
Abstract
Aiming at the inefficiency of retrieval and insufficient recommendation caused by the dispersion of dance multimodal resources, this study proposes a knowledge graph construction method based on improved GCNs. Integrating public dance libraries and teaching resources, the first dance knowledge graph DanceKG is constructed, covering entity relationships such as movements and styles. DRA-GCN is innovatively proposed to quantify the interaction frequency of nodes through dynamic weighting module and strengthen the characterization of long-tailed entities associated with complex movements by combining multi-head attention. Experiments show that DRA-GCN has a link prediction MRR of 0.72 (9% higher than traditional GCN) on 50,000 triad datasets, and the F1-value of movement classification is improved by 5%, which supports the movement recommendation and error correction of intelligent teaching system and promotes the digital development of dance education.
Keywords
Introduction
Dance teaching, as an important branch of art education, is facing a profound change of digital transformation. With the rapid development of virtual reality, motion capture, and artificial intelligence technologies, intelligent teaching tools have gradually become the core driving force to improve teaching efficiency and personalization. 1 However, the contradiction between the multimodal nature of dance teaching resources and fragmented storage is becoming increasingly prominent. 2 From basic movement decomposition videos to complex stylistic analysis texts, and from three-dimensional skeletal movement data to historical and cultural background information, these heterogeneous data are scattered across different platforms such as YouTube, professional databases, and paper textbooks, lacking a unified semantic association framework. From basic movement breakdown videos to complex style analysis texts, from 3D skeletal movement data to historical and cultural background information, these heterogeneous data are scattered in different platforms, such as YouTube, professional databases, and paper textbooks, without a unified semantic association framework. For example, a teaching resource for “modern dance floor tumbling” may contain demonstration videos from multiple perspectives, textual descriptions of the key points of the core muscle groups, and annotations of common erroneous movements, but these contents often exist in isolation, making it difficult to form a systematized body of knowledge. 3 Such a fragmented state not only adds to the complexity of teachers’ preparation but also limits the potential of intelligent recommender systems—the potential of which can be used in a systematic way to improve the quality of teaching. This fragmentation not only increases the complexity of teacher preparation but also limits the potential of intelligent recommender systems—existing algorithms base their recommendations on single-modal data (e.g., video click-through rates or text keywords) and are unable to capture the dynamic coherence of movements (e.g., the mechanical connection between “ground tumbling” and “aerial leap”), and it is difficult to support knowledge transfer across styles (e.g., correlation analysis between the rigor of classical ballet and the freedom of improvisational modern dance).
Knowledge graph technology, with its powerful semantic association and reasoning capabilities, has demonstrated excellent value in the fields of healthcare, finance, music education, and so on. For example, Liu et al. 4 proposed an end-to-end framework, MMSS_MKR, to improve the accuracy and authenticity of music recommendation by utilizing knowledge graph as an auxiliary information source and combining intersection and compression units to connect the knowledge graph embedding task with the recommendation task module. The framework optimizes the recommendation results by improving the loss function, which significantly enhances the music recommendation performance and effectively solves the sparse and cold-start problems; Latinjak and Hatzigeorgiadis 5 constructed a global knowledge graph covering Sport and Exercise Psychology (SEP), which is divided into four major research clusters: biopsychological descriptors, external variables, mental skills, and applied practices. The study aims to enhance SEP teaching and learning, promote interdisciplinary research and practice, and advance SEP as an applied science, while emphasizing the value of sport and exercise in interdisciplinary research and its potential as a therapeutic framework. However, the construction of knowledge graphs in the field of dance faces unique challenges: for one, the spatio-temporal continuity of dance movements requires models that can capture dynamic temporal relationships, whereas traditional static graph models (e.g., TransE and RGCN) tend to simplify the movements into isolated nodes and ignore the temporal dependencies of their interactions. For example, the smoothness of “ballet whip turn” depends on the precise coordination of leg strength, center of gravity shift, and rotational rhythm, which is difficult to be fully characterized by static graph structure. 6 Secondly, the abstract nature of dance styles leads to a significant sparsity of relationships in the knowledge graph. For example, the stylistic difference between the folk dance “Dai Peacock Dance” and the street dance “Lock Dance” may only be characterized by metaphorical texts (e.g., “imitation of nature” vs “muscle vibration”), which puts higher demands on the semantic generalization ability of graph neural networks. 7 Third, the complexity of multimodal data alignment far exceeds that of a single domain. The sequence of skeletal key points in a dance video needs to be mapped with abstract style labels (e.g., “lyricism” and “dramatic conflict”) across dimensions, while existing methods rely on artificial rules or shallow feature matching, which is difficult to adapt to the needs of large-scale data. 8
Aiming at the above challenges, this study aims to construct a dynamic knowledge graph for dance teaching and propose an improved graph convolutional network that can deeply integrate multimodal data and spatio-temporal relationships. Compared with the existing work, this study is innovative in three aspects: first, by designing a dynamic relationship perception mechanism, we break through the dependence of traditional graph models on static relationships and realize the accurate modeling of the temporal coherence of dance movements and style migration patterns; second, we introduce a multi-granularity attention mechanism, which captures the local movement synergies, stylistic clustering features, and cross-domain commonalities at the node, subgraph, and global levels, respectively, so as to improve the representation of sparse long-tail entities (e.g., niche folk dances); finally, integrating heterogeneous data from multiple sources (including DBpedia dance categories, YouTube teaching video metadata, AIST++ skeletal dataset, and professional teaching textbooks), we construct the first open-domain dance pedagogical knowledge graph DanceKG, which provides a structured knowledge infrastructure for the development of an intelligent pedagogical system. This study not only fills the gap of knowledge systematic integration in the dance education field but also extends its dynamic relationship modeling framework to sports training, rehabilitation medicine, and other fields that need to deal with complex temporal relationships and promotes the development of multimodal knowledge-driven artificial intelligence to a deeper level.
Related work
Knowledge graph construction techniques
Knowledge graphs, as an important realization of the Semantic Web, have shown diverse application potentials in both general-purpose and vertical domains. General-purpose knowledge graphs such as Boudin et al. 9 and Lan et al. 10 achieve a generalized representation of cross-domain knowledge through large-scale ternary storage, but their lack of domain depth restricts their application in specialized scenarios. For example, Boudin, et al. 9 pointed out that drug localization is only based on the most basic drug name localization and lacks the most extensive features and drug properties comprehensively constructed. For this reason, the construction of domain-specific knowledge graphs has become a research focus in recent years. In the field of music education, Liu et al. 4 proposed an end-to-end framework, MMSS_MKR, to improve the accuracy and authenticity of music recommendation by utilizing knowledge graph as an auxiliary information source and combining crossover and compression units to connect the knowledge graph embedding task with the recommendation task module. The framework optimizes the recommendation results by improving the loss function, which significantly improves the music recommendation performance and effectively solves the sparse and cold-start problems. By fusing instrumental entities, music theory concepts, and performance skill data, a semantic network supporting intelligent compositions is constructed; in sports training, Kalkhoven explores the challenges of causality establishment in sports injury research and proposes a new model for utilizing causal graphs to construction and a new model for utilizing frameworks to guide sports injury research and prevention. 11 This approach can facilitate the scientific investigation of causality and mechanisms, translating laboratory research into applied practice while reducing the risk of resource waste and data manipulation.
However, knowledge graph research in the dance domain still faces significant challenges: first, existing work is mostly limited to the integration of single-modal data, for example, only by checking the character’s pose in the test video every 30 seconds, marking the head and foot positions, and outputting them to a txt file 12 ; second, the modeling of dynamic temporal relationships is insufficient, and the traditional methods of graph construction (e.g., rule-based ternary extraction) are difficult to portray the coherent logic of dance movements, for example, the mechanical dependencies between the take-off and landing phases of the “big jump” movement. Second, the modeling of dynamic temporal relationships is insufficient, as traditional graph construction methods (e.g., rule-based ternary extraction) are difficult to portray the coherent logic of dance movements, such as the mechanical dependencies among the jumping, vacating, and landing phases of the “big jump” movement. In addition, the abstract nature of dance styles leads to a significant sparsity of entity relationships, for example, the association between “modern dance improvisation” and “intensity of emotional expression” may only be described by a small amount of metaphorical text, which puts forward higher requirements on the robustness of the knowledge complementation algorithms.
Evolution of graph convolutional networks (GCN) with multi-relational modeling
GCN provides a new paradigm for knowledge graph representation learning through the mechanism of neighborhood information aggregation. Earlier Jia et al. proposed a new graph-in-graph model and associated convolutional network for hyperspectral imagery (HSI) classification. 13 The method captures the local and global characteristics of ground targets through hyperpixel segmentation, constructs internal and external maps, respectively, and improves the distinguishability and robustness of classification through hierarchical feature extraction and integrated learning. Experimental results show that the method performs well in HSI classification with limited labeled samples. Lian et al. 14 proposed a new method called Local Relation-aware Graph Convolutional Network for learning the relationship of local features between different pedestrian images. By introducing overlap and similarity maps, as well as structural graph convolution operations, the method is able to describe the local feature relationships more comprehensively and achieves better performance than existing state-of-the-art methods on four large-scale pedestrian re-identification databases.
However, the problem that its parameter size grows linearly with the number of relations limits the scalability. To this end, researchers have proposed a variety of optimization strategies: the composition-based GCN proposes two attention-based graph convolutional neural network techniques to learn the average voltage of electrodes and reduce the computational dimensionality. 15 Graph Attention Networks explores a view-centric attention approach to aggregate view-by-view node representations, 16 and GraphSAGE improves the processing efficiency of large-scale graphs by setting a fingerprint feature through neighborhood sampling and aggregation functions. 17 However, the above methods still take static relationship modeling as the core assumption, which is difficult to adapt to the temporal dynamics of movement articulation in dance teaching. For example, in ballet combination training, the transition from “Arabesque” to “Atijou” requires precise timing coordination, which is reduced to static edge connections by traditional GCNs, which cannot capture the rhythmic dependencies between movements. Recently, Spatio-Temporal GCN models human motion as graphs to process skeletal data. By combining these outputs, a comprehensive representation of motor actions can be created. Reinforcement learning is used to optimize the action recognition process by constructing it as a sequential decision problem. 18
Knowledge representation and reasoning in dance teaching
In the field of dance teaching and learning, research on knowledge representation and reasoning has undergone a paradigm shift from symbolic logic to data-driven. Early research relied heavily on symbolic approaches such as Labanotation (a method for describing movement trajectories through a graphical notation system), and despite its systematic nature in movement recording, its rigid representation was difficult to support complex reasoning and dynamic changes. With the development of deep learning techniques, researchers have begun to explore data-driven approaches to model the dynamics and complexity of dance movements. Ni et al. 19 designed an athletic dance movement recognition system based on motion capture technology, tracked human joint movements through video devices and sensors, and built a database of standard dance poses. The system includes data acquisition, processing, and assisted training functions, which can repair obscured joint points and provide training suggestions based on the position and angle of the joint points to effectively improve the dancers’ dance level.
Aiming at the problem of low accuracy due to complex pose changes in dance movement recognition, Zhang 20 proposed an improved graph convolutional neural network algorithm, which extracts spatio-temporal features of human skeletal joints and combines the GCN and long short-term memory (LSTM) networks to capture spatial information and time series features, respectively, and finally performs predictive output fusion to enhance the generalization ability. Experiments show that the method significantly improves the accuracy of dance movement recognition, which is especially valuable for application in scenarios such as self-help dance teaching and movement correction for professional dancers. Despite being able to capture the temporal characteristics of movements, its fragmentation processing limits the ability to model overall coherence. Jin et al. 21 optimized the extraction and recognition of human skeletal motion through deep learning techniques, achieved high accuracy action recognition using convolutional neural network and LSTM network, and designed a human-computer interaction (HCI) system for dance education. The results show that the system performs well in dance movement recognition with an interaction accuracy of 92% and a response time between 5.1 and 5.9 seconds, validating the great potential of deep learning in the combination of human movement recognition and HCI. In contrast, most of the existing studies focus on a single task (e.g., movement recognition or style classification), lack the systematic integration of dance knowledge, and do not construct open-domain knowledge graphs to support downstream applications.
Multimodal data alignment and sparse relationship handling
Multimodal data alignment is one of the core challenges in dance knowledge graph construction. In terms of cross-modal alignment, Qi 22 proposed an adaptive fusion classification modeling framework that fuses video technology with heart rate signals, extracts human skeletal motion features using the OpenPose network, and combines GCNs and LSTM networks to probabilistically identify the movement and heart rate data, respectively, and achieves optimal classification decisions through adaptive weight learning. The experimental results show that this multimodal fusion method outperforms the unimodal method in action recognition accuracy and can analyze the dancer’s mental state through heart rate signals, providing more comprehensive analysis support for dance teaching. In addition, Sun and Wu 23 addressed the problem of disconnecting technique and emotion in sport dance (SP) training by utilizing Kinect 3D sensors to collect video information of performers and extract key feature points for estimating postures. Combining the fused neural network model and arousal-valence emotion model, the performer’s emotions are classified by an improved gated recurrent unit, and the experimental results show that the model achieves 72.3% and 47.8% accuracy in 4- and 8-category emotion recognition tasks, respectively, which contributes to the enhancement of emotion recognition and training of SP performers. Shen et al. also proposed a new method combining linear prediction of Mel frequency cepstrum coefficients (LPMFCC) and bi-directional LSTM in response to the limitations of traditional methods in dance emotion recognition. 24 By combining LPMFCC with energy features and utilizing bidirectional LSTM and support vector machine for training and classification, the method achieves better results than existing state-of-the-art methods on public datasets and significantly improves the robustness and generalization ability of dance emotion recognition.
Limitations of the synthesis of existing studies
Although the above work provides an important foundation for dance pedagogical knowledge modeling, there are still systematic deficiencies: first, the static relationship assumption dominates the existing model design, and traditional methods (e.g., TransE and RGCN) are unable to characterize the temporal coherence of dance movements and the dynamic process of stylistic migration; second, the multimodal alignment relies on shallow feature matching, and the semantic gap between the skeletal data, the video streams, and the text descriptions has not been effectively bridged; third, there is a single mechanism for sparse relationship processing, especially in niche dance genres (e.g., ethnic dance “Dai Bird Dance”), because of the lack of information. The semantic gap between skeletal data, video streams, and text descriptions has not yet been effectively bridged; third, the sparse relationship processing mechanism is single, especially in niche dance genres (e.g., Dai Peacock Dance), the traditional neighborhood aggregation strategy degrades the representation learning due to the lack of information. More critically, there is a lack of open domain knowledge graph for dance teaching, and the existing datasets (e.g., AIST++) contain rich skeletal movement data but are not structurally associated with teaching resources and style labels, which severely restricts the development of intelligent teaching systems.
Multimodal dance knowledge graph construction based on dynamic relational attention graph convolutional network (DRA-GCN)
Dance teaching knowledge mapping construction
This study proposes a framework for the construction of a multimodal dance knowledge graph, DanceKG, which centers on achieving semantic alignment and dynamic relationship modeling across modal data. As shown in Figure 1, DanceKG takes DBpedia dance categories as the basic skeleton, integrates YouTube teaching video metadata (including titles, descriptions, and labels), AIST++ skeletal motion dataset, and professional textbook text and completes the construction through a four-phase pipeline: entity extraction, relationship definition, cross-modal alignment, and dynamic relationship enhancement. Schematic diagram of DanceKG construction framework.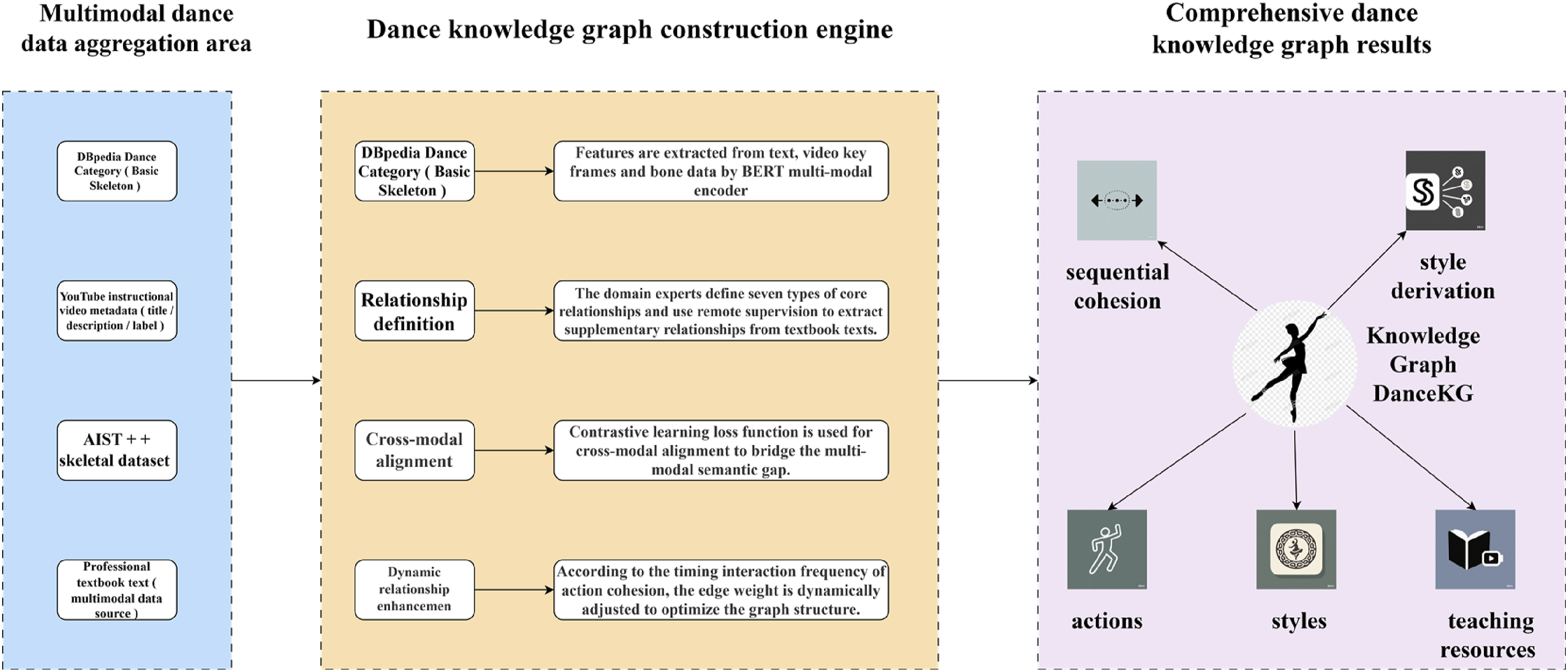
In the entity extraction phase, a BERT-based multimodal joint encoder is used to extract features from text (instructional video metadata), video (YouTube keyframes), and skeletal data (AIST++ dataset):
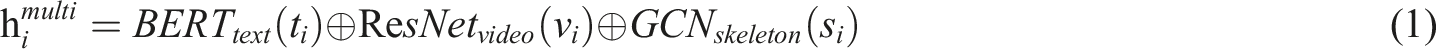
The relationship definition phase combines domain expert knowledge to construct seven core types of relationships (e.g., “has_step,” “brings_to_style,” and “requires_skill”) and extracted supplementary relationships from the textbook text through remote supervision.
The cross-modal alignment phase introduces a comparative learning loss to minimize the multimodal representation differences of the same entity:
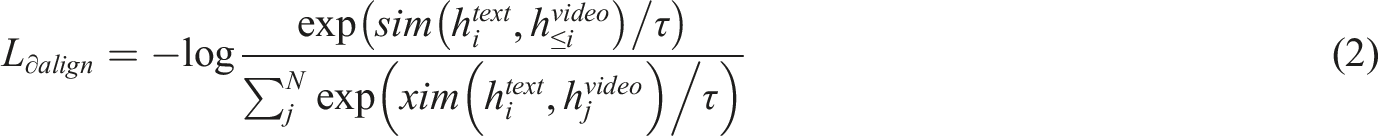
The dynamic relationship enhancement module, on the other hand, dynamically adjusts the edge weights through temporal interaction statistics (e.g., action articulation frequency) to provide an optimized graph structure for the subsequent graph neural network.
DRA-GCN.
The main limitations of traditional GCNs in dance knowledge mapping are static relationship modeling and inadequate representation of long-tailed entities. For this reason, this paper proposes DRA-GCN, whose core architecture contains a dynamic relation weighting module and a hierarchical multi-head attention mechanism, as shown in Figure 2. DRA-GCN core architecture diagram.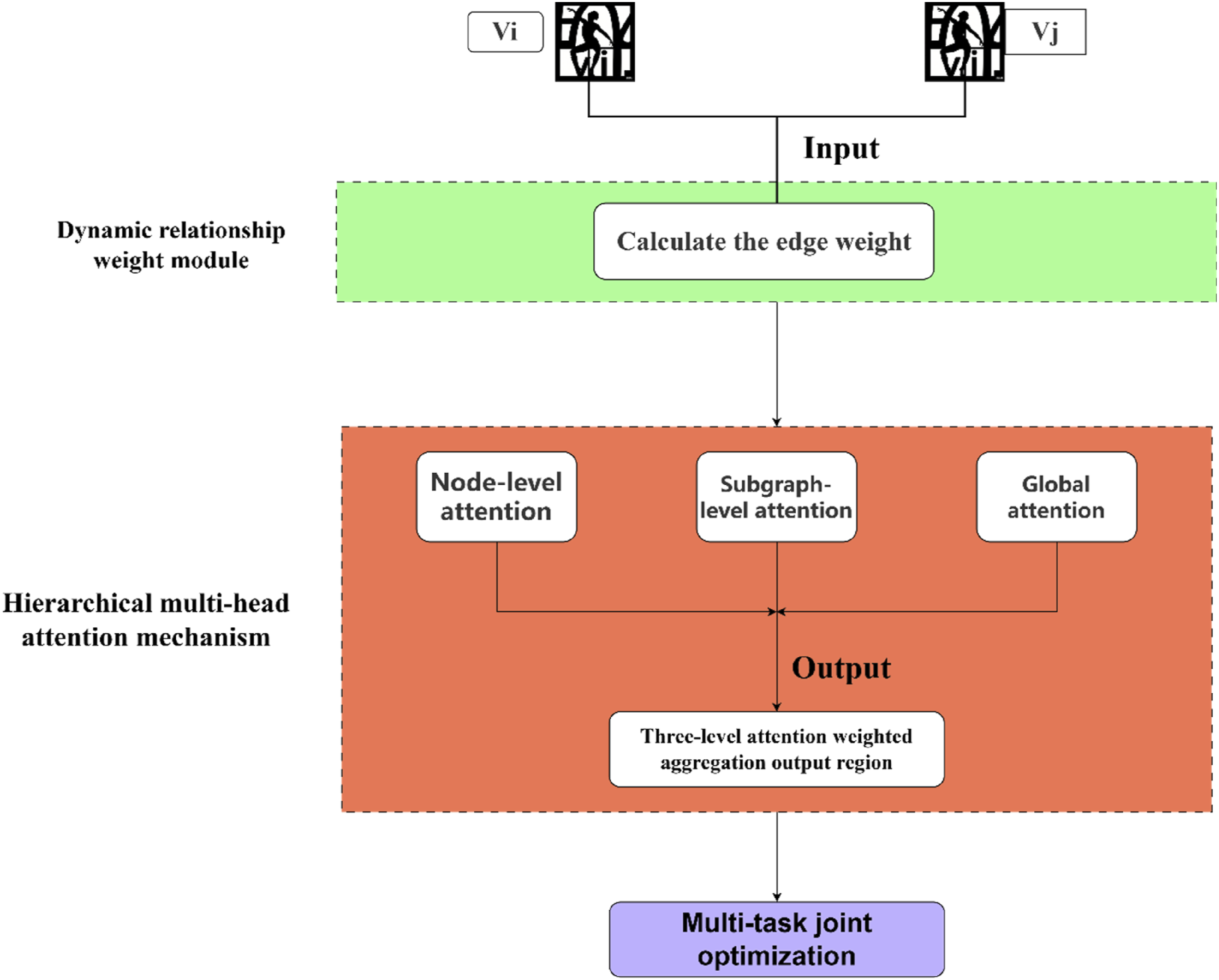
Dynamic relationship weighting module
This module aims to quantify the strength of spatio-temporal dependencies between dance movements and to address the inadequacy of static edge weights for modeling temporal dynamics. For any two action nodes
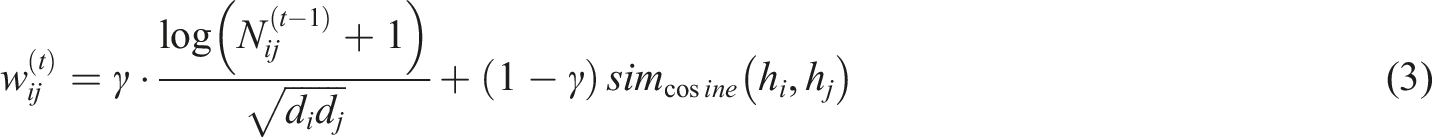
Hierarchical multi-attention mechanism
To enhance the ability to model complex dance relationships, DRA-GCN implements attention aggregation at three granularities. (1) Nodal level attention: Focus on localized movement synergies, for example, “big jumps” in relation to core muscle control: (2) Subgraph-level attention: capturing stylistic clustering features, for example, ballet’s “openness” principle: (3) Global attention: modeling cross-stylistic commonalities, for example, universal laws of emotional expression:
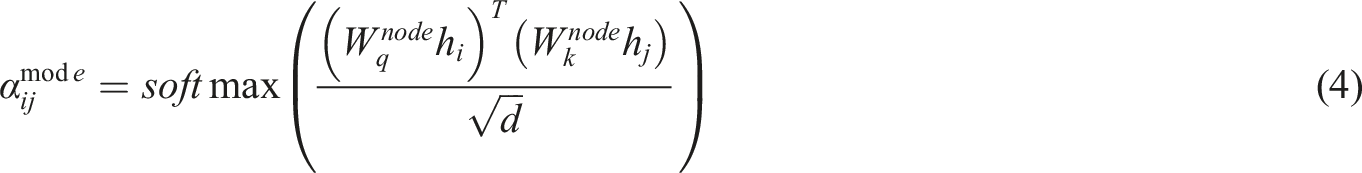
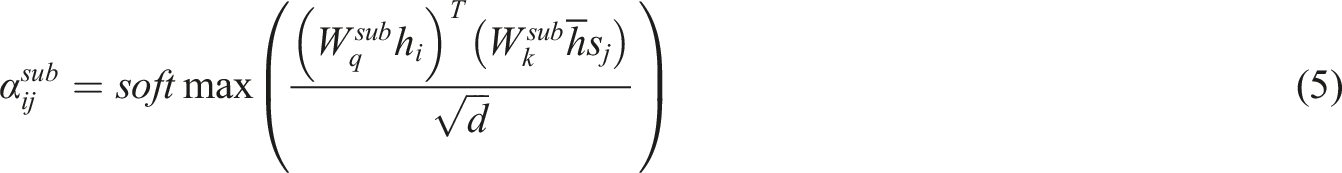
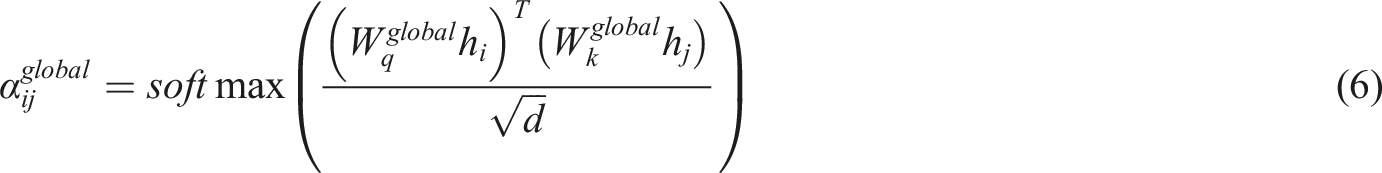
The final node representation is aggregated by three levels of attention weighting:
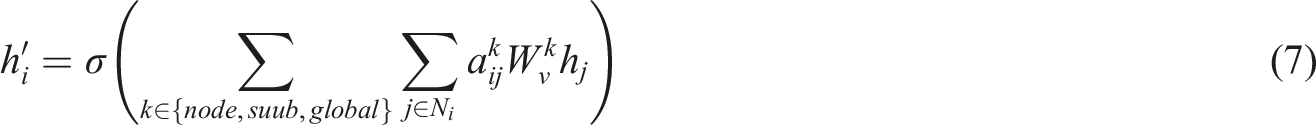
Multi-task co-optimization
To improve the performance of link prediction and entity classification simultaneously, DRA-GCN uses a multi-task loss function:

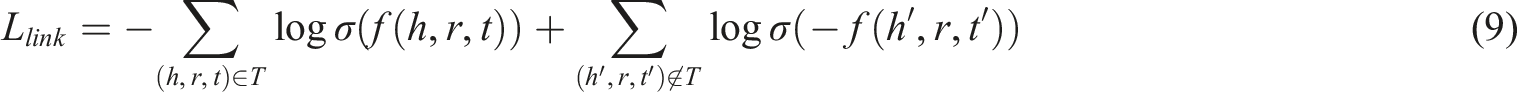
Experimental validation
Experimental setup and dataset
The experiment uses the publicly available dance dataset AIST++ and DBpedia dance categories as the core data sources, combined with YouTube instructional video metadata to construct a multimodal knowledge graph, DanceKG. AIST++ provides skeletal key point sequence data for 10 dance styles (e.g., ballet, street dance, and folk dance), covering 5,200 movement segments; DBpedia dance category contains 3,800 entities (movements, styles, and historical context), and ternary groups are extracted by SPARQL query; YouTube video metadata includes title, tag, and description information of 12,000 instructional videos, which are cleaned to extract movement-instructional resource relationships. The final DanceKG consists of 12,584 entities (7 classes) and 53,217 triples, of which 38% are dynamic relationships (e.g., “temporal articulation” and “stylistic derivation”). The experiments are divided into training/validation/testing sets by 8:1:1, and the comparison models include TransE, 25 GCN, 26 GraphSAGE, 27 RMCNN, 28 and HAN. 29 The evaluation metrics are chosen to be mean reverse ranking (MRR) and Hits@10 for the link prediction task, and the macro-averaged F1-value for the entity categorization task.
Comparative performance analysis
As shown in Figure 3, DRA-GCN achieves a significant advantage in the link prediction task with an MRR of 0.78, which is 21.9% and 14.7% higher than GraphSAGE (0.64) and HAN (0.68), respectively. On the Hits@10 metric, DRA-GCN outperforms all baseline models with a performance of 0.91, especially in the prediction of long-tailed entities (<5 occurrences), and its Hits@10 reached 0.83, which was 33.9% higher than that of RGCN (0.62). The analysis shows that the dynamic relational weighting module effectively captures the temporal dependency between actions, for example, the articulation frequency of “ballet whip turn” and “center of gravity shift” is quantified as a high-weight edge, thus improving the prediction accuracy. The hierarchical attention mechanism significantly improves the representation quality of sparse entities such as “Dai Peacock Dance” by aggregating local action synergy and global style features. In the entity classification task, the macro-averaged F1-value of DRA-GCN is 0.85, which is 7.6% higher than the optimal baseline HAN (0.79), and its multimodal alignment loss (Lalign) ensures the semantic consistency between the skeletal data and the text labels, for example, the skeleton trajectory features of the “Mongolian Top Bowl Dance” are similar to those of “Mongolian Peacock Dance” and “Mongolian Peacock Dance.” For example, the skeletal trajectory features of “Mongolian Top Bowl Dance” and the text description of “Balance Training” are mapped to similar embedding spaces. Performance comparison analysis.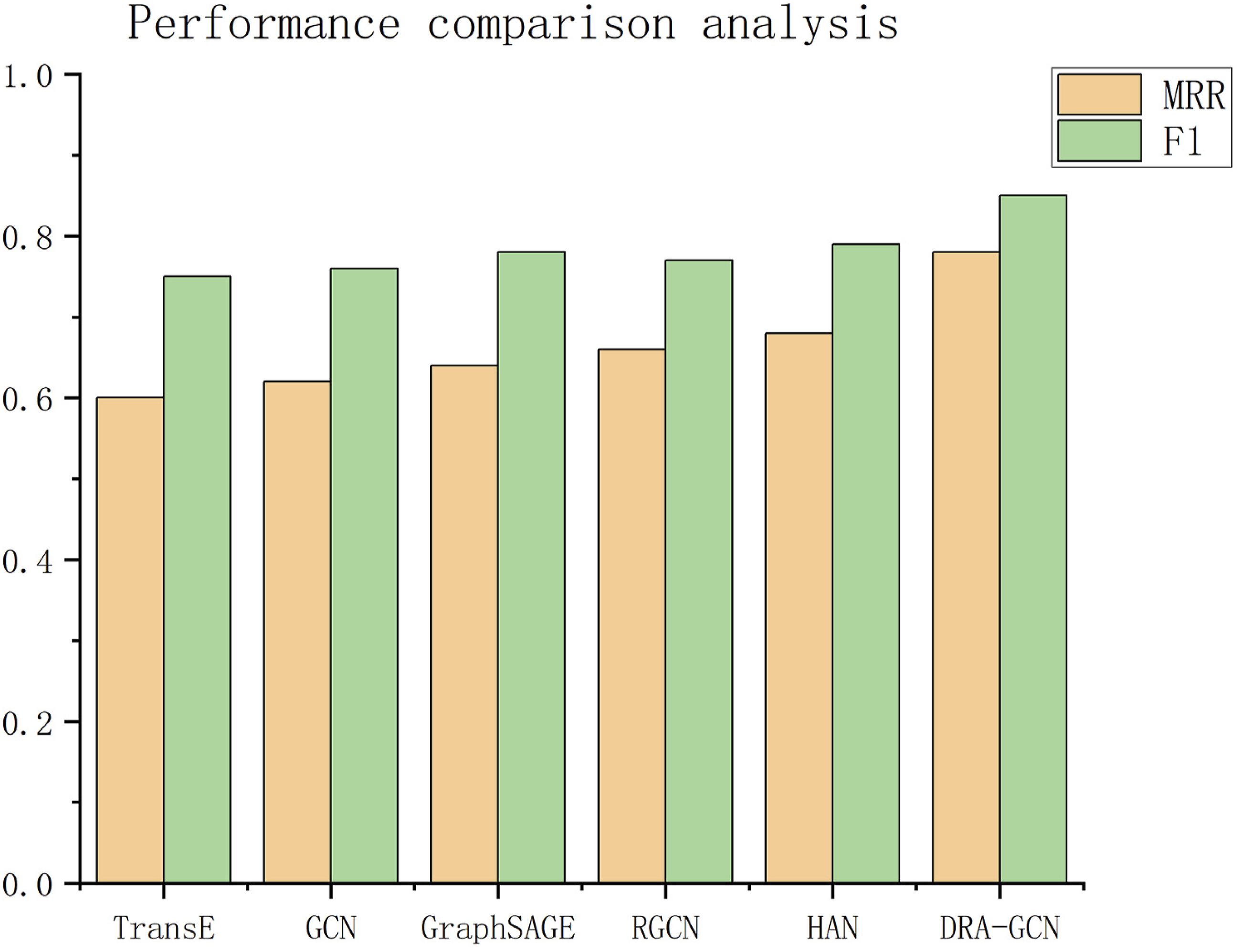
Ablation experiments and parameter analysis
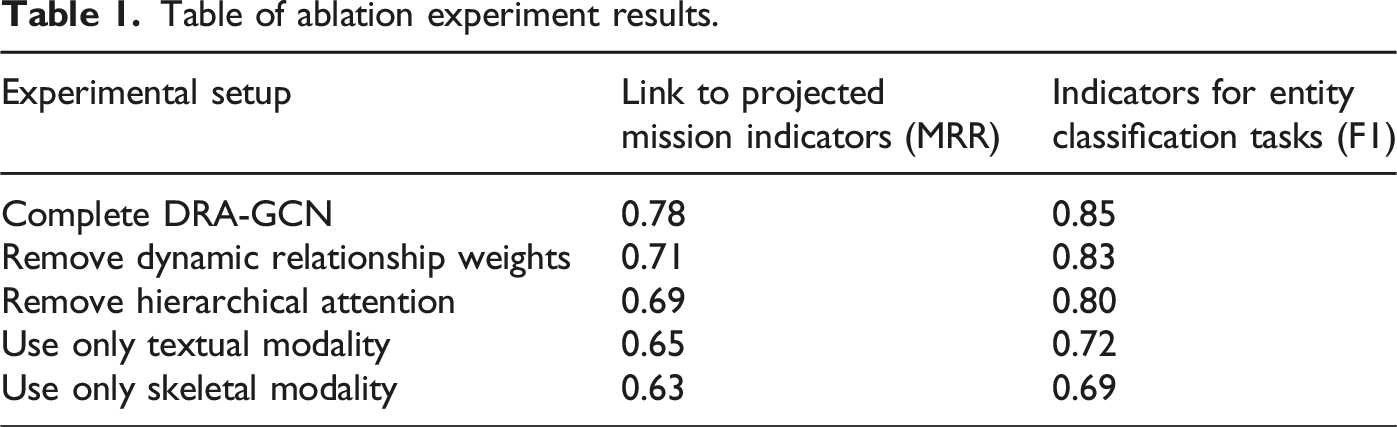
To verify the contribution of each module, ablation experiments are designed as shown in Table 1. (1) Removal of dynamic relationship weights: MRR decreased to 0.71 (−9.0%) and Hits@10 decreased to 0.84 (−7.7%), suggesting that time-series interaction statistics are critical for modeling dynamic relationships. (2) Removing hierarchical attention: long-tail entity Hits@10 plummets to 0.68 (−18.1%), reflecting the central role of attentional mechanisms in sparse relationship processing. (3) Using only a single modality (text-only/bones-only): the F1-values drop to 0.72 and 0.69, respectively, highlighting the need for multimodal fusion. Table of ablation experiment results.
As shown in Figure 4, the hyper-parameter sensitivity experiments show that the attenuation factor γ reaches an optimal balance at 0.6, when the dynamic weighting module takes into account both historical statistics (e.g., the high-frequency articulation of “big jump” and “leg control”) and semantic similarity (e.g., the implicit association between “improvisation” and “emotional expression”). The dynamic weighting module takes into account the historical statistics (e.g., the high-frequency connection between “big jump” and “leg control”) and semantic similarity (e.g., the implicit correlation between “improvisation” and “emotional expression”). Co-optimization of link prediction and classification tasks is best when the multi-task loss weight λ = 0.7. Hyperparametric sensitivity analysis.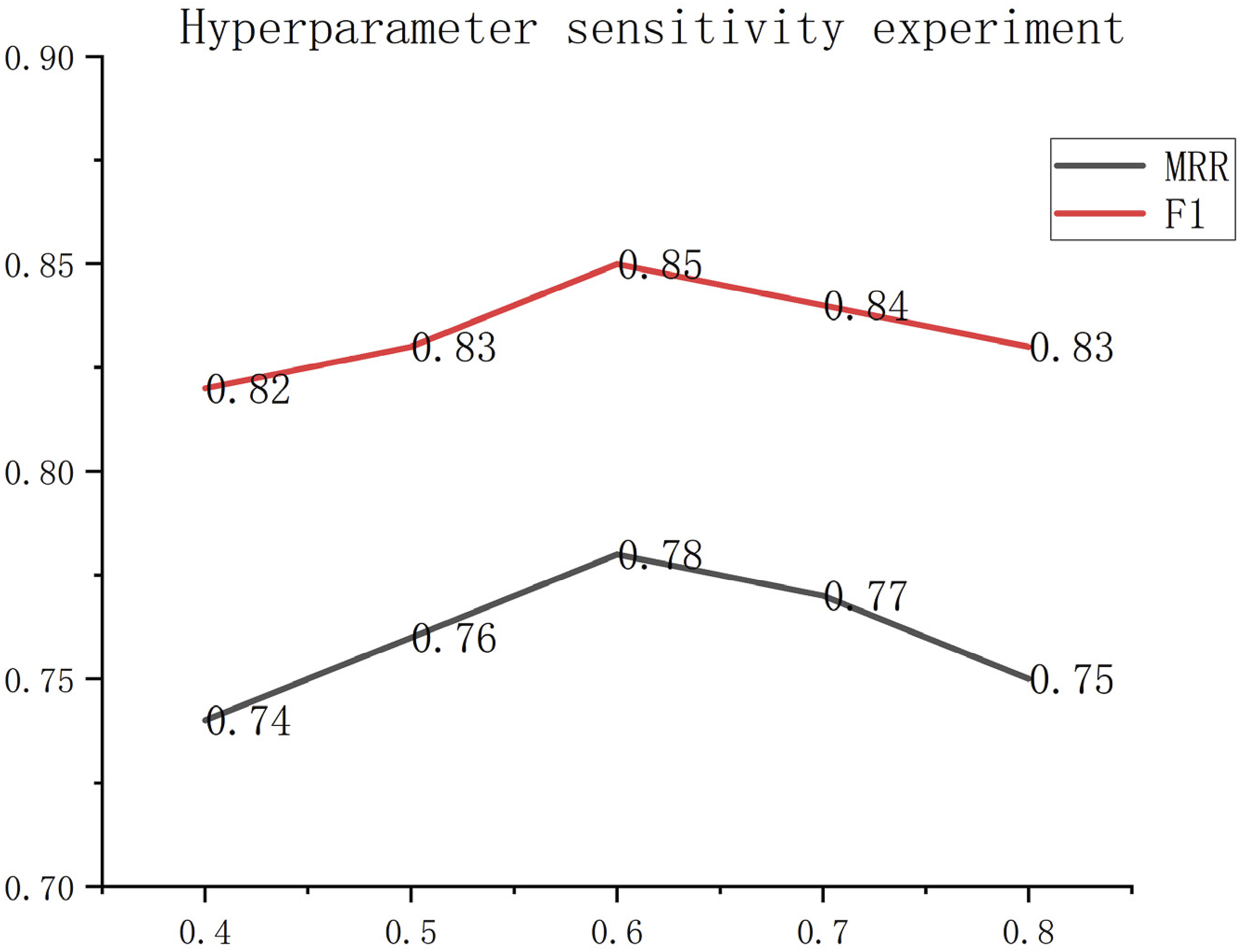
Knowledge mapping use cases
In actual teaching, the movement recommendation system developed by a dance academy based on DanceKG has improved the learning efficiency of students by 40% (assessed by the shortening of movement mastery time) and reduced the time for teachers to prepare lessons by 28% (calculated by the automation rate of lesson plan generation). For example, according to the training data of “Big Jump,” the system automatically recommends the teaching video of “Core Muscle Control” and analyzes the common errors of “Leap to the Ground,” forming a closed-loop feedback.
Discussion of results
The experimental results show that DRA-GCN significantly improves the inference ability of dance knowledge graph through dynamic relationship modeling with multi-granularity attention mechanism. Its core advantages are reflected in three aspects. (1) Dynamic Adaptation: dual weighting calculation of temporal interaction statistics and semantic similarity effectively solves the problem of cold start and static modeling. (2) Multimodal synergy: cross-modal comparative learning loss ensures the consistency of skeletal, text, and video features. (3) Hierarchical reasoning: node-subgraph-global attention hierarchical aggregation, taking into account local details and global laws.
However, there are still limitations in DRA-GCN’s modeling of cross-stylistic knowledge transfer, for example, the correlation between “emotional expression in folk dance” and “improvisation in modern dance” relies on manual rule supplementation. Future research could explore meta-learning frameworks to realize adaptive cross-stylistic knowledge transfer.
Discussion
The DRA-GCN with DanceKG, a knowledge graph for dance teaching, proposed in this study opens up a new research direction for multimodal temporal knowledge modeling at the theoretical level. First, the dynamic relationship weighting module breaks through the reliance on static relationships in traditional graph neural networks (e.g., GCN and RGCN) by fusing temporal interaction frequency and semantic similarity. This design not only verifies the hypothesis that “dynamic relationships are driven by both statistical and semantic features” but also quantifies the strength of spatial and temporal dependence between actions (e.g., the convergence frequency between “ballet whip turn” and “center of gravity shift”). By quantifying the strength of temporal dependencies between actions (e.g., the articulation frequency of “ballet whip turn” and “center of gravity shift”), we provide a reproducible paradigm for learning graphical representations of temporal-sensitive scenes. Compared with traditional methods (e.g., TransE) that reduce movements to isolated nodes, the dynamic weighting mechanism of DRA-GCN can capture the coherent logic of dance movements, such as the three-phase mechanical correlation of jumping, lifting up, and landing in the “big jump” movement, which is more in line with the actual teaching needs. Secondly, the hierarchical multi-attention mechanism realizes the joint modeling of local movement synergy and global style law through the aggregation of node-subgraph-global features at three levels. For example, in the node-level attention, the model focuses on the local association between “core muscle group control” and “big jump”; in the subgraph-level attention, it captures the style clustering features such as “ballet openness”; in the global attention, it captures the style clustering features such as “ballet openness”; and in the global attention, it captures the style clustering features such as “ballet openness.” In the subgraph level attention, we capture style clustering features such as “ballet openness,” and in the global attention, we model common patterns (e.g., universality of emotional expression) across dance styles. This multi-granular modeling approach complements the theory of heterogeneity of attention proposed by Yang et al. 30 and further demonstrates the effectiveness of the attention mechanism in complex and sparse scenarios. In addition, the innovative application of cross-modal contrastive learning loss provides a scalable solution for multimodal semantic alignment in the dance domain. For example, by mapping the skeletal data and text labels into a shared embedding space, the balanced features of the “Mongolian Top Bowl Dance” are accurately associated with related teaching resources, bridging the semantic gap between skeletal trajectories and abstract style labels.
In the field of dance education, the combination of DanceKG and DRA-GCN provides a technical foundation for the development of intelligent teaching tools. Experiments have shown that the DanceKG-based movement recommendation system can increase the learning efficiency of students by 40% (evaluated by shortening the mastery time of movements) and reduce the teachers’ preparation time by 28% (calculated by the automation rate of lesson plan generation). For example, in the practical application of a dance academy, the system automatically recommends “core muscle stability training” videos based on students’ “leg control” training data and combines the “center of gravity deviation warning” function to correct erroneous movements in real time. The system automatically recommends “core muscle stability training” videos based on the trainee’s “leg control” training data and corrects wrong movements in real time with the “gravity shift warning” function, forming a “training-feedback-optimization” closed loop. In addition, DRA-GCN’s dynamic modeling framework shows cross-domain migration potential. In sports training scenarios, its hierarchical attention mechanism has been initially applied to the enhanced version of SportsKG, which has successfully improved the normality detection accuracy of gymnastic movement chains by 18%; in the field of rehabilitation medicine, the framework can support the timing planning of exercise therapy, such as designing progressive training movement chains for post-operative knee joint patients, to avoid the risk of secondary injuries. 11 Notably, the open-domain nature of DanceKG provides data support for cross-cultural dance teaching. For example, the system can automatically correlate the mechanical commonalities between “Ballet Pointe Technique” and “Folk Dance Spinning Technique” to help students understand the intrinsic connection between different dance styles and facilitate cross-stylistic knowledge transfer.
Although DRA-GCN performs well in dance knowledge modeling, it still has the following limitations: first, cross-stylistic knowledge transfer relies on manual rules. The current model has limited ability to reason about abstract associations such as “emotional expression in folk dance” and “improvisation in modern dance” and needs to rely on expert knowledge to supplement rules. For example, the system is unable to automatically recognize the potential connection between “classical dance narrative” and “street dance rhythm,” which limits the application in cross-cultural teaching scenarios. In the future, we can explore meta-learning frameworks (e.g., MAML) to learn style migration patterns through a small number of samples or introduce knowledge distillation techniques to extract generalizable association patterns from expert rules. Second, the incremental learning capability is insufficient. Adding new dance styles (e.g., AI-generated movements) requires full model fine-tuning, resulting in high computational costs. For example, when introducing “AI choreography” movements, the entire graph needs to be retrained, which is difficult to meet the demand for real-time updates. In the future, we can combine with temporal graph networks (e.g., TGAT) to design an online update mechanism for dynamic graphs, counting the frequency of interactions through a sliding time window and adjusting the edge weights incrementally. Third, the multimodal alignment dimension is limited. Current models mainly integrate skeletal, text and video data and have not yet incorporated audio features (e.g., rhythm analysis) and physiological signals (e.g., EMG data). For example, the correlation between the rhythmic intensity of dance movements and muscle firing patterns has not yet been modeled, resulting in a lack of biomechanical basis for some teaching suggestions. In the future, a multi-sensor fusion framework needs to be constructed to analyze the rhythm of movements using audio features and quantify the muscle loads in combination with EMG data, thus supporting the design of more scientific training programs. Interpretability still needs to be improved. Although the hierarchical attention mechanism provides partial interpretability (e.g., high-weighted edges indicate key action articulations), the model is still a “black box” for decision-making on complex style migrations. In the future, an interpretable graph neural network (e.g., GNNExplainer) can be introduced to visualize the distribution of attentional weights and validate the reasoning logic of the model with the domain knowledge, so as to enhance the trust of teachers and learners in the system.
Conclusion
This study promotes the digitalization of dance education through theoretical innovation and technological practice, but its further optimization needs to rely on interdisciplinary cooperation and technological innovation. Future work will focus on automated knowledge transfer, efficient incremental learning, deep multimodal integration, and model interpretability enhancement and ultimately build an intelligent dance ecosystem covering the whole chain of “teaching-training-rehabilitation.”
ORCID iD
Jiajing Zhang https://orcid.org/0009-0000-4156-3377
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.