
Abstract
Knowledge graph (KG) has been widely used in the field of recommender systems. There are some nodes in KG that guide the occurrence of interaction behaviors. We call them guided nodes. However, the current application doesn’t take into account the guided nodes in KG. We explore the utility of guided nodes in KG. It is applied in repository recommendations. In this paper, we propose an end-to-end framework, namely Guided Node Graph Convolutional Network (GNGCN), which effectively captures the connections between entities by mining the influence of related nodes. We extract samples of each entity in KG as their guided nodes and then combine the information and bias of the guided nodes when computing the representation of a given entity. The guided nodes can be extended to multiple hops. We evaluate our model on a real-world Github dataset named Github-SKG and music recommendation dataset, and the experimental results show that the method outperforms the recommendation baselines and our model is much lighter than others.
Keywords
Introduction
Currently, users are overwhelmed by the overload of online information in Web applications ranging from search engines and e-commerce to social media sites and news portals. To address the information overload problem, recommender systems (RS) [32] are widely used to guide users to discover products or services of interest to them in a personalized manner from a large number of possible alternatives. Due to their importance in practice, recommender systems have been receiving attention from both industry and academic research communities. It is no exaggeration to say that almost all services that provide content to users are equipped with recommender systems. Primarily, user preferences are predicted in RS from widely available sources of user behavior data. There are many application areas for recommender systems, such as movies, music, books, news, etc. But, recently there are new expansions in recommendation-related directions that people are trying to research recommendations of papers, algorithms, APIs, etc. Recommendation for Github repositories is also one of them but few people do it. The most recent one we found is in [25]. They investigate to automatically classify Github repositories. The conceived approach is able to recommend GitHub topics.
The traditional recommendation technique is collaborative filtering (CF) [13, 14, 31], which is based on the assumption that people who have purchased similar goods in the past tend to make similar choices in the future [20]. However, CF-based approaches are usually limited in that they all assume that users have the same motivation to purchase goods, ignoring the fact that the formation of a true recommendation system is usually a complex, heterogeneous process driven by the interaction of multiple underlying components. Researchers often turn to consider the relationships between entities to build feature-rich scenarios. User and item attributes are used to compensate for the sparse home item interactions and cold starts of CF-based approaches, and to improve the performance of recommendations [27, 8].
The user-item interaction is uniformly represented by the edges in the user-item bipartite graph, but users may have a variety of motivations for purchasing items. For example, some people like cost-effective goods, and others like eye-catching appearance. The user-item interaction is not controlled by only one motivation. Therefore, indiscriminately treating all motivations will inevitably lose some valuable information. Considering the differences in motivations, current researches [17, 29, 36, 37, 39] often use knowledge graphs (KGs) [7, 6] consisting of attributes and entities, where nodes correspond to entities (items or item attributes) and edges correspond to relationships. The rich semantic relatedness among nodes in the knowledge graph, in which various relationships help to mine motivations rationally, and the knowledge graph also brings interpretability to the recommender system. This can capture more complex interaction features, reflect user preferences comprehensively, and provide more accurate recommendation cues.
Despite so many advantages already mentioned above, there is still considerable potential for utilizing KG in RS. Inspired by real-world scenarios where users’ purchases for goods may be guided by salesmen, we consider whether such a guidance effect exists in knowledge graphs. Guidance means that users are influenced to ignore negative attributes of the product and focus on the positive attributes because they are guided.
Our work is to make repository recommendations based on guided nodes. In the current Github, most of the user actions are finding projects and asking questions under their favorite projects. The repository recommendations can facilitate the spread of projects. Users can acquire knowledge based on interest and not just on-demand. Guided nodes in repository recommendations mean that a beginner will be guided by star users and star projects. In this regard, repository recommendations to beginners based on the guided node are better than normal recommendations. The goal of our design is to tap the influence of user-related and item-related attributes and nodes to effectively capture the connection between entities. We construct the model to explore its impact on recommendation effectiveness. In this paper, we propose the Guided Node Graph Convolutional Network (GNGCN) for repository recommendation. The core idea of GNGCN is to compute the representation of a given entity in the knowledge graph by non-uniformly sampling (importance sampling) its neighboring nodes and treating these nodes as guided nodes. This design has two advantages: (1) we consider the importance of nodes in the knowledge graph for guiding entities, (2) when considering the construction of the knowledge graph for guiding nodes, we add user-side knowledge graph attributes to enrich the information for recommendations. In the actual knowledge graph, the number of neighbors of an entity is different, and in some cases, it may be very large. Therefore, we set a fixed number of guided nodes for each node, which makes the cost of GNGCN manageable. The set of guided nodes for a given entity can also be extended to multi-hops layer by layer. In this way, we build a higher-order entity dependency model that captures the potential remote interest and influence of users. Empirically, we evaluate GNGCN to a real-world dataset: Github-SKG. In order to prove that our model has a wider impact, we also verify the effectiveness of our model on Last.FM(music) dataset. Experimental results show that our model outperforms the state-of-the-art baselines.
Our contributions in this paper are summarized as follows:
We propose the Guided Node Graph Convolution Network (GNGCN), an end-to-end framework to better model real-world scenarios and explore the impact of guided nodes for repository recommendation. GNGCN captures the higher-order personalized interests of users by learning the graph representation of each entity in KG. We demonstrate the superiority of our model through extensive experiments. The results show that GNGCN outperforms the state-of-the-art baselines.
An example of the knowledge graph.
Collaborative knowledge graph
In recommendation scenarios, we usually have historical user-item interactions (e.g., purchases and clicks). Here we represent the interaction data as a user-item bipartite graph. In addition to interactions, we have additional information about items (e.g., item attributes and external knowledge). Typically, such auxiliary data consists of real-world entities as a knowledge graph. Conceptually, our approach is influenced by the collaborative knowledge graph (CKG) [30], which is defined by Wang et al. and encodes user behavior and project knowledge into a unified relational graph. CKG first represents each user behavior as a triple, where the edges of the triples represent the additional relational interactions between users and items, and then seamlessly integrate the user-item graph with the knowledge graph into a unified graph based on the alignment of item entity pairs.
CKG adds the user project bipartite graph to the knowledge graph on the project side to build a new knowledge graph, but it does not build the knowledge graph on the user side, which means that there is a lot of valuable information on the user side that has not been utilized. The high-level connectivity of some users and projects in the topology is also more difficult for us to obtain. The similarity and user preference between user vector and item vector are also partially lost. We have expanded the CKG to include a user-side knowledge graph. Our knowledge graph is a unified knowledge graph that includes a user-side knowledge graph, item-side knowledge graph, and user-item bipartite graph.
We show part of the structure of the knowledge graph we built in Fig. 1. Many real-world websites and platforms have this network structure in Fig. 1, the most obvious being social networks, and others are shopping sites and knowledge-sharing platforms.
Graph convolutional network and graph attention network
Our method is conceptually inspired by GCN. Graph convolutional networks [4, 16], have been attracting considerable attention lately, because of their remarkable success in various graph analysis tasks. The early attempts [4, 16] to derive a graph convolutional layer are based on graph spectral theory, graph Fourier transformation [24] in particular. Then polynomial spectral filters are used to greatly reduce the computational cost [9], and the usage of a linear filter makes further simplification [18]. Along with spectral graph convolution, directly performing graph convolution in the spatial domain is also investigated [10, 1]. Later the attention mechanism [2] is employed to adaptively specify weights to the neighbors of a node when performing spatial convolution. DisenGCN [22] is proposed to learn disentangled node representations, which employs a novel neighborhood routing mechanism to find the factor that may have caused the edge from a given node to one of its neighbors. However, DisenGCN is a homogeneous graph representation learning method, which does not distinguish the different importance among latent components meanwhile.
The traditional graph convolution neural network does not pay attention to the interaction between nodes when aggregate vectors represent and capture the high-order connectivity of topology. This feature is valuable in improving the effectiveness of recommendations.
The GCN used in our model is to biasedly aggregate and merge neighborhood information when computing the representation of a given entity in KG. This design has two advantages over traditional GCNs: (1) The local neighborhood structure is successfully captured and stored in each entity by the neighborhood aggregation operation. (2) Neighborhoods are weighted according to connected relationships and user-specific ratings, which reflect both the semantic information of the KG and the user’s personalized interest in the relationship.
The use of Graph Attention Network (GAT) [26] can effectively improve the effectiveness of recommendations and is a very hot direction at the moment. The innovation and application of GAT is still a hot topic, and many papers [30, 33, 34, 38, 11] are created based on GAT.
Our method also connects to GAT. GAT uses an attention mechanism to reweight the existing edges of the given graph. Since the topological structure of the graph is not changed, the model is prone to be affected by noisy data when edges are sparse. While GAT reduces immediate neighbors iteratively to explore the graph structure in a breadth-first approach that processes all nodes and edges at each step, our method uses multi-step neighborhood samples to explore the graph structure.
Repository recommendation
There are a few recommendations for Github repositories other work also brings us a lot of inspiration. For example, sentiment analysis of Github repositories [35], natural language processing [21], prediction [40], and exploring developer influence [3]. The most recent model about GitHub repositories recommendation we found is Multinomial Naïve Bayesian Network (MNB) [25]. But our focus is on a different entry point. In MNB they investigate the application of MNB to automatically classify GitHub repositories. By analyzing the README file(s) of the repository to be classified and the source code implementing it, the conceived approach is able to recommend GitHub topics.
MNB method is a kind of fuzzy recommendation in recommendation application. MNB uses text information as the main information for a recommendation. After natural language processing, more information is lost, so it is difficult to fully express the user’s preference. And it can only vaguely recommend topics for users. Our model is used to accurately recommend specific repositories for users.
We use the knowledge graph to construct a representation of the partial Github community and make library recommendations based on it. Compared with MNB’s approach, our recommendation model uses much richer information. Our recommendations are based on user behavior and interests. This is more in line with personalization.
Illustration of the proposed GNGCN model. (a) The framework of GNGCN. (b) The example of two nodes, user node 
In this section, we first introduce the proposed Guided Node Graph Convolution Network model. We formulate the knowledge graph-based recommendation problem in the first part. Then in the second part, the design scheme of the single-layer Guided Node Graph Convolution Network model is given. Finally, the complete learning algorithm of the Guided Node Graph Convolution Network model is presented. We give the overall framework of our model in Fig. 2a and b shows a model extension to a multi-hop illustration.
Figure 2, as our model framework, shows the structure of a complete recommendation system, which can be used not only for our repository recommendations but also for areas with a similar knowledge graph structures, such as social networks. In social networks, users are more likely to be influenced by key users and the structure and knowledge graph of social networks match very well, so communities such as social networks are also the ideal environment for the application of our model.
Task description
We formulate the knowledge-graph-aware recommendation problem as follows. In a typical recommendation scenario, We have a set of users
We have given several examples of mining hidden connections, as follows.
Such as
Given the user-item interaction matrix
An example of a single-layer GNGCN structure. In this example a fixed sample of three neighbor nodes of item 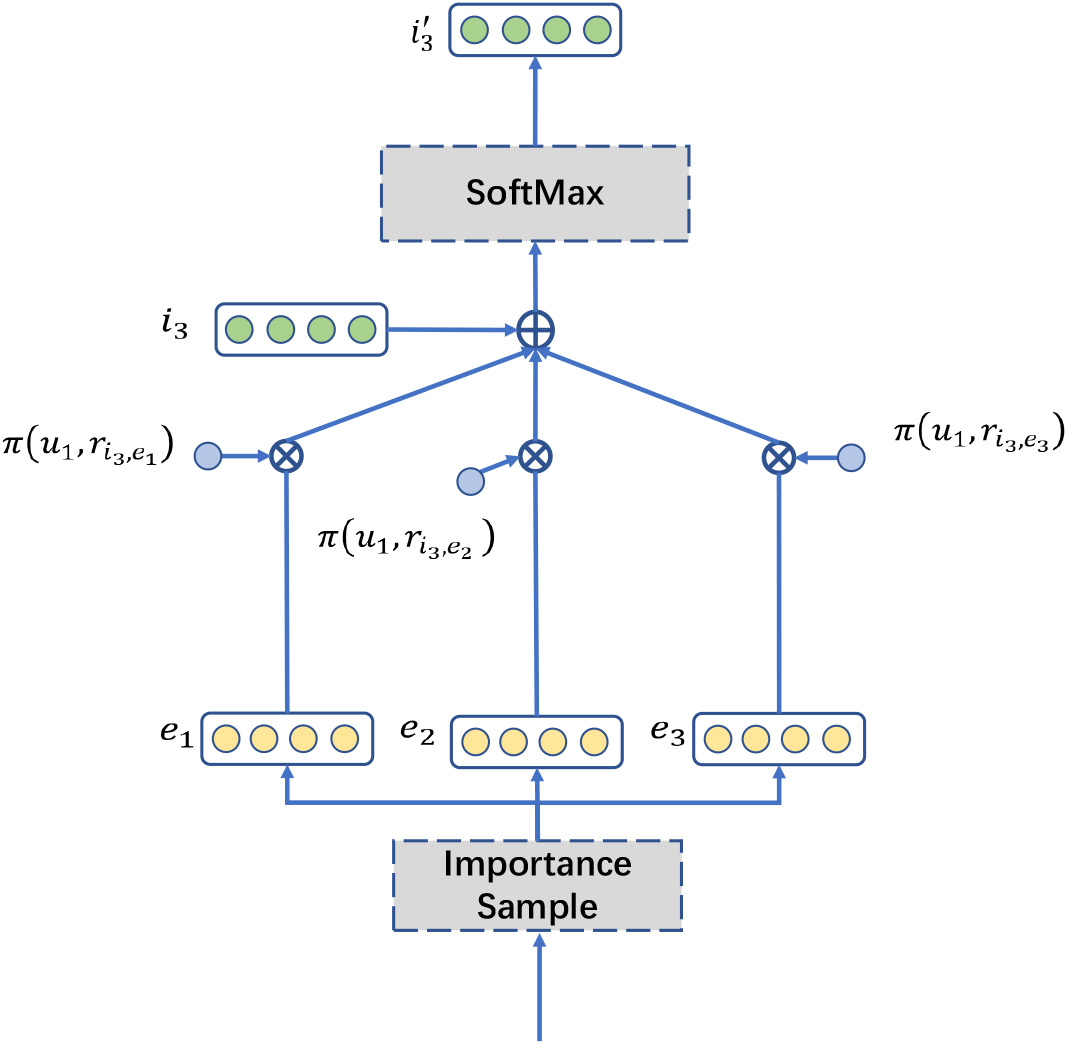
We first describe a GNGCN layer in this subsection. The structure of single-layer GNGCN is shown in Fig. 3. The single-layer GNGCN layer performs only one convolution operation and aggregates neighborhood information once. As a detailed structure of a convolutional layer, this structure can also apply alternatives to graph convolutional operations in other models. This convolutional operation can be used in representation vector learning with a similar knowledge graph structure. For example, predict user behavior in social networks. Aggregating neighborhood information makes the representation vector more characteristic, can better express the preference of the vector, and can better explore the high-dimensional connectivity of the topology between the two vectors. The single-layer GNGCN first samples by the importance for the neighbors of the incoming nodes.
In the beginning, a user node
In a real-world knowledge graph, the size of
We have indicated our sampling process as follows:
where
We use
where
To characterize the topological proximity structure of item
where
User-relation scores act as personalized filters when computing an entity’s neighborhood representation since we aggregate the neighbors with bias with respect to these user-specific scores. The linear combination representation of the neighborhood of user
It is the aggregation of the entity representation
This aggregator is also applied to the aggregation of users with their neighboring nodes. Aggregation is a key step in GNGCN because the representation of an item or user in GNGCN is bound to its neighbors by means of aggregation.
Through a single GNGCN layer, the final representation of an entity is dependent on itself and on the neighboring nodes directly connected to it, which is the first-order embedding representation of the entity. The 1st-order embedding representation of an entity is obtained by aggregating the initial representation of each entity (the 0th-order representation) with the initial embedding representation of its neighboring nodes, and then we can repeat this process to obtain the 2nd-order embedding representation of an entity, i.e., the 1st-order embedding representation of an entity and its neighboring nodes are aggregated to obtain the 2nd-order embedding representation of that entity. As shown in Fig. 2b. In this way, we complete the propagation in the knowledge graph.
It is worth mentioning that when we calculate the attention score of item
where
[h] Learning Algorithm of
The formal description of the above steps is presented in Algorithm 3.3.
Note that Algorithm 3.3 traverses all possible user-item pairs (line 3). To make computation more efficient, we use a negative sampling strategy during training. The complete loss function is as follows:
where
In this section, we evaluate GNGCN on two real-world scenarios: Github-SKG and Last.FM.
Datasets construction
We utilize the following two datasets in our experiments for Github and music recommendation, respectively:
GitHub-SKG contains information about 2681 Github repositories and 4245 users who interact with these repositories. Last.FM contains musician listening information from a set of 2 thousand users from Last.FM online music system.
Since the two datasets are explicit feedback, we transform it into implicit feedback where each entry is marked with 1 indicating that the user has rated the item positively, and sample an unwatched set marked as 0 for each user.
The construction of the Github-SKG dataset predates our GNGCN model. To put it differently, our model is inspired by the Github-SKG dataset we built. On the basis of our other work [5], we had the motivation to build our Github-SKG dataset. Our other work obtained information about more than 2000 algorithm papers and using these papers as seeds we obtained their relevant information on Github to build a knowledge base. This information includes the development language of the Github repository, the related domain, and the contributors of the repository. It constitutes the knowledge graph on the item side. Moreover, we obtained information about the users who collected these repositories to construct the user-item bipartite graph and the user-side knowledge graph. The user-side information contains the famous users followed by the users of the collection Github repository. We numbered the users, items, and entities in a unified way, and added the user-item bipartite graph to get the final knowledge graph. We excluded a portion of the interaction data for users who appeared less than three times in the entire interaction set. The behavioral value of these users is lower. Access to this information is mainly based on the API provided by Github. Our dataset has the potential to continue to be improved, the information in the knowledge graph can continue to be enriched although it may rely on external sources, and the size of the dataset can be further expanded.
About the Last.FM dataset we use Microsoft Satori 7 to construct the knowledge graph for each dataset. We first select a subset of triples from the whole KG with a confidence level greater than 0.9. Given the sub-KG, we collect Satori IDs of all valid musicians by matching their names with tail of triples (head, type.object.name, tail). Items with multiple matched or no matched entities are excluded for simplicity. We then match the item IDs with the head of all triples and select all well-matched triples from the sub-KG. When building the knowledge graph of Last.FM, we added the user-item bipartite graph into it. We renumbered the users as entities and constructed the triples (
Basic statistics for Github-SKG and Last.FM
The basic statistics of the Github-SKG dataset are presented in Table 1.
We compare the proposed GNGCN with the following baselines, in which the first baseline is KG-free while the rest are all KG-aware methods. Hyper-parameter settings for baselines are introduced in the next subsection.
NCF [15]: NCF designs a CF model based on a neural network structure. The neural network structure is used to model the latent features of users and items, and the MLP is used to give NCF the ability to obtain higher-order nonlinear interactions. FM [23]: This is a benchmark factorization model, where considers the second-order feature interactions between inputs. Here we treat IDs of a user, an item, and its knowledge (i.e., entities connected to it) as input features. NFM [12]: The method is a state-of-the-art factorization model, which subsumes FM under a neural network. Specially, we employed one hidden layer on input features as suggested in [12]. KGCN [19]: Utilizes GCN to collect high-order neighborhood information from the KG. To find the neighborhood which the user may be more interested in, it uses the user representation to attend to different relations to calculate the weight of the neighborhood. RippleNet [28]: A memory-network-like approach that represents the user by his or her related items. RippleNet uses all relevant entities in the KG to propagate the user’s representation for a recommendation. KGAT [30]: A GNN-based recommendation model equipped with a graph attention network. It uses a hybrid structure of the knowledge graph and user-item graph as a collaborative knowledge graph. KGAT employs an attention mechanism to discriminate the importance of neighbors and outperforms several state-of-the-art methods.
Hyper-parameter settings for Github-SKG and Last.FM
In GNGCN, we set functions
Operating System: Ubuntu 18.04.3 LTS RAM: 128GB DDR4 @ 3200MHz CPU: Intel (R) Core (TM) i9-9980XE CPU @ 3.00GHz GPU: 2 SSD: 2.0 TB (NVM Express, PCIe 3.0 x16) Software: NVIDIA CUDA 10.2, Python 3.7.6, Pytorch 1.3.1, and NumPy 1.18.1.
For KGAT, we set the depth to 2 and layer size to [16, 16]. For RippleNet, we set the number of hops to 2 and the sampling size to 64 for each dataset. For KGCN, we set the number of hops to 3, and the sampling size to 4 for GitHub-SKG, respectively. Other hyper-parameters are the same as reported in their original papers or as default in their codes.
We first compare the recommendation performance of all methods. The results of CTR prediction and model sizes are presented in Table 3. We show the ROC curves of GNGCN and baselines in Fig. 4.
Our observations are as follows:
The performance of our model GNGCN shows some improvement compared to the baseline model. This demonstrates the effectiveness of our model GNGCN on recommendations. Through the analysis of the parameters #, we can clearly see that our model is much smaller than other models, which shows that our model is lighter, the structure is relatively simple, and the operation efficiency is higher. NCF performs worse than the other models on Github-SKG, which shows that the introduction of knowledge graphs is effective for the recommendation. The results of AUC, ACC, and F1 in CTR prediction
The ROC curves of GNGCN and baselines.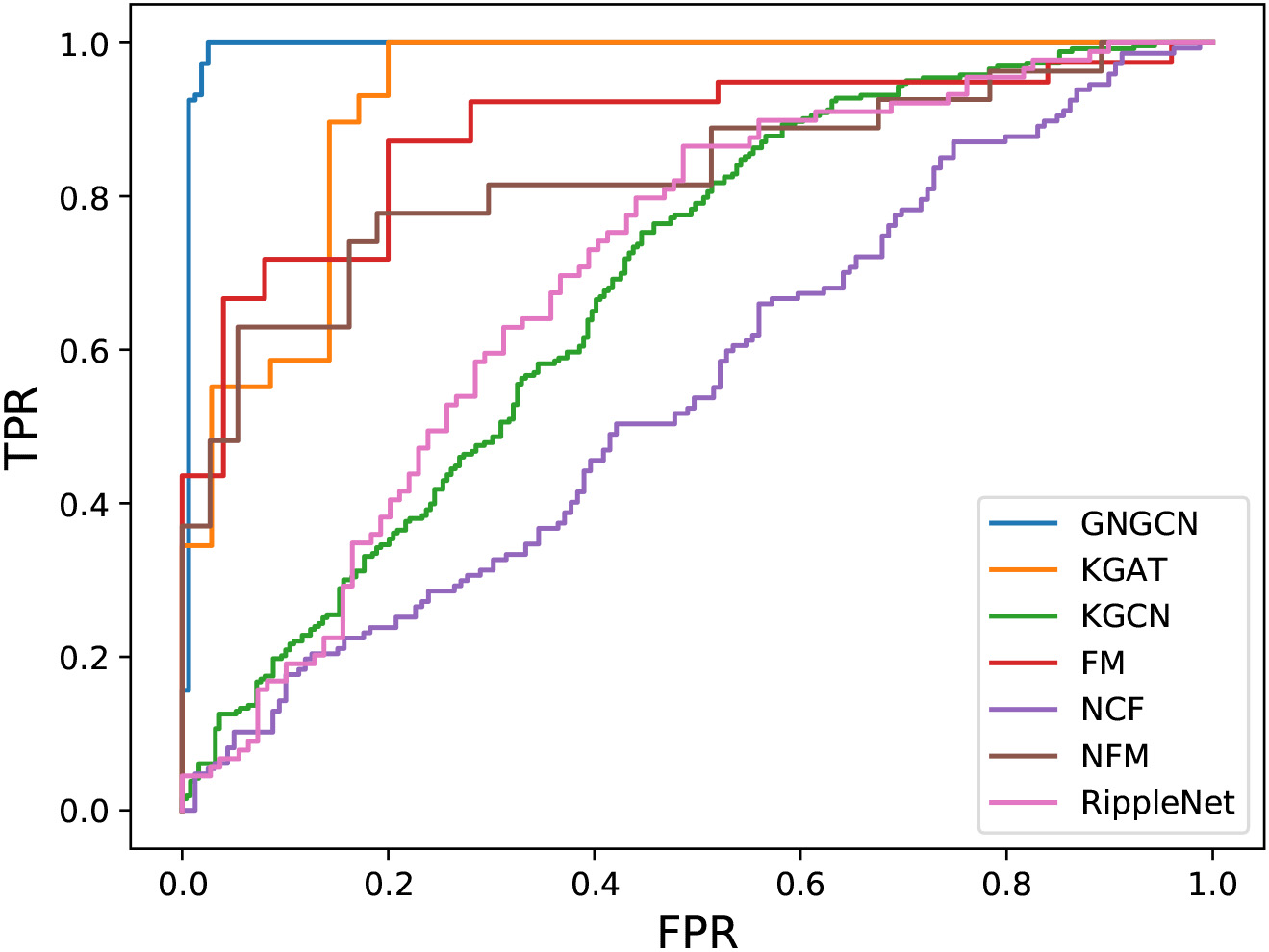
RippleNet and KGCN did not perform as well as we expected on the GitHub-SKG dataset. After comparing their performance with KGAT, FM, and NFM on the GitHub-SKG and Last.FM, we get a reasonable explanation. The FM and NFM models we use are reproduced in the KGAT paper, and they have in common that they all use collaborative knowledge graphs. The same user-side knowledge and user-item bipartite graphs are added to our GitHub-SKG dataset knowledge graph and renumbered. The RippleNet and KGCN models we use are reproduced from the authors’ publicly available code, which does not use the collaborative knowledge graph. The user-side knowledge graph we added occupies most of the entire knowledge graph, and the renumbered users are added to the entity set. This information is treated as a huge volume of noise in RippleNet and KGCN, and it can be concluded that the knowledge graph still works compared to NCF, but makes the improvement brought by the knowledge graph small.
AUC results of GNGCN with different number of aggregated neighbors 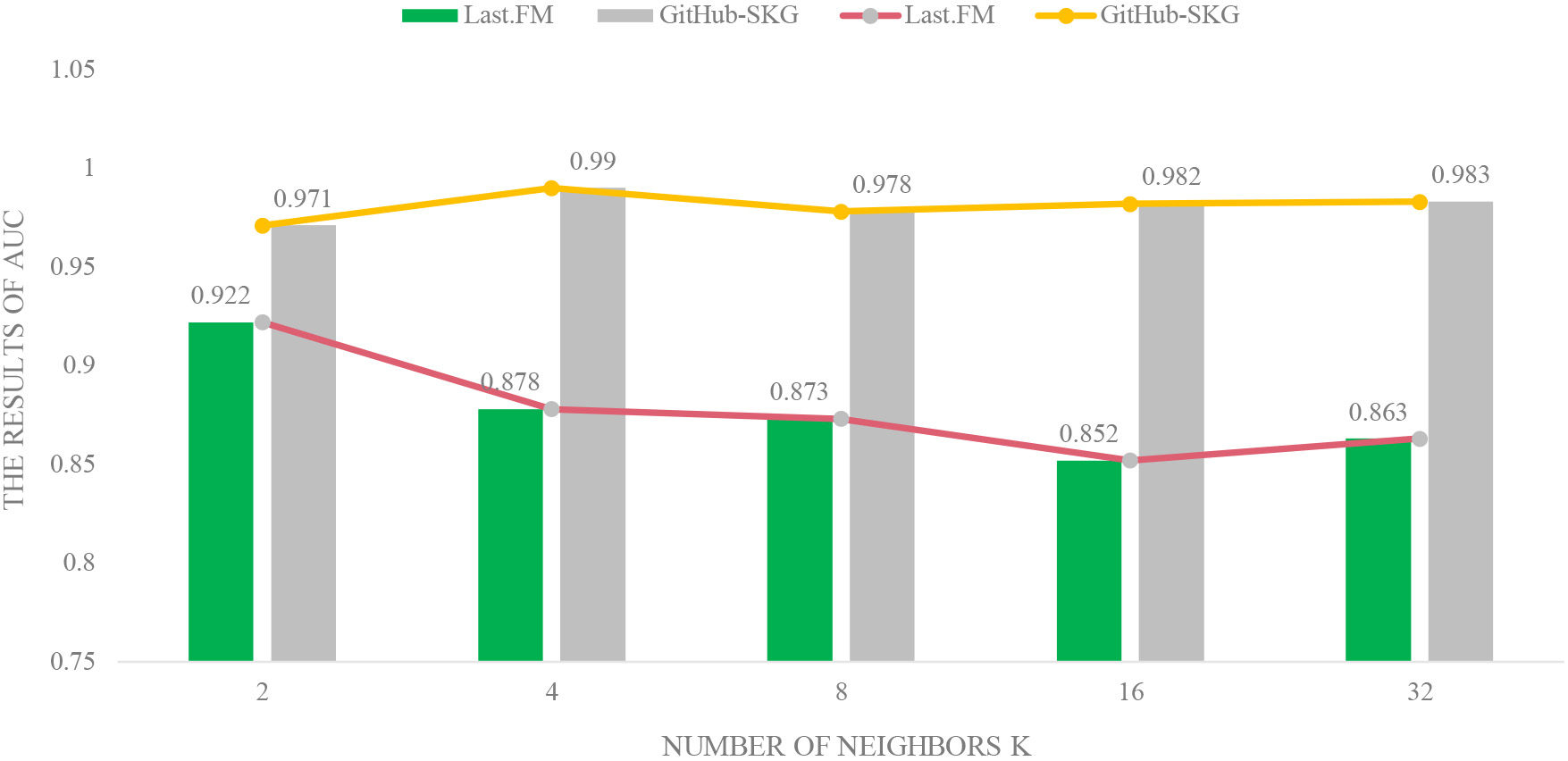
AUC result of GNGCN with different number of propagation 
In order to study the effectiveness of the components of our proposed GNGCN, we carried out ablation experiments, and the results are shown in the last two rows of Table 3. GNGCN
Both GNGCN
AUC results of KGCN with different dimensions of embedding. The performance of GNGCN
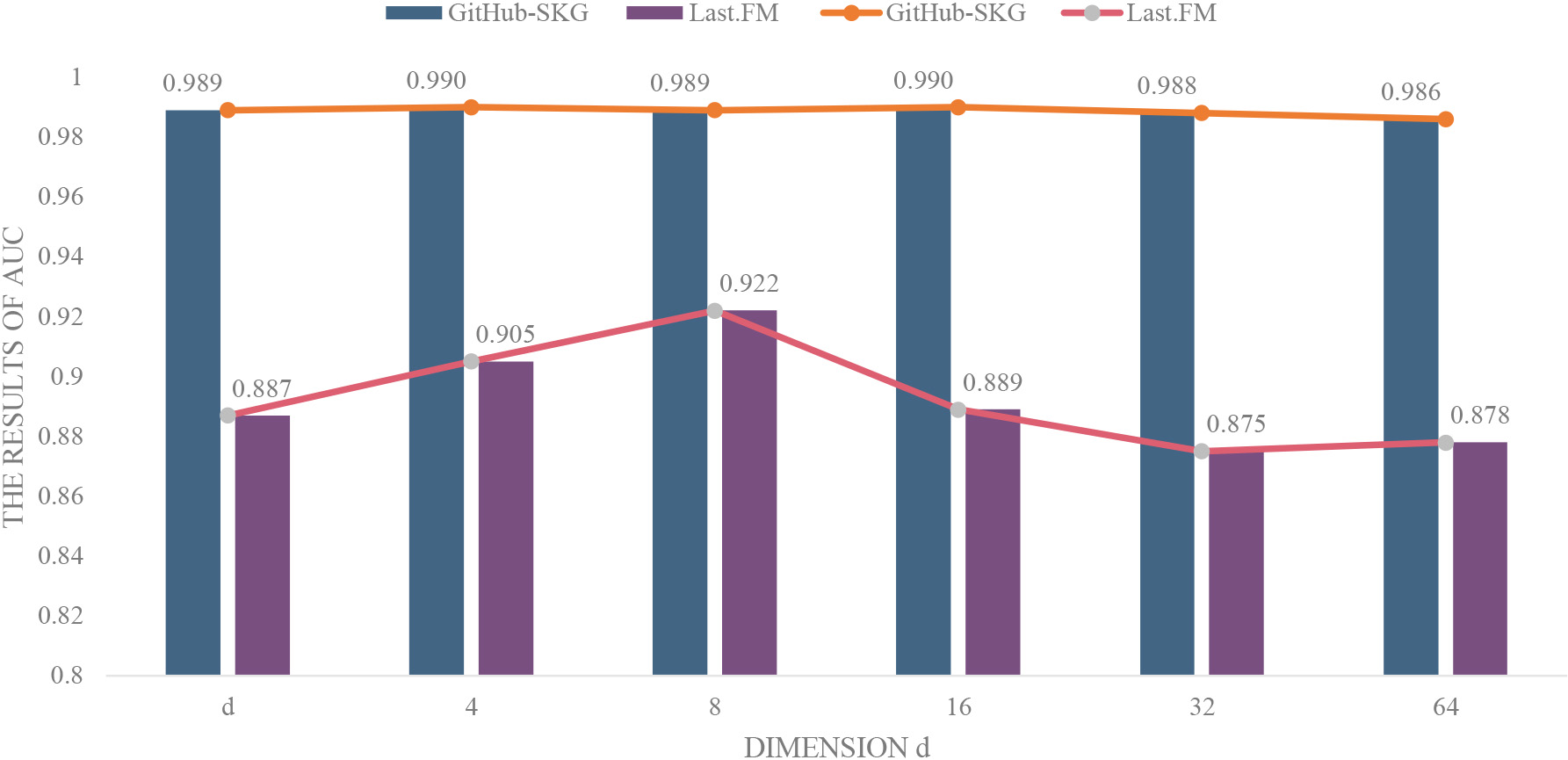
Knowledge graph propagation plays an important role in GNGCN. We investigate the effect of its two parameters in knowledge graph propagation, the number of aggregated neighbors
Impact of the number of aggregated neighbors Impact of the number of propagation Impact of the dimension of embedding For the noise in the data, mainly reflected in the model learning process of aggregated neighborhood information update the embedding representation, the number of aggregated neighbors, convolution, or too large dimensions, too large amount of data information will dilute the characteristics of the project or the user’s initial embedding representation, so that the aggregated embedding vector can not represent the entity. RippleNet and KGCN adopt random aggregation, and in the complexity of our data set, it is easily aggregated to weakly related data information, which also dilutes the characteristics of the entity. We consider this to be the main source of noise in the data.
In this paper, we propose a guided node knowledge graph convolutional network for repository recommendation. GNGCN extends the nonspectral GCN approach to knowledge graphs by selectively and biasedly aggregating neighborhood information to learn both the structural information of KGs and the personalized and latent interests of users. We also implement the proposed method in a small batch, which can operate on large datasets and knowledge graphs. Through extensive experiments on a real-world dataset, GNGCN consistently outperforms the state-of-the-art baseline for Github and music recommendations. Not only that, compared with other baselines, our model is lighter in scale and better in running time and efficiency, which should be considered frequently in our future work.
We point out two avenues for future work. (1) In this work, we construct the perceptual domain of an entity based on the importance of sampling its neighborhood nodes. Exploring personalized samplers (e.g., attentional mechanism sampling) is an important direction for future work. (2) Considering the evolution of people’s interests and the influence or importance of nodes is an interesting direction for future work to investigate whether time series on recommendations can help improve the performance of recommendations.
Footnotes
Acknowledgments
This research was supported by the National Key Research and Development Plan of China (No. 2018YFB1003804).