
Abstract
The real-time perception of hand gestures in a deprived environment is a demanding machine vision task. The hand recognition operations are more strenuous with different illumination conditions and varying backgrounds. Robust recognition and classification are the vital steps to support effective human-machine interaction (HMI), virtual reality, etc. In this paper, the real-time hand action recognition is performed by using an optimized Deep Residual Network model. It incorporates a RetinaNet model for hand detection and a Depthwise Separable Convolutional (DSC) layer for precise hand gesture recognition. The proposed model overcomes the class imbalance problems encountered by the conventional single-stage hand action recognition algorithms. The integrated DSC layer reduces the computational parameters and enhances the recognition speed. The model utilizes a ResNet-101 CNN architecture as a Feature extractor. The model is trained and evaluated on the MITI-HD dataset and compared with the benchmark datasets (NUSHP-II, Senz-3D). The network achieved a higher Precision and Recall value for an IoU value of 0.5. It is realized that the RetinaNet-DSC model using ResNet-101 backbone network obtained higher Precision (99.21 %for AP0.5, 96.80%for AP0.75) for MITI-HD Dataset. Higher performance metrics are obtained for a value of γ= 2 and α= 0.25. The SGD with a momentum optimizer outperformed the other optimizers (Adam, RMSprop) for the datasets considered in the studies. The prediction time of the optimized deep residual network is 82 ms.
Introduction
Human-Machine Interaction (HMI) facilitates a user-friendly interface system by directly incorporating the human’s natural communication and manipulation skills [1]. It is a non-verbal type of communication with symbolic meanings like hand actions or gestures. Hand gestures are a meaningful hand motion that is used to convey important information or to interact with the machine. Hand Gestures are made accessible due to the recent developments in the field of pattern recognition and computer vision [2]. Hand gesture control has a wide range of applications like human-computer interaction, sign language recognition, robotic device manipulation, automobile control, video surveillance system, and teleoperation system [3].
The real-time hand action recognition in an unconstrained environment is challenging and time-consuming. Self-occlusions, computational speed, rapid motion, illumination variations, uncertain environments, and high degrees of freedom (DOF) are the few factors that drastically affect the accuracy of the recognition systems. [4].
The conventional approach to accomplish a hand action recognition using the hand’s convex hull after the skin segmentation method has been reported. This method is used in controlling the robotic arm and is extremely sensitive to dynamic background interference. Furthermore, the hand must be entirely confronting the aperture, which is impossible to achieve with complex hand gestures.
In recent years, numerous research work has been reported on hand action recognition using machine learning architectures. Hidden Markov Models (HMM), Support Vector Machines (SVM), Recurrent Neural Network (RNN) Convolutional Neural Networks (CNN), etc., are the various algorithms used in training the recognition models [5]. CNN in deep learning architectures is used to extract the information from the visual data [6] and learn to discriminate between unique samples by training with a large number of samples. The speed of the computing device limits the functioning of CNN and tends to increase the computational time. The latest development in the field of semiconductor fabrication accelerates the computational speed of graphical processing units. Therefore, the hardware computing power bottleneck is minimized.
Convolutional Neural Networks are incorporated in localizing the objects (hands) in the input frame [7]. The computational speed and high precision are the two main parameters that determine the efficiency of the hand gesture recognition algorithm. Hence, a robust and efficient method is required to enhance the user experiences in a real-time Human-Machine Interaction [1].
The CNN based algorithms used in the hand gesture recognition are, the two-stage hand action recognition (Faster R-CNN Inception-V2 model [8]) system, the single-stage hand action recognition (SSD Inception-V2 [9], SSD Lite MobileNet-V2 [10], YOLO-V2 [11],) system. The two-stage recognition models are capable of achieving high precision values but the prediction time is on a larger scale. The single-stage recognition models identify the hand gestures with low computational time. But, the precision is lower than two-stage models. Also, the single-stage deep CNN models encounter a class imbalance problem leading to a large number of mispredictions.
In this paper, an optimized deep residual network is proposed in the context of a real-time hand action recognition system. The optimized deep residual network consists of a RetinaNet model (single-stage architecture for hand detection) and, Depthwise Separable Convolutional (DSC) layers (precise hand gesture recognition).
Related works
Huang et al. [1] proposed a high-speed and robust technique for a hand gesture recognition system. The author encountered the challenges such as unconstrained background, camera focus angles, and illumination variations. It resulted in a large number of mispredictions. The author identifies the hand region based on skin color. The contour generation and segmentation process are carried out to separate the hand portion in the image. The features are extracted from the hand region. Then, the features are provided as inputs to the deep learning architecture for recognizing the hand gestures. The method reported by the author achieved an accuracy of 98.41%on their dataset.
Tripathi et al. [4] proposed a hand detection and gesture recognition model for controlling the autonomous vehicle. A single-stage object detection algorithm is used for hand detection. The triplet loss function and majority voting model are utilized. The author achieved an Average Precision of 95.04%on the Auto-G database.
Nuzzi et al. [7] used Faster R-CNN architecture for the hand detection system. The custom prediction function (CPF) is used to evaluate the confidential probability of predicted hands. CPF discards all the predictions with a confidence score of less than 90%. The author obtained an Average Precision of 95.51%on their dataset with a computational speed of 130 ms. This hand gesture recognition system is utilized for interaction with industrial robots.
Gao et al. [12] proposed a method to utilize the hand feature and pose. Single Shot Multibox Detector with ResNet-Inception model extracts the hand feature information. The forward kinematic tree of the skeleton structure identifies the human body pose and then predicts the positions of the hand. The author adopted this model for the hand-gesture-based interaction between humans and robots. The authors achieved an average precision of 85.97 %on the SRSSL database.
Chaman et al. [13] proposed a real-time model for the gesture to text (G2T) conversion and text to gesture (T2G) conversion in the Hindi language. This model assists in the speech and hearing of physically impaired people. The 32 different gestures are identified using the feature extraction algorithms based on a 5-bit binary string. The reported gesture recognition algorithm achieved an accuracy of 97.65 %on Hindi Sign Language datasets.
Kopuklu et al. [14] proposed a Convolutional Neural Network (CNN) framework for hand gesture recognition. The lightweight CNN architecture, ResNet-10 is used as a gesture detector deep architecture, ResNeXt-101 CNN model is employed to classify the detected gestures. The author evaluated the architecture and obtained a classification accuracy of 94.04 %and 83.82 %on EgoGesture and NVIDIA datasets.
Avola et al. [15] demonstrated a Recurrent Neural Network (RNN) for hand gesture recognition. The leap motion controller is used to acquire the selected hand features. RNN is trained by using the hand features formed by incorporating the key points (joint angle, fingertip position) in human hands. The author achieved an accuracy of 96%by utilizing the American Sign Language dataset.
Neethu et al. [16] used a connected component analysis algorithm to segment the fingertip regions from the hand image. The segmented regions of a finger are given as the input to the CNN classification algorithm. The author achieved an accuracy and sensitivity of 96.2%and 98.1%, respectively.
Islam et al. [17] suggested a hand tracking method using kernelized correlation filter and median-flow algorithm. The author achieved an accuracy of 98.44%.
Xu et al. [18] utilized a fused feature model for Hand Gesture Recognition in Automotive interfaces. The ResNext network is used to extract the features for static and dynamic data. The static data features are followed by a Feature Embedding Branch. The features of dynamic and static data are fused with discriminant correlation analysis. Finally, the hand gesture patterns are recognized using a linear SVM classifier. The authors reported an accuracy of 98.35%.
Tan et al. [19] used a convolutional neural network combined with space pyramid pooling (CNN–SPP), the technique for hand gesture recognition. The author tested the CNN-SPP technique on the NUS hand posture (NUSHP) dataset. The author obtained an accuracy of 98.40%.
Rubin et al. [8, 9] proposed two different architectures, namely, Faster R-CNN Inception-V2 CNN model and SSD Inception-V2 CNN model for hand action recognition in an unconstrained background. Faster R-CNN is a two-stage detector and SSD is a one-stage detector. In these two models, Inception-V2-based CNN is used as a feature extractor. The Average Precision obtained for the Faster R-CNN Inception-V2 model is 99.10%and 99%for the SSD Inception-V2 model on the MITI-HD dataset. The prediction time is about 46 ms for the SSD model. It is lower compared to Faster R-CNN. But, it resulted in a large number of mispredictions, when it is exposed to real-time multi-hand gestures.
Mohammed et al. [20] proposed an architecture based on a single-stage object detection algorithm for hand detection and a lightweight CNN network for classification. The author utilized static gestures. The authors reported an Average Precision of 97.90%for hand detection. Also, an Average Precision of 91.36%is reported by the authors for the gesture classification process under complex environments.
Lin et al. [21] designed a dense object detector called RetinaNet. RetinaNet overpowers the other object detectors like two-stage Region-based Convolutional Neural Network (R-CNN) and Single Shot Detector (SSD) in terms of its accuracy and class imbalance, without any change in speed.
Based on the detailed survey, the various approaches employed for hand gesture recognition have their own pros and cons. The traditional deep approach [1, 18] is used for contour generation, segmentation of hand regions, feature extraction of hand, classification of hand regions, and hand tracking. The computational time of the traditional algorithms is high. The RNN model [15] is utilized for hand gesture recognition. The various CNN algorithms [4, 18–20] are used in the process of hand action recognition. The CNN algorithms perform well in dealing with spatial data. The RNN is good at temporal data and poor for spatial data processing. The various two-stage CNN algorithms (Faster R-CNN + CPF [7], Faster R-CNN Inception-V2 [8]) and single-stage CNN algorithms (SSD Inception-V2 [9], SSD Lite MobileNet-V2 [10], YOLO-V2 [11], and SSD ResNet-Inception [12]) are reported in the context of hand action recognition system. But, it resulted in a class imbalance problem leading to a large number of mispredictions.
Contribution
In this paper, an optimized deep residual network is proposed for a real-time hand action recognition system. It is used to mitigate the class imbalance problem encountered by the existing Single-stage models. The optimized residual network incorporates a RetinaNet-DSC model with ResNet-101 as a feature extractor. The RetinaNet model is utilized as a hand detector because of its high accuracy. The ResNet-101 CNN algorithm is used as a feature extractor because of its reliable performance and time efficiency. The innovation of adding a Depth-wise Separable Convolutional (DSC) layer enhances the precision of hand gesture recognition and reduces the computing parameters. DSC is a tiny version of the CNN model utilized in the classification of the detected hand gesture. The RetinaNet-DSC model with ResNet-101 backbone architecture is trained and evaluated by utilizing the MITI-HD (custom created) dataset. The performance metrics of the RetinaNet-DSC model using ResNet-101 as the backbone network is compared with the metrics of the ResNet-50 network. It helps to identify the hand actions in real-time more precisely. The model’s performance on the MITI-HD dataset is also compared with the benchmark datasets (NUSHP-II, Senz-3D).
Methodology
The block diagram representation of the optimum residual network is shown in Fig. 1. The model is trained and evaluated using two publicly available online datasets as NUS Hand posture dataset-II (NUSHP- II), Senz 3D dataset (Senz-3D), and one custom created dataset (MITI-HD).

Block diagram representation of Optimum Residual Network Architecture.
NUSHP-II [22, 23] is the hand posture dataset obtained from dynamic backgrounds with different hand sizes, shapes, genders, and various age groups. It consists of 10 classes and 200 samples per class.
Senz-3D [24, 25] samples are collected from 4 persons with 10 different postures. The color, confidence, and depth frames are part of this dataset. Each posture includes 120 samples (Total = 1200 samples).
MITI Hand Dataset (MITI-HD) [9] is a custom-developed hand posture dataset collected from diverse people with varying skin tones, dynamic backgrounds, disparate sizes, illumination conditions, geometry, rapid motions, and various age groups. The dataset consists of static gestures and it has about 10 classes and 750 samples per class. The sample frames of each class from MITI-HD are shown in Fig. 2.

Sample Frames of MITI-HD dataset.
The images in the dataset are resized using the Adaptive interpolation method into 300×300 pixels. The information points that lie outside the image territories are loaded with white pixels, by maintaining their aspect ratio. The process of resizing is followed by the process of selecting the region of interest (ROI) called Annotation. The annotation is performed by a graphical image annotation tool known as LabelImg. It is a machine learning process of nominating the proposed region on frames. Then, the feature extraction and training process are initiated. The training/testing data split ratio is in the order of 80:20.
RetinaNet-DSC Architecture
RetinaNet
RetinaNet [18] is an efficient single-stage object detection algorithm. It significantly reduces the class imbalance problem than its successors (SSD [9], YOLO [26]). In this paper, a RetinaNet architecture with focal loss function is used in the process of real-time hand gesture recognition process. The RetinaNet model utilizes a Residual Network (ResNet-101) as a backbone architecture. It is used in the process of generating feature maps. RetinaNet model can also be operated with other classical backbone architecture like VGGNet [27], DenseNet [28], or MobileNet [29]. In real-time hand action recognition, the ResNet architecture is preferred because of its low complexity and reduced computational time than its successors. The algorithm of the Single-Stage Hand Action Recognition system using RetinaNet-DSC is given in Algorithm 1.
The proposed system also consists of a feature pyramid network (FPN) [30], a classification subnet module, and a box regression subnet module as shown in Fig. 1. The subnet is a small fully convolutional network (FCN) appended to each level of FPN. The output of the backbone architecture is considered as an input to the feature pyramid network. The feature maps are categorized using the classification subnet module. At last, the box regression subnet module is used in predicting the bounding box coordinates.
RetinaNet addresses the two important problems encountered by its forerunners. In Faster R-CNN, the feature maps are generated after passing the input data through numerous convolutional layers. This resulted in a loss of low-level information. Hence, objects of small size are not detected by the network. A large number of anchor boxes are generated to discover the regions that contain the object. But, most of the boxes might not be the right fit for the object. This results in forming the classifier to be biased and focuses its attention on the background to minimize the loss. RetinaNet excels in minimizing the above-specified issue by using an FPN on top of the backbone architecture.
FPN is similar to the SSD architecture, where the feature maps at different scales are generated. SSD model utilizes the upper layers for generating the feature maps. Whereas, the FPN module generates the feature maps from both the lower and upper layers. Therefore, a top-down pathway and lateral connections are used to combine the low and high-level features. It results in increasing the performance of the RetinaNet model in detecting both the smaller and larger objects.
The imbalance between the foreground and background classes are addressed in RetinaNet by incorporating the Focal loss ((F
L
(ρ
t
)) function. The loss function is an improved version of the cross-entropy loss. It is determined by adding a modulating factor to the balanced cross-entropy loss, with an adjustable focusing parameter represented in Equation 1.
ρ is the estimated class probability of the model.
The depth-wise separable convolution (DSC) approach enabled the development of small image recognition models. This DSC replaces the CNN blocks used in the last three FCN’s. The small model of CNN is capable of classifying the identified hand motions into one of the pre-determined classes. This design offers a high classification efficiency and speed with minimal consumption of memory and low computational cost. It incorporates a depth-wise convolution, which is a spatial convolution executed separately on each channel of input, and then proceeds on to a point-wise convolution [29].
In the depth-wise convolution process, the convolution operation is performed on a single channel at a particular time instant, whereas in conventional CNN’s it is accomplished for all the M channels. The filters of size Dk×Dk×1 are used. The output size of depth-wise convolution is Dp×Dp×M. The mathematical expression of depth-wise convolution is expressed in Equation 3.
In point-wise convolution, a convolution operation of 1×1 is performed to the M channels. The filter size of 1×1×M is used for N filters. The output size of point-wise convolution is Dp×Dp×N. The mathematical expression of point-wise convolution is expressed in Equation 4.
The non-max suppression method is utilized to select the single entity out of the multiple overlapping entities. The bounding box with the highest probability (IoU≥0.5) is selected and all other bounding boxes are suppressed.
Experimental setup
Implementation
The real-time hand action recognition framework is put into effect using the Deep Learning toolbox of Python, Tensorflow as the backend. The architectures are trained using a computer (Intel®Core TM i7-4790 CPU @ 3.60 GHz, 64-bit processor, 20GB RAM, Windows 10 PRO operating system) and GPU (NVIDIA GeForce GTX TITAN X (PASCAL)). To provide parallel computations in a GPU, CUDA/CuDNN is used. The set of python modules like Numpy, Matplotlib, Cython, Pandas, Open-CV, Tensorflow are also utilized.
Training
The RetinaNet-DSC model is trained by using the fine-tuned weights of the COCO dataset. The models are trained and tested for three different datasets like NUSHP-II, Senz-3D, and MITI-HD. The gradient descent optimization techniques such as SGD with Momentum optimization [31, 32], ADAM optimization [31, 33] and RMSprop optimization [31, 34] are employed for training.
Testing and prediction
The RetinaNet-DSC architecture is evaluated using the test sample data. The performance metrics (Average Precision (AP), Average Recall (AR), F1-Score (F1), and Computation Time) of the CNN models are obtained by varying the values of Intersection over Union (IoU). The IoU value determines the precision of the object detection process. The error obtained by matching the predicted bounding box with the ground-truth box is used in the determination of IoU values. The zero error result in the IoU value of unity. The prediction is said to be accurate if the determined IoU value is above 0.5. The IoU value of 0.5 is considered to be a true prediction.
Results and discussion
The Average Precision and Average Recall metrics are standard metrics that evaluate the efficiency of the detector at various bounding box levels overlapping with the labeled box [35, 36]. The evaluation metrics of the hand action recognition algorithms (RetinaNet-DSC ResNet-101, RetinaNet-DSC ResNet-50) are estimated for various IoU values like 0.5, 0.75 and 0.5:0.95. The Average Precision of the hand in a frame less than 32×32 pixels is termed as APsmall, the hand size greater than 32×32 pixels and lower than 96×96 pixels is APmedium and greater than 96×96 pixels is APlarge. The overall Average Precision of the total recognized hands with all the above scales is APall. Similarly, the Average Recall is also defined as ARsmall, ARmedium, and ARlarge. The Average Recall for 1, 10, and 100 number of detections are termed as AR1, AR10, and AR100, respectively.
Precision is the ability of a hand action recognition model to recognize the relevant gestures. It refers to the proportion of positive predictions that are precise. The recall is the potential of a model to identify all ground-truth bounding boxes. It is the proportion of positive predictions that are accurate out of all the possible ground-truths.
Optimization of deep residual network
The proposed RetinaNet-DSC model is trained with various Stochastic Gradient Descent (SGD) Optimization techniques. The SGD optimization algorithms like Adam [31, 33], SGD with Momentum [31, 32] and RMSprop [31, 34] are incorporated in the training process. The optimization algorithm is synchronized with 1 GPU with a batch size of 4 images. The RetinaNet-DSC models using ResNet-101, and ResNet-50 backbone networks are trained for 35 k iterations with an initial learning rate of 0.04 for SGD with Momentum optimizer, 0.0002 for Adam optimizer, and 0.004 for RMSprop optimizer with Momentum of 0.9. The learning rates are subsequently reduced by a factor at 10 k and 20 k iterations.
The training loss is the sum of the focal loss and the standard smooth L1 loss used for box regression. Training time ranges between 5 to 6 hours for every model. Each model is trained on the MITI-HD dataset using the three optimization techniques. To identify the robustness of the custom (MITI-HD) dataset, the models are also trained and tested with other benchmark datasets like (NUSHP-II and Senz-3D). The MITI-HD 300 represents the data samples of MITI HD datasets with a dimension of 300×300 pixels. The model’s performance is evaluated on the various optimization algorithms, various scales of data samples. For all three datasets, the deep residual model using Momentum optimizer produces a state of the art results over the other optimization models.
The results of RetinaNet-DSC ResNet-101 using IoU = 0.5:0.95 are listed in Table 1. The Average Precision and Average Recall are calculated for the RetinaNet-DSC ResNet-101 model on datasets (MITI-HD, NUSHP-II, and Senz-3D) using various optimization techniques (SGD with momentum, Adam, and RMSprop). The Average Precision and Average Recall values on the MITI-HD dataset using SGD with Momentum optimizer yields better results than Adam and RMSprop optimizers. The same trend is followed on NUSHP-II and Senz-3D datasets. For the Senz-3D dataset, the smaller-sized object (hand region less than 32×32 pixel) in the image frame is not recognized. The RetinaNet-DSC model using ResNet-101 (trained on MITI-HD dataset) resulted in higher Average Precision and Average Recall for all ranges of detections. The hand actions in the input frames with a size less than 32×32 pixels are efficiently detected.
Performance metrics of RetinaNet-DSC ResNet-101 model obtained using various optimizers, and datasets for IoU of 0.5:0.95
Performance metrics of RetinaNet-DSC ResNet-101 model obtained using various optimizers, and datasets for IoU of 0.5:0.95
Table 2 exhibits the performance metrics of RetinaNet-DSC ResNet-50 for IoU 0.5:0.95. The Average Precision and Average Recall for the RetinaNet-DSC model are calculated using several optimization strategies (SGD with momentum, Adam, and RMSprop) on various datasets (MITI-HD, NUSHP-II, and Senz-3D). The SGD with momentum optimizer produces a higher value of Average Precision and Average Recall than the RMSprop and Adam optimizer, irrespective of the dataset considered. For the Senz-3D dataset, the hand detection of size less than 32×32 pixels (small) is fully terminated. However, for all detection ranges of the region, the RetinaNet-DSC with ResNet-50 model (trained on MITI-HD dataset) obtained higher Average Precision and Average Recall values.
Performance metrics of RetinaNet-DSC ResNet-50 model obtained using various optimizers, and datasets for IoU of 0.5:0.95
Table 3 shows the evaluation metrics of the RetinaNet-DSC model using ResNet-101 and ResNet-50 for the IoU ranges of 0.5:0.95, 0.5, and 0.75 on MITI-HD, NUSHP-II, and Senz-3D datasets. The ResNet-101 network with SGD momentum optimizer produces an Average Precision of 0.992 (IoU = 0.5), 0.968 (IoU = 0.75), and 0.789 (IoU = 0.5:0.95) on MITI-HD dataset. For ResNet-50, the MITI-HD dataset obtained an Average Precision, 0.991 (IoU = 0.5), 0.974 (IoU = 0.75), and 0.821 (IoU = 0.5:0.95). The obtained evaluation metrics for the network ResNet-101 and ResNet-50 using MITI-HD dataset is in correlation with the performance metrics obtained by using the benchmark datasets.
Average Precision of RetinaNet-DSC model obtained using various optimizers, and datasets for IoU range of 0.5:0.95, 0.5, and 0.75
From Tables 1, and 3, it is noticed that the performance metrics of RetinaNet-DSC ResNet-101 and RetinaNet-DSC ResNet-50 models on the MITI-HD dataset are highly correlated with the evaluation metrics of benchmark datasets. The higher Precision and higher Recall values obtained using the proposed model enhance the recognition accuracy of the hand action recognition framework.
Table 4 lists the accuracy speed trade-off of the RetinaNet-DSC model with ResNet-101 and ResNet-50 backbone architectures on different image scales. The performance of RetinaNet-DSC architectures using MITI-HD 300 (image size = 300×300 pixels) is high compared to MITI-HD 160 (image size = 160×160 pixels). The Average Precision is computed for different IoU ranges such as 0.5, 0.75, and 0.5:0.95. The Average Recall and F1-score values are obtained for the true prediction range (IoU = 0.5). The Average Precision, Average Recall, and F1-score obtained by utilizing the ResNet-101 model is 99.21 %, 96.99 %, and 98.10 %. Utilizing the ResNet-50 model resulted in 99.13 %, 96.93 %, and 98.01 %. The SGD with momentum optimizer resulted in obtaining higher performance metrics, irrespective of the backbone architectures.
Accuracy/speed trade-off of RetinaNet-DSC model for various scales of images (MITI-HD 300, MITI-HD 160)
Accuracy/speed trade-off of RetinaNet-DSC model for various scales of images (MITI-HD 300, MITI-HD 160)
The utilization of focal loss function in the proposed model resulted in reducing the number of misclassifications. It is an enhanced version of cross-entropy loss. It deals with the disparity of classes by focused training (adding more weights) on easily misclassified examples (hard or background objects) and non-focused training (reducing the weights) on easily classified examples (foreground objects). It resulted in the improvement of Average Recall values for the proposed model [35, 36]. The incorporation of a depth-wise separable convolutional layer enhances the accuracy of hand gesture recognition.
A good hand detector is expected to recognize all the ground-truth hand gestures (high Average Recall) and also to identify the appropriate hand gestures (high Average Precision). For a successful hand gesture recognition method, the Average Precision remains high as long as its Average Recall value is on a high scale. The Average Recall and Average Precision are retained as high, even if there is a change in the confidence threshold values [36]. The proposed RetinaNet-DSC model satisfies the conditions of a good hand gesture recognizer.
The prediction time of the RetinaNet-DSC model with ResNet-101 on MITI-HD 300 is 82 ms, and MITI-HD160 is 80 ms. The prediction time with ResNet-50 on MITI-HD 300 is 64 ms, and MITI-HD160 is 60 ms. The prediction time of a real-time hand gesture recognition system using the RetinaNet-DSC model with ResNet-50 is comparatively less than that of the ResNet-101 model.
The Average Precision of the individual classes of hand gestures for the RetinaNet-DSC model is shown in Fig. 3. The models imparted SGD with Momentum optimizer for training resulted in higher value for Average Precision in all the classes than its counterparts.

Average Precision curves of RetinaNet-DSC models (γ= 2 and α= 0.25) for each class on the MITI-HD dataset.
Table 5 shows the performance metrics of the RetinaNet-DSC model using ResNet-101 and ResNet-50 by varying γ (tunable focusing parameter) for Focal Loss with optimal α (weighting factor). To address the class imbalance problem in the hand action recognition system, the tunable focusing parameter γ is varied with an optimal weighting factor α. By keeping the value of γ as fixed and varying α values (0.25, 0.5, and 0.75), the performance of the hand recognition models is noted. After a deep investigation, it is observed that the RetinaNet-DSC models with ResNet-101 and ResNet-50 architectures resulted in higher Average Precision value for γ= 2 and α= 0.25.
Performance metrics of RetinaNet-DSC by varying γ for Focal Loss with optimal α
Initially, the proposed RetinaNet-DSC model is tested on the custom (MITI-HD 300) dataset and the performance metric results are compared with the two publicly available benchmark (NUSHP-II, Senz-3D) datasets. The performance metrics comparison of the proposed model on three datasets is illustrated in Table 6.
Performance metrics comparison of the proposed RetinaNet-DSC model using MITI-HD, NUSHP-II, and Senz-3D datasets
MITI-HD 300 dataset has more images compared to other benchmark datasets as visualized in Table 6. The complexity (variation in lighting condition, background, skin tone, shape, and size of hand geometry) of images in the MITI-HD 300 dataset is on a high scale when compared with other datasets. From Table 6, it is also observed that the performance metrics obtained by the RetinaNet-DSC model on MITI-HD 300 dataset are comparable with the results obtained by using NUSHP-II and Senz-3D datasets. The slight deviation in the performance metrics is related to the number of samples in the datasets and the complexity in input images.
Table 7 lists the performance metrics obtained by the RetinaNet-DSC model on MITI-HD dataset. The obtained results are compared with other methods such as SSD [9] and Faster R-CNN [8]. It is observed that the proposed RetinaNet-DSC model performed better in terms of improvement in performance metrics and minimizing the number of mispredictions. This is associated with the introduction of the Depth-wise Separable Convolution layer and Focal loss function in the architecture.
Performance metrics comparison of the proposed RetinaNet-DSC model with the existing models on the MITI-HD Dataset
The performance metrics obtained by the RetinaNet-DSC model on the MITI-HD dataset are compared with other models (RetinaNet-50 [20], Deep CNN [37], Faster R-CNN + CPF [7]) evaluated on different datasets as listed in Table 8. It is observed that the results obtained by the RetinaNet-DSC model are higher when compared with other reported methods. Since, the RetinaNet-DSC model resulted in the state-of-the-art result when evaluated on custom created MITI-HD dataset and Benchmark datasets (NUSHP-II, Senz-3D). The proposed model is also expected to perform better on other datasets such as 5-Signers [20], NUSHP [37], and Hand [7]. The comparison of the model’s performance metrics with the different datasets is carried out to illustrate the superiority of the proposed method. As a future endeavor, the proposed model will be evaluated on datasets such as 5-Signers, NUSHP and Hand.
Performance metrics comparison of the proposed RetinaNet-DSC model with the existing models on different datasets
The total training loss function of RetinaNet-DSC models using residual backbone architectures (ResNet-101, ResNet-50) for the MITI-HD 300 and MITI-HD 160 datasets are shown in Fig. 4. (a), (b), (c), and (d), respectively. Based on the loss plot of ResNet-101 and ResNet-50 backbone architectures, the models trained using SGD with momentum optimizer obtained low loss than the other optimizer.
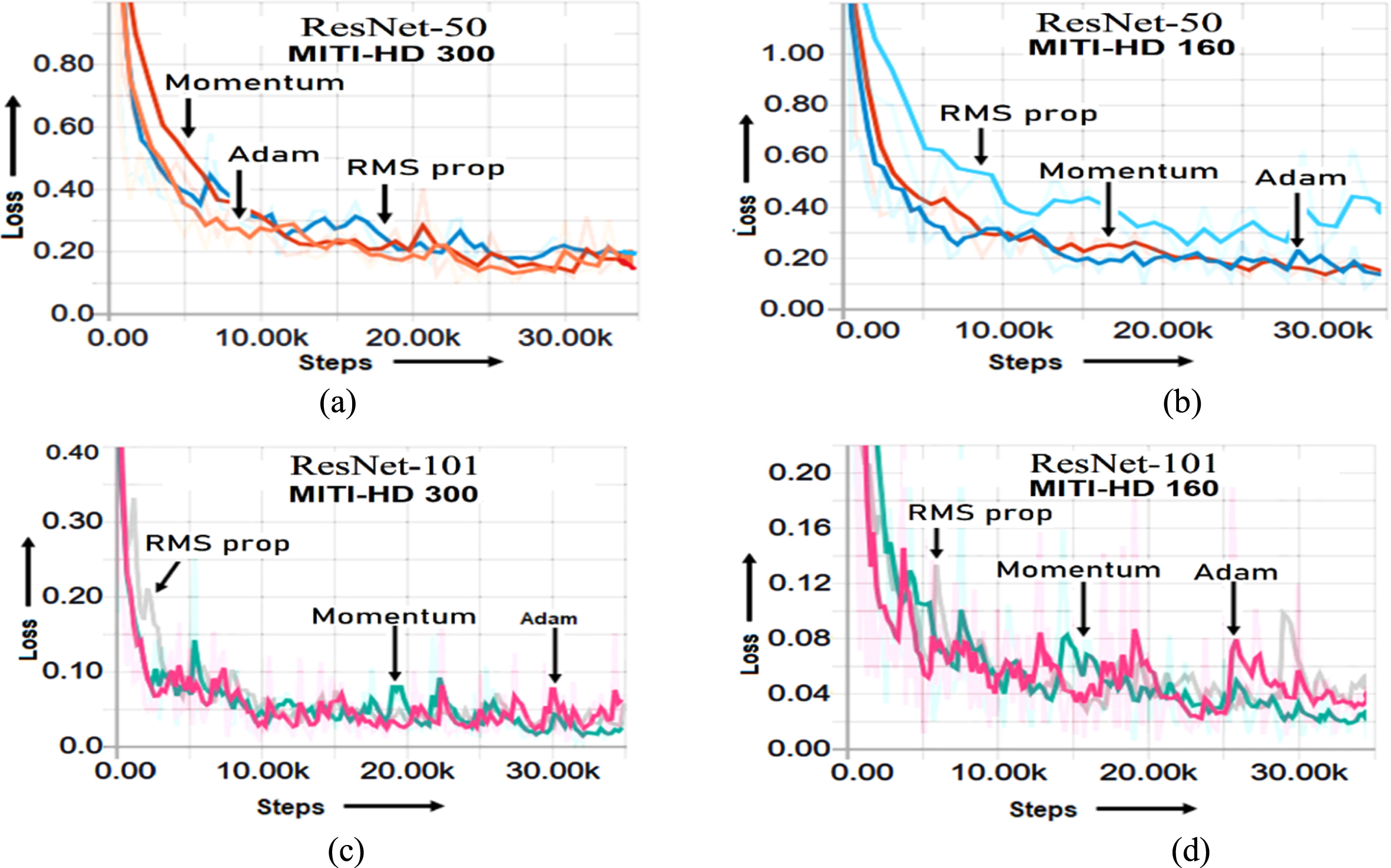
Training Loss Curves of RetinaNet-DSC model (a) ResNet-50 MITI-HD 300×300 pixels (b) ResNet-50 MITI-HD 160×160 pixels (c) ResNet-101 MITI-HD 300×300 pixels (d) ResNet-101 MITI-HD 160×160 pixels.
The experimental setup for the real-time Single and Multi-hand actions recognition in an unpredictable environment is shown in Fig. 5. The models are trained using single-hand gestures. Data augmentation process like mirroring, flipping and rotation is carried out during the training process. The trained model is used to perform recognition for the right hand, left hand, and multi-hands in a frame. The hand gesture recognition system using RetinaNet-DSC is implemented using the hardware modules that are discussed in section 4.1. The web camera (Model No: Quantum QHM495LM, 25 MP) is used to capture the hand gestures in real-time. The detection and classification of hand gestures are recorded for the proposed RetinaNet-DSC model using ResNet-101 and ResNet-50 backbone architectures. The RetinaNet-DSC based models are efficient to recognize the hands under a dynamic environment. The predicted sample frames of real-time hand action recognition are shown in Figs. 6, and 8, respectively. The sample frames are captured at various distances between the optical sensors and object, various skin tones, illumination, and complex background. Figure 6 (a), (b), and (c) shows the predicted samples of single-hand gestures at a distance of 100 cm, 150 cm, and 200 cm, respectively. Figure 7(a), (b), and (c) shows the predicted samples of two hands with gestures at a distance of 150 cm, 200 cm, and 250 cm, respectively. The real-time frames of multi-hand gesture recognition with a higher confidence score are shown in Fig. 8.
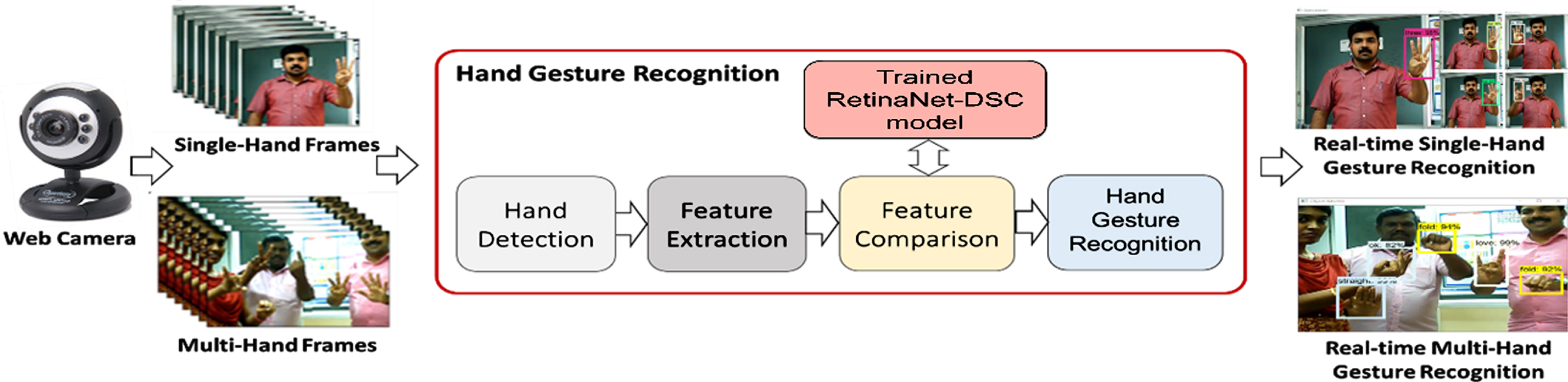
RetinaNet-DSC based real-time hand action recognition framework.

Sample frames were obtained by varying the distance between the optical sensor and object for The real-time Single Hand Action Recognition system (a) 100 cm (b) 150 cm (c) 200 cm.

Sample frames were obtained by varying the distance between the optical sensor and object for the real-time Two-Hand Action Recognition system (a) 150 cm (b) 200 cm (c) 250 cm.

A real-time Multi-Hand Action Recognition using RetinaNet-DSC CNN architectures.
Based on Fig. 9, it is observed that the proposed RetinaNet-DSC architectures using ResNet-101, ResNet-50 backbone networks identify the gestures correctly with lower prediction time when compared with the Faster R-CNN Inception-V2 model (140 ms). Even though the SSD model produces the results at a lower computation time (46 ms) when compared to the proposed RetinaNet-DSC model, it resulted in a large number of mispredictions. The improvement in the Average Recall value is modest for the proposed architecture compared to SSD and Faster R-CNN models, but the number of mispredictions is greatly reduced. The RetinaNet-DSC model with ResNet-101 and ResNet-50 backbone network produces similar performance metrics when it is evaluated on MITI-HD 300 dataset. Hence, any of the above-specified backbone networks can be utilized with the RetinaNet-DSC model for real-time implementation of hand gestures. In this work, the RetinaNet-DSC model with ResNet-101 backbone network is considered based on its prediction accuracy. However, for faster recognition of real-time hand gestures the RetinaNet-DSC model with ResNet-50 backbone network could be considered.
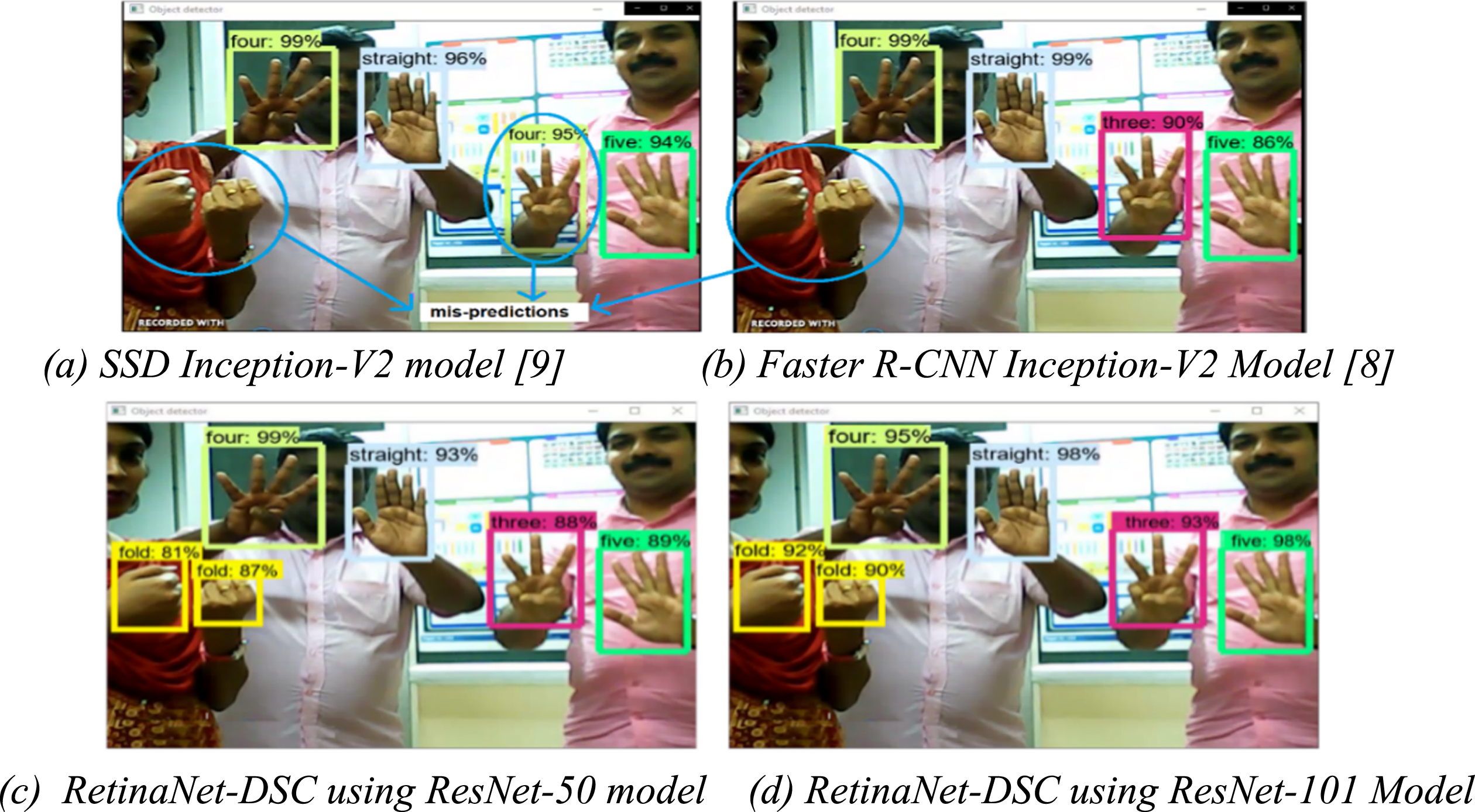
Multi-Hand Action Recognition using RetinaNet-DSC, (a), (b) Output of existing models with mispredictions, (c), (d) Output of proposed models without mispredictions with varying confidence scores.
Real-time hand action recognition is vital to perform numerous human-machine interactions. The optimum Deep Residual Network (RetinaNet-DSC) architecture is used for real-time hand action recognition. Experiments are carried out using a custom (MITI-HD) dataset and on benchmark (NUSHP-II, Senz-3D) datasets to reveal the effectiveness and robustness of the proposed technique. The performance of the proposed deep Residual models on ResNet-101 architecture is analyzed with a learning rate of 0.0001 for SGD with momentum and Adam optimizers, and 0.004 for RMSprop, for 35,000 training steps. The performance is compared with the ResNet-50 CNN architecture. SGD with momentum optimizer outperformed for both the number of layers (101, 50) of the model. The performance metrics (Average Precision, Average Recall, F1-Score) obtained by the RetinaNet-DSC model are listed below. For ResNet-101 architecture, the obtained performance metrics on IoU = 0.5 are 99.21%, 96.99%and 98.10%. The values of 99.13%(AP), 96.93%(AR) and 98.01%(F1), are obtained by using the ResNet-50 architecture (IoU = 0.5). The prediction time of the RetinaNet-DSC model with 50 layers (64 ms on MITI-HD 300 and 60 ms on MITI-HD 160) is comparatively lesser than the 101 layers (82 ms on MITI-HD 300 and 80 ms on MITI-HD 160). The RetinaNet-DSC model performs better for γ= 2 and α= 0.25. The number of mispredictions is significantly reduced by utilizing the proposed model. Hence the proposed model is ideal for a real-time hand action recognition system. The reduction in computation time will further enhance the system performance, which is considered to be our future scope.
Footnotes
Acknowledgments
The authors are grateful to NVIDIA for providing the GPU (Model No: NVIDIA TitanX) under University Research Grant Initiative.