
Abstract
Ordinal regression has been widely used in applications, such as credit portfolio management, recommendation systems, and ecology, where the core task is to predict the labels on ordinal scales. Due to its learning efficiency, online ordinal regression using passive aggressive (PA) algorithms has gained a much attention for solving large-scale ranking problems. However, the PA method is sensitive to noise especially in the scenario of streaming data, where the ranking of data samples may change dramatically. In this paper, we propose a noise-resilient online learning algorithm using the Ramp loss function, called PA-RAMP, to improve the performance of PA method for noisy data streams. Also, we validate the order preservation of thresholds of the proposed algorithm. Experiments on real-world data sets demonstrate that the proposed noise-resilient online ordinal regression algorithm is more robust and efficient than state-of-the-art online ordinal regression algorithms.
Introduction
Ranking plays a central role in the learning task where the labels of data samples need to be ordered. For example, the levels of bond credits can be sorted as “B”
As an important tool, ordinal regression, also called ordinal classification, has been successfully used for the ranking task in a wide variety of applications, e.g. collaborative filtering [3, 4], ecology [5], detecting the severity of Alzheimer disease [6], to name a few. A seminal work of ordinal regression can be traced back to the proportional odds model (POM) proposed by Mccullagh [7], in which a general class of regression models for ordinal data was studied. In order to balance the model complexity and model fitness over the training dataset, Herbrich et al. [8] studied ordinal regression under the framework of structural risk minimization and proposed a new distribution-independent learning algorithm based on double-rank inter-loss functions. Later, the algorithms of sorting with constraint conditions in [9] provide a unified framework for classification and regression. Shashua and Levin [10] used support vector regression to order labels, in which a continuous value range is divided into
Compared with a classical offline algorithm, an online learning algorithm uses only a few data samples in model training at each time and, thus, much less storage and computation time are needed. Although existing online algorithms have made huge progressin reducing the memory requirement and computational time for big data, training models over a dataset with poor quality, e.g. noisy datasets, remains challenging.
In this work, we aim to study a noise-resilient online learning algorithm to promote the online ordinary regression problem for noisy data streams. Particularly, we propose PA algorithm with Ramp loss (PA-RAMP) for ordinal regression in an online learning manner using interval labels. Our key contributions are as follows:
Propose a noise-resilient algorithm, i.e. PA-RAMP, and design a procedure to update the model parameters for online ordinary regression. The optimal parameters are obtained by solving convex problems using the Concave-Convex Procedure (CCCP). Present support class algorithm with ramp loss (SCA-RAMP) to find the support class set that describes the thresholds need to be updated by finding the active constraints in theKarush-Kuhn-Tucker (KKT) system. Theoretically prove that the proposed PA-RAMP algorithm maintains the order of the thresholds. Perform experiments on various data sets and show the effectiveness of the proposed algorithm by comparing it with state-of-the-arts.
The paper is organized as follows. In Section 2, we discuss the related work. Section 3 presents a generic framework of ordinal regression using interval labels and the update rules for PA-RAMP. Besides, the order preservation guarantees of the threshold of proposed algorithms are discussed here. In Section 4, we conduct experiments and present the comparison results between PA-RAMP and state-of-the-arts. We conclude this work with some remarks in Section 5.
In this section, we review the related work from two aspects: online ordinal regression and Ramp loss.
Machine learning approaches use loss functions to penalize learning errors in the training process, and thus selection of the loss function is critical to the output performance of learning models. Many works have studied the effectiveness of the loss function on ordinal regression. Pedregosa [12] proposed a novel surrogate of the squared error loss and the ordinal regression problem can be solved by minimizing a convex surrogate of the zero-one, absolute, or squared loss functions. Recently, the online learning algorithm has gained a lot of attention due to the emergence of big data. Manwani [13] proposed an online learning algorithm PRIL (perceptron ranking using interval labels) for ordinal regression. The algorithm converges in finite steps, and its regret bound was used as an index to evaluate the algorithm convergence. More recently, Sahoo et al. [14] proposed a set of online multiple kernel regression (OMKR) algorithms for nonlinear regression problems. The application of OMKR algorithms was discussed for the prediction tasks in AR, ARMA and ARIMA time series. A precise Passive-aggressive (PA) online algorithm for ordinary regression was proposed in [15, 16], where a series of convex subproblems were solved iteratively in each round of the experiments.
While many works focus on improving algorithmic performance, the study of noise tolerance analysis for ordinal regression algorithms is still in its early stages. Since the standard binary support vector machine adopts Hinge loss function, its decision hyperplane is determined by several support vectors. However, outliers tend to have the greatest marginal loss and become support vectors (SVs), which are the determinants of hyperplane structures. Therefore, traditional support vector machines are sensitive to outliers or noise. Outliers tend to have the greatest marginal loss and become support vectors (SVs), resulting in distortion of the decision hyperplane. As the Hinge loss function is sensitive to noise, different loss functions, such as Pinball loss and Ramp loss, have been studied to reduce the sensitivity of the SVM-based models. Huang et al. [17] found that the advantage of Ramp loss applied to SVM algorithm (RSVM) is that it has stronger robustness and sparsity than SVM. Compared with Pinball loss, this algorithm retains the sparsity to a large extent. The Ramp loss function gives an upper bound on loss for any outliers, and thus RSVM is not very sensitive to the presence of outliers. However, using Ramp losses causes a big computation challenge as the RSVM model is non-convex. To solve this problem, a concave convex procedure (CCCP) is introduced to convert the non-convex optimization problem into a series of convex optimization problems to obtain the optimal solution of RSVM. Many researchers have studied the Ramp loss by applying binary SVM, such as the non-parallel Ramp loss SVM proposed by Liu et al. [18], and the least square SVM proposed by Liu et al. [19]. Tian et al. [20] proposed a single-class SVM with Ramp loss and Lu et al. [21] proposed a double-spherical SVM with the largest Ramp loss, etc.
Method
Learning to rank in online ordinary regression
Comparing with the traditional batch learning framework, online learning (shown in Fig. 1) takes samples for training in a streaming fashion so that it is easy to scale and respond in real-time. We first introduce the online ordinary regression of PA algorithm and its variants, and then propose a noise-resilient online learning algorithm in the next section.
The framework of online ordinary regression. At round 
Consider a general setting for online ordinary regression [15], let
where function
Taken
As the Hinge loss
Hinge loss (left) and Ramp loss function (right).
Based on the above analysis, we propose a noise-resilient online learning algorithm in the next section. We first introduce the online ordinary regression of the PA algorithm and its variants.
PA algorithm and its variants
PA algorithm was first introduced in [15] for ordinal regression in online fashion. Let
For Eq. (3.2.1), it is passive if the Hinge loss is zero, that is,
Besides, the variants PA-I of PA algorithms are as follows:
where
In this section, we present the PA-RAMP procedure to minimize the estimated risk using the difference of two convex functions (DC) and convex-concave procedure (CCCP) structure [22] of ramp loss in online ordinary regression.
(1) Ramp loss
To reduce the negative influence of outliers in PA, the Ramp loss function, i.e. the robust hinge loss has been proposed and it can be denoted as follows,
Ramp loss is a DC function.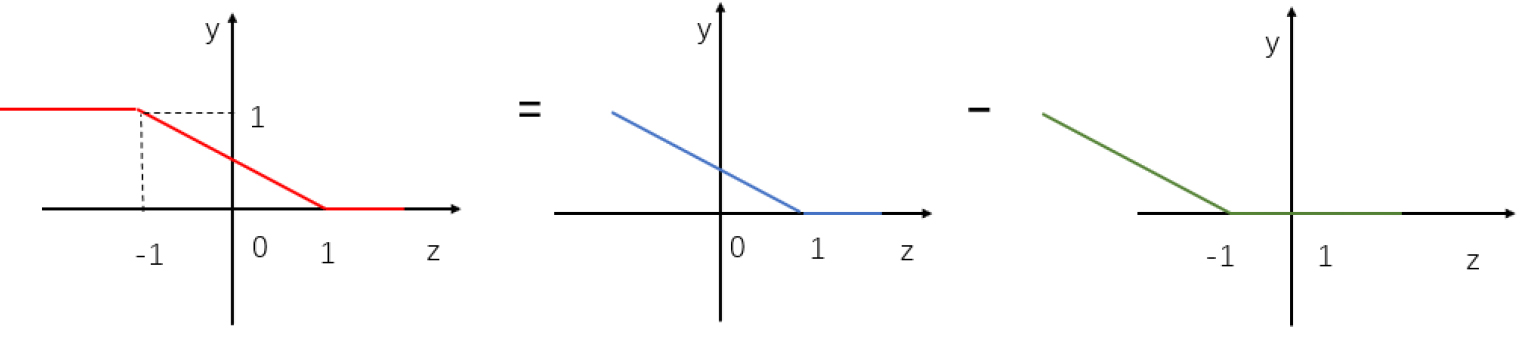
Notice that the Ramp loss is a noise-resilient function, that contributes to noise loss become 0 when
where
(2) PA-RAMP algorithm
In the setting of ordinal regression, instead of considering all the categories to contribute errors for threshold, we allow the Ramp loss function to update the thresholds. The ordinal inequalities on the thresholds are satisfied automatically at the optimal solution. Figure 4 illustrates the roles of slack variables
An illustration of slack variable in online ordinary regression.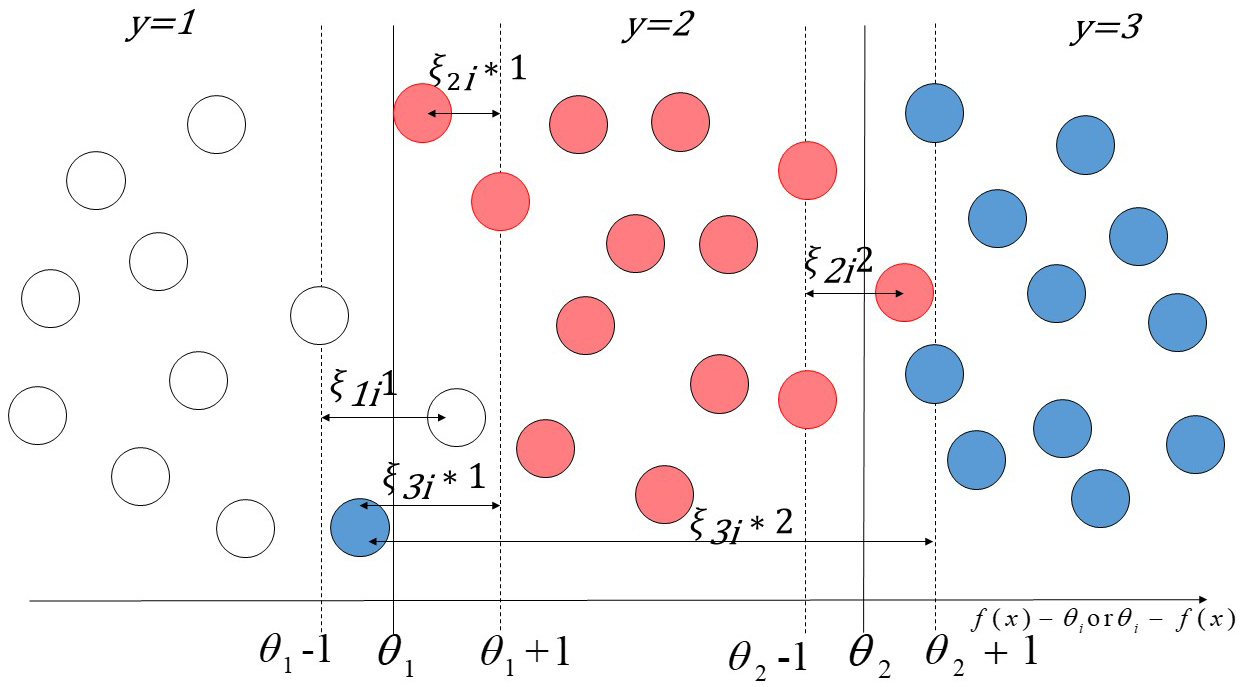
We now derive the PA-RAMP algorithm of the online ordinary regression to update the parameters to predict the label(s). Then we observe the actual label(s). In Eq. (3.2.1), the slack variable is eliminated and the Ramp loss is introduced to obtain the unconstrained optimization problem. It can be defined as follows.
In the above equation, we take the upper interval endpoint as an example. Since
So, it is found that the objective function Eq. (8) can be written as the sum of convex and concave functions. where
Note that
Let
Due to the non-convex term of the objective function in Eq. (11), we employe the CCCP algorithm to solve it. In order to get the optimal solution of Eq. (11), we solve the following equation iteratively. Non-convex function
where, the term
Partial derivatives
where,
Combining Eqs (9)–(12), we can only minimize the following convex optimization problems at each iteration of CCCP, and the optimal solution of the objective function Eq. (12) is obtained by iteratively updating the optimization variable
Let
where
Lagrangian for the above objective function is as follows.
where
The KKT optimality conditions are
Let
For
Similarly, for
In addition,
Note that sets
[H] : PA-RAMP Algorithm[1] Training set
: Support Class Algorithm (SCA-RAMP)[1]
Initialize
Note that Ramp loss
.
Consider a function
is gauranteed to monotonically decrease
Proof..
The convexity and concavity of
for all
This completes the proof. ∎
Considering the property of PA algorithms, we show that the PA-RAMP algorithm inherently maintains the ordering of thresholds in each iteration.
.
(Order preservation of thresholds in PA-RAMP algorithm) Let
Proof..
We need to analyse different cases as follows.
We know that
Thus
as
When
From
which is greater than 0 since When
There are four different cases.
This completes the proof. ∎
Similar arguments can be given for the right support class
In this section, we evaluate the performance of the proposed PA-RAMP algorithm by comparing it with other benchmarking methods on datasets with various ratios of noise.
The employed datasets can be obtained from UCI2
Available:
Available:
The employed datasets are as following. Each feature of datasets is normalized to zero mean and unit variance for coordinate wise. Interval labels of our datasets should be analyzed and designated by domain expert.
Table 1 shows the characteristics of the 5 datasets, including the number of instances, attributes, and classes, and also the number of instances per class. To show the statistical properties of different data sets, we drew a box plot as shown in Fig. 5. The blue dots represent outliers. As the figure shows, the data contain a small amount of noise, especially in Parkinsons-updrs and Wine datasets.
Ordinal regression datasets
Ordinal regression datasets
Box plots of five benchmark datasets.
To ascertain how the noise affects the prediction, we test our algorithm on the five datasets obtain from UCI with artificial perturbation. Considering that noise comes from two main sources,
We compare the performance of proposed PA-RAMP algorithm with other benchmarking methods in solving the online ordinal regression with interval labels, that is, PA in [15], PA-I in [15] and PRIL [13], where PRIL is PRank (perceptron rank [2]) based approach for online ordinal regression using interval labels. Moreover, the noise tolerance of PA-RAMP on five datasets is investigated with various ratios of noise. Thus, experiments on noise sensitivity study of target variables
Accuracy comparison results of PA, PA-I, PRIL and PA-RAMP under different noise data on target variables.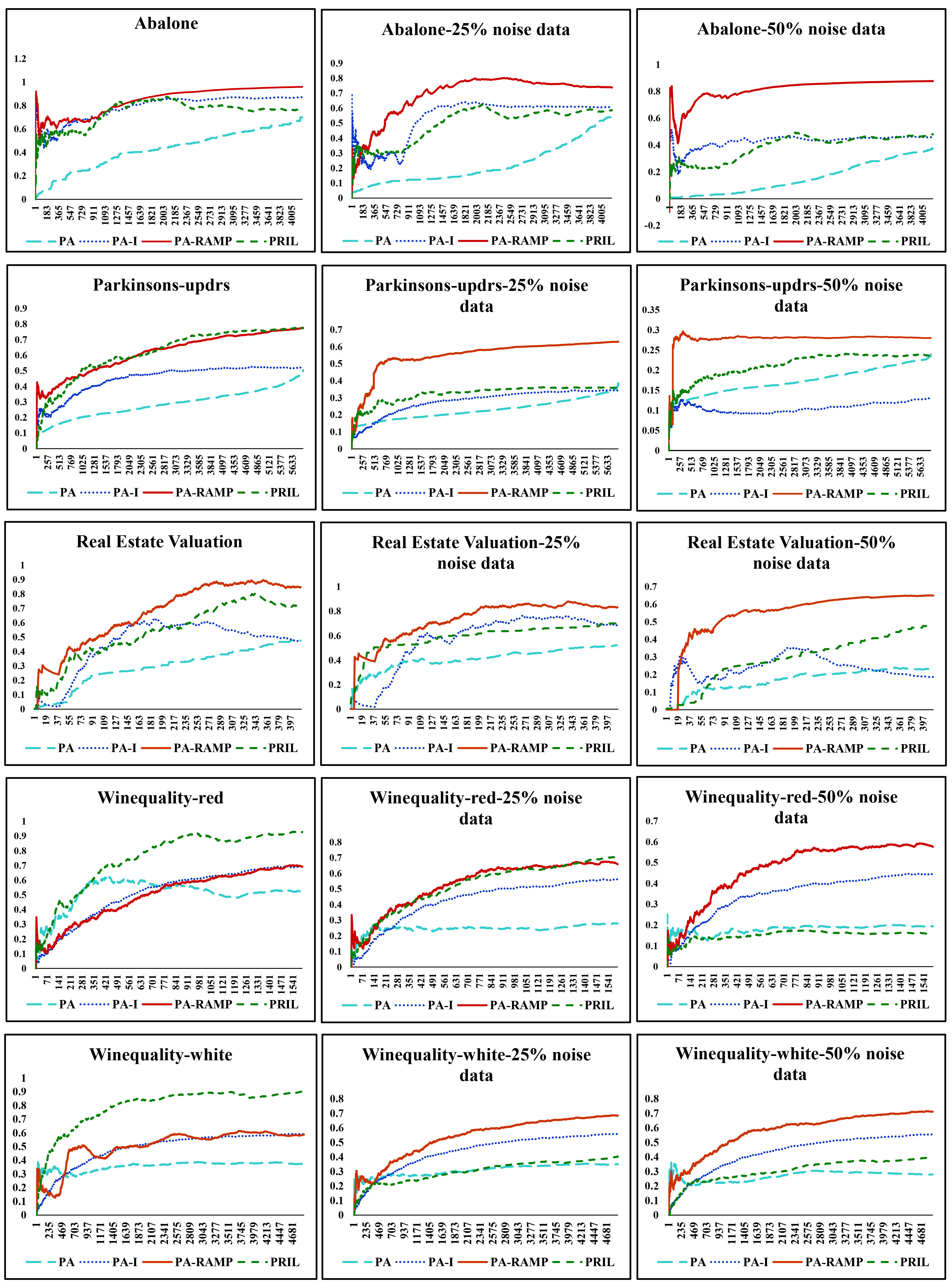
The purpose of this experiment is to compare the global exactitude performance of four methods with various ratios of noise on target variables. We employ the Accuracy in [9], defined by
For all the datasets, the Accuracy increases faster than the number of trial In general, the Accuracy of PA-RAMP is higher, and the PA-RAMP outperforms three methods over all datasets with different noise levels. Also, the noise-resilient PA-RAMP and noise-sensitive algorithms (PA, PA-I and PRIL) work equally well in terms of accuracy in no added noise environment. Moreover, the gap of Accuracy between PA-RAMP and other approaches increases along with the level of noise, especially in PA-I. On Abalone datasets, the Accuracies of PA-RAMP, PA-I and PRIL are almost close when the dataset has 0% noise. However, the predictive Accuracies of the PA, PA-I and PRIL are relatively low and unstable in datasets in two noisy data cases and this result shows the three algorithms are very sensitive to noise. Interestingly, PA-RAMP outperforms others while PA-I performs comparably to PRIL and consistently better than PA. In comparison, the PA-RAMP gets the better noise-resilient performance. On Parkinson and Real Estate Valuation datasets, the different degrees of the prediction Accuracy are obtained by PA, PA-I and PRIL in different label noise, whereas PA-RAMP shows better noise tolerance. On Winequality-red and Winequality-white datasets, the Accuracies of PA-I and PA-RAMP are close when the datasets have 0% noise. However, PA-RAMP outperforms PA-I across all levels of noise. Especially, the Accuracy of PRIL gradually decreases along with the level of noise while the prediction accuracy of PA-RAMP increases. PA shows consistently the lower test Accuracy than that of the others.
It is clear from the graphs of that that PA-RAMP outperforms the basic PA, PA-I and PRIL algorithms when the noise level is high. Thus, overall, the proposed noise-insensitive PA-RAMP algorithm significantly performs better than PA-I and PRIL, and consistently better than the PA algorithm, although the latter is more stable.
The primary difference between PA algorithms (PA, PA-I, PA-RAMP) and PRIL is that PRIL uses a constant step size whereas PA algorithms choose an appropriate step size to find the new
In this section, we conduct some experiments to evaluate the global Accuracy of four online methods on different noisy covariance variables and investigate the comparison of the proposed PA-RAMP algorithm with PA-I on various ratios of noise data by considering order and statistical details.
The accuracy comparison
Because of an artificial perturbation on covariance variables, the statistical properties of five datasets in 25% and 50% noise data are shown in Figs 7 and 8. The x-axis denotes the dimensions of examples and the y-axis corresponding to the perturbation of outliers. We analyze the Accuracy of four methods on the noise. As analysis of Accuracy in covariance variables noise in Fig. 10 is similar to target variables, we skip the details. Note that with 0% noise, the curve on covariance and target variables are the same ones.
Five benchmark datasets under 25% noise data.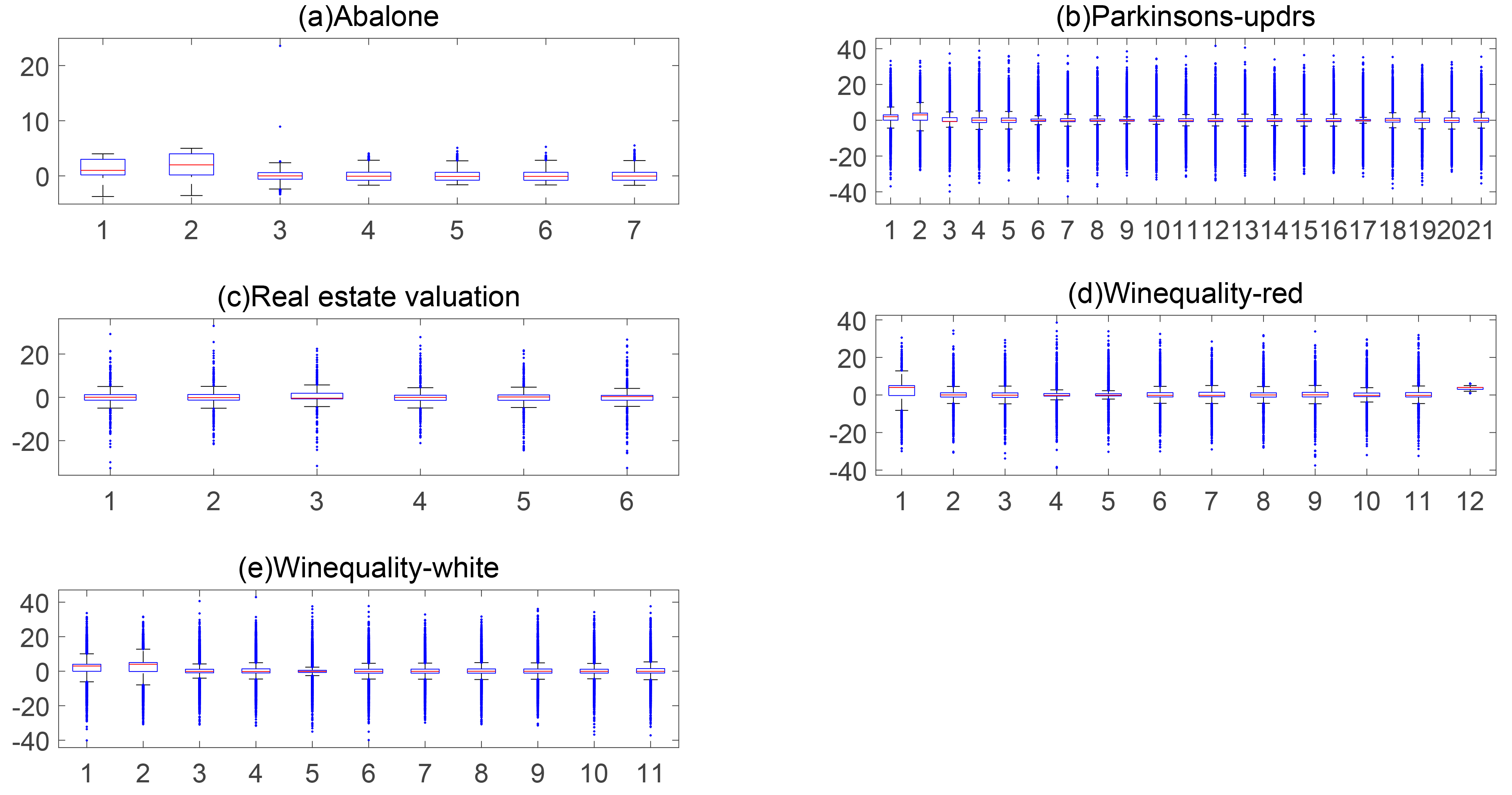
Five benchmark datasets under 50% noise data.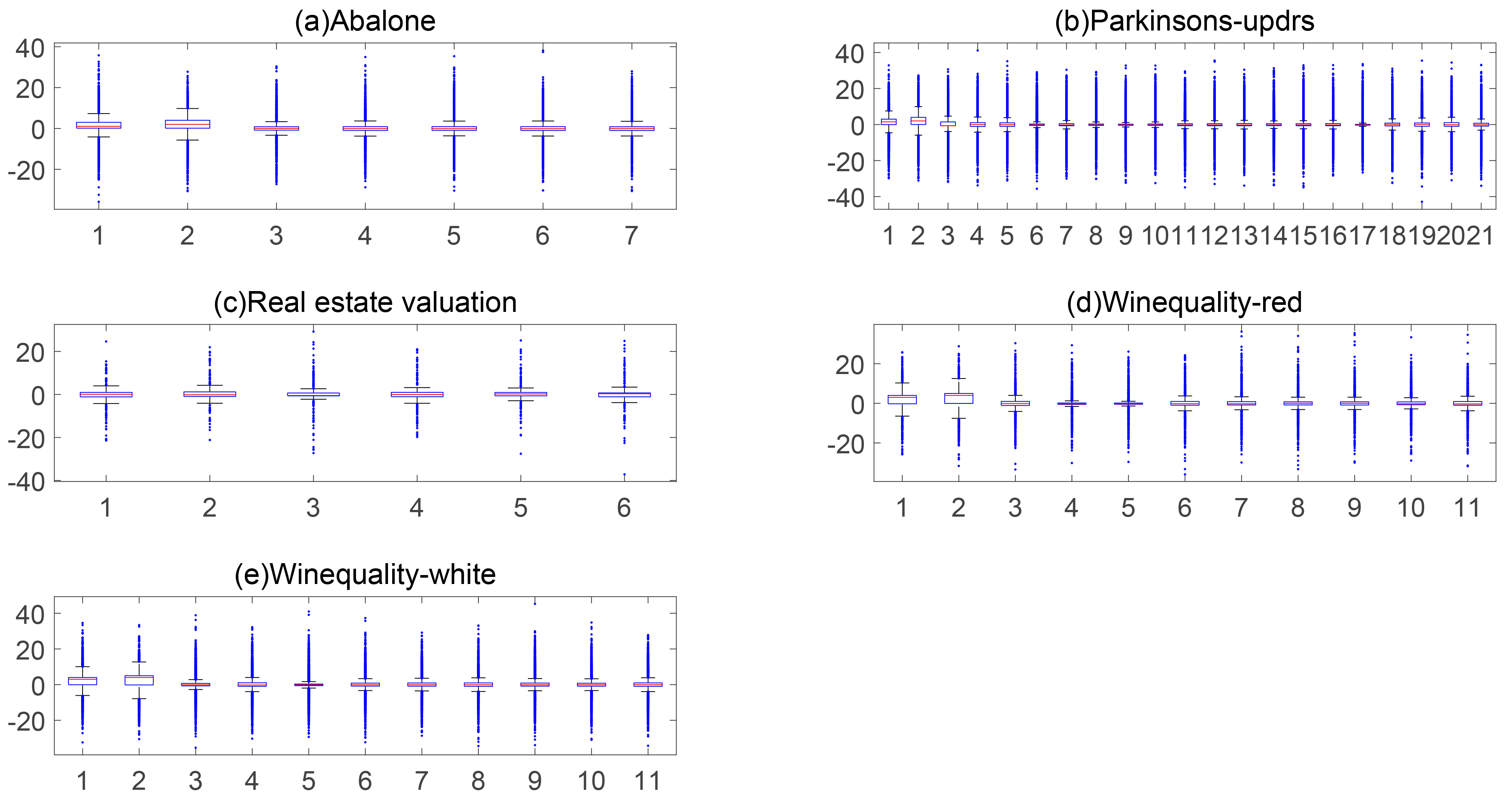
Accuracy comparison results of PA, PA-I, PA-RAMP and PRIL under different noise data on covariance variables.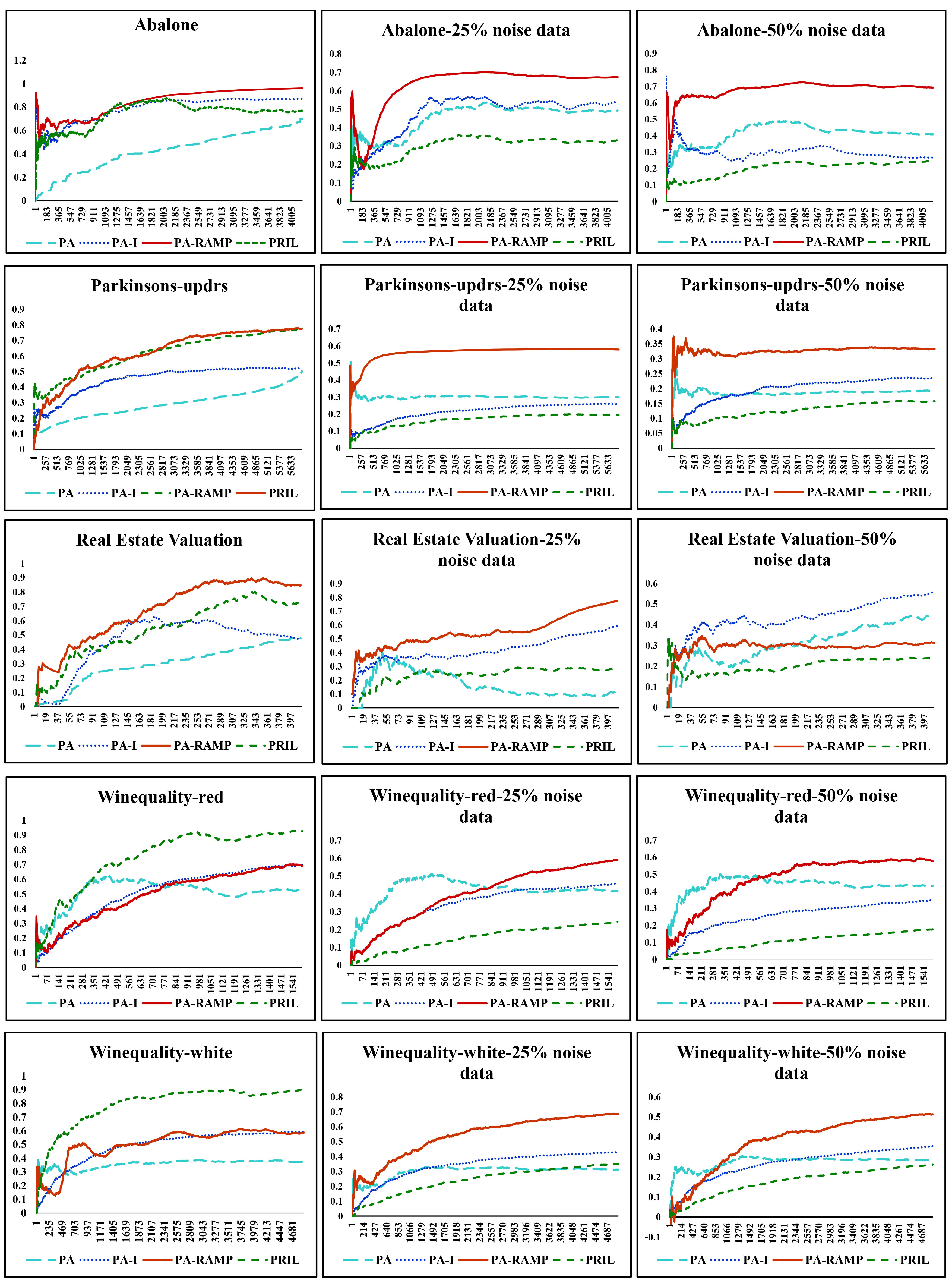
Sensitivity estimation of PA-I and proposed PA-RAMP algorithm of five datasets under 0% noise data. For each dataset, we have three noise scenarios to discuss:
Sensitivity comparison of PA-I and the proposed PA-RAMP in online ordinal regression under 25% noise data. For each dataset, we have three noise scenarios to discuss:
Sensitivity comparison of PA-I and the proposed PA-RAMP in online ordinal regression under 50% noise data. For each dataset, we have three noise scenarios to discuss:
We investigate the proposed noise-resilient online ordinal regression algorithm in the case of covariance variables noisy data by considering the order. Specifically, we attempt to apply the statistical measures to answer how effective the proposed PA-RAMP method is in handling data with noise input. In this subsection, we have reported a number of simulation studies on finite-sample performance evaluation (
The results are summarized in Tables 2–4. As can be seen from the columns of MAE and RMSE, the proposed PA-RAMP method outperforms the competing PA-I in two noisy data cases. Especially, in the case of a high level (50%), PA-RAMP significantly outperforms based algorithm PA-I. Spearman’s Correlation Coefficient shows that the correspondence of PA-RAMP in ranking terms of the two distributions is greater in three cases of noise. Empirically, as we increase the ratio of noise, the difference between the two methods in each evaluation index becomes apparent. Due to the intrinsic flaw of hinge loss, PA-I method is highly sensitive to noise. Ramp loss can effectively reduce the impact of noise data in some sense, except for individual data. Moreover, as we increase our sample, the number of discarded samples increases with the level of noise, compared with PA-I. Most of the samples are discarded when the noise level is 50%. Not surprisingly, the percentage of the noisy data significantly affects the discarded rate and the results of the algorithms. Empirically, the discarded rate is approximately equal to the noise ratio. Furthermore, the estimation of small samples can lead to the instability of the model because the prediction accuracy depends on the proportion of noise points that are used in the process of training the model. As for time, it depends on the size of the sample and how many times of
Noise sensitive comparison
Sensitivity analysis result between MAE and discard rate.
The purpose of this experiment is to compare the noise sensitivity of the three algorithms. In other words, when the noise ratio is constantly increasing, we compare the degree to which the prediction accuracy of the algorithm decreases. The slower the reduction, the weaker the algorithm’s sensitivity to noise, that is, the stronger the anti-noise stability. According to the data statistics in the previous section, we used indicator MAE to represent the accuracy of prediction and discard rate to represent the real noise addition rate. We observed the weakening degree of MAE of three algorithms (PA-I, PA-RAMP, and PRIL) with the increased sample discarding rate. We have plotted the 2D performance variation under the different settings of noise in Fig. 10. The left side of the graph represents the unit change of MAE, and the right side represents the unit change of the sample discard rate, i.e., the actual noise ratio, and the x-axis represents the theoretical noise ratio. Through observation, we get the following results:
The discard rate of each dataset is equal to the actual noise ratio approximately. With the increase of noise ratio, the MAE value of the three algorithms gradually increases, and the prediction accuracy gradually decreases. However, the MAE of the proposed algorithm PA-RAMP gradually tends to be stable with the increase of sample discard rate, and the degree of growth is the slowest. Especially when the outlier ratio is greater than 50%, most of the noisy samples are discarded, and the MAE increment of PA-RAMP is the smallest. That is, PA-RAMP has better anti-noise stability. To be specific, the proposed PA-RAMP outperforms the two competing methods (PA-I, PRIL) significantly in the cases of high level noisy data. Because of the perceptron loss, original PRIL is very sensitive to noise data. However, MAE of PA-I is higher than PRIL, because Hinge loss function is more sensitive. Not surprisingly, both PRIL and PA-I are sensitive to noise due to their loss functions. However, the MAE of PA-I is higher than that of PRIL as the Hinge loss function is more sensitive. Moreover, MAE will gradually increase and stabilize with increasing of noise ratio compared with two others. Specifically, when the noise ratio is greater than 50%, most of noisy samples are discarded, so the MAE of PA-RAMP will gradually stabilize though it increases with increase of noise data. Furthermore, due to the discard samples in the cases of high level noisy data, PA-RAMP can reduce the impact of noise data obviously and has the best anti-noise stability.
In this paper, we proposed an online ordinal regression method, PA-RAMP, where the Ramp loss function was employed for dealing with the noisy data. An efficient algorithm based on the CCCP framework has been presented to solve PA-RAMP, which iterations preserve the order of thresholds. Analysis shows that the proposed PA-RAMP is noise-resilient in the scenarios of interval label(s). At last, we conducted experiments on various datasets to validate that PA-RAMP is a robust and good candidate to deal with noisy data streams. While this paper focused on online settings, the proposed method could also serve as building blocks of large-scale batch algorithms. Future work will involve extending the ordinal regression model to a non-linear regression model by introducing kernel trick [26].
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant Nos. 71961004, 71461005 and 71561008, Thesis Cultivation Project of GUET Graduate Excellent Master under Grant No. 2019YJSPY01, Innovation Project of GUET Graduate Education under Grant No. 2019YCXS081.
Conflict of interest
The authors declare that they have no conflict of interest.
Appendix
PA-RAMP algorithm is derived as follows.
In Section 2, we have derivated the framework of PA-RAMP algorithm from Ramp loss using CCCP. From Eq. (8)
we have Eq. (16):
where
Lagrangian for the above objective function is as follows.
where
The KKT optimality conditions are as follows.
We now known
To solve
Let
For
That is
On the other hand, from ⟂, we get
So
For
where
On the other hand,
So
where
where
where
For
For
From ⟀, we have
For
For
where