
Abstract
For deep learning’s insufficient learning ability of a small amount of data in the Chinese named entity recognition based on deep learning, this paper proposes a named entity recognition of local adverse drug reactions based on Adversarial Transfer Learning, and constructs a neural network model ASAIBC consisting of Adversarial Transfer Learning, Self-Attention, independently recurrent neural network (IndRNN), Bi-directional long short-term memory (BiLSTM) and conditional random field (CRF). However, of the task of Chinese named entity recognition (NER), there are only few open labeled data sets. Therefore, this article introduces Adversarial Transfer Learning network to fully utilize the boundary of Chinese word segmentation tasks (CWS) and NER tasks for information sharing. Plus, the specific information in the CWS is also filtered. Combing with Self-Attention mechanism and IndRNN, this feature’s expression ability is enhanced, thus allowing the model to concern the important information of different entities from different levels. Along with better capture of the dependence relations of long sentences, the recognition ability of the model is further strengthened. As all the results gained from WeiBoNER and MSRA data sets by ASAIBC model are better than traditional algorithms, this paper conducts an experiment on the data set of Xinjiang local named entity recognition of adverse drug reactions (XJADRNER) based on manual labeling, with the accuracy, precision, recall and F-Score value being 98.97%, 91.01%, 90.21% and 90.57% respectively. These experimental results have shown that ASAIBC model can significantly improve the NER performance of local adverse drug reactions in Xinjiang.
Keywords
Introduction
Named Entity Recognition (NER) is an important task in the field of natural language processing (NLP) and can be used for many downstream tasks of NLP, such as relationship extraction, event extraction, machine translation, and question-answering systems. In recent years, with increasing in-depth research into deep learning, great breakthroughs have been made in image processing and NLP of deep learning. Deep learning refers to a series of methods for learning from data within a specified range and obtaining specific features of them. The better generalization ability of deep learning can make NER less dependent on manual annotation to a certain degree.
Adverse drug reactions (ADR) are harmful reactions caused by drug quality issues or improper use of drugs, ranging from side effects, toxic effects (toxic reactions), residual effects (post-effects), allergic reactions, idiosyncratic reactions, double infections and dependence caused by anti-infective drugs, and carcinogenic, teratogenic, mutagenic effects, as well as the effects of the drug itself or drug interactions, which are not related to the purpose of the drug and are not conducive to the patient. At present, adverse drug reactions are becoming the focus of medical R&D (research and development) departments, common users and major medical institutions. Therefore the safety of user’s medication is especially highlighted. Considering the bottleneck of researches into new drugs in medical research and development platforms, it’s impossible to research and develop drugs as well as conduct drug testing for a large number of people in short and limited time. Therefore, researches in adverse drug reactions and grasping known and potential drugs’ adverse reactions are of great value to medical research and development. Furthermore, they can also offer theorectical guidance for bettering the clinical drug research and development, together with provide more safe and effective drugs for patients, playing an important role in raising the whole level of local drugs and speeding up the regional development in Xinjiang.
Adverse drug reaction entities refer to drug names, adverse reactions, and indications, etc. The experimental data were obtained from users’ comments on medication on social network media. And the texts of ADR in social networks were obtained from the first-hand information of patients’ medication, which were characterized by adequacy, immediacy and rapid dissemination. There is a wealth of information about ADR that remains to be found accumulated in social networks, but the web text is written arbitrarily, with a lot of spelling mistakes and grammatical errors, which have brought great challenges to the subsequent text recognition work. Take the writing error in the drug name, for example, “zukamu granule” may be written as “zukam granule”. Internet text often contains a lot of “noise,” such as irregular drug aliases, patient information, and medication information. Therefore, in the task of NER of local ADR in Xinjiang, the data is processed by means of sequence labeling is used to process the data. Entities such as drug names, ADR, locations, in users’ medication reviews are labeled by BIO [1]. And a specific mark processing method is also adopted to filter the information outside the entity. Sequence labeling can remove impure information in a wide range and retain key experimental information to the maximum extent.
In the NER task, most of the researches on Chinese are based on the three research ways: word, character and word combined character. And the results of named entity recognition obtained from these three research methods are different. Among them, He and Wang [2], Liu [3], Li [4] et al. carried out an experimental comparison between character-based mode and word-based mode, showing the better performance of character-based method for NER. Chen [5], Lu [6], Dong [7] et al. also adopted the character-based approach in their latter research. And some other researchers like Zhao [8], Peng [9], He [10] et al. also took the character-based approach and began to use word segmentation information to reinforce learning. Although researchers used deep learning algorithm to continuously improve the accuracy of NER task, the results obtained so far have not reached a relatively high level. For example, the LSTM-based joint training proposed by Peng and Dredze [11] only in WeiboNER task, with the F value only achieving 47.92%. Luo and Yang [12] first started to use word segmentation information, and then use it as an additional feature of the sequence tag. This method has improved NER performance, yet the F value in SighanNER task only reached 89.21%. Therefore, the previous research is too singular. The methods proposed by these scholars are not applicable to data sets in small quantity and the accuracy of the model is not high. For these issues, we proposed a named entity recognition of local adverse drug reactions based on adversarial transfer learning. The difference lies in that we have introduced a transfer learning method to deal with data in small account. Furthermore, we use a joint model to solve the problem that the research is too single. This allows our research to obtain more comprehensive information and extract more obvious data features effectively.
What we research is how to further improve the accuracy of the Xinjiang local adverse drug reactions named entity recognition. Therefore, on the basis of these researches, this paper proposes an Adversarial Transfer Learning framework, using the similar processing steps of Chinese word segmentation tasks (CWS) task and entity recognition task of ADR to share multi-task study, and fully make use of the common boundary information. At the same time, it also prevents the special characteristics of CWS from affecting the recognition of Chinese named entities. But the application of traditional convolutional neural network in text lacks the acquisition of context information and the dependence between words, failing to achieve good effect of feature extraction, therefore, self-Attention mechanism and IndRNN are introduced. The experimental results show that the Adversarial Transfer Learning based self-Attention, IndRNN, Bi-directional long short-Term Memory (BiLSTM) and conditional random field (CRF) (ASAIBC) model has achieved good results on entity identification task of adverse drug reactions and public data set WeiBoNER and MSRA data set in Xinjiang.
To sum up, the main contributions of this paper are as follows: A kind of Adversarial Transfer Learning framework is proposed, using the common boundary information in the named entity recognition task of local ADR and the CWS task to conduct joint training, so as to realize task sharing and the transfer based on examples, as well as reduce the cost of manual labeling, and improve the accuracy of the experiment. Introducing the self-Attention into the ASAIBC model can capture the overall dependence of the whole sentence and learn the internal structural features of the sentence. In order to learn the long-term dependence of sentences better, IndRNN is introduced. According to current researches, this is the first time to apply IndRNN into Xinjiang NER task. The proposed ASAIBC model was tested on the Xinjiang local named entity recognition of ADR (XJADRNER) data set and obtained the experimental results F-Score as 90.75%, which was verified on the Chinese public data set WeiBoNER and MSRA. The experimental results showed that the results obtained by the ASAIBC model were all superior to traditional algorithms.
The remaining of this paper is structured as follows: the next section surveys related work on named entity recognition of adverse drug reactions. Section 3 describes the techniques employed. Sections 4 describes the experimental results. Lastly, some conclusive remarks are given in Section 5.
Related work
Named entity recognition of adverse drug reactions
In the named entity recognition task, two processing methods are generally adopted: linear statistical model and deep learning method. Linear statistical models include support vector machines [13], hidden Markov models [14] and conditional random fields. For deep learning methods, Hammerton et al. [15] were the first to adopt neural networks in NER tasks, while Collobert [16] was earlier combined with deep learning algorithms applied to NER. Turian [17] combines pre-trained word embedding in feature processing and traditional CRF methods to be applied to NER tasks. Lample [18] uses two Bi-LSTM to extract features, one of which extracts the features of each word in the corpus, while the other Bi-LSTM extracts the word-level features, and finally uses the CRF layer to carry out the model of sequence prediction. Ma [19] proposed a model similar to Lample’s, but different in that convolutional neural network is used for character-level feature extraction in model selection. In 2011, Collobert et al. [20] came up with a CNN-CRF structure, and got more precise results. In 2015, Santos et al. [21] proposed using character CNN to enhance the CNN-CRF model. In 2017, Strubell et al. [22] proposed applying Improved Dilated Convolutional Neural Network (IDCNN-CRF) into NER task. This new neural network can extract sequence information efficiently and accurately. Peters [23] pre-trained a character language model [24] to generate word context representation to enhance word representation, and in 2018 Devlin et al. [25] used Bert, a pre-trained model with strong semantic expressive ability which proposed in Google, to train the language model.
At present, the exponential growth of biomedical literature along with the rapid development of social media, has generated unlimited potential research resources. Foreign researchers mainly focus on biomedical texts [26] and Twitter messages [27]. At the same time, this study is based on Chinese social media, such as Baidu Tieba, Blog, user medication websites to crawl users’ medication comments, and the obtained user medication comments are manually marked by BIO for experimental data.
Entity recognition of ADR uses deep learning methods to extract adverse reaction information from users’ medication reviews. For example, in the case that “Because of having a cold and the following runny nose, the doctor prescribed the Zukamu granules. Yet, why the child has no spirit after taking all of the medicine?” The drug adverse reaction in the BIO sequence is “no spirit”. When the BIO sequence is used for annotation, the result of corpus tagging is shown in Table 1.
Corpus tagging for entity recognition of adverse drug reactions
Corpus tagging for entity recognition of adverse drug reactions
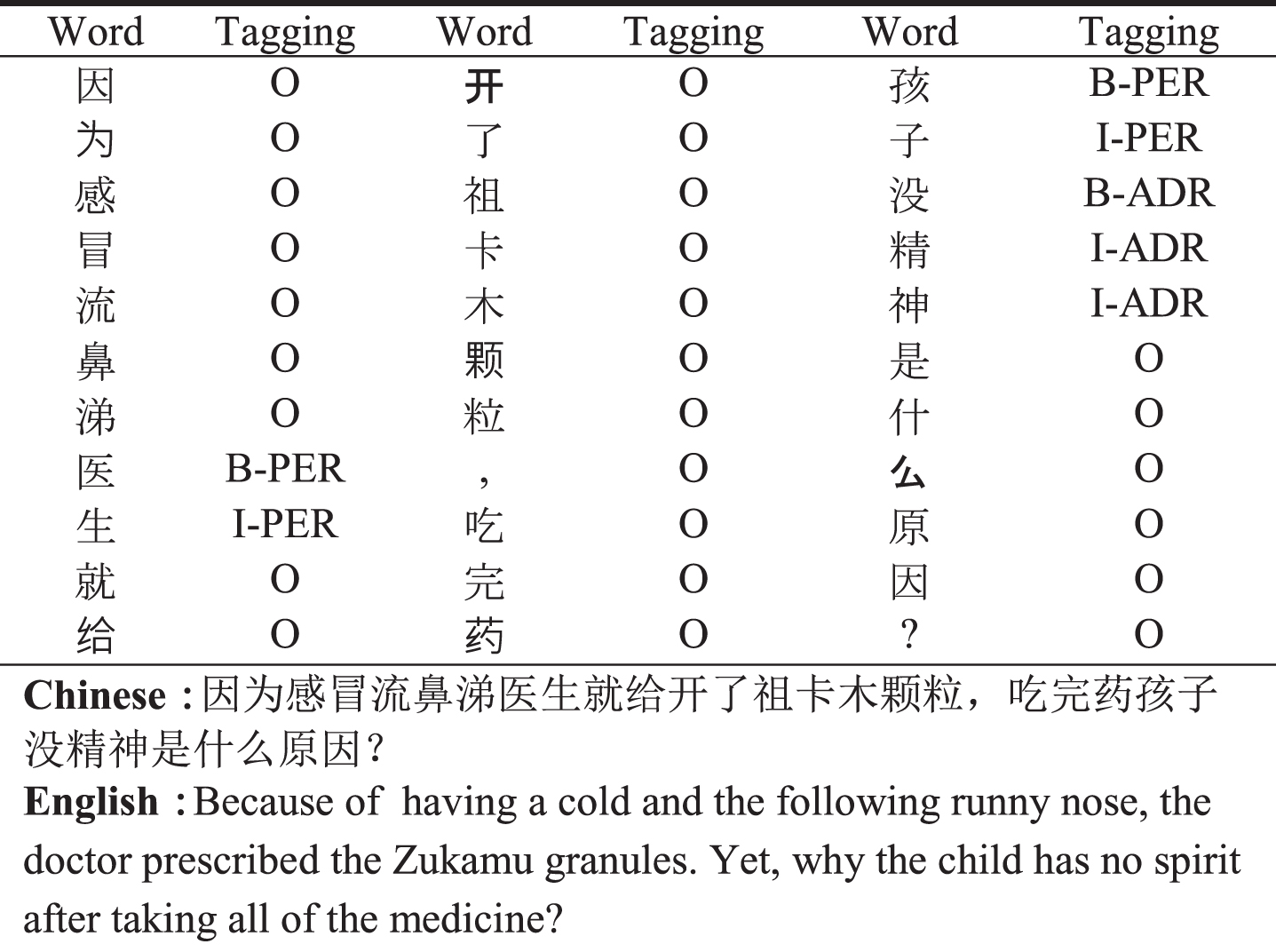
In Table 1, we can see that the corpus contains a large number of invalid information, which are labeled with the mark “O”. For ADR entity, we respectively tag them with mark “B-ADR” and “I-ADR”. Then, ASAIBC model is adopted to learn a large number of training sets. Finally, the accuracy of the trained model is verified through the test set.
Transfer learning refers to a learning process in which the models learned in the old field are applied to the new field based on the similarity between data, tasks, or models. Since its inception, transfer learning has been widely used in fields like computer vision [28], NLP [29], text classification [30]. According to the classification of learning method forms, the earliest definition was given in authoritative reviews concerning transfer learning [31]. It divides transfer learning methods into the following four categories: Instance based Transfer Learning, Feature based Transfer Learning, Model based Transfer Learning, and Relation based Transfer Learning. According to the characteristics of CWS task and Xinjiang local named entity recognition of ADR (XJADRNER), this study adopted the method of the instance based transfer learning, and added the deep adversarial network on the basis of transfer learning. In summary, an Adversarial Transfer Learning framework was proposed to conduct the NER task of Xinjiang local adverse drug reactions.
In the framework of Adversarial Transfer Learning, the similar processing method of labeling data of CWS task and XJADRNER task is used to make full use of the common boundary information, and at the same time to prevent the influence of the characteristic characteristics of CWS task on XJADRNER, in which the CWS task and XJADRNER task are used to deal with, for example, “why is the child spiritless after taking medicine?”, the comparison of its annotation methods is shown in Fig. 1.

Comparison of annotation methods between XJADRNER and CWS.
In Fig. 1, when the CWS and XJADRNER tasks deal with the corpus “What reason is the child no spirit after taking medicine”, the entity “child” and “no spirit” are annotated. For non-entity words, they are marked with “O” and “S” respectively, therefore it can make use of rich knowledge of CWS on joint training mission in XJADRNER task to solve the cost of manual annotation, and to improve the efficiency of Xinjiang local entity recognition of ADR. In the defined framework of Adversarial Transfer Learning, both the source domain and the target domain are composed of two parts: the public part and the private part. The public part can learn the public characteristics of the XJADRNER and CWS tasks, and the private part is used to keep the separate features of each domain. The Adversarial Transfer Learning loss function is defined as:
Where in Ltask, Ldifference, Lsame, Lrefactor respectively represent the conventional training loss of the network, the difference loss of the public part and the private part, the similarity loss of the public part of the source domain and the target domain, and the reconstruction loss. They are introduced to ensure that the private part can still play a role in the learning goal.
In this study, the constructed schematic diagram of Adversarial Transfer Learning framework is shown in Fig. 2, in which embedding layer for multitasking learning, encoding the embedding of XJADRNER, CWS two parts at the same time, and then loaded adversarial network to get loss (adversarial_loss), finally through the normalized processing can get the final result of the adversarial transfer learning’s outputs. These obtained outputs are used as the input of the ASAIBC model, iterating continuously through the current loss to train the optimal model.

Schematic diagram of building adversarial transfer learning framework.
In this paper, the adversarial network is first introduced to realize the sharing of boundary information between CWS and XJADRNER. Due to the limited number of manual annotation, the introduction of the adversarial network can not only reduce the cost of manual annotation, but also expand the amount of experimental data, which is also a discovery of the application of transfer learning in the field of NLP. Through the processing of Adversarial Transfer Learning framework we can get two parts: public and private part. Public part refers to XJADRNER and public characteristics of CWS tasks, and the data of this part can be directly combined with the boundary of public information, which expands the experimental data of the entity identification task of local adverse drug reactions in Xinjiang. While the private part was used to maintain the independent characteristics of each field, because some information could not be shared in the CWS task, the private part of the data is excluded from the confrontation processing. Then, the self-Attention mechanism makes full use of the semantic information within texts and input them into BiLSTM to extract local features of the text. Besides, IndRNN is combined to mine in-depth contextual information to effectively complete the entity identification task of local adverse drug reactions in Xinjiang. As shown in Fig. 3, ASAIBC model is mainly composed of six parts:
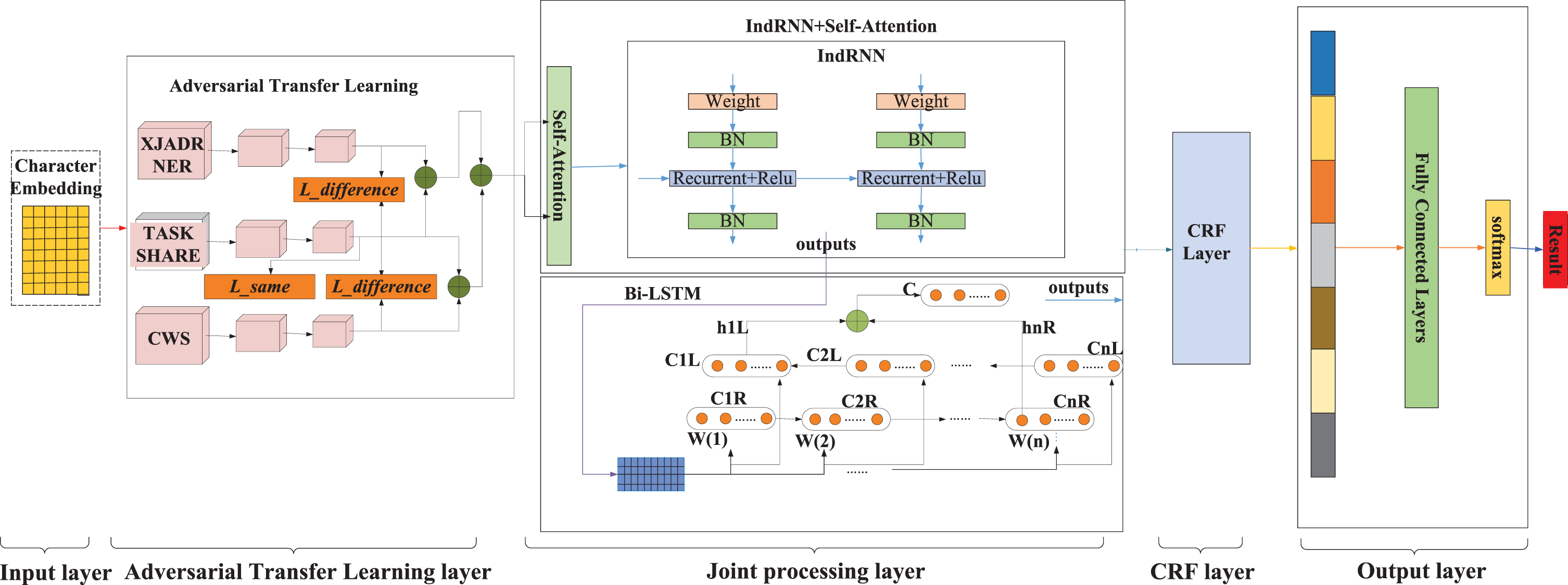
ASAIBC neural network model framework.
Input layer of character embedding: For an experimental corpus S with length N, there is {s1, s2, s3... ... s
n
}, which contains M labeled entity labels {e1, e2, e3... ... e
m
}. The input layer can convert the experimental corpus S into a matrix X, which includes word embedding, position embedding and BIO tag embedding for each word. The martix X is shown in the input layer in Fig. 3. Layer of Adversarial Transfer Learning: Firstly, by inputting CWS and XJADRNER into the adversarial network for word embedding training, we can get their private parts respectively as well as their public parts. Then we conduct the feature extraction of these public and private parts. In the Adversarial Transfer Learning layer, the biggest innovation is to combine the task of entity identification of local adverse drug reactions in Xinjiang with the similar labeling method of CWS data set, therefore there is mutual reference and integration in data processing, which is also the main reason for the introduction of the Adversarial Transfer Learning framework. Joint processing layer: Input the word embedding obtained from the Adversarial Transfer Learning layer into the self-Attention and IndRNN, which w
i
is the I th word vector. Self-Attention can capture the important information in the input sequence, IndRNN can learn long term text dependencies, and dig text context characteristics deeper, then the features obtained in the self-Attention and IndRNN is input into BiLSTM to mine sequence data information. CRF layer: CRF is a probabilistic undirect graphical model [32], which calculates the optimal joint probability in a sequence and optimizes the whole sequence instead of splicing the optimal solution at each moment. In this respect, CRF is better than LSTM. Therefore, the output of joint processing layer is decoded by CRF in this paper to obtain the globally optimal annotation sequence. Fully connected layer: The fully connected layer is usually placed at the end of the network and used to synthesize all information. Features representation gained in the CRF layer is mapped to the sample mark space. In this paper, the full connection layer adopts Softmax as the activation function. The schematic diagram of the fully connected layer is shown in Fig. 4. Output layer: This paper selects the Softmax classifier to classify and determine the sequence of sequence tags of the predicted and the actual labels, thus the accuracy of the local entity recognition of adverse drug reactions in Xinjiang can be obtained. In the predicted results, ASAIBC model has predicted the labels B-, I- and O corresponding to their entities. At the same time, a loss rate is also generated to stand for the ratio of the predicted labels to the actual labels.
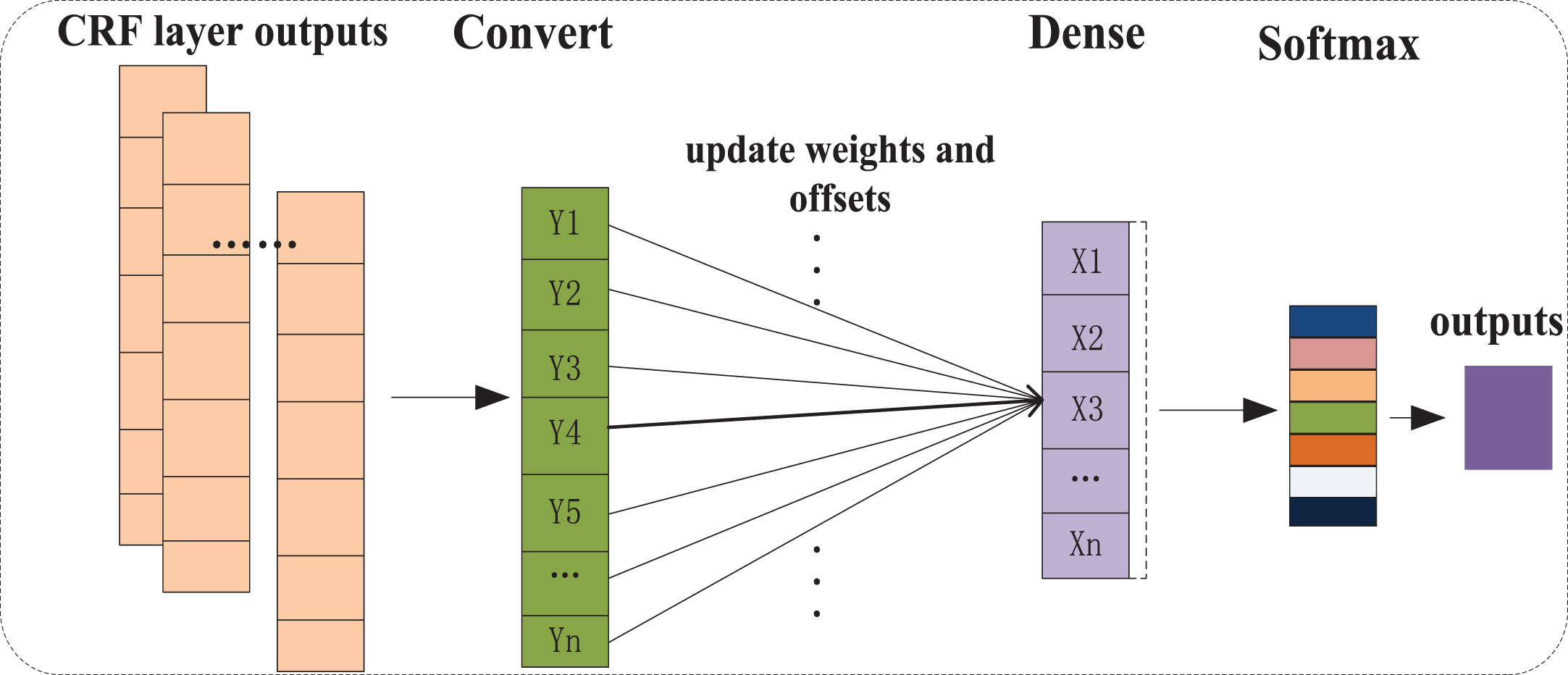
The schematic diagram of the fully connected layer.
The experimental data used in this paper is the XJADRNER obtained by manual BIO sequence labeling method. In order to complete NER of ADR in Xinjiang better, this paper introduced Adversarial Transfer Learning framework. First of all, a basic network was trained on the CWS task, and then the learned features were readjusted and transferred to the trained network of the XJADRNER task for training target data sets and tasks. Then the obtained character embedding vectors were input to the self-Attention mechanism, so as to make the model focused on entity important information from different levels. Besides, IndRNN model was added to study long-term dependence of sentences and mine sequence information. Then the obtained feature vectors were merged with and the other feature vectors trained by BiLSTM and then input to optimize the whole sequence CRF layer, eventually getting predict entity sequence tags. Then it entered the full connection layer for processing, and the accuracy rate of XJADRNER was obtained after normalization by using Softmax as activation function.
Embedding layer
The embedding layer can be considered as a fully connected layer. The parameter of the full connection layer can be constructed as a matrix, and then the one-hot coding of each word is multiplied by the coefficient matrix of the full connection layer. A new vector is obtained by reducing or increasing the dimension, which is the word vector. Finally, the word is mapped to the mapping matrix of the vector.
Word embedding (distributed word representation) [33] refers to the ability to capture semantic and syntactic information of words from a large unlabeled corpus. Compared with the BOW (bag-of-word), the word vector has the characteristics like low dimension and density. Most of the corpus obtained by XJADRNER task is from user comments, which are authentic but inevitably contain some noisy words. Therefore, considering the characteristics of the data sets of XJADRNER task, word vectors can obtain better experimental results. In recent years, Word2vec [34] and GloVe [35] have been widely used in various fields of NLP, such as NER, text classification, machine translation, etc., which tend to use Word2vec model. Thus, Word2vec is used in this study to obtain the word vector. Firstly, whether a word is a named entity is related to its context, therefore language model is used to train the word vector on large-scale unlabeled corpus. Word2vec has two implementation models: Skip-gram and CBOW [36]. Skip-gramm can predict the words of the context by current words, while the CBOW is precisely the opposite. In the NER task, CBOW is generally used for this implementation. Since in NER, CBOW plays a smaller role in predicting the contextual information by current words, but bigger role in predicting the current words based on contexts, making for entity identification.
Therefore, this paper adopts CBOW model to train the corpus, the first step of our proposed model is to map discrete characters into the distributed representations. For a given Chinese sentence s ={ s1, s2, s3 …… s
n
} from XJADRNER dataset, we look up embedding vector from pre-trained embedding matrix for each character, denoted as
Load embedding
Load embedding
The adversarial network first achieved great success in computer vision [37, 38]. In NLP, adversarial network training learning has been applied to domain adaptability [39, 40] and multi-tasking [41, 42] processing. Different from these studies, the XJADRNER task and CWS task are jointly trained by the adversarial network in this paper, aiming to extract the shared boundary information from the CWS task and filter out the specific information in the CWS. This paper adopts instance-based transfer learning and adversarial network. The core idea is to set XJADRNER as the target domain and CWS as the source domain. The purpose is to calculate the similarity between XJADRNER sample and CWS sample, Then adjusting the weight of CWS can update the CWS sample. At the same time, a threshold value is set. If the sample similarity is lower than the threshold, the sample is discarded and a new data set CWS1 is generated after updating. The final experimental training set Train = {XJADRNER, CWS1}. The ultimate goal is to make the training data set meet the training requirements of the ASAIBC model in terms of size and quality. The samples here refer to the named entities in XJADRNER and CWS tasks. The sample similarity refers to the similarity betweent the two named entities in the composition and structure, which is mainly used to evaluate the contribution of CWS samples to XJADRNER samples.
In this paper, the sample similarity is mainly processed by two methods: entity similarity and part-of-speech similarity, which are calculated in units of words. Entity similarity is to calculate the sample similarity at the semantic level, which reflects the semantic information of entities well. Part-of-speech similarity considers considering the application of part-of-speech tagging to the composition of entities as the comprising features of some entities is often accompanied by similar part-of-speech expressions.
For the two experimental corpora C1 and C2, C1 = {t1, t2, t3 . . . Tm}, C2 = {z1, z2, z3 . . . zn}. Where t1 and z1 represent the words in C1 and C2 respectively, and m and n denote the length of corpus C1 and C2 respectively. Calculation methods of the two kinds of similarity are as follows:
Entity similarity refers to the ratio of the maximum number of identical words in two different entities to the maximum number of entities under the premise of the same sequence. The calculation formula is:
Where s represents the number of identical entities in C1 and C2 under the premise of the same sequence.
Part-of-speech similarity refers to the ratio of the maximum number of parts of speech in two different entities to the maximum number of entities under the premise of the same sequence. The calculation formula is:
Where p represents the number of parts of speech of the same entity in C1 and C2 under the premise of the same sequence.
Meanwhile, the sample similarity obtained can be used to calculate the similarity between source domain CWS and target domain XJADRNER:
For the source domain CWS and the target domain XJADRNER, if the same sample number of CWS and XJADRNER is m
c
and m
x
, when after the sample similarity of the source domain and the target domain is obtained, according to the set threshold δ, when the sample similarity of a sample in the source domain CWS is lower than the threshold δ, the sample is discarded directly, and the weight w
e
and w
p
of the entity similarity and part-of-speech similarity of the source domain and the target domain can be obtained at the same time:
Finally, entity similarity and part-of-speech similarity weights of source domain and target domain are integrated, and the final weight of the sample can be obtained as the follow:
Among which, α, β is the weight coefficient, and α + β = 1, α, β reflects the degree of different factors’ influence on the results, which can better improve the reliability of the Adversarial Transfer Learning framework.
In summary, the idea of the Adversarial Transfer Learning framework is to obtain the weights of the source domain and the target domain according to the entity similarity and part-of-speech similarity of the source domain. Selective discarding is carried out according to the weight size of specific samples. On the one hand, the contribution of the source domain to the target domain can be maximized; on the other hand, the experimental data can be expanded to make up for the lack of the deep learning model to learn a small amount of data. The adversarial transfer learning process pseudo code is shown in Table 3.
Adversarial transfer learning
In the joint processing layer, the BiLSTM model is used to mine the input sequence data information to ensure that the over-fitting phenomenon is not easy to occur in the training process. The introduction of self-Attention can capture the important information in the current input sequence, and IndRNN can learn the long-term dependencies in the input information and dig deeper contextual characteristics.
Among which,
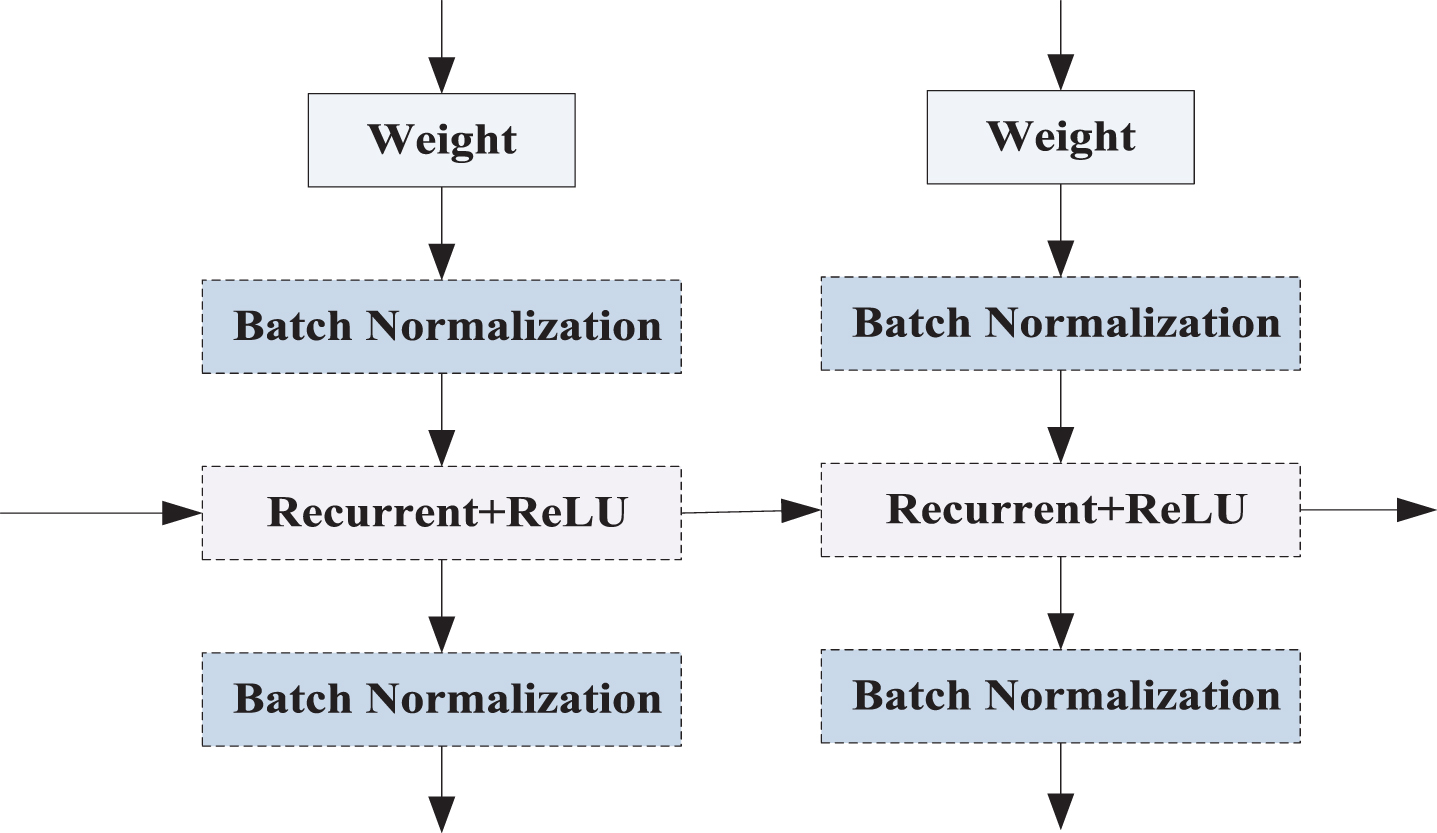
IndRNN model framework.
Among them, Weight and Recurrent+ReLU represent the processing steps of input at each time step. ReLU is an activation function. In order to speed up training, Batch Normalization is inserted after each layer.
Then a deep IndRNN network can be established, whose formula can be expressed as:
Where the cyclic weight μ is a vector and ⊙ represents the Hadamard product (the product of the corresponding elements). Each neuron in the same layer is not connected to other neurons. But the neurons can be connected by superimposing two or more layers of IndRNN. And its simple structure makes it easy to be added to different network structures.
The second step is to calculate the memory gate. Selecting the information that needs to be memorized. Input the hidden layer state ht-1 at the previous moment and the input word X
t
at the current moment. The outputs are the value of the memory gate i
t
as well as the temporary cell State
The third step is to calculate the state of the cell at the current moment. The inputs are the memory gate i
t
, the value of the forgetting gate f
t
, the temporary cell state
The fourth step is to calculate the output gate and the current hidden state. Inputting the hidden layer state ht-1 at the previous moment, the input word X
t
and the cell state C
t
at the current moment. The outputs are the value of the output gate o
t
and the hidden layer state h
t
. Just as follows:
Finally, the sequence {h0, h1, h2, h3, …… hn-1} with the same length as the sentence can be obtained. In the coding layer of LSTM, word2vec can usually be used to train the word vector, normally adopting one-hotting coding. The difference between BiLSTM and traditional LSTM is that the latter can only obtain information before the current word, while BiLSTM can acquire the context semantics and grammatical information of the current word. In XJADRNER task, how to find the characteristics of the contextual information corresponding to entity information is particularly important.
The basic structure of the BiLSTM model is shown in Fig. 6. In the figure, BiLSTM is used to learn the sentence sequence {w (1) , w (2) , … w (n)} obtained by Adversarial Transfer Learning. Cir and Cil represent the right and left implicit unit states respectively, and h1l and hnr decibels represent the output of the left and right hidden layers respectively. Learning from the right layer first and we can get Cnr. When it comes to the left one, C1l can be gained. Through the end-to-end connection of the hidden vector, the final output vector C can be obtained which contains the overall information of the text and enhances the expression performance of features.
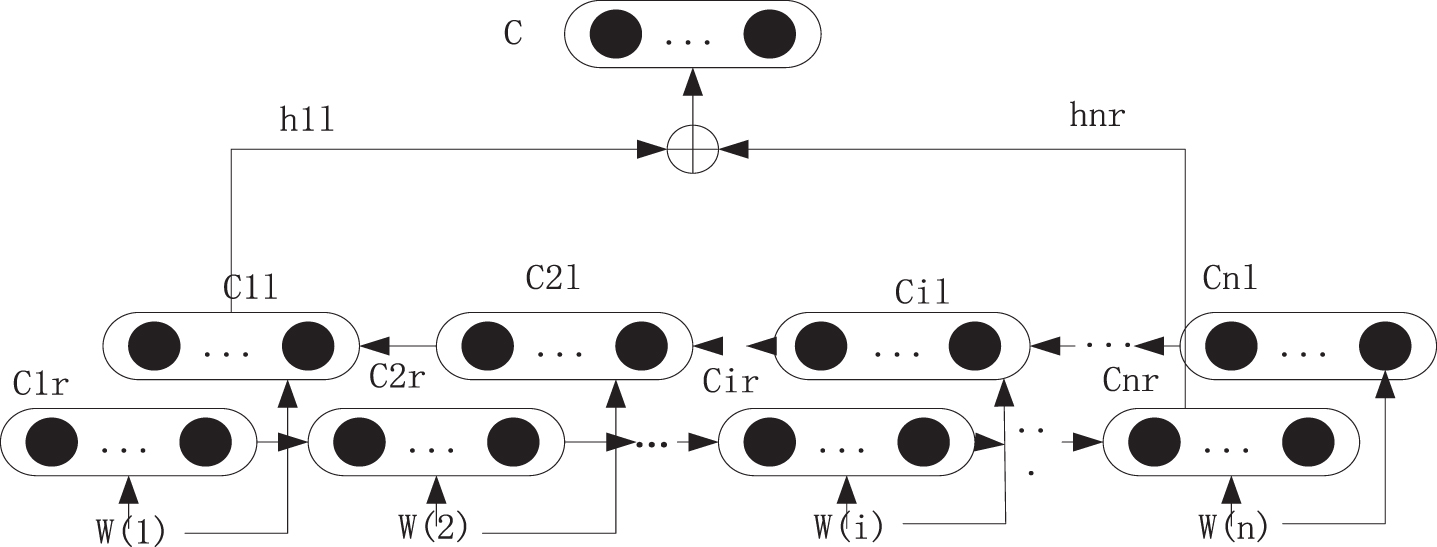
BiLSTM layer.
In this paper, BIO sequence annotation method is adopted, and considering the correlation between adjacent tags, CRF [44] is selected to obtain the global optimal output sequence of a given sequence.
Through the joint processing layer, the output sequence O = {o1, o2, o3 …… o
n
} can be obtained, which o
n
represents the n-th word vector of the output sequence O. If Y = {y1, y2, y3 …… y
n
} represents the corresponding label sequence of the output sequence O, the CRF probability model can be obtained:
Where Weight, b represents the weight vector and deviation transferred from label Y’ to label Y respectively. In the training process, the maximum likelihood estimation principle is used to optimize the logarithmic likelihood function as follows:
According to the maximum likelihood estimation principle, the maximized logarithmic likelihood function is the maximized CRF conditional probability model, that is, to optimize objective function as:
In this paper, BIO sequence annotation method is adopted, and considering the correlation between adjacent tags, CRF is selected to obtain the global optimal output sequence of a given sequence.
According to Fig. 3, the XJADRNER word vector and CWS word vector are inputted in the input layer. Inputting the word vectors of the two tasks into the Adversarial Transfer Learning framework, and using the trained adversary network to learn the CWS word vectors, and the private part of the CWS task is discarded. In addition, the common part of CWS task is extracted, and finally the common part and XJADRNER word vector fusion are input into the joint processing layer, which is denoted as B, and the attention weight is calculated firstly, and the formula is as follows:
In the above formula, f
i
represents the i-th feature (f
i
∈ B); w
f
means the weight; b
f
represents the offset, and Ai represents f
i
’s attention weight, which can lead to the output att of the attention mechanism:
As the input of IndRNN, the matrix output of the obtained attention mechanism can be used to learn fi’s long-term dependency relationship and dig deeper contextual features. After IndRNN, the eigenvector graph can be obtained, where:
In the obtained eigenvector graph Ft, fw represents the weight matrix, att represents the output result of the self-Attentional mechanism and the bias of the f function is represented by fb.
At the same time, inputting the word vector B obtained in the adversarial transfer layer into the BiLSTM layer, we can get
In the above formula, f i stands for the i-th word vector, where f i ∈ B, and BiLSTM is used to extract the feature and then directly join the vectors obtained from the two directions.
Taking the output result Ft of Self-Attention+IndRNN layer and the result B
t
of BiLSTM layer as the input of CRF, we can get:
Where, M
crf
represents the input of the CRF layer, Y represents the prediction label corresponding to M
crf
, and Weight, b represents the weight and deviation respectively. Finally, the output of CRF layer is inputted to the fully connected layer. And the sigmoid activation function is used to capture the nonlinear characteristics of the input vector and enhance the expression ability of ASAIBC model. Among which:
Connecting all the features in the full connection layer, extracting the correlation among these features after nonlinear changes of the previously extracted features, finally mapping to the output space and sending the output value to the softmax classifier. In the classification results, the predicted labels can be obtained:
Where, w i represents the weight matrix in the fully connected layer; b i stands for the offset. The chain rule in bp backpropagation algorithm is used for updating and iterating the weight until the error is minimized.
Dataset
The data in this paper are from the major network social media of Xinjiang local medicine. The comments on medication on social media reflect the real experience of users and can improve the effectiveness of the experiment. The experimental data in this paper were collected from various major medication consultation websites, blogs, microblogs, baidu tieba, news journals and other social media sites. A total of 5392 user comments on medication were selected. Under the guidance of experts, 5392 corpus were marked as XJADRNER data set. Among the 5392 user medication comments, 1079 were positive cases of adverse drug reactions (including ADR entities), and 4313 were negative cases without adverse drug reactions. In the experiment, the length of each corpus was about 15 Chinese characters. In the process of annotation, according to the guidance of experts, BIO sequence annotation method is adopted, in which B represents the beginning of entity, I represents the non-beginning part of entity, and O represents the no-entity, so as to ensure that each corpus annotated can provide sufficient theoretical evidence basis for experimental results. At the same time, the experimental corpus of XJADRNER is continuously expanding and enriching. We set the ratio of training set, validation set, and the test set as 0.6 : 0.2 : 0.2 when the best experimental effect can be achieved. The validation set is used for cross-validation. Finally, we verify the model on the test set to guarantee the model’s generalization ability.
In order to verify the validity of the proposed ASAIBC model based on transfer learning, two public data sets WeiboNER data set and MSRA data set are introduced. The WeiboNER data set contains the following four types of entities: person names, place names, organization names and geopolitical entity (region). And the MSRA data set contains three types of entities: person names, institution names and place names. The MSRA data set is a NER data set published by Microsoft, which includes training set and test set. The training set contains 46.4 k sentences and 2169.9 k words. The test set consisted of consists of 4.4k sentences and 172.6k words. At the same time, WeiboNER data set and MSRA data set are the two most widely used public data sets in Chinese NER, which can provide experimental data basis for the validity of ASAIBC model. The WeiboNER, MSRA data sets and the hand-annotated XJADRNER datasets are detailed in Table 4.
Statistics of entities in MSRA and WeiboNER datasets
Statistics of entities in MSRA and WeiboNER datasets
This paper adopts the ASAIBC neural network based on transference learning. In the experiment, the original vector matrix and weight matrix are combined to get the attention matrix, which is taken as the input of IndRNN. After that, the obtained semantic features and BiLSTM neural network were input to the CRF layer, and the final experimental results were obtained through the full connection layer. After continuous training and adjustment of the experimental model, when the experimental parameters are set as shown in Table 5, the identification effect is the best. The experimental parameter adjustment method adopted in this paper is as follows: firstly, the parameters are randomly initialized; then, the objective function is minimized by gradient descent.
Experimental parameter setting
Experimental parameter setting
In order to verify the effectiveness of the experimental parameters, a learning curve has be used in the process of parameter selection. The experimental results show that the experimental parameters can ensure the reliability of the model. The learning curve as shown in Fig. 7.
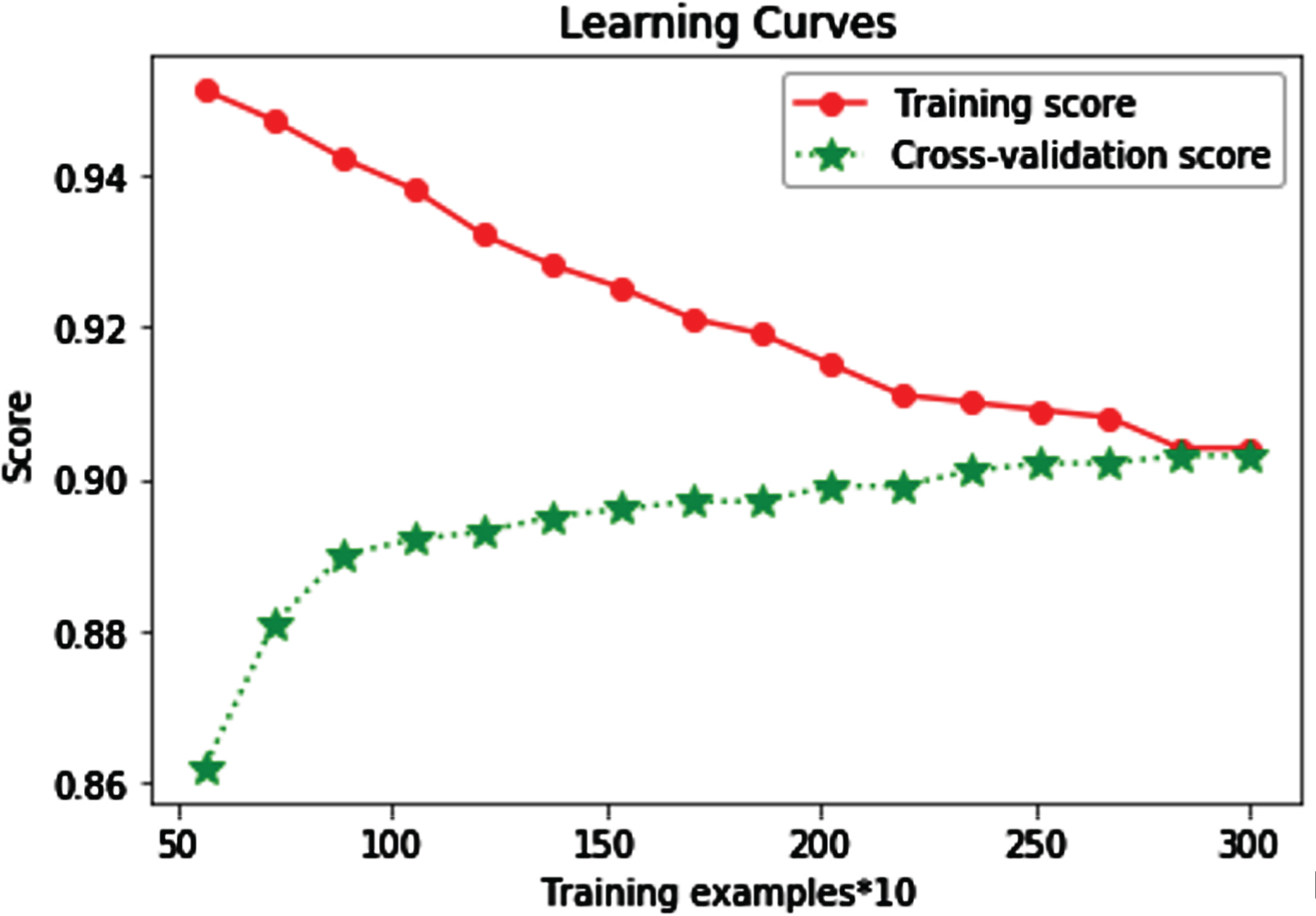
The learning curve.
In order to evaluate the effect of entity identification of local drug adverse reactions based on transfer learning in Xinjiang, the Recall (R), Precision (P), F-Measure(F) value and Accurary are used in this paper as indicators of model training effects.
The Accuracy is the ratio of the samples correctly classified by the classifier to the total samples in the data set given by the experiment, which can be used to reduce losses. The Precision refers to the ration of the item correctly identified to that totally identified of the ADR, which can further reflect the degree of accuracy in processing. The Recall refers to the ratio between the item of the correctly identified entity of adverse drug reaction and the item of the entity of adverse drug reaction that should be identified, which can be used to judge the completeness of the model, F value is a comprehensive index used to measure precision and recall, which can be expressed as:
At the meantime, Precision, Accuracy, Recall and F value have high tolerance rate in model evaluation, which are also the mainstream model evaluation indicators at present.
In Chinese NER task, most scholars research the validity of the model based on the MSRA data set and WeiboNER data set. In order to verify the reliability of the ASIBC model, it was trained on the WeiboNER data set and MSRA data set, which obtained good experimental results, specifically shown in Table 6.
Performance comparison between different models trained on WeiboNER dataset and MSRA dataset
Performance comparison between different models trained on WeiboNER dataset and MSRA dataset
Table 6 provides the experimental results of our proposed model as well as its simplified models on MSRA dataset and WeiboNER dataset. According to Table 6, the CRF, CRF+word, CRF+character, CRF+character+position models proposed by Peng and Dredze et al. [45]. were tested on WeiboNER data set. It can be observed that the CRF+character+position models obtained the best experimental results. The CRF model with word vector was 1.9% higher than the CRF model, and the CRF model withword embedding was 6.01% higher than the CRF model with word vector. Thus it can be seen that the performance of word embedding is usually better than that of word embedding in NER task. Meanwhile, the F value of CRF+character+position model is 0.23% higher than that of CRF+character model, indicating that position information plays an auxiliary role in entity recognition. The F values of BiLSTM+CRF model on MSRA data set and WeiboNER data set are 88.06% and 50.95% respectively; the F values of BiLSTM+CRF+Transfer model on MSRA data set and WeiboNER data set are 89.60% and 52.19%; the F values of BiLSTM+CRF+Transfer+self-Attention model on MSRA data set and WeiboNER data set are 88.62% and 52.64%. In this paper, the F values of ASAIBC model based on the Adversarial Transfer Learning framework are 90.63% and 54.07% respectively on MSRA dataset and WeiboNER dataset.
In summary, the experimental results of ASAIBC model on MSRA data set and WeiboNER data set are the best. As shown in Table 6, we can find that the recognition efficiency of deep learning model in WeiboNER data set is not high, mainly due to the fact that the quantity of current public WeiboNER data set data is relatively small, only 400 or so. Meanwhile, since the WeiboNER data set come from weibo, the experimental data is not standard, with entity nesting, abbreviation and ambiguity. Therefore the F value of deep learning model in WeiboNER data set is not high on the whole.
At the same time, in order to demonstrate the effectiveness of ASAIBC model on XJADRNER data set, different models were tested on XJADRNER data set. The experimental results are shown in Table 7.
Performance comparison of different models on XJADRNER dataset
In Table 7, the XJADRNER data set was tested by using the currently popular deep learning algorithm. The experimental results showed that the F value of ASAIBC model in entity recognition of local adverse drug reactions in Xinjiang was 90.57%. From the experimental results of Table 7, we have following observations: by introducing adversarial training, ASAIBC boosts the performance as compared with Self-Attention+BiLSTM+CRF model, showing 3.53% improvement on XJADRNER dataset. It proves that adversarial training can prevent specific features of CWS task from creeping into shared space. ASAIBC boosts the performance as compared with ATR+Self-Attention+BiLSTM+CRF model, showing 1.58% improvement on XJADRNER dataset. It proves that IndRNN model can learn the long-term dependence of sentences better. At the same time, ASAIBC boosts the performance as compared with CRF model, showing 13.41% improvement on XJADRNER dataset. It proves that ASAIBC model complements the advantages and disadvantages of the single model and can enhance the expression performance of features.
In order to show the changes of ASAIBC model more clearly during training, the loss curve of the model is drawn below and shown in Fig. 8. It can be seen from Fig. 8 that the loss function of ASAIBC model with IndRNN has a fast convergence the minimum convergence value. In the experiment, 100 is the step length. When the iterative training step = 5000, the loss of ASAIBC model is close to 0.500. This shows that the IndRNN model is easier to train and has better fitting property, which can better fit the data in the training set.
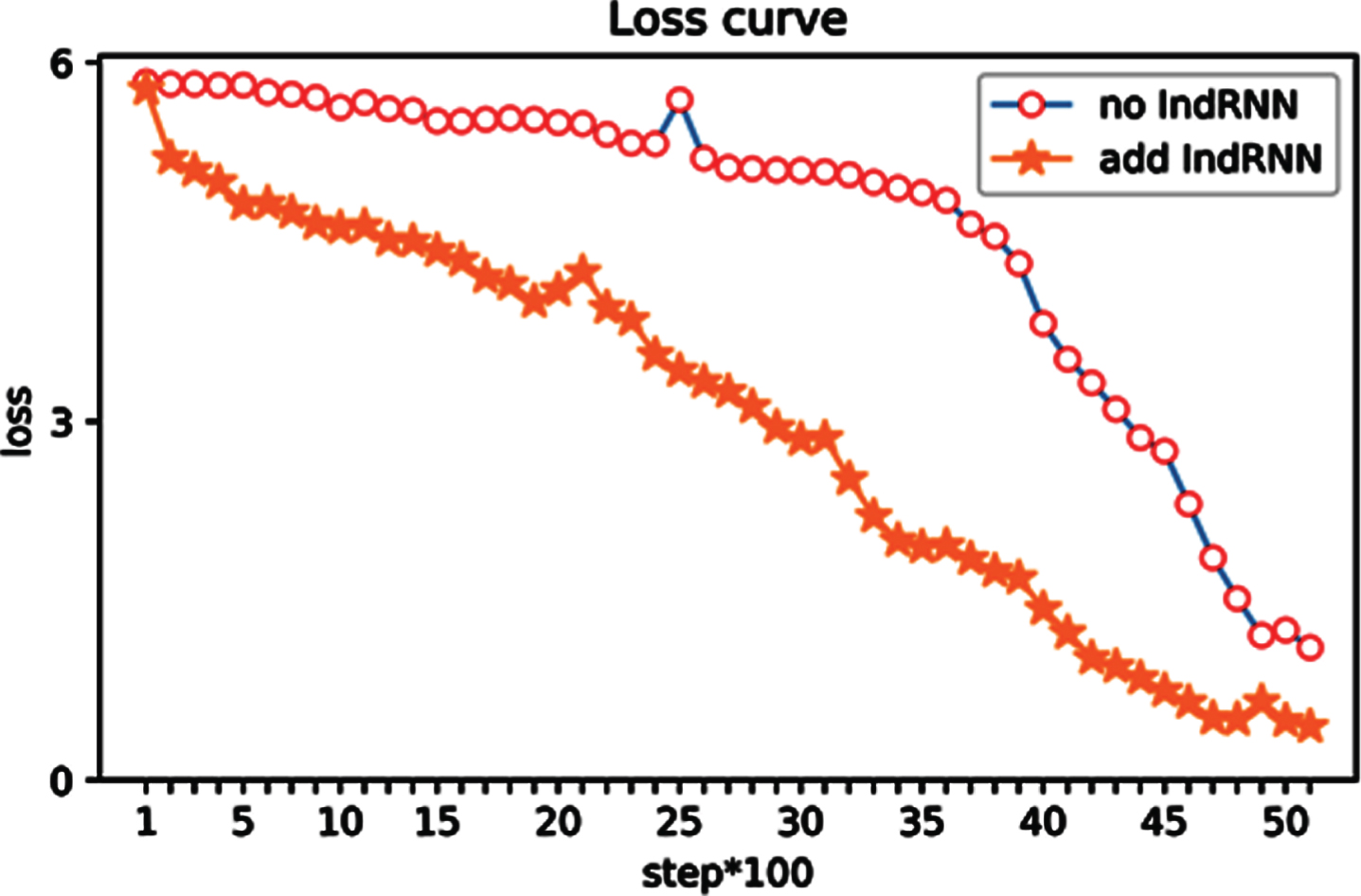
Comparison curve of model loss.
In order to verify the effectiveness of ASAIBC model based on transfer learning in drug entity recognition of local adverse drug reactions in Xinjiang province from different perspectives, the following comparative experiments were designed in this paper.
The effect of word vector dimension on experimental performance.
In the experiment, the use of different word vector dimension will have different effects on the experimental performance. The semantic information varies in different word vector dimension. In order to get the optimal word vector dimension, the experimental parameters need to be constantly adjusted and updated. In this paper, 20∼200 are selected as the word vector dimension to conduct experiments.
Figure 9 shows that different vector dimensions have a certain influence on experimental performance. When the word vector dimension is increasing, the semantic and grammatical information also rises up. When the word vector is 100, the experimental results are the best. As the dimension of the word vector increases, the semantic and grammatical information also contains more impurity information unrelated to the experiment, which will have a negative impact on the experiment. When the word vector dimension increased to 160 dimensions, the F value obtained by ASAIBC model decreased by 3.3%, and when it increased to 200 dimensions, the F value obtained by ASAIBC model decreased by 4%. As a result, it is necessary to choose an appropriate word vector dimension to improve the experimental performance.
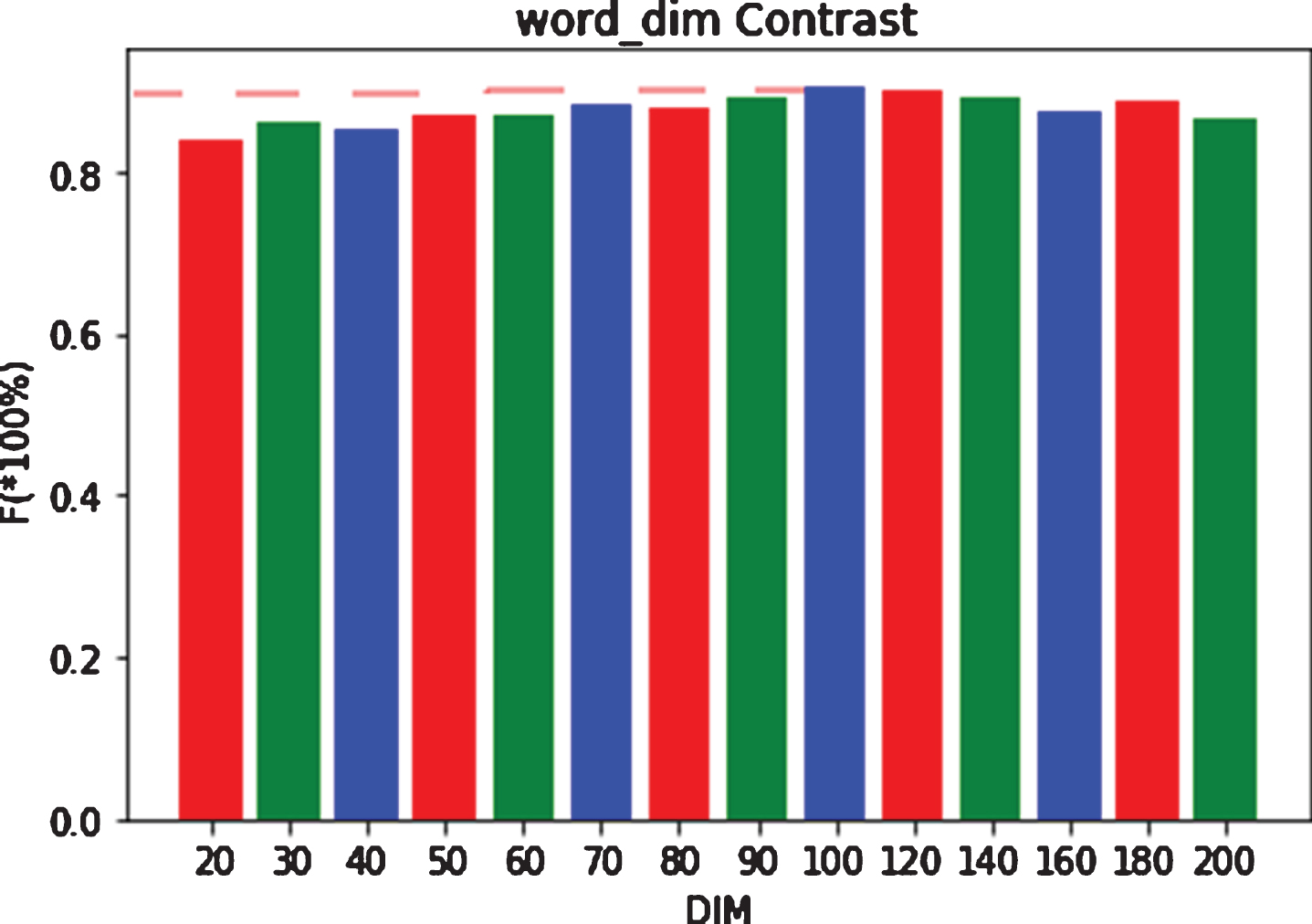
Influence of different word vector dimensions on experimental performance.
In the Chinese NER method based on deep learning, a NER method for ADR based on the Adversarial Transfer Learning framework is proposed to address deep learning’s insufficient ability to learn a small amount of data. The CWS data set is taken as the source domain, while the experimental data set XJADRNER as the target domain in this paper. The boundary sharing information of CWS and XJADRNER data sets was fully utilized to share information, the specific information in CWS was filtered at the same time. Beyond improving the accuracy of entity recognition, the problem of few manual annotation of the current XJADRNER data set was solved. Moreover, the IndRNN is applied in the NER task for the first time, and self-Attention is used to capture the overall dependence of the whole sentence, learn the internal structure characteristics of the sentence, and make full use of the context information to predict the current entity attributes. The experimental results show that the ASAIBC models introduced with the transfer learning framework are superior to the current models and can improve the effect of Chinese NER.
Footnotes
Acknowledgments
We thank the anonymous reviewers for their insightful comments. This work was supported by the National Natural Science Foundation of China (61962057), Key Program of National Natural Science Foundation of China (U2003208), Major science and technology projects in the autonomous region (2020A03004-4).