
Abstract
Stock price forecasting has been an important topic for investors, researchers, and analysts. In this paper, a prediction model of Dynamic Gaussian Deep Belief Network (DGDBN) is proposed. Generally, the network structure of traditional Deep Belief Network (DBN) determines the performance of its time series prediction. Most previous research uses artificial experience to adjust the network structure, it is difficult to ensure performance and time efficiency by constantly trying. In addition, the accuracy of the traditional DBN stacked by binary Restricted Boltzmann Machines(RBM) needs to be improved when solving the time series problem. The DGDBN designed in this paper contains two points: The first point is to add Gaussian noise to the RBM. The second point is to realize the increase or decrease branch algorithm of hidden layer structure according to the connection weights and average percentage error (MAPE). Finally, the forecast for the stocks of United Technologies Corporation and Unisys Corp, DGDBN is compared with DBN and LSTM. The root means square error (RMSE) increases by 15% and 65%. The interesting thing we found is that the number of neurons in the last layer of the DGDBN network has a greater effect than other layers.
Keywords
Introduction
Financial market data is non-linear, dynamic, complex, and chaotic, which is considered to be one of the most challenging problems in time series forecasting [1, 2]. Nevertheless, many empirical studies show that financial markets are predictable to some extent [3]. Scholars have tried to achieve relatively accurate predictions of financial markets, such as the Autoregressive Integrated Moving Average Model (ARIMA) [4] and Neural Network (NN) [5]. However, there are defects such as a large amount of calculation, easy to fall into a local minimum, and poor accuracy [6]. In recent years, deep learning has emerged as a particularly attractive candidate for financial forecast [7]. Deep Belief Network (DBN), as a core model of deep learning, has attracted much attention due to its real-time and good nonlinear capabilities [8]. It has played a role in a variety of machine learning problems, such as object recognition [9], image recognition [10], fault detection prediction [11], financial data prediction [12] et al.
DBN is a probabilistic generation model proposed by computer scientist and “Father of Neural Networks”, Geoffrey Hinton, which simulates the learning mechanism of the human brain for data feature processing [13]. As a deep network, DBN is stacked by Restricted Boltzmann Machine (RBM). The output of the previous RBM is the input of the next RBM [14]. In addition, DBN achieves the learning and extraction of data feature information through an unsupervised learning process [13]. Compared with the superficial network, it is better to learn from a large amount of data and find the underlying data rules. Through the previous research, we found that DBN still has some issues. First of all, the network structure is commonly a fixed structure set in advance, and the network structure does not change during the training process, which cannot guarantee the superiority of the initial network parameters. Secondly, when traditional DBN deals with continuous data, the prediction accuracy is reduced due to its discrete type. When DBN solves nonlinear data similar to stocks, different network structures will lead to reduced predictions or over-fitting [15]. The common methods for determining the network structure of neural networks include the empirical setting method [16], trial and error method [17], growth method, and pruning method. Basheer et al. designs the hidden neurons of artificial neural networks based on experience [15]. Zhao et al. proposed to delete hidden neurons in artificial neural networks based on weights [18].
Based on artificial neural network structure optimization, scholars began to examine how to construct an appropriate DBN network to better fit nonlinear data. However, compared with artificial neural networks, the research is still at the initial stage [19]. In the existing literature, most of the DBN network structures are designed through empirical methods and trial-and-error methods. Farahat M. et al. used the trial and error method to determine the structure of the DBN network and used it to noise-robust speech recognition [20]. Shen et al. set up the DBN network structure through manual experience used a conjugate gradient algorithm to accelerate learning and applied it to exchange rate prediction [21]. Regardless of the trial and error method or the manual experience method, it takes a lot of time, and it is difficult to guarantee that the result obtained is the optimal network structure. S.Pirmoradi et al. used the separability to automatically determine the network structure by using the average of the weights as the threshold, which improved the classification ability of the DBN single-layer network restricted Boltzmann machine [22]. Qiao et al. designed an organizational deep belief network based on the spike intensity and root mean square error of neurons, but this method has a large amount of calculation [23]. Zhang et al. designed a self-organizing DBN network, but only considered the hidden layer neurons, the hidden layer is fixed to two layers [24]. To solve the problem of DBN network structure, this article is based on the above research [18, 23]. Take the norm square root of the connection weights as the judgment basis to select the hidden layer neurons to discard or split, and then determine the depth of the neural network according to the average absolute percentage error of the network. This design method not only adjusts the number of hidden neurons but also considers the changes in the hidden layer. The resulting network retains the main structure of the original network, improves the network performance, and the calculation in the operation process is relatively simple.
As a component of DBN, RBM also affects the forecast effect of the DBN model. Although the traditional DBN has achieved good results in the field of artificial intelligence, the accuracy of time series prediction still needs to be improved. The traditional DBN network uses a discrete method in feature extraction, which is essentially due to the traditional DBN network is composed of binary restricted Boltzmann machine stack (RBM), so the effect of processing continuous data is poor [25]. To solve this problem, some scholars have proposed a continuous RBM network. Zhang converts discrete input layer signals of restricted Boltzmann machine (RBM) into continuous signals by adding Gaussian noise, converts discrete RBM into continuous RBM, and makes exchange rate prediction with the proposed model [26]. However, this method only considers the RBM of the input layer. In this paper, by adding Gaussian noise to RBM and combining it with the structural change of the DBN network, we increase the RBM with Gaussian noise layer by layer. Compared with previous studies, the method proposed in this paper ensures that each layer of the unit network is a continuous restricted Boltzmann machine, which improves the prediction performance of traditional DBN for continuous data.
Based on the above discussion, a dynamic Gauss Depth Belief Network (DGDBN) is proposed, which optimizes the performance of traditional DBN in time series prediction and has three main contributions:
To improve the prediction effect of traditional DBN in time series prediction, Gaussian noise is added to the restricted Boltzmann machine so that continuous data can be better processed. It is proposed for the first time to determine the number of hidden layer neurons and hidden layer according to the root of the quadratic norm and the average absolute percentage error of connection weights between layers, so as to dynamically adjust the DBN network structure in the training process. The relationship between the prediction performance of DGDBN during training and the number of network structure layers and neurons is analyzed and summarized.
The rest of the paper is organized as follows. Section 2 briefly introduces theoretical knowledge. In Section 3, the detail of DGDBN model is proposed. The stock market experimental validation and analysis of DGDBN is performed in Section 4. Finally, Section 5 concludes our findings and presents a number of directions for future study.
Gaussian deep belief network
Deep Belief Network (DBN) is a probability generation model stacked by the Restricted Boltzmann machine (RBM). RBM is a single-layer neural network with randomness, which is essentially an undirected graph model composed of a random layer of visible neurons (input layer) and a layer of hidden neurons [27]. The RBM model is fully connected between layers, but there is no connection within layers. Figure 1 shows the model diagram of RBM. V represents the visible layer, H represents the hidden layer, and W represents the connection weights between the visible layer and the hidden layer.
The structure of RBM model.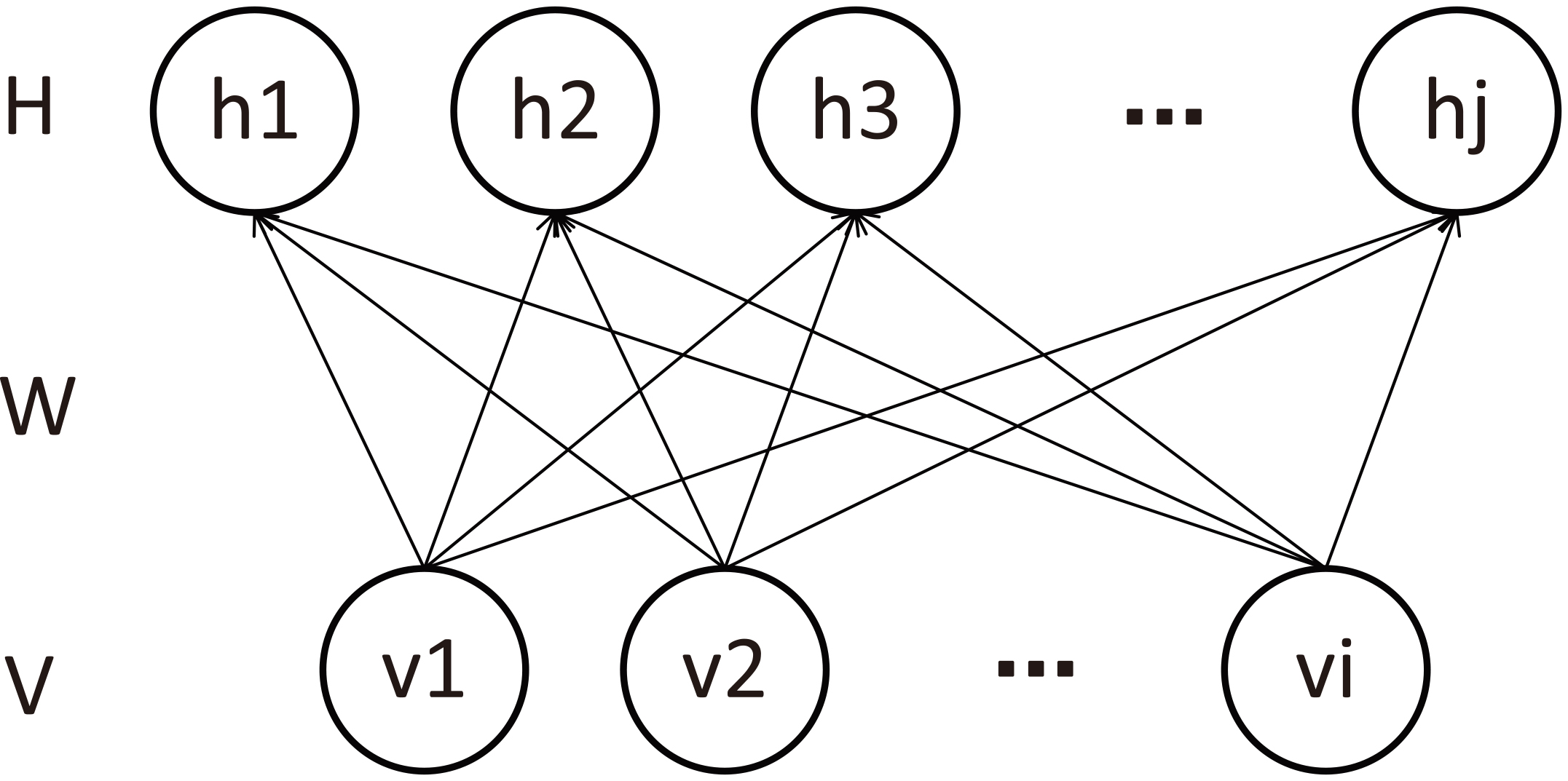
RBM as a model based on energy function, the energy function
where
From Eq. (1), it can be deduced that the joint function between visual layer V and hidden layer H is:
where
Because there is no link between neurons in the same layer of RBM, it can be concluded that the conditional probability of visible layer neurons and hidden layer neurons is:
where
Traditional DBN may map continuous data into discontinuous binary data according to Eqs (4) and (5). Therefore, this paper adds Gaussian noise on this basis to ensure the continuity of RBM in the training process. After the change, the conditional probability of the visible layer neuron and the hidden layer neuron is:
where
The training process of the Gaussian deep belief network is the same as the traditional deep belief network. Its training process is divided into two steps: unsupervised training and supervised training, as shown in Fig. 2 Unsupervised training is to train RBM layer by layer to ensure that each layer of RBM reaches the optimal state at the end of training. This process is a greedy algorithm and can not ensure that the overall structure reaches the optimal state. After unsupervised training, the parameters of each layer are adjusted reversely layer by layer according to the error between the output of the last layer RBM and the real value. This process also solves the problem caused by a greedy algorithm in the process of unsupervised training.
The structure of GDBN model.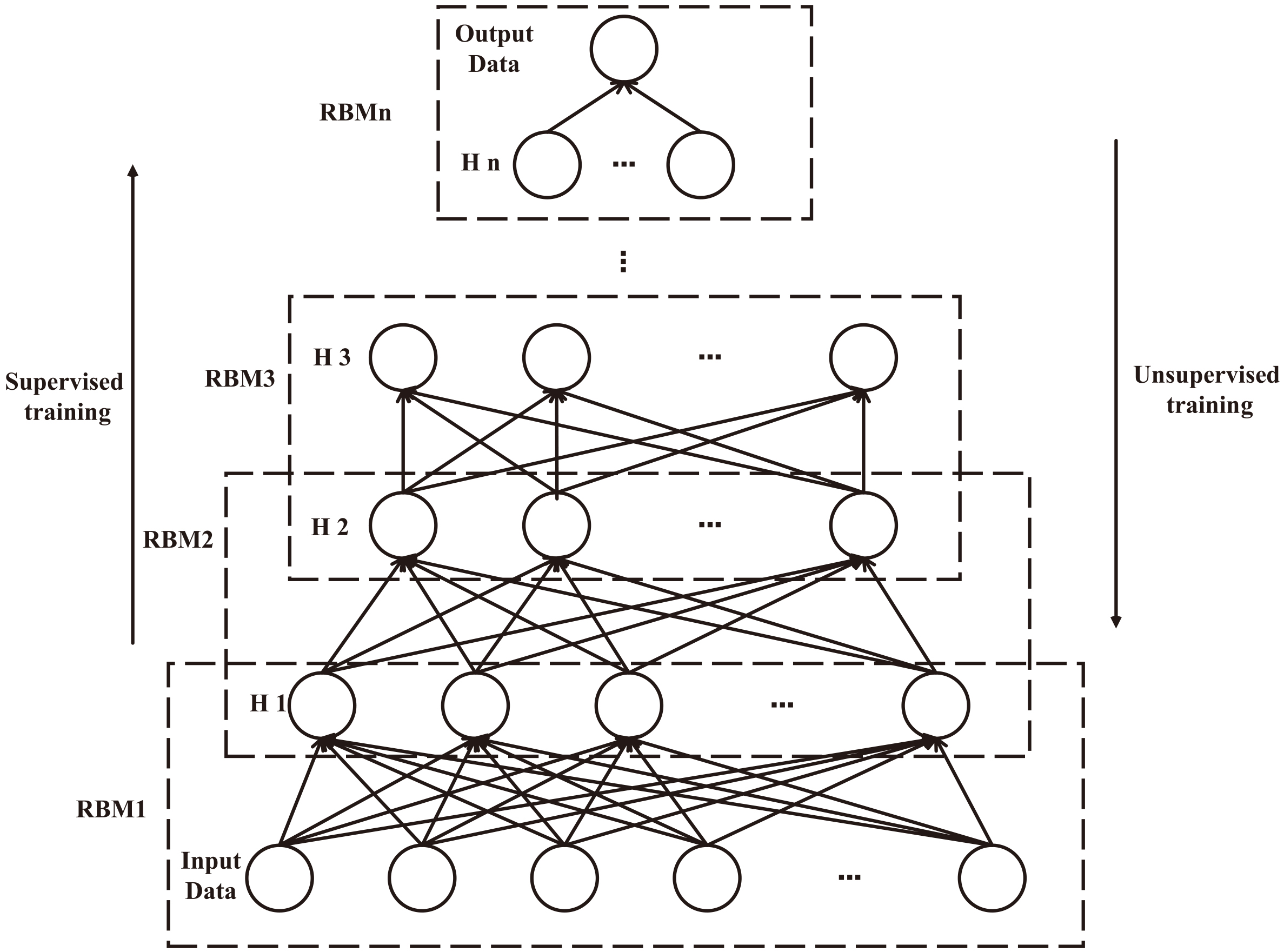
In the unsupervised training process, the training goal of RBM is to maximize the fitting of the input data by calculating the maximum likelihood estimation of the input data to make Eq. (2) maximum. In the solution process, the conditional probability is calculated alternately through Eqs (7) and (8) to maximize the final reconstruction error. This process is called Gibbs sampling, as shown in Fig. 3. However, too many iterations in Gibbs sampling lead to a long calculation time [28]. In this paper, the Contrastive Divergence (CD) algorithm is used to train RBM. Taking
After the unsupervised training, the model enters the supervised training. In this process, we use the classical BP algorithm to reverse fine-tune the parameters of DBN.
Gibbs sampling process.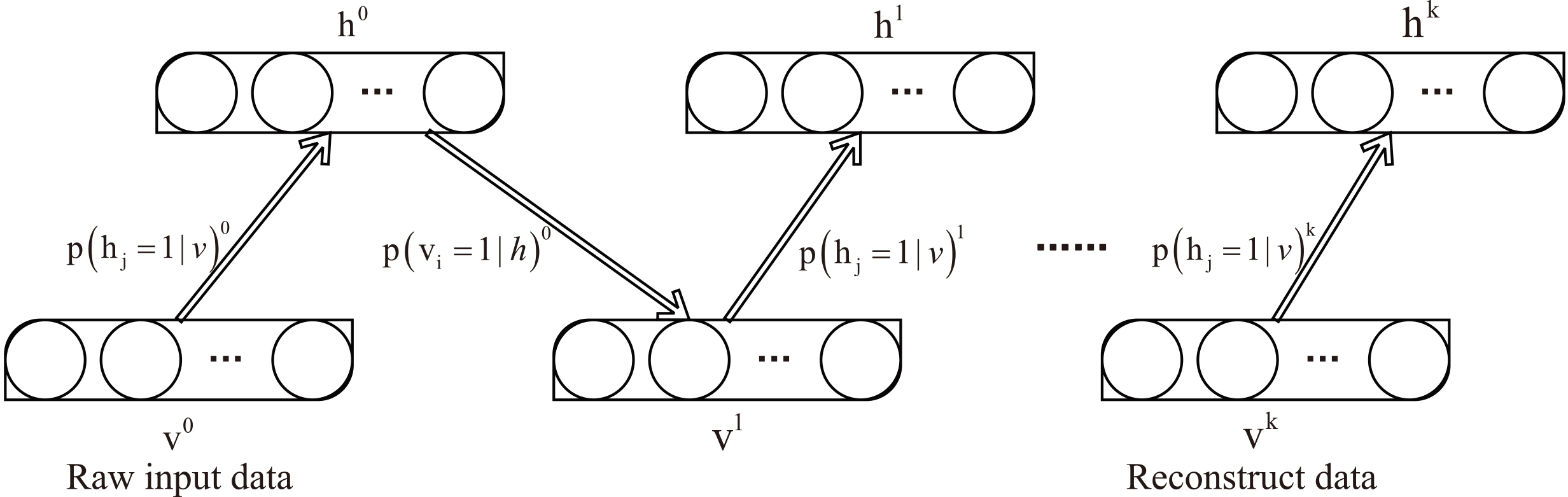
In fact, GDBN training is the process of mapping the visual layer data to the hidden layer. In an ideal state, although the data form changes the hidden layer data contains the same information as the visual layer. As shown in Fig. 2, we need to evaluate how many hidden neurons and hidden layers can ensure that the hidden layer data is infinitely close to the visual layer. Artificial experience testing requires a lot of energy and time, so we designed a Dynamic Gaussian Deep Belief Network (DGDBN), which not only ensures that Gaussian noise is added to each layer of the network but also can automatically find the optimal network structure.
In this section, we present the main ideas of the DGDBN model. Report to the fixed network structure of traditional DBN. DGDBN has two areas of improvement: segmentation or deletion of hidden layer neurons; adding Gaussian RBM hidden layer. The method used in the two improvements and the training process of the DGDBN model is described as follows:
Split and delete hidden layer neurons algorithm
After trial and error on the single-layer GDBN model. We discovered that when the number of neurons is too small, the information contained in the neurons in the visual layer will be lost during the mapping process. Upper layer neurons cannot capture complete feature information. Therefore, the prediction effect of the network will be lowered. When there are too many hidden neurons, redundant data information will be mixed, resulting in overfitting of the network model. In short, too many or too few hidden layer neurons will lead to a decrease in the prediction effect of the model network.
In order to select an appropriate number of hidden neurons, it is necessary to add or delete hidden neurons. The change of the number of neurons will affect the change of the connection weights. In this paper, the increase or decrease of the hidden neurons depends on the quadratic norm square root
For deleting or splitting hidden neurons, the following criteria are designed according to the principle of multiple stepwise regression.
First, calculate the sum of
Then,
Finally, the thresholds
The network obtained by the above method not only deletes redundant neurons, but also splits a small number of important neurons. Ultimately, the structure of the DBN network is optimized and the prediction accuracy of the network is improved.
When the DBN of a single hidden layer has enough neurons, it can approximate most nonlinear systems [29]. But it cannot well fit high complexity and nonlinear systems. The single-layer DBN needs to increase the hidden layer and hidden neurons to improve the nonlinear fitting rate. Taking into account the network prediction error rate changes, the addition and deletion of hidden layers are judged according to the average absolute percentage error (MAPE) of the prediction results.
During the network training process, we set the MAPE threshold
where
DGDBN training flowchart.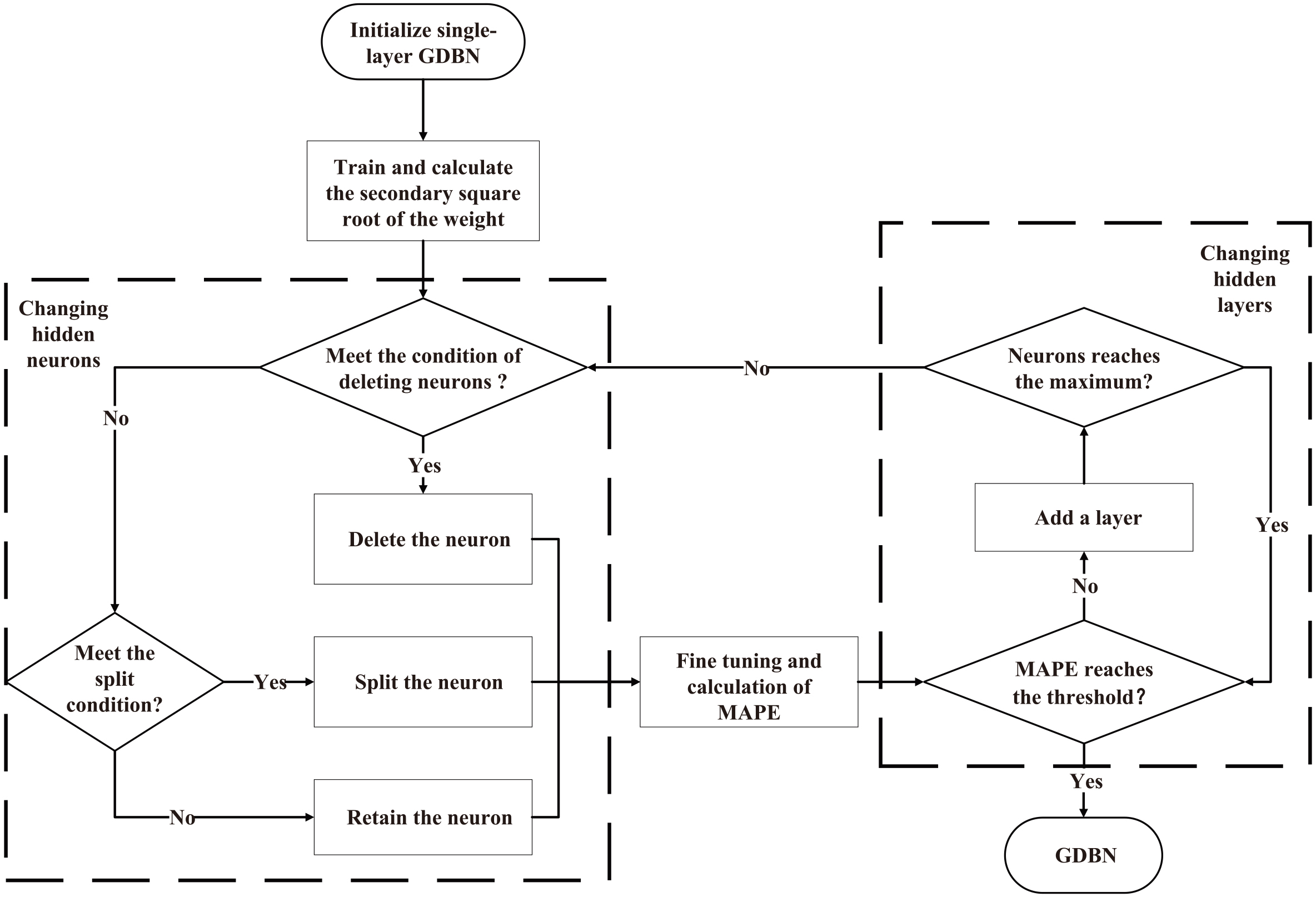
Based on the GDBN training introduced in Section 2.2, the DGDBN model dynamically adjusts the network structure according to the methods introduced in Sections 3.1 and 3.2. The training flowchart is shown in Fig. 4. The specific steps are described as follows:
Initialize a single-layer Gaussian RBM, the number of neurons in the hidden layer can be given arbitrarily. After Gibbs sampling, RBM splits and deletes neurons according to the method of Section 3.1. Calculate the MAPE of the network at this time, and add a new Gaussian RBM if Eq. (11) is satisfied. The number of neurons in the hidden layer ranges from half to equal to the number of neurons in the upper layer. Repeat steps (1) and (2) until the MAPE of the network satisfies Eq. (11) or the MAPE of the network begins to increase. The network training is terminated.
The main algorithms in the training process are given in Algorithm 4, which mainly include the training function of each layer of RBM and the increase of the hidden layer function.
The training process of DGDBN[1] train set:
In this section, two groups of different stock data were used to demonstrate the effectiveness and superiority of the proposed DGDBN. Moreover, the results were compared with DBN and LSTM. To reduce the influence of other irrelevant factors on the simulation results, the compilation software and operating environment of all simulation experiments are set as follows: the compilation software is PyCharm 2020.1 version, the operating environment is Microsoft Windows 10, the computer clock frequency is 2.1 GHz, and the RBM is 12.0 GB. Four benchmark evaluation functions are used to evaluate the performance of the model: root means square error
where
The SCP is one of the most concerning indicators in the stock financial market. Therefore, it is necessary to accurately predict the future closing price of stocks. In this paper, a model-based method is used to predict the closing price of the two sets of stock data using the proposed DGDBN.
Data
We used two sets of stock data in the experiment. Tables 1 and 2 respectively show part of the information of the two sets of data.
The first one is the stock data of United Technologies Corporation (UTX) from September 4, 2012, to September 1, 2017. The data comes from Yahoo Finance (
The second group is Unisys Corp (UIS) stock data from October 1, 2008, to November 10, 2017. The data comes from the New York Stock Exchange (
Some historical data of UTX stock
Some historical data of UTX stock
Some historical data of UIS stock
In order to prevent the influence of abnormal data on the prediction results, we use box plots to filter out abnormal data in the two groups of data. The judgment results of the box plot are shown in the Fig. 5.
Box plot judgment results.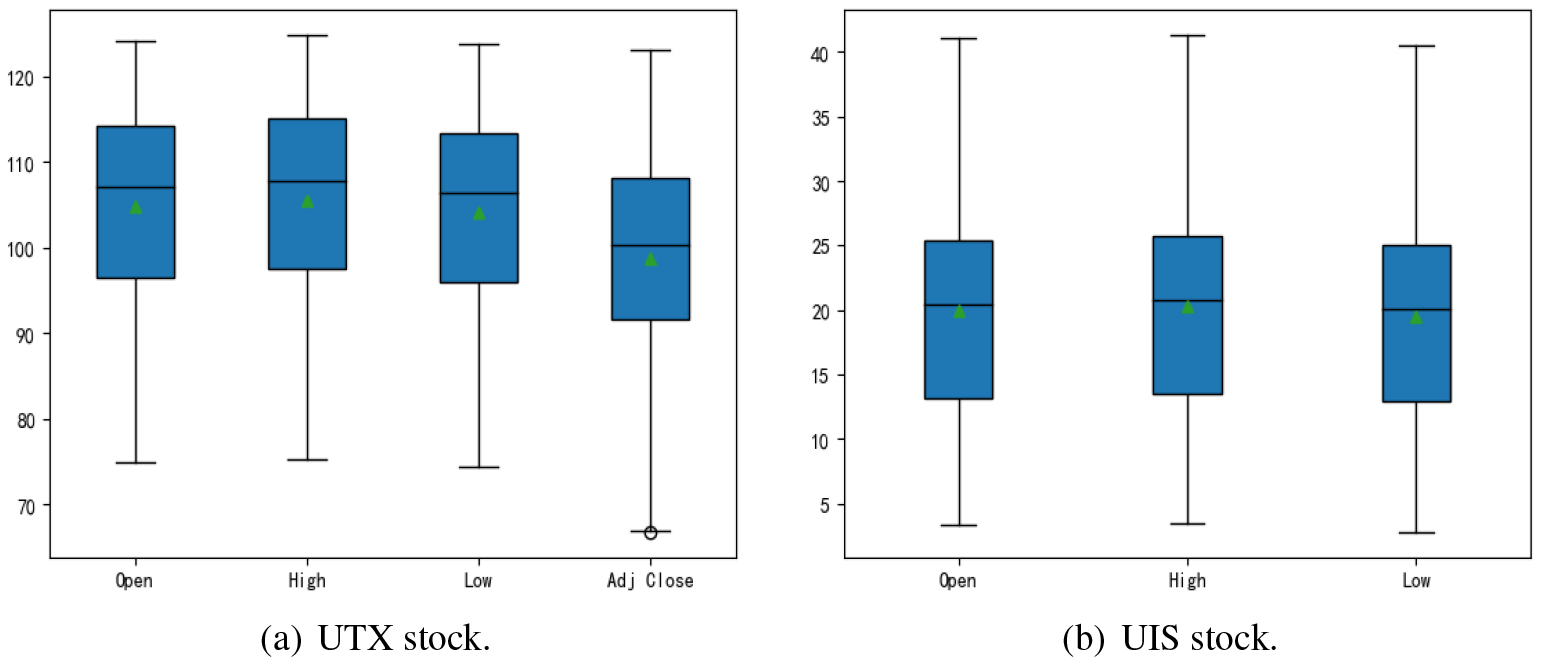
Replace abnormal data according to the following formula.
Where
All the sample data are standardized by Min-Max normalization. For each value of the sample data, the normalization calculation formula is:
Where
For the closing price prediction of the two groups of data, the time sliding window takes five, that is, the closing price on the fifth day is predicted by using the data information of the past four days. At the beginning of the simulation experiment, the initial network structure is a single-layer Gaussian depth belief network, and the number of iterations is 600 in the unsupervised training process; In the process of supervised training, the number of iterations is 300. Preset
The model structure of DGDBN gradually tends to be stable in the training process. In the first group of experiments, the hidden layer neurons initializing the single-layer Gaussian depth belief network are 100, and the final stable structure is 81-59-49. That is, the number of hidden layer neurons is
DGDBN forecast results.
During the experiment, we recorded the MAPE value of the network prediction result after each change in the number of hidden layer neurons and hidden layers, as shown in Fig. 7. Through the study of the changing trend of MAPE in two groups of experiments, we found that the value of MAPE will increase when adding a new hidden layer. This is because when adding a new hidden layer in the experimental process, the number of neurons is 1/2 of the number of neurons in the upper hidden layer. At this time, there are too few neurons in the last hidden layer, which reduces the prediction performance of the model. With the increase of the number of hidden neurons in this layer, neurons can map more data information, MAPE decreases gradually, and finally reaches a stable state. This shows that for the DGDBN network, the number of neurons in the last layer has a greater impact on the network effect.
The value of MAPE in network structure changes.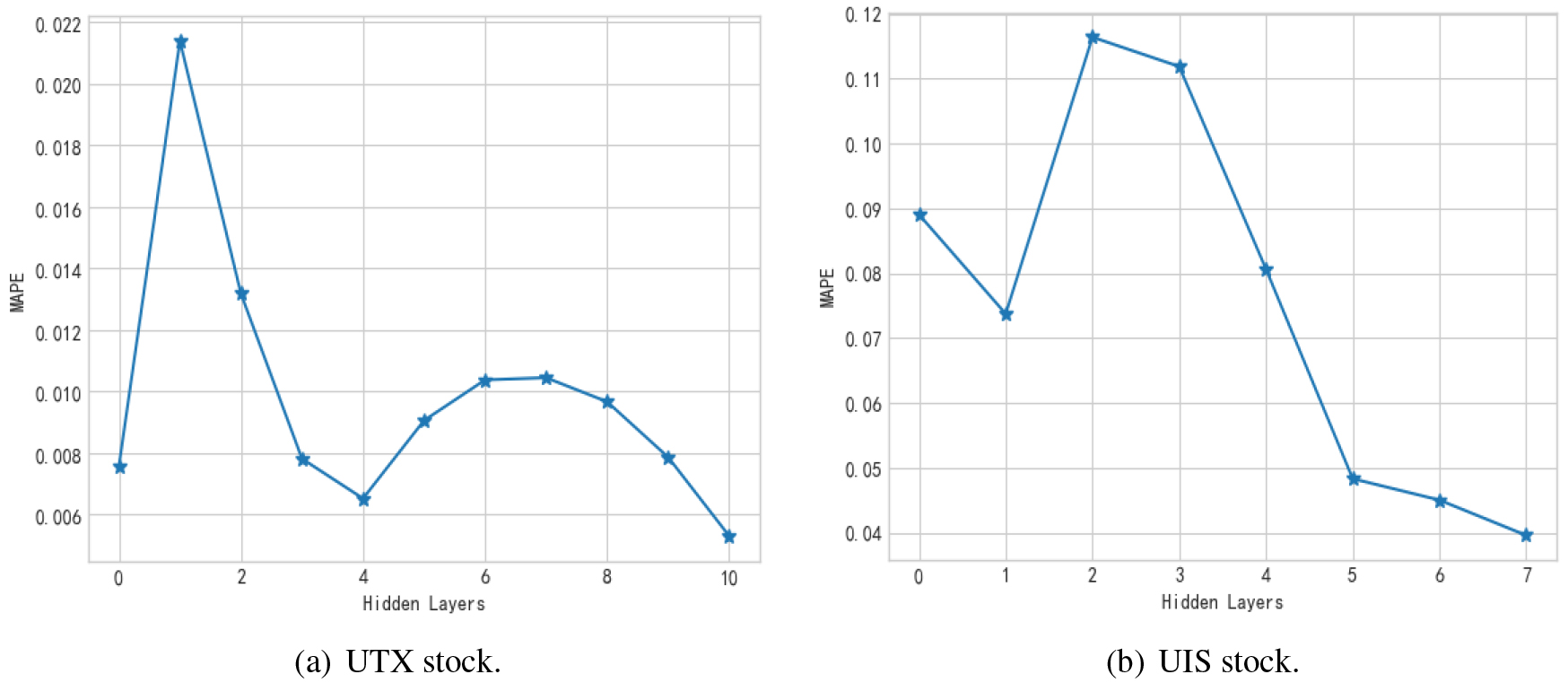
The main purpose of this study is to evaluate the performance of DGDBN in stock forecasting. In this section, the DGDBN model proposed in this paper is compared with the traditional DBN and LSTM. For the traditional DBN model, the network structure is set to the same number of hidden layer and hidden layer neurons before the dynamic change of the network. As for the activation function, DGDBN and DBN adopt the same Sigmoid activation function, LSTM takes its better activation function Relu. In order to reduce the influence of other parameters on the experimental comparison results, the training times are 300, and 128 sample data are processed each time. The comparison results of DGDBN, DBN, and LSTM are shown in Fig. 8.
Comparison of DDBN, LSTM and DBN.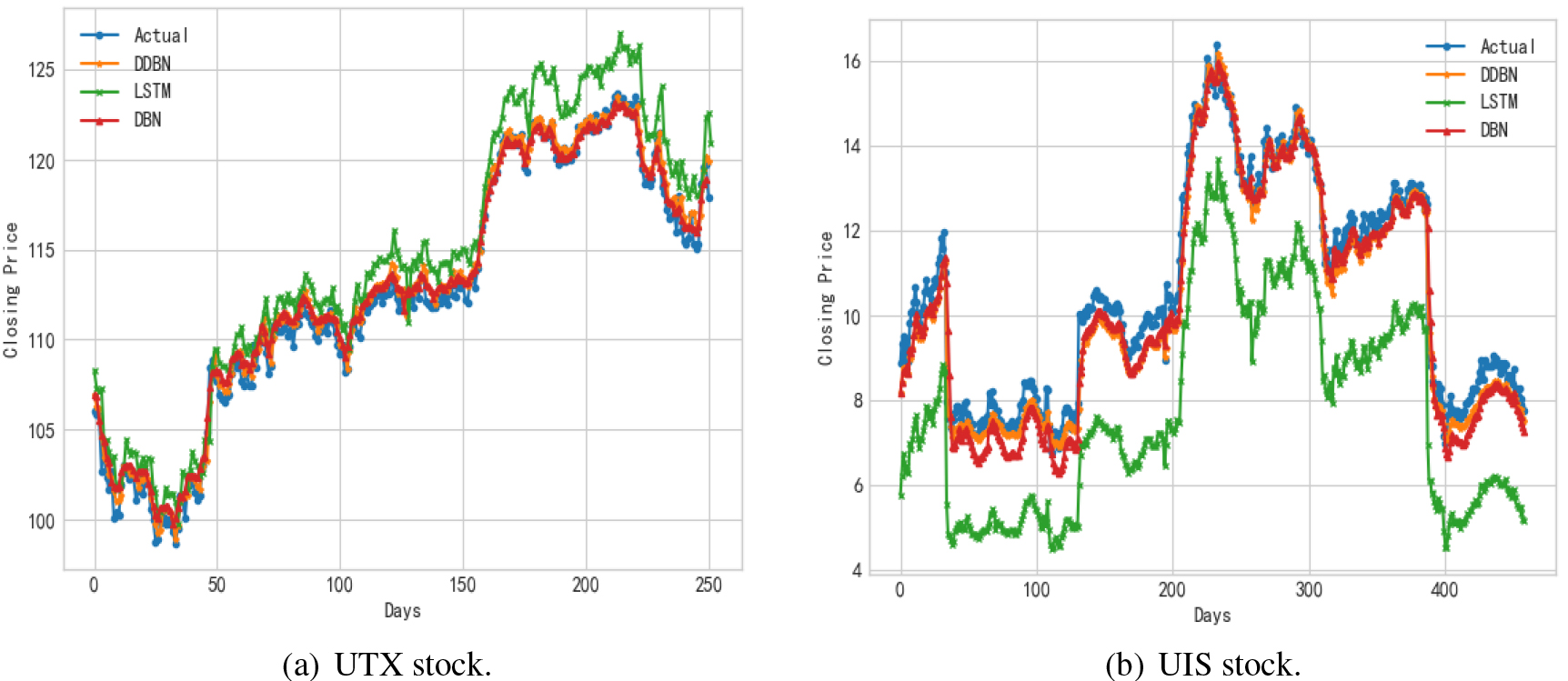
Comparison of evaluation indexes (UTX stock).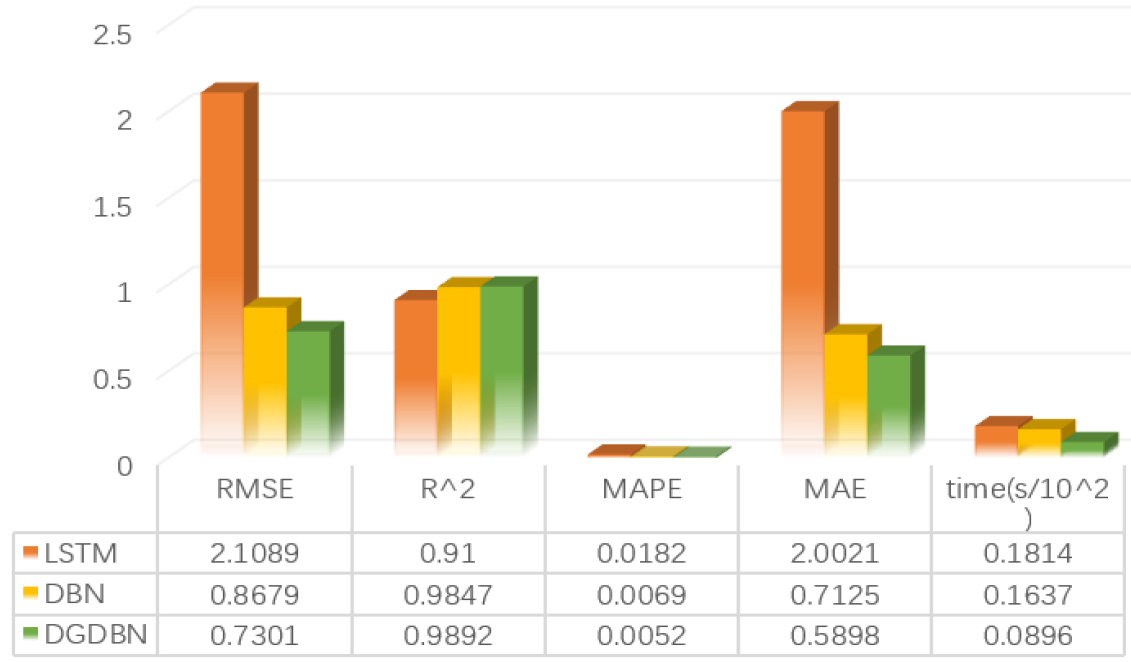
It can be seen from Fig. 8 that the DGDBN model proposed in this paper has a better fitting effect. For the test set of UTX, the MAPE of DBN is 0.0064, that of LSTM is 0.0175, and that of DGDBN is 0.0052. For the test set of UIS, the MAPE of DBN is 0.0505, that of LSTM is 0.2794, and that of DGDBN is 0.0396. Therefore, it can be seen that the prediction effect of the DGDBN model on stock closing price is better than DBN and LSTM. Although the prediction effect of DBN is better than LSTM, it is obvious that the prediction effect of the DGDBN model after network dynamic adjustment is better. DGDBN can better capture data information and determine the appropriate network structure by adding hidden layers and hidden neurons while deleting DBN redundant neurons.
Comparison of evaluation indexes (UIS stock).
After 20 independent experiments, the following table shows the average results predicted by DGDBN, DBN, and LSTM models. Figure 9 shows the experimental results of UTX data, and Fig. 10 shows the experimental results of UIS data. In UTX data, the RMSE of LSTM is 2.1089, the RMSE of DBN is 0.8679, and the RMSE of DGDBN is 0.7301, which is 65% and 15% higher than that of LSTM and DBN respectively. In UIS data, the RMSE of LSTM is 2.8349, the RMSE of DBN is 0.5685, and the RMSE of the DGDBN is 0.4812, which is 83% and 15.4% higher than that of LSTM and DBN respectively. It can be seen from Figs 9 and 10 that the overall accuracy of DGDBN model is higher. In addition, the prediction time of the DGDBN model is slightly improved compared to DBN and LSTM. In UXT stock, the prediction time of LSTM is 18.14, the prediction time of DBN is 16.37, the prediction time of DGDBN is 8.96; In UIS stock, the prediction time of LSTM is 24.85, the prediction time of DBN is 10.95, the prediction time of DGDBN is 10.26.
According to the above analysis, DGDBN can well fit two sets of stock data. However, the trends in the two sets of data are different: UTX stocks generally show a slow upward trend; UIS stocks go up and down, with no obvious upward or downward trend. Therefore, it can be seen that DGDBN has a good fit for nonlinear data with different trends, and can be extended to other nonlinear systems.
In recent years, people have become increasingly interested in changing the model structure. This paper proposes a structure of dynamic Gaussian deep belief network (DGDBN), which improves the classical deep belief network by using the quadratic norm root of connection weights, MAPE, and adds Gaussian noise. Weights optimization is considered in the network structure design. According to the root of the quadratic paradigm of the connection weights obtained after training, the redundant hidden layer neurons are deleted and neurons with larger influence are divided. After the network training is completed, the hidden layers are added one by one until the MAPE of the whole network reaches the required threshold. Meanwhile, during the neuronal division, the weights of newly split neurons are duplicated equally, not randomly assigned. This optimization method makes the weights adjust less in the reverse fine-tuning process, and the learning speed of the DGDBN networks is faster. The effectiveness of the DGDBN model is verified by two different stock data sets. Compared with the existing LSTM and DBN, the proposed DGDBN can obtain a more suitable network structure, and the prediction effect of the model is also improved.
As an important future work, we will try to change the learning rate of the DGDBN, which will make the prediction rate of the DGDBN more accurate. In this method, we can try more stock data to discover more interesting patterns.
Footnotes
Acknowledgments
This work was supported by the Shanghai, China Municipal Science and Technology Commission Project (115105024).