Collecting and learning with auxiliary information is a way to further reduce the labeling cost of active learning. This paper studies the problem of active learning for ordinal classification by querying low-cost relative information (instance-pair relation information) through pairwise queries. Two challenges in this study that arise are how to train an ordinal classifier with absolute information (labeled data) and relative information simultaneously and how to select appropriate query pairs for querying. To solve the first problem, we convert the absolute and relative information into the class interval-labeled training instances form by introducing a class interval concept and two reasoning rules. Then, we design a new ordinal classification model for learning with the class interval-labeled training instances. For query pair selection, we specify that each query pair consists of an unlabeled instance and a labeled instance. The unlabeled instance is selected by a margin-based critical instance selection method, and the corresponding labeled instance is selected based on an expected cost minimization strategy. Extensive experiments on twelve public datasets validate that the proposed method is superior to the state-of-the-art methods.
Ordinal classification (OC), also known as ordinal regression [1], is a multi-class supervised learning problem where the target variables exhibit a natural semantic total ordering. OC uses machine learning techniques to recognize human ordinal semantics and is a valuable study in many real applications, such as medical diagnosis [2, 3], credit risk prediction [4], and so on. As a supervised learning problem, ordinal classification requires a sufficient amount of labeled instances to train a model or extract rules. However, the acquisition of labels is expensive and time-consuming in real applications due to the dependence on domain knowledge and human experts. In this situation, active learning (AL) [5, 6, 7] that reduces the labeling cost by labeling the most informative instances is an economical way to induce an accurate ordinal classifier. However, if the available query budget is meager, the traditional AL methods are far from satisfactory for training a promising ordinal classifier.
Learning with auxiliary information has drawn increasing attention in active learning research since it can further reduce the labeling cost [8, 9, 1]. In this paper, we study the problem of active learning for ordinal classification (active ordinal classification) with pairwise queries by considering that human experts can provide low-cost relative information. In the considered scenario, the expert is asked “what is the relation between instances and ?”. The feedbacks are as follows: “”, which means the class of instance is of a higher level than the one of instance ; “”, which means the classes of instances and are at the same level. In an ordinal classification scenario, if the expert knows two instances do not belong to the same class, it is natural for the expert to know the ordinal relationship between them. Recently, many works have incorporated the instance-pair relation information into machine learning and active learning [8, 10, 11, 1, 12, 13]. Fu et al. [8] first introduce the pairwise query paradigm into the active learning for binary classification to reduce labeling costs. Tang et al. [1] have noted that collecting relative information is significantly easier than gathering explicit label information since novices and non-expert annotators can do this work. They have shown that collecting additional relative information improves the ordinal classification performance of their model. The above works motivate this paper’s novel study of active ordinal classification by querying relative information (instance-pair relation information).
Although the cost of collecting relative information is much lower than that of obtaining explicit label information, it is not negligible in most cases. Therefore, the core issue in this paper is how to effectively use a limited pairwise query budget to obtain a promising ordinal classifier. Consequently, two challenging issues arise, one is to select suitable query pairs, and the other is to train an ordinal classification model using relative information.
In the considered active learning scenario, a small set of labeled instances exists initially and one can obtain relative information by providing query pairs to experts. Therefore, the base learner in our active learner needs to have the ability to learn with labeled instances and relative information simultaneously. To this end, we introduce a concept of class interval and two reasoning rules. Based on these, the labeled instances and the relative information can be converted into a unified training instance form, such as , where is a class interval, and are the -th and -th class, and has . Then, we construct an OC model based on a reduction-based ordinal classification framework [14] to learn with the instances with class-interval labels.
Intuitively, the smaller the class interval of a training instance, the greater its contribution to model training. Therefore, query pair building is a nontrivial task. We find that when a query pair is built with an unlabeled instance and a labeled instance, we can have a chance to reduce this unlabeled instance’s class interval based on the relative information. Moreover, an appropriate combination can lead to a substantial class interval reduction for the unlabeled instance in the query pair. When the class interval of an unlabeled instance reduces to the minimum, we thus obtain its explicit label, i.e., the absolute information. To maximize the utility of each pairwise query, we let one of the instances in each query pair be an informative unlabeled instance (critical instance) and the other a carefully selected labeled instance.
For query pair building, we introduce a margin-based critical instance selection method to provide an unlabeled instance for each query pair. This method prefers to select the unlabeled instance closest to the nearest decision boundary. To determine the labeled instance in a query pair, we shall determine which class of labeled instance is most appropriate to pair with the current critical instance. If the critical instance and its paired labeled instance have an identical class label, we can obtain the critical instance’s label through a one-time pairwise query. But, this case does not invariably occur. We aim to reduce the critical instance’s class interval as much as possible through each pairwise query, thus obtaining more labeled instances with limited pairwise queries. To this end, we design a labeled instance selection method from the perspective of expected cost minimization.
For the sake of brevity, the main contributions of this paper are summarized as follows.
To our knowledge, this paper is the first active learning study for ordinal classification by querying relative information.
We design a new method to learn an ordinal classifier based on absolute and relative information simultaneously.
We design an effective query pair selection method based on a margin-based critical instance selection method and an expected cost minimization-based labeled instance selection method. This query pair selection method helps to quickly reduce the class interval of each critical instance through pairwise queries, resulting in more explicit labels under a given pairwise query budget.
Extensive experiments show that the proposed method can utilize pairwise query resources more efficiently than to the state-of-the-art methods, resulting in a better ordinal classifier.
The remainder of this paper is structured as follows. Section 2 reviews the related works. The technical details of the proposed pairwise query active learning method for ordinal classification are described in Section 3. In Section 4, we comparatively study the performance of our method and report the experimental results. Following this, a brief conclusion is drawn in Section 5.
Related work
This section briefly reviews the related works from the aspects of active learning and the ordinal classification by using absolute information and relative information. Moreover, a reduction-based ordinal classification framework [14] as preparatory knowledge is recalled in this section.
Active learning
Active learning aims to induce a prediction model while minimizing the labeling cost through interactive instance selection and label inquiry. It is suitable for machine learning scenarios where a large amount of unlabeled data are available or easy to collect, but label acquisition is expensive. The fundamental issue of active learning is to determine which instances would be most valuable if it is labeled and used as training instances [15]. Informativeness and representativeness are two primary considerations for assessing the value of an unlabeled instance. Active learning strategies focusing on the informativeness of unlabeled instances include uncertainty sampling [5, 16, 17], query-by-committee [18, 19], expected change [20, 21], and so on. Active learning strategies that concentrate on the representativeness of unlabeled instances prefer to select the instances that can represent the data distribution. The commonly used methods of this type include clustering-based AL methods [22, 23], experimental designs [24, 25], and so on. Combining multiple assessment criteria for active instance selection is usually encouraged in the active learning community and often results in robust active learning performance.
Although great progress has been made in active learning research on classification, little effort has been devoted to the active learning problem for ordinal classification. Soons and Feelders [26] first proposed an active learning method for ordinal classification by exploiting the monotonicity constraints in the data. However, this work is only suitable for monotonic ordinal classification data [27] and cannot scale up to the general ordinal classification data. Recently, Li et al. [6] designed an active ordinal classification method based on the adjacent category logistic model and an A-optimal experimental design criterion. The major shortcoming of this method is that it has to calculate the inverse of a large matrix in each iteration for each unlabeled instance, which may limit its usability in practice. In the study of the imbalanced ordinal classification problem, Ge et al. [10] proposed an uncertainty sampling-based active learning method to achieve the minority class oversampling in the ordinal data. This method labels the instance with the smallest distance from its nearest decision boundary. Although this method may suffer from sampling redundancy, it generally performs satisfactorily. To our knowledge, the above two methods are the only two active learning methods for the general ordinal classification. In practice, obtaining labels directly from human experts is often expensive or time-consuming. When the query budget is insufficient, collecting sufficient training instances using the aforementioned pointwise query AL methods is unaffordable.
In recent years, active learning by soliciting low-cost instance-pair relation information has attracted more attention. Nevertheless, most of those studies concentrate on active clustering [28] and active learning for ranking [29]. Since there are essential differences between learning for ranking and ordinal classification [30], the active ranking methods cannot be used for active ordinal classification. Fu et al. [8] first developed a pairwise query active learning method by asking the annotator “whether instances and belong to the same class?”. However, this method is only suitable for binary classification problems and cannot immediately extend to multiclass problems. Chien et al. [31] presented a hypergraph-based pairwise query active learning method. Although this method is compatible with multiclass classification, it needs to pair the critical instance with the labeled instances of different classes, which costs times pairwise queries to obtain one explicit label. Here, the is the number of classes. In addition, this method is computationally expensive due to the breadth-first searching for the shortest path in a hypergraph. So far, no research has been devoted to pairwise query active learning for ordinal classification. In addition, the existing pairwise query AL methods are unsuitable for solving this problem. The above situation motivates us to carry out the new study in this paper.
Ordinal classification with absolute and relative information
It is believed that non-expert annotators or novices can provide low-cost relative information, and the cost is much lower than that of asking experts for absolute information. Therefore, To reduce the labeling cost of ordinal classification problems, researchers have recently constructed various new ordinal classification models to learn with absolute and low-cost relative information simultaneously. Tang et al. [1] proposed a nearest neighbors-based ordinal classification model by fusing absolute and relative information. This method was further extended based on a distance metric learning technique in [32]. However, the performance of these methods is heavily dependent on the number of labeled instances. If there are not enough labeled instances, these methods usually perform unsatisfactorily. Therefore, these methods are unsuitable for active learning scenarios where only a small number of labeled samples exist. Sader et al. [12] proposed a novel proportional odds model, where the relative information is formulated as the constraint component in the loss function. Subsequently, Tang et al. [13] extended this scheme to several existing ordinal classification models and conducted a comparative study. The comparative study shows that the methods SVLORR and LDLORR generally perform better. However, one apparent shortcoming of these methods is that they were only suitable for linear separable ordinal data and cannot be immediately extended to nonlinear methods. In this study, we overcome this limitation. The proposed method is suitable for nonlinear data by leveraging the kernel trick.
Although the above works paid much effort into designing ordinal classification models for learning with absolute and relative information simultaneously, they failed to consider how to select valuable query pairs. When requesting relative information, these models randomly select query pairs from the unlabeled pool for querying, which leads to inefficient use of pairwise query resources. On the one hand, these methods do not guarantee that the instances in the query pair are informative. On the other hand, when the two instances in a query pair belong to an identical class, one cannot obtain any valuable information. All the above issues have been addressed in this paper. This paper builds each query pair with an informative unlabeled instance and a carefully selected labeled instance. In this setup, we can obtain useful information from the annotator regardless of whether the two instances in a query pair belong to an identical class. In particular, the proposed method can produce labeled instances during pairwise query active learning.
Reduction-based ordinal classification framework
To solve the ordinal classification problem more effectively, Li and Lin [14] have proposed a reduction framework to reduce an ordinal classification problem to a binary classification problem and gave a theoretical explanation. The model based on this framework is essentially a threshold-based OC model. We instantiate an OC model in this paper based on this reduction-based framework to learn with labeled instances and instance-pair relation information simultaneously. Therefore, in what follows, we will recall this framework’s formulations.
To predict the class label of an instance , the threshold-based ordinal classification model typically learns orderd thresholds: , where and are typically assumed. Thus, the instance is classified as in the case that the predictive output falls in the range of , where , is the inner product of and .
For each original training instance , the reduction framework extends it into binary training instances by the following rule:
where denotes a vector with the -th element as value 1 and the rest of the elements are all 0, and is an indicator function that returns 1 if the inside condition holds; otherwise, a zero is returned. Thus, for each extended instance , there is a binary class label associated with it.
The weight vector in the extended binary classification problem
can be learned to predict the output of , such that , where . Therefore, the can be explained as the distance from to the -th threshold. Whereafter, the predictive ordinal label of instance can be obtained with the computed as
For an unlabeled instance , its cumulative probabilities can be computed as [33]
where is the number of classes. Consequently, we can obtain the posterior probability estimate of by decomposing the cumulative probabilities as follows
Note that the function in Eq. (3) can be any of the existing well-established binary prediction models [14], such as support vector machine, logistic regression, and so on. In Section 3, we instantiate this reduction framework with the kernel extreme learning machine [34] and introduce how to train the new OC model using labeled instances and relative information.
Active ordinal classification with pairwise queries
This section provides the technical detail of the proposed pairwise query active ordinal classification method. The problem setting and method overview are first introduced in Subsection 3.1 to facilitate the descriptions. Then, the base learner and the query pair selection method are successively presented in the subsequent subsections.
Problem setting and method overview
In the considered scenario, let be the initial training set (also referred to as seed set) where each instance is a feature vector and associated with a label . There is a total ordering among the classes, such as , where the notation “” indicates a certain ordering relation or grading relation. Let be the unlabeld pool, where . Thereinafter, if not specified, indicates the number of classes.
Instead of directly querying the instance label in a traditional active learning way, we consider a pairwise query setting in this paper. In each pairwise query, when a query pair is determined, the annotator is inquired “what is the relation between instances and ?”. The feedbacks of the annotator are as follows:
“”, which means the class of is of a higher level than that of . Without loss of generality, if the class of is of a higher level than that of , the feedback will be “”.
“” or “”, which means the classes of and are at the same level.
In order to use the labeled instance and the instance-pair relation information simultaneously in the pairwise query active learning process, we introduce a class interval concept and two reasoning rules.
(Class Interval).
Given an instance , we define there is a class interval associates with it, where , and has . It is only known that the real label of lies in the class interval , i.e., . The size of the class interval of is defind as .
Without loss of generality, the class interval of an unlabeled instance is at the initial time. If the class interval size of an instance is larger than 1, this instance is essentially still an unlabeled instance. Intuitively, an unlabeled instance belongs to each class within its class interval with an identical probability if no additional information exists. Given a labeled instance , we say corresponds to a narrow class interval . Therefore, we can obtain an explicit label once the class interval size of an unlabeled instance is reduced to 1. Based on the concept of class interval, two reasoning rules are designed as follows.
.
In the case that the relative information is “”, according to the ordinal constraint, the class interval of can be inferred as:
and the class interval of can be inferred as:
.
In the case that the relative information is “”, the class intervals of and can be inferred as:
Based on the above two reasoning rules, we can update the class interval of the critical instance in the query pair after information acquisition from the annotator. Accordingly, we can convert the labeled instances and the relative information into the class interval-labeled form, i.e., . We call the training instance of this form the class interval-labeled training instance. The instance that its class interval size is smaller than can be used to train the base learner. Thus, we can construct a interval-labeled training set , . For any unlabeled instance, we can always obtain its explicit label through a few pairwise queries and reasonings. Therefore, the goal of our method is to obtain more labeled instances with the least number of pairwise queries, thus producing a promising ordinal classifier.
In our method, each query pair is built with an unlabeled instance and a labeled instance. Such that we can obtain useful information for model training from each pairwise query and reasoning, and we have a chance to infer the critical instance’s explicit label with a few pairwise queries. If the two instances in the query pair are all unlabeled, such as , where and . It is just when the intersection size of the class intervals of the two instances is less than or equal to 2 that there is a chance to obtain the explicit label. This usually requires a large number of pairwise queries. Compared to the latter, the former query pair building form can obtain more explicit labels with a given pairwise query budget, facilitating the learning of a good ordinal classifier.
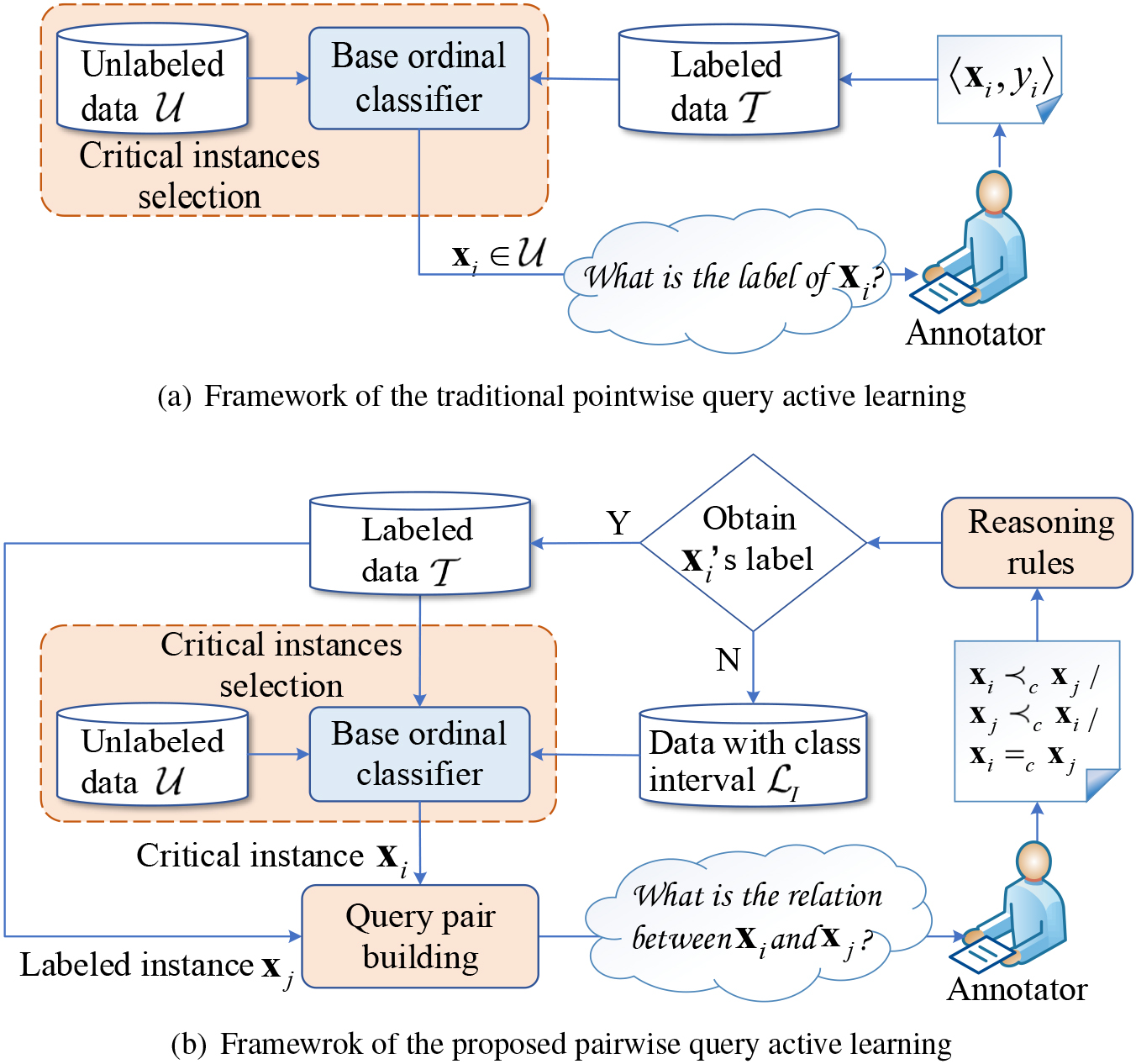
To visually show the difference between pointwise query active learning and pairwise query active learning, we depict the traditional pointwise query active learning framework and the proposed pairwise query active learning framework in Fig. 1a and b, respectively. In the traditional pointwise query active learning, the annotator must provide a reliable label for each query instance. In such a situation, the label acquisition usually depends on experts with domain knowledge or even rigorous physical or chemical testing. In the proposed pairwise query active learning, we can induce an ordinal classifier by interactively asking for low-cost relative information. Since it is not difficult to compare two instances with each other in the context of ordinal classification, non-experts or novices can provide relative information [1]. Therefore, a non-expert or novice can be employed as an annotator.
Active ordinal classification frameworks with pointwise queries and pairwise queries.
We summarize the algorithmic procedure of the proposed method in Algorithm 1. In the algorithm, lines 1 and 2 correspond to the initialization stage, where the initial training instances in are converted into the class interval-labeled training instances. Based on the class interval-labeled training set , the base learner is induced. The base learner will be presented in Section 3.2. In each iteration, the algorithm selects one critical unlabeled instance and joins it into ; this corresponds to line 4. The critical unlabeled instances selection method will be introduced in Section 3.3.1. In each iteration, for each class interval-labeled instance, if its class interval size is larger than 1, we will pair a labeled instance with it to build a query pair for querying. The labeled instance selection method will be introduced in Section 3.3.2. After the annotator feeds back the relative information, we will update the class interval of the unlabeled instance and retrain the base learner. The above operations correspond to line 5 to line 15. The algorithm is terminated when the pairwise query budget is exhausted.
[h] : Active Ordinal Classification Based on Pairwise Queries (AOCpair).[1] Seed set , unlabeled set , pairwise query budget , base learner . The trained base learner , the extened labeled instance set . ; ; Convert the training instances in into the class interval-labeled instances and join them into ; Train with ; Select a critical instance ; ; ; and Build a query pair ; , Inquire the instance-pair relation information about ; Update ’s class interval according to the reasoning rules; ; ; ; Retrain with ; ;
Ordinal classification based on class interval-labeled instances
Before introducing how to use the class interval-labeled instances to train an OC model, we first instantiate an OC model based on the reduction-based framework [14] introduced in Section 2.3. As mentioned in Section 2.3, the can be any well-developed binary prediction model. Therefore, we employ a kernel extreme learning machine (KELM) model to instantiate the reduction-based ordinal classification framework. The KELM model is simple to implement and has comparable performance to the SVM model [34].
An extreme learning machine is a generalized single-hidden-layer feedforward neural network where the hidden layer need not be tuned, and we can formulate it as
where the is the vector of the output weights between the hidden layer of nodes and the output node, is the output vector of the hidden layer about input , , is an identity matrix, and . For binary classification, the decision function is
Following the work in [34], the kernel-based extreme learning machine model takes the hidden layer as an unknown feature mapping from the input space to a feature space. Thus, the Mercer’s condition can be applied and a kernel matrix can be defined as , and has , where is a kernel function. Then, the output weight vector can be computed as
and the predictive output can be formalized as
where .
We can instantiate the reduction-based OC framework by plugging the in Eq. (12) into Eq. (3). Thus, for an unobserved instance , we can obtain
where is a resultant kernel [35, 10]. In this paper, we consider the perceptron kernel [35], i.e., . Here, can be interpreted as the distance from to the -th decision hyperplane. Of course, could be a negative value. Then, instance ’s ordinal scale label can be calculated based on Eq. (3). We refer to the above ordinal classification model as the RKELM model.
In order to train the RKELM model using class interval-labeled training instances, we change the original extended binary training instances generation rule in Eq. (2.3) into a new rule. Suppose is a class interval-labeled training instance, the extended binary training instances are generated as follows
Instead of generates binary instances for each training instance , the RKELM model with the new rule generates binary instances for each class interval-labeled training instance . Table 1 shows the examples of extended binary instances generation for an instance when it associates with different class intervals. In the table, “” denotes that the binary label of is undetermined, and the instance is therefore not involved in the extended binary training set. The complexity of the RKELM model is , where is the number of class interval-labeled training instances.
Examples of extended binary instances generation for an instance under different class intervals ()
()
()
()
()
For an unlabeled instance , suppose it associates with a class interval , its cumulative probabilities are computed as
Accordingly, we can obtain the posterior probabilities of by decomposing the cumulative probabilities as follows
Query pair selection
In our method, each query pair is built with a critical unlabeled instance and a labeled instance. Therefore, in what follows, we will describe how to choose the two instances separately.
Critical unlabeled instance selection
Uncertainty sampling is one of the most commonly used supervised AL strategies and is among the top performers in earlier extensive benchmark experiments [36]. In ordinal classification, the hard-to-predict instances are usually located between adjacent classes. Therefore, we prefer to select the instance closest to the decision boundary. For an unlabeled instance , the distance from it to the -th decision boundary in the RKELM model can be computed as
where denotes the absolute value of . Since there are decision boundaries (thresholds), we define the critical instance as the instance with the smallest distance from its nearest decision boundary. We can formulated the critical instance as
It is worth noting that this paper focuses on proposing a pairwise query active learning paradigm for ordinal classification rather than a pointwise query active instance selection method. Therefore, we do not design a complex active instance selection method here. In case there are incomplete or noise values in the ordinal data, one can use the AL method in our previous work [37] to select critical instances.
Labeled instance selection
This subsection solves the problem of how to effectively select a labeled instance to pair with a critical unlabeled instance. We aim to obtain more labeled instances by fewer pairwise queries. Therefore, for each query pair building, we attempt to reduce the class interval of the critical instance as much as possible through each information acquisition and reasoning. Since the reasoning results are affected directly by the class of the labeled instance, the specific task of labeled instance selection is to determine which class of labeled instance is more suitable for pairing with the critical instance.
To reduce the class interval of the critical instance, the class of the labeled instance in the query pair must lie within the class interval of the critical instance. Suppose is the class interval of the critical instance . When there is no additional information, it might be reasonable to pair a labeled instance that belongs to the median class of , i.e., , to . We refer to this method as the median-class assignment, which costs times queries to obtain ’s explicit label. Fortunately, the posterior estimates derived from the base learner can be used to guide the query pair building. Therefore, in the following, we will analyze the above issue from a decision-theoretic view and propose an expected cost minimization strategy.
Let (shorted as ) denotes the posterior estimate of a critical instance , which is computed by Eqs (3.2) and (16), where . Let be the class interval size of after one time pairwise query and reasoning. As we have mentioned above, the smaller of , the greater the contribution of the class interval-labeled training instance . Therefore, in order to effectively use each pairwise query, we should minimize the value of . We term this idea the expected class interval minimization (EIM). We can compute the expectation of by pairing with different classes of labeled instances as follows
where is the label of labeled instance . Based on Eq. (19), we can derive the following theorem.
.
Given a query pair , in which and . Suppose , and has . Then, the two inequalities and always hold.
Proof..
According to Eq. (19), we have . When the equation holds. Meanwhile, we also have . When the equation holds. ∎
According to the above analysis, we can constrain the class of the labeled instance within , thus obtaining a higher opportunity to reduce the class interval of significantly, where . Therefore, Eq. (19) can be reduced to the following formula
Based on the policy of EIM, the class which produces the minimal value of is the target class. For ease of understanding Eq. (3.3.2), Table 2 presents an example of calculating the . In this example, the class interval of is .
Decision table for EIM ()
It is intuitive and reasonable for the EIM strategy to reduce the class interval of the current critical instance as much as possible with the current pairwise query. However, it failed to consider the subsequent query costs when the explicit label is not obtained in the current pairwise query. To overcome this shortcoming, we use the query costs to replace the class interval size in Eq. (3.3.2) and endow the equation with a new interpretation.
The query costs for obtaining an explicit label contain current and future costs. Here, we defined the costs as the pairwise query budget consumption. Let be a critical instance, and be the class interval size of after one time pairwise query and reasoning. If , i.e., ’s explicit label is obtained, thus only one pairwise query budget is consumed. This case does not need future costs. In the case that , i.e., we failed to obtain ’s label in the current pairwise query, but one query budget is already consumed (the current cost). To obtain ’s label, we still need one or more pairwise queries (the future costs) in the following iterations. However, the future costs are unknown. The only available information in this situation is the value of . Therefore, we approximately estimate the further cost as , i.e., the costs of the aforementioned median-class assignment method. When the , the future cost is 1, which is consistent with the value of . Based on the above analysis, Eq. (3.3.2) can be rewritten as follows
Decision table for ECM ()
The new equation can be interpreted as the expected cost of obtaining ’s explicit label. Therefore, we can determine the class of the labeled instance by minimizing . We refer to this method as expected cost minimization (ECM). For ease of understanding, Table 3 illustrates an example of calculating the expected cost. In this example, the class interval of is .
Based on the above analysis, the class of the labeled instance in a query pair can be determined as follows
Then, one of the labeled instances that belongs to class is selected to pair with the critical instance .
Computational complexity
Let be the number of all instances and be the number of classes. Suppose in the current iteration, the size of the training set is and the size of the class interval-labeled training set is . We will then analyze the computational complexity of one pairwise query from the aspects of base learner training, critical instances selection, and labeled instance selection, respectively.
The time complexity of training the based learner RKELM model is . Selecting the critical unlabeled instance for the query pair requires the following two operations: (1) calculate in Eq. (3.2) for all the instances in requires time; (2) obtain the critical unlabeled instance based on Eq. (18) requires time. Therefore, the time complexity of selecting a critical unlabeled instance is . For the labeled instance selection, the main computational cost is the calculation of the expected cost with Eq. (21), which requires time in the worst case.
In summary, suppose , the time complexity of performing one pairwise query is .
Experiment
In this section, we empirically study the performance of the proposed pairwise query active ordinal classification method. Subsection 4.1 reports the used datasets and experimental configuration. The experimental results are reported in Subsection 4.2. Finally, we discuss the feasibility conditions of the proposed pairwise query active ordinal classification method in Subsection 4.3. All the experiments are implemented on a Windows 10 64-bit operating system with 32GB RAM and a Intel(R) Core(TM) i7-8700 CPU@3.20 GHz processor. The programming language is Python. The source codes are available at https://github.com/DeniuHe/AOCpair.
Table 4 summarizes the information of the twelve used datasets. The datasets Cleveland and Obesity are from the KEEL dataset repository and the UCI dataset repository, respectively. The other ten datasets are from reference [30]. Since a part of the attributes in Obesity are nominal attributes, we have preprocessed those nominal attributes using one-hot encoding. Before experiments, all the datasets are standardized by the following Z-score:
where denotes the -th attribute value of instance , and and are the mean value and the standard deviation of the -th attribute, respectively.
In the experiments, each of the datasets is split based on four times five-fold cross-validation, i.e., each dataset is split into an unlabeled pool (80% of the data) and a testing set (20% of the data) in each run (a total of 20 runs). The metrics of Mean Zero-one Error (MZE), Mean Absolute Error (MAE), and Macro F1 score (F1) are employed in the experiments. MZE and MAE are the longstanding benchmark metrics to measure the performance of ordinal classification [38]. Macro F1 score is a commonly used metric to measure the performance of multi-class classification.
To verify the effectiveness of our method (denoted as AOCpair), we compare it with the following three state-of-the-art methods:
LDLORR [13] is the method of linear discriminant learning for ordinal classification with labeled instances and instance-pair relation information.
SVLORR [13] is the method of support vector learning for ordinal classification with labeled instances and instance-pair relation information.
KNNORR [1] is the recently proposed kNN-based ordinal classification method by fusing absolute and relative information. In this method, the number of pointwise neighbors and the number of pairwise neighbors are both set as .
The above methods are the three existing methods most related to our method. These three methods select the query pairs from the pool set and request the relative information interactively from the annotators. In the proposed method, the coefficient in the RKELM model is fixed as 10. We assume that the annotators provide the ground-truth instance-pair relation information in each pairwise query. In each run, the performances of the compared methods are evaluated on the testing set. Finally, the average results of 20 runs for the different methods are reported.
We are interested in whether our approach can achieve a better ordinal classification performance under a given pairwise query budget. To comparatively study the performance of the proposed method and the three competitors, we set the given pairwise query budget as and and compare those methods under three different sizes (, , and ) of the initial training set (seed set). The seed set consists of instances selected from each class randomly from the unlabeled pool.
In addition to the above comparison, we also conducted an ablation study. Our method selects the query pairs based on a margin-based unlabeled instance selection and an ECM-based labeled instance selection method. To verify the effectiveness of the ECM-based labeled selection method, we replace it with four different alternatives. Thus, the following five methods are compared in the ablation study.
AOCpair-ECM is the proposed method.
AOCpair-EIM is a method in which the labeled instance in each query pair is selected based on the expected class interval minimization (EIM) strategy, which has been introduced in Section 3.3.2.
AOCpair-Med is a method in which the labeled instance in each query pair is selected based on the median-class assignment strategy, which has been mentioned in Section 3.3.2.
AOCpair-Near selects the labeled instance that is closest to the critical unlabeled instance. Thus, the two instances in each query pair are more likely have the same class label.
AOCpair-Post selects the labeled instance that belongs to the class on which the critical instance has the maximum posterior probability estimate.
To compare the above five methods, we set the size of the seed set as and set the pairwise query budget as . We will visualize the evaluation results of the five methods by plotting the learning curves of MZE, MAE, and F1.
Experimental results and analysis
Tables 5–7 summarize the classification results of AOCpair and the three competitors under three different initial training set sizes. When the size of the initial training set is , the results in Table 5 show
Classification results of the four compared methods when the number of initial training instances is set as (the best results are marked in boldface)
Metric
Datasets
10K
20K
SVLORR
LDLORR
KNNORR
AOCpair
SVLORR
LDLORR
KNNORR
AOCpair
MZE
SWD
0.64 0.08
0.67 0.07
0.65 0.07
0.50 0.03
0.66 0.09
0.66 0.10
0.64 0.07
0.48 0.03
Car
0.50 0.15
0.44 0.09
0.54 0.09
0.20 0.04
0.41 0.15
0.37 0.12
0.52 0.07
0.14 0.02
Automobile
0.56 0.10
0.62 0.10
0.64 0.09
0.48 0.11
0.55 0.09
0.60 0.10
0.64 0.08
0.38 0.10
Cleveland
0.54 0.11
0.62 0.12
0.59 0.12
0.46 0.07
0.55 0.12
0.57 0.14
0.61 0.13
0.46 0.05
Housing-5bin
0.55 0.07
0.56 0.09
0.58 0.07
0.43 0.06
0.49 0.08
0.53 0.08
0.57 0.07
0.38 0.04
Stock-5bin
0.49 0.07
0.48 0.05
0.45 0.07
0.24 0.05
0.48 0.06
0.49 0.07
0.40 0.06
0.17 0.03
Computer-5bin
0.50 0.06
0.51 0.05
0.56 0.04
0.43 0.03
0.50 0.05
0.51 0.05
0.52 0.05
0.40 0.03
Winequality-red
0.78 0.06
0.79 0.09
0.71 0.07
0.45 0.02
0.76 0.08
0.76 0.11
0.70 0.07
0.43 0.02
Obesity
0.49 0.09
0.47 0.08
0.62 0.05
0.39 0.04
0.37 0.09
0.36 0.06
0.58 0.04
0.29 0.05
Housing-10bin
0.67 0.05
0.65 0.05
0.71 0.06
0.64 0.04
0.66 0.05
0.66 0.04
0.69 0.04
0.59 0.05
Stock-10bin
0.64 0.05
0.65 0.04
0.57 0.06
0.42 0.04
0.64 0.05
0.64 0.05
0.55 0.06
0.34 0.05
Computer-10bin
0.65 0.03
0.66 0.04
0.71 0.03
0.63 0.01
0.64 0.04
0.64 0.04
0.69 0.03
0.61 0.02
p-value
2.89E-05
2.47E-05
MAE
SWD
0.81 0.16
0.87 0.17
0.85 0.15
0.54 0.04
0.84 0.18
0.85 0.21
0.83 0.13
0.53 0.04
Car
0.62 0.24
0.55 0.14
0.83 0.18
0.22 0.04
0.48 0.20
0.43 0.18
0.76 0.13
0.15 0.02
Automobile
0.73 0.17
0.86 0.23
0.89 0.13
0.58 0.15
0.68 0.13
0.78 0.18
0.91 0.17
0.47 0.14
Cleveland
0.90 0.30
0.99 0.26
0.92 0.22
0.63 0.08
0.89 0.20
0.91 0.27
0.96 0.23
0.62 0.07
Housing-5bin
0.75 0.14
0.75 0.16
0.78 0.17
0.50 0.07
0.63 0.15
0.71 0.19
0.74 0.13
0.43 0.05
Stock-5bin
0.61 0.10
0.62 0.09
0.54 0.12
0.25 0.06
0.57 0.10
0.60 0.12
0.46 0.08
0.18 0.04
Computer-5bin
0.64 0.12
0.67 0.10
0.73 0.10
0.49 0.04
0.61 0.07
0.64 0.10
0.66 0.08
0.45 0.03
Winequality-red
1.26 0.20
1.31 0.28
0.98 0.15
0.49 0.03
1.16 0.20
1.21 0.32
0.99 0.16
0.47 0.03
Obesity
0.60 0.16
0.59 0.13
0.97 0.09
0.46 0.06
0.40 0.11
0.41 0.08
0.90 0.09
0.32 0.06
Housing-10bin
1.12 0.17
1.16 0.20
1.27 0.20
0.98 0.11
1.14 0.16
1.13 0.13
1.20 0.09
0.85 0.10
Stock-10bin
1.06 0.17
1.05 0.11
0.80 0.15
0.48 0.06
1.13 0.24
1.08 0.12
0.75 0.11
0.36 0.05
Computer-10bin
1.09 0.11
1.16 0.13
1.21 0.11
0.95 0.03
1.06 0.14
1.08 0.16
1.14 0.09
0.90 0.04
p-value
2.34E-05
2.88E-05
F1
SWD
0.32 0.07
0.29 0.07
0.31 0.07
0.39 0.06
0.30 0.08
0.30 0.09
0.32 0.07
0.42 0.04
Car
0.39 0.11
0.40 0.05
0.32 0.04
0.50 0.08
0.44 0.09
0.48 0.09
0.33 0.05
0.63 0.07
Automobile
0.42 0.11
0.37 0.11
0.32 0.09
0.46 0.14
0.44 0.08
0.39 0.10
0.33 0.09
0.59 0.12
Cleveland
0.29 0.08
0.25 0.06
0.28 0.07
0.31 0.06
0.29 0.06
0.25 0.07
0.27 0.08
0.33 0.07
Housing-5bin
0.43 0.08
0.42 0.10
0.41 0.07
0.57 0.06
0.48 0.09
0.44 0.10
0.42 0.08
0.62 0.04
Stock-5bin
0.49 0.07
0.48 0.05
0.53 0.08
0.76 0.06
0.49 0.07
0.48 0.08
0.58 0.07
0.82 0.04
Computer-5bin
0.49 0.06
0.47 0.05
0.43 0.05
0.57 0.03
0.48 0.06
0.47 0.06
0.46 0.06
0.59 0.02
Winequality-red
0.16 0.03
0.15 0.04
0.20 0.04
0.22 0.04
0.17 0.04
0.17 0.06
0.21 0.03
0.22 0.02
Obesity
0.50 0.09
0.52 0.08
0.37 0.05
0.60 0.04
0.61 0.09
0.62 0.06
0.40 0.04
0.71 0.05
Housing-10bin
0.31 0.05
0.32 0.06
0.27 0.06
0.35 0.05
0.32 0.05
0.31 0.04
0.30 0.05
0.41 0.05
Stock-10bin
0.33 0.06
0.32 0.04
0.42 0.06
0.56 0.04
0.33 0.06
0.32 0.04
0.43 0.06
0.65 0.05
Computer-10bin
0.32 0.03
0.31 0.04
0.29 0.04
0.37 0.02
0.33 0.05
0.33 0.04
0.31 0.03
0.39 0.02
p-value
2.06E-05
2.79E-05
Classification results of the four compared methods when the number of initial training instances is set as (the best results are marked in boldface)
Metric
Datasets
10K
20K
SVLORR
LDLORR
KNNORR
AOCpair
SVLORR
LDLORR
KNNORR
AOCpair
MZE
SWD
0.63 0.07
0.65 0.05
0.64 0.03
0.49 0.04
0.59 0.06
0.65 0.07
0.64 0.04
0.49 0.04
Car
0.46 0.11
0.41 0.11
0.52 0.04
0.19 0.02
0.43 0.11
0.35 0.08
0.48 0.04
0.13 0.02
Automobile
0.54 0.08
0.59 0.10
0.57 0.10
0.44 0.09
0.51 0.11
0.57 0.07
0.57 0.08
0.34 0.08
Cleveland
0.59 0.07
0.56 0.10
0.58 0.10
0.46 0.04
0.57 0.08
0.52 0.09
0.57 0.07
0.43 0.04
Housing-5bin
0.49 0.06
0.49 0.05
0.51 0.05
0.41 0.06
0.48 0.04
0.49 0.07
0.51 0.05
0.36 0.05
Stock-5bin
0.43 0.05
0.44 0.04
0.36 0.04
0.22 0.03
0.42 0.04
0.41 0.05
0.35 0.04
0.17 0.03
Computer-5bin
0.46 0.04
0.49 0.05
0.51 0.03
0.42 0.02
0.45 0.03
0.46 0.04
0.50 0.04
0.40 0.02
Winequality-red
0.70 0.07
0.76 0.07
0.64 0.05
0.45 0.04
0.74 0.07
0.74 0.06
0.65 0.06
0.43 0.03
Obesity
0.39 0.07
0.33 0.06
0.53 0.04
0.35 0.05
0.35 0.06
0.30 0.05
0.52 0.04
0.25 0.04
Housing-10bin
0.68 0.06
0.68 0.04
0.72 0.05
0.60 0.05
0.68 0.04
0.66 0.05
0.70 0.05
0.57 0.05
Stock-10bin
0.66 0.05
0.63 0.04
0.50 0.04
0.38 0.04
0.66 0.05
0.62 0.04
0.50 0.04
0.31 0.03
Computer-10bin
0.65 0.04
0.65 0.07
0.67 0.03
0.62 0.02
0.63 0.04
0.62 0.08
0.66 0.02
0.60 0.02
p-value
1.25E-04
3.20E-05
MAE
SWD
0.78 0.14
0.82 0.10
0.80 0.07
0.55 0.05
0.70 0.09
0.82 0.15
0.81 0.08
0.55 0.05
Car
0.53 0.13
0.54 0.18
0.80 0.08
0.20 0.03
0.48 0.14
0.41 0.12
0.73 0.07
0.13 0.03
Automobile
0.65 0.12
0.83 0.17
0.80 0.16
0.52 0.12
0.60 0.14
0.79 0.14
0.79 0.13
0.40 0.10
Cleveland
0.86 0.14
0.89 0.23
0.90 0.19
0.64 0.08
0.84 0.12
0.79 0.16
0.87 0.14
0.60 0.07
Housing-5bin
0.59 0.09
0.62 0.11
0.65 0.07
0.48 0.07
0.57 0.07
0.61 0.10
0.66 0.10
0.41 0.06
Stock-5bin
0.50 0.05
0.52 0.07
0.39 0.07
0.23 0.03
0.48 0.04
0.47 0.06
0.38 0.06
0.17 0.03
Computer-5bin
0.53 0.05
0.60 0.08
0.64 0.04
0.47 0.03
0.52 0.04
0.55 0.05
0.62 0.05
0.45 0.03
Winequality-red
1.02 0.16
1.22 0.23
0.86 0.09
0.50 0.04
1.12 0.18
1.13 0.19
0.91 0.11
0.47 0.03
Obesity
0.44 0.09
0.39 0.08
0.86 0.10
0.39 0.05
0.37 0.07
0.32 0.06
0.83 0.08
0.28 0.04
Housing-10bin
1.23 0.22
1.19 0.14
1.21 0.12
0.90 0.07
1.19 0.13
1.11 0.12
1.19 0.12
0.84 0.08
Stock-10bin
1.21 0.19
1.04 0.08
0.66 0.07
0.43 0.05
1.24 0.20
1.02 0.10
0.64 0.08
0.33 0.03
Computer-10bin
1.06 0.10
1.21 0.73
1.15 0.06
0.94 0.06
0.99 0.09
1.13 0.75
1.11 0.05
0.89 0.04
p-value
5.49E-05
4.54E-05
F1
SWD
0.33 0.07
0.32 0.04
0.33 0.03
0.44 0.06
0.37 0.06
0.32 0.06
0.33 0.03
0.43 0.04
Car
0.45 0.06
0.42 0.08
0.35 0.03
0.56 0.08
0.48 0.08
0.47 0.06
0.36 0.03
0.67 0.09
Automobile
0.44 0.10
0.41 0.10
0.42 0.11
0.50 0.12
0.47 0.12
0.43 0.07
0.41 0.09
0.63 0.10
Cleveland
0.29 0.05
0.29 0.07
0.30 0.07
0.32 0.05
0.29 0.05
0.31 0.06
0.30 0.06
0.34 0.05
Housing-5bin
0.50 0.06
0.51 0.06
0.48 0.05
0.58 0.06
0.51 0.04
0.50 0.07
0.47 0.06
0.64 0.05
Stock-5bin
0.56 0.05
0.55 0.05
0.63 0.05
0.77 0.04
0.56 0.05
0.58 0.05
0.64 0.05
0.83 0.04
Computer-5bin
0.53 0.05
0.51 0.05
0.49 0.02
0.58 0.02
0.54 0.04
0.54 0.03
0.49 0.04
0.60 0.02
Winequality-red
0.19 0.04
0.17 0.04
0.23 0.03
0.25 0.04
0.17 0.04
0.18 0.04
0.23 0.03
0.23 0.03
Obesity
0.59 0.07
0.66 0.06
0.46 0.04
0.65 0.05
0.64 0.06
0.70 0.05
0.47 0.04
0.75 0.04
Housing-10bin
0.29 0.06
0.29 0.04
0.28 0.05
0.40 0.05
0.29 0.05
0.30 0.05
0.30 0.05
0.42 0.05
Stock-10bin
0.29 0.05
0.33 0.03
0.49 0.04
0.62 0.04
0.30 0.06
0.34 0.03
0.49 0.04
0.69 0.04
Computer-10bin
0.34 0.04
0.34 0.07
0.33 0.03
0.38 0.02
0.35 0.05
0.36 0.07
0.34 0.02
0.40 0.02
p-value
1.33E-04
7.88E-05
Classification results of the four compared methods when the number of initial training instances is set as (the best results are marked in boldface)
Metric
Datasets
10K
20K
SVLORR
LDLORR
KNNORR
AOCpair
SVLORR
LDLORR
KNNORR
AOCpair
MZE
SWD
0.62 0.05
0.65 0.06
0.63 0.05
0.50 0.03
0.62 0.03
0.61 0.06
0.63 0.05
0.49 0.03
Car
0.46 0.12
0.37 0.08
0.48 0.04
0.18 0.03
0.44 0.10
0.30 0.07
0.46 0.04
0.13 0.02
Automobile
0.51 0.09
0.61 0.11
0.53 0.09
0.37 0.07
0.57 0.08
0.58 0.08
0.53 0.09
0.31 0.07
Cleveland
0.58 0.09
0.51 0.07
0.57 0.10
0.45 0.07
0.52 0.08
0.48 0.06
0.56 0.07
0.44 0.05
Housing-5bin
0.48 0.05
0.50 0.06
0.48 0.04
0.38 0.04
0.47 0.05
0.46 0.05
0.48 0.03
0.34 0.04
Stock-5bin
0.43 0.05
0.43 0.06
0.32 0.05
0.20 0.03
0.44 0.07
0.40 0.04
0.31 0.05
0.16 0.02
Computer-5bin
0.47 0.05
0.45 0.03
0.50 0.03
0.42 0.02
0.45 0.04
0.42 0.03
0.49 0.03
0.40 0.02
Winequality-red
0.73 0.08
0.73 0.07
0.64 0.05
0.45 0.03
0.70 0.07
0.74 0.07
0.67 0.05
0.44 0.02
Obesity
0.36 0.06
0.30 0.07
0.49 0.03
0.33 0.05
0.36 0.07
0.27 0.06
0.48 0.04
0.26 0.05
Housing-10bin
0.68 0.05
0.68 0.05
0.68 0.04
0.60 0.04
0.69 0.05
0.68 0.03
0.67 0.05
0.57 0.03
Stock-10bin
0.67 0.04
0.63 0.04
0.45 0.04
0.35 0.03
0.68 0.05
0.65 0.04
0.44 0.04
0.30 0.03
Computer-10bin
0.64 0.04
0.62 0.03
0.65 0.02
0.61 0.02
0.64 0.04
0.61 0.03
0.65 0.02
0.59 0.02
p-value
1.23E-04
3.18E-05
MAE
SWD
0.76 0.10
0.81 0.11
0.78 0.06
0.55 0.03
0.75 0.06
0.73 0.09
0.79 0.07
0.55 0.04
Car
0.51 0.13
0.45 0.12
0.72 0.09
0.19 0.03
0.47 0.11
0.34 0.09
0.67 0.07
0.13 0.02
Automobile
0.62 0.14
0.86 0.24
0.76 0.17
0.44 0.10
0.70 0.13
0.82 0.17
0.75 0.18
0.37 0.09
Cleveland
0.93 0.17
0.81 0.12
0.88 0.16
0.64 0.09
0.82 0.15
0.72 0.09
0.84 0.14
0.59 0.07
Housing-5bin
0.56 0.07
0.65 0.10
0.61 0.05
0.44 0.05
0.56 0.07
0.56 0.08
0.61 0.05
0.39 0.05
Stock-5bin
0.49 0.09
0.49 0.07
0.36 0.06
0.20 0.03
0.54 0.16
0.45 0.04
0.33 0.05
0.16 0.02
Computer-5bin
0.55 0.07
0.57 0.06
0.62 0.06
0.47 0.03
0.52 0.06
0.50 0.04
0.62 0.06
0.44 0.02
Winequality-red
1.05 0.14
1.15 0.21
0.88 0.09
0.50 0.03
0.99 0.15
1.17 0.22
0.92 0.10
0.48 0.02
Obesity
0.38 0.07
0.34 0.09
0.78 0.09
0.37 0.07
0.39 0.09
0.29 0.06
0.74 0.08
0.28 0.06
Housing-10bin
1.28 0.21
1.19 0.17
1.15 0.15
0.87 0.08
1.24 0.16
1.16 0.13
1.11 0.14
0.80 0.08
Stock-10bin
1.28 0.29
1.01 0.09
0.56 0.07
0.39 0.04
1.31 0.21
1.09 0.13
0.53 0.05
0.32 0.03
Computer-10bin
1.06 0.12
1.02 0.11
1.12 0.06
0.91 0.06
1.06 0.12
0.98 0.11
1.10 0.06
0.85 0.04
p-value
2.22E-04
3.38E-05
F1
SWD
0.34 0.04
0.32 0.05
0.34 0.04
0.42 0.03
0.34 0.03
0.36 0.05
0.34 0.04
0.44 0.04
Car
0.47 0.10
0.47 0.07
0.37 0.04
0.64 0.08
0.49 0.08
0.54 0.07
0.38 0.03
0.71 0.05
Automobile
0.47 0.09
0.40 0.12
0.46 0.09
0.60 0.08
0.41 0.08
0.42 0.07
0.46 0.09
0.67 0.07
Cleveland
0.28 0.07
0.32 0.06
0.29 0.07
0.33 0.08
0.32 0.06
0.33 0.06
0.30 0.06
0.33 0.07
Housing-5bin
0.52 0.06
0.49 0.07
0.51 0.04
0.62 0.04
0.52 0.06
0.53 0.06
0.51 0.04
0.66 0.04
Stock-5bin
0.55 0.07
0.56 0.06
0.67 0.05
0.80 0.03
0.53 0.10
0.59 0.04
0.69 0.05
0.84 0.02
Computer-5bin
0.52 0.05
0.54 0.03
0.50 0.03
0.58 0.02
0.54 0.05
0.57 0.03
0.51 0.03
0.60 0.02
Winequality-red
0.18 0.04
0.18 0.04
0.24 0.03
0.29 0.05
0.19 0.04
0.18 0.04
0.22 0.03
0.27 0.06
Obesity
0.63 0.06
0.69 0.07
0.50 0.04
0.67 0.05
0.63 0.07
0.72 0.06
0.51 0.04
0.74 0.05
Housing-10bin
0.30 0.06
0.30 0.06
0.32 0.04
0.40 0.04
0.28 0.06
0.29 0.03
0.33 0.05
0.43 0.03
Stock-10bin
0.29 0.05
0.34 0.04
0.54 0.04
0.64 0.03
0.28 0.05
0.33 0.04
0.55 0.04
0.70 0.03
Computer-10bin
0.34 0.05
0.36 0.04
0.35 0.02
0.39 0.02
0.34 0.05
0.38 0.04
0.35 0.02
0.41 0.02
p-value
1.43E-04
2.00E-05
that the proposed method AOCpair consistently outperforms the competitors on all the datasets about the metrics MZE, MAE, and F1 under the given pairwise query budgets as and . The results in Tables 6 and 7 show that when the size of the initial training set is and , our method is still superior to the competitors on most datasets.
To detect whether there are significant differences between the compared methods, we have conducted the Friedman test [39] on the three metrics at a confidence level of . The -values of the Friedman tests are shown in the three tables. Since the -values are all less than , statistically significant differences exist between at least two methods on each performance measure under different performing conditions. Furthermore, to detect whether a compared method performs significantly differently from the AOCpair on each dataset under different performing conditions, we conduct the Wilcoxon signed-rank test [40] between AOCpair and the competitors at a confidence level of . The marker “” denotes that there is a statistically significant difference. The results of the Wilcoxon tests in the three tables demonstrate that the AOCpair significantly outperforms the compared methods on most datasets under different performing conditions.
The above experimental results illustrate that the proposed method can use the query resources more effectively. Since the cost of the pairwise query is often non-negligible in practical applications, the proposed method can further reduce the cost of inducing a good ordinal classifier. Multiple factors result in the outstanding performance of the proposed method. The proposed method builds each query pair with an informative unlabeled instance and a labeled instance. This setup ensures that the annotator can provide useful information in each pairwise query. The reasoning rules can reduce the class interval of the critical unlabeled instance after each pairwise query. In particular, the proposed method employs a margin-based critical instance selection method to select the most informative instance for each query pair; this ensures the informativeness of the class-interval labeled training instances. In addition, the ECM-based labeled instance selection method can quickly reduce the critical instances’ class interval, enabling the algorithm to produce more labeled instances, which benefits the learning of a good ordinal classifier.
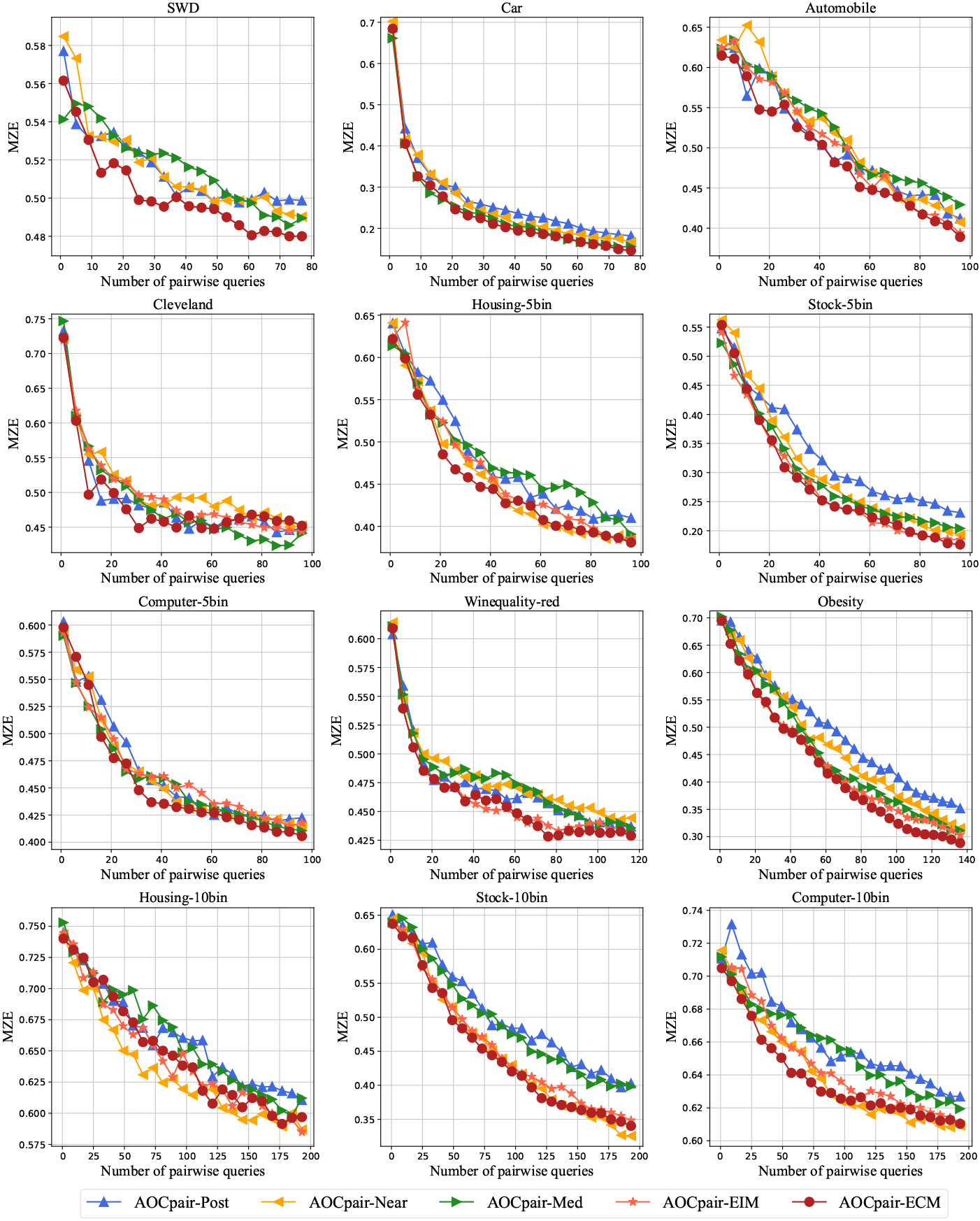
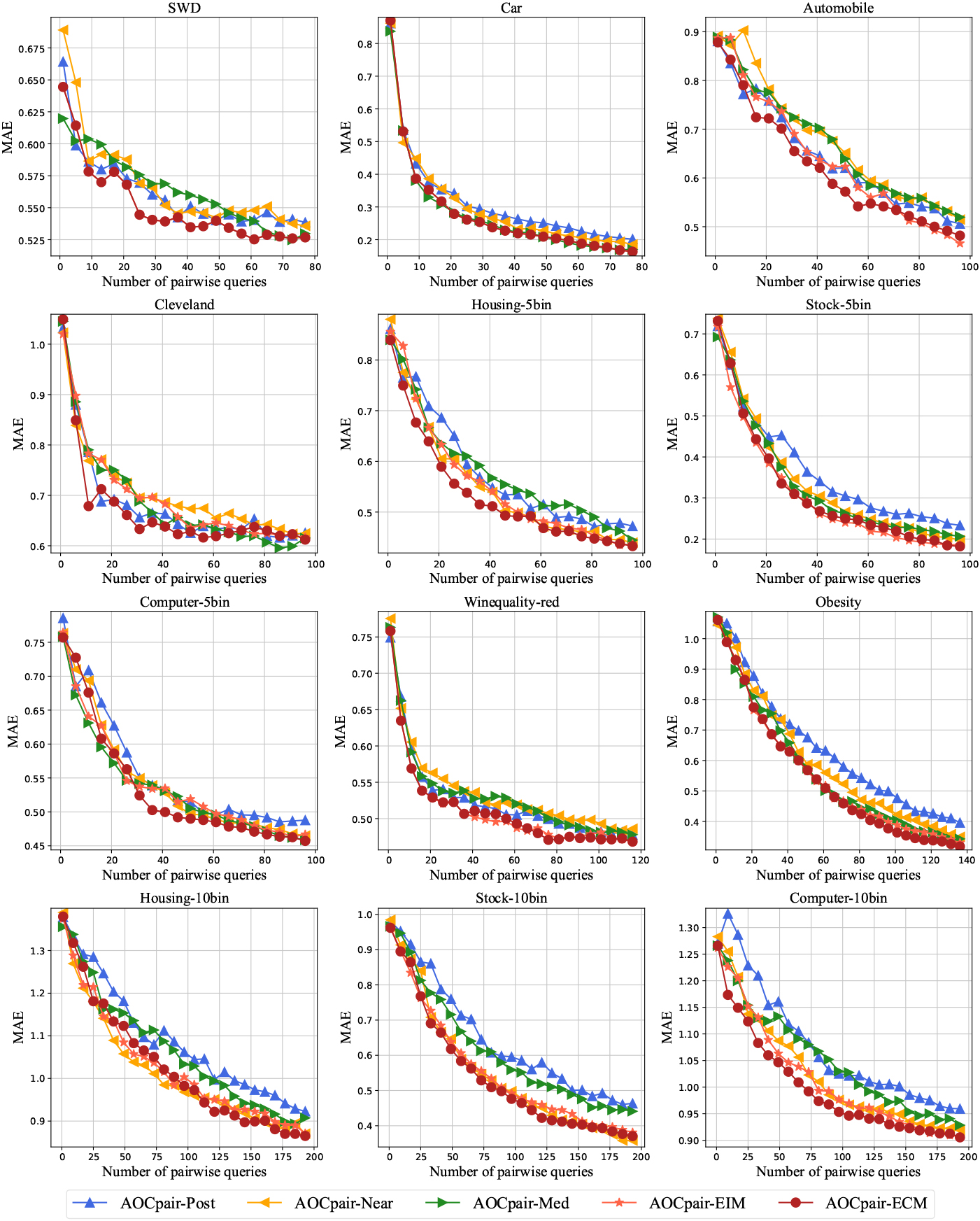
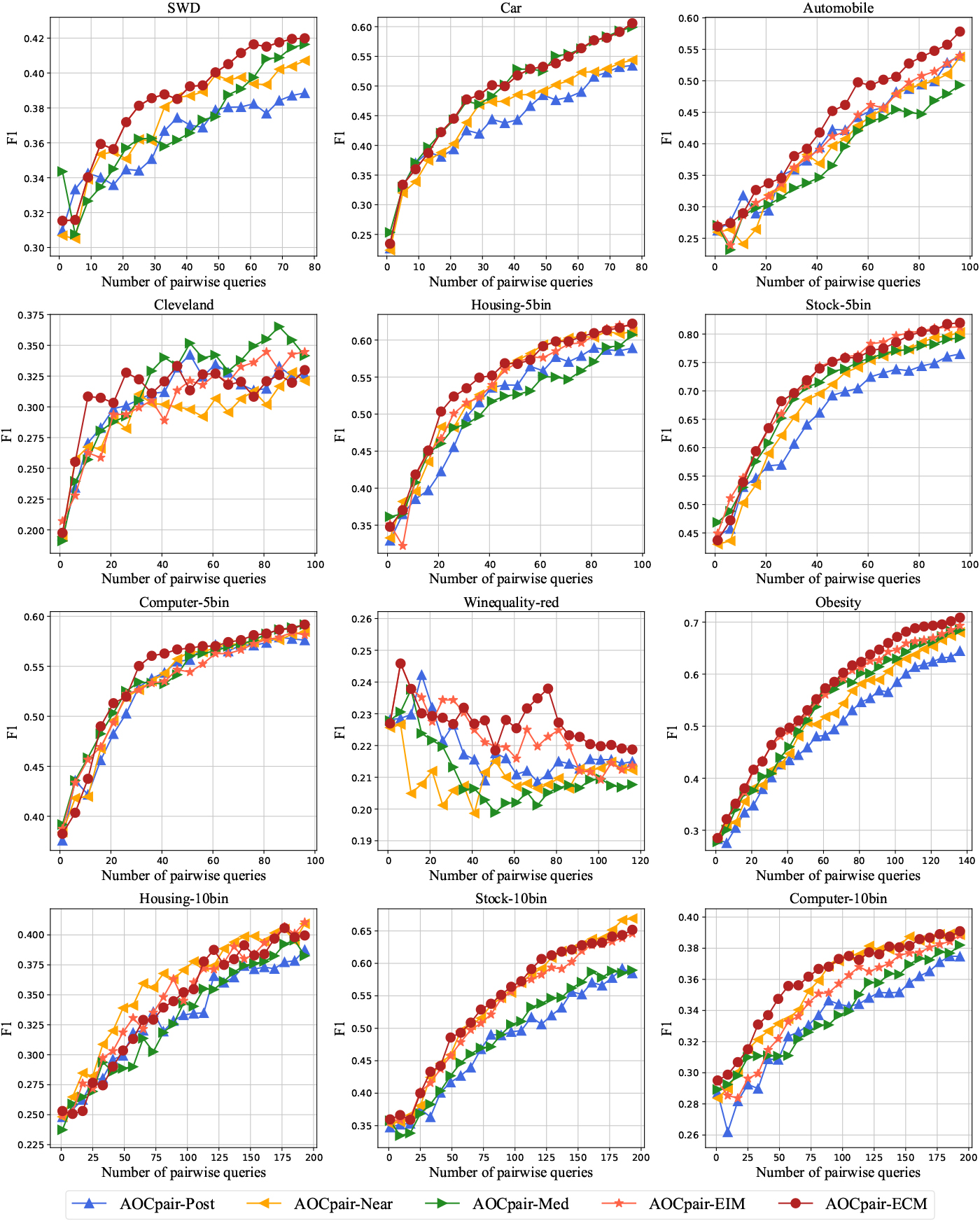
Figures 2–4 show the learning curves of the AOCpair method with different query pair selection strategies on metrics MZE, MAE, and F1. The results show that the AOCpair-ECM generally performs better on most datasets. This indicates that the ECM strategy is more effective than the other four strategies in query pair building. The ECM strategy employs a cost minimization idea by considering the current and future costs of pairwise queries so that more explicit labels can be obtained under a given pairwise query budget, thus leading to a better learning performance.
Learning curves of MAE for the AOCpair methods with different query pair selection strategies.
Learning curves of MAE for the AOCpair methods with different query pair selection strategies.
Learning curves of F1 for the AOCpair methods with different query pair selection strategies.
Feasibility analysis
In this subsection, we will discuss the conditions under which our pairwise query active ordinal classification method is preferable to the pointwise query one.
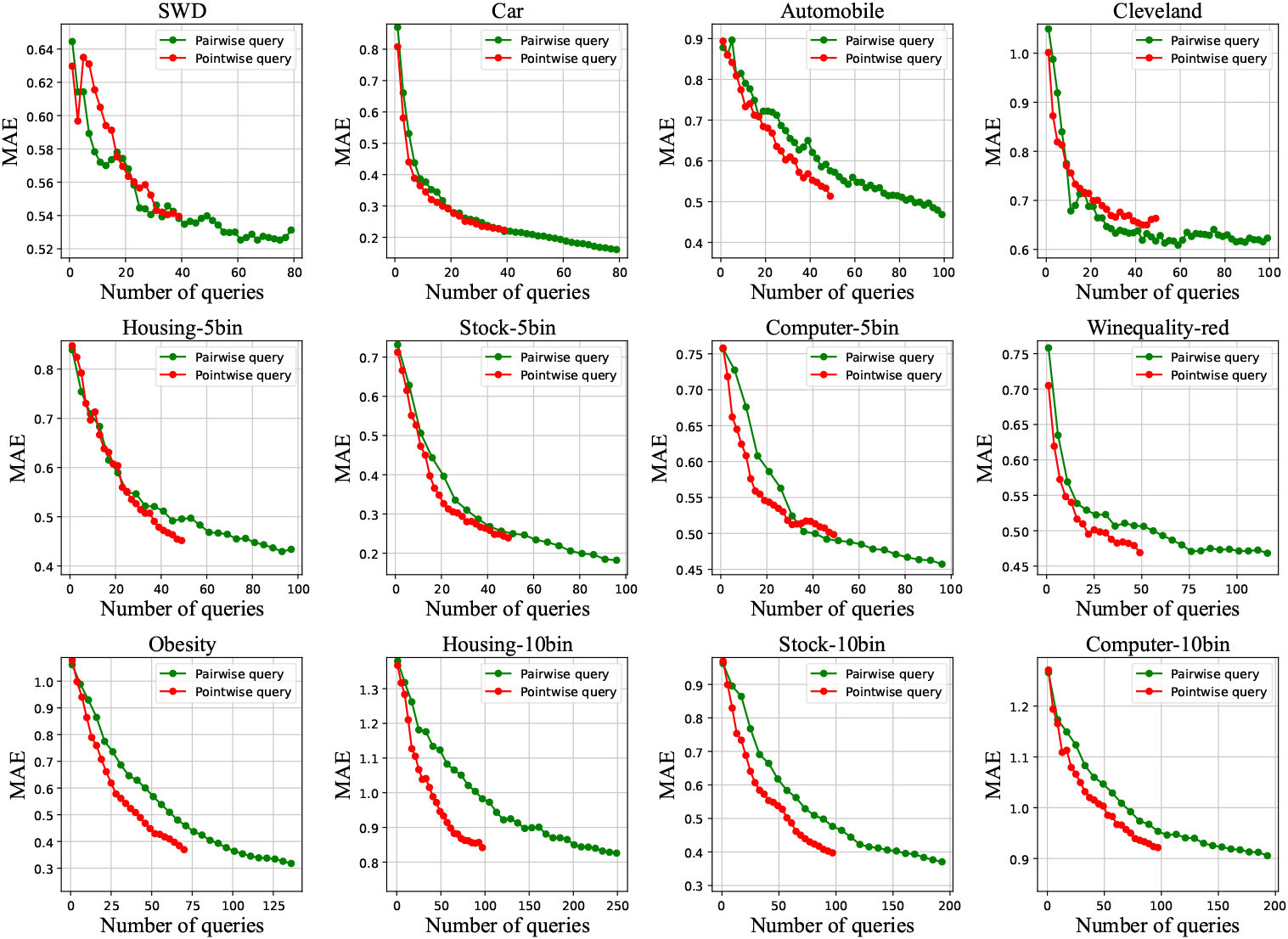
Suppose the price per pointwise query is . The proposed method costs times pairwise queries to obtain one explicit label in the worst situation. Therefore, if the price per pairwise query is lower than , the proposed method is theoretically preferable to the pointwise query method, i.e., the margin-based sampling in Section 3.3.1. As mentioned in Section 3.3.2, the method AOCpair-Med costs times pairwise queries to obtain one explicit label in the worst situation. The learning curves in Figs 2–4 show that the proposed method is generally superior to AOCpair-Med. Therefore, we can empirically conclude that if the pairwise query price is lower than , the proposed method will be superior to the traditional pointwise query paradigm.
To verify the above analysis, we plot the learning curves of MAE for the AOCpair-based pairwise query active learning and the margin-based pointwise query active learning in Fig. 5. The maximum pointwise query budget is set as . When both methods achieve the same performance, we can see that the pairwise query method consumes no more than times the number of queries consumed by the pointwise method. This is consistent with the above analysis.
Learning curves of MAE for pairwise query and pointwise query on the twelve datasets.
Conclusions
This paper proposes a pairwise query active learning method for ordinal classification. The proposed method can learn a promising ordinal classifier by soliciting low-cost relative information, reducing the labeling cost of active ordinal classification. By introducing the concept of class interval and two reasoning rules, we convert the labeled instances and the instance-pair relation information into class interval-labeled training instances. Then a new ordinal classification model is designed to learn with the class interval-labeled training instances. For query pair selection, we specify that each query pair is built with an informative unlabeled instance and a labeled instance. Consequently, the class interval of the critical unlabeled instance can be reduced after each pairwise query and reasoning. The informative unlabeled instance in each query pair is selected by a margin-based sampling method. This ensures the informativeness of the class interval-labeled training instances. The corresponding labeled instance is selected based on an expected cost minimization strategy. This strategy is beneficial for quickly reducing the critical instances’ class interval, enabling the algorithm to produce more labeled instances. Finally, the experiments on several public datasets demonstrate the effectiveness of the proposed method.
Two works merit further investigation: (1) In our method, the critical instance in each query pair is selected based on a margin-based sampling method. This method can be replaced with more robust active instance selection methods, thus achieving a better pairwise query active learning performance. In ordinal classification, the ordering information that the cost of misclassifying an instance as an adjacent class is lower than that of misclassifying it as a more disparate class is commonly used in the solution. We can use this ordering information to design a better active instance selection method. (2) There is no guarantee that human annotators always provide ground-truth information in real applications. Therefore, developing a pairwise query active ordinal classification method that can learn with noise relative information is worthwhile.
Footnotes
Acknowledgments
This work was supported by Chongqing Key Laboratory of Computational Intelligence.
References
1.
TangM.Pérez-FernándezR. and De BaetsB., Fusing absolute and relative information for augmenting the method of nearest neighbors for ordinal classification, Information Fusion56 (2020), 128–140.
2.
GeorgoulasG.KarvelisP.GavrilisD.StyliosC.D. and NikolakopoulosG., An ordinal classification approach for CTG categorization, in: 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, South Korea, July 11–15, 2017, IEEE, 2017, pp. 2642–2645.
3.
FeldmannU. and KonigJ., Ordinal classification in medical prognosis, Methods of Information in Medicine41(02) (2002), 154–159.
4.
KimK. and AhnH., A corporate credit rating model using multi-class support vector machines with an ordinal pairwise partitioning approach, Computers and Operations Research39(8) (2012), 1800–1811.
5.
TongS. and KollerD., Support vector machine active learning with applications to text classification, Journal of Machine Learning Research2 (2001), 45–66. doi: 10.1162/153244302760185243.
6.
LiJ.ChenZ.WangZ. and ChangY.I., Active learning in multiple-class classification problems via individualized binary models, Computational Statistic and Data Analysis145 (2020), 106911.
7.
SantosD.P.D.PrudêncioR.B.C. and CarvalhoA.C.P.D.L.F.D., Empirical investigation of active learning strategies, Neurocomputing326–327 (2019), 15–27.
8.
FuY.LiB.ZhuX. and ZhangC., Active learning without knowing individual instance labels: A pairwise label homogeneity query approach, IEEE Transactions on Knowledge and Data Engineering26(4) (2014), 808–822. doi: 10.1109/TKDE.2013.165.
9.
XueY. and HauskrechtM., Active learning of multi-class classification models from ordered class sets, in: The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, Hawaii, USA, January 27–February 1, 2019, AAAI Press, 2019, pp. 5589–5596.
10.
GeJ.ChenH.ZhangD.HouX. and YuanL., Active learning for imbalanced ordinal regression, IEEE Access8 (2020), 180608–180617.
11.
ShethD.Y. and RajkumarA., Active ranking from pairwise comparisons with dynamically arriving items and voters, in: CoDS-COMAD 2020: 7th ACM IKDD CoDS and 25th COMAD, Hyderabad India, January 5–7, 2020, ACM, 2020, pp. 229–233.
12.
SaderM.VerwaerenJ.Pérez-FernándezR. and BaetsB.D., Integrating expert and novice evaluations for augmenting ordinal regression models, Information Fusion51 (2019), 1–9. doi: 10.1016/j.inffus.2018.10.012.
13.
TangM.Pérez-FernándezR. and BaetsB.D., A comparative study of machine learning methods for ordinal classification with absolute and relative information, Knowledge-Based Systems230 (2021), 107358. doi: 10.1016/j.knosys.2021.107358.
14.
LiL. and LinH.T., Ordinal regression by extended binary classification, in: Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, December 4–7, 2006SchölkopfB.PlattJ.C. and HofmannT., eds, MIT Press, 2006, pp. 865–872.
15.
HeX.MinW.CaiD. and ZhouK., Laplacian optimal design for image retrieval, in: SIGIR 2007: Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, July 23–27, 2007KraaijW.de VriesA.P.ClarkeC.L.A.FuhrN. and KandoN., eds, ACM, 2007, pp. 119–126. doi: 10.1145/1277741.1277764.
16.
JingF.LiM.ZhangH. and ZhangB., Entropy-based active learning with support vector machines for content-based image retrieval, in: Proceedings of the 2004 IEEE International Conference on Multimedia and Expo, ICME 2004, 27–30 June 2004, Taipei, Taiwan, IEEE Computer Society, 2004, pp. 85–88.
17.
CulottaA. and McCallumA., Reducing labeling effort for structured prediction tasks, in: Proceedings, The Twentieth National Conference on Artificial Intelligence and the Seventeenth Innovative Applications of Artificial Intelligence Conference, July 9–13, 2005, Pittsburgh, Pennsylvania, USAVelosoM.M. and KambhampatiS., eds, AAAI Press/The MIT Press, 2005, pp. 746–751.
18.
SeungH.S.OpperM. and SompolinskyH., Query by committee, in: Proceedings of the Fifth Annual ACM Conference on Computational Learning Theory, COLT 1992, Pittsburgh, PA, USA, July 27–29, 1992, ACM, 1992, pp. 287–294.
19.
KeeS.CastilloE.D. and RungerG., Query-by-committee improvement with diversity and density in batch active learning, Information Sciences454-455 (2018), 401–418. doi: 10.1016/j.ins.2018.05.014.
20.
RoyN. and McCallumA., Toward Optimal Active Learning through Sampling Estimation of Error Reduction, in: Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williams College, Williamstown, MA, USA, June 28– July 1, 2001, Morgan Kaufmann, 2001, pp. 441–448.
21.
ParkS.H. and KimS.B., Robust expected model change for active learning in regression, Applied Intelligence50(2) (2020), 296–313. doi: 10.1007/s10489-019-01519-z.
22.
DasguptaS. and HsuD., Hierarchical sampling for active learning, in: Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, June 5–9, 2008CohenW.W.McCallumA. and RoweisS.T., eds, ACM International Conference Proceeding Series, Vol. 307, ACM, 2008, pp. 208–215.
23.
WangM.MinF.ZhangZ. and WuY., Active learning through density clustering, Expert Systems with Applications85 (2017), 305–317.
24.
YuK.BiJ. and TrespV., Active learning via transductive experimental design, in: Machine Learning, Proceedings of the Twenty-Third International Conference (ICML 2006), Pittsburgh, Pennsylvania, USA, June 25–29, 2006, ACM International Conference Proceeding Series, Vol. 148, ACM, 2006, pp. 1081–1088. doi: 10.1145/1143844.1143980.
25.
ParkS.H. and KimS.B., Active semi-supervised learning with multiple complementary information, Expert Systems with Applications126 (2019), 30–40. doi: 10.1016/j.eswa.2019.02.017.
26.
SoonsP. and FeeldersA., Exploiting monotonicity constraints in active learning for ordinal classification, in: Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, Pennsylvania, USA, April 24–26, 2014, SIAM, 2014, pp. 659–667.
27.
XuH.WangW. and QianY., Fusing complete monotonic decision trees, IEEE Transactions on Knowledge and Data Engineering29(10) (2017), 2223–2235.
28.
MazumdarA. and SahaB., Query complexity of clustering with side information, in: Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4–9, 2017, Long Beach, CA, USA, 2017, pp. 4682–4693.
29.
DavidsonI.LiH.QianB.WangJ. and WangX., Active learning to fank using pairwise supervision, in: Proceedings of the 13th SIAM International Conference on Data Mining, May 2–4, 2013. Austin, Texas, USA, SIAM, 2013, pp. 297–305.
30.
GutiérrezP.A.Pérez-OrtizM.Sánchez-MonederoJ.Fernández-NavarroF. and Hervás-MartínezC., Ordinal regression methods: survey and experimental study, IEEE Transactions on Knowledge and Data Engineering28(1) (2016), 127–146.
31.
ChienI.ZhouH. and LiP., HS: active learning over hypergraphs with pointwise and pairwise queries, in: The 22nd International Conference on Artificial Intelligence and Statistics, AISTATS 2019, 16–18 April 2019, Naha, Okinawa, Japan, Vol. 89, PMLR, 2019, pp. 2466–2475.
32.
TangM.Pérez-FernándezR. and BaetsB.D., Distance metric learning for augmenting the method of nearest neighbors for ordinal classification with absolute and relative information, Information Fusion65 (2021), 72–83. doi: 10.1016/j.inffus.2020.08.004.
33.
McCullaghP., Regression models for ordinal data, Journal of the Royal Statistical Society: Series B (Methodological)42(2) (1980), 109–127. doi: 10.1111/j.2517-6161.1980.tb01109.x.
34.
HuangG.B.ZhouH.DingX. and ZhangR., Extreme learning machine for regression and multiclass classification, IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)42(2) (2012), 513–529. doi: 10.1109/TSMCB.2011.2168604.
35.
SeahC.W.TsangT.W. and OngY.S., Transductive ordinal regression, IEEE Transactions on Neural Networks and Learning Systems23(7) (2012), 1074–1086.
36.
YangY. and LoogM., A benchmark and comparison of active learning for logistic regression, Pattern Recognition83 (2018), 401–415.
37.
HeD., Active learning for ordinal classification on incomplete data, Intelligent Data Analysis (2023). doi: 10.3233/IDA-226664.
38.
GutiérrezP.A. and GarcíaS., Current prospects on ordinal and monotonic classification, Progress in Artificial Intelligence5(3) (2016), 171–179.
39.
FriedmanM., A comparison of alternative tests of significance for the problem of m rankings, The Annals of Mathematical Statistics11(1) (1940), 86–92.
40.
WilcoxonF., Individual comparisons by ranking methods, Biometrics Bulletin1(6) (1945), 80–83.