
Abstract
The conventional fuzzy C-means (FCM) is sensitive to the initial cluster centers and outliers, which may cause the centers deviate from the real centers when the algorithm converges. To improve the performance of FCM, a method of initializing the cluster centers based on probabilistic suppression is proposed and an improved local outlier factor is integrated into the model of FCM. Firstly, the probability of an object as cluster center is defined by its local density, and all initial centers are obtained by the cluster center’s probability and probability suppression function incrementally. Next, an improved local outlier factor is reconstructed according to the local distribution of an object, and its reciprocal is regarded as the contribution degree of an object to cluster center. Then, the improved local outlier factor is integrated into FCM to alleviate the negative effect caused by outliers. Finally, experiments on synthetic and real-world datasets are provided to demonstrate the clustering performance and anti-noise ability of proposed method.
Introduction
Clustering analysis aims to find the most natural way to partition dataset. It is a research hotspot of unsupervised learning and widely used in data mining, pattern recognition and computer vision [1, 2, 3, 4]. The essence of clustering is a process of dividing a dataset into multiple non-empty disjoint subsets, each of which is called a cluster. In the final result of partitioning, it is necessary to ensure that objects in the same cluster have a high similarity, and have a low similarity in different clusters.
Researchers have proposed many clustering algorithms, which can be roughly divided into the following categories: partitioning clustering, spectral clustering, hierarchy-based clustering, density-based clustering, grid-based clustering, etc. The main idea of partitioning clustering algorithm is: Given a dataset
Adaptively obtain the number of clusters to avert it’s given manually. Adaptively initialize cluster centers to avoid falling into the local optimum. While updating the cluster centers in iteration, a weighting factor is integrated into the model of FCM to reduce sensitivity to outliers. Introduce an appropriate distance metric, which has a positive effect on dataset with complicated geometric structure.
This paper focuses on the second and third issues mentioned above. On the one hand, to weaken the influence of random initial cluster centers on the clustering performance, some scholars adopt the adaptive method of obtaining the initial cluster centers instead of random selection. Their core idea is: the objects with high density are used as initial centers, and the distance among them is large. On the other hand, some scholars have proposed a sample-weighted or feature-weighted method that provided weight for each object. In recent years, many researchers use local outlier factor to modify the cluster centers and optimize the clustering process.
Although a large number of fruitful works have been done by predecessors, there are still further works on the points (1) and (3) mentioned above. In this study, we propose a method to initialize the cluster centers with probabilistic suppression and an improved FCM algorithm integrated with a new local outlier factor. The Probability Suppression Method is referred to as PSM and the improved FCM is named as FCM-iLOF. The works of this study can be summarized as follows:
A new method called PSM is proposed to improve the selection rule of initial centers. A novel local outlier factor is redefined to estimate the contribution degree of objects. The experimental results indicate the proposed approaches achieve better performance than others.
The rest of this paper is organized as follows: Section 2 introduces the method of initializing cluster centers and the improved local outlier factor proposed by previous scholars. Section 3 describes the original FCM algorithm. PSM and FCM-iLOF algorithm are proposed in Section 4. In Section 5, we analyze the experiments. Finally, the summary of this work is given in Section 6.
In this section, we mainly review the method of selecting initial centers and the algorithm for measuring outliers.
Many scholars have done researches to improve the rule of selecting initial cluster centers to avoid the local optimum caused by the randomness of the initial cluster centers [6]. Li et al. [7] proposed a novel initial clustering centers selection algorithm, which first calculates the density and nearest neighborhood distance of each object within a specified radius, and then constructs the ratio of density to nearest neighborhood distance, and finally objects with the
However, multiple centers may be contained in a cluster caused by the irrationality of neighborhood radius. To solve this shortcoming, Yu et al. [11] optimized the K-MEDOIDS clustering method by increasing the number of clusters from 2 to
Outliers are a special subset that occupy a relatively small part of the dataset, which are greatly distinct from its neighbors in spatial distribution. In the clustering problem, objects should have different weights. In other words, the contribution degree of the outlier should be smaller than normal object. Therefore, it is worthwhile employing an appropriate weighting function to assign a weight for each object [17].
To implement the above requirement, some researchers used sample-weighted and feature-weighted to assign a weight to each object to distinguish outlier from normal object. The idea of density peak clustering (DPC) [18] was integrated into the FCM algorithm by applying local density that reflected the denseness or sparsity [12]. Yu et al. [17] adopted a sample-weighted method based on the probability distribution and the maximum entropy principle. Pimentel et al. [19] proposed two methods to obtain the weight, the first was modeling the membership degree of each object, and the second was modeling the dispersion degree by adaptive distance. Both of them have superior robustness to the dataset with outliers.
In addition to adopting the sample-weighted or feature-weighted approach, some scholars calculated the contribution degree by local outlier factor (LOF) [20]. The LOF algorithm was first proposed for outlier detection, and its main idea is that the abnormality of an object is judged by the similarity of the spatial distribution between the object and its neighbors. The greater similarity an object gains, indicates it has more opportunity to be a normal object, conversely, it is more likely to be an outlier. In literatures [21, 22, 23, 24, 25, 26, 27], many scholars continued to improve the LOF algorithm and achieved success. To avoid outliers affecting the performance of the clustering algorithm, Zhang et al. [21] proposed an improved FCM algorithm using the outlier factor to weaken the weights of outliers. Muhima et al. [22] combined the LOF algorithm with the K-Means algorithm to divide the dataset after deleting the outliers, which overcomes the influence of outliers to some extent and achieves better performance. However, many improved LOF algorithm proposed by previous scholars only depend on the neighborhood mean distance to measure the degree of local deviation, without considering the local distribution of an object within its neighborhood. Recently, Su et al. [23] redefined a new factor called LDC that first integrates variance and expectation of the neighborhood distance into LOF to compute the degree of local deviation. In literature [24], the LOF was extended by utilizing the entropy of the relative
In summary, all of the above improved LOF-based algorithms judge whether the object is an outlier by employing the neighborhood mean distance to calculate the local outlier factor. Only a few papers have considered the variation of neighborhood distance, but their calculation rules can’t fully reflect the local distribution of an object within its neighborhood. In this study, we define a new local outlier factor, which is fully taking advantage of the local distribution. The local outlier factor proposed in this paper integrates both distance and distribution information. And, the module of intra-cluster k-neighborhood vector’s sum is used to describe the distribution information of an object within its neighborhood, weakening the deficiency of variance. It is more applicable compared to existing algorithms when quantifying distribution information. The details are given in Section 4.
Fuzzy C-means algorithm
FCM is a clustering algorithm based on objective function minimization, which iteratively updates membership matrix and cluster centers to minimize objective function until it converges. Let dataset
where
Finally, the objective function
A method for initial centers selection
The randomness of initial cluster centers will affect the clustering performance of FCM. The DPC is based on the following two assumptions. The cluster centers are distributed in high-density region, and the distance among them is large. But DPC still needs to manually determine the centers. Inspired by the above assumption, we propose a method of initial centers selection based on probabilistic suppression to obtain the initial cluster centers automatically.
.
(Local Density of Object
where
.
(Cluster Center’s Probability of Object
Obviously, Eq. (6) conforms to the first assumption of DPC. The first initial center
where
However, to further reduce the risk of multiple initial centers falling into the same cluster, it is necessary to judge whether these existing initial centers can be reached from initial center just gained. The rule for determining reachability are shown in Definition 3.
.
(Reachable Initial Center): Given two initial centers
where
Now, assuming that
[ht] : PSM[1] dataset
Initialize an empty set
Obtain the
Unreachable and reachable cases.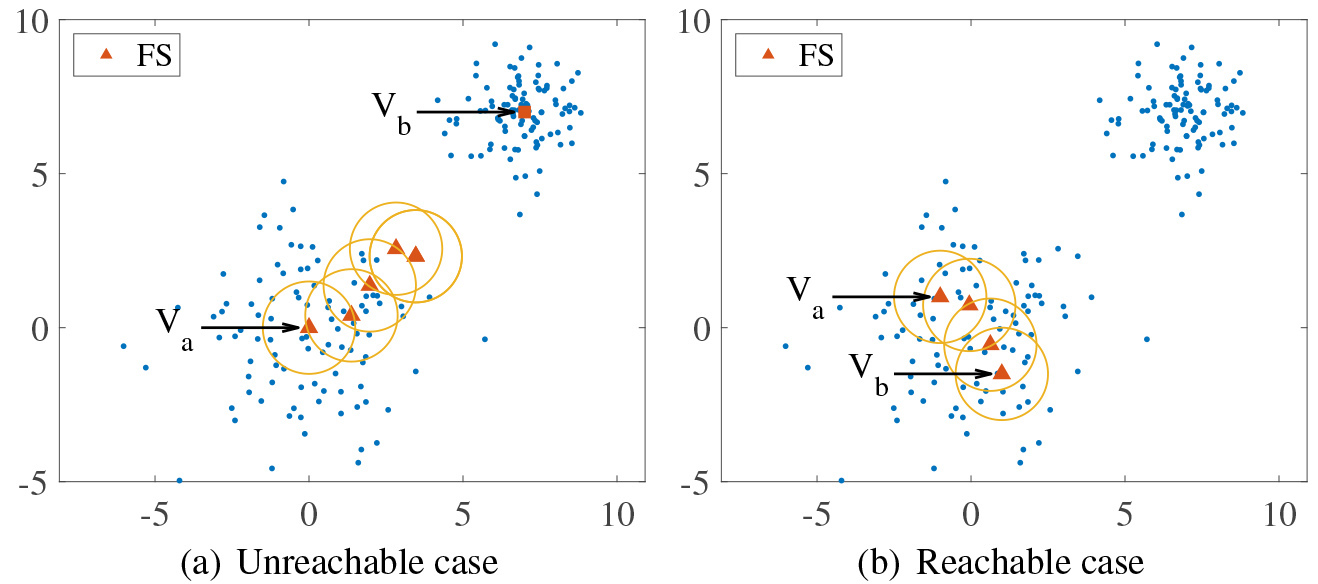
Equation (3) shows that each object equally participates in the updating process of cluster centers without considering the difference among objects. In fact, each object should be assigned a unique weight. According to the analysis in Section 2, the LOF can be used to describe the deviation of objects, but most of the existing improved LOF are still inadequate. For example, Fig. 2 shows two different local distributions of object
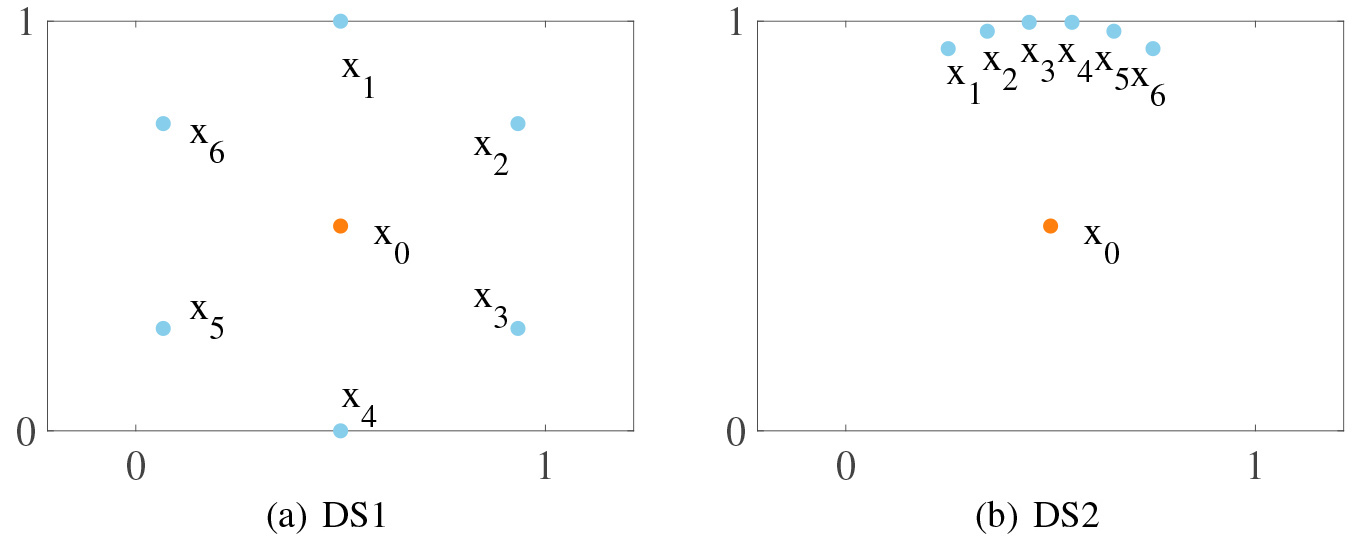
.
(Intra-Cluster k-Neighborhood of Object
.
(Intra-Cluster k-Neighborhood Mean Distance of Object
.
(Module of Intra-Cluster k-Neighborhood Vector’s Sum of Object
As we know, normal object generally has a higher density than outlier in the same cluster, so the
If Conversely, if
In general, outlier has a larger value of
.
(Dispersion Degree of Object
.
(Improved Local Outlier Factor of Object
.
(Contribution Degree of Object
The contribution degree is utilized to improve objective function of FCM, then the objective function of FCM-iLOF is defined as:
where
In order to obtain estimators of
The
The
The membership matrix
[ht] : FCM-iLOF[1] dataset
Initialize parameter
Update membership matrix
To verify the effectiveness of the proposed algorithms, a series of experiments are performed on synthetic datasets and real-world datasets from UCI machine learning library [29]. The comparison algorithms include DP-K-Means [10], INCK [11], FCM [5], DSFCM [12], LOFKMeans [22] and KMO [28]. All the experiments are implemented on the platform which runs Windows 10 professional workstation edition and has Intel (R) Xeon (R) Silver 4114CPU with 2.19 GHz and 64 GB RAM.
Summary of synthetic dataset
Summary of synthetic dataset
Table 1 shows the parameters of synthetic datasets with three clusters, where include 10 groups of parameters. Each one is used to generate 10 groups of datasets, a total of 100 groups of datasets. In Table 1,
Evaluation of initial cluster centers
The effectiveness of the PSM algorithm is verified on the synthetic datasets with known centers. The mean error
where
Error of initial centers.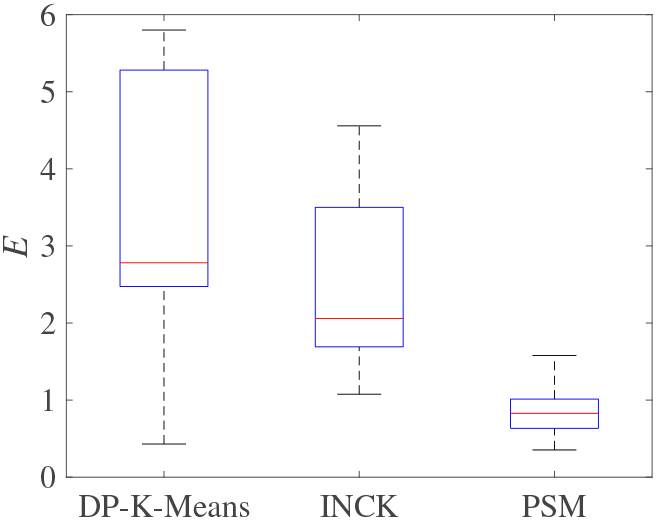
Initial centers obtained by different algorithms.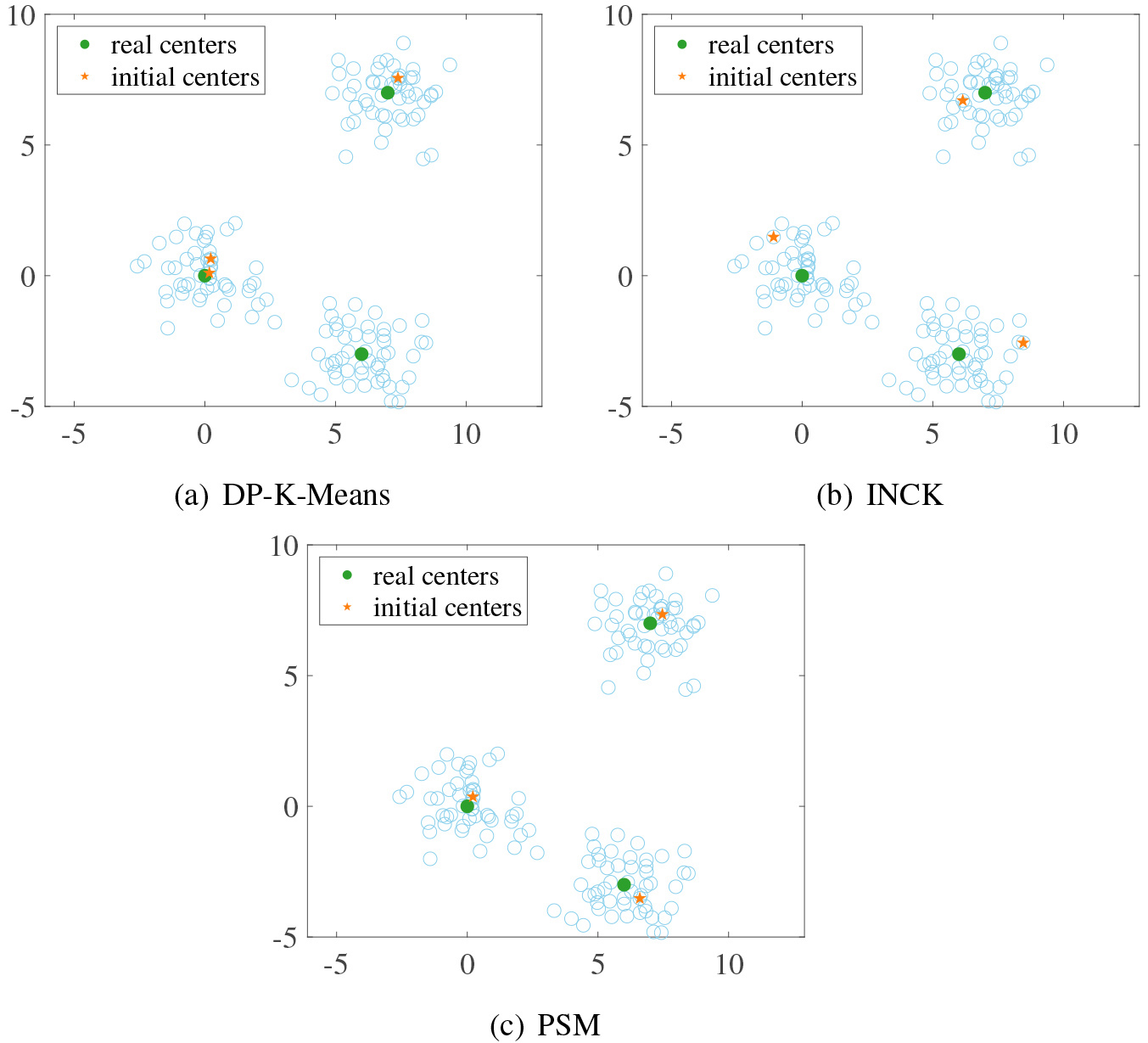
From Fig. 3, we see that the PSM algorithm achieves the best result among the three algorithms in the aspect of
To easily control the local distribution of objects, the two synthetic datasets in Fig. 2 are adopted to illustrate the effectiveness of contribution degree proposed in this paper. As shown in Fig. 5, the contribution degree of LOF and LDC is compared with Eq. (15) in this paper. Due to LOF and LDC factors are used to describe the abnormity, the reciprocal of them are calculated to quantify the contribution degree. From Fig. 2, it is not difficult to find that the object
Contribution degree of each object in Fig. 2 calculated by the reciprocal of different local outlier factors.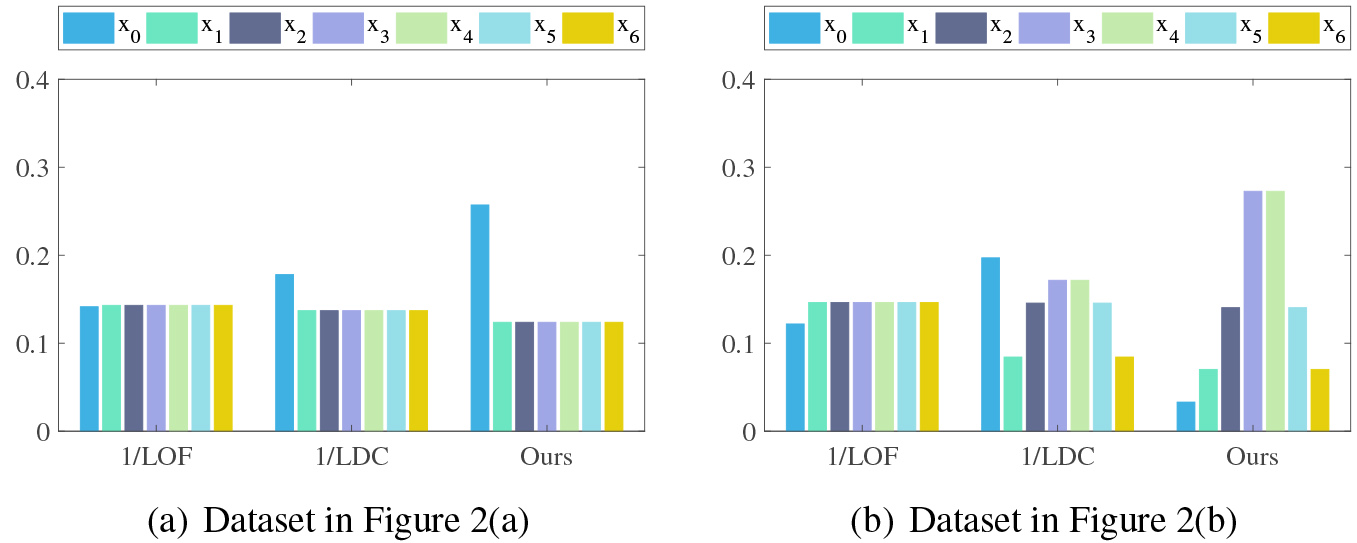
Next, we select 10 datasets generated by the first synthetic dataset parameter and add a few outliers to each cluster to evaluate the anti-noise ability of different algorithms. For the convenience of subsequent description, the 10 datasets of adding outliers are called DSO. The outliers added to each cluster are shown in Table 2, which are far from cluster centers. To visually show the dataset with noise, a dataset is selected from DSO and shown in Fig. 6. Obviously, the artificially added outliers are far away from the corresponding clusters, which can be used to test the anti-noise ability. The FCM-iLOF and four comparison algorithms are executed on DSO, and the intra-cluster distance of each algorithm is shown Table 3. The intra-cluster distance is defined in Eq. (21). As shown in Eq. (19), in order to make the centers closer to the real centers when the algorithm converges, a small weight will be assigned to the outlier to weaken the influence of the outlier on the center update. Therefore, a smaller value of the intra-cluster distance indicates a better anti-noise ability. Note: the four comparison algorithms are executed 100 times respectively. In Table 3, the experimental results of each row are the mean of the intra-cluster distance of the 100 clustering results. In this experiment, we set
where
Added outliers artificially
ICD of different clustering algorithms on DSO
A dataset with artificially added noise.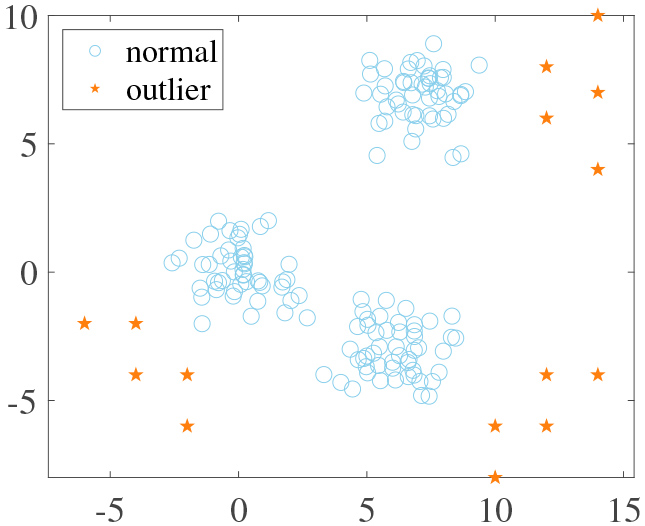
The intra-cluster distance of each algorithm on DSO is shown in Table 3, and the best results of all algorithms are highlighted in bold font. It can be seen from Table 3 that although the DSFCM algorithm has the smallest intra-cluster distance in the
In this subsection, we chose real-world datasets obtained from UCI machine learning library, including Iris, Seeds, Wine, Glass, and New Thyroid, to evaluate the performance of five different algorithms. The detail descriptions of datasets are shown in Table 4. These datasets are often used for clustering and outlier detection [32, 33, 34, 35, 36]. Rand Index (
where
Descriptions of real-world datasets
In order to decrease the influence of the randomness of initial centers on FCM, DSFCM, LOFKMeans and KMOR, these four comparison algorithms are executed 100 times respectively, and the mean
In this study, we propose an adaptive FCM algorithm integrated with local outlier factor.
The probability of an object becoming a initial center is defined by the local density, and the initial centers are obtained by combining cluster center’s probability with probability suppression function incrementally. A new improved local outlier factor is reconstructed by defining the intra-cluster k-neighborhood mean distance and module of intra-cluster k-neighborhood vector’s sum, and it is integrated into FCM to improve the iterative formula of cluster center. The effectiveness of the proposed algorithm is verified on synthetic and real-world datasets. The initial centers obtained by PSM are close to the real centers, which is helpful to increase the possibility of algorithm convergence to the global optimum. Not only is the reconstructed local outlier factor effective in the aspect of describing the degree of deviation, but also it improves the anti-noise performance of FCM. Besides, after replacing intra-cluster k-neighborhood in Definition 4 with k-neighborhood, the local outlier factors reconstructed in this study can be applied to the outlier detection directly.
The shortcoming of this paper is that the number of clusters can’t be obtained adaptively, and it still needs to be given artificially. In the future, it is significant to enhance the theoretical proof and analysis, and to apply the proposed approach in engineering applications.
Footnotes
Acknowledgments
This work was supported by the Key Science and Technology Research Program of Chongqing Municipal Education Commission (KJZD-K201900505), Chongqing University Innovation Research Group Funding (CXQT20015), and Innovation Project of Chongqing Normal University (YKC20032).