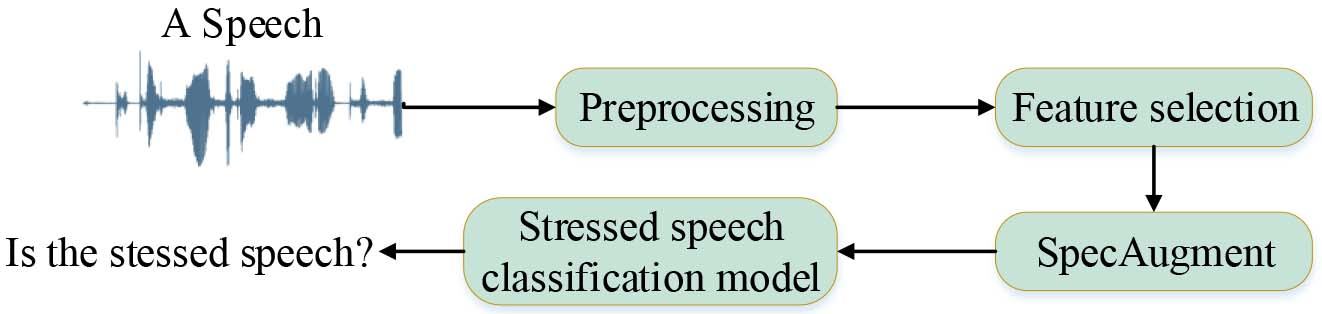
Since the stressed speech has the instantaneous characteristic, the speech sentence labeled as stressed wholly may not only contains truly stressed segments, but also includes some normal phonation segments. So, each segment of the stressed speech possesses varying importance in stress classification. Traditional methods assume that all frames equally contribute to stress classification, however, attention mechanism enables model to learn to focus different attention on the frames at different time.
Compared to the traditional recursive neural network (RNN), the structure of LSTM selectively retains the memory of the previous node while selectively absorbing the new memory at each node, thereby achieving a consideration for context. Speech as a time series signal is related to the before and after states, with the length of speech. The attention mechanism is able to alleviate the problem. Traditional LSTM outputs the last node for stress detection, but the combination of attention mechanism and LSTM retains the intermediate node output, and the weights of different speech frames are learned through the attention mechanism, achieving selective learning of the input speech vector.
In order to improve the classification performance while taking computational cost into account, a stress classification model for multi-feature fusion LSTM based on the attention mechnism (Att_MF-LSTM) is proposed. In this study, multiple features are selected as model inputs, and stressed speech is described more comprehensively.
Overall architecture of the proposed multi-feature fusion LSTM based on the attention mechanism for stressed speech classification.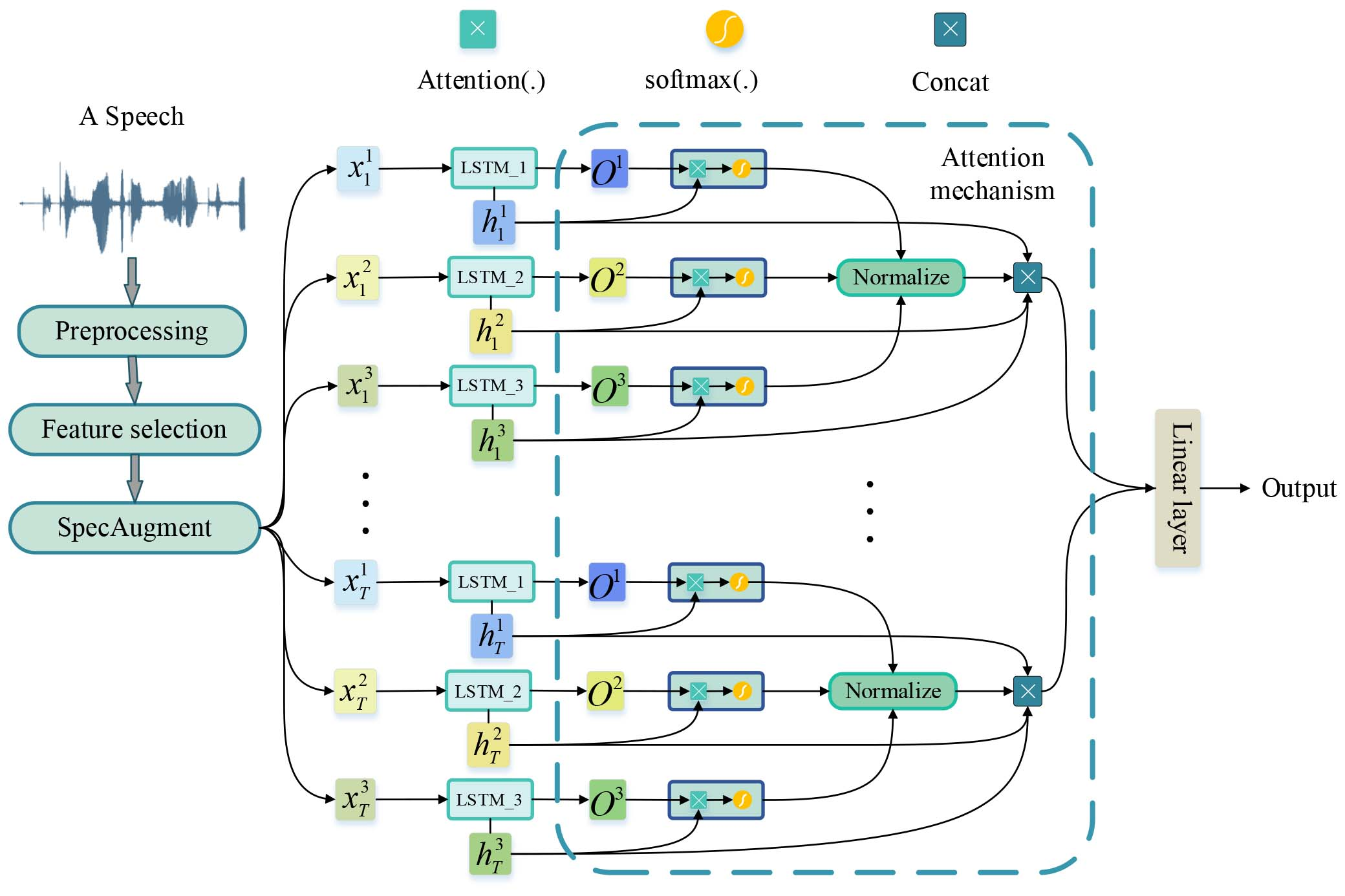
Feature selection based on attention mechanism, where similarity between output of hidden layer and output of LSTM at last moment is calculated to distinguish frames. Then feature selection is performed according to variance of 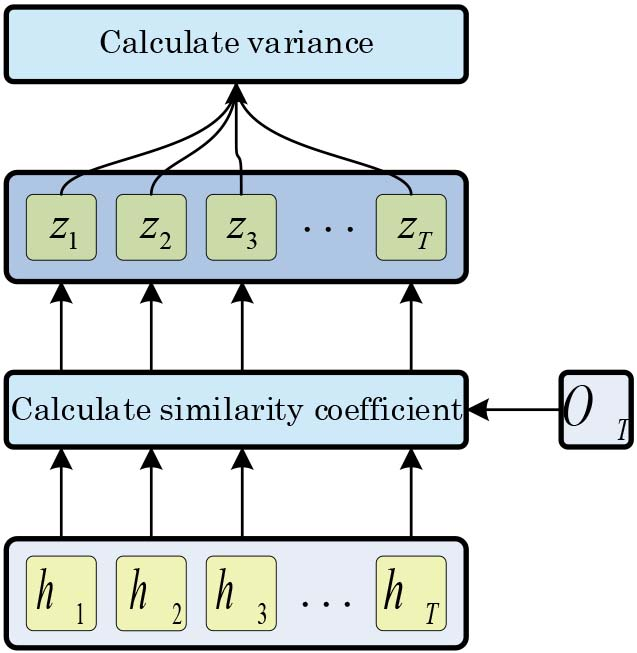
The structure of Att_MF-LSTM is shown in Fig. 6. Feature selection refers to the selection of various effective features from the original features in order to reduce the dimensionality of data [33]. Each feature was input into LSTM models we calculate the weight of each frame through the attention mechanism. Accumulated information is most abundant in the output of LSTM at last moment, therefore the last moment output of LSTM should obtain a large weight in attention mechanism. This study takes the output of last moment in LSTM as a reference to ensure that it can obtain a large weight, as shown in Fig. 7 the attention score of the each speech frame is calculated as:
Where
Due to the transient nature and ambiguous of stressed speech, only a few frames play a decisive role in the recognition results, such as laughter and speech segments becoming lighter and slower. In stress classification, the attention mechanism highlights some important frames while ignoring various insignificant frames. For each feature, we calculate the weight of each frame through the attention mechanism mentioned above. If the weight variance of each frame of the feature is large, attention mechanism of the feature will be more likely to identify key frames. On the other hand, if weight values of each frame are close to each other, each frame will have similar degrees of effect on the recognition results, which means that attention mechanism of the feature can not distinguish the key frames of stressed speech. Therefore, variance of weight can be used for feature selection based on attention mechanism. We discuss different features within a feature set, and the variance of the attention mechanism weights of all frames in dataset is calculated, and the feature selection is performed according to the magnitude of the variance, as represented in Fig. 5.
The variance is calculated as follows:
where
After feature selection and data augment three speech features
Here,
Different attention focus for three speech features results in different weights. The weights learned from the three speech features are further normalized to obtain the final weight of t-th frame in speech:
where
Each hidden state is then multiplied with the normalized weights, and features are fused by performing matrix concatenation.
Finally, the feature fusion matrix is input into the embedding linear layers, mapped to the classification result:
Therefore, the model essentially uses the output of all hidden nodes in LSTM to obtain information concerning the entire speech. Meanwhile, the importance weights for each speech frame of different features are learned through attention mechanism, which is beneficial to stress classification.
Training models requires a large amount of data. However, the data set in this study poses some problems, such as difficulty in collection and high subjectivity of sample labeling. Moreover, the speech data labeled as stressed only includes a small number of truly stressed speech segments, resulting in a small training sample size. Small sample sizes often lead to overfitting of the model, making the model lack generalization and reliability.
In order to avoid overfitting of the network, a data augment method based on feature spectra was proposed. SpecAugment [34] is extended to non-log mel spectra, and data augment is performed by time warping, time masking and feature channel masking. The algorithm is shown as following.
This method can enhance the robustness of the model to resist the distortion of time series and the partial loss of feature channel. Moreover, the augment based on the feature spectrum is directly applied to the features, which may be performed dynamically to avoid influencing the training speed. A simplified example are shown in the Fig. 8, where the matrix represents the feature vector in a certain speech segment and denotes the n-dimensional feature of the m-th frame. The features of the first and third frames are exchanged in a time sequence, covering the 2nd-dimensional feature vector and the 2nd-frame.
Experimental evaluation
Database and experimental method
Fujitsu stressed speech corpus
A stressed speech corpus used in the paper is collected by Fujitsu containing speech samples from telephone conversations that perform different tasks. Three different tasks are introduced to simulate stressed speech which is caused by psychological stress: 1. Solving logical puzzles; 2. spotting differences; 3. gambling games. These tasks are performed by the speaker while talking with the operator. Among them, the logical puzzle task is shown in Table 1. During the phone call, the speaker is required to give a logical answer to the puzzle and explain its reasoning according to the given hints. Spotting difference tasks is shown in Fig. 9. A speaker is asked to examine the differences between the two pictures, and required to answer questions at the same time. While solving logical puzzles and spotting differences, the remaining time on the display is shown to exert time pressure on the speaker, and the speaker must answer the questions within the given time. Gambling games are used to assess the speakers’ desire for monetary gain. In a gambling game, the goal of the speaker is to win the target amount. If the speaker loses all the money, the speaker must borrow money from the operator over the phone in order to continue playing the game.
Logic puzzle task. During the phone cell, the speaker is required to fill out the form according to the given tips
Logic puzzle task. During the phone cell, the speaker is required to fill out the form according to the given tips
A simplified example of data augment based on feature spectra.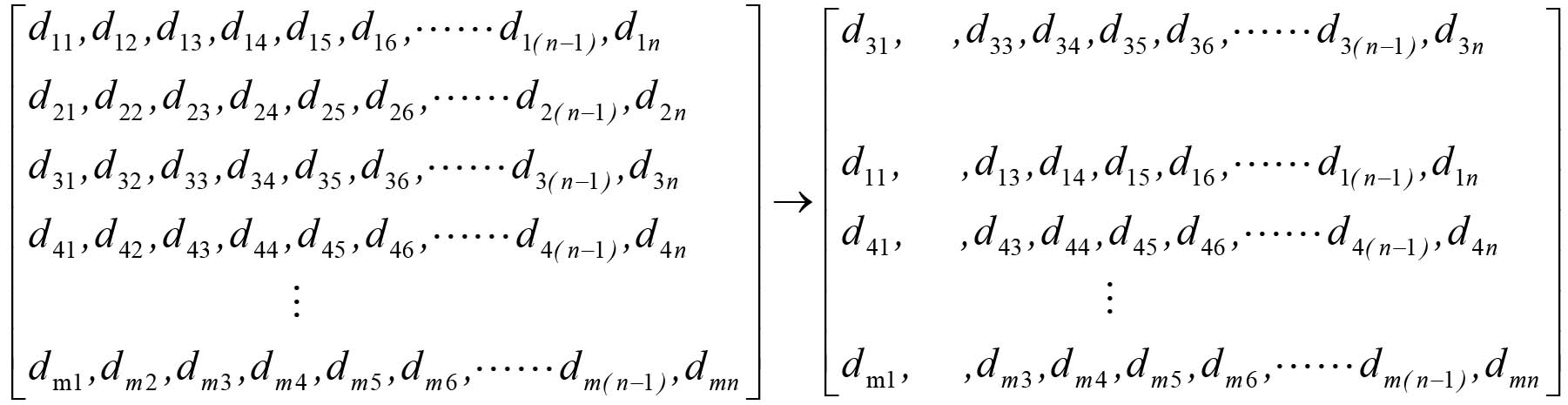
Spotting difference. During the phone cell, the speaker is required to find difference between above two figures.
In this corpus, four different conversations are collected for each speaker. The first conversation is regarding a relaxed topic without any tasks. In the second and third conversations, speaker is required to complete a task under workload. The speaker imposed pressure, must focus on the task within the limited time. Finally, the fourth task is a light topic and does not involve any tasks. This corpus is divided into neutral and stressed speech, which collected from 100 people, including 50 men and 50 women. We assume that the stressed speech is generated under the workload conditions, and the neutral speech is collected during the relaxed discussion. Eleven speakers’ speech are selected through the subjective evaluation, whose voice under stress is obviously different from the speech under relax. Hence, this corpus contains 156 stressed speech examples and 61 neural speech examples totally.
Emotional speech is another type of stressed speech. CASIA Chinese emotion corpus is provided by institution of Automation, Chinese Academy of Sciences. The speech data of this corpus is recorded by four subjects (i.e., two men and two women) in a clean recording environment (SNR is about 35 dB), adopting 16 kHz sampling, 16 bit quantified. It has 9600 short utterances, in which six emotional states (i.e., sad, angry, fear, surprise, happy, and neutral) are contained in total. In order to compare with the experimental results of Fujitsu corpus, the CASIA corpus is also divided into two classes: neutral speech and stressed speech. The speech with emotion as sadness, anger, fear, surprise and happiness is classified as stressed speech, and neutral speech is classified as another category, that means there are 8352 short utterances in stressed speech, while only 1248 short utterances in neutral speech.
Experimental method
The next experimental process is shown in Fig. 10. Firstly, the corresponding features are extracted from original corpus according to feature selection and then we performed SpecAugment Based on Feature Spectra to enhance the extracted features. In the next, the features are input to the classification model, which divides the corpus into two categories (i.e., stressed and neutral). In the end, we analyze the experiment according to the confusion matrix of the experimental results. We get the recognition rate (Accuracy) according to the confusion matrix, and evaluate the results of experiments.
The experimental flow of stress classification. In confusion matrix, TP and TN means the correct classification of stressed and neutral samples while FP and FN means the error classification of those. Specifically, FP means that neutral samples are wrongly classified into stressed samples, while FN is the opposite.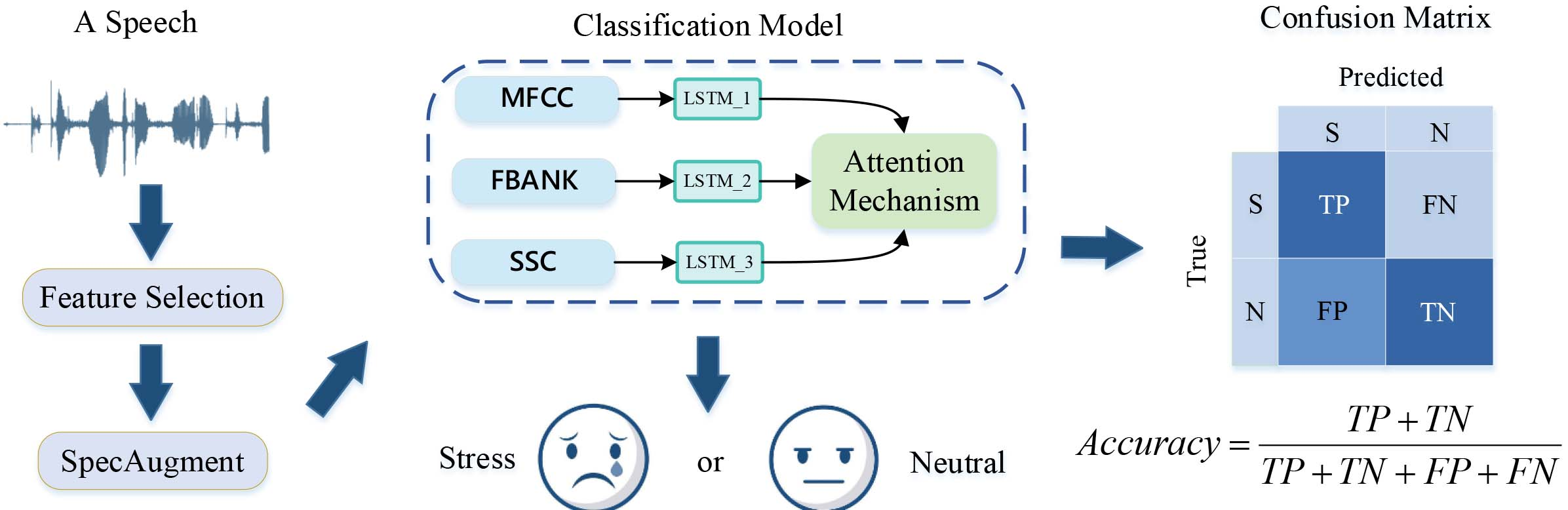
In preprocessing, we performed endpoint detection to eliminate long periods of silence in speech, and pre-emphasis on the high frequency of speech to remove the influence of the lips’ radiation and enhance the high-frequency resolution of the speech. The pre-emphasis is realized by a FIR high-pass digital filter with a transfer function shown as:
The sampling frequency selected was 16000 HZ, and the Hamming window was used for framing. The frame size chosen to perform the experiment was 32 ms, with 16 ms for frame shift.
Seven features are selected to form a feature set: Mel Frequency Cepstral Coefficients (MFCC), Filterbank Energies (FBANK) [35], Spectral Subband Centroids (SSC) [36], Energy, Linear Prediction Coefficient (LPC), Pitch (f0) and Zero-crossing rate. The features are further measured based on the attention mechanism, and the results are sorted according to the variance. The results are shown in the Table 2.
Attention mechanism weights’ variance of different feature mechanism
Attention mechanism weights’ variance of different feature mechanism
The results demonstrate the three speech features: MFCC, FBANK, and SSC are more suitable as inputs for the stress classification. According to the variance, the coefficients in Eq. (14) were assigned. MFCC corresponds to the coefficient
The feature extraction steps of MFCC, FBANK and SSC.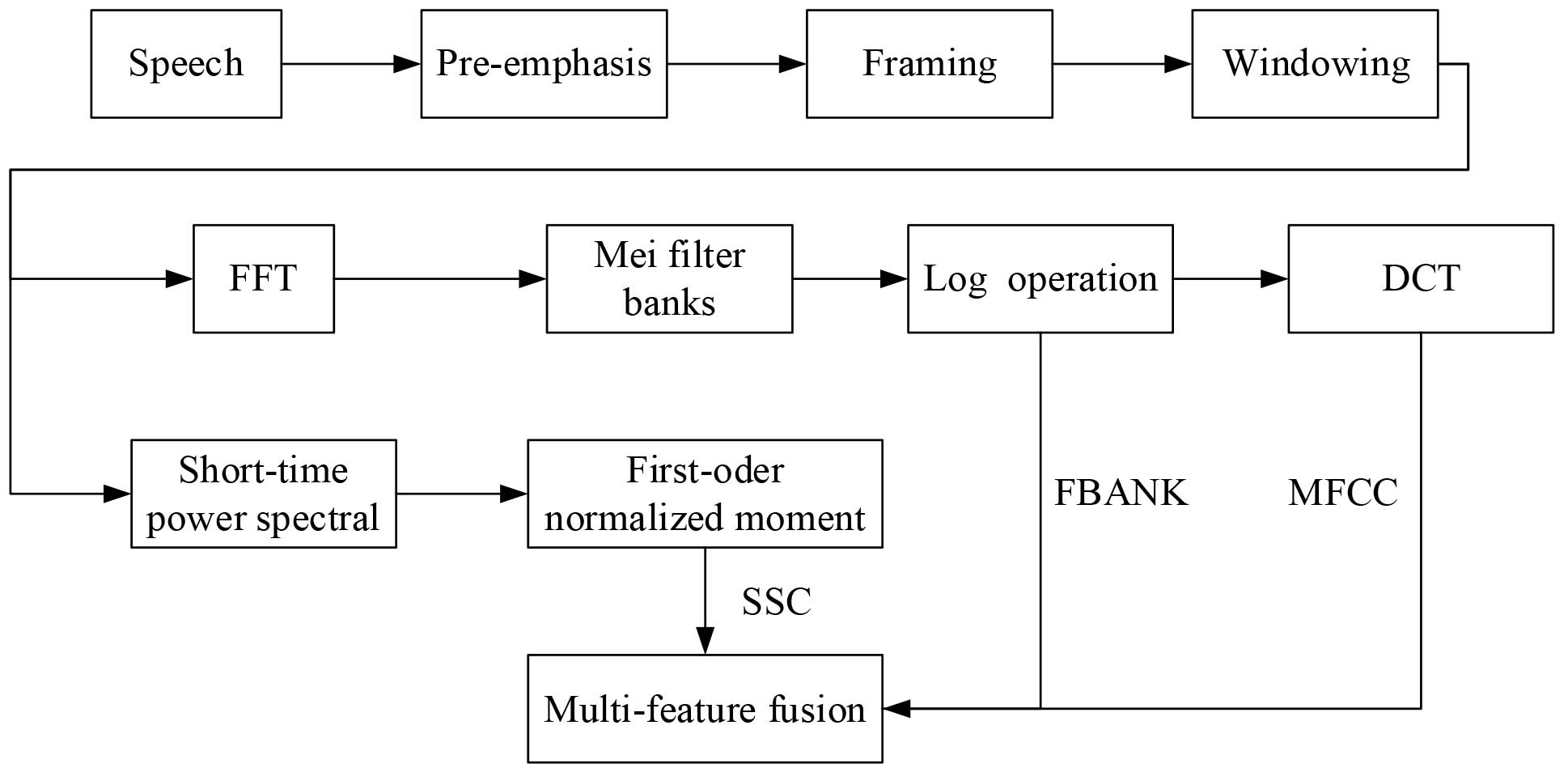
In order to verify the effectiveness of feature selection algorithm, seven features mentioned above were extracted from the Fujitsu stressed speech corpus and separately input into the LSTM based on attention mechanism, where the layer number is 2 and hidden nodes is 512. The results of classification accuracy is shown in Fig. 12.
The classification accuracy of the LSTM model based on attention mechanism with each feature as input separately.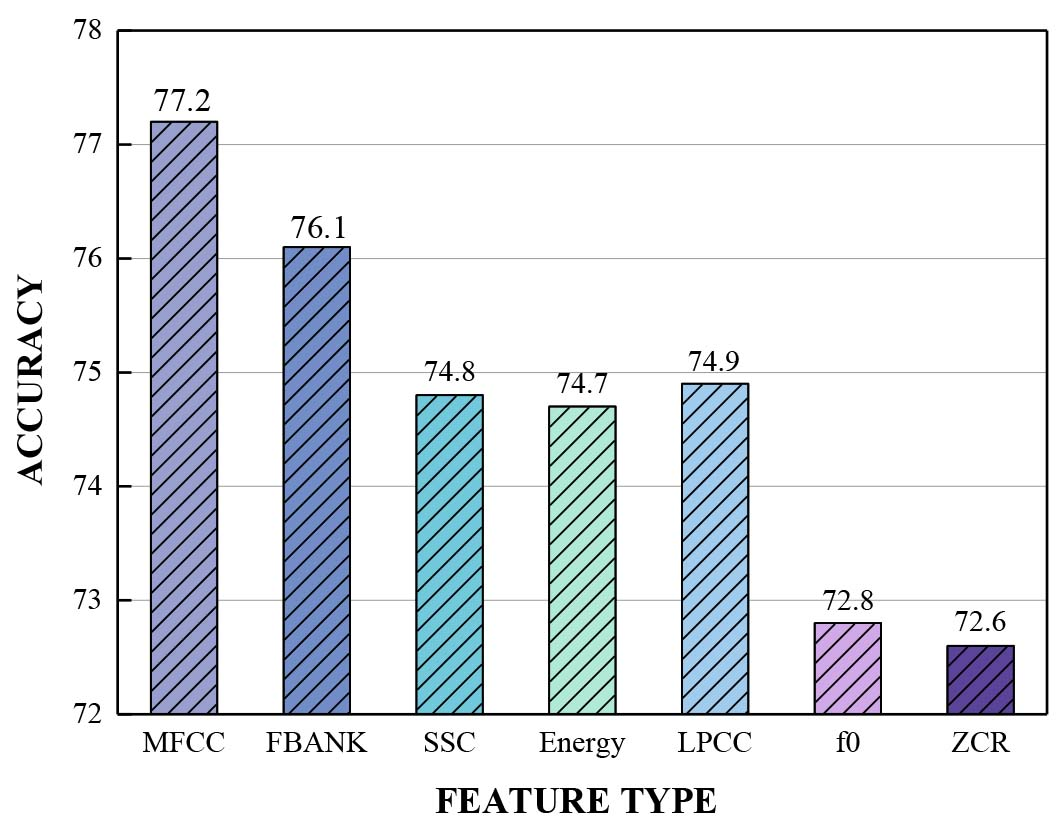
We found from the experimental results that the recognition accuracy of each feature is basically consistent with the result of feature selection. Although LPCC was close to SSC in view of classification accuracy, the results for MFCC and FBANK is perform obviously better, which basically verified the hypothesis of feature selection.
Furthermore, we compared the above algorithm with the traditional feature selection algorithm, including correlation analysis (CA), information gain (IG) and forward selection algorithm (FS). Results of the above feature selection algorithm for the feature set are that CA selected MFCC, LPCC, f0, and IG selected MFCC, FBANK, LPCC, and MFCC, FBANK, SSC for FS. It is found that MFCC is the first choice for the three feature selection algorithms, which was also consistent with the experimental results in Fig. 12. Moreover, FS algorithm had the same result as our method. The selected features based on above algorithms are inputted into Att_MF-LSTM to perform the classification. Results are shown in Fig. 13.
Comparison of ours and traditional feature selection algorithms for stressed speech classification.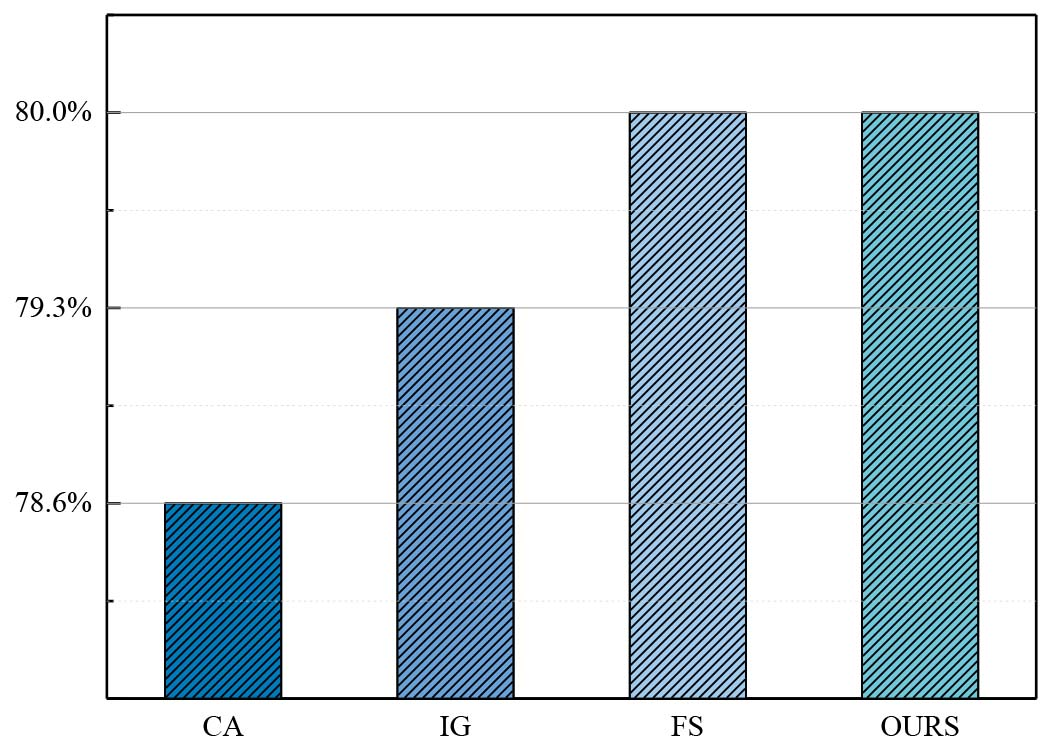
According to experimental results, FS and our algorithm have the same recognition effect because the selected features were consistent, which are better than the other two algorithms. In Fig. 13, CA was obviously inferior to the other three algorithms because of the generally low correlation and discrimination among the features. Therefore, we still followed the result of feature selectin and MFCC, FBANK and SSC features are selected as the input of the model.
In the end, we compared the proposed features with previous feature set. [14, 37] respectively chose spectrogram and reduced GeMAPS as the input of emotional recognition model. Therefore, we compare the effect of our proposed features with MFCC, spectrogram, and reduced GeMAPS respectively. Spectrogram is inputted into the CNN model proposed in [14], and other three features are inputted into the proposed Att_MF-LSTM. Results are shown in Fig. 14.
Comparison of the proposed features and previous feature sets for stressed speech classification.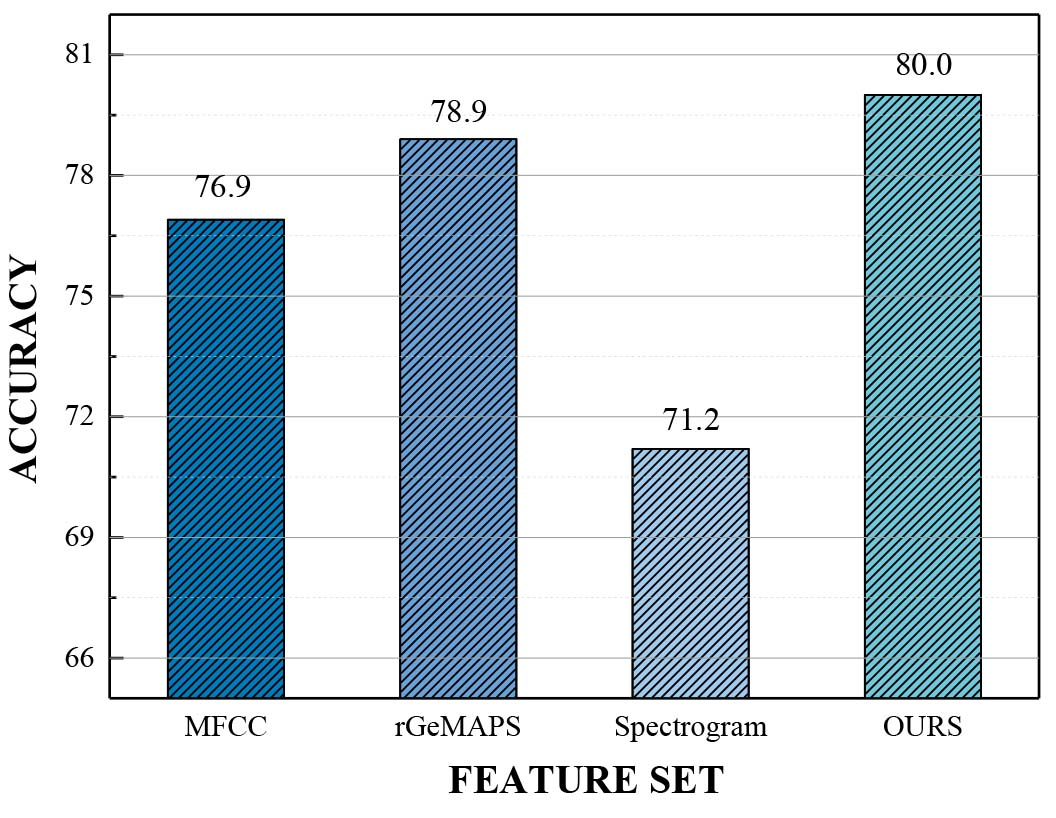
We found that the proposed feature is slightly better than rGeMAPS. The major difference between our feature and rGeMAPS is SSC, which further proves that SSC feature is benefit for cepstrum features. Moreover, MFCC as a sub feature of the proposed features have a satisfactory performance for classification.
In order to verify the generalization of the model to different corpus, we performed the experimental evaluation on CASIA corpus. The dichotomy of CASIA led to the imbalance of samples, that is, the stressed speech took up 87% of the data, which made it difficult to classify correctly neutral speech that only took up 13% in the corpus. In order to reduce the influence of unbalance sample, we replace the standard cross entropy loss function with focal loss function. The loss function is as follows [38]:
The main differences between focal loss function and standard cross loss entropy function are weighting factor
The focal loss functions with different weighting factor and modulating factor are applied to the proposed model for experimental comparison. The experimental results show that the best classification performance can be obtained when
Influence of modulating factor parameters
When
In next evaluation, features for MFCC, FBANK, and SSC were extracted from the speech data. Data augment was performed, four speakers’ speech feature is divided into the stressed and the neutral. We utilized 4-fold cross-validation method to train speaker-independent condition, the three sessions are used for training and one sessions used for testing in each fold. Parameter configuration of the proposed model is shown in Table 4. tanh activation function in traditional LSTM model was replaced by softsign activation function. softsign curve is smoother and derivative changes more slowly comparing with tanh, which can better solve the problem of gradient disappearance.
Att_MF-LSTM model configuration parameters
Next, we compared the effectiveness of the proposed framework with traditional models, including SVM, GMM, spectrogram
Configuration parameters for traditional models
Confusion matrix of models for speaker-independent stress classification on CASIA stressed speech corpus.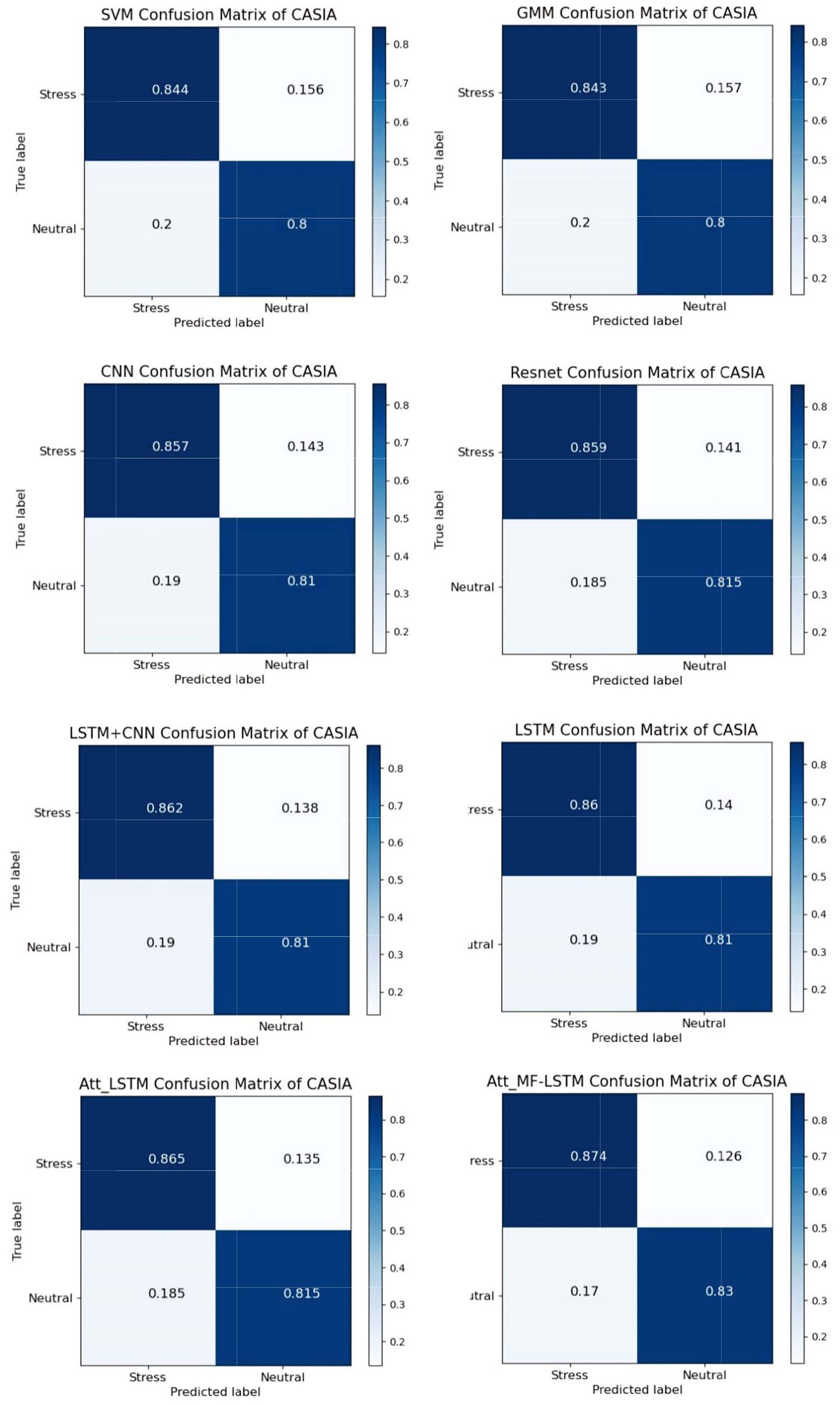
Performance of the speaker-independent stress classification on CASIA stressed corpus with demographic feature (%)
Figure 15 presents the class level accuracy of the proposed model and other traditional model in a confusion matrix which indicated the true label and predicted label. Similar to the proposed model, focal loss also effectively solved the problem of imbalanced samples in CNN, LSTM and other models. Figure 16 shows the classification accuracy of each model. The proposed model highly classify the stress and neutral speech with 86.7% and improves classification accuracy compared with the traditional model, hence the proposed model is qualified for CASIA corpus. Further, we found that attention mechanism contributed, but is not a major factor in improving performance by comparing the classification rate of LSTM and Att_LSTM. This is largely due to each example in CASIA corpus consisted of one simple sentence and only one emotion type. Each frame in a CASIA corpus example is consistent with the emotional label of example, hence the influence of each frame in the example for classification result is not close, which weakens the function of attention mechanism.
Performance of the speaker-independent stress classification on Fujitsu stressed corpus with demographic feature (%)
Comparison of Att_MF-LSTM model and other methods in CASIA, where Model 1 is SVM, Model 2 is GMM, Model 3 is CNN, Model 4 is Resnet, Model 5 is LSTM 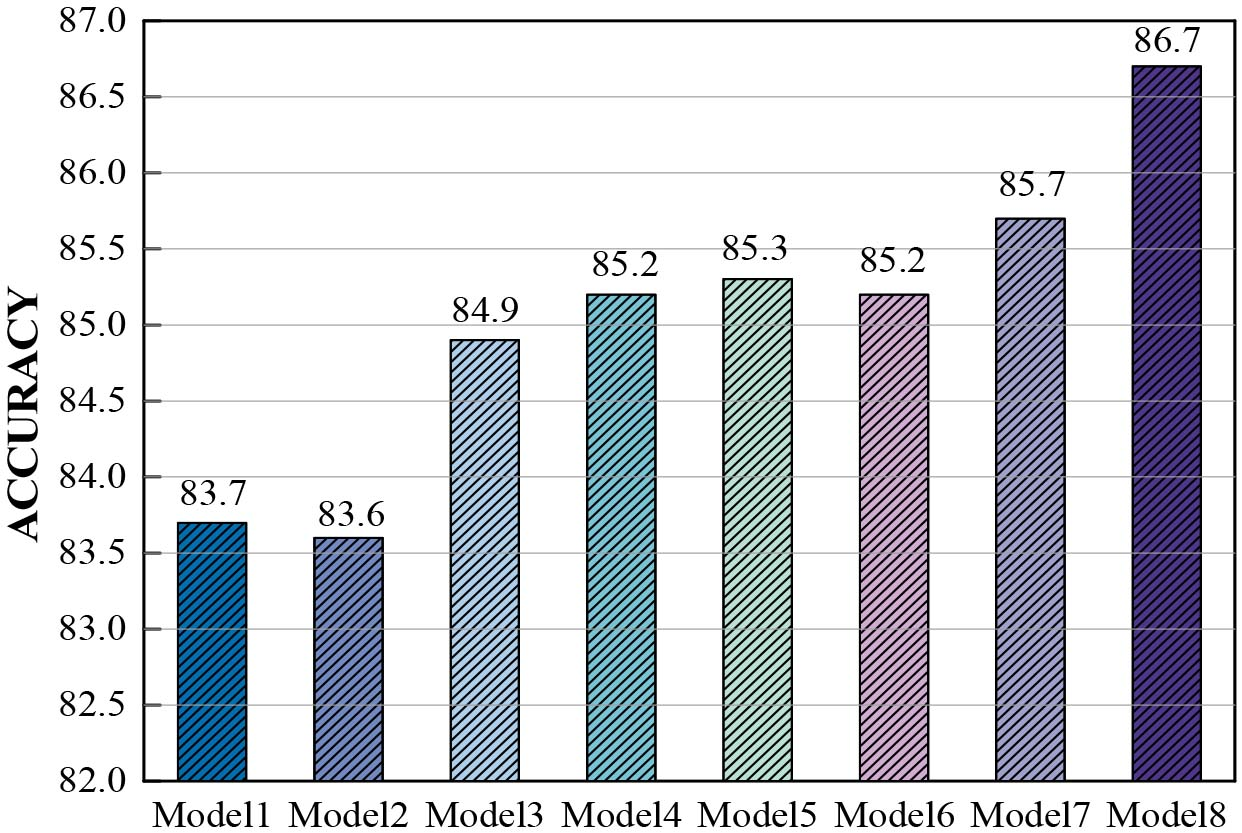
Confusion matrix of models for speaker-independent stress classification on Fujistu stressed speech corpus.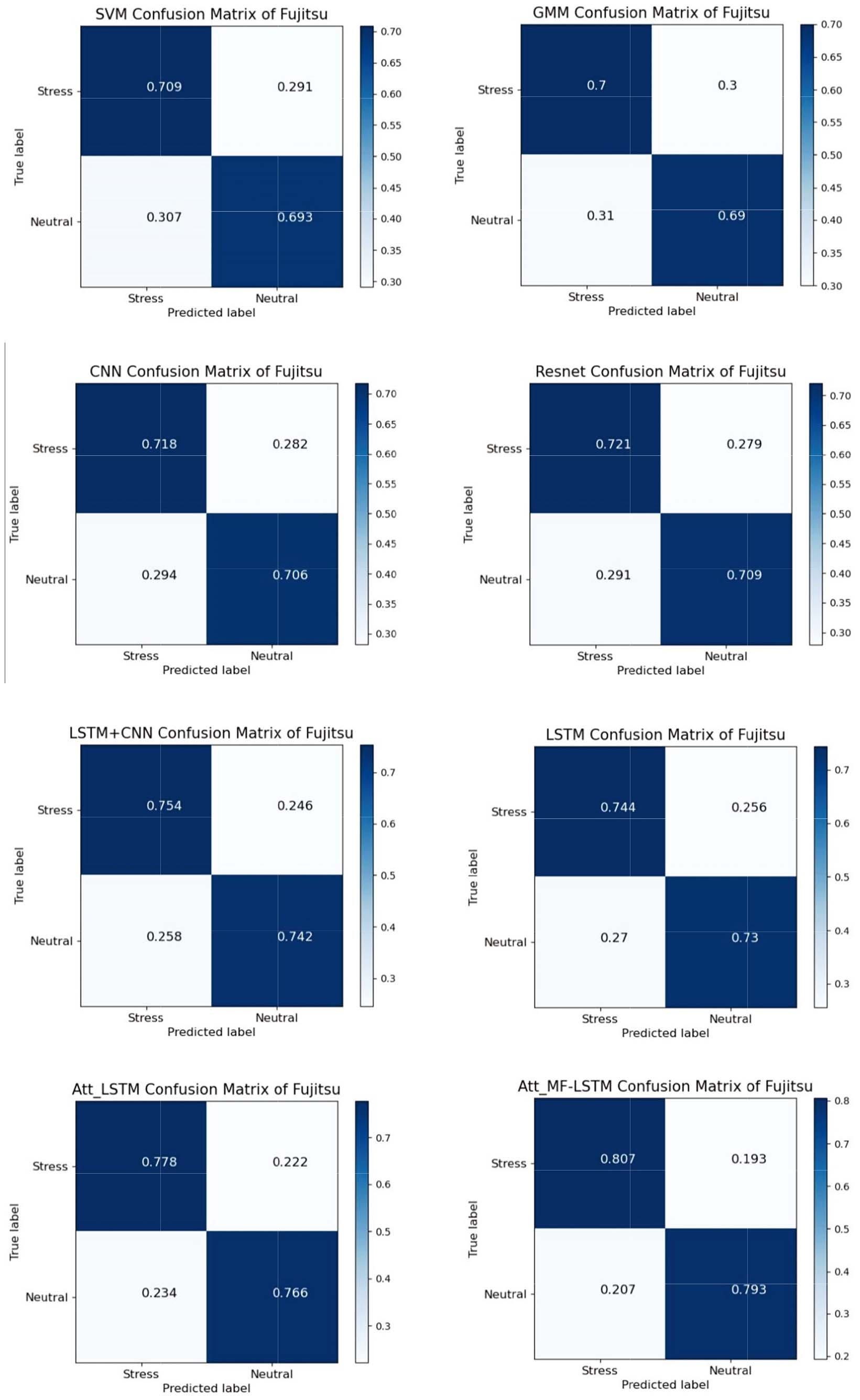
Comparison of Att_MF-LSTM model and other methods with the Fujistu stressed speech corpus, where Model 1 is SVM, Model 2 is GMM, Model 3 is CNN, Model 4 is Resnet, Model 5 is LSTM 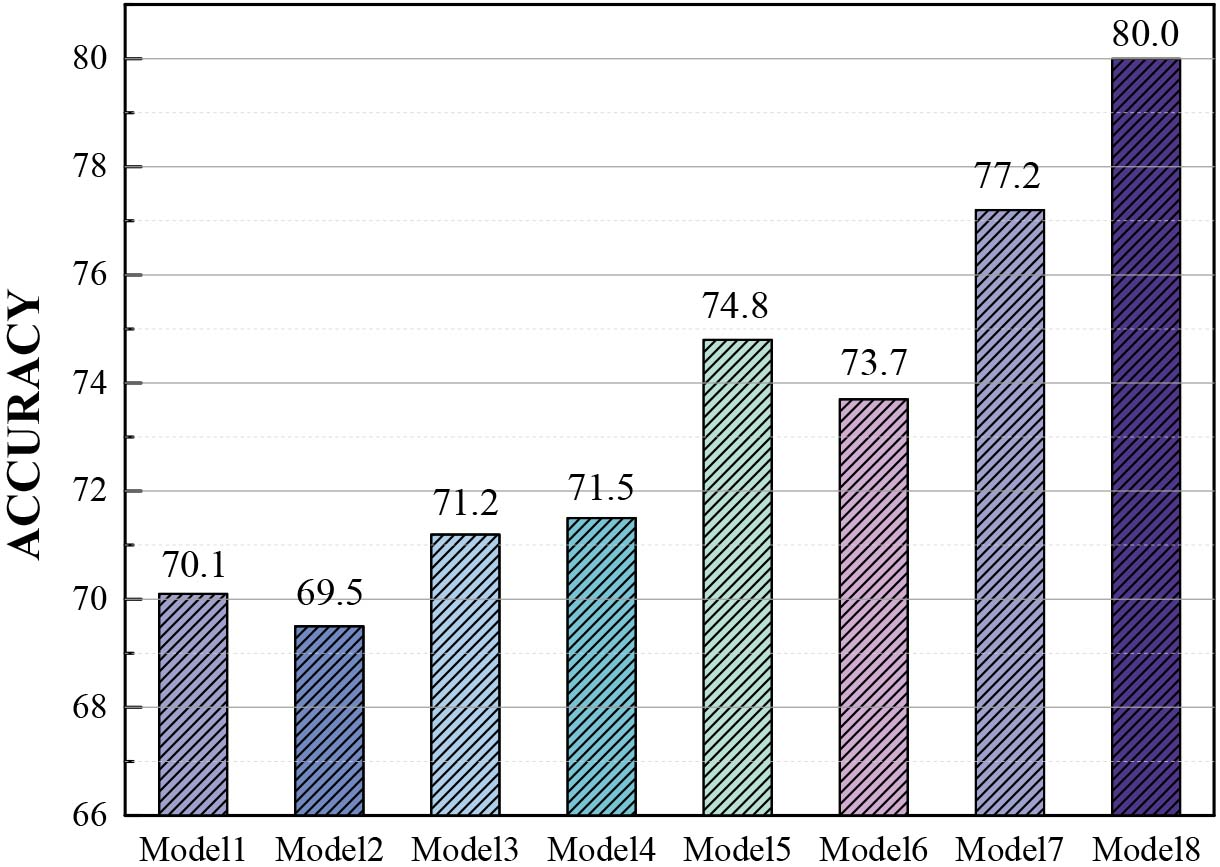
Evaluation under speaker-independent condition
Speaker-independent refers to classification of neutral and stressed speech without distinguishing speakers. In this evaluation, features for MFCC, FBANK, and SSC were extracted from the speech data. Data augment was performed, and different speakers’ speech features were mixed to form a speaker-independent data set. The standard cross entropy function was still utilized because of the balanced sample in this corpus.
Next, we still compared the effectiveness of the proposed framework with traditional models, including SVM, GMM, spectrogram
According to the experimental results, the proposed method Att_MF-LSTM is found to have an improvement in classification accuracy comparing with the other models. Through comparative experiments, the following conclusions may be achieved.
First, neural networks perform better compared with traditional machine learning algorithms SVM. The results show that the overfitting does not occur for SVM training without data augment, and the classification rate was almost the same before and after data augment. Moreover, it is found that GMM model has a similar phenomenon in the experiment. This indicates that traditional machine learning algorithms are prone to bottlenecking in classification, and data augment does not contribute higher classification rates. While neural networks can obviously learn more data, and a increase of data can improve the recognition rate.
Compared with the Spectrogram
In addition, results show the accuracy of the Att_LSTM model increases by 3.6% compared to LSTM
Attention mechanism proved more effective in Fujistu stressed speech corpus by comparing the classification accuracy of LSTM and Att_LSTM in Figs 16 and 18. This is largely due to each example in CASIA corpus consisted of one simple sentence and only one emotion type. All speech segments of each sample in CASIA are speech data under real emotional state. However, samples in Fujitsu stressed speech corpus are continuous speech. A continuous speech labeled as “stressed” includes not only the stressed segments under the brain load, but also some neutral segments. A continuous speech experiences these two different states alternately, which is closer to natural context. Since the state transition between neutral and stress state is instantaneous and ambiguous, it is difficulty to make a clear frame-level division. We believe from the experimental results that the effect of attention mechanism will be more obvious for the continuous stressed speech in the natural context. Learning importance of different frames is a preliminary solution to fuzzy representation of the stressed speech.
Furthermore, frame-level speech labels can not be achieved due to subjectivity involved in stress labeling, and the ambiguity of the label leads to a drop in classification rate in some extent. Therefore, we consider if objective evaluation is performed for frame-level labeling, the classification performance could be further improved.
Ablation studies
In order to verify the effectiveness of the selected parameters and the generalization of the model, we compared the effects of feature for different frame length and different model training optimizers on the classification accuracy. We perform experiments with the frame length of 20 ms, 35 ms, 30 ms and 32 ms respectively. Except for the frame length, other experimental conditions are the same as Att_MF-LSTM model conditions in 4.4.1, and the results are shown in Table 8.
Comparison of different length feature for stressed speech classification, where time represents the model training time
Comparison of different length feature for stressed speech classification, where time represents the model training time
The experimental results show that, the feature with frame length of 32 ms achieves a better performance for classification task from the perspective of accuracy and training time. Moreover, the influence of the frame length on the training time can be ignored. Furthermore, we compared various optimizers.
Comparison of different optimizer classification results, where time represents the model training time
The results reflected that Adam optimizer was the best choice from two aspects of accuracy and training time. Moreover, the Adam optimizer itself is quite robust to the selection of hyperparameters.
In the evaluation, speaker-dependent stress classification was performed on the proposed model. Considering that speakers have different physical and psychological characteristics, leading to difference in vocal properties as well as stress expression, we train the models for each speaker to perform classification. In traditional classification learning tasks, in order to ensure the accuracy and high reliability of the classification model, two basic assumptions exist: (1) The training samples and testing samples used for learning satisfy the conditions of independent identical distribution; (2) enough training samples are required to train the model. However, sufficient speaker-dependent samples are not available in the original database to obtain a reliable classification model. As results shown in Fig. 19, the classification rate for the training set is above 95%, but the average classification accuracy for testing is only 66.4%, which indicates that the generalization ability of model is not strong and cannot classify unknown data samples, resulting in overfitting.
Transfer learning was employed to solve the small samples of speaker-dependent stressed speech. In the experiment, the target speaker is selected, and samples from the remaining ten speakers were utilized for pre-training, after which model is transferred to the target speaker using fine-tuning. 4-fold cross-validation was also utilized to divide each speaker’s corpus into training corpus and test corpus, and we tested the each speaker’s classification accuracy of the model in test corpus. The experimental results for each speaker are shown in Fig. 19. Following transfer learning, the classification rate for testing set increases to 74.6%, which illustrates the generalization ability is improved. The problems of overfitting and small sample have been solved.
Experimental comparison before and after transfer learning, where F1 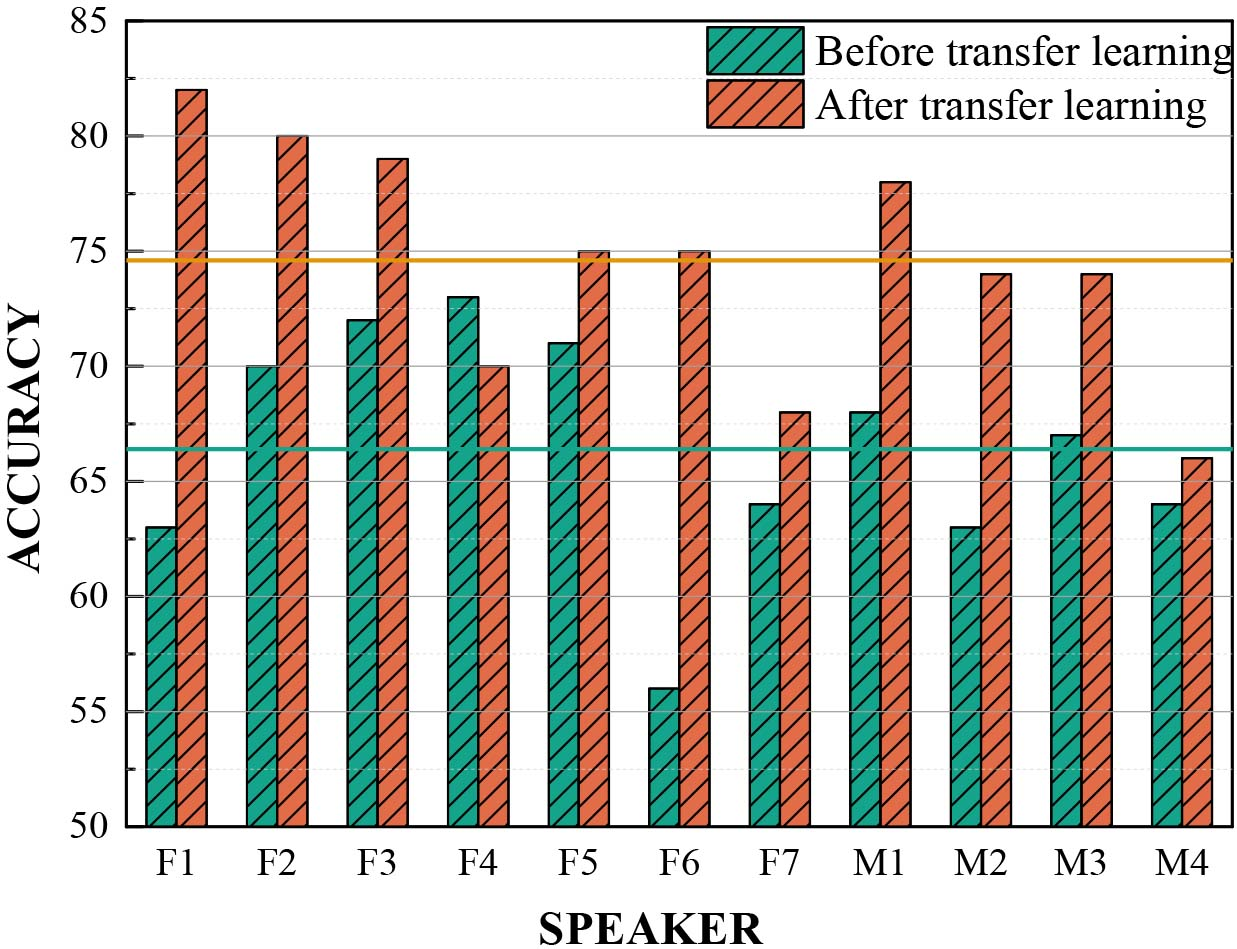
Speaker-dependent experiments reflected the different degrees of phonetic variation among different speakers under multitasking workloads. Results demonstrated that the stress classification rates of different speakers were varied, which proved that speakers had different expressions of stress due to their physiological and psychological states. In the figure, F represents female while M for male. It was found that following transfer learning, the average classification rate of women is 75.6% while 73.1% for men, which indicate that the speakers of different gender can differ at expressing depressed pressure.
Furthermore, results show there is no direct relationship between duration of stressed speech and classification rate. However, the generalization ability of the pre-trained model behaves a linear relationship with the number of speech pre-trained sample. The model will be more generalized if the pre-trained samples are sufficient. Therefore, even in case of a single speaker with a small number of data samples, satisfactory effects in classification are achieved through transfer learning, and the training time is shortened.
In this study, we consider the importance differences of speech frames for stress classification, and a multi-feature fusion framework based on the attention mechanism is proposed. LSTM hidden node information and multi-feature fusion is utilized to improve attention mechanism. Compared to the traditional model, the speaker-independent stress classification rate is improved by 5.2%. During the speaker-dependent experiments, the proposed method is not as effective for classification because of small sample problem, resulting in overfitting for model. The proposed model combined with transfer learning is verified to have a better performance in generalization and problem of small sample size is solved. Future works will further discuss the fuzzy representation of stressed speech under workload and enhance the generalization and robustness of stressed speech recognition.
Footnotes
Acknowledgments
This work is supported by the Fundamental Research Funds for the Central Universities B200202205, National key research and development program 2018AAA0100800, the Key Research and Development Program of Jiangsu under grants BK20192004, BE2018004-04, BE2017071, and BE2017647, National Nature Science Foundation of China under grants (61501170, 41876097 61401148), the Open Research Fund of State Key Laboratory of Bioelectronics, Southeast University under grant 2019005, and the State Key Laboratory of Integrated Management of Pest Insects and Rodents under grant IPM1914.