
Abstract
Credit scoring is an important topic in financial activities and bankruptcy prediction that has been extensively explored using deep neural network (DNN) methods. DNN-based credit scoring models rely heavily on a large amount of labeled data. The accuracy of DNN-based credit assessment models relies heavily on large amounts of labeled data. However, purely data-driven learning makes it difficult to encode human intent to guide the model to capture the desired patterns and leads to low transparency of the model. Therefore, the Probabilistic Soft Logic Posterior Regularization (PSLPR) framework is proposed for integrating prior knowledge of logic rule with neural network. First, the PSLPR framework calculates the rule satisfaction distance for each instance using a probabilistic soft logic formula. Second, the logic rules are integrated into the posterior distribution of the DNN output to form a logic output. Finally, a novel discrepancy loss which measures the difference between the real label and the logic output is used to incorporate logic rules into the parameters of the neural network. Extensive experiments were conducted on two datasets, the Australian credit dataset and the credit card customer default dataset. To evaluate the obtained systems, several performance metrics were used, including PCC, Recall, F1 and AUC. The results show that compared to the standard DNN model, the four evaluation metrics are increased by 7.14%, 14.29%, 8.15%, and 5.43% respectively on the Australian credit dataset.
Introduction
Credit scoring methods have been widely investigated by researchers. As an important part of the financial industry, credit scoring plays an important role in modern affairs such as credit customer selection, risk measurement, supervision before and after loans, comprehensive performance evaluation, and asset portfolio risk management [1]. In the financial industry, the increasing number of bank collapses and massive losses has lead to international banking regulation’s demand for the development of more appropriate credit risk models for scoring their financial loan portfolios[2]. The credit scoring model classifies credit applicants into good credit applicants and bad credit applicants based on annual income, bank account type and bank balance, occupation type, marital status, age, and education level [3]. Hence, credit scoring can be regarded as a binary classification problem.
With the deep integration of Internet technology into the financial industry, previous studies have proposed a variety of machine learning methods applied to credit scoring, such as decision trees (DT), logistic regression (LR), discriminant analysis, and support vector machines (SVMs). Over the last decade, deep neural network (DNN) have emerged as a popular artificial intelligence technique that has employed in a wide range of areas. Credit scoring models based on DNN have gradually become a research hotspot with excellent accuracy[4]. The successful application of DNN in credit scoring is grounded in the data-based nature of the approach of learning from a tremendous number of examples. However, there are many circumstances where purely data-driven approaches can reach their limits or lead to unsatisfactory results[5]. The most obvious case is that there is not enough data to train models that perform well and generalize enough. Another important aspect is that purely data-driven models may not meet the constraints, such as the transparency conditions given by regulatory or security guidelines, which is a major challenge for credit scoring models. A recent scientific report on artificial intelligence suggests: “ML and AI practice treats datasets in the same way and ignore domain knowledge that extends far beyond the raw data. Improving our ability to systematically incorporate diverse forms of domain knowledge can impact every aspect of AI.” [6] The field of credit scoring has a wealth of theoretical knowledge, but the current DNN-based credit scoring model completely relies on labeled data sets, ignoring the rich credit scoring logic rules. Therefore, incorporating prior knowledge to guide credit scoring model training is also one of the future research directions.
Recently, some research has explored the method to integrating DNN with logic rules. A fairly standard way is by introducing an additional loss term into the loss function that the network optimises. The additional loss term contains the constraint on the logic rules to be learned by the DNN model. Inspired by them, we propose a DNN-based credit scoring model based on the Probabilistic Soft Logic Posterior Regularization (PSLPR) framework, which will formulate the probabilistic soft logic riles of credit scoring knowledge as a posterior regularization term to integrate DNN with logic rules. At the same time, it was found that combining DNN with logical rules, and using the flexibility of logic rules to improve the interpretability of DNN is a feasible method[7]. In summary, our main contributions are listed as follows:
The PSLPR framework enables the DNN model to learn not only from the labeled dataset for training but also from the logic rules. The PSLPR framework improves the DNN-based credit scoring model’s prediction accuracy by incorporating the logic rules into the DNN model. Integrating DNN with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models.
The other parts of this paper are as follows. Section 2 reviews related resarch on credit scoring models and integrating DNN with logic rules methods. In Section 3, we review the definition of soft logic rules and the knowledge of posterior regularization. In Section 4, the PSLPR framework is established. In Section 5, we carry out experimental verification and analysis. Finally, Section 6 presents conclusions and looks forward to future work.
In this paper, we propose the Probabilistic Soft Logic Posterior Regularization (PSLPR) framework for DNN-based credit scoring models. For this reason, this section’s focus will be on reviewing the credit scoring models and integrating DNN with logic rules methods.
Credit scoring model
A broad range of techniques have been applied to solve the credit scoring problem. The research methods on credit scoring mainly include statistical methods, machine learning and deep learning. Among them, statistical techniques were often used, including logistic regression (LR) [8] and linear discriminant analysis (LDA) [9]. The rational behind statistical models is to find an optimal linear combination of explanatory input variables able to model, analyze, and predit default risk [10]. In general, the main drawback of statistical methods is their non-sufficiently high accuracy whereas their main advantage is simplicity.
Later on, machine learning techniques were considered to achieve higher accuracy in the presence of complex credit risk datasets. Applications of machine learning techniques include SVM, DT, KNN, and Random Forest (RF). In the literature on SVM-based methods. Huang et al. [11] employed three methods to build hybrid SVM-based credit score models to determine each applicant’s input credit score. Their results showed that SVMs work better than existing methods of data mining. Chern et al. [12] proposed a decision tree credit assessment approach (DTCAA) to solve vast, messy data sources and ever-changing loan regualtion problems. KNN, LR and Bayes were used by Itoo and Singh [13] to assess the credit worthiness of applicants. Ensemble methods, which combine the advantages of various single classifiers,have been developing fast recently. For example, Zhang et al. [14] proposed a novel multi-stage ensemble model with enhanced outlier adaptation. The ensemble approach improved the prediction performance against other base classifiers validated over ten real-world credit scoring datasets. Compared with traditional statistical models, machine learning models do not rely on individual subjective judgment and have relatively outstanding predictive power on complex nonlinear systems, making them more suitable for application in personal credit assessment with complicated features.
In recent years, researchers have shown an interest in the application of DNN models in credit scoring. For instance, Neagoe et al. [15] applied Deep Convolutional Neural Networks (DCNN) and Deep Multilayer Perceptron (DMLP) respectively in the field of credit scoring, and the results showed the DCNN significantly outperformed DMLP. Kvamme et al. [16] applied CNN to consumer transaction data to predict mortgage default. Dastile et al. [17] proposed an explainable deep learning model for credit scoring which convert tabular datasets into images and then use 2DCNN. The predictions from the 2DCNN were explained using Saliency Map [18], Gradient weighted Class Activation Map (Grad-CAM) [19] and Local Interpretable Model-Agnostic Explanations (LIME) [20]. Yu et al. [21] proposed a new multi-level deep belief network (DBN) based on the Extreme Learning Machine (ELM) integrated learning method to improve the accuracy of credit scoring. Ala’raj et al. [22] used directional Long-Short Term Memory (LSTM) neural network in credit scoring and the results showed that this method performed better than traditional methods. Despite DNN-based credit models’ superior performances, the complex networks make learning harder when the amount of training data is insufficient. Moreover, the automation in DNNs makes it challenging to inject prior knowledge to guide the training process.
Intergrating DNN with logic rule methods
Xu et al. [23] proposed a semantic loss that signifies how well the outputs of the DNN matches some given constrains encoded as propositional rules. Proposition rules have restricted expression capabilities, making it difficult to explain complex background information. Fischer et al. [24] constructed a system DL2 for training a DNN with domain-knowledge encoded as logical constraints. Unlike semantic loss, each individual logic operation (such as negation, and, or) is translated to a loss term. The closest ones to the setting are Probabilistic Soft Logic. Zhou et al. [25] proposed a method based on Probabilistic Soft Logic Regularization to extract the clinical time relations for global reasoning. This method summarizes the clinical knowledge into first-order logic rules [26] (FOL), uses the soft logic calculation method to calculate the satisfaction distance between the sample and the rule, and then uses it as a loss function to transfer the clinical knowledge to the neural network. The three approaches discussed above are all investigating ways to better express prior knowledge. They express prior knowledge using propositional rules, DL2 and PSL, respectively, and then transformed by mathematical axioms into a prediction that satisfies a priori knowledge. Although the above three methods can convert the prior knowledge into differentiable data to obtain prediction results that satisfy the prior knowledge, the problem with such methods is that they cannot guarantee that the logic prediction satisfies the prior knowledge while remaining close to the prediction results of DNN. Hence, the PSLPR framework uses a posteriori regularization method to obtain the logical prediction results, which efficiently incorporates indirect supervision via constraints on the posterior distributions of probabilistic models with latent variables. Hu et al. [7] fused logical knowledge into deep models through knowledge distillation [27] and posterior regularization (PR) [28]. Specifically, this method improves the knowledge distillation, and uses the logic rule as a loss function to transfer it to the weight of the deep neural network through each iteration. Kalpesh et al. [29] conducted decomposition experiments on the effectiveness of the techniques in Hu.
The field of credit scoring has a wealth of theoretical knowledge, but the current DNN-based credit scoring model completely relies on labeled data sets, ignoring the rich credit scoring logic rules. Therefore, it is important to study the integration of applied background knowledge. This study proposes a PSLPR framework that integrates credit scoring logic rules with the DNN model to further improve the predictive performance of the DNN model.
Preliminaries
Probabilistic Soft Logic
Probabilistic Soft Logic is proposed by Kimmig et al.[30], Probabilistic soft logic is to build a joint probability model of atoms based on the rules of first-order logic. Specifically,soft logic allows continuous truth values from
.
A predicate p is a relation defines by a unique identifier, used to describe the nature of the object. An atom a is combined with a sequence of objects and predicates. Specifically, atoms in PSL take on continuous values in the unit interval
.
A PSL rule
where
.
The PSL rule in Definition 3.2 can also be represented as Eq. (5).
.
The distance to satisfaction
where PSL program determines a rule
The following example program encodes a simple model to predict loan default based on credit scoring rules. The rule is illustrated as Eq. (7).
consider loan applicants with annual income and marital status features, this rule means people who earn less than 100K and are not married will default. Given that
according to the previous definition, the instance does not satisfy the rule
Posterior regularization (PR) was first proposed by Ganchev [28] in order to make machine learning models imitate the human learning process, not only to obtain knowledge from a large amount of labeled data, but also to learn some experience related to specific problems. Posterior regularization provides a set of formal definition methods that use mathematical formulas to define prior knowledge, and incorporate prior knowledge into the model by constraining the posterior probability distribution of the model.
In PR, the log-likelihood of a model is penalized with KL-devation between the prior knowledge and the expected distribution of the model posterior. We define the constraint set
where
Framework overview
PSLPR framework contains three parts, which are the DNN model, the probabilistic soft logic posterior regularization unit and the error calculation unit. The functions of these three parts are as follows.
DNN model takes the dataset as input and generates a DNN output for each credit applicant. The logic posterior regularization unit accepts the DNN output as input, then constrains it by using the posterior regularization principle and generates a logic output. The error unit introduces a new term to calcute the difference between DNN output, logic output and true label.
In general, the PSLPR framework enables the DNN model to learn from both labeled datasets and soft logic rules. This is achieved by constraining the DNN outputs in each iteration by adapting the posterior regularization, and updating the DNN model throughout the training process. The parameters of the DNN are updated using the error BackProgation (BP) algorithm until convergence. In this framework, domain expert are responsible for providing datasets and domain knowledge. Domain knowledge can encode human intetion to guide the models to capture desired patterns. The framework is shown in Fig. 1.
Probabilistic soft logic posterior regularization framework.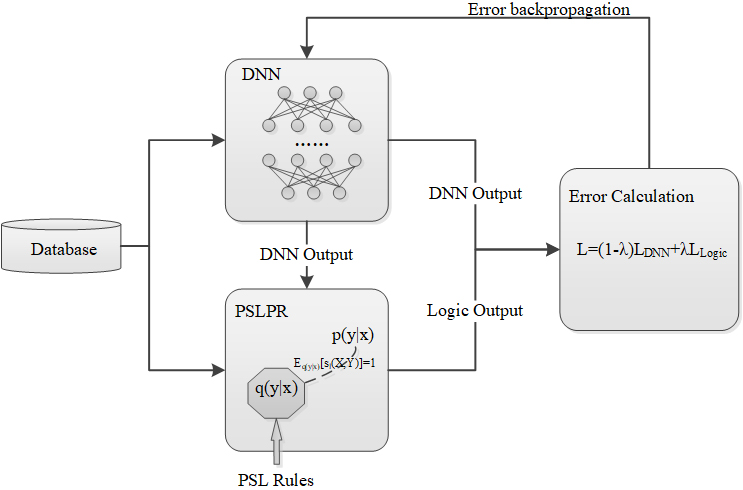
The DNN model in this study uses a Multilayer Perceptron (MLP) model, which is based on a forward-feedback artificial neural network containing multiple layers of nodes, including an input layer, a hidden layer, and an output layer, with each layer fully connected to the nodes of the next layer of the network. The MLP model is shown in Fig. 2.
Multilayer perceptron.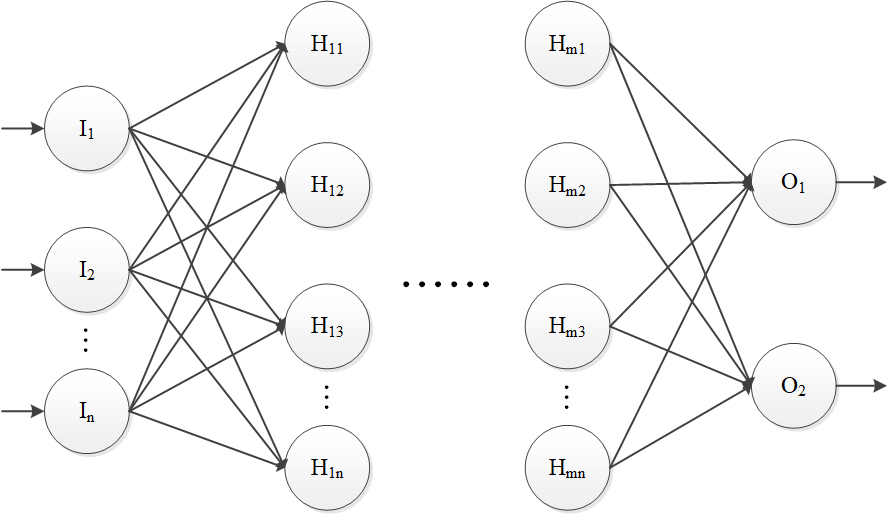
For the purpose of credit scoring, we consider a MLP with one input layer with
In this paper, Relu function is used in the hidden layer, which is given by Eq. (12).
The output value of
where
Specifically, the MLP-based credit scoring model will learn from the credit scoring dataset. Assume the dataset
where
The probabilistic soft logic poeterior regularization unit is designed to incorprate the logic rule into the DNN model through posterior regularization. We organize the priori knowledge into a soft logic rule base. Define the rule base as
The probability obtained after incorporating the rules is defined as
where,
After obtaining the logic output
where
where
[1] Initialize network parameters
The configuration of the experimental environment in this paper is as follows: CPU Intel(R) Core(TM) i7-8565U CPU @ 1.80 GHz 1.99 GHz; RAM 8 G; OS Windows 10 64-bit. The development language used in this paper is Python (3.6), and the deep learning framework is selected from the Python-based deep learning library Tensorflow version 2.0. In order to test the performance of the model, the following three main experiments are done in this paper on two different data sets.
Parametric sensitivity experiments to verify the model’s performance results when different values of the importance parameter Comparing the performance of the improved DNN-based credit scoring model with other credit scoring models. Compare the performance of the improved DNN-based credit scoring model with PSLPR framework and other intergrating DNN with logic rules methods.
Data set
Two datasets are used in evaluating the performance of our method. The Australian credit dataset and the default of credit card clients dataset are both from the UCI repository of machine learning databases (
The characteristics of three datasets used in the experiment.
The characteristics of three datasets used in the experiment.
The Australian credit dataset has 14 features and 6 of features are numerical and 8 are categorical. Their names have been changed to meaningless symbols to protect the confidentiality of the data. Particular data records belong to one of two classes: application rejected or application approved. In general, the bad cases occupy 55.5% of the whole set, whereas the remaining 45.5% represents the good cases. The Australian credit dataset is a balanced dataset.
The default of credit card clients has 23 numerical features. There are four demographic features covering gender, education, marital satatus and age of each client. These are followed by 18 features providing a history of payments and bill statements, i.e., repayment status as well as the amount of bill statements and previous payments for the six consecutive months. Like the Australian credit dataset, this data set is divided into two categories. In general, the bad cases occupy 77.88% of the whole set, whereas the remaining 22.12% represents the good cases. The default of credit card clients dataset is an imbalanced dataset. In this paper, 70% of the data is randomly selected as the training set and 20% of the data is used as the test set.
The performance evaluation criterion is an indispensable part of the measurement model. There are many evaluation metrics which are used in the literature. The following metrics are the most popular metrics for assessing the performance of modeks in credit scoring. The Percentage Correctly Classified (PCC), Kolmogorov-Smirnov Statistic(K-S), Recall, F1 and Area Under Receiver Operating Characteristics Curve (AUC).
A confusion matrix consists of True Positives (TP), True Negatives (TN), False Positives (FP) and False Negatives (FN) and is used for calculating the metrics which are discussed in this section. In order to test the accuracy of our model, we selected the following four evaluation indexes. From the confusion matrix. These performance metrics can be derived accourding to Eqs (20)–(23).
Confusion matrix
MLP model parameter settings on the Australian credit dataset
In order to prove the advantages of our method, we make a detailed comparative analysis. We selected two types of comparison models: the credit scoring models and the intergrating DNN with logic rules methods. The details are as follows.
The PSLPR framework is agnostic to the network architecture, and thus applicable to general types of DNN models, including MLP and CNN. In order to verify the effectiveness of the PSLPR framework, the MLP-based credit scoring model was chosen for the experiments in this study. The MLP model is shown in Fig. 2, and the parameter settings of the model on different datasets are shown in Tables 3 and 4.
MLP model parameter settings on the default of credit card clients dataset
MLP model parameter settings on the default of credit card clients dataset
Parametric sensitivity result on the Australian credit dataset
The purpose of this study is to construct a framework that enables the fusion of DNN models with logic rules to optimize the models. The logic rule on the Australian credit dataset are derived from the experimental results of the paper by Marian et al. [3]. The logic rule on the default of credit card clients dataset are derived from the experimental results of the paper by Kampfer [31]. For the Australian credit dataset,
Equation (23) indicates that for each instance when
Equation (24) indicates that for each instance when
Parameter sensitivity
In this section, we explore how the labeled dataset and the logic rules affect the accuracy of our method. We vary the relative importance of the labeled dataset and the logic rules parameters (
Parametric sensitivity on the default of credit card clients dataset
Parametric sensitivity on the default of credit card clients dataset
Parametric sensitivity result on Australian credit dataset. (a) PCC. (b) Recall. (c) F1. (d) AUC.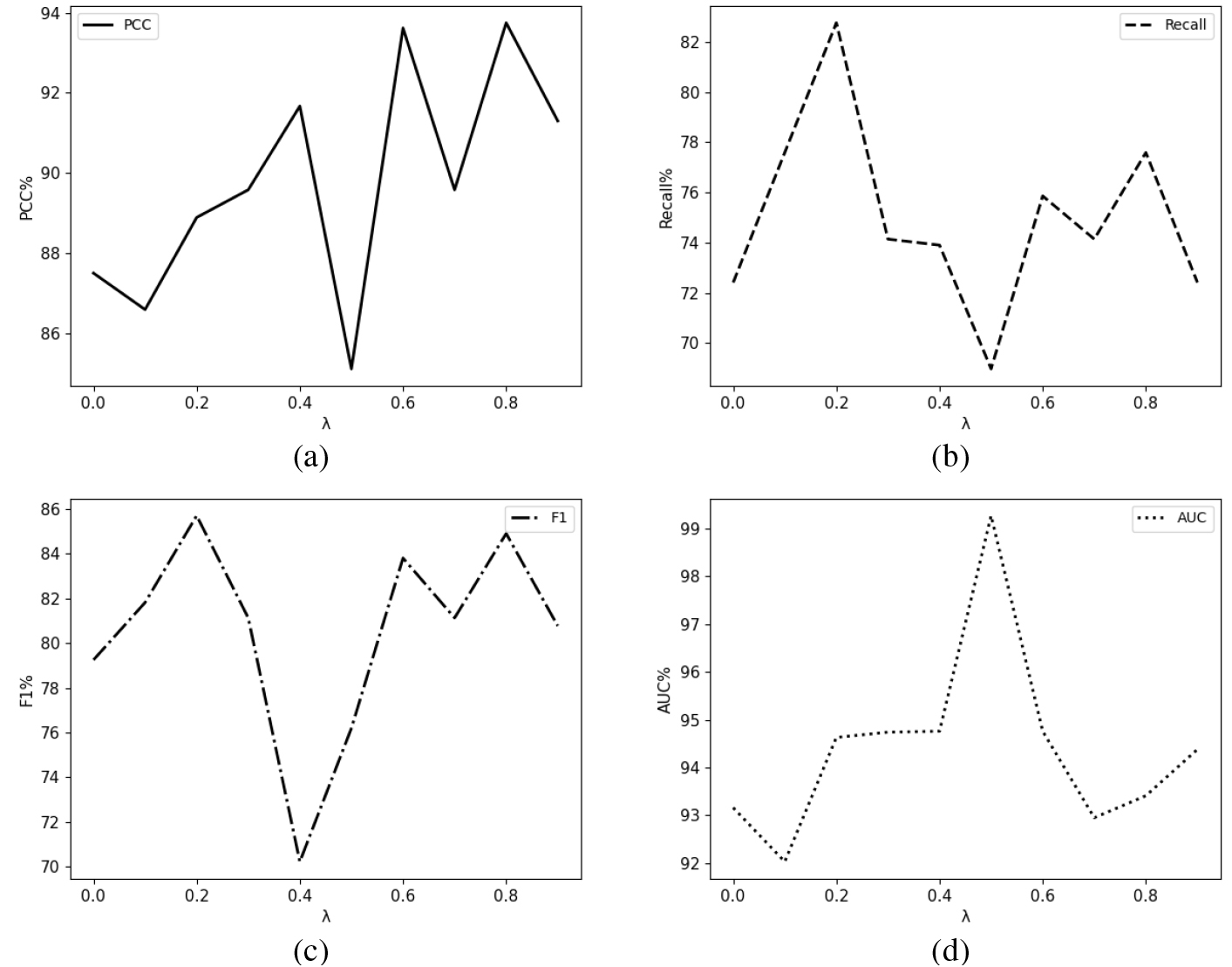
Parametric sensitivity result on default of credit card clients dataset. (a) PCC. (b) Recall. (c) F1. (d) AUC.
Figure 3 shows the influence of the parameters
The highest PCC of 93.75% was achieved when The average effect of the evaluation metrics is best when
Figure 4 shows the influence of the parameters
PCC reaches a maximum of 96.89% when The average effect of the evaluation metrics is best when
Overall, the PSLPR framework can improve the overall performance of the MLP model, especially on the Australian Credit dataset with large improvements. Also, in the experiments on both datasets, the improvement in Recall exceeds the other metrics, which may be due to the enhanced ability of the model to identify counterexamples, since the logic rules incorporated into the model are all about how to identify samples as negative. This situation also further indicates that the logic rules can be effectively intregrated into the DNN model through the PSLPR framework of this study.
To verify the effectiveness of MLP-based credit scoring model incorporated with logic rules, its performance was compared with five commonly used credit scoring models, namely LR, SVM, RF, CNN and stardand MLP. Table 7 reports PCC, Recall, F1, and AUC of the credit scoring models for the Australian credit dataset and the default of credit card clients dataset.
Histogram of each model metrics value on Australian credit dataset. (a) PCC. (b) Recall. (c) F1. (d) AUC.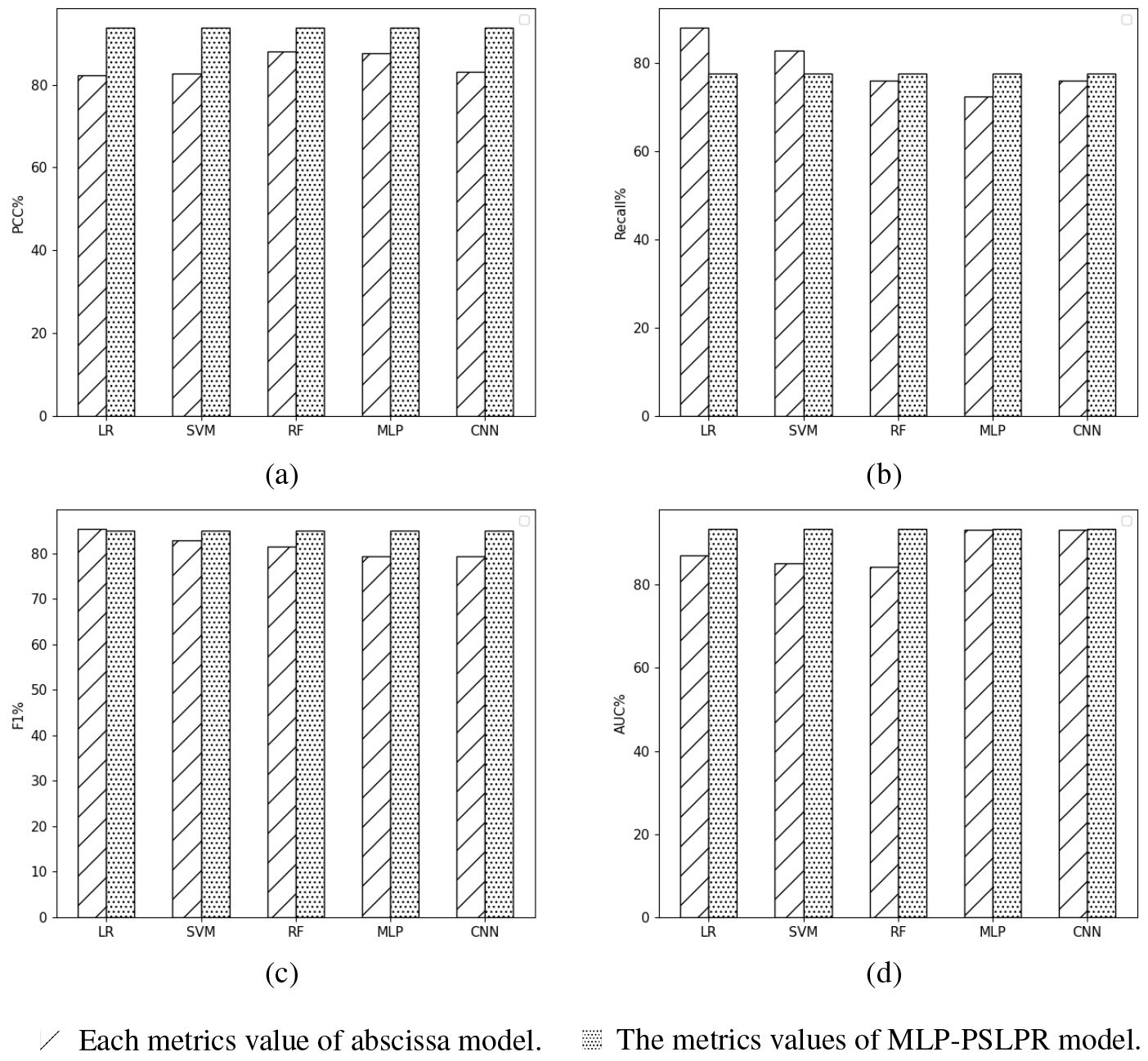
Performance comparison of five different credit scoring models
Histogram of each model metrics value on default of credit card clients dataset. (a) PCC. (b) Recall. (c) F1. (d) AUC.
Figure 5 shows the PCC, Recall, F1 and AUC of credit scoring models on the Australian credit dataset. As shown, the MLP-PSLPR credit scoring model performs better than other credit scoring models. Based on the above results, initial fingings are frawn in following.
The results show that on the Australian credit dataset, the MLP-PSLPR credit scoring model performs better in terms of PCC and AUC. The LR model achieves the highest Recall and F1. However, its performance on PCC is the worst of several models. In the terms of PCC and AUC, the DNN-based credit scoring model like MLP and CNN performe better than all machine learning-based credit scoring models. However, Recall and F1 values are not as good as the machine learning-based models. The MLP-PSLPR model compensates for these drawbacks by intregrating logic rules into the MLP model, resulting in higher Recall and F1 values, while maintaining PCC and AUC.
Figure 6 presents the PCC, Recall, F1 and AUC of models on the default of credit card clients dataset. As shown, the MLP-PSLPR model performs better than other credit scoring models, which can been seen as follows.
The MLP-PSLPR credit scoring model performs better in term of F1 and AUC. The LR model achieves the highest PCC and the SVM model achieves the highest Recall. Similarly, they both perform poorly on AUC. The improvement effect of MLP-PSLPR model on the default of credit card clients dataset is smaller than that on the Australian Credit dataset. This situation may be due to the imbalance of positive and negative samples in the default of credit card clients dataset, with a small percentage of negative samples. As a result, when the logic rules are used to determine negative samples, the model’s overall performance does not increase significantly.
To demonstrate the effectiveness of our intergrating neural network with logic rules framework, it is compared with two intergrating neural network with logic rule approaches: HDNNLR [7] and PSLR [24]. These methods all involve different selections of
Performance comparison of two different intergrating neural network with logic rule methods
Performance comparison of two different intergrating neural network with logic rule methods
Observe the effect of the MLP model on two datasets after being improved by different intergrating logic rules approaches. On the Australian credit dataset, the HDNNLR approach improves the AUC better than our approach. On the default of credit card clients dataset, PSLR method has the best effect on improving the Recall value of the MLP model. However, on both datasets, the MLP-PSLPR model has the best overall results. In general, the PSLPR method has the best improvement on the MLP model.
Credit scoring is an important component of a critical financial decision. The credit scoring model based on DNN has gradually become a research hotpot. However, over-reliance on good quality data and low transparency limits its further development. Therefore, the PSLPR framework that intergrating logic rules into the DNN is proposed. In particular, we formulate the probabilistic soft logic rules of credit scoring knowledge as a posterior regularization term to integrate deep learning and logical rules, and introduce new error terms to incorporate logic rules into the parameters of the DNN model.
In order to measure the effectiveness of the proposed model, this paper conducts experimental validation using a public dataset of credit scoring. The experimental results show that the new approach proposed in this paper for building a DNN-based credit scoring model can utilize credit scoring prior knowledge and dataset together to guide the generation of a DNN model with improvements in several assessment metrics. It shows superiority compared to other inergrating the DNN with logic rule approaches. Meanwhile, the flexible first-order logic rules provide some interpretability for the DNN model.
Although the framework proposed in this paper achieves the incorporation of prior knowledge of credit scoring in the modeling process, provides some interpretability and achieves the improvement of model accuracy. However, it still cannot achieve the transparency of the inference stage like the decision tree model. Therefore, future work in this study will further investigate the neural network rule extraction method to achieve interpretability of the inference process, and use the generated rules to improve the rule base.
Footnotes
Acknowledgments
This work was funded by the National Key Research and Development Program of China under Grant (2019YFB1405000) and Shaanxi Natural Science Foundation of China (2020JQ-758). The authors also, acknowledge with thanks Professors in Xi’an University of Science and Technology for theoretical support.