
Abstract
Text clustering has been widely used in data mining, document management, search engines, and other fields. The K-means algorithm is a representative algorithm of text clustering. However, traditional K-means algorithm often uses Euclidean distance or cosine distance to measure the similarity between texts, which is not effective in face of high-dimensional data and cannot retain enough semantic information. In response to the above problems, we combine word rotator’s distance with the K-means algorithm, and propose the WRDK-means algorithm, which use word rotator’s distance to calculate the similarity between texts and preserve more text features. Furthermore, we define a new cluster center initialization method that improves cluster instability during random initial cluster center selection. And, to solve the problem of inconsistent length between texts, we propose a new iterative approximation method of cluster centers. We selected three suitable datasets and five evaluation indicators to verify the feasibility of the proposed algorithm. Among them, the RI value of our algorithm exceeds 90%. And for Marco_F1, our scheme was about 37.77%, 23.2%, 13.06% and 20.12% better than other four methods, respectively.
Introduction
With the development of the Internet and the explosive growth of text data, more attention has been paid to the research of text clustering. Cluster analysis is a technique based on statistics, which is widely used in fields such as, machine learning, data mining, pattern recognition, and image analysis. The clustering algorithms divides the sample set into different subsets according to the difference in similarity between samples by distance measurement. The purpose is to make the similarity of samples in the same subset as high as possible, and the similarity of samples in different subsets as low as possible [1].
K-means algorithm is widely used in text clustering due to its simple principle and fast convergence speed. The traditional K-means algorithm uses Euclidean distance to measure the similarity between data [2]. However, unlike the clustering of numerical data, the semantic information of the context of the text data needs to be considered when clustering the text data. In addition, at this stage, like many other types of data, high dimensionality and sparsity are a major feature of text data. Since the Euclidean distance considers the attribute values of the data to be the same, it cannot consider the correlation between them, and the performance is also poor when dealing with high-dimensional data. Therefore, the effect of the traditional K-means clustering algorithm in text clustering is not ideal.
In view of the distance and similarity measurement problems in the traditional K-means algorithm for text clustering, we propose an improved K-means text clustering algorithm (WRDK-means). The algorithm combines the word rotation distance (Word Rotator’s Distance, WRD) suitable for text distance calculation, and uses the semantic features of the words extracted by the CBOW model [3] under the Word2vec tool to calculate the similarity between two texts. The improved K-means algorithm shows a good clustering effect for text processing, especially for high-dimensional text data containing a large amount of contextual semantic information.
The rest of this article is organized as follows. In Section 2, the relevant research work in the field of text clustering is analyzed; Section 3 briefly discusses related technical knowledge; Section 4 elaborates on the improved K-means algorithm proposed in this paper for text clustering; Section 5 uses the algorithm proposed in this paper to carry out clustering experiments and analysis; Section 6 is a summary of this article.
Related works
According to different principles, clustering algorithms can be divided into hierarchical-based methods, density-based methods, partition-based methods, and grid-based methods. The partition-based clustering method, also known as distance-based clustering. It divides the data set into several subsets according to the distance so that the distance between different subsets is as large as possible and the distance within the same subset is as small as possible. The K-means algorithm, as one of the representative algorithms of the partition method, was first proposed by J. MacQueen at the Fifth Berkeley International Mathematics Symposium in 1967 [4]. One of the main disadvantages of the K-means algorithm is the high-dimensionality and sparsity of the data. So the traditional distance measurement methods cannot effectively process the data.
Based on this, domestic and foreign experts and scholars have optimized and improved the K-means algorithm. J. Li and J.H. Li combined the K-means algorithm with the SVM decision tree [5] to improve the efficiency and accuracy of the traditional algorithm. K-means becomes slow for large and high dimensional datasets. The traditional FPAC algorithm had mitigated this problem. But the improvement in the speed was reached at the cost of reducing the quality of the clustering results. So S. Bejos [6] proposed the improved FPAC algorithm without highly increasing the runtime. In [7], Xiao-Dong Wang et al. propose a fast adaptive K-means (FAKM) type subspace clustering model, where an adaptive loss function is designed to provide a flexible cluster indicator calculation mechanism, thereby suitable for datasets under different distributions.
It is easy to fall into the problem of superiority when it is like the problem. In addition, many researchers use the idea of dimensionality reduction and then adopt clustering to improve the algorithm. For example, Q. Xu et al. [8] used the K-means algorithm to cluster the data after dimensionality reduction through principal component analysis, and the clustering results were greatly improved. In [9], a new type of multi-view k-means, called a feature-reduction multi-view k-means (FRMVK), is proposed. In this paper, a learning mechanism for the multi-view k-means algorithm to automatically compute individual feature weight is constructed. It can reduce these irrelevant feature components in each view. A new multi-view K-means objective function is firstly proposed for constructing the learning mechanism for feature weights in multi-view clustering. A schema for eliminating irrelevant feature(s) with small weight(s) is then considered for feature reduction. A. Chakraborty et al. [10] discussed the performance of K-means clustering algorithm on city block, cosine and correlation distance which are used to get the results and further their performance had been shown in terms of accuracy. For classification, K-means had claimed 98% accuracy on city block and correlation distance.
The traditional K-means algorithm cannot well retain contextual semantic information when processing high-dimensional data, showing a relatively unsatisfactory effect. Therefore, we improve the above shortcomings and propose the WRDK-means algorithm.
Key technologies
Text clustering process
According to the general process of text clustering, we divide text clustering into four steps: text preprocessing, feature extraction, similarity calculation, and clustering realization, as shown in Fig. 1.
1. Text preprocessing
Due to the unstructured or semi-structured nature of text data, they need to be converted into structured data that can be directly recognized by the computer. Therefore, text preprocessing is required first. The quality of the preprocessing results will affect the results of clustering. Text preprocessing mainly includes two steps: word segmentation and stop word removal. We use jieba word segmentation to segment the Chinese text words according to the dictionary and use Baidu stop vocabulary to remove words with high occurrence probability, such as pronouns, auxiliary words, prepositions, conjunctions, etc.
Technical route of text clustering.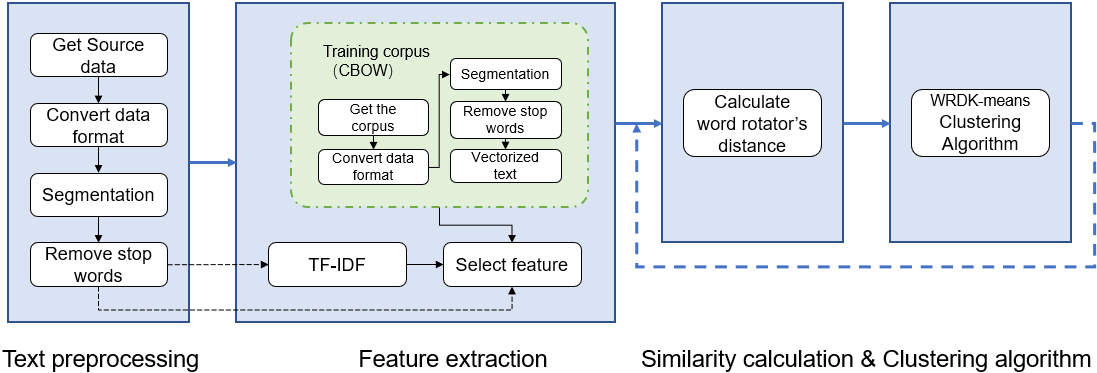
2. Feature extraction
For long text, firstly, we use the TF-IDF algorithm to extract keywords to reduce the time complexity; for short text, we directly perform feature selection. For the task of Chinese text clustering, we choose a suitable data set as the corpus, perform the same text preprocessing as in step 1, and use the CBOW language model to vectorize it, so that each word in the corpus can be unique the vector corresponds to it. Finally, vector matching is performed on the text preprocessed in the previous step according to the trained corpus.
3. Similarity calculation and clustering algorithm
Since text clustering is divided by the size of the similarity between different texts, the calculation method of the text similarity will directly affect the clustering results. In clustering, similarity calculation methods such as Euclidean distance and cosine distance are usually used. However, such type of methods have disadvantages such as not being able to handle high-dimensional data well and performing poorly in long text clustering tasks. To solve these problems, we choose to use word rotation distance (WRD) as the calculation method of similarity between different texts, and propose a WRDK-means text clustering algorithm that reasonably combines WRD and traditional K-means algorithm.
TF-IDF (Term Frequency-Inverse Document Frequency) is a commonly used weighting technique used in information retrieval and text mining to evaluate the importance of a word to a document set [11]. The importance of a word increases proportionally with the number of times it occurs in the document set and decreases inversely with the frequency in the corpus. The term frequency (
Where
The inverse document frequency IDF reflects the prevalence of keywords:
Among them,
Then the
In 2013, Google’s Tomas Mikolove et al. [13] improved and optimized the probabilistic language model (NNLM) of feedforward neural networks, and launched the word2vec tool. After training, the tool can vectorize all words, quantitatively measure the relationship between words, and the output word vectors can be used for tasks related to natural language processing, such as clustering. The CBOW chosen in our paper is a language model in word2vec, which predicts the current word through context and constructs a supervised training criteria from unsupervised data [14].
The full name of CBOW is Continuous bag of words. It uses Hierarchical Softmax to train the word vector model of text data and maps the text feature words to a low-dimensional space in a distributed manner, so that the positional relationship of the word vectors in the low-dimensional space can well reflect their semantic connection. The model consists of an input layer, a projection layer and an output layer [15]. The structure of the model is shown in Fig. 2. Among them, the input layer is composed of context
CBOW model structure.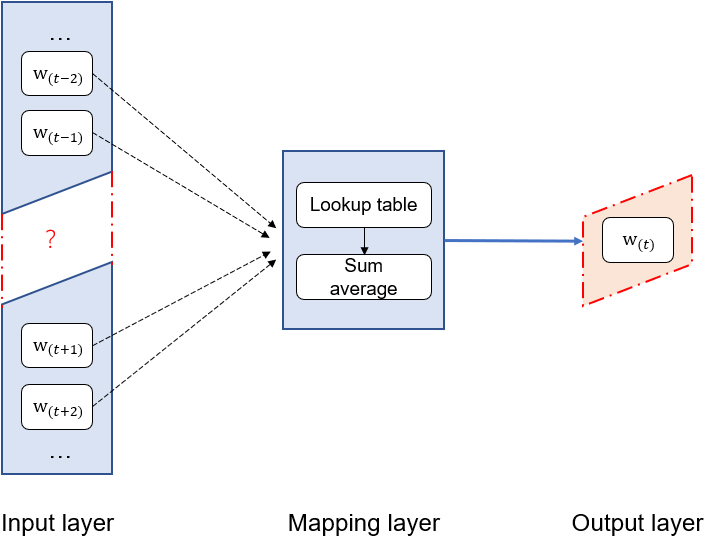
In 2020, the WRD (Word Rotator’s Distance) published by S. Yokoi et al. was proposed after improving WMD [16]. In 2015, Matt Kusner and others put forward the concept of Word Mover’s Distance (WMD) in a paper published at the Washington Conference [17]. WMD abstracts the weights of words in two texts into transfer and capacity. Semantic similarity is defined as the minimum cumulative distance required for the total weights of words in one text to fully migrate and fill the total capacity of words in another text. The larger the WMD, the smaller the text similarity; conversely, the greater the text similarity.
There are two sentences
The Euclidean distance used in WMD is less effective in measuring the distance between words than using cosine distance. Furthermore, WMD is theoretically an unlimited amount, and its threshold of similarity cannot be adjusted well. In order to solve the above problems, WRD came into being.
WRD [16] first proposed and proved the concept that the modulo length of a word vector is positively related to the importance of the word. The larger the WRD, the smaller the text similarity, and vice versa. Since the similarity measure used is cosine distance, the transformation between two vectors is more like a rotation than a movement. The WRD model is expressed as follows [17]:
K-means clustering algorithm
The K-means algorithm is a typical representative of partition-based clustering algorithm. It usually uses Euclidean distance as a measure of similarity between data objects, that is, the smaller the distance between data objects, the higher the similarity, and the more likely they belong to the same cluster. On the contrary, the lower the similarity, the less likely it is to belong to the same cluster. Based on the above principles, the data to be clustered is finally divided into k categories.
Assuming that there is a data set to be classified
The specific algorithm flow of K-means is shown in Algorithm 1 [19].
The K-means algorithm has the advantages of simple principle and fast convergence speed, but it also has its limitations, mainly as follows:
The number Sensitive to initial conditions. The random selection of the initial cluster center makes it easy to fall into local optimum during the clustering process, which will lead to fluctuations and instability of the clustering results. The disaster of dimensionality. The K-means algorithm is suitable for processing low-dimensional data. As the dimensionality increases, the metric utility of the Euclidean distance will decrease, and the convergence of cluster centers will become more difficult.
Unsupervised text clustering algorithms usually use dimensionality reduction and highly sparse matrix methods to select text features, and then use methods such as Euclidean distance to calculate text similarity. This approach largely ignores the semantic information in the text. This leads to such algorithms can not better express text features in the face of synonyms, polysemy and strong contextual context.
Therefore, this paper introduces WRD into the K-means algorithm and proposes the WRDK-means clustering algorithm. WRD has many advantages. It can measure the similarity between texts of different lengths, and fully consider the comprehensive meaning of the context. Calculating the word rotation distance between texts is essential for calculating the minimum value of word transfer cost, and the weight of word transfer is obtained by solving the transportation problem in linear programming in WRD. Although the solution to the transportation problem is peculiar and may cause the word order relationship of the text context to be ignored, in general, the semantic information contained in the calculation of word rotation distance is still significantly improved. In addition, in the face of long text data clustering, the TF-IDF algorithm can be used to extract keywords from the long texts, reducing the time cost by sacrificing a small amount of unimportant semantic information.
However, the introduction of the WRD has brought a lot of difficulties to the K-means algorithm, mainly in the following two aspects:
The regular text features passed through after dimensionality reduction can unify the dimensions, which greatly simplifies subsequent calculations. In order to preserve the semantic information of the text as much as possible, WRD has different sizes of the text after matrix, which is not conducive to the selection of the initial cluster center. The traditional K-means algorithm uses a summation and average method to update cluster centers, which is not suitable for text features with different dimensions.
In view of the above shortcomings and difficulties, We propose the WRDK-means clustering algorithm. The WRDK-means clustering algorithm defines the characteristics of the word set
The following is a detailed description of the algorithm.
For the determination of the number of clusters
Initialize cluster center
For the initialization of cluster centers, especially for high-dimensional data, due to the large word shift distance between different types of texts, it is necessary to ensure that the initialized cluster centers maintain a certain distance from each other, which helps to improve the stability of the algorithm. But for real text data, there tends to be a small amount of extreme data (i.e. points far away from almost all the sample space). If the extreme data is used as the initial cluster center, the cluster center point may be “dead” and cannot be divided into other points to update. At the same time, in order to ensure that the cluster centers have the conditions to accommodate enough semantic information, the size of the cluster centers should be the same as the size of the longest text matrix in the data set. The algorithm proposed in this paper first randomly selects a text
1. Randomly select a text
2. Initialize a blank cluster center matrix and select the
Fill the matrix as the
After dividing the dataset
If the number of words contained in
The iterative approximation formula between the word
In order to stabilize the iteration of the algorithm,
Among them, iteration is the number of rounds of the current iteration.
The specific process of WRDK-means algorithm is shown in Algorithm 2.
Data set
Experimental corpus
The corpus comes from the dataset THUCNews of the Natural Language Processing Laboratory of Tsinghua University. The corpus is generated by filtering historical data of the Sina News RSS subscription channel from 2005 to 2011. It contains 740,000 news documents, totaling 2.19 GB [20].
Experimental data set
The experiment used three Chinese datasets to demonstrate the effect of the WRDK-means clustering algorithm proposed in our paper. The datasets are as follows:
The Tsinghua University Natural Language Processing Laboratory dataset THUCNews dataset THUCNews has 14 candidate categories, namely: Finance, Lottery, Real Estate, Stocks, Home Furnishing, Education, Technology, Society, Fashion, Current Affairs, Sports, Constellation, Games, and Entertainment. We randomly select 200 pieces of data from each category as the classification dataset 1. There are 20 candidate categories in the Chinese text classification corpus data of the Natural Language Processing Group of the International Database Center, Department of Computer Information and Technology, Fudan University. After removing the categories with less than 200 data, the remaining 9 categories are: C3-Art, C7-History, C11-Space, C19-Computer, C31-Environment, C32-Agriculture, C34-Economy, C38-Politics and C39-Sports. We randomly select 200 pieces of data from each category as the classification dataset 2. The text classification corpus provided by Sogou Lab. This corpus contains the news corpus and the corresponding category labels of the news collected by the Sohu News website that are manually classified by category. There are 9 candidate categories, namely: Internet, Sports, Health, Military, Recruitment, Education, Culture, Tourism and Finance. We randomly select 200 pieces of data from each category as the classification dataset 3.
We take the dataset THUCNews from the Natural Language Processing Laboratory of Tsinghua University as an example. The dataset consists of 14 categories of folders, and each category folder contains a large number of text files, and there is no blank file data. Take a file under the category of “Games” as an example, it consists of two parts: the news title and the text, as shown in Fig. 3.
Data display of the data set THUCNews from the Natural Language Processing Laboratory of Tsinghua University.
For many indicators of clustering algorithm performance evaluation, we choose purity, rand index, precision, recall and
Purity
Purity is a simple cluster evaluation method. It needs to calculate the ratio of the number of correctly clustered data to the total number of data. The formula is as follows:
Where
RI is a means of evaluating clusters. It uses the principle of permutation and combination. The formula is as follows:
TP represents the number of positive samples predicted to be positive samples. FP represents the number of negative samples predicted to be positive samples. FN represents the number of positive samples predicted to be negative samples. TN represents the number of negative samples predicted to be negative samples.
Precision is a commonly used evaluation metric. It is calculated as the probability that all samples predicted to be positive are positive. The formula is as follows:
The recall is calculated as the probability that the actual positive sample is predicted to be a positive sample, and the formula is as follows:
In order to avoid the contradiction between precision and recall, the two need to be considered comprehensively. The most common method is the
When the parameter
First, the above-mentioned evaluation index values of each category are counted, and then the arithmetic mean of all categories is calculated, such as Eqs (22)–(24).
Among them,
Initial point selection experiment for clustering
In the WRDK-means algorithm, the value of the threshold
Initial point selection experiment for clustering
Initial point selection experiment for clustering
All the experimental results are averaged after 10 experiments. In order to balance the running speed and running accuracy of the WRDK-means algorithm, the dimensionality of the text vectorization of the CBOW model is unified to 300 dimensions. After each data is sorted by TF-IDF, the top 20 keywords in importance are retained, and the length of the cluster center is uniformly 20. In dataset 1, rand index, precision
As can be seen from Table 2, the F1 value of each category is unbalanced. The performance of some categories such as “Home” and “Finance” are significantly lower than the macro average. This may be because the keywords of such topics are scattered, and the 20 keywords intercepted by TF-IDF are not enough to retain semantic information. During the experiment, different initialized cluster centers have a significant impact on the experimental results between categories, indicating that the cluster center initialization method still has a lot of room for improvement. For text clustering tasks, the more categories in the dataset, the more imbalanced the number of categories, and the greater the difficulty of clustering. Therefore, the clustering result of dataset 2 are better than dataset 1. The corpus of the experiment in this paper is the same as the dataset 1. Since the classification of dataset 1 basically overlaps with the classifications of dataset 2, and the classification of dataset 1 is quite different from that of dataset 3, and the clustering result of dataset 3 is lower than that of dataset 2. It shows that the choice of corpus also has a greater impact on the clustering results.
WRDK-means clustering results of the Chinese dataset of Tsinghua University
WRDK-means clustering results of the Chinese dataset of Tsinghua University
Clustering results of three data sets
Comparison of WRDK-means algorithm with four document schemes
Tsinghua University Chinese data set WRDK-means clustering confusion matrix.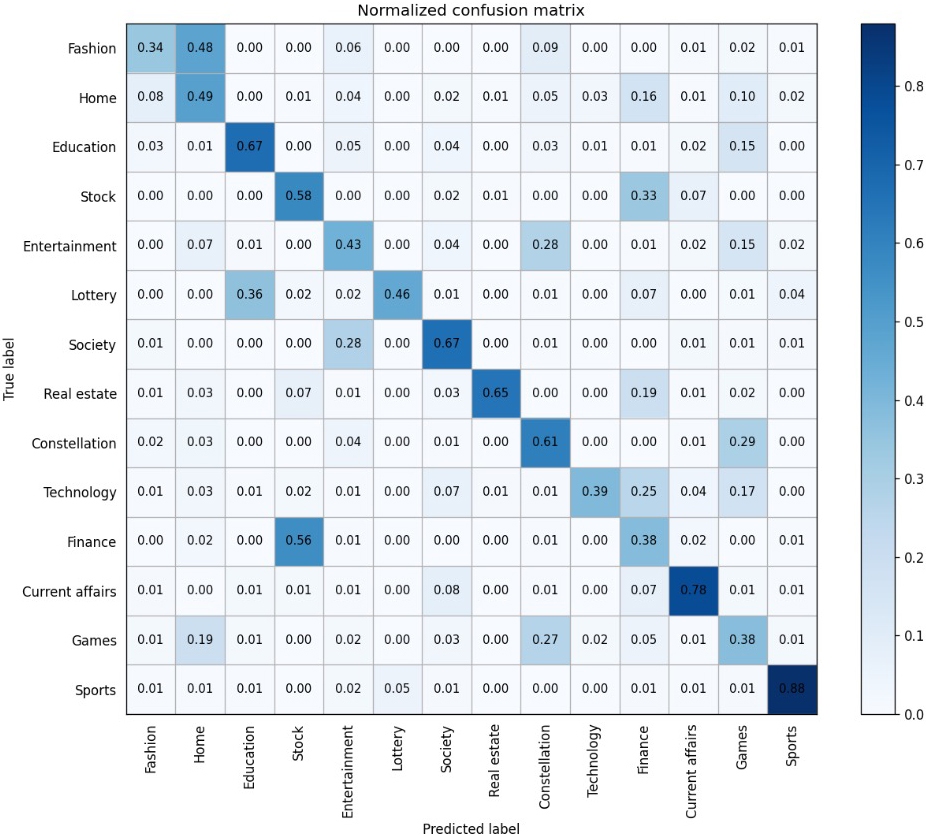
Under dataset 1, we compared the clustering algorithm proposed in this paper with four traditional text clustering algorithms under five evaluation indicators. We compared the proposed scheme with the specific algorithms used by the other four algorithms and list them in Table 4. They are four-stage algorithms of feature extraction algorithm, similarity comparison method and clustering method. The purity, rand index,
Results of comparative experiments
Results of comparative experiments
In this paper, we propose WRDK-means, a text clustering algorithm based on WRD improved K-means. According to the related concepts and properties of WRD, the algorithm replaces the Euclidean distance under the traditional VSM model to measure the similarity between text data, and fully retains the contextual semantic information. In order to make the combination of WRD and K-means, fully and reasonably, we redesign the feature extraction method of text, improve the cluster instability problem in the process of random initial cluster center selection, and propose a new cluster center iterative approximation method. We use the algorithm proposed in this paper to conduct experiments on three datasets respectively, and compare with other four traditional algorithms. The results show that for text clustering, especially high-dimensional text data clustering, the WRDK-means algorithm has significantly improvements in the evaluation indicators of purity, rand index, precision, recall and F1 value. Among them, the RI value of our algorithm exceeds 90%. And the Macro_F1 is improved by about 38% at most. However, the algorithm runs slowly, and the initialization method still has room for improvement, which will become the next improvement direction.
Data availability
All data, models and codes generated or used during the study are available from the corresponding author by request.
Ethical approval
The work is a novel work and has not been published elsewhere nor is it currently under review for publication elsewhere.
Author’s contributions
Cui Zicai – Conceptualization, modeling, methodology, analysis and computer simulation, writing. Zhong Bocheng – conceptualization, modeling, analysis and supervision. Bai Chen – modeling, computer simulation, analysis, supervision and writing.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (62006150).
Conflict of interest
The authors declare that they have no conflict of interest.