
Abstract
Data classification is a data mining task that consists of an algorithm adjusted by a training dataset that is used to predict an object’s class (unclassified) on analysis. A significant part of the performance of the classification algorithm depends on the dataset’s complexity and quality. Data Complexity involves the investigation of the effects of dimensionality, the overlap of descriptive attributes, and the classes’ separability. Data Quality focuses on the aspects such as noise data (outlier) and missing values. The factors Data Complexity and Data Quality are fundamental for the performance of classification. However, the literature has very few studies on the relationship between these factors and to highlight their significance. This paper applies Structural Equation Modeling and the Partial Least Squares Structural Equation Modeling (PLS-SEM) algorithm and, in an innovative manner, associates Data Complexity and Data Quality contributions to Classification Quality. Experimental analysis with 178 datasets obtained from the OpenML repository showed that the control of complexity improves the classification results more than data quality does. Additionally paper also presents a visual tool of datasets analysis about the classification performance perspective in the dimensions proposed to represent the structural model.
Introduction
The data’s content and structure are the key factors that influence the quality of results in data analysis, particularly the data classification. Problems such as missing values and outliers can compromise the results of data analysis [29]. For this reason, data preparation during pre-processing and transformation activities are essential to Knowledge Discovery in Databases (KDD) and Big Data analytics [15]. Data Quality (DQ) from the KDD perspective consists of outlier analysis, missing values, and inconsistent values, i.e., aspects related to data cleansing. The literature also included other aspects of DQ, such as dimensionality, sparsing, resolution, and dataset size [26, 44, 19, 55, 5, 17].
In supervised learning there are other aspects of the data that also affect the results. Studies on the distribution of data and its dimensionality have been concentrated under the name of Data Complexity (DC), that consists of investigating mainly the effects of overlapping of objects’ descriptive attributes from the dataset and the separability of each object’s classificatory attribute (classes). The main DC measures are Fisher’s Discriminant Ratio (F1), the Maximum (Individual) Feature Efficiency (F3), Ratio of Average Intra/Inter Class Nearest Neighbor Distance (N2), and Class Density in the overlap region (D3) [6, 12, 39].
However, the combined effect of data quality and complexity of data analysis is a gap to be explored, especially the effects on data classification. The objectives of the present work emerge from this gap, which lists DC, DQ, and Classification Quality (CQ) indicators grouped as per the dimensions that are related in a model obtained through Structural Equation Modeling (SEM). Besides, this article shows the structural model’s application as a visual tool of datasets analysis about the indicators’ classification performance perspective.
For the experiments 27 indicators of complexity, quality, and classification analysis performance on 178 real datasets from OpenML repository were measured and submitted for analysis.
This article is structured as follows: Section 2 defines the problem and reviews the literature; Section 3 explores the structural model methodology and the dimensions of complexity and quality that affect data classification tasks; Section 4 describes the experimental procedure that relates the identified dimensions to data classification results; Section 5 presents and discusses, results, and applicability; Section 6 concludes the article and presents contributions, limitations, and future research opportunities.
Problem definition and literature review
Some of the important academic references on Data Quality (DQ) date back to the 1990s, from the semiotic perspective of the data as a representation of facts, objects, or people [34], or the declarative perspective, which sees the data as a raw material for information [53]. In the declarative perspective, the dimensions of intrinsic quality that explain the data can be grouped, such as those imposed by the metadata, schema patterns, or business rules. From the perspective of usage, there are dimensions whose evaluation depends on the user, such as those related to the efficiency and effectiveness of the creation and usability of the data. Dimensions can be classified in terms of granularity in which they apply: to a data element (attribute of an entity), a data record (collection of resources that make up an entity), or an information object (collection of records) [30].
The application of DQ in data analysis finds different importance for the dimensions. For example, the research of [7] shows the effect of currency, accuracy, completeness, and consistency variations on the mining of association rules. On the other hand, [20] points to outliers and missing values as more expressive problems in Multivariate Data Analysis, describing the procedures of identification and addressing these quality problems in datasets. Recent studies have reported the effects of data quality issues on data migration processes [29, 4], data mining systems [29], Big Data Analytics systems [54, 49], Internet of Things (IoT) systems [31] and in Software Engineering [42, 52, 10]. Additionally, data dimensions that are identified as relevant vary according to the focus of the study [32].
The Structural Equation Modeling (SEM) method and the Partial Least Squares Structural Equation Modeling (PLS-SEM) algorithm are applied by [4] to analyse the relationship between the success of a data migration between systems and data quality problems, specifically correctness, completeness, consistency and timeliness, and also by [54] to measure the effect of Big Data traits (the various Vs of Big Data) on aspects of data quality that can affect data analysis in Big Data. Some of data quality dimensions considered relevant for analysis are accuracy, believability, completeness, timeliness, and ease of operation [54]. In the line of data quality research for Big Data systems, [49] proposes the Big Data Quality Management Framework (BDQMF) to identify and solve data quality problems of the Big Data lifecycle. Several dimensions of data quality are identified and treated in the BDQMF, grouped into intrinsic dimensions (completeness, consistency, accuracy, timeliness), contextual dimensions (believability, relevancy, value-added, quantity, accessibility, reputation), accessibility dimensions (access, security) and representational dimensions (interpretability, manipulability, ease of understanding, conciseness of representation, representational consistency). In the direction of identifying and quantifying data quality problems, Data Mining techniques, namely Clustering, Subspace Clustering, and Data Classification, were used by [29], and the metamorphic testing technique, used in software tests, was proposed by [2].
Data classification is a Data Mining task that adjusts an algorithm with a training dataset content objects and a classificatory attribute to predict an object’s class (unclassified) on analysis. More recently, structural aspects of the data have been also identified as relevant in data classification, possibly due to this task’s sensitiveness to geometric data characteristics. These structural aspects of the data have been studied under the name of Data Complexity (DC). Types of challenges for classification tasks related to DC are identified: a) the ambiguity of classes that takes place when dataset features are not enough for a classification algorithm to distinguish between classes, either the classes are not clearly defined, or features are not informative enough for classes separation; b) border complexity, whose degree can be measured by the quantity of information necessary to describe the limit between classes in a dataset; and c) sparsing of sample and dimensionality of features space that occurs when the generalization capacity of a classifier is damaged by samples that may insufficiently represent datasets, even when features space is large, increasing the variability of the classifier decision area [26, 27].
The concern with the performance of classification algorithms related to both DQ and DC is shared in literature by other researchers, such as [44], who discusses the negative effect some dimensions of data complexity on the supervised learning algorithm
The relationship between the dimensions of DC and the performance of classification algorithms is further addressed by [5]. This study applies complexity measures in both real and artificial datasets to identify the effect of classes overlapping on classification tasks where classes are unbalanced. The search for visualization of the relationship between DC and its effects in data analysis is addressed by [55], which presents a measure of visual complexity with direct application in data reduction of classifiers training stage [55].
In the literature review there is the absence of a study of the combined effects of DQ and DC on the performance of classification algorithms, also called Classification Quality (CQ). A highly relevant research outcome is found in [8], which analyzed four DQ problems (accuracy, completeness, consistency, and timeliness) and one DC problem (entropy), artificially introduced, to test their effects on the CQ. F-measure of six data classification algorithms (Multilayer Perceptron (MLP), J48, Sequential Minimal Optimization (SMO), IBk, Bayesian network, and logistic regression) measured the quality of data classification.
The present research attempts to fill this gap: to study DQ and DC’s combined effect on QC, looking in the literature for the most recent indicators for these variables, and a methodology that quantifies this relationship.
Methodological formulation
Indirect approaches to measuring the complexity of a dataset are the most commonly adopted path in the literature, such as approaches that analyze DC for their geometric, statistical, or quality dimensions [27]. The relationship existing between these dimensions was initially verified using Decision Trees and Support Vector Machines [35].
Understanding the combined influence of complexity and quality on the classification task can be interpreted as searching for a model that relates these variables. Although there are mathematical instruments within the Data Mining itself that allow the search for an optimal function within a viable set, similar to what Neural Networks can do, it is noted that variables such as Data Complexity and Data Quality lack a direct measure that allows its quantification [4]. This conclusion is deduced from the absence of a formal definition for Data Complexity and multiple perspectives on what it is and how to measure Data Quality [29, 42, 52, 30, 32, 31, 10, 2, 4, 54, 49].
In this context, Structural Equation Modeling (SEM) presents as a tool that allows discussions of either exploratory or confirmatory nature on the interactions of variables, offering subsidies to understand how variables are constructed and measured through an SEM model, also called path model [22].
Path model
An SEM model, also called path model, illustrated in Fig. 1, is a graphical representation of the relationships between variables. The path model consists of two elements: a structural model and a measurement model. This graphical representation is built by the arrangement of the constructs, indicators, and the relationships between these. Constructs, or latent variables, can be understood as elements representing conceptual variables in a theoretical model defined by the project. Since they represent concepts whose observation is not direct, the constructs are measured indirectly through indicators that are directly measured, that is, a measurement model. In the path model, the constructs are represented by circles (
Path model with latent variables, indicators, and their relationships. In the spotlight, the structural and measurement models. Adapted from [45].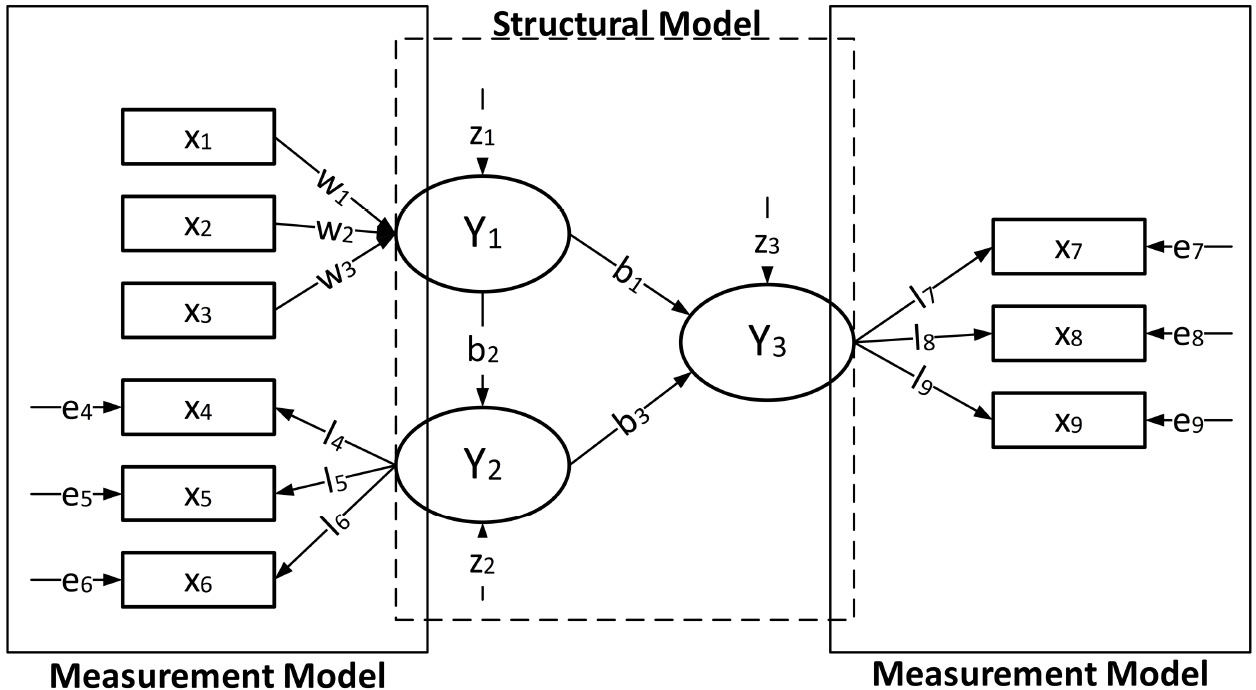
The Structural Model is also called the internal model, and it consists of the arrangement of constructs and their relationship. The internal model represents the hypotheses and their relationships with the theory being tested, based on the researcher’s literature, logic, and practical experiences, which requires knowledge of the domain in which the study is being conducted. The organization of the structural model is an important tool for discussing ideas between researchers and domain experts, and should be prepared as one of the initial steps of a research [22].
In the model, independent variables, or predictors, or even exogenous latent variables, are arranged to the left (
Once the sequence of constructs has been defined, the relationships between them are then represented as arrows pointing to the right, indicating that the constructs on the left predict the constructs on the right. Causal relationships must be grounded in theory. The strength of the relationship between the constructs is indicated by coefficients (
Measurement model
A measurement model represents the relationship between the latent variable and its indicators. How the constructs are measured must be well grounded in theory. The direction of the arrows informs the contribution of the indicators to the construct: reflective or formative.
A reflective model represents the effects or manifestations of a given construct. This kind of effect is indicated by arrows whose direction starts from the construct (
being
In the formative model, the direction of the arrows starts from the indicators to the construct (
where
The contribution of formative indicators to the construct must be differentiated as causal or as composite. In the constructs measured by causal indicators, an error measure must be added, indicating that causes not considered can contribute to the construct’s formation [22].
In addition to contributing resources for constructing a path model representing the relationship between variables, SEM has instruments for deducting the interaction between variables themselves and between variables and their indicators. Among these instruments, the Partial Least Squares Structural Equation Modeling (PLS-SEM) statistical method is widely used in the exploratory multivariate data analysis in Social Sciences, Accounting, Health Care, Business, Management Information Systems, Supply Chain Management, Tourism, and Marketing [51, 56, 23, 3].
PLS-SEM utilizes sample data to estimate the contribution of variables and the strength of their relationships in an SEM model, seeking to minimize the unexplained residual variance of dependent variables. The PLS-SEM algorithm calculates and uses the coefficients of the latent variables (
The PLS-SEM algorithm could be represented as in Algorithm 3.1.3.
[h]
PLS-SEM algorithm. Adapted from [24, 33].
As presented by [33], the PLS-SEM algorithm is initiated by the preliminary definition of the coefficients of the latent variables, assigning a weight of 1 (one) to all the indicators of the measurement model (line 3.1.3 of Algorithm 3.1.3). In practice, the algorithm performs Step 4 of Stage 1 (line 3.1.3 of Algorithm 3.1.3), calculating the coefficients of the latent variables by the sum of the product of the normalized coefficient (
Stage 1 estimates the internal weights (
In Step 2 of Stage 1 (line 3.1.3 of Algorithm 3.1.3) the coefficients of the latent variables are updated based on the new internal weights obtained from Step 1. For the exogenous latent variables
In Step 3 of Stage 1 (line 3.1.3 of Algorithm 3.1.3), new weights (
The Step 4 of Stage 1 (line 3.1.3 of Algorithm 3.1.3) linearly combines the weights
In Stage 2 the weights of the latent variables (
Path model evaluation
The objective of the PLS-SEM algorithm is to predict hypothetical relationships between constructs to maximize the explained variance of the dependent constructs (
The PLS-SEM results validation follows a procedure consisting of three stages: starting with the validation of the reflective measurement model, going through the validation of the formative measurement model, and, if there is support for the quality of the measurement, reaching the validation of the structural model. The validation procedure is described in the next three subsections, following explanations and limits provided by [22, 45].
Reflective measurement model validation
In a reflective measurement model each indicator that measures a latent variable, or construct, represents one effect or manifestation of that construct. For this reason, indicators are expected to have a high correlation with each other. The way in which these indicators are evaluated takes into account the fact that they are correlated, but must ensure that they do not measure the same phenomenon.
The reflective measurement model is evaluated by examining the indicator’s loads (
To ensure that reflective indicators of a latent variable have closely related outer loadings, the composite validity (or internal consistency reliability) of the indicators is calculated. The composite validity measures the inter-correlation between indicators of the same reflective latent variable, and its bounds are calculated at the lower limit by the Cronbach’s Alpha
where
where
Convergent validity is the extent to which an indicator correlates positively with alternative indicators for the same construct. As reflective indicators are treated as different approaches to measuring the same construct, indicators must converge or share a high proportion of variance. A standard measure of convergent validity is the Average Variance Extracted (AVE) (Eq. (5)):
where
Discriminant validity can be understood as the extent to which a construct is, in fact, distinct from other constructs by empirical standards. If the discriminant validity is established, that construct is unique and captures a phenomenon not represented by other constructs in the model. Discriminant validity is measured by examining the cross loads of the indicators (i.e., a load of an item in one construct must be greater than its load in other constructs). Another measuring is the Fornell-Larcker criterion, which establishes that the square root of the AVE of each latent variable must be greater than a more significant correlation between latent variables [22, p.105].
In a formative measurement model each indicator that measures a latent variable, or construct, captures a specific aspect of the construct’s domain. For this reason, indicators are combined linearly to form the construct, and the outer weights (
The first instrument is the verification of the convergent validity, which in the context of formative constructs will ensure that the complete domain of the construct and all its facets have been covered by the adopted indicators. The convergent validity of formative constructs is determined as the extent to which this construct correlates with another reflective construct that captures the same concept. This procedure requires the prior inclusion of reflective indicators in research and data collection phases [22, p.121]. In the case of current research, it is assumed that the proposed formative construct is completely covered by its indicators, since the research was limited to measuring the construct only by the indicators most commonly found in the literature (Section 3.1.2).
As they capture different aspects of the construct, it is not expected to find a high correlation between the formative indicators. High correlations in formative indicators are called collinearity, which can be measured by the variation inflation factor (VIF) index in each indicator of the formative latent variables. The VIF index (Eq. (6)) calculation consists of applying a multiple regression of each indicator to all other indicators of the same latent variable:
where
The final step is assessing each indicator’s relative contribution to the latent variable’s construction. Normalized values of the indicators’ weights close to 0 indicate weak relationships, and values close to 1 or
The bootstrapping procedure allows the computation of standard errors and the significance of the indicator weight [48]. If the weight of the indicator is statistically significant, the indicator is maintained. If the indicator’s weight is not statistically significant, but its load is equal to or greater than 0.50, the indicator can be maintained with adequate evidence to support this. The indicator must be removed if the weight is less than 0.50 and there is no statistical significance of the weight. In the case of various formative indicators and the presence of some statistically insignificant weights, the indicators should be grouped into other constructs if there is theoretical support [24].
After completing the measurement models’ evaluation, the structural model is evaluated for problems of collinearity between latent variables and for its predictive capacity. The assessment of collinearity problems in constructs uses the same instrument used in assessing the collinearity in indicators of formative constructs, the VIF index, with the difference that instead of indicators, the equation’s input will be the exogenous latent variables. VIF values greater than five will indicate collinearity between the latent predictive variables [45].
As for assessing the model’s predictive capacity, three criteria must be considered: the determination coefficient
Finally, but no less important is the validation of the weights of the relationships between the latent variables, whose standardized values vary between
where
As previously presented, Structural Equation Modeling seeks to find a relationship between dimensions of latent variables that are represented by indicators that, in fact, measure the model. Since this paper aims to relate indicators of Data Quality and Data Complexity concerning the impact on Classification Quality, in the next subsections these dimensions will be discussed, and the indicators to be adopted in this work will be presented.
Data Quality (DQ) is a vast concept in the literature that can have different meanings in each step of the Data Analysis pipeline, starting from data collection to its transformation for analytical purposes [34, 53, 30]. In this work context, DQ can be defined as the level of confidence and precision that the data found so that applying an analytical method can be trusted.
In the literature of KDD, several works have shown the effect of currency, accuracy, completeness, consistency, and timeliness of data on tasks of data mining as association rules and data classification [7, 8, 20]. For the specific case of data classification, that is the interest of this work, outliers and missing values problems are appointed as the main DQ indicators [20].
The accounting of outliers could be measured through the Validity indicator proposed by [30]. The validity of a dataset
where
The missing values could be measured by the Completeness indicator, which supposes the randomness of the generation process of missing values (Missing Completely at Random, MCAR). An observation with a missing value will be classified as MCAR when any other object is equally likely to contain a missing value [14]. The Completeness of a set
where
Data complexity categories and indicators. Adapted from [17]
Data Complexity (DC) in KDD can be defined as the way data is distributed and the level of overlap between objects of different classes. The DC indicators proposed in the literature and of interest in this present research are presented by [37], based originally on [26, 36], and summarized in Table 1 under four categories: Feature-based measures, Neighborhood measures, Linearity measures, Dimensionality measures, Class balance measures, and Structural representation measures.
Feature-based measures
Feature-based measures assess the discriminating power of data attributes, treating datasets that have at least one discriminating attribute as less complex [25]. The first measure is Maximum Fisher’s Discriminant Ratio (
Linearity measures
The measures in the linearity category attempt to quantify the possibility of separating classes by a Support Vector Machine-based hyperplane, assuming that a linearly separable problem is less complex than a problem requiring a non-linear decision limit [37]. The first measure, the sum of the error distances by linear programming (
Neighborhood measures
The neighborhood measures attempt to characterize the class overlap, capturing the shape of the decision region and the classes’ internal structure by analyzing the neighborhood of the points. The distances between pairs of points are stored in a matrix, measured by the Gower distance. The first measure, fraction of borderline points (
Structural representation measures
In structural representation measures, the dataset is represented as a graph, preserving the distances or similarities between the original data points. In this graph, the vertices correspond to the objects, connected by edges weighted by the objects’ distance. The distances between pairs of points, measured by the Gower distance, are stored in a matrix. The process includes pruning the edges between data points of different classes. The first measure of this category, average density of the network (
Dimensionality measures
Dimensionality measures indicate the sparsity of the data based on the size of the dataset. The first indicator, the average number of points per dimension (
Class balance measures
Finally, the last category, class balance measures, groups together measures that capture significant differences in the number of exemplars per class, which indicate more complex problems. The first measure, the entropy of class proportions (
Classification quality
Classification is the Data Mining task that models a dataset’s grouping structure using the objects of a dataset. The most popular classification models are decision-trees, rule-based classifiers, probabilistic models, instance-based classifiers, support vector machines, and neural networks [1]. For the present research, some algorithms were selected that do not require previous treatment of data quality problems: C4.5, CART, and Random Forests. As evidenced by the KDD process’s pre-processing step, missing values and outliers tend to reduce dataset analyses’ quality. However, it remains to be seen how these problems affect the C4.5, CART, and Random Forests data classification models.
Decision tree algorithms are based on a tree structure built based on training data to classify new objects. In this tree, the internal nodes correspond to attribute tests, the branches correspond to test results, and the leaves represent the classes. An induction algorithm determines the most appropriate choice for a node, and some of the classic induction algorithms are C4.5, ID3, and CART. C4.5 is a decision tree induction algorithm that uses information as a criterion for deciding the tree breaking attribute. In the decision tree’s induction, missing values are considered in the nodes’ construction, either treating them as a possible branch or distributing these occurrences between the branches respecting the distribution of data utilizing weights. At the time of classification, missing data causes each branch of the node corresponding to the attribute to be tested [43]. On the other hand, outliers can lead the process of inducing overfitting of the tree to the data, requiring algorithms that handle the overfitting [50].
Another tree-based algorithm is CART (Classification And Regression Trees), which uses the Gini index to decide the tree’s breaking attribute. The CART algorithm ignores occurrences with missing values in measuring the quality of a break and uses surrogate splits to determine how to deal with missing values in the test step of the classification [16]. As in the C4.5 algorithm, trees induced by the CART algorithm require treatment to avoid overfitting. As for the effect of outliers on the CART algorithm, the literature argues that the CART algorithm is not significantly affected by outliers in independent variables but is affected locally by outliers present in the dependent variables [28, p.552][40, p.161].
Random Forests (RF) is a class of tree-based classification methods that apply the bootstrapping method to the dataset to decrease the prediction variance. The predictions of multiple trees are combined to present the classification model. Random Forests are resistant to noise and discrepancies of independent variables because they apply the binning method’s normalization to the variables [1, p.381]. In the original definition of Random Forests by [11], missing values are treated by imputation. Random Forests implementations using C4.5 decision trees instead of CART take the C4.5 algorithm approach to deal with missing values.
Table 2 summarizes the behavior of the classification algorithms used in the present research in the face of missing values and outliers. The research initially chose not to use algorithms that required previous treatment of outliers and missing values by imputing data or deleting objects.
Experimental methodology
Proposed structural and measurement models
Literature provides the elements that support a proposition of a path model in which Classification Quality is affected by the complexity and the quality of data. Nevertheless, both Data Quality and Data Complexity are concepts whose observation is not direct. Thus, for a SEM analysis, these concepts have to be defined as constructs or latent variables. Each construct is measured indirectly through indicators that manifest themselves as quality and complexity dimensions. For structural modeling, the constructs need to be conceptually defined. Thus, this work has opted for an adaptation of complexity definition by Kolgomorov (1965) to Data Complexity [26, 9] and Data Quality following the Jayawardene definition [30]. Consequently, the constructs that are the focus of this research can be defined as follows:
Data Complexity (DC) – Necessary effort to describe a dataset. The greater the effort, the more complex are the data; Data Quality (DQ) – Fidelity with which data represent people, objects, events, or concepts. The bigger the quality, the closer the proximity between the representation and the object or fact represented; Classification Quality (CQ) – Effectiveness with which the non-labeled objects are classified correctly. The bigger the quality, the closer the proximity of labeled objects to their correct classes.
From these definitions, the relation between constructs can be initially modeled as in Fig. 2.
Behavior of the classification algorithms used in the search for missing values and outliers
Proposed models of path and measurement of constructs.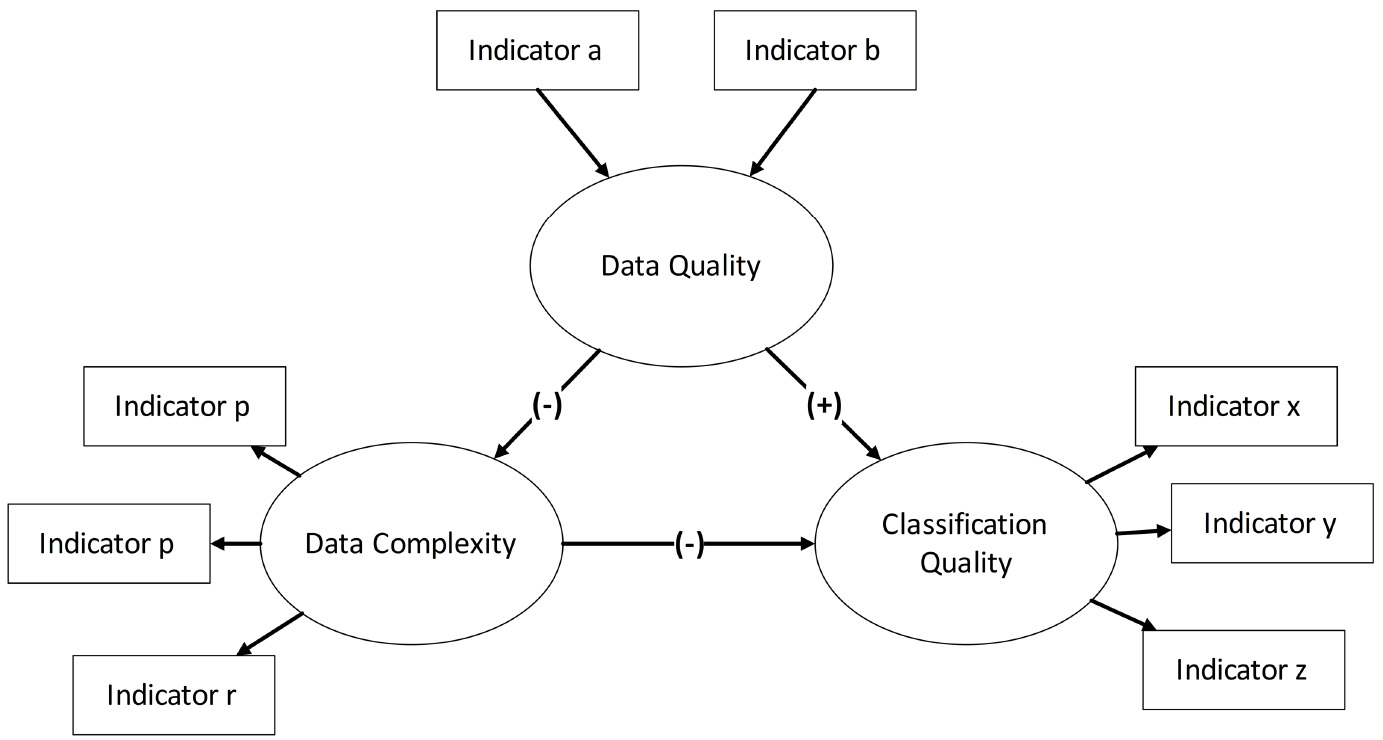
In Fig. 2, it is possible to note from the signs that the construct Data Quality (DQ) has a positive effect (
These effects were noted, for instance, by [35] when observing that outliers (a quality dimension) affect the data in its variance-dependent dimensions, such as overlapping measures (complexity dimensions), which may in turn affect the result of classifiers (classification dimensions) such as Decision Trees and Support Vector Machines.
The model for measuring the constructs, shown in Fig. 2, was theoretically based on the literature presented in Subsections 3.2 and 3.3. The indicators of the Data Quality construct (Indicators a and b) are Completeness and Validity. For the Data Complexity construct, the data complexity dimensions presented in Table 1 correspond to Indicators p, q, and r. The results of the classifiers listed in Table 2 correspond to Indicators x, y, and z.
The approach adopted to obtain the experimental dataset, based on [26], was to build a space for measures of Data Complexity and Data Quality for data classification problems, where the attributes are the Data Quality, Data Complexity and Classification Quality indicators, obtained for public datasets. It was of interest to the researchers to know the effect of data containing outliers and missing values not submitted to pre-processing on classification algorithms’ results. Thus, the experiments predicted a dataset’s constitution that contained classification results for datasets containing outliers and untreated missing values.
The experimental dataset’s size is directly related to statistical power, that is, the probability of rejecting a null hypothesis when it is false. By adopting a dataset with missing values, the statistical power is reduced, and there is a risk of compromising a data distribution that is assumed to have with the complete data [38, p.34]. To calculate the sample size for PLS-SEM algorithm, the following values were assumed, as suggested by [22, pp.20-22]: minimum size of the effect detected as significant (0.3), statistical power (80%) and level of significance (5%).
Attributes and data points
The attributes of the dataset are the following: a) the dimensions of Data Complexity presented in Table 1, b) Validity and Completeness, calculated as described in Eqs (8) and (9), and c) the AUC values (Area Under the ROC Curve) representing the performance of the classification algorithms in Table 2. The AUC represents the degree of separability, that is, how much an algorithm is able to distinguish between the classes, and its measurement varies between [0, 1]. For the calculation of AUC, the ROCR package [46] was used, applied to each of the classification algorithms in Table 2, using the cross-validation method in k-folders, for
Experimental dataset attributes
Experimental dataset attributes
Considering the 27 attributes for the experimental dataset (22 dimensions of Data Complexity, 2 dimensions of Data Quality, and 3 dimensions of Classification Quality), the minimum sample size necessary to detect the effect was calculated as 119 exemplars [22, p.21][47].
To obtain the values for the experimental dataset’s attributes, this work searched in OpenML repository [13] for datasets that met the following criteria: number of instances between 100 and 3,000, number of attributes between 2 and 20, number of classes equal to 2, number of missing values equal to or greater than 0. The rationale why binary datasets (2 classes) have been adopted is that a majority of complexity measures are defined for binary classification problems only. However, multi-class problems can be decomposed into binaries by the OVO (One-vs-One) strategy [37]. The number of attributes was defined considering that the dimensionality of the dataset affects its complexity [25, 26, 35, 44, 19, 55, 5]. The number of missing values defined in the selection criterion aimed at obtaining mixed datasets, with and without missing values. The range for the number of instances has been set arbitrarily.
After applying the criteria, 178 datasets were obtained from the OpenML repository. The datasets that were redundant and had problems with data were deleted. From these 178 datasets, metadata were collected to build the space for measures of complexity and data quality for classification problems.
Descriptive analysis
A complete descriptive analysis of the experimental dataset was carried out. For the reasons related to space, only the results of the quality attributes of the classification will be presented.
As for the Classification Quality construct indicators, the classifiers’ AUC measures presented in Table 2 were adopted. The selected classification algorithms are sensitive to missing values and outliers, capturing these anomalies’ variations in the analyzed datasets.
The summary measures for the classification quality indicators are:
C4.5 RF CART
Min. :0.4833 Min. :0.3605 Min. :0.4420
1st Qu.:0.6582 1st Qu.:0.6778 1st Qu.:0.6508
Median :0.8033 Median :0.8410 Median :0.8084
Mean :0.7724 Mean :0.7969 Mean :0.7714
3rd Qu.:0.9069 3rd Qu.:0.9296 3rd Qu.:0.8677
Max. :1.0000 Max. :1.0000 Max. :1.000
By observing the summary, these classifiers’ desirable performance can be seen in 50% of the analyzed datasets. The frequency distribution of the classifiers C4.5, RF, and CART indicators can be seen in Fig. 3.
Histogram for classification quality indicators.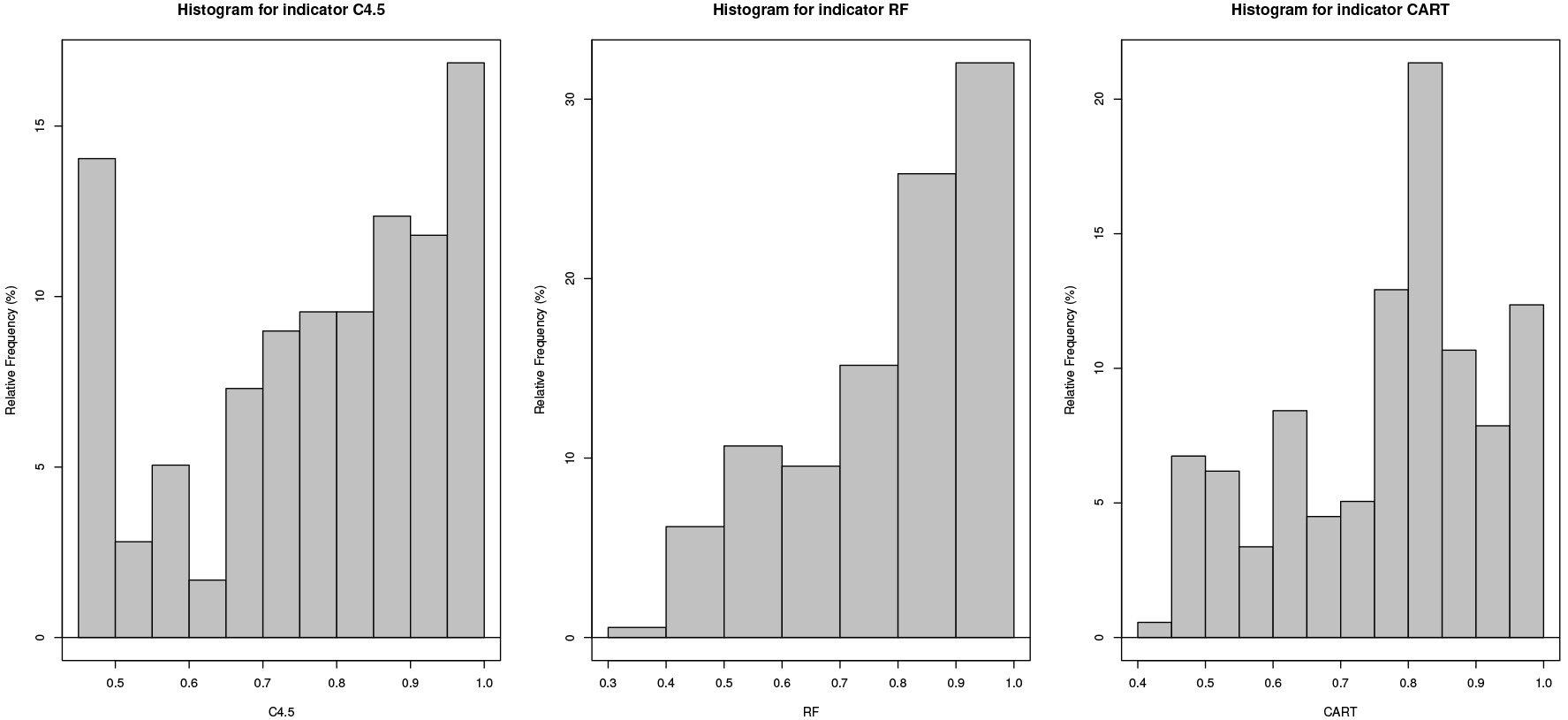
The correlation between the indicators was calculated as:
C4.5 RF CART
C4.5 1.0000000 0.8626815 0.8608670
RF 0.8626815 1.0000000 0.9287369
CART 0.8608670 0.9287369 1.000000
For the indicators of the Classification Quality construct, the value of Cronbach’s alpha coefficient as well as the gain of reliability in case of exclusion of any of the indicators, are presented below:
Alpha reliability = 0.9571
Standardized alpha = 0.9581
Reliability deleting each item in turn:
Alpha Std.Alpha r(item, total)
C4.5 0.962 0.963 0.878
CART 0.926 0.926 0.927
RF 0.923 0.925 0.927
A Cronbach’s alpha value of 0.958 is considered a high-reliability value for the Classification Quality construct’s measurement model [22, p.101].
The evaluation of the PLS-SEM algorithm results begins by validating the reflective and formative measurement models’ quality. Only if the measurement characteristics of the constructs are acceptable can the results of the structural model be validated [22, p.101].
The evaluation of the reflective model begins with assessing the reliability of the internal consistency of the constructs. For this evaluation, Cronbach’s alpha measure
Reflective constructors reliability
Reflective constructors reliability
Although high values for composite reliability
The researchers opted to retain the Data Complexity construct as it is, with an expectation to reduce the redundancy in measures through the elimination of the indicators with much clearer guidelines. As for the Classification Quality construct, the research opted for maintaining the three indicators in Table 2, considering that: a) indicator removal simulations did not show any significant gain in the values of Cronbach’s alpha and composite reliability; b) although the three algorithms adopted, CART, C4.5, and Random Forests, are based on trees and their classification performances are close, the permanence of their measures in the analysis is justified by the fact that it deals with different algorithms and since no other classification algorithms are found that are both sensitive to outliers and missing values.
The next stage of analysis of the reflective constructs consists of measuring the convergent validity of each construct’s indicators, that is, a measure of how much the indicator is positively correlated with other indicators of the same construct. For this evaluation, loads of the indicators and the Average Variance Extracted (AVE) are considered. Although standardized values of 0.708 or greater are expected for the indicator loads, [22, pp.103,104] recommend considering the impact of excluding an indicator with a load between 0.40 and 0.708 on the Average Variance Extracted and on the composite reliability.
The values for loads of the Data Complexity and Classification Quality constructs’ reflective indicators are presented in Table 5.
Loads of the Data Complexity and Classification Quality constructs’ reflective indicators
It is possible to note that the Classification Quality construct indicators showed high commonality, being kept unchanged. However, some Data Complexity construct indicators presented loads below 0.40 (bold lines in Table 5). The researchers chose to exclude the indicators D1, D2, D3, G2, and G3, evaluating the exclusion of gains in composite reliability and the AVE for each exclusion. After this exclusion, loads of indicators B1 and B2 (indicators of class unbalance) remained negative. The research option was based on exclusion of indicators B1 and B2. The results for reliability and validity are shown in Table 6.
Reliability and validity for reflective constructs after exclusion of indicators D1, D2, D3, G2, G3, B1, and B2
The values for loads of the Data Complexity and Classification Quality constraints’ reflective indicators after the exclusions of indicators D1, D2, D3, G2, G3, B1, and B2 are shown in Table 7.
Loads of the Data Complexity and Classification Quality constraints’ reflective indicators after the exclusions of indicators D1, D2, D3, G2, G3, B1, and B2
Although high, the values of reliability and validity were considered acceptable for the analysis, considering that: a) the research has only three indicators to measure the Classification Quality, representing the few classification algorithms sensitive to values outliers and missing values; b) the different aspects of the data complexity discussed by [37] were summarized in just one latent variable; c) the AVE values for the constructs are above 0.5, being considered acceptable [22, p.107].
Finally, the analysis of reflective constructs involves assessing their discriminant validity, that is, how different the construct is from other constructs. For this validation, the cross loads of the indicators are analyzed, which must be greater than all their loads in other constructs, and the results of the Fornell-Larcker [22, p.105] criterion.
The values for the cross loads of the indicators are presented in Table 8.
Reflective indicators’ cross loads (highlighted in bold) of Data Complexity (DC) and Quality of Classification (CQ) constructs
The values of the discriminant analysis by the Fornell-Larcker criterion are presented in Table 9.
Values of the discriminant analysis by the Fornell-Larcker criterion for reflective constructs
It is possible to conclude by the results of cross loads and the values of the discriminant analysis with the Fornell-Larcker criterion that the Quality of Classification and Data Complexity constructs are different from each other, that is, they measure different phenomena.
The validation of the formative model followed the steps evaluating different aspects of the reflective model.
The first instrument for the validation of the formative model is verifying convergent validity. Convergent validity is the extent to which the formative construct correlates with another reflective construct of a single item that captures the same concept but uses different indicators. The reflective construct of a single global item that captures the same concept is defined in the design phase of research in Social Sciences, but does not exist in the present research because all the data quality attributes that are of interest in the research form the Data Quality construct.
The second instrument used to validate the formative model is the collinearity of its indicators, that is, a high correlation between them. Since formative indicators measure different aspects of the construct’s phenomenon, a high correlation between them is not anticipated. The VIF indicator (Variance Inflation Factor) measures the degree to which the standard error increases due to the presence of collinearity. For collinearity values that are considered as non-critical (VIF
The validation of the formative model involves evaluating the indicator’s contribution, expressed by its weight. In addition to being compared with each other to calculate their relative contribution, the weights of the indicators are tested by the bootstrapping approach to see if they are significantly different from zero. For the execution of bootstrapping, 5,000 sub-samples were generated (
The values of collinearity, original weights, and significance after bootstrapping observed for the Data Quality construct’s formative indicators are shown in Table 10.
Collinearity, weight, and significance values for the indicators of the Data Quality construct
Collinearity, weight, and significance values for the indicators of the Data Quality construct
For the DQCompleteness indicator, the weight of 0.993 was considered significantly different from zero, at a significance level of 0.05, for the two-tailed test. For the DQValidity indicator, the weight of 0.162 was considered insignificant, at a significance level of 0.05, for the two-tailed test. However, it was decided to maintain the DQValidity indicator to keep the construct domain compatible with the theory.
In this step, the structural model representing the relationship between Data Quality, Data Complexity, and Classification Quality are validated. The results allow understanding how well the empirical data supports the structural model’s concepts and verify whether these concepts have been empirically confirmed.
The initial analysis step is the search for collinearity in the structural model, which is identified with VIF values above 5. The next step aims to validate the significance and relevance of the structural model’s relationships. Then follows the evaluation of the explained variance (
Table 11 presents the results and indicators significance of the relationships proposed by the structural model.
Results and significance indicators of the relationships proposed by the structural model. DC stands for Data Complexity constructor, DQ stands for Data Quality constructor, and CQ stands for Classification Quality constructor. SD stands for standard deviation
Results and significance indicators of the relationships proposed by the structural model. DC stands for Data Complexity constructor, DQ stands for Data Quality constructor, and CQ stands for Classification Quality constructor. SD stands for standard deviation
The values presented in Table 11 indicate that no collinearity was observed in the sets of predictor variables. The standardized structural coefficients’ values represent the coefficients of the relationships between the constructs, with a standardized value ranging between
The adjusted
Figure 4 shows the paths between the constructs, highlighted proportionally about their contribution to the result of the endogenous construct. The values of arrows connecting the constructs represent the partial regression coefficients between the dependent and the independent constructs. The values of arrows that link the DQCompleteness and DQValidity indicators to the Data Quality construct represent the multiple regression coefficients between these indicators and the construct. The values that appear on the arrows that link the indicators to the Data Complexity and the Classification Quality constructs represent the simple regression coefficients between each indicator and the construct. The
Knowing the proportion as CQ is affected by DQ and DC allows anticipating the result of a classification analysis, based on the results of the dataset’s quality and complexity indicators. Before submitting a dataset for analysis, it is possible to collect the Data Quality and Data Complexity indicators to show the trend of the classification task’s result: high values for Data Complexity indicators may suggest an unsatisfactory performance for classifiers in this dataset.
The contribution of the model of relationships between Data Complexity, Data Quality and Classification Quality generated by the PLS-SEM algorithm is to allow a more accurate estimate of the influence of data quality and complexity on the final result of classification quality.
An example of application of the structural model presented in Fig. 4 can be the generation of a radar chart, like the one presented in Fig. 5. In this chart, four datasets from the OpenML repository [13] were submitted to the data quality and complexity metadata collection procedures described in the Sections 3.2 and 3.3. It is possible to represent the collected indicators directly on the chart, or group them into categories before the graphical representation.
In Fig. 5, the Data Quality and Data Complexity indicators were grouped, and the new values were calculated by weighted average of the indicators loads and weights, represented in Fig. 4 (Table 12).
Calculation of grouped measures of Data Complexity and Data Quality, by weighted average criterion. The weights were obtained from the model generated by the PLS-SEM algorithm (Fig. 4)
Calculation of grouped measures of Data Complexity and Data Quality, by weighted average criterion. The weights were obtained from the model generated by the PLS-SEM algorithm (Fig. 4)
Structural model showing paths, weights and loads, and 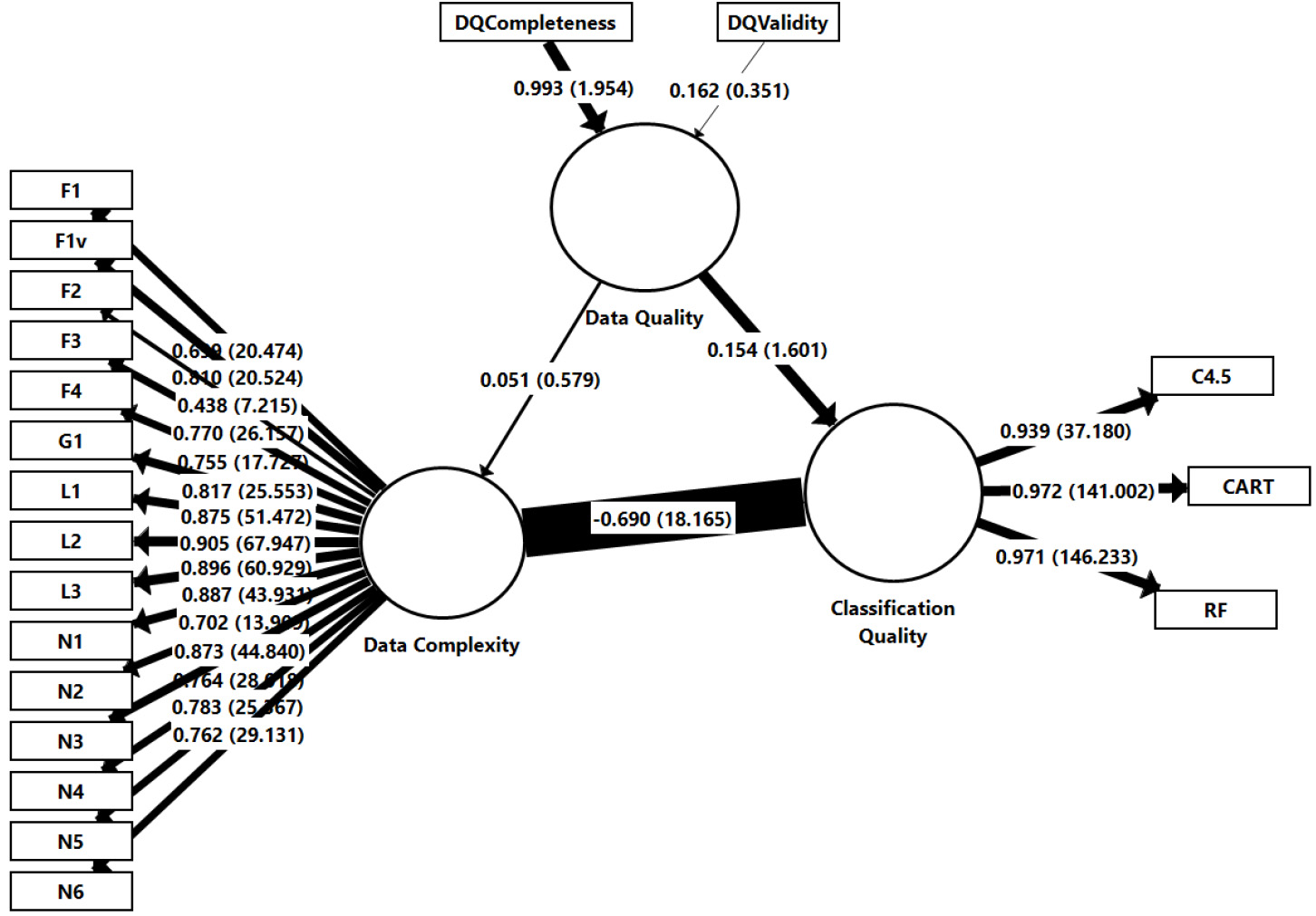
Graphical representation of Data Quality and Data Complexity measures. Source: Author.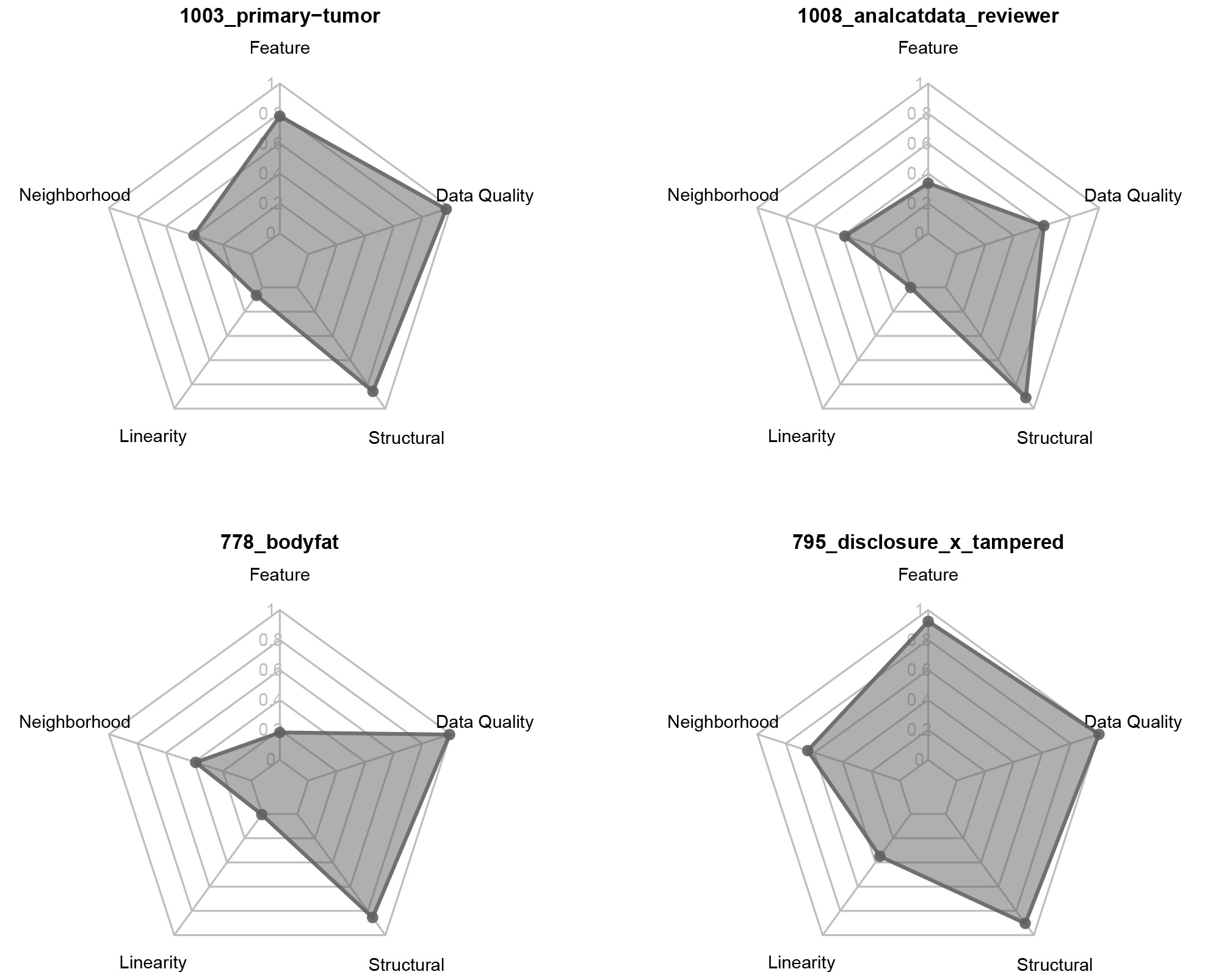
The graphical representation of the clustered measures of data complexity and quality can be interpreted from the results of the PLS-SEM process (Section 5.4): data complexity exerts a strong negative impact (0.690) on quality of the classification results. Together, the complexity and quality of the analyzed data can explain approximately 48% of the variation in classification results. In simpler terms: the greater the complexity of the data and the lower its quality, and the worse the classification results for that data.
Data quality is a real and well-represented concern in the process of Knowledge Discovery in Databases. A better understanding regarding the relation of Data Quality and Data Complexity may bring quality gains to analyses, which should not be ignored in a Big Data reality.
The research proved itself to be innovative by relating data aspects that, in general, are treated separately and whose effect is nearly ignored: Data Quality affects Data Complexity, and both affect Classification Quality. Validity and completeness were shown in the current model as two vital quality problems whose effect on Data Complexity deserves to be studied more thoroughly. Besides, the use of Structural Equation Modeling and the PLS-SEM algorithm for studying the relations between quality and complexity dimensions, to the best of our knowledge, is unprecedented in literature, and it has opened a new platform for this tooling in the areas of Data Mining, Big Data, and Data Governance.
PLS-SEM’s use allowed for the quantification of the combined contribution of data quality and complexity to the success of classifications in the datasets of two classes. The results suggest that the structural factors that interfere in a dataset’s complexity deserve more attention in classification problems than the occurrence of missing values and outliers, and this requires a greater investment of time by the analyst in the pre-processing steps.
As a continuation of the research, it is suggested that the study of the relationship between Data Quality and Data Complexity be deepened, including new indicators to verify the impact on the relationships discovered in this work. Besides, it is also intended to think of other works to validate the application of the model discovered in this research. The resulting model allows, among other things, to know a priori the types of problems that a dataset has and the classifier’s probable performance in case no corrective action is taken. In this sense, it is suggested to research the proposed model’s use to recommend corrective actions that reduce datasets’ pre-processing time in analyzes.