
Abstract
The growing smart cities in urban areas are becoming more intelligent day by day. Massive storage and high computational resources are required to provide smart services in urban areas. It can be provided through intelligence cloud computing. The establishment of large-scale cloud data centres is rapidly increasing to provide utility-based services in urban areas. Enormous energy consumption of data centres has a destructive effect on the environment. Due to the enormous energy consumption of data centres, a massive amount of greenhouse gases (GHG) are emitted into the environment. Virtual Machine (VM) consolidation can enable energy efficiency to reduce energy consumption of cloud data centres. The reduce energy consumption can increase the Service Level Agreement (SLA) violation. Therefore, in this research, an energy-efficient dynamic VM consolidation model has been proposed to reduce the energy consumption of cloud data centres and curb SLA violations. Novel algorithms have been proposed to accomplish the VM consolidation. A new status of any host called an almost overload host has been introduce, and determined by a novel algorithm based on the Naive Bayes Classifier Machine Learning (ML) model. A new algorithm based on the exponential binary search is proposed to perform the VM selection. Finally, a new Modified Power-Aware Best Fit Decreasing (MPABFD) VM allocation policy is proposed to allocate all VMs. The proposed model has been compared with certain well-known baseline algorithms. The comparison exhibits that the proposed model improves the energy consumption by 25% and SLA violation by 87%.
Introduction
The demand for living in smart cities is increasing rapidly. In 1900, just 16.4% of the world’s 1650 million inhabitants were thought to reside in cities [1]. By 2015, the worldwide percentage had climbed to 54%, roughly 3970 million out of a global population of 7350 million. The UN predicts this growing urbanisation to continue, with the globe becoming two-thirds urban by 2050 [2]. A growing proportion of the urban population resides in mega-cities, the cities having a population of 10 million or more [3]. Smart cities employ big data to better the quality of life for residents by addressing difficulties with housing, transportation, government services, education, and healthcare through intelligent responses. Therefore, smart cities have emerged as a new paradigm for modern urban development. The growth of intelligence-enabled transportation, e-commerce, smart cities, government services, education, and healthcare in urban areas has resulted in a massive growth of data. Big data methods are crucial in processing and evaluating this massive data. The difficulty is that processing this massive data needs more computer resources and storage areas. Cloud computing is a more promising answer to these problems than traditional computing. It delivers processing, storage, and networking resources to users, relieving them of the cost of managing these resources. Any application can benefit from cloud computing resources and computing services. Regardless, in a time-sensitive scenario, such as an IoT context, a device must select what to do next.
Today’s organisations rely on intelligence cloud computing to deliver nearly all their livelihood services in unban areas. Given these developments, it is worth considering how cloud computing demands influence energy consumption in data centres. In 2020, the global cloud computing market was valued at $219 billion. The global cloud computing market grew by 13.07% in 2020 compared to the average yearly growth from 2017 to 2019. The market is expected to grow at a compound annual growth rate of 17.19%, from $250.04 billion in 2021 to $791.48 billion in 2028 [4]. The rapidly increasing demand for cloud services is also increasing the energy consumption of cloud data centres. According to International Energy Agency (IEA), total energy consumption by the global data centres in 2020 was 200–250 Terawatt hour (TWh), which is approximately 1% of the total required global electricity [5]. The energy consumed by cryptocurrency mining is not included, which reached approximately 100 TWh in 2020 [6]. In 2014, data centres in the USA accounted for 1.8% of US power usage, almost identical to New Jersey’s electricity consumption [7].
The escalating energy demand of data centres has piqued the interest of researchers, not just because of the smart cite’s growth but also because of the consequences of the smart cite’s energy consumption on greenhouse gas (GHG) emissions and water use. Data centres consume water and generate greenhouse gases both directly and indirectly. In the United States, electricity generation is the second most significant user of water [8] and the second-highest emitter of greenhouse gases [9].
In [10], authors found that by making data centres more energy-efficient, it may be possible to reduce their power consumption by data centres by up to 45% compared to existing trends. Utilizing Virtual Machine (VM) consolidation is the most popular method for enhancing virtualized data centres’ energy and resource efficiency. With the help of the dynamic VM consolidation, several virtual machines may be placed on a single physical host. Additionally, live VM migration enables dynamic consolidation of VMs for improved VM placement and increased energy savings by converting idle hosts to low power modes [11]. Even though dynamic VM consolidation may significantly reduce energy consumption, live VM migration [12] raises service level agreement violations (SLAVs). The main reason is that energy consumption and SLAVs are inversely related [13]. So, a compelling dynamic VM consolidation strategy becomes crucial to reduce energy consumption, the number of migrations and maintain service level agreements in cloud data centres. In this paper, We proposed an effective dynamic VM consolidation approach based on a machine learning approach called Naive Bayes Classifier [14]. The main focus of the research is on CPU utilization since the CPU consumes the most significant share of electricity in data centres [8]. The ability to accurately predict the future host status is crucial for achieving these goals. There is a linear relationship between a host CPU utilization and energy consumption. Therefore, a novel approach has been proposed to classify the host status using the Naive Bayes Classifier. The host status is classified in four different states. The CPU utilization history is used to prepare the data set. The machine learning model has been trained by the prepared data set and tested to predict the future status of any host. The CloudSim toolkit [15] and a genuine Cloud trace log made available by the CoMon project [16] is used to assess the effectiveness of the proposed VM consolidation approach.
The following are the significant features of this research:
Host status is classified as overloaded, almost overloaded, moderately loaded, and underloaded. The machine learning model has been trained by a data set prepared from CPU utilization history and tested to predict the future status of any host. The name of the novel method is Host Status Prediction using Naive Bayes Classifier (HSPNBC). Host overload and almost overload detection algorithm using HSPNBC method has been proposed to predict the overloaded and almost overloaded hosts. A new VM selection algorithm called Exponentially Fit (EF) VM selection based on exponential binary search has been proposed to prepare the Migratable VMs list. A new Modified Power-Aware Best Fit Decreasing (MPABFD) methodology based on the HSPNBC method has been developed to discover suitable hosts for the Migratable VMs.
The remainder of the paper is organised as follows: Section 2 contains a summary of the literature review and state of the art. Section 3 provides an overview of the Naive Bayes Classifier. Section 4 describes the phases of VM consolidation. Section 5 depicts the suggested Host Status Prediction based on the Naive Bayes Classifier (HSPNBC) model. The experimental setup is shown in Section 6. Section 7 displays a detailed analysis of the proposed model. Finally, Section 8 discusses the proposed method’s conclusions and future research directions.
Research on data centre energy efficiency has been conducted extensively in recent years. In order to reduce energy consumption in cloud data centres, most research focuses on the VM consolidation approach. Beloglazov et al. [11]developed many dynamic consolidation approaches and are used in conjunction with the Power-Aware Best Fit Decreasing (PABFD) VM placement algorithm. Their approaches to overloaded host identification and VM selection are the key distinctions between these methods. W. Lin et al. [17] presented an online VM consolidation strategy to improve the performance and energy usage of cloud data centres.The authors introduced a new metric called peak power efficiency and proposed a Peak Efficiency Aware Scheduling (PEAS) based online VM allocation and reallocation approach. The PEAS approach constantly makes an effort to keep hosts engaged by consolidating VMs to reach their maximal power efficiency. K. Haghshenas et al. [10] proposed a Multi-Agent machine learning-based approach for energy-efficient dynamic VM consolidation (MAGNETIC). The proposed approach is not just a centralized-distributed but also low-overhead failure-aware. The method uses a distributed multi-agent Machine Learning (ML) based strategy to choose the best power mode and frequency for each host during run-time and then perform the migration by that choice. The proposed MAGNETIC method can identify host performance fluctuation brought on by failures, migrate virtual machines from faulty hosts autonomously, and relieve them from the load. J. Zeng et al. [18] proposed an energy-efficient VM consolidation approach based on Adaptive Deep Reinforcement Learning (DRL). The process was divided into two phases. The first phase was to compute the Influence Coefficient, a VM’s impact on causing host overload. A Prediction Aware DRL-based VM allocation approach was proposed in the second phase.
F. Farahnakian et al. [19] was introduced a utilization prediction strategy for energy-aware VM consolidation in cloud environment. The strategy was based on the k-nearest neighbour regression model to forecast future CPU and memory usage of VMs as well as hosts. The authors show that their proposed model significantly reduced the energy consumption of cloud data centres. M.S. Ricardo [20] et al. proposed a methodology for testing several machine learning and deep learning based algorithms to predict the servers’ CPU utilization. It influences virtual machines’ migration, affecting SLA and energy exhaustion in data centres. The authors show that the Long Short-Term Memory (LSTM) and Simple Moving Average (SMA) methods yield good results. VM selection is one of the steps of dynamic VM consolidation. N.K. Biswas et al. [21] suggested a VM selection methodology to decrease cloud data centre energy usage and SLA violations. The maximum value among the difference of the Sum of Squares Utilization Rate (MdSSUR) characteristic is used to select VMs from overloaded hosts. A difference is determined between an overloaded host’s Sum of Squares Utilization Rate (SSUR) and Remaining Sum of Squares Utilization Rate (RSSUR), and the VM was selected, which had a maximum difference. The authors demonstrate that the suggested MdSSUR VM selection greatly decreased cloud data centre energy usage and SLA violations. J.P.B. Mapetu et al. [22] proposed a dynamic load-balancing method for VM consolidation in the cloud that uses Pearson correlation. The dynamic load balancing is based on VM consolidation to reduce the trade-off between energy usage, SLAV, and number of migrations while maintaining minimal number host shutdowns and lower computational complexity for heterogeneous systems.
A machine learning (ML) model was developed for the first step of dynamic VM consolidation by S.M. Moghaddam et al. [23] to predict the ideal moment to start migrations for each VM. The authors also developed a VM placement policy established on Best Fit Decreasing (BFD) algorithm. The proposed dynamic consolidation was able to reduced energy consumption of cloud data centres. The CompVM initial virtual machine (VM) allocation strategy, which combines complementary VMs using spatial and temporal awareness, was proposed by H. Shen et al. [24]. Complementary virtual machines are those whose combined demand for all available resources exceeds the host’s capacity over the VM lifespan. The process makes predictions about VM resource use patterns based on the observation that such patterns exist. It manages the needs for various resources based on projected trends and consolidates complementing VMs on the same host. By decreasing the number of hosts required to offer VM service, this method improves resource usage and energy efficiency, decreases VM migrations, and prevents SLA violations. In order to maximize both energy savings and service quality, Z. Li et al. [25] developed the EQ-VMC approach for effective and efficient VM consolidation. The authors created a discrete differential evolution algorithm to look for the placement of virtual machines that is globally optimal. The EQ-VMC efficiently lowers energy consumption by combining this approach with a collection of algorithms designed for efficient host overload detection, VM selection, and under-loaded host identification. I. El-Taani et al. [26] proposed a VM placement policy to reduce energy consumption and maximise resource efficiency in cloud data centres. The proposed policy was based on statistical approaches for measuring the similarity of resource vectors between hosts and VMs. It minimises resource waste by deploying VMs on hosts by maintaining intra-workload balancing of the different resources.
Summary of literature survey
Summary of literature survey
L. Li et al. [27] proposed consolidating the VMs model in Cloud Data Centers While Being Aware of SLAs and applying a Robust Linear Regression Prediction Model. The authors’ algorithms for all dynamic VM consolidation steps are based on their proposed Robust Simple Linear Regression prediction model. H. Xiao et al. [28] developed a meta-heuristics-based VM consolidation technique. The authors proposed a threshold and Ant Colony System (ACS) based multi-objective VM Consolidation approach. The method uses two CPU usage criteria to determine the condition of the host load; if any host is overloaded or underloaded, VM consolidation is initiated. The approach employs ACS to choose hosts and migrate VMs at the same time. A VM placement policy was introduced by A. Ibrahim et al. [29] according to Particle Swarm Optimization (PSO) for the last step of VM consolidation. The migrated VMs are mapped to the most suitable hosts using discrete form of PSO based on a decimal encoding. A powerful minimization fitness mechanism is also used to lower power consumption while satisfying the Service Level Agreement (SLA). X. Xiao et al. [30] developed a coalitional game-theoretic technique based on merge and split to enabling VM consolidation in diverse clouds. The proposed method divides hosts into various groups according to the workload level of hosts, uses a coalitional game-based consolidation method (CGMS) to select members from these groups to form effective coalitions, and performs migrations one of the coalition members to maximize the benefits of each coalition, and then maintains hosts in a state of high energy efficiency.
Increasing the energy efficiency of data centres using VM consolidation has been the subject of several studies (see Table 1). Machine learning (ML) based dynamic VM consolidation aspect has not yet flourished well. Therefore, we develop a novel dynamic VM consolidation approach based on the Naive Bayes Classifier model to trade-off between energy consumption and SLA violations of cloud data centres.
The Naive Bayes Classifier is founded on the theorem of Bayes [14]. Let A, B represent two occurrences from a sample space
Now, using Eqs (1) and (2) it can assert that:
therefore,
Now, suppose that a data set has n occurrences
The common divisor in Eq. (5) is the joint probability of
Suppose that the component
Now, it can be put in Eq. (5) and, it can be rewritten as:
Suppose anyone wants a precise classification rule which will assign each occurrence to precisely one class, compute the value of the common divisor for each class and choose the class with the highest value. It is called the maximum posterior rule, and it is computed as:
The model that performs Eq. (8) is the Simple Naive Bayes classifier.
The major rationale for dynamic VM consolidation is to process as many VMs as possible in a host to improve the performance and minimize the energy consumption of cloud data centers. Beloglazov and Buyya [11] introduced an approach to handling the dynamic VM consolidation, which consists of four steps:
Detection of Overloaded Hosts. Detection of Underloaded Host. Some VMs select from overloaded hosts, and All VMs select from the underloaded host and migrate them to some suitable hosts. VM placement for all VMs selected in step no. (iii).
This whole procedure of dynamic VM consolidation is represented by Algorithm 1 [23].
Virtual Machine Consolidation
host_List
vm_Migration_Map
start
Select some VMs and add them into vmsToMigrate;;Add the host to overutilized_Host_List;
Find the underutilized_host; Add all VMs of underutilized_host to vmsToMigrate;
In this section, the Host Status Prediction using the Naive Bayes Classifier (HSPNBC) model for dynamic VM consolidation in cloud data centers is described in detail. In Section 4 a brief discussion on dynamic VM Consolidation was given. The proposed dynamic VM consolidation model is to reduce the energy consumption of cloud data centers and curb SLA violations.
Host Status Prediction using Naive Bayes Classifier (HSPNBC)
The Naive Bayes Classifier model is a machine learning model which can classify various items based on certain attributes. In this research work, we want to predict the future status of any host using CPU utilization history. Using the most recent CPU utilization history, we created ‘
Over-Loaded Host(OLH): If the future predicted utilization of any host is equal to or more than 90%, than the host status is classified as overloaded. Almost Over-Loaded Host (AOLH): If the future predicted utilization of any host is between 70% to 89%, then the host status is classified as almost overloaded. Moderately-Loaded Host (MLH): If the future predicted utilization of any host is between 10% to 69%, then the host status is classified as almost moderately loaded. Under-Loaded Host (ULH): If the future predicted utilization of any host is between 1% to 9%, then the host status is classified as almost under-loaded.
The mapping of predicted utilization and host status is shown in the Table 2.
Host Status Prediction using Naive Bayes Classifier
Set Data[i][1]
Set Data[i][1]
Set Data[i][1]
Set Data[i][1]
Using the Data build the Naive Bayes Classifier; Compute
The proposed Host Status Prediction using Naive Bayes Classifier is described in Algorithm 2. The CPU utilization history is given as input of the Algorithm 2. Then the input CPU utilization has been reversed to get the latest CPU utilization. The host status is classified as described in Table 2 and the data set is prepared by the proposed model. A two dimensional matrix is created by the CPU utilization history. The first column of the matrix represents the utilization of CPU, second column represents under loaded host, third column represents moderately loaded host, fourth column represent almost loaded host, and fifth column represents over loaded host. The first column stores the CPU utilization value, depending on that any one column is set by 1 and other columns are set by minimum value. Now, the proposed model is trained by the prepared data set, it can predict the future host status and classify as per our proposed host status classification by the Naive Bayes Classifier.
Host status classification based on utilization
The detection of overloaded hosts is the initial stage in dynamic VM consolidation. The proposed HSPNBC model can classify any host. If the host status is predicted as overloaded by the Algorithm 3, add the overloaded host to the over-utilized host list. To conduct the migration and change the host state to moderately loaded, the Algorithm 5 must choose certain VMs from the overloaded host.
Almost overloaded hosts detection
The proposed HSPNBC model introduced a new status for any host, i.e., almost overloaded hosts. Whether the status of any host is almost overloaded or not is determined by Algorithm 4. The main reason to classify a host status as almost overloaded is explained in Section 5.1.5.
Under-load host detection
The Under-load Host Detection is the second step of VM consolidation. In the proposed HSPNBC model for VM consolidation, the underloaded host detection is accomplished by an algorithm which was proposed in [11]. After detecting the underloaded host, all VMs of the underloaded host are selected and added to the vmsTomigrate list.
VM selection
VM Selection is the third step of dynamic VM consolidation. It is a crucial step in reducing the number of migration. The proposed Exponentially Fit (EF) VM selection is shown in Algorithm 5. The proposed EF VM selection is based on an unbounded Exponential Search [31]. The input to Algorithm 5 is a list of active hosts. Find out all assigned VMs from a overload hosts and add them to the VMs list and compute the VM size. Now, the upper threshold of the overloaded host is computed.
Overload Hosts Detection (isOLHD)
Overload Hosts Detection (isOLHD)
return true;
return false;
Almost Overloaded Hosts Detection (isAOLHD)
return true;
return false;
VM Selection
Bound
SelectedVM
SelectedVM
Add SelectedVM in VMs to Migratable VMs;
The SelectedVM list is initially empty. All VMs of an overloaded host is sorted in ascending order based on their utilization. The difference of utilization Differ set by the difference between current host utilization and the upper threshold uThrld of host. Now, assign the Position value as 0 and Bound value as 1. While the value of Bound is less than
VM placement is the final step of dynamic VM consolidation. All VMs selected by the proposed EF VM selection must be placed in some hosts so that the total energy utilization and SLA violatios are reduced. One of the most popular VM placement approaches is Power-Aware Best Fit Decreasing (PABFD), introduced in [11]. In PABFD policy, the power of the host is estimated after the allocation of the VM. Now, the power difference between estimated power and current power is computed. Finally, VM is placed in a host with the minimum power difference.
We propose a Modified Power Aware Best Fit Decreasing (MPABFD) VM placement policy in Algorithm 7. Host status of almost overloaded has a significant role in the proposed MPABDF VM placement algorithm 7. Whether a host status is almost overloaded or not is determined in Algorithm 7. If the host status is almost overloaded, exclude that host from the available host list to place VMs. The main reason for finding the almost overloaded hosts and excluding them from the available host list is that if VMs are placed into the almost overloaded hosts, that will increase the probability of getting overloaded hosts. Instate of that if the VMs are placed into the moderately loaded host, the probability of getting an overloaded host will decrease as well as the number of migrations also decrees. A reduced number of migrations has a direct positive impact on SLA violations.
Modified Power Aware Best Fit Decreasing (MPABFD)
Modified Power Aware Best Fit Decreasing (MPABFD)
continue;
In this section, we first go through the simulation setup for evaluating the proposed model. Then, we go through the PlanetLab [32] workloads traces, which evaluate the proposed model. Finally, Section 6.3 shows the performance metric to analyse the performance of the proposed model.
Simulation setup
The most widely used simulator for extensive virtualized cloud applications is the CloudSim [15] toolkit. Compared to other simulators, it offers a more robust virtualized representation of cloud architecture. Additionally, it offers scalability and dynamic resource management. A data centre consisting of eight hundred dissimilar hosts is used to simulate the suggested model. One-half of them are HP ProLiant G4 servers with a clock speed of 1,860 MHz, while the other half are HP ProLiant G5 servers with a clock speed of 2,660 MHz. Each contains two cores, four gigabytes of memory, and one gigabit per second of network bandwidth. Table 4 depicts the features of the hosts.
Energy consumption of PMs at different load [11]
Energy consumption of PMs at different load [11]
Characteristics of hosts [11]
The proposed algorithms have been evaluated using the Amazon EC2 [33] types of virtual machine instances. The VMs come in four different varieties. Each VM instance has been created into the hosts according to the workload. Table 5 displays the VMs properties.
Properties of VMs [34]
To strengthen the acceptability of simulation-based methodologies, the proposed model’s assessment was applied to actual workload traces. The workload traces were obtained from a platform for infrastructure monitoring system, called CoMon [16] by Planet-Lab [32].
Attributes of workload data (CPU utilization) [11]
Attributes of workload data (CPU utilization) [11]
These traces comprise the CPU utilization information from several servers spread over more than 500 locations worldwide and over a thousand VMs. The utilization metrics were captured every 300 seconds. Ten days at random from the workload traces throughout March and April 2011 were selected. The Table 6 lists the attributes of workload traces.
To evaluate the proposed Host Status Prediction using Naive Bayes Classifier dynamic VM consolidation policy several performance metric has been used. The first one is the total energy consumption of hosts, computed by host CPU utilization in % and in Table 3 shows the mapping of CPU utilization and energy consumption in Watts. Second metric is number of VM migrations. VM migrations is not of cost [35]. The third metric is Service level Agreement Violations (SLAV). SLAV has a inverse relation with energy consumption. The fourth metric is Energy and SLA Violations(ESV). It is computed by the following equation:
In addition to these four main metric, two more metric have been used to evaluate the proposed dynamic VM consolidation policy. SLA time per active host (SLATAH) is the share of time of a lively host that finished a hundred percent CPU utilization. The host serving demand is accomplished by 100% CPU utilization. The another metric is number of hosts shutdown. The number of VM migrations have an impact on the number of hosts that are shut down. Repeated turning on or off of hosts can increase the cost and energy consumption of hosts. All of these metrics were proposed in [11].
This section contains a thorough analysis of the outcomes of the proposed dynamic VM consolidation. In [11], several overload host detection algorithms is introduced, like, Local Regression (LR), Inter Quartile Range (IQR), Median Absolute Deviation (MAD), and Static Threshold (THR). LR is the best overload host detection algorithm between the above baseline overload host detection algorithms. The baseline algorithms of VM selections are Minimum Migration Time (MMT), Maximum Correlation(MC), and Minimum Utilization (MU). MMT is the best VM selection algorithm between the above baseline VM selection algorithms. Power-Aware Best fit Decreasing (PABFD) algorithm the the baseline algorithm for VM placement. All combinations of baseline algorithms are consider and compare with our proposed algorithms represented from Figs 1 to 6.
Analysis of energy consumption.
Analysis of number of VM migration.
Analysis of SLAV.
Analysis of energy and SLAV.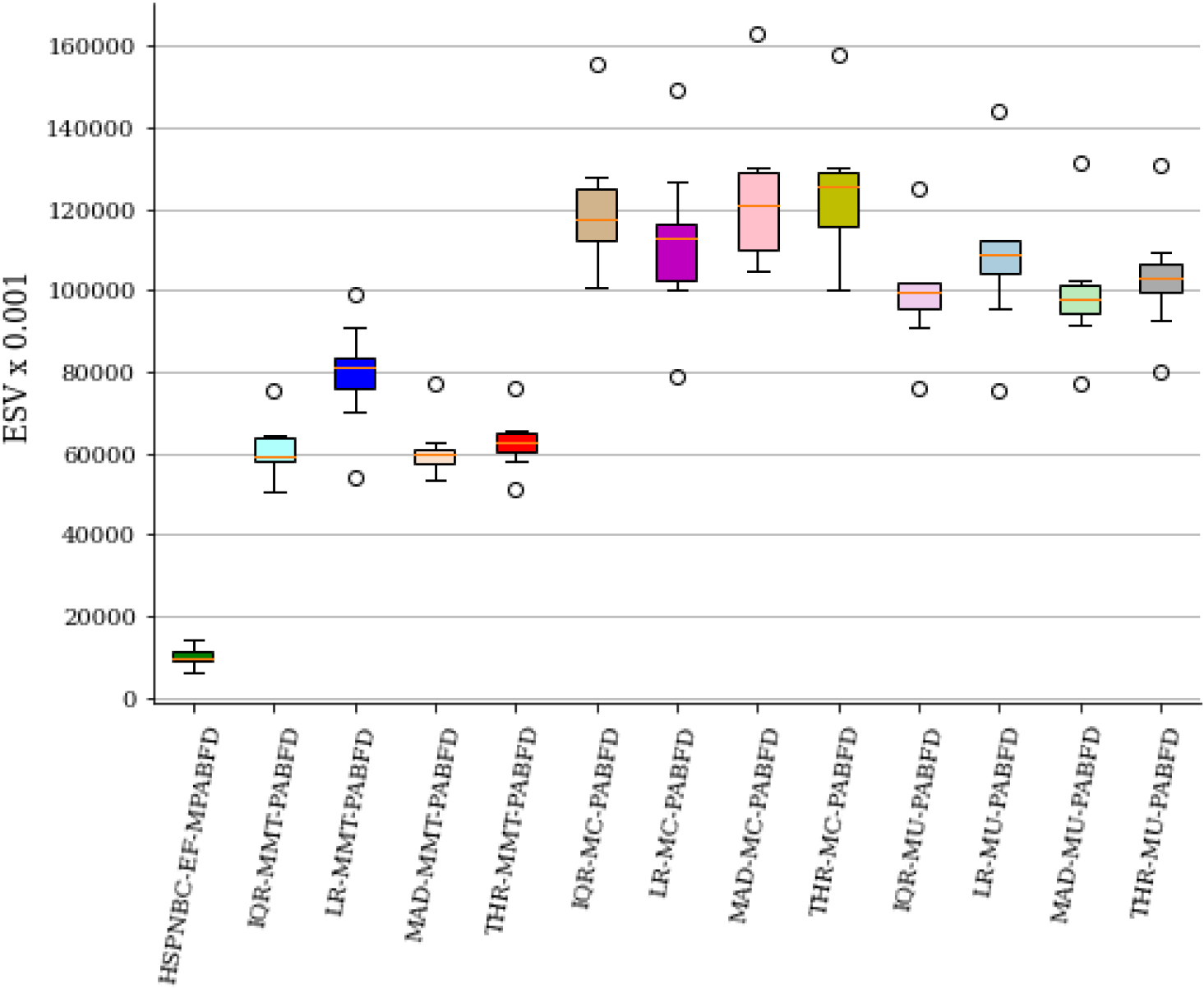
Analysis of SLATAH.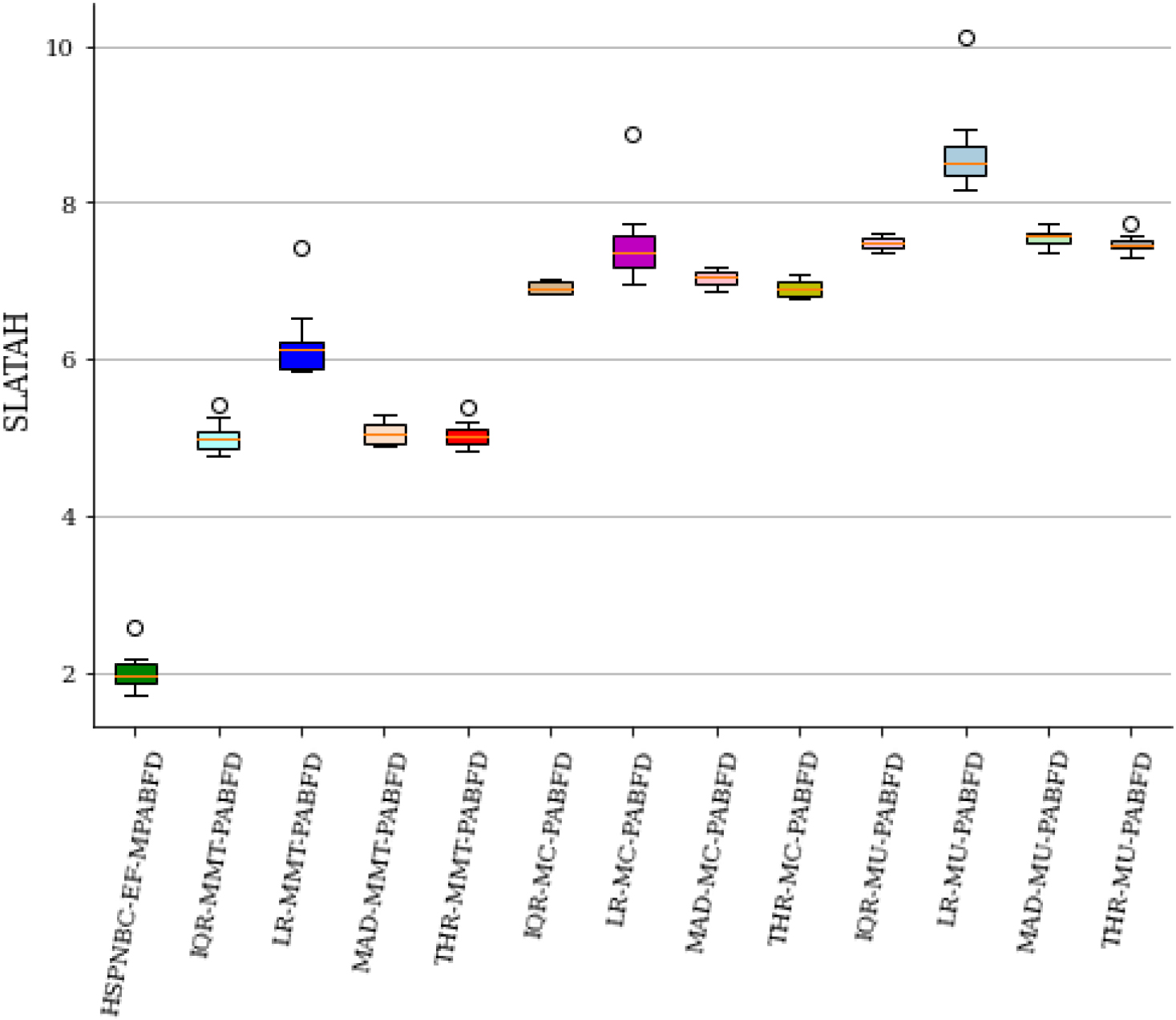
Analysis of number of hosts shutdown.
To analyze the performance of the proposed HSPNBC, EF, and MPABFD algorithms; statistical analysis is done. The median value of energy consumption of HSPNBC-EF-MPABFD policy is 132.9 kWh., whereas the median value of LR-MMT-PABFD policy is 158.27 kWh., and the average median of all other baseline policies is 177.4 kWh. The proposed HSPNBC-EF-MPABFD policy’s improvement value is 25% compare to other baseline policies regarding total energy consumption. The median value of number of migration of proposed HSPNBC-EF-MPABFD is 5087, whereas the median value of LR-MMT-PABFD policy is 27481, and the average median of all other baseline policies is 25992. It improves 80% compare to other baseline policies regarding number of migrations.
SLA violation is inversely related to energy consumption. The proposed HSPNBC-EF-MPABFD algorithm significantly reduced the energy consumption, so SLA violation become the key concern. The median value of SLAV of the HSPNBC-EF-MPABFD policy is 67, LR-MMT-PABFD policy is 462, and the average median of all other baseline policies is 522.87. The improvement rate of the proposed HSPNBC-EF-MPABFD policy is 87% compare to other baseline policies. In the statistical analysis the median value of Energy and SLAV (ESV) of the proposed HSPNBC-EF-MPABFD policy is found as 9420.56, LR-MMT-PABFD policy is 811066.925, and the average median of other baseline policy found as 95747.65. The improvement rate is 90% compare to other baseline policies.
Pair
Pair
The median SLATAH value of the proposed HSPNBC-EF-MPABFD algorithm is 1.96, LR-MMT-PABFD policy is 6.12, and the average median of all other baseline policies is 6.7. The proposed algorithm improves 70% compare to other baseline policies. The median value of Number of Host shutdown of the proposed HSPNBC-EF-MPABFD algorithm is 1447.5, LR-MMT-PABFD policy is 4985.5, and the average median of all other baseline policies is 4960.31. It indicates 74% improvement compare to other baseline algorithms.
A pair
To check the effectiveness of the proposed EF VM selection policy, a pair
Pair
Finlay, the performance of MPABFD VM placement is evaluated by the pair
Five days energy consumption analysis.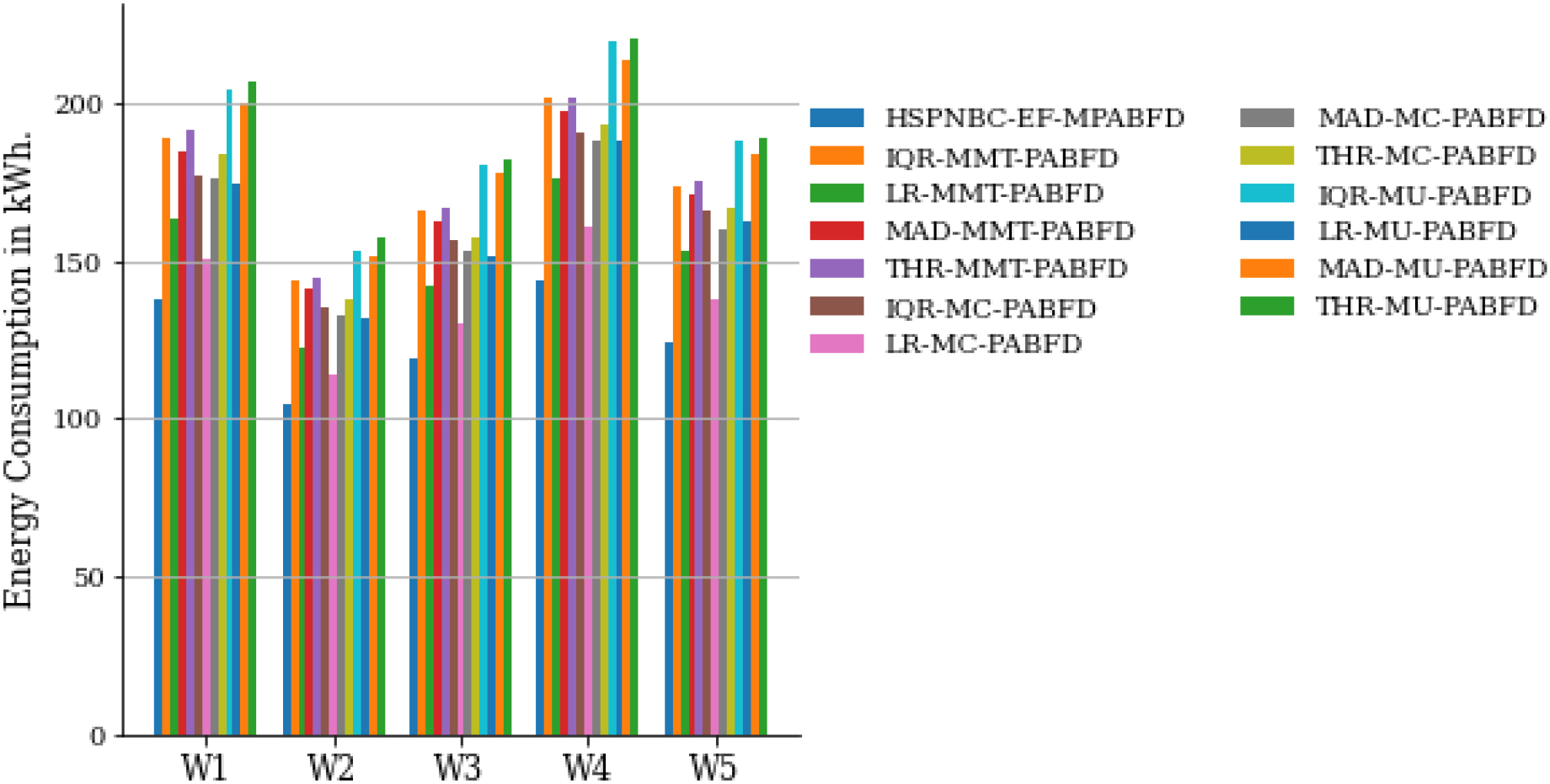
Five days number of VM migration analysis.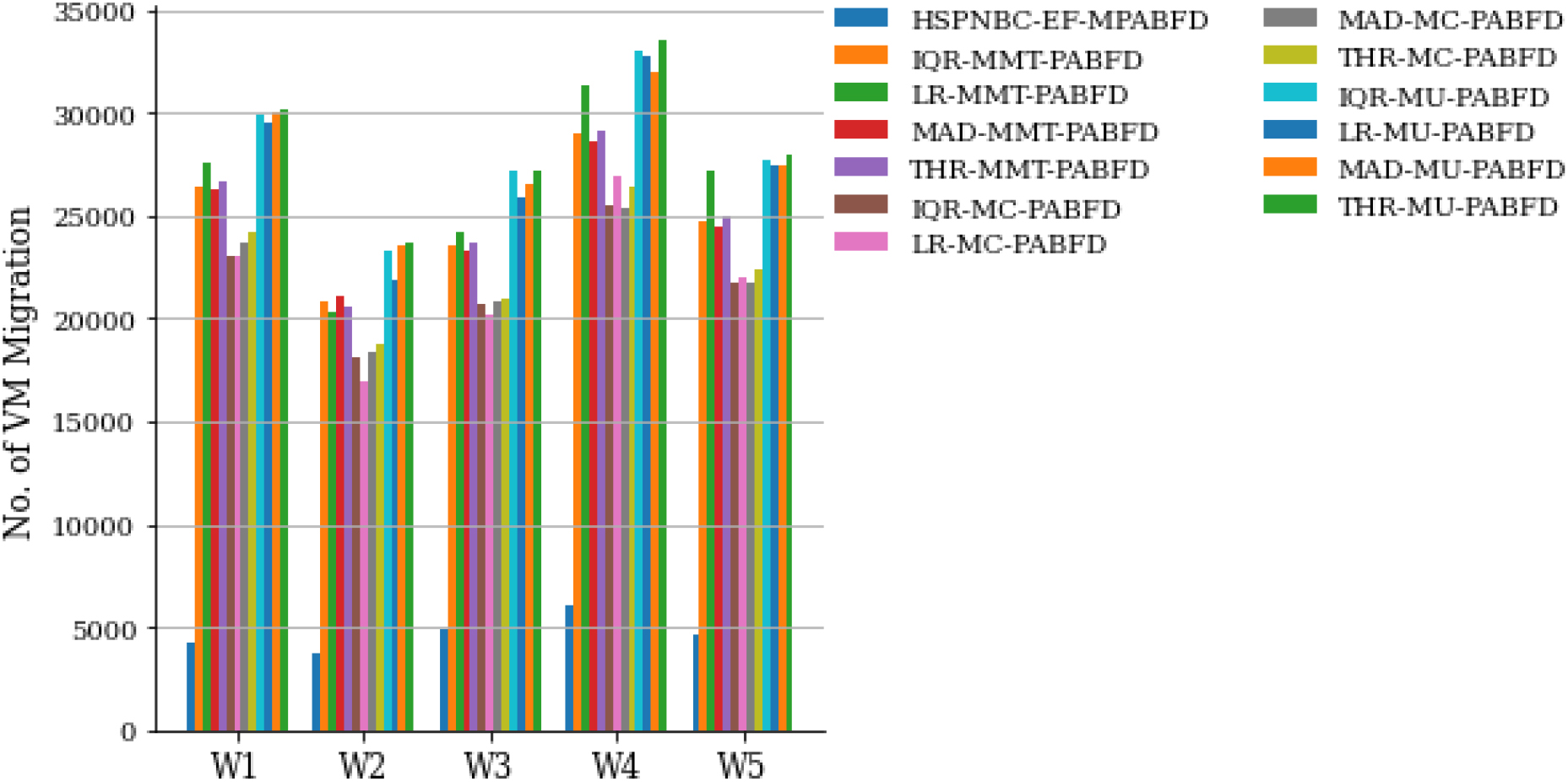
Five days analysis of SLAV.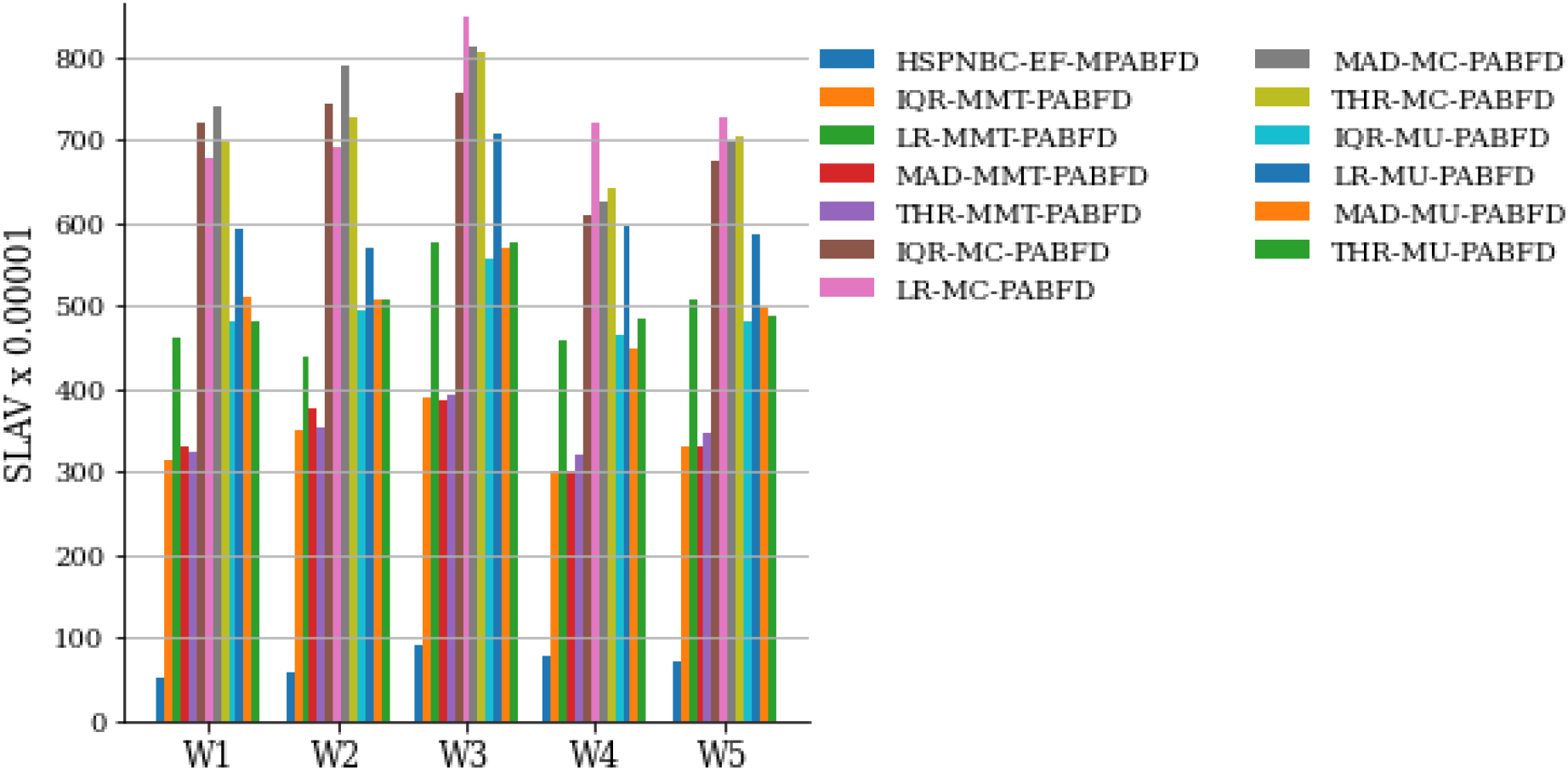
Five days ESV analysis.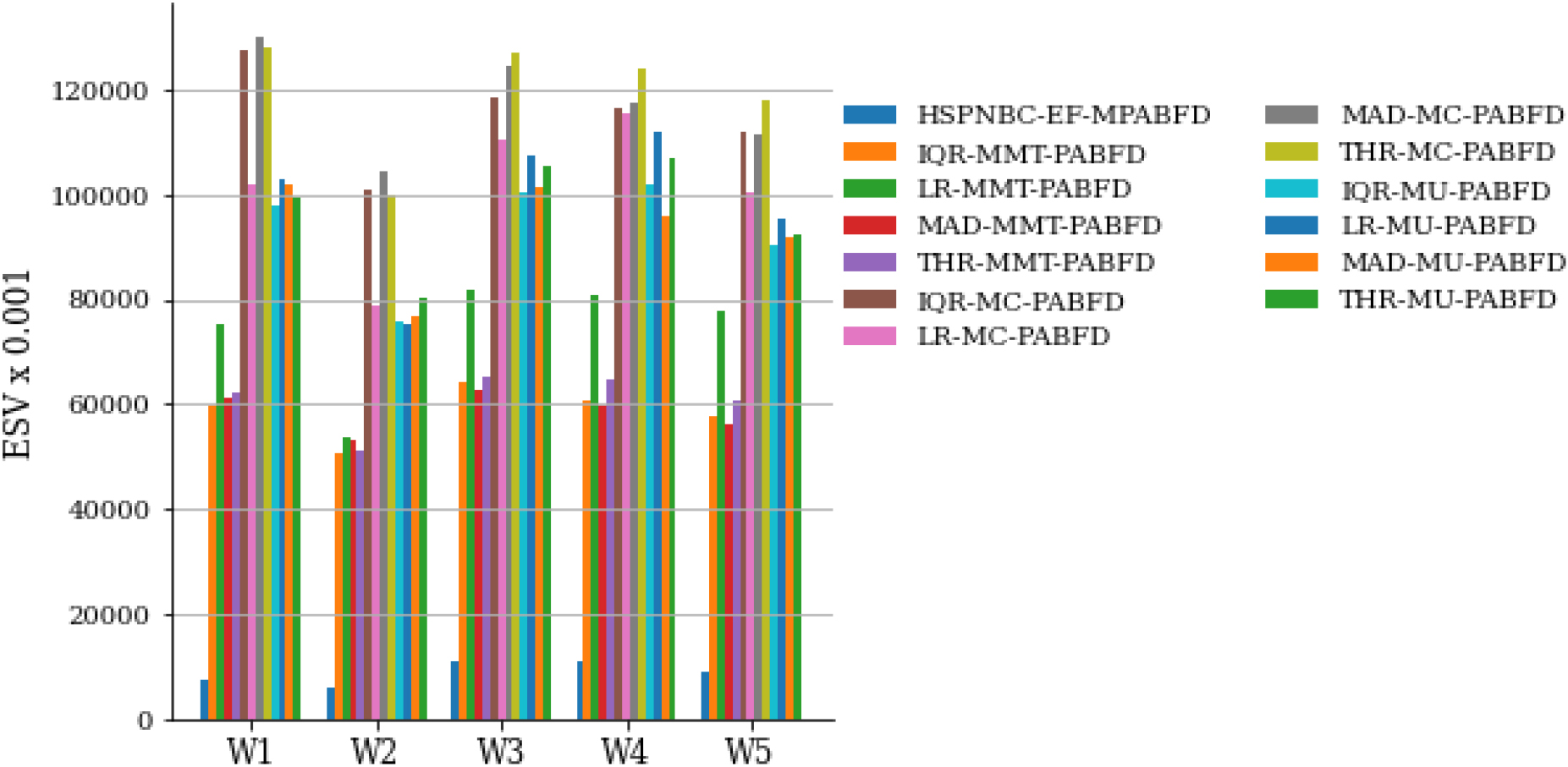
Five days SLATAH analysis.
Five days number of hosts shutdown analysis.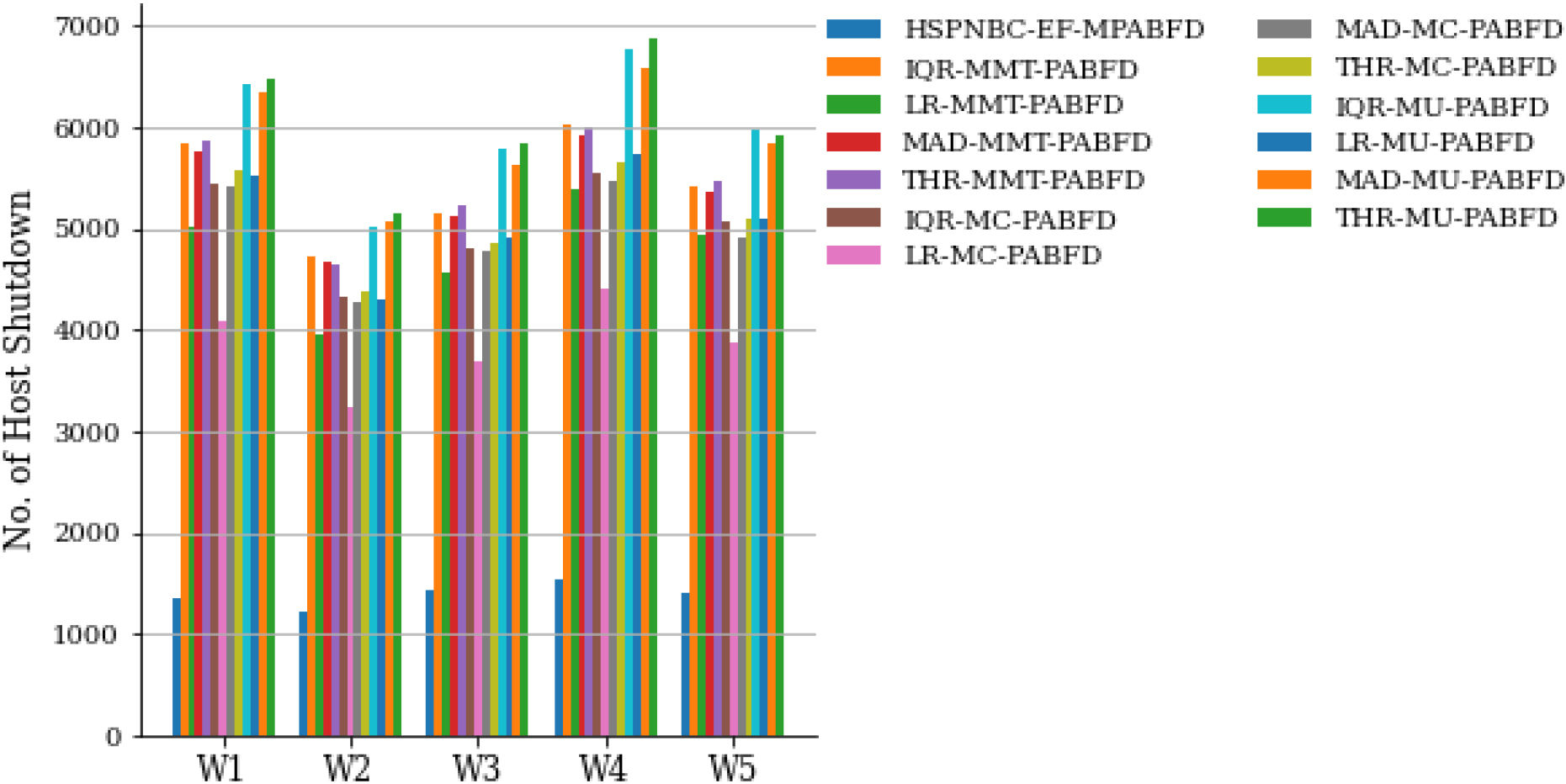
Another performance analysis was accomplished using first five days workload is represented from Figs 7 to 12. The mean value of energy consumption of the proposed model for the first five days is 126.9 kWh, and the average mean value of the other baseline model is 169.62 kWh. The proposed model reduced 25.66% energy consumption compare to other policies. The proposed model’s average number of migrations over the first five days of work is 4741.2, whereas the average mean value of number of migration of the other baseline model is 25105.27, the improvement rate is 81.11%. SLAV’s mean value for the five days is 70 and the average mean value of other baseline policies is 543.55, the proposed model improves the SLAV by 87.12%. The mean value of ESV of the proposed model is 8827.12 for the five days workload, however the average mean value of the ESV of othe baseline policies is 90695.34. The proposed model improves the ESV by 90.26%. The Table 10 shows the comparative study for the first five days workload with mean value of all metrics.
Mean value analysis of the proposed model for the first five days workload
Thus the proposed model defeat all the other baseline policies.
Intelligence cloud computing can provide intelligent services in urban areas. However, the key concern of cloud data centres is energy consumption. The overall energy consumed by data centres may be reduced while maintaining SLAs due to dynamic VM consolidation approaches. In reality, a dynamic VM consolidation strategy that works best must be able to correctly forecast future host status before migrating VMs from hosts to the most suitable targeted hosts. This research proposes a dynamic VM consolidation method for predicting impending VM CPU usage, selecting VMs for migration, and selecting a destination host for a VM based on CPU usage prediction. Real workload traces from PlanetLab were used to assess the proposed algorithms. The simulation results demonstrate that the proposed model (HSPNBC-EF-MPABFD) decreases energy usage by 25%, the number of VM migrations by 80%, SLAVs by 87%, ESV by 90%, and SLATAH by 70% compared to baseline models.
We only tested our proposed model in a simulated setting. Nevertheless, we want to look at how the proposed algorithm performs in a genuine cloud environment. A future study might look into using other machine learning models to improve the predictability of CPU utilization. Small size data set is used in the proposed model. However, in the future, an extensive data set want to be prepared to perform the training and testing of the ML model to preciously predict the host status and reduce the overall energy consumption with maintaining the SLA of the cloud data centres.