
Abstract
The autoencoder network has been proven to be one of the powerful techniques for recommender systems. Currently, the ways of utilizing autoencoder in recommender systems can be divided into two categories: modeling user-item interaction rely solely on autoencoder and integrating autoencoder with other models. Most existing methods based on autoencoder assume that all features of model’s input are equally the same contributing to the final prediction, which can be regarded as attention weight vectors; however, this hypothesis is not reliable, especially when exploring users’ interaction frequency with different items. Moreover, combining autoencoder with traditional methods, the usual strategy is to leverage a linear kernel of the inner product of user and item vectors to predict user preferences, which will lead to insufficient expression power and hurt the performance of recommendation when facing data sparsity and cold start problems. To tackle the above two problems, we propose a novel hybrid deep learning model for top-n recommendation, called attentive stacked sparse autoencoder (A-SAERec), which can capture attention weights vector of a user for items, and then combined with the neural matrix factorization to improve the performance of recommender model. Extensive experiments on four real-world datasets show that our A-SAERec algorithm has significant improvements over state-of-the-art algorithms.
Introduction
Personalized recommender systems have became a powerful tool to alleviate information overload issue in multiple scenarios (e.g. social recommendation [1], POI recommendation [2], et al.). Traditional collaborative filtering techniques, such as matrix factorization (MF) [3], have achieved great success in recommendation tasks. Relying on the user-item ratings matrix, MF methods often represent users’ interests and items’ features as latent factor vectors in a common latent space, and then predict user preferences for an item with a linear kernel, i.e., a dot product of their latent factors. When suffering from the data sparsity and cold start problems; however, MF methods often fail to capture the complicated user-item interactions, which will lead to slow model learning and overfitting [4, 5].
In recent years, deep learning has been widely used in recommender systems [12], and it has been verified the capability of capturing the complex relationships within data. As an unsupervised neural network, the autoencoder, is capable of learning a representation of the input data, also known as feature extraction and dimensionality reduction, which has attracted researchers’ attention on how to leverage it in recommender systems [7]. Different methods have been explored to leverage autoencoder in recommender systems, for example, AutoRec method employs the user rating vectors or item rating vectors as input and predict user ratings in the output layer [8]. CDAE model directly leverages user-item implicit feedback matrix as input to predict user preferences [9]. The variational autoencoder as a generative model with multinomial likelihood is extended to collaborative filtering for implicit feedback [10]. Besides, the side information is utilized in autoencoder model to alleviate data sparsity problems and improve the recommendation performance [11, 12, 19]. To sum up, existing works integrate autoencoder with traditional methods to improve the performance of recommender systems, such as combining the denoising autoencoder with matrix factorization and integrating the contractive autoencoder with single value decomposition [23, 13].
Although these methods have achieved better performance than the MF method, all of them ignore the fact that users usually place different attention weight vectors for items, which could result in misleading recommendation results. Motivated by this observation, we propose a novel hybrid model for top-n recommendation, called attentive stacked sparse autoencoder (A-SAERec), which integrates the attention mechanism into the stacked sparse autoencoder to learn complex feature representation from input data and capture the attention weights of user-item pair and make more relevant recommendations. The major contributions of this paper are summarized below.
We design a hybrid deep learning framework for top-n recommendation. Instead of leveraging a linear kernel of the inner product of user and item vectors to predict user preferences, we employ attentive stacked sparse autoencoder to learn features and integrate them into the neural matrix factorization model to exploit user-item interactions. We combine the attention network with stacked sparse autoencoder, in which the output of hidden layer is utilized as the input of the attention network, to capture the attention weight vectors of each specific user-item pair, then the element-wise product of the hidden layer output and the attention weight vector to form the latent vector. As far as we know, we are the first attempt to leverage a joint neural network to tightly couple the attention mechanism with the stacked sparse autoencoder for personalized recommendation. We conduct comprehensive experiments on four real-world datasets, which demonstrates that our algorithm outperforms state-of-the-art algorithms and improves the accuracy of recommendation.
The rest of this paper is organized as follows. Section 2 discusses the related work on autoencoder techniques used for recommender systems. Sections 3 and 4 illustrate the basic knowledge of autoencoder and the proposed model architecture, respectively. Section 6 shows the experiment results and analyses. Finally, we conclude the work of this paper.
Early researches on recommendation have mainly focused on using traditional machine learning approaches, for example, Robles et al. [14] present a new Bayes approach for collaborative filtering, Xu et al. [15] design a SVM (Support Verctor Machine)-based prediction method for personal recommender system for TV programs, and Oku et al. [16] utilize SVM for context-aware recommendation. However, with the rapid growth of Internet service, traditional methods face data sparsity and cold start problems, which are able to satisfy the needs of personalized recommendations. Recently, employing deep learning to recommender systems has been demonstrated great success [17]. As a popular choice for the deep learning architecture of recommendation systems, autoencoders have attracted more attention from researchers. The existing works about autoencoder can be classified two categories in recommender systems: modeling user-item interaction rely solely on autoencoders and integrating autoencoders with other models.
Modeling rely solely on autoencoders
Ouyang et al. [18] design an autoencoder based collaborative filtering (ACF), which first converts the rating in range of [1, 5] to a vector consists of 0 as well as 1, and then takes the vector as input to predict ratings. However, the ACF method contains only one hidden layer, so that the capability of extracting features is limited. Sedhain et al. [8] propose AutoRec that can be seen as a variant of ACF method, in which the user’s ratings are directly utilized as inputs. Strub et al. [20] design a collaborative filtering neural network based on stacked denoising autoencoder (SDAE) to make the model more robust where the side information is exploited to enhance the accuracy of recommendation. Wu et al. [9] present the collaborative denoising autoencoder (CDAE) method, which learns latent representations of corrupted user-item preferences that can best reconstruct the full input. Zhang et al. [21] propose the hybrid collaborative recommendation via semi-autoencoder, which exploits both content information and the learned non-linear characteristics to produce personalized recommendations. Liang [10] and Karamanolakis [22] et al. employ the variational autoencoder to learn feature representation through from side information to alleviate data sparsity problem.
Although these methods have improved the performance of recommender systems, all algorithms default that a user keeps the same attention weight vector when facing different items, which will result in misleading recommendation.
Integrating autoencoders with other models
Existing works prefer to combine the autoencoder with traditional collaborative filtering methods, such as matrix factorization algorithms. Dong et al. [23] propose a novel deep learning model (aSDAE), which integrates the SDAE with matrix factorization and leverages the side information to provide an accurate recommendation. Li et al. [24] integrate the variational autoencoder with matrix factorization and leverage both content data and rating information for recommendation. Alfarhood et al. [25] design a dual autoencoder framework with matrix factorization for recommending scientific articles. Analyzing above approaches, we find that they prefer to utilize the matrix factorization methods to predict user final preferences; however, simply using a linear kernel with an inner product of user and item vectors may fail to give an accurate prediction of user-item interactions.
To sum up, we propose a novel hybrid deep learning framework, instead of leveraging a linear kernel to model user-item interactions, which combines with neural matrix factorization to make final recommendation and employ an attention network to capture attention weights for each user-item pair to improve the recommendation performance.
Illustration of the architecture of sparse autoencoder.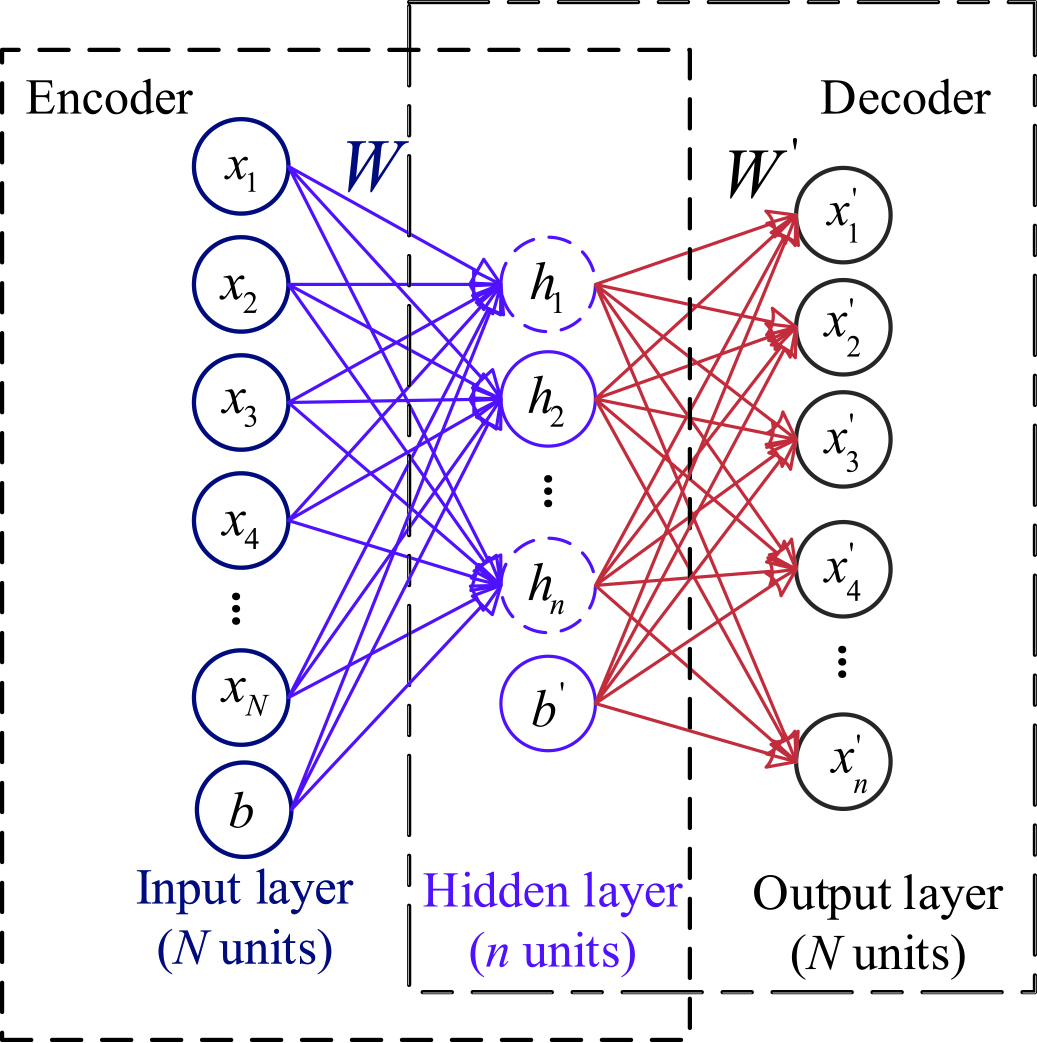
Sparse autoencoder
The autoencoder is an unsupervised learning neural network for feature representations extraction and dimensionality reduction, which contains of two main parts: the encoder and the decoder. The encoder
where
For a training set of
where the first term is an average sum-of-squares error term, and the second term is weight decay term which is used to help prevent overfitting,
The autoencoder tries to approximate an identity function
where
where
where
A deep learning architecture which consists of multiply layers of basic sparse autoencoder, Stacked Sparse Autoencoder (SSAE), where the outputs of each layer are wired to the input of successive layer. For each instance
Existing works have demonstrated that a deep structure autoencoder with more hidden layers can generate more complicated hierarchies of features; however, the computational cost of training model may increase significantly as stacking more hidden layers. The impact of the number of stacked hidden layers on model performance will be discussed in Section 5.4.2
In our proposed model, we employ
where the value 1 of
In this section, we design a novel deep learning network, attentive sparse autoencoder (A-SAE), which is a generic framework by integrating attention mechanism into sparse autoencoder. Inspired by the visual attention mechanism of human being can focus to specific part of an image or words in sentences, the attention mechanism in deep learning can be simply understood as a vector of weights to measure the importance of input elements. We assume that there is a user-item implicit interaction with
and the hidden representation
where
The final output of the feature representation of the attentive sparse autoencoder can be computed as
We combine the hidden layer output with the softmax function output via element-wise product. The reconstruction vector
where
Structure of the A-SAERec model. For simplicity, we did not show the decoder parts of each basic SAE.
The hybrid architecture of the proposed A-SAERec is shown in Fig. 2, which contains two main networks: the A-SAE network for modeling features and the Neural Collaborative Filtering (NCF) framework for modeling interactions between users and items. The traditional collaborative filtering methods, such as matrix factorization, employ a linear kernel with an inner dot product of user and item to predict the user-item interactions; however, linear functions may fail to capture the complex structure of user-item interactions and existing literature has demonstrated that non-linearities have a potential advantage of improving recommendation performance. By replacing the inner dot product, He et al. [29] devise a general neural collaborative filtering architecture, which leverages a general matrix factorization (GMF) and a non-linearities multi-layer perceptron (MLP) to model the user-item interaction; however, the representation of users and items is randomly initialized via the one-hot encoding of user (item) ID of the input layer in NCF model, which only explores the items’ and users’ features in a limit manner. A-SAERec method exploits a attentive stacked sparse autoencoder to capture both user and item features and then the output of A-SAE severs as the input of the second network to model user-item interactions.
Instead of randomly initializing the users’ and items’ representation in the NCF framework, both GMF and MLP first use the A-SAE to extract the feature representations of users and items. Let
then the result is projected to the output layer as
where
In order to further model the interaction between user and item, MLP uses a large level of flexibility and non-linearity to learn the relationship between the extracted user latent vector
where
the loss function of the proposed A-SAERec method will be discussed in Section 4.3.
For the feature extraction part, the Stochastic Gradient Descent (SGD) algorithm is employed to optimizer the objection function of A-SAE. The gradients of parameters are given as
where
where
The deep interactions modeling process outputs the predicted rating
where
where
Learning Algorithm for A-SAERecthe user-item implicit feedback matrix
epoch in range[Epochs]
An extensive experiments is conducted with aim of answer the following research questions:
Datasets
Four real-world datasets are exploited to demonstrate the validly of our proposed attentive stacked sparse autoencoder model including Movielens-10M,1
For above all datesets, we filter the user with less than 10 interactions. The characteristic of the datasetes are summarized in Table 1.
The statistics of the datasets
To evaluate the performance of our model, we randomly split each dataset into training set and test set. For each user, we randomly hold her one item has interacted and sample 100 items that are not interacted by the user to form test set. Two common ranking evaluation metrics, i.e., Hit Radio (HR) and Normalized Discounted Cumulative Gain (NDCG), are adopted to measure the performance of model. The HR intuitively measures how many test items are in present the top-n recommendation list, which is defined as
where
where
We use the python library of tensorflow5
For our proposed A-SAERec, we randomly select 70% of each dataset as the training set, 10% as th evalidation set, and the rest 20% as test set. The optimizer is the Adam optimizer, and the learning rate
Performance comparison (Q1)
Table 2 displays the performance of our A-SAERec algorithm and other baseline algorithms in HR@5 and NDCG@5 metrics. As we can see, the A-SAERec algorithm achieves the best performance compared with other adopted five algorithms. In detail, on Ml-10M dataset, the HR@5 and NDCG@5 metrics of A-SAERec algorithm has reached 0.7136 and 0.5546, respectively. The relative improvement over the state-of-the-art model RecVAE is 3.39% and 10.12% on Book-Crossing dataset. The HR@5 of A-SAERec significantly outperforms the NeuMF algorithm by a large margin on Ml-10M dataset and the improvement is 4.07%. For AutoSVD
Performance of recommendation models with metric HR@5 and NDCG@5
Performance of recommendation models with metric HR@5 and NDCG@5
Performance of recommendation models with metric HR@10 and NDCG@10
The HR@5 and NDCG@5 performance of our A-SAERec algorithm compared with other baselines on four datasets, with latent dimension ranging from 10 to 50.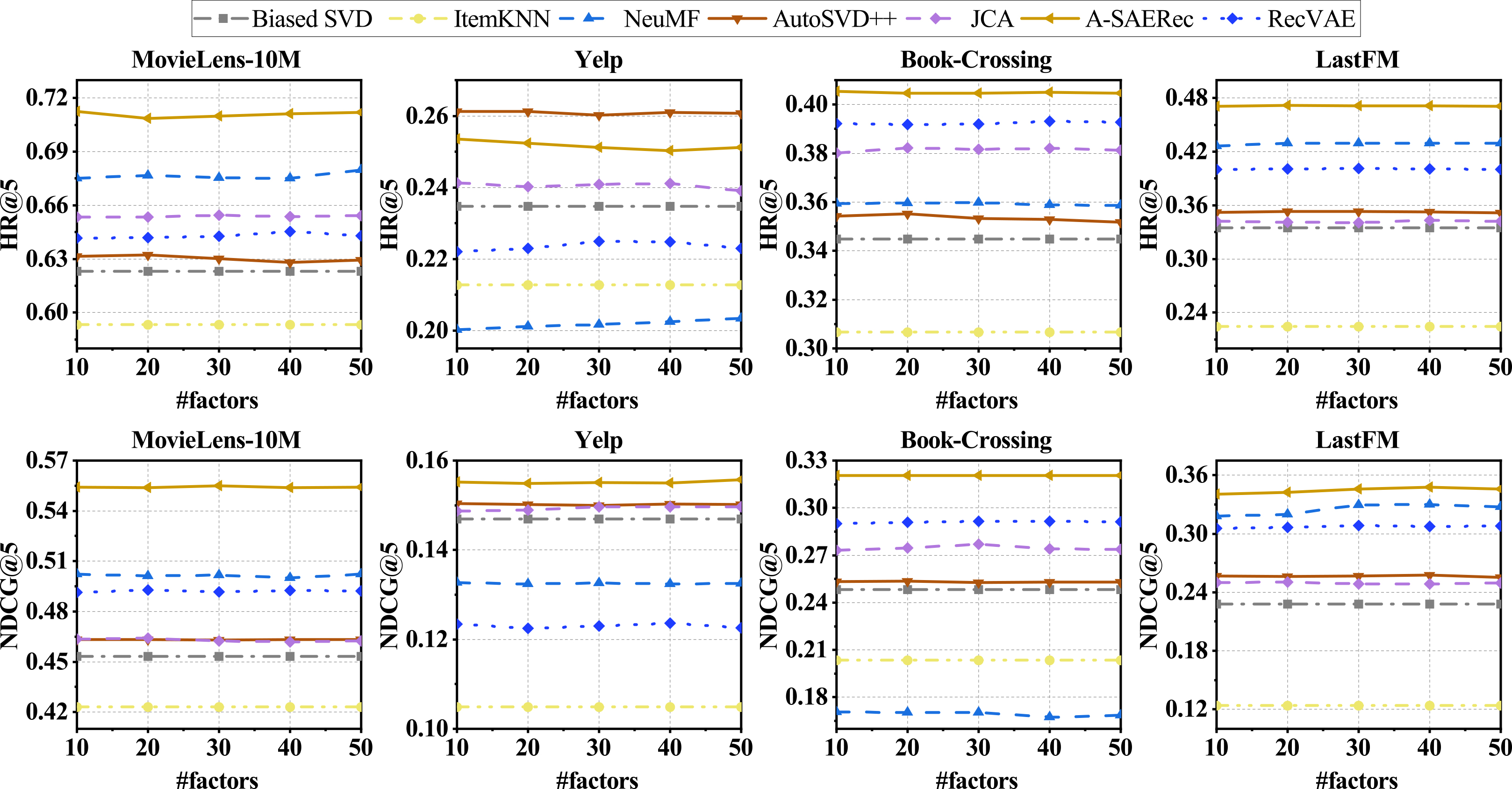
The HR@10 and NDCG@10 performance of our A-SAERec algorithm compared with other baselines on four datasets, with latent dimension ranging from 10 to 50.
Table 3 shows the performance of HR@10 and NDCG@10 of all adopted algorithms. Analyzing the results, it is easy to find that the A-SAERec performs better than other baseline algorithm. Such as, in the metrics of HR@10 and NDCG@10, the A-SAERec improves 5.79% and 9.07% compared with RecVAE on LastFM dataset, respectively. In the rest three datasets, HR@10 improvements range from 5.47% on Yelp dataset, 4.83% on Book-Crossing dateset, and 7.60% on Ml-10M dataset.The NDCG@10 improvements range from 5.65%, 5.60%, and 7.19% on Yelp, Book-Crossing, and Ml-10M dataset, respectively. In additions, the NeuMF, AutoSVD
Figure 3 shows the performance of (HR@5 and NDCG@5) all competitive algorithms with respect to the different number of latent factors
In Fig. 4, we have shown the performance of (HR@10 and NDCG@10) all adopted algorithms with respect to the different numbers of dimension factors
Illustration of the four metrics performance of A-SAERec on four datasets, with the number of hidden layer ranging from 1 to 5.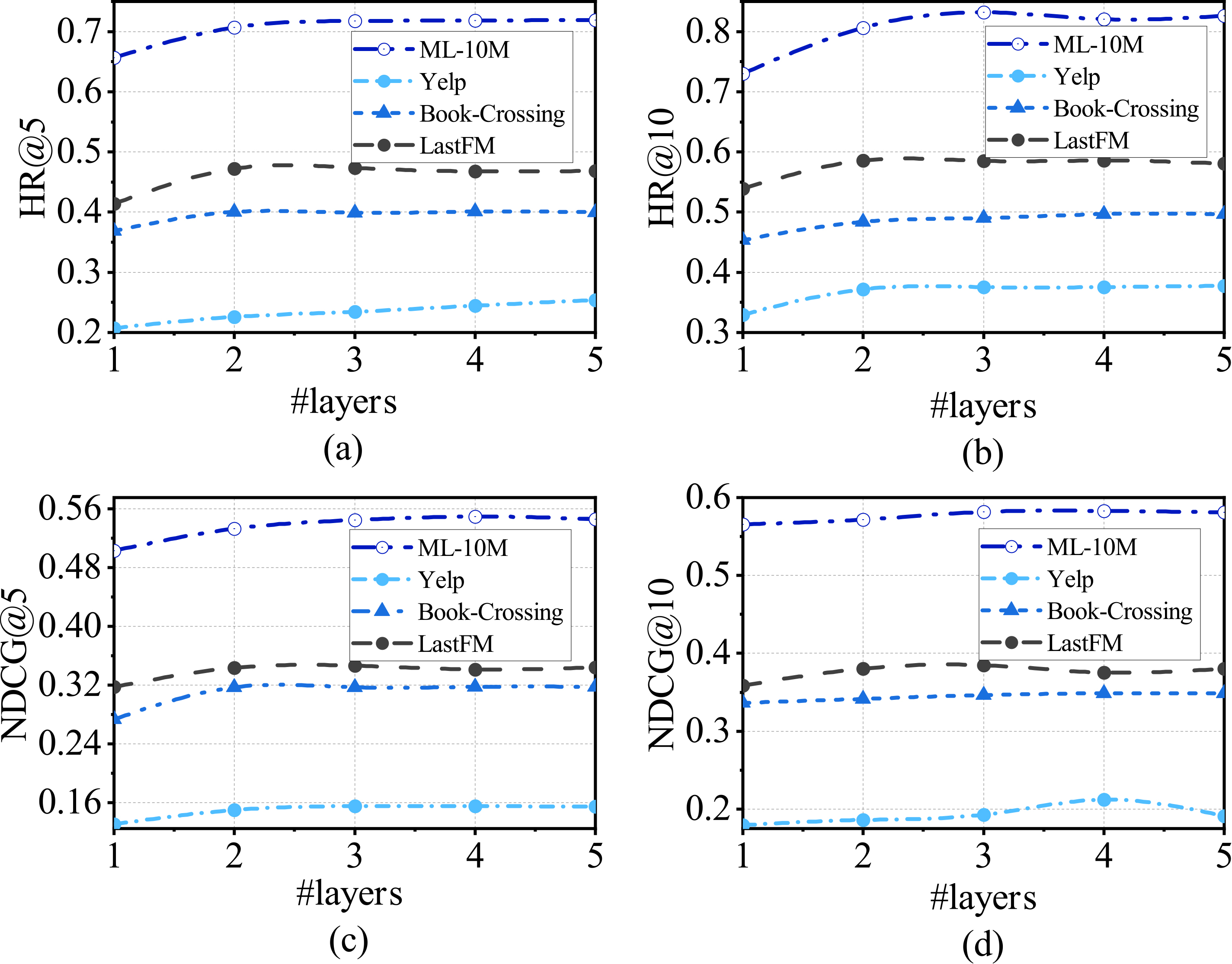
The experimental results shown in Figs 3 and 4 indicate the utility of our A-SAERec algorithm on the task of top-N recommendation. The attention weights learned from user-item interactions has a potential on the learned representation of users and items. The substantial improvement of A-SAERec over the baselines can be credited to two reasons: (1) our A-SAERec algorithm employs complicate user’s and item’s features extracted from the implicit matrix via non-linear network to model user-item interactions, instead of traditional methods apply a linear kernel with an inner product of user and item vector to predict score. (2) our model leverage an attention network to capture user’s and item’s attention weights on different aspects of each item and each user, which could improve the performance of recommender system.
Figure 5 shows the performance of (HR@5, NDCG@5, HR@10 and NDCG@10) A-SAERec with respect to the different number of hidden layers
In our A-SAERec model, we suppose the user place different important aspect of different items and use an attention network to capture attention weights. In order to verify and validate the utility of attention mechanism in A-SAERec method, we designed an ablation experiment in which the following two models are compared with our A-SAERec algorithm.
Illustration of the four metrics performance of compared three algorithms on four datasets.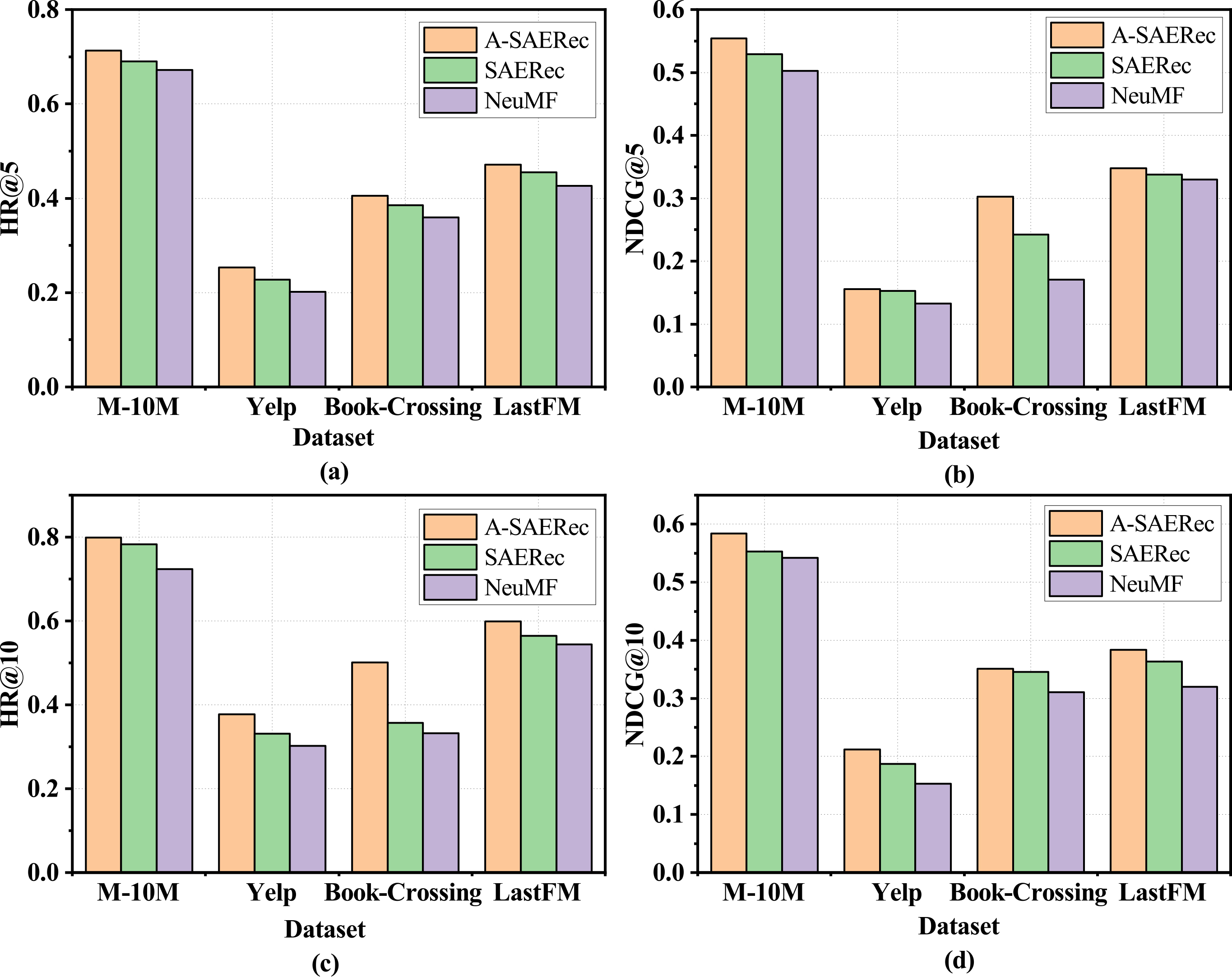
The results are shown in Fig. 6, we test each algorithm on four datasets in metric HR@5, NDCG@5, HR@10, and NDCG@10. From Fig. 6, we can see: (1) the SAERec algorithm outperforms the NeuMF algorithm by a large margin, especially, the metric of HR@5, NDCG@5, HR@10, and NDCG@10 of SAERec algorithm have reached 0.692, 0.5287, 0.7832, and 0.5532, respectively. The relative improvement over NeuMF algorithm is 2.93%, 5.25%, 8.26%, and 1.82%, which shows the utility of extracting representation from user-item interactions data and also demonstrates the effectiveness of our proposed structure on improving the performance of recommender systems. (2) the A-SAERec algorithm performs better than SAERec across all datasets, which verifies the effectiveness of mechanism on capturing the attention weights for each user-item pair.
In this paper, we present a hybrid deep collaborative filtering framework (A-SAERec), which combines the attentive stacked sparse autoencoder with neural collaborative filtering. As far as we know, we are the first attempt to leverage a joint neural network to tightly couple the attention mechanism with the stacked sparse autoencoder for personalized recommendation. For the user and item feature extraction, we utilize a attentive stacked sparse autoencoder and the implicit feedback as input. Then the neural matrix factorization is exploited to model user-item interactions using the user’s and item’s features as input. In order to improve recommendation performance, we employ the attention network to capture the attention weights for each user-item pair. Experiments on four real-world datasets show that our algorithm outperforms other baselines and demonstrates the utility of improvement the performance of recommender systems.
Footnotes
Acknowledgments
The work is supported by the National Natural Science Foundation of China (No. 61702063), the Natural Science Foundation of Chongqing (No. cstc2019jcyj-msxmX0544), the Science and Technology Research Program of Chongqing Municipal Education Commission (No. KJQN202001136).