
Abstract
A new clustering algorithm, based on Adaptive Local Density (ALD) and Evidential
Keywords
Introduction
The task of cluster analysis is to divide a dataset into several groups or clusters according to their intrinsic characteristics or similarities, therefore intracluster points have high similarities and intercluster points have few similarities. Since clustering has powerful ability to unveil inherent, unknown and complex rules in real-world, it becomes one of the most important tasks in many fields such as extracting information [23], machine learning [32], pattern recognition [16], image analysis [39] and bioinformatics [30]. So far, many clustering algorithms [42, 12, 3, 44] have been proposed including partitioning clustering, hierarchical clustering, density-based clustering, gird-based clustering and distributed-based clustering.
Recently, Rodriguez and Laio [35] proposes another density-based clustering method: clustering by fast search and find of density peaks (DPC). With the assumption that a cluster center is surrounded by the points with lower local densities and far away from the points with higher local densities, DPC can efficiently find cluster centers and then assign remaining points to their corresponding groups. DPC has powerful ability to detect non-spherical clusters and identify the number of clusters. Parmar et al. [31] computes the local density by a residual error to handle low density datasets and assign remaining points according to ascending order of their residual errors. Du et al. [8] propose a novel density peak clustering algorithm called DPC-MD, which extends DPC to deal with mixed data (with both numerical and categorical value).
To our best knowledge, DPC and most of DPC successors can not handle the datasets with variable-density very well, because they use global cut-off distance to compute local density. Here, we introduce a strategy to calculate local density based on local cut-off distance. Since local information of each point is considered, the local density could be adaptive to both variable-density datasets and invariable-density datasets. Additionally, assigning strategy in DPC may cause propagation errors. And it means that many points with lower density may be assigned incorrectly once a point with higher density is assigned erroneously. To reduce the probability of this wrong assignment, two modifications are made here. Firstly, these remaining points are assigned according to ascending order of their minimum distances. Secondly, the point’s
The main contributions of ALD-EKNN are: (1) a novel density metric named ALD is proposed to handle muti-density datasets; (2) EKNN can reduce the risk of false assignation in order to improve the clustering performance; (3) EKNN can provide a credal partition to identify border and noise points simultaneously.
Simulations on both synthetic and real-world datasets can show advantages of our ALD-EKNN. The rest of the paper is organized as follows. In Section 2, DPC algorithm and evidential theory is introduced briefly. Section 3 introduces our algorithm, including the adaptive local density strategy and assigning strategy based on EKNN rule. In Section 4, we give some experiments to test our algorithm. Section 5 gives the conclusion.
Preliminaries
In this section, we will recall some related works and briefly introduce DPC algorithm and evidential theory.
Related works
DPC is a well-known clustering algorithm and it has many followers. To handle local structure and high dimension of the datasets, Du et al. [7] propose a density peaks clustering based on
Density peak clustering
In DPC [35], a cluster center is defined as a point which has higher local density than its neighbors and a relatively large distance from the points with higher local densities. To detect cluster centers, two important quantities of each point are defined. The first one is local density
or
where
To compute these two quantities
where
Evidence theory, also named as Dempster-Shafer (DS) theory, is widely used to handle the reasoning and decision making problems [36, 37, 28]. In DS theory, some independent pieces of evidence are represented by belief functions, and they can be combined, by Dempster’s rule (refer to DS rule), to help us make a decision. Let
Each subset
The contour function
To simplify the calculation, the combination of two contour functions is computed by
Our clustering algorithm consists of two steps. Firstly, cluster centers are detected by the adaptive local density strategy; Secondly, the remaining points are assigned in terms of assigning strategy based on EKKN rule. The two algorithms are introduced respectively as follows.
Adaptive local density strategy
In DPC, all points in the dataset use a global cut-off distance
In our strategy, each point has its own cut-off distance
where
The distance
The adaptive local density strategy is summarized in Algorithm 1:
[htb] The adaptive local density strategyDataset X, parameters
By comparison with DPC, there are two improvements in our assigning strategy. Firstly, remaining points are ranked by ascending order of the minimum distance, which is a minima of the distances between the point
After detecting cluster centers, which can be regarded as a framework
The points, once being allotted, can provide pieces of evidence for those points in group two. So we hope that one point closer to a cluster center can be assigned earlier since it can provide more reliable evidence. According to the ideology, the points in group two are sorted in ascending order of their minimum distances, which is defined by
where
In terms of the assigning order, points in group two are assigned one by one. Without loss of generality, we assume that
where
where
After
After the point
The process of EKNN is summary in Algorithm 2:
[htb] Assigning strategy based on EKNN ruleDataset Dataset X and its Cluster centers
Assume that the dataset has
As for time complexity of ALD-EKNN, it depends on the following parts: (1) computing the distance matrix and sorting them
Experiment results
This section consists of two parts. In Section 4.1, some illustrative examples are used to show the characteristics of ALD-EKNN. In Section 4.2, we compare the performance of ALD-EKNN with Self-Organization Map (SOM), DPC and some of DPC’s successors on synthetic and real-world datasets. To compare the performance of clustering results among different clustering algorithms, many cluster quality indices, i.e. accuracy [17], F-measurement [17], Normalized Mutual Information (NMI) [17], Adjust Rand Index (ARI) [41] can be good candidates. ARI is used here since it is a popular and comprehensive performance index. To make the results independent from the units for different attributes, these input data points are normalized into [0, 1] by a min-max rule
In addition, to evaluate the dissimilarities between different points, many distance measures can be selected. These measures include Euclidean distance [27], Manhattan distance [14], Mahalanobis distance [4], Minkowski distance [18] etc. To yield better performance, some researchers [34] combine some of distance metrics and some researchers [1, 46] propose some new distance metric learning methods. Distance measures play an important role in clustering and classification tasks, and it is a big topic. However, it is not the topic for this paper. We choose Euclidean distance here since it is simple and widely used in many literatures.
Artificial dataset.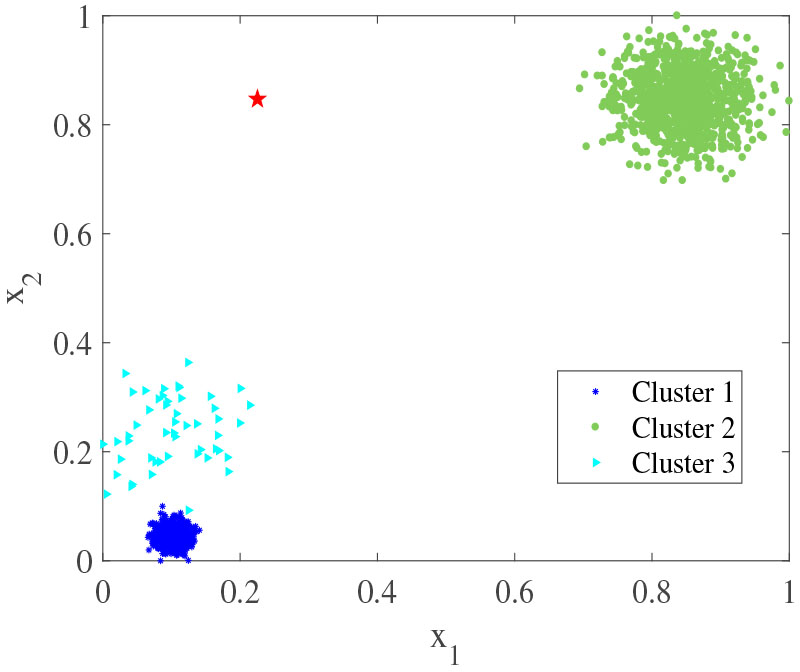
The cut-off distance
where
Graph of 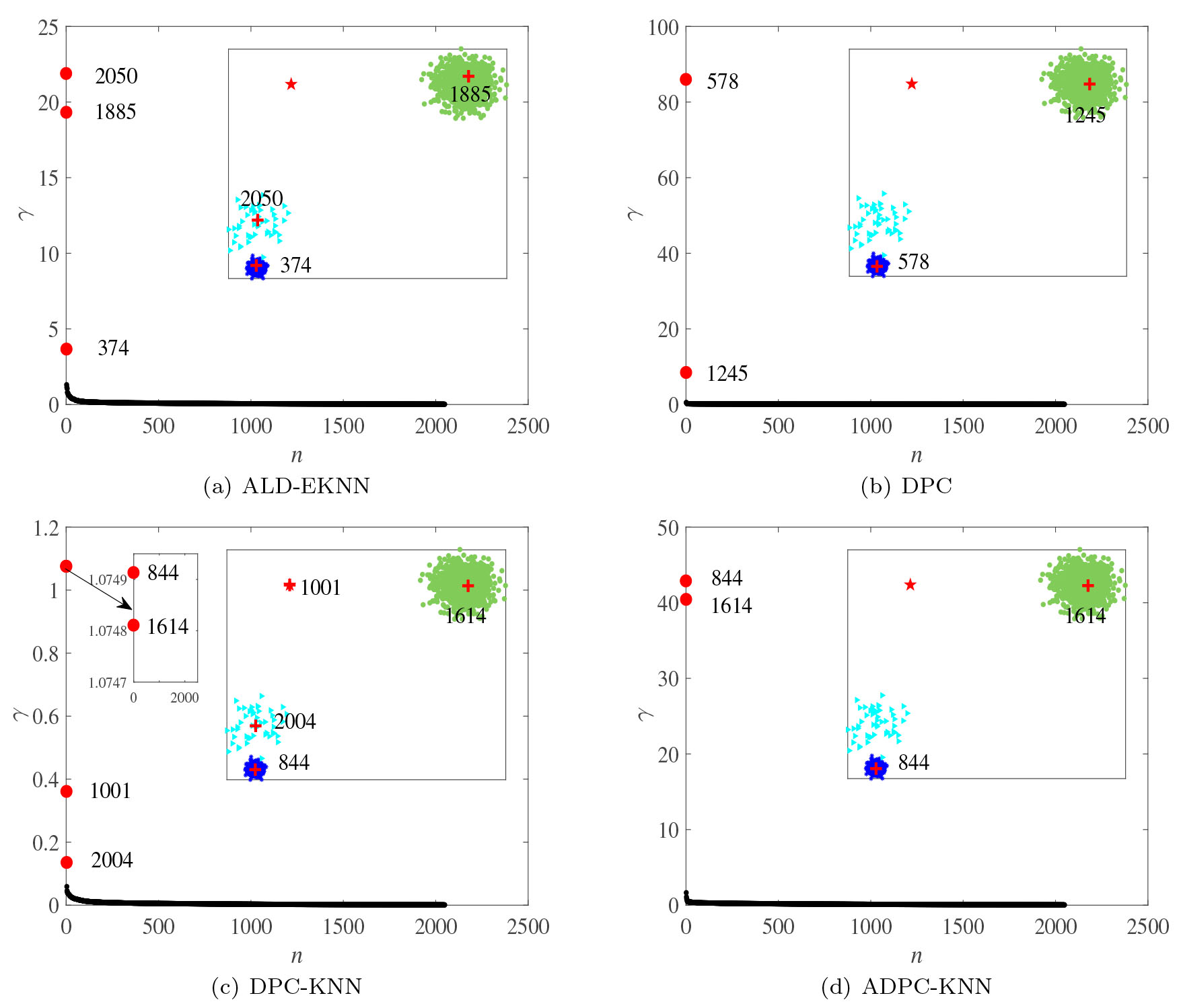
Figure 2 shows the graph of
To pinpoint the specific cause, we do some studies on the cut-off distance
Exponential function with different cut-off distances.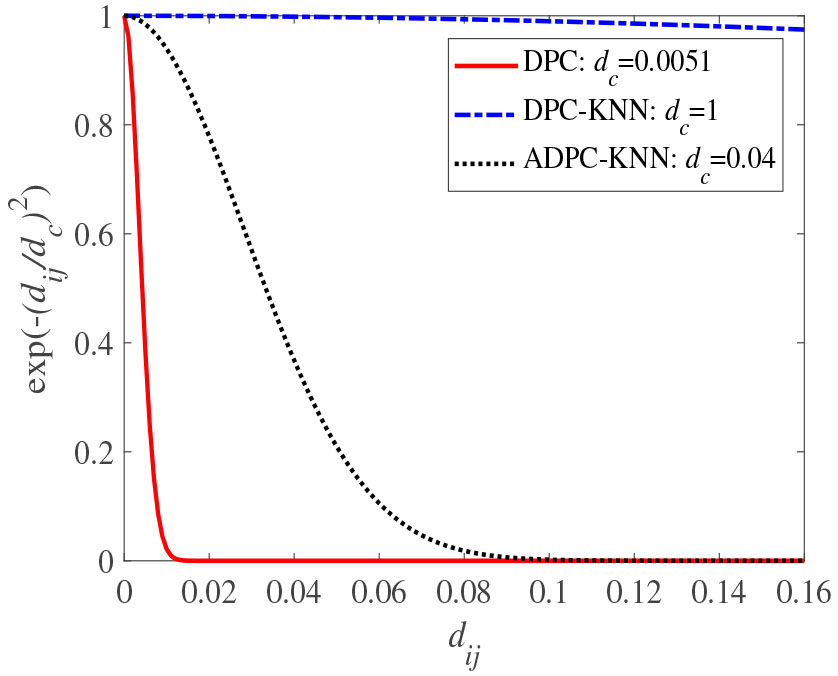
Distance statistical distribution.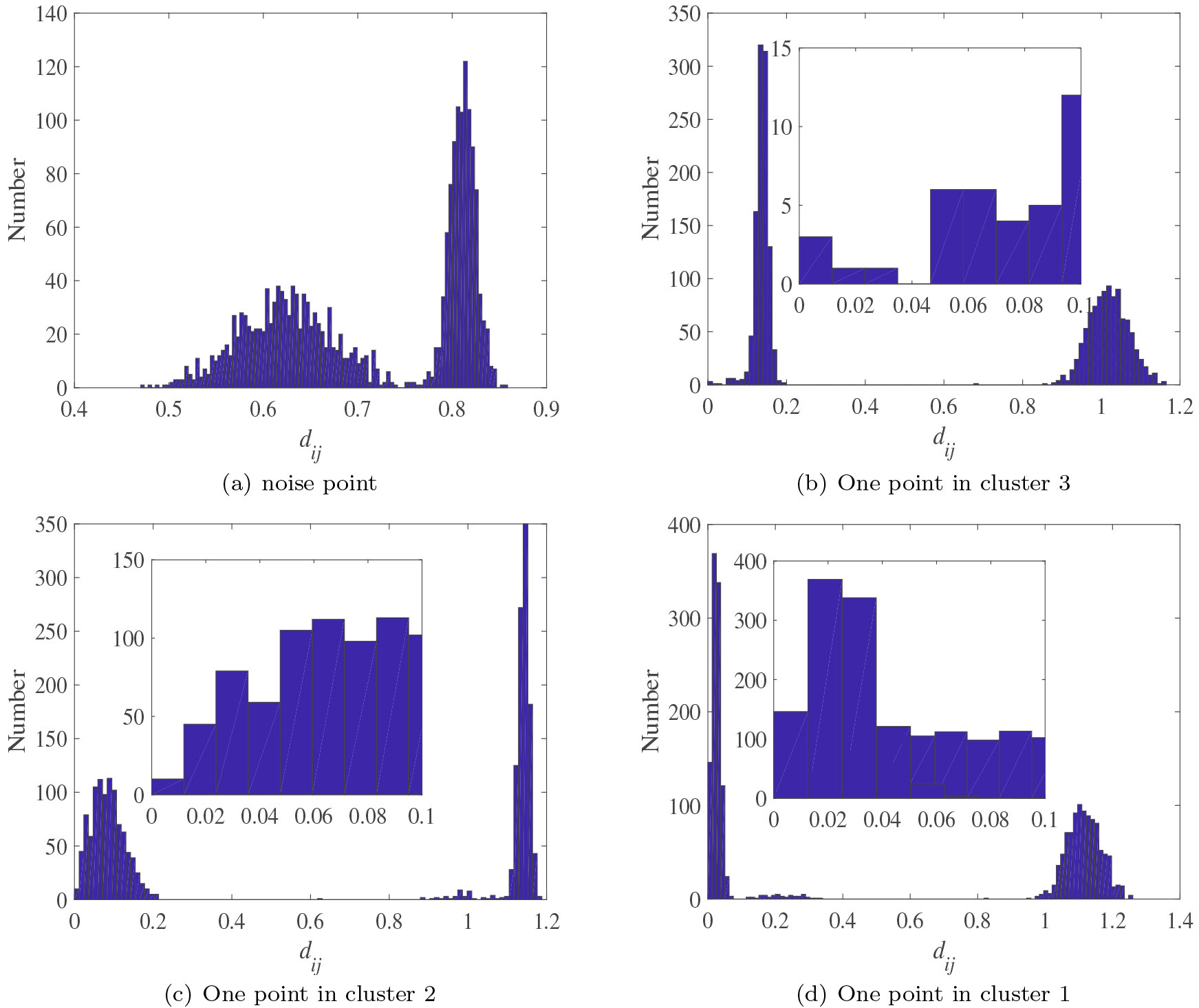
Figure 4 displays the statistical result of distance
In our algorithm, ALD-EKNN, cut-off distance
Clustering results on artificial dataset with four classes.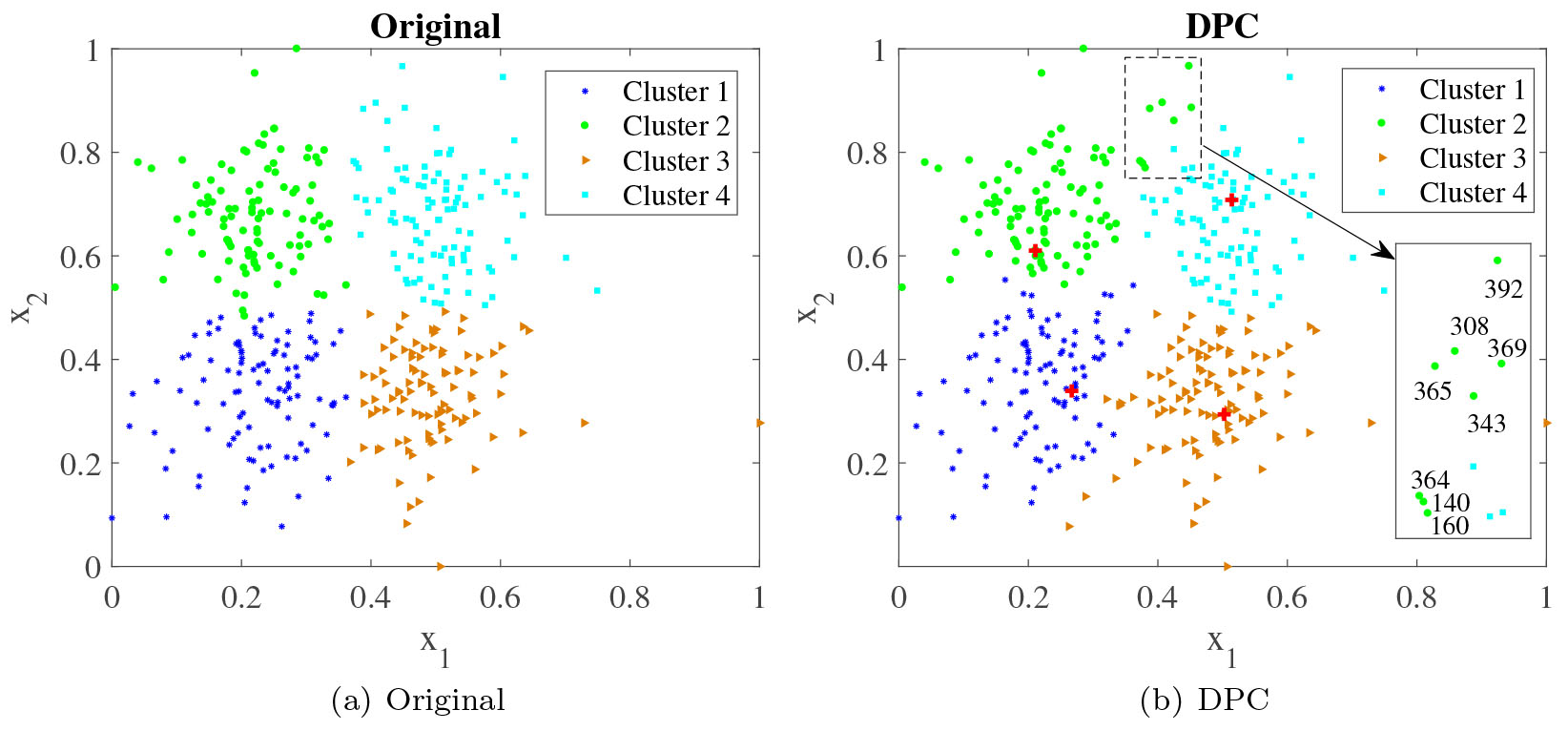
According to DPC’s assigning rule, point 140 will be assigned firstly among these eight points due to its highest local density. Unfortunately, it is assigned wrongly since its nearest higher-density neighbor, point 380, belongs to cluster 2. Then it passes wrong information to other points with lower local density. This phenomenon is named as the ripple effect. The probable reason is that, in DPC, only the first nearest higher-density neighbor has been considered while making the decision. Once the undetermined point and its first nearest higher-density neighbor are not in the same cluster de facto, it will be wrongly assigned.
The assigning information for some points
To reduce the risk of wrong assignation,
In addition,
Point 140’s 15-nearest higher-density neighbors
Contour surfaces of the clustering results.
Clustering performance via different parameters.
In this subsection, ALD-EKNN is tested on some synthetic and real-world datasets with characteristics shown in Table 3. There are 7 synthetic datasets and 7 real-world datasets, which are widely used in many literatures [20, 40, 11, 10, 21, 33]. a3, d31 and s2 have mild overlapping. dim 1024 has 16 clusters with very high dimensions. s4 has 15 clusters with severe overlapping. Unbalance has 8 clusters with multi-density. All these real-world datasets have high dimensions.
To show the advantage of our assigning strategy, after detecting the cluster centers through adaptive local density strategy, we assign the remaining points via different methods. Firstly, we compare EKNN through distance sorting (shortly for EKNN-Dis) with EKNN through density sorting (shortly for EKNN-Den). Secondly, we compare EKNN-Dis with assigning strategy in ADPC-KNN, assigning the remaining points to their nearest centers (shortly for NC). Figure 8 displays the ARI values by EKNN-Dis versus those obtained by EKNN-Den and NC. Two datasets dim1024 and unbalance are not shown in Fig. 8, and their ARI values are all equal to 1 via these three methods, which indicates that there is no difference among them. Figure 8a shows that EKNN-Dis outperforms EKNN-Den on 8 datasets whereas EKNN-Den outperforms EKNN-Dis on 2 datasets and 2 draws on parkinsons and iris. It can be seen from Fig. 8b that NC only outperforms EKNN-Dis on pima while EKNN-Dis outperforms NC on 9 datasets and 2 draws on d31 and parkinsons. Therefore, it can be concluded that EKNN-Dis is superior to EKNN-Den and NC on most cases.
Dataset description
Dataset description
ARI values via different assigning methods.
ARI values: Comparison between our algorithm and several other algorithms
For comparison, other clustering algorithms, like Self-Organization Map (SOM) [29], DPC [35] and several DPC successors, including ADPC-KNN [45], FKNN-DPC [43], DPC-KNN [7], are applied to these datasets. Table 4 shows the ARI values of six clustering algorithms on both synthetic and real world datasets. The bold font represents the best result on this dataset. The parameter
To further compare these algorithms, the combination of Friedman test and Nemenyi test is applied here. To do the Friedman test, the ranking table should be obtained. We rank these algorithms on each dataset in terms of their ARI values. If some algorithms have the same ARI value, for example, on dataset dim1024, five algorithms have the same ARI, they will all rank 3, which are computed by
where
where
In this case, the critical value is 2.550 when
where
Performance ranking on our algorithm and several other algorithms
Nemenyi test: Comparison between our algorithm and several other algorithms.
A novel clustering algorithm based on adaptive local density and evidential
However, ALD-EKNN has a large time complexity when confronting big data. Therefore, future studies are needed to deal with it.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant No. 51976032).