
Abstract
The Internet is a vital part of today’s ecosystem. The speedy evolution of the Internet has brought up practical issues such as the problem of information retrieval. Several methods have been proposed to solve this issue. Such approaches retrieve the information by using SPARQL queries over the Resource Description Framework (RDF) content which requires a precise match concerning the query structure and the RDF content. In this work, we propose a transfer learning-based neural learning method that helps to search RDF graphs to provide probabilistic reasoning between the queries and their results. The problem is formulated as a classification task where RDF graphs are preprocessed to abstract the N-Triples, then encode the abstracted N-triples into a transitional state that is suitable for neural transfer learning. Next, we fine-tune the neural learner to learn the semantic relationships between the N-triples. To validate the proposed approach, we employ ten-fold cross-validation. The results have shown that the anticipated approach is accurate by acquiring the average accuracy, recall, precision, and f-measure. The achieved scores are 97.52%, 96.31%, 98.45%, and 97.37%, respectively, and outperforms the baseline approaches.
Introduction
Owing to the availability of knowledge, the modern era comes with a range of problems for the Site. People record, upload, archive, and digitize nearly every operation in the everyday routine of life over the Internet of today’s modern society. Communication systems today have the potential to independently attach to the Internet to spread valuable information without the involvement of users. As a result, data grows on a regular basis which results in an abundance of information. The quest for such data contributed to the development of the Semantic Web and its related data. The development of machine inference [1] is considered to facilitate the flow of information that can connect data from dispersed databases to make it relevant. The expression Web 3.0 was added by this mash-up of results. For Web 3.0, which is acquired using RDF, linking the dispersed information is critical. A RDF triple can then be interpreted as an atomic representation of fact or claim[2] where each triple includes a
Similar datasets can be described as linked data[5], which can be interpreted as ‘all about using the Web to build typed connections between different source data’. Due to its related connections [5, 6], Related information incorporates entities from different sources/locations to be monitored as data space. This encourages to use of the information needed from dispersed sources and creates connections that could assist in information search. RDF triples make it simple for entities to query and link together. RDF and SPARQL are used by current studies to query the content and run search results, respectively.
The RDF is massive and crucial, so collecting data for an average user is not straightforward. Nevertheless, connected data and SPARQL deliver a major increase in search techniques. To read and understand RDF data [7], however, the complexity requirements (similar triples according to the rules of RSFS and OWL) and human labor are important. In order to extract RDF components, SPARQL queries, for example, need structure consistency. These queries do not offer the opportunity for statistical analysis to check the concern against the content of RDF; for example, Basket features may not be sufficient to classify online shopping basketas an input. Several methods have been suggested to accomplish this form of RDF search utilizing related information and SPARQL[8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]. Notably, instead of calculating the resemblance within the RDF material that contributes to the initial inspiration of this work, certain methods reply to inquiries with a particular match. Hadi et al.[20], While on the other side, Used a machine learning method to query for RDF graphics. Though their approach is based on statistical estimation, when looking for RDF graphs, it does not accept semantic relationships and needs substantial improvement.
A challenging issue of neural learning-based approaches [21] is that they are problem-specific which requires training from starch with afresh data source or for a different related problem. Further, deep learning-based approaches are data-hungry which means they require training on large data set to produce satisfactory results. Moreover, now a day the information is continually evolving making it challenging to build tools that could take advantage of pre-trained tools and leverage the information that already exists. To overcome these issues, we exploit the concept of transfer learning in this work. In transfer learning, the learned knowledge from a pre-trained model is extracted and then be fine-tuned to achieve optimal performance without requiring the model training from scratch.
In this work, for RDF graphs, a deep transfer learning-based method is proposed that utilizes the historical data from the DBpedia. These documents are first validated using the W3C validation service. Then, validated documents are reprocessed to have an abstraction of features from the RDF graphs. Next, we use the attention-based pre-trained neural learner to help transfer the knowledge. The pre-trained neural model helps to abstract the pre-learned knowledge without requiring it to be retrained from scratch. The abstracted knowledge is then fine-tuned by utilizing Gated Recurrent Unit (GRU) recurrent neural network. Finally, the proposed solution is validated using a ten-fold cross-validation method. The observations of the assessment reflect that the average scores of accuracy, recall, precision, and f-measure are up to, respectively, 97.52%, 96.31%, 98.45%, and 97.37%.
The primary contributions of this work are as follows:
For RDF graph searching, a transfer learning-based approach is proposed that leverages pre-learned knowledge. We are the first to take advantage of transfer learning in the recovery estimation of RDF graphs. Evaluation findings of the projected method indicate that the recommended approach based is reliable and exceeds the state-of-the-art.
The remainder of the article is arranged as follows: the suggested solution is outlined in Section 2. Section 3 outlines the assessment process and implications of the suggested strategy. The risks are stated in Section 4. The linked work and thesis are discussed in Sections 5 and 6, respectively.
WWW is a space for knowledge. While the URLs represent RDF graphics and other web resources, That could be connected and granted access through the Internet. Because of the data explosion created by the new digital age, it is hard to get the correct URLs against requested queries. Tim Burner Lee launched the semantic web to tackle this problem, which offers a common structure that enables data to be exchanged and reused across applications. Instead of keyword matching and question answers, it considers semantics for searching. The fundamental of the semantic web is to connect knowledge from various tools together. In addition, Linking data is important for connecting and searching data across the semantic web. RDF graphs that contain RDF format data are based on related information. Several approaches to the effective search of RDF graphs have been proposed. These techniques (graph-based or keyword-based search) rely largely on classical RDF searches.
Tran et al. suggested the concept of developing summary-graphs for the initial RDF graph for the processing and classification of SPARQL queries.[22]. Then a solution to this idea was suggested by Zhang et al.[23]. In addition, Yang et al. [24] recommended tree patterns to connected user-specified keywords that are arranged in tree patterns by their significance to scale, Zheng et al. [25] suggested a tool for searching for semantically related Patterns of Structure. In the end, De Virgilio[26] Suggested RDF-based keyword inquiry for Tensor Calculus that is extended through MapReduce [27] to an apportioned world. An approach was suggested by Nhuan et al. [28] Identifies the degrees of equality indicated by different vocabulary between relationships (properties). They suggest the incidents of matched pairs of RDF triples to determine the ranges showing property equality of upper and lower degrees. As a consequence, they selected a graph of related properties where degrees of similarity among properties are indicated by the strength of the edges based on the interval.
Another method that is being adopted for information retrieval is based on fuzzy logic. Although these are not related to machine learning approaches but are worth mentioning. Nagarajan et al.[29] introduced a multi semantic data retrieval system focused on ontology. It is founded on the principle of integrating information of domains and images and uses a fuzzy set of rules to retrieve the appropriate multi-modal information. It also can provide the semantic image by designing and building visual terms using the probabilistic latent semantic. Additional Research [30, 31, 32] have suggested formalization and semantic visualization templates focused on a collection of fuzzy rules. Jaafar et al.[33] suggested a knowledge-based method based on fuzzy to recognize an operation of definition and visualize F-RDF retrieval, to help end-user improve Web data request and access. To simplify the retrieval of information, a fuzzy logic-based ranking feature was introduced by Gupta et al.[18]. The function is based on the estimation of term-weighting schemes, like frequency, inverse paper, as well as normalization.
In conclusion, researchers have suggested various methods [8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 34, 35] for information retrieval using RDF; however, major changes are needed. Besides, none of them employs algorithms for the classification of machine learning to resolve this problem. Notably, the suggested solution differs in that, since we are the first to implement the help vector machine for RDF graph recovery, the current approaches differ.
Approach
Overview
The overall workflow of the proposed approach is illustrated in Fig. 1. The suggested method performs the estimation of RDF graph information retrieval in the following manner:
Overview of the proposed approach.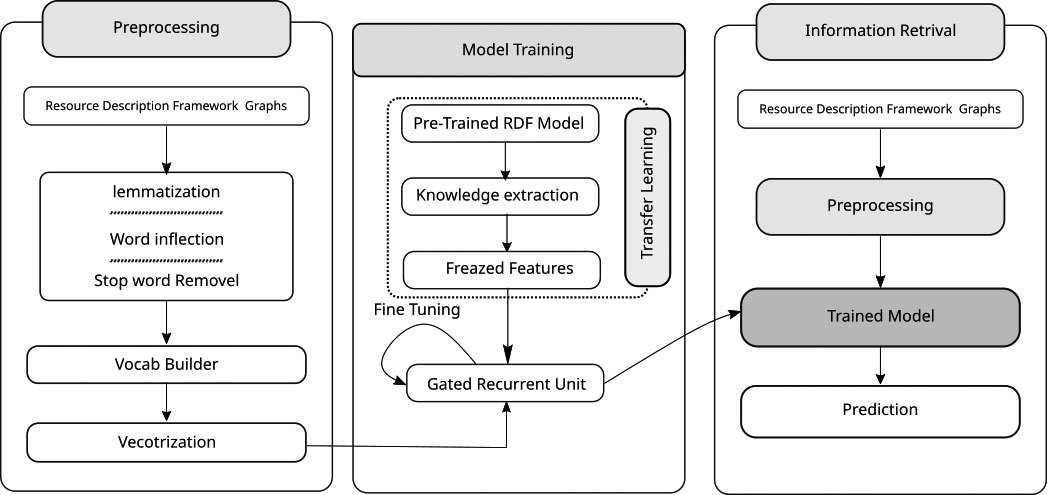
The history-data of RDF graphs are first validated and then reused for the purpose of model training. Next to abstract a generalized feature state, we perform lemmatization, word inflection, and stop word removal. Then we make a global vocabulary system to limit the out-of-vocabulary words. Afterwards, we convert the abstracted features into vector encoded form that can be used for model training purposes. Finally, we train transfer learning-based neural model that learned to predict RDF graphs being retrieved.
To better understand the presented approach, analyze an illustration presented in Fig. 2 to learn how the suggested solution looks for an RDF graph for information retrieval. The example presents an abstraction of the RDF graph that is taken from DBpedia.
Illustrative example of a RDF graph.
An RDF
Where in the RDF graph,
The suggested solution takes the issue of looking for an RDF graph as a problem of classification and suggests whether or not to retrieve an RDF graph. The description of retrieval of the newly RDF graph
Where,
It is vital to validate the syntax of each RDF graph thus, we use the Apache Jena API1
where,
Illustrative example of preprocessed RDF graph.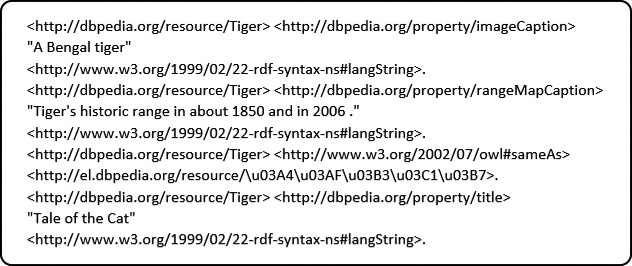
In transfer learning, the information learned during solving one problem is transferred and fine-tuned for another related problem. In recent years, transfer learning methods have applied in several fields such as metric learning [36], machine learning [37], image and text classification [38, 39, 40, 41] and dimensional reduction [42]. Figures 4 and b represents the model used for transfer learning that is based on the attention model for deep feature representation and CNN-based classifier.
Architecture of pre-trained neural learning model used for deep transfer learning.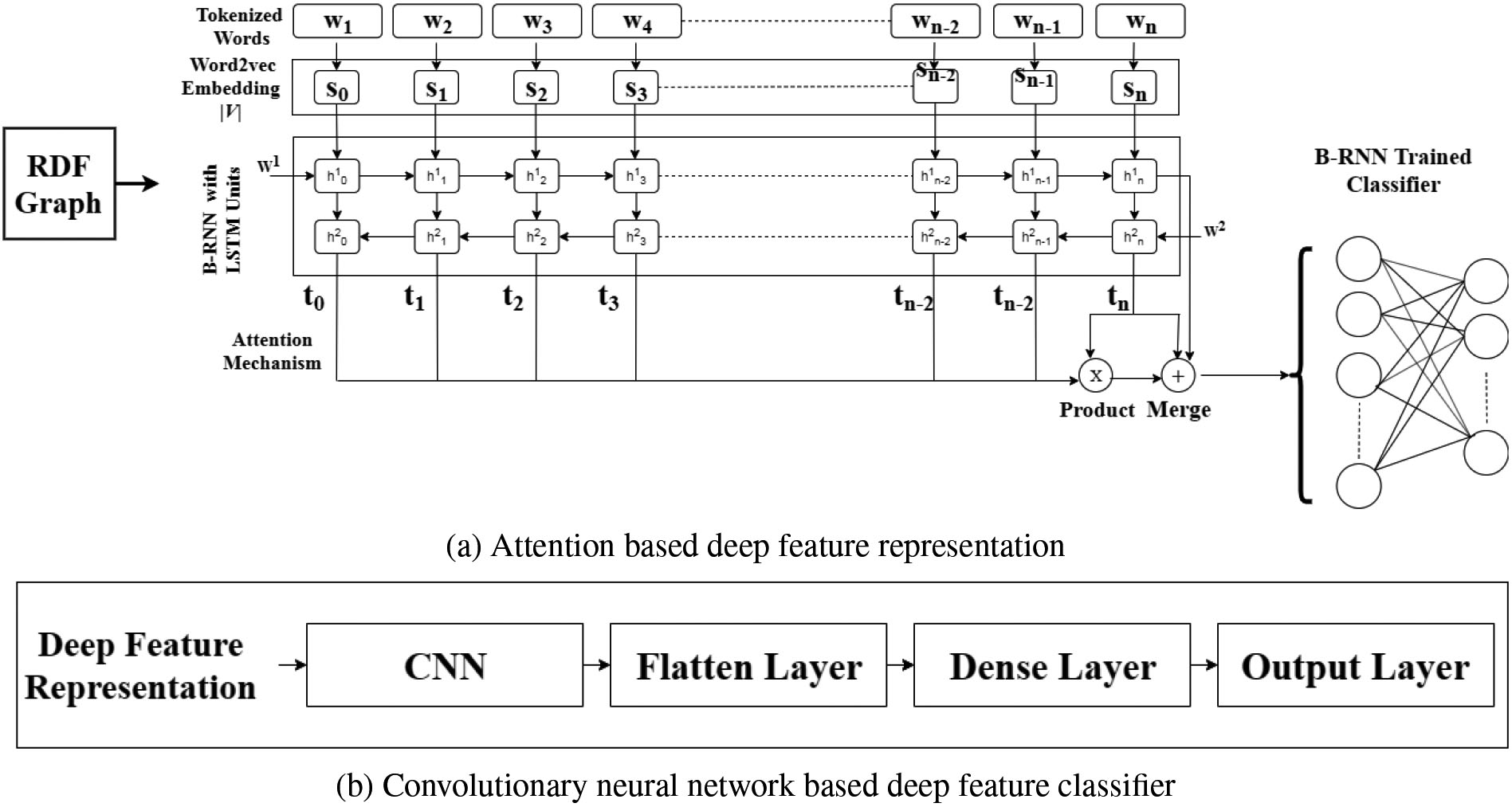
The pre-trained neural model [21] is then used to transfer knowledge from RDF graphs. The model is trained for information recovery prediction of RDF graphs with the blend of word2vec embedding technique combined with convolutional neural network (CNN) for the succeeding causes, we choose the convolutionary neural network: 1) it is capable of learning deep semantic relationship among terms [43]; 2) by applying different filter sizes And avoids the gradient issue of the repeated neural network [44].
An important understanding of the anticipated approach is to freezing the knowing information and then fine-tune it with fresh knowledge. For this purpose, we utilize the GRU [45] based recurrent neural network. The GRU learner pays consideration to the RDF-specific features to accomplish optimum performance. The overall workflow of the anticipated method is illustrated in Fig. 5.
Architecture of transfer learning for RDF graphs.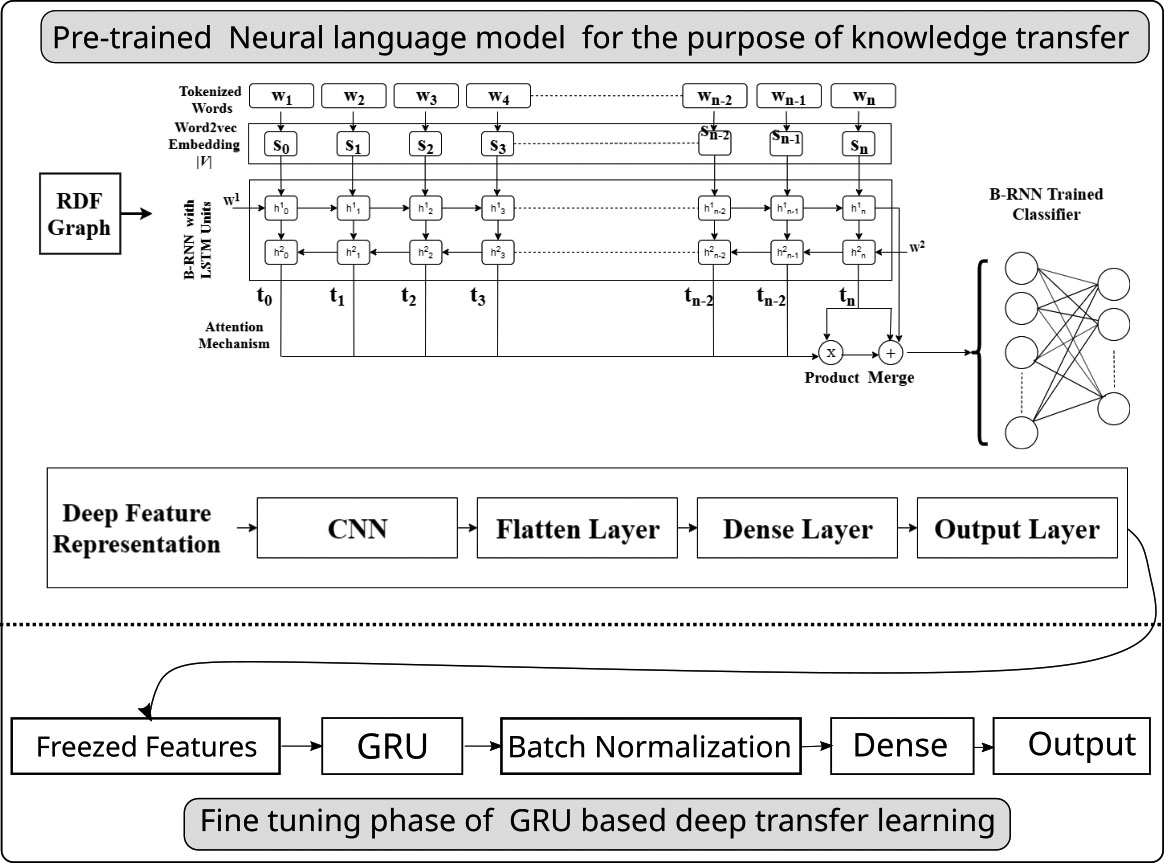
The construction of the RNN neuron is presented in Fig. 6, where
Normally
where the input to the hidden layer weight matrix is
here
A RNN neuron architectural structure.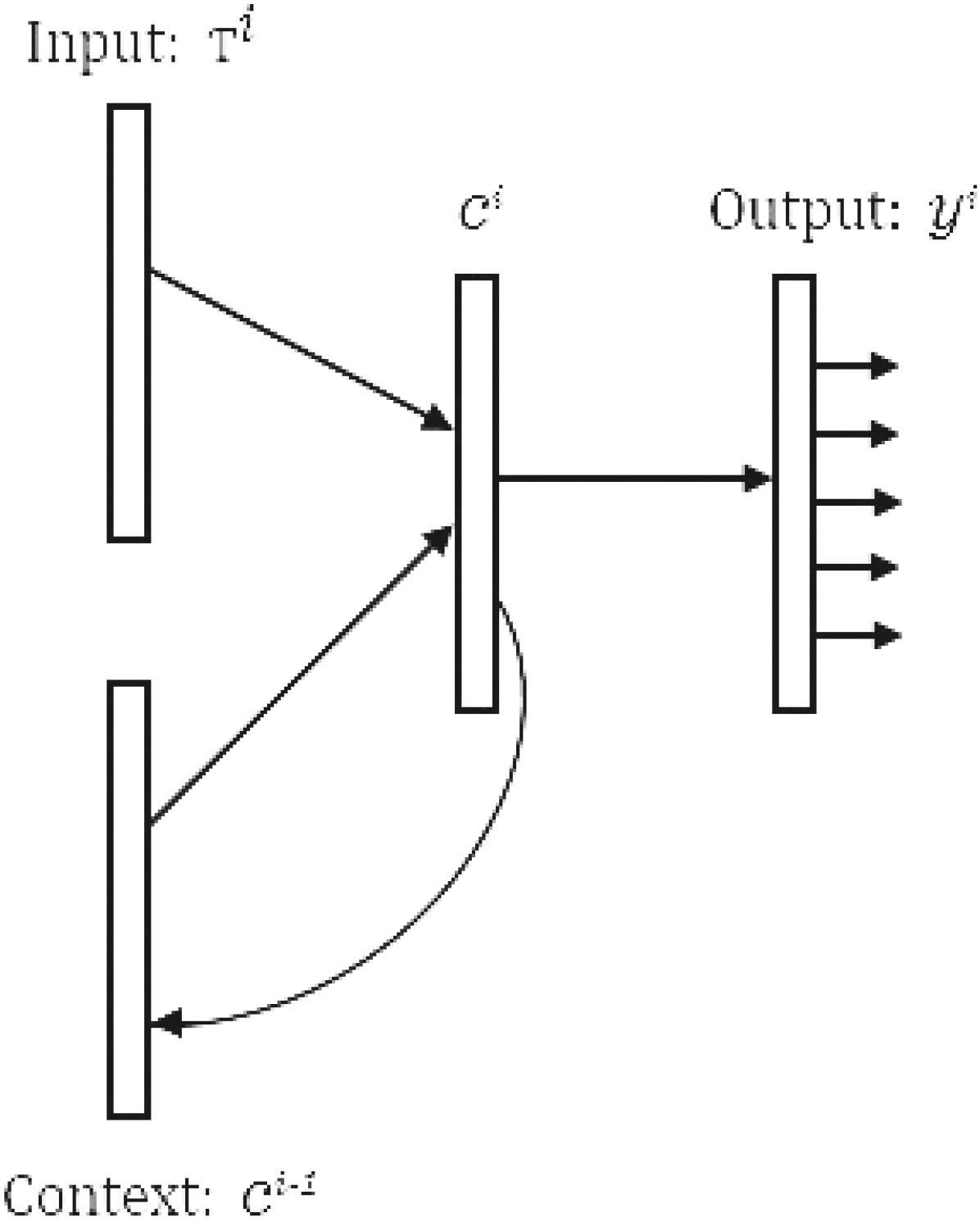
The difference from Eq. (5) is that
To evaluate the suggested approach, this section describes the research questions, Explanation on how to gather RDF graphs, Introduces the suggested method metrics and calculation process, While addressing the study questions and explaining the findings.
Questions regarding research
The recommended solution is assessed by investigating the issues related to research:
RQ1: How precise is the recommended solution in the RDF graph retrieval prediction? RQ2: Does the classification model that was suggested exceed other algorithms of machine/deep learning in the recovery estimation of RDF graphs? RQ3: Does the preprocessing of features affect the estimation of the RDF graph retrieval?
RQ1 tests the accuracy of the solution presented. The suggested methodology is contrasted with a state-of-the-art technique in this perspective: RDF retrieval based on graphs (GRSearch) [47] and retrieval of RDF based on a machine (MLSearch) [20]. To emphasize the effectiveness of the proposed technique proposed, The suggested solution also is equated with two basic algorithms: algorithm for unselected prediction and algorithm of No-Rule prediction.
The RQ2 analyze the performance of various machine learning and deep learning classification models to show whether RDF is estimated in retrieval, Suggested methodology enhances other machine/deep learning classification models.
RQ3 explores the effect of transfer learning and the preprocessing of features. In this sense, the efficiency of the proposed solution with and without transfer learning and preprocessing is calculated and compared.
The dataset is compiled from DBpedia.3
There are three components of the evaluation process for the optimal classification model (CNN). Cross-validation (sometimes referred to as rotation estimation) [48]
We use
For performance appraisal of classification algorithms [49, 50, 51, 52, 53, 54, 55], the chosen metrics are widely accepted metrics. Therefore, accuracy, recall, precision, and f-measure for the performance assessment of the proposed method, sufficient retrieval is calculated on the given RDF graphs, which can be described as,
TP describes the number of predictions defined by the suggested approach as hit, TN describes the number of predictions estimated by the suggested approach as miss, FP Refers to the number of predictions which are wrongly estimated by the proposed solution as hit, And FN Refers to the number of predictions wrongly estimated by the solution suggested as miss.
RQ1: Efficiency of the suggested model
We answer to
Table 1 presents test consequences for the recommended strategy and baseline methods. In the first column of the table, methods are presented. For each classifier, the effects of the output metrics (
Comparative analysis among baseline methods
Comparative analysis among baseline methods
The performance results of the unselected prediction evaluation, no-rule, and suggested solution are seen in the Table 2. In the first column of the table, methods are presented. For each classifier, the effects of the output metrics (
Comparative analysis with random prediction and zero rule
The following are the observations from Tables 1 and 2:
The proposed solution outperforms the The advancement of the projected method upon MLSearch in The advancement of the projected method upon GRSearch in The advancement in the performance of the projected method upon unselected prediction in The advancement in the performance of the projected method upon no-rule in
For the recommended method and baseline methods in Fig. 8, we show the accuracy distribution for 10-fold cross-validation. The distributions of each approach are equated with
Machine learning methods compared
Visualization of learned semantics from RDF Graphs with Gated Recurrent Unit.
F-measure distribution comparison.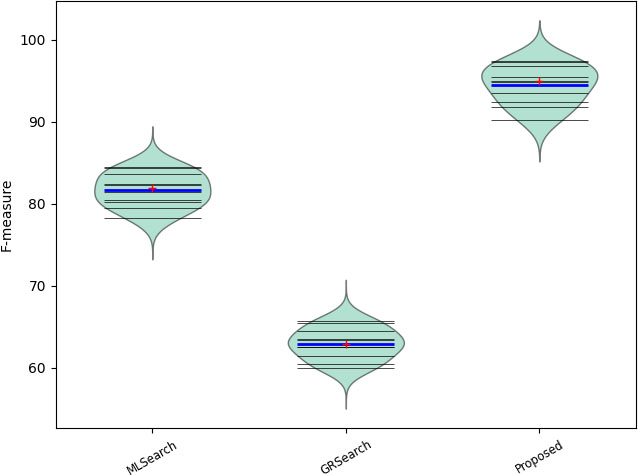
Due to their competitive results, [56, 57, 54, 43], we respond to RQ2 By implementing the most commonly used algorithms for machine and deep learning classification (Transfer Learning, CNN, LSTM, LR, SVM, MNB, and RF). The validation of the recommended solution with SVM yields the most detailed outcomes and the other classification methods of the dataset outperform.
The Table 3 shows Transfer Learning, CNN, LSTM, LR, SVM, MNB, and RF evaluation performance.For each classifier, the output results of
The average
The Table’s conclusions 3 are as follows:
The Transfer Learning classification algorithm exceeds any of the other algorithms in accuracy,
recall,
precision, and While current [58] research states that the MNB classification algorithm is successful, It’s not, however, Compatible with the provided dataset approach. One potential explanation is that input features are interconnected with the training classification model, and MNB working well if [59, 43] is independent of the features. As opposed to LR, RF, and SVM with the projected method, evaluation performance of MNB on the provided dataset are not efficient. The LR and RF output figures are indeed identical to the SVM values.
It is deduced by the prior analysis that Transfer Learning fits better for the suggested solution than other classifiers.
There may be identical features or superlative/comparative phrases for different RDF graphs. It is an undertaking to pass on information such as attributes to a machine learning model. It decreases performance and increases the cost of machine classification methods for processing. Moreover, we analyze the impact of transfer learning to improve modeling performance.
We respond to RQ3 by analyzing the results of the evaluation of the current approach with and without the pre-processing of the features and transfer learning. The results of the assessment are displayed in Table 4. In the first column of the table, the preprocessing input settings are displayed. The output results of
Impact of transfer learning and preprocessing
Impact of transfer learning and preprocessing
Impact of transfer learning and preprocessing.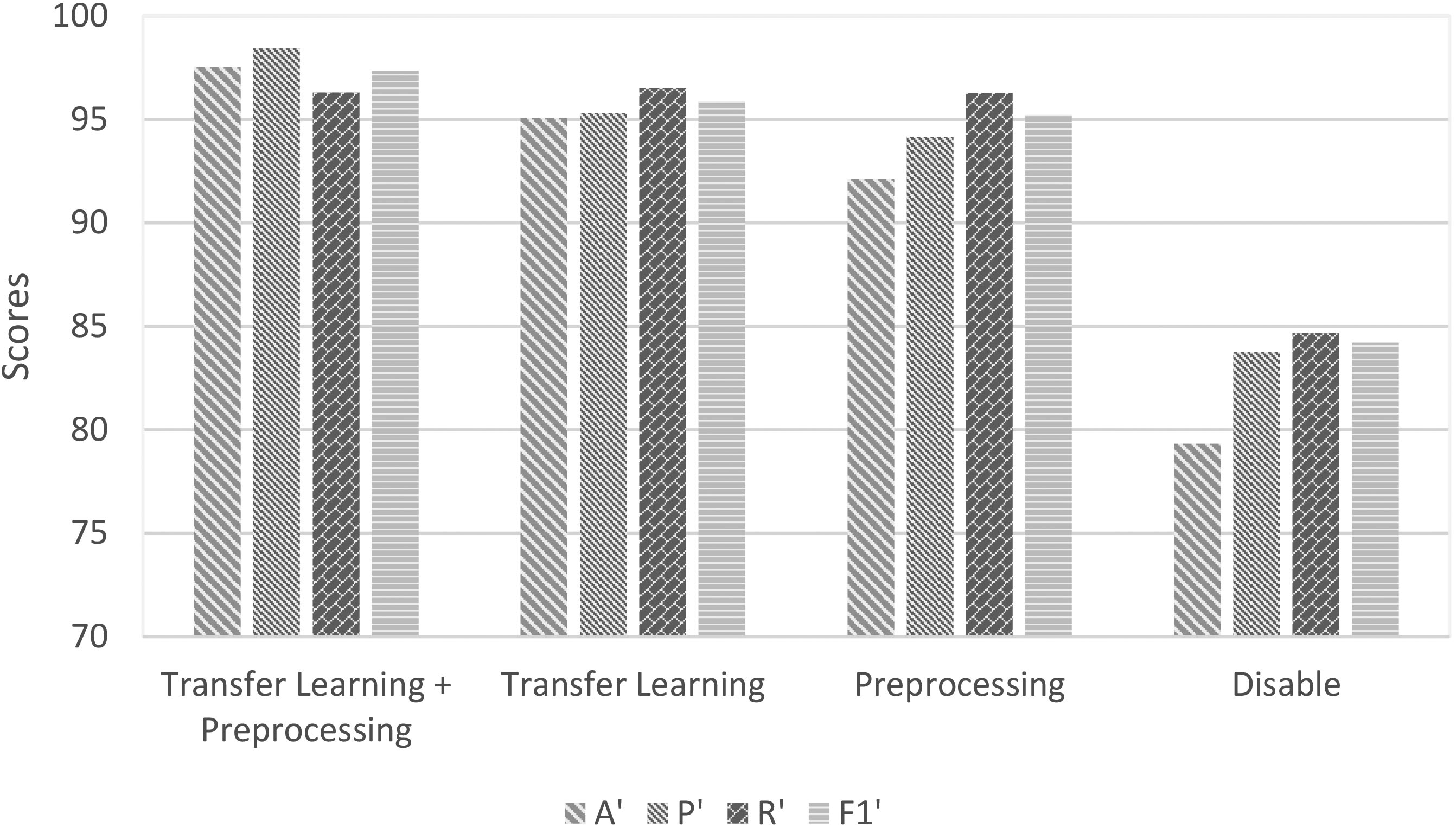
We render the following findings from the Table 4:
The proposed solution allowed by preprocessing and transfer learning achieves considerable performance improvement. The findings of the assessment show that the efficiency achieved in The disabled preprocessing method substantially cuts
The preceding review concludes that the suggested solution includes transfer learning and preprocessing characteristics.
Any factors that could impact the output of the proposed solution may be present. The foregoing are the drawbacks to the validity of the recommended technique.
The validity threat to construct is by choosing the measurement metrics. To test the proposed method, we picked A challenge to create validity is the leveraging of python toolkit (NLTK) for preprocessing (Section 3.4). Due to its success and popularity, [54], we prefer NLTK. The use of some other repository for processing natural language could influence the above-mentioned effects of the projected method. The generalization of the solution is an external validity hazard. For the assessment of the suggested solution, we concentrate on RDF graphs from the (DBpedia) open-access dataset. In the case of other datasets, we do not guarantee the conclusions of the proposed method.
Online users are continuously posting the moments of their life on the Internet in this modern age, creating information overload. Consequently, without knowing the semantics and syntax of the content, it is challenging to extract the necessary information accurately. To this end, we presented a transfer learning-based approach to the search for RDF graphs which addresses RDF graph requests as a classification problem. For the retrieval forecast of RDF graphs, the proposed solution applies a deep learning classifier to the specified dataset. The suggested solution provides a new way of looking for RDF graphs which encourages Web users to respond to their queries. Using DBpedia (open-source) RDF graphs, the 10-fold cross-validation is employed for the assessment of the projected method. The findings of the assessment suggest that the method presented is precise with an accuracy rate of 97.52%. The proposed approach explores this direction with the intention of information retrieval in the form of classification. In our future, work we intend to further explore this direction with domain-specific and cross-domain knowledge extraction.