
Abstract
In classification problems, feature selection is used to identify important input features to reduce the dimensionality of the input space while improving or maintaining classification performance. Traditional feature selection algorithms are designed to handle single-label learning, but classification problems have recently emerged in multi-label domain. In this study, we propose a novel feature selection algorithm for classifying multi-label data. This proposed method is based on dynamic mutual information, which can handle redundancy among features controlling the input space. We compare the proposed method with some existing problem transformation and algorithm adaptation methods applied to real multi-label datasets using the metrics of multi-label accuracy and hamming loss. The results show that the proposed method demonstrates more stable and better performance for nearly all multi-label datasets.
Keywords
Introduction
Recently, researchers have gained interest in multi-label learning as well as single-label classification. Multi-label classification problems have been applied to various domains including scene annotation, emotion data, gene function prediction, text categorization, and healthcare data. In classification problems, the high dimensionality of input data can cause problems such as increased prediction error, high computational complexity, decreased interpretability, and data sparsity. Feature selection addresses this problem by reducing the dimensionality of the input space while preserving classification performance by selecting important features.
Therefore, studies on feature selection for multi-label learning have been actively conducted. There are two main approaches: the problem transformation method and the algorithm adaptation method. The problem transformation method is algorithm-independent and transforms a multi-label data representation into a single-label representation [1, 2, 3, 4]. In contrast, the algorithm adaptation method extends a single-label algorithm to directly handle multi-label data [5, 6, 7, 8, 9]. In this paper, we primarily focus on the algorithm adaptation method because it is easy to understand the label relation without information loss caused by reconstructing labels.
Feature selection methods in general can be categorized into the following three groups: filter methods, wrapper methods, and embedded methods [10]. A filter method does not incorporate learning but directly selects the best feature subset based on the intrinsic properties of the data. This approach is usually used for high-dimensional data, as it is relatively simple and fast [11]. A wrapper method selects a subset of features that provides the best classification performance with a specific classifier [12]. In the embedded method, the feature selection procedure is part of classifier learning itself [11]. Because both the wrapper and embedded methods use a classifier, their performance largely depends on the classifier used. In addition, classifier learning has a high computational cost during an exhaustive feature subset search. For these reasons, filter methods are a reasonable choice for high-dimensional data, as they do not depend on a classifier. When applying a filter method to a classification problem, information theory and rough set theory are commonly used for selecting significant features, as they can measure the properties of categorical features. In particular, for mixed-type data, a specific discretization technique is utilized in information theory [13, 14, 15], and Pawlak’s rough set model and neighborhood rough set model are employed in rough set theory [16, 17, 18]. Entropy and mutual information are used to handle linear or non-linear relations between features, as well as mixed-type data with a specific discretization technique. In addition, relevance and redundancy among features are calculated directly using information theory.
Existing multi-label learning feature selection algorithms based on the algorithm adaptation method estimate mutual information in a whole input space but cannot accurately express the relevance between features and labels. For this reason, dynamic mutual information (DMI) has been proposed by Liu et al. [13]. The whole input space is divided into recognized and unrecognized instances, which will be defined in Section 2.3. DMI estimates the relevance information on unrecognized instances, not the whole input space. Through this measure, relevance information among features can be estimated more accurately. However, existing studies using DMI mainly focus on feature selection in single-label classification not in multi-label learning.
In this paper, we propose DMI-based feature selection for multi-label learning (DMIML). To the best of our knowledge, this is the first work to extend DMI to feature selection for multi-label learning. To this end, we first extend the original DMI algorithm to implement it for multi-label learning. We then utilize the score function in DMI so that recognized instances are captured by selected features with candidate features in multi-label learning. Second, rarely occurring combinations in the training set are ignored, as they lead to significant performance loss. Finally, we determine a score function that fits DMIML, as DMI already takes redundancy among features into account. The proposed method through these process contributes accurate information among the features and labels of multi-label datasets to be estimated by removing redundant information. In addition, our proposed method demonstrates more stable classification performance for most of the benchmark multi-label datasets than the benchmark methods in experimental results. Also, it makes full use of the information of the features and labels which can be said to have the faster entropy-reducing capability and can be clearly shown from the remaining entropy for interpretation.
The remainder of this paper is structured as follows. In Section 2, we briefly review related works, while in Section 3 we present the DMIML and DMIML-M algorithms. In Section 4, we present and discuss our experimental results. Finally, in Section 5, we present our conclusions and ideas for future work.
Related works
This section introduces fundamental information theory concepts and terminology, as well as methods related to our proposed feature selection method. Here, we first characterize our notations of feature selection for multi-label learning. Assume that
Information theory
In information theory, entropy is widely used a key measure of information in many fields, including feature selection, as it can quantify the uncertainty of random variables and effectively scale the amount of information shared among them. Here the definition of the entropy is based on Shannon’s entropy [19].
Let
where
where
where
The mutual information
Equation (4) can be expressed by entropy as follows:
A higher value of
Entropy and mutual information.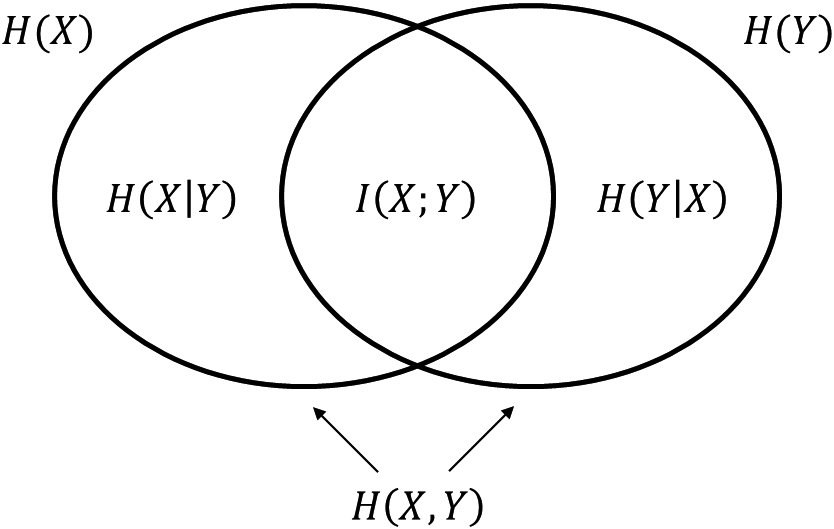
For the case of three variables, multivariate mutual information is defined as follows:
In addition, Eq. (6) can be represented in various forms:
The relation between entropy and multivariate mutual information for the case of three variables is illustrated in Fig. 2.
Entropy and multivariate (3-variable) mutual information.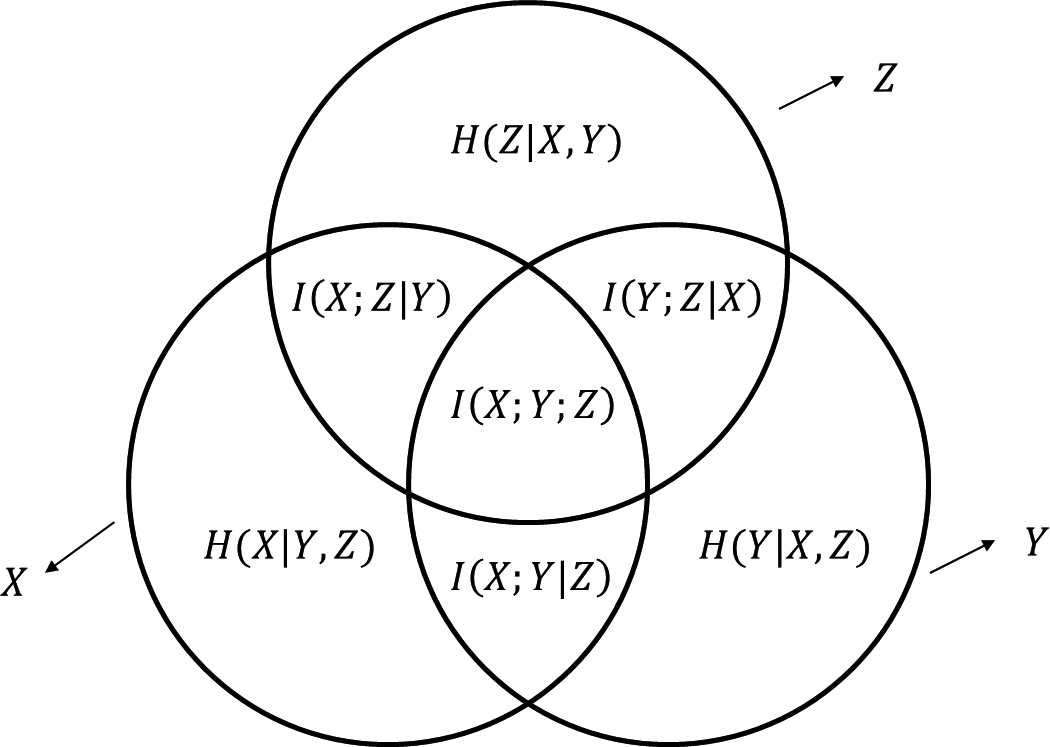
For any set of variables
where
From the perspective of feature selection, the value of multivariate mutual information provides rich information about the interaction between variables. Suppose that
The objective Eq. (9) is positive when variable
In this subsection, we introduce the mutual information based multi-label feature selection method called MIMF proposed by Lee and Kim [7], and discuss its limitations. MIMF introduces multivariate mutual information and proposes the
To calculate the multivariate mutual information, each component in Eq. (10) is calculated using Eqs (2) and (8) as follows:
where
where
When candidate feature
According to Eqs (9) and (14), Eq. (15) can be expressed as follows:
However, it is computationally expensive to calculate a higher degree of multivariate mutual information. Therefore, to relax the score function, Lee and Kim [7] have proposed a
One of MIMF’s limitations is that mutual information is only estimated on the whole input space and cannot exactly express the relevance between features and labels, as there may be redundant information among features for labels. In this paper, we focus on resolving this problem by developing DMI for a multi-label classification problem. DMI estimates the relevance information on unrecognized instances, not the whole input space. The DMI for feature selection in a single-label classification problem is introduced in detail in Section 2.3.
The whole input space
In traditional mutual information based feature selection algorithms, mutual information estimated on the whole input space cannot exactly express the relevance between features and labels. For this reason, Liu et al. [13] proposed DMI to estimate relevance information on unrecognized instances, not the whole input space. The utilized evaluation function is as follows:
where
where
Related to this phase, the following proposition has been described by Liu et al. [13]: suppose that
Therefore, studies on feature selection for multi-label learning have been actively conducted. There are two main approaches to feature selection methods for multi-label learning. One is the problem transformation method, which transforms a multi-label data representation into a single-label representation. The works by [1, 2, 3, 4] fall in this approach. The other one is the algorithm adaptation methods, which extends a single-label algorithm to directly handle multi-label data [5, 6, 7, 8, 9].
Although its simplicity and algorithm independent, there is a main drawback of the problem transformation that there is great loss of information with respect to the label dependency. For this reason, in this paper, we primarily focus on the algorithm adaptation method because it is easy to understand the label relation without information loss caused by reconstructing labels.
Proposed algorithms: DMIML and DMIML-M
In this section, we provide a detailed discussion of the proposed algorithm based on the foundation presented in Section 2. We also present the concept of DMI for information theory, which is the fundamental principle behind the proposed feature selection algorithm. In addition, we dynamically use score functions to select important features.
Motivation
In the DMI algorithm, mutual information can be recalculated only on unrecognized instances
Extension of DMI to multi-label learning
First, we redefine the recognized instances in our proposed method. In DMI, single-label (i.e., single class) values are compared with candidate feature values. To perform an operation similar to DMI, we create possible label combination set
Example of obtaining possible combination set.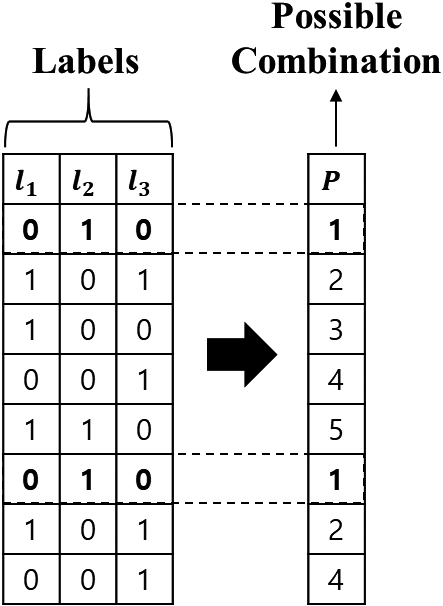
The next step of the proposed method is to divide the data into a recognized instance group and an unrecognized instance group using the possible combination set
Similar to MIMF, we employ a 3-degree score function D3 as
where D3 is a 3-degree approximation score function, D2F is a score function that emphasizes feature dependency, and D2L is a score function that focuses on the relation between pairs of labels. Estimation is performed on
As mentioned earlier in Section 1, DMI handles redundant information and can generate recognized instances
Example of assigning recognized instances with 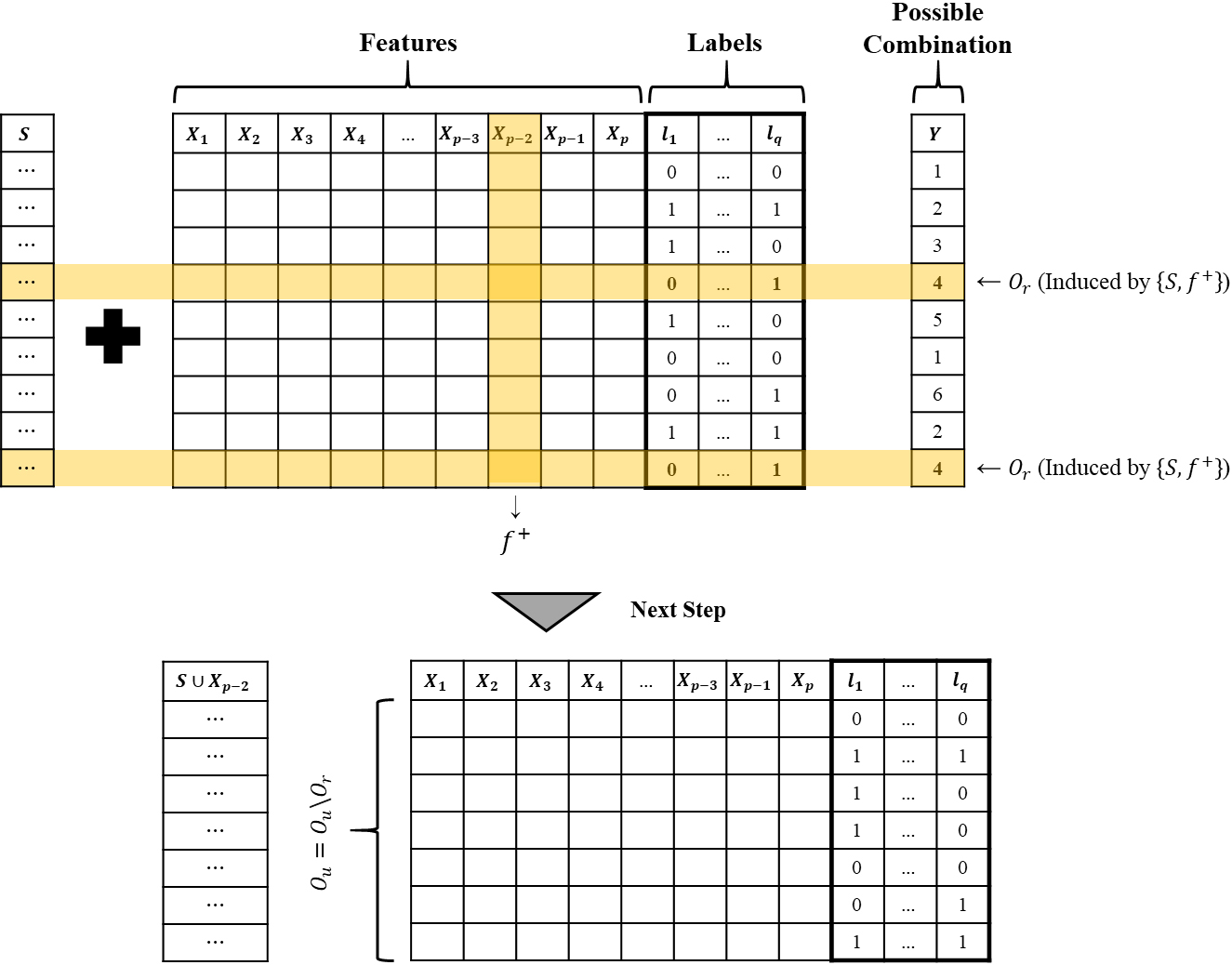
An example of selecting one feature among candidate features is illustrated in Fig. 4. That is, if candidate feature
Datasets
In experiments, we used the following four benchmark multi-label datasets from Knowledge Extraction based on Evolutionary Learning (
Summary of multi-label datasets
Summary of multi-label datasets
The proposed algorithms DMIML and DMIML-M were compared with the benchmark method MIMF to evaluate the effects of using DMI. In MIMF, the score functions D3 and D2F were employed, as they were known to demonstrate higher performance than others, including D2L. For both the benchmark methods and proposed algorithms, we discretized the Scene dataset using an equal-width interval scheme with three bins to apply the mutual information based feature selection methods [24]. In addition, we set
In this study, ML
Hamming loss calculates the fraction of incorrect labels to the total number of labels.
We used 5-fold cross-validation for all datasets, dividing each dataset randomly into five equal subsets. Each subset was used in turn as the test dataset, with the other four subsets used for training. This procedure was repeated ten times, generating a total of 50 results for each classifier and dataset.
Comparison with existing algorithm adaptation methods
To verify the performance of our proposed methods, we compared DMIML and DMIML-M to MIMF, which was proposed as an algorithm adaptation method. In MIMF, D3, D2F, D2L, and D2 were used as score functions in experiments, and D3 and D2F were empirically suggested as the final score functions. In this study, we use D3 and D2L because D2F is a score function that emphasizes feature dependency; we already focus on feature redundancy via DMI.
In this subsection, we present the results of our experiments and discuss the findings. Figures 5 and 6 illustrate the classification performance according to the multi-label accuracy and Hamming loss (vertical axis) of four multi-label datasets from 1 to 70 selected features (horizontal axis).
Comparison of classification performance with benchmark method
Comparison of classification performance with benchmark method
Multi-label accuracy with benchmark methods.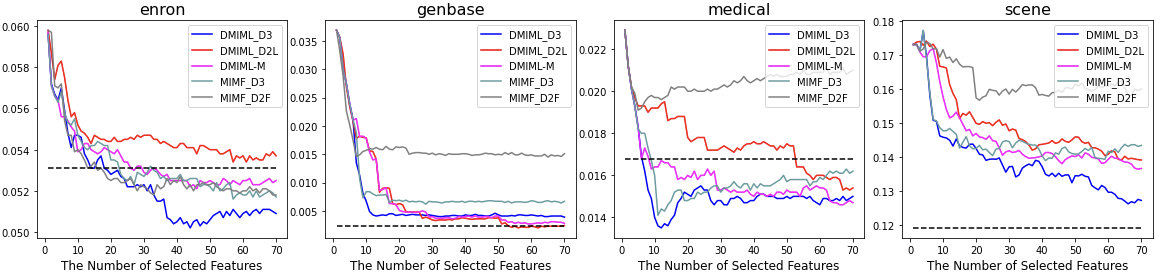
Hamming loss with benchmark methods.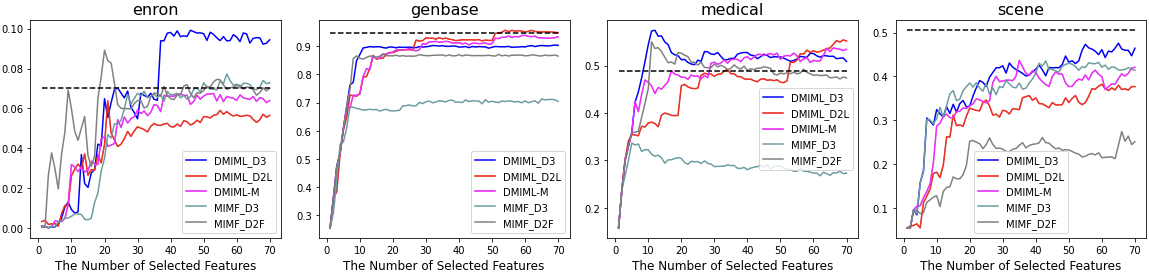
The black dotted line represents the performance of the original multi-label data. The results are also summarized in Table 2 with its standard deviation in bracket, in which the best performance for each dataset is boldfaced.
Overall, the proposed methods DMIML and DMIML-M lead to superior experimental results for most of the datasets, in particular, Enron, Genbase, and Medical. For Scene, the performance does not reach the performance of the original multi-label data; however, our proposed methods demonstrate better results than those of MIMF. In particular, for Enron and Genbase, the performance sharply increases after certain features are selected; this is a phenomenon not observed in MIMF without DMI.
In comparing DMIML and DMIML-M, we expected DMIML-M to have a better performance than DMIML_D3 and DMIML_D2L. However, DMIML_D3 was determined to be the most stable algorithm. DMIML-M displayed moderate performance regardless of the performance ranks of DMIML_D3 and DMIML_D2L. Table 2 indicates that DMIML has superior performance to that of benchmark methods MIMF_D3 and MIMF_D2F; therefore, it can be recommended as the final proposed method. Because it is unknown whether DMIML_D3 or DMIML_D2L has superior performance before learning, DMIML-M can be used for stable results.
For a more detailed experimental comparison, we conducted two additional feature selection methods for multi-label learning. These belong to the problem transformation method, not the algorithm adaptation method. To verify the novelty of our proposed methods DMIML_D3 and DMIML_D2L, we compared them with ELA
Comparison of classification performance with ELA
Chi and PPT
Chi
Comparison of classification performance with ELA
Multi-label accuracy with ELA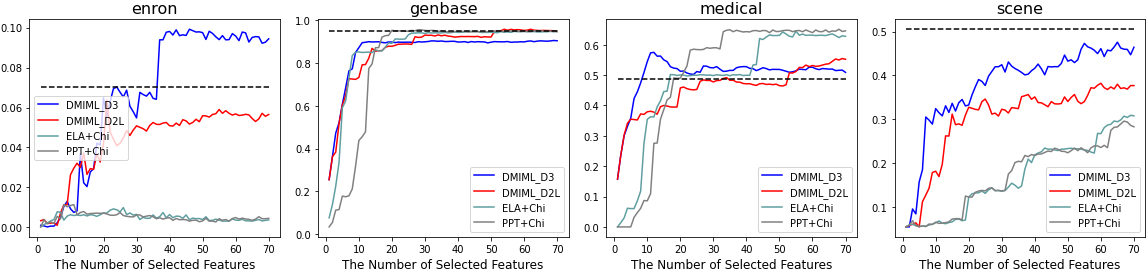
Hamming loss with ELA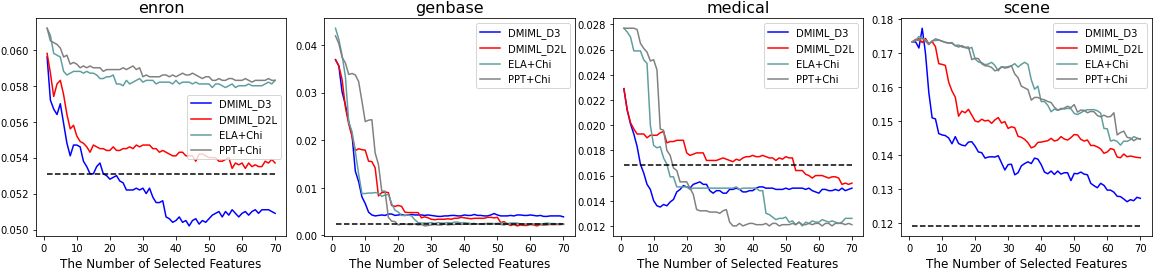
We determined that the performance of our proposed method led to better results to those of the problem transformation methods ELA
Figures 5–8 and Tables 2 and 3 indicate that because of its stability and high performance, DMIML is suitable for multi-label datasets. In various considerations, DMIML outperformed other benchmark methods, including MIMF as an algorithm adaptation method and ELA
It was observed that the proposed method DMIML significantly outperforms the benchmark methods which are MIMF, PPT
Remaining entropy for interpretation of DMIML and MIMF (on scene data)
Remaining entropy for interpretation of DMIML and MIMF (on scene data)
A theory in Fano [27], the error bound of classification performance decreases according to the remaining conditional entropy [7]. The entropy
According to the Table 4, since the remaining entropy is significantly reduced from initial entropy of each label, the result indicates that the proposed method DMIML successfully reduces the entropy of each label. Moreover, DMIML makes the best use of Beach and Sunset when the number of selected features is 25, and of Beach, Sunset, Fall foliage, and Urban when the number of selected features is 40. On the other hand, the benchmark method MIMF used a lot of entropy of labels, but it is confirmed that MIMF does not select the features that utilize entropy better than the proposed method DMIML. That is, this study found that it works in practice to find the features that describe the labels by handling the input space through DMI. In the case of other three benchmark multi-label datasets, the proposed method DMIML utilized entropy better than the MIMF.
When plotting how quickly the proposed method DMIML finds actually important features compared to benchmark method MIMF, it is confirmed that the DMIML using DMI utilizes the entropy of labels more efficiently. That is, the proposed method DMIML has shown that it can find important features more accurately than existing methods on multi-label data with mixed information.
In this paper, we propose DMIML and DMIML-M, a feature selection method for multi-label learning with DMI. This method makes two contributions to the field. First, it extends DMI to multi-label learning. This novel capability allows accurate information among the features and labels of multi-label datasets to be estimated by removing redundant information. In addition, observations that occur
Second, in view of multi-label accuracy and Hamming loss, DMIML demonstrates more stable classification performance for most of the benchmark multi-label datasets than the benchmark methods MIMF (algorithm adaptation method) and ELA
Although it demonstrates better performance, the proposed method has several limitations, which will be the focus of future work. First, although it can effectively estimate information among features in multi-label datasets, users who desire a subset of important features may require additional work because the proposed method is a filter ranking method that only allocates a significant order of features. Hence, we are going to conduct an optimal feature selection algorithm on our proposed method for getting global optimal feature subset. Second, we intend to add more multi-label learners or classifiers and compare their performance. Finally, as one of the most important tasks, we aim to investigate why the proposed method shows higher performance than the benchmark methods in certain multi-label datasets.
Footnotes
Acknowledgments
This work was supported by a grant of the National Research Foundation of Korea (Project Number: 2023R1A2C1002911).
Appendix A
Remaining entropy for interpretation of proposed method DMIML (on enron data)
Remaining entropy
0.3410
0.1105
1.0000
0.0959
0.2658
0.3765
0.0996
0.6005
0.3893
0.0187
0.3365
0.1089
0.9898
0.0957
0.2543
0.3472
0.0972
0.5861
0.3612
0.0179
0.3257
0.1045
0.9389
0.0869
0.2332
0.2391
0.0906
0.5279
0.3478
0.0174
0.3110
0.1002
0.9068
0.0830
0.2185
0.1952
0.0775
0.4806
0.3327
0.0171
0.2883
0.0943
0.8207
0.0720
0.1877
0.1381
0.0663
0.3027
0.3057
0.0107
0.2721
0.0914
0.7701
0.0645
0.1709
0.1115
0.0582
0.2787
0.2836
0.0095
0.2123
0.0744
0.6294
0.0386
0.1164
0.0699
0.0344
0.2002
0.1497
0.0047
0.1512
0.0619
0.4533
0.0228
0.0793
0.0345
0.0236
0.1450
0.1112
0.1031
0.0467
0.3153
0.0149
0.0603
0.0253
0.0139
0.1070
0.0846
0.0844
0.0292
0.2427
0.0083
0.0513
0.0167
0.0094
0.0825
0.0746
0.0543
0.0207
0.1366
0.0075
0.0349
0.0096
0.0069
0.0497
0.0473
0.0424
0.0197
0.1035
0.0074
0.0316
0.0091
0.0056
0.0468
0.0448
0.0376
0.0195
0.0930
0.0071
0.0298
0.0091
0.0055
0.0468
0.0390
0.0352
0.0177
0.0862
0.0065
0.0261
0.0091
0.0042
0.0451
0.0318
Remaining entropy for interpretation of benchmark method MIMF (on enron data)
Remaining entropy
0.3410
0.1105
1.0000
0.0959
0.2658
0.3765
0.0996
0.6005
0.3893
0.0187
0.3325
0.1072
0.8915
0.0948
0.2269
0.2211
0.0977
0.4950
0.2597
0.0177
0.3241
0.1051
0.8716
0.0904
0.2177
0.2036
0.0929
0.4805
0.2456
0.0160
0.3165
0.0995
0.8509
0.0852
0.1997
0.1682
0.0813
0.4528
0.2365
0.0137
0.2894
0.0946
0.8147
0.0794
0.1845
0.1123
0.0696
0.3911
0.2230
0.0131
0.2631
0.0886
0.7672
0.0679
0.1651
0.0835
0.0586
0.3513
0.2036
0.0092
0.2149
0.0736
0.6185
0.0446
0.1211
0.0446
0.0428
0.2763
0.1606
0.0057
0.1525
0.0593
0.4852
0.0301
0.0858
0.0287
0.0296
0.2144
0.1257
0.0023
0.1056
0.0417
0.3356
0.0152
0.0575
0.0228
0.0153
0.1326
0.0897
0.0782
0.0348
0.2533
0.0097
0.0470
0.0169
0.0126
0.1082
0.0732
0.0643
0.0262
0.1728
0.0060
0.0453
0.0149
0.0084
0.0860
0.0615
0.0523
0.0207
0.1277
0.0057
0.0383
0.0091
0.0059
0.0792
0.0462
0.0458
0.0189
0.1066
0.0056
0.0327
0.0091
0.0057
0.0671
0.0408
0.0427
0.0171
0.0899
0.0042
0.0287
0.0091
0.0056
0.0549
0.0332
Remaining entropy for interpretation of benchmark method MIMF (on medical data)
Remaining entropy
0.0212
0.0116
0.0539
0.0685
0.1265
0.0116
0.1144
0.1552
0.1144
0.2602
0.0194
0.0100
0.0421
0.0612
0.1159
0.0100
0.1054
0.1423
0.1007
0.2508
0.0188
0.0099
0.0415
0.0588
0.1110
0.0099
0.1012
0.1369
0.0713
0.2422
0.0180
0.0069
0.0405
0.0553
0.1065
0.0097
0.0972
0.1250
0.0680
0.2308
0.0164
0.0058
0.0319
0.0534
0.1012
0.0083
0.0903
0.1147
0.0642
0.2235
0.0161
0.0058
0.0276
0.0521
0.0948
0.0081
0.0828
0.1112
0.0585
0.2172
0.0154
0.0053
0.0221
0.0246
0.0806
0.0072
0.0668
0.0849
0.0521
0.1850
0.0120
0.0053
0.0145
0.0213
0.0655
0.0063
0.0581
0.0636
0.0396
0.1561
0.0113
0.0040
0.0099
0.0124
0.0525
0.0033
0.0441
0.0462
0.0288
0.1269
0.0112
0.0037
0.0056
0.0095
0.0413
0.0028
0.0394
0.0315
0.0152
0.1070
0.0081
0.0049
0.0061
0.0357
0.0028
0.0334
0.0307
0.0115
0.0893
0.0040
0.0041
0.0055
0.0311
0.0319
0.0231
0.0097
0.0776
0.0040
0.0041
0.0054
0.0263
0.0272
0.0178
0.0077
0.0724
0.0037
0.0020
0.0053
0.0259
0.0266
0.0125
0.0077
0.0685
Remaining entropy for interpretation of benchmark method MIMF (on genbase data)
Remaining entropy
0.5142
0.8242
0.2728
0.4680
0.2595
0.1478
0.1722
0.0641
0.0418
0.0418
0.4354
0.0154
0.2421
0.0986
0.1342
0.1556
0.0593
0.0389
0.0389
0.0409
0.0143
0.2265
0.0421
0.1266
0.1377
0.0541
0.0358
0.0260
0.0137
0.0585
0.0421
0.0574
0.0689
0.0245
0.0338
0.0260
0.0130
0.0544
0.0416
0.0571
0.0689
0.0245
0.0318
0.0258
0.0535
0.0416
0.0371
0.0641
0.0224
0.0314
0.0255
0.0520
0.0386
0.0275
0.0615
0.0208
0.0306
0.0254
0.0516
0.0386
0.0275
0.0606
0.0208
0.0304
0.0254
0.0499
0.0294
0.0236
0.0596
0.0208
0.0296
0.0250
0.0491
0.0294
0.0195
0.0574
0.0166
0.0292
0.0250
0.0483
0.0294
0.0134
0.0564
0.0125
0.0288
0.0250
0.0480
0.0294
0.0134
0.0555
0.0125
0.0287
0.0250
0.0476
0.0294
0.0134
0.0555
0.0125
0.0249
0.0469
0.0288
0.0134
0.0532
0.0125
Remaining entropy for interpretation of proposed method DMIML (on medical data)
Remaining entropy
0.0212
0.0116
0.0539
0.0685
0.1265
0.0116
0.1144
0.1552
0.1144
0.2602
0.0194
0.0100
0.0421
0.0612
0.1159
0.0100
0.1054
0.1423
0.1007
0.2508
0.0183
0.0100
0.0373
0.0588
0.1069
0.0100
0.0976
0.1042
0.0964
0.2360
0.0127
0.0093
0.0362
0.0558
0.0991
0.0093
0.0907
0.0989
0.0680
0.2313
0.0123
0.0093
0.0358
0.0538
0.0940
0.0093
0.0862
0.0849
0.0668
0.2232
0.0119
0.0091
0.0357
0.0505
0.0849
0.0091
0.0783
0.0849
0.0646
0.0458
0.0082
0.0072
0.0185
0.0407
0.0622
0.0067
0.0576
0.0619
0.0441
0.0318
0.0077
0.0040
0.0049
0.0181
0.0438
0.0020
0.0445
0.0350
0.0176
0.0230
0.0070
0.0041
0.0157
0.0356
0.0354
0.0231
0.0146
0.0159
0.0070
0.0041
0.0079
0.0235
0.0286
0.0199
0.0110
0.0150
0.0041
0.0020
0.0071
0.0134
0.0172
0.0129
0.0110
0.0098
0.0020
0.0020
0.0057
0.0056
0.0028
0.0050
0.0090
0.0082
0.0020
0.0020
0.0033
0.0049
0.0020
0.0033
0.0069
0.0082
0.0020
0.0028
0.0041
0.0020
0.0033
0.0020
0.0082