
Abstract
A co-location pattern is a set of spatial features that are strongly correlated in space. However, some of these patterns could be neglected if the prevalence metrics are based solely on the clique (or star) relationship. Hence, the
Keywords
Introduction
With the rapid development of location-based services (LBS) and the technological maturity of the Internet of Things (IoT), spatial data and even spatio-temporal data have come into their own [1, 2]. These types of data serve various fields, such as astronomical observation, geographic information detection, trajectory tracking, and medical imaging [3]. Accordingly, pattern queries (e.g., spatial co-location pattern mining) have acquired great developments over the past several decades [4].
Context
A co-location pattern represents a set of class labels (each named a feature) whose objects (each named an instance of a feature) are frequently located together in a proximate geographic space (e.g., Euclidean distances between instances are within a distance threshold from each other) [5]. Taking the co-location pattern mosquitoes, poultry, West Nile virus as an example, it can be seen that the outbreak of West Nile viruses frequently appears in the regions where both mosquitoes are abundant and poultry are kept. Accordingly, sanitation workers can control the spread of the viruses by eliminating mosquitoes and poultry in sensitive areas [6].
Most methods for existing co-location pattern mining involve two steps [7], as follows:
First, given an instance set Two examples of spatial neighbor relationship graphs. Fig. 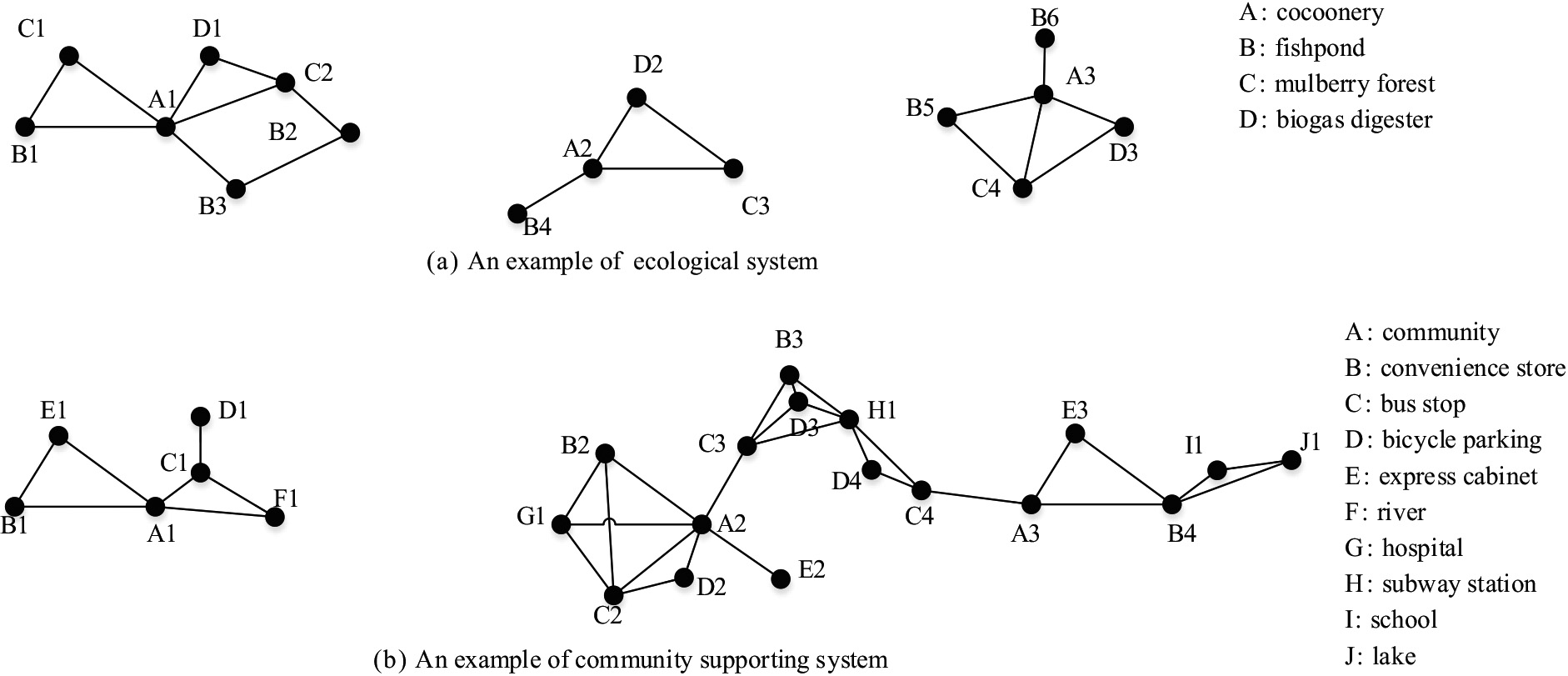
Since the majority of existing models in this field only account for clique relationships among instances, some interesting spatial correlations among features can be neglected in practice [11]. Therefore, the sub-prevalent pattern based on the star relationship is introduced in [12]. A star participation instance (i.e., a star relationship) is a set that comprises instances where each instance is a neighbor of the centric instance. However, the neglect of interesting patterns has just been mitigated.
For example, Fig. 1a locally suggests a famous interesting ecological system named mulberry dike-pond agriculture in the Yangtze River Delta [13]. It is acknowledged that the cocoonery (A), fishpond (B), mulberry forest (C) and biogas digester (D) are strong cooccurrence sites in mulberry dike-pond agriculture. However, it is difficult to obtain the corresponding pattern {A, B, C, D} from the spatial neighbor relationship graph shown in Fig. 1a with either the classical co-location pattern or the sub-prevalent pattern.
Similarly, in urban planning, a community (A) usually leads instances of convenience stores (B), bus stops (C), bicycle parking (D), and express cabinets (E), as shown in Fig. 1b. Traditional models based on clique or star relationships also tend to neglect the corresponding co-location pattern {A, B, C, D, E}.
Interestingly, the members of each instance pair can be reachable to each other in one (or two steps across the centric instance in shortest paths) in a clique (or star) relationship. Therefore, the
Roadmap
Since the
Similar to co-location patterns, we will prove
The baseline method updates the spatial neighbor relationship graph into the
Comparison of our frameworks. The baseline method bridges the maximal 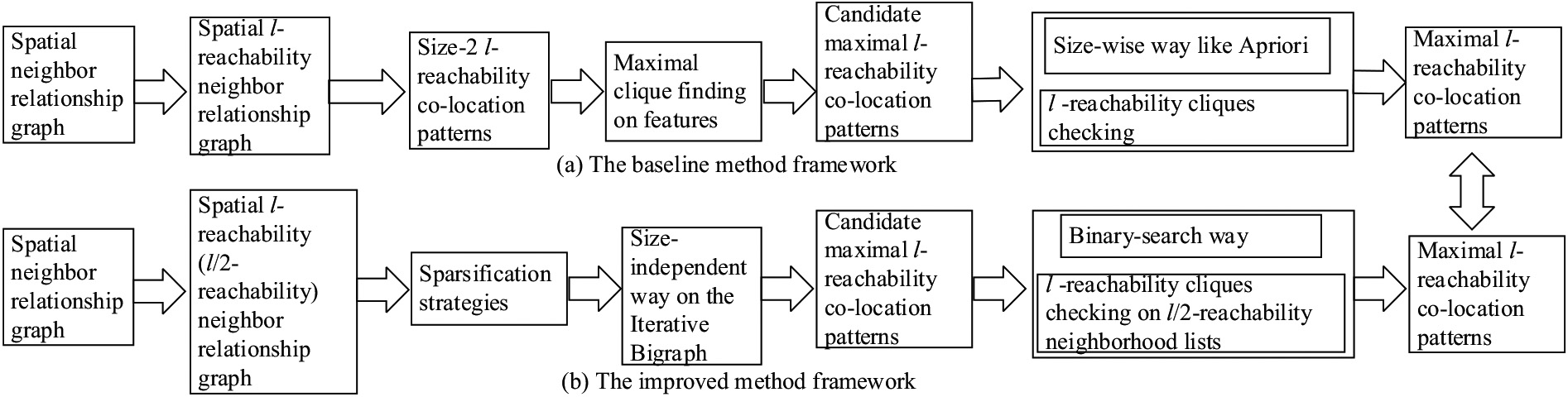
Fortunately, the baseline method to mine maximal
First, since it is much easier to mine co-location patterns in a sparser spatial neighbor relationship graph (or
Second, candidate maximal co-location patterns (or candidate maximal
Third, since the number of subsets of a size-
Fourth, checking the prevalence (e.g., participation index) of each candidate maximal co-location pattern (or candidate maximal
In other words, the baseline method is improved, as shown in Fig. 2b. First, the
In summary, the main contributions of this paper include the following:
A more general To improve maximal Extensive experiments on both real and synthetic data sets show the superiority of the
The remainder of this paper is organized as follows. In Section 2, related works are reviewed. In Section 3, the
The co-location pattern mining has got its own since the concept was firstly introduced by Shashi Shekhar Huang [15]. The traditional mining model generally includes three steps whatever in classical or uncertain data sets [16, 17, 18]. First, the neighbor relationship generating. Second, the prevalence check of patterns. Third, the secondary mining for user interest.
The neighbor relationships between spatial instances are generally driven by distance thresholds [19] or nearest neighbors [20] with static or dynamic models [21]. Moreover, there are some variants, such as Delaunay triangulation [22] and so on [23, 24]. We focus on reachability of instances in given basic neighbor relationship graphs but not the generation of graphs in this paper. A spatial neighbor relationship graph is generally materialized by star or clique neighborhood lists [12, 25].
For specific applications, some prevalence metrics [5, 6, 26, 27] have been defined for such as rare feature finding, overlap clique partitioning. The most popular index is the participation index [8], which is followed in this paper.
The methods of mining co-location patterns can be mainly classified into three groups. The first group exploits an Apriori-like method to generate prevalent patterns with considerable time to check co-location instances [8, 28, 29]. This size-wise manner makes approaches in this group inefficient in obtaining longer-size patterns.
The second group suggests using maximal cliques [25, 30, 31] in the spatial neighbor relationship graph to discover co-location patterns. Maximal cliques can be regarded as transactions, and then association analysis methods such as Apriori [19] and FP-growth [32] can come in handy. However, maximal clique finding is an NP-hard problem.
The third one first generates candidate maximal co-location patterns [33, 14, 34] and then checks their prevalence. A candidate maximal co-location pattern is a pattern whose true super sets cannot be prevalent according to some properties, such as the Apriori property. [33] first finds all sub-prevalent patterns (called clique candidates on star candidates in the original text) on star neighborhood lists with a modified FP-tree.
Similarly, [14] finds candidate maximal co-location patterns on MCP trees (similar to the FP tree). A candidate maximal co-location pattern corresponds to the longest path of an MCP tree. [34] finds maximal cliques on a size-2 co-location pattern graph with a degenerated order list [31], and then, each maximal clique is regarded as a candidate maximal co-location pattern. Once the candidate maximal co-location patterns have been generated, the third group tends to check each of them in a size-wise way. For example, if a size-
The first group is troubled with long-size pattern finding, and the second group is limited to the maximal clique finding problem. Since
Maximal
-reachability co-location pattern
In this section, the
-reachability co-location pattern
For ease of exposition, suppose that we have a spatial neighbor relationship
(
-reachability neighborhood list).
Given a graph
where
Each instance in
(
-reachability clique).
Given a spatial neighbor relationship graph
(Nestedness of
-reachability cliques).
Given a nonnegative integer
Proof..
Given a non-negative integer
Importantly, Lemma 1 is true only when the reachability is considered in the whole spatial neighbor relationship graph
.
In Fig. 1a, {A1, B1, B2, B3, C1, C2, D1} is a 3-reachbility clique. In addition, any of its subsets is also a 3-reachability clique. More specifically, {B1, D1} is a 3-reachability clique since B1 (or D1) can be reachable to D1 (or B1) across A1 in Fig. 1a.
Obviously, a clique must be a 1-reachability clique and vice versa. Since the members of any instance pair in a star neighborhood instance can be reachable to each other directly or across the centric instance, each star neighborhood instance must be a 2-reachability clique. In other words, the
(
-reachability instance).
Given a step length
.
In Fig. 1a, {A1, B1, C1, D1} is a 3-reachability instance of {A, B, C, D}. Although {A1, B1, B2, B3, C1, C2, D1} is a 3-reachability clique, it is not a 3-reachability instance of {A, B, C, D} because duplicate features B (B1, B2, B3) and C (C1, C2) exist.
(
-reachability participation ratio).
Given a step length
.
In Fig. 1a,
(
-reachability participation index).
Given a step length
(
-reachability co-location pattern).
Given a step length
.
In Fig. 1a,
Similar to the
(Anti-monotonicity of
and
).
Let
Proof..
Assuming that
Certainly,
Thus,
Furthermore,
Lemma 2 declares that the Apriori property is accepted by the
(Maximal
-reachability co-location pattern).
Given an
.
In Fig. 1a, {A, B, C, D} is a maximal 3-reachability co-location pattern, but neither any true subset nor any true superset occurs when
An example of the baseline method.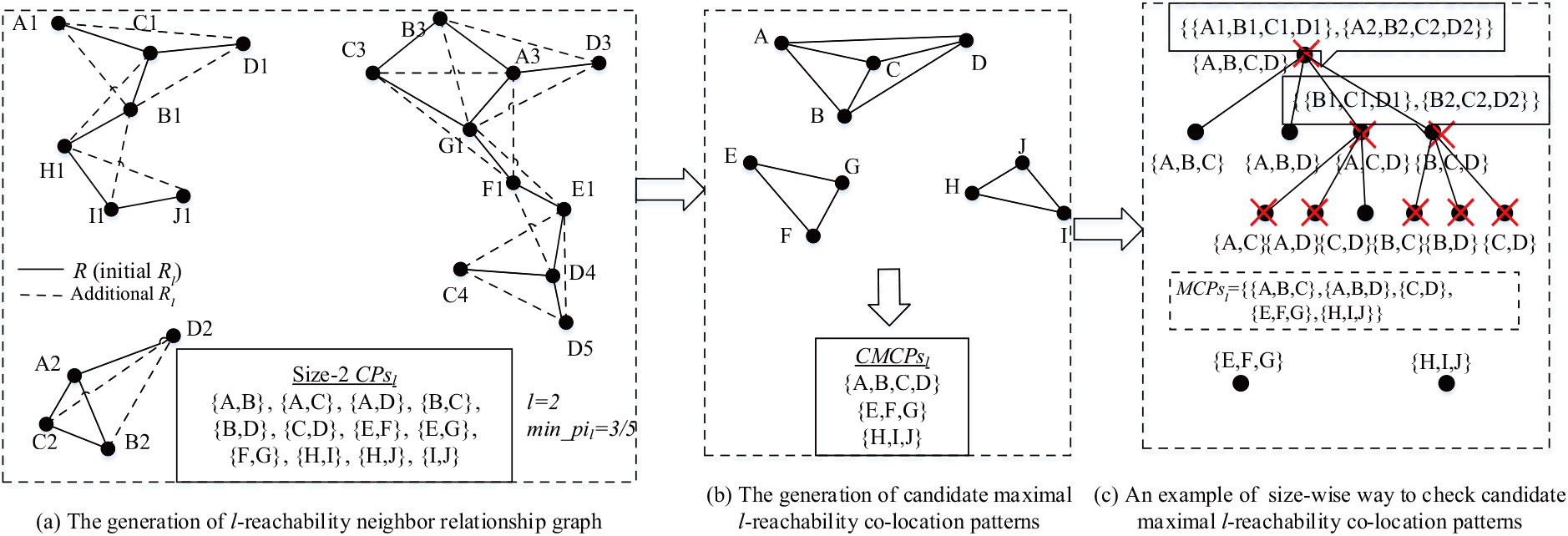
Learning from traditional co-location pattern mining approaches,
[h] : The Baseline Method (
Algorithm 3 works for maximal
Since the generation of the
In this section, a natural
A natural
-reachability clique
Since steps from Step 3 to Step 3 in Algorithm 3 follow an Apriori-like way from 1 to
(A natural
-reachability clique).
Given a spatial neighbor relationship graph
Proof..
Given a spatial neighbor relationship graph
.
In Fig. 3a, since
(Reversed binary-search of
).
Given a spatial neighbor relationship graph
Proof..
Given a spatial neighbor relationship graph
Letting
Thus,
If
If
∎
Lemma 4 declares that
For example, in Fig. 3a,
It is acknowledged that mining co-location patterns over a very large-scale sparse spatial dataset is much faster than in a denser dataset [31], and we will briefly introduce sparsification strategies to make the
First, it is understandable that edges whose endpoints are not related to any size-2
Once
(
-reachability neighborhood list cluster).
Given an
In detail, the label set of
where
(Star
-reachability neighborhood instance).
We are given a pattern
.
There exist two 2-reachability neighborhood list clusters whose labels are {A, B, C, D} and {A, B, C} in Fig. 3a. Moreover,
(Upper participation ratio).
Assume that we are given a pattern
(Upper participation index).
Assume that we are given a pattern
.
In Fig. 3a,
(Anti-monotonicity of
and
).
Assume that we are given two patterns
Furthermore, the upper participation index of
Proof..
We are given two patterns
Certainly,
Thus,
Furthermore,
Obviously, an
(Candidate maximal
-reachability co-location pattern).
Assume that we are given an
Interestingly, some table instance sets appear in this paper, such as the co-location table instance, the
(Maximal subset winner).
Assume that we are given a pattern
.
We are given
(Suggestion for
).
Assume that we are given an
Proof..
Assume that we are given an
According to Lemma 5 and Lemma 6, a size-independent way to mine maximal
(Iterative bi-graphs).
An iterative bi-graph is a bi-graph
In detail, nodes that correspond to parents in an iteration are called parent nodes, and nodes that correspond to children are called child nodes. For a node
.
Given parent nodes {A, B, C} and {A, B, D}, {A, B} is a child node of the two because {A, B, C}
(The perfect matching for
mining).
Given an
Proof..
Assume that we are given an
Similarly, there must exist parent nodes of
Given a parent node
Assume that we are given a child node
Since
Therefore, given an
This strategy responds to the fact that once a candidate maximal
An example of the size-independent method on iterative bi-graphs.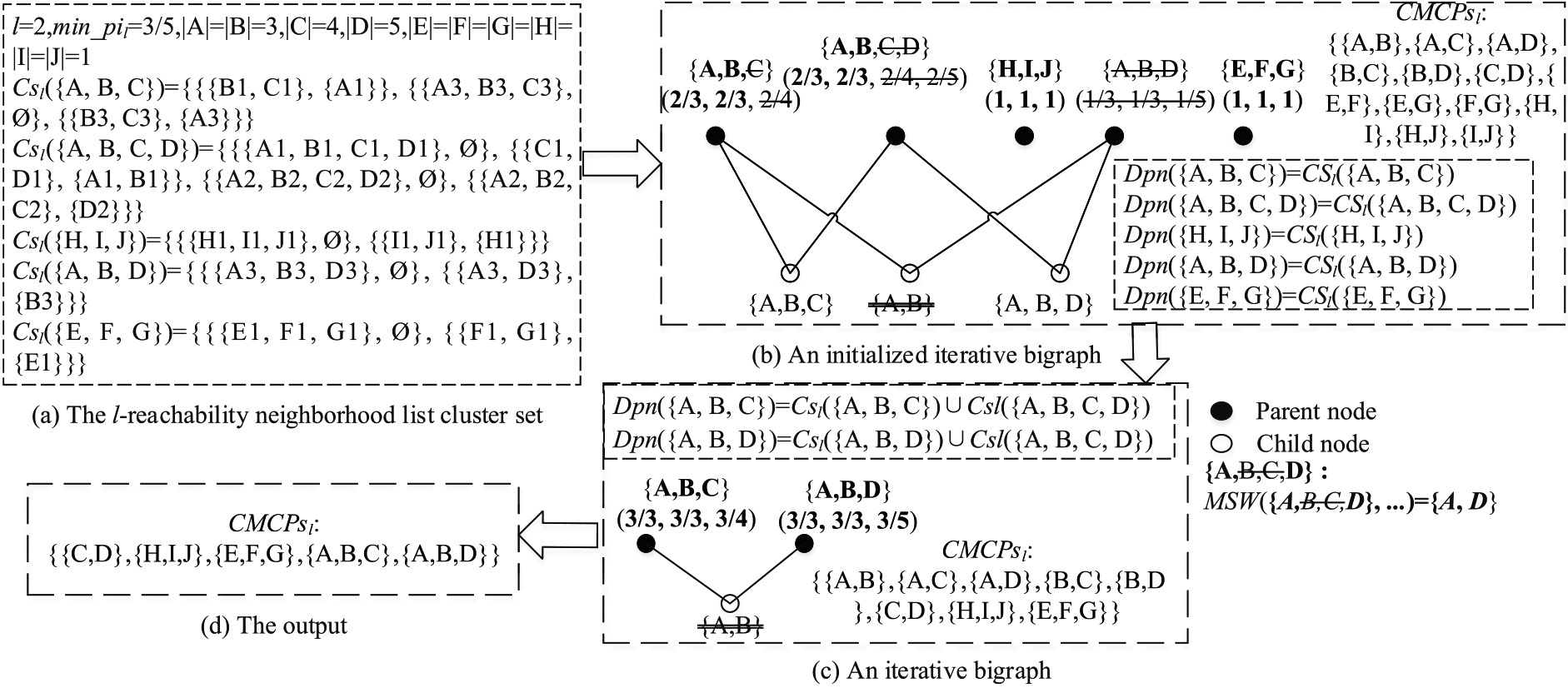
Thus, an example for candidate maximal co-location pattern (or candidate maximal
[h] : The Iterative Bigraphs (
To summarize, see Algorithm 4 for details. Algorithm 4 tends to iteratively find candidate maximal
In Algorithm 4, iterative bi-graphs are initialized by Step 4 to Step 4 and cost
Once candidate maximal
.
Given
.
Assume that {{C1, D1}, {A1, B1}} is a star 2-reachability neighborhood instance of {A, B, C, D}. If A1 does not appear in
Once a candidate maximal
(Binary-subset).
We are given two patterns
.
(Acceptance of
).
Assume that we are given an
Proof..
Assume that we are given an
.
We are given a candidate maximal
Obviously, a binary-subset winner can be checked to determine whether it has appeared in the maximal
on average, where
Since sparsification strategies, iterative bi-graphs and binary search methods have been proposed, an improved method called the improved method (
: The Improved Method (
Since the time complexities of both steps from Step 4.4 to Step 4.4 of Algorithm 3 and Algorithm 4 have been analyzed, we only need to analyze the time complexities of steps from Step 4.4 to Step 4.4 for Algorithm 4.4. Although Step 4.4 is an NP-hard problem, it is acceptable that the candidate maximal
Experiments
In this section, both the baseline method and the improved method in this paper are evaluated with synthetic and real data sets distributed as shown in Fig. 5. The coordinates of both graphs are accurate in meters. Table 1 shows the abbreviations. In addition, the experimental platform is based on a personal computer with an Intel (R) Core (TM) i7-8700 CPU running 3.20 GHz and 3.19 GHz in addition to 32 GB RAM following Windows10 64-bit OS.
The abbreviation table for experiments
The abbreviation table for experiments
Spatial instance distributions of experimental data sets.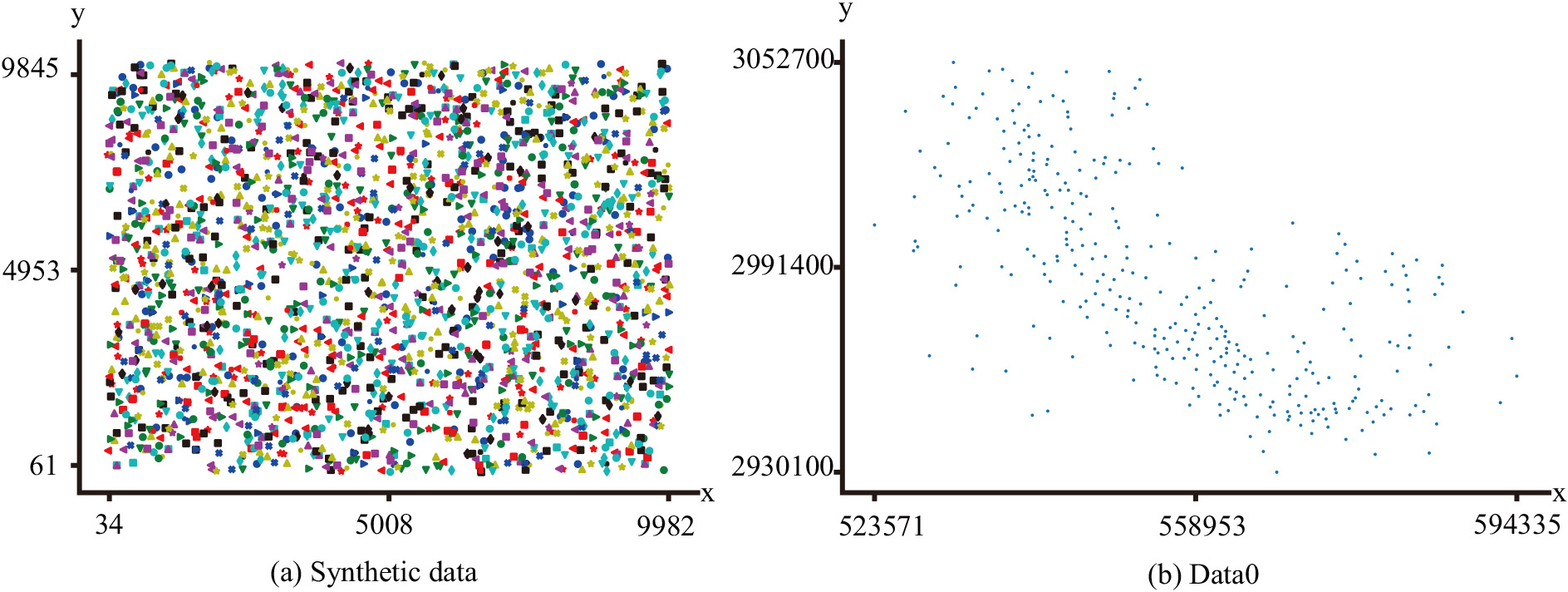
Synthetic data sets
The synthetic data sets called synthetic data (i.e., Fig. 5a) tend to synthesize spatial feature instances that contain 100 expected maximal patterns. The 100 patterns are called expected positive examples of patterns (
Real data sets
The real data sets called Data0 (i.e., Fig. 5b) present a rare plant spatial distribution in the Three Parallel Rivers Yunnan Protected Areas [28]. All 337 rare plants classified into 31 features were evenly and sparsely distributed. The distance threshold
The test result on synthetic data.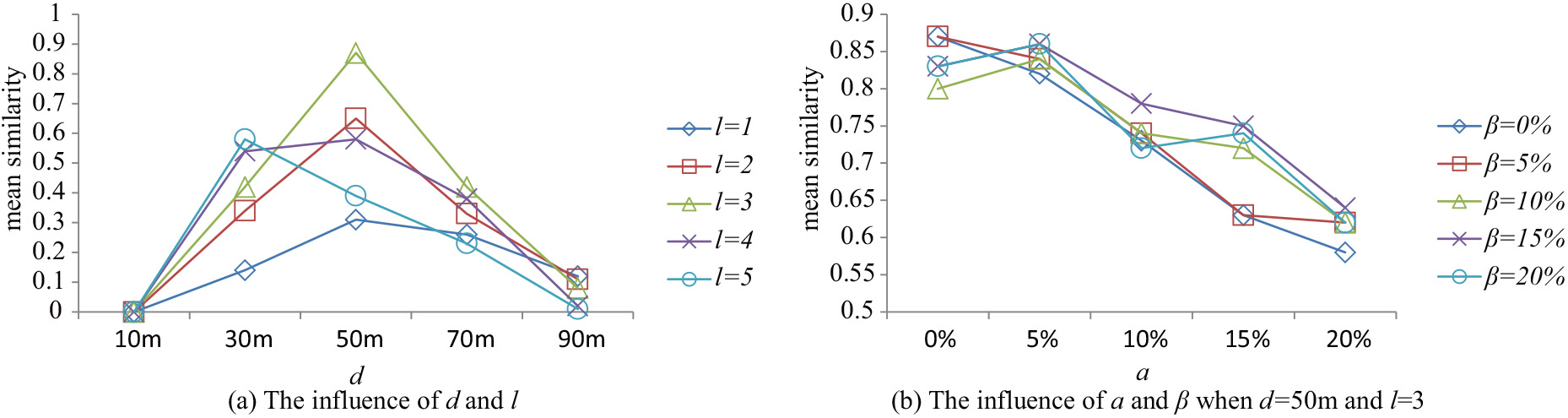
The coordinates of the data sets are accurate to meters. The suggested prevalence threshold
The 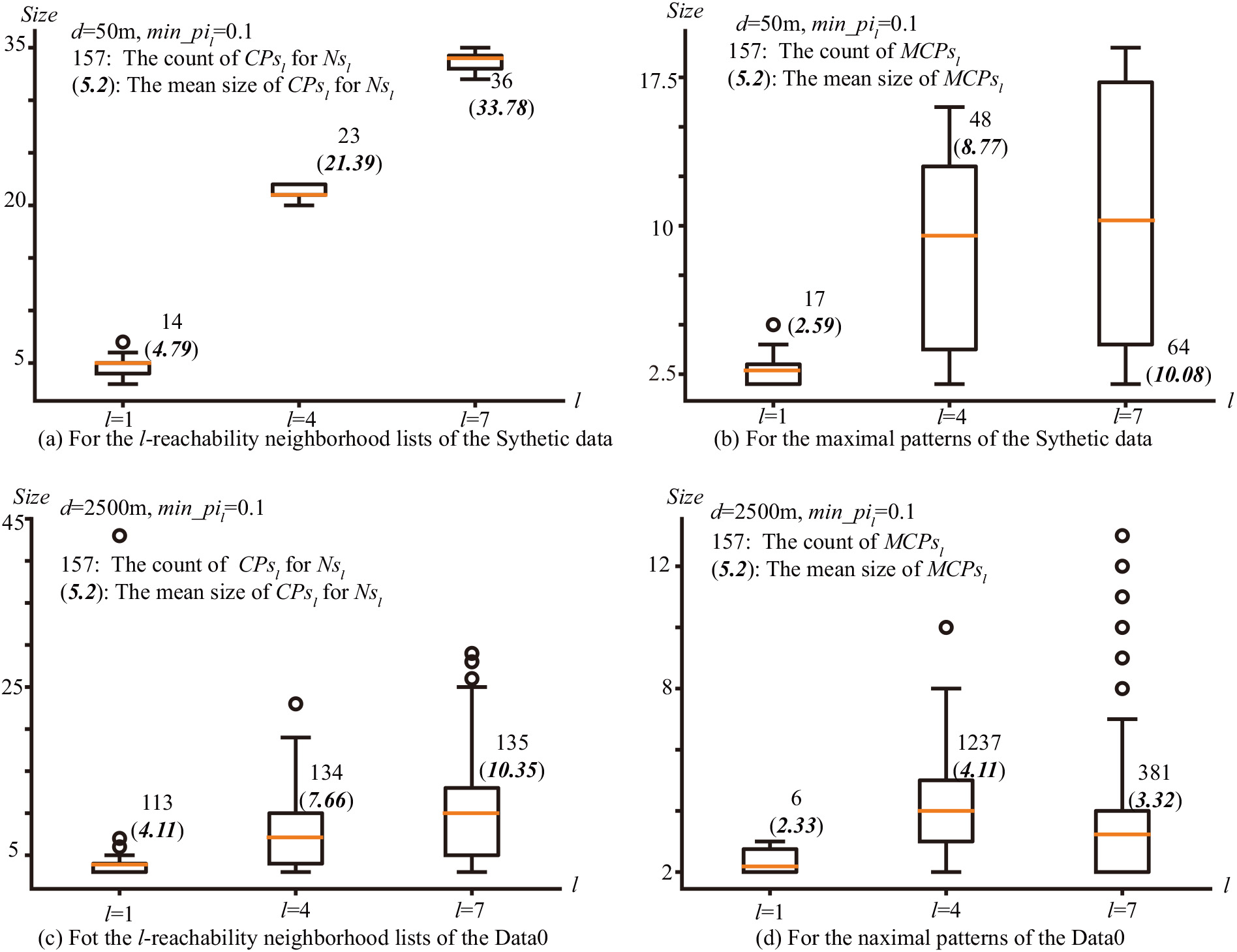
The comparison of the intermediate results (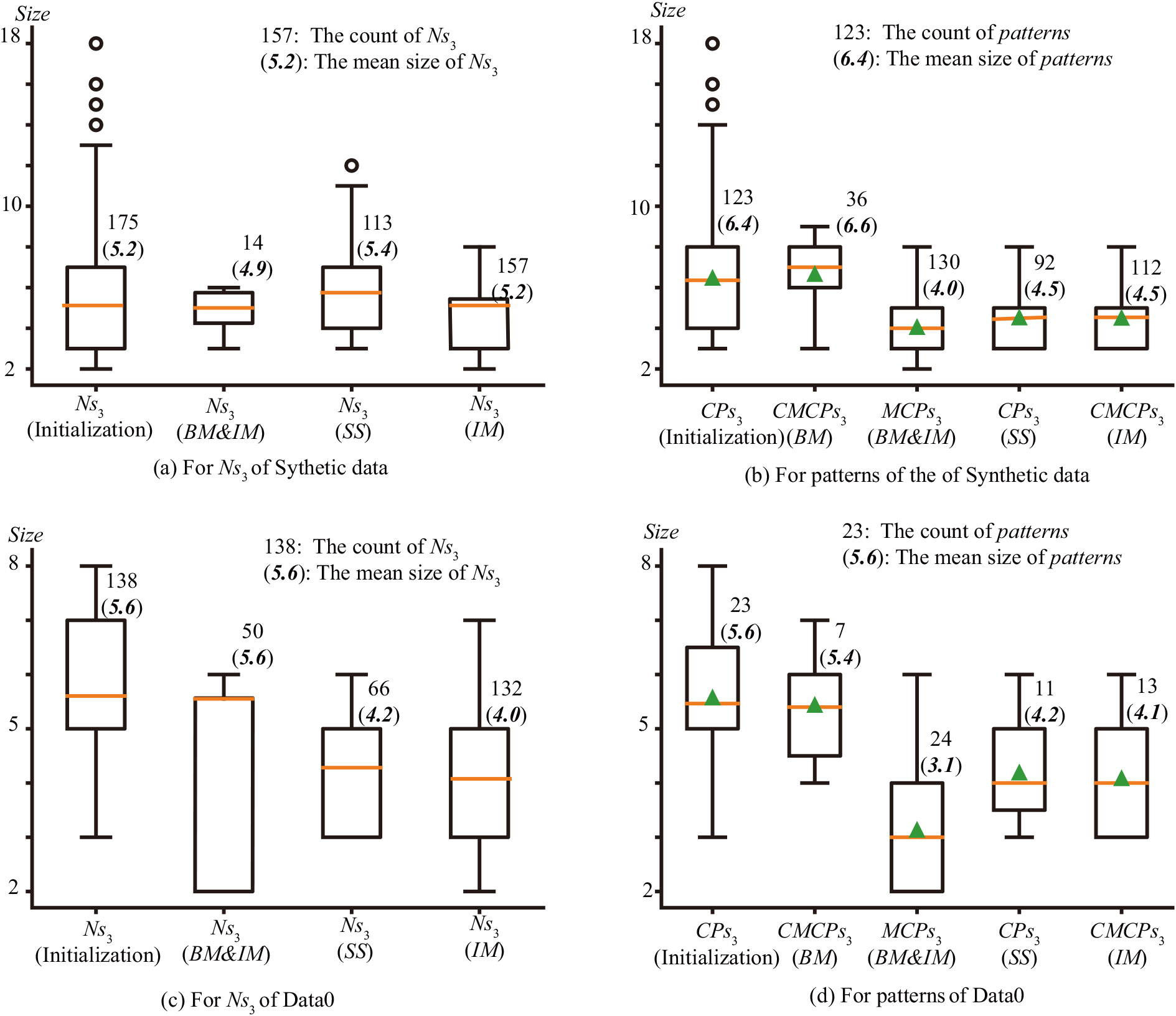
The comparison of checked objects (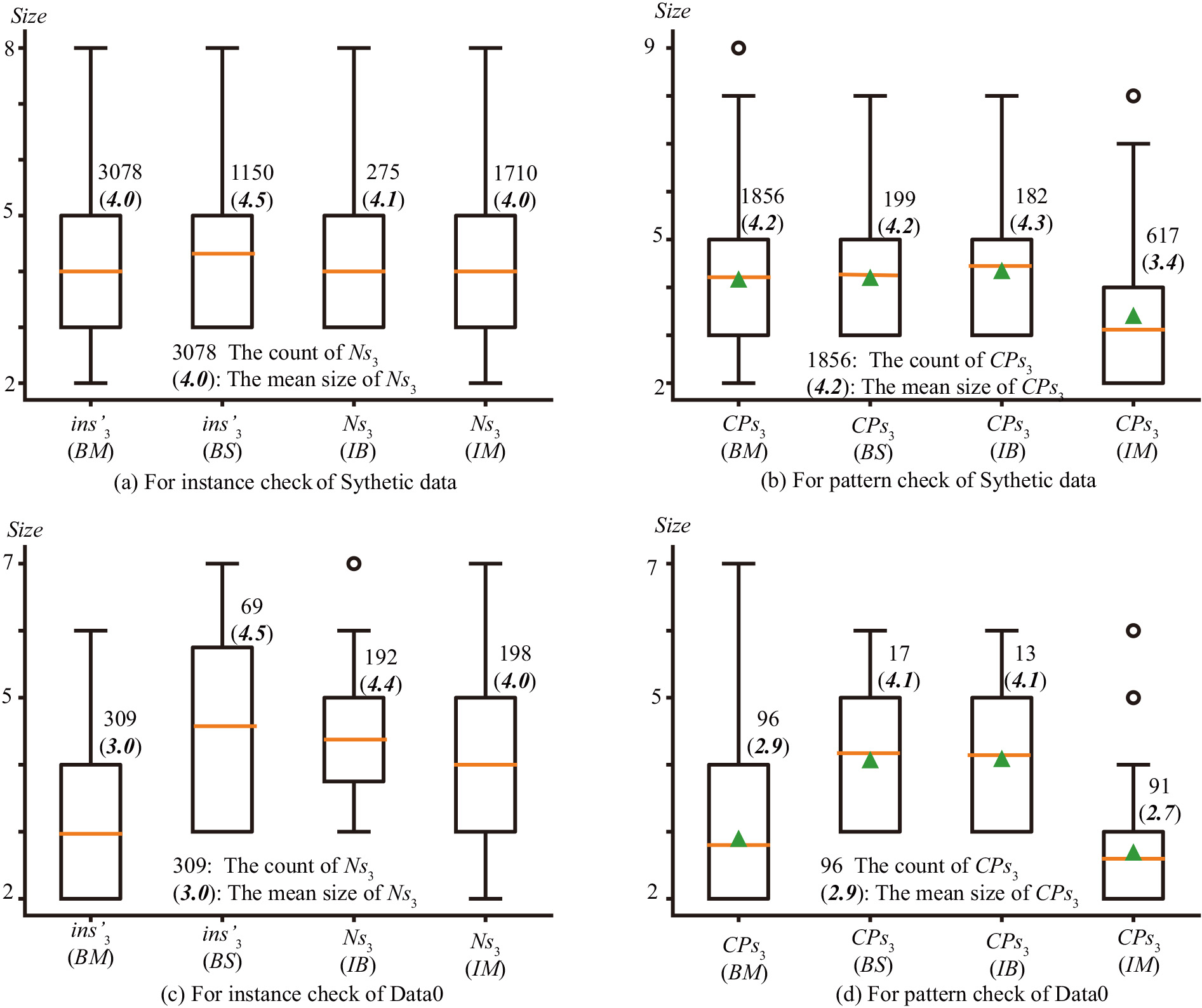
The execution times on synthetic data.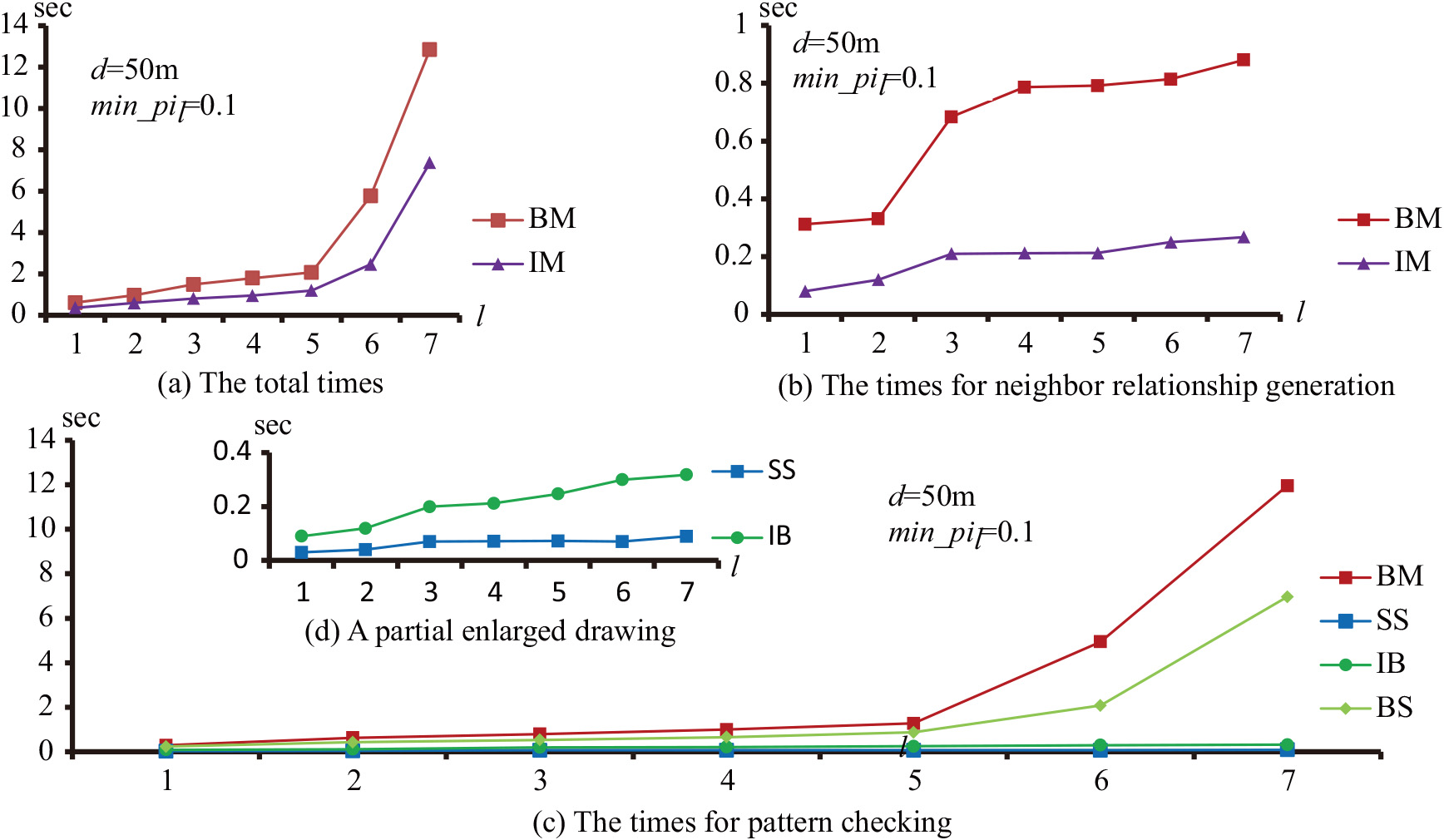
Mean similarity
The mean similarity between expected patterns (i.e.,
The closer the mean similarity is to 1, the better the performance of our maximal
Figure 6a shows the mean similarity of our
Figure 6b shows the influence of noise instances (its ratio denotes
Sensibility
The sensibility is used to test the effect of
Effectiveness
The effectiveness is used to evaluate our improved
The most time-consuming part of
Therefore, Fig. 8 shows the distributions of procedure results. This figure reveals that the mean sizes of candidate maximal
The execution times on Data0.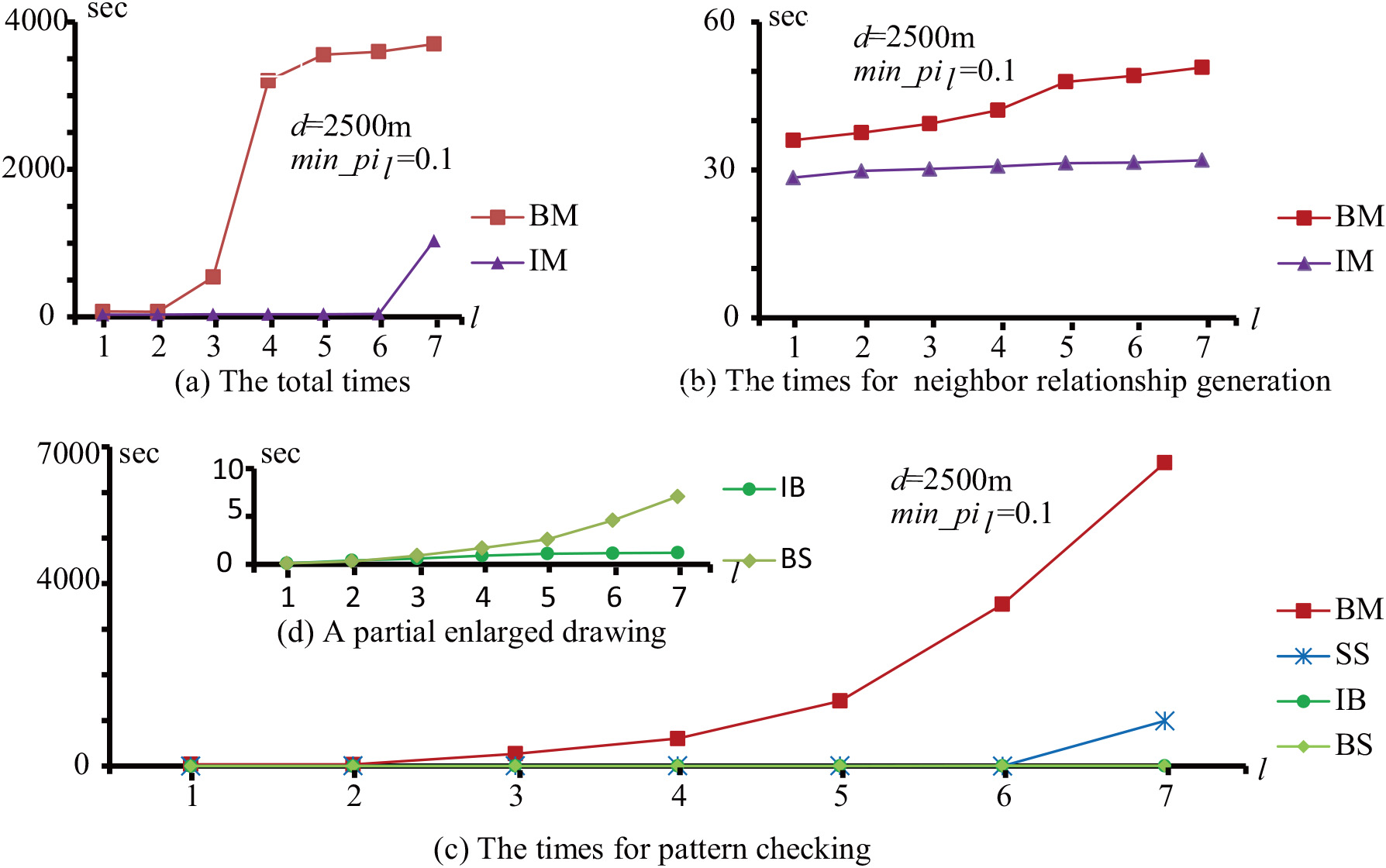
The efficiency of the improved method is evaluated in comparison to the baseline method by the execution times of the algorithms. Figures 10 and 11 show that the improved method is highly efficient when a distance threshold
In other words, our
Conclusions
The
In a co-location pattern, a feature tends to be more important if the feature’s instances always have a high closeness centrality in its co-location instances. The closeness centrality of each instance in an
Footnotes
Acknowledgments
This paper is supported by the National Natural Science Foundation of China (No. 61966036, 61662086, 62066023), the Yunnan Province Scientific Innovation Team Project (No. 2018HC019), and the Scientific Research Project of Kunming University (No. XJZZ1706).
Conflict of interest
The authors declare that they have no conflict of interest.