
Abstract
Performance of neural networks greatly depends on quality, size and balance of training dataset. In a real environment datasets are rarely balanced and training deep models over such data is one of the main challenges of deep learning. In order to reduce this problem, methods and techniques are borrowed from the traditional machine learning. Conversely, generative adversarial networks (GAN) were created and developed, a relatively new type of generative models that are based on game theory and consist of two neural networks, a generator and a discriminator. The generator’s task is to create a sample from the input noise that is based on training data distribution and the discriminator should detect those samples as fake. This process goes through a finite number of iterations until the generator successfully fools the discriminator. When this occurs, sample becomes a part of new (augmented) dataset. Even though the original GAN creates unlabeled samples, variants that soon appeared removed that limitation. Generating artificial data through these networks appears to be a meaningful solution to the imbalance problem since it turned out that artificial samples created by GAN are difficult to differentiate from the real ones. In this manner, new samples of minority class could be created and dataset imbalance ratio lowered.
Keywords
Introduction
Most machine and deep learning algorithms entail normal data distribution [1, 2]. When data are not stratified there is an additional danger of model overfitting [3]. For example, in (binary) classification it could possibly happen that the neural networks learn to classify all unknown samples into the majority class with a high degree of accuracy, but the created model has actually learned very little or nothing. Bank fraud attempts, attacks on computer networks and applications, text classification, computer vision tasks and rare event occurrences in general, represent a potential source of datasets with pronounced class imbalances [1, 4, 5]. Training traditional neural networks over such data will not produce good results [6]. There are three basic approaches to solving this problem, namely, (i) data-level manipulation, (ii) modifications in existing algorithms and (iii) a combination of the above. Over the last two decades numerous methods and techniques that purport to solve this problem were developed, however certain authors [7, 8] still maintain that the field remains relatively unexplored and that existing methods are not sufficiently effective. Any improvement in this field would be of immense importance since it would potentially result in accuracy improvement across multiple branches of science that use neural networks and also in machine learning in general. The purpose of this paper is to highlight data manipulations, or more specifically, the creation of artificial samples in a process that is known as oversampling. At present, there are many approaches that deal with oversampling, however, virtually all have some limitations and are relatively prone to model overfitting.
One simple way to create new samples from an existing dataset is to use linear transformations, such as rotating and scaling images [9]. However, such an increase in data does not improve the data distribution determined by the higher-level features of [10]. This topic is well known within machine learning where a number of techniques have been developed such as SMOTE [11], but also its variations, of which there are many. It has been shown that most of the approaches that deal with this problem in machine learning can be successfully applied in deep learning [12]. However, such approaches have certain limitations which we will describe in the second chapter. Conversely, generative adversarial networks [13] are one of the most attractive topics in deep learning because of their ability to create exceptionally realistic synthetic data that are similar to the training dataset, yet still differ. These networks are capable of finding data distribution and, based on this capability, they generate new data that bear the characteristics of that set. This paper presents the chronological development of generative adversarial networks, along with descriptions of some of the most distinguished works and concrete implementations, applications and comparisons of these networks for data oversampling. Even though very good results in this field have been achieved, there are still many open questions as this is still a relatively new field of deep learning that still has a lot to show.
As there are few overview papers available on the topic of data augmentation with GAN (especially in the last few years), and also because all the review papers are focused on a specific GAN variant or a specific area of application, while this paper covers a whole range of both of the above, there was obvious need for this paper. The contributions of this paper are two-fold, (i) to the best of our knowledge, this is the first review paper dealing with such a large number of GAN variants and areas of application, and (ii) the paper provides insights and analysis of processed articles, potential improvements and further development and mutual comparison. Besides this, we investigate whether these networks have enough potential to generate quality synthetic data samples which would provide wide ranging applications in all branches of science and industry. The increase in minority class samples creates a greater balance of the training dataset, and the better and more diverse these samples are, the dataset will be more valuable. The end result of this may increase accuracy in various state-of-the-art deep learning models, but also, more generally, machine learning models.
This paper is divided into five sections, including the introduction. The second section provides an overview of related works on class imbalance. In the third section, generative models and generative adversarial networks are described along with the architecture, training method and known problems with these networks. Aside from the basic model there are also described seven prominent, well-known, GAN variants. The third section is divided into two parts - descriptions of papers that deal with structured (tabular data), seven in all, and papers that deal with unstructured (image and audio) data, six in total. Finally, the last section comprises the conclusions and the overall review of the paper.
Related work
One of the most common and most demanding problems of machine and deep learning is the issue of unbalanced number of samples within classes. Standard deep learning methods are poorly effective in unbalanced data clusters because they cause bias in favor of the majority class [14], and this is particularly evident in problems with computer vision where convolutional neural networks predominate [12]. For the last two decades this was a well researched subject and numerous solutions were presented, as described in [12]. Generally, there are three basic approaches to solve this problem, and those are (i) data manipulation (increase in minority or decrease in majority class); (ii) algorithm modifications (e.g. introduction of sensitivity or threshold movement); (iii) hybrid model that combines these two methods. In the following subsections we will describe in detail each of the approaches above, with the most attention given to oversampling because it is the focal point of this paper.
Data manipulations
Sampling is a technique of data processing that ultimately aims to generate a balanced data distribution that is later used in model training. This technique can be divided into undersampling and oversampling. The simplest techniques associated with these two terms are random undersampling (RUS) and random oversampling (ROS). The main goal of the RUS method is to eject a certain number of samples from the majority class through random selection and consequently to reduce the gap between classes, while the ROS method generates new synthetic data of the already extant minority class data. Both approaches carry potential danger - oversampling slows down the process of training and can cause model overspecialization, while undersampling can lead to a loss of valuable information [12, 15].
Oversampling is more commonly encountered in literature since it generally provides better results [16] even though some earlier research claimed otherwise [17]. Oversampling in particular is the focus of this paper, therefore, undersampling, algorithm manipulations and hybrid model will only receive a cursory overview. More advanced techniques of oversampling have developed over time. The most important technique that represents a turning point in this field is the Synthetic Minority Oversampling Technique (SMOTE) [11]. More specifically, SMOTE generates artificial data along the line segment which connects to the minority class samples. Nevertheless, samples that do not belong to the real distribution of the relevant class can be created in this manner [18]. In order to solve this problem, a great number of SMOTE variations arose, such as Borderline-SMOTE [19], Safe-Level-SMOTE [20] and MWMOTE [21]. Furthermore, along with classical methods, new approaches appeared that are based on unsupervised learning, such as Cluster-SMOTE [22] and DBSMOTE [23]. DBSMOTE is an interesting combination of SMOTE and DBSCAN [24] algorithms [14]. Bordeline-SMOTE performs oversampling exclusively near the class boundaries, while Safe-Level-SMOTE defines the so-called safe areas in order to prevent excessive sampling in overlapping areas or areas of noise.
Algorithm modifications
Sampling is not a single solution for advancing a model accuracy. Modifications of existing algorithms represents another group of solutions with the goal of reducing the algorithm dependency on the balance of input cluster of training data. Generally, algorithm modifications can be divided into 4 different approaches: (i) thresholding; (ii) one-class classification (OCC); (iii) cost-sensitive learning; and (iv) hybrid model [16]. The simplest one to grasp and implement is thresholding which refers to determining, or in other words, raising or lowering the decision threshold during sample classification (e.g. 0.5 raised to 0.7). Classification is a task of determining a sample association with one of two (binary classification) or more classes (multiclass classification), while one-class classification is a somewhat more demanding variant of the ordinary classification [25], with the only difference being that the algorithm decides only whether the sample belongs to a specific, normal class or not.
The third approach is the cost-sensitive learning and it is mostly relatively simple to implement with neural networks. In cost-sensitive learning different penalties are determined for erroneous prediction. For example, there is a problem of ascertaining whether the patient is healthy or sick (binary classification). If the algorithm erroneously predicts that a healthy person is sick, they will subsequently probably discover that they are healthy and no great harm will be done. However, if the algorithm predicts that a sick person is healthy and they go home without treating their condition, the outcome is potentially far more detrimental. Similar issues can be seen on the example of autonomous driving of automobile while predicting dangerous situations on the road. In order to implement cost-sensitive learning in neural networks (that are most often in deep learning) modifications of loss function are necessary. Nevertheless, this method is not always applicable since the cost matrix (sensitivity) is unknown or difficult to determine [15]. CoSen [26] neural network uses the cost-sensitive procedure of training neural networks that simultaneously learns the cost of predicting the wrong class and weighted parameters of neural network. This means that the cost matrix is autonomously generated during training, which is of exceptional importance. A new architecture of neural networks, referred to as Twin NN, was presented in [4], wherein the authors took the idea from Twin SVM [27]. Although the work was based on binary classification, a multiclass classification model had been presented as well. The main idea of the paper was to find, with the aid of two neural networks, for each class a single hyperplane that is positioned a single measure (1) from the edge of class. The model was validated on 20 UCI clusters, and it achieved the most modern results on 15 of those. The hybrid algorithm modification model is, clearly, a combination of two or three above mentioned approaches and considering that it is not the focus of this paper it will receive a cursory overview.
Hybrid models
Above mentioned approaches, data manipulation and algorithm modification, can be combined and hybrid approach is created in this manner. As stated earlier, this paper focuses on manipulation over data and the hybrid model is of no large significance. Nevertheless, we believe that it merits a mention, so we will take a part of listed technologies from [12]. SMOTEBoost [28] and DataBoost-IM [29] combine sampling and ensemble method, and EasyEnsamble and BalanceCascade [30] train multiple classification models that alternate the majority class subclusters with the minority one, therefore generating pseudo-symmetrical clusters for a particular classifier. We will also mention a significant paper published this year, which refers to the architecture of a deep neural network that uses Gumbel activation function instead of sigmoid function. This change resulted in accuracy increase on over 100 data clusters and the authors refer to this architecture as Gev-NN [31]. Nevertheless, we believe that hybrid approach, even though highly important, is not as popular as manipulations over data or algorithm modifications, since it is considerably more tailored to certain problems or algorithms and this, in turn, causes it to lose some appeal to data scientists.
Background
Generative adversarial networks [13] have gained widespread attention from scientific community because of its extraordinary prowess in generating realistic samples. At present, they are one of the most important branches of artificial intelligence due to their commercial application. The general idea is based on two neural networks - the first one is tasked with generating a sample from the input noise, and the second one is assigned to classify this sample as fake. The first network is called the generator (G) and the second one the discriminator (D). This procedure is carried out in a large number of iterations and since the discriminator provides feedback on the sample to the generator, the generator subsequently attempts to create a better and more realistic sample. This process goes on until the generator successfully fools the discriminator or until the highest specified epoch number is completed. Therefore, the goal of the generator is to create the most realistic sample possible that belongs to the real training data distribution. Conversely, as already said, the goal of the discriminator is to recognize those pieces as false. From this competition between two networks the term adversarial networks arose. This fact is graphically illustrated on Fig. 1.
Generative models
There are two basic approaches in machine learning, namely discriminative and generative. Generative modeling is assigned to unsupervised learning that has the capability to spot patterns and data distribution based on which it generates new and similar but still different data. Conversely, discriminative model is tasked with calculating the probability that a certain sample belongs to a certain class. For example, the generative model creates sound based on songs that it is familiar with, and the discriminative model determines which genre this audio signal sequence belongs to. Generally, generative is more difficult than discriminative. Generative adversarial networks make use of a generative model based on game theory and they are one of the rising technologies, a conclusion supported by extremely large number of scientific papers and a large number of available versions, some of which are described further in this paper due to their importance. It is these networks that this paper explores due to their potential as a promising tool with a proven capability to generate synthetic data enabling wide ranging applications in all branches of science and industry. The end result of this may increase accuracy in various state-of-the-art models.
Architecture of GAN networks
Generative and discriminative network in GAN have separated built-in loss functions that are designated with
In Eq. (1)
Therefore, it is clear that the goal of the discriminator is to be very close to
Overview of vanilla GAN architecture.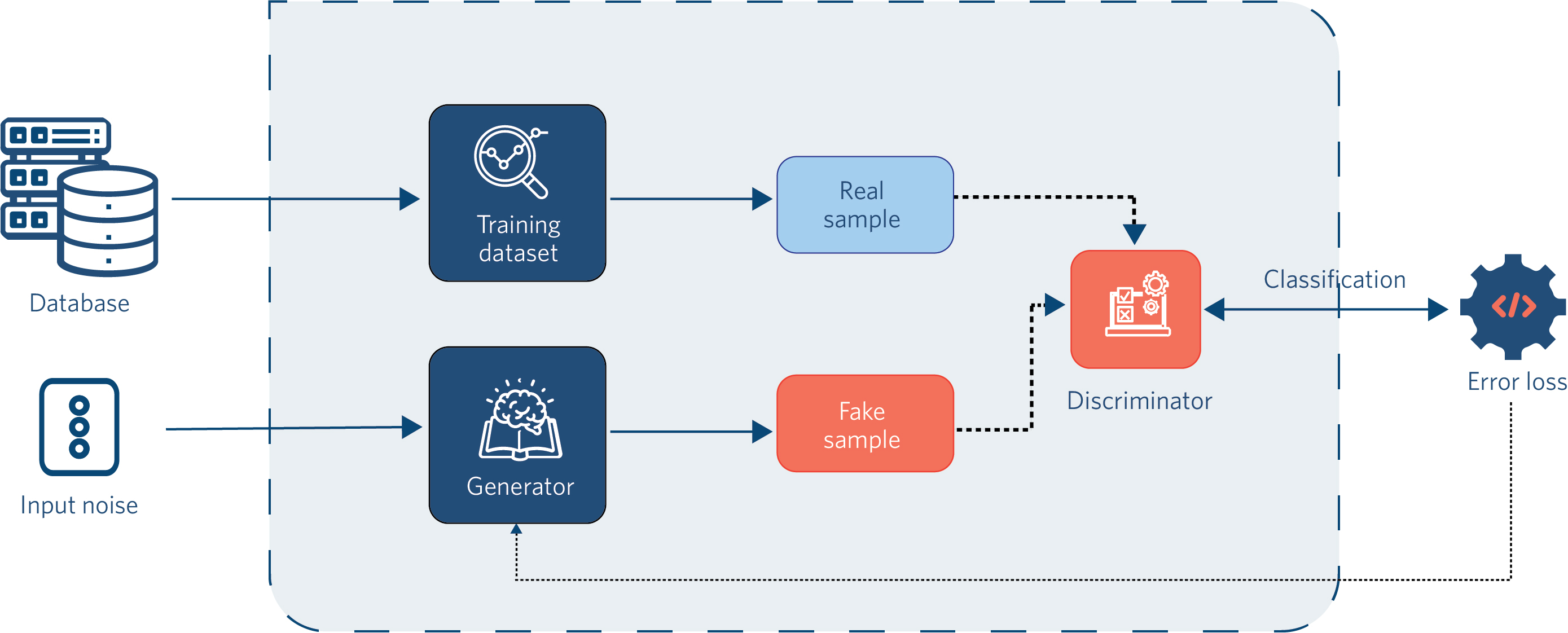
Generator with new fake artificial sample tries to fool the discriminator that the sample is real. The discriminator penalizes the generator for providing bad samples and those samples become negative training examples for the discriminator. At the outset of training when it comes to noise generated data, the discriminator has no difficulty in filtering out false data. The longer the training goes and a number of epochs through which both networks go through increases, the samples should become more plausible and the discriminator’s task significantly harder. It is important to mention that the discriminator can be any kind of neural network that corresponds to input data since it is an ordinary classifier, however, both the generator and the discriminator are typically implemented as multilayered networks with convolutional or completely connected layers [33]. The most extensive and most direct application of GAN is in the field of convolutional neural networks and generation of impressive imagery, but also in some other computer vision tasks.
Generally, generative networks training proceeds in three steps, namely, (i) training the discriminator through one or more epochs, (ii) training the generator through one or more epochs and finally (iii) the finite repetition of the first two steps. In practice, however, it is not as simple and the first two steps are broken down to sub phases. It is important to emphasize that the training on both networks is carried out simultaneously, but independently. The discriminator receives samples which are later classified and categorized as real or false and then it returns that information to the generator which it penalizes for sending bad quality samples. Finally, backpropagation is performed where the discriminator task difficulty levels are updated and the ones in the generator remain the same.
Generator’s training is somewhat more difficult since as the first step it receives data from random distribution, which it then uses to create an artificial sample that is later mapped through real data distribution. This sample is sent to the discriminator for evaluation which it receives as feedback based on which it calculates the loss and performs propagation through both subnetworks (the discriminator weights are included) but in the end only the generator weights are updated. Clearly, this means that during the generator training weights from the discriminator network affect the updating of generator weights even though the reverse is not the case.
During training certain problems may arise and three most common ones are: (i) training instability and (ii) mode collapse which occurs even in more advanced versions. Training is always unstable with vanilla architecture because of constant Jensen - Shannon divergence. The mode collapse can be seen as a kind of overfitting because the model starts to create identical or very similar data compared to previously generated. The training process of GAN networks is explained in detail in a publicly available course from Google1
The most prominent limitation of traditional GAN is the fact that this is an unsupervised learning method, meaning that the data samples it generates are not labeled. In other words, it is not possible (automatically) to augment the dataset. By providing additional information to the generator and the discriminator it is possible to assign generated data to one of the classes. This can be any kind of additional information and it most often is class label or data from other modalities. This is solved in conditional GAN (CGAN) network developed by Mirza et al. [34]. Conditional networks have an additional element c which can be an additional sample information like a label or some other attribute. Conditionality is carried out through additional layer and the objective function can be written as shown in Eq. (3).
LapGAN [35] is a variant of generative adversarial networks that introduces hierarchical structure of Laplace pyramid which gradually creates a higher quality image on each successive level of the pyramid. This architecture enables LapGAN network to create high quality samples of natural images. Every k-level of the pyramid has its own generative convolutional network
The discriminator uses a version of LeakyReLU in every layer. LeakyReLU is a continuous function that has been experimentally proven to be an extremely good choice in many cases, including this one, and therefore seems like a sensible choice to increase the resolution of these images. This is the first effort that applied a deconvolutional network within the generator, therefore it is an important turning point in GAN development. Due to model capacity and optimization limitations however, this network was successful only with low resolution images, and even then with poor variety [37].
The two well-known problems exhibited by the classic GAN are considerably mitigated in Wasserstein GAN network [38] that authors simply refer to as WGAN. Authors Arjovsky et al. have substituted the usual Jensen-Shanon divergence from the classic GAN value function with Wasserstein distance
Translations performed by CycleGAN [39].
Image-to-image translations represent a computer vision task to transform characteristics of a certain domain, in other words features of an image, to another image. This task can be supervised (paired images) or unsupervised (unpaired images). The approach that deals with translating the image to image without paired samples and uses GAN networks is presented in [39], and authors call it CycleGAN. Figure 2 is taken from this paper and it clearly shows exactly what this model does. In 2018, Karras et al. from NVIDIA company presented a few valuable contributions in the field of generative networks in [40]. The main contribution is in a new model of training generative adversarial networks in a way that enables both subnetworks to progressively grow. This means that the model starts with low resolution training and then, going through epochs, new layers are added in order to increase image resolution. Even though at first it appears more computer intensive, training of such networks accelerates and stabilizes the training process and the end result are images of exceptional quality. During experiment the network was trained on 8 Tesla V100 graphics cards over the course of 4 days in total, until changes in image quality were no longer detected. This is one of the most important works in the field in its publication year.
Attention concept [41] was borrowed from psychology and it is considered to be the best deep learning idea in the last decade. This simple and intuitive concept is based on the idea that during the processing of large volume of data we pay attention only to a handful of important attributes and we ignore the rest of data. The intuition behind this idea is explained in the following example taken from [42] with minimal modifications. When a person observes an image of a class in an elementary school classroom, they can easily spot a teacher and the children sitting in rows of desks. During head count of children, the brain focuses exclusively on children’s heads and it ignores all other image details. Likewise, when the task is to find teacher the brain easily filters the rest of the image searching only for the older person features in the image.
Self-attention is a new concept that arose from attention and is based on the idea that inputs self-communicate in order to determine who needs to receive more attention. It is applied in generative adversarial networks in [43] where one of the paper authors is Ian Goodfellow, the creator of original GAN networks. Self-attentive generative adversarial networks (SAGAN) [43] efficiently find global relations within image instead of local learning that is usual in most other GAN networks that perform image processing and use convolutions. In conducted experiments SAGAN network was evaluated over ImageNet (also known as LSVRC2012) dataset and for comparison with other models Inception Score metrics and Fréchet Inception Distance (FID) were used. SAGAN exhibited significantly better results for both networks compared to ACGAN network [44] that previously set the bar high and which is described in more detail in the following pages.
Little attention has been paid to domain knowledge within GAN models and this is certainly one of the possible directions for further development. However, there is research that addresses this issue and domain knowledge could be embedded in GAN networks in different ways. For instance, in [45] domain knowledge is formalized as a constraint function, in [46] as a heuristic and in [47] as a knowledge graph. The constraint function determines whether an image has features of a particular class and authors evaluate their model on the Oxford flowers dataset.2
In this section, 13 papers in total are examined ranging from the period of 2016 to 2020 and a complete overview is available in Table 1. All papers refer to GAN application in data oversampling in various domains and with various variants. Each of the papers is classified into one of two groups, (i) data-structured and (ii) data-unstructured papers. Within the subsection, the articles are sorted by the years in which they were published. At the end of the first subsection, Table 2 provides an overview of the classifiers and metrics used in papers working with structured data.
GAN variants and used datasets for data augmentation in examined papers
GAN variants and used datasets for data augmentation in examined papers
Classifiers and metrics used in structured data papers
DOPING: Generative Data Augmentation for Unsupervised Anomaly Detection with GAN (2018)
Lim et al. [48] are focused on events that are considered completely normal but their appearance is very rare (but not an anomaly). They believe that these samples are “culprits” for the false positives during anomaly detection. The idea is to oversample records of these events, however, this presents a challenge for the real high dimensional multimodal distribution data. In order to remove this problem, a GAN variant that is used is also known as adversarial auto encoder (AAE). In simple terms, auto encoders are neural networks that create new representations of data in an unsupervised manner. Additional sampling is performed on the “fringe” of latent distribution in order to increase the density of rare normal samples. This unique model that authors call DOPING is generally applicable, and it is also the first one that deals with the problem of data increase for anomaly detection in an unsupervised environment. Compared to SMOTE [11] method that increases density of all samples non-selectively, this approach synthesizes samples on the fringe of normal distribution. DOPING is pure unsupervised data augmentation technique for anomaly detection based on the idea taken from physics to oversample data on the edge of latent space, and the whole process is done in 4 steps. The first step is to train the most basic unlabeled autoencoder architecture where each network consists of two layers of 1000 hidden units. ReLU activation function is used in every network and every layer, except in the decoder’s output layer which uses a linear activation functions. The AAE encoder, in the second step, encodes the input dataset which produces a set of latent vectors. From this set, those vectors that are at the end of the tail of the latent distribution are selected and thus a new subset is created. This new set is used in the third step for random sampling and creation of new vectors which again now form another, new, set of artificial (synthetic) latent vectors. These vectors are created by interpolating selected latent vectors with their nearest neighbor. In the last step, this set of artificial latent vectors is finally used to create artificial samples that are later added to the original dataset, which should cause a reduction in class imbalance and ultimately raise the accuracy of the models to be trained on that dataset. DOPING has been validated experimentally on synthetic and real-world data. For the purposes of the experiment, 3 artificial data sets were created, and for the real data MNIST4
This is one of the exceptionally valuable and important works where effectiveness of GAN, or more specifically CGAN, is confirmed. Douzas and Bacao [50] use a simple conditional version of generative adversarial network (CGAN) in order to try to balance the dataset by creating new data that represent minority class. Performance has been compared with several conventional oversampling algorithms and during the work it was shown that CGAN achieved much better results in terms of quality of the created samples. From the UCI, 12 imbalanced datasets were taken and the imbalance ratio for each one was increased to approximately 2, 4, 6, 10, 15 and 20. Interestingly, this was done by dropping samples from the majority class in order to change the imbalance ratio, but the threshold for stopping was when at least 8 samples remained in the minority class. Aside from those, 10 synthetic datasets were created that were used for training the GAN. It was demonstrated that they were able to achieve superior overall mean score with CGAN (in all metrics) compared to other used alternative data augmentation methods. Classifiers used in this paper are linear regression (LR), support vector machines (SVM), k-nearest neighbors (k-NN), decision trees (DT) and Accuracy comparison was performed with a AUC, F and G metrics. The authors believe that the capability of CGAN to improve in this manner arises from its recovery of training data distribution when enough time and computing resources are available. The limitation of this paper is that it is focused only on a binary classification, but in spite of that it is pretty important research.
Generative adversarial networks for data augmentation in machine fault diagnosis (2019)
Shao et al. [44] developed a program framework based on GAN networks that is called auxiliary classifier generative adversarial network (ACGAN) that serves to process signals from mechanical sensors and to create one dimensional raw data. Data standardization is done within generator in order to avoid vanishing gradient problem during training. Compared to classic GAN, ACGAN creates high quality labeled samples thanks to additional information on class labels so this network is appropriate for classification tasks that are a part of supervised learning. In order to perform a generative model quality assessment, the authors experimental verification and statistical attributes, namely Euclidean distance, Pearson’s correlation coefficient and Kullback – Leibler divergence to assess similarities between generated samples and real samples on training. These metric values are used to calculate the generator’s ability to model the training data distribution. Since the data are one-dimensional, it is very interesting that the authors use convolutional networks. A 1D-CNN network was applied in the generator and discriminator, which performs a one-dimensional convolutional operation. The generator network uses the original ReLU and hyperbolic tangent activation function. On the other hand, the first two layers of the discriminatory network use the LeakyReLU activation function. The generator output is a sample of one dimension, while the discriminator actually gives two predictions, (1) whether the sample is real or fake (the sigmoid function is output), and (2) in which category that sample falls (softmax is output). The authors use ADAM for optimization [59]. This model achieved results that exceeded previous ones in this field and they kept the bar high for two years, so we consider it an extremely important and valuable work from this group.
Data augmentation in fault diagnosis based on the Wasserstein generative adversarial network with gradient penalty (2020)
The fault problem in the industry presents a serious issue and a considerable challenge for a long time. These faults are usually rare and hard to predict and data on such occurrences is extremely scarce. For this reason, great effort is invested into rare data augmentation models and some of those are based on GAN networks. One such approach is presented in [57] where Wasserstein GAN with Gradient Penalty (WGAN-GP) was applied, which was presented in [60]. Original WGAN network is improvement of GAN network because loss function of WGAN network was changed and that improved the optimization stability that was described earlier. However, WGAN is sometimes unsuccessful in this regard and therefore a convergence problem occurs and new low quality samples are created. In order to eliminate the previously mentioned problem the paper applied a newer model called WGAN-GP which introduces an additional element into the value function that denotes penalty (penalty term). This also implies faster convergence and ultimately the creation of better quality samples. The authors (Gao et al.) evaluated WGAN-GP on three referent datasets (Wine Quality Dataset, FD Dataset, Tennessee Eastman Proccess) and the results showed there was an increase in accuracy in fault diagnosis field. We would conclude that the greatest improvement is possible in replacing multilayer perceptrons with deep neural networks (both in the generator and in the discriminator), which the authors themselves described in the conclusion as the future direction of this research, but with larger dataset.
Deep learning fault diagnosis method based on global optimization GAN for unbalanced data (2020)
Research described in [6] examines similar issues as [57], furthermore it was stated previously that deep learning did not turn out to be a good model for fault diagnosis problems because such datasets are almost always imbalanced and the results achieved by deep neural networks can be misleading. The authors of this paper presented modified elements of GAN networks, more precisely the generator and the discriminator, that generate samples labeled as fault assisted by global optimization. In the paper an auto encoder is used and the data it creates is used to train the generator. Interestingly, the authors used a hierarchical discriminator with two levels where a traditional discriminator, as usual, disqualifies samples that did not meet the basic criteria, but the adjacent deep neural model which takes into the account the effect the generated samples have on fault diagnosis result. Still, the most important contribution of this generative adversarial network, also referred to as GOGAN by the authors, is the fact it relies on the global optimization of samples and this approach certainly impresses and clears the path for a great variety of research. The vibration (bearing) data used in the first case study are one-dimensional and relatively long, so the authors used a sliding window to preprocess data. Here we see an opportunity to apply recurrent neural networks (RNNs) which have been proven when working with sequential data. Also, the results of the experiments were compared with accuracy and we believe that a comparison would be more credible with the F1-score, G-means and AUC since it is known that overall accuracy is not suitable for unbalanced datasets [18].
Forecasting emerging technologies using data augmentation and deep learning (2020)
A group of scientists in [58] performed oversampling with GAN over the dataset containing data from GETHC and T1 patent set in the period from 2000 to 2016 and then they trained the deep neural network classifier that performs forecasting of emerging technologies for the year of 2017. The samples were divided into two classes – promising technologies and the ones that are not. Generating artificial samples goes in two phases. In the first phase, GAN creates synthetic data only when the loss functions of both subnetworks of GAN start to converge (after at least thousand epochs). In the second phase, the generator creates synthetic samples while the discriminator filters them, and the data that successfully fool the discriminator end up as the chosen samples. Testing results showed that the prediction accuracy reached 77% when the synthetic sample size was 1000, that is, when 4 out of 6 technologies were correctly classified. GAN-DNN model performances were compared to 3 other models and in this comparison it exhibited a substantially better result in terms of classic accuracy, but also in F1-score and G-median. Since the data preprocessing process is not explained, certain improvements may be possible right there.
Unstructured data
RenderGAN: Generating realistic labeled data (2016)
The framework that is presented in this paper [51] has the capability to create realistic synthetic images by combining a 3D model and GAN networks. The authors presented two fundamental modifications compared to the basic model. A simple 3D model is built into the generator in order to create samples based on input labels and this same generator learns to create missing attributes of an image by using numerous functions for creating new data. In other words, RenderGAN creates labeled samples with altered background, lighting and similar elements. These changes in environmental elements are learned from unlabeled data while labels for newly created samples were taken from the 3D model.
ARIGAN: Synthetic arabidopsis plants using generative adversarial network (2017)
Giuffrida et al. [52] presented a new architecture based on the well-known DCGAN networks that creates realistic artificial images of rosette-shaped plants. Three data subsets were used (A1, A2, and A4) that are contained within CVPPP 2017 LCC dataset. The augmentation of DCGAN architecture consists of adding another deconvolutional layer that generates images in a two times higher resolution (128
Biomedical data augmentation using generative adversarial neural networks (2017)
GAN has the capability to create new artificial images of magnetic resonance (MRI) on parts of human brain [53]. This 2017 research is the first attempt to create biomedical images with GAN assistance and the model successfully created new samples that are very similar to the real ones, which can be seen in figure 3. Used dataset contains nearly 48 thousand MRI brain images. Medical experts, specifically specialists in this particular medical field, examined the newly created human brain samples which turned out to be difficult to differentiate from the real samples, a conclusion reinforced by a low F1-score. However, the same experts noticed that there was a low level of contrast between the white matter and the grey matter and that both hemispheres are overly symmetrical. Nevertheless, the authors believe that the model is most certainly satisfactory but that there is still room for improvement, mainly in use of deep convolutional generative adversarial networks (DCGAN).
Real (left) and artificial (right) samples [53].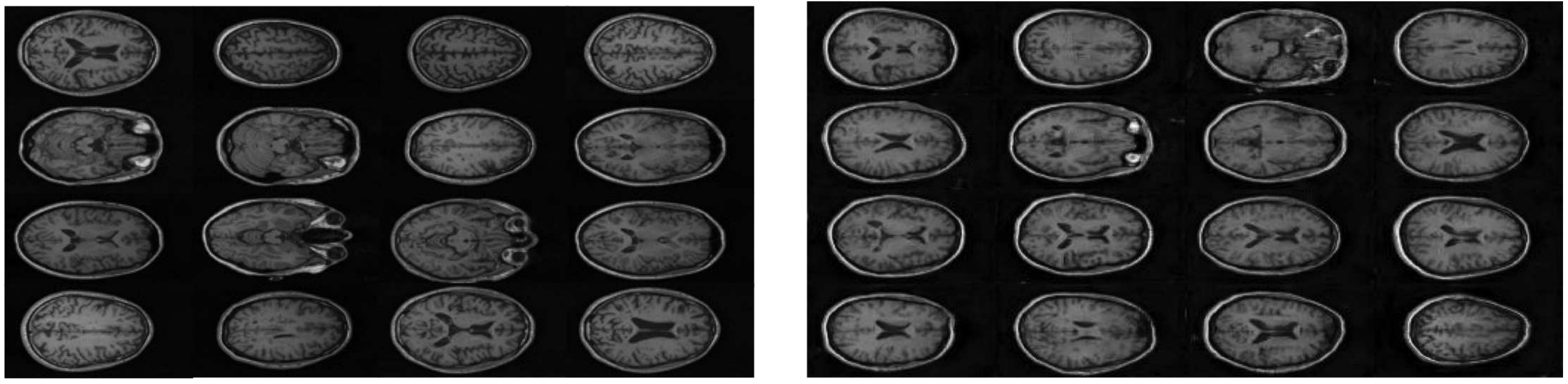
Obstructive sleep apnea (OSA) is a serious health issue affecting 2% to 7% of the population, mostly adult males. It is clear that this is not only an unpleasant, but also a serious health problem because the affected people are sometimes deprived of air in their sleep up to one minute. In order to create a non-invasive method for automatic classification for obstructive sleep apnea, the scientists in [10] use a dataset known as The Munich-Passau Snore Sound Corpus. The problem with automatic snore sound classification (ASSC) is linked to a lack of sufficient number of labeled data, especially the data on the obstructive apnea onset. In order to eliminate the problem of insufficient minority data, the authors presented a new generative model that is called semi-supervised conditional GAN, or SCGAN for short. Compared to classic GANs, the process of generating SCGANs is conditionally controlled. Therefore, there is no need for additional procedure of labeling data. Furthermore, the authors analyze and use sequential data where they use GAN and recurrent neural networks, and the proposed model as compared with ordinary GAN and CGAN networks and SCGAN was determined to be significantly superior in this particular problem.
Infinite brain MR images: PGGAN-based data augmentation for tumor detection (2019)
Han et al. [54] make use of multi-class method of generative training to create 256
Augmenting data with GANs to segment melanoma skin lesions (2020)
The purpose of this research [55] is to show the effect of a variety of artificially generated images during segmentation and detection of melanoma skin lesions. Experiments showed that the process of creating artificial images effects the increase in general accuracy in convolutional neural networks. The authors used ISIC 2017 dataset and modifications of DCGAN and LAPGAN generative networks. DCGAN network is tasked with creating 192
Real (left) and artificial (right) sample [55].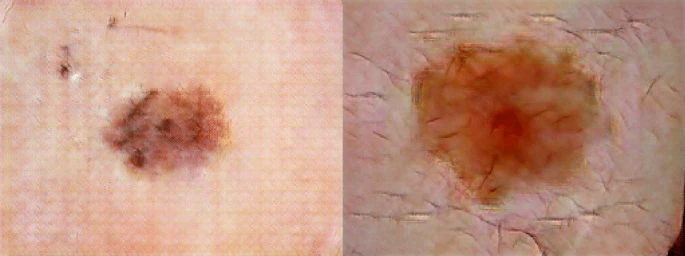
In a year when all the attention is on the corona virus pandemic, numerous scientific papers on the subject were published. In [56] the authors focus on creating artificial X-ray chest images of COVID-19 patients. Initial dataset consists of 1124 images, 721 of which are images of healthy lungs and 403 images of COVID-19 infected patients. The dataset is created from three different publically available datasets, namely, (i) IEEE Covid CXR, (ii) COVID-19 radiographic database and (iii) COVID-19 CXR Initiative dataset. During the merging some duplication of certain images occurred so the authors filtered them manually. Image classification with ordinary convolutional network reached 85% accuracy, and adding artificial images created with assistance from CovidGAN model the accuracy increased by as much as 10% to 95%. Aside from accuracy, the authors used sensitivity, F1-score, and specificity to evaluate the result and according to each parameter an improvement was made by applying the new model. The authors use the ReLU activation function in all layers of the convolutional neural network, and therefore we believe that it would potentially improve if certain layers were replaced by LeakyReLU.
Conclusions
Data augmentation with generative adversarial networks significantly improves performance of deep neural network models. These networks have proven to be a serious competition to the currently known oversampling techniques. Oversampling of the minority class contributes to the lowering of the imbalance ratio which benefits the neural networks and consequently no modifications, such as introduction of new loss functions and cost-sensitive matrices, are needed. Determining these matrices can be an arduous task that requires significant effort and additional human resources. Although GAN networks are often associated with image-to-image translation, generating super resolution images and image processing in general, one of their important applications is the creation of balanced datasets.
Overview of 13 scientific papers that are focused on this subject is provided in this paper. It is abundantly clear that in all these papers GAN application ultimately led to an accuracy improvement. The above mentioned provides an impetus for continuing development of such solutions, especially since the creation of quality datasets is always an ongoing topic. Future development is always difficult to predict, but advancements are possible in several segments. we believe that the concepts of attention and self-attention are an extremely interesting and good direction for further development. On the other side, creating higher quality samples, implementing new architectures, introducing sensible metrics for evaluation of created samples, loss function modifications and finding new applications of GAN are also possible further directions. We would also highlight the importance of incorporating domain knowledge for specific tasks that may affect the final overall accuracy of the created models. To conclude, the field is highly applicable and commercial so it is attractive for a large number of scientists and engineers. This represents a dynamic and competitive environment in which it is difficult to impose, but also an opportunity for valuable contributions.