
Abstract
Traditionally, RFID is frequently used in identification and localization. In this paper, an extension application of RFID is designed to recognize gestures. Currently, gesture recognition is mainly used for feature extraction through wearable sensors and video cameras, which have shortcomings such as inconvenience to carry and interference with obstacles. This paper proposes a gesture recognition system based on radio frequency identification (RFID), where users do not need to wear devices. In the proposed model, the interference information generated by the gesture action on the tag signal is used as the fingerprint feature of the action. To obtain satisfactory recognition, the signal diversity is first increased through the tag array. Then, the RSSI and phase signal are normalized to eliminate offset and noise before training. Furthermore, a residual neural network (ResNet) is carefully built as a gesture classification model. The experimental results show that the recognition system achieves more recognition accuracy than existing methods, and the average gesture recognition accuracy reaches 95.5%.
Introduction
Recently, human-computer interaction has gradually evolved from a computer-centric interaction to a human-centric approach due to the rapid development of human-computer interaction technology. It is a key issue to perceive and understand human activity behavior for human-computer interaction. Specifically, gesture recognition has attracted increasing attention and has been widely used in computer games, virtual reality [1, 2], and smart homes [3, 4]. Through automatic recognition of user gesture changes, gestures can be directly translated into instructions to control hardware operations.
Gesture recognition based on RFID technology is potentially used in human-computer interaction since tags have excellent characteristics, such as low cost, easy deployment, passive nature, and small size. In this paper, a ResNet [5] gesture recognition method is proposed based on a wear-free RFID array. Furthermore, the radio frequency signal strength and phase are used as characteristic data for detection. To increase signal diversity, a tag array is designed to reflect more radio signals. In this scheme, the user does not need to wear the device or tags, which increases user’s convenience. First, gesture segmentation methods are used to quickly segment gesture data from the data sequence to reduce the computational load caused by irrelevant data. Then, the ResNet algorithm is performed to classify the collected data. Finally, rapid gesture recognition is tested to evaluate the premise of detection. The main works of this paper are listed as follows:
High quality and diversiform signals of RFID tags are obtained through tag array and preprocessing. In particular, the signal diversity is significantly enhanced through multiple tags. This contributes to achieving high accuracy recognition. Then, to eliminate the offset and noise of the primal signal, the received signal strength indication (RSSI) first-order difference sequence is used to segment the signal and normalize the gesture signal in a unified time. To achieve high recognition accuracy, a ResNet is used to extract deep features from normalized RSSI and phase sequence. The layer of ResNet is carefully designed to enhance recognition speed and accuracy. Furthermore, the parameters of ResNet are adjusted according to experiments. To evaluate the performance of the model, diverse experiments are conducted to compare the effects on the results of factors such user diversity, distance, and the number of tags. In addition, a simple gesture control game is tested based on the proposed RFID method.
The rest of the paper is organized as follows: Section 2 introduces some works related to the use of sensors or radio frequency signals to detect human activities. Section 3 presents the RFID communication model and an overview of the identification system proposed in this paper. Section 4 explains the data collection, processing, and model building process of the recognition system in detail. In section 5, the evaluation results obtained in actual experiments are analyzed. Finally, we discuss the relevant experimental results and proposed future work in the conclusion.
Traditional human posture or gesture recognition methods are mainly based on vision [6, 7]. Through data processing and analysis in the form of videos or images, human postures or gestures can be identified. Saman et al. recognized gestures according to pictures collected by a camera. They separated the skin from the background of the picture, and judged the gestures by detecting the parameters contained in the separated gestures [6]. Although the existing image and video-based recognition methods have a high recognition rate, the recognition error will increase significantly when the illumination is insufficient or the line of sight is insufficient. In addition, when there is an obstacle between the recognition target and the camera, this method cannot be recognized. Furthermore, recognition through a camera easily leaks the user’s privacy.
Sensor-based methods: Sensors are also used for gesture detection [9, 10, 11, 12, 13], and Saleh et al. proposed a gesture recognition system for smart gloves. They made a custom glove with five flexible sensors and a gyroscope to recognize gestures [10]. Chu et al. constructed a gesture recognition method for a capacitive sensor board. A capacitive sensor controller is used to collect user gesture signals, and then a relational convolutional neural network is combined to train the sample data [11]. In the literature [12], the built-in acceleration sensor and gravity sensor of a mobile phone are used to identify recognition, and the temporal characteristics of these human motion data are used for classification. Sensor-based identification methods often need the device to be carried. In the literature [9, 10], a sensor glove method has been used. Users have to carry multiple sensors, microprocessors, and communication modules, which leads to great inconvenience. In addition, wearable sensors require more user operation, and the use of built-in sensors such as mobile phones needs to maintain a stable state for detection, which affects the user experience [12].
Wi-Fi-based methods: Wi-Fi-based behavior recognition technology can be implemented through existing wireless local networks. Xiao et al. designed a gesture recognition system based on Wi-Fi channel status information. An improved linear discriminant analysis algorithm is used to reduce the size of active features, and a logistic regression algorithm is combined for learning classification [14]. In the literature [15], Abdelnasser et al. used the signal strength to identify actions, extracted and compared the combination of action primitives in signal feature information to determine actions, and used changes in channel subcarriers to determine the direction of gestures. Venkatnarayan et al. proposed multiuser gesture recognition, which first determines the number of users, and then performs matching based on the collected single-user gesture combination virtual samples [16]. Domenico et al. proposed a Wi-Fi-based human body recognition method in a partition wall, which uses the naive Bayes algorithm for classification by calculating the Doppler spectrum features contained in the channel state information [17]. Wi-Fi-based gesture recognition can solve the situation of insufficient light and line of sight, even allowing detection through a wall [17], which effectively protects user privacy. At the same time, there is no need to carry complicated equipment. However, the network cards currently carried by most PC devices do not support the extraction of CSI data in communication technology. Only some network cards (Intel 5300 [14, 15, 16, 17]) support obtaining CSI data, which limits the use of Wi-Fi detection. On the other hand, Wi-Fi signals are more sensitive and easily affected by the environment.
RFID-based methods: In recent years, due to the low cost, easy deployment, passive nature, and small size of RFID technology, an increasing number of RFID tags and devices have been applied to the detection of human activity, and significant results have been achieved [18, 19, 20]. Yao et al. proposed a human body state detection system based on radio frequency identification technology and activity-specific dictionary learning algorithms [18]. The system captures the RSSI data that changes between the reader and the tag due to human activities, divide the input raw RSSI data into activity segments of the same size, calculate statistical characteristics to build an activity dictionary, and reduce the computational cost by reducing the data size, so that the recognition algorithm can be executed on a lightweight device. Oguntala et al. also used the method of maximum likelihood estimation to identify the statistical information of feature data [19]. In the literature [20], the position of the finger was located by RFID equipment, and the trajectory of the point is used to track the writing of the finger. Furthermore, they used convolutional neural networks (CNNs) to identify the trajectory image of the writing of multiple fingers to determine what the user wants to perform operations. At present, RFID-based recognition methods and existing gesture recognition methods also have some problems. In the literature [21, 23], researchers proposed an activity recognition system based on wearable RFID devices. The system infers human activities by analyzing the time characteristics of the RSSI of the RFID devices installed on the user’s body, arms, and feet. However, this method of carrying a large number of antennas and tags in the body or clothes is difficult to apply in real life. In the literature [24, 25, 26], gestures on the line of sight path of the antenna and the tag were detected, and the DTW algorithm and improved algorithm were used to classify the gestures. Although the algorithm is simpler, it has the disadvantage of low recognition accuracy and long detection time.
System model
In this section, we introduce the RFID communication model of the system. In addition, we give a general introduction of the recognition system, which is designed to realize actual gesture recognition.
Communication model
When a COTS RFID reader successfully inquires tags, the reader can report low-level signal characteristics such as
According to the Friis equation and signal reflection process [22], we can use Eqs (2) and (3) to quantify the RSSI reading of the reader:
where
where
where
To construct a simple, low-cost, high-stability gesture recognition system, a new wear-free gesture detection scheme is first designed to improve the convenience and accuracy of gesture detection. RSSI and phase signals are obtained through the RFID array, and then gesture classification is achieved by ResNet of deep learning.
The system model is presented in Fig. 1. The whole system includes four main modules: an RFID data acquisition module, a data processing module, a deep learning module, and a gesture prediction module. First, the phase data stream and RSSI data stream of each RFID tag are collected through an RFID reader. Then, the collected phase and RSSI data stream are processed to form a characteristic data block. Next, a two-layer ResNet is proposed to extract key features. Finally, the gesture will be classified by the gesture prediction module.
RFID gesture recognition system structure.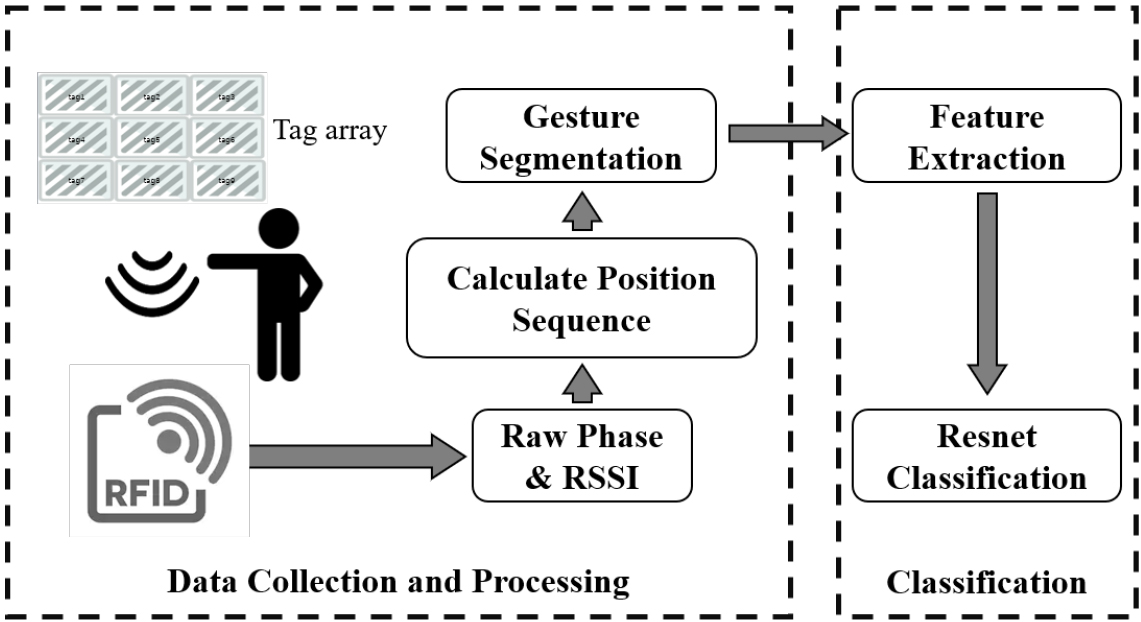
The recognition process includes four functional modules: data processing, Gesture segmentation, model training, and gesture recognition. The processing procedure is described in detail below.
Data preprocessing
Phase unwrapping
As shown in Eq. (4), the original phase is a periodic function. When the phase value decreases to 0, it will jump to
where
Since the phase and RSSI values depend on the distance of the signal path, in different scenarios, the signal reflection may be affected by the environment or the distance between the reader and the tag. Among them, the main influence comes from the change in distance between the reader and the tag [29]. Figure 2a shows the phase and RSSI data changes of the same action sample of a tag collected in different environments. The curve changes of the two cases are similar, however, the signal values have similar jumps.
To overcome the signal change caused by the change of the distance between the tag and the reader, In each acquisition process, we collect the static phase and RSSI in the state of no gesture. the original phase stream subtract the static phase to obtain the new phase stream. Similarly, the new RSSI stream from raw RSSI stream subtract the static RSSI. This process not only suppresses the influence of the change in the distance between the antenna and the tag, but also eliminates the effectiveness of the reader’s transmitting circuit, the reflective characteristics of the tag, and the phase shift of the reader’s receiving circuit. The process can be expressed by the following formula:
where
Figure 2b shows the signals change of the same action of a tag collected in different environments after removing the static phase and RSSI. Compared with the original signal in Fig. 2a, Fig. 2b shows that the operation in Eq. (9) can effectively remove the phase shift caused by the hardware and the distance between the antenna and the tag.
Phase sequence and RSSI sequence changes.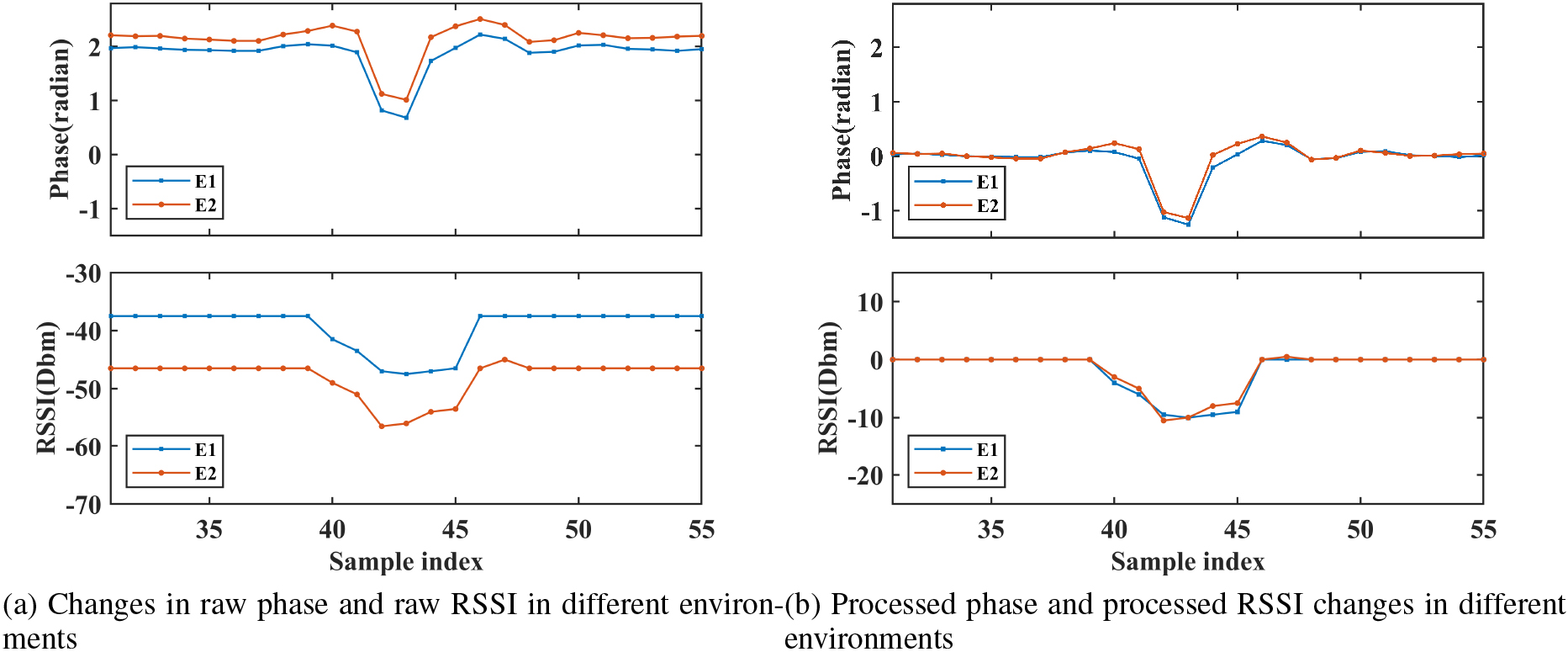
The characteristics of the phase data are quite different from those of the RSSI data. The significant differences will increase the training time and may cause convergence failure. Therefore, the data need to be normalized before training. Here, min-max standardization is used to linearly transform the original data, and normalize all the data to [0, 1]. The mapping process of the
where
We collected different gesture data and stored them in the form of a two-dimensional array. The continuously collected data contains non-gesture data. These non-gesture data are useless for gesture recognition, and even have a negative impact. Therefore, we need to segment the collected data to obtain important gesture data in the data.
It can be seen from Eqs (2)–(4) that the phase and RSSI are affected by the propagation distance of the signal. In the absence of gestures, the propagation distance of the signal remains the same, and the phase and RSSI will remain unchanged. When the user’s gesture appears in the detection area, the signal propagation path changes. According to this change characteristic of the signal, we propose the following gesture segmentation method.
We differentiate the original RSSI data of multiple tags to obtain multiple differential sequences, and add these sequences as the positioning sequence for judging the position of the gesture. The result is shown in Fig. 3. By observing the positioning sequence, it can be seen that the positioning sequence is relatively stable without being disturbed by the gesture. When there is gesture interference, the positioning sequence changes significantly. Therefore, RSSI is more convenient and effective as a segmentation standard for gestures. the gesture interval and the idle interval can be found intuitively.
The positioning sequence for ten gestures.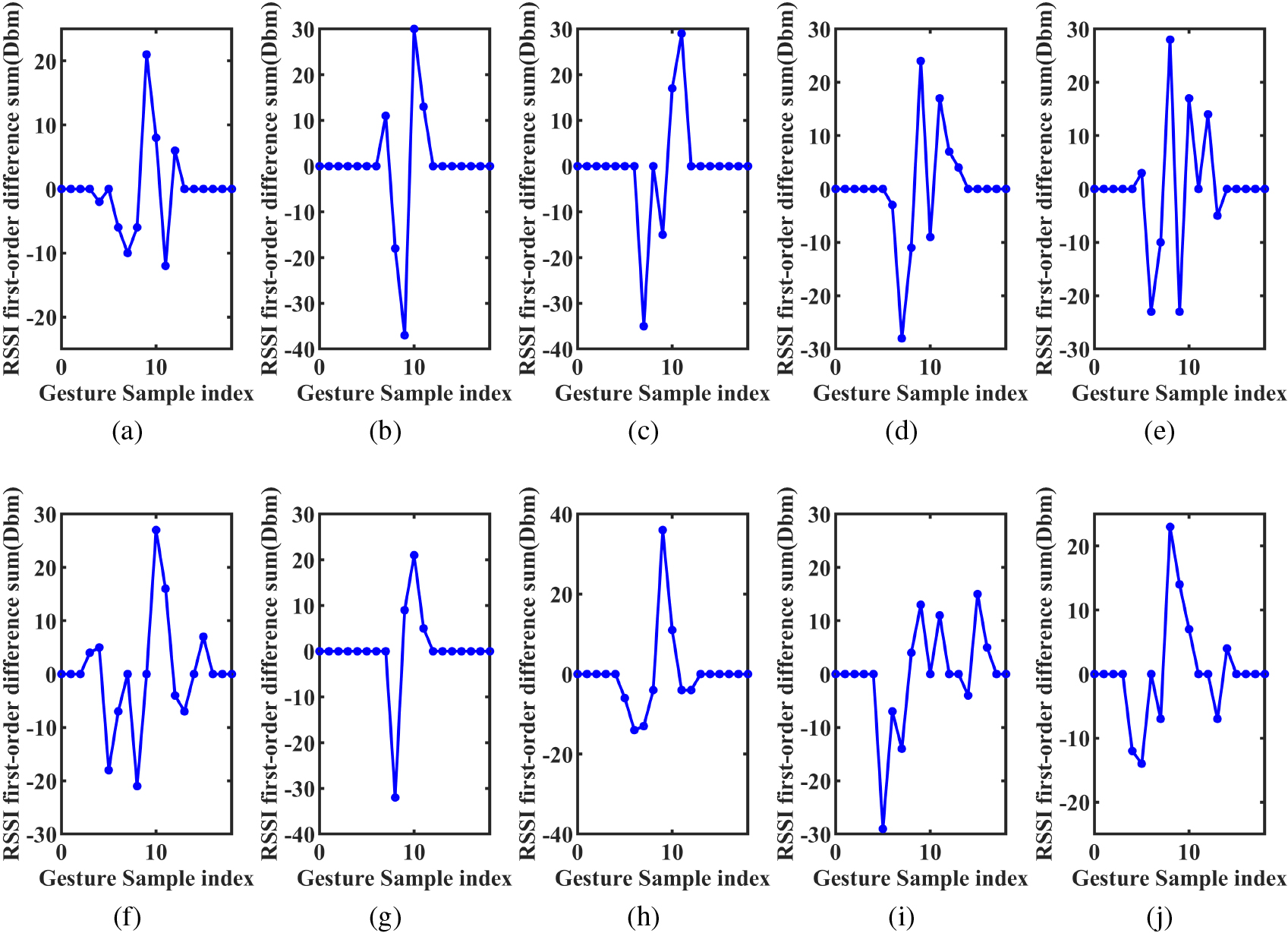
The specific process of segmenting gestures according to the position sequence is as follows: If there are consecutive k values greater than the threshold
where
[htb] : Gesture feature segmentation[1] RSSI vector space
Based on the position sequence, the feature data affected by gestures can be easily intercepted. Then, they can be used for the training and detection of the ResNet classification model.
After getting segmented gesture features, these gesture features are used to train and verify the classification model. The gesture classification model of the gesture recognition system in this paper is a ResNet based on CNN. CNN has excellent performance in the field of image recognition [30, 31]. It can automatically learn parameters and find effective solutions to complex problems and has excellent performance on classification problems. Compared with the direct learning of CNN, the residual learning of ResNet [32, 33] easily converges quickly. ResNet can obtain higher accuracy by increasing the number of layers than CNN. As shown in Fig. 4, a ResNet network is built through multiple convolutional layers and a pooling layer, and a fully connected classifier is also integrated. The structure and settings of each layer are described below.
Residual neural network structure.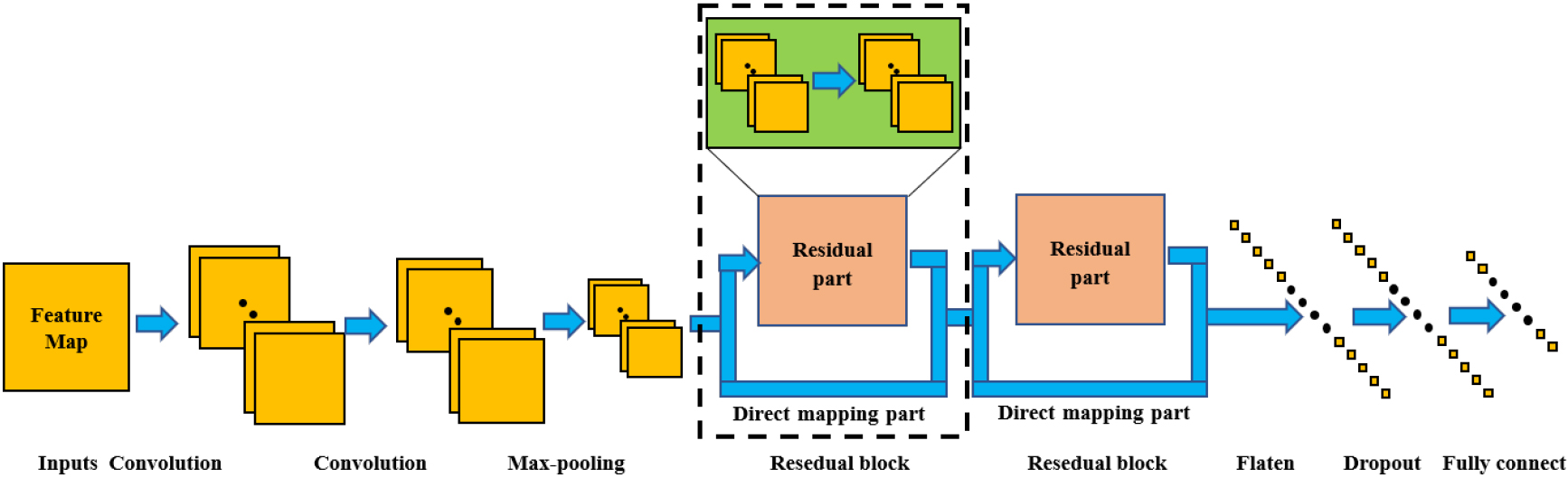
Convolutional layer: To obtain the deep features of the feature matrix, two convolutional layers are used. In addition, the filter of the convolutional layer uses a two-dimensional convolution kernel
Pooling layer: Pooling is an important concept in convolutional neural networks, which downsamples the input feature matrix. In this paper, we use the max-pooling function as the pooling layer. Specifically, the input is
Residual block: The residual block consists of two parts: residual and direct mapping. The residual part contains a double-layer convolutional layer. To ensure that the input size of the residual block is the same as the output size, the convolutional layer is filled with padding. Thus, the output of the direct mapping part is the same as the input of the residual part. The addition of the residual part and the output of the direct mapping part is the output of the residual block. In the process of convolution, the information may be lost, while the residual block can play a role in supplementing information. Assuming that the input of the residual block is
Dropout layer: In this layer, some part of the input matrix will be randomly selected and set as 0, where the replacement ratio is set by the dropout ratio. The objective of this layer is to reduce the scale of the model on the training set.
Flatten layer: In this layer, the multiple three-dimensional output tensors of the convolutional layer are transformed into one-dimensional data to match the input requirements of the fully connected layer. To facilitate the following presentation, set the output of this layer to
Fully connected layer: The output
where
where
where
To measure the performance of the proposed approach, an RFID tag array and a reader are established to verify and evaluate the system performance.
Reader, antenna and tag.
Implementation: We use COTS RFID equipment to implement the gesture recognition system. The equipment include an Impinj R420 RFID reader, am Impinj H47 omnidirectional tag, and an 8 dBi linear polarization antenna. Figure 5 shows the actual hardware diagram. The communication frequency of the reader uses the default 920.625 MHz. The antenna is placed parallel to the tag, and the height of the device is 1.2 meters. Limited by the antenna gain, to control the miss rate of the tag at a low level, we set the distance between the antenna and the tag to 50 cm. The actual device layout is shown in Fig. 6. After completing the data collection, a laptop with a CPU R7-4800U (1.8 GHz) and 16 GB RAM is used to complete the gesture segmentation, model training, and testing. The data acquisition module is implemented in C# language using Octane SDK based on the LLRP protocol and runs on a personal computer. The reader queries the tag at a rate of 17 times per second, and can obtain physical layer information such as phase, RSSI, and Doppler shift. The feature extraction and gesture classification modules are based on TensorFlow2.0, and the ResNet model in these two modules is built in Python3.0. The relevant parameters of the recognition model are set as follows: In the gesture segmentation part, the feature interval length
Data set: Five volunteers participated in our experiment: 3 male and 2 female college students. Ten gestures are selected as shown in Fig. 7. These gestures include (a) from bottom to top; (b) from top to bottom; (c) from right to left; (d) from left to right; (e) from upper left corner to lower right corner; (f) from lower right corner to upper left corner; (g) from the upper right corner to lower-left corner; (h) from lower-left corner to upper right corner; (i) left semicircle; (j) right semicircle. For these ten gestures, each gesture of each volunteer was collected more than 30 times. If the user’s gesture action is outside the line of sight of the antenna and the tag, the user’s action will have less influence on the signal, which is not conducive to the detection of the gesture. Therefore, the user should try to be in the middle of the line of sight of the two. We collected more than two thousand samples in total, and the number of samples is shown in Table 1.
Sample size
Sample size
Experimental layout.
Schematic diagram of gestures.
Evaluation index: Two metrics, including the confusion matrix and accuracy, are used to evaluate the overall performance of the system. In particular, each column of the confusion matrix represents a prediction category, each row represents the actual category of the sample, and each cell represents the probability of identifying the number of samples. Accuracy denotes the proportion of the number of samples correctly predicted compared to the total samples.
For the collected data, the 5-fold cross-validation method is used to train and test the model. The result of the classification is shown in the confusion matrix in Fig. 8. The vertical axis in the figure represents the true classification of the gesture, and the horizontal axis represents the predicted classification of the system. The cells on the diagonal are the correct rates of different gesture predictions. As seen in the figure, the recognition accuracy of each gesture is not less than 90%, and the total accuracy is 95.5%. This shows that ResNet has an excellent ability to distinguish gesture signals.
Classification result.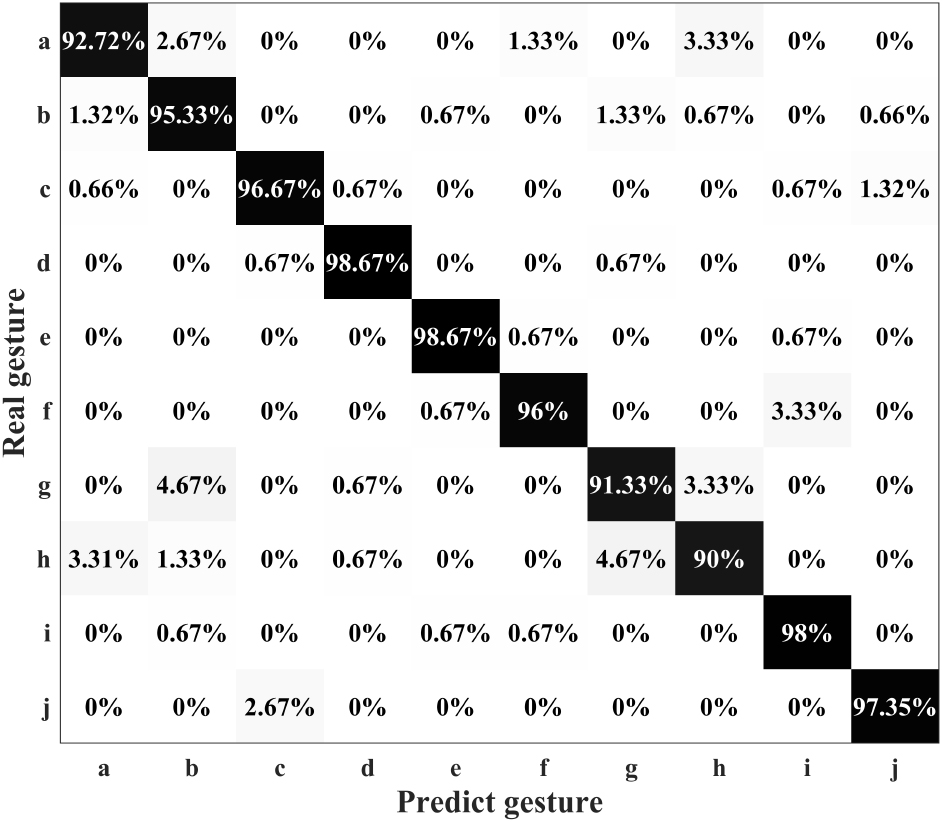
To evaluate the impact of different users on the recognition efficiency, 5 volunteers were tested to collect 20 samples for each gesture. Then, the recognition accuracy of five volunteer samples is obtained by testing, and the recognition results are shown in Fig. 9. The accuracy of every volunteer gesture recognition is also slightly different depending on the user’s body shape and position. Among the five volunteers, the lowest recognition accuracy is 92.9%, the highest is 97.5%, and the average accuracy is 95.4%. The recognition results verified that the recognition model has a good ability to recognize different user gestures.
Detection accuracy of different users.
The influence of distance between tag array and reader.
To verify the influence of recognition performance on different distances, the trained model is used to detect the recognition accuracy when the distance between the antenna and the tag is 46 cm, 48 cm, 52 cm, 54 cm. The experimental results are shown in Fig. 10. When the distance between the antenna and the tag is 48 cm and 52 cm, the average accuracy is 89.4% and 86.6%, respectively. The recognition model has high recognition accuracy. When the distance between the antenna and the tag increases to 54 cm, the detection accuracy of the recognition model is not less than 60%. We also compared the recognition results of using the original data and using the data with static data removed. The result demonstrates that removing static data can suppress the influence of the distance change between the reader and the tag compared with directly using raw data, and improve the recognition performance of the recognition system. This denotes the effectiveness of our data preprocessing process.
Comparison of existing methods
To verify the advantages of the ResNet model constructed in this paper in gesture recognition, the same data sets are used to compare with the literature [26]. Then, CNN, GRU, LSTM, and SVM are compared to construct learning models. The comparison of the average recognition accuracy and average detection time of these methods is shown in Table 2. It can be found that the residual network has better results. The residual structure is still 2.2% higher than the linear CNN. According to the construction method of the gesture fingerprint database given in the literature [26], ten sets are randomly selected from sample data to construct the gesture fingerprint database. Then, the remaining samples are used as detection data. After selecting multiple sets of different gesture data to construct a fingerprint database, the average accuracy of the DTW-based identification method is 78.5%. Due to the influence of samples, the accuracy is slightly lower than the accuracy reported in the literature [26]. This method takes a long time to detect, and the detection time of a single sample is longer than 1 s, while the method in this paper can perform the detection of a sample within 150 ms. Thus, the detection method based on ResNet is superior to the existing DTW-based detection method in terms of detection time and recognition accuracy. Compared with the learning models of CNN, GRU, LSTM, and SVM, ResNet also obtains excellent results. This is because ResNet has a richer network structure, and the residual block part can play a role in supplementing information.
Accuracy comparison between ResNet and other models
Accuracy comparison between ResNet and other models
Convolution function
In the convolutional layer of the model, we compare the performance of the one-dimensional convolution function and two-dimensional convolution function on feature extraction. In the experiment, to explore the best effect of using a one-dimensional convolution function, we established multiple sets of experiments for different sizes of convolution kernels. The experimental results are shown in Fig. 11. The results show that the accuracy has small change when the size of the convolution kernel varies from 1 to 12. When the size of the convolution kernel is 10, the best recognition accuracy of the recognition model using the one-dimensional function is 93.2%, which is lower than the recognition effect of the model using the two-dimensional convolution function. Therefore, a two-dimensional convolution function is used in the convolution layer to extract the deep features of the data.
Accuracy of one-dimensional convolution function model.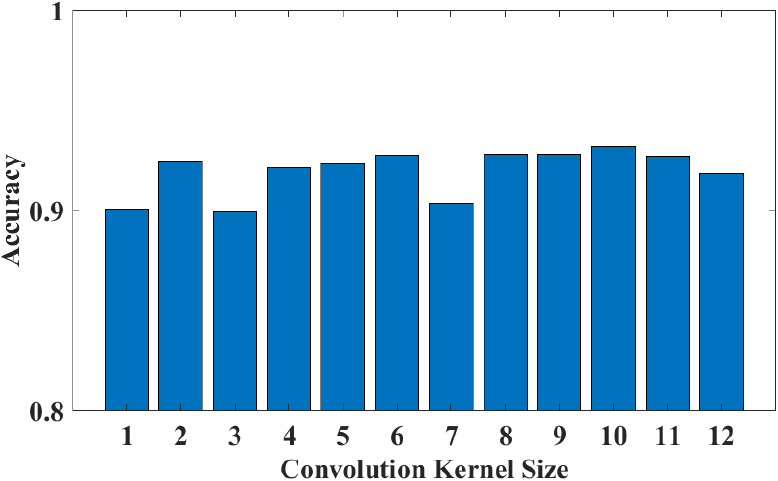
The impact of different activation functions on accuracy.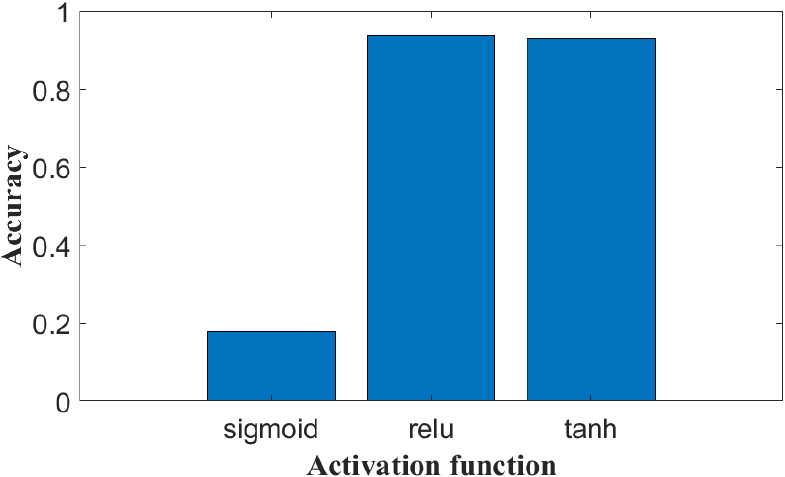
In the experiment, the softmax function is used in the last layer for classification, and the linear rectification unit (ReLU) function is used in the other layers as the activation function. We compared the detection efficiency of sigmoid, ReLU and tanh functions as activation functions, and plotted them in Fig. 12. Sigmoid has a poor effect and is not suitable for the detection of gesture samples. On the premise of ensuring the best detection, we choose the ReLU function as the activation function of the model, and its function is defined as:
The ReLU function enhances the nonlinear characteristics of the network, and it is efficient in gradient descent and backpropagation, which avoids the problems of gradient explosion and gradient disappearance.
To prevent the model from overfitting on the training set, the training accuracy and testing accuracy of the model are compared over different dropout rates. As shown in Fig. 13, after training and testing the model, the average training accuracy and average testing accuracy of the recognition model are obtained over different dropout rates. As the dropout rate increases, the difference between the training accuracy and test accuracy will continue to decrease. The greater the dropout rate is, the more obvious the suppression of overfitting. When the dropout rate is greater than 0.6, the training accuracy of the model begins to be lower than the test accuracy. When the dropout rate is 0.5 and 0.6, the fitting effect is the best. However, when the dropout rate is 0.5, the test accuracy of the model is higher. As a result, we set the dropout rate to 0.5.
The impact of dropout ratios on accuracy.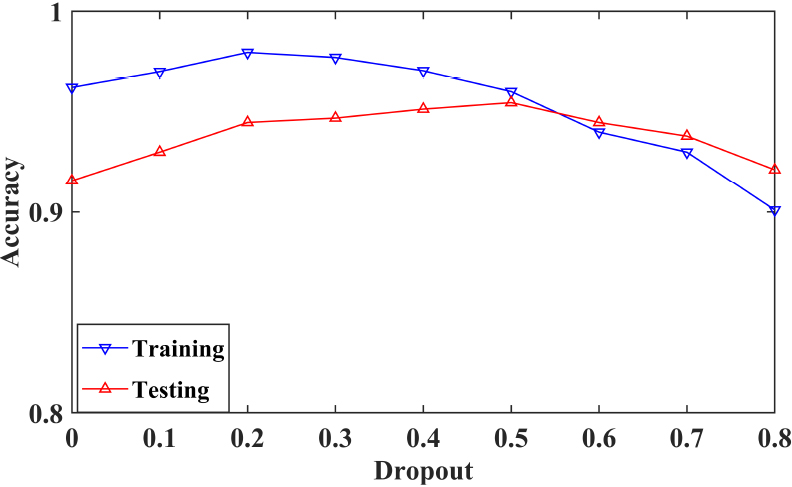
The impact of the number of tags on accuracy.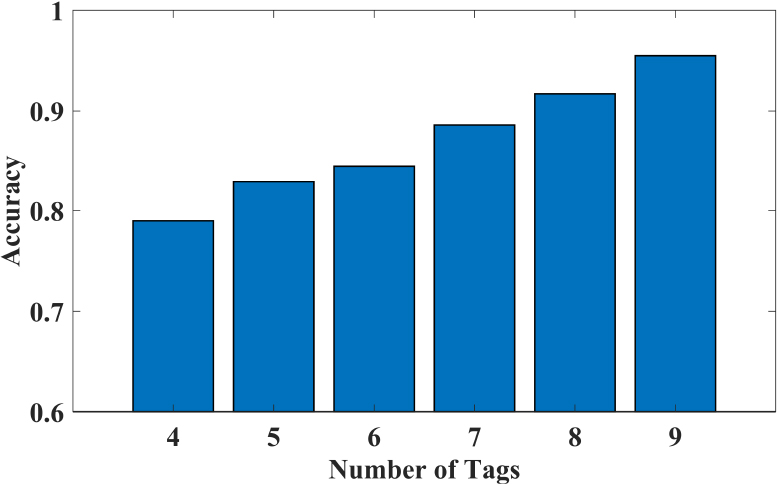
In our experiments, the influence of different numbers of tag arrays on recognition accuracy is analyzed. We arrange 9 tags into a
Game interface.
The influence of phase, RSSI and fusion data on the model.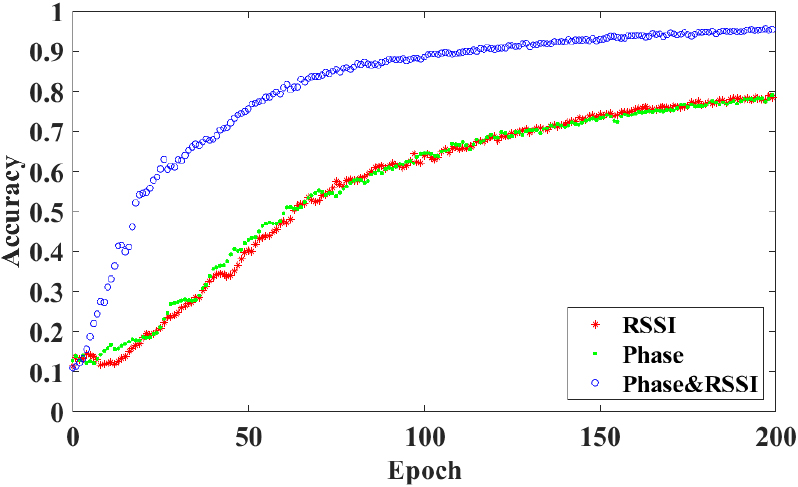
Application case.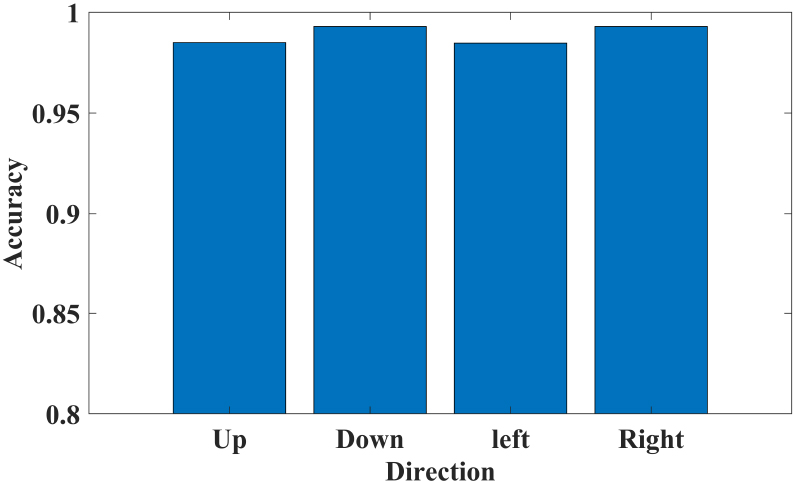
Experimental layout.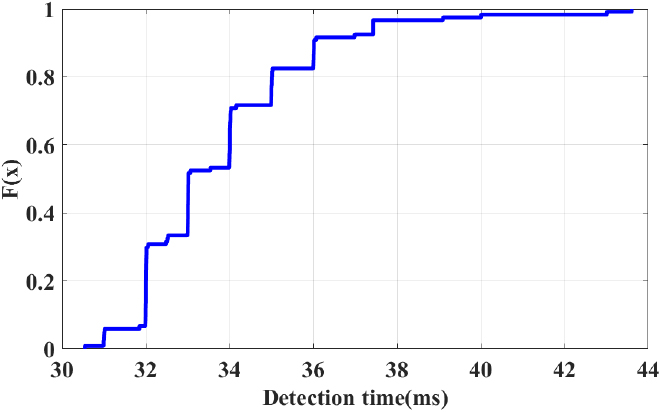
In this section, we discuss the importance of multimodal RFID data mixing. On the one hand, RSSI and phase information are fused as the sample features to train and recognize the model. On the other hand, single RSSI data or phase data are used as sample features for training and recognition, respectively. Figure 16 shows the changes in recognition accuracy of mixed data, phase data, and RSSI data at different training epochs. RSSI data and phase data carry different gesture features, and the accuracy improvement trend during training is also similar. However, the final detection accuracy of RSSI data or phase data as model input is approximately 79%, while the mixed data generated by the combination of RSSI data and phase data can reach a 95% recognition rate under the same amount of training. The detection accuracy is also improved faster. This shows that mixed data are more effective than monomodal data as a sample feature for recognition work.
Application case
In addition, in order to verify the practicability of this method, we constructed a gesture recognition game case. We have written a small airplane game that detects four gestures up, down, left, and right through the method proposed in this paper, and the direction of the airplane is controlled based on the detected actions. The game interface is shown in Fig. 15. To test the accuracy of the aircraft’s motion control in various directions, we conducted 30 experiments in each direction. As shown in Fig. 17, excellent accuracy of the movement control can be obtained when the player controls the aircraft to move in different directions. The recognition system not only responds quickly to commands issued by players, but the accuracy of recognition has also reached more than 95%. The cumulative distribution function of the real-time gesture recognition delay is shown in Fig. 18. For any sample, the model can complete the detection within 50 ms. The fast and accurate operation of the player in the airplane game shows the feasibility of the wear-free RFID identification system in the control of games and applications.
Conclusions and future work
With the development of the Internet of Things, human-computer interaction is also changing. In this paper, we designed a gesture recognition system based on an RFID tag array. The identification system uses a small number of RFID tags. Each RFID tag can be used for a long time and carrying any equipment on the palm or arm is avoided. This significantly improves the convenience of the system. The system segmented gesture features from the collected data according to the position sequence, and used deep learning to recognize and classify gestures to improve system performance. Experimental results show that the system has good recognition performance, with an average recognition accuracy rate of 95.5%. Experimental results also show that the proposed system has high accuracy performance. The method proposed in this paper can be applied to the control of games and applications, and can also be applied to non-contact scenarios where users are inconvenient to directly contact, but there are also some shortcomings. When the user deviates from the antenna and the tag, the signal change is small, the difference between the user data and the sample increases, and it is difficult to identify. Secondly, when the experimental equipment changes greatly, the recognition accuracy is not ideal. Finally, due to the limitations of equipment, it is impossible to detect a wide range of human activities. In future work, we will improve the classification algorithm, extract more sample information to identify small amplitude signal changes, and improve the recognition accuracy when the distance between the antenna and the tag changes greatly. And increase the antenna gain to increase the detection range.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 61871412 and Grant 61972438.