
Abstract
Compact data models have become relevant due to the massive, ever-increasing generation of data. We propose Observers-based Data Modeling (ODM), a lightweight algorithm to extract low density data models (aka coresets) that are suitable for both static and stream data analysis. ODM coresets keep data internal structures while alleviating computational costs of machine learning during evaluation phases accounting for a O(n log n) worst-case complexity. We compare ODM with previous proposals in classification, clustering, and outlier detection. Results show the preponderance of ODM for obtaining the best trade-off in accuracy, versatility, and speed.
Introduction
Data is a key resource for Artificial Intelligence (AI) applications since generalization and prediction require considerable volumes of information to build reliable Ground Truth (GT). In principle, and assuming a sufficient data quality, the more data available during Machine Learning (ML) training stages, the better the quality of the obtained models and classifications.
Managing, processing, and analyzing such ever-increasing volumes of data is a pressing challenge. Many algorithms either (1) cannot cope with massive raw data on-the-fly (freezing or collapsing) or (2) suffer from performance degradation due to noisy data, therefore requiring lightweight data summarization in between. For example, Zimek et al. show how sub-sampling in instance-based methods improves accuracy for outlier detection [46], introducing the counter-intuitive concept of “higher accuracy with less data”. Henceforth, data summaries become key middle boxes for future ML, either to understand data, avoid degradation, or to reduce computational costs. A way of summarizing data is by extracting a low density model from it, which is equivalent to what is commonly known as a coreset. A coreset is a subset
To this end, we propose ODM, a lightweight algorithm for extracting low density data models that scales properly and helps to simplify and understand huge volumes of both static and stream data, creating optimized models for clustering, outlier analysis, and classification. ODM retrieves the idea of data observers presented in [43], which is a subset of data points used for approximating the original distribution, hence a coreset. Moreover, ODM admits some parameterization to adjust the granularity of the desired model and leverages the fact that observers do not necessarily have to be real data points.
The rest of this article is organized as follows. Section 2 explores similar methods and previous alternatives. Section 3 describes the ODM algorithm and presents its mathematical foundations. Experimental setups and datasets for the method evaluation are introduced in Section 4. Experimental results are shown and discussed in Section 5. Finally, the conclusions and a summary of the paper contributions are outlined in Section 6.
Related work
A way of understanding the processes that generate data is by finding simplified models that keep the underlying data structures with minimal amount of information. Regardless of the type of planned analysis, handling raw data is complex and time-demanding. Furthermore, because modern data is frequently noisy and unstable, data models are a suitable solution for eliminating unnecessary noise and retaining only the relevant structures, many times improving analysis performances [46]. Some research focuses on the task of extracting subsets from larger sets by using novel methods under a variety of objectives and constraints. Popular alternatives are listed below.
Statistics and error optimization
Among the most used, Bayesian coresets [28, 11, 12, 10] sample data with probabilistic models to create subsets that mimic the whole data in terms of approximating the posterior inference. The problem can be differently tackled with Gaussian Mixture Models [6, 36]; here the shape of the original data is reconstructed in a coreset by using a mixture of Gaussian functions whose parameters are adjusted accordingly. Feldman et al. [21] propose an alternative method that imposes constraints driven by Principal Component Analysis (PCA) and K-Means clustering. This method projects data into a low dimensional space, strategically selects some data points, and maps them back into the original space. The process ensures that both the whole dataset and the coreset yield similar principal components and centroids. Mirzasoleiman et al. [38] develop a technique for selecting a subset from a larger set with gradient-based learning algorithms. This method minimizes the error of an objective function in such a way that training with the entire dataset and the subset obtain the same error. Authors propose a greedy search algorithm to improve speed and avoid trying multiple combinations. The approaches introduced above build coresets very differently from each other, all of them also having a different theoretical basis from that used in ODM.
Distance-based methods
To generate coresets some methods combine smart data point sampling with measurements of point-to-point distances. For instance, Condensed Nearest Neighbor (CNN) [26, 4] was originally proposed as a solution for supervised training with a small number of representative samples. The algorithm is based on the 1-Nearest Neighbor label to retain only necessary samples and eliminate redundancy. The KMeans algorithm can also be used to find coresets [7] by extracting the shape of the input with a set of centroids that reflect major clusters in data. Finally, Iglesias et al. [43] mint the concept of “observers” to create a model of the data and use it later for detecting anomalies with the SDO (Sparse Data Observers) algorithm. Authors define observers as a set of sampled data points in which potential outliers have been removed according to a distance-based metric. These observers are later used as anchors to evaluate data points based on proximity calculations. ODM inherits the idea of “observers” from this work, but extends it by making them dynamically adaptable and controlling their generation and location. As a result, the set of observers in ODM is more density isotropic and homogeneous and less random.
Neural networks
Finally, techniques for extracting coresets with Neural Networks deserve a separate mention due to their peculiarities. Developed by Kohonen et al. [35], self-organizing maps (SOM) are strong alternatives for disclosing connections within multi-dimensional numerical data. They project complex input spaces into two-dimensional neural grids while trying to keep topological structures that are inherent to the original data. Based on SOM, Martinez et al. [37] propose Neural Gas and, later, Fritzke et al. present Growing Neural Gas [24]. These algorithms learn typologies by means of iterative fitting (or “growing”) processes. Intuitively, neurons behave like gas particles that extend and expand into the data, whose multidimensional shapes are seen as containers. This expansion of data points to occupy the entire space is analogous to the concept of low density models in ODM and play a similar role to the observers.
ODM
This section describes the ODM algorithm explicitly and with a few visual examples, shows its complexity and elaborates on its mathematical formulation. The algorithm framework is open-source and available in our git-hub repository.1
Notation
*: Algorithm parameter. **: Default value.
In [43],
Algorithm
The goal of the ODM algorithm is to build a set of proper observers; aka an optimal coreset
with
ODM starts taking a random data point as the first observer. Later, it processes the remaining data points sequentially as follows. Given a
if the distance to the closest observer ( instead, if the distance is larger than the radius then
Some parameters to comment on are:
(Required)
Shuffle
Set a random sample
ODM
Algorithm 3.2 shows the core routine of ODM, its mathematical formulation is discussed in Section 3.5. The process depicted in Algorithm 3.2, explained in a more intuitive way, goes though the following steps:
Shuffle the dataset (to avoid bias). If The coreset is initialized with a first observer Later, the remaining data points are processed sequentially. For a given
The central loop of Algorithm 3.2 can be parallelized to enable faster extraction. Each data-batch is processed individually and the resulting subcoresets can be simply joined together afterwards. Moreover, the current implementation of ODM allows either omitting shuffling data points or picking them at random. Shuffling the data is useful when the arbitrary arrangement of data samples is to be ignored; otherwise, samples sorted by default might be prone to belong to the same cluster, and this could make observer radius to converge and shrink quickly, which ultimately creates more observers than needed. To avoid this, and to enable a better space reconstruction, data points should be picked at random. Finally, if the size of the coreset is externally fixed as a parameter (
Two observers (in green) modeling a two-cluster dataset. Gradual observers locations are shown in blue.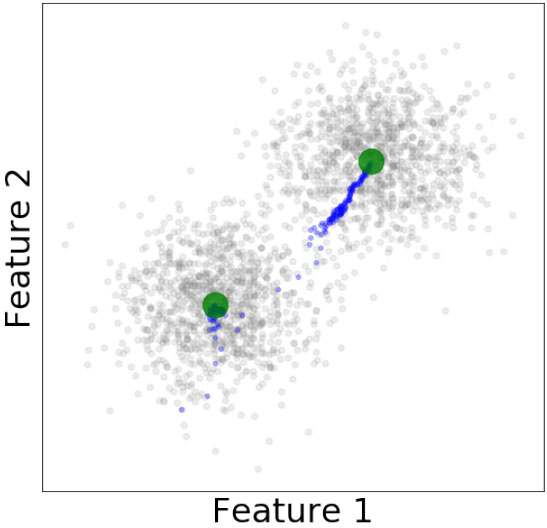
Six observers (green) modeling a five-clusters dataset. Gradual observers locations are shown in blue.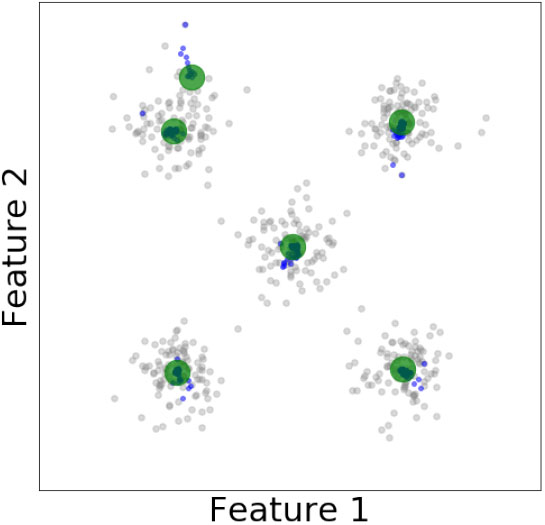
Convergence path of an observer to the center of a sample cloud.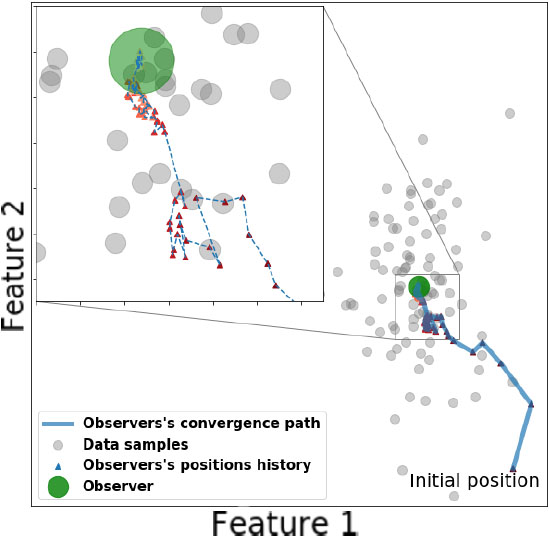
The operation of ODM can be better understood with a few simple examples. Figures 1 and 2 represent two datasets [22, 40] with two and five clusters. For these two cases ODM has been applied to obtain coresets with two and six points respectively. Data points are shown in gray-color, the final positions of observers in green, and the displacement of an observer is tracked with blue dots. We can see how observers end up in the respective clusters centers. If the number of observers is set to a higher number, the observers placement is expected to be distributed based on data density variations. We show a zoomed-in observer movement capture in Fig. 3 with a different dataset [23]. Here we can see that the observer placement converges and its displacement is progressively smaller.
The previous examples use very few observers in order to show the natural tendency of observers to be attracted by density centers. In practical modeling, higher granularity is commonly required, especially in cases with complex data structures. Figure 4 shows three datasets [32, 17, 42] for which ODM has been adjusted with low, medium, and high number of observers. As discussed above, denser coresets can be created by simply adjusting ODM parameters. Obviously, the size of a coreset cannot be larger than the size of the modeled dataset.
ODM coresets extracted from three different datasets. Each column shows a parameterization with a different number of observers. Data points are shown in gray-color and observers in red.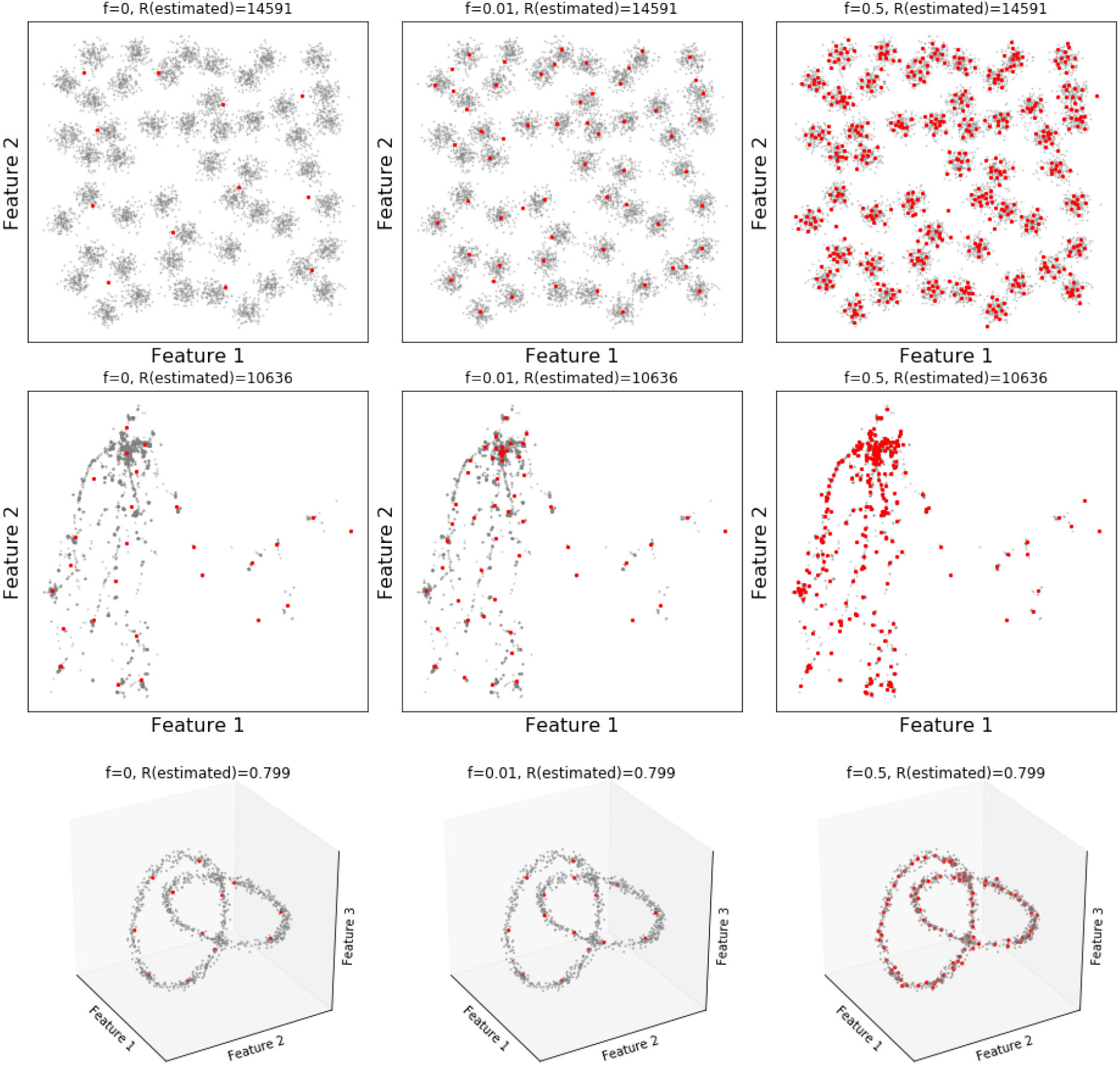
The computational demand of ODM is mainly concentrated on the search of closest observers. Different algorithms can be used for this task; for instance kd-Trees [8] and m-Trees [15]. We opt for m-Trees in our implementation since they are robust, fast, and allow changes in the tree without need for reconstruction. The tree is built once at the beginning and keeps track of the observers. Based on Algorithm 3.2, each new data point involves: one k-nearest neighbor query, one insert (either a new observer or an updated one), and optionally one removal (remove an old observer if it has been updated and re-inserted). In the highly improbable average worst case scenario, which happens if the number of observers increases with each iteration and approaches the number of data points, the complexity
In this section we address the mathematical formalism underlying ODM. ODM accepts different metrics for distance calculation (for instance, Aggrawal et al. [3] recommend using the Manhattan distances instead of Euclidean distances for high-dimensional spaces).
Initially, assuming that at least one observer exists in a coreset
If the distance between
The coordinates of
Where
Equation (7) shows that after many iterations, more observers become lazy and their location tends to be bounded in a smaller region in the output space. Moreover, Eq. (7) always holds since the distance vector
The radius of the closest observer is at the same time updated regardless of the distance check performed in Eq. (4):
Depending on the distance check, the radius
By applying Eq. (9), the initial radius 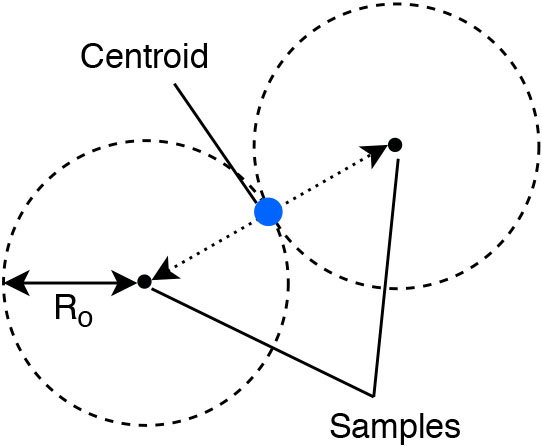
If not specified as an external parameter, the initial radius of new observers is estimated as follows:
Whereby
In this section we describe experiments conducted to evaluate ODM. They are tasks related to anomaly detection, clustering, and supervised classification. In the experiments, ODM is compared with alternative coreset extraction algorithms (described in Section 2), namely:
For the experiments we used public datasets that are commonly applied for algorithm testing in the literature. A prerequisite when selecting datasets was that they should contain a considerable number of samples in order to make the application of coresets meaningful. The datasets used are:
Table 2 shows characteristics (max and min values) of each family of datasets. The noise level is calculated as the percentage of outliers. Whenever a dataset showed missing values, the corresponding vector was removed from the analysis. “na” stands for cases in which the GT was not given by dataset publishers, therefore such values depend on the algorithm used for analyzing the dataset.
Datasets characteristics
Scheme of the anomaly detection experiments.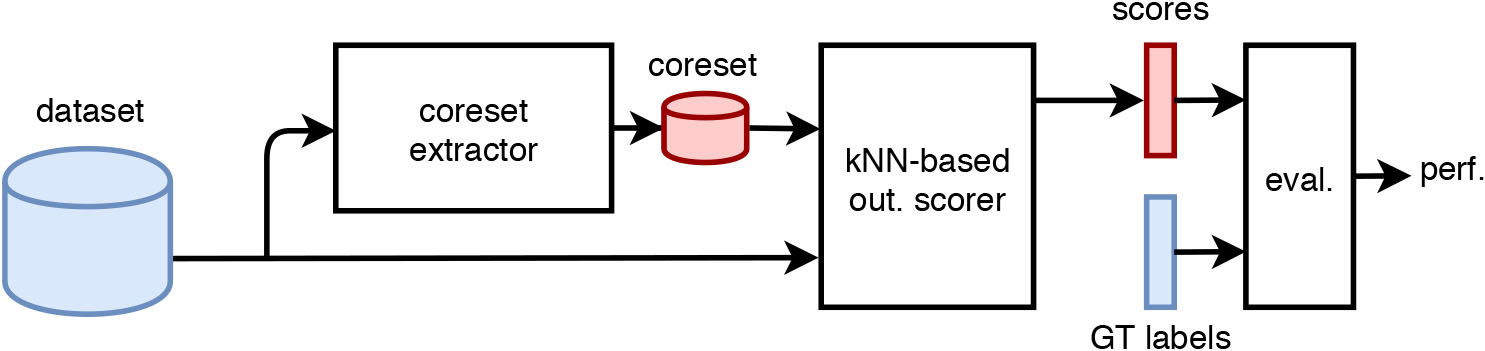
Coresets can help anomaly detection to alleviate the computational cost of instance-based methods and avoid degradation [46]. The traditional way of measuring outlierness is by considering the whole dataset (or all previous data points) when evaluating each single data point. Instead, with coresets each single data point is contrasted only with the coreset to decide if it is considered as anomaly, therefore considerably reducing the computational burden. The experiment methodology is shown in Fig. 6, its elements are described as follows:
Datasets. We used OTDT-datasets (Section 4.1).
Coreset extractors. Competitor algorithms were tuned to create coresets with different
Since anomaly detection is unsupervised learning, additional parameters of each algorithm are tuned with the default values suggested in the respective references.
Outlierness scorer. We use the kNN-based outlier detection algorithm proposed by Ramaswamy et al. [39] to obtain outlierness scores. The number of neighbors is set to five (
Evaluator. We evaluate performance by computing the P@n, average precision, ROC-AUC and MaxF1 scores using the GT labels as suggested by [13]. We show adjusted metrics to allow fair comparisons regardless of the number of outliers. We additionally measure coreset extraction and k-NN-based outlierness scoring (empirical) average runtimes.
The setup shown in Fig. 6 covers 144 experimental runs (6 algorithms
Scheme of the clustering experiments.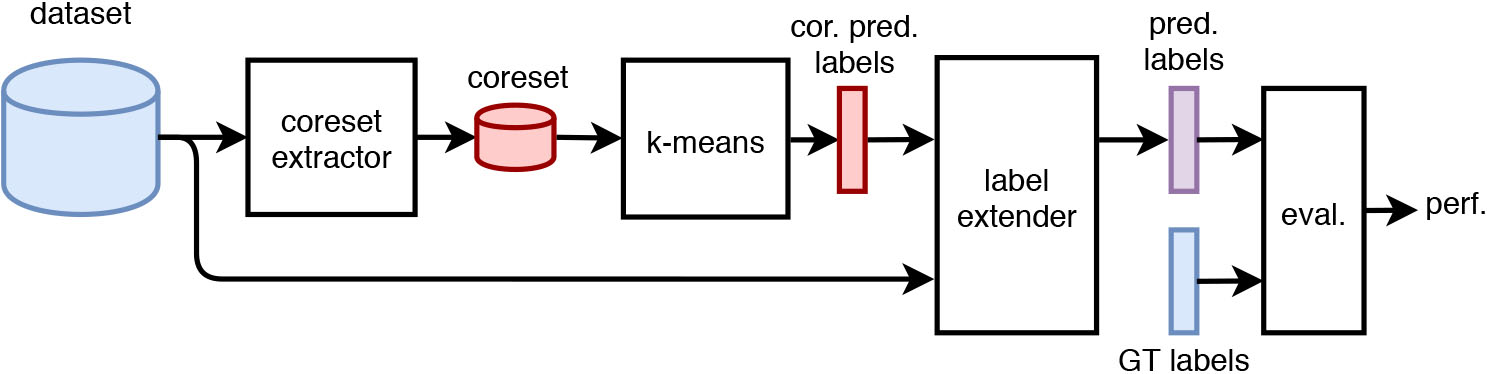
Similarly to the anomaly detection case, in order to reduce memory and time requirements, label assignment in clustering can be performed by clustering a coreset and extending labels to the whole dataset based on proximity calculations. We reproduced this scheme in our experiments and used k-means as core algorithm. The methodology is shown in Fig. 7. Elements are:
Datasets. We used MDCG-datasets (Section 4.1).
Coreset extractors. Competitor algorithms were tuned with different
k-means. Clustering is undertaken by the k-means++ algorithm [5]. The initial number of cluster
Label extender. This block calculates coreset cluster centers (centroids) and assigns final labels to the whole dataset by extending the label of the closest center (1-NN distance metric).
Evaluator. We evaluate performances with the external validity rand index [27] between predicted labels and GT labels and the internal validity silhouette score [41]. We additionally measure coreset extraction, k-means and label extender (empirical) average runtimes.
The setup shown in Fig. 7 covers 360 experimental runs (6 algorithms
Scheme of the supervised classification experiments.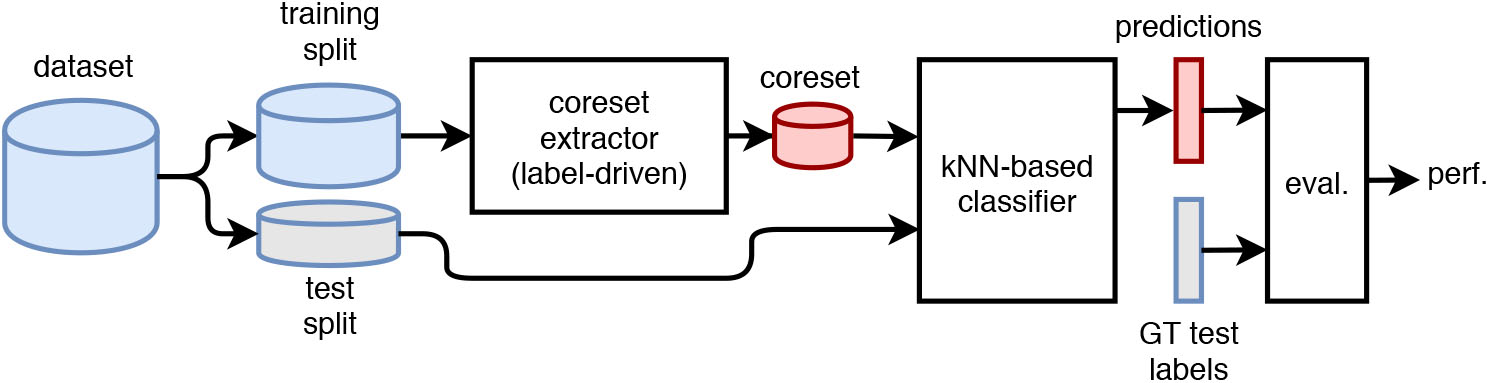
Coresets can also be used in supervised classification for data reduction, therefore suppressing noise, favoring generalization, and reducing training and/or evaluation complexity. Here coresets are intended to retain the essential set of training points for the subsequent classification. Note that such data reduction is strongly recommended for instance-based (aka lazy) learners that deal with large datasets, in which the coreset would work as a model and make it closer to eager learning options. This approach would be consistent with the sampling recommendations given by Zimek et al. in [46] for the anomaly detection case. In our experiments we reproduce the setup with the following blocks (Fig. 8):
Datasets. We used MCC-datasets (Section 4.1). We divided each dataset in training (70%) and test (30%) splits with stratified sampling. Datasets show different categories, therefore this becoming a multiclass classification experiment.
Coreset extractors. Competitor algorithms were tuned again with different Other algorithm parameters were adjusted by using Evolutionary search on training data.
k-NN based classifier. We use a vanilla kNN-classifier to predict labels. The number of neighbors is set to five (
Evaluator. We provide accuracy as well as micro and macro precision and recall metrics. We additionally measure coreset extraction and k-NN-based classification (empirical) average runtimes.
The setup shown in Fig. 8 covers 140 experimental runs (7 algorithms
In this section, we show and discuss results obtained from the experimental evaluation.
Anomaly detection
Results in Table 3 support the claims in [46] and show that, as a general rule, sub-sampling data improves the accuracy of outlier detection algorithms, since the baseline approach (i.e., using the whole dataset) performs worse than experiments that use coresets regardless of the used technique and the considered metric. Beyond that, all studied algorithms seem to obtain representative coresets for the analysis, KMC, SDO, and ODM slightly standing out over the rest.
Performance of detecting anomalies
Performance of detecting anomalies
Ext. Time: Time needed to build a coreset.
On the other hand, analysis times (k-NN time) are considerably reduced when using coresets and such time reduction is expected to increase the larger the dataset is. If we additionally take coreset extraction costs into account (Ext. Time), only RS, SDO, and ODM seem to be light and fast enough for the undertaken task.
Visual representation of the anomaly detection performance.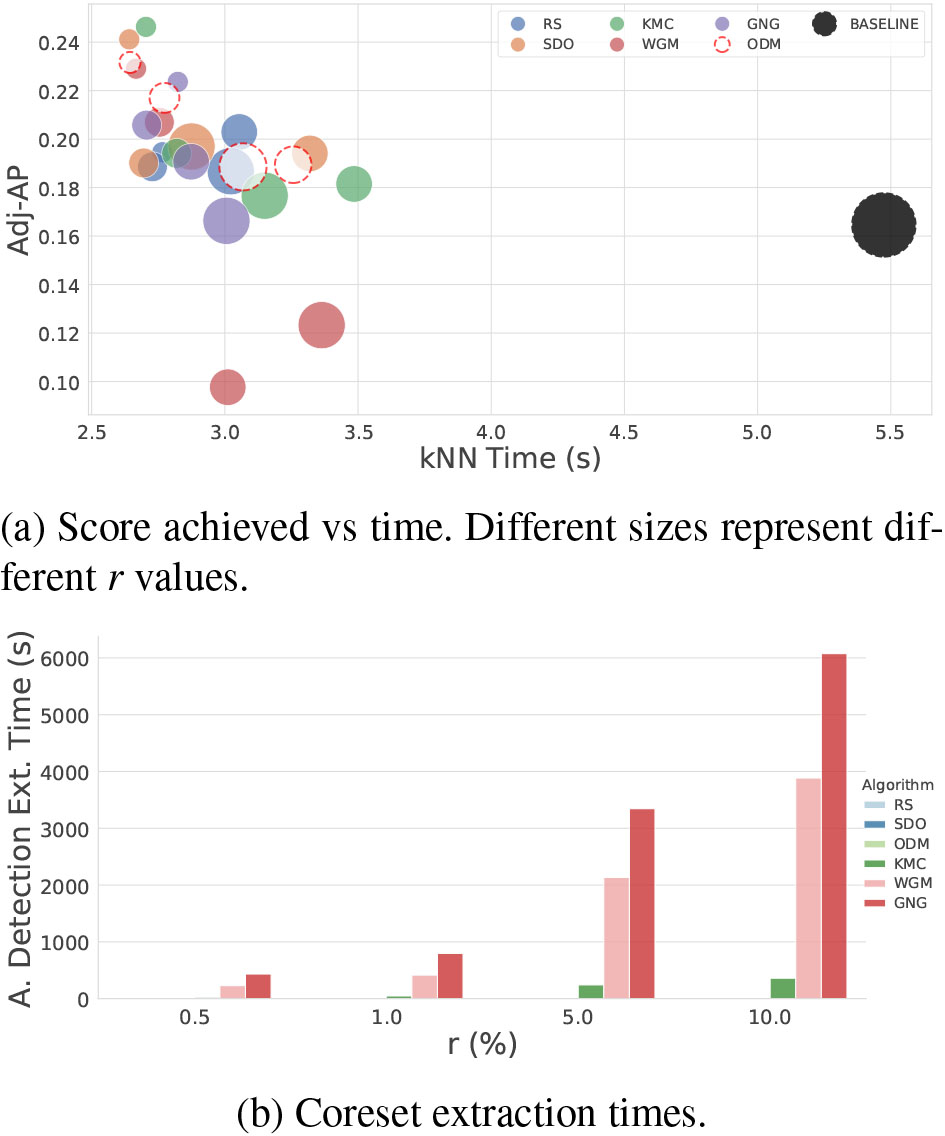
Weighting accuracy and time performances together, only SDO and ODM satisfactorily meet problem requirements. Figure 9a shows a visual comparison of coresets by plotting accuracy (Adjusted Average Precision) versus analysis time (k-NN time). A comparison of coreset extraction times (Ext. Time) is shown in Fig. 9b.
In the clustering experiments (results in Table 4), all tested algorithms show poor performances for very low
Clustering performance
Clustering performance
Ext.T.: Time needed to build a coreset. kM.T.: Time needed to build a kMeans model. Lab.E.T.: Time needed to extend labels.
Visual representation of the clustering performance.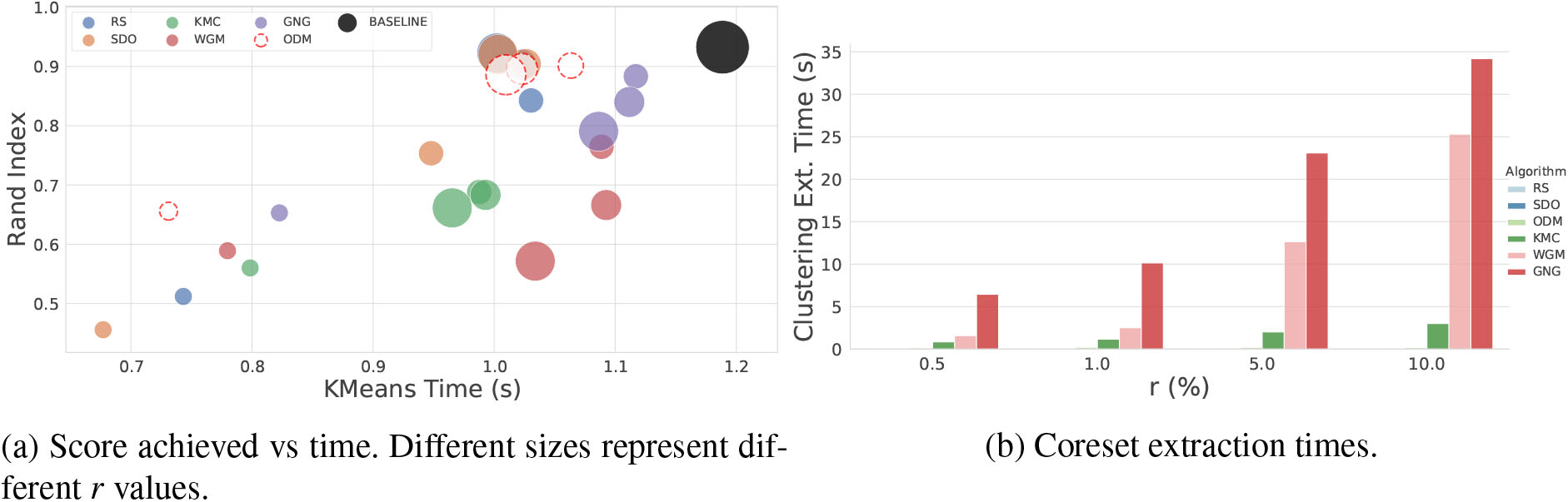
Again, coreset extraction costs (Ext.T.) are considerably high for WGM and GNG. Weighting accuracy and time performances together, the best trade-off is obtained by SDO and ODM, or even RS. Figure 10a shows a scatter plot comparing accuracies (RAND index) vs analysis time (kMeans time). A comparison of coreset extraction times (Ext. Time) is displayed in Fig. 10b.
Similarly to the unsupervised classification experiments, in the supervised classification framework higher values of
Supervised learning performance
Supervised learning performance
Ext.T.: Time needed to build a coreset. Ma.: Macro. Mi.: Micro.
Visual representation of the supervised learning performance.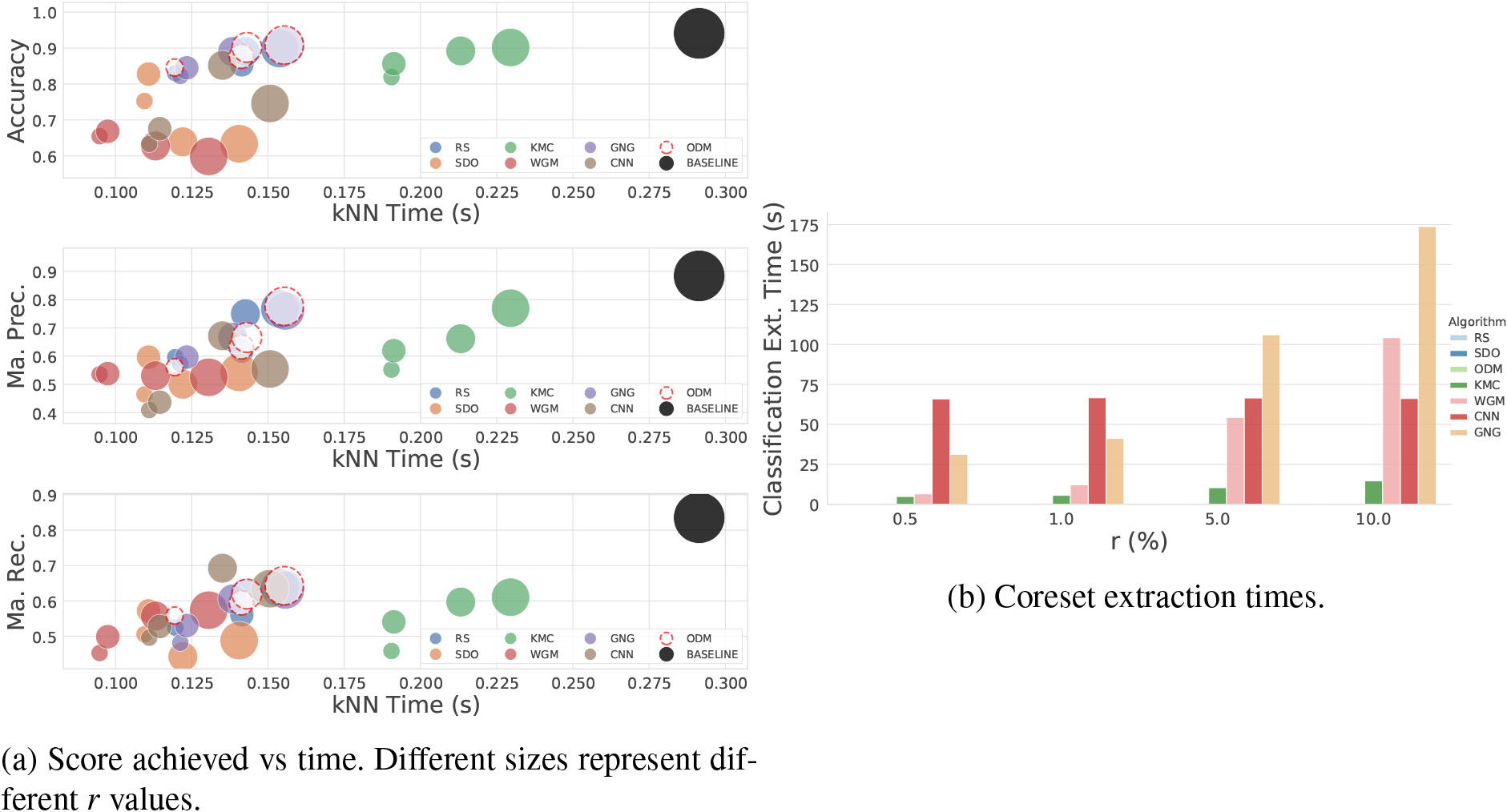
The CNN additionally appears in this set of experiments as it was specifically proposed for alleviating the computational costs of k-nn-based classification. However, it is a heavy algorithm in terms of extraction costs when compared to ODM or SDO, and accuracy performances are in line or below most of the competitors. Note that, in its original implementation, CNN automatically establishes the size of the coreset according to dataset properties and cannot be externally implemented. This fact might be affecting its capability of obtaining better performances.
Alike previous experiments, Fig. 11a compares coresets by using classification metrics (Accuracy, Macro Precision, Macro Recall) vs analysis time (kNN time). A comparison of coreset extraction times (Ext. Time) is displayed in Fig. 11b.
Critical Difference Diagrams. The methods are ordered in such a way that the best one is the rightmost one. Methods whose difference is not shown to be significant in the tests are joined with a thick line.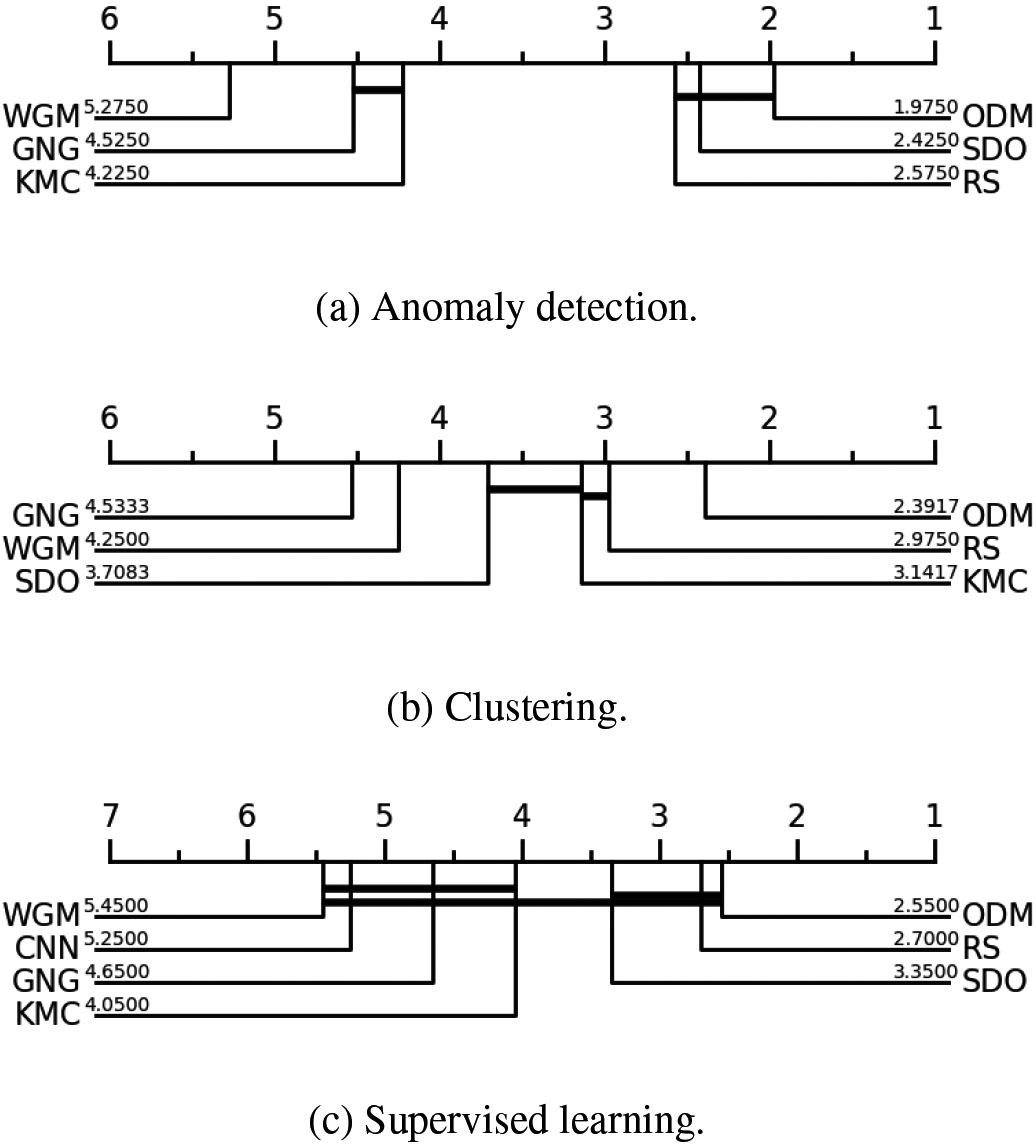
Evaluating all experiments together, ODM stands out as it is the only particularly stable method (i.e, its performance are among the top ones regardless of the application) and keeps considerable low time-complexity costs.
To confirm statistically significant differences among the coreset extractor methodologies under test, we used Critical Difference Diagrams (CDD) [19, 30], which are based on the Wilcoxon signed-rank test [44]. Figure 12 show CDD for the three experimental applications: anomaly detection, clustering, and supervised classification. For the calculation of CDD, we combined all metrics shown in Tables 3–5 after z-scoring them to make them comparable and addable. Thus, we obtained one summary metric for each experimental application. In CDD methods are ordered to keep the best ones on the right side of the diagram. Methods whose different performances are not deemed significant are joined by thick horizontal lines. CDD confirm the preponderance of ODM over competitors regardless of application, followed by RS and SDO.
We have presented ODM, a lightweight algorithm for the extraction of low-density data models (data summaries, coresets) in log-linear times. We have tested ODM and compared it with state-of-the-art alternatives by using multiple datasets in fundamental machine learning areas, namely: anomaly detection, clustering, and supervised classification. Obtained results place ODM as the most stable option and the best trade-off between time-complexity and performance accuracy. ODM is strongly recommended for alleviating computational demands when facing the analysis of large datasets. Future research includes: using ODM as an under-sampling method for applications where classes show strong imbalance (e.g., attack detection in network traffic); applying ODM for streaming data, where it is necessary to keep a model of the data up to date (therefore, able to evolve), but, at the same time, preventing that the accumulation of new samples deteriorate the model in use. Finally, also concerning streaming applications, evaluate the potential of ODM to discover emerging clusters and differentiate them quickly and efficiently from simple anomalies.