
Abstract
Imbalanced data classification has received much attention in machine learning, and many oversampling methods exist to solve this problem. However, these methods may suffer from insufficient noise filtering, overlap between synthetic and original samples, etc., resulting in degradation of classification performance. To this end, we propose a hybrid sampling with two-step noise filtering (HSNF) method in this paper, which consists of three modules. In the first module, HSNF denoises twice according to different noise discrimination mechanisms. Note that denoising mechanism is essentially based on the Euclidean distance between samples. Then in the second module, the minority class samples are divided into two categories, boundary samples and safe samples, respectively, and a portion of the boundary majority class samples are removed. In the third module, different oversampling methods are used to synthesize instances for boundary minority class samples and safe minority class samples. Experimental results on synthetic data and benchmark datasets demonstrate the effectiveness of HSNF in comparison with several popular methods. The code of HSNF will be released.
Introduction
Imbalanced data classification problem arises frequently in supervised learning and has received considerable attention from researchers in recent years. In other words, imbalanced data is also class imbalance. Generally, class imbalance can be divided into binary and multi-class imbalance, in terms of binary class imbalance that the most of the sample size belongs to the majority category, only a small portion belongs to the minority category [1]. The imbalance ratio (IR) can be used to express the degree of imbalance in datasets, which is defined as the ratio of the majority class to the minority class, a larger (smaller) IR indicates a higher (lower) degree of sample imbalance. At present, the class imbalance problem often occurs in many practical applications, such as fraud detection [2], disease diagnosis [3, 4], network intrusion detection [5, 6], detection of oil spills in radar images [7], environment resource management [8], and security management [9], etc. The final goal of classifiers is to achieve higher classification accuracy. However, traditional classification algorithms may not be used in class imbalance scenarios [10]. They may be affected by skewed distribution of data and cannot effectively identify minority class samples [11], even in cases of extreme imbalance, where minority samples cannot be identified. Therefore, the traditional classifier has a disadvantage in dealing with the class imbalance problem, that is, if all samples are identified as the majority class samples, the classification accuracy obtained may be very high, but this classification accuracy is worthless, because it is almost impossible to correctly identify the minority samples, and often important information is stored in the minority samples. For example, in the case of tumor cell detection, there is a class imbalance in this data. The number of majority class (representing normal, 90% of the dataset) in the dataset will be much more than the number of minority class (representing sick, 10% of the dataset), and if these data are directly taken to the traditional classifier for training, the classification accuracy will be as high as 90% if the classifier classifies all samples as normal, which means that the diseased samples will be misclassified as normal, and the cost of this misclassification is very huge. Class imbalance not only diminishes the performance of traditional classifiers, but also has an impact on deep learning. Ghosh et al. detailed the impact of class imbalance on deep learning architecture, such as the gradient of majority class is much larger than minority class, thus the majority class dominates the weight update of the model, and introduced the solution and future research direction [12].
Many methods have been proposed to deal with class imbalance. These methods can be classified into three categories: data-level methods [13, 14], cost-sensitive learning [15, 16], and ensemble learning [17, 18, 19]. Data-level methods use oversampling or undersampling to rebalance the data distribution. Cost-sensitive learning invokes the concept of cost matrix and assigns a larger cost to misclassified samples. Ensemble learning trains multiple subclassifiers and the final result is obtained from the voting results of each subclassifier.
Data-level methods mainly include oversampling and undersampling. Random oversampling [20, 21] and random undersampling [22] are the simplest oversampling and undersampling algorithms. The former is random replication of minority class instances from the dataset, while the latter is a random removal of majority class instances from the dataset, both to achieve a balanced distribution of data. For random oversampling, the model may be overfitted due to the random addition of minority class instances in the dataset, while random undersampling randomly removes most class samples from the dataset, which may contain important information and thus limit the performance of the classifier. Although both oversampling and undersampling exhibit their respective advantages and disadvantages, it has been demonstrated that the oversampling method is superior to the undersampling method in practical applications [23, 24]. Therefore, in this paper, we mainly discuss the oversampling method.
At present, many oversampling algorithms have been published in in the literature, including synthetic minority oversampling technique (SMOTE) [25], which is one of the most popular ones. Although SMOTE has shown excellent performance in dealing with class imbalance, it often ignores the distribution characteristics of minority and majority data and has a high probability of generating noisy samples, weakening the performance of the classifier. In order to solve the shortcomings of SMOTE, many SMOTE-based variant algorithms have been proposed, such as Borderline1-SMOTE [26], Borderline2-SMOTE [26], Safe-Level-SMOTE [27], ADASYN [28], ASN-SMOTE [29], etc. These SMOTE-based variant algorithms largely overcome the drawbacks of SMOTE, but introduce some new problems, such as small disjuncts problems [30], decision boundary overlap [31], and incomplete noise removal. In this paper, we propose a method hybrid sampling with two-step noise filtering for handling class imbalance in classification scenarios, this method can adequately filter noisy samples, reduce the overlap between synthetic samples and original samples, and improve the classification accuracy in the presence of class imbalance.
The main contributions of the paper are as follows:
We use different noise filtering mechanisms to conduct noise filtering twice to make the noise samples in the dataset more sufficiently filtered. We divide the minority samples into safe minority samples and boundary minority samples and remove few boundary majority samples. The boundary minority samples are extremely imbalanced with respect to the majority samples, so we use the swim-rbf method to generate samples for them; the safe minority samples use adaptive qualified neighbor selection method to synthesize samples for them. The purpose is to reduce the overlap between the synthesized samples and the original samples. We conduct extensive experiments show that the effectiveness of the proposed method compare to several popular methods by qualitative analysis and quantitative analysis.
The remainder of this article is organized as follows. We review some of the already existing oversampling methods in Section 2. In Section 3, we describe the proposed algorithm in detail. Experimental results and analysis are provided in Section 4. Finally,we we conclude this paper in Section 5.
The main purpose of oversampling is to increase the number of minority classes in an imbalanced dataset to make the dataset as balanced as possible. In this section, we briefly review some of the popular oversampling methods and their limitations.
Random linear interpolation by using SMOTE (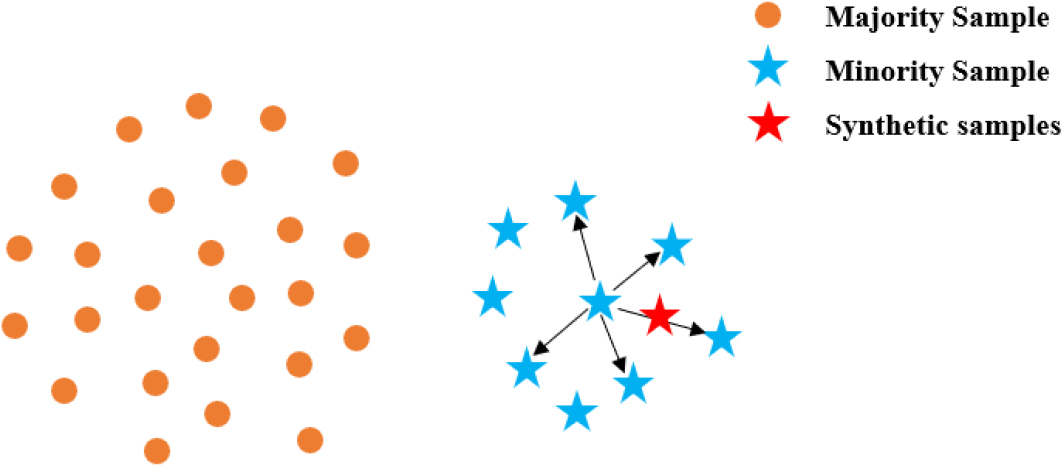
Synthetic Minority Oversampling Technique (SMOTE) [25] is the most classical and widely used oversampling algorithm, which overcomes the problem of random oversampling that tends to produce overfitting. It generates synthetic minority samples by randomly interpolating between a minority class and its nearest minority classes. As shown in Fig. 1, Specifically, for a chosen minority class instance
where
An example of possible noise generation when using SMOTE.
To overcome the above drawbacks, many improved algorithms of SMOTE have been proposed, such as Borderline-SMOTE [26], which instead of synthesizing all minority class instances, it introduces the number of majority classes
Safe-Level-SMOTE (SL-SMOTE) [27] introduces Safe-Level-Ratio, divides minority class samples into five cases according to Safe-Level-Ratio, and adjusts the position of synthetic instances for each case in order to make it closer to minority class sample. However, most of the sample positions generated by SL-SMOTE will be concentrated in the places where the minority class density is relatively concentrated, which avoids the generation of noisy instances but does not improve the recognition rate of minority classes on the decision boundary.
ADASYN [28] generates a different number of synthetic instances based on the size of the weight of each minority class. That is, the algorithm assigns different sampling weights to each minority class sample based on the number of majority class instances in the
K-means and SMOTE (KM-SMOTE) [32] is a combination of K-means clustering algorithm and SMOTE, which first clusters the input data samples using K-means algorithm, then calculates the imbalance ratio of each class cluster, filters according to the imbalance ratio, calculates the sampling weights, etc. It focuses on synthesizing instances only in safe regions especially safe sparse regions, so that although it avoids generating noisy instances and solving the within-class imbalance problem, however, finding a suitable number of clusters k is very difficult.
MWMOTE [31] redefines hard-to-learn samples by introducing
ASN-SMOTE [29] first filters noisy samples base on the Euclidean distance between samples. Then the minority class samples with the noise removed are combined with the whole data set to select qualified instances for linear interpolation. In particular, unlike the oversampling method mentioned above that brings the number of minority class samples to the same level as the number of majority class samples after processing is completed, this algorithm calculates the number of generated samples based on the number of samples in the dataset. ASN-SMOTE effectively avoids the effect of noisy samples and results in a more uniform distribution of synthetic samples. However, ASN-SMOTE has the problem of inadequate noise filtering. As show in Fig. 3, both minority class A and B should be considered as noise, but only B can be filtered out if noise filtering is performed with this algorithm.
An example of inadequate noise filtering.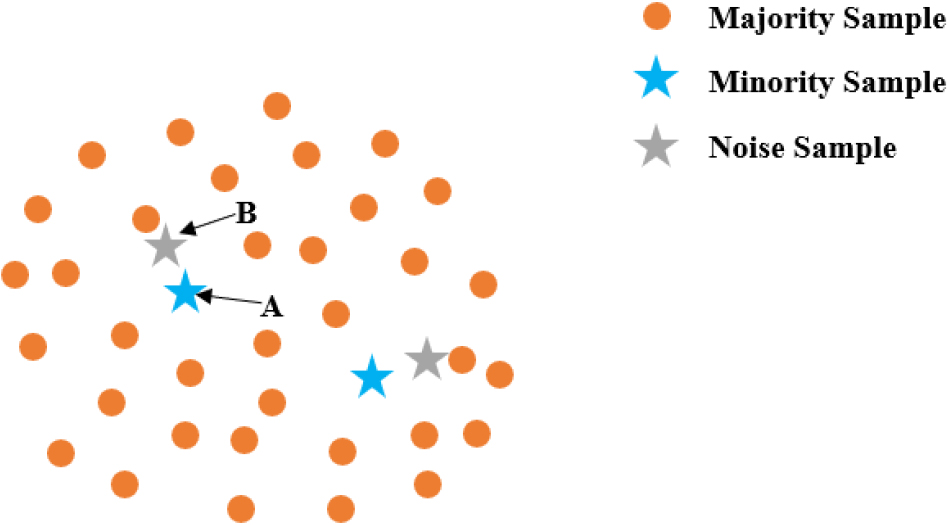
In this section, we propose a new method that combines hybrid sampling and two-step noise filtering. The method not only effectively removes the noisy samples, but also greatly reduces the overlap between the synthetic samples and the original boundary samples, which makes the classification decision boundary more reasonable and improves the recognition accuracy of minority samples and the classification performance. The flowchart of the HSNF approach is shown in Fig. 4, which mainly consists of noise filtering and dividing the minority class samples into two categories and then processing them by different methods.
The flowchart of HSNF method.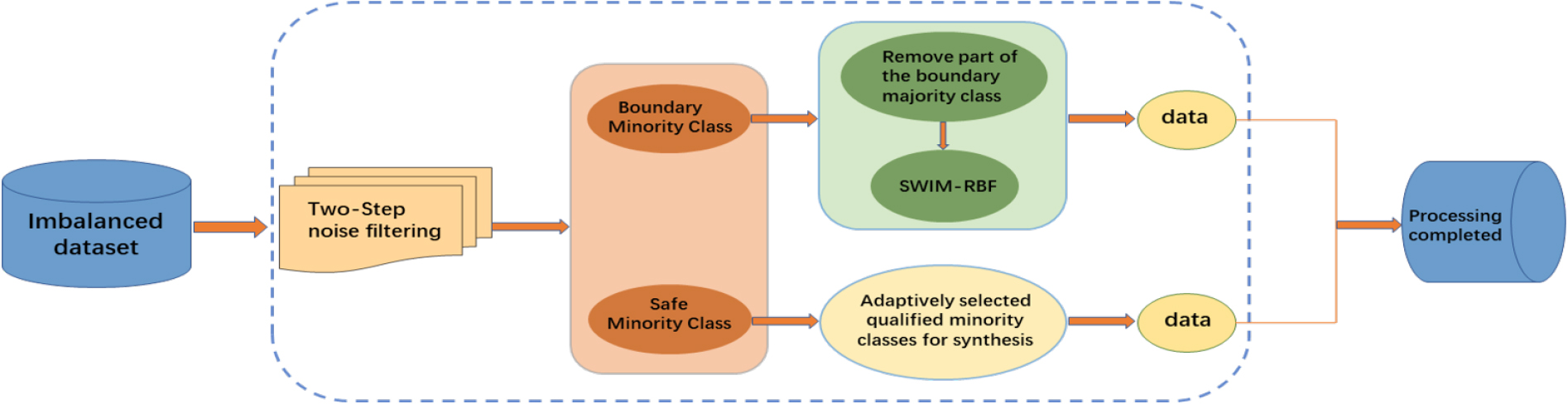
Before introducing the proposed method in detail, we introduce the SWIM-RBF algorithm. SWIM-RBF is an effective method for dealing with extreme imbalances by using the density distribution of minority class samples relative to majority class samples in a dataset to guide the generation of samples, rather than using Euclidean distances between samples. SWIM-RBF uses a radial basis function with a Gaussian kernel to evaluate the density of the minority class relative to the majority class, and the Gaussian kernel is computed by the Eq. (2):
where
in the instance generation phase, regions with the same or lower density than the current minority class are selected for sample synthesis based on the size of rbf_score.
Generate instances using the density of the minority class relative to the majority class distribution.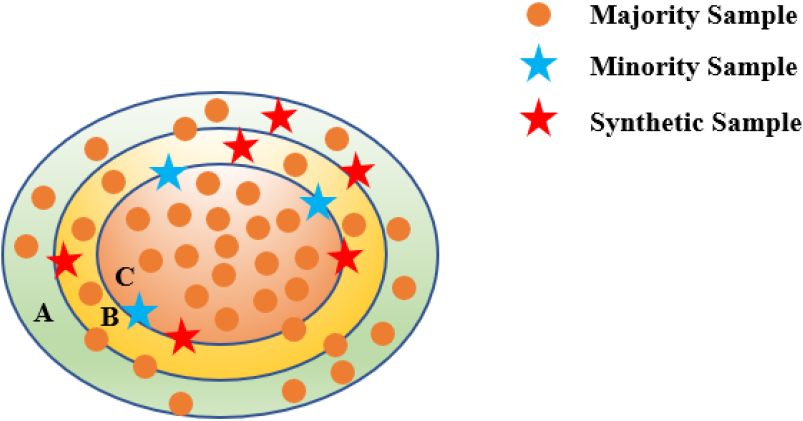
[h] : Two-step noise filtering[1] Input Data(Q), Dividing the dataset into majority(Maj) and minority classes(Min)
We combine ASN-SMOTE, Borderline-SMOTE, Undersampling and SWIM-RBF methods to divide the minority samples into different categories, and to reduce the chance of overlap between the synthetic samples and the original samples, especially the boundary majority class samples, we remove some of the boundary majority class samples and use different methods to synthesize samples for different categories. specifically, our approach can be divided into three steps.
Step 1: Two-step noise filtering
As show in Algorithm 5, we divide the input data set(denoted by Q) into majority class set (denoted by Maj), and minority class set (denoted by Min). First, for each
[h] : Remove some boundary majority classes and use SWIM-RBF for boundary minority classes[1] Input data set
[b] : Oversampling of safe minority classes using ASN-SMOTE[1] Input data set
Remove some boundary majority classes and use SWIM-RBF for boundary minority classes
As show Algorithm 3.2.1, following the completion of the first step, we can obtain the boundary minority class
Oversampling of safe minority classes using ASN-SMOTE
As show Algorithm 3.2.1, for each
The pseudocode of the proposed method is described in Algorithms 5, 3.2.1, and 3.2.1. For Algorithms 1, 2, and 3, we have two remarks.
.
The two-step noise filtering is based on the Euclidean distance between samples. The first step of noise filtering uses the Euclidean distance between minority class samples and the whole datasets; the second step of noise filtering uses the Euclidean distance between the minority class samples and the whole datasets after removing the noise from the previous step.
.
When the second noise filtering step is finished, the division of minority class samples into safe minority class and boundary minority class is completed simultaneously.
Experiments
In this section, we perform experiments to verify the effectiveness of the proposed algorithm HSNF, and report the comparison results on both synthetic data and benchmark datasets.
Experimental settings
To test the performance of the proposed method, we used 16 benchmark imbalanced datasets and compared the proposed method with Random Oversampling (ROS), SMOTE [25], ADASYN [28], B1-SMOTE [26], B2-SMOTE [26], SL-SMOTE [27], D-SMOTE [34], KM-SMOTE [32], ASN-SMOTE [29], the data for comparison are obtained by running KNN [35], SVM [36], and GaussianNB (NB) classifiers. The oversampling methods and classifiers used in the experiments can be found in smote_variants [37], sklearn [38], and imbalanced-learn [39], respectively. Where, for the parameters of the SVM classifier, we set the penalty term to
Benchmark dataset description
We conduct comparison experiments with 16 datasets that come from Keel1
Description of the datasets
We mentioned in introduction that the traditional evaluation metrics are no longer applicable to class imbalance scenarios. Therefore, we use F-measure, G-mean, and AUC as evaluation criteria [40], which are defined by Eqs (4)–(8), respectively. where, TP indicates the number of minority (positive) classes correctly classified, FP indicates the number of majority (negative) classes misclassified as minority (positive) classes, TN indicates the number of majority (negative) classes correctly classified, and FN indicates the number of minority (positive) classes misclassified as majority (negative) classes.
Sensitivity: The probability of actual positive samples being predicted as positive samples; Precision: The probability of actual positive samples out of all the samples predicted to be positive; Specificity: The probability of actual negative samples being predicted as negative samples. These are defined as follows.
Results visualization on two-dimensional synthetic data
The purpose of data visualization is to observe the data distribution after applying the oversampling method to the original data set. We create the circle and moon datasets using the make_circles and make_moons methods in sklearn, then the two datasets are processed by the HSNF method and the comparison method, respectively. As shown in Figs 6 and 7 respectively, we can see that the minority samples generated using HSNF are more uniformly distributed, more adequately filtered for noise, and less overlapping with the boundary samples than the comparison method.
Distribution of circle data after using different sampling methods.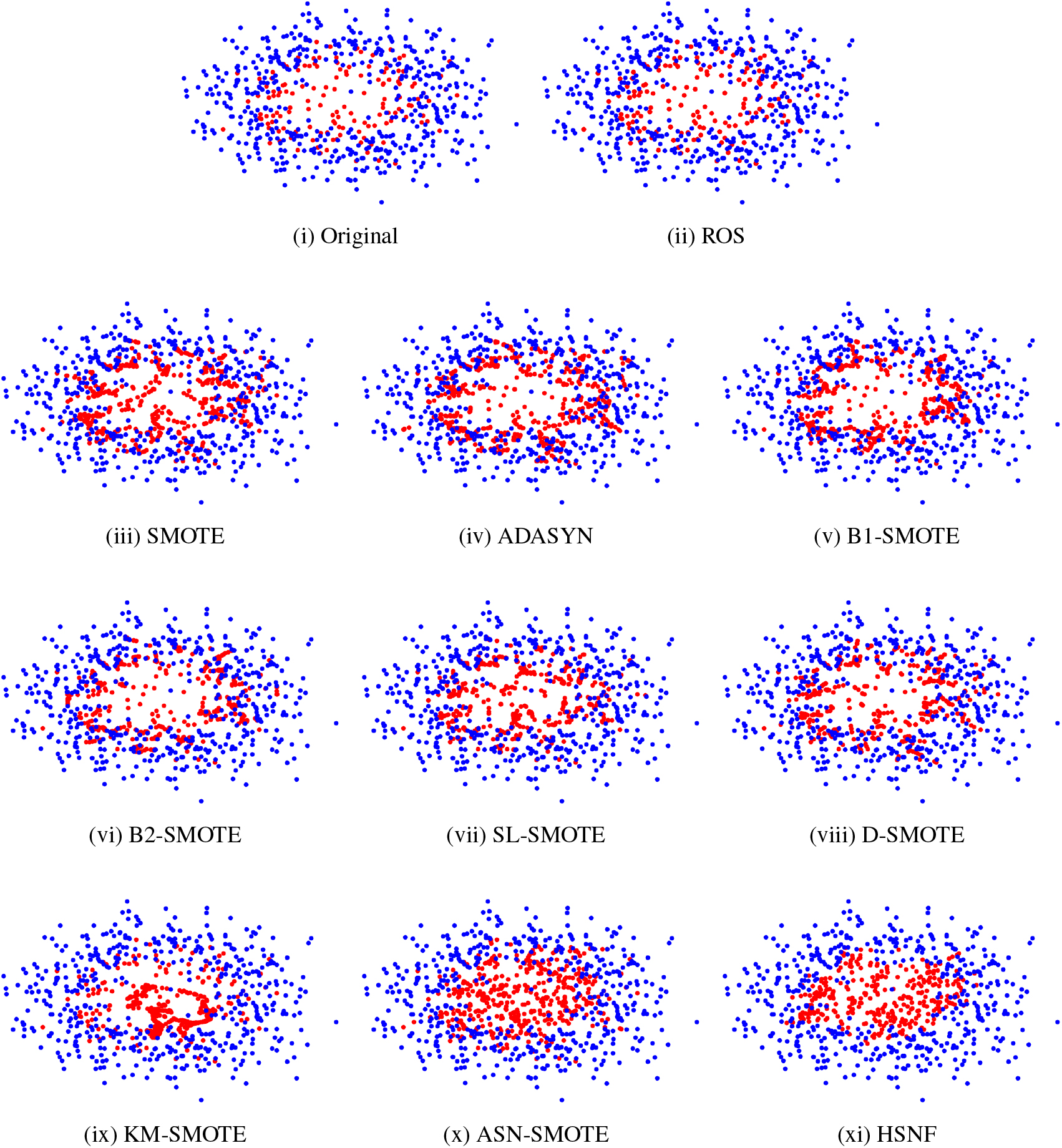
Distribution of moon data after using different sampling methods.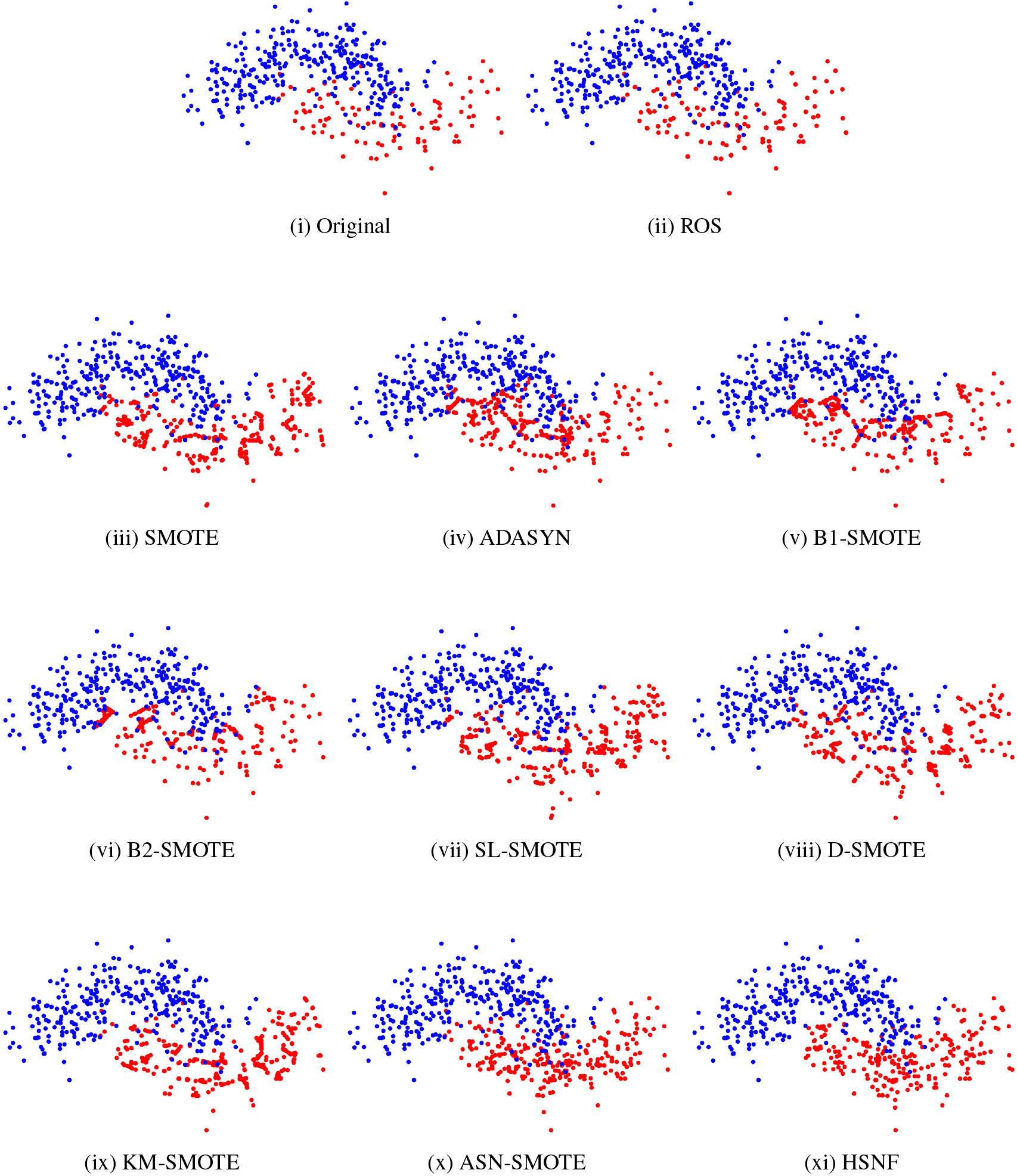
In this subsection, we evaluate the performance of the HSNF method on the benchmark dataset. Tables 3 to 10 show the experimental results of our method and the comparison method on KNN, NB, and SVM classifiers, respectively. As shown in tables, the best results are shown in red font and the second best results are shown in blue font. Figure 8 shows the average ranking of each method on the 16 benchmark datasets,specifically, smaller ranking averages represent higher performance. Wilcoxon signed rank test is used to test whether the difference between the proposed method and the comparison method is statistically significant. Results are shown in Table 11,
Tables 3 to 5 show the results of using F-measure, G-mean, and AUC as evaluation metrics on the KNN classifier. As shown in Tables 3 to 5, the HSNF method obtains the highest number of sums of optimal and suboptimal values on F-measure and G-mean, and the sum of optimal and suboptimal values obtained by HSNF on AUC is comparable to ASN-SMOTE. But, HSNF has the highest ranking on three measures (Fig. 8), which indicates that our method outperforms the comparison method. From Table 11, it can be concluded that the HSNF method significantly outperforms ADASYN, B2-SMOTE, SL-SMOTE and ASN-SMOTE on F-measure, significantly outperforms KM-SMOTE on G-mean and significantly outperforms B1-SMOTE on AUC.
Tables 5 to 7 show the results of using F-measure, G-mean, and AUC as evaluation metrics on the NB classifier. As shown in Tables 5 to 7, the HSNF method obtains the highest number of sum of optimal and suboptimal values on AUC, and the sum of optimal and suboptimal values on F-measure and G-mean is competitive with KM-SMOTE and more than other comparison methods. In addition, the HSNF method obtains the highest ranking in all three measures (Fig. 8), and HSNF significantly outperforms B2-SMOTE and SL-SMOTE in F-measure and KM-SMOTE in G-mean (Table 11).
Tables 9 to 10 show the results of using F-measure, G-mean, and AUC as evaluation metrics on the SVM classifier. As shown in Tables 9 to 10, the HSNF method obtains the highest number of sum of optimal and suboptimal values on F-measure and AUC, and is ranked with ADASYN, B2-SMOTE and
| Data | ROS | SMOTE | ADASYN | B1-SMOTE | B2-SMOTE | SL-SMOTE | D-SMOTE | KM-SMOTE | ASN-SMOTE | HSNF |
|---|---|---|---|---|---|---|---|---|---|---|
| Yeast-0-5-6-7-9_vs_4 | red0.507636 | 0.48774 | 0.473483 | 0.456374 | 0.439081 | 0.457943 | blue0.490704 | 0.446416 | 0.47121 | 0.451799 |
| Ecoli | 0.554689 | 0.54507 | 0.562411 | 0.573083 | 0.565195 | 0.562038 | 0.556216 | blue0.594814 | 0.584649 | red0.596853 |
| Wine | 0.844447 | 0.831657 | blue0.856296 | red0.87849 | 0.849069 | 0.831657 | 0.820418 | 0.833569 | 0.834418 | 0.842234 |
| Haberman | 0.420924 | 0.437401 | 0.417259 | 0.423661 | 0.4314 | blue0.4522 | 0.430904 | 0.392326 | 0.422518 | red0.457029 |
| Ecoli3 | 0.590735 | 0.59593 | 0.587821 | 0.638349 | 0.584919 | 0.586488 | 0.582197 | blue0.642647 | 0.605702 | red0.671207 |
| Ecoli1 | 0.767392 | 0.761983 | 0.716714 | 0.747474 | 0.746468 | 0.744305 | 0.757391 | blue0.777178 | 0.735109 | red0.789831 |
| Iris | 0.922334 | 0.922334 | 0.891609 | 0.915088 | 0.893696 | 0.90597 | 0.915419 | blue0.935556 | 0.921668 | red0.938897 |
| Parkinsons | 0.401167 | blue0.415566 | 0.401865 | nan | nan | nan | nan | nan | nan | red0.496354 |
| Yest5 | red0.669183 | 0.650928 | 0.645916 | 0.646617 | 0.580827 | 0.61756 | blue0.662909 | 0.650595 | 0.595948 | 0.618592 |
| Yeast-0-2-5-6_Vs_3-7-8-9 | 0.421908 | 0.405615 | 0.344864 | 0.423114 | 0.438455 | 0.425842 | 0.381501 | 0.500923 | blue0.509439 | red0.558125 |
| Heart2 | 0.510725 | 0.528678 | 0.536963 | 0.5366 | 0.527769 | 0.533464 | blue0.542891 | 0.498647 | red0.551123 | 0.541522 |
| Liver_disorders2 | blue0.500932 | 0.476836 | 0.488726 | 0.498235 | 0.466282 | 0.495939 | 0.478016 | 0.375091 | 0.442101 | red0.526954 |
| Vehicle2 | blue0.736717 | 0.721916 | 0.718465 | 0.735435 | 0.681988 | 0.719242 | 0.722596 | red0.753948 | 0.646743 | 0.724202 |
| Glass0 | 0.678641 | 0.689576 | 0.701141 | 0.687937 | blue0.703132 | 0.684184 | red0.722105 | 0.670242 | 0.666015 | 0.660743 |
| Pima | 0.586211 | 0.574454 | 0.5943 | 0.593503 | blue0.594555 | 0.58939 | 0.593457 | 0.574793 | red0.602979 | 0.574064 |
| Ecoli-0-1-4-7_vs_5-6 | 0.704824 | blue0.708915 | 0.665716 | 0.693142 | 0.70101 | 0.684183 | 0.688283 | 0.676487 | 0.627232 | red0.736111 |
G-mean results obtained using KNN classifier on 16 datasets
| Data | ROS | SMOTE | ADASYN | B1-SMOTE | B2-SMOTE | SL-SMOTE | D-SMOTE | KM-SMOTE | ASN-SMOTE | HSNF |
|---|---|---|---|---|---|---|---|---|---|---|
| Yeast-0-5-6-7-9_vs_4 | 0.835261 | red0.88543 | 0.874604 | 0.832388 | 0.865248 | 0.868244 | 0.869393 | 0.825066 | blue0.874986 | 0.770476 |
| Ecoli | 0.881655 | 0.888365 | 0.90573 | 0.893048 | 0.908341 | red0.917654 | 0.893977 | 0.887034 | blue0.917631 | 0.900078 |
| Wine | 0.971838 | 0.967527 | 0.949793 | 0.95099 | 0.960616 | 0.961657 | 0.955803 | red0.978627 | blue0.971886 | 0.968809 |
| Haberman | 0.649289 | 0.647737 | 0.630686 | 0.642304 | blue0.649608 | 0.636912 | 0.635319 | 0.640817 | 0.651528 | red0.651528 |
| Ecoli3 | 0.900835 | 0.903872 | 0.902955 | 0.911019 | red0.921998 | 0.90888 | 0.902701 | blue0.917186 | 0.904906 | 0.90929 |
| Ecoli1 | 0.910476 | 0.914943 | 0.910135 | 0.90377 | 0.901937 | 0.91967 | 0.924185 | 0.924246 | red0.932849 | blue0.924841 |
| Iris | 0.989 | 0.9845 | 0.979237 | 0.983737 | 0.982237 | blue0.9885 | 0.989 | 0.989 | 0.988 | red0.989 |
| Parkinsons | 0.594506 | 0.592307 | 0.609333 | 0.574559 | 0.599414 | 0.623257 | 0.586782 | 0.624559 | blue0.631908 | red0.675153 |
| Yest5 | 0.967385 | 0.966922 | 0.966035 | 0.967226 | 0.965133 | 0.966797 | 0.967467 | 0.969112 | blue0.973973 | red0.977739 |
| Yeast-0-2-5-6_Vs_3-7-8-9 | 0.774721 | 0.765638 | 0.75694 | 0.758876 | 0.771058 | blue0.78403 | 0.76081 | red0.802232 | 0.782329 | 0.779842 |
| Heart2 | 0.69 | 0.675278 | 0.675 | 0.700278 | 0.684722 | 0.707222 | 0.688889 | 0.7025 | blue0.718611 | red0.729722 |
| Liver_disorders2 | 0.685048 | 0.672607 | 0.664512 | 0.681655 | 0.668524 | blue0.693393 | 0.68656 | 0.667679 | 0.675036 | red0.699357 |
| Vehicle2 | 0.956635 | blue0.969009 | 0.96892 | red0.969756 | 0.951835 | 0.961534 | 0.956007 | 0.960129 | 0.954347 | 0.963344 |
| Glass0 | 0.855621 | 0.858612 | 0.868482 | 0.870408 | red0.88143 | 0.85811 | 0.873962 | blue0.874411 | 0.859817 | 0.852155 |
| Pima | 0.72808 | 0.729726 | 0.729927 | 0.727284 | 0.730853 | 0.743416 | 0.74032 | 0.742657 | blue0.751451 | red0.757389 |
| Ecoli-0-1-4-7_vs_5-6 | 0.835447 | blue0.847583 | red0.857462 | 0.812179 | 0.842041 | 0.832887 | 0.827277 | 0.836108 | 0.826653 | 0.824601 |
F-measure results obtained using NB classifier on 16 datasets
| Data | ROS | SMOTE | ADASYN | B1-SMOTE | B2-SMOTE | SL-SMOTE | D-SMOTE | KM-SMOTE | ASN-SMOTE | HSNF |
|---|---|---|---|---|---|---|---|---|---|---|
| Yeast-0-5-6-7-9_vs_4 | 0.131783 | 0.232432 | 0.227281 | blue0.297051 | 0.242813 | 0.187911 | 0.269779 | red0.502284 | 0.268577 | 0.152603 |
| Ecoli | 0.523265 | 0.711698 | 0.606987 | 0.75151 | 0.708214 | 0.575207 | 0.677221 | blue0.751838 | 0.728722 | red0.768794 |
| Wine | 0.947933 | 0.961513 | 0.970425 | blue0.974537 | 0.970054 | red0.974549 | 0.961513 | 0.947661 | 0.961142 | 0.956269 |
| Haberman | 0.560456 | 0.548795 | 0.563339 | 0.547371 | red0.576396 | 0.539833 | blue0.570486 | 0.509134 | 0.54986 | 0.55662 |
| Ecoli3 | 0.800715 | 0.864046 | 0.801139 | 0.852945 | 0.862196 | 0.840585 | 0.839986 | blue0.869583 | 0.842804 | red0.872144 |
| Ecoli1 | 0.667204 | 0.743565 | 0.697733 | 0.747203 | 0.728831 | 0.734733 | 0.752339 | blue0.760512 | red0.803779 | 0.758551 |
| Iris | 0.869832 | 0.856841 | 0.850638 | 0.836705 | 0.817571 | 0.858279 | 0.863864 | blue0.879633 | 0.858279 | red0.879972 |
| Parkinsons | 0.694885 | 0.696051 | 0.673269 | 0.691767 | 0.610298 | 0.647541 | 0.694269 | blue0.6966 | 0.663968 | red0.700704 |
| Yest5 | 0.751056 | 0.849672 | 0.82194 | 0.82176 | 0.629512 | 0.829522 | red0.88126 | 0.822712 | blue0.853152 | 0.834055 |
| Yeast-0-2-5-6_Vs_3-7-8-9 | 0.558014 | 0.565505 | 0.611612 | 0.581894 | 0.612535 | 0.567679 | 0.563745 | 0.339777 | blue0.630204 | red0.643484 |
| Heart2 | red0.852482 | 0.809922 | blue0.843022 | 0.822766 | 0.838867 | 0.810168 | 0.808865 | 0.797815 | 0.839654 | 0.820228 |
| Liver_disorders2 | 0.43389 | 0.445507 | 0.446631 | 0.443617 | 0.45973 | 0.442986 | blue0.488953 | 0.389816 | 0.440618 | red0.549186 |
| Vehicle2 | 0.707002 | red0.724557 | 0.68944 | 0.688531 | 0.673712 | 0.702289 | blue0.717765 | 0.28381 | 0.701211 | 0.693815 |
| Glass0 | 0.623064 | blue0.653284 | 0.623179 | 0.607876 | 0.602568 | 0.639171 | 0.623179 | red0.664414 | 0.636931 | 0.622256 |
| Pima | blue0.727181 | 0.727062 | 0.721934 | 0.723853 | 0.718003 | 0.722589 | 0.718948 | 0.673674 | red0.73003 | 0.723792 |
| Ecoli-0-1-4-7_vs_5-6 | 0.83755 | red0.856574 | 0.829976 | 0.748843 | 0.663228 | blue0.839953 | 0.824607 | 0.578267 | 0.804748 | 0.628354 |
AUC results obtained using NB classifier on 16 datasets
| Data | ROS | SMOTE | ADASYN | B1-SMOTE | B2-SMOTE | SL-SMOTE | D-SMOTE | KM-SMOTE | ASN-SMOTE | HSNF |
|---|---|---|---|---|---|---|---|---|---|---|
| Yeast-0-5-6-7-9_vs_4 | 0.468014 | 0.480775 | 0.456651 | 0.479359 | 0.483168 | 0.460948 | blue0.49275 | nan | 0.462092 | red0.494193 |
| Ecoli | 0.507546 | 0.489046 | 0.481369 | 0.541103 | 0.521103 | 0.534202 | 0.509142 | 0.52044 | blue0.54381 | red0.59639 |
| Wine | 0.975304 | 0.96792 | red0.984 | 0.967333 | 0.945778 | 0.975304 | blue0.97592 | 0.96792 | 0.96792 | 0.975333 |
| Haberman | 0.433229 | blue0.441275 | 0.433617 | 0.410173 | 0.421984 | 0.439507 | 0.412266 | 0.339439 | 0.435878 | red0.448768 |
| Ecoli3 | 0.544235 | 0.595066 | 0.548137 | 0.605473 | 0.580606 | 0.558754 | 0.569807 | 0.609265 | blue0.619295 | red0.627591 |
| Ecoli1 | 0.727568 | red0.766677 | blue0.751844 | 0.732184 | 0.718781 | 0.741892 | 0.748505 | 0.724871 | 0.723032 | 0.74194 |
| Iris | 0.588898 | 0.582574 | red0.669642 | blue0.640819 | 0.628221 | 0.576859 | 0.567563 | 0.535922 | 0.579289 | 0.585003 |
| Parkinsons | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan |
| Yest5 | 0.544176 | 0.535436 | 0.547201 | blue0.549541 | 0.47534 | 0.532854 | red0.550226 | nan | 0.511806 | 0.512952 |
| Yeast-0-2-5-6_Vs_3-7-8-9 | 0.497892 | 0.478632 | 0.388444 | 0.39682 | 0.39396 | 0.490762 | 0.493282 | nan | blue0.534221 | red0.546602 |
| heart2 | 0.740703 | blue0.777633 | 0.743153 | 0.751026 | 0.728227 | 0.715501 | red0.779029 | 0.739353 | 0.753 | 0.749176 |
| Liver_disorders2 | blue0.508205 | 0.486973 | 0.497246 | 0.442527 | 0.433885 | 0.449242 | 0.503387 | 0.274238 | 0.461915 | red0.509745 |
| vehicle2 | 0.817912 | 0.821722 | 0.817086 | 0.815548 | 0.748023 | 0.800076 | blue0.827104 | red0.846078 | 0.790952 | 0.798159 |
| Glass0 | 0.646386 | 0.648999 | 0.630848 | red0.660158 | 0.640299 | 0.642673 | 0.643929 | 0.536405 | 0.652018 | blue0.660113 |
| Pima | 0.662385 | 0.660714 | 0.65994 | red0.670236 | blue0.669659 | 0.66448 | 0.66338 | 0.639234 | 0.654286 | 0.629177 |
| Ecoli-0-1-4-7_vs_5-6 | 0.578676 | blue0.665346 | 0.571795 | 0.594242 | 0.643794 | 0.629195 | red0.692634 | nan | 0.627872 | 0.642547 |
G-mean results obtained using SVM classifier on 16 datasets
AUC results obtained using SVM classifier on 16 datasets
Wilcoxon signed rank test
Mean rank distribution of different methods.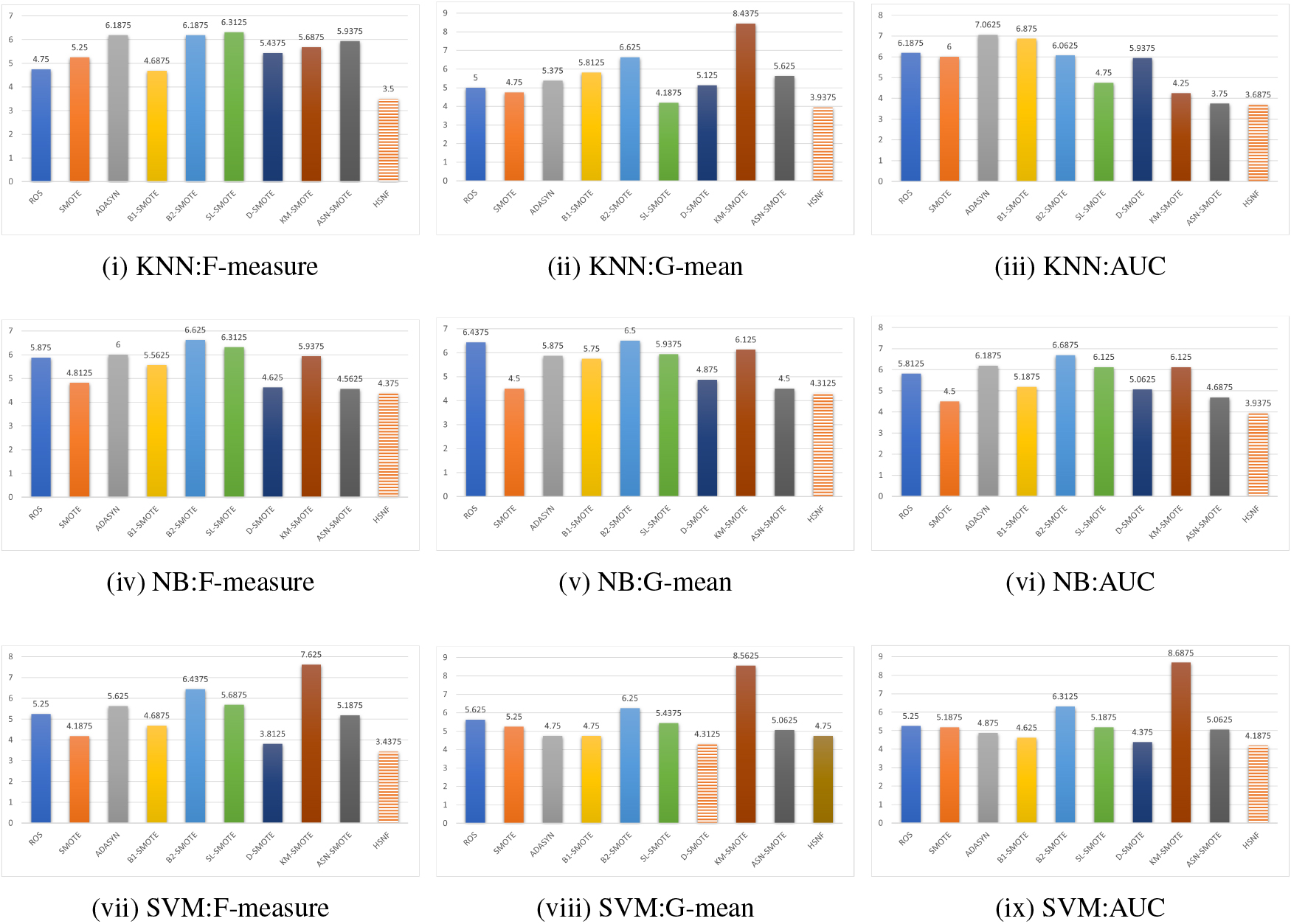
The trend of classification performance with various 
D-SMOTE on G-mean for the highest sum of optimal and suboptimal values. Further, HSNF has the highest ranking on F-measure and AUC, and the second highest ranking on G-mean, but with comparable performance to the highest ranking D-SMOTE (Fig. 8). From Table 11, it can be concluded that the HSNF method significantly outperforms KM-SMOTE on all three measures, and significantly outperforms B2-SMOTE, SLSMOTE and ASN-SMOTE on the F-measure.
In conclusion, HSNF method overall outperforms the comparison method. The reason is that HSNF filters noise more adequately and weakens the influence of noisy samples in the sample synthesis stage; and the HSNF method divides minority samples into categories and uses different oversampling methods to synthesize new samples for them, which reduces the overlap between samples especially between samples of different categories at the boundary and improves the recognition accuracy of minority samples, which in turn improves the overall performance.
In our method the parameter
Conclusion
In this paper, a hybrid sampling method is proposed for imbalanced data scenarios. Compared with some existing sampling methods, this method not only can filter noise samples sufficiently, it also can synthesize minority class samples with different methods for different minority categories and remove some boundary majority class samples, so as to reduce the overlap between samples. We conducted experiments on 16 datasets with three classifiers and nine sampling methods, and the results indicate that our method outperforms the comparison methods. In the future work, we plan to investigate different noise filtering mechanisms and work on solving multi-class imbalance problems.
Footnotes
Acknowledgments
This work was supported by the Anhui Provincial Natural Science Foundation (Grant No. 2208085 MF168).