
Abstract
Recently, rapid growth of social networks and online news resources from Internet have made text stream clustering become an insufficient application in multiple domains (e.g.: text retrieval diversification, social event detection, text summarization, etc.) Different from traditional static text clustering approach, text stream clustering task has specific key challenges related to the rapid change of topics/clusters and high-velocity of coming streaming document batches. Recent well-known model-based text stream clustering models, such as: DTM, DCT, MStream, etc. are considered as word-independent evaluation approach which means largely ignoring the relations between words while sampling clusters/topics. It definitely leads to the decrease of overall model accuracy performance, especially for short-length text documents such as comments, microblogs, etc. in social networks. To tackle these existing problems, in this paper we propose a novel approach of graph-of-words (GOWs) based text stream clustering, called GOW-Stream. The application of common GOWs which are generated from each document batch while sampling clusters/topics can support to overcome the word-independent evaluation challenge. Our proposed GOW-Stream is promising to significantly achieve better text stream clustering performance than recent state-of-the-art baselines. Extensive experiments on multiple benchmark real-world datasets demonstrate the effectiveness of our proposed model in both accuracy and time-consuming performances.

Introduction
Clustering is one of common primitive tasks in text mining area [1, 2, 3]. Text clustering have been found to be useful for numerous real-world applications such as improving the information retrieval [2], text summarization [4], search result diversification, sampling text documents in latent topic space, etc. In short, text clustering is a process of partitioning/grouping a set of unlabeled documents into specific
From the past, most of studies in text clustering are majorly concentrated on the long-length static text corpora. In fact, designed models for this traditional clustering approach is unable to be applied for rapid changeable text corpora with short-length text documents such as comments/posts/microblogs in social networks, such as: Twitters, Facebook, etc. Clustering rapid and short-length text documents is considered as more difficult than traditional static text clustering approach due to three main properties, including diverse document’s length (very short with only few words or very long), sparsity of text data representation and fast change/evaluation of existing clusters/topics in different text document batches (sequentially coming from the text streams). Moreover, in the case of a rapidly coming textual data of streams from social media resources traditional text clustering techniques are considered as not either not applicable to handle such high-velocity temporal as well as natural sparse of short-length text collections.
Recently, many researchers have paid a lot of attention on studies related text stream clustering in order to achieve better performance in both terms of clustering output accuracy and model’s time-effectiveness. Topic modeling is one of the most common approach for handling text stream clustering task. Topic modelling based models are designed depending on an assumption that text documents are generated by a mixture model. Then, by estimating model’s parameters via multiple techniques, such as Gibbs Sampling (GS), Sequential Monte Carlo (SMC), etc. the distributions of topics/clusters of give text corpus can be achieved. Inspired from the original Latent Dirichlet Allocation (LDA) [5] model, several extensions have been proposed to tackle text stream topic modelling tasks, such as well-known models: DTM [6], TM-LDA [7], ST-LDA [8], DCT [9], MStream/MStreamF [10], etc. These mixture model-based techniques try to infer the topic distributions over documents in given text steam to fulfill the clustering task. However, LDA-based models like as DTM, TM-LDA, ST-LDA, etc. are considered as not applicable for handling short-length text documents. Due to the original drawback of LDA-based technique, the topic-document mixture model must have a reasonable number of common words from each document to infer high-quality topics. Therefore, these LDA-based models can only achieve good performance with rich enough contextual long-length text stream documents. Recently, the DCT and MStream/MStreamF models are proposed to overcome the challenge of short-length text stream clustering, however, these models still encounter the limitation of largely ignoring word’s relations while inferring the topics/clusters distributions of given documents.
Problem definitions
There are two key problems of text stream clustering which has been investigated by researchers in the past. The first key challenge is related to short-length document in given text streams, especially occurring within topic modelling based approach. The second key challenge in text stream clustering is the lack of word’s dependency evaluation while inferring the topic/cluster distributions over text documents.
Shortage in short-text stream clustering
A major mechanism of inferring cluster/topic by using topic modelling/mixture model approach in text stream clustering is mostly relied on the content (distributed words) of documents. The content of documents in streams must be rich enough (have a reasonable number of occurring words) in order to properly infer topic’s multinomial distributions on each document. Therefore, with the low quantity of occurring words in documents, the overall model accuracy will be significantly decreased. Recent researches demonstrates that most of topic modelling/mixture model based text stream clustering techniques cannot achieve good performance on short-length text documents, with only few words like as comments or microblogs on social networks. In fact, one of the major difficulty in clustering streaming data is the rapid changes of topics/clusters over the time, such as hot trends or frequent discussing topics on common social networks. Therefore, topic/cluster distributions of the text streams are considered as dynamic overtime, or also known as “concept drift”. Multiple short-length text documents within each streaming batch might cover different topics and sparse nature in their raw structures. Within topic modeling based approach, properly choosing the number of clusters for each document batch from a given stream with the diversity of textual structure and covered topics is not an easy task. Moreover, applying fixed number of clusters/topics like as previous topic modelling approach for all document batches in a given text stream is considered as inflexible and unable to deal with concept drift problem. Hence, identifying the changes on the topic distribution of over very short-length text documents like as comments (Facebook), tweets (Twitter), etc. are extremely challenging task which has attracted a lot of attentions from many researchers in recent years.
Lack of word dependency evaluation
Beside challenges related to concept drift problem in short-length text stream clustering, word dependency is also considered as a major drawback of recent text stream clustering approaches. In most of model-based text stream clustering techniques, document’s words are separately evaluated with considering their occurring orders and relationships within specific textual contexts. It is needless to say that a text document is a complex natural human-based structure. Depending on language usage, words in each document are organized strictly following a specific systematic structure. Therefore, different words’ orders or combinations (relationships between words) might carry out different semantic meanings which definitely influence to the covered topics of documents which they are occurred. A common assumption of model-based text stream clustering techniques is that group of documents which share the same sets of common words will tend to choose the same topics/clusters, it is also known as traditional bag-of-words (BOW) representation. The major drawback of BOW representation is the largely ignoring of word’s orders (e.g.: “the lazy fox jumps over the brown dog” is totally different “the brown dog jumps over the lazy fox”, etc.) and relationships (like as combined words: “United States”, “corona virus”, etc.). Therefore, sampling common words distribution over documents during the topic/cluster inferring process without considering the occurrence orders of words might lead to the downgrade of clustering accuracy output. It should be better to extend the word dependency evaluation within different document’s contexts during the process of inferring clusters in order to improve the quality of text stream clustering output.
Our contributions
To meet existing challenges, in this paper we propose a novel approach of mixture model-based text stream clustering which utilize the occurring graph-of-words (GOW) evaluation in given text corpus, which is inspired from our previous works [11], called GOW-Stream. The GOW-Stream is designed to leverage both accuracy and time-consuming performances for text stream clustering tasks by thorough evaluation on words’ relationships while inferring clusters. The overall contributions of our works in this paper can be summarized as three main points, which are:
We proposed an approach of applying n-gram text-to-graph (text2graph) transformation with frequent sub-graph mining (FSM) technique for extracting common GOWs from the given text corpus. Then, the occurrences of common GOWs in each text document are used to support the process of estimating the distributions of topics/clusters over documents. Next, we formally define the mechanism of GOW-Stream which is a mixture model-based for effectively handling short-text stream clustering task by combining both word independent (separated words in each document) and dependent (co-occurred words in common GOWs) evaluations. GOW-Stream is not only applicable for tackle challenges related to natural concept drift of text stream but also better accuracy and time-consuming performances in comparing with previous word-independent evaluation based models. Extensive experiments on real-world standard datasets demonstrates the efficiency and effectiveness of our proposed GOW-Stream model for short-text steam clustering task in comparing with recent state-of-the-art algorithms, such as: DTM [6], Sumblr [4] and MStream [10].
In general, the rest of the paper is structured in 5 main parts. In the second part, we generally present literature reviews on recent studies of common trends of text stream clustering. In this second part, we also discuss about pros/cons of recent proposed text streaming models which are played as main motivations for our contributions in this paper. Next, in the third part, we formally describe the methodology of our proposed GOW-Stream model with details of concepts and implementations. In the fourth part, we present empirical studies on the performance of the proposed GOW-Stream model in comparing with recent well-known text stream clustering baselines with two benchmark labelled datasets. Furthermore, in this part, we also demonstrate extensive experimental studies on model’s hyper-parameter sensitivity and time-consuming performance of our proposed model. Finally, in the last part, we give the conclusion for our works as well as highlight some possible directions for future improvement.
Recent studies of textual data stream clustering can be categorized as three main categories, which are topic modelling, dynamic mixture model-based and similarity based approaches.
Traditonal topic modelling based approach
Considering as the earliest approach for textual data stream clustering, topic modelling is a family of algorithms which support to discover latent topics/thematic structure from given text documents. Latent Dirichlet Allocation (LDA) [5] is one of the most well-known topic modelling algorithm which support to infer latent topics from a set of text documents which are biased probability distributions over words. LDA represents latent discovered topics as subsets of distributed words and documents as subsets of distributed latent topics. Researches have demonstrated that topic modelling can be applied to effectively model temporal nature of topics/clusters in textual data streams as well as dealing with the sparsity of documents. Many LDA-based extensions have been introduced to cope with the dynamic nature of topics/clusters in different batches of text streams, such as topic over time (TOT) [12], dynamic topic model (DTM) [6], topic tracking model (TTM) [13], temporal LDA (TM-LDA) [7], streaming LDA (ST-LDA) [8], etc. These proposed models can support to effectively infer dynamic topics from given long-length document in streams. However, these LDA-based models need to initially identify a fixed number of topics/clusters for all different document batches in a stream which is considered as unable to deal with the changeability of topics/clusters over time.
Dynamic mixture model-based approach
Since the number of topics/clusters are varied with time and different document batches in streams, fixed number of topics is considered as major limitation for applying LDA-based techniques in dealing with natural topic evolution problem of text streams. To overcome this drawback, continuous improvements related to dynamic topic modelling approach have been proposed. This approach is also called as Dirichlet Process (DP) [14] method which is widely used for handling topic evolution problem in text stream clustering. Mostly inspired from LDA-based models, mixture model-based text stream clustering algorithms are designed to infer distributions of topics/clusters over documents which are considered as a generated mixture model. Then, multiple sampling techniques such as Gibbs Sampling, Sequential Monte Carlo, etc. are applied estimate model’s parameters, so as to achieve the distributions of topics/clusters over a given text stream. In other words, dynamic mixture model-based text clustering techniques mostly rely on Bayesian non-parametric theorem for dynamic topic modeling. Dynamic mixture model-based approach has demonstrated its effectiveness in automatic topics/clusters discovering from sparse text streams. Recent well-known models in this approach such as: Dirichlet-Hawkes Topic Model (DHTM) [15], Dynamic Clustering Topic Model (DCT) [9] and Temporal Dirichlet Process Mixture Model (TDPM) [16]. These Dirichlet process based baselines have shown potential solutions for tackling concept/topic drift problem of text streams. However, these proposed models still have existing drawbacks. The DHTM is considered as incapable to work well on short-length text documents. In contrast, DCT is designed to work with short-length text streams, however, DCT cannot investigate the evolution of topics/clusters in different document batches of text streams where the number of topics/cluster might be changed overtime. Hence, it fails to deal with the concept drift challenge. For the TDPM, it is considered as an offline text clustering framework which requires the whole set of text documents from a given stream. Therefore, TDPM is unsuitable to be applied in the context of high-velocity in-coming text clustering task. Recently, there is a novel upgrade of short-length text stream clustering depending on Dirichlet Process Multinomial Mixture Model (DPMM) [17], called MStream/MStreamF which enable to effectively predicting latent topics/clusters from given short-length text streams. However, MStreamF also still encountered a common shortage of exploiting independent word representation while inferring topics/clusters. The sparsity and word dependency ignore might lead to the cause ambiguity of discovered topics/clusters from given text streams.
Vector space representation based approach
Similar to the classical text clustering approach for static text corpora, give text documents in streams are transformed and represented as feature vectors, then out-of-the-shelf distance-based metrics such as cosine similarity, Euclidean distance, etc. are applied to measure the similarity between text documents and given topics/clusters. From the past, vector space representation (VSR) based approach has been widely studied for handling high-velocity text stream clustering task with well-known similarity-based text stream clustering models, such as: CluStream [18], DenStream [19], Sumblr [4], etc. However, these VSR-based text clustering techniques have two major drawbacks. The first drawback is related to concept/topic drift challenge which number of topics/clusters should be specified first. The second drawback of VSR-based models is related to initial threshold of document-topic/cluster similarity which means we must manually select a proper similarity threshold in order to identify a new text document from a given stream should belong to a specific topic/cluster or not. Moreover, the quality of document represented vectors also be influenced by the document’s length. Due to the existence of these severe challenges, the VSR-based approach is less attractive than mixture model-based approach in handling text stream clustering task.
Methodology
In this part, we formally present mixture model based approach which leverage the word’s dependency evaluation by applying common graph-of-words (GOW) distributions over documents in a given text stream, called GOW-Stream. Our proposed GOW-Stream is an Dirichlet Process Multinomial Mixture (DPMM) based text stream clustering method which can significantly improve the quality of clustering short-length sparse text streams. At first, we briefly introduce an approach of extracting common graph-of-words (GOW) from text documents by applying text2graph transformation and frequent sub-graph mining (FSM) technique. Then, we present a novel topics/clusters inference technique mostly inspired from previous MStream/MStreamF model, as the multinomial distributions of documents which are represented as distribution of occurred words and common GOWs. Thereby, both independent word and common GOWs in each document of a given text stream are well considered in the process of topic/cluster generation.
Preliminaries and background concepts
In this section, we briefly introduce preliminary concepts which our proposed GOW-Stream model in this paper are inherited from.
Graph-of-words (GOW) representation
Text2graph transformation. GOW-based text document representation is a well-known NLP approach which aims to transform a text document (
Frequent common subgraphs (FCS) as the unsupervised document’s features. Then, with a set of constructed textual graphs (
Where,
Illustrations of text document to graph-based structure transformation (text2graph).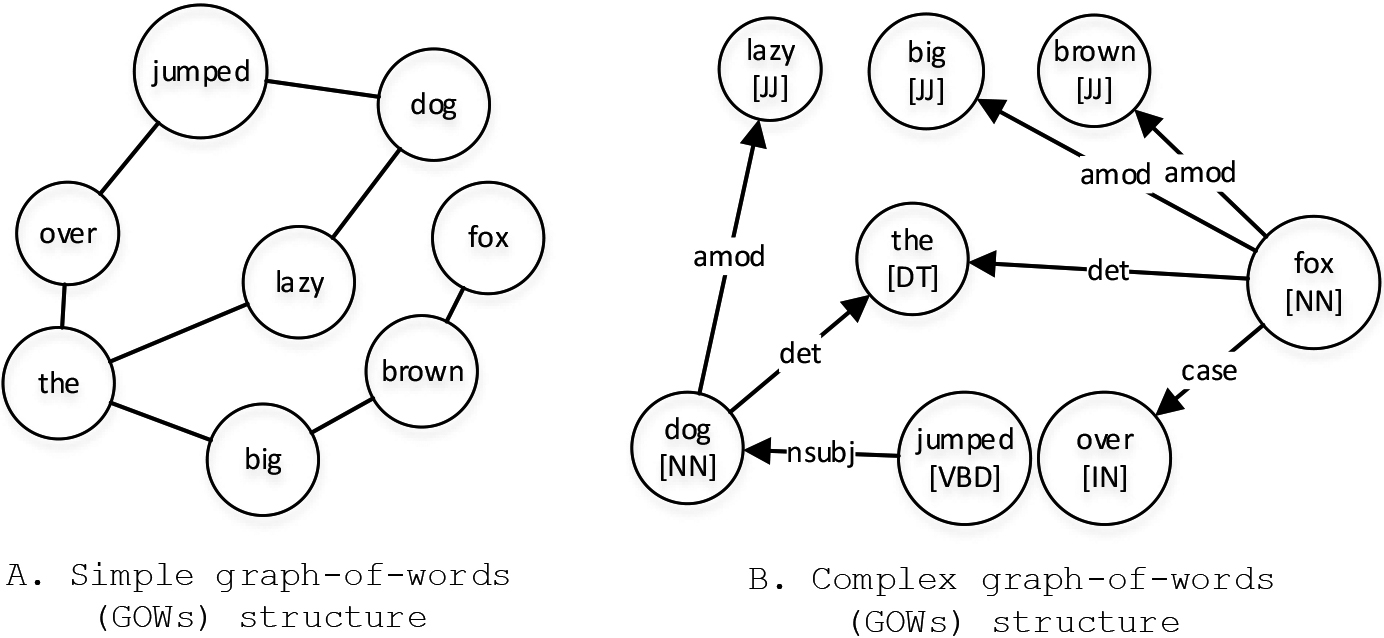
For each common GOWs
Mixture model-based text stream clustering. In general, text stream clustering is totally different from classical static text clustering approach. In context of continuous coming of different-length text documents over the time. For common text stream data, such as comments, microblogs, etc. from social networks, the number of documents, document’s length and covered clusters/topics might be diverse and rapidly changeable at different time (
Dirichlet Process [14] & Poly-Urn schema. Commonly applied in multiple mixture model-based text stream approach, the Dirichlet Process (DP) is considered as non-parametric processes for modelling data. It supports to draw a sample
Where,
Repeating the
Where,
From the given Eq. (3.1.2), the Bayesian assumption is that, the generation of words (
Generative process of our proposed GOW-Stream model.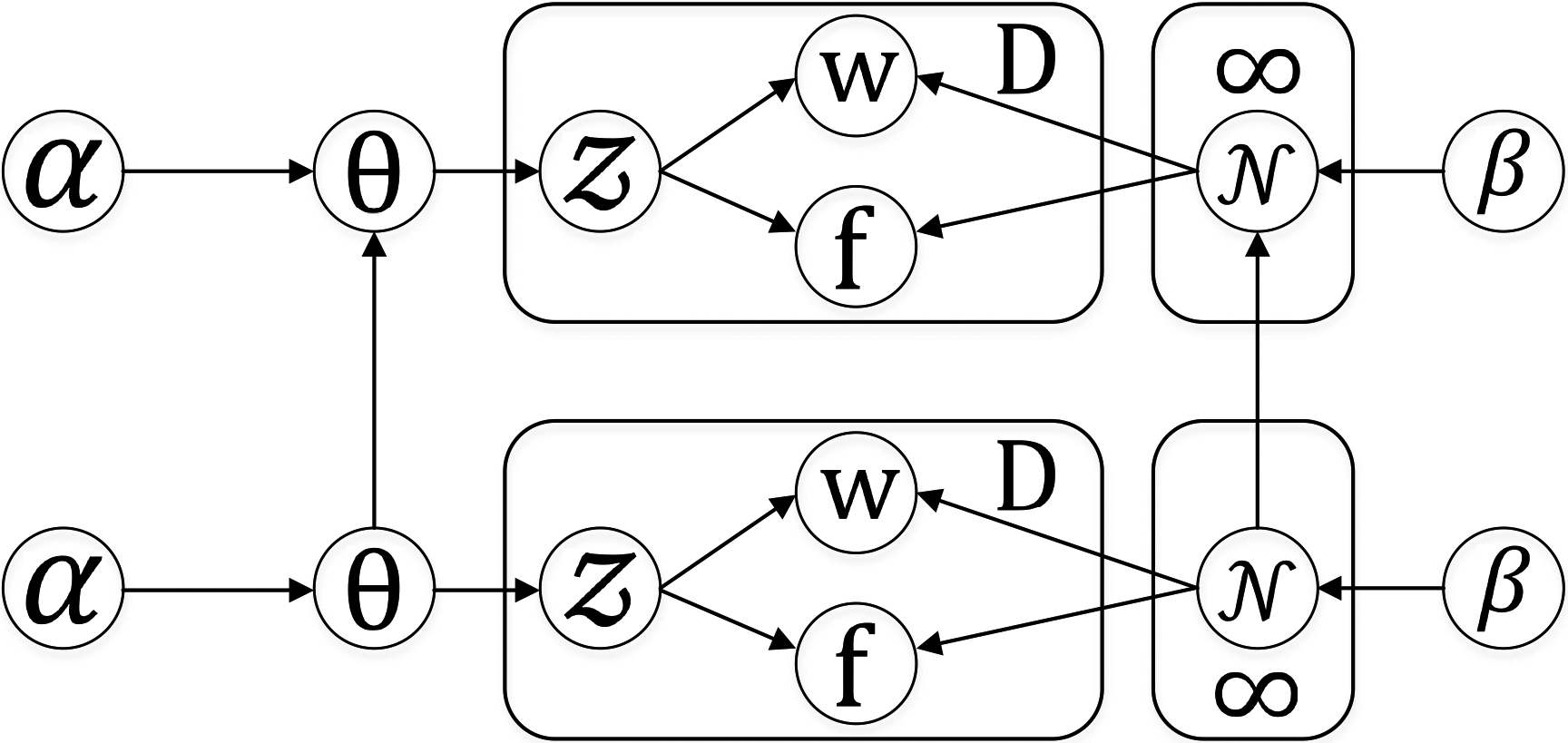
In this section, we formally present our main contributions in this paper by an effective text stream clustering techniques which leverage the quality of identified topics/clusters in given text stream by utilizing extracted common GOWs distributions over documents. Our proposed GOW-Stream is an DPMM based model which inspired from previous works of MStream/MStreams model.
GOW-based cluster/topic representation
Different from traditional approach of static text corpus clustering, the clusters are represented as means of document sets in the given vector spaces. In recent approach of mixture model, the clusters are represented as cluster’s feature vectors, or simply cluster vectors. A cluster vector is formed as a tuple, denoted as:
Where,
Similar to previous approach of MStream/MStreams model, this cluster vector representation also has important properties, including: addible and removable. The addible and removable properties of our proposed GOW-Stream model are described as the following (as shown in Eq. (5a) and (5b)):
Where,
The most important part of mixture model-based text stream clustering algorithm is the definition of relationships between documents and the decomposed topics/clusters. It means the probability of a new document might be assigned to a specific topic/cluster. The traditional approach of similarity-based text clustering mainly utilizes the similarity threshold to control the process of topic/cluster assignment for each text document in a given stream. However, selecting a proper similarity threshold is considered as a challenging task due to the concept/topic drift and variety in document’s length of real-world text streams. Inspired from previous works, we apply a dynamic cluster inferring technique which is majorly based on DPMM to achieve the probability of a document (
Where,
Adding a document to an existing topic/cluster. As given in the Eq. (6), the first part of this equation:
Where,
For the second part of Eq. (6):
Where,
Adding a document to a new topic/cluster. In previous part, we have defined a probability case that a new document chose an existing cluster. Then, in case that a new document isn’t matched to any existing topic/cluster, we will need to create a new cluster for it by defining the probability for a document to create a new topic/cluster. For DPMM based dynamic topic/cluster inference approach in case that the quantity of clusters is infinite, the transformation of
Where,
In fact, our proposed GOW-Stream model is a combination of word and common GOWs distributions in topic/cluster inference for text streams via DPMM based approach. By integrating with the distributions of common GOWs within documents, the GOW-Stream model is aimed to capture richer semantic meanings of discovered clusters by utilizing the word co-occurring relationships in text documents. It not only helps to leverage the clustering output accuracy but also eliminate the ambiguity in discovered clusters. The overall procedure of our proposed GOW-Stream is described in Algorithm 2.
At the first stage, the input document sets will be evaluated to extract common GOWs, denoted as:
In this section, we demonstrate extensive experiments on real-world datasets to evaluate the performance of our proposed GOW-Stream model in comparing with recent state-of-the-art mixture model-based text stream clustering baselines, including: DTM, Sumblr and MStream.
Dataset and evaluation metric usage
Dataset descriptions
In order to fairly evaluating the performance of different text stream clustering models including our proposed GOW-stream, we use two main real-world labelled datasets which are commonly used for most of empirical studies in previous works. These two datasets are:
Google News:
Tweets (TREC) dataset:
Similar to previous works, we apply a simple text preprocessing process including: transforming all text to lower case, removing all stop-words and word’s stemming. These two datasets are mainly used in our experiments are also considered as short-length and sparse due to the low average number of words in each document as well as the large amount of covered topics (as shown from the statistics in Table 1).
Details of the experimental datasets
In overall, the Tw/Tw-T dataset is considered as more challenging than GN/GN-T due to large number of covered labelled topics for text documents in this dataset.
To evaluate the accuracy performance of text clustering task with different text stream clustering algorithms, we use three main evaluation metrics which are NMI and F1 measure. These evaluation metrics are used in our experiment as following:
Normalized Mutual Information (NMI). This is the most common evaluation metric which is widely used to evaluate the quality of clustering output with the given ground truth. The NMI is considered as the strictest metric for evaluating the performance of clustering task within the range [0, 1]. In case that the clustering outputs are totally matched with the given ground truth/labelled classes, the NMI value will be [1], whereas its value will be close to [0] when the clustering outputs are randomly generated. The NMI metric is formally defined as the following (see Eq. (10a)):
Where,
F1 measure. This is a well-known metric for both clustering and classification tasks. The F1 metric considers both precision (
Where,
To compare the performance of our proposed GOW-Stream model, three main state-of-the-art text stream clustering baselines are implemented in our experiments, which are: DTM [6], Sumblr [4] and MStream [10]. The configurations for these text stream clustering models briefly described as the following:
For the initial configurations of each model, we apply different settings which are corresponding with the default setups of each model to achieve highest accuracy performance from the original works. The details of configurations for each text stream clustering model with different used datasets are described in the Table 2. For the DTM and Sumblr models, the initial number of topics/clusters must be specified first, with different datasets, we applied different numbers of clusters/topics, respectively. In order to come with these model’s hyper-parameter configurations (in Table 2), we have conducted extensive studies related to the fluctuations of model’s hyper-parameters w.r.t overall model’s accuracy performance in Section 4.3.3.
Details of configurations for text stream clustering models
For each text streaming model, the number of iterations for each arrival document batch is all configured as 10. In overall, the given datasets are divided into different 16 document batches, then each batch clustering output is evaluated by using above listed metrics (in Section 4.1.2). For experiments in each document batch, we run 10 independent trials for each model and reported the average results.
Text stream clustering task
Of-the-art text stream clustering baselines, including: DTM, Sumblr and MStream in two standard Google News and Twitter datasets. For each model, we conducted experiments of text clustering task with both two datasets 10 times and reported the average results with standard deviations in terms of NMI and F1 metrics. Tables 3 and 4 shows experimental outputs for text stream clustering task with different models in terms of NMI and F1 metrics, respectively.
Average outputs of text clustering task with different models in terms of NMI metric
Average outputs of text clustering task with different models in terms of NMI metric
Experimental outputs of text clustering task with different models in terms of F1 metric
Experimental results for different number of document batches in terms of NMI metric.
Experimental results for different number of document batches in terms of F1 metric.
In this experiment, we compare the performance of our proposed GOW-Stream model with different state-
In general, through experimental outputs which are demonstrated in Tables 3 and 4, our proposed GOW-Stream always achieves better accuracy performance than recent text stream clustering models with all given datasets. The GOW-Stream model gains the highest performance in Google News (GN and synthetic GN) dataset with averagely 91.25% and 96.03% in term of NMI and F1 metrics, respectively. For the Tweets dataset which is considered as more challenging than GN dataset, the GOW-Stream model also stably achieves a reasonable accuracy performance with 88.96% and 96.15% in terms of NMI and F1 metrics. In comparing with recent text stream clustering task, the GOW-Stream significantly outperforms Sumblr and DTM models about 60.12% and 30.26% in terms of NMI metric, respectively. Experimental results also show that GOW-Stream slightly gets better performance than the recent well-known mixture model-based MStream model about 2.68% in terms of NMI metric.
Further evaluations (as shown in Figs 3 and 4) on the accuracy performance with separated document batch of each text stream clustering model demonstrates that both MStream and GOW-Stream produce better and more stable text stream clustering outputs than previous DTM and Sumblr models. Moreover, the evaluations with F1 metric on text stream task with different models in Table 4 also indicate that the mixture model-based approach of MStream and GOW-Stream is considered as more flexible and stable with different length of documents in compare with classical approach of topic modelling and similarity-based. To sum up, through experiments, our proposed GOW-Stream demonstrates the effectiveness and outperformance in text stream clustering task in compare with recent baselines which prove that the use of GOWs distribution in text documents can help to leverage the accuracy performance of short-length text stream clustering task.
Model’s speedup performance. In this part, we try to evaluate the scalability of our proposed GOW-Stream model with other text stream clustering models. We implemented and run GOW-Stream, MStream, Sumblr and DTM in a same CentOS 6.5 computer with Intel Xeon CPU E5-2620 v4 2.10 GHz (8 cores – 16 threads) CPU and 64 Gb memory. All models are configured with 10 iterations for each document batch, with 16 batches for two GN and Tw datasets. Each model has been run 5 times and reported the average execution times (in seconds) as the final result. Figure 5 shows the speed of different text stream clustering model within Tw (Fig. 5A) and GN (Fig. 5B) datasets. As shown from experimental outputs, both MStream and GOW-Stream significantly faster than traditional approaches of Sumblr and DTM. Specifically, GOW-Stream faster than DTM approximately 20.08 and 7.29 times in compare with DTM and Sumblr for both GN and Tw datasets, respectively. With MStream model, GOW-Stream also slightly improves about 2.8 times of model speedup. Experiments on model’s scalability demonstrates that the combination between independent words and common GOWs evaluation while inferring topics/clusters from given text streams can help to fasten the model’s coverage process.
Scalability performance of different text stream clustering techniques.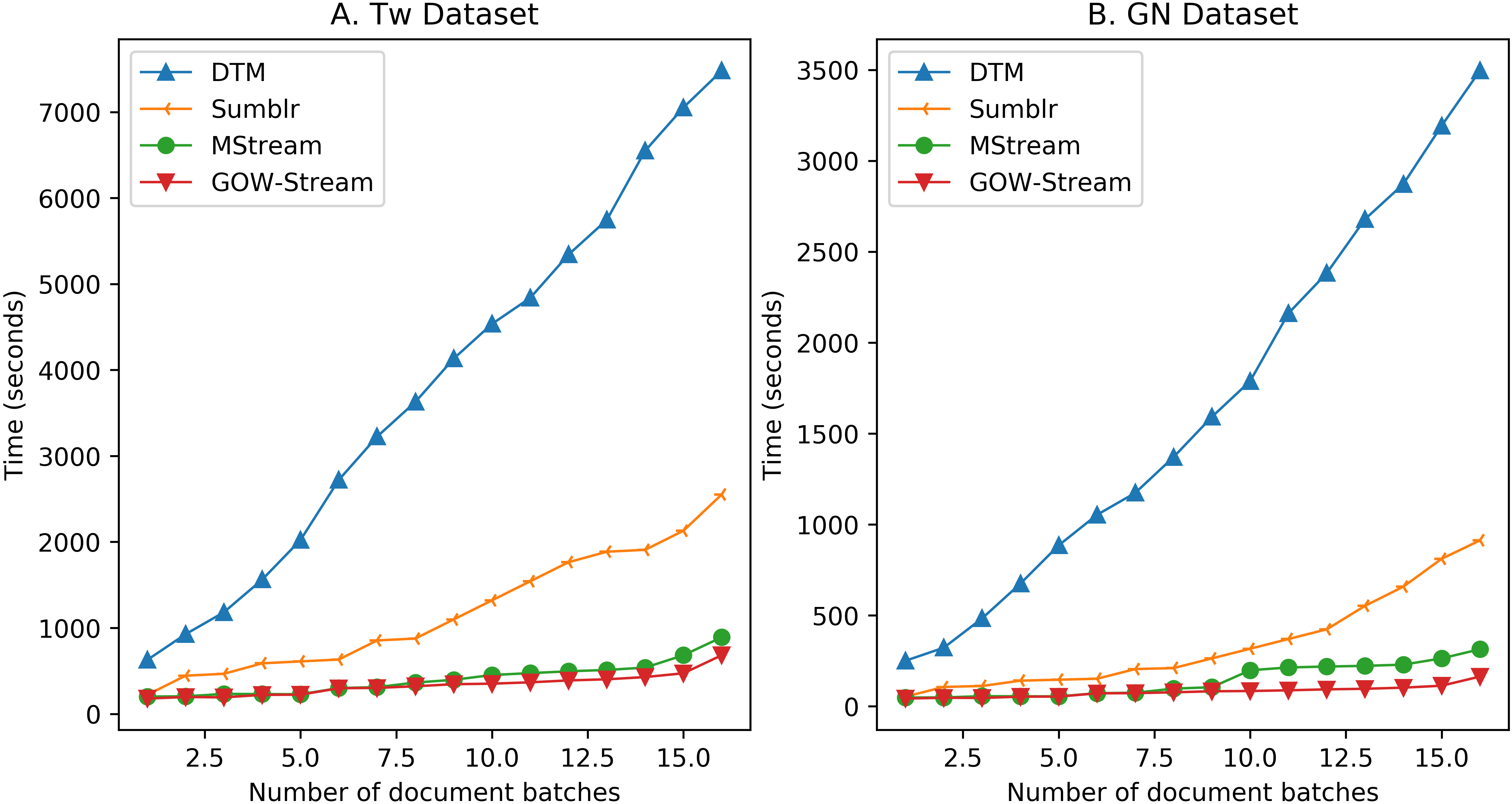
Evaluation on the influence of number of iterations on the accuracy performance of GOW-Stream model.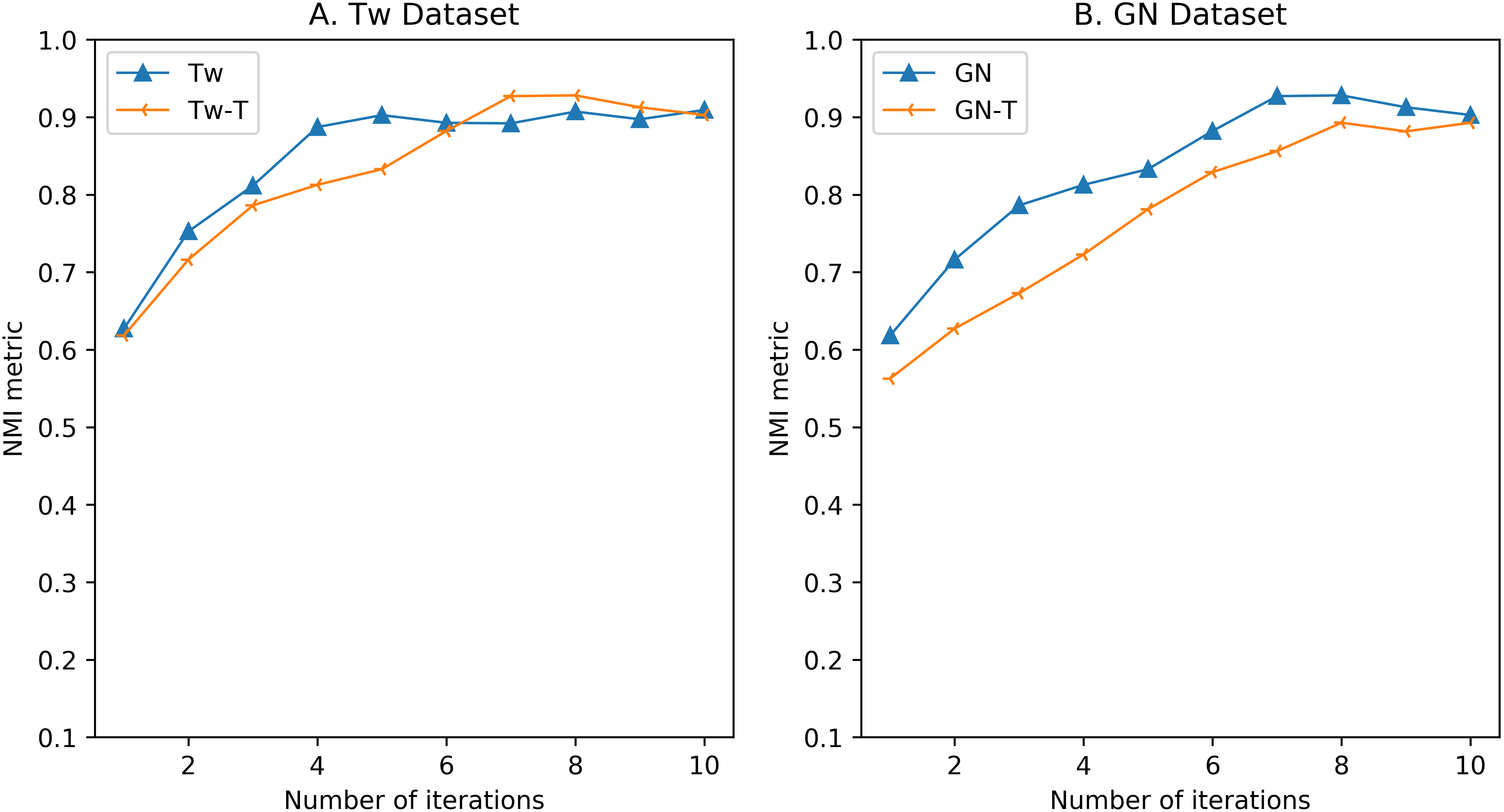
Experimental results for influence of the 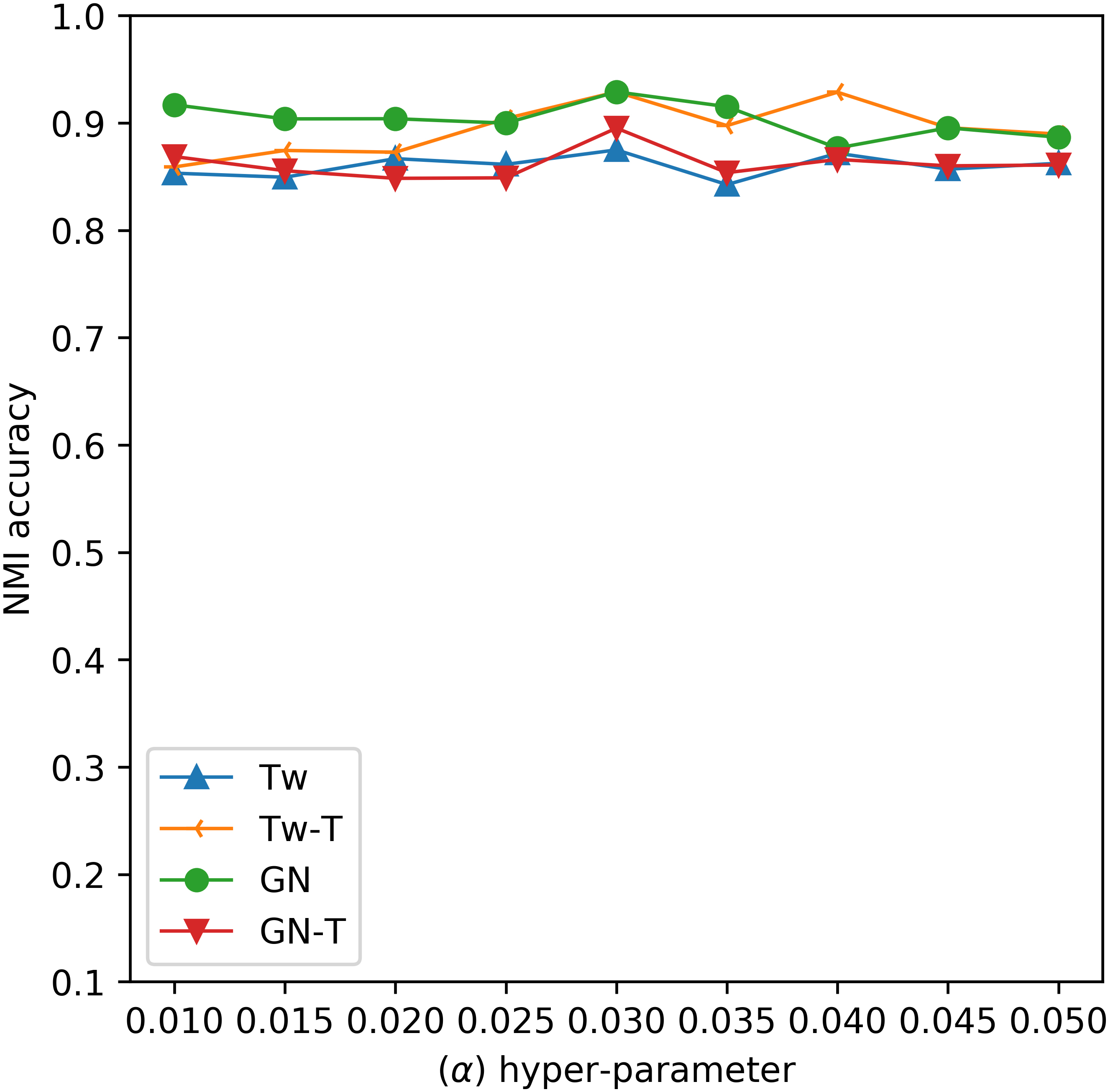
Experimental results for influence of the 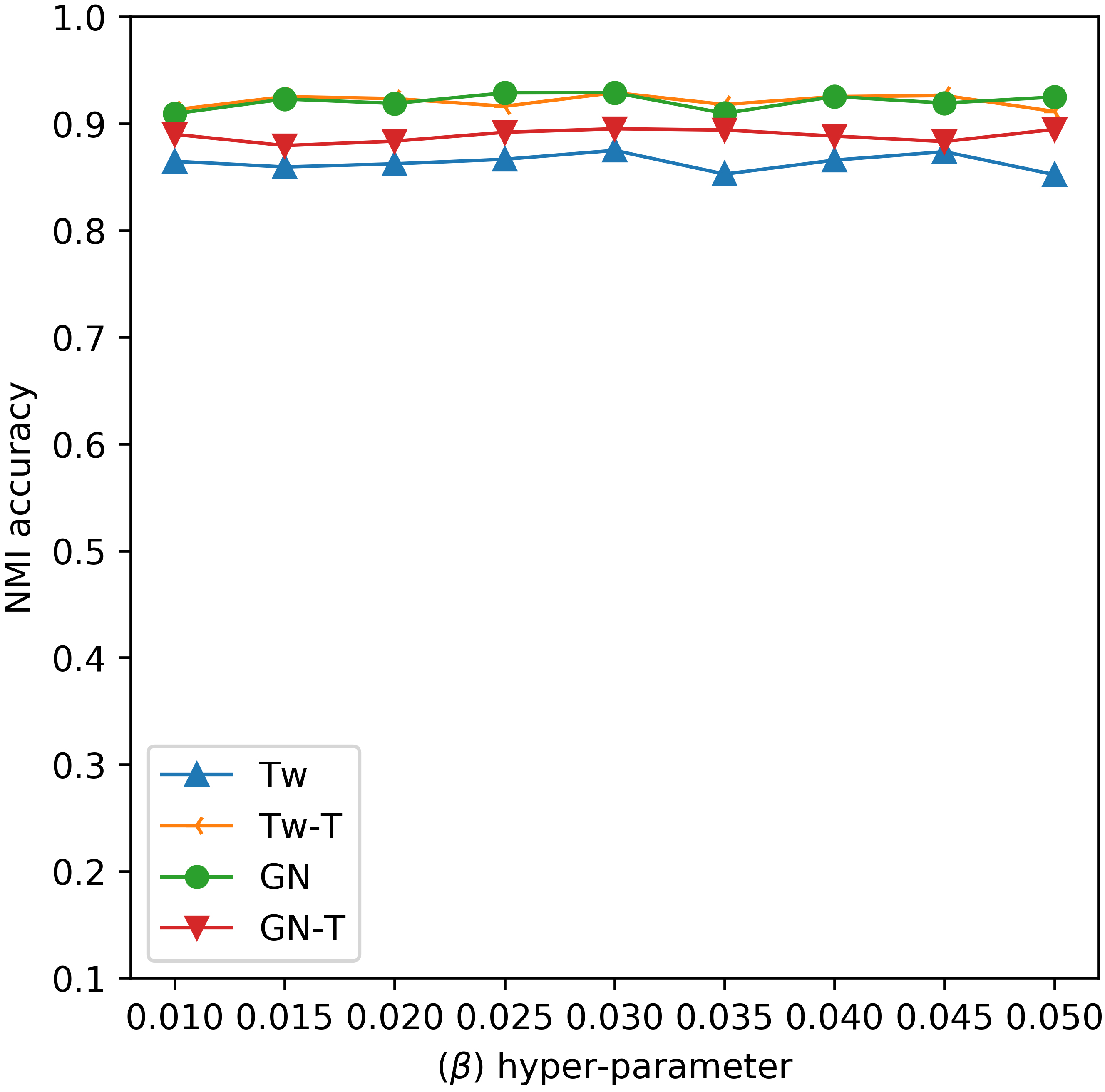
Influence of number of iterations. Most of topic modelling and mixture model-based approaches need a reasonable number of iterations for each document batch to reach the acceptable accuracy performance. In this part, we try to investigate the influence of number of iterations for each document batch on the overall our GOW-Stream model accuracy performance in terms of NMI metric. Similar to previous ones, we conducted the experiments on two dataset Tw and GN with different number of iterations for each document batch. Each experiment is run repeatedly 10 times and reported the average results. Figure 6 shows the changes on the accuracy performance of text stream clustering task with different number of iterations for each document batch in both Tw and GN datasets. Experimental results demonstrate that our proposed model achieve the balance in accuracy performance within range 7–10 iterations per each document batch. This shows that our proposed GOW-Stream model are quite fast to coverage.
To evaluate the influence of model’s parameters on the accuracy performance, we conducted extensive experiments for investigating the changes of
As shown from the experimental results, we can see that the proposed GOW-Stream model can achieve a stable accuracy performance with different values of both
Conclusions and future works
In this paper, we formally propose a novel semantic-enhanced approach for text stream clustering by applying common graph-of-words (GOWs) distributions over short-length text documents. The application of GOWs evaluation in text mining task has demonstrated several effectiveness related to the capability of naturally capturing words’ dependent relationships such as co-occurring and order relationships. GOWs is considered as unsupervised text restructuring technique which has been widely applied in multiple sematic-enhanced approaches due to its simple and efficiency in implementation without using any advanced supervised NLP technique. By combining with frequent subgraph mining (FSM), we can extract common GOWs from the given text corpora, these common GOWs play as distinctive features for text documents. To overcome drawbacks relation to word’s dependency evaluation of previous text stream clustering models, we combine the word-independent and common GOWs based evaluation in the topic/cluster inference process of Dirichlet Process Multinomial Model (DPMM) to enhance the text clustering outputs from the given streams. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed model on handling short-length sparse text stream clustering task in compare with recent state-of-the-art baselines, including: DTM, Sumblr and MStream. In future improvements, we tend to extend the implementation of our proposed GOW-Stream model on the distributed processing environment which is mainly designed for handling large-scale and high-velocity textual data stream, such as Apache Spark Streaming.
Footnotes
Acknowledgments
This research is funded by Thu Dau Mot University under grant number DT.20-031 and Vietnam National University Ho Chi Minh City (VNU-HCMC) under the grant number DS2020-26-01.