
Abstract
Existing active learning algorithms typically assume that the data provided are complete. Nonetheless, data with missing values are common in real-world applications, and active learning on incomplete data is less studied. This paper studies the problem of active learning for ordinal classification on incomplete data. Although cutting-edge imputation methods can be used to impute the missing values before commencing active learning, inaccurately imputed instances are unavoidable and may degrade the ordinal classifier’s performance once labeled. Therefore, the crucial question in this work is how to reduce the negative impact of imprecisely filled instances on active learning. First, to avoid selecting filled instances with high imputation imprecision, we propose penalizing the query selection with a novel imputation uncertainty measure that combines a feature-level imputation uncertainty and a knowledge-level imputation uncertainty. Second, to mitigate the adverse influence of potentially labeled imprecisely imputed instances, we suggest using a diversity-based uncertainty sampling strategy to select query instances in specified candidate instance regions. Extensive experiments on nine public ordinal classification datasets with varying value missing rates show that the proposed approach outperforms several baseline methods.
Introduction
Ordinal classification (OC), also known as ordinal regression, is a particular case of multi-class classification where the instances are labeled by ordinal scales [1]. Since an ordered relation exists among the categories in many real situations, ordinal classification has a wide range of applications, such as disease severity estimation [2] in the medical field, bank failure prediction [3] in the financial area, and facial age estimation [4] in the computer vision domain, and so on. As a supervised learning task, OC usually relies on a sufficient amount of labeled data to train an ordinal prediction model. However, the label acquisition for ordinal instances is usually expensive and time-consuming due to the dependence on domain expertise [1], preventing the collection of a large number of labeled instances. In this circumstance, active learning (AL) [5] that interactively query the annotators of the most valuable unlabeled instances can be a cost-effective way to obtain an accurate ordinal prediction model [6, 7].
It is worthy of note that one can frequently encounter that the collected ordinal data are incomplete [8]. For instance, the ordinal data collected in clinical trials will almost inevitably be incomplete [9]. In general, incomplete data arise due to imperfect data collection procedures, such as device malfunction, sensor failure, operator mistakes, and so on [10]. Motivated by the above fact, this paper studies the problem of active ordinal classification in the presence of missing values. In the active learning community, despite the emergence of a large body of well-established active learning algorithms in the past few decades, little attention has been paid to active learning for incomplete data.
Illustion of imputation results of two different imputation methods on a three-class artificial ordinal classification dataset. The dataset is simulated incompleteness by removing 30% of the values based on the MCAR mechanism [13]. (a) is the original ordinal data without value missing; (b) shows the imputation result by the incomplete-case 
Data completeness is a major assumption of most active learning algorithms. Listwise deletion, which discards the instances with missing values, is the simplest method for preprocessing incomplete data. However, it may result in a significant information loss. Therefore, the better way to perform an active learning algorithm on incomplete ordinal data is to fill the missing values beforehand. We can utilise any state-of-the-art imputation method to fill the missing values. More complicated imputation methods, in general, may result in better value-filling quality. But, even if an imputation method is well-developed, imprecise imputations will inevitably exist in the imputed data. Figure 1 illustrates the imputation results by implementing two state-of-the-art imputation methods on a three-class artificial ordinal classification data with a value missing rate of 30%. The results of the two imputations methods show that many imputed instances have considerable distortion. Because of the inherent uncertainty in missing value imputation, some values may be imputed inaccurately [14]. The underlying distorted instances, i.e., the imprecisely imputed instances, can be considered detrimental to an active learning procedure. The ordinal classifier’s performance will suffer once the highly distorted instances are labeled. Therefore, in this study, two fundamental questions arise: how to prevent labeling the severely imprecisely imputed instances and how to mitigate the negative impact of the underlying labeled imprecisely imputed instances on active learning.
To perform active learning, we fill the missing values by a multiple imputation method, MICE [12]. In order to avoid selecting filled instances with high imputation imprecision, we devise a novel imputation uncertainty measure to penalize the query selection function. In the seminal work of [14], a feature-level imputation uncertainty is suggested to penalize the base query selection function for avoiding high inaccurately imputed instances from being selected. In contrast, our method considers not only the feature-level imputation uncertainty but also the imputation uncertainty on the knowledge level. The feature-level imputation uncertainty aggregates the imputation variances in an instance and reflects the scatter of the multiple imputations. The knowledge-level imputation uncertainty reflects the prediction uncertainty of an ordinal prediction model on the multiple imputations of an incomplete instance.
The proposed novel imputation uncertainty can penalize a query selection function less likely to select the highly distorted instances. Nevertheless, it cannot wholly avoid distorted instances from being selected. The labeled distorted instances may inhibit the base learner’s hyperplanes from quickly converging to the proper positions, thus causing the active learner to label more low-value instances. To mitigate the negative impact of the potentially labeled distorted instances on active ordinal classification, we suggest conducting diversity-based uncertainty sampling in specified candidate instances region based on the structure of a threshold-based ordinal classification model, i.e., the support vector machine with reduction framework (RED-SVM) [15]. We specify the candidate instance region based on the state of the decision hyperplanes in the prediction model before each query selection. Based on the condition of a specially designed hyperplane state coefficient, we restrict the query instance to be selected only in a specific region where the instances from which be labeled are likely to promote the convergence of the current hyperplane.
The contributions of this work are outlined as follows.
We introduce a novel imputation uncertainty measure by simultaneously considering the feature-level imputation uncertainty and the knowledge-level imputation uncertainty. The proposed imputation uncertainty measure can prevent the query selection function from selecting the highly distorted instances. To mitigate the negative impact of the potentially labeled imprecisely imputed instances on active learning, we specify the candidate instance region based on the state of the current decision hyperplane. The ordinal predictive model is more likely to be promoted by labeling the instance from the specified region. We conduct experiments on several public ordinal classification datasets under different value missing rates, and the results demonstrate that the proposed method is superior to the competitors.
The remainder of this paper is structured as follows. Section 2 reviews the related work from aspects of active learning and incomplete data processing and briefly recalls the formulation of the threshold-based ordinal classification model with a reduction framework. Section 3 provides the technical details of the proposed method. The experiment setting and experimental results are reported in Section 4. Finally, the conclusion is drawn in Section 5.
This section gives a brief overview of active learning, incomplete data processing, and threshold ordinal classification with a reduction framework.
Active learning
Active learning aims to train a reliable predictive model while minimizing labeling costs. Thus, it is beneficial for many machine learning scenarios where label acquisition is expensive. The key issue of active learning is to develop a query selection strategy to determine which unlabeled instances would be the most useful (i.e., improve the prediction model most) if they are labeled and used as training instances. Informativeness and representativeness are two conventional policies to measure the usefulness of an unlabeled instance.
The query selection strategies that based on instance’s informativeness includes uncertainty sampling [16], query by committee [17], expected change [18] and so on. Uncertainty sampling methods select the instances for which its current prediction is maximally uncertain [16]. Query-by-committee trains a set of prediction models and selects the unlabeled instances on which the models disagree the most [17]. The methods based on expected change calculate the change in the model under an unlabeled instance being assigned to the possible labels and weight the change by probability estimate [18]. The query selection concerning instance’s representativeness includes clustering-based methods [19, 20], experimental design-based methods [21, 22], and so on. The clustering-based active learning methods explore the clustering or manifold structure of the data and select the instances that represent the intrinsic geometry of the data. The experimental design-based methods rely on a data reconstruction framework, ensuring that the selected data has high representative power [22].
While much progress has been made for active learning algorithms, little attention has been focused on ordinal classification. Li et al. [6] introduced an A-optimal experimental design method for ordinal classification based on an adjacent category logistic model. However, this method needs to calculate the inverse of a large matrix, limiting its usability in real situations. Ge et al. [7] proposed an uncertainty sampling method for ordinal classification. But, potential sampling redundancy cannot be avoided in this method. To the best of our knowledge, the two works mentioned above are the only two active learning studies for ordinal classification, and active learning for ordinal classification in the presence of missing values has not been investigated. Therefore, designing an effective active learning algorithm that targets ordinal classification with missing values is essential.
In previous active learning studies that encountered incomplete data, one typically imputes the data in the preprocessing stage and rarely considers the impact or the validity of imputed values [14]. Recently, Han and Kang [14] proposed an active learning paradigm in which the imputation uncertainty is considered in the query selection. However, this method only considers the feature-level imputation uncertainty and ignores the uncertainty of the predictive output derived from the multiple imputations. Therefore, this study introduces a novel imputation uncertainty by simultaneously considering the feature-level imputation uncertainty and the knowledge-level imputation uncertainty. Furthermore, we also seek to mitigate the negative impact caused by the underlying labeled imprecisely imputed instances.
Incomplete data processing
The presence of missing values makes it difficult to apply traditional active learning methods immediately to incomplete data. Removing the instances with missing values is a simple ad hoc solution. However, a significant information loss will occur if the missing rate is high. Filling the missing values with plausible values before active learning can be an appealing solution. A variety of imputation methods, including single and multiple imputation methods, have been proposed to address the missing values.
Some prevalent single imputation methods, such as the incomplete-case
Threshold ordinal classification based on reduction framework
Ordinal classification is generally defined as the problem of classifying input instances on an ordinal scale. Various dedicated methods have been developed to solve the ordinal classification, such as ordinal binary decomposition-based methods [26], threshold-based methods [15], and so on. Prior studies have indicated that threshold models generally produce competitive performances [26]. Therefore, this study recruits a well-developed threshold-based ordinal classification model as the base learner in our active learner. This model is particularly designed based on a reduction framework [15]. We recall the formulation of this model here to be a preliminary of the proposed method.
Let
Ordinal classification based on a reduction framework reduces the ordinal-class problem to extended binary classification problems. Then, all the binary classification problems are solved jointly to obtain a single binary classifier [15]. For each original training instance
where
Let the weight vector in the binary classification problem be
Thus, the prediction output of
where
The above reduction framework has been instantiated based on the binary SVM model [7]. We call this model RED-SVM. Based on the SVM formulation, the loss function of ordinal classification can be derived as the following primal problem
where
The dual form of the minimization problem in Eq. (2.3) is then derived as
where
where
The dual problem in Eq. (2.3) can be solved by standard SVM solvers. The computational complexity of the RED-SVM model
This section provides the technical details of the proposed active learning method. We first introduce a novel imputation uncertainty measure in Subsection 3.1. Following this, In Subsection 3.2, we design a novel query selection strategy by incorporating the novel imputation uncertainty with a particularly designed diversity-based uncertainty measure. In this query selection strategy, a hyperplane state measure is designed to specify the candidate instance region for each query instance to promote the prediction model. Subsection 3.3 summarizes the computational complexity of the proposed active learning method.
Imputation uncertainty
Before active learning, we first impute the missing values by the multiple imputation method MICE. For each incomplete instance
Suppose there are
where
To quantify the imputation uncertainty of an imputed instance more effectively and comprehensively, we suggest considering the feature-level imputation uncertainty and the knowledge-level imputation uncertainty simultaneously. We define the knowledge-level imputation uncertainty as
where
In order to prevent labeling highly inaccurate imputed instances, this paper proposes penalizing the base query selection function with the feature-level imputation uncertainty and the knowledge-level imputation uncertainty simultaneously. Suppose the base query selection function is
In order to select the most informative instances in the active learning process, we design a diversity-based uncertainty sampling-based query selection function based on the RED-SVM model. According to the policy of margin sampling strategy [5], the instances close to the decision hyperplane are the most informative instances. In contrast to the binary SVM model, there are
To avoid the unbalanced hyperplane-updating problem, we adopt a Round Robin sampling style. By this sampling style, each
Let
where
In order to take into account sampling diversity in the query selection, we incorporate the cosine angular diversity into the uncertainty sampling criterion. The cosine angular diversity of
where
The uncertainty sampling seeks to select the instance with a minimal value of
The unlabeled instance that maximizes the value of
Diagram of ordinal classification in an active learning setting on a three-class ordinal dataset. The symbols 
Although the imputation uncertainty measures can restrict the query function from selecting the high imprecisely imputed instances, they cannot prevent the algorithm from choosing imputed instances. The underlying imprecisely imputed instances in the training set may prevent the learning model’s decision hyperplanes from rapidly converging to the correct positions. Figure 2 shows an illustration of ordinal classification in an active learning setting on a three-class ordinal dataset with imprecisely imputed instances being labeled. We can observe that the two decision hyperplanes
To accomplish the above idea, we resort to exploring the state of the current decision hyperplane and determining the candidate instance region based on the state. We assume that the state of a hyperplane is determined by the labeled instances that are closest to it. Let
where
where
Once the specified candidate region is determined, the labeled instances that are used to calculate the diversity measure also need to be restricted in a specified region. The labeled instance subset, that is used to derive the diversity measure, should be determined corresponding to the candidate instance region as follows
Thus, the final query selection function becomes as follows
Specifying the candidate instance region can promote the performance of the base learner and improve the computational efficiency due to the size of each candidate region being much smaller than that of the unlabeled pool. We name the proposed method as
[htp] Active learning for ordinal classification on incomplete data[1] Incomplete initial training set
Suppose the size of the initial training set is
Before each query selection, we need to perform the operations from line 6 to line 9 in Algorithm 2. The time complexity of the
In summary, suppose
Experiments
Datasets
Nine public ordinal classification datasets are employed in the experiments. Table 1 summarizes the information of the used datasets. The Toy, Stock, Computer, Automobile, and Bank datasets are from reference [26]. The other four datasets are from the UCI dataset repository.1
Information of the used datasets
The datasets in Table 1 are all complete. In experiments, each dataset is randomly split into an unlabeled instance pool (80% of the data) and a testing set (20% of the data). The experiments repeated the above partition ten times independently. We simulate the incomplete case by removing some of the attribute values from the unlabeled instance pool using the MCAR mechanism [13]. We generate three incomplete versions for each unlabeled instance pool with the missing rate as 20%, 30%, and 40%, respectively. Here, the missing rate is defined as
where
Before performing active learning, we impute the incomplete unlabeled instance pool by the random forest regression-based MICE [12] with ten times round-robin iterations. We set the number of imputations as
Information of the unlabeled instance pool
We have counted the incomplete instances in the unlabeled pool and the noise percentage information under three different missing rates and summarized the information in Table 2. In the table, “IP” indicates the percentage of incomplete instances, and “NP” denotes the percentage of noisy instances in the pool. We use the “All
To comparatively study the effectiveness of the proposed method
MCSVMA is the SVM-based multi-class active learning method, i.e., the method MC_SVMA McPAL [29] is the multiclass probabilistic active learning method, which selects the instances with maximal probabilistic gain. LogitA [6] is the A-optimal experimental design method for ordinal classification based on an adjacent category logistic model. This method tends to select the representative and discriminative instances. ALOR [7] is the active ordinal classification method based on the RED-SVM model. It selects the instances with the smallest distance from the nearest decision boundary. DUSR is the same method as DUSR-TIU, except it does not include any imputation uncertainty measures. DUSR-FIU is the method differs from the DUSR-TIU only on imputation uncertainty measure. In DUSR-FIU, the query selection is penalized by the featrue-level imputation uncertainty as described in reference [14].
In the above methods, MCSVMA and McPAL are two state-of-the-art multi-class active learning methods. LogitA and ALOR are both recently proposed active learning algorithms for ordinal classification. DUSR and DUSR-FIU are involved in the comparison in the form of an ablation experiment. For fair comparison, each of the compared methods uses the labeled instances to train a RED-SVM model in each iteration and evaluate its ordinal classification performance on the testing set. In the RED-SVM model, the kernel function is set as RBF kernel with
Furthermore, to perform the quantitative comparison, the metric area under learning curve (ALC) is employed. The metric ALC is one of the frequently used metrics to quantify the overall performance of active learning [30]. We use the trapezoidal approximation rule [30] to calculate the area under learning curve ACC (ALC-ACC) and the area under learning curve MAE (ALC-MAE). Due to the length limitation of the article, the comparison results about ALC-ACC and ALC-MAE are placed in Section Appendix A. Based on the above metrics, the average results of ten-time repeats are ultimately reported. In the experiments, we simulate the annotator to provide the labels of the selected instances. We assume that the annotator can always provide an instance’s ground-truth label based on its observed components. The instances with all attributes unobserved were removed from the pool.
The experiments were implemented on Windows 10 64-bit operating system with 128GB RAM and Intel(R) Xeon(R) Silver 4214 CPU@2.20GHz processor, using Python 3.6 software. The source codes and the used datasets are available at
Learning curves of ACC for the compared methods on the nine datasets with a missing rate of 20%.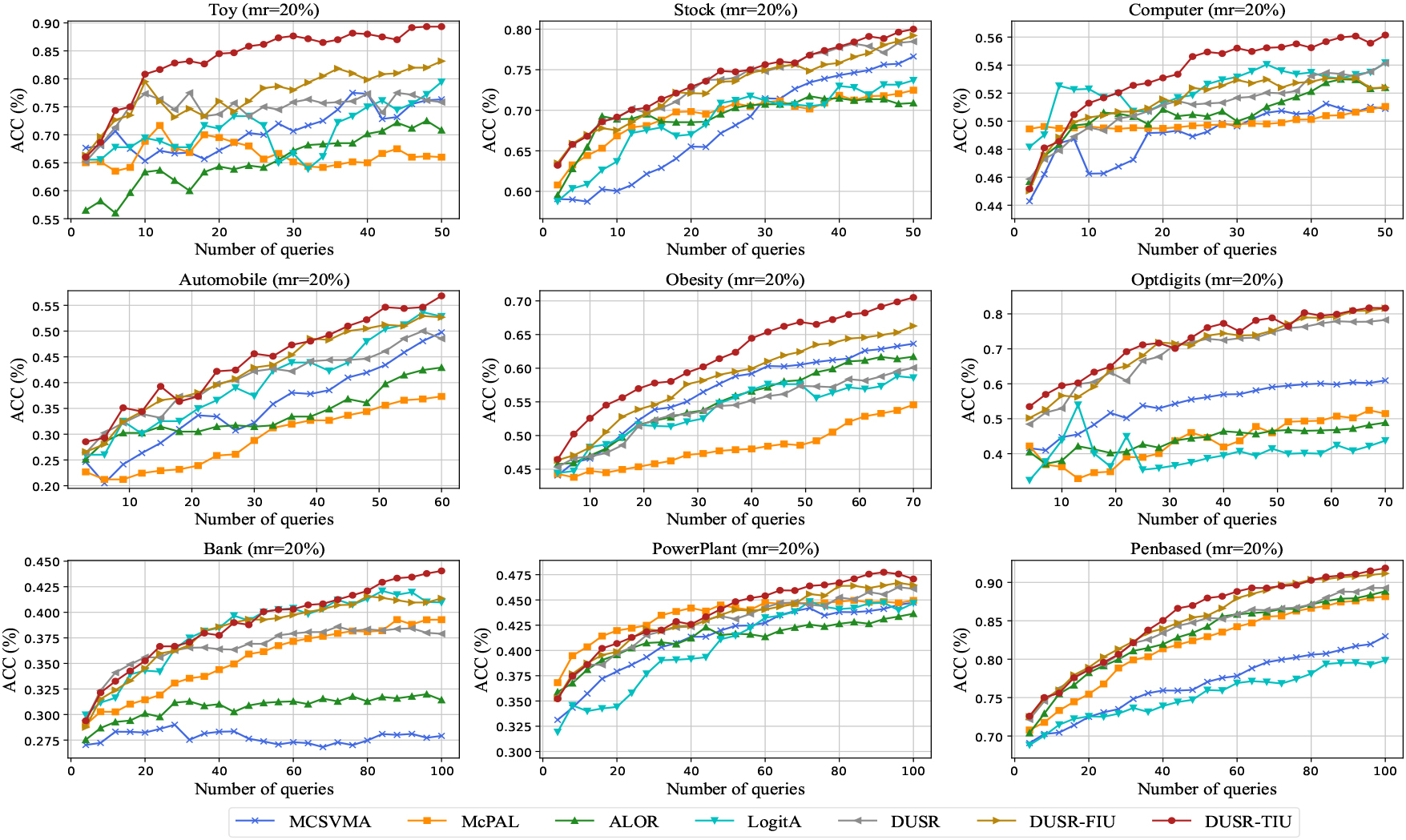
Learning curves of ACC for the compared methods on the nine datasets with a missing rate of 30%.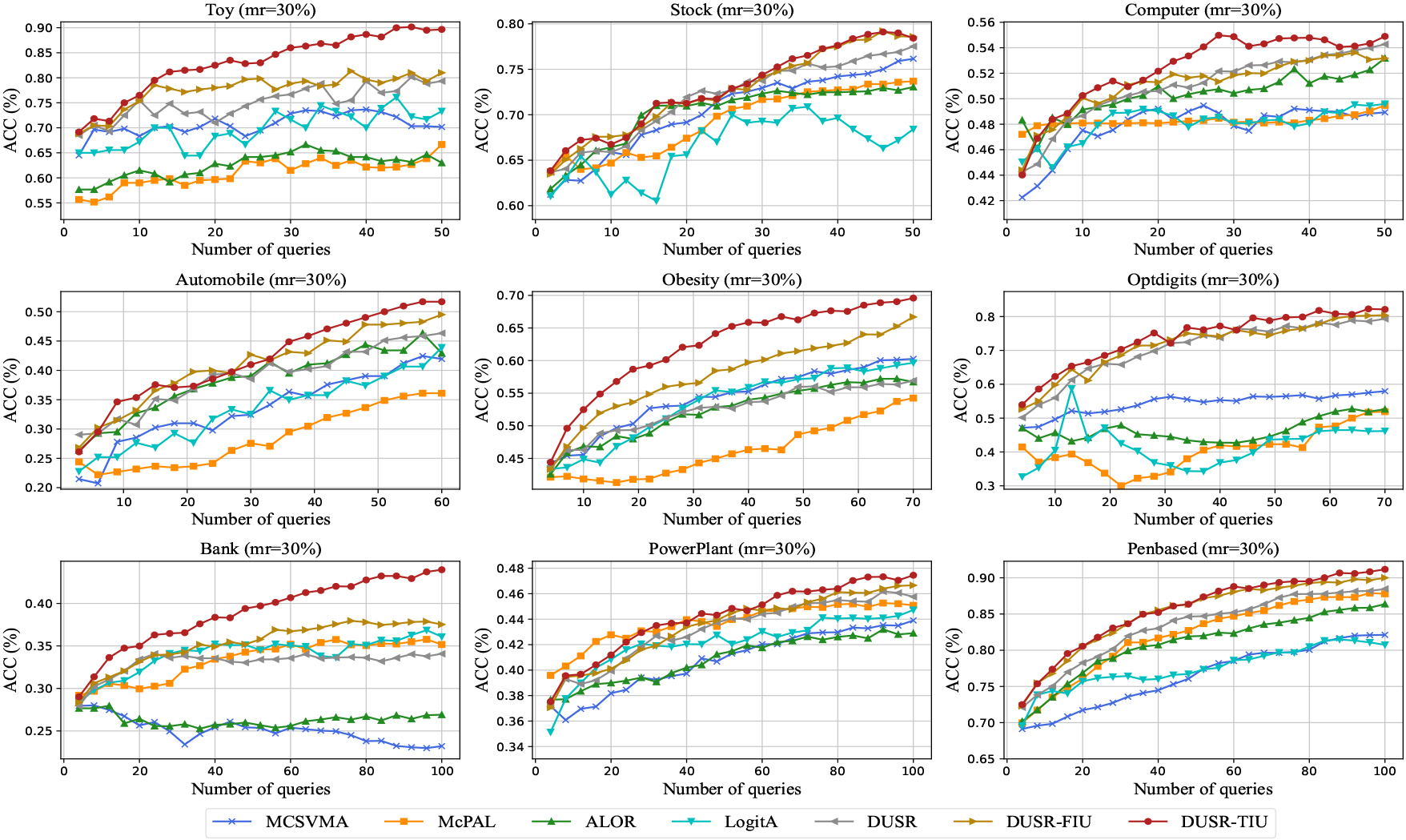
Learning curves of ACC for the compared methods on the nine datasets with a missing rate of 40%.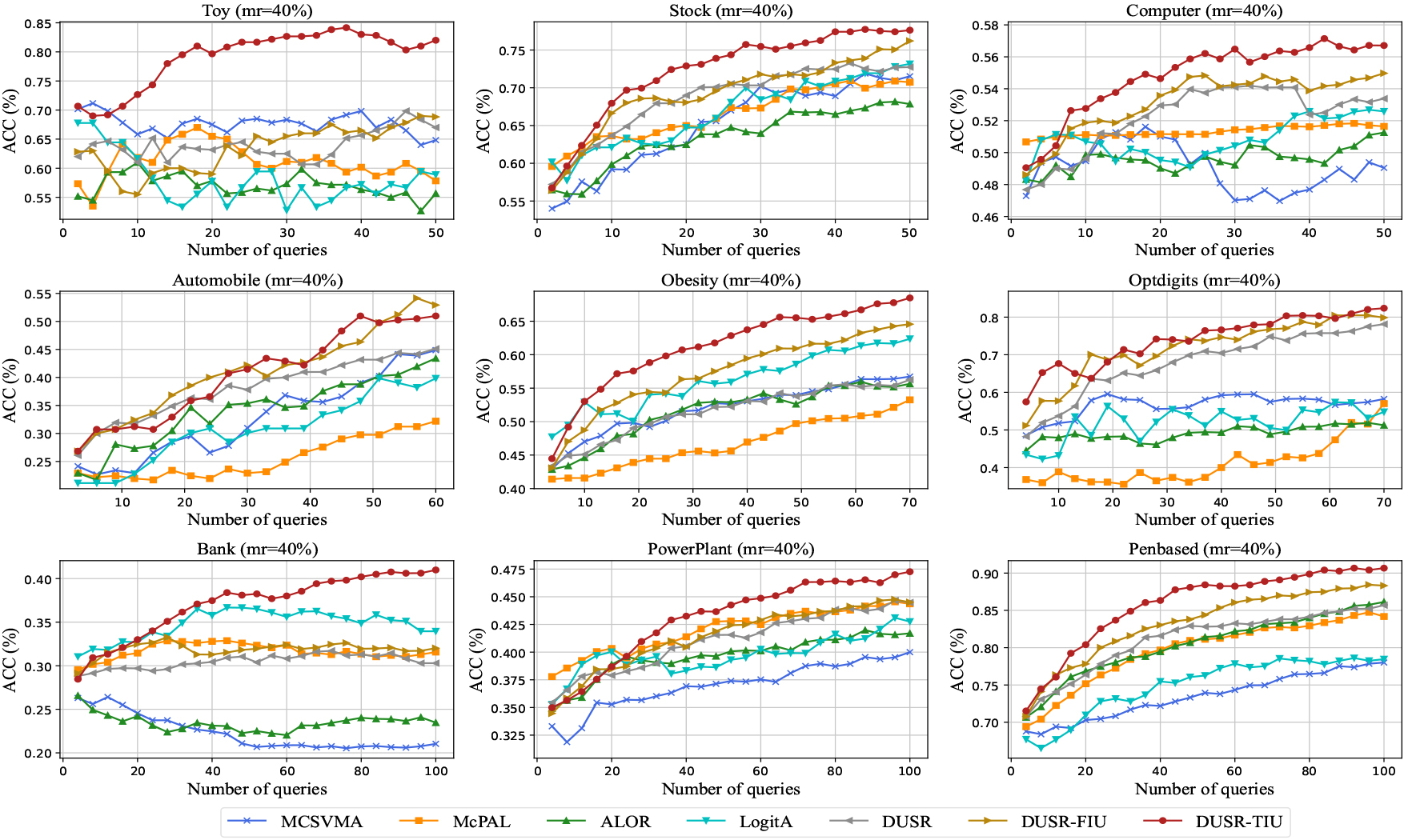
Learning curves of MAE for the compared methods on the nine datasets with a missing rate of 20%.
Learning curves of MAE for the compared methods on the nine datasets with a missing rate of 30%.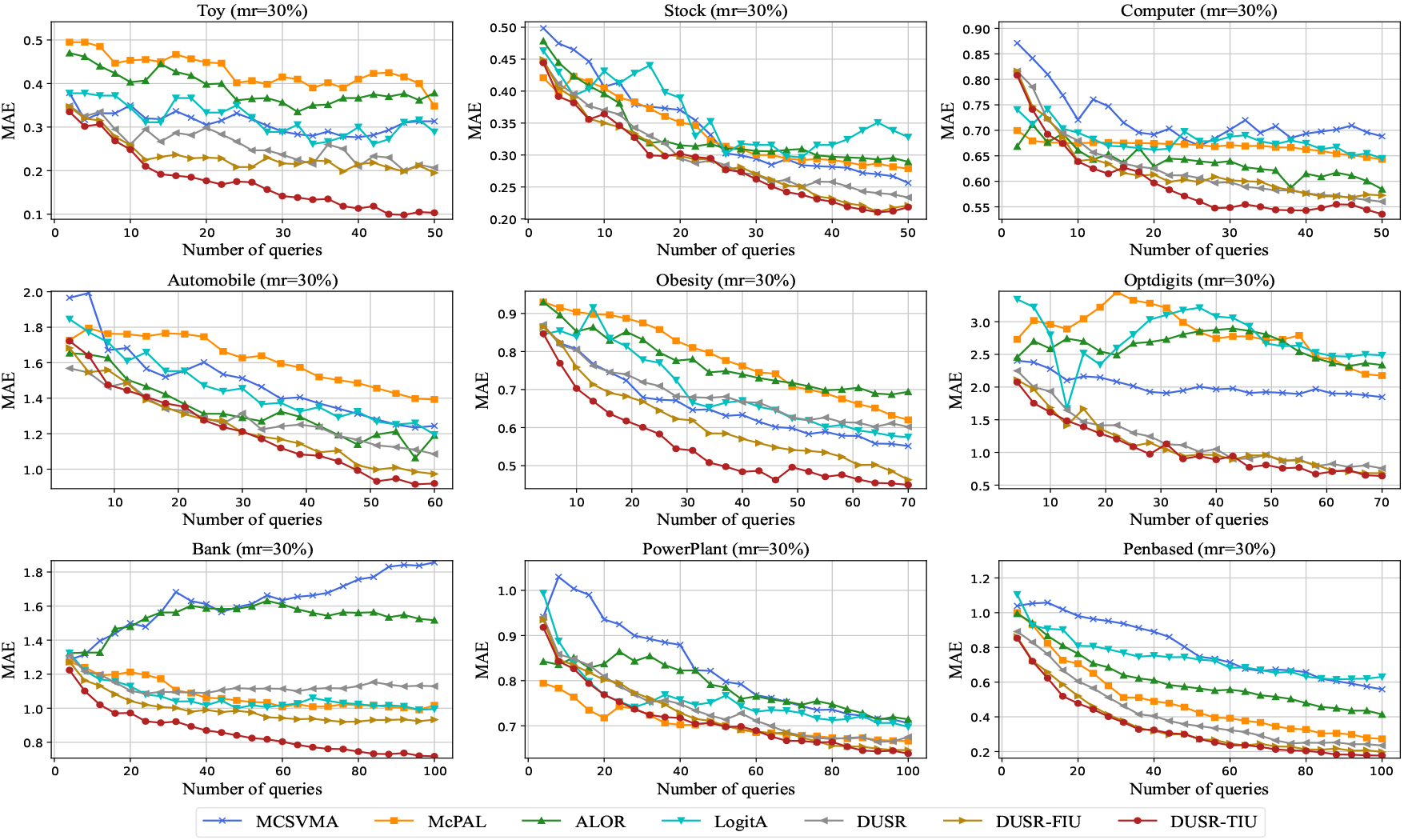
Learning curves of MAE for the compared methods on the nine datasets with a missing rate of 40%.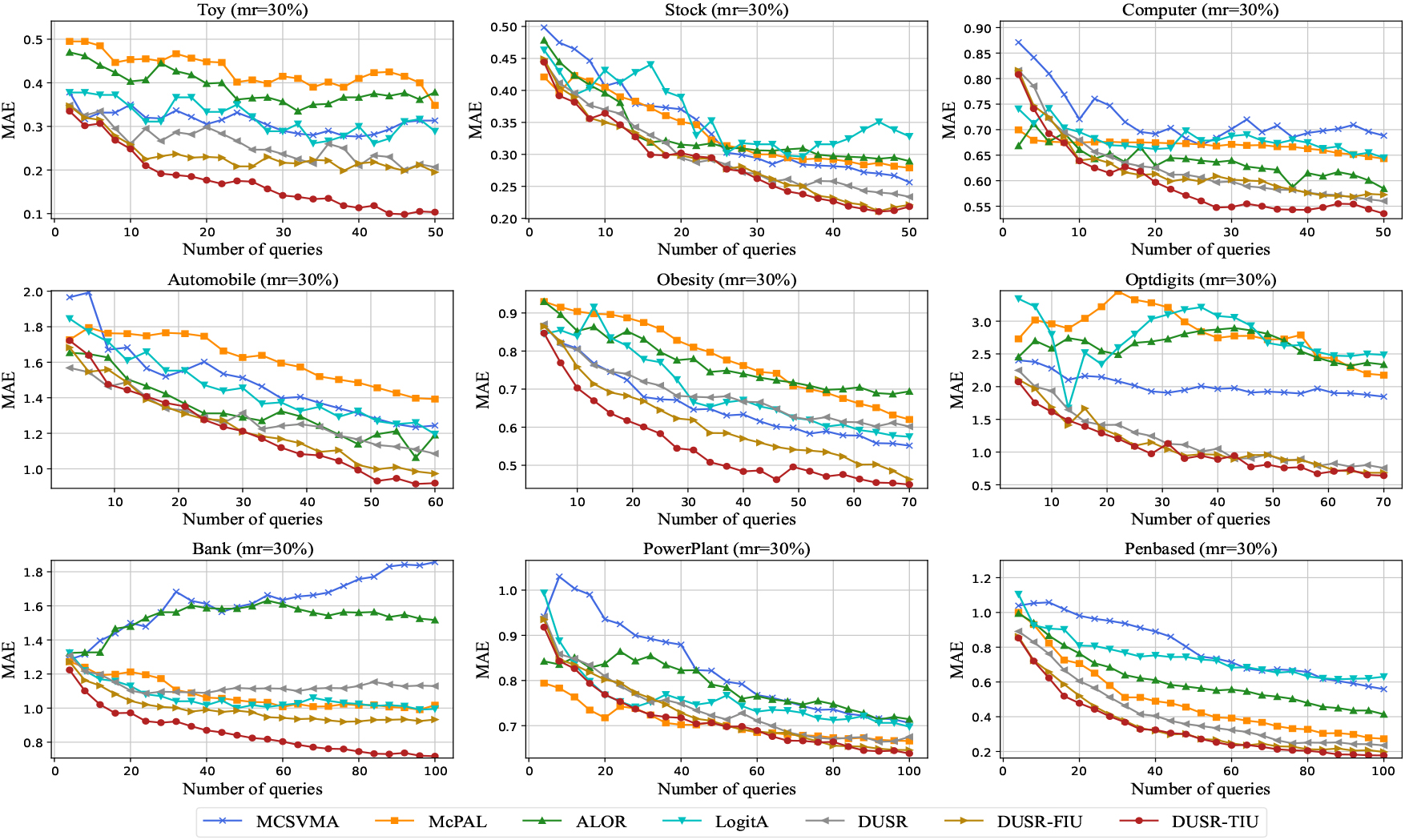
Figures 3–5 plot the learning curves about ACC for the seven compared methods on the nine datasets, respectively, under three distinct missing rates (20%, 30%, and 40%). While, Figs 6–8 visualize the learning curves of MAE on the nine datasets with the three different missing rates, respectively. From the learning curves in the six figures, we can observe that the proposed method outperforms the baseline methods on most of the datasets in the active learning process in various missing rates on metrics classification accuracy and mean absolute error. Out of the seven methods, we can see that the DUSR-FIU generally performs second best. This indicates that it is essential to consider the imputation uncertainty in active learning on incomplete ordinal data. While DUSR-TIU performs better than DUSR-FIU, this illustrates that it is advantageous to consider feature-level imputation uncertainty and knowledge-level imputation uncertainty simultaneously. When the missing rates are 30% and 40%, the learning curves for some algorithms, such as LogitA, ALOR, and MCSVMA, fluctuate considerably. It is mainly because of the negative impact of the imprecisely imputed instances. But, the learning curves of the proposed method generally show a steady increase in ACC and a steady decrease for MAE as the query proceeds. This illustrates that the proposed method has advantages in dealing with imputed incomplete ordinal data for active ordinal classification.
Result of parameters (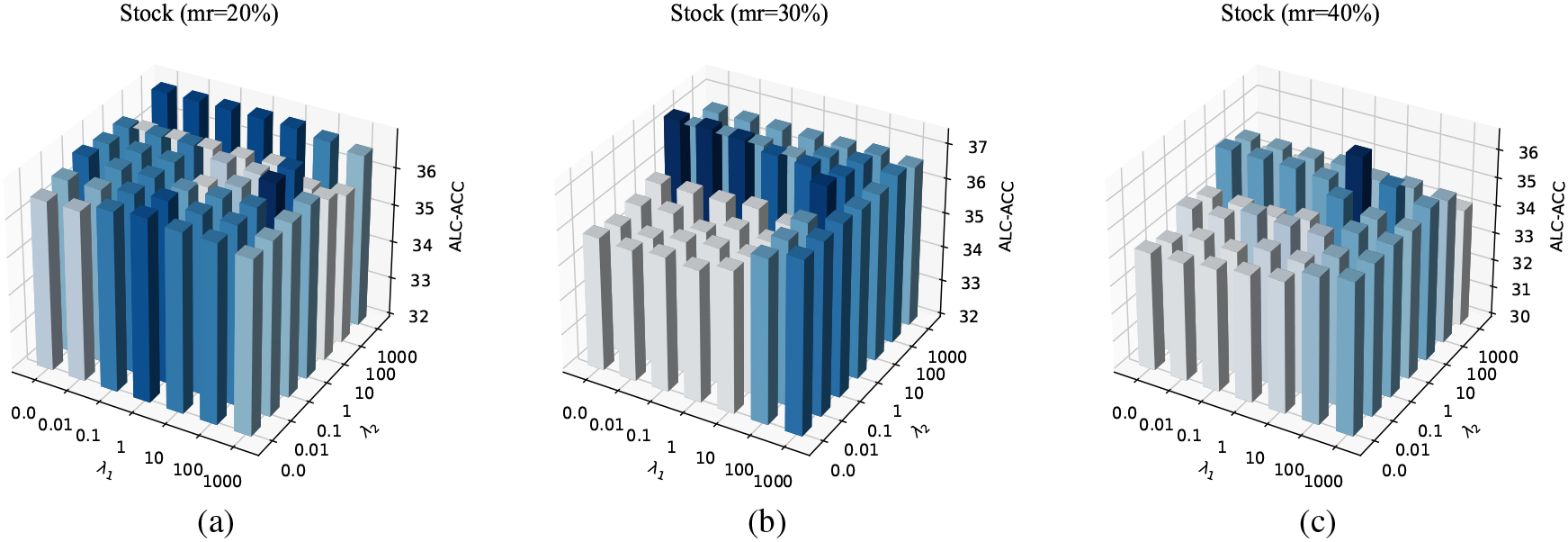
The parameters
This paper proposes an active learning method for incomplete ordinal classification data. To prevent the high imprecisely imputed instances from being labeled, we propose to penalize the query selection with the feature-level imputation uncertainty and the knowledge-level imputation uncertainty simultaneously. To mitigate the negative impact of the potentially imprecisely imputed instances in the training set, we suggest selecting instances in specified candidate instance regions based on the state of the hyperplane of the base learner. The extensive experiments on several public ordinal datasets with different missing rates demonstrate the effectiveness of the proposed method.
In this paper, we only consider the issue of active instance selection for incomplete ordinal data, and the missing values are imputed automatically without considering the potential help from the domain expert in the loop. It is known that active feature acquisition for incomplete data is also an essential issue in the machine learning community. In practice, we can buy not only the labels of the samples from the experts, but also the missing attribute values from the experts. Based on the domain knowledge, perhaps we can know the price of obtaining a label and the price of acquiring each attribute value. In such a situation, we would like to design a cost-sensitive acquisition method with a trade-off mechanism between the missing attribute values and the labels, thus achieving a better ordinal classification model with lowest cost. The imputation uncertainty proposed in this paper can also be used in the above problem to quantify the utility of a missing attribute value being purchased. This is a work that merits investigation in the future.
Footnotes
Acknowledgments
This work is supported by Chongqing Key Laboratory of Computational Intelligence.
Appendix A: Additional experimental results
For quantitative comparison, Tables 5–5 report the results about ALC-ACC for the seven methods on the nine datasets under three different missing rates, respectively. While, Tables 8–8 summarize the results about metric ALC-MAE. In the six tables, the best results are highlighted in boldface. The average ranks of the compared methods are also listed in the tables. The first five methods, i.e., MCSVMA, McPAL, LogitA, ALOR, and DUSR, without considering the imputation uncertainty. The experimental results in the six tables show that our designed method DUSR performs superior to the other four methods. Therefore, the method of diversity-based uncertainty sampling with specified candidate instance region is more effective to conduct active instance selection on imputed incomplete ordinal data. In the compared methods, DUSR-FIU and DUSR-TIU are the two methods that take into account imputation uncertainty. The results show that DUSR-FIU and DUSR-TIU generally perform superior to the other five methods which do not consider the imputation uncertainty. This demonstrates that the potentially imprecisely imputed instances can indeed degrade the performance of active learning. Therefore, it is crucial to involve
Results of ALC-ACC for the compared methods on the nine datasets with a missing rate of 20% Results of ALC-ACC for the compared methods on the nine datasets with a missing rate of 30% Results of ALC-ACC for the compared methods on the nine datasets with a missing rate of 40%
MissingRate
Datasets
MCSVMA
McPAL
LogitA
ALOR
DUSR
DUSR-FIU
DUSR-TIU
20%
Toy
35.36
3.53
33.26
4.02
32.70
4.77
35.32
2.02
37.36
3.59
38.60
3.15
Stock
33.82
1.87
34.53
1.30
34.56
1.53
34.23
0.83
36.50
1.73
36.27
1.03
Computer
24.50
1.76
24.92
2.13
25.29
2.05
26.12
2.73
25.50
1.87
25.66
2.33
Automobile
20.94
3.79
17.30
2.22
20.21
4.19
23.67
2.70
24.07
2.91
25.12
3.01
Obesity
39.27
1.03
33.59
1.85
38.33
1.96
37.41
0.61
37.56
1.64
40.48
1.76
Optdigits
56.62
5.92
47.79
5.54
46.31
9.92
41.28
5.33
71.56
2.76
73.38
2.45
Bank
27.80
1.74
35.19
1.78
30.74
2.00
38.05
1.56
36.50
0.83
37.96
2.50
PowerPlant
40.98
1.80
43.25
1.64
41.05
2.50
40.18
1.83
42.49
1.61
42.89
2.16
Penbased
76.54
1.92
81.50
1.87
82.61
1.93
75.16
1.34
83.34
2.26
84.60
1.90
AvgRank
5.44
5.33
5.22
5.11
3.44
2.44
1.00
MissingRate
Datasets
MCSVMA
McPAL
LogitA
ALOR
DUSR
DUSR-FIU
DUSR-TIU
30%
Toy
35.26
2.13
30.48
3.39
31.29
2.55
34.90
1.96
37.50
2.30
38.65
2.40
Stock
35.10
1.47
34.60
1.65
35.03
1.28
33.06
1.16
35.82
1.80
36.19
1.38
Computer
23.89
2.49
24.12
1.70
25.18
2.26
24.01
1.82
25.42
1.86
25.53
1.54
Automobile
20.16
4.01
16.98
2.77
22.86
4.02
19.76
1.99
23.22
3.33
24.17
4.71
Obesity
37.70
2.46
32.20
3.35
36.34
2.74
37.02
3.01
36.47
2.28
40.08
1.69
Optdigits
55.62
5.91
45.55
5.48
48.65
9.48
43.75
6.61
73.40
1.33
73.72
0.87
Bank
25.15
2.33
33.27
1.66
26.29
2.45
33.94
2.25
33.00
2.67
35.22
1.40
PowerPlant
40.69
1.93
43.58
2.41
40.81
2.70
41.91
2.29
43.01
1.22
43.32
1.17
Penbased
76.22
2.43
81.80
1.67
80.68
2.94
77.35
3.20
82.97
2.19
84.84
1.07
AvgRank
5.33
5.33
5.22
5.44
3.56
2.11
1.00
MissingRate
Datasets
MCSVMA
McPAL
LogitA
ALOR
DUSR
DUSR-FIU
DUSR-TIU
40%
Toy
33.87
2.87
30.61
5.07
28.55
3.92
29.19
3.96
32.11
3.14
31.78
3.07
Stock
32.42
1.70
33.25
1.62
31.72
1.71
33.25
1.19
34.22
1.63
34.54
1.78
Computer
24.54
1.38
25.65
1.96
24.78
1.50
25.39
1.85
26.10
1.31
26.57
1.82
Automobile
19.39
3.08
15.26
3.58
20.44
4.58
18.15
4.30
22.50
3.05
24.26
2.76
Obesity
36.13
2.00
32.60
3.92
35.81
3.44
39.05
0.91
35.80
2.85
39.75
2.29
Optdigits
57.09
4.31
47.45
5.19
50.78
8.00
51.04
1.67
71.20
1.56
74.54
1.47
Bank
22.36
2.36
31.62
1.99
23.58
2.35
34.72
1.14
30.43
2.94
31.78
1.72
PowerPlant
36.84
2.49
41.88
1.64
39.55
1.56
39.55
1.06
40.86
2.35
41.20
2.26
Penbased
73.34
1.88
79.40
1.51
80.17
2.84
74.88
1.71
80.86
1.80
82.94
1.79
AvgRank
5.44
5.11
5.67
4.67
3.67
2.33
1.11
Results of ALC-MAE for the compared methods on the nine datasets with a missing rate of 20% Results of ALC-MAE for the compared methods on the nine datasets with a missing rate of 30% Results of ALC-MAE for the compared methods on the nine datasets with a missing rate of 40%
Metric
MissingRate
MCSVMA
McPAL
LogitA
ALOR
DUSR
DUSR-FIU
ALC-ACC
20%
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
30%
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
40%
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
7.81e-03
ALC-MAE
20%
3.91e-03
7.81e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
30%
3.91e-03
7.81e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
40%
3.91e-03
3.91e-03
3.91e-03
3.91e-03
3.91e-03
1.95e-02
an imputation uncertainty measure in the query selection procedure in active learning on incomplete data. In addition, the DUSR-FIU performs inferior to the DUSR-TIU. This further indicates that it is effective to simultaneously consider the feature-level imputation uncertainty and the knowledge-level imputation uncertainty in the query selection.
To examine whether a compared method performs equivalently or significantly different from the DUSR-TIU, we conduct the Wilcoxon signed-rank tests between DUSR-TIU and the six compared methods at a confidence level of