
Abstract
The integration of incomplete and uncertain information has emerged as a crucial issue in many application domains, including data warehousing, data mining, data analysis, and artificial intelligence. This paper proposes a novel approach of mediation-based integration for integrating these types of information from heterogeneous relational databases. We present in detail the different processes in the layered architecture of the proposed flexible mediator system. The integration process of our mediator is based on the use of fuzzy logic and semantic similarity measures for more effective integration of incomplete and uncertain information. We also define fuzzy views over the mediator’s global fuzzy schema to express incomplete and uncertain databases and specify the mappings between this global schema and these sources. Moreover, our approach provides intelligent data integration, enabling efficient generation of cooperative answers from similar ones, retrieved by queried flexible wrappers. These answers contain information that is more detailed and complete than the information contained in the initial answers. A thorough experiment verifies our approach improves the performance of data integration under various configurations.
Keywords
Introduction
The integration of incomplete and uncertain information from heterogeneous relational databases is an important research topic. The intent of data integration is to enable the user to extract information from heterogeneous data sources using a unified model [1]. The data integration system (DIS) is considered as an interoperable information system, which copes with heterogeneity and changeability in data sources to be integrated.
The DIS can be classified into five categories [2]: (1) the multi-base system allows users to access directly to the different data sources [3], (2) the federation system provides a federated schema for integrating heterogeneous databases called federated databases [4], (3) the mediator system provides a virtual integration of data at query time [5], (4) the data warehouse system is a materialized integration which feeds integrated data into data warehouses [6], and (5) the hybrid system that supports the data integration using a hybrid of the virtual and materialized approaches [7].
Data integration systems will continue to exploit data from heterogeneous data sources. There are different types of heterogeneity between data sources, such as structural heterogeneity, semantic heterogeneity, syntactic heterogeneity, etc. [8]. Furthermore, the data source often contains precise, incomplete, and uncertain information. Such heterogeneity of the information’s nature makes data integration even very challenging within the database system community [9]. This paper focuses more particularly on the challenges posed by this heterogeneity to data integration.
There are many sources of incomplete and uncertain information, including random data sets, inherently imprecise data sets, data poorly documented, data entry errors, statistical measures, measurement errors, inaccurate human judgments, etc.
There are different ways to define incomplete and uncertain information [10]. In the incompleteness problem of relational database, the information can be of two different types [11, 12]: the missing information and disjunctive information. The missing or inapplicable or even better unknown information of an attribute of a relational table is represented by a special value “NULL”, which means that the attribute has a value, but it is unknown. For example, the accepted paper of Maria is not included in the conference proceeding since Maria does not validate the registration. The disjunctive information can be represented by a finite set of possible worlds separated by the “OR” disjunction operator. This information states that one of the possible worlds being the true value, but it is unknown which one. For example, Mr. Christian is a professor of computer science at the University of Aalborg or Aarhus, but we do not know precisely to which University he belongs.
On the other hand, the uncertain information is related to the degree of the information’s accuracy. Uncertainty concept includes inconsistency, ambiguity, probability, possibility, maybe, fuzzy, vague, and imprecise terms that refer to the handling of data subject to doubt on their validity or being linked with forecasting or estimation [13]. In general, these uncertainty aspects represent uncertain information as fuzzy information or probabilistic information [13, 14]. The fuzzy information of an attribute value can be defined by a set of possible states associated with a degree of truth taking its values in the interval [0, 1] or a linguistic value, such as high, medium, or low. For example, we talk about the high possibility of extending the paper submission deadline.
The second type of uncertain information concerns the probabilistic information, which associates with each attribute value a probability between 0 and 1 according to a known distribution for that attribute domain. For example, the likelihood that a manuscript of Maria will be accepted is 0.9.
In general, the uncertain information can be formalized using mathematical logic, such as probabilistic logic, possibilistic logic, and fuzzy logic whose values belong to 0 and 1 [15, 16]. The probabilistic logic is frequently used for managing statistical measures and its predictions to obtain approximate answers, while the fuzzy logic is more generic for representing different forms of uncertain information than other formalisms [15, 16]. In our article, we use fuzzy logic as an effective and sound formalism to integrate heterogeneous data under incompleteness and uncertainty.
Dealing with incompleteness and uncertainty in relational databases has attracted significant attention from researchers for many years. Some of the research works have focused on data representation and modeling using different mathematical theories and leveraging techniques, such as machine learning methods, neural networks, Petri Nets, ontology, etc. [17, 18, 19, 20]. Other studies have focused on query processing challenges. Fuzzy logic-based flexible queries and preferences-based skyline queries are the most used solutions to provide accurate results that best meet the user requirements [21, 22, 23].
While the querying of incomplete and uncertain databases has already been addressed, there is still a need for further research toward more advanced studies, in particular research on the integration of incomplete and uncertain information from heterogeneous databases. The early version of this article is extended, and some major enhancements have been involved in data integration processes. The detailed differences are summarized as follows. First, the previous work [24] does not consider the integration of disjunctive and probabilistic information. Second, Resnik’s similarity measure does not give better results when computing the semantic similarity between compounded concepts. Thus, the similarity value between two similar concepts is greater than 1, which gives thorny issues in the analysis of experimental results. Third, a new method is included to provide intelligent data integration via the generation of cooperative answers more detailed and complete than the initial ones. Fourth, important algorithms are proposed, and a flexible mediator system has been developed to validate the proposed approach for the integration of incomplete and uncertain information from heterogeneous relational databases (HRDB). Finally, to further evaluate the performance of our approach against the related works, thorough experiments have been conducted on three categories of databases.
The main contributions in this paper are listed as follows:
We improve the flexible mediation approach to integrate disjunctive and probabilistic information. We introduce a new method for producing cooperative answers from similar ones. We propose some algorithms required in the data integration process. We propose a semantic similarity-based method for dealing with semantic conflicts during data integration processes and therefore guarantee meaningful data integration. We develop a flexible mediator system and provide extensive experiments.
The remainder of this paper is outlined as follows. We review grounding research in the integration of incomplete and uncertain information in Section 2. Section 3 provides our intelligent mediation approach, while in Section 4 we present in detail the flexible mediator system. The experiments and discussions are reported in Section 5. The final section draws a conclusion and suggests further research.
The most critical data integration problems are closely related to data sources heterogeneity, interoperability issues, and query processing complexity [25]. The heterogeneity of information’s nature is a thorny problem in the area of data analysis. The efficient integration of multiple sources containing incomplete and uncertain information may help resolve the incompleteness and uncertainty, yielding accurate results that better meet user requirements. Most of the data integration (DI) literature assumes that the integrated data are either incomplete or uncertain without identifying the different types of each nature of the information.
Some related works have only studied the incompleteness in the DI field. Nikolaou et al. [26] proposed an ontology-based approach to define integrity constraints over data source schemas and specify the functional dependencies used to extend the database with missing information. Exploiting integrity constraints may be useful for overcoming portions of incompleteness in databases. Such a method cannot ensure the integration of disjunctive information presenting possible values, but we do not know which one is true.
Another work proposed a bag semantics-based approach to investigate approximation schemas for computing precise answers to queries that have been proposed for bag semantics [27]. During the data integration process, one of the local schemata requires computing an intractable query, while the other remains tractable. The approach focused on the semantic-based query representation without considering the different issues within incomplete databases themselves.
Hannou et al. [28] proposed a pattern-based approach for extracting complete query answers from incomplete databases. The method involves the evaluation of a query over the data and the extraction from the corresponding pattern dataset, the completeness of the query answer. This method costs a lot of computing and effort to define and incorporate completeness patterns for integrating incomplete databases.
The second group of related works focused on the problem of uncertain data integration. Jaradat et al. [29] propose a new best-effort data integration framework that copes with the challenges of uncertain data integration. The proposed framework relaxes the traditional data integration by explicitly incorporating probability-based mappings into the data integration process. This solution is likely less precise and therefore becomes less efficient when there are different information’s natures.
A fuzzy RDF data model proposed in [30] attempts to combine fuzzy logic with the semantic web RDF (Resource Description Framework) model in order to deal with uncertain and semantic conflicts. This extended RDF model provides a new method for ensuring the mapping between RDF data and relational databases containing uncertain information. Despite the effectiveness of the uncertain data integration, such a method cannot ensure high efficiency in diverse scenarios that can occur in practice.
Gal et al. [31] proposed a learn-to-rerank algorithm, which aims to rerank a list of schema matches to put the best at the top of the data integration process. This method must use matching predictors as learning features to integrate data, and therefore it is less effective when the data sources contain more uncertain information.
In real-world applications, the information is subject to both incompleteness and uncertainty. While many efforts have been proposed to address these problems, to the best of our knowledge, there are few efforts regarding the issue of integration from heterogeneous relational databases (HRDB) containing both incomplete and uncertain information.
In 2005, Leone et al. [32] have proposed INFOMIX, a novel system that supports incomplete and inconsistent information integration. The key idea of INFOMIX is that the integrated data must satisfy the integrity constraints defined on the global schema and the mapping between this schema and data sources. Besides, the system used logic-based methods for answering user queries that are sound and complete. We point out that this system is employed only in materialized integration that aims to extract and transform data from sources and load the results into a data warehouse.
In our previous work [24], we have proposed a fuzzy logic-based flexible mediator architecture for integrating incomplete and uncertain information from HRDB. This approach is briefly described below, which helps set the stage for the description of the proposed approach in this article.
The flexible mediator architecture is split into three layers: flexible mediation layer, flexible wrappers layer, and data sources layer. The flexible mediation layer receives the initial query written in a common vocabulary language provided by the global fuzzy schema, representing unified querying support. The submitted query has been enhanced to integrate incomplete information, especially the missing information. For ensuring the mapping between the global fuzzy schema and the local schemata of different data sources, we have defined fuzzy views over the global schema, which are based on measuring Resnik’s similarity between elements of the global schema and those of the local schemas.
The flexible wrappers layer is a middle layer between the flexible mediation layer and the data sources layer. The query can be rewritten and decomposed to a set of sub-queries over the participating local sources through the fuzzy mappings of each flexible wrapper. Each queried wrapper sends its answers back to the flexible mediation layer, which provides a preprocessing phase for eliminating redundant answers. The retained answers will be collected and sorted in descending order according to their membership degrees, yielding approximate answers.
Overview of our intelligent mediation approach
In this article, we adopt our flexible mediation architecture to improve the quality, interoperability, and efficiency of the data integration process. Our approach is able to efficiently integrate different types of incompleteness and uncertainty, such as missing, disjunctive, fuzzy, and probabilistic information. The handling of these kinds of information’s nature is a challenging problem in different data integration processes, such as global schema representation, data mapping, rewriting queries, etc.
Our intelligent mediation approach aims at dealing with these issues by using fuzzy logic that is a more pragmatic approach to imprecise data than recent trends towards probabilistic models. To be clear, Fig. 1 shows a general overview of the proposed intelligent mediation approach.
Overview of the intelligent mediation approach.
In the uncertain database modeling by fuzzy logic, each uncertain attribute value, carrying uncertain information is related to a set of fuzzy predicates P. Each
CREATE VIEW name-of-FV (
Such that the fuzzy view
The fuzzy mapping between elements of schemata (i.e., name of tables, name of attributes, etc.) is based on a well-known semantic similarity measure, which aims to determine the semantic likeness between terms or text [35]. In our work, we rely on Wu and Palmer (Wup) [36] and cosine [37], two core knowledge-based semantic similarity measures.
Using fuzzy logic with semantic similarity measure in the data integration process alleviates the designer’s task compared to other semantic-based data integration approaches such as fuzzy RDF and fuzzy ontology.
At the flexible wrappers layer, the query processing over the global fuzzy schema involves rewriting queries using fuzzy views. Moreover, each flexible wrapper provides query cooperation processing, which relies on exploiting relationships between rewritten queries and others that extract incomplete information (more details see Section 4.2.2).
The cooperative query answers have been rewritten in terms of the global fuzzy schema and submitted to the flexible mediation layer. The latter provides now answer management process to produce cooperative answers from similar ones.
The purpose of focusing on the cooperative feature between answers was twofold. First, we decrease the number of returned answers that are still more contained incomplete and uncertain information. Second, we reduce the degree of uncertainty and incompleteness in the answers.
We present Flexible Mediator, an end-to-end data integration system, which allows the user to ask queries over integrated data from HRDB containing incomplete and uncertain information. The layered architecture of flexible mediator system is described as follows:
General architecture of the flexible mediator system.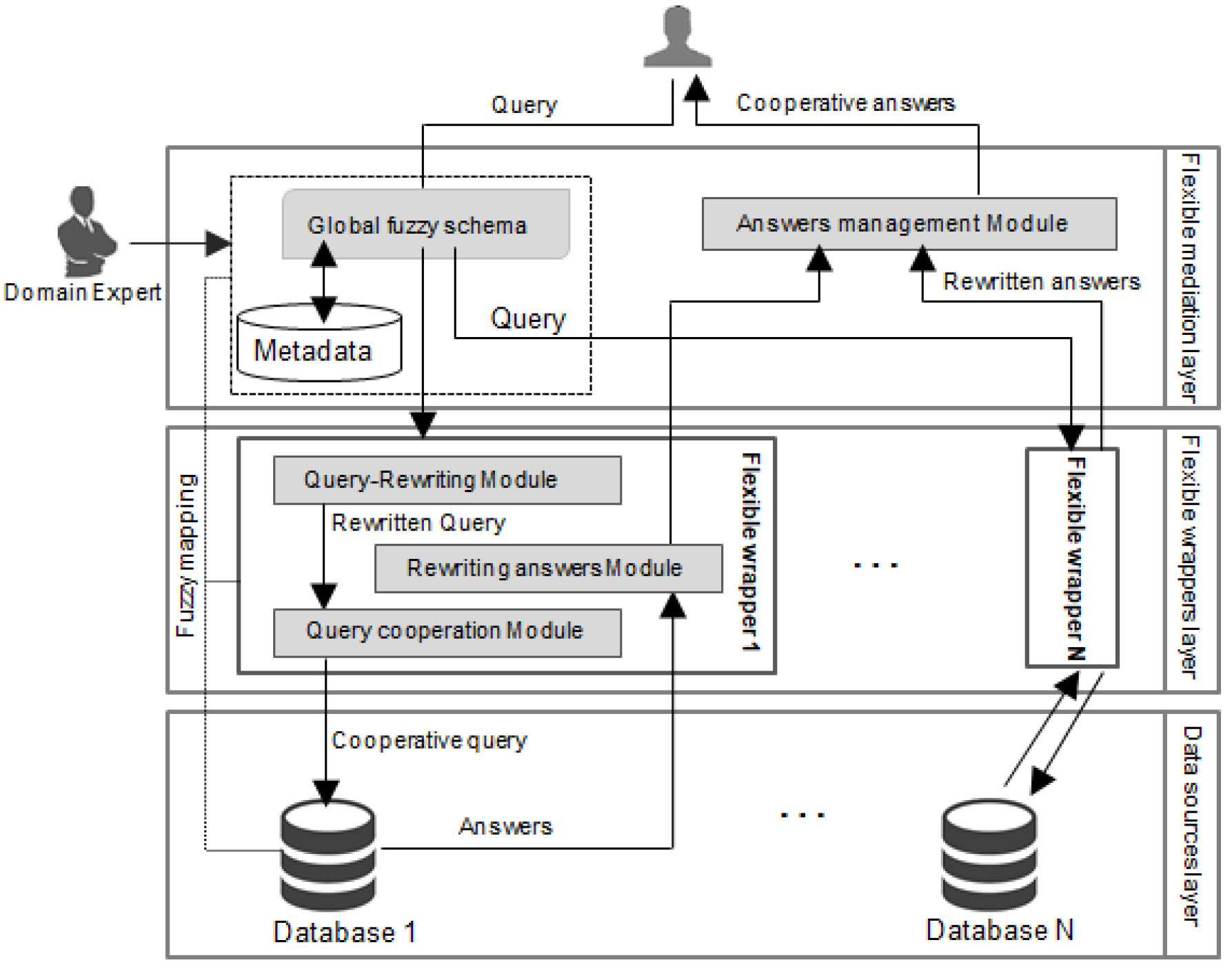
The integration of incomplete and uncertain databases has become an intrinsic property in many application domains, such as transportation planning, weather information, e-business, bioinformatics field, etc. While the flexible mediator system is generic for many application domains, we focus on the food safety domain. The datasets in this field represent a great example of a scientific database that includes several uncertain and incomplete pieces of information [38, 39]. For example, some microbes do not explicitly specify the danger degree. Other food calories are represented as ranges instead of exact values. The use of the flexible mediator system in microbiology laboratories and industries provides reliable and efficient management of such datasets, taking into account the conditions of growth of microorganisms in food.
The flexible mediator system provides a form-based query interface that helps the user to pose queries and view the results in a single tabular structure. Using the query formulation form rather than writing SQL statements directly or in a natural language makes the system flexible enough and easy to use and can minimize or avoid errors such as typing mistakes.
Note that the main elements of the global fuzzy schema, such as tables, attributes, fuzzy predicates, etc., have been automatically extracted by SQL queries and loaded in the corresponding graphical components using Java programming language.
The flexible mediator system.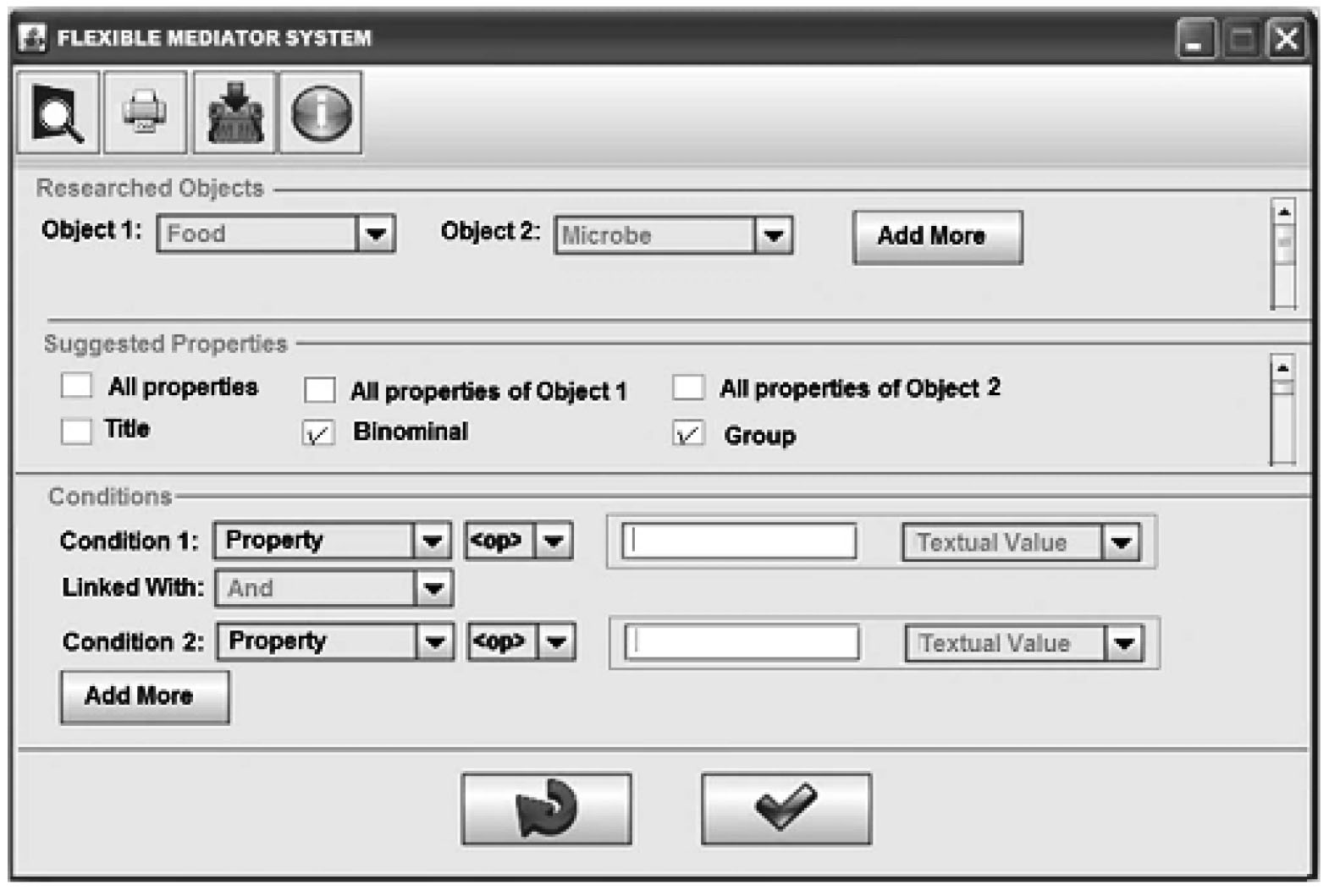
In Fig. 3, the graphical user interface (GUI) of the flexible mediator guides the user to formulate query according to the SQL statement syntax. The first part, “Researched objects” allows the user to select the relational tables to be used in the well-known “FROM” clause of the SQL query. The second part, “Suggested properties” represents the “SELECT” clause, where the user can be select all or some attributes to be displayed. The third part, named Conditions, represents the “WHERE” clause, which allows the user to define the search conditions (restrictions). In this part, the condition consists of three components:
A left operand defines an attribute or a column of a relational table to be compared. A comparison or research operator such as A right operand is a value that can directly be entered in the text field or selected from the Textual-value list, including fuzzy predicates.
Before representing the main module of the flexible mediation layer, we first define the global fuzzy schema.
Where each relation
As for our approach, contrary to related works for fuzzy databases modeling, which define an additional column for indicating the membership value of a tuple [41], it aims at using metadata that contains a set of fuzzy predicates with their membership functions.
Our global fuzzy schema
Microbe (Title_Microbe, Family_microbe, Date_of_Discovery, Discovery, Danger, Length, Diameter, Propagation).
In this relation, we can distinguish that the domains: D (Title_Microbe), D (Family_microbe), and D (Discovery) are ordinary sets, while D (Date_of_Discovery), D (Danger), D (Length), D (Diameter), and D (Propagation) can be presented by fuzzy predicates. Note that some attributes of this relation can contain incomplete information.
The fuzzy predicate
Where
From example 1, the fuzzy set of the attribute, “Propagation” of Escherichia coli bacteria is then represented as follows:
The definition of these membership functions is based on an interview with domain experts in food safety and online documentation, such as the world health organization website (
For example, as pictured in Fig. 4, the membership function of the fuzzy predicate “Medium” is defined by (11, 14, 24, 27). Thus, our metadata includes 321 fuzzy predicates. Table 1 gives a part of the metadata related to the Microbe table of the global fuzzy schema.
Part of metadata related to the microbe table of the global fuzzy schema
Membership functions of fuzzy predicates of the attribute “Danger”.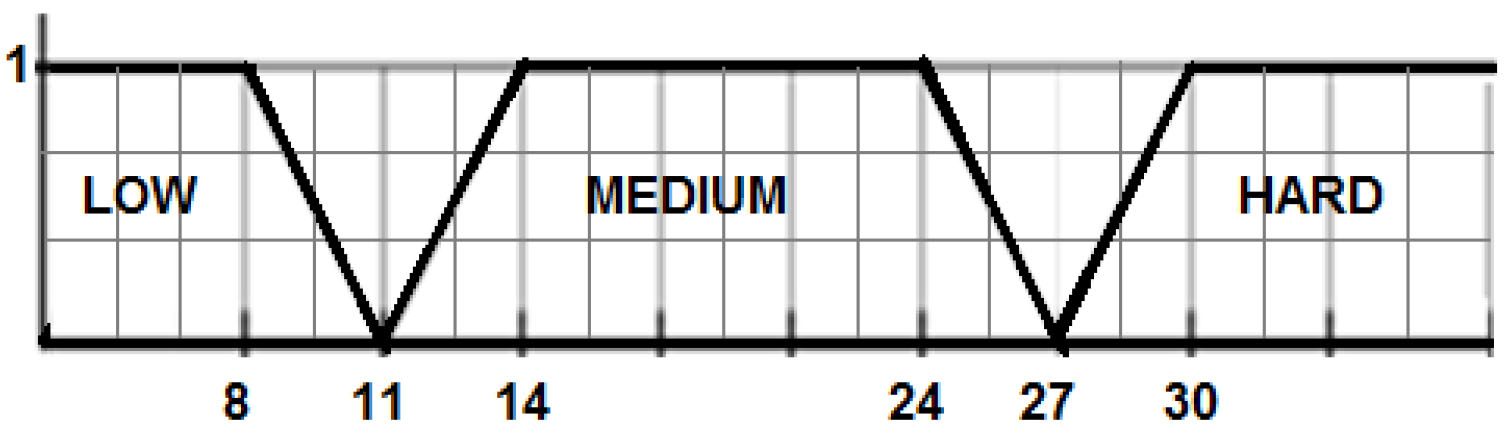
For the sake of clarity, we shall give an example of user query
SELECT FM.Title_Microbe, FM.Date_of_Discovery, FM.Length, FM.Danger FROM FS.Microbe FM WHERE FM.length
This formal representation of the fuzzy query expresses the uncertain information through the fuzzy predicates ‘Long’ and ‘Medium’, which are not treated as a string (see Section 4.2).
After retrieving and rewriting the query answers at the flexible wrappers layer (see Section 4.2), the flexible mediator system awaits the answers from all queried wrappers. The answers management module is proposed to combine similar answers and generate cooperative ones that are more detailed when accurate data are not available. On this basis, we establish a semantic similarity-based method to determine the redundant answers from the heterogeneous ones. The method is based on two semantic similarity measures: Wup and cosine [36, 37], which tend to give more accurate results and are very much in coincidence with human similarity [25].
The Wup similarity is one of the most commonly used knowledge-based similarity measures, which takes advantage of overcoming structural and semantic conflicts [36]. This measurement is widely used for computing the word-to-word semantic similarity, which can be extended between fuzzy predicates defined by linguistic terms (atomic terms). Wup similarity is based on measuring the depth of two concepts
On the other hand, we used the Cosine similarity measure to compute the similarity between vectors of words or numbers. Cosine similarity has proven to be a robust metric in the information retrieval domain for determining how similar the documents are [43]. The cosine similarity of two vectors X, Y is given by the following formula [37]:
Where
The similarity-based method aims at combining these two similarity measures. Such measurement can take values between 0 and 1, making its results easy to interpret and analyze.
Let
Example of some heterogeneous answers
The answers
The similarity degree between The natural idea is to ensure that the similarity degrees between
The similarities between the answers acquired through the use of the Sim-Responses algorithm are given in Table 3.
Detailed similarities between some answers
As shown in Table 3, the ‘Sim1’ column reflects the similarity results between the values of attributes that may be atomic or compounded concepts. For example, from the attribute ‘Title_Microbe’ and using algorithm 1, we apply the Wup similarity between atomic concepts as Salmonella and the Cosine measure between compounded concepts, such as Escherichia coli.
The second column, called ‘Sim2’, indicates the cosine similarity results between vectors of numeric values. Each vector consists of three membership degrees: the membership degree of the attribute Date_of_discovery that contains incomplete information and the membership degrees of attributes Length and Danger, which correspond to the values of attributes Degree1 and Degree2, respectively. Note that if one of the values that will be compared represents precise information, its membership degree is still equal to 1, such as the date of discovery of the Proteus bacteria (see answer
The content of the column ‘Sim’ is the average values of the similarity results defined in columns Sim1 and Sim2. Sim column indicates the similarity degrees between answers. The rightmost column shows the decision to fulfill the first condition (‘Yes’ to the answers that meet the first condition or ‘No’ otherwise). We can see that the first condition of similarity between answers
In the second condition, we evaluate if similarities between the answer
For example,
In the second phase of the answers management module, the cooperation process between similar answers is applied to each attribute, skipping the missing information:
Aggregate the precise and disjunctive values into one value that is disjunctive information. Maintain the uncertain information that has the highest membership degree. If two values have the same membership degree, we take both as two possible values. Delete the additional attributes that reflect the degrees of query conditions, such as Degree1 and Degree2 (see Table 2).
The cooperative answer is a more detailed response that aggregates the possible values from similar answers, taking into account the uncertain values having the highest membership degree. In this way, we can have greater integration of sources and better meet user needs.
Example of some final answers
Form Table 4, the first row represents the cooperative answer, which has been generated from similar answers
This second layer of the flexible mediator provides support for query processing and dealing with heterogeneity problems. The flexible wrapper is the basic building block of the flexible mediator. Figure 5 shows a zoom-in the structure of the flexible wrapper.
Overview of a flexible wrapper.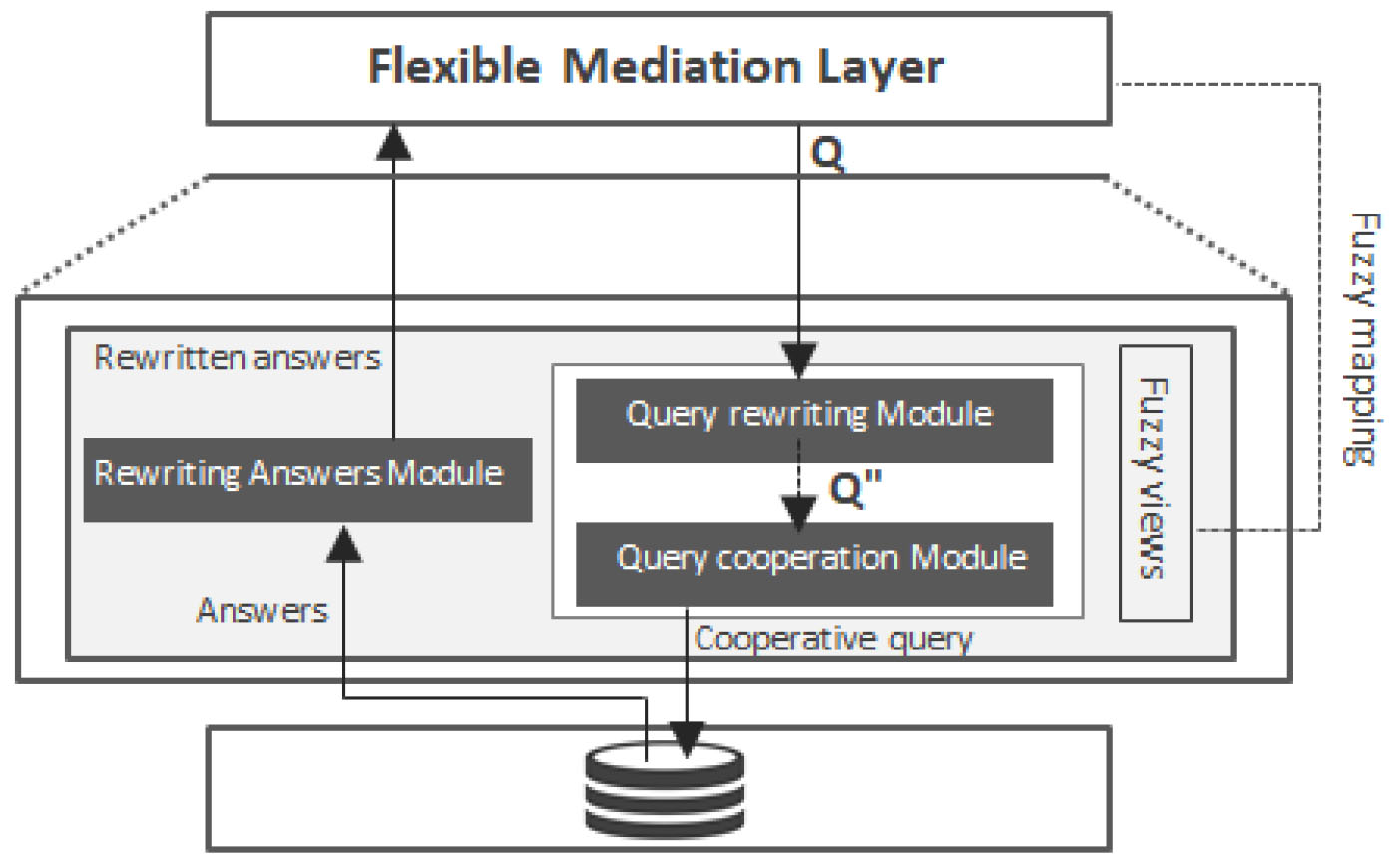
It aims to reformulate the user query to refer to the data sources by using fuzzy views, which are based on the LAV mapping approach.
Several query-rewriting algorithms are proposed in the literature, the three known are the Bucket algorithm, Inverse-rules algorithm, and Minicon algorithm [45, 46, 47]. The first two algorithms do not fit well when handling queries involving cooperation with other queries [47]. The Minicon algorithm scales up to a large number of views and outperforms the previous algorithms. It aims at finding the maximally-contained rewriting of a conjunctive query using a set of conjunctive views [47]. Hence, we use the Minicon algorithm to define the fuzzy view-based query rewriting method. For this purpose, the creation of fuzzy views over global fuzzy schema
The fuzzy view-based query-rewriting algorithm (see Algorithm 3) takes the user query
Using fuzzy views, semantic similarity measures, and the MiniCon algorithm can better characterize our approach for integrating incomplete and uncertain databases modeled by fuzzy logic.
SELECT F.Name, F.Calorie, F.Category, F.Family, M.Title_Microbe, M.Length, M.Discovery, M.Danger, M.family_microbe
FROM FS.Food F, FS.Microbe M
SELECT M.Title_Microbe, M.family_microbe, FM.Date_of_Discovery, M.Discovery, M.Length, M.Danger, M.Propagation
FROM FS.Microbe M
From these views, we produce two queries
SELECT V1. NameMicrobe, V1.Lengthiness, V1.Risk FROM Microbio_Food_view V1 WHERE V1.Lengthiness
The
SELECT V2. Name, V2.Discovery_date, V2.Length, V2.Danger FROM Microorganism_view V2 WHERE V2.Length
We can see that the rewritten query
Query cooperation module
The query cooperation module serves two purposes. First, it ensures the integration of incomplete and uncertain information in which the rewritten query has cooperated with others that extract these types of information. Second, it executes the cooperative query, taking into account the membership degrees assigned to each incomplete and uncertain piece of information.
The rewritten query
Query cooperation process.
We first detect missing attributes in the query
In the case where
From the information extracted in the previous step,
SELECT V1. NameMicrobe, NULL AS Date_of_Discovery, V1.Lengthiness, V1.Risk FROM Microbio_Food_view V1 WHERE V1.Lengthiness IS NULL or V1.Risk IS NULL
Note that, in the ‘SELECT’ bloc of the above query, our method generates the missing attribute ‘Date_of_Discovery’ having a null value (using step 2). The second query related to
SELECT V2. Name, V2.Discovery_date, V2.Length, V2.Danger FROM Microorganism_view V2 WHERE V2.Length IS NULL or V2.Danger IS NULL
Our key idea of using queries with missing information in their conditions is that they may get more data, retaining their representation, thus improving the quality of rewritten query answers.
The last step of the query cooperation-driven method aims to combine via the union of the rewritten query with the additional one to generate a cooperative query ready to be executed. Therefore, for executing such a cooperative query, the flexible wrapper assigns each incomplete and uncertain piece of information defined in the query conditions, a membership degree according to the metadata of fuzzy predicates. Due to the limitation of space, we skip the description of the algorithm Get-Degree (T, a, A, B, b), which just implemented the different membership degrees defined by the quadruplet
In the preliminary version of this article, we have assigned to missing information defined by the null value, the average value of membership function, which equals 0.5 because it may be that this incomplete value corresponds to the user’s need or not [24]. We extended this solution for considering the disjunctive and probabilistic information.
In the case of disjunctive information, we attempt to give importance to each possible value since one value may be true in the current situation and false in another one. Therefore, we distribute the membership degree over different possible values of the disjunctive information.
On the other hand, the probabilistic information can be attached by membership degrees, which are corresponded to the probability values between 0 and 1.
SELECT V1. NameMicrobe, 0.5 AS Date_of_Discovery, V1.Lengthiness, Get-Degree (Length, 5, 10, 0, 0) AS Degree1, V1.Risk, Get-Degree (Danger, 11, 14, 24, 27) AS Degree2 FROM Microbio_Food_view V1 UNION SELECT V1. NameMicrobe, 0.5 AS Date_of_Discovery, V1.Lengthiness, 0.5 AS Degree1, V1.Risk,
This cooperative query,
We can see that the missing attribute ‘Date_of_Discovery’ is associated with the value 0.5 as a completeness degree. Moreover, each query answer is represented by the following six attributes rather than four: NameMicrobe, Date_of_Discovery, Lengthiness, Degree1, Risk, and Degree2.
The queried flexible wrapper receives its answers written in terms of the data source vocabulary, which may be different of the global fuzzy schema. We recall that the query rewriting algorithm (see Algorithm 3) allows storing the different matchings between the user query Q and rewritten query
From the query-rewriting module, extract the matchings between Q and Translate the table name of answers to the corresponding name in Q. Omit attributes that represent the membership degree, such as Degree1, Degree2 from example 8. Translate each attribute name of answers to the corresponding name in Q.
The result of the rewriting answers module is a set of answers whose representation (table name and attribute name) corresponds to that indicated in the user query, providing transparent access to multiple data sources.
Examples of answering the cooperative query
From Table 5, we apply our rewriting answers process, and the result is shown in Table 6.
Result of rewriting answers presented in Table 5
Summary of the different databases
Except for additional attributes, the rewritten answers’ structure (e.g., the names of attributes) is suitable to the user query, as expected. Each flexible wrapper sends now its rewritten answers to the flexible mediation layer.
The data sources layer represents multiple heterogeneous relational databases that we want to integrate. The uncertain and incomplete information are two existing information’s natures together in the data source: Dealing with data uncertainty by removing records with uncertain information leads to incomplete query results. In contrast, the incomplete information in the data source allows us to insert inaccurate or uncertain information for completing the data lacking.
In our flexible mediator, we use relational databases (RDBs) as an example of the data source since they are commonly used in information systems and enterprises [48]. Thus, RDBs were easier to administrate and manipulate by using a database management system (DBMS). In our previous work [24], we have arbitrarily created five heterogeneous RDBs in the domain of food safety. In this article, we improve this layer by creating six databases classified into three categories. The first one introduces two databases with only precise and incomplete information. The second presents two other databases that only cover precise and uncertain information. And the third category identifies two other databases containing precise, incomplete, and uncertain information. This data categorization is because few works have been devoted to study the integration of both incomplete and uncertain databases. Therefore, to give a sound and complete experimental study, we must compare our work with three related works classes depending on this categorization.
On the other hand, when facing the heterogeneity of information’s nature, several semantic conflicts can be detected. Using semantic similarity measures in our intelligent mediation approach provides a promising method to cope with these heterogeneity challenges. Table 7 summaries the different databases.
Table 7 shows the principal features of databases used in our experiments, such as the total number of tables and records, the average number of attributes. We also present the percentages of occurrences of missing, disjunctive, fuzzy, and probabilistic information.
Recall that our flexible mediator system used LAV-based fuzzy mappings between schemas, making the system interoperable enough. Any source can then freely be added to or left without harming other sources from the data source layer. In fact, adding a new source involves the auto-creation of fuzzy views. In contrast, deleting the data source leads to remove its flexible wrapper includes its fuzzy mapping.
Experiments and performance evaluation
To evaluate the performance of the flexible mediator system, we have performed extensive experiments and the results shall be discussed thoroughly. Regarding implementation details, our system was developed using Java programming language with WS4J (Wordnet Similarity for Java) Java library that includes a set of semantic similarity measures, such as Wup similarity [49]. All the experiments are performed on an Intel Core i7 CPU 4.0 GHz PC with 8 GB RAM.
In the aforementioned section, we have introduced the relational databases used in our experiments. These databases were built by using Oracle DBMS, release 11.2.0.2.0, which provides the ability to view tables back in time, superior compression of all types of data, and offered the grid computing functions [50].
Experimental settings
To report the evaluation of the proposed approach, we used three categories of relational databases in our experiments (see Section 4.3). Generally, noise in datasets hinders most types of data analysis. For a good performance of data integration methods, it is necessary to remove identified noise, giving high-quality datasets. On the other hand, we apply the three popular performance measures: precision
Typically, these metrics of performance indicate the effectiveness and accuracy of the data integration system. Precision
Furthermore, these metrics require the use of ground truth, which has been defined as training data. In our work, producing ground truth for each category of databases is a tedious task. For a sound experimental study, we have taken a lot of effort and time to generate these training data. We conducted a total of 150 queries and 3837 results for three ground truths (
Description of the ground truths
From Table 8,
Our intelligent mediation approach aims to produce more detailed cooperative answers from similar ones. Determining similar answers plays a vital role in generating cooperative answers that are expected to achieve better performance. The closeness of answers is related to the similarity degree measured between them by applying the Sim-Responses algorithm. So, we need to find a suitable value of threshold denoted
We start for the initial value
Result of the correctness and effectiveness study
Result of the correctness and effectiveness study
We compare the results in Table 9. From the first category of data integration, DI1, for the value of the threshold
We study the efficiency of the proposed approach in terms of data integration time. Experiments were set up to consider two distinct scenarios:
Varying percentages of each piece of incomplete and uncertain information in databases. Query complexity: The robustness of the data integration system is related to the query processing complexity.
In the first scenario, we vary the percentages of incomplete and uncertain information and we compute the running time of three data integration categories (DI1, DI2, and DI3). Figure 7. shows the experimental results.
Efficiency with varying percentages of incomplete and uncertain information.
Overall, from the first and second categories of data integration (DI1, DI2), it appears that the execution time stands stable when the ratio of incomplete or uncertain information increases. Moreover, the time cost gap between DI1 and DI2 is quite small when the percentages of information increase, as expected. It reveals that our approach performs better when the incompleteness and uncertainty are studied separately. On the other hand, the time cost for DI3 is also stable with a small-gap between DI3 and other data integrations. This result means that the increase in the amounts of incomplete and uncertain information does not influence in the data integration effectiveness.
The second scenario of the approach’s efficiency study is related to the complexity of queries, which has a great impact on the performance of data integration. Hence, we have used 150 queries with different complexities, for example, conjunctive and disjunctive queries, flexible queries (queries with the condition over uncertain or incomplete information), query with an aggregate function, query with join operators, etc. We give an example of a complex query, which returns information about high-calorie foods that can quickly become contaminated and produce dangerous microbes. This request can be interpreted by the flexible query as follows.
SELECT F.* FROM FS.Contamine C JOIN (FS.Food F, FS.Microbe M) ON (C.idF
Figure 8 shows the experimental results.
Efficiency with various query complexities.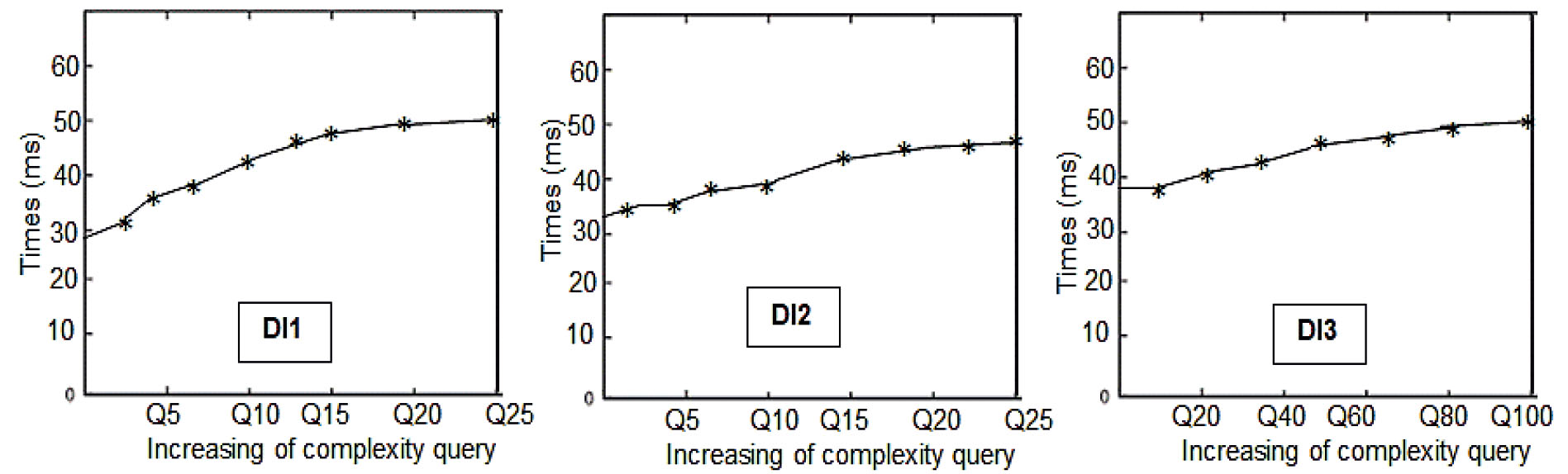
Overall, from Fig. 8, it appears that all three curves show a slight upward trend when the complexity of queries increases. The efficiency of the approach determines the robustness of flexible wrappers against the complexity of queries on the one hand and the accuracy of generation cooperative answers on the other hand. In ID1 and ID2, the execution time of different queries is quite stable, while ID3 shows a slight rise. The reason is that the integration of incomplete and uncertain information leads to more processing than the separate integration of these types of information.
In summary, the intelligent data integration approach can scale up to the number of incomplete and uncertain information and query processing complexity with faster computation.
The third evaluation study aims at comparing the performance of our proposed approach to that of the relevant work taking into account precision, recall, and F-measure. We have stated earlier that very few works in data integration from incomplete and uncertain databases. Hence, we must compare the performance of our approach with three categories of most important works: Semantic-based approach proposed in [27] for incomplete data integration, fuzzy RDF data model [30] for uncertain data integration, and fuzzy mediation in our previous work [24] for integrating incomplete and uncertain information. We have also conducted 50 queries for comparing with the first two works and 100 for our previous work. Figure 9 shows the average of both precision
Result of comparative performance.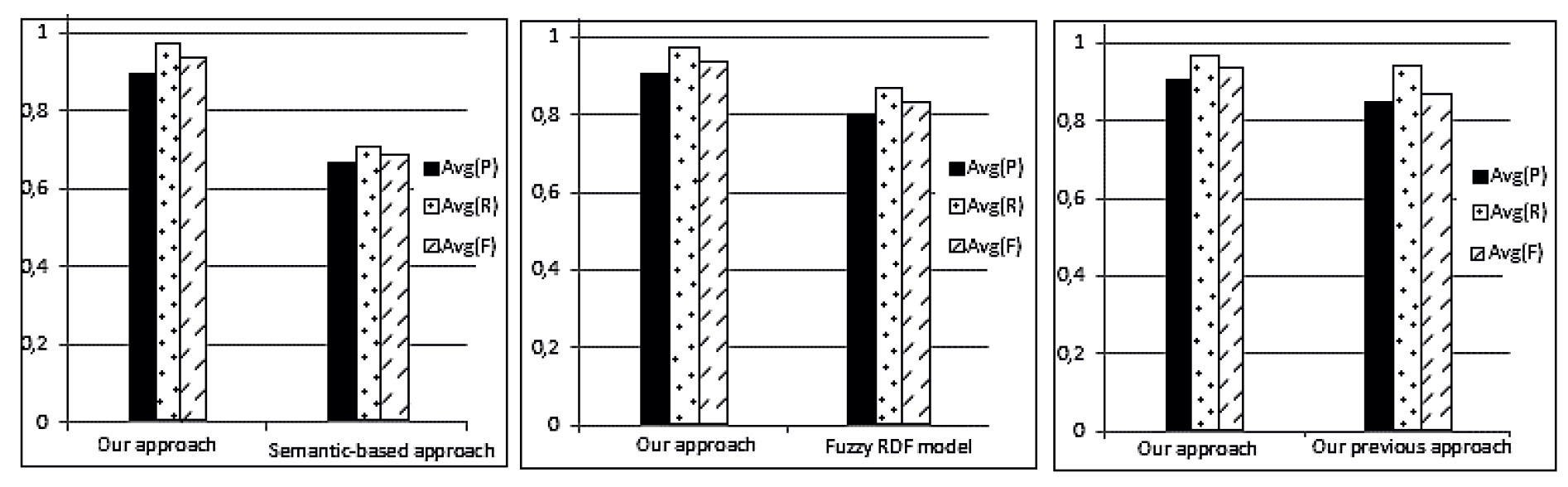
Based on the results presented in Fig. 9, our approach outperforms other approaches and gives the highest precision, recall, and F-measure, which are very close to one. In the integration of incomplete information, our work achieves high accuracy compared to the semantic-based integration approach [27], with
Finally, the proposed approach performs quite better than our previous work [24]. Our intelligent data integration approach achieves a significant improvement in efficiency due to the cooperation between queries for integrating more information on the one hand and between similar answers to give cooperative ones on the other hand. These answers contain information that is more detailed and completed than the information contained in approximate ones from our previous work [24]. This indicates that the use of similar answers is successful in enhancing results rather than removing them.
In summary, the experimental results show the effectiveness and efficiency of the proposed intelligent mediation approach, based on fuzzy logic and semantic similarity measures for integrating incomplete and uncertain information from HRDB.
Several of the existing methods have independently investigated the problems of incompleteness and uncertainty in data integration. Our contribution presented in this paper aims at correctly integrating both incomplete and uncertain information from heterogeneous relational databases. We have presented an intelligent data integration approach, proving cooperative answers that best meet the user requirements.
To examine the efficiency and effectiveness of our proposed approach, we have developed the flexible mediator system and performed extensive experiments. The results prove that the approach improves data integration performance when the incompleteness and uncertainty problems are available independently or simultaneously. Though our solution gives dramatic performance improvements in data integration, we still have some room for optimization. For instance, enrich the metadata of fuzzy predicates with linguistic modifiers, usually called hedges (e.g., more or less, very, etc.), to improve the description power of incomplete and uncertain information.
Integrating information from large amounts of data is another thorny issue of our industry now, and it will continue to be a problem in the future. Our ongoing work also aims to improve the proposed approach to maintain high efficiency for intelligent integrating large-scale databases when the incompleteness and uncertainty are available in their data.